
A Family of Automatic Modulation Classification Models Based on Domain Knowledge for Various Platforms

 , , , , , and
, , , , , and
Abstract
1. Introduction
- We propose a family of AMC models based on domain knowledge for various platforms. The model can be configured for different resource constraints by tuning the branches, network width, depth, convolution kernel sizes, and basic modules.
- The proposed model achieves significantly higher top-1 and average classification accuracy while having much fewer parameters than the existing SOTA models, among which the lightweight model, which has only 4.61k parameters, has the fastest inference speed across the four different computing platforms. The high-accuracy models achieve new SOTA average accuracies of 64.63%, 67.22%, and 65.03% on three benchmark datasets, i.e., 2016A, 2016B, and 2018A, respectively.
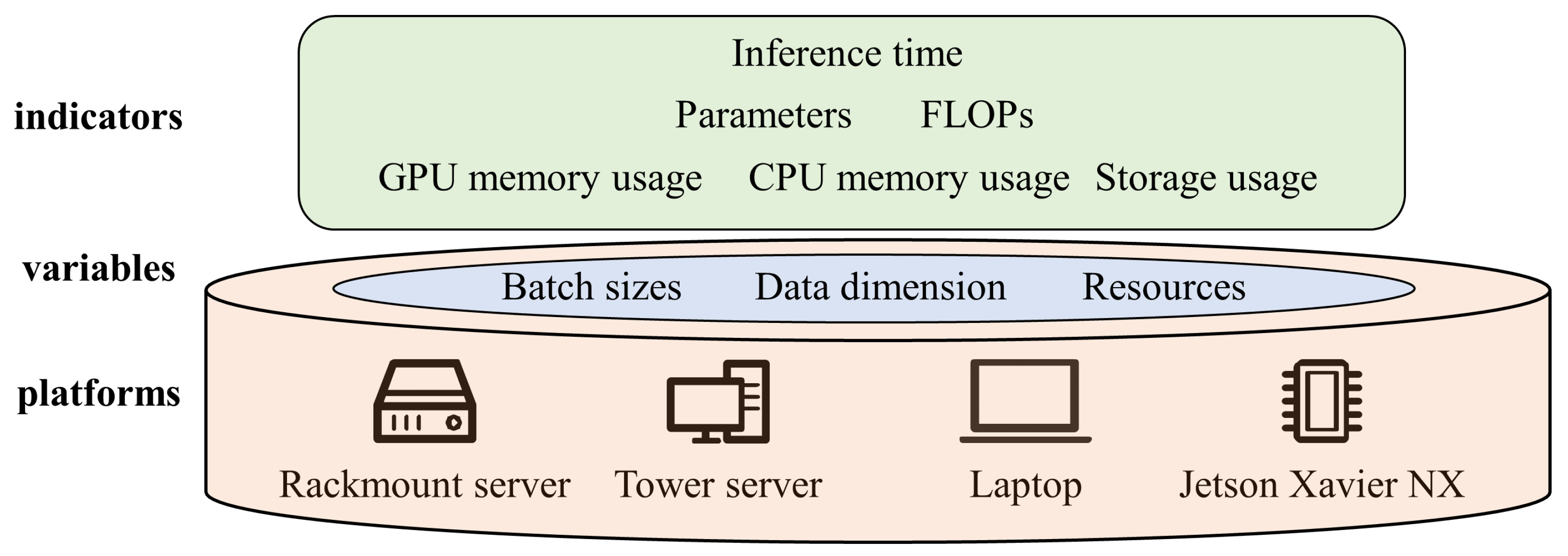
- To assess model complexity, we developed a multi-dimensional evaluation system. This system includes a variety of metrics, including the number of parameters, floating point operations (FLOPs), storage usage, memory usage, and inference time, to provide a thorough and comprehensive evaluation of the model’s complexity.
2. Methods
2.1. Problem Formulation
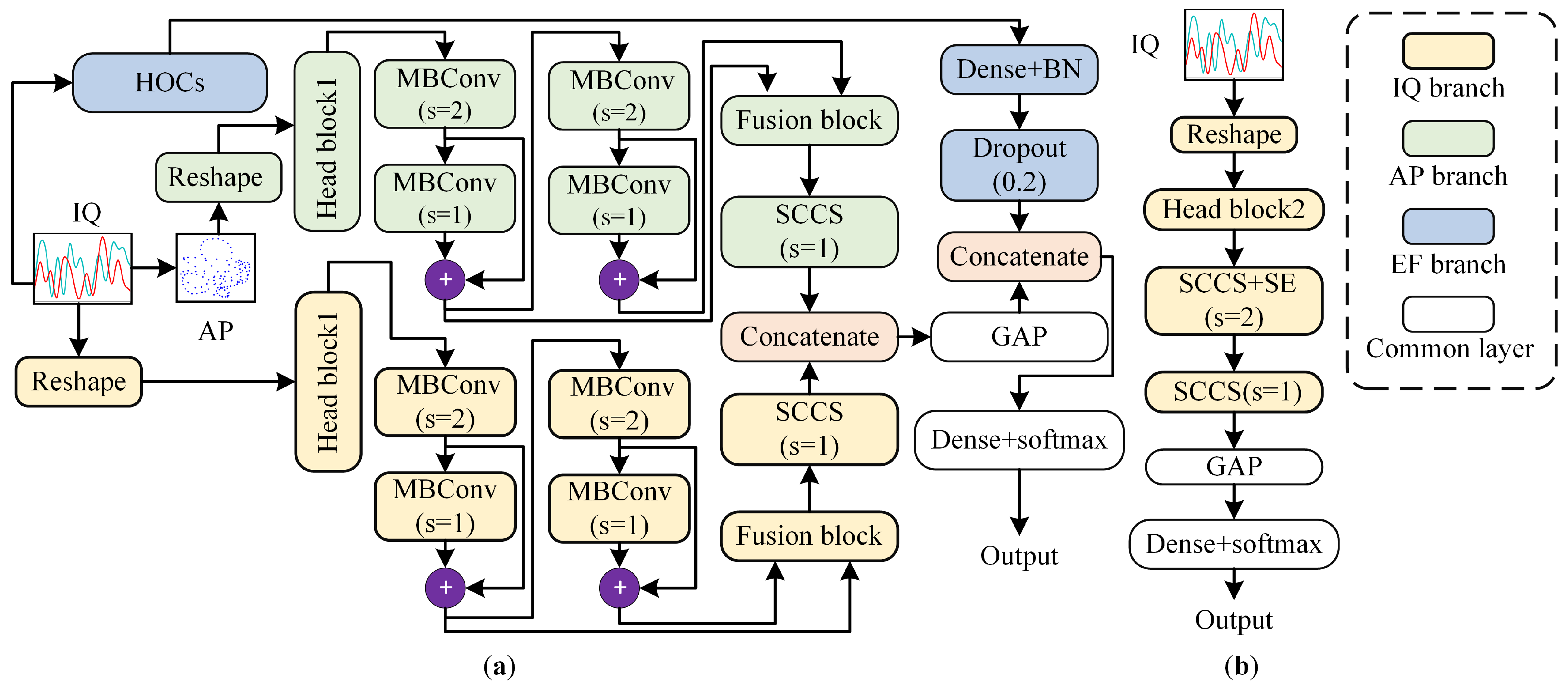
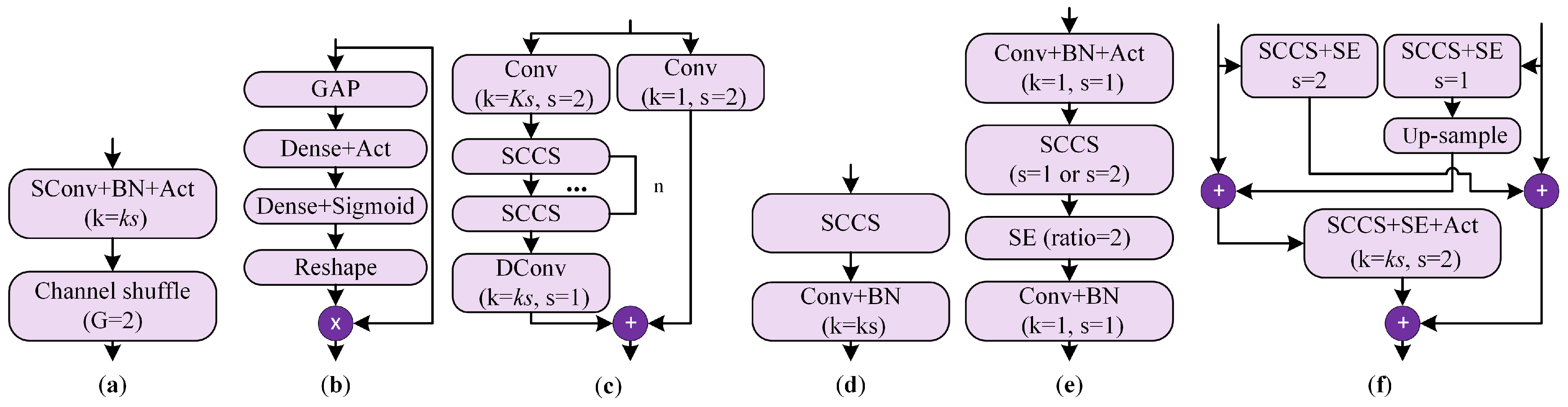
2.2. Network Architecture
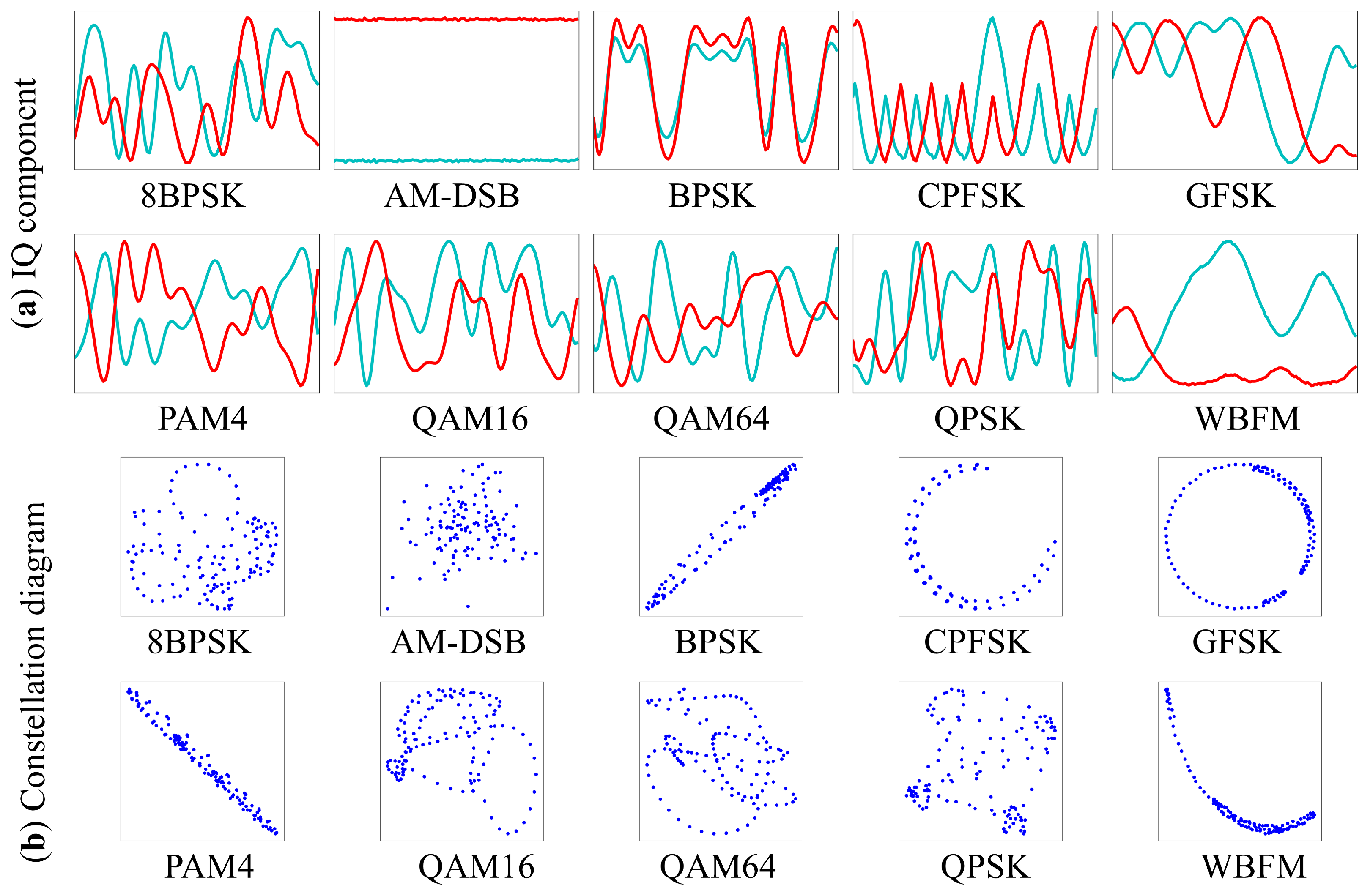
2.3. Incorporating Domain Knowledge to Create CNN-Based Models
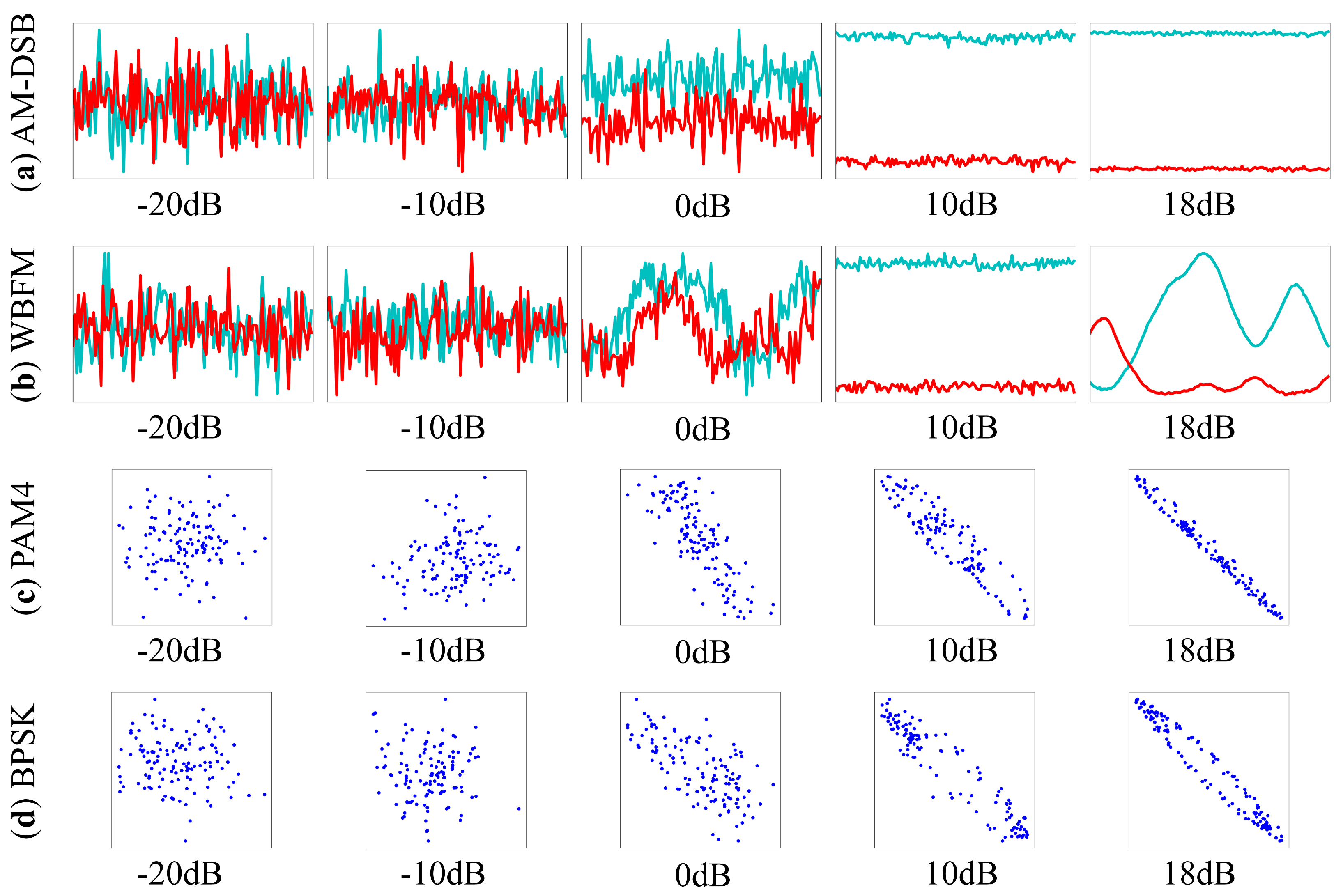
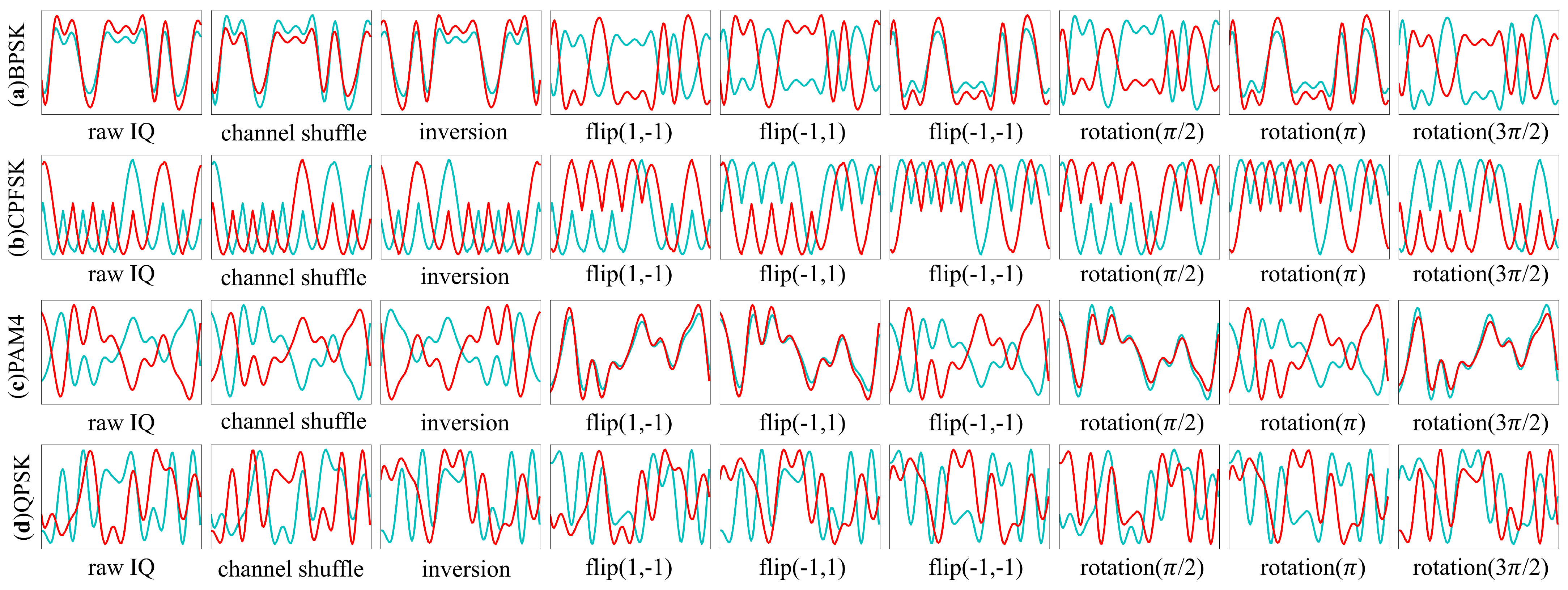
2.4. Random Data Augmentation for AMC
2.5. Strategy for Hyperparameter Optimization
3. Results and Discussion
3.1. Experimental Settings
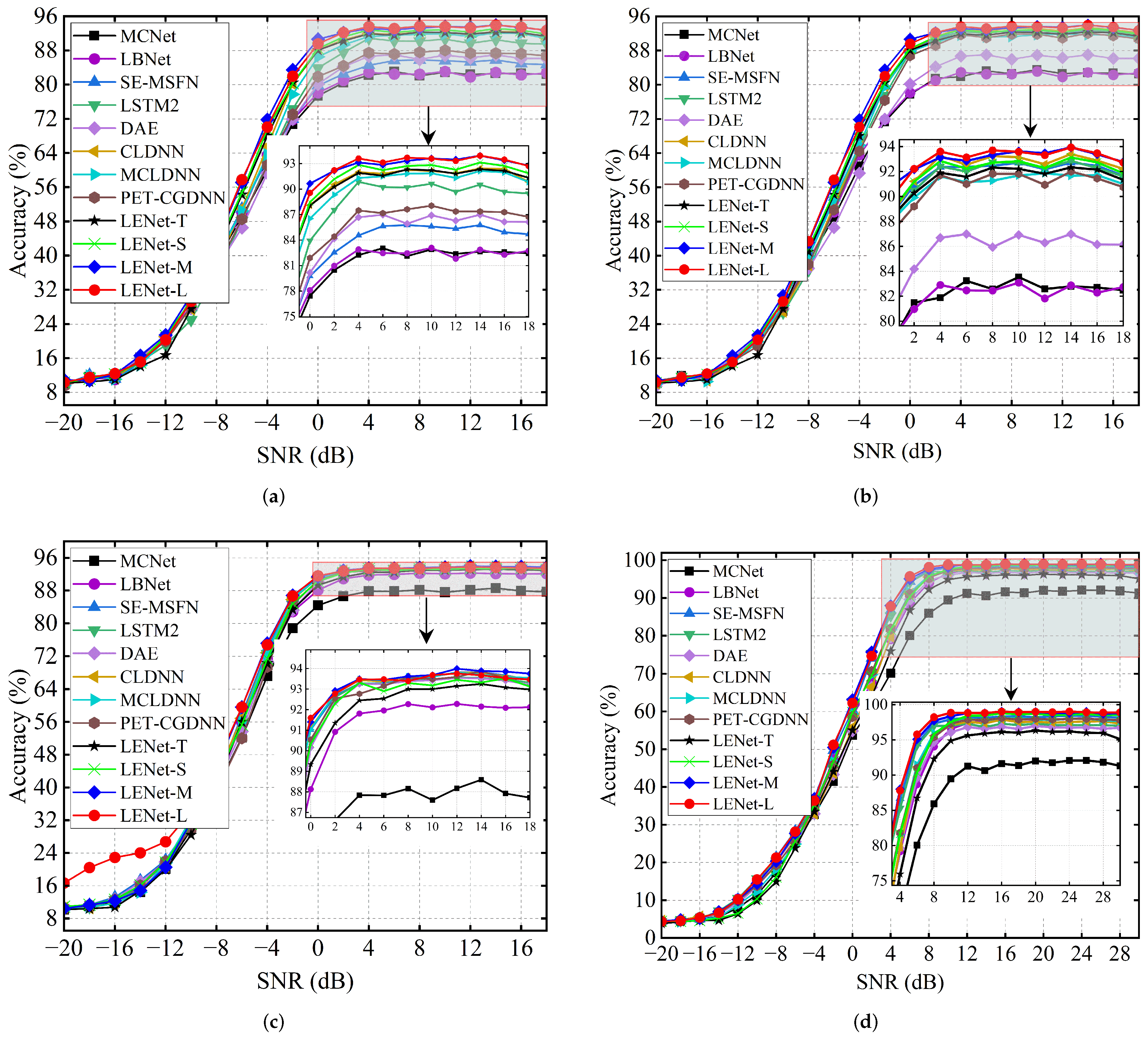
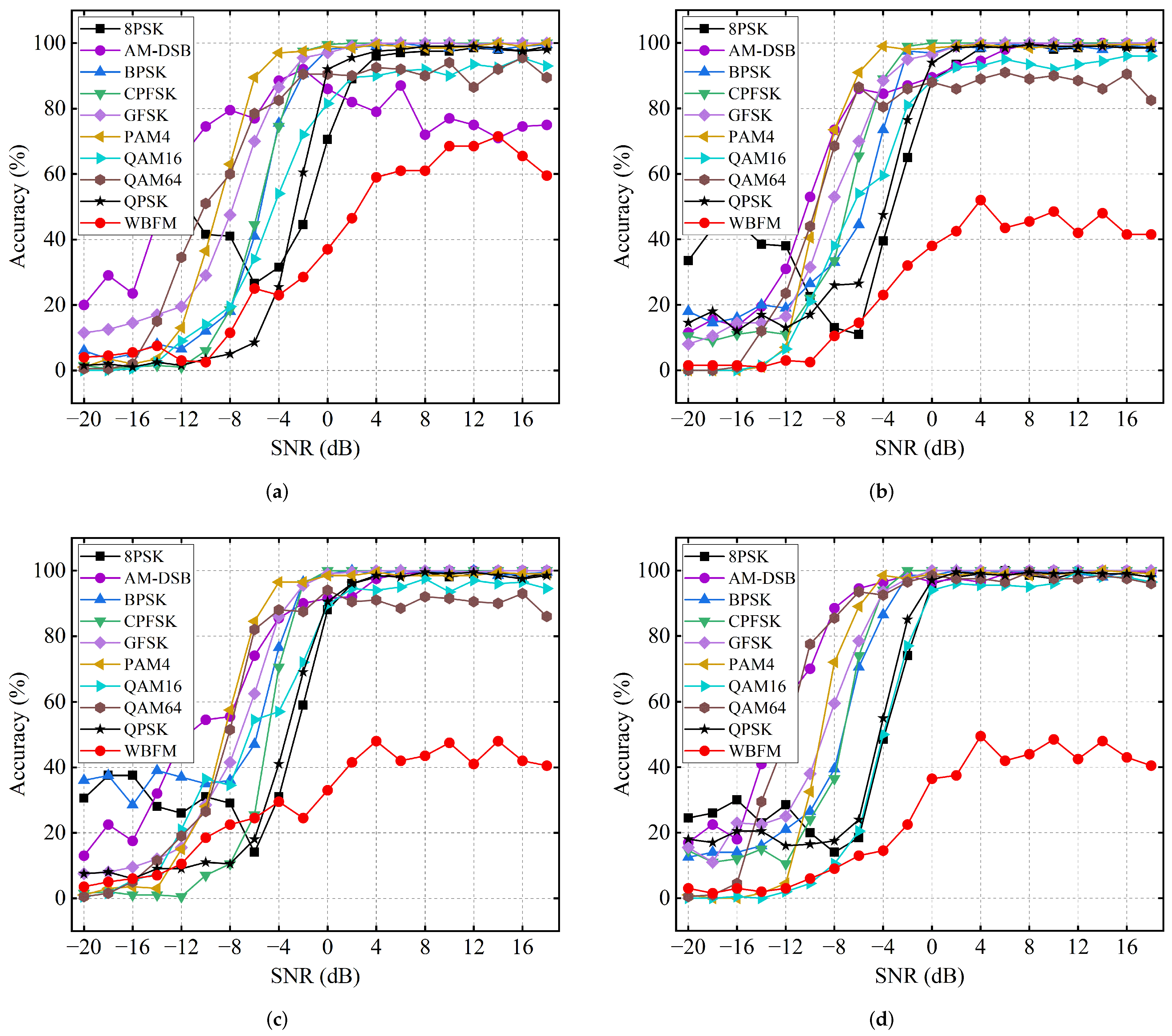
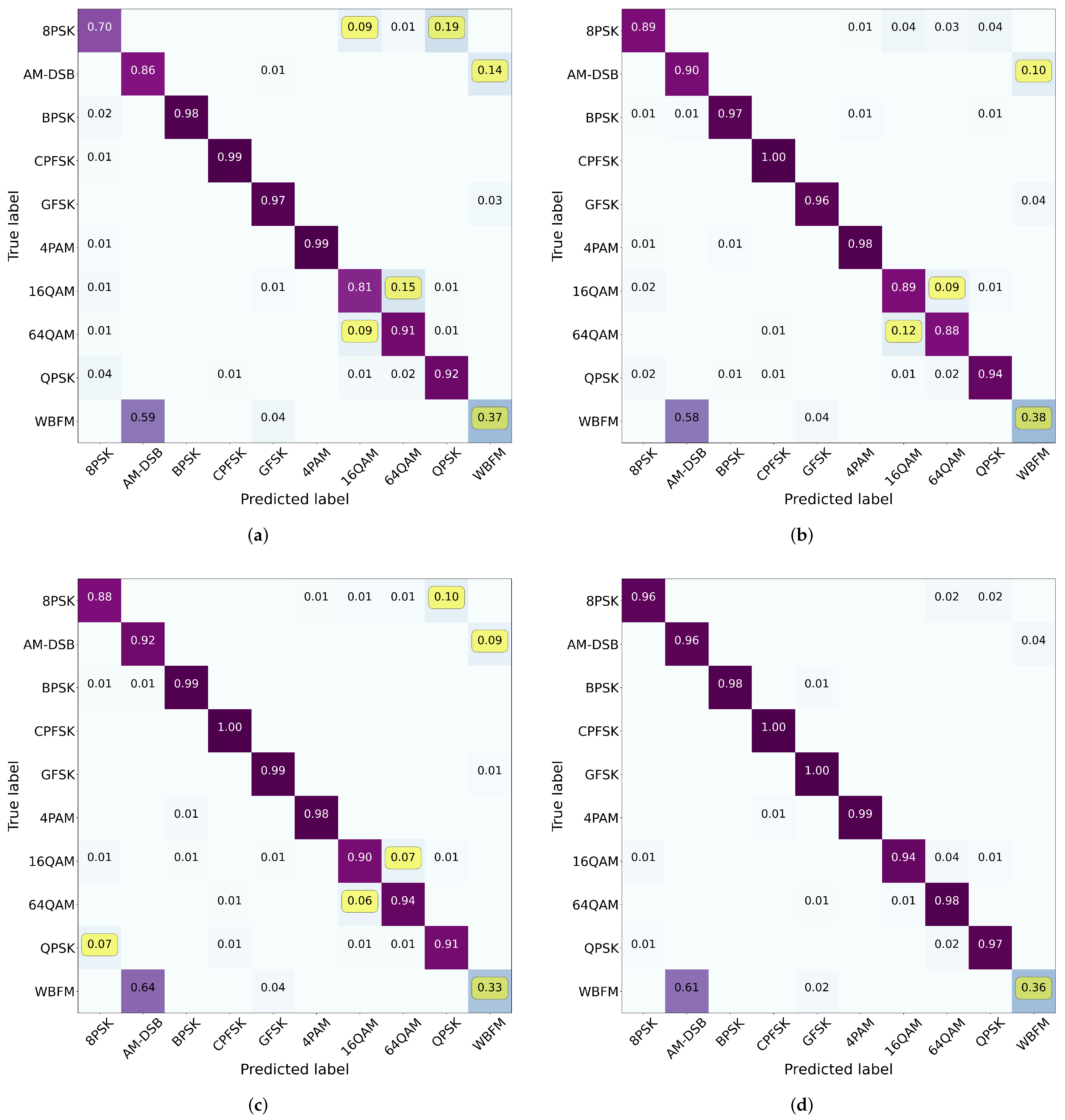
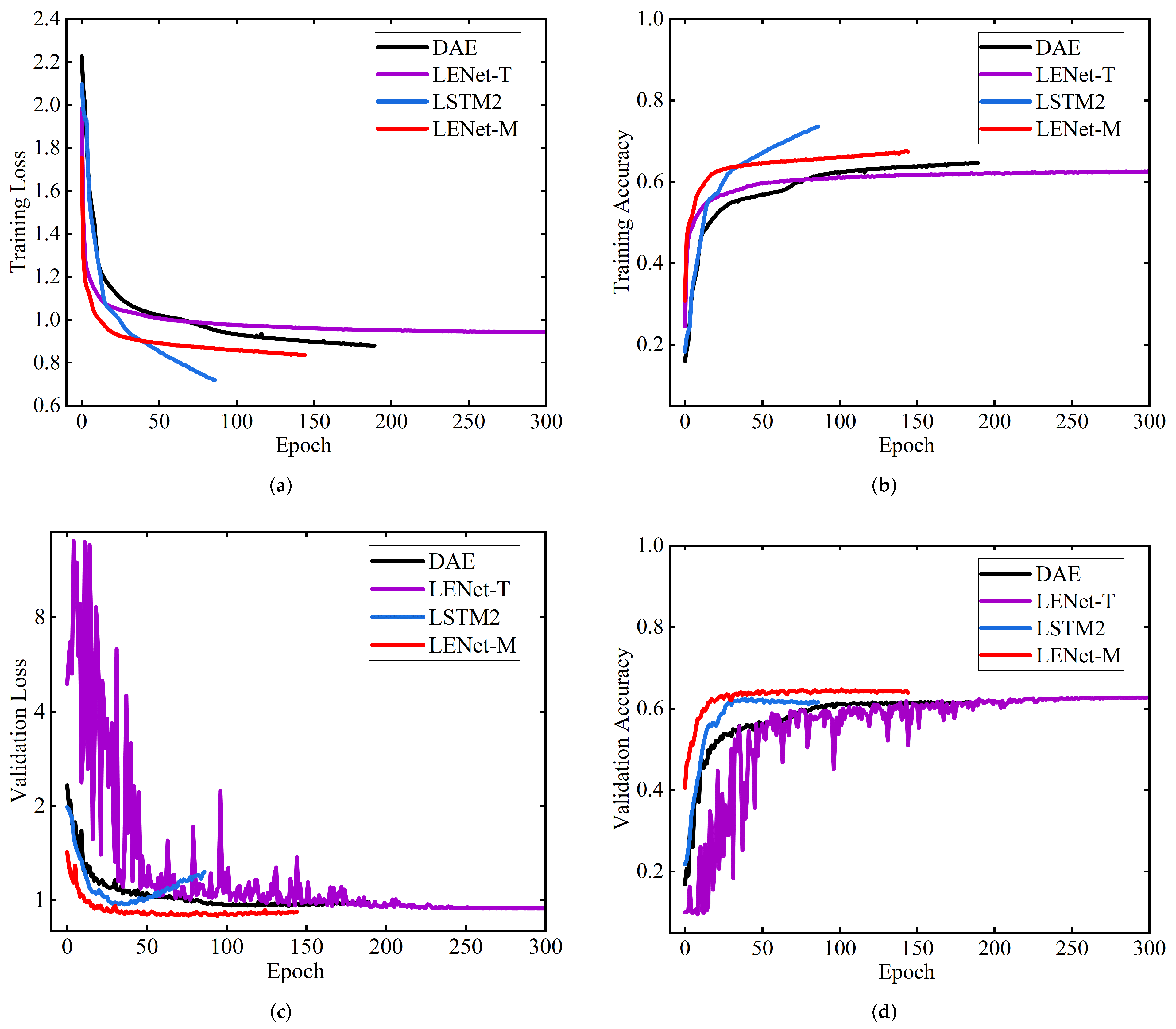
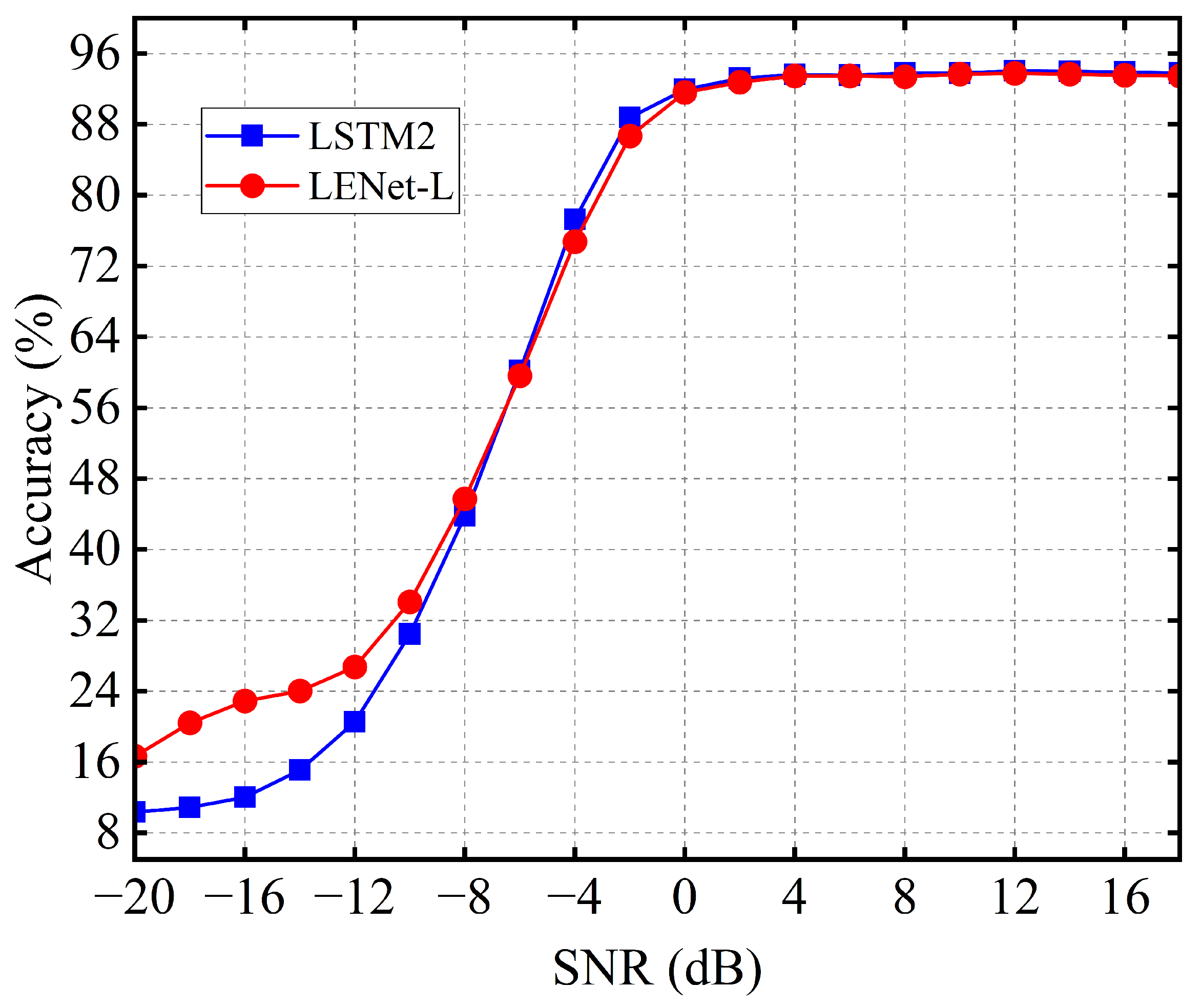
3.2. Comparison with SOTA Models
3.3. Data Augmentation
3.4. Ablation Study
3.5. Complexity Analysis
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Jagannath, A.; Jagannath, J.; Melodia, T. Redefining Wireless Communication for 6G: Signal Processing Meets Deep Learning with Deep Unfolding. IEEE Trans. Artif. Intell. 2021, 2, 528–536. [Google Scholar] [CrossRef]
- O’Shea, T.J.; Roy, T.; Clancy, T.C. Over-the-Air Deep Learning Based Radio Signal Classification. IEEE J. Sel. Top. Signal Process. 2018, 12, 168–179. [Google Scholar] [CrossRef]
- Huynh-The, T.; Hua, C.H.; Pham, Q.V.; Kim, D.S. MCNet: An Efficient CNN Architecture for Robust Automatic Modulation Classification. IEEE Commun. Lett. 2020, 24, 811–815. [Google Scholar] [CrossRef]
