
An Optimal Active Defensive Security Framework for the Container-Based Cloud with Deep Reinforcement Learning

Abstract
1. Introduction
- (1)
- In order to comprehensively analyze the complex attack scenarios in microservices, a Holistic System Attack Graph (HSAG) model is established, and the security gain and defensive efficiency of MTD strategies are described based on the HSAG model.
- (2)
- In order to optimize the defense efficiency, we propose an OADSF. It can dynamically adjust defense configurations by sensing the changes in the microservice state.
- (3)
- We propose an adaptive security configuration algorithm based on Prioritized Dueling Double DQN (P3DQN). It can optimize the defense configuration in real time with the state of the microservice application changes, thereby improving the defense efficiency of the system.
2. Related Work
2.1. Container Security
2.2. Microservice Security
2.3. Active Defense Technology
2.4. Deep Reinforcement Learning
3. Threat Model
- (1)
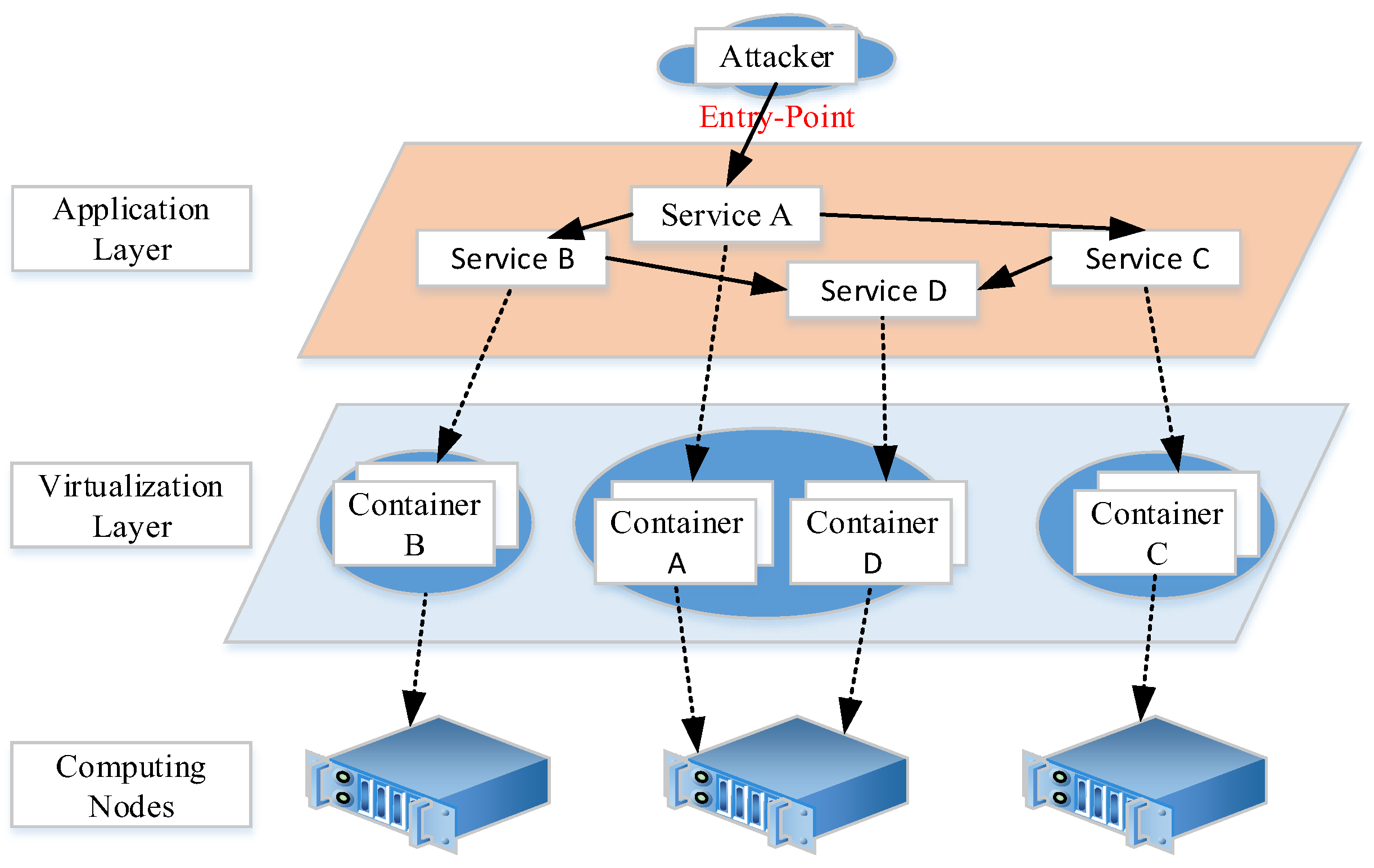
- Attack targets: In the container cloud environment, all microservices may become the target of attackers. For the service, its attack surface can be composed of an application layer attack surface and a container layer attack surface, which can be expressed as .The application layer attack surface is composed of service code and dependent libraries, and the container layer attack surface refers to the container operation environment of the service. As shown in Figure 1, the attack surfaces of microservices lies in the application layer and virtualization layer, respectively. In addition, we assume that some vulnerabilities in these targets can be exploited by attackers.
