


Intrusion Detection Method Based on CNN–GRU–FL in a Smart Grid Environment



Abstract
1. Introduction
- In order to solve the problem of a smart grid having a large number of distributed power sources [12], we designed a local detection method based on CNNs and GRUs, deployed it in multiple independent branch nodes, and used the attention mechanism to extract the key flow information, so as to further improve the comprehensiveness of the smart grid detection.
- FL was introduced to aggregate and optimize the parameters globally, resulting in a unified and efficient intrusion detection method.
- A node selection mechanism was designed to improve the convergence ability of FL in real environments.
- A new parameter aggregation mechanism was designed to improve the training effect of the intrusion detection model under FL, while also allowing for the efficient training of the model without the direct aggregation of the original data.
2. Related Works
3. Distributed Intrusion Detection Method for Smart Grid
- Each node uses the intrusion detection model based on the CNN–GRU algorithm to train the local data, and different nodes are maintained within the same algorithm network;
- The selection mechanism is implemented for each node. The selected node uploads the model parameters after local training in the center for model aggregation, and the other nodes will not participate in this round of training aggregation;
- The center aggregates the uploaded parameters, updates the global model parameters, and distributes them to each node;
- Repeat steps 2 and 3 until the model converges with or reaches the specified maximum aggregation time, and end the training. At this point, the CNN–GRU model parameters with the best global effect will be obtained in the center.
4. Local Intrusion Detection Model Based on CNN–GRU
4.1. Local Training Process
4.2. One-Dimensional CNN Unit
4.3. GRU Algorithm Unit
4.4. Attention Mechanism
5. Parameter Training Based on FL
5.1. Federal Learning Process in the Smart Grid Scenario
- In an actual smart grid environment, considering the technical level of the different branch structures, the quality and volume of the local data may vary greatly. While the FA algorithm distributes the average weights of the nodes participating in the aggregation during the parameter aggregation, it does so without taking into account the volume and quality of the local dataset, which may reduce the accuracy of the global model [32].
- There are many branches in a smart grid, and the network status among the branches may be uncertain. This leads to an uncontrollable aggregation and training time, and the overall training time depends on the maximum communication delay of each round.
- A smart grid is vulnerable to multiple types of network attacks, and malicious nodes participating in FL will cause the model performance to decline. Normal nodes may be transformed into malicious nodes by identity theft, and be attacked by increasing the weight of their own nodes in the process of FL. In addition, considering the large size of smart grid nodes, it is possible to have a number of legal nodes. A large number of similar nodes participating in the aggregation will reduce the efficiency of the model aggregation.
5.1.1. Parameter Updating Mechanism of FA Algorithm
5.1.2. Improved Model Aggregation Mechanism
5.2. Trust-Based Node Selection Mechanism
- Communication delay Trustd: specify the maximum training times m and the maximum training duration tm when each sub-model conducts local training. ti is the time required for node i to complete m times of training, and Ti is the actual delay of each sub-model. When the number of training times of node i reaches m or the training time exceeds the specified maximum duration, the index is assigned as 0, or otherwise score is assigned according to the grading rules:
- Node data quality Trustq: in this paper, the node quality mainly takes into account the proportion of the node dataset size within the entire dataset. The higher the proportion, the higher the score is.
- Node historical behavior Trusth: it stores the node’s historical behavior trust value in a trust list. After each round of node selection, a new trust value will be updated. Node i has no historical behavior when participating in node selection for the first time; thus, it is assigned a minimum trust value Thmin. The calculation process is shown in Algorithm 1.
| Algorithm 1: Trust value algorithm for node history behavior. |
| Input: Thmin, Trustdi, Trustqi, Trusthi’ Output: Trusthi |
| if(Trusthi’ = NULL) Trusthi = Thmin else scorei = σ * Trustdi + (1 − σ) * Trustqi if(scorei/scorei’ > 1 + γ) Trusthi = Trusthi’ + α else if (scorei/scorei’ < 1 − γ) Trusthi = Trusthi’ − α else Trusthi = Trusthi’ end end |
- 4.
- Direct trust value: the three indicators of Trustd, Trustq, and Trusth are comprehensively considered, and Formula (14) is used to calculate the direct trust value DT:
- 5.
- Indirect trust value: the similarity is calculated by the distance of dimension space. In this paper, the Chebyshev distance is calculated. The dimension of the sample space is s, and the distance between of any sample object Qm and Qn is:The average value of all Chebyshev distances is calculated as the threshold value, and the indirect trust value of the nodes with a distance greater than the average value is assigned a full score. The nodes with a distance less than the average value have a high similarity, which is assigned 0.
