

Transformer-Based User Alignment Model across Social Networks

Abstract
1. Introduction
2. Methodology
2.1. Development of Transformer
2.2. Transformer Model
2.3. Problem Definition
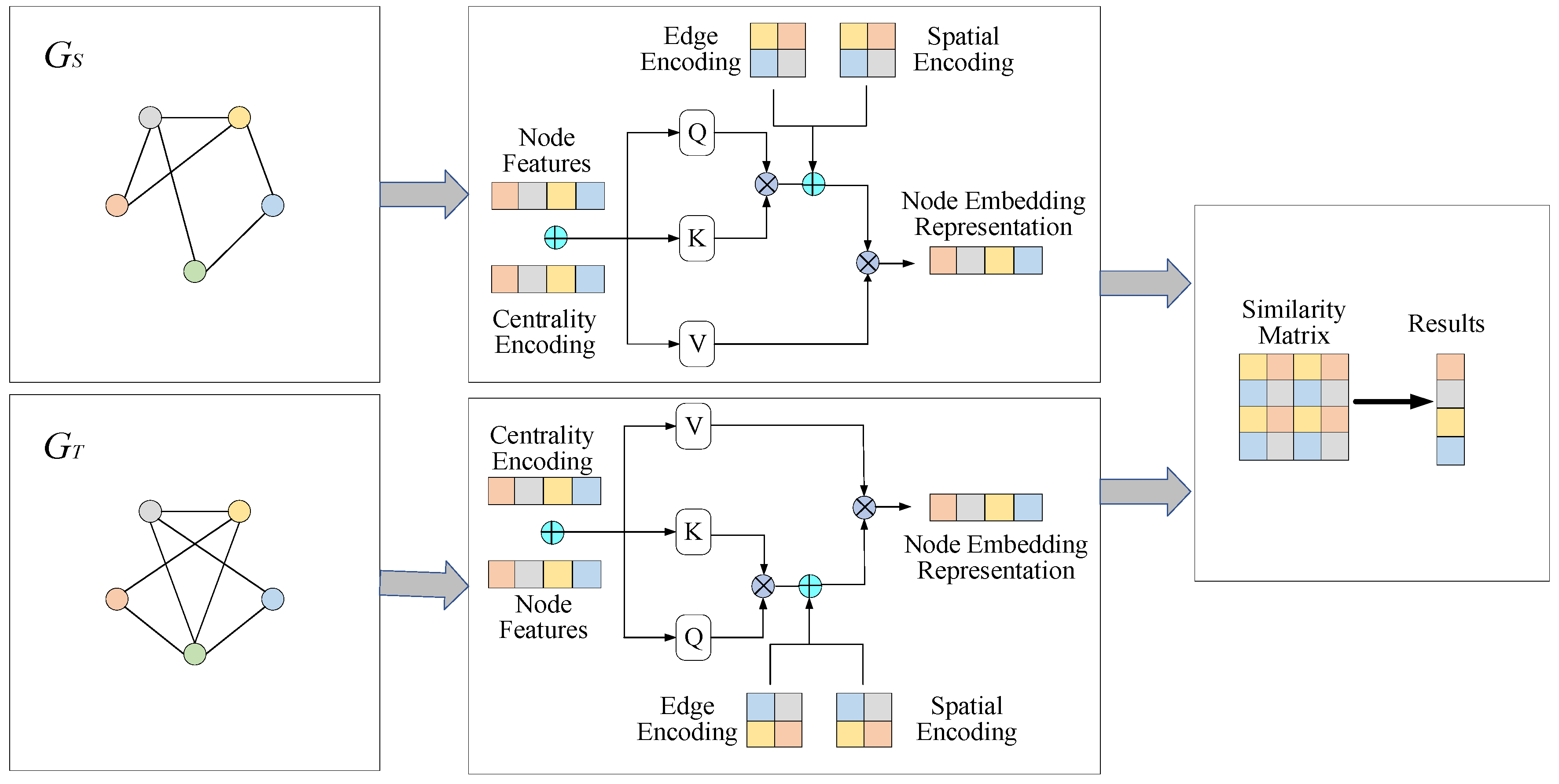
3. A Transformer-Based User Alignment Model
3.1. Centrality Encoding
3.2. Spatial Encoding
3.3. Edge Encoding
3.4. User Identification Layer
4. Datasets and Experiments
4.1. Datasets
4.2. Comparable Models
4.3. Evaluation Metric
4.4. Analysis of Experimental Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Huang, S.; Zhang, J.; Wang, L.; Hua, X.S. Social friend recommendation based on multiple network correlation. IEEE Trans. Multimed. 2016, 18, 287–299. [Google Scholar] [CrossRef]
- Peng, C.; Xu, K.; Wang, F.; Wang, H. Predicting information diffusion initiated from multiple sources in online social networks. In Proceedings of the 6th International Symposium on Computational Intelligence and Design, Washington, DC, USA, 28–29 October 2013; Volume 2, pp. 96–99. [Google Scholar]
- Zafarani, R.; Liu, H. Users joining multiple sites: Distributions and patterns. In Proceedings of the 8th International Conference on Weblogs and Social Media, Michigan, MI, USA, 1–4 June 2014; pp. 635–638. [Google Scholar]
- Zhang, J.; Yu, P.S.; Zhou, Z.H. Meta-path based multi-network collective link prediction. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; pp. 1286–1295. [Google Scholar]
- Zafarani, R.; Liu, H. Users joining multiple sites: Friendship and popularity variations across sites. Inf. Fusion 2016, 28, 83–89. [Google Scholar] [CrossRef]
- Riederer, C.; Kim, Y.; Chaintreau, A.; Korula, N.; Lattanzi, S. Linking users across domains with location data: Theory and validation. In Proceedings of the 25th International Conference on World Wide Web, Montréal QC, Canada, 11–15 April 2016; pp. 707–719. [Google Scholar]
- Chen, W.; Yin, H.; Wang, W.; Zhao, L.; Zhou, X. Effective and efficient user account linkage across location based social networks. In Proceedings of the 34th IEEE International Conference on Data Engineering (ICDE), Paris, France, 16–19 April 2018; pp. 1085–1096. [Google Scholar]
- Liu, J.; Zhang, F.; Song, X.; Song, Y.I.; Lin, C.Y.; Hon, H.W. What’s in a name? An unsupervised approach to link users across communities. In Proceedings of the 6th ACM International Conference on Web Search and Data Mining, Rome, Italy, 4–8 February 2013; pp. 495–504. [Google Scholar]
- Liu, S.; Wang, S.; Zhu, F.; Zhang, J.; Krishnan, R. HYDRA: Large-scale social identity linkage via heterogeneous behavior modeling. In Proceedings of the 2014 ACM SIGMOD International Conference on Management of Data, Snowbird Utah, UT, USA, 22–27 June 2014; pp. 51–62. [Google Scholar]
- Tan, S.; Guan, Z.; Cai, D.; Qin, X.; Bu, J.; Chen, C. Mapping users across networks by manifold alignment on hypergraph. In Proceedings of the 28th AAAI Conference on Artificial Intelligence, Québec, QC, Canada, 27–31 July 2014; pp. 159–165. [Google Scholar]
