4.1. Experimental Design
The manual annotation-based supervised learning algorithm in this paper uses a language model. Language models can be probabilistic based or non-probabilistic. Twitter emotion analysis is actually a classification problem. In order to use language models to conduct twitter emotion analysis, this article combines twitter short essays from the same class (positive or negative) to form a large document. The learning process of the affective language model is similar to the subjective classification problem, except that the category becomes both subjective and objective [
15].
Recently, in the field of twitter short text sentiment analysis, there are more and more learning algorithms that do not need manually annotated data [
16]. Such algorithms learn the classifiers from the training data with noisy annotations, which are emoticons or other specific markers. The advantage of these learning algorithms is that they eliminate the heavy manual annotation process. A large number of training data with noisy annotation information can be automatically obtained through programs, including twitter’s open API or other existing twitter emotion analysis websites. Although a number of noise-annotation-based algorithms have been proposed. However, there are still some flaws in these methods.
First, none of these methods solve the problem of subjective classification very well. Second, they all need to climb a large number of twitter short texts and store them locally, considering that the twitter crawl is limited, so it is also a time-consuming and inefficient way. Third, because the annotation information is inherently noisy, the classifier obtained only using such training data with noisy annotation has limited accuracy. Fourth, at present, few models can effectively use the artificial annotation information and the noise annotation information simultaneously to integrate these two kinds of information into a set of framework.
For subjectivity classification, the two sentiment categories are subjective and objective. This paper assumes that tweets containing “:)” or “:(” are subjectively colored by the publisher. Therefore, the search phrase posted to the twitter search API constructed in this paper is “:)” or “:(”, which is used to estimate the subjective emotion language model [
17].
For the language model of objective emotion, it is more difficult to calculate Pu(|), that is, the occurrence probability of words in the objective emotion category, than the subjective category. To the best of our knowledge, no academics have made valid assumptions about objective tweets. This paper has tried a hypothetical strategy such that if a tweet does not contain any expressions, then it is likely to be objective. The experimental results show that this hypothesis is not satisfactory. It tries to use hashtags, such as “#jobs”, as tags for objective tweets, but there are some problems with this assumption. For one, the number of tweets that contain specific hashtags is limited. Second, the sentiment of tweets can bias specific hashtags, such as “#jobs,” without ensuring objectivity.
In this paper, we propose a novel hypothesis to label objective tweets. If a tweet contains an objective url link, it is more likely to be objective. Based on our observations, we find that if url links come from image sites (such as twitpic.com) or video sites (such as youtube.com), they are likely to be subjective. But if the url link is from a news site, there is a good chance it is an objective tweet. Therefore, if a url link does not come from a picture website or a video website, this article calls this url an objective url link. Based on the above findings and assumptions, the search phrase submitted to the twitter search API constructed in this paper is “wifilter:links”, where filter:links indicates that the returned tweets are linked by url. This paper does this to obtain the information of objective tweets [
18].
Considering that both algorithms based on manual annotation and only using noise annotation information have their own disadvantages, the best strategy is to use both manual and noise annotation information and use two types of training data for model training. How to seamlessly integrate these two different types of data into a unified framework is the challenge addressed in this chapter. This paper presents a brand new model, based on the emoji smoothing language model, namely emoticonsmoothedlanguagemodel (ESLAM).
The main contributions of ESLAM are as follows:
After training the language model through manually annotated data, ESLAM smoothed the language model using training data annotated with emoticons. Thus, ESLAM seamlessly integrates manual and noisy annotated data to form a unified probabilistic model framework. The large amount of noise annotation data allows the ESLAM language model to handle misspelled words, slang, tone words, abbreviations, and their various unlogged words. This ability is not found in a common supervised learning model based on manual annotation.
In addition to discriminating between positive and negative polarity classification, ESLAM can also be used for subjective classification. The previous noise annotation-based algorithm cannot be used for subjective classification.
Most noise annotation-based learning algorithms need to crawl a large number of twitter short texts and store them locally, but considering that twitter crawling has access frequency limited, it is also a time-consuming, storage space consuming and inefficient way [
19]. The ESLAM in this paper proposes an innovative and simple method to directly estimate the probability of each word in the language model by using twitter’s open API, without the need to download any original text from twitter.
Experiments on real data from twitter show that ESLAM can effectively integrate artificial and noise annotation information and work better than other algorithmic models that use only one of these information.
