


Evolution of Socially-Aware Robot Navigation



Abstract
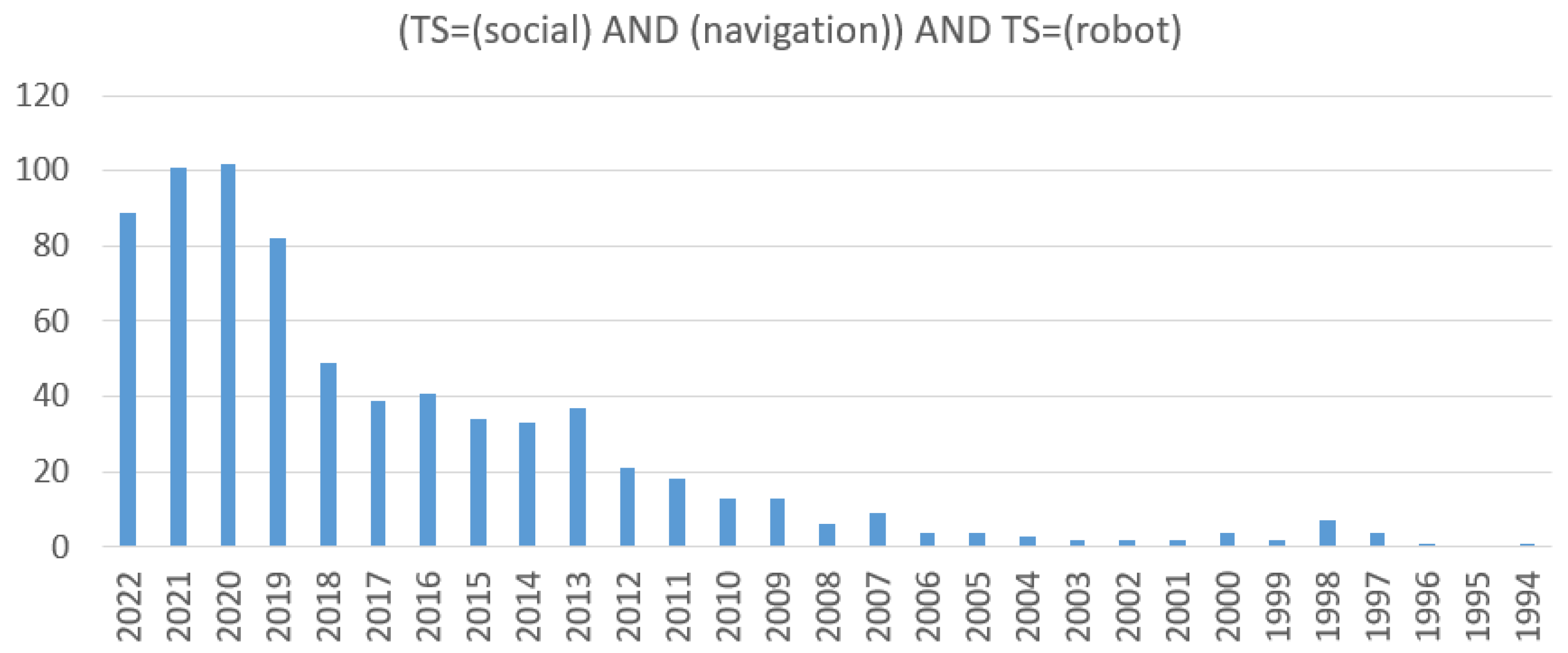
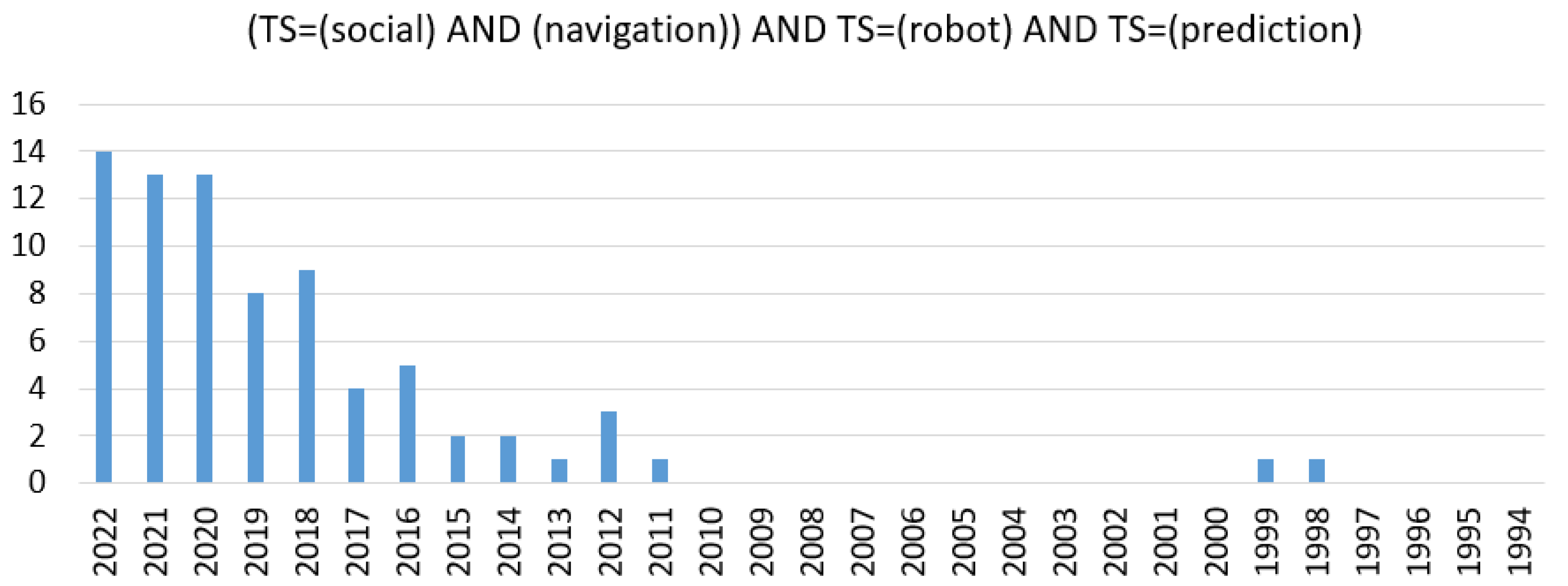
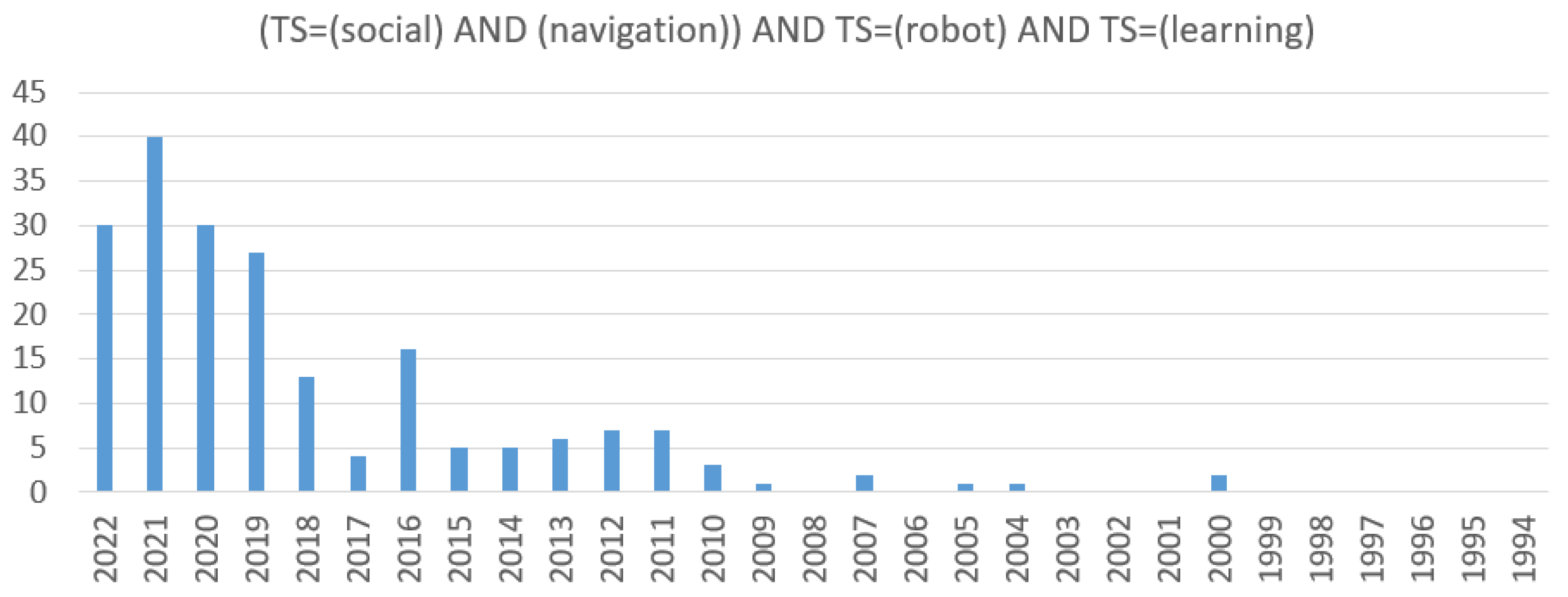
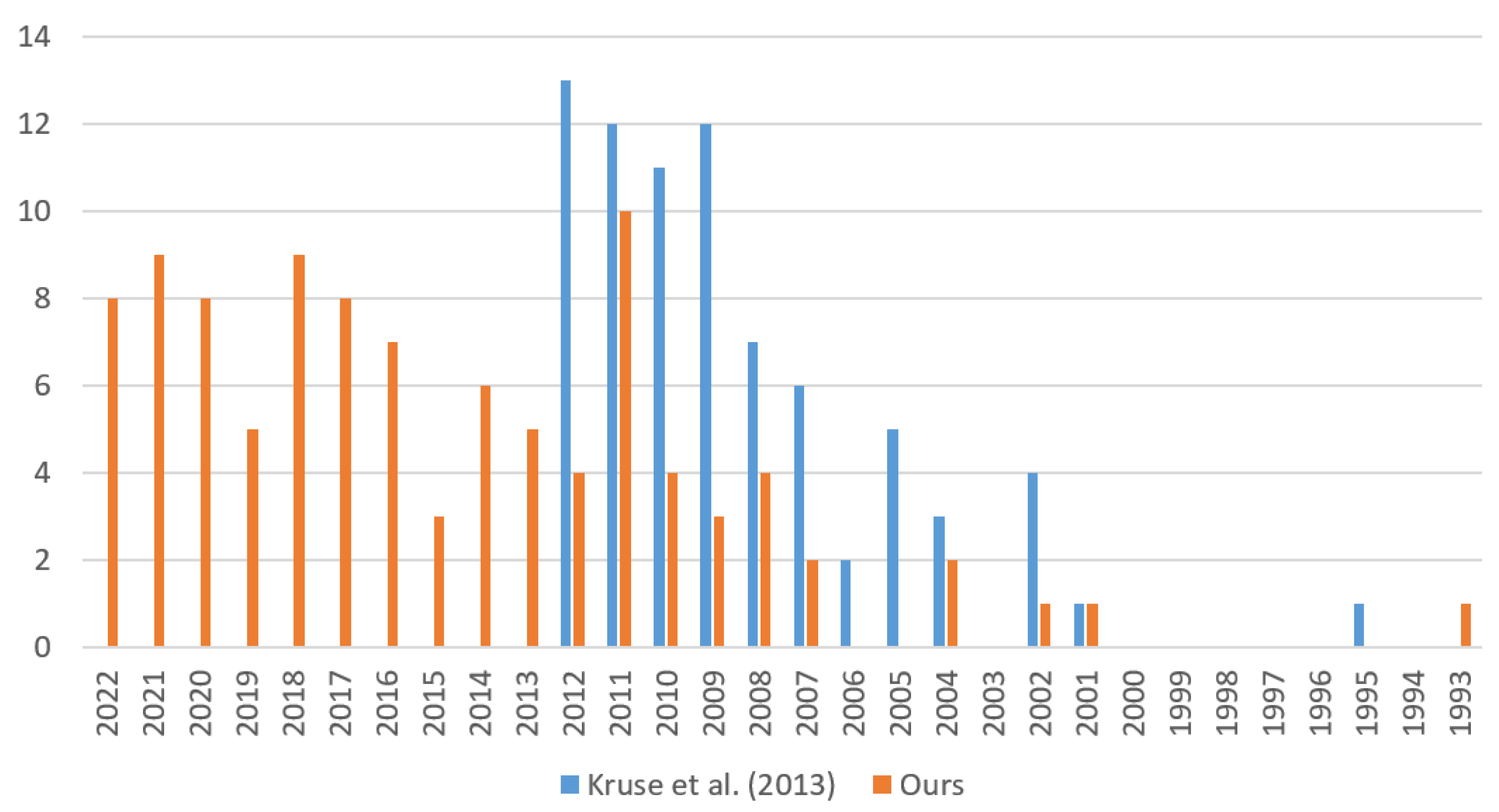
1. Introduction
2. Methodology
2.1. Article Selection Criteria
2.2. Article Classification Criteria
3. Socially Aware Navigation Approaches
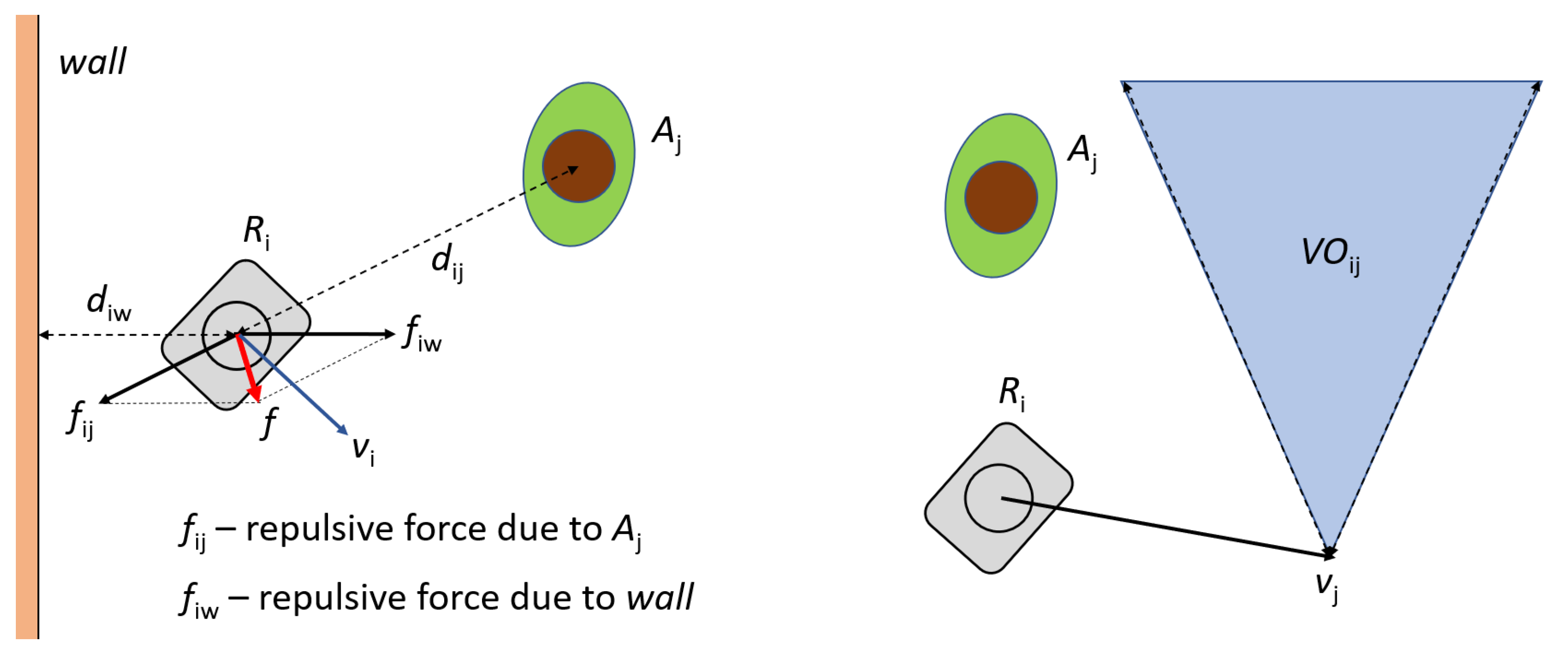
3.1. Reactive Approaches
3.2. Proactive Approaches
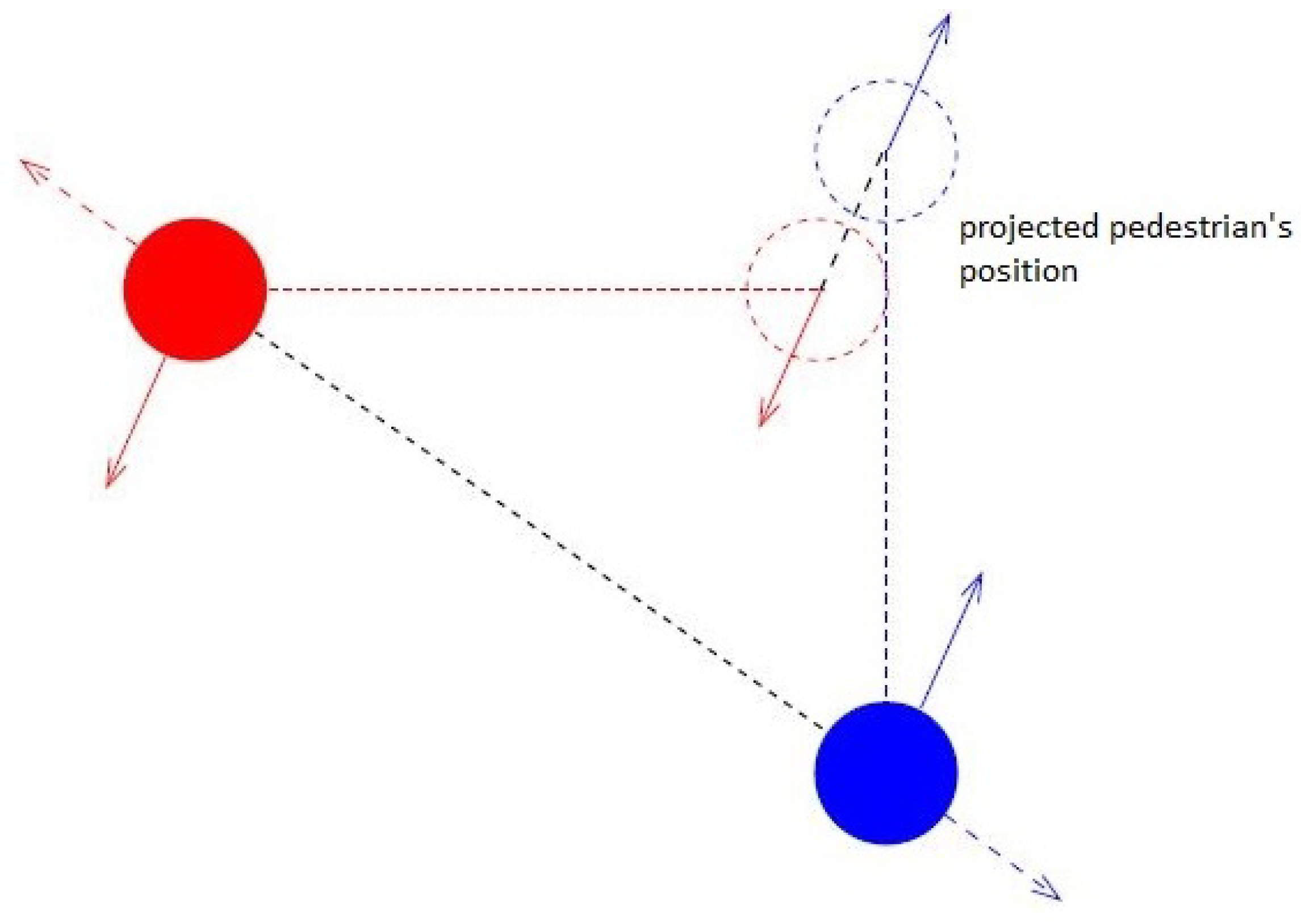
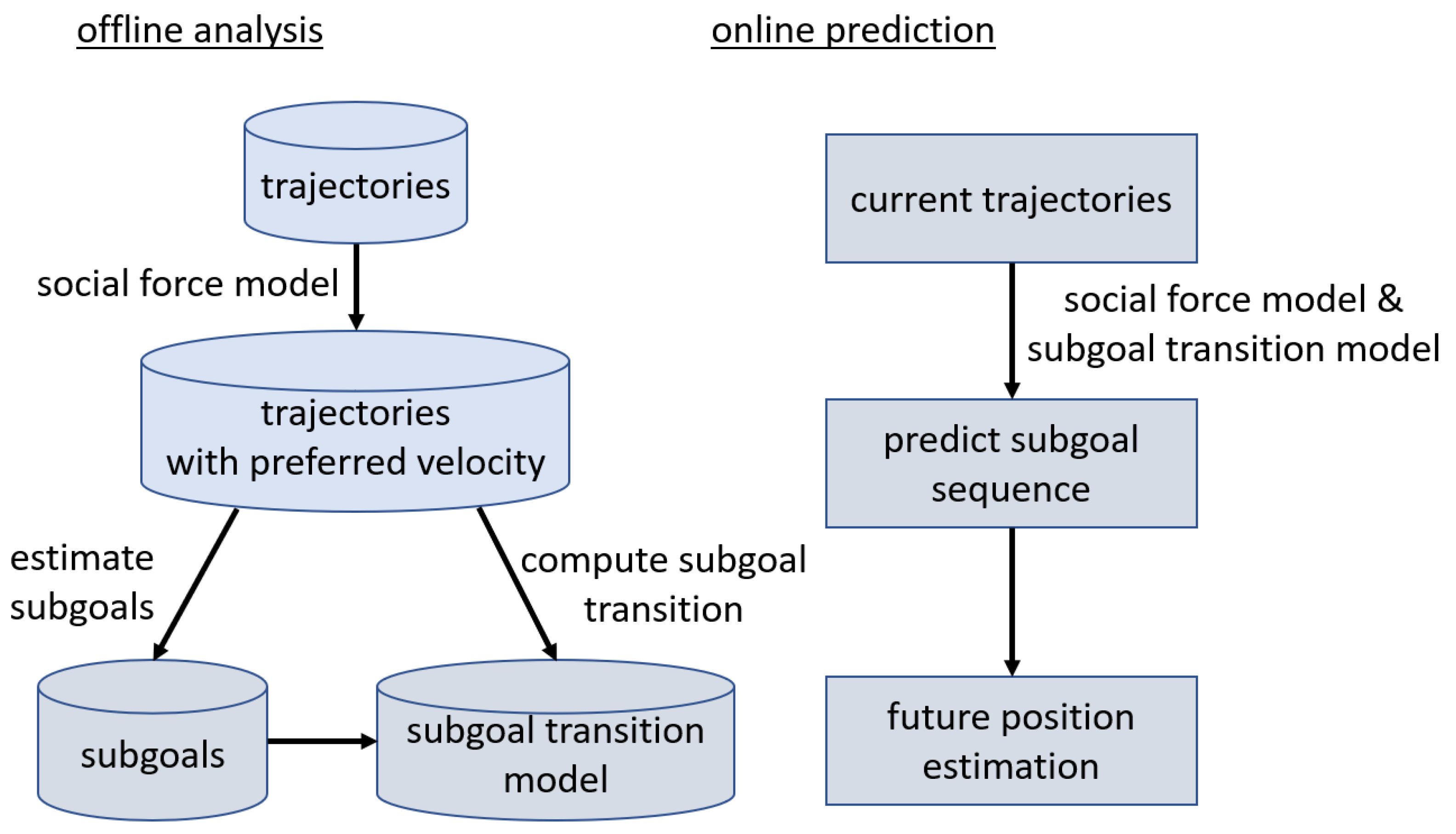
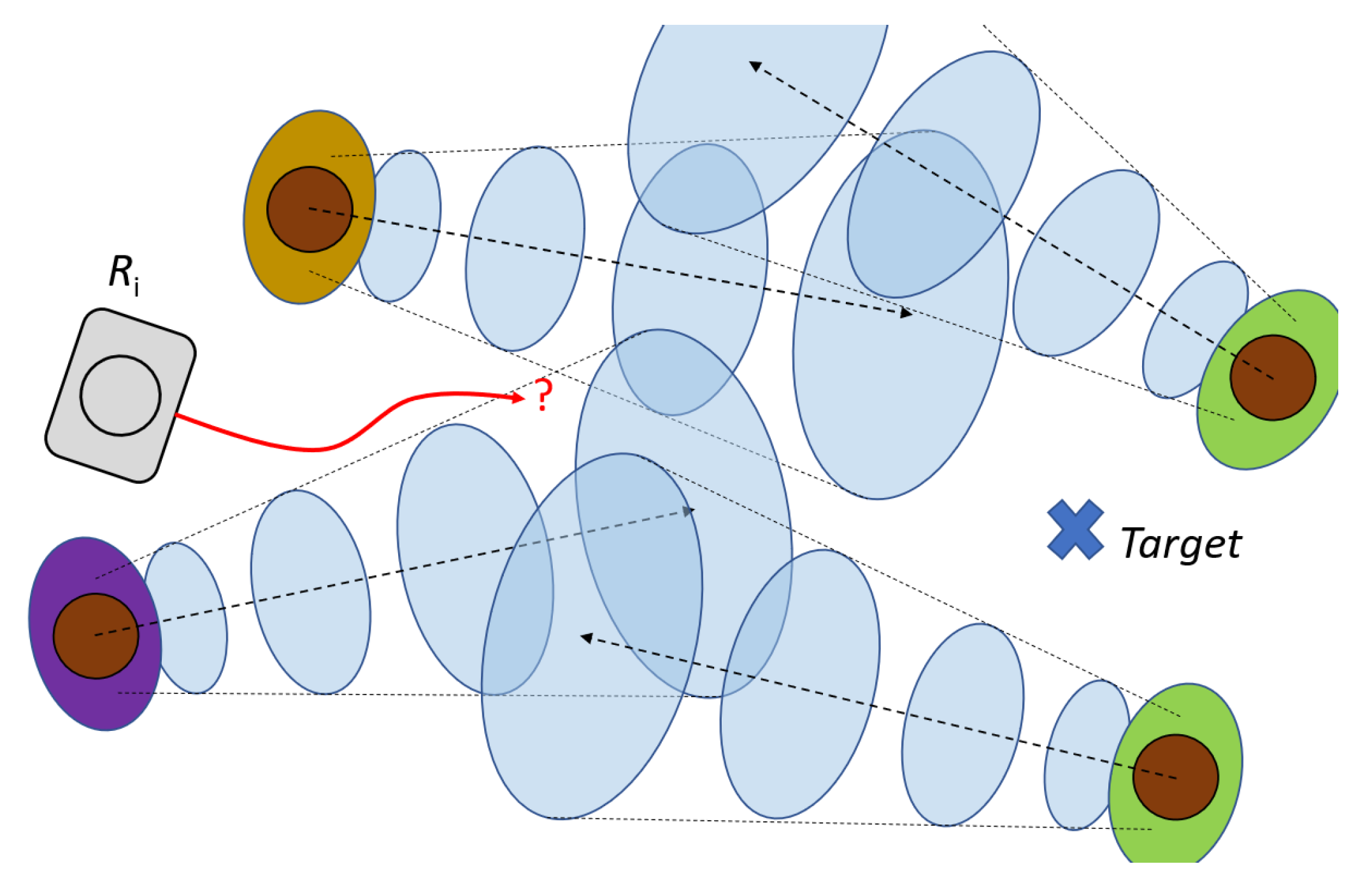
3.2.1. Predictive Models

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Methods |
|---|---|
| van den Berg et al. [35] | Reciprocal Velocity Obstacle |
| Snape et al. [34] | Hybrid Reciprocal Velocity Obstacles |
| Zanlungo et al. [36] | SFM extended to the near future |
| Ferrer et al. [37] | Social Force Model (SFM) |
| Shiomi et al. [38] | Collision Prediction Social Force Model (CP-SFM) |
| Trautman et al. [39] | Multiple Goal Interacting Gaussian processes algorithm |
| Large et al. [40] | Velocity Obstacle (VO) & Obstacles motion prediction |
| Thompson et al. [41] | Probabilistic Model of Human Motion |
| Du Toit and Burdick [42] | Thresholding the uncertainty |
| Joseph et al. [43] | Gaussian processes (GP) & Dirichlet process (DP) prior over mixture weights |
| Aoude et al. [44] | RR-GP—Learned motion pattern model by combining the flexibility of Gaussian |
| processes (GP) with the efficiency of RRT-Reach | |
| Ziebart et al. [45] | Maximum entropy inverse optimal control |
| Bennewitz et al. [46] | Learned human motion patterns |
| Kuderer et al. [47] | Maximum entropy |
| Ferrer and Sanfeliu [48] | CLP-Time Window Predictor |
| Kabtoul et al. [49] | Quantitative time-varying function to model HR cooperation |
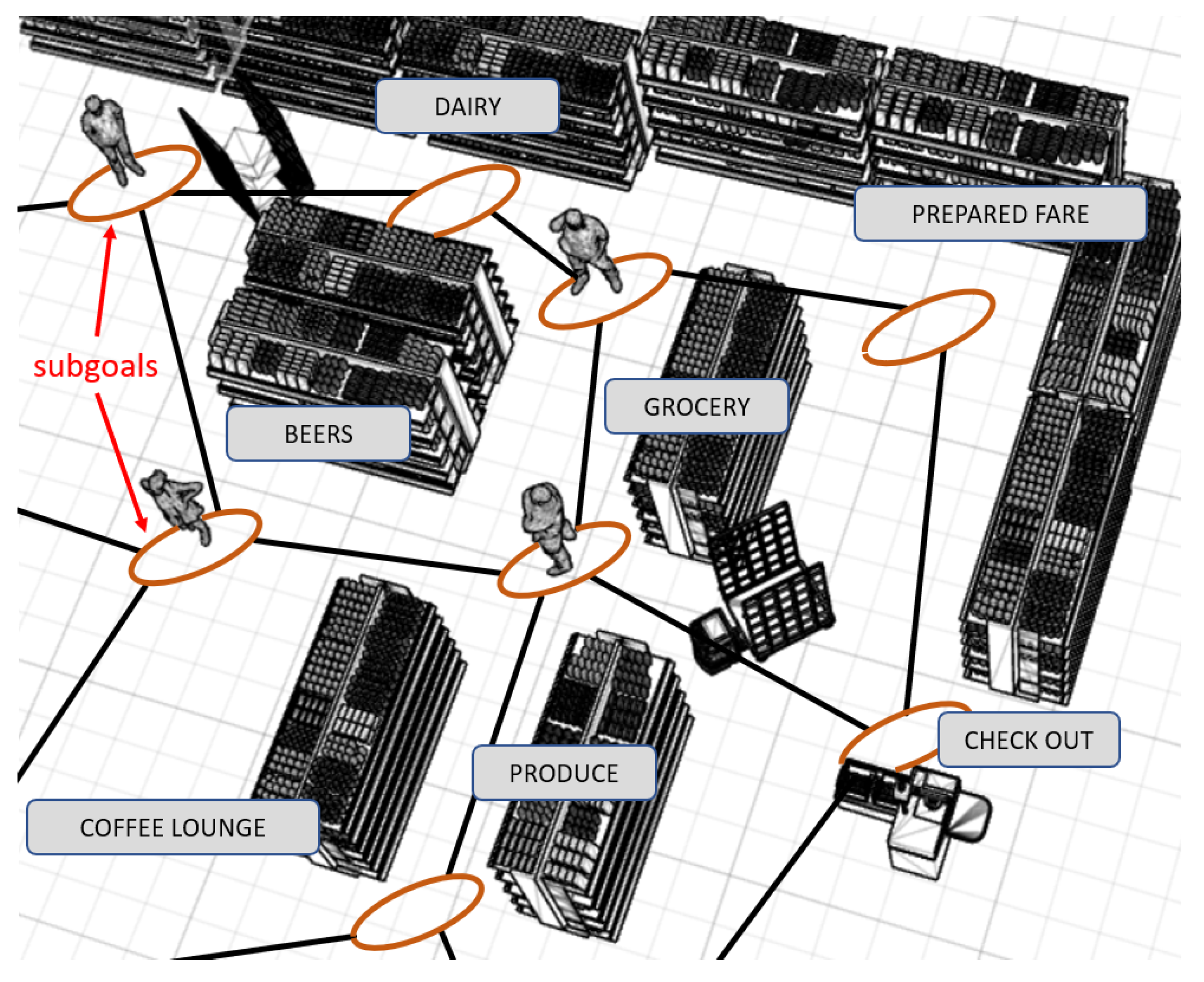
| Ikeda et al. [50] | Sub-goals to retrieve useful information not only for prediction but also for robot navigation, environment modeling and pedestrian simulation. |
| Sub-goals used as the nodes of the robot global path planner, and as the nodes of the planner in the pedestrian simulator | |
| Luber et al. [51] | Non-homogeneous spatial Poisson process |
| Bayesian inference from observations of track creation | |
| Matching and false alarm events | |
| Gained by introspection of a laser-based multi-hypothesis people tracker | |
| Vega et al. [53] | Adaptive Spatial Density Function |
| Asymmetric Gaussian representation for personal space | |
| Inclusion of the space affordances | |
| Probabilistic Road Mapping (PRM) | |
| Rapidly-exploring Random Tree (RRT) | |
| Elastic band algorithm | |
| Mead and Mataric [54] | Probabilistic framework for proxemic behavior production in HRI |
| Mead et al. [55] | Heuristic-Based vs. Learned Approaches |
| Sisbot et al. [15] | Safety and visibility related criteria |
| Svenstrup et al. [56] | Adaptive potential functions respecting social spaces |
| Castro-González et al. [57] | Hidden Markov Models for predictions |
| Ratsamee et al. [58] | Modified SFM (MSFM) considering body pose, face orientation and personal space |
| Truong and Ngo [33] | Proactive Social Motion Model (PSMM) |
| Ferrer and Sanfeliu [59] | Extended SFM (ESFM) |
| Farina et al. [60] | SFM with Laumond’s human locomotion models |
| van den Berg et al. [61] | Reciprocal n-body collision avoidance |
| Bera et al. [62] | GLMP approach-Global and Local Movement Patterns |
| Pedestrian trajectory data using Bayesian Inference | |
| Ensemble Kalman Filters (EnKF) and Expectation Maximization (EM) | |
| Luo et al. [63] | Pedestrian Optimal Reciprocal Collision Avoidance (PORCA) combines with a Partially Observable Markov Decision Process algorithm (POMDP) |
| Chen et al. [14] | Interactive MPC (iMPC) framework |
| Intention Enhanced ORCA (iORCA) | |
| Xu et al. [65] | Emotional Reciprocal Velocity Obstacles (eRVO) |
| Alahi et al. [67] | Social Long-Short Term Memory networks (Social-LTSM) |
| Vemula et al. [68] | Social Attention |
| S-RNN architecture |
3.2.2. Navigation Strategies Using Agent Motion Models
3.3. Learning-Based Approaches
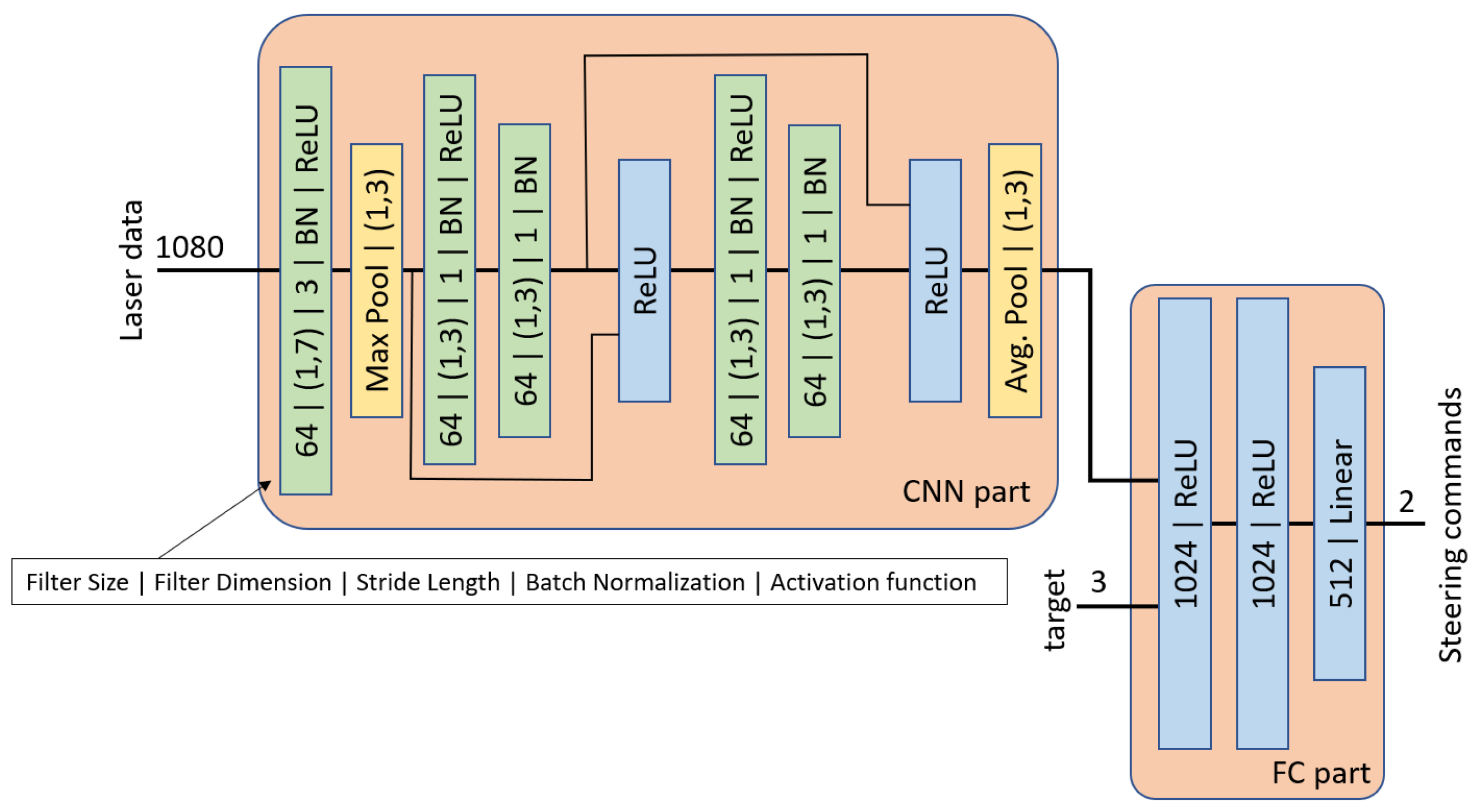
3.3.1. Deep Reinforcement Learning and End-to-End Approaches
- the robot moves according to a given action and obtains information from the environment (observations) and a reward;
- following a policy, and given the captured observation, an action is generated;
- the policy is updated by an RL-based algorithm.
| Reference | Methods |
|---|---|
| Chen et al. [79] | Decentralized Multi-agent Collision Avoidance algorithm based on a novel |
| application of deep reinforcement learning | |
| Chen et al. [84] | SA-CADRL, a multi-agent collision avoidance algorithm that considers and |
| exhibits socially compliant behaviors | |
| Time-efficient navigation policy that respects common social norms | |
| Reinforcement learning framework | |
| Everett et al. [85] | Collision avoidance algorithm, GA3C-CADRL, that is trained in simulation |
| with deep RL without requiring any knowledge of other agents’ dynamic | |
| Long Short-Term Memory (LSTM) | |
| LSTM that enables the algorithm to use observations of an arbitrary number | |
| of other agents | |
| Samsani and Muhammad [86] | Human Behavior Resemblance Using Deep Reinforcement Learning |
| The Danger Zones are formulated by considering the real time human behavior | |
| Hu et al. [87] | Deep reinforcement learning framework (DRL) and the value network |
| The DRL framework incorporating these social stress indexes | |