- (2)
- Attack strategies: We assume that attackers adopt the cyber killing chain (CKC) model to carry out attacks. In this model, the attacker first performs various reconnaissance actions to identify the target’s vulnerabilities. Then, the attacker selects an appropriate vulnerability and prepares the corresponding network attack tool against it. Next, attackers can use these tools to execute malicious code to compromise the target.
- (3)
- Attackers’ capabilities: We assume that the attacker is outside the cloud platform and attacks the microservices through the Internet. In general, microservice applications open specific service access portals. Therefore, attackers can attack only the application layer attack surface, such as service A. When attackers successfully hijack service A through the application layer vulnerability, attackers have the following two attack modes to expand their foothold in the container-based cloud.
- Application layer: After escaping from the application layer, attackers continue to search for network-reachable microservices and attack the application layer attack surface. It is assumed that the network configuration in the container-based cloud is subject to the network isolation policy on the management node [13]. Only when there is a dependency relationship between microservices, the networks are reachable. As Figure 1 shows, after hijacking service A, attackers can continue to attack services B and C.
- Virtualization layer: After escaping from the application layer, attackers can also attack the container hosting them. If container escape is successful, attackers can escape from the virtual environment to the worker node. Then, they can obtain the permission of the worker node where the container directly hijacks the services running in the container environment. As Figure 1 shows, attackers can directly enter container A after hijacking service A. If attackers successfully escape from container A, they can enter container D and hijack service D.
4. Problem Modeling
4.1. HSAG Model
4.2. Problem Description
5. Detailed Design of the Framework
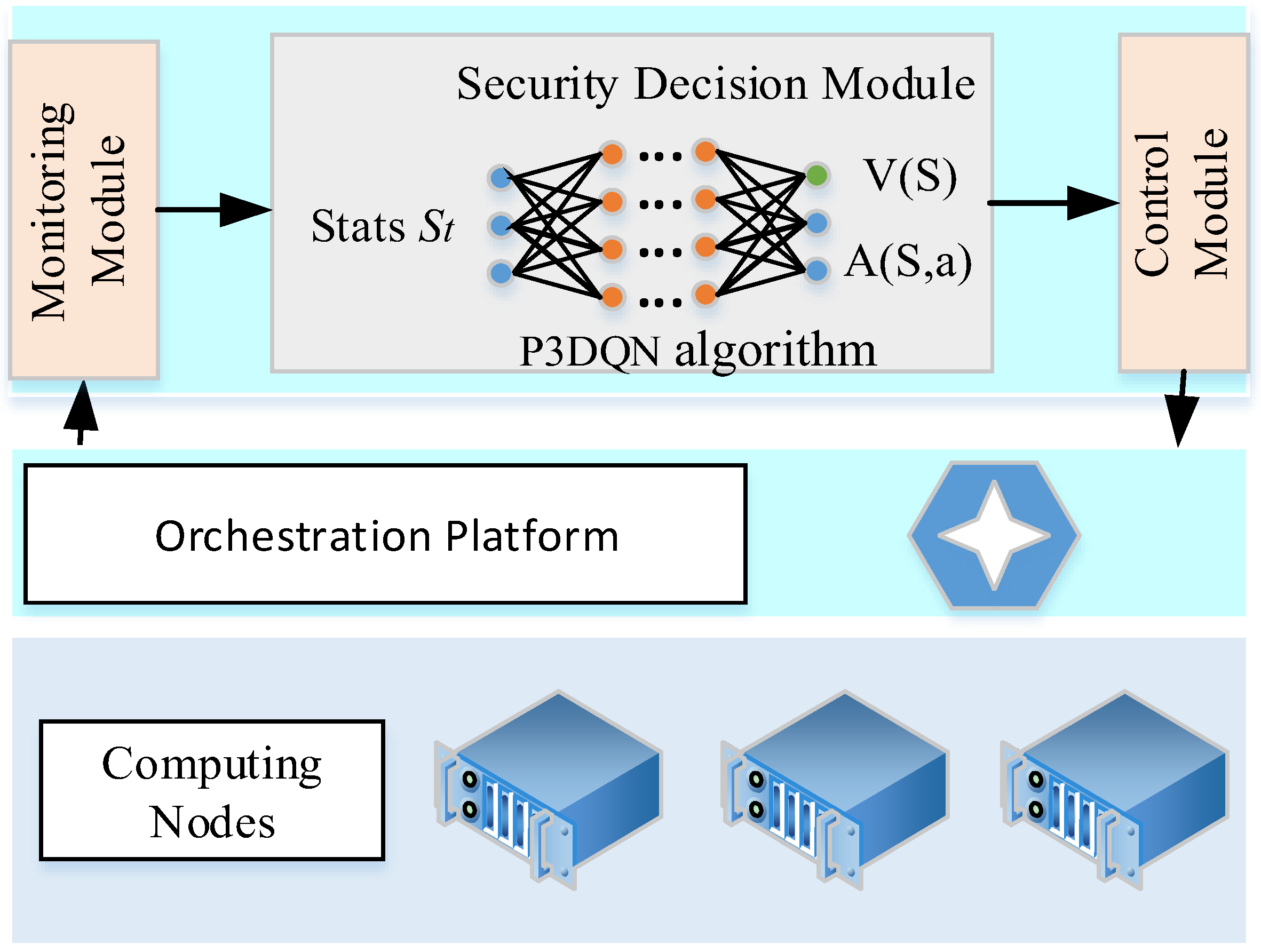
5.1. Design of OADSF
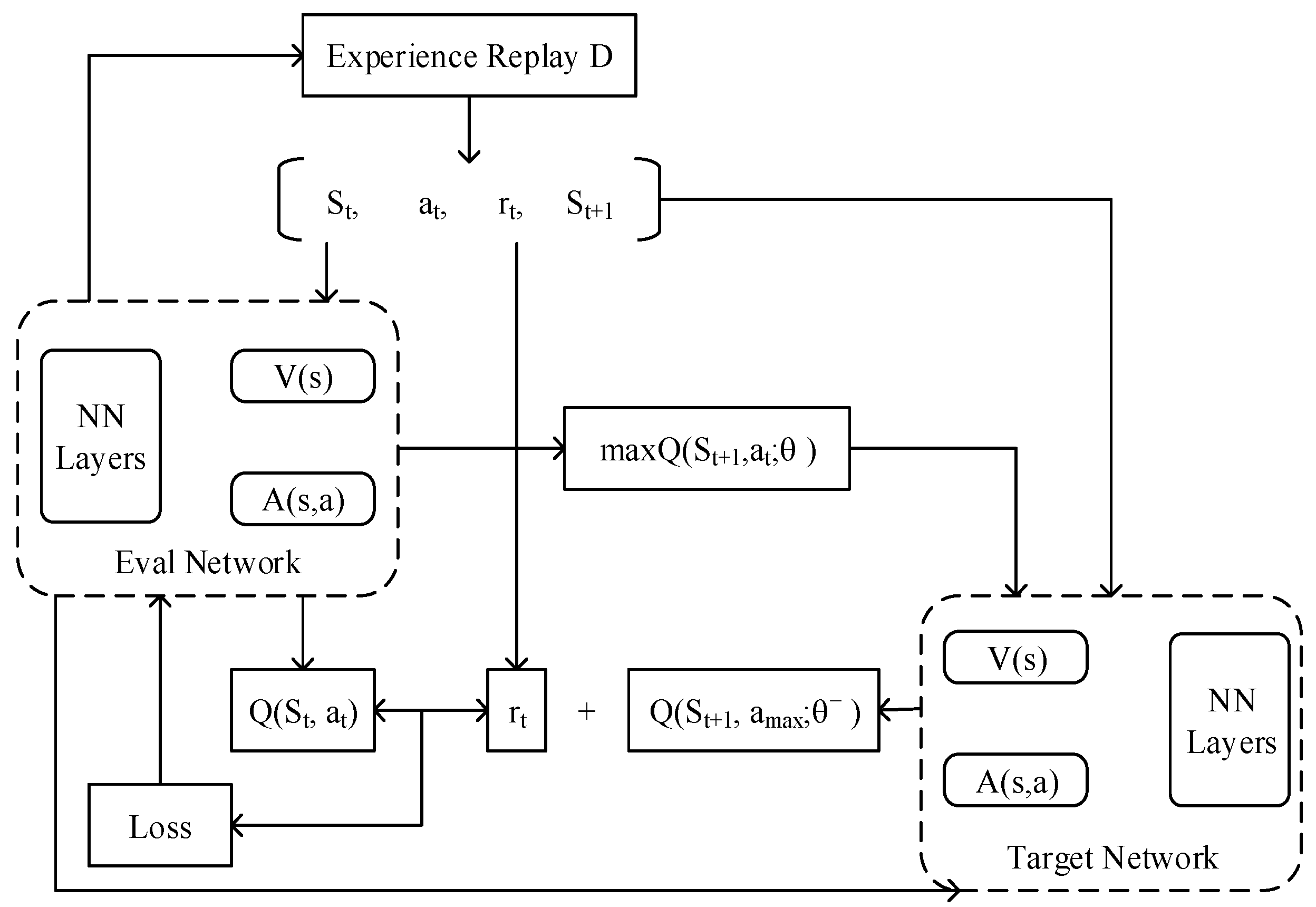
5.2. Adaptive Security Configuration Algorithm Based on P3DQN
| Algorithm 1: Security configuration optimization algorithm based on P3DQN. |
| Input: Call relationship between microservices Output: P3DQN neural network parametersInitialization: neural network parameters
|
- (1)
- State: the state consists of running the state and security configurations. In order to facilitate neural network processing, it is assumed that there are UN computing nodes and M microservices in the cluster. The upper limit of the i-th service replica is URi, and the running state of the i-th service is , where is the compute node serial number. The running state can be composed of the running state of all the microservices, namely . The input state can be obtained by combining the current running state and security configuration. In order to generate a large number of training data, we randomly generated the replicas and performed simulation scheduling according to the cloud platform strategy, with the results as the current running state. At the same time, the security configuration can also be randomly generated.