- Shi, F.; Yue, C.; Han, C. A lightweight and efficient neural network for modulation recognition. Digit. Signal Process. Rev. J. 2022, 123, 103444. [Google Scholar] [CrossRef]
- Wu, X.; Wei, S.; Zhou, Y. Deep Multi-Scale Representation Learning with Attention for Automatic Modulation Classification. In Proceedings of the International Joint Conference on Neural Networks (IJCNN), Padua, Italy, 18–23 July 2022. [Google Scholar]
- Meng, F.; Chen, P.; Wu, L.; Wang, X. Automatic modulation classification: A deep learning enabled approach. IEEE Trans. Veh. Technol. 2018, 67, 10760–10772. [Google Scholar] [CrossRef]
- Xu, Y.; Li, D.; Wang, Z.; Guo, Q.; Xiang, W. A deep learning method based on convolutional neural network for automatic modulation classification of wireless signals. Wirel. Netw. 2019, 25, 3735–3746. [Google Scholar] [CrossRef]
- Rajendran, S.; Meert, W.; Giustiniano, D.; Lenders, V.; Pollin, S. Deep Learning Models for Wireless Signal Classification with Distributed Low-Cost Spectrum Sensors. IEEE Trans. Cogn. Commun. Netw. 2018, 4, 433–445. [Google Scholar] [CrossRef]
- Ke, Z.; Vikalo, H. Real-Time Radio Technology and Modulation Classification via an LSTM Auto-Encoder. IEEE Trans. Wirel. Commun. 2022, 21, 370–382. [Google Scholar] [CrossRef]
- West, N.E.; O’Shea, T. Deep architectures for modulation recognition. In Proceedings of the 2017 IEEE International Symposium on Dynamic Spectrum Access Networks (DySPAN), Baltimore, MD, USA, 6–9 March 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Xu, J.; Luo, C.; Parr, G.; Luo, Y. A Spatiotemporal Multi-Channel Learning Framework for Automatic Modulation Recognition. IEEE Wirel. Commun. Lett. 2020, 9, 1629–1632. [Google Scholar] [CrossRef]
- Zhang, F.; Luo, C.; Xu, J.; Luo, Y. An Efficient Deep Learning Model for Automatic Modulation Recognition Based on Parameter Estimation and Transformation. IEEE Commun. Lett. 2021, 25, 3287–3290. [Google Scholar] [CrossRef]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. Yolox: Exceeding yolo series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar] [CrossRef]
- Tan, M.; Le, Q.V. EfficientNet: Rethinking model scaling for convolutional neural networks. In Proceedings of the 36th International Conference on Machine Learning, ICML 2019, Long Beach, CA, USA, 9–15 June 2019; pp. 10691–10700. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 6848–6856. [Google Scholar]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2011–2023. [Google Scholar] [CrossRef] [PubMed]
