

Keyword-Aware Transformers Network for Chinese Open-Domain Conversation Generation

 and
and
Abstract
1. Introduction
- We propose a novel architecture KAT to ensure a deep fusion of keyword information as an aid to the dialog generation task.
- We propose a joint modeling approach for both keyword predicting and dialog generation tasks to improve the dialog-generating performances.
- We experimentally demonstrate that our KAT approach not only has significantly higher automatic and manual evaluation metrics than the baseline model but also has improved robustness and convergence speed.
2. Related Work
2.1. Chinese Conversation Dataset
2.2. Chinese Pre-Training Model
2.3. Keyword-Aware Dialog System
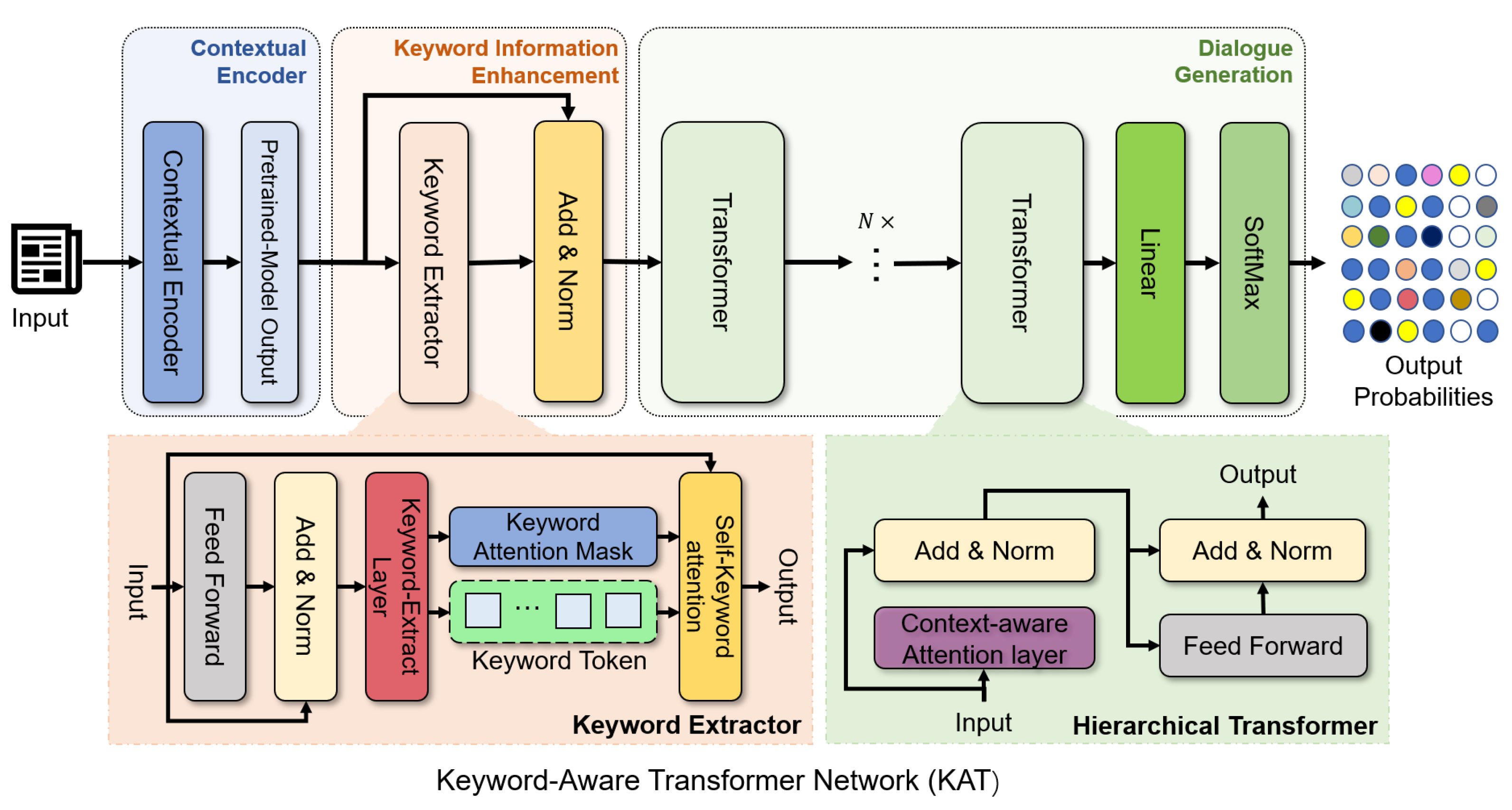
3. Approach
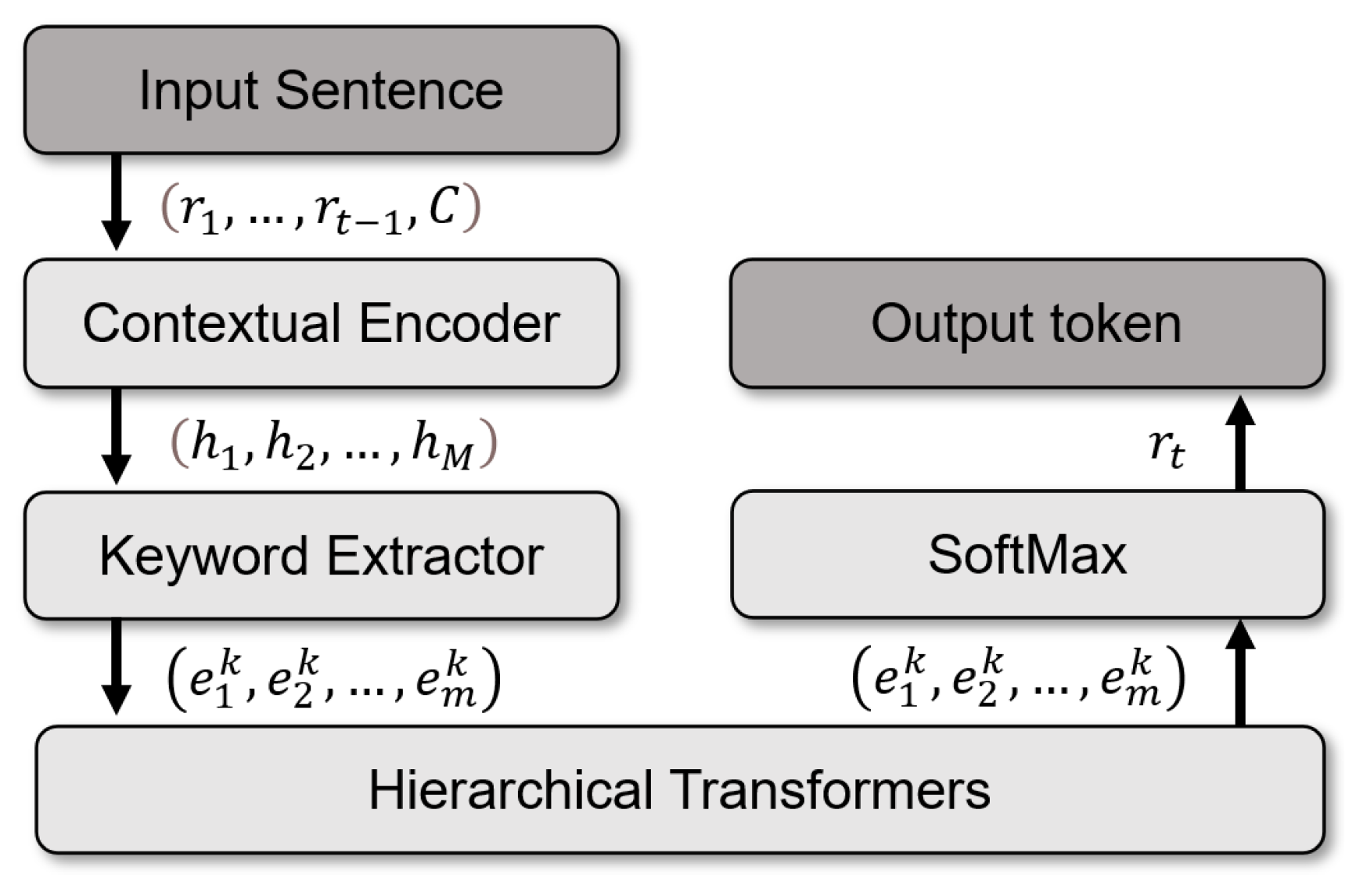
3.1. Task Formulation
3.2. Contextual Encoder
3.3. Keyword Information Enhancement Module
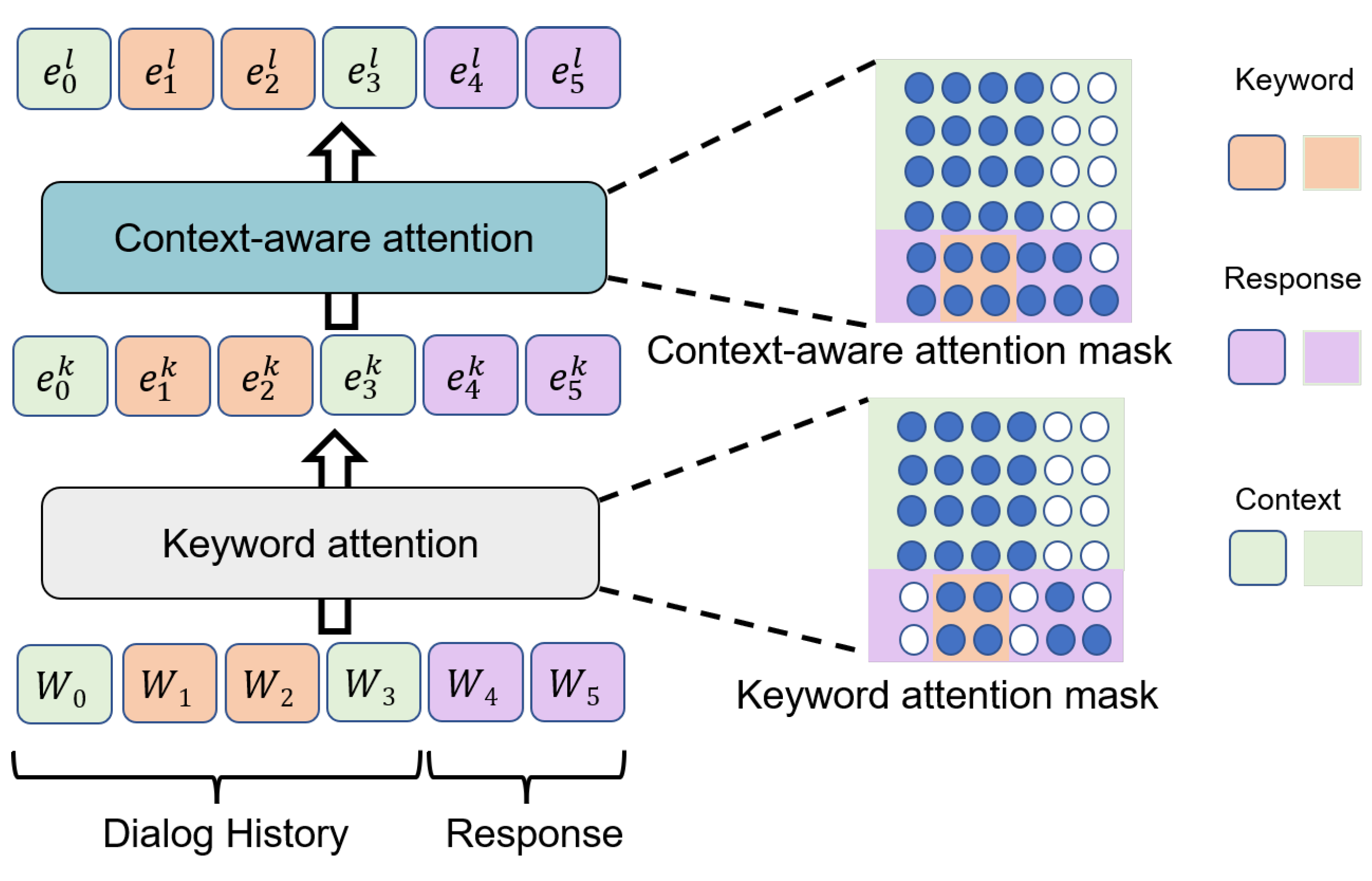
3.3.1. Self-Keyword Attention
3.3.2. Keyword Attention Mask
3.4. Context-Aware Attention Layer
3.5. Joint Dialog Generation and Keyword Prediction
4. Experiments
4.1. Dataset
4.1.1. Chinese Dailydialog
4.1.2. STC Dataset
4.2. Evaluation Metrics
4.2.1. Automatic Evaluation
4.2.2. Manual Evaluation
4.3. Experimental Setup
4.4. Baselines
- Transformer–ED contains a transformer–encoder and a transformer–decoder, without pre-training [34].