| Dugas et al. [88] | Reinforcement Learning of Robot Navigation in Dynamic Human Environments |
| NavRepSim environment is designed with RL applications in mind | |
| Gil et al. [89] | Social Force Model (SFM) allowing human-aware |
| Two Machine Learning techniques: Social navigation and Neural Network (NN) | |
| RL technique | |
| Francis et al. [90] | PRM-RL:Probabilistic road-maps (PRMs) as the sampling-based planner and |
| reinforcement learning-RL method in the indoor navigation context | |
| Chen et el. [80] | Crowd-Robot Interaction (CRI) |
| Attention-based Deep Reinforcement Learning | |
| Liu et al. [81] | Imitation learning and deep reinforcement learning approach for motion planning |
| in such crowded and cluttered environments | |
| Chen et al. [91] | Graph convolutional network (GCN) for reinforcement learning to integrate |
| information | |
| Attention network trained using human gaze data for assigning adjacency values. | |
| Gao et al. [92] | Learn an efficient navigation policy that exhibits socially normative navigation |
| behaviors | |
| Convolutional social pooling layer that robustly models human–robot | |
| co-operations and complex interactions between pedestrians | |
| Partial observability in socially normative navigation | |
| Long et al. [93] | Decentralized sensor-level collision avoidance policy for multi-robot systems |
| Policy gradient-based reinforcement learning algorithm | |
| Gromniak and Stenzel [94] | End-to-end Deep reinforcement learning |
| Shi et al. [95] | Navigation strategy based on deep reinforcement learning (DRL) |
| Conventional A3C algorithm, an ICM A3C model was proposed | |
| Li et al. [96] | Role Playing Learning (RPL) |
| NN policy is optimized end-to-end | |
| [97] | A deep Q-network (DQN), combine reinforcement learning with a deep neural |
| networks | |
| Lee and Yusuf [98] | Deep reinforcement learning for autonomous mobile |
| The trained DQN and DDQN policies are robot navigation in an unknown | |
| environment evaluated in the Gazebo testing environment | |
| Two types of deep Q-learning agents, such as deep Q-network and double deep | |
| Q-network agents | |
| Pfeiffer et al. [99] | Data-driven end-to-end motion planning approach for a robotic platform |
| End-to-end model is based on a CNN | |
| Learn navigation strategies | |
| Pfeiffer et al. [100] | Imitation learning(IL) and reinforcement learning (RL) |
| Tai et al. [101] | A map-less motion planner was trained end-to-end through continuous control |
| deep-RL from scratch | |
| The learned planner can generalize to a real non-holonomic differential robot | |
| platform without any fine-tuning to real-world samples | |
| Fan et al. [104] | Multi-robot, multi-scenario, and multi-stage training framework |
| Gao et al. [107] | Two-level hierarchical approach:Model-free deep learning and model-based path |
| planning | |
| Neural-network motion controller, called the intention-net, is trained end-to-end to | |
| provide robust local navigation | |
| Path planner uses a crude map | |
| Pokle et al. [108] | Hierarchical planning and machine learning |
| Traditional global planner to compute optimal paths towards a goal | |
| Deep local trajectory planner and velocity controller to compute motion commands | |
| Combines traditional planning with modern deep learning techniques | |
| Pérez-D’Arpino et al. [109] | Reinforcement learning to learn robot policies |
| The proposed model uses a motion planner that provides a globally planned | |
| trajectory whereas the reinforcement component handles the local interactions | |
| needed for on-line adaptation to pedestrians | |
| Choi et al. [110] | Novel deep RL navigation method that can adapt its policy to a wide range of |
| parameters and reward functions without expensive retraining | |
| Bayesian deep learning method |
3.3.2. Inverse Reinforcement Learning
3.4. Multi-Behavior Navigation Approaches
4. Discussion
5. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Gladden, M.E. Who Will Be the Members of Society 5.0? Towards an Anthropology of Technologically Posthumanized Future Societies. Soc. Sci. 2019, 8, 148. [Google Scholar] [CrossRef]
- SPARC. Robotics 2020 Multi-Annual Roadmap for Robotics in Europe; Technical Report; SPARC: The Partnership for Robotics in Europe, euRobotics Aisbl: Brussels, Belgium, 2015. [Google Scholar]
- Seibt, J.; Damholdt, M.F.; Vestergaard, C. Integrative social robotics, value-driven design, and transdisciplinarity. Interact. Stud. 2020, 21, 111–144. [Google Scholar] [CrossRef]
- Rossi, S.; Rossi, A.; Dautenhahn, K. The Secret Life of Robots: Perspectives and Challenges for Robot’s Behaviours during Non-interactive Tasks. Int. J. Soc. Robot. 2020, 12, 1265–1278. [Google Scholar] [CrossRef]
- Sandini, G.; Sciutti, A.; Vernon, D. Cognitive Robotics. In Encyclopedia of Robotics; Springer: Berlin/Heidelberg, Germany, 2021. [Google Scholar]
- Hellström, T.; Bensch, S. Understandable robots-What, Why, and How. Paladyn J. Behav. Robot. 2018, 9, 110–123. [Google Scholar] [CrossRef]
- Rios-Martinez, J.; Spalanzani, A.; Laugier, C. From Proxemics Theory to Socially-Aware Navigation: A Survey. Int. J. Soc. Robot. 2015, 7, 137–153. [Google Scholar] [CrossRef]
- Samarakoon, S.M.B.P.; Muthugala, M.A.V.J.; Jayasekara, A.G.B.P. A Review on Human–Robot Proxemics. Electronics 2022, 11, 2490. [Google Scholar] [CrossRef]
- Charalampous, K.; Kostavelis, I.; Gasteratos, A. Recent trends in social aware robot navigation: A survey. Robot. Auton. Syst. 2017, 93, 85–104. [Google Scholar] [CrossRef]
- Gao, Y.; Huang, C.M. Evaluation of Socially-Aware Robot Navigation. Front. Robot. AI 2022, 8, 721317. [Google Scholar] [CrossRef]
