
Multi-Hop Knowledge Graph Question Answer Method Based on Relation Knowledge Enhancement

Abstract
:1. Introduction
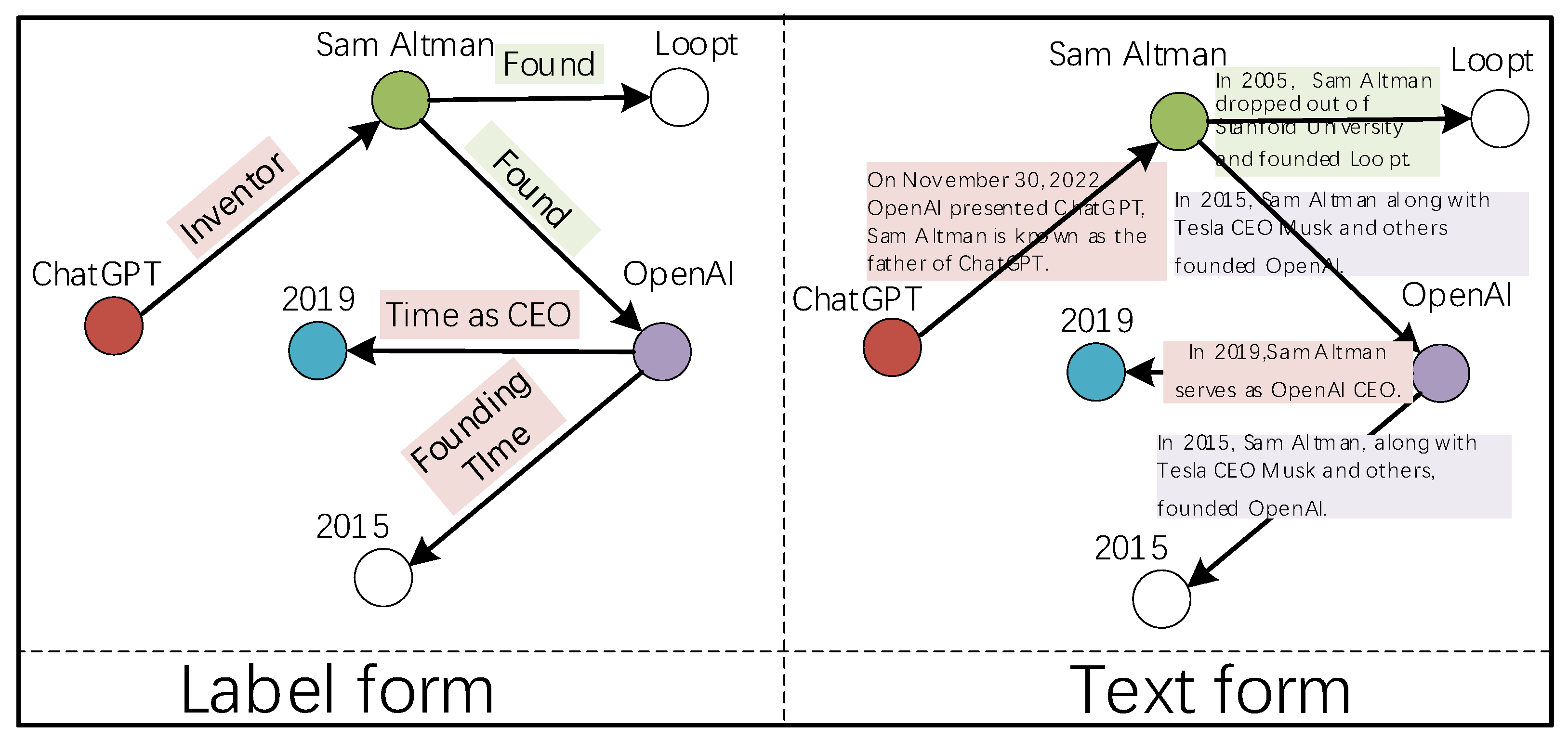
- We propose a tree structure to fuse relation structures in label form and text form to achieve relation knowledge enhancement.
- We propose an encoding approach that fuses global attention and soft location encoding to obtain the weight information of the relation tree structure.
- We propose a pre-trained model to solve the challenge of the model processing long text, especially for the problem of missing links, and the incorporation of text corpus can make the cross-hop semantic association between multi-hop KGQA possible.