- Transformer–Dec contains only a transformer–decoder, which uses a left-to-right attention mask in both the context and response sections.
- CDialGPT-LCCC-base contains the model architecture GPT1, trained on the Large Chinese Conversation base dataset (LCCC-base) [19].
- CDialGPT2-LCCC-base contains model architecture GPT2, trained on LCCC-base [19].
- CDialGPT-LCCC-large contains the model architecture GPT1, trained on the LCCC-large dataset.
4.5. Automatic Metrics on Chinese Daily-Dialogue Dataset
4.5.1. Automated Evaluation Metrics
4.5.2. Manual Evaluation Metrics
4.6. Ablation Experiments
- Pre-trained-model + keyword-enhance: We used the keywords extracted by jieba and hanlp as the input of the model directly, and made the model pay more attention to the keyword token by the keyword information enhancement module;
- Pre-trained-model + keyword-enhance + keyword-extractor: We used the keywords extracted by jieba and hanlp as tags and added keyword-extractor to make the model have keyword extraction capability by itself. The model’s ability to extract key information was enhanced by joint multi-task learning.
4.7. Evaluation on the STC Dataset
- The training set was STC-clean after pre-processing and the test set was test-clean;
- The training set was STC-clean after pre-processing and the test set was test-original.
- The STC data volume is very large and the scenario is single and simple. The model extracted enough information from the dataset species to complete the conversation task on that dataset.
- The microblogging dataset of STC is rather heterogeneous, and there are a large number of identical contexts corresponding to different target responses in the training set, which means that context and response appear to be many-to-one.
4.8. Case Study
4.9. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhang, D.; Chen, X.; Xu, S.; Xu, B. Knowledge Aware Emotion Recognition in Textual Conversations via Multi-Task Incremental Transformer. In Proceedings of the 28th International Conference on Computational Linguistics, COLING 2020, Barcelona, Spain, 8–13 December 2020; Scott, D., Bel, N., Zong, C., Eds.; International Committee on Computational Linguistics: Barcelona, Spain, 2020; pp. 4429–4440. [Google Scholar] [CrossRef]
- Peng, W.; Hu, Y.; Xie, Y.; Xing, L.; Sun, Y. CogIntAc: Modeling the Relationships between Intention, Emotion and Action in Interactive Process from Cognitive Perspective. In Proceedings of the IEEE Congress on Evolutionary Computation, CEC 2022, Padua, Italy, 18–23 July 2022; pp. 1–8. [Google Scholar] [CrossRef]
- Huang, M.; Zhu, X.; Gao, J. Challenges in Building Intelligent Open-domain Dialog Systems. ACM Trans. Inf. Syst. 2020, 38, 1–32. [Google Scholar] [CrossRef]
- Chen, F.; Meng, F.; Chen, X.; Li, P.; Zhou, J. Multimodal Incremental Transformer with Visual Grounding for Visual Dialogue Generation. In Proceedings of the Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, Online Event, 1–6 August 2021; pp. 436–446. [Google Scholar]
- Peng, W.; Hu, Y.; Xing, L.; Xie, Y.; Sun, Y.; Li, Y. Control Globally, Understand Locally: A Global-to-Local Hierarchical Graph Network for Emotional Support Conversation. In Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence, IJCAI 2022, Vienna, Austria, 23–29 July 2022; pp. 4324–4330. [Google Scholar] [CrossRef]