- Zhu, K.; Zhang, T. Deep reinforcement learning based mobile robot navigation: A review. Tsinghua Sci. Technol. 2021, 26, 674–691. [Google Scholar] [CrossRef]
- Chik, S.; Fai, Y.; Su, E.; Lim, T.; Subramaniam, Y.; Chin, P. A review of social-aware navigation frameworks for service robot in dynamic human environments. J. Telecommun. Electron. Comput. Eng. 2016, 8, 41–50. [Google Scholar]
- Kruse, T.; Pandey, A.K.; Alami, R.; Kirsch, A. Human-aware robot navigation: A survey. Robot. Auton. Syst. 2013, 61, 1726–1743. [Google Scholar] [CrossRef]
- Chen, Y.; Zhao, F.; Lou, Y. Interactive Model Predictive Control for Robot Navigation in Dense Crowds. IEEE Trans. Syst. Man Cybern. Syst. 2022, 52, 2289–2301. [Google Scholar] [CrossRef]
- Sisbot, E.A.; Marin-Urias, L.F.; Alami, R.; Simeon, T. A Human Aware Mobile Robot Motion Planner. IEEE Trans. Robot. 2007, 23, 874–883. [Google Scholar] [CrossRef]
- Kamezaki, M.; Tsuburaya, Y.; Kanada, T.; Hirayama, M.; Sugano, S. Reactive, Proactive, and Inducible Proximal Crowd Robot Navigation Method Based on Inducible Social Force Model. IEEE Robot. Autom. Lett. 2022, 7, 3922–3929. [Google Scholar] [CrossRef]
- Fiorini, P.; Shiller, Z. Motion planning in dynamic environments using the relative velocity paradigm. In Proceedings of the 1993 IEEE International Conference on Robotics and Automation (ICRA), Atlanta, GA, USA, 2–6 May 1993; Volume 1, pp. 560–565. [Google Scholar] [CrossRef]
- Rudenko, A.; Palmieri, L.; Arras, K.O. Joint Long-Term Prediction of Human Motion Using a Planning-Based Social Force Approach. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 4571–4577. [Google Scholar] [CrossRef]
- Lee, J.; Won, J.; Lee, J. Crowd Simulation by Deep Reinforcement Learning. In Proceedings of the 11th ACM SIGGRAPH Conference on Motion, Interaction and Games, MIG ‘18, Limassol, Cyprus, 8–10 November 2018; Association for Computing Machinery: New York, NY, USA, 2018. [Google Scholar] [CrossRef]
- Karlsson, S.; Koval, A.; Kanellakis, C.; Agha-mohammadi, A.; Nikolakopoulos, G. D*+s: A Generic Platform-Agnostic and Risk-Aware Path Planing Framework with an Expandable Grid. arXiv 2021, arXiv:2112.05563. [Google Scholar]
- Shiller, Z.; Large, F.; Sekhavat, S. Motion planning in dynamic environments: Obstacles moving along arbitrary trajectories. In Proceedings of the 2001 IEEE International Conference on Robotics and Automation (ICRA), Seoul, Korea, 21–26 May 2001; Volume 4, pp. 3716–3721. [Google Scholar] [CrossRef]
- Kluge, B.; Prassler, E. Reflective navigation: Individual behaviors and group behaviors. In Proceedings of the 2004 IEEE International Conference on Robotics and Automation (ICRA), New Orleans, LA, USA, 26 April–1 May 2004; Volume 4, pp. 4172–4177. [Google Scholar] [CrossRef]
- Fulgenzi, C.; Spalanzani, A.; Laugier, C. Dynamic Obstacle Avoidance in uncertain environment combining PVOs and Occupancy Grid. In Proceedings of the 2007 IEEE International Conference on Robotics and Automation (ICRA), Roma, Italy, 10–14 April 2007; pp. 1610–1616. [Google Scholar] [CrossRef]
- Khatib, O. Real-time obstacle avoidance for manipulators and mobile robots. In Proceedings of the 1985 IEEE International Conference on Robotics and Automation (ICRA), St. Louis, MO, USA, 25–28 March 1985; Volume 2, pp. 500–505. [Google Scholar] [CrossRef]
- Yao, Q.; Zheng, Z.; Qi, L.; Yuan, H.; Guo, X.; Zhao, M.; Liu, Z.; Yang, T. Path planning method with improved artificial potential field—A reinforcement learning perspective. IEEE Access 2020, 8, 135513–135523. [Google Scholar] [CrossRef]
- Borenstein, J.; Koren, Y. The vector field histogram-fast obstacle avoidance for mobile robots. IEEE Trans. Robot. Autom. 1991, 7, 278–288. [Google Scholar] [CrossRef]
- Babinec, A.; Duchoň, F.; Dekan, M.; Mikulová, Z.; Jurišica, L. Vector Field Histogram* with look-ahead tree extension dependent on time variable environment. Trans. Inst. Meas. Control 2018, 40, 1250–1264. [Google Scholar] [CrossRef]
- Palm, R.; Driankov, D. Velocity potentials and fuzzy modeling of fluid streamlines for obstacle avoidance of mobile robots. In Proceedings of the 2015 IEEE International Conference on Fuzzy Systems (FUZZ-IEEE), Istanbul, Turkey, 2–5 August 2015; pp. 1–8. [Google Scholar] [CrossRef]
- Zheng, Z.; Zhu, G.; Sun, Z.; Wang, Z.; Li, L. Improved Social Force Model Based on Emotional Contagion and Evacuation Assistant. IEEE Access 2020, 8, 195989–196001. [Google Scholar] [CrossRef]
- Reddy, A.; Malviya, V.; Kala, R. Social Cues in the Autonomous Navigation of Indoor Mobile Robots. Int. J. Soc. Robot. 2021, 13, 1335–1358. [Google Scholar] [CrossRef]
- Helbing, D.; Molnar, P. Social Force Model for Pedestrian Dynamics. Phys. Rev. E 1995, 51, 4282. [Google Scholar] [CrossRef] [PubMed]
- Trautman, P.; Krause, A. Unfreezing the Robot: Navigation in Dense, Interacting Crowds. In Proceedings of the 2010 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Taipei, Taiwan, 18–22 October 2010; pp. 797–803. [Google Scholar] [CrossRef]
- Truong, X.T.; Ngo, T.D. Toward Socially Aware Robot Navigation in Dynamic and Crowded Environments: A Proactive Social Motion Model. IEEE Trans. Autom. Sci. Eng. 2017, 14, 1743–1760. [Google Scholar] [CrossRef]
- Snape, J.; Berg, J.V.D.; Guy, S.J.; Manocha, D. The Hybrid Reciprocal Velocity Obstacle. IEEE Trans. Robot. 2011, 27, 696–706. [Google Scholar] [CrossRef]
- van den Berg, J.; Lin, M.; Manocha, D. Reciprocal Velocity Obstacles for real-time multi-agent navigation. In Proceedings of the 2008 IEEE International Conference on Robotics and Automation (ICRA), Pasadena, CA, USA, 19–23 May 2008; pp. 1928–1935. [Google Scholar] [CrossRef]