- Abdelmutalab, A.; Assaleh, K.; El-Tarhuni, M. Automatic modulation classification based on high order cumulants and hierarchical polynomial classifiers. Phys. Commun. 2016, 21, 10–18. [Google Scholar] [CrossRef]
- O’Shea, T.J.; West, N. Radio Machine Learning Dataset Generation with GNU Radio. In Proceedings of the GNU Radio Conference, Boulder, CO, USA, 12–16 September 2016. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Wang, Y.; Yang, J.; Liu, M.; Gui, G. LightAMC: Lightweight automatic modulation classification via deep learning and compressive sensing. IEEE Trans. Veh. Technol. 2020, 69, 3491–3495. [Google Scholar] [CrossRef]
- Zhang, Y.; Cui, M.; Shen, L.; Zeng, Z. Memristive quantized neural networks: A novel approach to accelerate deep learning on-chip. IEEE Trans. Cybern. 2019, 51, 1875–1887. [Google Scholar] [CrossRef]
- Ma, H.; Xu, G.; Meng, H.; Wang, M.; Yang, S.; Wu, R.; Wang, W. Cross model deep learning scheme for automatic modulation classification. IEEE Access 2020, 8, 78923–78931. [Google Scholar] [CrossRef]
- Wang, J.; Sun, K.; Cheng, T.; Jiang, B.; Deng, C.; Zhao, Y.; Liu, D.; Mu, Y.; Tan, M.; Wang, X.; et al. Deep High-Resolution Representation Learning for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 3349–3364. [Google Scholar] [CrossRef] [PubMed]
- Liu, X.; Li, C.J.; Jin, C.T.; Leong, P.H.W. Wireless Signal Representation Techniques for Automatic Modulation Classification. IEEE Access 2022, 10, 84166–84187. [Google Scholar] [CrossRef]
- Majhi, S.; Gupta, R.; Xiang, W.; Glisic, S. Hierarchical Hypothesis and Feature-Based Blind Modulation Classification for Linearly Modulated Signals. IEEE Trans. Veh. Technol. 2017, 66, 11057–11069. [Google Scholar] [CrossRef]
- Caterini, A.L.; Chang, D.E. Deep Neural Networks in a Mathematical Framework; Springer: Berlin/Heidelberg, Germany, 2018. [Google Scholar]
- Huang, L.; Pan, W.; Zhang, Y.; Qian, L.; Gao, N.; Wu, Y. Data Augmentation for Deep Learning-Based Radio Modulation Classification. IEEE Access 2020, 8, 1498–1506. [Google Scholar] [CrossRef]
- Cubuk, E.D.; Zoph, B.; Mané, D.; Vasudevan, V.; Le, Q.V. AutoAugment: Learning Augmentation Strategies From Data. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 113–123. [Google Scholar] [CrossRef]
- Cubuk, E.D.; Zoph, B.; Shlens, J.; Le, Q.V. Randaugment: Practical automated data augmentation with a reduced search space. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 3008–3017. [Google Scholar]
- Wei, S.; Sun, Z.; Wang, Z.; Liao, F.; Li, Z.; Mi, H. An Efficient Data Augmentation Method for Automatic Modulation Recognition from Low-Data Imbalanced-Class Regime. Appl. Sci. 2023, 13, 3177. [Google Scholar] [CrossRef]