- Mazaré, P.E.; Humeau, S.; Raison, M.; Bordes, A. Training Millions of Personalized Dialogue Agents. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November; pp. 2775–2779. [CrossRef]
- Qiu, X.; Sun, T.; Xu, Y.; Shao, Y.; Dai, N.; Huang, X. Pre-trained models for natural language processing: A survey. Sci. China Technol. Sci. 2020, 63, 1872–1897. [Google Scholar] [CrossRef]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language models are unsupervised multitask learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Bao, S.; He, H.; Wang, F.; Wu, H.; Wang, H. PLATO: Pre-trained Dialogue Generation Model with Discrete Latent Variable. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; Association for Computational Linguistics: Toronto, ON, Canada, 2020; pp. 85–96. [Google Scholar] [CrossRef]
- Zhang, Y.; Sun, S.; Galley, M.; Chen, Y.C.; Brockett, C.; Gao, X.; Gao, J.; Liu, J.; Dolan, B. DIALOGPT: Large-Scale Generative Pre-training for Conversational Response Generation. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics: System Demonstrations, Online, 5–10 July 2020; Association for Computational Linguistics: Toronto, ON, Canada, 2020; pp. 270–278. [Google Scholar] [CrossRef]
- Roller, S.; Dinan, E.; Goyal, N.; Ju, D.; Williamson, M.; Liu, Y.; Xu, J.; Ott, M.; Smith, E.M.; Boureau, Y.L.; et al. Recipes for Building an Open-Domain Chatbot. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics, Online, 19–23 April 2021; Main Volume. Association for Computational Linguistics: Toronto, ON, Canada, 2021; pp. 300–325. [Google Scholar] [CrossRef]
- Adiwardana, D.; Luong, M.; So, D.R.; Hall, J.; Fiedel, N.; Thoppilan, R.; Yang, Z.; Kulshreshtha, A.; Nemade, G.; Lu, Y.; et al. Towards a Human-like Open-Domain Chatbot. arXiv 2020, arXiv:2001.09977. [Google Scholar]
- Wang, W.; Huang, M.; Xu, X.S.; Shen, F.; Nie, L. Chat More: Deepening and Widening the Chatting Topic via A Deep Model. In Proceedings of the 41st International ACM SIGIR Conference on Research & Development in Information Retrieval, SIGIR’18, Ann Arbor, MI, USA, 8–12 July 2018; Association for Computing Machinery: New York, NY, USA, 2018; pp. 255–264. [Google Scholar] [CrossRef]
- Zhang, Z.; Han, X.; Zhou, H.; Ke, P.; Gu, Y.; Ye, D.; Qin, Y.; Su, Y.; Ji, H.; Guan, J.; et al. CPM: A large-scale generative Chinese Pre-trained language model. AI Open 2021, 2, 93–99. [Google Scholar] [CrossRef]
- Zhang, Z.; Gu, Y.; Han, X.; Chen, S.; Xiao, C.; Sun, Z.; Yao, Y.; Qi, F.; Guan, J.; Ke, P.; et al. CPM-2: Large-scale cost-effective pre-trained language models. AI Open 2021, 2, 216–224. [Google Scholar] [CrossRef]
- Han, X.; Zhang, Z.; Ding, N.; Gu, Y.; Liu, X.; Huo, Y.; Qiu, J.; Yao, Y.; Zhang, A.; Zhang, L.; et al. Pre-trained models: Past, present and future. AI Open 2021, 2, 225–250. [Google Scholar] [CrossRef]
- Wang, H.; Li, J.; Wu, H.; Hovy, E.; Sun, Y. Pre-Trained Language Models and Their Applications. Engineering, 2022, in press. [CrossRef]
- Kim, Y.; Kim, J.H.; Lee, J.M.; Jang, M.J.; Yum, Y.J.; Kim, S.; Shin, U.; Kim, Y.M.; Joo, H.J.; Song, S. A pre-trained BERT for Korean medical natural language processing. Sci. Rep. 2022, 12, 1–10. [Google Scholar] [CrossRef]