- (2)
- Action: in the P3DQN algorithm, the action depends on the output layer. In each iteration, we selected as the basic unit to increase or decrease the cleaning period, or keep the security configuration unchanged.
- (3)
- Reward: when calculating the current reward, we generated the HSAG model based on the input running state, and calculated the defense efficiency DE as a reward by combining the security configuration.
6. Simulation and Evaluation
6.1. Simulation Setup
6.2. Comparison Strategy
- (1)
- The unified configuration strategy simplifies dynamic cycle configuration. It is assumed that the dynamic cycle of all microservices is the same, which greatly reduces the computation, and the dynamic cycle can be obtained through traversal. In the reference [6], this strategy is used to simplify the problem of implementing dynamic cleaning strategy.
- (2)
- The optimal strategy is to find out the optimal defense configuration by brute-force search, which provides a reference for each algorithm.
- (3)
- DSEOM depicts the attack difficulty by the attack graph model. The strategy computes the critical nodes through betweenness centrality and only protects the critical nodes. The betweenness centrality calculates by the ratio of the number of shortest paths passing through node N to the total number of shortest paths.
- (4)
- SmartSCR also depicts the attack difficulty with the attack graph model and protects all nodes. However, this strategy uses the S-function to calculate the probability to determine the attack difficulty of nodes. It only takes the security after MTD deployment into consideration, and the optimization algorithm overestimates defense efficiency.
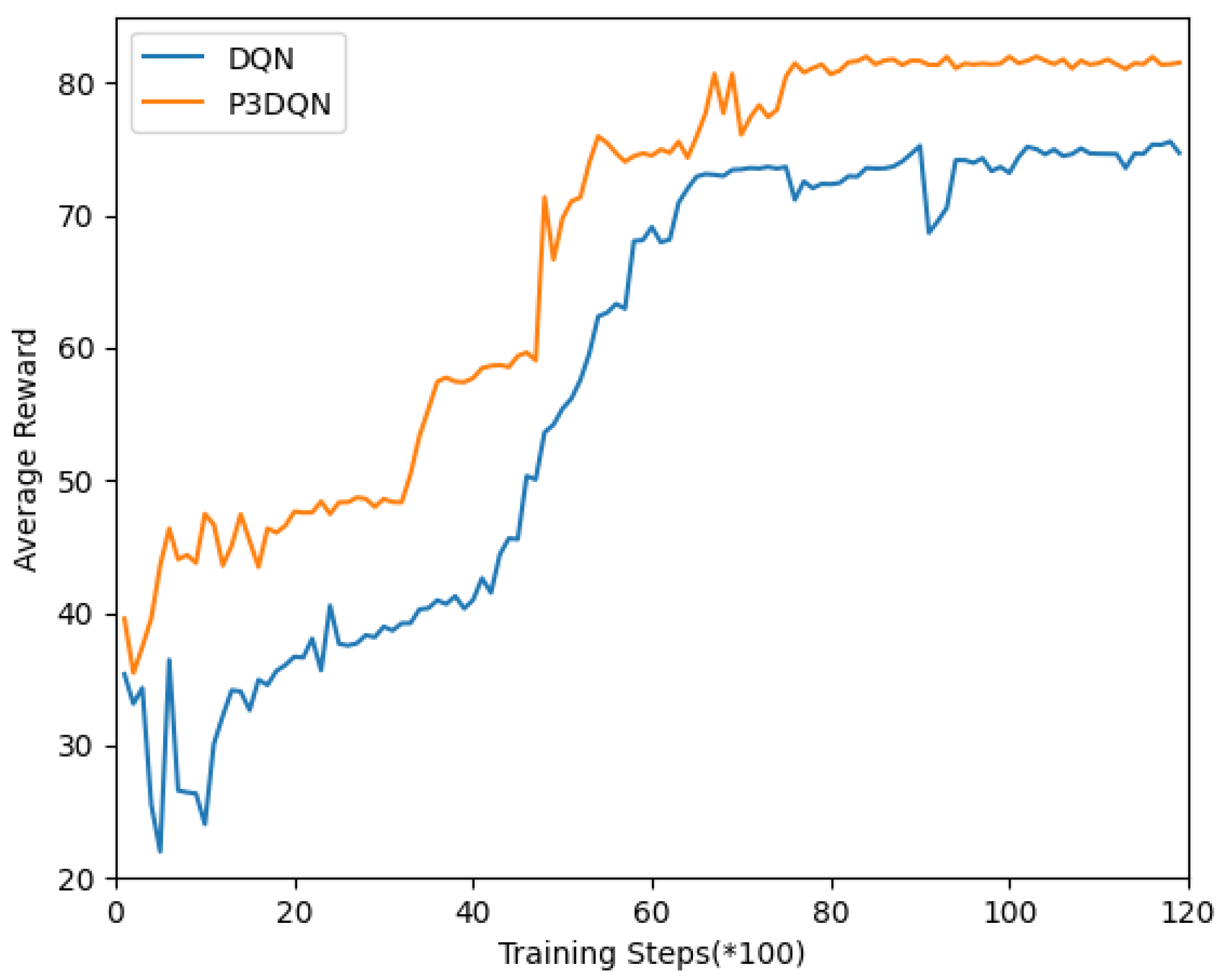
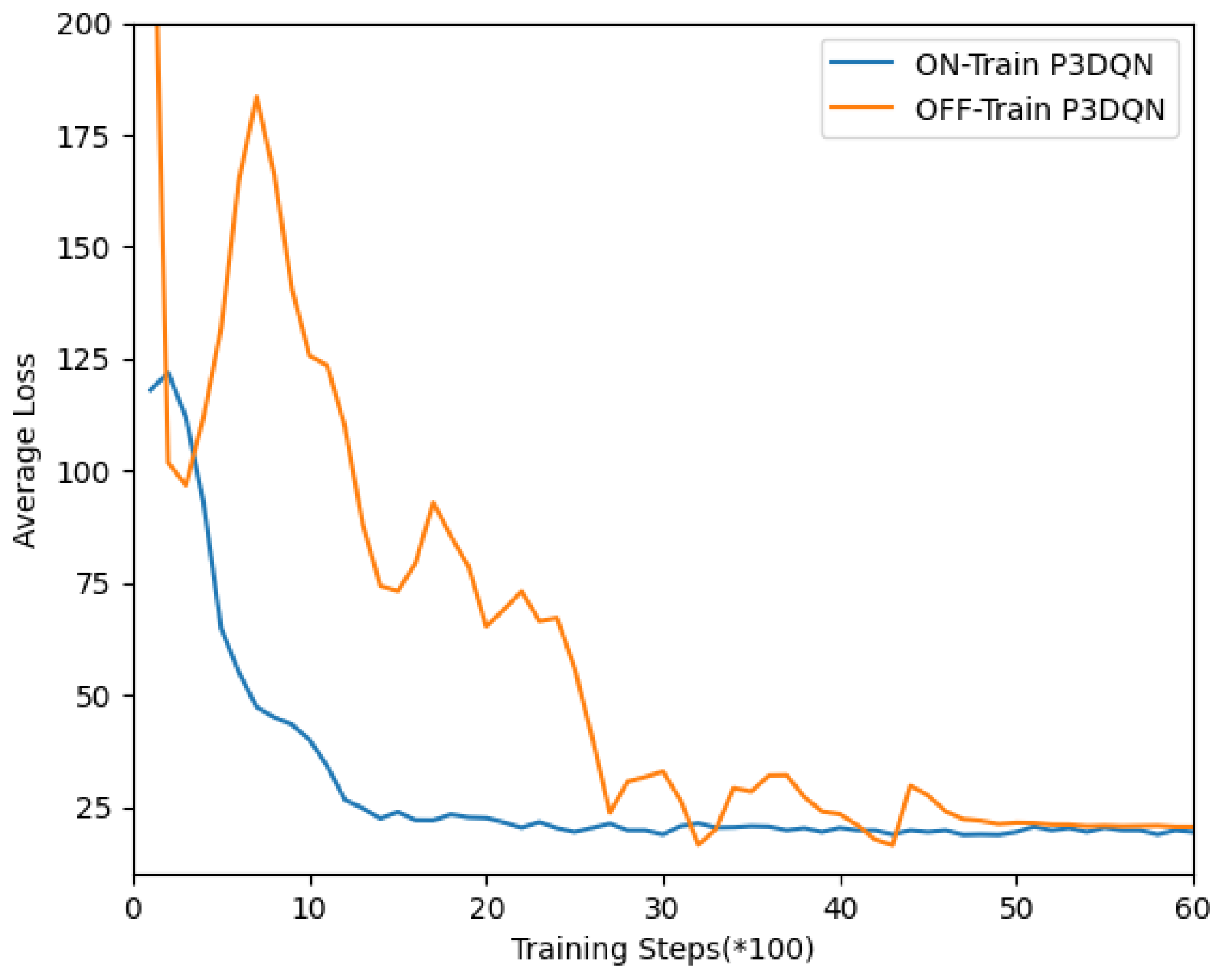
6.3. Simulation Results
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhou, X.; Peng, X.; Xie, T.; Sun, J.; Ji, C.; Li, W.; Ding, D. Fault Analysis and Debugging of Microservice Systems: Industrial Survey, Benchmark System, and Empirical Study. IIEEE Trans. Softw. Eng. 2021, 47, 243–260. [Google Scholar] [CrossRef]
- Gokan Khan, M.; Taheri, J.; Al-dulaimy, A.; Kassler, A. PerfSim: A Performance Simulator for Cloud Native Microservice Chains. IEEE Trans. Cloud Comput. 2021, 1, 1–18. [Google Scholar] [CrossRef]
- Arouk, O.; Nikaein, N. Kube5G: A Cloud-Native 5G Service Platform. In Proceedings of the GLOBECOM 2020–2020 IEEE Global Communications Conference, Taipei, Taiwan, 11–13 December; 2020; pp. 1–6. [Google Scholar]
