



Improved Graph Convolutional Network with Enriched Graph Topology Representation for Skeleton-Based Action Recognition
 , , and
, , and
Abstract
:1. Introduction
- This paper proposes aligning the graph learning on the channel level by introducing a graph convolution with an enriched topology based on attentive channel-wise correlations (ACC-GCs). By integrating ACC-GC in GCN, we obtain an enhanced GCN with an enriched topology representation (ACC-GCN) for skeleton-based action recognition.
- This paper explores the advantage of integrating our ACC-GC configuration over dynamic topology non-shared GCN-based models.
- By performing extensive experiments, we demonstrate the effectiveness of our proposed ACC-GCN using two large-scale human action recognition datasets, mainly the NTURGB60 and Northwestern-UCLA datasets.
2. Related Work
2.1. DNN-Based Approaches
2.2. GCN-Based Models
2.3. Transformer-Based Methods
2.4. Attention in Deep Learning
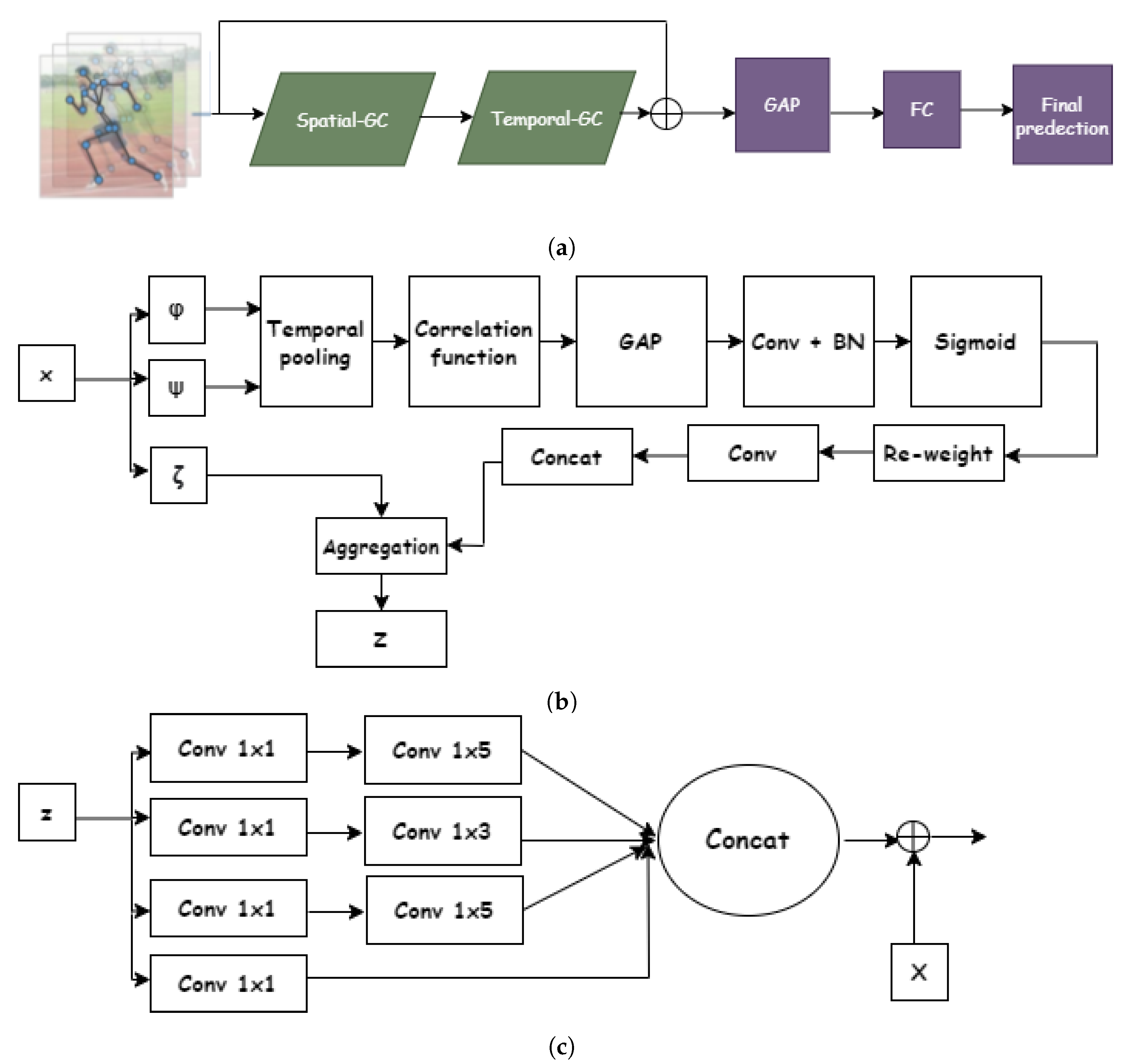
3. Proposed Method
3.1. GCN for Action Recognition Using Skeletons
3.2. Attention-Based Correlation-Driven Graph Convolution (ACC-GC)
3.3. Our Enhanced Graph Convolution Network
4. Experimental Settings
4.1. Datasets
4.2. Implementation Details
4.3. Ablation Study
4.3.1. Effect of the Model Components
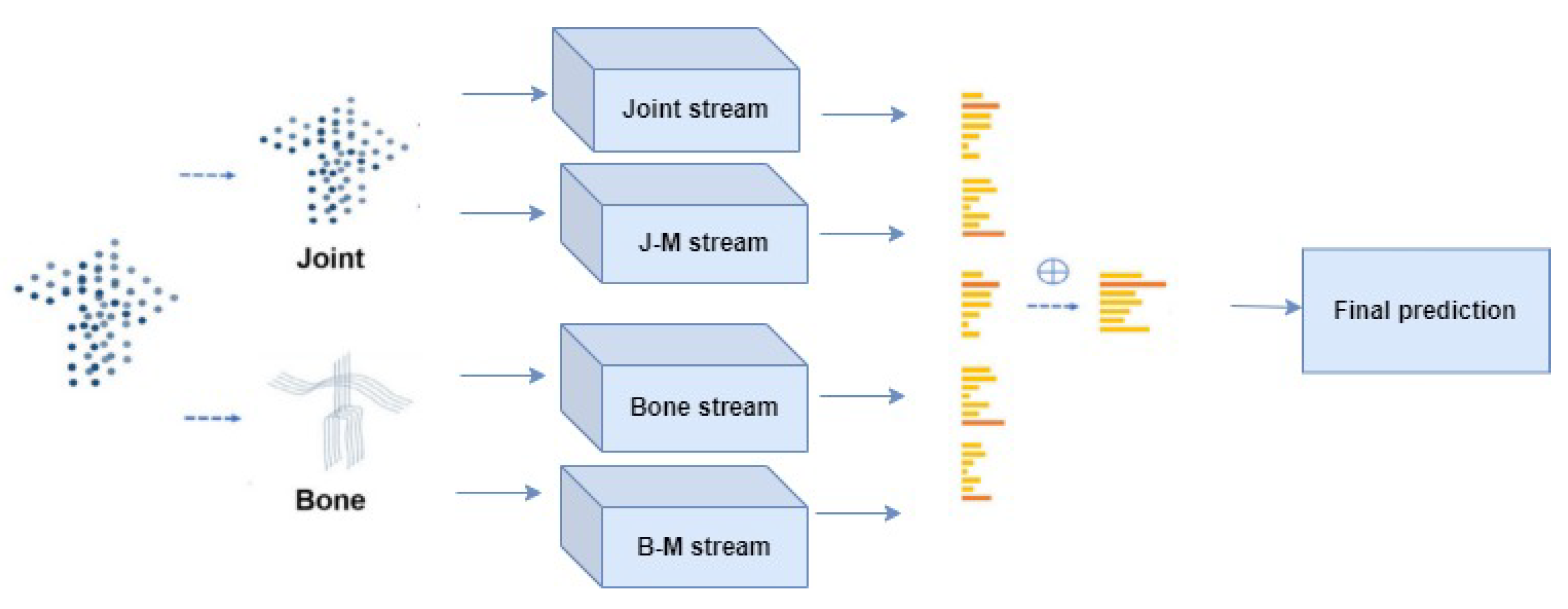
4.3.2. Effect of Multi-Stream Structure
4.4. Visualize Learned Topology
4.5. Improving over GCN-Based Models
4.6. Comparison with the State of the Art
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Chang, Y.; Tu, Z.; Xie, W.; Yuan, J. Clustering driven deep autoencoder for video anomaly detection. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 329–345. [Google Scholar]
- Zengeler, N.; Kopinski, T.; Handmann, U. Hand gesture recognition in automotive human–machine interaction using depth cameras. Sensors 2019, 19, 59. [Google Scholar] [CrossRef] [PubMed]
- Liu, J.; Shahroudy, A.; Xu, D.; Wang, G. Spatio-temporal lstm with trust gates for 3d human action recognition. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 816–833. [Google Scholar]
- Tu, Z.; Xie, W.; Qin, Q.; Poppe, R.; Veltkamp, R.C.; Li, B.; Yuan, J. Multi-stream CNN: Learning representations based on human-related regions for action recognition. Pattern Recognit. 2018, 79, 32–43. [Google Scholar] [CrossRef]
- Yang, Z.; Li, Y.; Yang, J.; Luo, J. Action recognition with spatio–temporal visual attention on skeleton image sequences. IEEE Trans. Circuits Syst. Video Technol. 2018, 29, 2405–2415. [Google Scholar] [CrossRef]
- Li, C.; Xie, C.; Zhang, B.; Han, J.; Zhen, X.; Chen, J. Memory attention networks for skeleton-based action recognition. IEEE Trans. Neural Netw. Learn. Syst. 2021, 33, 4800–4814. [Google Scholar]
