
Inaudible Attack on AI Speakers

 ,
,  and
and
Abstract
1. Introduction
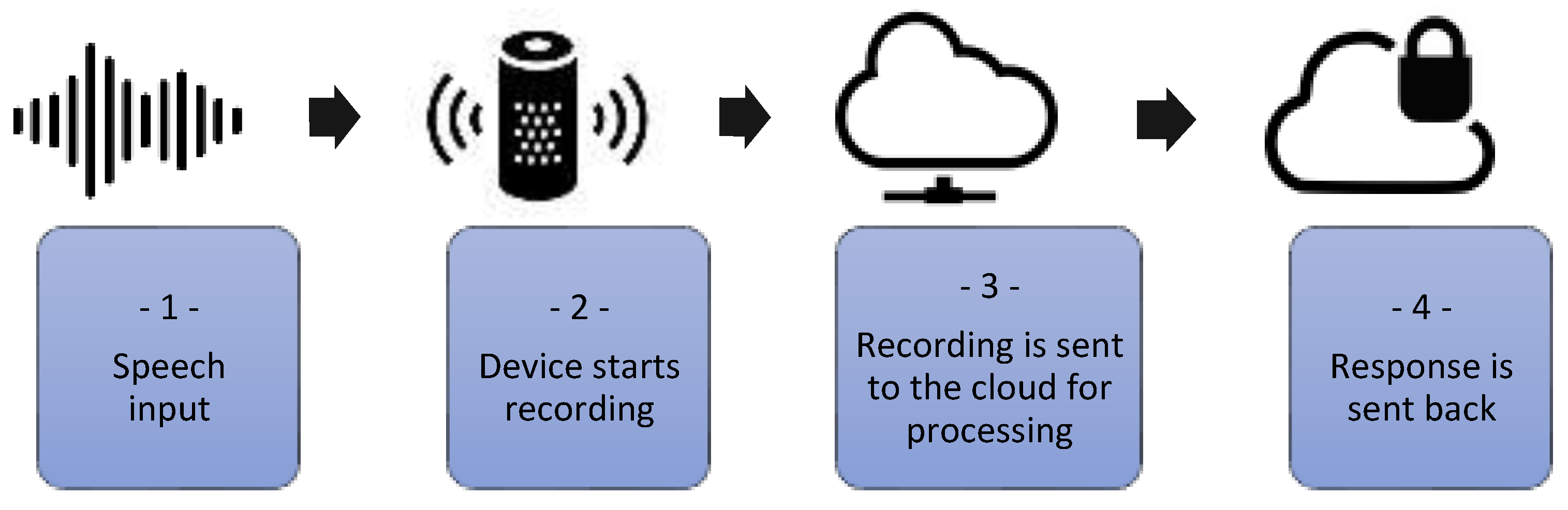
- Speech input;
- Device starts recording when the trigger word is heard, e.g., “Hey Siri or Alexa”. The LED indicates recording status;
- Recording is sent to the cloud for processing and stored;
- Response is sent back; traffic is SSL encrypted.
1.1. Scammers Can Hack a Voice Assistant
1.2. AI Recognizes Speech That Humans Cannot Hear
1.3. Voice Assistant Working Process—Command and Voice Recognition
1.4. Request Processing, Scripts, and Their Execution
1.5. How the Paper Is Structured
2. Related Works
2.1. Injection of Malicious Commands
2.2. Inaudible Voice Commands
2.3. Skill Squatting Attack
2.4. Hidden Attack
2.5. Ultrasound: Machines Hear, Humans Do Not
2.6. Chorus of the Speakers
2.7. Protection against Inaudible Attacks
2.8. DolphinAtack: Inaudible Voice Commands
2.9. LightCommands or Laser Attack
- Make purchases online at the device owner’s expense;
- Unlock the facility’s entrance doors or unlock garage doors if they are managed by a smart speaker;
- Find, open, and launch various automobiles (such Tesla and Ford) linked to the facility’s Google account.
- Amazon and Google are looking into the problem to resolve it.
2.10. Adversarial Attacks against ASR Systems via Psychoacoustic Hiding
2.11. SurfingAttack
2.12. Defending against Voice Impersonation Attacks on Smartphones
2.13. Towards Evaluating the Robustness of Neural Networks
3. Attack on AI Smart Speakers with a Laser Beam
3.1. Directing the Signal by Converting Sound into a Laser
3.2. Experimental Setup
- Hey Siri or OK, Google—wake word (normalized to adapt the general loudness to pick up the microphone, no device specific calibration);
- Do you hear me? —the foundational level of our experiments. This was done to ensure that everything functions properly and replies;
- What Time Is It? —Our experiments will be based on using this command because it only needs the device to correctly detect it and be connected to the Internet in order to restore the current time;
- Set the volume to down…—This voice command is crucial and dangerous since it will be used by an attacker as their first attempt to avoid garnering the attention of the target’s legitimate owner;
- Purchasing…—By using this command, it will be possible to demonstrate the purpose of a hacker who will order a variety of items on the owner of voice assistants’ dime. As a result, a potential attacker may easily wait for delivery close to the delivery address and take the purchased items.