- Gao, X.; Steenkamer, B.; Gu, Z.; Kayaalp, M.; Pendarakis, D.; Wang, H. A Study on the Security Implications of Information Leakages in Container Clouds. IEEE Trans. Dependable Secur. Comput. 2021, 18, 174–191. [Google Scholar] [CrossRef]
- Nife, F.N.; Kotulski, Z. Application-Aware Firewall Mechanism for Software Defined Networks. J. Netw. Syst. Manag. 2020, 28, 605–626. [Google Scholar] [CrossRef]
- Bardas, A.G.; Sundaramurthy, S.C.; Ou, X.; DeLoach, S.A. MTD CBITS: Moving Target Defense for Cloud-Based IT Systems. In Proceedings of the 22nd European Symposium on Research in Computer Security, Oslo, Norway, 1–3 December; 2017; pp. 167–186. [Google Scholar]
- Zhuang, R.; DeLoach, S.A.; Ou, X. Towards a Theory of Moving Target Defense. In Proceedings of the First ACM Workshop on Moving Target Defense, Scottsdale, AZ, USA, 3 November 2014; pp. 31–40. [Google Scholar]
- Lu, K.; Song, C.; Lee, B.; Chung, S.P.; Kim, T.; Lee, W. ASLR-Guard: Stopping Address Space Leakage for Code Reuse Attacks. In Proceedings of the 22nd ACM SIGSAC Conference on Computer and Communications Security, Denver Colorado, CO, USA, 12 October 2015; pp. 280–291. [Google Scholar]
- Larsen, P.; Homescu, A.; Brunthaler, S.; Franz, M. SoK: Automated Software Diversity. In Proceedings of the 2014 IEEE Symposium on Security and Privacy, San Jose, CA, USA, 7–9 May 2014; pp. 276–291. [Google Scholar]
- Meier, R.; Tsankov, P.; Lenders, V.; Vanbever, L.; Vechev, M. NetHide: Secure and Practical Network Topology Obfuscation. In Proceedings of the 27th USENIX Security Symposium, Baltimore, MD, USA, 15–18 August 2018; pp. 1–18. [Google Scholar]
- Debroy, S.; Calyam, P.; Nguyen, M.; Stage, A.; Georgiev, V. Frequency-Minimal Moving Target Defense Using Software-Defined Networking. In Proceedings of the 2016 International Conference on Computing, Networking and Communications (ICNC), Kauai, HI, USA, 2–5 February 2016; pp. 1–6. [Google Scholar]
- Carroll, T.E.; Crouse, M.; Fulp, E.W.; Berenhaut, K.S. Analysis of Network Address Shuffling as a Moving Target Defense. In Proceedings of the 2014 IEEE International Conference on Communications (ICC), Sydney, NSW, Australia, 10–14 June 2014; pp. 701–706. [Google Scholar]
- Jin, H.; Li, Z.; Zou, D.; Yuan, B. DSEOM: A Framework for Dynamic Security Evaluation and Optimization of MTD in Container-Based Cloud. IEEE Trans. Dependable Secur. Comput. 2021, 18, 1125–1136. [Google Scholar] [CrossRef]