2. Related Work
3. Models and Methods
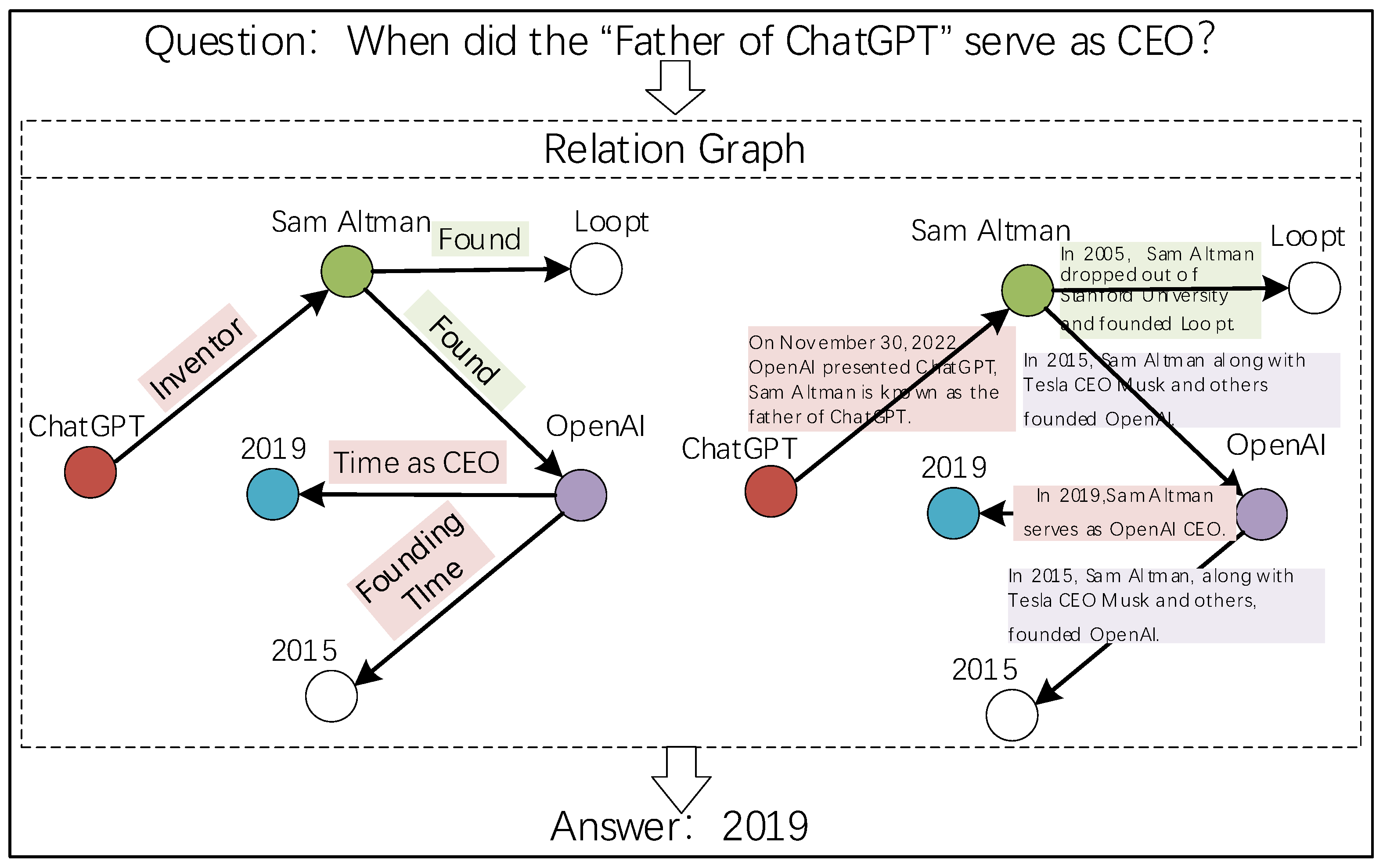
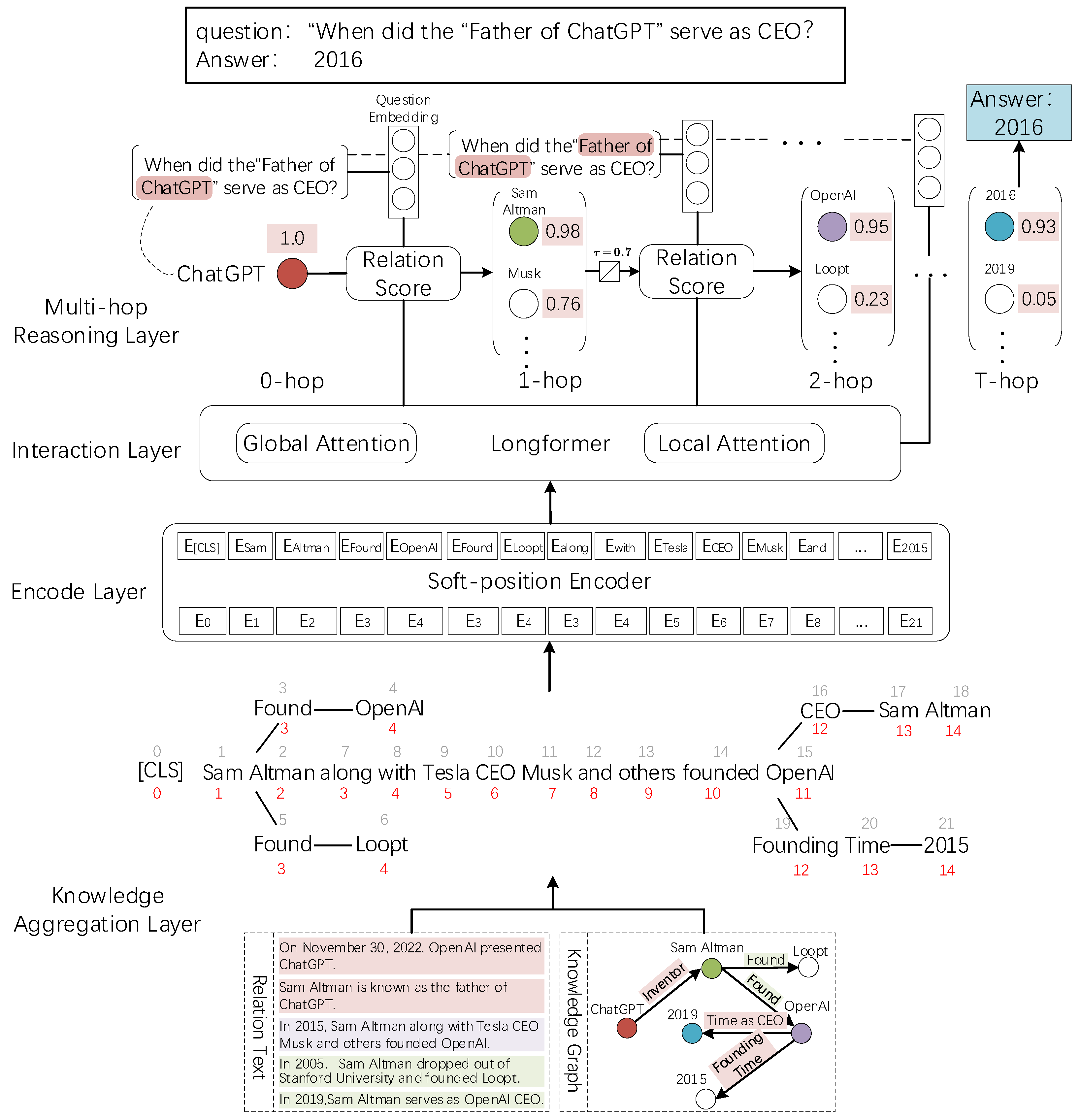
3.1. Knowledge Aggregation Layer
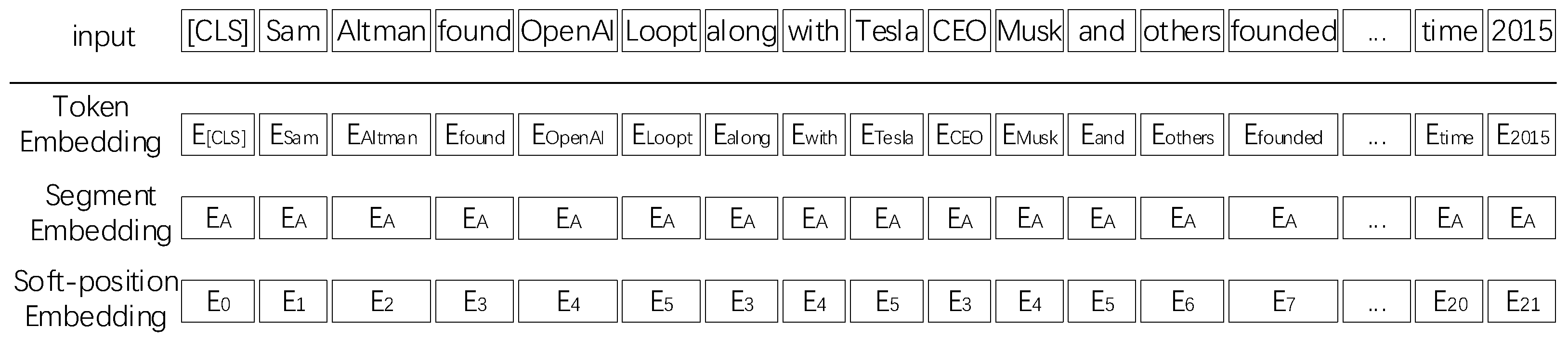
3.2. Encoding Layer
3.3. Interaction Layer
3.4. Link Reasoning Layer
4. Experiment
4.1. Dataset
4.2. Experiment Parameters
4.3. Experimental Parameter Configuration
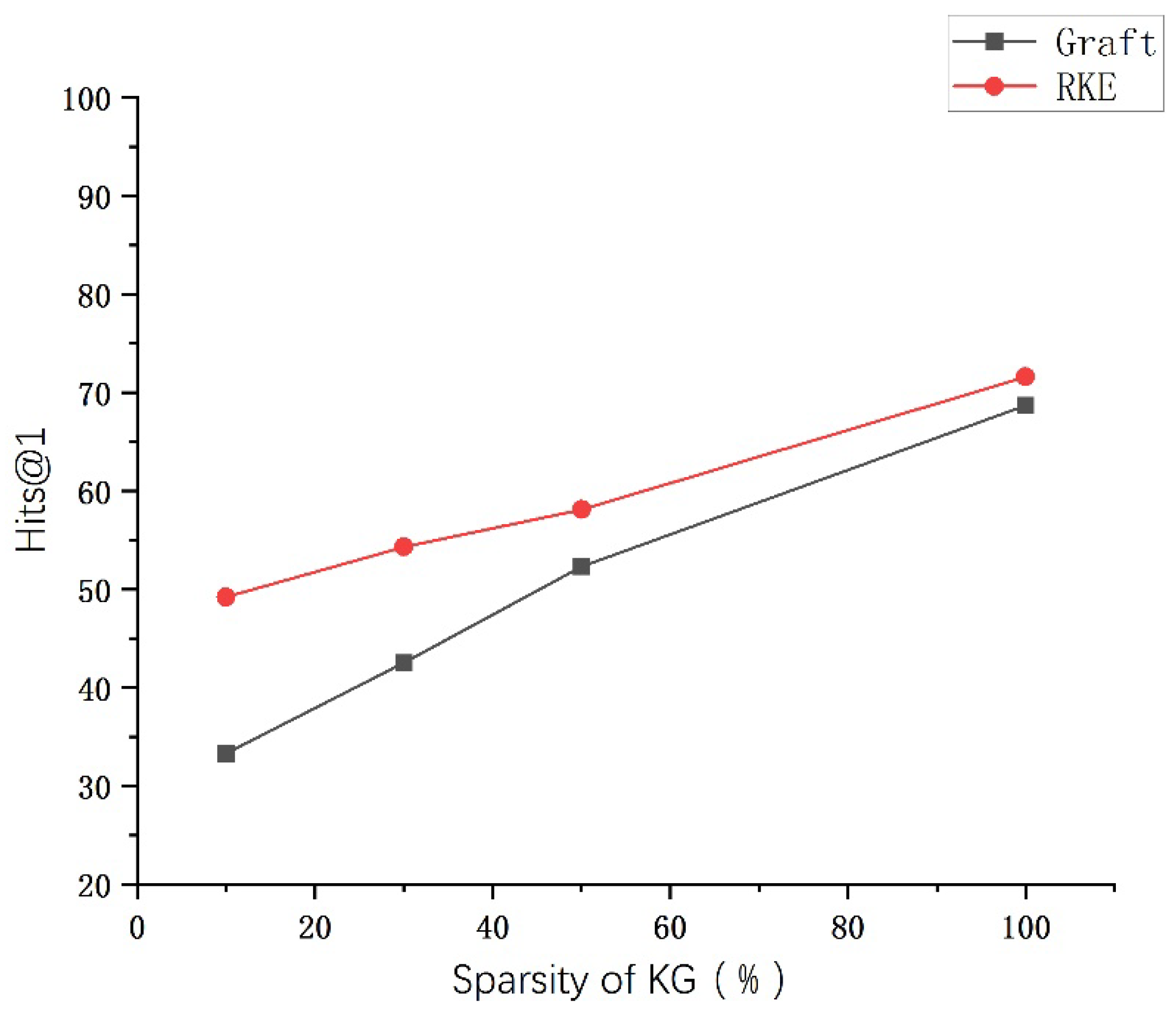
4.4. Experiment Results and Analysis
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Lan, Y.; He, G.; Jiang, J.; Jiang, J.; Zhao, W.X.; Wen, J.R. A Survey on Complex Knowledge Base Question Answering: Methods, Challenges and Solutions. In Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence, Montreal, QC, Canada, 19–27 August 2021; pp. 4483–4491. [Google Scholar]
- Petrochuk, M.; Zettlemoyer, L. Simple Questions Nearly Solved: A New Upper Bound and Baseline Approach. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 554–558. [Google Scholar]
- Du, H.; Wang, H.; Shi, Y. Progress, challenges and research trends of reasoning in multi-hop knowledge graph based question answering. Big Data Res. 2021, 7, 2021026. [Google Scholar]
- Sun, H.; Dhingra, B.; Zaheer, M.; Mazaitis, K.; Salakhutdinov, R.; Cohen, W.W. Open Domain Question Answering Using Early Fusion of Knowledge Bases and Text. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 4231–4242. [Google Scholar]