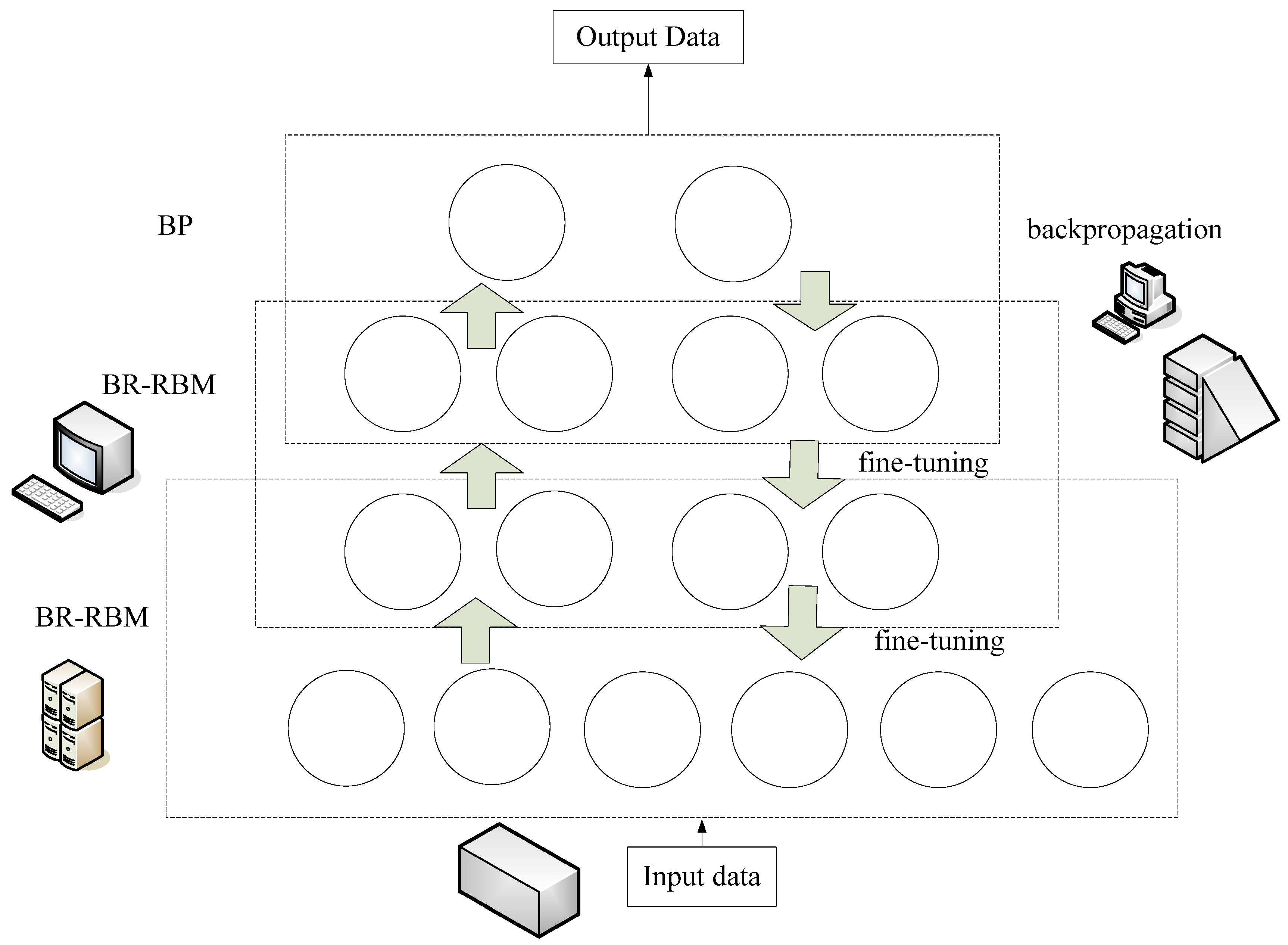
To test the role of meta-learning methods based on deep belief networks in text emotion classification, two sets of contrast experiments were used. The first group compares the results of the meta-learning method of deep belief network and the deep belief network directly acting on the text feature vector in text emotion classification, and the results of metalearning and fixed rules in text emotion classification.
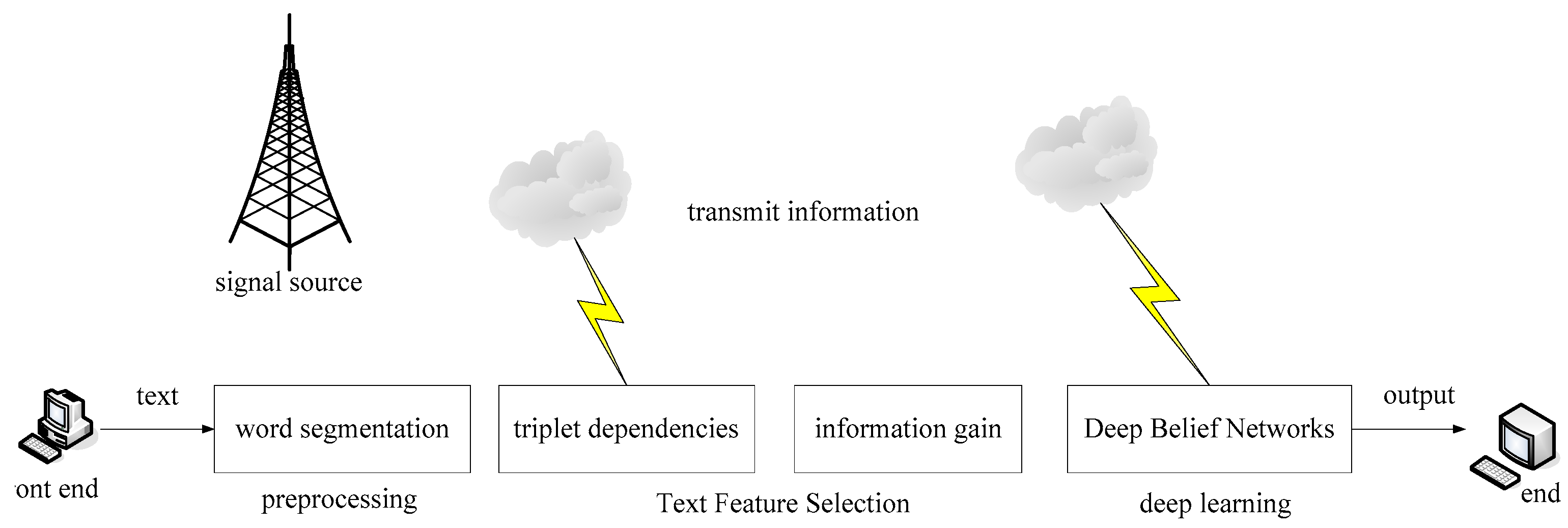
The deep persuasion of the network directly affects the emotional classification of the text. The work process consists of three parts: text pre-processing, text feature selection, and learning in the deep neural network. The process is shown in
Figure 4.