- 6.
- The global trust value TG is calculated as follows:where is the weight of the DT. We set a predetermined global trust value threshold of , and if the TG is greater than , the node is trusted.
6. Experiment and Analysis
6.1. Experiment Preparation
6.1.1. Experimental Environment and Data Preprocessing
6.1.2. Parameters of Local Detection Model
6.1.3. FL Model Parameters
6.1.4. Experimental Evaluation Index
6.2. Experiment and Result Analysis
6.2.1. Effect Analysis of CNN–GRU Centralized Inspection Model
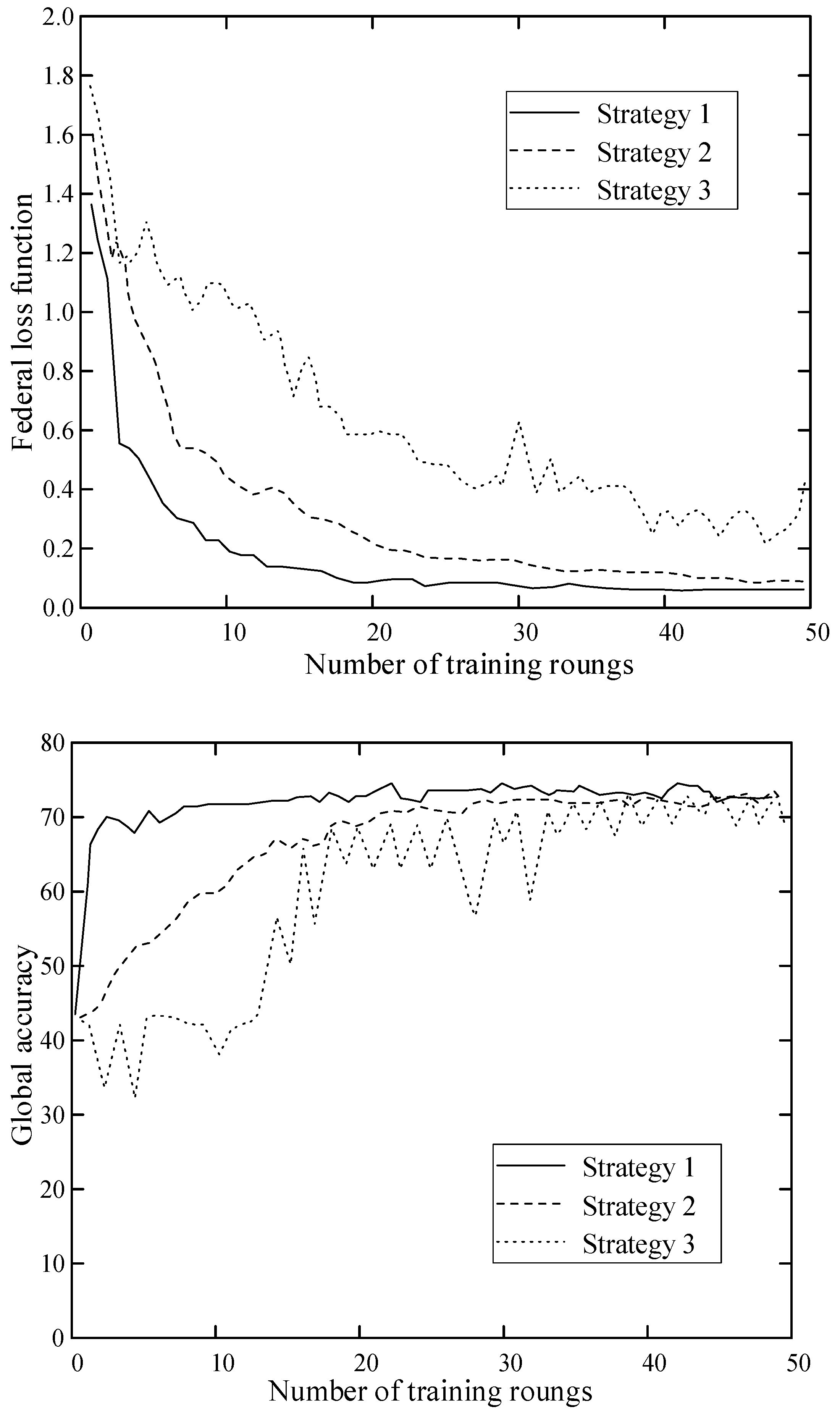
6.2.2. Effect of Node Selection in FL Algorithm
6.2.3. Analysis and Comparison of FL Detection Effects
6.2.4. Intrusion Detection Time Comparison
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Kim, H.; Choi, J. Intelligent Access Control Design for Security Context Awareness in Smart Grid. Sustainability 2021, 13, 4124. [Google Scholar] [CrossRef]
- Yin, X.C.; Liu, Z.G.; Nkenyereye, L.; Ndibanje, B. Toward an Applied Cyber Security Solution in IoT-Based Smart Grids: An Intrusion Detection System Approach. Sensors 2019, 19, 4952. [Google Scholar] [CrossRef] [PubMed]
- Waghmare, S. Machine Learning Based Intrusion Detection System for Real-Time Smart Grid Security. In Proceedings of the 2021 13th IEEE PES Asia Pacific Power & Energy Engineering Conference (APPEEC), Thiruvananthapuram, India, 21–23 November 2021. [Google Scholar]
- Subasi, A.; Qaisar, S.M.; Al-Nory, M.; Rambo, K.A. Intrusion Detection in Smart Grid Using Bagging Ensemble Classifiers. Appl. Sci. 2021, 13, 30. [Google Scholar]
- Zhong, W.; Yu, N.; Ai, C. Applying Big Data Based Deep Learning System to Intrusion Detection. Big Data Min. Anal. 2020, 3, 181–195. [Google Scholar] [CrossRef]
- Khan, F.A.; Gumaei, A.; Derhab, A.; Hussain, A. A Novel Two-Stage Deep Learning Model for Efficient Network Intrusion Detection. IEEE Access 2019, 7, 30373–30385. [Google Scholar] [CrossRef]
- Mohamed, M.; Shady, S.R.; Haitham, A. Intrusion Detection Method Based on SMOTE Transformation for Smart Grid Cybersecurity. In Proceedings of the 2022 3rd International Conference on Smart Grid and Renewable Energy (SGRE), Doha, Qatar, 20–22 March 2022. [Google Scholar]
- Yin, C.L.; Zhu, Y.F.; Fei, J.L.; He, X. A Deep Learning Approach for Intrusion Detection Using Recurrent Neural Networks. IEEE Access 2017, 5, 21954–21961. [Google Scholar] [CrossRef]
- Nguyen, T.D.; Marchal, S.; Miettinen, M.; Fereidooni, H.; Asokan, N.; Sadeghi, A.-R. DoT: A Federated Self-learning Anomaly Detection System for IoT. In Proceedings of the 2019 IEEE 39th International Conference on Distributed Computing Systems (ICDCS), Dallas, TX, USA, 7–10 July 2019. [Google Scholar]