3.3. Attack Range
3.4. Experimental Conditions
3.5. Attacking Authentication
3.6. The PIN Code Can Be Caught, Too
3.7. Study of Hidden Attacks
3.8. Acoustic Secrecy
3.9. Reducing the Attack Costs
3.10. Laser Diode and Optics
3.11. Laser Driver
3.12. Sound Source and Test Results
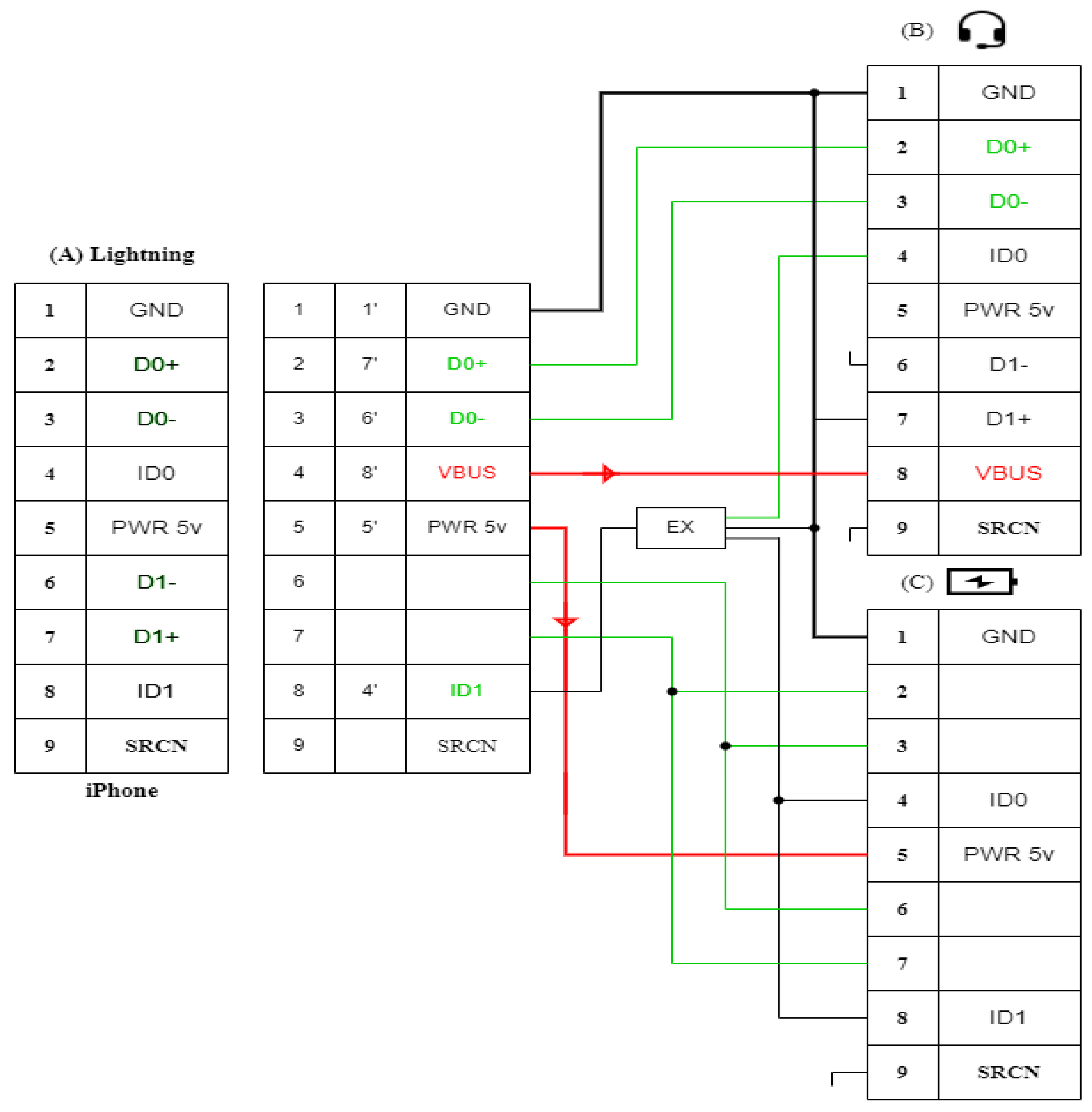
4. Cable Attack, Attacking with the Help of Charging Cable
- Amazon Echo and Google Home speakers can be “deafened” by muting the microphone using the corresponding button on the device. The disadvantage of the method: we will always have to keep in mind the need to “neutralize” the assistant;
- Purchases through Echo can either be completely prohibited or password protected in the account settings;
- Antivirus protection of computers, tablets, and smartphones reduces the risk of any leaks, preventing intruders from hosting your device;
- Amazon Echo users who have the same name as Alexa should change the word to which the assistant responds. Otherwise, any conversation in the presence of an electronic assistant will turn into a real torment.