- Zhang, H.; Kan, M.Y.; Liu, Y.; Ma, S. Online social network profile linkage. In Proceedings of the 10th Asia Information Retrieval Societies Conference, Kuching, Malaysia, 3–5 December 2014; pp. 197–208. [Google Scholar]
- Zhao, Y.; Liu, Y.; Guo, X.; Sun, X.; Wang, S. User naming conventions mapping learning for social network alignment. In Proceedings of the 2021 13th International Conference on Computer and Automation Engineering (ICCAE), Melbourne, Australia, 20–22 March 2021; pp. 36–42. [Google Scholar]
- Zhou, X.; Liang, X.; Zhang, H.; Ma, Y. Cross-platform identification of anonymous identical users in multiple social media networks. IEEE Trans. Knowl. Data Eng. 2016, 28, 411–424. [Google Scholar] [CrossRef]
- Liu, L.; Cheung, W.K.; Li, X.; Liao, L. Aligning users across social networks using network embedding. In Proceedings of the 25th International Joint Conference on Artificial Intelligence, New York, NY, USA, 9–15 July 2016; pp. 1774–1780. [Google Scholar]
- Zhang, W.; Shu, K.; Liu, H.; Wang, Y. Graph neural networks for user identity linkage. arXiv 2023, arXiv:1903.02174. [Google Scholar]
- Feng, Y.; You, H.; Zhang, Z.; Ji, R.; Gao, Y. Hypergraph neural networks. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27–31 January 2019; pp. 3558–3565. [Google Scholar]
- Chen, H.; Yin, H.; Sun, X.; Chen, T.; Gabrys, B.; Musial, K. Multi-level graph convolutional networks for cross-platform anchor link prediction. In Proceedings of the 26th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Virtual, CA, USA, 23–27 August 2020; pp. 1503–1511. [Google Scholar]
- Yan, Z.; Liu, L.; Li, X.; Cheung, W.K.; Zhang, Y.; Liu, Q.; Wang, G. Towards improving embedding based models of social network alignment via pseudo anchors. IEEE Trans. Knowl. Data Eng. 2021, 35, 4307–4320. [Google Scholar] [CrossRef]
- Li, Y.; Cui, H.; Liu, H.; Li, X. Triple-layer attention mechanism-based network embedding approach for anchor link identification across social networks. Neural. Comput. Appl. 2022, 34, 2811–2829. [Google Scholar] [CrossRef]
- He, J.; Liu, L.; Yan, Z.; Wang, Z.; Xiao, M.; Zhang, Y. User alignment across dynamic social networks based on heuristic algorithm. In Proceedings of the 7th International Conference on Systems and Informatics (ICSAI), Chongqing, China, 13–15 November 2021; pp. 1–7. [Google Scholar]
- Liu, L.; Wang, C.; Zhang, Y.; Wang, Y.; Liu, Q.; Wang, G. Denoise network structure for user alignment across networks via graph structure learning. In Proceedings of the 7th Data Mining and Big Data, Beijing, China, 21–24 November 2022; pp. 105–119. [Google Scholar]
- Zheng, C.; Pan, L.; Wu, P. CAMU: Cycle-consistent adversarial mapping model for user alignment across social networks. IEEE Trans. Cybern. 2022, 52, 10709–10720. [Google Scholar] [CrossRef] [PubMed]