- Radiuk, P.M. Impact of training set batch size on the performance of convolutional neural networks for diverse datasets. Inf. Technol. Manag. Sci. 2017, 20, 20–24. [Google Scholar] [CrossRef]
- Keskar, N.S.; Mudigere, D.; Nocedal, J.; Smelyanskiy, M.; Tang, P.T.P. On large-batch training for deep learning: Generalization gap and sharp minima. arXiv 2016, arXiv:1609.04836. [Google Scholar]
- Kandel, I.; Castelli, M. The effect of batch size on the generalizability of the convolutional neural networks on a histopathology dataset. ICT Express 2020, 6, 312–315. [Google Scholar] [CrossRef]
- Masters, D.; Luschi, C. Revisiting small batch training for deep neural networks. arXiv 2018, arXiv:1804.07612. [Google Scholar]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. TensorFlow: A system for Large-Scale machine learning. In Proceedings of the 12th USENIX Symposium on Operating Systems Design and Implementation (OSDI 16), Savannah, GA, USA, 2–4 November 2016; pp. 265–283. [Google Scholar]
- Zhang, H.; Cisse, M.; Dauphin, Y.; Lopez-Paz, D. mixup: Beyond empirical risk management. In Proceedings of the 6th Int. Conf. Learning Representations (ICLR), Vancouver, BC, Canada, 30 April–3 May 2018; pp. 1–13. [Google Scholar]
- Lewy, D.; Mańdziuk, J. An overview of mixing augmentation methods and augmentation strategies. Artif. Intell. Rev. 2023, 56, 2111–2169. [Google Scholar] [CrossRef]
- Iwana, B.K.; Uchida, S. An empirical survey of data augmentation for time series classification with neural networks. PLoS ONE 2021, 16, e0254841. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Modules/Parameters | LENet-T | LENet-S | LENet-M | LENet-L |
|---|---|---|---|---|
| Input | IQ | IQ + HOCs | IQ + HOCs | IQ + AP + HOCs |
| Head | Head block1 | Head block2 | Head block2 | Head block2 |
| Feature extraction | (SCCS + SE)*1 | (SCCS + SE)*4 | (SCCS + SE)*4 | (MBConv + SE)*4 |
| Fusion | SCCS + SE + Act | Fusion block | Fusion block | Fusion block |
| f | 16 | 16 | 32 | 32 |
| ks | (8, 2) | (8, 2) | (15, 2) | (15, 2) |
| d | 0 | 0 | 36 | 36 |
| Dataset | Dataset Size | Training Set | Validation Set | Testing Set |
|---|---|---|---|---|
| 2016A | 200,000 | 120,000 | 40,000 | 40,000 |
| 2016B | 1,200,000 | 720,000 | 240,000 | 240,000 |
| 2018A | 2,555,904 | 2,044,722 | 255,591 | 255,591 |
| Statistics | MCNet | LBNet | SE- MSFN | LSTM2 | DAE | CLDNN | MCL DNN | PET- CGDNN | LENet | |||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| T | S | M | L | |||||||||
| −20∼−12 dB | 13.88 | 13.74 | 14.04 | 13.64 | 14.02 | 13.42 | 13.32 | 13.61 | 12.50 | 14.03 | 14.17 | 13.96 |