- Gupta, H.D.; Sheng, V.S. A Roadmap to Domain Knowledge Integration in Machine Learning. In Proceedings of the 2020 IEEE International Conference on Knowledge Graph, Nanjing, China, 9–11 August 2020; pp. 145–151. [Google Scholar]
- Sun, H.; Bedrax-Weiss, T.; Cohen, W.W. PullNet: Open Domain Question Answering with Iterative Retrieval on Knowledge Bases and Text; Association for Computational Linguistics: Toronto, ON, Canada, 2019; pp. 2380–2390. [Google Scholar]
- Wang, X.; Zhao, S.; Cheng, B.; Yin, Y.; Yang, H. Explore Modeling Relation Information and Direction Information in KBQA. Neurocomputing 2022, 471, 139–148. [Google Scholar] [CrossRef]
- Li, Z.; Wang, H.; Zhang, W. Translational relation embeddings for multi-hop knowledge base question answering. J. Web Semant. 2022, 74, 100723. [Google Scholar] [CrossRef]
- Guo, Q.; Wang, X.; Zhu, Z.; Liu, P.; Xu, L. A knowledge inference model for question answering on an incomplete knowledge graph. Appl. Intell. 2023, 53, 7634–7646. [Google Scholar] [CrossRef]
- Shi, J.; Cao, S.; Hou, L.; Li, J.; Zhang, H. TransferNet: An Effective and Transparent Framework for Multi-Hop Question Answering over Relation Graph; Association for Computational Linguistics: Toronto, ON, Canada, 2021; pp. 4149–4158. [Google Scholar]
- Wu, W.; Zhu, Z.; Qi, J.; Wang, W.; Zhang, G.; Liu, P. A dynamic graph expansion network for multi-hop knowledge base question answering. Neurocomputing 2023, 515, 37–47. [Google Scholar] [CrossRef]