- Zhang, S.; Guo, Y.; Sun, P.; Cheng, G.; Hu, H. Deep reinforcement learning based moving target defense strategy optimization scheme for cloud native environment. J. Electron. Inf. Technol. 2022, 44, 608–616. [Google Scholar] [CrossRef]
- Belair, M.; Laniepce, S.; Menaud, J.-M. Leveraging Kernel Security Mechanismsto Improve Container Security: A Survey. In Proceedings of the 14th International Conference on Availability, Reliability and Security, New York, NY, USA, 11–13 October 2019; pp. 1–6. [Google Scholar]
- Lopes, N.; Martins, R.; Correia, M.E.; Serrano, S.; Nunes, F. Container Hardening Through Automated Seccomp Profiling. In Proceedings of the 2020 6th International Workshop on Container Technologies and Container Clouds, Delft, The Netherlands, 7 December 2020; pp. 31–36. [Google Scholar]
- Lin, X.; Lei, L.; Wang, Y.; Jing, J.; Sun, K.; Zhou, Q. A Measurement Study on Linux Container Security: Attacks and Countermeasures. In Proceedings of the 34th Annual Computer Security Applications Conference, San Juan, PR, USA, 3 December 2018; pp. 418–429. [Google Scholar]
- Flora, J.; Antunes, N. Studying the Applicability of Intrusion Detection to Multi-Tenant Container Environments. In Proceedings of the 2019 15th European Dependable Computing Conference (EDCC), Naples, Italy, 4 September 2019; pp. 133–136. [Google Scholar]
- Lim, S.Y.; Stelea, B.; Han, X.; Pasquier, T. Secure Namespaced Kernel Audit for Containers. In Proceedings of the ACM Symposium on Cloud Computing (SoCC), New York, NY, USA, 15–17 December 2021; pp. 518–532. [Google Scholar]
- Lin, Y.; Tunde-Onadele, O.; Gu, X. CDL: Classified Distributed Learning for Detecting Security Attacks in Containerized Applications. In Proceedings of the Annual Computer Security Applications Conference, Austin, TX, USA, 7 December 2020; 2020; pp. 179–188. [Google Scholar]
- Almeida, W.H.C.; de Aguiar Monteiro, L.; Hazin, R.R.; de Lima, C.; Ferraz, F.S. Survey on Microservice Architecture—Security, Privacy and Standardization on Cloud Computing Environment. In Proceedings of the 12th International Conference on Software Engineering Advance, Athenas, Greek, 20 December 2017; pp. 1–7. [Google Scholar]
- Zhao, P.; Wu, L.; Hong, Z.; Sun, H. Research on Multicloud Access Control Policy Integration Framework. China Commun. 2019, 16, 222–234. [Google Scholar] [CrossRef]
- Pereira-Vale, A.; Fernandez, E.B.; Monge, R.; Astudillo, H.; Márquez, G. Security in Microservice-Based Systems: A Multivocal Literature Review. Comput. Secur. 2021, 103, 102200. [Google Scholar] [CrossRef]
