
Ultra-Low-Power Voice Activity Detection System Using Level-Crossing Sampling

Abstract
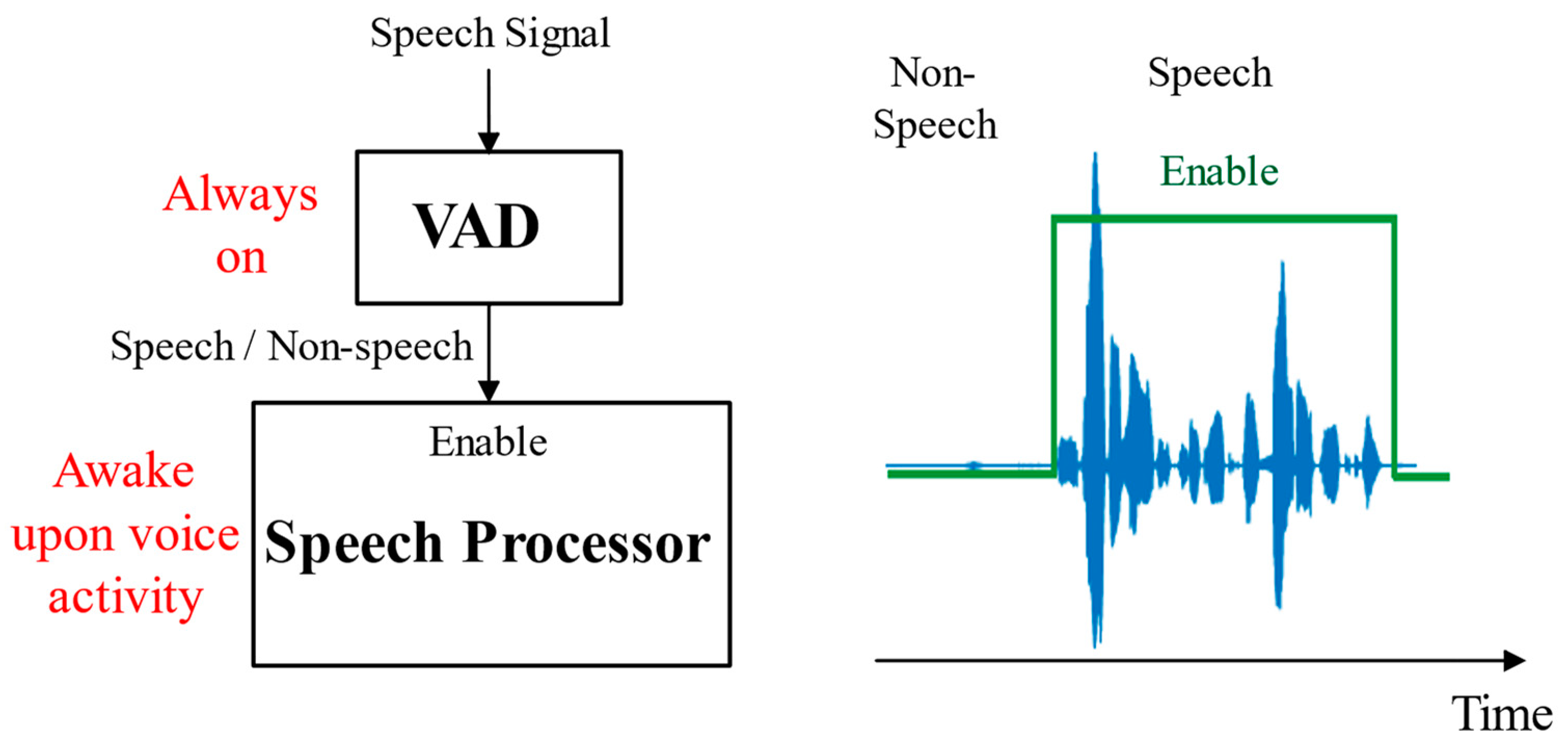
:1. Introduction
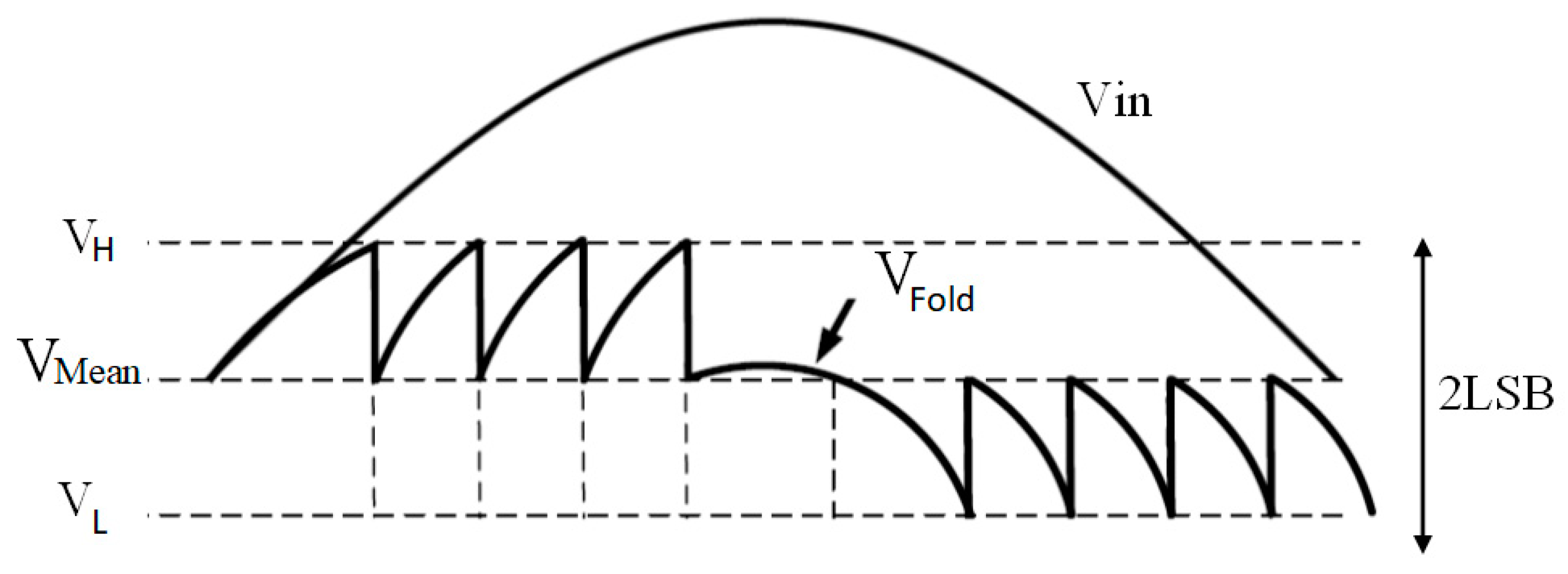
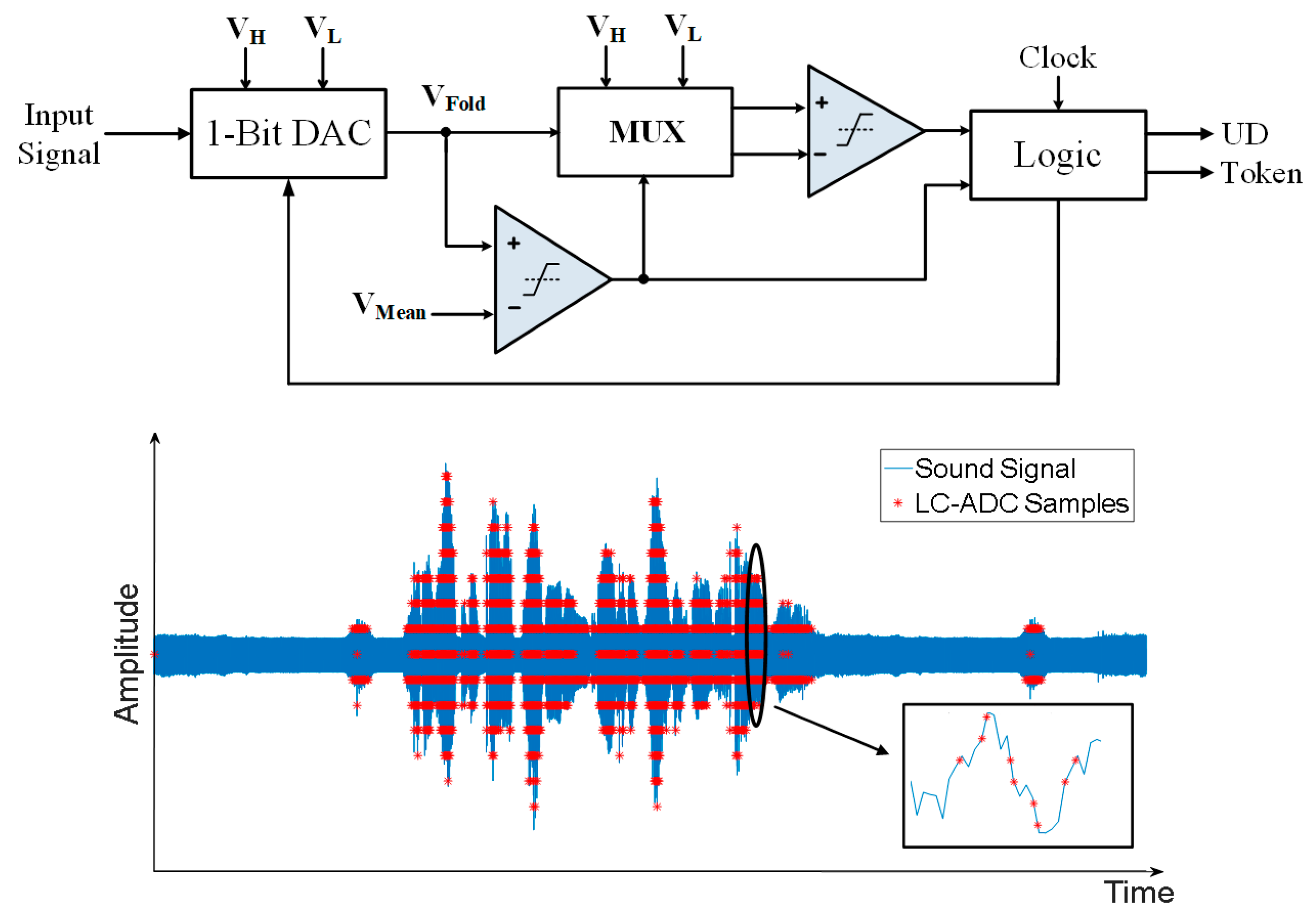