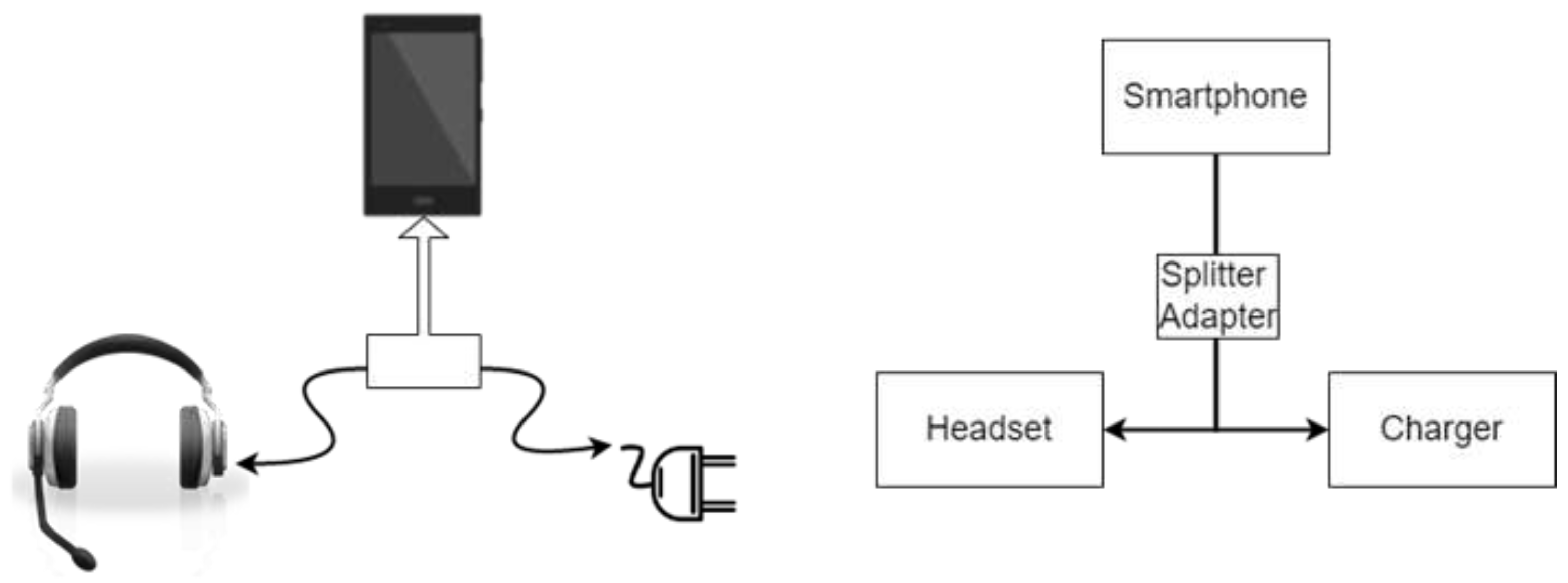
- Physically, headphones (and passive speakers) are microphones inside out: headphones plugged into a computer input may well pick up sound;
- Some sound chips allow you to programmatically remap audio jacks. This function is not a secret at all, and is indicated in the specifications of motherboards.
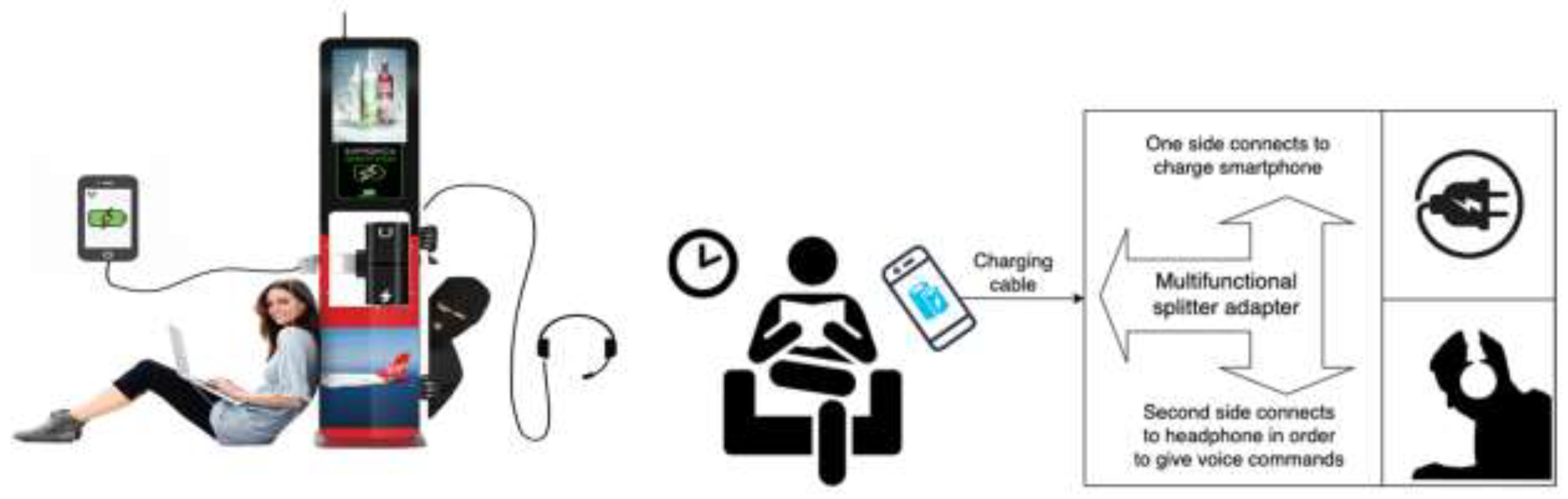
- A public charging power bank is what offers a variety of charging cables connected to charging stations from a service provider. They can be both paid by scanning a QR code to make a payment or in other ways, and can also be completely free;
- A public charging port is a regular USB port that allows you to charge your smartphones using your own cable (lightning cable or USB-c).
4.1. The Danger of Charging Our Smartphones with This Way
4.2. An Overview of the Connection Configuration
4.2.1. Charging Cable
- USB Type-C is a progressive standard with a bunch of goodies: the ability to turn on a connecting cable at either end, a high power of transmitted energy, and a high data exchange rate. The most common and at the same time the most promising is the USB Type-C connector for mobile equipment, which was designed for use with gadgets with the Android operating system, but manufacturers of other mobile equipment also use it;
- Lighting is a special standard used by Apple in its gadgets. This connector is used in Apple mobile devices. It replaced the bulky 30-pin terminal and is the standard for gadgets manufactured by this company, although there is information about the company’s plans to switch to USB Type-C. The connector is two-sided—you can connect either one or the other side. This solution was used for the first time in the development of the connector, and at that time it was a breakthrough.