| −10∼−2 dB | 49.39 | 50.48 | 54.20 | 51.34 | 48.50 | 52.37 | 53.25 | 51.48 | 54.24 | 56.77 | 57.56 | 56.51 |
| 0∼10 dB | 81.74 | 81.66 | 91.50 | 91.35 | 85.14 | 91.93 | 90.56 | 90.39 | 91.06 | 92.22 | 93.19 | 92.63 |
| 12∼18 dB | 82.64 | 82.43 | 92.26 | 92.25 | 86.39 | 92.77 | 91.56 | 91.28 | 91.91 | 92.88 | 93.69 | 93.36 |
| −20∼18 dB | 56.87 | 57.04 | 62.96 | 62.10 | 58.45 | 62.58 | 62.12 | 61.65 | 62.38 | 63.94 | 64.63 | 64.08 |
| Highest accuary | 83.53 | 83.08 | 92.72 | 92.85 | 86.98 | 93.40 | 91.87 | 92.00 | 92.33 | 93.75 | 93.93 | 93.93 |
| Statistics | MCNet | LBNet | SE- MSFN | LSTM2 | DAE | CLDNN | MCL DNN | PET- CGDNN | LENet | |||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| T | S | M | L | |||||||||
| −20∼−12 dB | 13.51 | 14.35 | 14.98 | 13.90 | 14.60 | 13.75 | 13.76 | 14.47 | 13.22 | 14.54 | 13.88 | 22.15 |
| −10∼−2 dB | 53.51 | 56.20 | 58.07 | 57.03 | 56.00 | 57.96 | 57.83 | 55.01 | 55.79 | 57.04 | 59.59 | 60.18 |
| 0∼10 dB | 87.07 | 91.20 | 92.89 | 92.75 | 92.64 | 92.99 | 93.00 | 92.68 | 91.95 | 92.55 | 93.09 | 93.07 |
| 12∼18 dB | 88.10 | 92.16 | 93.69 | 93.48 | 93.42 | 93.69 | 93.66 | 93.61 | 93.12 | 93.35 | 93.87 | 93.61 |
| −20∼18 dB | 60.50 | 63.43 | 64.87 | 64.25 | 64.12 | 64.56 | 64.53 | 63.90 | 63.46 | 64.33 | 65.07 | 67.22 |
| Highest accuary | 88.59 | 92.28 | 93.82 | 93.56 | 93.54 | 93.80 | 93.81 | 93.87 | 93.25 | 93.52 | 93.99 | 93.76 |
| Statistics | MCNet | LBNet | SE- MSFN | LSTM2 | DAE | CLDNN | MCL DNN | PET- CGDNN | LENet | |||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| T | S | M | L | |||||||||
| −20∼−8 dB | 8.05 | 9.55 | 9.68 | 9.69 | 8.95 | 9.26 | 8.32 | 9.17 | 6.96 | 7.39 | 9.49 | 9.74 |
| −6∼6 dB | 52.15 | 57.70 | 61.46 | 61.57 | 56.05 | 56.58 | 58.41 | 58.29 | 54.75 | 58.43 | 62.46 | 62.34 |
| 8∼20 dB | 90.33 | 97.08 | 98.06 | 97.11 | 96.36 | 97.24 | 97.59 | 97.49 | 95.32 | 98.06 | 98.66 | 98.81 |
| 22∼30 dB | 91.81 | 97.89 | 98.33 | 97.08 | 96.72 | 97.51 | 97.87 | 97.92 | 95.89 | 98.58 | 98.83 | 98.93 |
| −20∼30 dB | 58.18 | 63.07 | 64.46 | 64.00 | 62.04 | 62.66 | 63.06 | 63.24 | 60.72 | 63.08 | 64.94 | 65.03 |
| Highest accuary | 92.08 | 98.09 | 98.45 | 97.30 | 96.97 | 97.89 | 98.12 | 98.10 | 96.33 | 98.79 | 99.02 | 99.03 |
| S | −20 dB∼−12 dB | −10 dB∼−2 dB | 0 dB∼10 dB | 12 dB∼18 dB | All SNRs | Highest Accuary | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Mean | Std | Mean | Std | Mean | Std | Mean | Std | Mean | Std | Mean | Std | |
| 0 | 13.88 | 0.61 | 53.83 | 0.95 | 90.09 | 0.97 | 91.33 | 0.74 | 62.22 | 0.30 | 91.95 | 0.69 |