Figure 4 shows the process from the original text of using the deep belief network to obtain the classification results. First, the preprocessing steps of sentence sentences, polarity annotation, and word segmentation are carried out. Then, on the basis of word segmentation, the onery words of sentences, binary words, word sex, dependency label, ternary dependency relationship and other characteristics of the sentence are extracted to form the text representation vector. In general, for the feature vector space with large dimension, the information gain feature selection algorithm is used. Finally, the training set is used for the deep belief network for training to obtain the determined network structure. The network structure was tested with the test set, and the final available deep belief network was determined by adjusting the corresponding network structure and parameters [
20].
This paper uses a publicly available Sanders dataset containing 5513 manually annotated tweets. The tweets are all about one of the four themes, namely Apple, Google, Microsoft, and Twitter. After removing non-English tweets and junk tweets, there are still 3723 tweets left. The larger the index value, the more accurate the text emotion classification results are. Six sets of different features were selected, including monary word, binary word, word sex, dependency label, combined features of emotion score, and triplet dependency feature. The dimensions of each functional set were network input with 1000, 2000, 4000, 6000, 8000, 12000, 14000 items with the highest information gain score. The number of different network layers and their corresponding hidden layer nodes are shown in
Table 2.
In
Table 2, the network structure with X representing the input nodes and 2 layers is X-600-300, indicating the first hidden layer knots of 600 and the second hidden layer knots of 300.
Experimental results record the classification accuracy and reconstruction error of different feature dimensions under different network structures. It records the accuracy of the network DBN: X-2000-1000-500-200-100, DBN: X-600-300-100, DBN: X-600-300 and BP: X-600 in different dimensions of six sets of feature sets. The reconstruction errors are numbered according to the corresponding number of hidden layers.
4.2. Classification and Calculation
Experimental calculations were performed according to the experimental flow in
Figure 5. Experimental results record the classification accuracy and reconstruction error of different feature dimensions under different network structures. They are the results of network DBN: X-2000-1000-500-200-100, DBN: X-600-300-100, DBN: X-600-300, and BP: X-600 in different dimensions of six sets of feature sets. The reconstruction errors are numbered according to the corresponding number of hidden layers [
21].
The minimum, maximum, and mean values of the source data results were calculated. Statistical results are presented in
Table 3,
Table 4,
Table 5 and
Table 6.