- Zanlungo, F.; Ikeda, T.; Kanda, T. Social force model with explicit collision prediction. EPL Europhys. Lett. 2011, 93, 68005. [Google Scholar] [CrossRef]
- Ferrer, G.; Garrell, A.; Sanfeliu, A. Social-aware robot navigation in urban environments. In Proceedings of the 2013 European Conference on Mobile Robots (ECMR), Barcelona, Spain, 25–29 September 2013; pp. 331–336. [Google Scholar] [CrossRef]
- Shiomi, M.; Zanlungo, F.; Hayashi, K.; Kanda, T. Towards a Socially Acceptable Collision Avoidance for a Mobile Robot Navigating Among Pedestrians Using a Pedestrian Model. Int. J. Soc. Robot. 2014, 6, 443–455. [Google Scholar] [CrossRef]
- Trautman, P.; Ma, J.; Murray, R.M.; Krause, A. Robot navigation in dense human crowds: Statistical models and experimental studies of human—Robot cooperation. Int. J. Robot. Res. 2015, 34, 335–356. [Google Scholar] [CrossRef]
- Large, F.; Vasquez, D.; Fraichard, T.; Laugier, C. Avoiding cars and pedestrians using velocity obstacles and motion prediction. In Proceedings of the 2004 IEEE Intelligent Vehicles Symposium, Parma, Italy, 14–17 June 2004; pp. 375–379. [Google Scholar]
- Thompson, S.; Horiuchi, T.; Kagami, S. A probabilistic model of human motion and navigation intent for mobile robot path planning. In Proceedings of the 2009 4th International Conference on Autonomous Robots and Agents, Wellington, New Zealand, 10–12 February 2009; pp. 663–668. [Google Scholar]
- Du Toit, N.E.; Burdick, J.W. Robot Motion Planning in Dynamic, Uncertain Environments. IEEE Trans. Robot. 2012, 28, 101–115. [Google Scholar] [CrossRef]
- Joseph, J.M.; Doshi-Velez, F.; Huang, A.S.; Roy, N. A Bayesian nonparametric approach to modeling motion patterns. Auton. Robot. 2011, 31, 383–400. [Google Scholar] [CrossRef]
- Aoude, G.; Luders, B.; Joseph, J.M.; Roy, N.; How, J.P. Probabilistically safe motion planning to avoid dynamic obstacles with uncertain motion patterns. Auton. Robot. 2013, 35, 51–76. [Google Scholar] [CrossRef]
- Ziebart, B.D.; Ratliff, N.; Gallagher, G.; Mertz, C.; Peterson, K.; Bagnell, J.A.; Hebert, M.; Dey, A.K.; Srinivasa, S. Planning-based prediction for pedestrians. In Proceedings of the 2009 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), St. Louis, MO, USA, 11–15 October 2009; pp. 3931–3936. [Google Scholar] [CrossRef]
- Bennewitz, M.; Burgard, W.; Thrun, S. Learning motion patterns of persons for mobile service robots. In Proceedings of the 2002 IEEE International Conference on Robotics and Automation (ICRA), Washington, DC, USA, 11–15 May 2002; Volume 4, pp. 3601–3606. [Google Scholar] [CrossRef]
- Kuderer, M.; Kretzschmar, H.; Sprunk, C.; Burgard, W. Feature-Based Prediction of Trajectories for Socially Compliant Navigation. In Robotics: Science and Systems VIII; MIT Press: Sydney, Australia, 2013; pp. 193–200. [Google Scholar] [CrossRef]
- Ferrer, G.; Sanfeliu, A. Comparative analysis of human motion trajectory prediction using minimum variance curvature. In Proceedings of the 2011 6th ACM/IEEE International Conference on Human-Robot Interaction (HRI), Lausanne, Switzerland, 8–11 March 2011; pp. 135–136. [Google Scholar] [CrossRef]
- Kabtoul, M.; Spalanzani, A.; Martinet, P. Towards Proactive Navigation: A Pedestrian-Vehicle Cooperation Based Behavioral Model. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 6958–6964. [Google Scholar] [CrossRef]
- Ikeda, T.; Chigodo, Y.; Rea, D.; Zanlungo, F.; Shiomi, M.; Kanda, T. Modeling and Prediction of Pedestrian Behavior based on the Sub-goal Concept. In Robotics: Science and Systems VIII; MIT Press: Sydney, Australia, 2013. [Google Scholar] [CrossRef]
- Luber, M.; Tipaldi, G.D.; Arras, K. Place-Dependent People Tracking. Int. J. Robotic Res. 2011, 30, 280–293. [Google Scholar] [CrossRef]
- Ferrer, G.; Garrell, A.; Sanfeliu, A. Robot companion: A social-force based approach with human awareness-navigation in crowded environments. In Proceedings of the 2013 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Tokyo, Japan, 3–7 November 2013; pp. 1688–1694. [Google Scholar] [CrossRef]
- Vega, A.; Manso, L.J.; Macharet, D.G.; Bustos, P.; Núñez, P. Socially aware robot navigation system in human-populated and interactive environments based on an adaptive spatial density function and space affordances. Pattern Recognit. Lett. 2019, 118, 72–84. [Google Scholar] [CrossRef]
- Mead, R.; Mataric, M.J. A Probabilistic Framework for Autonomous Proxemic Control in Situated and Mobile Human-Robot Interaction. In Proceedings of the HRI ’12, Seventh Annual ACM/IEEE International Conference on Human-Robot Interaction, Boston, MA, USA, 5–8 March 2012; Association for Computing Machinery: New York, NY, USA, 2012; pp. 193–194. [Google Scholar] [CrossRef]
- Mead, R.; Atrash, A.; Matarić, M.J. Proxemic Feature Recognition for Interactive Robots: Automating Metrics from the Social Sciences. In Proceedings of the International Conference on Software Reuse, Pohang, Republic of Korea, 13–17 June 2011. [Google Scholar]
- Svenstrup, M.; Tranberg, S.; Andersen, H.J.; Bak, T. Pose estimation and adaptive robot behaviour for human–robot interaction. In Proceedings of the 2009 IEEE International Conference on Robotics and Automation (ICRA), Kobe, Japan, 12–17 May 2009; pp. 3571–3576. [Google Scholar] [CrossRef]
- Castro-González, A.; Shiomi, M.; Kanda, T.; Salichs, M.A.; Ishiguro, H.; Hagita, N. Position prediction in crossing behaviors. In Proceedings of the 2010 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Taipei, Taiwan, 18–22 October 2010; pp. 5430–5437. [Google Scholar] [CrossRef]