- Tu, Z.; Zhang, J.; Li, H.; Chen, Y.; Yuan, J. Joint-bone Fusion Graph Convolutional Network for Semi-supervised Skeleton Action Recognition. arXiv 2022, arXiv:2202.04075. [Google Scholar] [CrossRef]
- Ali, A.; Zhu, Y.; Zakarya, M. Exploiting dynamic spatio-temporal graph convolutional neural networks for citywide traffic flows prediction. Neural Netw. 2022, 145, 233–247. [Google Scholar] [CrossRef]
- Si, C.; Chen, W.; Wang, W.; Wang, L.; Tan, T. An attention enhanced graph convolutional lstm network for skeleton-based action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1227–1236. [Google Scholar]
- Zhang, P.; Lan, C.; Xing, J.; Zeng, W.; Xue, J.; Zheng, N. View adaptive recurrent neural networks for high performance human action recognition from skeleton data. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2117–2126. [Google Scholar]
- Du, Y.; Wang, W.; Wang, L. Hierarchical recurrent neural network for skeleton based action recognition. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1110–1118. [Google Scholar] [CrossRef]
- Zhang, P.; Lan, C.; Zeng, W.; Xing, J.; Xue, J.; Zheng, N. Semantics-guided neural networks for efficient skeleton-based human action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1112–1121. [Google Scholar]
- Liu, Z.; Zhang, H.; Chen, Z.; Wang, Z.; Ouyang, W. Disentangling and unifying graph convolutions for skeleton-based action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 143–152. [Google Scholar]
- Ye, F.; Pu, S.; Zhong, Q.; Li, C.; Xie, D.; Tang, H. Dynamic gcn: Context-enriched topology learning for skeleton-based action recognition. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 55–63. [Google Scholar]
- Pen, L.Z.; Xian Xian, K.; Yew, C.F.; Hau, O.S.; Sumari, P.; Abualigah, L.; Ezugwu, A.E.; Shinwan, M.A.; Gul, F.; Mughaid, A. Artocarpus Classification Technique Using Deep Learning Based Convolutional Neural Network. In Classification Applications with Deep Learning and Machine Learning Technologies; Springer: Berlin/Heidelberg, Germany, 2022; pp. 1–21. [Google Scholar]
- Abd Elaziz, M.; Dahou, A.; Abualigah, L.; Yu, L.; Alshinwan, M.; Khasawneh, A.M.; Lu, S. Advanced metaheuristic optimization techniques in applications of deep neural networks: A review. Neural Comput. Appl. 2021, 33, 1–21. [Google Scholar] [CrossRef]
- Li, B.; Li, X.; Zhang, Z.; Wu, F. Spatio-temporal graph routing for skeleton-based action recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 8561–8568. [Google Scholar]
- Shi, L.; Zhang, Y.; Cheng, J.; Lu, H. Two-stream adaptive graph convolutional networks for skeleton-based action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 12026–12035. [Google Scholar]
- Buades, A.; Coll, B.; Morel, J.M. A non-local algorithm for image denoising. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 2, pp. 60–65. [Google Scholar]