| 1 | 13.56 | 0.47 | 55.93 | 0.62 | 92.00 | 0.41 | 92.94 | 0.40 | 63.56 | 0.40 | 93.70 | 0.39 |
| 2 | 13.69 | 0.34 | 56.24 | 0.93 | 92.21 | 0.29 | 92.92 | 0.45 | 63.73 | 0.48 | 93.45 | 0.36 |
| 3 | 13.56 | 0.47 | 55.93 | 0.62 | 92.00 | 0.41 | 92.94 | 0.40 | 63.56 | 0.40 | 91.95 | 0.69 |
| 4 | 14.03 | 0.21 | 56.77 | 0.58 | 92.22 | 0.38 | 92.88 | 0.09 | 63.94 | 0.26 | 93.70 | 0.39 |
| Methods | −20 dB∼−12 dB | −10 dB∼−2 dB | 0 dB∼10 dB | 12 dB∼18 dB | All SNRs | Highest Accuary | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Mean | Std | Mean | Std | Mean | Std | Mean | Std | Mean | Std | Mean | Std | |
| w/o augmentation | 13.88 | 0.61 | 53.83 | 0.95 | 90.09 | 0.97 | 91.33 | 0.74 | 62.22 | 0.30 | 91.95 | 0.69 |
| Rotation | 13.21 | 0.30 | 55.88 | 0.17 | 92.01 | 0.30 | 92.80 | 0.30 | 63.44 | 0.20 | 93.45 | 0.25 |
| Flip | 13.54 | 0.78 | 53.61 | 0.90 | 91.33 | 0.73 | 92.15 | 0.67 | 62.61 | 0.48 | 92.88 | 0.59 |
| Channel shuffle | 14.19 | 0.26 | 54.36 | 0.57 | 91.21 | 0.46 | 92.11 | 0.60 | 62.92 | 0.46 | 92.82 | 0.38 |
| Inversion | 14.59 | 0.55 | 54.11 | 0.46 | 91.35 | 0.60 | 92.31 | 0.28 | 63.04 | 0.45 | 93.00 | 0.31 |
| SigAugment | 14.03 | 0.21 | 56.77 | 0.58 | 92.22 | 0.38 | 92.88 | 0.09 | 63.94 | 0.26 | 93.70 | 0.39 |
| Methods | −20 dB∼−12 dB | −10 dB∼−2 dB | 0 dB∼10 dB | 12 dB∼18 dB | All SNRs | Highest Accuary | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Mean | Std | Mean | Std | Mean | Std | Mean | Std | Mean | Std | Mean | Std | |
| w/o augmentation | 14.72 | 0.89 | 54.27 | 0.75 | 90.90 | 0.21 | 92.03 | 0.10 | 62.93 | 0.20 | 92.78 | 0.19 |
| w/o EF | 13.49 | 0.46 | 57.05 | 0.89 | 92.43 | 0.26 | 93.26 | 0.32 | 64.02 | 0.45 | 93.87 | 0.18 |
| w/o CS | 13.96 | 0.30 | 56.87 | 1.09 | 92.69 | 0.30 | 93.52 | 0.20 | 64.22 | 0.32 | 94.07 | 0.18 |
| w/o SE | 13.11 | 0.47 | 54.09 | 1.69 | 90.41 | 1.58 | 91.23 | 1.41 | 62.17 | 1.18 | 91.92 | 1.40 |
| w/o 2D CK | 12.14 | 0.40 | 56.48 | 0.69 | 92.36 | 0.44 | 92.84 | 0.26 | 63.43 | 0.30 | 93.53 | 0.28 |
| Our model | 14.40 | 0.65 | 57.24 | 0.88 | 92.63 | 0.37 | 93.39 | 0.21 | 64.63 | 0.32 | 93.93 | 0.25 |
| Models | Params (k) | FLOPs (M) | Size (kb) | Memory (GB) | Time (s/Sample) | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| P1 | P2 | P3 | P4(CPU) | P4(GPU) | P1 | P2 | P3 | P4 | ||||
| LBNet | 44.11 | 2.99 | 262 | 2.6 | 2.9 | 2.9 | 3.4 | 3.2 | 6.38 × 10−5 | 6.03 × 10−5 | 4.32 × 10−5 | 3.36 × 10−4 |
| DAE | 14.97 | 0.21 | 92 | 0.7 | 1.2 | 1.0 | 3.2 | 1.3 | 6.85 × 10−5 | 7.30 × 10−5 | 6.29 × 10−5 | 4.18 × 10−4 |
| LENet-T | 4.61 | 0.38 | 115 | 0.8 | 1.0 | 1.3 | 3.3 | 1.4 | 5.29 × 10−5 | 3.37 × 10−5 | 2.54 × 10−5 | 2.77 × 10−4 |