4.2.2. USB Type-C
- power source and consumer determining;
- plug orientation determining;
- host and device roles defining;
- USB Power Delivery (USB PD) protocol communication;
- power supply profile determining;
- an alternative operating mode setting (if necessary).
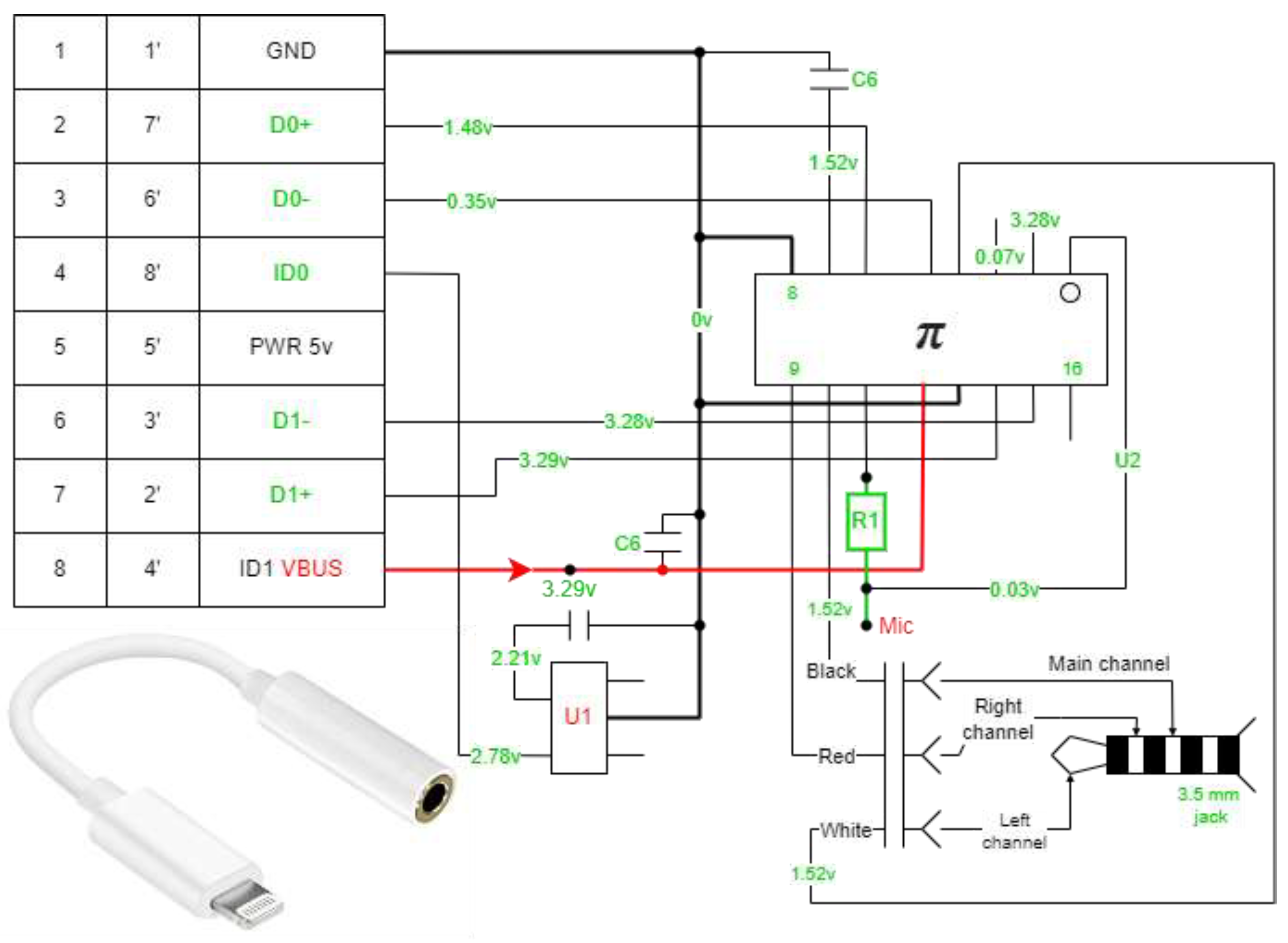
4.2.3. Lighting Cable
- Inside Lightning is a full-fledged microcomputer that controls the charging process of the device. It analyzes the battery level at the current moment and manages the charging process;
- Several chips are involved in data transfer using the function of a cable to connect to a computer;
- Two chips are responsible for converting the incoming electric current signal into a state that is maximally adapted for the battery installed in the smartphone;
- Chip Apple technology—the plug can be connected to either side, the built-in microprocessor analyzes the position of the wire and commands the necessary contacts in the direction of voltage.
4.2.4. Headset
4.2.5. Headset Button for Smartphone
- One short press—the playing track is paused;
- Two fast short ones—turn on the next track;
- Three quick presses—previous song.
- One long press brings up the voice assistant from Google or Siri. By the way, it is very convenient.
4.2.6. Working Process of the Headset Button
4.2.7. Adapters
Dongle Adapter
Digital Part of the Adapter
- The 16-pin chip is responsible for the interface and the DAC (digital-to-analog converter);
- The 6-pin chips are responsible for identification.
Analog Part of the Adapter
Splitter Adapter
4.3. Attack Motivation
4.4. Attack Preparation
4.5. Working Process
4.6. Attack Implementation
4.7. Experiment
5. Discussion
5.1. Laser Attack
5.1.1. Programmatic Approach
5.1.2. Hardware Approach
5.1.3. Hardware Limitations
5.1.4. MEMS Microphones Respond to Light
5.1.5. Cable Attack with Help the of Charging Cable
5.1.6. Protection Our Smartphones from This Particular Attack
- Fully charge our gadgets before leaving the house: the higher the capacity of the battery and the more economically you use the charge, the less likely you will have to use chargers outside the home;
- Be careful about charging in public places—cafes, airports, train stations, rental cars—and minimize their use if possible;
- Do not use donated charging cables. Promoters can give them out in high traffic areas ostensibly as gifts from well-known brands. Guess what you can pay for such a free gift?