- Ying, C.; Cai, T.; Luo, S.; Zheng, S.; Ke, G.; He, D.; Shen, Y.; Liu, T.Y. Do Transformers really perform badly for graph representation? In Proceedings of the Annual Conference on Neural Information Processing Systems 2021, Virtual, 6–14 December 2021; pp. 28877–28888. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomes, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Kaplan, J.; Mccandlish, S.; Henighan, T.; Brown, T.B.; Chess, B.; Child, R.; Gray, S.; Radford, A.; Wu, J.; Amodei, D. Scaling Laws for Neural Language Models. arXiv 2023, arXiv:2001.08361. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. In Proceedings of the Advances in Neural Information Processing Systems, Virtual, 6–12 December 2020; pp. 1877–1901. [Google Scholar]
- Zeng, W.; Ren, X.; Su, T.; Wang, H.; Liao, Y.; Wang, Z.; Jiang, X.; Yang, Z.; Wang, K.; Zhang, X.; et al. Pangu: Large-scale autoregressive pretrained Chinese language models with auto-parallel computation. arXiv 2023, arXiv:2104.12369. [Google Scholar]
- Lepikhin, D.; Lee, H.; Xu, Y.; Chen, D.; Firat, O.; Huang, Y.; Krikun, M.; Shazeer, N.; Chen, Z. Gshard: Scaling giant models with conditional computation and automatic sharding. arXiv 2023, arXiv:2006.16668. [Google Scholar]
- Fedus, W.; Zoph, B.; Shazeer, N. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity. arXiv 2023, arXiv:2101.03961. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Unterthiner, T.; Dehghani, M.; Heigold, G.; Gelly, S.; Uszkoreit, J.; Houlsby, N. An image is worth 16x16 words: Transformers for image recognition at scale. In Proceedings of the International Conference on Learning Representations, Virtual, Austria, 3–7 May 2021. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 9992–10002. [Google Scholar]
- Mu, X.; Zhu, F.; Lim, E.P.; Xiao, J.; Wang, J.; Zhou, Z.H. User identity linkage by latent user space modelling. In Proceedings of the 22nd ACM SIGKDD International Conference Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1775–1784. [Google Scholar]
- Huang, Z.; Lin, D.K.J. The time-series link prediction problem with applications in communication surveillance. Inf. J. Comput. 2009, 21, 286–303. [Google Scholar] [CrossRef]
- Lee, C.; Pham, M.; Jeongm, M.K.; Kim, D.; Lin, D.K.J.; Chavalitwongse, W.A. A network structural approach to the link prediction problem. Inf. J. Comput. 2015, 27, 249–267. [Google Scholar] [CrossRef]
- Li, Z.; Fang, X.; Bai, X.; Sheng, O.R.L. Utility-based link recommendation for online social networks. Manag. Sci. 2015, 63, 1657–2048. [Google Scholar] [CrossRef]
- Yang, J.; Zhang, X.D. Predicting missing links in complex networks based on common neighbors and distance. Sci. Rep. 2016, 6, 38208. [Google Scholar] [CrossRef]
- Marshall, P.D. The promotion and presentation of the self: Celebrity as marker of presentational media. Celebr. Stud. 2010, 1, 35–48. [Google Scholar] [CrossRef]
- Marwick, A.; Boyd, D. To see and be seen: Celebrity practice on Twitter. Convergence 2011, 17, 139–158. [Google Scholar] [CrossRef]
- Cao, X.; Yu, Y. ASNets: A benchmark dataset of aligned social networks for cross-platform user modeling. In Proceedings of the 25th ACM International Conference on Information and Knowledge Management, Indianapolis, IN, USA, 24–28 October 2016; pp. 1881–1884. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | References | User Location | User Profile | Network Structure | Weight Assignment | Open Datasets | Over-Smooth | |
