6.3.1. First Round of k Value Selection
In this paper, Algorithms 1 and 2 are used to classify 1000 transactions into 5 priority queues using the KNN algorithm, in which the number of nearest neighbors,
k is an important parameter. First, we apply Algorithm 4 to the selection of the best
k value. It adopts the KNN classification using Scikit-learn in python. Generally, the dataset is split into a training set and a testing set. We then run the KNN classifier with different
k values. The accuracy score is used to check the accuracy of our KNN model and the
k value. The
k value with the highest accuracy score should be selected as the best
k value for handling unknown incoming transactions and checking its target priority.
| Algorithm 4: KNN k value selection with a single training/test set split. |
Input: : The prepared transaction training data; : The target priority of the prepared transaction training data; k: The k value used in KNeighborsClassifier function;
Output: : The accuracy score of the given k value;
- 1:
=; ▹ The dataset is split into a training set and a testing set, and the testing set size is 30 percent - 2:
= neighbors.KNeighborsClassifier(k, = “distance”) ▹ Prepare the KNN classifier by using the Scikit-learn module with the specified k value - 3:
.fit(, ) ▹ Fit the KNN classifier with the split training set - 4:
= knn.predict() ▹ Predict the target priority of the split testing set - 5:
▹ Check the accuracy of the target priority of the testing set - 6:
return
|
We plotted the accuracy of different
k values ranging from 1 to 20 in
Figure 7. It demonstrates that
can achieve the highest accuracy among all
k values. Therefore, we used
for KNN in all remaining experiments. A flowchart for classifying all 1000 transactions into the 5 priority queues once
k is fixed is shown in
Figure 8.
6.3.2. Choose a k Value in K-Fold cross-Validation
In
Section 6.3.1, we presented the initial method for selecting the best value of
k. However, is this the optimal
k value? In the first round’s KNN
k value, we only use a single training/test set split. The test set will only include a small portion of randomly selected data. In this scenario, the test set may not accurately represent “new unseen data”, which could lead to an overestimation of performance if it is used alone (due to potentially significant variability in the test results). By using cross-validation, all available data can be used for testing purposes, thereby ensuring that “bad” observations also play a role during the testing process. The train–test split and k-fold cross-validation are both examples of resampling methods in statistics. Resampling methods involve taking a sample from a dataset and using it to estimate unknown quantities. These techniques are particularly useful in machine learning and data analysis when a limited amount of data is available for model training and evaluation. The
k value generated by using only one training/test set split will change due to the selection of the training/test set. We must use k-fold cross-validation to eliminate this effect, so we use the following algorithm to ensure that we consider all of the elements in the dataset. We finally obtain a
k value of 4, as shown in
Figure 9 below.
6.3.3. Performance Optimization and Evaluation
When we obtain an optimal
k value, we use 1000 transactions as the training set, and their layout is shown in
Figure 10. In the figure, different categories of data in the training set data sometimes overlap (meaning that the categories of this part of the data are blurred). This part of the data will cause some model overfitting. Based on the learning curve in
Figure 11, we know that there are still opportunities to optimize performance. One idea is to directly remove this part of the overlapping data, which is referred to as a clipping method.
The clipping method randomly divides the training set, D, into two parts. One part is used as a new training set, and the other part is used as a test set. Based on the new training set, the KNN method is used to classify the test set, and the misclassified samples are removed from the entire training set. Since the division of the training set D is randomly divided, it is difficult to ensure that the samples in the overlapping part of the data will be eliminated in the first clip. After obtaining the new training set, the above operations can be repeated, and clearer class boundaries can be obtained. We can obtain its layout image (
Figure 12) and learning curve (
Figure 13), as shown below. Compared with the original training set, we achieved improved performance with a smaller size.