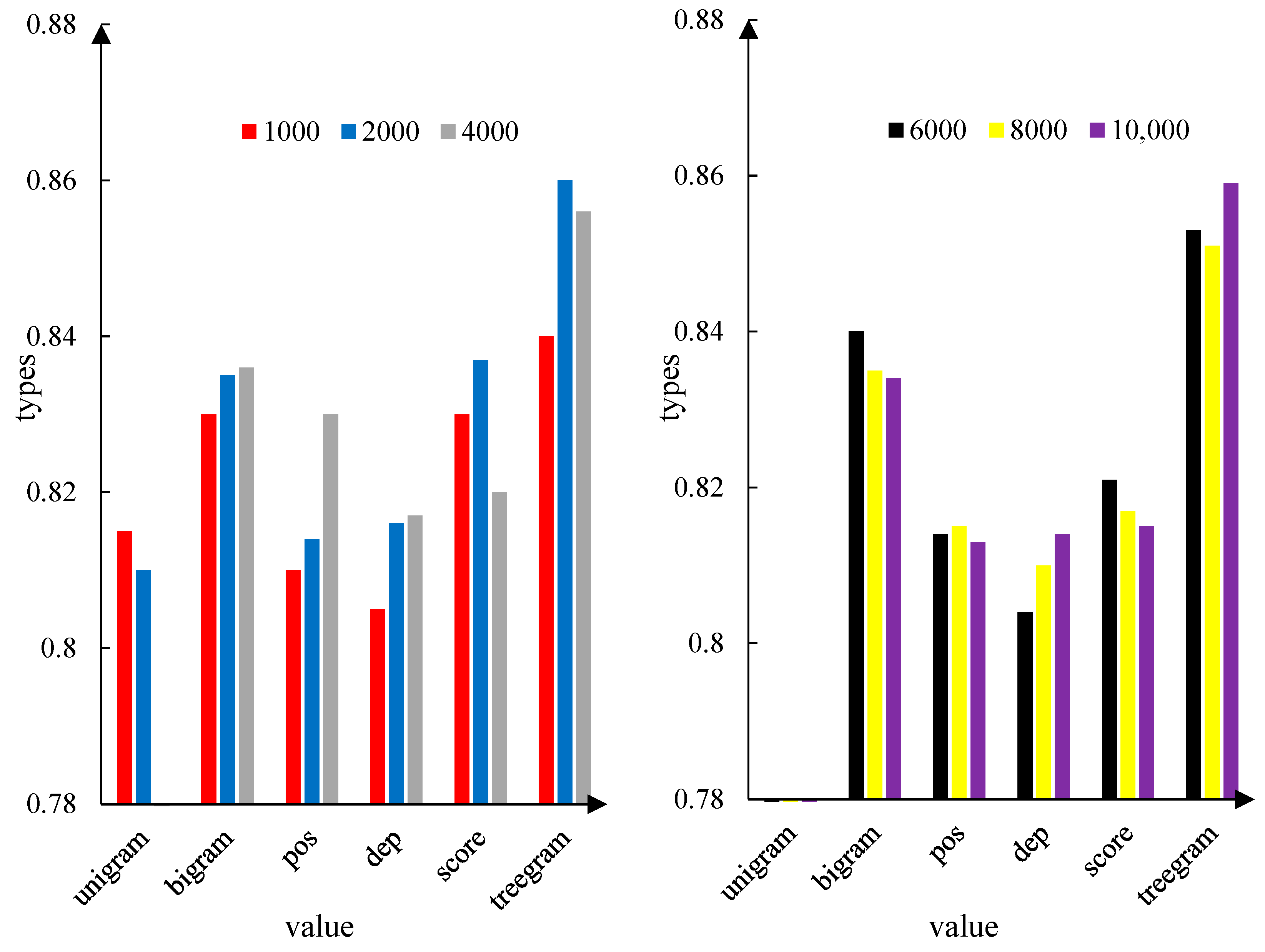
Table 3 shows the results of the network DBN: X-2000-1000-500-200-100. Among them, the minimum classification accuracy was 0.8058 and the maximum was 0.8692, obtained when the triplet dependency feature dimension was 14,000, the average classification accuracy of the 5-layer deep belief network was 0.8303. However, the first-layer restricted Boltzmann machine reconstruction error for a single training set is 9.4408 to 22.5903, and the average reconstruction error is 16.0944. The reconstruction error increases with the input nodes. The reconstruction error in the second layer ranged from 6.0798 to 10.3566, with an average value of 8.7713. The first layer is greatly reduced in the reconstruction error. The reconstruction error of the third layer ranges from 2.4241 to 5.2308, and the average reconstruction error is 3.9798, which is also reduced from the reconstruction error of the second layer. The fourth layer reconstruction error ranged from 2.4355 to 5.2445, with an average of 4.1796, and the third layer showed little change. The reconstruction error in the fifth layer ranges from 1.4961 to 4.3040, with an average of 3.0649, decreasing compared with the reconstruction error in the previous layer. The network running time ranged from 166.3 to 1503.6 s, increasing with increasing input nodes.
Table 4 shows the results of the network DBN: X-600-300-100. Among them, the minimum range of classification accuracy is 0.8116, the maximum is 0.87, taken when the triplet dependency feature input node is 12,000, the average classification accuracy is 0.8301. The reconstruction error range of the first layer confined Boltzmann machine is between 7.3175 and 26.5429, increasing with increasing input nodes. The reconstruction error of the second layer ranges from 2.7168 to 6.2811, which is less accurate from that of the previous layer. The reconstruction error of the third layer ranges from 1.3974 to 4.4129, which is also reduced compared with the previous layer. The time period ranged from 166.3 s to 1503.6 s.
Table 5 shows the results of the network DBN: X-600-300. Among them, the minimum classification accuracy was at 0.8116 and the maximum was 0.87, obtained when the triplet dependency feature input node was 14,000, and the average classification accuracy was 0.8326. However, the reconstruction error range of the training set is 7.3296 to 26.5921, increasing with more input nodes. The reconstruction error in the second layer ranges from 2.7044 to 9.5712, which is lower than that of the previous layer. The time period ranged from 142.2 s to 1409.4 s.