- Xu, R.; Jin, W.; Kim, D. Microservice Security Agent Based On API Gateway in Edge Computing. Sensors 2019, 19, 4905. [Google Scholar] [CrossRef] [PubMed]
- Sankaran, A.; Datta, P.; Bates, A. Workflow Integration Alleviates Identity and Access Management in Serverless Computing. In Proceedings of the Annual Computer Security Applications Conference, Austin, TX, USA, 7 December 2020; pp. 496–509. [Google Scholar]
- Torkura, K.A.; Sukmana, M.I.H.; Meinel, C. Integrating Continuous Security Assessments in Microservices and Cloud Native Applications. In Proceedings of the 10th International Conference on Utility and Cloud Computing, Austin, TX, USA, 5 December 2017; 2017; pp. 171–180. [Google Scholar]
- Ahmed, N.O.; Bhargava, B. From Byzantine Fault-Tolerance to Fault-Avoidance: An Architectural Transformation to Attack and Failure Resiliency. IEEE Trans. Cloud Comput. 2018, 8, 847–860. [Google Scholar] [CrossRef]
- Li, Y.; Dai, R.; Zhang, J. Morphing Communications of Cyber-Physical Systems towards Moving-Target Defense. In Proceedings of the 2014 IEEE International Conference on Communications (ICC), Sydney, NSW, Australia, 10–14 June 2014; pp. 592–598. [Google Scholar]
- Yu, H.; Li, H.; Yang, X.; Ma, H. On Distributed Object Storage Architecture Based on Mimic Defense. China Commun. 2021, 18, 109–120. [Google Scholar] [CrossRef]
- Qiang, W.; Chunming, W.; Xincheng, Y.; Qiumei, C. Intrinsic Security and Self-Adaptive Cooperative Protection Enabling Cloud Native Network Slicing. IEEE Trans. Netw. Serv. Manag. 2021, 18, 1287–1304. [Google Scholar] [CrossRef]
- Wang, Y.; Guo, Y.; Guo, Z.; Liu, W.; Yang, C. Protecting Scientific Workflows in Clouds with an Intrusion Tolerant System. IET Inf. Secur. 2020, 14, 157–165. [Google Scholar] [CrossRef]
- Wang, Y.; Guo, Y.; Wang, W.; Liang, H.; Huo, S. INHIBITOR: An Intrusion Tolerant Scheduling Algorithm in Cloud-Based Scientific Workflow System. Future Gener. Comput. Syst. 2021, 114, 272–284. [Google Scholar] [CrossRef]
- Nguyen, T.T.; Reddi, V.J. Deep Reinforcement Learning for Cyber Security. IEEE Trans. Neural Netw. Learn. Syst. 2021, 1–17. [Google Scholar] [CrossRef] [PubMed]
- Uprety, A.; Rawat, D.B. Reinforcement Learning for IoT Security: A Comprehensive Survey. IEEE Internet Things J. 2021, 8, 8693–8706. [Google Scholar] [CrossRef]