- Ratsamee, P.; Mae, Y.; Ohara, K.; Takubo, T.; Arai, T. Human–robot collision avoidance using a modified social force model with body pose and face orientation. Int. J. Humanoid Robot. 2013, 10, 1350008. [Google Scholar] [CrossRef]
- Ferrer, G.; Sanfeliu, A. Proactive Kinodynamic Planning using the Extended Social Force Model and Human Motion Prediction in Urban Environments. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Chicago, IL, USA, 14–18 September 2014; pp. 1730–1735. [Google Scholar] [CrossRef]
- Farina, F.; Fontanelli, D.; Garulli, A.; Giannitrapani, A.; Prattichizzo, D. When Helbing meets Laumond: The Headed Social Force Model. In Proceedings of the 2016 IEEE 55th Conference on Decision and Control (CDC), Las Vegas, NV, USA, 12–14 December 2016; pp. 3548–3553. [Google Scholar] [CrossRef]
- van den Berg, J.; Guy, S.J.; Lin, M.; Manocha, D. Reciprocal n-Body Collision Avoidance. In Proceedings of the Robotics Research; Pradalier, C., Siegwart, R., Hirzinger, G., Eds.; Springer: Berlin/Heidelberg, Germany, 2011; pp. 3–19. [Google Scholar]
- Bera, A.; Kim, S.; Randhavane, T.; Pratapa, S.; Manocha, D. GLMP- realtime pedestrian path prediction using global and local movement patterns. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; pp. 5528–5535. [Google Scholar] [CrossRef]
- Luo, Y.; Cai, P.; Bera, A.; Hsu, D.; Lee, W.S.; Manocha, D. PORCA: Modeling and Planning for Autonomous Driving Among Many Pedestrians. IEEE Robot. Autom. Lett. 2018, 3, 3418–3425. [Google Scholar] [CrossRef]
- Kim, S.; Guy, S.J.; Liu, W.; Wilkie, D.; Lau, R.W.; Lin, M.C.; Manocha, D. BRVO: Predicting pedestrian trajectories using velocity-space reasoning. Int. J. Robot. Res. 2015, 34, 201–217. [Google Scholar] [CrossRef]
- Xu, M.; Xie, X.; Lv, P.; Niu, J.; Wang, H.; Li, C.; Zhu, R.; Deng, Z.; Zhou, B. Crowd Behavior Simulation with Emotional Contagion in Unexpected Multihazard Situations. IEEE Trans. Syst. Man, Cybern. Syst. 2021, 51, 1567–1581. [Google Scholar] [CrossRef]
- Curtis, S.; Guy, S.J.; Zafar, B.; Manocha, D. Virtual Tawaf: A Velocity-Space-Based Solution for Simulating Heterogeneous Behavior in Dense Crowds. In Modeling, Simulation and Visual Analysis of Crowds; The International Series in Video Computing; Springer: Berlin/Heidelberg, Germany, 2013; Volume 11, pp. 181–209. [Google Scholar]
- Alahi, A.; Goel, K.; Ramanathan, V.; Robicquet, A.; Fei-Fei, L.; Savarese, S. Social LSTM: Human Trajectory Prediction in Crowded Spaces. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 961–971. [Google Scholar] [CrossRef]
- Vemula, A.; Muelling, K.; Oh, J. Social Attention: Modeling Attention in Human Crowds. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, QLD, Australia, 21–25 May 2018; pp. 4601–4607. [Google Scholar] [CrossRef]
- Foka, A.; Trahania, P. Probabilistic Autonomous Robot Navigation in Dynamic Environments with Human Motion Prediction. Int. J. Soc. Robot. 2010, 2, 79–94. [Google Scholar] [CrossRef]
- Svenstrup, M.; Bak, T.; Andersen, H.J. Trajectory planning for robots in dynamic human environments. In Proceedings of the 2010 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Taipei, Taiwan, 18–22 October 2010; pp. 4293–4298. [Google Scholar] [CrossRef]
- Park, J.J.; Kuipers, B. A smooth control law for graceful motion of differential wheeled mobile robots in 2D environment. In Proceedings of the 2011 IEEE International Conference on Robotics and Automation (ICRA), Shanghai, China, 9–13 May 2011; pp. 4896–4902. [Google Scholar] [CrossRef]
- Park, J.J.; Johnson, C.; Kuipers, B. Robot navigation with model predictive equilibrium point control. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vilamoura-Algarve, Portugal, 7–12 October 2012; pp. 4945–4952. [Google Scholar] [CrossRef]
- Rios-Martinez, J.; Spalanzani, A.; Laugier, C. Understanding human interaction for probabilistic autonomous navigation using Risk-RRT approach. In Proceedings of the 2011 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), San Francisco, CA, USA, 25–30 September 2011; pp. 2014–2019. [Google Scholar] [CrossRef]
- Ferrer, G.; Sanfeliu, A. Bayesian Human Motion Intentionality Prediction in urban environments. Pattern Recognit. Lett. 2014, 44, 134–140. [Google Scholar] [CrossRef]
- Palm, R.; Chadalavada, R.; Lilienthal, A.J. Recognition of human–robot motion intentions by trajectory observation. In Proceedings of the 2016 9th International Conference on Human System Interactions (HSI), Portsmouth, UK, 6–8 July 2016; pp. 229–235. [Google Scholar] [CrossRef]
- Ferrer, G.; Zulueta, A.; Cotarelo, F.; Sanfeliu, A. Robot social-aware navigation framework to accompany people walking side-by-side. Auton. Robot. 2017, 41, 775–793. [Google Scholar] [CrossRef]
- Khambhaita, H.; Alami, R. A Human-Robot Cooperative Navigation Planner. In Proceedings of the 2017 ACM/IEEE International Conference, Vienna, Austria, 6–9 March 2017; pp. 161–162. [Google Scholar] [CrossRef]
- Kabtoul, M.; Spalanzani, A.; Martinet, P. Proactive Furthermore, Smooth Maneuvering For Navigation Around Pedestrians. In Proceedings of the 2022 International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022; pp. 4723–4729. [Google Scholar] [CrossRef]
- Chen, Y.F.; Liu, M.; Everett, M.; How, J.P. Decentralized non-communicating multiagent collision avoidance with deep reinforcement learning. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 285–292. [Google Scholar] [CrossRef]
- Chen, C.; Liu, Y.; Kreiss, S.; Alahi, A. Crowd-Robot Interaction: Crowd-Aware Robot Navigation with Attention-Based Deep Reinforcement Learning. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 6015–6022. [Google Scholar] [CrossRef]