- Cheng, K.; Zhang, Y.; Cao, C.; Shi, L.; Cheng, J.; Lu, H. Decoupling GCN with DropGraph Module for Skeleton-Based Action Recognition. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 536–553. [Google Scholar]
- Chen, Y.; Zhang, Z.; Yuan, C.; Li, B.; Deng, Y.; Hu, W. Channel-wise topology refinement graph convolution for skeleton-based action recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 13359–13368. [Google Scholar]
- Garcia-Hernando, G.; Kim, T.K. Transition forests: Learning discriminative temporal transitions for action recognition and detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 432–440. [Google Scholar]
- Xia, L.; Chen, C.C.; Aggarwal, J.K. View invariant human action recognition using histograms of 3d joints. In Proceedings of the 2012 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Providence, RI, USA, 16–21 June 2012; pp. 20–27. [Google Scholar]
- Yu, G.; Liu, Z.; Yuan, J. Discriminative Orderlet Mining for Real-Time Recognition of Human-Object Interaction. In Proceedings of the ACCV, 12th Asian Conference on Computer Vision, Singapore, 1–5 November 2014. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Zhang, P.; Xue, J.; Lan, C.; Zeng, W.; Gao, Z.; Zheng, N. Adding Attentiveness to the Neurons in Recurrent Neural Networks. IEEE Trans. Image Process. 2019, 29, 1061–1073. [Google Scholar]
- Du, Y.; Fu, Y.; Wang, L. Skeleton based action recognition with convolutional neural network. In Proceedings of the 2015 3rd IAPR Asian Conference on Pattern Recognition (ACPR), Kuala Lumpur, Malaysia, 3–6 November 2015; pp. 579–583. [Google Scholar]
- Ke, Q.; Bennamoun, M.; An, S.; Sohel, F.; Boussaid, F. A new representation of skeleton sequences for 3d action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3288–3297. [Google Scholar]
- Li, B.; Dai, Y.; Cheng, X.; Chen, H.; Lin, Y.; He, M. Skeleton based action recognition using translation-scale invariant image mapping and multi-scale deep CNN. In Proceedings of the 2017 IEEE International Conference on Multimedia & Expo Workshops (ICMEW), Hong Kong, China, 10–14 July 2017; pp. 601–604. [Google Scholar]
- Bruna, J.; Zaremba, W.; Szlam, A.; LeCun, Y. Spectral networks and locally connected networks on graphs. arXiv 2013, arXiv:1312.6203. [Google Scholar]
- Defferrard, M.; Bresson, X.; Vandergheynst, P. Convolutional neural networks on graphs with fast localized spectral filtering. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; Volume 29. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Chi, H.g.; Ha, M.H.; Chi, S.; Lee, S.W.; Huang, Q.; Ramani, K. InfoGCN: Representation Learning for Human Skeleton-Based Action Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 19–20 June 2022; pp. 20186–20196. [Google Scholar]