| MCNet | 121.23 | 1.55 | 585 | 0.8 | 1.0 | 1.3 | 3.4 | 1.2 | 6.36 × 10−5 | 7.18 × 10−5 | 4.32 × 10−5 | 2.75 × 10−4 |
| PET-CGDNN | 71.74 | 1.43 | 316 | 2.7 | 3.1 | 3.0 | 3.7 | 3.3 | 5.15 × 10−5 | 5.39 × 10−5 | 3.65 × 10−5 | 6.36 × 10−4 |
| LENet-S | 14.72 | 0.5 | 266 | 2.7 | 2.9 | 2.9 | 3.6 | 3.2 | 5.25 × 10−5 | 4.96 × 10−5 | 4.05 × 10−5 | 6.58 × 10−4 |
| SE-MSFN | 327.66 | 12.08 | 1630 | 4.6 | 4.9 | 4.2 | 3.0 | 4.5 | 1.28 × 10−4 | 1.49 × 10−4 | 1.42 × 10−4 | 8.15 × 10−4 |
| LSTM2 | 200.97 | 1.32 | 804 | 1.2 | 1.5 | 1.9 | 3.4 | 2.1 | 6.21 × 10−5 | 1.03 × 10−4 | 6.77 × 10−5 | 4.32 × 10−4 |
| CLDNN | 106.06 | 0.54 | 438 | 2.7 | 3.0 | 3.0 | 3.6 | 3.3 | 5.14 × 10−5 | 6.04 × 10−5 | 3.52 × 10−5 | 2.41 × 10−4 |
| MCLDNN | 406.07 | 18.67 | 1633 | 4.7 | 5.1 | 4.4 | 3.0 | 4.8 | 1.04 × 10−4 | 1.00 × 10−4 | 6.90 × 10−5 | 6.23 × 10−4 |
| LENet-M | 55.86 | 1.9 | 437 | 4.7 | 4.9 | 4.2 | 3.3 | 4.0 | 6.61 × 10−4 | 3.34 × 10−4 | 2.09 × 10−4 | 1.60 × 10−3 |
| Batch Size | MCNet | LSTM2 | CLDNN | LENet-T | ||||
|---|---|---|---|---|---|---|---|---|
| Memory (GB) | Time (s/Sample) | Memory (GB) | Time (s/Sample) | Memory (GB) | Time (s/Sample) | Memory (GB) | Time (s/Sample) | |
| 128 | 1.0 | 7.18 × 10−5 | 1.5 | 1.04 × 10−4 | 3.0 | 6.04 × 10−5 | 1.1 | 4.61 × 10−5 |
| 256 | 1.1 | 4.35 × 10−5 | 2.2 | 6.44 × 10−5 | 5.1 | 3.96 × 10−5 | 1.2 | 2.94 × 10−5 |
| 512 | 1.4 | 3.05 × 10−5 | 3.5 | 4.63 × 10−5 | 2.6 | 2.70 × 10−5 | 1.5 | 2.28 × 10−5 |
| 1024 | 2.0 | 2.35 × 10−5 | 5.6 | 3.84 × 10−5 | 3.3 | 2.03 × 10−5 | 2.2 | 1.79 × 10−5 |
| 2048 | 3.1 | 2.03 × 10−5 | 10.4 | 3.83 × 10−5 | 3.5 | 1.74 × 10−5 | 3.5 | 1.64 × 10−5 |
| 3072 | 3.3 | 1.86 × 10−5 | 10.9 | 3.79 × 10−5 | 5.0 | 1.73 × 10−5 | 3.6 | 1.60 × 10−5 |
| 4096 | 5.3 | 1.83 × 10−5 | OOM | ∼ | 6.1 | 1.80 × 10−5 | 6.0 | 1.59 × 10−5 |
| Batch Size | MCNet | LSTM2 | CLDNN | LENet-T | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Memory (GB) | Time (s/Sample) | Memory (GB) | Time (s/Sample) | Memory (GB) | Time (s/Sample) | Memory (GB) | Time (s/Sample) | |||||
| CPU | GPU | CPU | GPU | CPU | GPU | CPU | GPU | |||||
| 128 | 3.4 | 1.2 | 2.89 × 10−4 | 3.4 | 2.1 | 4.32 × 10−4 | 3.6 | 3.3 | 2.41 × 10−4 | 3.3 | 1.4 | 2.90 × 10−4 |
| 256 | 3.4 | 1.4 | 2.19 × 10−4 | 3.4 | 3.1 | 3.95 × 10−4 | 3.3 | 4.6 | 2.21 × 10−4 | 3.4 | 1.7 | 2.24 × 10−4 |
| 512 | 3.4 | 1.6 | 1.80 × 10−4 | 3.1 | 4.4 | 3.58 × 10−4 | OOM | OOM | ∼ | 3.4 | 2.3 | 1.95 × 10−4 |
| 1024 | 3.4 | 2.2 | 1.78 × 10−4 | OOM | OOM | ∼ | OOM | OOM | ∼ | 3.4 | 3.6 | 2.01 × 10−4 |
| 2048 | 3.4 | 3.3 | 1.79 × 10−4 | OOM | OOM | ∼ | OOM | OOM | ∼ | 3.1 | 4.6 | 2.17 × 10−4 |