- Xiao, L.; Wan, X.; Dai, C.; Du, X.; Chen, X.; Guizani, M. Security in Mobile Edge Caching with Reinforcement Learning. IEEE Wirel. Commun. 2018, 3, 116–122. [Google Scholar] [CrossRef]
- Lopez-Martin, M.; Carro, B.; Sanchez-Esguevillas, A. Application of Deep Reinforcement Learning to Intrusion Detection for Supervised Problems. Expert Syst. Appl. 2020, 141, 112963. [Google Scholar] [CrossRef]
- Sun, P.; Guo, Z.; Liu, S.; Lan, J.; Wang, J.; Hu, Y. SmartFCT: Improving power-efficiency for data center networks with deep reinforcement learning. Comput. Netw. 2020, 179, 107255. [Google Scholar] [CrossRef]
- Li, H.; Guo, Y.; Sun, P.; Wang, Y.; Huo, S. An Optimal Defensive Deception Framework for the Container-based Cloud with Deep Reinforcement Learning. IET Inf. Secur. 2022, 16, 178–192. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Microservice | Name | CVE ID | ED | W | D (Ei) |
|---|---|---|---|---|---|
| A | Tomcat | CVE-2019-14768 | 2.8 | 7.4 | 3.1497 |
| CVE-2019-10104 | 3.9 | 8.6 | |||
| CVE-2019-0232 | 2.2 | 7.9 | |||
| CVE-2020-26510 | 3.9 | 8.3 | |||
| CVE-2020-17388 | 2.8 | 7.4 | |||
| B | Memcached | CVE-2016-8704 | 3.9 | 8.3 | 3.406 |
| CVE-2016-8705 | 3.9 | 8.3 | |||
| CVE-2016-8706 | 2.2 | 6.8 | |||
| C | ImageMagick | CVE-2017-14650 | 2.2 | 6.8 | 2.2561 |
| CVE-2017-14224 | 2.8 | 8.3 | |||
| CVE-2019-11832 | 1.6 | 6.3 | |||
| D | Mysql | CVE-2020-11974 | 3.9 | 8.3 | 3.1192 |
| CVE-2016-6663 | 1 | 6.3 | |||
| CVE-2016-6662 | 3.9 | 8.8 | |||
| - | Container | CVE-2020-7606 | 0.5 | 5.4 | 2.5599 |
| CVE-2020-35197 | 3.9 | 8.3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Y.; Hu, H.; Liu, W.; Yang, X. An Optimal Active Defensive Security Framework for the Container-Based Cloud with Deep Reinforcement Learning. Electronics 2023, 12, 1598. https://doi.org/10.3390/electronics12071598
Li Y, Hu H, Liu W, Yang X. An Optimal Active Defensive Security Framework for the Container-Based Cloud with Deep Reinforcement Learning. Electronics. 2023; 12(7):1598. https://doi.org/10.3390/electronics12071598
Chicago/Turabian StyleLi, Yuanbo, Hongchao Hu, Wenyan Liu, and Xiaohan Yang. 2023. "An Optimal Active Defensive Security Framework for the Container-Based Cloud with Deep Reinforcement Learning" Electronics 12, no. 7: 1598. https://doi.org/10.3390/electronics12071598
APA StyleLi, Y., Hu, H., Liu, W., & Yang, X. (2023). An Optimal Active Defensive Security Framework for the Container-Based Cloud with Deep Reinforcement Learning. Electronics, 12(7), 1598. https://doi.org/10.3390/electronics12071598