- If possible, use an AC outlet for recharging, not charging stations, and carry our own cable (it takes up minimal space in a backpack or bag);
- If recharging in a public place cannot be avoided, turn off the gadget in advance and only then connect it to the charging station. Power over the cable can only be transmitted in one direction, while data transmission is possible in two directions at once. The owners of smartphones on a Windows Phone are in the most disadvantageous position—their devices turn on automatically after you connect the charger to them.
5.2. Open Issues/Problems for the Researchers
5.2.1. Disadvantages of Modern Voice Assistants
5.2.2. Standard Templates
5.2.3. Everything Will Be but Not Immediately
5.2.4. Tech Companies Defend against “Voice” Threats
5.2.5. Voice Device Protection
- By using strong, unique passwords for your voice devices;
- By not leaving your smartphone unlocked if you are not using it;
- By protecting voice assistant tasks related to your security, personal data, finances or medical records with a PIN. Better yet, do not associate this information with voice control devices.
5.2.6. No Interlocutor Model
5.2.7. The Dialogue Depth Is Equal to One
5.2.8. The Main Problem with Voice Assistants
5.2.9. Not an Assistant, but a Companion
5.2.10. Applications on Phones Will Die, No One Will Use Them
6. Conclusions
- To read our recent SMS messages and make fraud calls;
- To identity theft that can be manipulated and blackmailed;
- To purchase via the Internet at the expense of the owner of the device.
Author Contributions
Funding
Conflicts of Interest
References
- Brannon, D. Attacking Private Networks from the Internet with DNS Rebinding. Available online: https://medium.com/@brannondorsey/attacking-private-networks-from-the-internet-with-dnsrebinding-ea7098a2d325 (accessed on 20 June 2022).
- Diao, W.; Liu, X.; Zhou, Z.; Zhang, K. Your voice assistant is mine: How to abuse speakers to steal information and control your phone. In Proceedings of the 4th ACM Workshop on Security and Privacy in Smartphones & Mobile Devices, Scottsdale, AZ, USA, 7 November 2014; pp. 63–74. [Google Scholar]
- Xiao, X.; Kim, S. A study on the user experience of smart speaker in China-focused on Tmall Genie and Mi AI speaker. J. Digit. Converg. 2018, 16, 409–414. [Google Scholar]
- Kumar, D.; Paccagnella, R.; Murley, P.; Hennenfent, E.; Mason, J.; Bates, A.; Bailey, M. Skill squatting attacks on Amazon Alexa. In Proceedings of the 27th USENIX, Santa Clara, CA, USA, 14–16 August 2018; pp. 33–47. [Google Scholar]
- Clinton, I.; Cook, L.; Banik, S. A survey of Various Methods for Analyzing the Amazon Echo; Citadel, Military College South Carolina: Charleston, SC, USA, 2016; Available online: https://vanderpot.com/2016/06/amazon-echo-rooting-part-1/ (accessed on 8 March 2023).
- Zhang, N.; Mi, X.; Feng, X.; Wang, X.; Tian, Y.; Qian, F. Dangerous skills: Understanding and mitigating security risks of voice-controlled third-party functions on virtual personal assistant systems. In Proceedings of the IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 20–22 May 2019; pp. 1381–1396. [Google Scholar]
- Lau, J.; Benjamin, Z.; Florian, S. Alexa, are you listening: Privacy perceptions, concerns and privacy-seeking behaviors with smart speakers. Proc. ACM Hum.-Comput. Interact. 2018, 2018, 102. [Google Scholar] [CrossRef]
- Gruber, J.; Hargittai, E.; Karaoglu, G.; Brombach, L. Algorithm Awareness as an Important Internet Skill: The Case of Voice Assistants. Int. J. Commun. 2021, 15, 1770–1788. [Google Scholar]
- Masina, F.; Orso, V.; Pluchino, P.; Dainese, G.; Volpato, S.; Nelini, C.; Mapelli, D.; Spagnolli, A.; Gamberini, L. Investigating the Accessibility of Voice Assistants with Impaired Users: Mixed Methods Study. J. Med. Internet Res. 2020, 22, e18431. [Google Scholar] [CrossRef] [PubMed]
- Vincent, J. Lyrebird claims it can recreate any voice using just one minute of sample audio. Verge 2017, 24, 65. [Google Scholar]
- Wah, B.W.; Lin, D. Transformation-based reconstruction for audio transmissions over the Internet. In Proceedings of the 17th IEEE Symposium on Reliable Distributed Systems, West Lafayette, IN, USA, 20–23 October 1998; pp. 211–217. [Google Scholar]
- Huart, P.H.; Surazski, L.K. Method and Apparatus for Reconstructing Voice Information. U.S. Patent 7,013,267, 14 March 2006. [Google Scholar]
- Carlini, N.; Mishra, P.; Vaidya, T.; Zhang, Y.; Sherr, M.; Shields, C.; Wagner, D.; Zhou, W. Hidden Voice Commands. In Proceedings of the 25th USENIX Conference on Security Symposium, SEC’16, Austin, TX, USA, 10–12 August 2016. [Google Scholar]