- Cohen, W.W.; Sun, H.; Hofer, R.A.; Siegler, M. Scalable Neural Methods for Reasoning with a Symbolic Knowledge Base. In Proceedings of the 8th International Conference on Learning Representations, Addis Ababa, Ethiopia, 26–30 April 2020; pp. 26–30. [Google Scholar]
- Feng, Y.; Chen, X.; Lin, B.Y.; Wang, P.; Yan, J.; Ren, X. Scalable Multi-Hop Relational Reasoning for Knowledge-Aware Question Answering. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, Online, 16–20 November 2020; pp. 1295–1309. [Google Scholar]
- Zhou, M.; Huang, M.; Zhu, X. An Interpretable Reasoning Network for Multi-Relation Question Answering. In Proceedings of the 27th International Conference on Computational Linguistics, Santa Fe, NM, USA, 20–26 August 2018; pp. 2010–2022. [Google Scholar]
- Zhang, Y.; Dai, H.; Kozareva, Z.; Smola, A.; Song, L. Variational Reasoning for Question Answering with Knowledge Graph. In Proceedings of the 30th Innovative Applications of Artificial Intelligence (IAAI-18), New Orleans, LA, USA, 2–7 February 2018; pp. 6069–6076. [Google Scholar]
- Qiu, Y.; Wang, Y.; Jin, X.; Zhang, K. Stepwise Reasoning for Multi-Relation Question Answering over Knowledge Graph with Weak Supervision. In Proceedings of the Thirteenth ACM International Conference on Web Search and Data Mining, Singapore, 3–7 February 2020; pp. 474–482. [Google Scholar]