- Zhang, Z.; Zhang, Y.; Guo, D.; Ya, L.; Li, Z. SecFedNIDS: Robust defense for poisoning attack against federated learning-based network intrusion detection system. Future Gener. Comput. Syst. FGCS 2022, 134, 154–169. [Google Scholar] [CrossRef]
- Vy, N.C.; Quyen, N.H.; Duy, P.T.; Pham, V.H. Federated Learning-Based Intrusion Detection in the Context of IIoT Networks: Poisoning Attack and Defense. In Proceedings of the Network and System Security: 15th International Conference, Tianjin, China, 23 October 2021. [Google Scholar]
- Halid, K.; Kambiz, T.; Mo, J. Fault Diagnosis of Smart Grids Based on Deep Learning Approach. In Proceedings of the 2021 World Automation Congress (WAC), Taipei, Taiwan, 1–5 August 2021. [Google Scholar]
- Vinayakumar, R.; Soman, K.P.; Poornachandran, P. Applying convolutional neural network for network intrusion detection. In Proceedings of the 2017 International Conference on Advances in Computing, Communications and Informatics (ICACCI), Udupi, India, 13–16 September 2017. [Google Scholar]
- Hafeez, G.; Alimgeer, K.S.; Wadud, Z.; Khan, I.; Usman, M.; Qazi, A.B.; Khan, F.A. An Innovative Optimization Strategy for Efficient Energy Management With Day-Ahead Demand Response Signal and Energy Consumption Forecasting in Smart Grid Using Artificial Neural Network. IEEE Access 2020, 8, 84415–84433. [Google Scholar] [CrossRef]
- Hafeez, G.; Khan, I.; Jan, S.; Shah, I.A.; Khan, F.A.; Derhab, A. A novel hybrid load forecasting framework with intelligent feature engineering and optimization algorithm in smart grid. Appl. Energy 2021, 299, 117178. [Google Scholar] [CrossRef]
- Hafeez, G.; Alimgeer, K.S.; Wadud, Z.; Shafiq, Z.; Ali Khan, M.U.; Khan, I.; Khan, F.A.; Derhab, A. A Novel Accurate and Fast Converging Deep Learning-Based Model for Electrical Energy Consumption Forecasting in a Smart Grid. Energies 2020, 13, 2244. [Google Scholar] [CrossRef]
- Khan, I.; Hafeez, G.; Alimgeer, K.S. Electric Load Forecasting based on Deep Learning and Optimized by Heuristic Algorithm in Smart Grid. Appl. Energy 2020, 269, 114915. [Google Scholar]
- Hafeez, G.; Javaid, N.; Riaz, M.; Ali, A.; Umar, K.; Iqbal, Z. Day Ahead Electric Load Forecasting by an Intelligent Hybrid Model Based on Deep Learning for Smart Grid. In Proceedings of the Conference on Complex, Intelligent, and Software Intensive Systems, Sydney, Australia, 3–9 July 2019; Springer: Cham, Switzerland, 2019. [Google Scholar]
- Zhang, J.; Ling, Y.; Fu, X.; Yang, X.; Xiong, G.; Zhang, R. Model of the intrusion detection system based on the integration of spatial-temporal features. Comput. Secur. 2020, 89, 101681. [Google Scholar] [CrossRef]
- Al-Marri, A.A.; Ciftler, B.S.; Abdallah, M. Federated Mimic Learning for Privacy Preserving Intrusion Detection. In Proceedings of the 2020 IEEE International Black Sea Conference on Communications and Networking (BlackSeaCom), Odessa, Ukraine, 26–29 May 2020. [Google Scholar]