- Schönherr, L.; Kohls, K.; Zeiler, S.; Holz, T.; Kolossa, D. Adversarial Attacks Against ASR Systems via Psychoacoustic Hiding. Netw. Distrib. Syst. Secur. Symp. 2019. [Google Scholar] [CrossRef]
- Zhang, G.; Yan, C.; Ji, X.; Zhang, T.; Zhang, T.; Xu, W. DolphinAtack: Inaudible Voice Commands. In Proceedings of the ACM Conference on Computer and Communications Security (CCS), Dallas, TX, USA, 30 October 2017. [Google Scholar]
- Jang, Y.; Song, C.; Chung, S.P.; Wang, T.; Lee, W. A11y attacks: Exploiting accessibility in operating systems. In Proceedings of the ACM Conference on Computer and Communications Security (CCS), Scottsdale, AZ, USA, 3–7 November 2014. [Google Scholar]
- Vaidya, T.; Zhang, Y.; Sherr, M.; Shields, C. Cocaine noodles: Exploiting the gap between human and machine speech recognition. In Proceedings of the USENIX Workshop on Offensive Technologies (WOOT), Washington, DC, USA, 10–11 August 2015. [Google Scholar]
- Cisse, M.M.; Adi, Y.; Neverova, N.; Keshet, J. Houdini: Fooling deep structured visual and speech recognition models with adversarial examples. In Advances in Neural Information Processing Systems; The MIT Press: Cambridge, MA, USA, 2017. [Google Scholar]
- Roy, N.; Hassanieh, H.; Choudhury, R.R. Backdoor: Making microphones hear inaudible sounds. In Proceedings of the ACM International Conference on Mobile Systems (MobiSys), New York, NY, USA, 19–23 June 2017. [Google Scholar]
- Song, L.; Mittal, P. Inaudible voice commands. arXiv 2017, arXiv:1708.07238. [Google Scholar]
- Roy, N.; Shen, S.; Hassanieh, H.; Choudhury, R.R. Inaudible voice commands: The long-range attack and defense. In Proceedings of the USENIX Symposium on Networked Systems Design and Implementation (NSDI), Renton, WA, USA, 9–11 April 2018. [Google Scholar]
- Seiderer, A.; Ritschel, H.; André, E. Development of a privacy-by-design speech assistant providing nutrient information for German seniors. In Proceedings of the 6th EAI International Conference on Smart Objects and Technologies for Social Good, Online, 14–16 September 2020; pp. 114–119. [Google Scholar]
- Jesús-Azabal, M.; Medina-Rodríguez, J.A.; Durán-García, J.; García-Pérez, D. Remembranza Pills: Using Alexa to Remind the Daily Medicine Doses to Elderly. In Proceedings of the Gerontechnology: Second International Workshop, IWoG 2019, Cáceres, Spain, 4–5 September 2019. [Google Scholar]
- Conde-Caballero, D.; Rivero-Jiménez, B.; Cipriano-Crespo, C.; Jesus-Azabal, M.; Garcia-Alonso, J.; Mariano-Juárez, L. Treatment Adherence in Chronic Conditions during Ageing: Uses, Functionalities, and Cultural Adaptation of the Assistant on Care and Health Offline (ACHO) in Rural Areas. J. Personal. Med. 2021, 11, 173. [Google Scholar] [CrossRef] [PubMed]
- Zhang, N.; Mi, X.; Feng, X.; Wang, X.; Tian, Y.; Qian, F. Understanding and mitigating the security risks of voicecontrolled third-party skills on amazon alexa and google home. arXiv 2018, arXiv:1805.01525. [Google Scholar]
- Saparmammedovich, S.A.; Al-Absi, M.A.; Koni, Y.J.; Lee, H.J. Voice Attacks to AI Voice Assistant. In Proceedings of the Intelligent Human Computer Interaction, Daegu, Republic of Korea, 24–26 November 2020. [Google Scholar]
- Kuskibiki, J.; Akashi, N.; Sannomiya, T.; Chubachi, N.; Dunn, F. VHF/UHF range bioultrasonic spectroscopy system and method. IEEE Trans. Ultrason. Ferroelectr. Freq. Control. 1995, 42, 1028–1039. [Google Scholar] [CrossRef]
- Carlini, N. Evaluation and Design of Robust Neural Network Defenses; University of California: Berkeley, CA, USA, 2018. [Google Scholar]
- Chen, G. Uncovering the Unheard: Researchers Reveal Inaudible Remote Cyber-Attacks on Voice Assistant Devices. UTSA Today University Strategic Communications, The University of Texas at San Antonio. Available online: https://www.utsa.edu/today/2023/03/story/chen-nuit-research.html (accessed on 20 March 2023).
- Kobie, N. Siri and Alexa can be Turned against You by Ultrasound Whispers. NewScientist. Available online: https://www.newscientist.com/article/2146658-siri-and-alexa-can-be-turned-against-you-by-ultrasound-whispers/ (accessed on 7 September 2017).
- Hammi, B.; Zeadally, S.; Khatoun, R.; Nebhen, J. Survey on smart homes: Vulnerabilities, risks, and countermeasures. Comput. Secur. 2022, 117, 102677. [Google Scholar] [CrossRef]
- Schwartz, E.H. Lasers Can Hack Voice Assistants in Example Worthy of Mission Impossible But the Risk is Minimal for Consumers. Voicebot. Available online: https://voicebot.ai/2019/11/05/lasers-can-hack-voice-assistants-study/ (accessed on 5 November 2019).