- Wang, Y.; Ke, P.; Zheng, Y.; Huang, K.; Jiang, Y.; Zhu, X.; Huang, M. A Large-Scale Chinese Short-Text Conversation Dataset. In Proceedings of the Natural Language Processing and Chinese Computing, Zhengzhou, China, 14–18 October 2020; Zhu, X., Zhang, M., Hong, Y., He, R., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 91–103. [Google Scholar]
- Li, Y.; Su, H.; Shen, X.; Li, W.; Cao, Z.; Niu, S. Dailydialog: A manually labelled multi-turn dialogue dataset. arXiv 2017, arXiv:1710.03957. [Google Scholar]
- Shang, L.; Lu, Z.; Li, H. Neural responding machine for short-text conversation. arXiv 2015, arXiv:1503.02364. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.u.; Polosukhin, I. Attention is All you Need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 30. [Google Scholar]
- Zhou, H.; Ke, P.; Zhang, Z.; Gu, Y.; Zheng, Y.; Zheng, C.; Wang, Y.; Wu, C.H.; Sun, H.; Yang, X.; et al. EVA: An Open-Domain Chinese Dialogue System with Large-Scale Generative Pre-Training. arXiv 2021, arXiv:2108.01547. [Google Scholar]
- Gu, Y.; Wen, J.; Sun, H.; Song, Y.; Ke, P.; Zheng, C.; Zhang, Z.; Yao, J.; Zhu, X.; Tang, J.; et al. EVA2.0: Investigating Open-Domain Chinese Dialogue Systems with Large-Scale Pre-Training. arXiv 2022, arXiv:2203.09313. [Google Scholar] [CrossRef]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to Sequence Learning with Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, USA, 8–13 December 2014; Ghahramani, Z., Welling, M., Cortes, C., Lawrence, N., Weinberger, K., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2014; Volume 27. [Google Scholar]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Xing, C.; Wu, W.; Wu, Y.; Liu, J.; Huang, Y.; Zhou, M.; Ma, W.Y. Topic Aware Neural Response Generation. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Volume 31. [Google Scholar] [CrossRef]
- Wu, C.H.; Zheng, Y.; Wang, Y.; Yang, Z.; Huang, M. Semantic-Enhanced Explainable Finetuning for Open-Domain Dialogues. arXiv 2021, arXiv:2106.03065. [Google Scholar]
- Li, Y.; Su, H.; Shen, X.; Li, W.; Cao, Z.; Niu, S. DailyDialog: A Manually Labelled Multi-turn Dialogue Dataset. In Proceedings of the Eighth International Joint Conference on Natural Language Processing, Taipei, Taiwan, 27 November–1 December 2017; Asian Federation of Natural Language Processing: Taipei, Taiwan, 2017; Volume 1, pp. 986–995. [Google Scholar]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. Bleu: A Method for Automatic Evaluation of Machine Translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Philadelphia, PA, USA, 7–12 July 2002; Association for Computational Linguistics: Philadelphia, PA, USA, 2002; pp. 311–318. [Google Scholar] [CrossRef]
- Lin, C.Y. ROUGE: A Package for Automatic Evaluation of Summaries. In Proceedings of the Text Summarization Branches Out, Barcelona, Spain, 25–26 July 2004; Association for Computational Linguistics: Cedarville, OH, USA, 2004; pp. 74–81. [Google Scholar]
- Li, J.; Galley, M.; Brockett, C.; Gao, J.; Dolan, B. A Diversity-Promoting Objective Function for Neural Conversation Models. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016; Association for Computational Linguistics: Cedarville, OH, USA, 2016; pp. 110–119. [Google Scholar] [CrossRef]