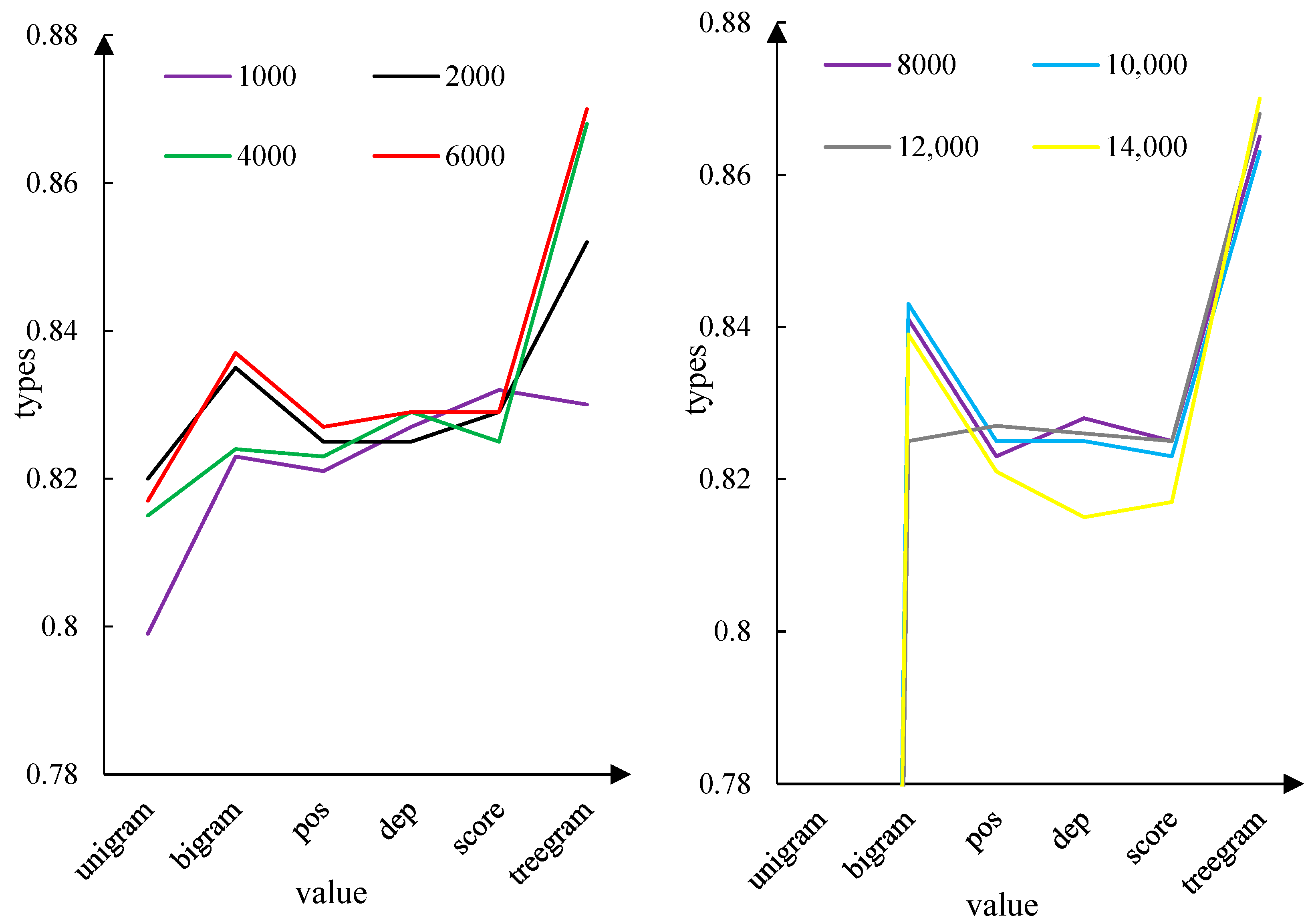
Table 6 shows the results of network BP: X-600. Among them, the minimum classification accuracy was 0.8133 and the maximum was 0.8641, obtained when the ternary dependency feature input dimension was 14,000, and the average classification accuracy was 0.8333. The time period ranged from 45.35 s to 1117.5 s.
4.3. Experimental
(1) Effect of different feature sets on the classification accuracy
As can also be seen from
Figure 5, in order to verify numerical, by calculating the average classification accuracy of different feature sets, the results are 0.81, 0.8381, 0.8195, 0.8152, 0.8220, and 0.8620. The highest classification accuracies were 0.8142, 0.8433, 0.8308, 0.825, 0.8342, and 0.8692, respectively. We show that the triple dependence is a feature representation that achieves the highest classification accuracy, followed by combined features of monary and binary words.