- Rahman, S.A.; Tout, H.; Talhi, C.; Mourad, A. Internet of Things Intrusion Detection: Centralized, On-Device, or Federated Learning? IEEE Netw. 2020, 34, 310–317. [Google Scholar] [CrossRef]
- Wang, R.; Ma, C.; Wu, P. An intrusion detection method based on federated learning and convolutional neural network. Netinfo Secur. 2020, 20, 47–54. [Google Scholar]
- Prk, A.; Ps, B. Unified deep learning approach for efficient intrusion detection system using integrated spatial-temporal features. Knowl.-Based Syst. 2021, 226, 107132. [Google Scholar]
- Li, J.; Xia, S.; Lan, H.; Li, S.; Sun, J. Network intrusiondetection methodbasedon GRU-RNN. J. Harbin Eng. Univ. 2021, 42, 879–884. (In Chinese) [Google Scholar]
- Mothukuri, V.; Khare, P.; Parizi, R.M.; Pouriyeh, S.; Dehghantanha, A.; Srivastava, G. Federated Learning-based Anomaly Detection for IoT Security Attacks. IEEE Internet Things J. 2021, 9, 2327–4662. [Google Scholar] [CrossRef]
- Luo, C.; Chen, X.; Song, S.; Zhang, S.; Liu, Z. Federated ensemble algorithm based on deep neural network. J. Appl. Sci. 2022, 1, 1–18. [Google Scholar]
- Chandiramani, K.; Garg, D.; Maheswari, N. Performance Analysis of Distributed and Federated Learning Models on Private Data—ScienceDirect. Procedia Comput. Sci. 2019, 165, 349–355. [Google Scholar] [CrossRef]
- Yang, Y.R.; Song, R.J.; Guo-Qiang, H.U. Intrusion detection based on CNN-ELM. Comput. Eng. Des. 2019, 40, 3382–3387. [Google Scholar]
- Alferaidi, A.; Yadav, K.; Alharbi, Y.; Razmjooy, N.; Viriyasitavat, W.; Gulati, K.; Gulati, K.; Kautish, S.; Dhiman, G. Distributed Deep CNN-LSTM Model for Intrusion Detection Method in IoT-Based Vehicles. Math. Probl. Eng. 2022, 2022, 3424819. [Google Scholar] [CrossRef]
- Bengio, Y. Learning long-term dependencies with gradient descent is difficult. IEEE Trans. Neural. Netw. 2002, 5, 157–166. [Google Scholar] [CrossRef] [PubMed]
- Hao, Y.; Sheng, Y.; Wang, J. Variant Gated Recurrent Units With Encoders to Preprocess Packets for Payload-Aware Intrusion Detection. IEEE Access 2019, 7, 49985–49998. [Google Scholar] [CrossRef]
- Geng, D.Q.; He, H.W.; Lan, X.C.; Liu, C. Bearing fault diagnosis based on improved federated learning algorithm. Computing 2021, 104, 1–19. [Google Scholar] [CrossRef]
- Ren, J.; He, Y.; Wen, D.; Yu, G.; Huang, K.; Guo, D. Scheduling for Cellular Federated Edge Learning with Importance and Channel Awareness. IEEE Trans. Wirel. Commun. 2020, 19, 7690–7703. [Google Scholar] [CrossRef]
- Kang, J.W.; Xiong, Z.H.; Niyato, D.; Xie, S.; Zhang, J. Incentive mechanism for reliable federated learning: A joint optimization approach to combining reputation and contract theory. IEEE Internet Things J. 2019, 6, 10700–10714. [Google Scholar] [CrossRef]