- Saxena, A.; Tripathi, A.; Talukdar, P. Improving Multi-Hop Question Answering over Knowledge Graphs using Knowledge Base Embeddings. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 4498–4507. [Google Scholar]
- Trouillon, T.; Welbl, J.; Riedel, S.; Gaussier, É.; Bouchard, G. Complex Embeddings for Simple Link Prediction. In Proceedings of the 33nd International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 2071–2080. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Jin, W.; Zhao, B.; Yu, H.; Tao, X.; Yin, R.; Liu, G. Improving embedded knowledge graph multi-hop question answering by introducing relational chain reasoning. Data Min. Knowl. Discov. 2023, 37, 255–288. [Google Scholar] [CrossRef]
- He, G.; Lan, Y.; Jiang, J.; Zhao, W.X.; Wen, J.R. Improving Multi-Hop Knowledge Base Question Answering by Learning Intermediate Supervision Signals; The Association for Computational Linguistics: Toronto, ON, Canada, 2021; pp. 553–561. [Google Scholar]
- Miller, A.; Fisch, A.; Dodge, J.; Karimi, A.H.; Bordes, A.; Weston, J. Key-Value Memory Networks for Directly Reading Documents. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–4 November 2016; pp. 1400–1490. [Google Scholar]
- Chen, H.; Ji, H.; Sun, L.; Wang, H.; Qian, T.; Ruan, T. Knowledge Graph and Semantic Computing: Semantic, Knowledge, and Linked Big Data. Commun. Comput. Inf. Sci. 2016, 650. [Google Scholar]
- Liu, W.; Zhou, P.; Zhao, Z.; Wang, Z.; Ju, Q.; Deng, H.; Wang, P. K-BERT: Enabling Language Representation with Knowledge Graph. In Proceedings of the Tenth AAAI Symposium on Educational Advances in Artificial Intelligence, Hangzhou, China, 7–12 February 2020; pp. 2901–2908. [Google Scholar]