- Liu, L.; Dugas, D.; Cesari, G.; Siegwart, R.; Dubé, R. Robot Navigation in Crowded Environments Using Deep Reinforcement Learning. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 25–29 October 2020; pp. 5671–5677. [Google Scholar] [CrossRef]
- Henry, P.; Vollmer, C.; Ferris, B.; Fox, D. Learning to navigate through crowded environments. In Proceedings of the 2010 IEEE International Conference on Robotics and Automation (ICRA), Anchorage, AK, USA, 3–8 May 2010; pp. 981–986. [Google Scholar] [CrossRef]
- Kim, B.; Pineau, J. Socially Adaptive Path Planning in Human Environments Using Inverse Reinforcement Learning. Int. J. Soc. Robot. 2016, 8, 51–66. [Google Scholar] [CrossRef]
- Chen, Y.F.; Everett, M.; Liu, M.; How, J.P. Socially aware motion planning with deep reinforcement learning. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 1343–1350. [Google Scholar] [CrossRef]
- Everett, M.; Chen, Y.F.; How, J.P. Motion Planning Among Dynamic, Decision-Making Agents with Deep Reinforcement Learning. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 3052–3059. [Google Scholar] [CrossRef]
- Samsani, S.S.; Muhammad, M.S. Socially Compliant Robot Navigation in Crowded Environment by Human Behavior Resemblance Using Deep Reinforcement Learning. IEEE Robot. Autom. Lett. 2021, 6, 5223–5230. [Google Scholar] [CrossRef]
- Hu, Z.; Zhao, Y.; Zhang, S.; Zhou, L.; Liu, J. Crowd-Comfort Robot Navigation Among Dynamic Environment Based on Social-Stressed Deep Reinforcement Learning. Int. J. Soc. Robot. 2022, 14, 913–929. [Google Scholar] [CrossRef]
- Dugas, D.; Nieto, J.; Siegwart, R.; Chung, J.J. NavRep: Unsupervised Representations for Reinforcement Learning of Robot Navigation in Dynamic Human Environments. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; pp. 7829–7835. [Google Scholar] [CrossRef]
- Gil, O.; Garrell, A.; Sanfeliu, A. Social Robot Navigation Tasks: Combining Machine Learning Techniques and Social Force Model. Sensors 2021, 21, 7087. [Google Scholar] [CrossRef] [PubMed]
- Francis, A.; Faust, A.; Chiang, H.T.L.; Hsu, J.; Kew, J.C.; Fiser, M.; Lee, T.W.E. Long-Range Indoor Navigation with PRM-RL. IEEE Trans. Robot. 2020, 36, 1115–1134. [Google Scholar] [CrossRef]
- Chen, Y.; Liu, C.; Shi, B.E.; Liu, M. Robot Navigation in Crowds by Graph Convolutional Networks with Attention Learned From Human Gaze. IEEE Robot. Autom. Lett. 2020, 5, 2754–2761. [Google Scholar] [CrossRef]
- Gao, X.; Sun, S.; Zhao, X.; Tan, M. Learning to Navigate in Human Environments via Deep Reinforcement Learning. In Proceedings of the Neural Information Processing, Sydney, Australia, 8–11 December 2019; Gedeon, T., Wong, K.W., Lee, M., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 418–429. [Google Scholar]
- Long, P.; Fan, T.; Liao, X.; Liu, W.; Zhang, H.; Pan, J. Towards Optimally Decentralized Multi-Robot Collision Avoidance via Deep Reinforcement Learning. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 6252–6259. [Google Scholar] [CrossRef]
- Gromniak, M.; Stenzel, J. Deep Reinforcement Learning for Mobile Robot Navigation. In Proceedings of the 2019 4th Asia-Pacific Conference on Intelligent Robot Systems (ACIRS), Nagoya, Japan, 13–15 July 2019; pp. 68–73. [Google Scholar] [CrossRef]
- Shi, H.; Shi, L.; Xu, M.; Hwang, K.S. End-to-End Navigation Strategy with Deep Reinforcement Learning for Mobile Robots. IEEE Trans. Ind. Inform. 2020, 16, 2393–2402. [Google Scholar] [CrossRef]
- Li, M.; Jiang, R.; Ge, S.; Lee, T. Role Playing Learning for Socially Concomitant Mobile Robot Navigation. CAAI Trans. Intell. Technol. 2018, 3, 49–58. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.A.; Fidjeland, A.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef]
- Lee, M.F.R.; Yusuf, S.H. Mobile Robot Navigation Using Deep Reinforcement Learning. Processes 2022, 10, 2748. [Google Scholar] [CrossRef]
- Pfeiffer, M.; Schaeuble, M.; Nieto, J.; Siegwart, R.; Cadena, C. From Perception to Decision: A Data-driven Approach to End-to-end Motion Planning for Autonomous Ground Robots. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Piscataway, NJ, USA, 29 May–3 June 2017; pp. 1527–1533. [Google Scholar]
- Pfeiffer, M.; Shukla, S.; Turchetta, M.; Cadena, C.; Krause, A.; Siegwart, R.; Nieto, J. Reinforced Imitation: Sample Efficient Deep Reinforcement Learning for Mapless Navigation by Leveraging Prior Demonstrations. IEEE Robot. Autom. Lett. 2018, 3, 4423–4430. [Google Scholar] [CrossRef]
- Tai, L.; Paolo, G.; Liu, M. Virtual-to-real deep reinforcement learning: Continuous control of mobile robots for mapless navigation. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 31–36. [Google Scholar] [CrossRef]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. TensorFlow: A system for large-scale machine learning. arXiv 2016, arXiv:1605.08695. [Google Scholar]
- Achiam, J.; Held, D.; Tamar, A.; Abbeel, P. Constrained Policy Optimization. In Proceedings of the 34th International Conference on Machine Learning (ICML), Sydney, Australia, 6–11 August 2017; Volume 70, pp. 22–31. [Google Scholar]
- Fan, T.; Cheng, X.; Pan, J.; Manocha, D.; Yang, R. CrowdMove: Autonomous Mapless Navigation in Crowded Scenarios. arXiv 2018, arXiv:1807.07870. [Google Scholar]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal Policy Optimization Algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- Gao, W.; Hsu, D.; Lee, W.S.; Shen, S.; Subramanian, K. Intention-Net: Integrating Planning and Deep Learning for Goal-Directed Autonomous Navigation. In Proceedings of the Conference on Robot Learning, Mountain View, CA, USA, 13–15 November 2017. [Google Scholar]