- Sugawara, T.; Cyr, B.; Rampazzi, S.; Genkin, D.; Fu, K. Light Commands: Laser-Based Audio Injection Attacks on Voice-Controllable Systems. In Proceedings of the 29th USENIX Conference on Security Symposium, Berkeley, CA, USA, 12–14 August 2020. [Google Scholar]
- Albrecht, K. Amazon’s Alexa Can Be Hacked Using the Sound of What? Government Technology. Available online: https://www.govtech.com/question-of-the-day/question-of-the-day-for-10042018.html (accessed on 3 October 2018).
- Nekkalapu, E. The Backend of Inaudible Voice Hacking. Medium. Available online: https://medium.com/@Gentlemen_ESWAR/the-backend-of-inaudible-voice-hacking-60ae7641dec6 (accessed on 10 September 2022).
- Potter, G. Study Describes How App, Soon to be Available, will Help Thwart Growing Cybersecurity Threat. University at Buffalo. Available online: https://www.buffalo.edu/news/releases/2017/06/007.html (accessed on 5 June 2017).
- Carlini, N.; Wagner, D. Towards Evaluating the Robustness of Neural Networks. In Proceedings of the 2017 IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 22–24 May 2017; pp. 39–57. [Google Scholar]
- Carlini, N.; Wagner, D. Audio Adversarial Examples: Targeted Attacks on Speech-to-Text. In Proceedings of the 2018 IEEE Security and Privacy Workshops (SPW), San Francisco, CA, USA, 24–24 May 2018; pp. 1–7. [Google Scholar]
- Seyitmammet, A.; Al-Absi, M.A.; Al-Absi, A.A.; Lee, H.J. Attack on AI Smart Speakers with a Laser Beam. In Proceedings of the 2nd International Conference on Smart Computing and Cyber Security. SMARTCYBER 2021. Lecture Notes in Networks and Systems, Kyungdong University, Global Campus, South Korea 16–17 June 2021; Pattnaik, P.K., Sain, M., Al-Absi, A.A., Eds.; Springer: Singapore, 2021; Volume 395. [Google Scholar]
- Laser Lenses, Optics, and Focus. Available online: https://lasergods.com/laser-lenses-optics-and-focus/ (accessed on 24 November 2022).
- Mao, J.; Zhu, S.; Liu, J. An inaudible voice attack to context-based device authentication in smart IoT systems. J. Syst. Arch. 2020, 104, 101696. [Google Scholar] [CrossRef]
- Melena, N. Covert IR-Laser Remote Listening Device. Bachelors Thesis, The University of Arizona, Tucson, AZ, USA, 2012. [Google Scholar]
- Los Angeles County Attorney’s Office (USA). USB Charger Scam. 2019. Available online: https://da.lacounty.gov/sites/default/files/pdf/110819_Fraud_Friday_USB_Charger_Scam_ENGLISH_FLIER.pdf (accessed on 8 January 2023).
- Black Hat. MACTANS: Injecting Malware into iOS Devices Using Malicious Chargers. In Proceedings of the BlackHat Security Conference, Las Vegas, NV, USA, 3–4 August 2016. [Google Scholar]
- Yan, Q.; Liu, K.; Zhou, Q.; Guo, H.; Zhang, N. SurfingAttack: Interactive Hidden Attack on Voice Assistants Using Ultrasonic Guided Waves. In Proceedings of the Network and Distributed System Security Symposium, San Diego, CA, USA, 23–26 February 2020. [Google Scholar]
- Seyitmammet, A.; Al-Absi, M.A.; Al-Absi, A.A.; Lee, H.J. Attack on AI smart speakers with a laser beam. In Proceedings of the Proceedings of 2nd International Conference on Smart Computing and Cyber Security, Gangwon, Republic of Korea, 16–17 June 2021; pp. 250–261. [Google Scholar]
- Andy Greenberg. Great. Now Even Your Headphones Can Spy on You. 2016. Available online: https://www.wired.com/ (accessed on 22 February 2023).
- Davidson, D.; Wu, H.; Jellinek, R.; Singh, V.; Ristenpart, T. Controlling UAVs with sensor input spoofing attacks. In Proceedings of the 10th USENIX Conference on Offensive Technologies, Austin, TX, USA, 8–9 August 2016. [Google Scholar]
- Zhang, X.; Huang, J.; Song, E.; Liu, H.; Li, B.; Yuan, X. Design of Small MEMS Microphone Array Systems for Direction Finding of Outdoors Moving Vehicles. Sensors 2014, 14, 4384–4398. [Google Scholar] [CrossRef] [PubMed]
- Cimpanu, C. Officials Warn about the Dangers of Using Public USB Charging Stations. 2019. Available online: https://www.zdnet.com/ (accessed on 14 December 2022).