- Yan, S.; Xiong, Y.; Lin, D. Spatial temporal graph convolutional networks for skeleton-based action recognition. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Han, K.; Wang, Y.; Chen, H.; Chen, X.; Guo, J.; Liu, Z.; Tang, Y.; Xiao, A.; Xu, C.; Xu, Y.; et al. A survey on vision transformer. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 87–110. [Google Scholar] [CrossRef] [PubMed]
- Ahn, D.; Kim, S.; Hong, H.; Ko, B.C. STAR-Transformer: A Spatio-Temporal Cross Attention Transformer for Human Action Recognition. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 2–7 January 2023; pp. 3330–3339. [Google Scholar]
- Ma, L.; Xie, H.; Liu, C.; Zhang, Y. Learning Cross-Channel Representations for Semantic Segmentation. IEEE Trans. Multimed. 2022, 1. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Zhao, H.; Jia, J.; Koltun, V. Exploring self-attention for image recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 10076–10085. [Google Scholar]
- Zhang, Z.; Lan, C.; Zeng, W.; Jin, X.; Chen, Z. Relation-Aware Global Attention for Person Re-Identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Zhang, J.; Xie, Z.; Sun, J.; Zou, X.; Wang, J. A cascaded R-CNN with multiscale attention and imbalanced samples for traffic sign detection. IEEE Access 2020, 8, 29742–29754. [Google Scholar] [CrossRef]
- Niu, B.; Wen, W.; Ren, W.; Zhang, X.; Yang, L.; Wang, S.; Zhang, K.; Cao, X.; Shen, H. Single image super-resolution via a holistic attention network. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 191–207. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Li, X.; Wang, W.; Hu, X.; Yang, J. Selective kernel networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 510–519. [Google Scholar]
- Stollenga, M.F.; Masci, J.; Gomez, F.; Schmidhuber, J. Deep networks with internal selective attention through feedback connections. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, USA, 8–13 December 2014; Volume 27. [Google Scholar]
- Shahroudy, A.; Liu, J.; Ng, T.T.; Wang, G. NTU RGB+D: A Large Scale Dataset for 3D Human Activity Analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1010–1019. [Google Scholar]
- Wang, J.; Nie, X.; Xia, Y.; Wu, Y.; Zhu, S.C. Cross-View Action Modeling, Learning, and Recognition. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 2649–2656. [Google Scholar]
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; DeVito, Z.; Lin, Z.; Desmaison, A.; Antiga, L.; Lerer, A. Automatic Differentiation in Pytorch. 2017. Available online: https://openreview.net/forum?id=BJJsrmfCZ (accessed on 9 January 2023).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Shi, L.; Zhang, Y.; Cheng, J.; Lu, H. Skeleton-Based Action Recognition With Multi-Stream Adaptive Graph Convolutional Networks. IEEE Trans. Image Process. 2020, 29, 9532–9545. [Google Scholar] [CrossRef]