- Beltagy, I.; Peters, M.E.; Cohan, A. Longformer: The Long-Document Transformer. arXiv 2020, arXiv:2004.05150. [Google Scholar]
- Yih, W.T.; Richardson, M.; Meek, C.; Chang, M.W.; Suh, J. The Value of Semantic Parse Labeling for Knowledge Base Question Answering. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016. [Google Scholar]
- Bollacker, K.; Evans, C.; Paritosh, P.; Sturge, T.; Taylor, J. Freebase: A Collaboratively Created Graph Database for Structuring Human Knowledge. In Proceedings of the ACM SIGMOD International Conference on Management, Vancouver, BC, Canada, 10–12 June 2008; pp. 1247–1250. [Google Scholar]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Liu, L.; Jiang, H.; He, P.; Chen, W.; Liu, X.; Gao, J.; Han, J. On the Variance of the Adaptive Learning Rate and Beyond. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 26–30 April 2020. [Google Scholar]
- Li, F.; Chen, M.; Dong, R. Multi-hop Question Answering with Knowledge Graph Embedding in a Similar Semantic Space. In Proceedings of the International Joint Conference on Neural Networks, Budapest, Hungary, 18–23 July 2022; pp. 1–7. [Google Scholar]
- Jiao, S.; Zhu, Z.; Wu, W.; Zuo, Z.; Qi, J.; Wang, W.; Zhang, G.; Liu, P. An improving reasoning network for complex question answering over temporal knowledge graphs. Appl. Intell. 2023, 53, 8195–8208. [Google Scholar] [CrossRef]