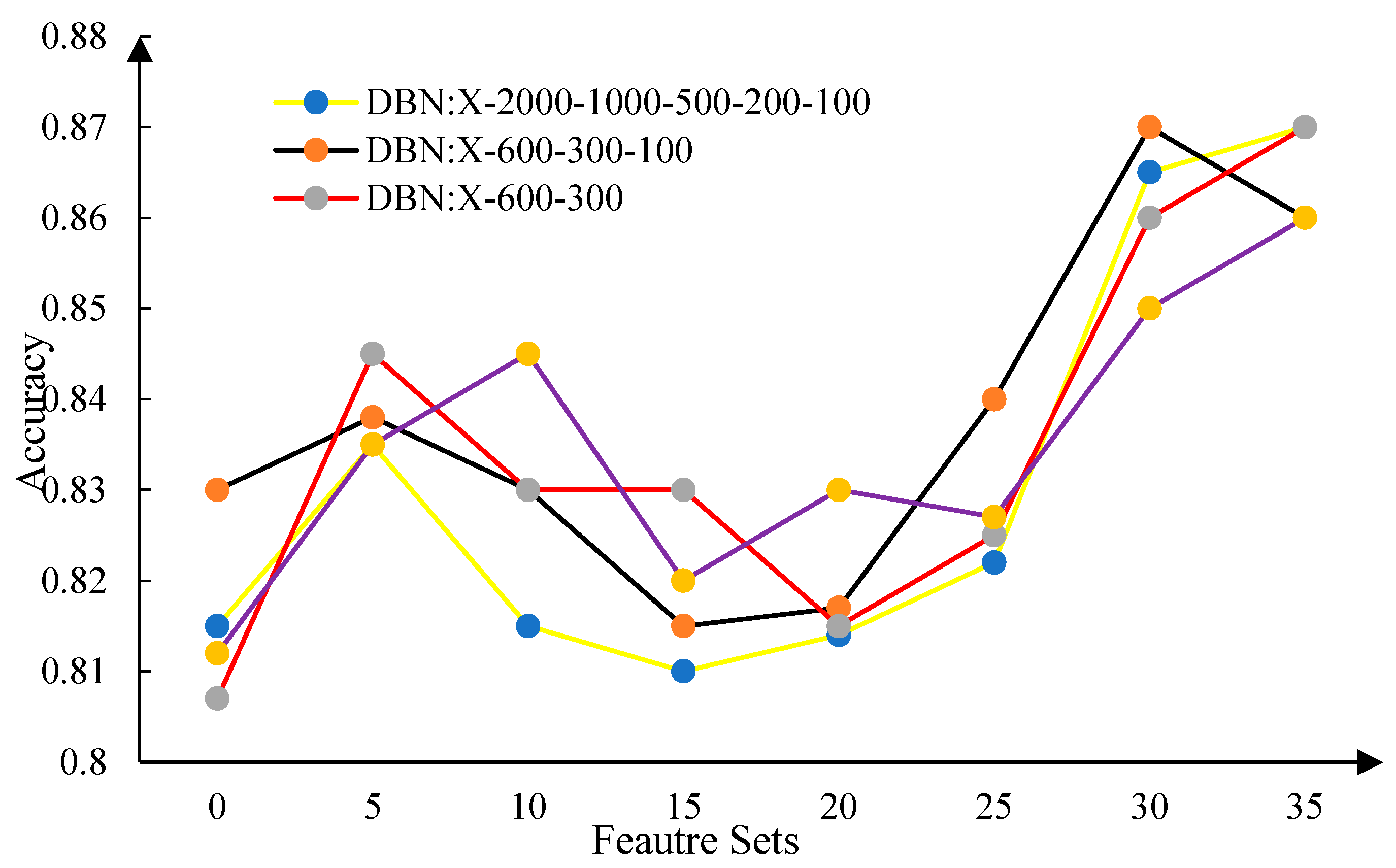
As can be seen from
Figure 6, the average classification accuracy according to different feature sets is 0.8202, 0.8379, 0.8214, 0.8175, 0.8215, and 0.8585. The highest classification accuracy obtained was 0.8291, 0.845, 0.8283, 0.8325, 0.8375, and 0.87.
As can be seen from
Figure 7, when the triplet dependency feature dimension is taken at 4000 or above, the classification accuracy exceeds other features and feature combinations. Second, the combination of monary word features achieves good classification results in some dimensions. On the basis of binary words, the classification accuracy between adding words, dependency label, and emotion score features is not very different, and the average classification accuracy of single word features is the lowest. According to the calculation, the average classification accuracy according to different feature sets is successively: 0.8106, 0.8341, 0.8272, 0.8243, 0.8272, and 0.8605. The best classification accuracy on different feature sets is 0.82, 0.8441, 0.8341, 0.8308, 0.8341, and 0.87. Conclusion DBN: X-2000-1000-500-200-100, DBN: X-600-300-100.