- Holtzman, A.; Buys, J.; Du, L.; Forbes, M.; Choi, Y. The Curious Case of Neural Text Degeneration. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Zheng, Y.; Zhang, R.; Huang, M.; Mao, X. A Pre-Training Based Personalized Dialogue Generation Model with Persona-Sparse Data. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 9693–9700. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| Model | Architecture | If Fine-Tuned | Fine-Tuned Dataset |
|---|---|---|---|
| Transformer-ED | Transformer | No | - |
| Transformer-Dec | Transformer Decoder | No | - |
| CDialGPT-LCCC-base | GPT | Yes | LCCC-base dataset |
| CDialGPT2-LCCC-base | GPT2 | Yes | LCCC-base dataset |
| CDialGPT-LCCC-large | GPT | Yes | LCCC-large dataset |
| NO. | Model | BLEU-1 | BLEU-2 | BLEU-4 | ROUGE-2 | D-1 | D-2 | Epoch |
|---|---|---|---|---|---|---|---|---|
| 1 | Transformer-Decoder | 22.63 | 15.01 | 10.62 | 9.62 | 27.27 | 24.29 | 30 |
| 2 | Transformer-ED | 22.97 | 14.24 | 9.24 | 8.96 | 21.46 | 20.54 | 30 |
| 3 | GPT-LCCC-Large | 28.13 | 20.50 | 15.69 | 14.32 | 26.66 | 14.32 | 17 |
| 4 | GPT-LCCC-Base | 26.64 | 18.32 | 14.82 | 13.12 | 26.15 | 26.38 | 17 |
| 5 | GPT-LCCC-Base+KAT | 28.78 | 21.17 | 16.34 | 14.71 | 26.28 | 26.45 | 10 |
| 6 | GPT2-LCCC-Base | 25.40 | 17.15 | 11.92 | 11.04 | 26.70 | 25.11 | 27 |
| 7 | GPT2-LCCC-Base+KAT | 27.20 | 19.90 | 15.48 | 12.06 | 26.94 | 26.99 | 20 |
| Model | +2 | +1 | +0 | Mean-Score |
|---|---|---|---|---|
| GPT-LCCC-Base | 41.38% | 30.46% | 28.16% | 1.1322 |
| GPT-LCCC-Base+KAT | 62.43% | 23.7% | 13.87% | 1.4855 |
| GPT2-LCCC-Base | 39.33% | 30.0% | 30.67% | 1.0867 |
| GPT2-LCCC-Base+KAT | 53.95% | 27.63% | 18.42% | 1.3553 |
| Model | BLEU-1 | BLEU-2 | BLEU-4 | ROUGE-2 | D-1 | D-2 |
|---|---|---|---|---|---|---|
| GPT-LCCC-Base | 26.64 | 18.32 | 14.82 | 13.12 | 26.15 | 26.38 |
| GPT-LCCC-Base+Key-Word Enhance | 28.04 | 20.44 | 15.64 | 14.46 | 26.17 | 26.77 |
| GPT-LCCC-Base+KAT | 28.77 | 21.17 | 16.34 | 14.71 | 26.28 | 26.45 |
| GPT2-LCCC-Base | 26.49 | 18.59 | 13.63 | 13.29 | 26.70 | 25.11 |
| GPT2-LCCC-Base+Key-Word Enhance | 26.52 | 19.04 | 14.43 | 11.61 | 26.79 | 25.34 |
| GPT2-LCCC-Base+KAT | 27.20 | 19.90 | 15.48 | 12.06 | 26.94 | 26.99 |
| Model | BLEU-1 | BLEU-2 | BLEU-4 | ROUGE-2 | D-1 | D-2 |
|---|---|---|---|---|---|---|
| GPT-LCCC-Base-Oridata | 11.88 | 6.46 | 3.21 | 3.61 | 15.26 | 22.44 |
| GPT-LCCC-Base+KAT-Oridata | 12.80 | 7.29 | 3.79 | 4.33 | 15.33 | 23.81 |
| Model | BLEU-1 | BLEU-2 | BLEU-4 | ROUGE-2 | D-1 | D-2 |
|---|---|---|---|---|---|---|
| GPT-LCCC-Base | 14.11 | 7.46 | 3.96 | 3.93 | 15.20 | 23.07 |
| GPT-LCCC-Base+Key Word | 14.78 | 8.01 | 4.25 | 4.41 | 15.43 | 24.09 |
| GPT-LCCC-Base+Key Word+Multask-Ori | 14.87 | 8.08 | 4.29 | 4.45 | 15.56 | 23.78 |
| Context | speaker: 你不介意的话,我想和你谈谈。 speaker: I would like to talk to you if you don’t mind. |
| GPT-Base | 我一点也不介意。 I don’t mind at all. |
| GPT-Base+KAT | 当然, 鲍勃。我很乐意。 Sure, Bob. I’d love to. |
| GPT2-Base | 不太感兴趣。 Not really interested. |
| GPT2-Base+KAT | 好吧, 当然。 Well, of course. |
| Keyword | 不介意,想和你,谈谈 Don’t mind. I want to talk with you. |
| Gold | 你想跟我谈什么? What do you want to talk to me about? |
| Context | speaker: 现在,奇尔兹小姐把你的简历交给了我,我有机会看了一遍,我必须说我印象深刻。 speaker: Now, Miss Childs handed me your CV and I had the opportunity to look it over and I must say I was impressed. |
| GPT-Base | 非常感谢你。我会的。我能先告诉你一些情况吗? Thank you very much. I will. Can I tell you something first? |
| GPT-Base+KAT | 非常感谢你。我试着保持简洁明了。如果有任何问题,请随时问我。 Thank you very much. I’ll try to keep it simple and clear. If you have any questions, please feel free to ask me. |