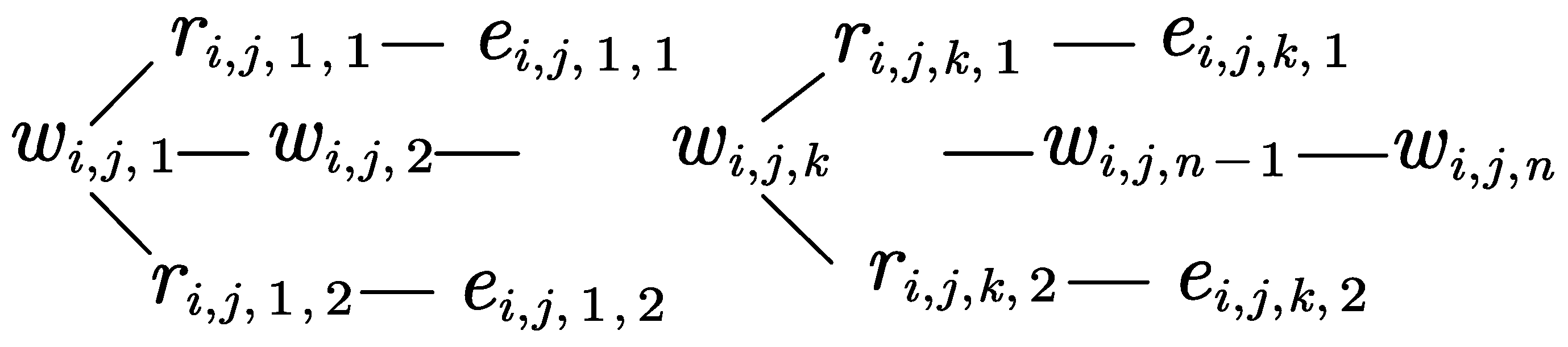
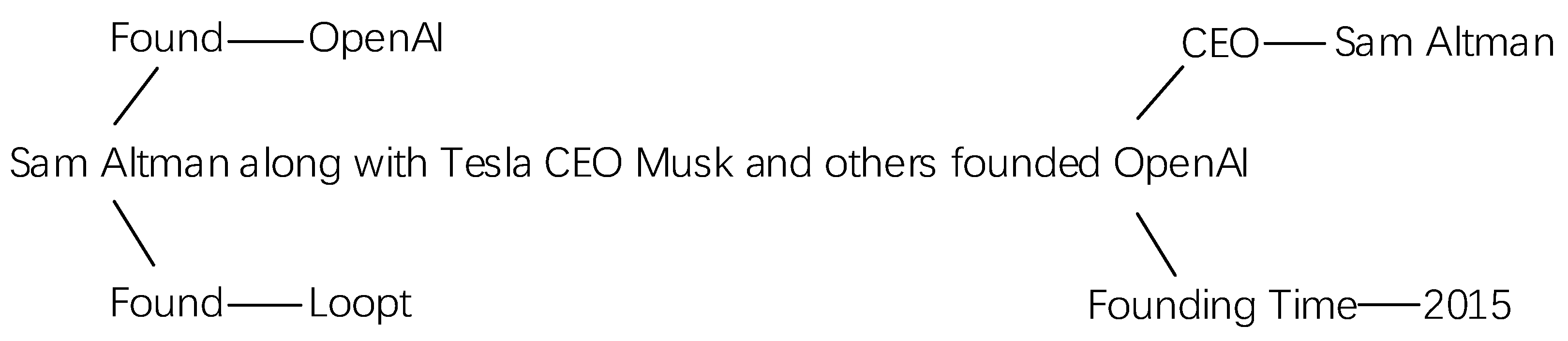



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Train | Dev | Test |
|---|---|---|---|
| MetaQA 1-hop | 96,106 | 9992 | 9947 |
| MetaQA 2-hop | 118,948 | 14,872 | 14,872 |
| MetaQA 3-hop | 114,196 | 14,274 | 14,274 |
| WebQSP | 2998 | 100 | 1639 |
| ComWebQ | 27,623 | 3518 | 3531 |
| Operating System | Type |
|---|---|
| CPU | Intel(R) Xeon(R) CPU E5-2620 v4 @ 2.10 GHz |
| GPU | 8 NVIDIA Corporation GP102 [TITAN Xp] |
| Python | 3.6.6 |
| Pytorch | 1.3.1 |
| Parameter | MetaQA | WebQSP | CompWebQ |
|---|---|---|---|
| Max_seq_length | 1024 | 1024 | 1024 |
| Epochs | 20 | 20 | 20 |
| Batch_Size | 64 | 64 | 64 |
| Hidden dimensions | 768 | 768 | 768 |
| Learning rate | 3 × 10−5 | 3 × 10−5 | 3 × 10−5 |
| Init_sliding_windows | 128 | 128 | 128 |
| Threshold | 0.7 | 0.7 | 0.7 |
| Model | MetaQA | WebQSP | ComWebQ | ||
|---|---|---|---|---|---|
| 1-Hop | 2-Hop | 3-Hop | |||
| KVMemNN [22] | 95.8 | 25.1 | 10.1 | 46.7 | 21.1 |
| VRN [15] | 97.5 | 89.9 | 62.5 | - | - |
| GraftNet [4] | 97.0 | 94.8 | 77.7 | 66.4 | 32.8 |
| PullNet [6] | 97.0 | 99.9 | 91.4 | 68.1 | 47.2 |
| SRN [16] | 97.0 | 95.1 | 75.5 | - | - |
| ReifKB [12] | 96.2 | 81.1 | 72.3 | 52.7 | - |
| EmbedKGQA [17] | 97.5 | 98.8 | 94.8 | 66.6 | - |
| TransferNet [10] | 97.5 | 100 | 100 | 71.4 | 48.6 |