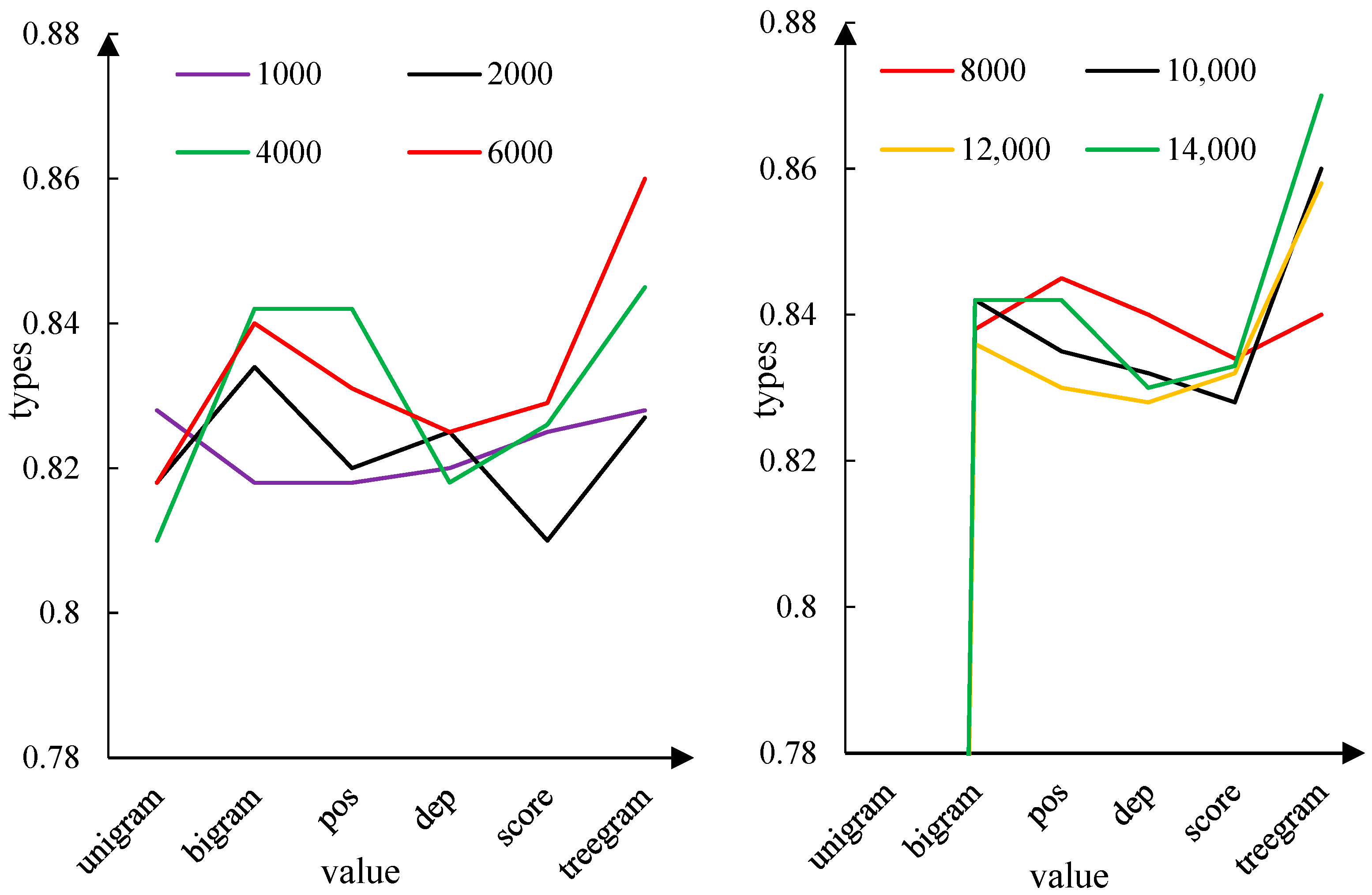
As can be seen from
Figure 8, when the triplet dependency feature dimension is taken at 4000 or above, the classification accuracy exceeds other features and feature combinations. The average classification accuracy of binary word features is higher than the addition of word features, dependency labels, and emotion score. The lowest average classification accuracy was on unitary word features. According to the calculation, the average classification accuracy of different feature sets is: 0.8196, 0.8349, 0.8307, 0.8276. Meta-learning text emotion classification 850.8306, 0.8479. Based on deep belief network, the highest classification accuracy obtained was: 0.8275, 0.8416, 0.8425, 0.8375, 0.8391, and 0.8641.
(2) Analysis and comparison of deep belief network and BP network
The deep belief network is composed of the multilayered restricted Boltzmann machine in the stack form, and the initial weights of the network are learned by the restricted Boltzmann machine algorithm, and then adjusted by the BP algorithm according to the label data. However, the initial value of the network is randomly assigned, which is adjusted by the BP algorithm, which leads to the non-convergence of the BP network due to the error decline. This section analyzes the classification accuracy and convergence of deep belief networks and BP networks in experiments.
The deep belief network structure with different numbers of layers was compared with the classification accuracy of the BP networks, They are: One yuan word 4000, One Word 6000, +Binary word 4000, +Binary word 6000, +Binary word 8000, +Binary word 10,000, +Binary word 12,000, +Binary word 14,000, +Sex of Words 4000, +Sex of Words 6000, +Sex of Words 8000, +Sex of words 10,000, +Sex of Words 12,000, +Sex of Words 14,000, +Lalabel 4000, +Lalabel 6000, +Lalabel 8000, +Lalabel 10,000, +dependent label 12000, +Lalabel 14,000, +Emotional score of 4000, +5 Emotional score of 6000, +Emotional score of 8000, +Emotional score of 10,000, +Emotional Score of 12,000, +Emotional score of 14,000, Terplet dependency 4000, Terplet dependency 6000, Terplet dependency 8000, Terplet dependency 10,000, Terplet dependencies 12,000, Terplet dependency 14,000. The comparison of the obtained results is shown in
Figure 9.