| Batch Size | MCNet | LSTM2 | CLDNN | LENet-T | ||||
|---|---|---|---|---|---|---|---|---|
| CPU Memory (GB) | Time (s/Sample) | CPU Memory (GB) | Time (s/Sample) | CPU Memory (GB) | Time (s/Sample) | CPU Memory (GB) | Time (s/Sample) | |
| 128 | 2.3 | 2.76 × 10−3 | 2.6 | 9.55 × 10−3 | 2.3 | 6.30 × 10−3 | 2.2 | 3.05 × 10−3 |
| 256 | 2.4 | 5.80 × 10−4 | 2.7 | 4.16 × 10−3 | 2.4 | 1.37 × 10−3 | 2.3 | 1.07 × 10−3 |
| 512 | 2.5 | 4.48 × 10−4 | 2.8 | 3.50 × 10−3 | 2.5 | 1.34 × 10−3 | 2.4 | 9.74 × 10−4 |
| 1024 | 2.6 | 4.45 × 10−4 | 2.9 | 2.47 × 10−3 | 2.6 | 1.25 × 10−3 | 2.5 | 9.29 × 10−4 |
| 2048 | 2.8 | 4.07 × 10−4 | 3.2 | 2.24 × 10−3 | 2.6 | 1.32 × 10−3 | 2.6 | 8.91 × 10−4 |
| Batch Size | MCNet | LSTM2 | CLDNN | LENet-T | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Memory (GB) | Time (s/Sample) | Memory (GB) | Time (s/Sample) | Memory (GB) | Time (s/Sample) | Memory (GB) | Time (s/Sample) | |||||
| CPU | GPU | CPU | GPU | CPU | GPU | CPU | GPU | |||||
| 32 | 3.4 | 3 | 3.82 × 10−3 | 3.1 | 2.4 | 6.50 × 10−3 | 3.5 | 1.7 | 9.76 × 10−3 | 3.1 | 2.8 | 3.70 × 10−3 |
| 64 | 3.4 | 3.6 | 3.64 × 10−3 | 3.0 | 3.8 | 6.41 × 10−3 | 3.4 | 2.2 | 5.62 × 10−3 | 3.0 | 4.4 | 3.89 × 10−3 |
| Methods | LENet-T | LENet-M | ||||||
|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | Mean | 1 | 2 | 3 | Mean | |
| w/o augmentation | 62.60 | 62.16 | 62.17 | 62.31 | 63.03 | 62.70 | 63.05 | 62.93 |
| SigAugment-R(4) | 61.81 | 62.73 | 62.62 | 62.38 | 64.72 | 64.43 | 64.73 | 64.63 |
| SigAugment-R(8) | 61.23 | 62.23 | 61.97 | 61.81 | 65.09 | 64.78 | 64.43 | 64.77 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wei, S.; Wang, Z.; Sun, Z.; Liao, F.; Li, Z.; Zou, L.; Mi, H. A Family of Automatic Modulation Classification Models Based on Domain Knowledge for Various Platforms. Electronics 2023, 12, 1820. https://doi.org/10.3390/electronics12081820
Wei S, Wang Z, Sun Z, Liao F, Li Z, Zou L, Mi H. A Family of Automatic Modulation Classification Models Based on Domain Knowledge for Various Platforms. Electronics. 2023; 12(8):1820. https://doi.org/10.3390/electronics12081820
Chicago/Turabian StyleWei, Shengyun, Zhenyi Wang, Zhaolong Sun, Feifan Liao, Zhen Li, Li Zou, and Haibo Mi. 2023. "A Family of Automatic Modulation Classification Models Based on Domain Knowledge for Various Platforms" Electronics 12, no. 8: 1820. https://doi.org/10.3390/electronics12081820
APA StyleWei, S., Wang, Z., Sun, Z., Liao, F., Li, Z., Zou, L., & Mi, H. (2023). A Family of Automatic Modulation Classification Models Based on Domain Knowledge for Various Platforms. Electronics, 12(8), 1820. https://doi.org/10.3390/electronics12081820