| RKEKGQA (our) | 97.3 | 99.1 | 98.4 | 71.6 | 49.2 |
| Model | MetaQA Text + 50% Label | ||
|---|---|---|---|
| 1-Hop | 2-Hop | 3-Hop | |
| KVMemNN | 75.7 | 48.4 | 35.2 |
| GraftNet | 91.5 | 69.5 | 66.4 |
| PullNet | 92.4 | 90.4 | 85.2 |
| TransferNet | 95.5 | 98.1 | 94.3 |
| RKEKGQA (our) | 96.1 | 97.4 | 95.2 |
| Model | MetaQA | WebQSP | ComWebQ |
|---|---|---|---|
| RKEKGQA | 98.2 | 71.6 | 49.2 |
| w/o global attention | 95.2 | 62.4 | 42.8 |
| w/o threshold | 96.4 | 65.3 | 45.6 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, T.; Huang, R.; Wang, H.; Zhi, H.; Liu, H. Multi-Hop Knowledge Graph Question Answer Method Based on Relation Knowledge Enhancement. Electronics 2023, 12, 1905. https://doi.org/10.3390/electronics12081905
Wang T, Huang R, Wang H, Zhi H, Liu H. Multi-Hop Knowledge Graph Question Answer Method Based on Relation Knowledge Enhancement. Electronics. 2023; 12(8):1905. https://doi.org/10.3390/electronics12081905
Chicago/Turabian StyleWang, Tianbin, Ruiyang Huang, Huansha Wang, Hongxin Zhi, and Hongji Liu. 2023. "Multi-Hop Knowledge Graph Question Answer Method Based on Relation Knowledge Enhancement" Electronics 12, no. 8: 1905. https://doi.org/10.3390/electronics12081905
APA StyleWang, T., Huang, R., Wang, H., Zhi, H., & Liu, H. (2023). Multi-Hop Knowledge Graph Question Answer Method Based on Relation Knowledge Enhancement. Electronics, 12(8), 1905. https://doi.org/10.3390/electronics12081905