- Li, W.; Liu, X.; Liu, Z.; Du, F.; Zou, Q. Skeleton-Based Action Recognition Using Multi-Scale and Multi-Stream Improved Graph Convolutional Network. IEEE Access 2020, 8, 144529–144542. [Google Scholar] [CrossRef]
- Vemulapalli, R.; Arrate, F.; Chellappa, R. Human Action Recognition by Representing 3D Skeletons as Points in a Lie Group. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 588–595. [Google Scholar] [CrossRef]
- Song, S.; Lan, C.; Xing, J.; Zeng, W.; Liu, J. An End-to-End Spatio-Temporal Attention Model for Human Action Recognition from Skeleton Data. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, AAAI’17, San Francisco, CA, USA, 4–9 February 2017; pp. 4263–4270. [Google Scholar]
- Liu, M.; Liu, H.; Chen, C. Enhanced skeleton visualization for view invariant human action recognition. Pattern Recognit. 2017, 68, 346–362. [Google Scholar] [CrossRef]
- Tang, Y.; Tian, Y.; Lu, J.; Li, P.; Zhou, J. Deep progressive reinforcement learning for skeleton-based action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 5323–5332. [Google Scholar]
- Li, M.; Chen, S.; Chen, X.; Zhang, Y.; Wang, Y.; Tian, Q. Actional-structural graph convolutional networks for skeleton-based action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3595–3603. [Google Scholar]
- Cheng, K.; Zhang, Y.; He, X.; Chen, W.; Cheng, J.; Lu, H. Skeleton-Based Action Recognition with Shift Graph Convolutional Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Song, Y.F.; Zhang, Z.; Shan, C.; Wang, L. Stronger, faster and more explainable: A graph convolutional baseline for skeleton-based action recognition. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 1625–1633. [Google Scholar]
- Song, Y.F.; Zhang, Z.; Shan, C.; Wang, L. Richly activated graph convolutional network for robust skeleton-based action recognition. IEEE Trans. Circuits Syst. Video Technol. 2020, 31, 1915–1925. [Google Scholar]
- Trivedi, N.; Sarvadevabhatla, R.K. PSUMNet: Unified Modality Part Streams are All You Need for Efficient Pose-based Action Recognition. arXiv 2022, arXiv:2208.05775. [Google Scholar]
- Veeriah, V.; Zhuang, N.; Qi, G.J. Differential recurrent neural networks for action recognition. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 4041–4049. [Google Scholar]
- Wang, J.; Liu, Z.; Wu, Y.; Yuan, J. Learning actionlet ensemble for 3D human action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 36, 914–927. [Google Scholar]
- Lee, I.; Kim, D.; Kang, S.; Lee, S. Ensemble deep learning for skeleton-based action recognition using temporal sliding lstm networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1012–1020. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | C(.) | E(.) | Act(.) | Acc (%) | Param |
|---|---|---|---|---|---|
| Baseline | - | - | - | 88.1 | 1.21 M |
| A | matrix multiplication | Yes | Tanh | 89.3 | 1.55 M |
| B | element-wise sub | No | Tanh | 89.5 | 1.46 M |