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Laser Power | Taking Control Over | Brand | Voice Assistant |
|---|---|---|---|
| 5 mW | Many well-known smart home devices | Amazon Echo Google Home Apple HomePod | Alexa Google assistant Siri |
| 60 mW | Almost all smart devices (smartphones and tablets) | Samsung smartphone iPhone | Google assistant Siri |
| Commands | Explanation | Attack Possibility | Verification |
|---|---|---|---|
| OK, Google; Hey Siri | Word that serves as a trigger or wake-up signal for a VA | ✓ | Optional |
| Do you hear me? What Time Is It? | Device preparation asking few simple questions | ✓ | Optional |
| Set the volume to up or down… | Receiving both audible or inaudible response from the device | ✓ | Optional |
| Purchase attempts | Probability of a successful order | ✗ | Required |
| Device Type | Operating System | Voice Assistant | Min/Max Distance | Verification | Laser Power | Successful Attack Power | Achieved Distances | |
|---|---|---|---|---|---|---|---|---|
| iPhone 6 | IOS | Siri | 30 sm~ ~87 m | ✓ | 60 (mW) | 22 mW | 25 m | Farther, the devices do not recognize the laser |
| Galaxy J6 | Android | Google Assistant | ✓ | 60 mW | 25 m | |||
| iPhone 8 Plus | IOS | Siri | ✓ | 21 mW | 87 m | Maximum space that we managed to stretch | ||
| Galaxy A7 | Android | Google Assistant | ✓ | 59 mW | 87 m | |||
| Device Brand | Samsung | iPhone | ||
|---|---|---|---|---|
| Device Name | Galaxy J6 | Galaxy A7 | 6s | 8 Plus |
| Device Type | Smartphone | Smartphone | Smartphone | Smartphone |
| Laser Power | 60 mW | 60 mW | 60 mW | 60 mW |
| Successful Attack Power | 60 mW | 59 mW | 22 mW | 21 mW |
| Distance/Meter | Attack Accuracy | |||
| 1~2 (m) | 100%—All devices successfully attacked | |||
| 3 (m) | 80–90% | 100% | 100% | 100% |
| 4 (m) | 50–60% | 100% | 80–90% | 100% |
| 5 (m) | 40–50% | 50–60% | 60–70% | 50–60% |
| 10 (m) | Attack success is only 10–30% | |||
| 25 (m) | Attack success is only 5–10% | |||
| 87 (m) | failed | 0–1% | failed | 0–1% |
| Voice Commands | Attack Possibility | Distance Attack Accuracy | |||
|---|---|---|---|---|---|
| 0.5 m | 5 m | 10 m | |||
| Voice assistant activate word | OK, Google; Hey Siri | ✓ | All devices successfully attacked | 40–70% | 10–30% |
| Device preparation | Do you hear me? What time Is It? | ✓ | |||
| Making device silent | Set the volume to up or down… | ✓ | |||
| Malicious commands | Purchase attempts | ✗ | |||
| No. | Smartphone | Model | OS | Voice Assistants | ASR | Activation | Response |
|---|---|---|---|---|---|---|---|
| 1 | Apple | iPhone 13 pro | iOS | Siri | 100% | ✓ | ✓ |
| 2 | Samsung | Galaxy Note 20 | Android | Google Assistant | 100% | ✓ | ✓ |
| 3 | Samsung | Galaxy A33 | Android | Google Assistant | 100% | ✓ | ✓ |
| 4 | Apple | iPhone 10 | iOS | Siri | 100% | ✓ | ✓ |
| 5 | Apple | iPhone 12 Pro | iOS | Siri | 100% | ✓ | ✓ |
| 6 | Huawei | Honor 10 | Android | Google Assistant | 100% | ✓ | ✓ |
| 7 | Apple | iPhone 8 | iOS | Siri | 100% | ✓ | ✓ |
| 8 | Apple | iPhone X | iOS | Siri | 100% | ✓ | ✓ |
| 9 | Xiaomi | MI 8 Lite | Android | Google Assistant | 100% | ✓ | ✓ |
| 10 | Samsung | Galaxy S9 | Android | Google Assistant | 100% | ✓ | ✓ |
| The Way | Definition | Materials |
|---|---|---|
| The Light Diffraction | It changes direction of light | Hologram Light entering a dark room; Crepuscular Rays |
| Light Absorption | Light is absorbed | Coal Black paint; Black perfect |
| Light Reflection | A beam of light reflects off a smooth polished surface | Glass Mirror; Acrylic Mirror; Can Lids |
| Light Barrier | Light stops passing | Plastic Metal |
| Fabric | Light stops passing | Net Polyester Silk |
| No. | Attack Name | Required Equipment | Required Actions | Inaudible | Response |
|---|---|---|---|---|---|
| 1 | DolphinAttack | Ultrasound speakers Function generator Power supply Power amplifier | Converting Generating Powering Measuring | ✓ | ✓ |
| 2 | Psychoacoustic hiding attack | Preprocessing audio input decoding | - | ✓ | |
| 3 | SurfingAttack | Piezoelectrick disk Function generator Power supply | Converting Generating Powering Measuring | ✓ | ✓ |
| 4 | LightCommands | Audio amplifier Laser current driver Power supply Laser pointer Photo lens | Converting Generating Powering Measuring | ✓ | ✓ |
| 5 | Ghostalk | Cable modification Power supply Battery more than 95% | Converting Generating Powering Measuring | ✓ | ✓ |
| 6 | Laser Attack | Audio amplifier Laser current driver Power supply Laser pointer Photo lens | Converting Generating Powering Measuring | ✓ | ✓ |
| 7 | Cable Attack | Splitter adapter | Connecting | ✓ |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alchekov, S.S.; Al-Absi, M.A.; Al-Absi, A.A.; Lee, H.J. Inaudible Attack on AI Speakers. Electronics 2023, 12, 1928. https://doi.org/10.3390/electronics12081928
Alchekov SS, Al-Absi MA, Al-Absi AA, Lee HJ. Inaudible Attack on AI Speakers. Electronics. 2023; 12(8):1928. https://doi.org/10.3390/electronics12081928
Chicago/Turabian StyleAlchekov, Seyitmammet Saparmammedovich, Mohammed Abdulhakim Al-Absi, Ahmed Abdulhakim Al-Absi, and Hoon Jae Lee. 2023. "Inaudible Attack on AI Speakers" Electronics 12, no. 8: 1928. https://doi.org/10.3390/electronics12081928
APA StyleAlchekov, S. S., Al-Absi, M. A., Al-Absi, A. A., & Lee, H. J. (2023). Inaudible Attack on AI Speakers. Electronics, 12(8), 1928. https://doi.org/10.3390/electronics12081928