- Liu, Y.; Kang, Y.; Li, L.; Zhang, X.; Cheng, Y.; Chen, T.; Hong, M.; Yang, Q. Communication Efficient Vertical Federated Learning Framework. Comput. Sci. 2019. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Attack Type | Training Set Distribution | Test Set Distribution |
|---|---|---|
| Normal | 125,973 | 9652 |
| Dos | 45,729 | 7845 |
| Probe | 15,661 | 2718 |
| R2L | 972 | 2699 |
| U2R | 52 | 200 |
| Total | 188,387 | 23,114 |
| Accuracy | Precision | Recall | F1 Value | |
|---|---|---|---|---|
| Decision tree | 0.7534 | 0.9621 | 0.6067 | 0.7330 |
| Logistic regression | 0.7374 | 0.9261 | 0.5854 | 0.7174 |
| Naive bayes | 0.5880 | 0.5922 | 0.8875 | 0.7104 |
| Random forest | 0.7514 | 0.9740 | 0.5787 | 0.7260 |
| CNN–GRU centralized model | 0.7979 | 0.9726 | 0.6455 | 0.7860 |
| Upper Limit | Lower Limit | |
|---|---|---|
| Strategy1 | 30 | 15 |
| Strategy 2 | 20 | 10 |
| Strategy 3 | 10 | 5 |
| Accuracy | Precision | Recall | F1 Value | |
|---|---|---|---|---|
| Node 1 | 0.7615 | 0.9650 | 0.6030 | 0.7422 |
| Node 2 | 0.7436 | 0.9678 | 0.5685 | 0.7163 |
| Node 3 | 0.7442 | 0.9621 | 0.5733 | 0.7185 |
| Node 4 | 0.7503 | 0.9695 | 0.5796 | 0.7255 |
| Node 5 | 0.7540 | 0.9737 | 0.5836 | 0.7298 |
| Proposed method | 0.7879 | 0.9733 | 0.6415 | 0.7690 |
| CNN–GRU centralized model | 0.7979 | 0.9726 | 0.6455 | 0.7860 |
| Accuracy | Precision | Recall | F1 Value | |
|---|---|---|---|---|
| Node 1 | 0.8789 | 0.8108 | 0.0109 | 0.0004 |
| Node 2 | 0.8836 | 0.8466 | 0.0581 | 0.0015 |
| Node 3 | 0 | 0 | 0 | 0 |
| Node 4 | 0.8781 | 0.6923 | 0.0033 | 0.0002 |
| Node 5 | 0 | 0 | 0 | 0 |
| Proposed method | 0.8834 | 0.9699 | 0.1068 | 0.0010 |
| CNN–GRU centralized model | 0.8919 | 0.9620 | 0.1550 | 0.0012 |
| Accuracy | |
|---|---|
| Decision tree | 0.1617 |
| Logistic regression | 0.2152 |
| Naïve Bayes | 0.2098 |
| Random forest | 0.2163 |
| CNN–GRU centralized model | 0.2681 |
| Proposed method | 0.2359 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhai, F.; Yang, T.; Chen, H.; He, B.; Li, S. Intrusion Detection Method Based on CNN–GRU–FL in a Smart Grid Environment. Electronics 2023, 12, 1164. https://doi.org/10.3390/electronics12051164
Zhai F, Yang T, Chen H, He B, Li S. Intrusion Detection Method Based on CNN–GRU–FL in a Smart Grid Environment. Electronics. 2023; 12(5):1164. https://doi.org/10.3390/electronics12051164
Chicago/Turabian StyleZhai, Feng, Ting Yang, Hao Chen, Baoling He, and Shuangquan Li. 2023. "Intrusion Detection Method Based on CNN–GRU–FL in a Smart Grid Environment" Electronics 12, no. 5: 1164. https://doi.org/10.3390/electronics12051164
APA StyleZhai, F., Yang, T., Chen, H., He, B., & Li, S. (2023). Intrusion Detection Method Based on CNN–GRU–FL in a Smart Grid Environment. Electronics, 12(5), 1164. https://doi.org/10.3390/electronics12051164