The structural classification accuracy of the three different deep belief networks in
Figure 9 has almost the same trend at each input node. In the comparison of deep belief network and BP between the 11th node and the 26th node, BP: X-600 is better than other networks, while DBN-X-2000-1000-500-500-200-100, from the 28th to 32nd junction, BP: X-600 has the lowest classification accuracy, indicating that BP learns less under complex features, less than the deep belief network [
22].
BP network algorithm is an essential gradient descent method, and the high dimensional characteristics of network input and the nature of text emotion classification itself make optimization objective function very complex, therefore, the process of “zigzag” phenomenon is used. When the optimization of neuron output is close to 0 or 1, the weight error change is small, in the error spread to pause, leading to network convergence. However, in the deep belief network, the optimization of weights is realized by limiting the Boltzmann machine to avoid the non-convergence due to too small error in the gradient descent algorithm [
23].












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
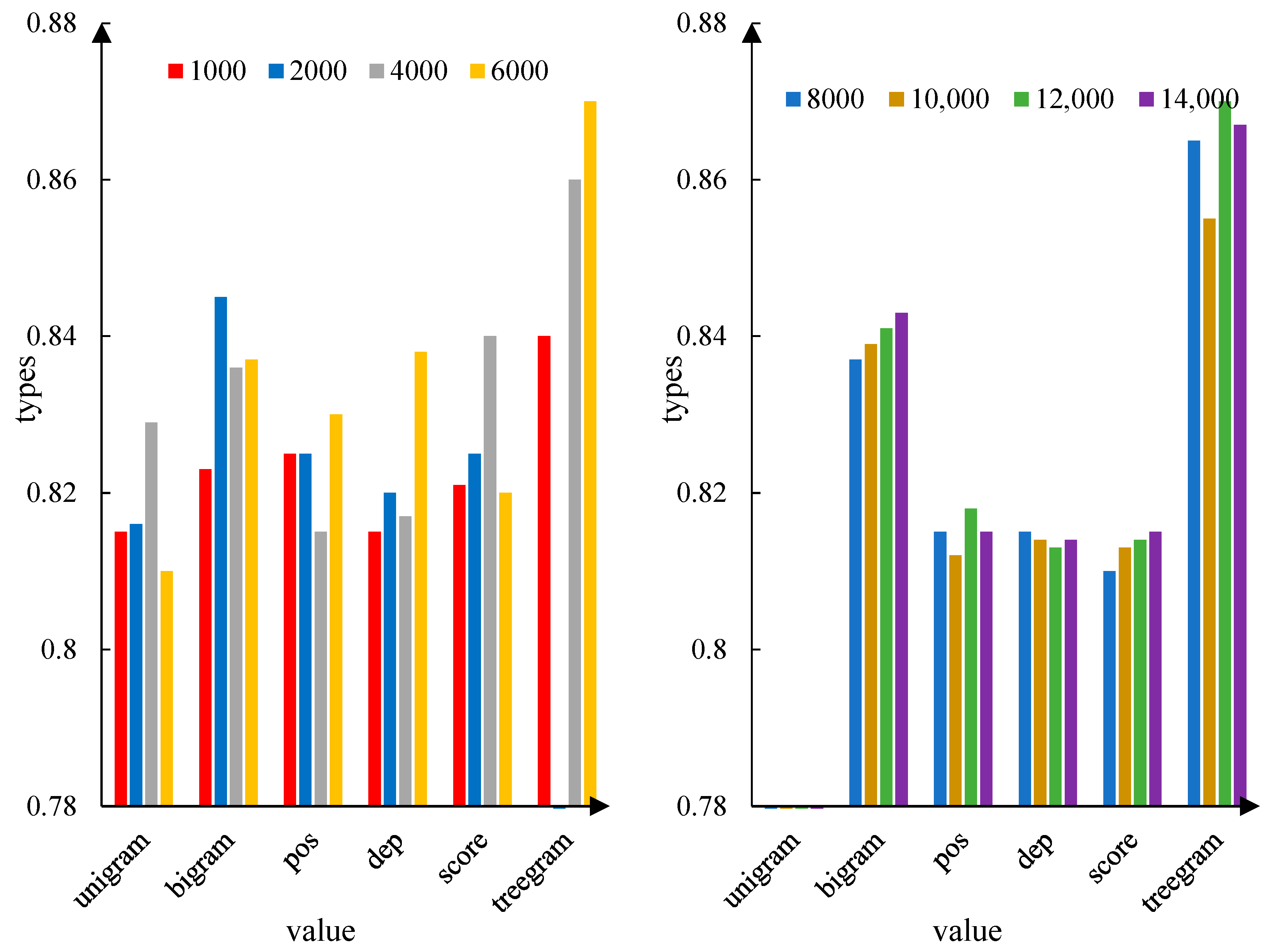{kind=link}
{kind=link}
{kind=link}
{kind=link}