By observing the learning curve optimized by the clipping method, it can be seen that when the number of samples is around 300, it already has a good fitting performance. At the same time, as shown by the layout of samples in
Figure 12, there are a large number of samples in the center of each class, indicating that we can reduce the size of the training set by compressing the KNN training set. The compressing method is used when a large number of samples of the same type are concentrated in the center of the cluster, and these concentrated samples have little effect on classification, so these samples can be discarded. The training set is divided into two parts in this method. The first part is a store that contains a portion of the samples, and the second part is a grab bag that contains the remaining samples. The store is used for the training set of the KNN model, and the grabbag is used for the test set. The misclassified samples are moved from the grab bag to the store. The store continues to be used with increased samples, and the grab bag with decreased samples is used to train and test the KNN model again until all samples in the grab bag are correctly classified or until the number of samples in the grab bag is 0. After compression, the store keeps a portion of the randomly selected samples at initialization as well as the misclassified samples in each subsequent cycle. Since the clipping method removes all outliers, these selected misclassified samples are concentrated at the edge of the cluster and are considered correct samples with a large classification effect. The final training set is smaller. We can see its layout in
Figure 14. The learning curve in
Figure 15 shows that the training set still has a similar accuracy to that of the clipping training set.
Each transaction will be executed with its priority, and arrival time is only used when the transactions have the same priority. If two transactions have the same priority, the transaction that arrived earlier will be executed earlier.
Table 9 describes the priority and new start time of each transaction based on its attributes.
With the proposed KNN consensus algorithm, the scatter diagram of the transactions is shown in
Figure 16, where 1 is the highest priority, and 5 is the lowest priority. Differently from the start time that only relates to the arrival time in the FIFO method, as shown in
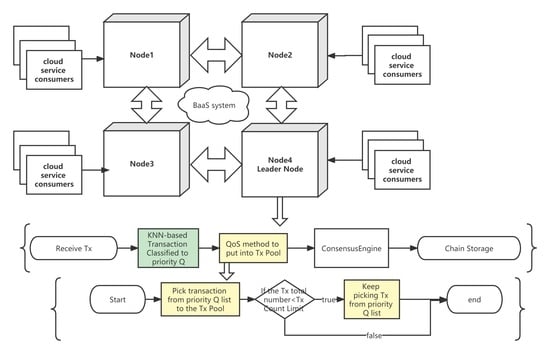
Figure 6, the start time with the KNN-based consensus algorithm relates to the priority of the transaction, which introduces the QoS method to the consensus algorithm and helps to better achieve SLA requirements and provide BaaS users an improved experience.
When a new transaction needs to be added to the transaction pool, it needs to be classified by the KNN algorithm. The prediction is only determined by the number of sample points in the training set, which is a constant value once the training set is finalized. The time complexity of this algorithm is O(1), and the space complexity is also O(1), which is irrelevant to the number of transactions in the transaction pool. After adopting the clipping and compressing algorithms, the number of samples in the training set is greatly reduced while ensuring a good fitting performance. The given example reduces the number of samples from 1000 to 200+. Algorithm 5 describes how a new transaction is added to the priority queue with the new compressed training set.
| Algorithm 5: New transaction classification. |
Input: : The new transaction; : The priority Q list from to ; k: The best k in K-fold Cross-Validation : The compressed training data; : The compressed training target;
Output: Updated - 1:
Initial = ; ▹ Prepare KNeighborsClassifier with the best k value - 2:
▹ Fit the compressed training data and target to the KNeighborsClassifier - 3:
▹ Predict the class of new incoming - 4:
if () and () then - 5:
PUSH to ; ▹ PUSH to once the Q isn’t full - 6:
else - 7:
Save to memory pool; ▹ Otherwise temporarily save the to memory pool - 8:
end if - 9:
return
|
Compared with existing blockchain consensus algorithms, the proposed KNN-based consensus algorithm guarantees that higher priority transactions are executed earlier.
Table 9 shows that the CSC type is important for calculating the priority. If a CSC has a short SLA requirement, its CSC type should be assigned with a high priority. This helps to deliver services to the CSCs within the SLA limitation in the BaaS system. Considering the transaction with attributes {0.034, 0.143, 0.545} in
Table 9 as an example, its arrival time is 331. Without the proposed KNN-based optimization consensus algorithm, the transaction pool assigns it with a sequence number of 331. If the SLA of this transaction has a short duration, the transaction may miss the SLA. With the KNN-based consensus algorithm, however, it should be classified into a higher target priority queue. In this way, the transaction pool assigns it with a sequence number of 13 and, therefore, is more likely to satisfy the SLA.





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}