- Pokle, A.; Martín-Martín, R.; Goebel, P.; Chow, V.; Ewald, H.M.; Yang, J.; Wang, Z.; Sadeghian, A.; Sadigh, D.; Savarese, S.; et al. Deep Local Trajectory Replanning and Control for Robot Navigation. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 5815–5822. [Google Scholar] [CrossRef]
- Pérez-D’Arpino, C.; Liu, C.; Goebel, P.; Martín-Martín, R.; Savarese, S. Robot Navigation in Constrained Pedestrian Environments using Reinforcement Learning. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; pp. 1140–1146. [Google Scholar] [CrossRef]
- Choi, J.; Dance, C.; Kim, J.E.; Park, K.S.; Han, J.; Seo, J.; Kim, M. Fast Adaptation of Deep Reinforcement Learning-Based Navigation Skills to Human Preference. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 30 May–4 June 2020; pp. 3363–3370. [Google Scholar] [CrossRef]
- Baghi, B.H.; Dudek, G. Sample Efficient Social Navigation Using Inverse Reinforcement Learning. arXiv 2021, arXiv:2106.10318. [Google Scholar]
- Ziebart, B.D.; Maas, A.L.; Bagnell, J.A.; Dey, A.K. Maximum Entropy Inverse Reinforcement Learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Chicago, IL, USA, 13–17 July 2008. [Google Scholar]
- Pérez-Higueras, N.; Ramón-Vigo, R.; Caballero, F.; Merino, L. Robot local navigation with learned social cost functions. In Proceedings of the 2014 11th International Conference on Informatics in Control, Automation and Robotics (ICINCO), Vienna, Austria, 1–3 September 2014; Volume 2, pp. 618–625. [Google Scholar] [CrossRef]
- Gerkey, B.; Konolige, K. Planning and control in unstructured terrain. In Proceedings of the ICRA Workshop on Path Planning on Costmaps, Pasadena, CA, USA, 19–23 May 2008. [Google Scholar]
- Vasquez, D.; Okal, B.; Arras, K.O. Inverse Reinforcement Learning algorithms and features for robot navigation in crowds: An experimental comparison. In Proceedings of the 2014 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Chicago, IL, USA, 14–18 September 2014; pp. 1341–1346. [Google Scholar] [CrossRef]
- Kretzschmar, H.; Spies, M.; Sprunk, C.; Burgard, W. Socially compliant mobile robot navigation via inverse reinforcement learning. Int. J. Robot. Res. 2016, 35, 1289–1307. [Google Scholar] [CrossRef]
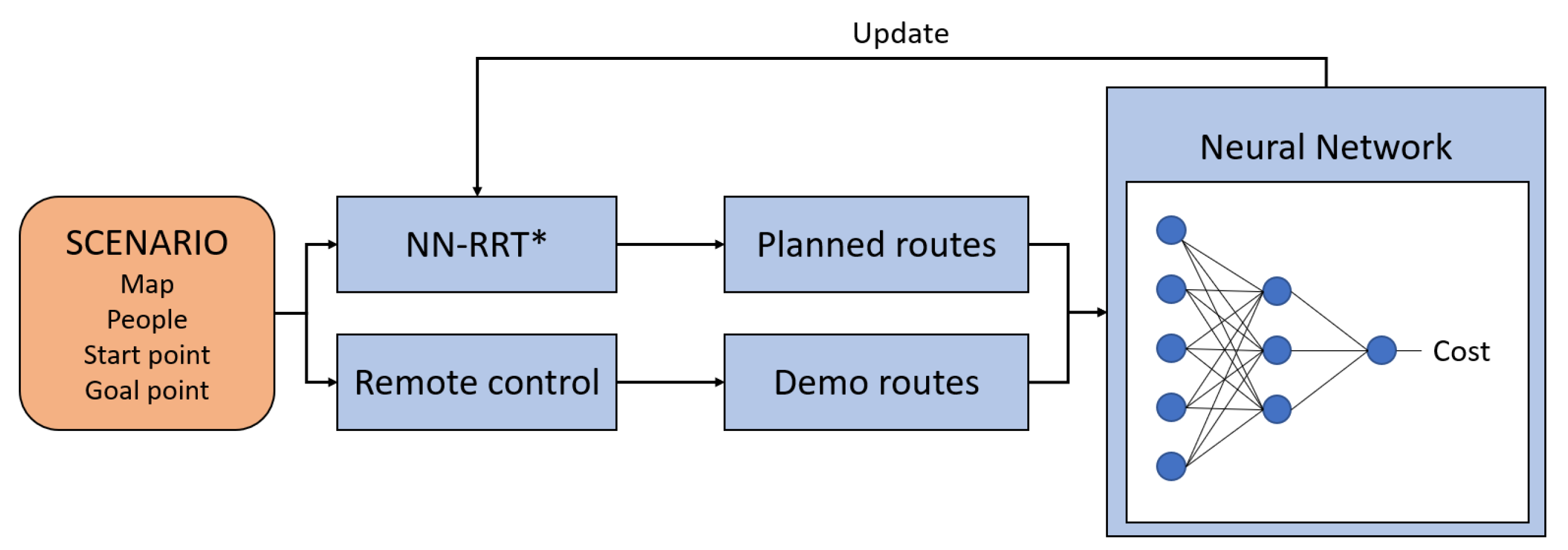
- Wang, Y.; Kong, Y.; Ding, Z.; Chi, W.; Sun, L. NRTIRL Based NN-RRT* Path Planner in Human-Robot Interaction Environment. In Proceedings of the Social Robotics, Florence, Italy, 13–16 December 2022; Cavallo, F., Cabibihan, J.J., Fiorini, L., Sorrentino, A., He, H., Liu, X., Matsumoto, Y., Ge, S.S., Eds.; Springer: Cham, Switzerland, 2022; pp. 496–508. [Google Scholar]
- Ramachandran, D.; Amir, E. Bayesian Inverse Reinforcement Learning. In Proceedings of the 20th International Joint Conference on Artificial Intelligence (IJCAI), Hyderabad, India, 6–12 January 2007; pp. 2586–2591. [Google Scholar]
- Okal, B.; Arras, K.O. Learning socially normative robot navigation behaviors with Bayesian inverse reinforcement learning. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 6–21 May 2016; pp. 2889–2895. [Google Scholar] [CrossRef]
- Dugas, D.; Nieto, J.; Siegwart, R.; Chung, J.J. IAN: Multi-Behavior Navigation Planning for Robots in Real, Crowded Environments. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 24 October 2020–24 January 2021; pp. 11368–11375. [Google Scholar] [CrossRef]
- Vega-Magro, A.; Gondkar, R.; Manso, L.; Núñez, P. Towards efficient human–robot cooperation for socially-aware robot navigation in human-populated environments: The SNAPE framework. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; pp. 3169–3174. [Google Scholar] [CrossRef]
- Chen, Z.; Song, C.; Yang, Y.; Zhao, B.; Hu, Y.; Liu, S.B.; Zhang, J. Robot Navigation Based on Human Trajectory Prediction and Multiple Travel Modes. Appl. Sci. 2018, 8, 2205. [Google Scholar] [CrossRef]
- Freitas, R.S.D.; Romero-Garcés, A.; Marfil, R.; Vicente-Chicote, C.; Cruz, J.M.; Inglés-Romero, J.F.; Bandera, A. QoS Metrics-in-the-Loop for Better Robot Navigation. In Advances in Intelligent Systems and Computing, Proceedings of the WAF, Alcala de Henares, Spain, 19–20 November 2020; Springer: Berlin/Heidelberg, Germany, 2020; Volume 1285, pp. 94–108. [Google Scholar]
- Bozhinoski, D.; Wijkhuizen, J. Context-based navigation for ground mobile robot in semi-structured indoor environment. In Proceedings of the 2021 Fifth IEEE International Conference on Robotic Computing (IRC), Taichung, Taiwan, 15–17 November 2021; pp. 82–86. [Google Scholar] [CrossRef]
- Bustos, P.; Manso, L.J.; Bandera, A.; Rubio, J.P.B.; García-Varea, I.; Martínez-Gómez, J. The CORTEX cognitive robotics architecture: Use cases. Cogn. Syst. Res. 2019, 55, 107–123. [Google Scholar] [CrossRef]
- Marfil, R.; Romero-Garcés, A.; Rubio, J.P.B.; Manso, L.J.; Calderita, L.V.; Bustos, P.; Bandera, A.; García-Polo, J.; Fernández, F.; Voilmy, D. Perceptions or Actions? Grounding How Agents Interact within a Software Architecture for Cognitive Robotics. Cogn. Comput. 2020, 12, 479–497. [Google Scholar] [CrossRef]
- Luber, M.; Tipaldi, G.D.; Arras, K. Better models for people tracking. In Proceedings of the 2011 IEEE International Conference on Robotics and Automation (ICRA), Shanghai, China, 9–13 May 2011; pp. 854–859. [Google Scholar] [CrossRef]












| Reference | Methods |
|---|---|
| Fiorini and Schiller [17] | Velocity Obstacle (VO) |
| Shiller et al. [21] | Non-Linear Velocity Obstacle (NLVO) |
| Kluge and Prassler [22] | Recursive Probabilistic Velocity Obstacles |
| Fulgenzi et al. [23] | Probabilistic Velocity Obstacle (PVO) |