| C | element-wise sub | Yes | Sigmoid | 89.4 | 1.55 M |
| D | element-wise sub | Yes | Tanh | 89.7 | 1.55 M |
| E | element-wise sub | Yes | Relu | 89.6 | 1.55 M |
| Modality | Top-1 (%) |
|---|---|
| Joint (J) | 89.70 |
| Joint-motion (JM) | 87.87 |
| Bone (B) | 90.30 |
| Bone-motion (BM) | 87.45 |
| J + B + JM + BM | 92.0 |
| Model | GFLOPs | Acc (%) | Original Accuracy |
|---|---|---|---|
| ST-GCN [35] | 16.3 | 82.5 | 81.5 |
| 2s-AGCN [18] | 37.3 | 89.6 | 88.5 |
| Ours | 1.9 | 92.0 | - |
| Model | x-Sub (%) | x-View (%) | GFLOPs |
|---|---|---|---|
| Lie Group [53] | 50.1 | 52.8 | - |
| H-RNN [11] | 59.1 | 64.0 | - |
| PA-LSTM [47] | 62.9 | 70.3 | - |
| ST-LSTM+TS [3] | 69.2 | 77.7 | - |
| STA-LSTM [54] | 73.4 | 81.2 | - |
| Visualize CNN [55] | 76.0 | 82.6 | - |
| C-CNN+MTLN [29] | 79.6 | 84.8 | - |
| VA-LSTM [10] | 79.2 | 87.7 | - |
| ST-GCN [35] | 81.5 | 88.3 | 16.3 |
| DPRL [56] | 83.5 | 89.8 | - |
| AS-GCN [57] | 86.8 | 94.2 | - |
| DC-GCN+ADG [20] | 90.8 | 96.6 | 25.7 |
| 4s-ShiftGCN [58] | 90.7 | 96.5 | 10.0 |
| 2s-AGCN [18] | 88.5 | 95.1 | 37.3 |
| PA-ResGCN [59] | 90.9 | 96.0 | 18.5 |
| RA-GCN [60] | 87.3 | 93.6 | 32.8 |
| MS-G3D [13] | 91.5 | 96.2 | 48.8 |
| PSUMNet [61] | 92.9 | 96.7 | 2.7 |
| Our ACC-GCN | 92.0 | 96.5 | 1.93 |
| Model | Northwestern-UCLA Top-1 (%) | GFLOPs |
|---|---|---|
| Lie Group [62] | 72.2 | - |
| Actionlet ensemble [63] | 76.0 | - |
| H-RNN [11] | 78.5 | - |
| Ensemble TS-LSTM [64] | 89.2 | - |
| AGC-LSTM [9] | 93.3 | - |
| Shift-GCN [58] | 94.6 | - |
| 2s AGC-LSTM | 93.3 | 10.9 |
| CTR-GCN | 96.5 | 1.97 |
| ACC-GCN (ours) | 96.1 | 1.93 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alsarhan, T.; Harfoushi, O.; Shdefat, A.Y.; Mostafa, N.; Alshinwan, M.; Ali, A. Improved Graph Convolutional Network with Enriched Graph Topology Representation for Skeleton-Based Action Recognition. Electronics 2023, 12, 879. https://doi.org/10.3390/electronics12040879
Alsarhan T, Harfoushi O, Shdefat AY, Mostafa N, Alshinwan M, Ali A. Improved Graph Convolutional Network with Enriched Graph Topology Representation for Skeleton-Based Action Recognition. Electronics. 2023; 12(4):879. https://doi.org/10.3390/electronics12040879
Chicago/Turabian StyleAlsarhan, Tamam, Osama Harfoushi, Ahmed Younes Shdefat, Nour Mostafa, Mohammad Alshinwan, and Ahmad Ali. 2023. "Improved Graph Convolutional Network with Enriched Graph Topology Representation for Skeleton-Based Action Recognition" Electronics 12, no. 4: 879. https://doi.org/10.3390/electronics12040879
APA StyleAlsarhan, T., Harfoushi, O., Shdefat, A. Y., Mostafa, N., Alshinwan, M., & Ali, A. (2023). Improved Graph Convolutional Network with Enriched Graph Topology Representation for Skeleton-Based Action Recognition. Electronics, 12(4), 879. https://doi.org/10.3390/electronics12040879