|---|---|---|---|---|---|---|---|---|
| Local | Global | |||||||
| Non-deep learning | [6] | ✓ | - | - | ✗ | ✗ | ✗ | - |
| [7] | ✓ | - | - | ✗ | ✓ | ✓ | - | |
| [11] | - | ✓ | - | ✗ | ✗ | ✗ | - | |
| Deep learning | [12] | - | ✓ | - | ✗ | ✓ | ✓ | ✗ |
| [16] | - | - | ✓ | ✗ | ✓ | ✓ | ✓ | |
| [17] | - | - | ✓ | ✗ | ✓ | ✓ | ✓ | |
| [18] | - | - | ✓ | ✗ | ✓ | ✓ | ✓ | |
| [19] | - | - | ✓ | ✓ | ✓ | ✓ | ✓ | |
| [20] | - | - | ✓ | ✓ | ✓ | ✓ | ✓ | |
| [21] | - | - | ✓ | ✗ | ✓ | ✓ | ✓ | |
| [22] | - | - | ✓ | ✗ | ✓ | ✓ | ✓ | |
| TUAM | - | - | ✓ | ✗ | ✓ | ✓ | ✗ | |
| Dataset | |V| | |E| | |CV| |
|---|---|---|---|
| 3481 | 7224 | 1874 | |
| 3211 | 6020 | ||
| Weibo 1 | 1241 | 1625 | 471 |
| Douban 2 | 1170 | 1695 |
| Dataset | Model | ACC@1 | ACC@10 | ACC@20 | ACC@50 |
|---|---|---|---|---|---|
| Facebook–Twitter | DeepWalk | 0% | 1.32% | 1.97% | 6.58% |
| GCN | 3.22% | 31.11% | 40.00% | 53.33% | |
| HGCN | 0.89% | 9.43% | 18.87% | 47.17% | |
| MGCN | 1.42% | 10.32% | 20.15% | 58.30% | |
| GAT | 3.77% | 28.89% | 42.22% | 62.22% | |
| TUAM | 8.01% | 40.50% | 57.85% | 78.51% |
| Dataset | Model | ACC@1 | ACC@10 | ACC@20 | ACC@50 |
|---|---|---|---|---|---|
| Weibo–Douban | DeepWalk | 0.21% | 2.34% | 9.55% | 14.23% |
| GCN | 9.77% | 39.92% | 49.89% | 62.85% | |
| HGCN | 4.25% | 30.15% | 47.56% | 59.45% | |
| MGCN | 5.31% | 31.85% | 50.32% | 63.69% | |
| GAT | 11.25% | 37.37% | 52.65% | 66.88% | |
| TUAM | 12.06% | 53.90% | 65.25% | 90.07% |
| Centrality Encoding | Spatial Encoding | Edge Encoding | ACC@1 | ACC@10 | ACC@20 | ACC@50 |
|---|---|---|---|---|---|---|
| × | √ | √ | 6.94% | 35.41% | 48.40% | 72.16% |
| √ | × | √ | 7.65% | 32.56% | 46.62% | 68.86% |
| √ | √ | × | 6.58% | 32.92% | 47.86% | 68.51% |
| √ | √ | √ | 8.01% | 40.50% | 57.85% | 78.51% |
| Centrality Encoding | Spatial Encoding | Edge Encoding | ACC@1 | ACC@10 | ACC@20 | ACC@50 |
|---|---|---|---|---|---|---|
| × | √ | √ | 7.09% | 51.77% | 67.38% | 85.80% |
| √ | × | √ | 9.22% | 48.94% | 63.12% | 83.69% |
| √ | √ | × | 6.38% | 41.84% | 63.83% | 78.72% |
| √ | √ | √ | 12.06% | 53.90% | 65.25% | 90.07% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lei, T.; Ji, L.; Wang, G.; Liu, S.; Wu, L.; Pan, F. Transformer-Based User Alignment Model across Social Networks. Electronics 2023, 12, 1686. https://doi.org/10.3390/electronics12071686
Lei T, Ji L, Wang G, Liu S, Wu L, Pan F. Transformer-Based User Alignment Model across Social Networks. Electronics. 2023; 12(7):1686. https://doi.org/10.3390/electronics12071686
Chicago/Turabian StyleLei, Tianliang, Lixin Ji, Gengrun Wang, Shuxin Liu, Lan Wu, and Fei Pan. 2023. "Transformer-Based User Alignment Model across Social Networks" Electronics 12, no. 7: 1686. https://doi.org/10.3390/electronics12071686
APA StyleLei, T., Ji, L., Wang, G., Liu, S., Wu, L., & Pan, F. (2023). Transformer-Based User Alignment Model across Social Networks. Electronics, 12(7), 1686. https://doi.org/10.3390/electronics12071686