| GPT2-Base | 非常感谢你。我试着保持简洁明了。在我现在的工作中,你应该保持耐心。 Thank you very much. I try to keep it simple and clear. In my current job, you should be patient. |
| GPT2-Base+KAT | 非常常感谢你。我试着保持简洁明了。如果有任何问题,请随时问我。 Thank you very often. I’ll try to keep it simple and clear. If you have any questions, please feel free to ask me. |
| Keyword | 简历,交给了我,看了,一遍,必须,印象深刻 CV, handed to me, read, over, must, impressed. |
| Gold | 非常感谢你。我试着保持简洁明了。如果有任何问题,请随时问我。 Thank you very much. I’ll try to keep it simple and clear. If you have any questions, please feel free to ask me. |
| Context | speaker: 你的学习成绩如何?; listener: 我一直做得很好。我曾两次获得奖学金。 … speaker: 你当过学生干部吗? speaker: How have you been doing in your studies?; listener: I have always done well. I have won scholarships twice. … speaker: Have you ever been a student leader? |
| GPT-Base | 不仅我是学生,我还被分配到管理学院。 Not only was I a student but I was also assigned to the School of Management. |
| GPT-Base+KAT | 是的,我以前是班上的班长。 Yes, I used to be class president. |
| GPT2-Base | 是的,我是个消防员,我以前是个工程师。 Yes, I’m a firefighter and I used to be an engineer. |
| GPT2-Base+KAT | 是的,我以前是班上的班长。 Yes, I used to be class president. |
| Keyword | 学习成绩,奖学金,自学,经济学,工商管理,会计学,学生干部 Academic achievement, scholarship, self-study, economics, business administration, accounting, student leader |
| Gold | 对,我曾经是我们班的班长。 Yes, I used to be the class president of my class. |
| Context | speaker: 基思多大了?; listener: 他21岁。詹姆斯多大了? … speaker: 他很好。他上周退休了。这是他人生的转折点。现在他可以放松享受退休生活了。 speaker: How old is Keith?; listener: He’s 21. How old is James? … speaker: He’s fine. He retired last week. It was a turning point in his life. Now he can relax and enjoy his retirement. |
| GPT-Base | 你和他一起工作多久了? How long have you been working with him? |
| GPT-Base+KAT | 他可以花更多的时间和孙子孙女在一起了。 He can now spend more time with his grandchildren. |
| GPT2-Base | 他要去哪里? Where is he going? |
| GPT2-Base+KAT | 他可以花更多的时间和孙子孙女在待在一起了。 He can now spend more time with his grandchildren. |
| Keyword | 多大,大一岁,更年轻,父亲,人生,转折点,放松,享受,退休,生活 how old, one year older, younger, father, life, turning point, relax, enjoy, retirement, life |
| Gold | 他可以花更多的时间和孙子孙女在一起 He can spend more time with his grandchildren |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, Y.; Zhi, C.; Xu, F.; Cui, W.; Wang, H.; Qin, A.; Chen, X.; Wang, Y.; Huang, X. Keyword-Aware Transformers Network for Chinese Open-Domain Conversation Generation. Electronics 2023, 12, 1228. https://doi.org/10.3390/electronics12051228
Zhou Y, Zhi C, Xu F, Cui W, Wang H, Qin A, Chen X, Wang Y, Huang X. Keyword-Aware Transformers Network for Chinese Open-Domain Conversation Generation. Electronics. 2023; 12(5):1228. https://doi.org/10.3390/electronics12051228
Chicago/Turabian StyleZhou, Yang, Chenjiao Zhi, Feng Xu, Weiwei Cui, Huaqiong Wang, Aihong Qin, Xiaodiao Chen, Yaqi Wang, and Xingru Huang. 2023. "Keyword-Aware Transformers Network for Chinese Open-Domain Conversation Generation" Electronics 12, no. 5: 1228. https://doi.org/10.3390/electronics12051228
APA StyleZhou, Y., Zhi, C., Xu, F., Cui, W., Wang, H., Qin, A., Chen, X., Wang, Y., & Huang, X. (2023). Keyword-Aware Transformers Network for Chinese Open-Domain Conversation Generation. Electronics, 12(5), 1228. https://doi.org/10.3390/electronics12051228