| Dynamic occupancy grid provided by a general sensor system. | |
| Palm and Driankov [28] | Velocity potential of an incompressible fluid |
| Babinec et al. [27] | Vector Field Histogram (VFH*) |
| Yao et al. [25] | BHPF. Calibrated using the Black-hole potential field deep Q-learning (BHDQN) |
| Zheng et al. [29] | Improved Social Force Model Based on Emotional Contagion and Evacuation |
| Assistant | |
| Reddy et al. [30] | Extend Social Force Model to incorporate the social cues by adding new social forces |
| Extends the Geometric approach to incorporate the social cues by selecting the | |
| geometric gap as per the social reference | |
| Hybrid approach combining the social potential field and geometric method |
| Reference | Methods |
|---|---|
| Svenstrup et al. [70] | Rapidly-exploring Random Tree (RRT) |
| Trajectory Generation Problem | |
| Model Predictive Control (MPC) | |
| Dynamic Potential Field | |
| Foka and Trahania [69] | Predictive navigation performed in a global manner with the use of a POMDP |
| Polynomial Neural Network (PNN) | |
| Future motion prediction | |
| Robot Navigation-HPOMDP (RN-HPOMDP) | |
| Rios-Martinez et al. [73] | RISK-RRT algorithm navigation |
| Learned Gaussian Processes | |
| Personal Space | |
| Model of o-space in F-formations | |
| Park and Kuipers [71] | The formulation of the kinematic control law |
| The pose-following algorithm for smooth and comfortable motion of unicycle-type robots | |
| Park et al. [72] | Model Predictive Equilibrium Point Control (MPEPC) framework |
| Du Toit and Burdick [42] | Motion Planning |
| Ferrer et al. [52] | SFM and prediction information |
| Ferrer and Sanfeliu [74] | Bayesian Human Motion Intentionality Prediction |
| Sliding Window BHMIP (BHMIP) | |
| Two variants: the Sliding Window BHMIP and the Time Decay BHMIP | |
| Expectation-Maximization method | |
| Palm et al. [75] | Recognize the human intention with relative speeds |
| Collision avoidance by extrapolation of human intentions and heading angle | |
| Compass dial | |
| Fuzzy rules for Human-Robot interactions | |
| Ferrer et al. [76] | Socially-aware navigation framework for allowing a robot to navigate accompanying the person |
| Khambhaita and Alami [77] | Cooperative navigation planner |
| Trajectory Optimization: Elastic band | |
| Expectation-Maximization method | |
| Optimization framework | |
| Graph-based optimal solver | |
| Time-to-collision and directional constraints during optimization | |
| Kabtoul et al. [78] | Cooperative navigation planner |
| Reference | Methods |
|---|---|
| Ziebart et al. [112] | Maximum Entropy Inverse Reinforcement Learning |
| Inverse reinforcement and imitation learning | |
| Henry et al. [82] | Inverse Reinforcement Learning with |
| Gaussian Processes for environmental | |
| Pérez-Higueras et al. [113] | Inverse reinforcement learning |
| Global path planner- Dijkstra’s algorithm | |
| Gerkey and Konolige [114] | DARPA Learning Applied to Ground |
| Globally optimal paths on a cost map | |
| Vasquez et al. [115] | Compare IRL based learning methods |
| Motion Planning -grid-based GPU | |
| Kretzschmar et al. [116] | Hamiltonian Markov Chain Monte Carlo (MCMC) |
| Learn a model of the navigation behavior of cooperatively | |
| navigating agents such as pedestrians | |
| Voronoi graph of the environment | |
| Wang et al. [117] | Neural Network Rapidly-exploring Random Trees |
| A cost function based on neural network | |
| Ramachandran and Amir [118] | Bayesian IRL (BIRL) |
| Reward learning is an estimation task | |
| Markov Decision Process | |
| Apprenticeship learning task | |
| Kim et al. [83] | Path planning module |
| Inverse Reinforcement Learning | |
| Framework for socially adaptive path planning in dynamic | |
| environments | |
| Generating human-like path trajectory | |
| Okal and Arras [119] | Graph-based representation of the continuous |
| New extension of BIRL |
| Reference | Methods |
|---|---|
| Chen et al. [122] | Travel model selection according to the traffic state |
| Freitas et al. [123] | Self-adaptation based on QoS metrics |
| Planning encoded in Behaviour Trees. CORTEX | |
| software architecture | |
| Bozhinoski and Wijkhuizen [124] | Self-adaptation based on MROS framework |
| Quality models for adapting the local planner | |
| configuration at run-time | |
| Kamezaki et al. [16] | Proximal Crowd Navigation (PCN) approach |
| (proximity and physical-touching). | |
| inducible SFM (i-SFM) for predicting human motion. | |
| Dugas et al. [120] | The IAN framework |
| Interaction actions (saying, touching, and gesturing) | |
| for navigating in crowded scenarios | |
| Vega-Magro et al. [121] | The SNAPE framework |
| CORTEX cognitive software architecture |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guillén-Ruiz, S.; Bandera, J.P.; Hidalgo-Paniagua, A.; Bandera, A. Evolution of Socially-Aware Robot Navigation. Electronics 2023, 12, 1570. https://doi.org/10.3390/electronics12071570
Guillén-Ruiz S, Bandera JP, Hidalgo-Paniagua A, Bandera A. Evolution of Socially-Aware Robot Navigation. Electronics. 2023; 12(7):1570. https://doi.org/10.3390/electronics12071570
Chicago/Turabian StyleGuillén-Ruiz, Silvia, Juan Pedro Bandera, Alejandro Hidalgo-Paniagua, and Antonio Bandera. 2023. "Evolution of Socially-Aware Robot Navigation" Electronics 12, no. 7: 1570. https://doi.org/10.3390/electronics12071570
APA StyleGuillén-Ruiz, S., Bandera, J. P., Hidalgo-Paniagua, A., & Bandera, A. (2023). Evolution of Socially-Aware Robot Navigation. Electronics, 12(7), 1570. https://doi.org/10.3390/electronics12071570