2. Level-Crossing Sampling
3. VAD Algorithm Using Level-Crossing Samples
3.1. Exploiting LC-ADC for VAD Algorithm
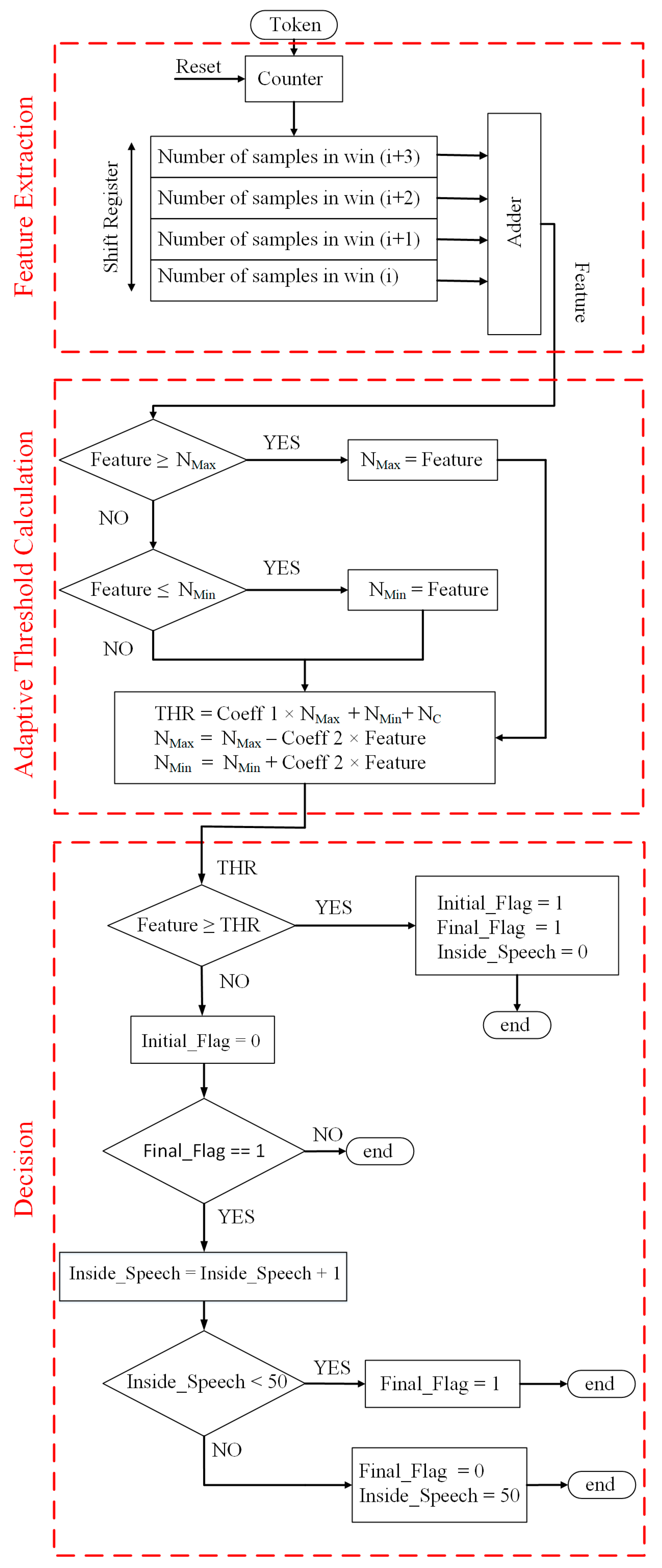
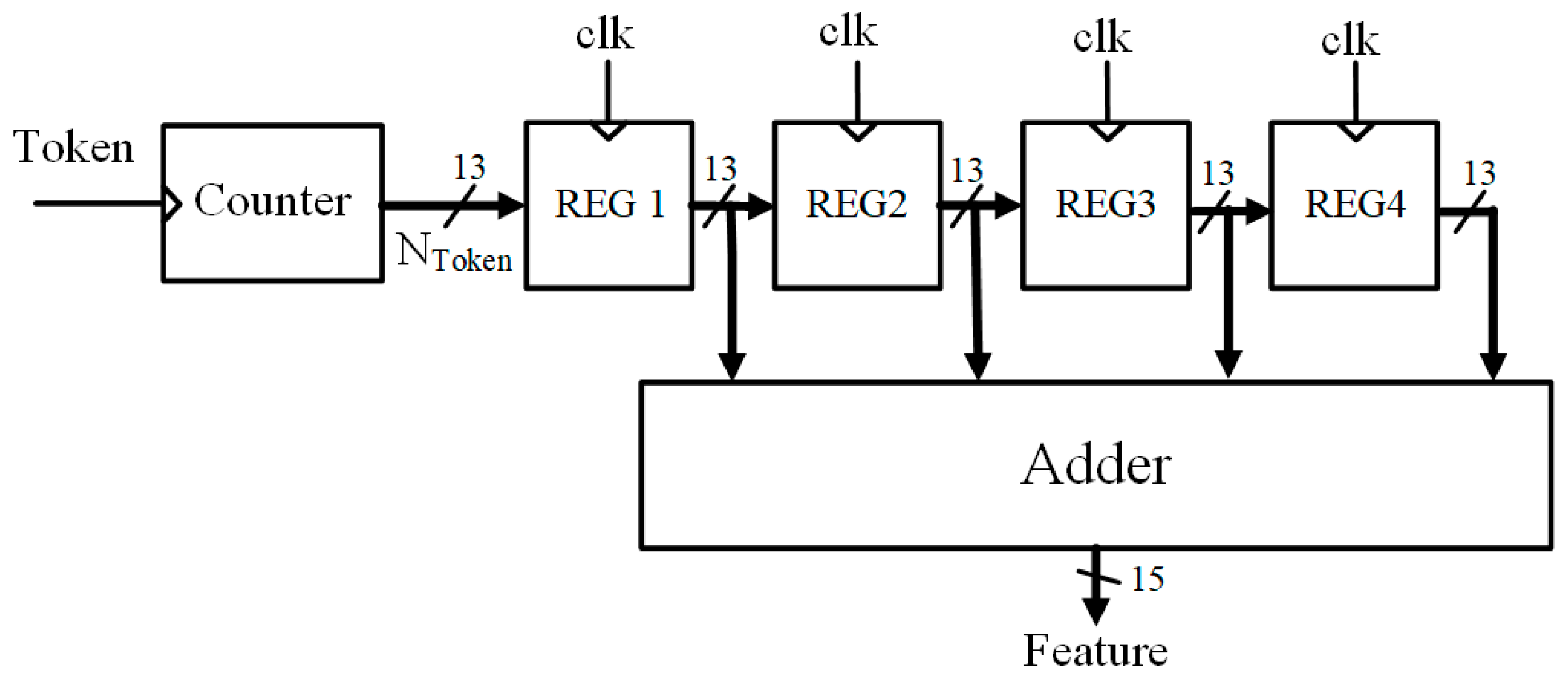
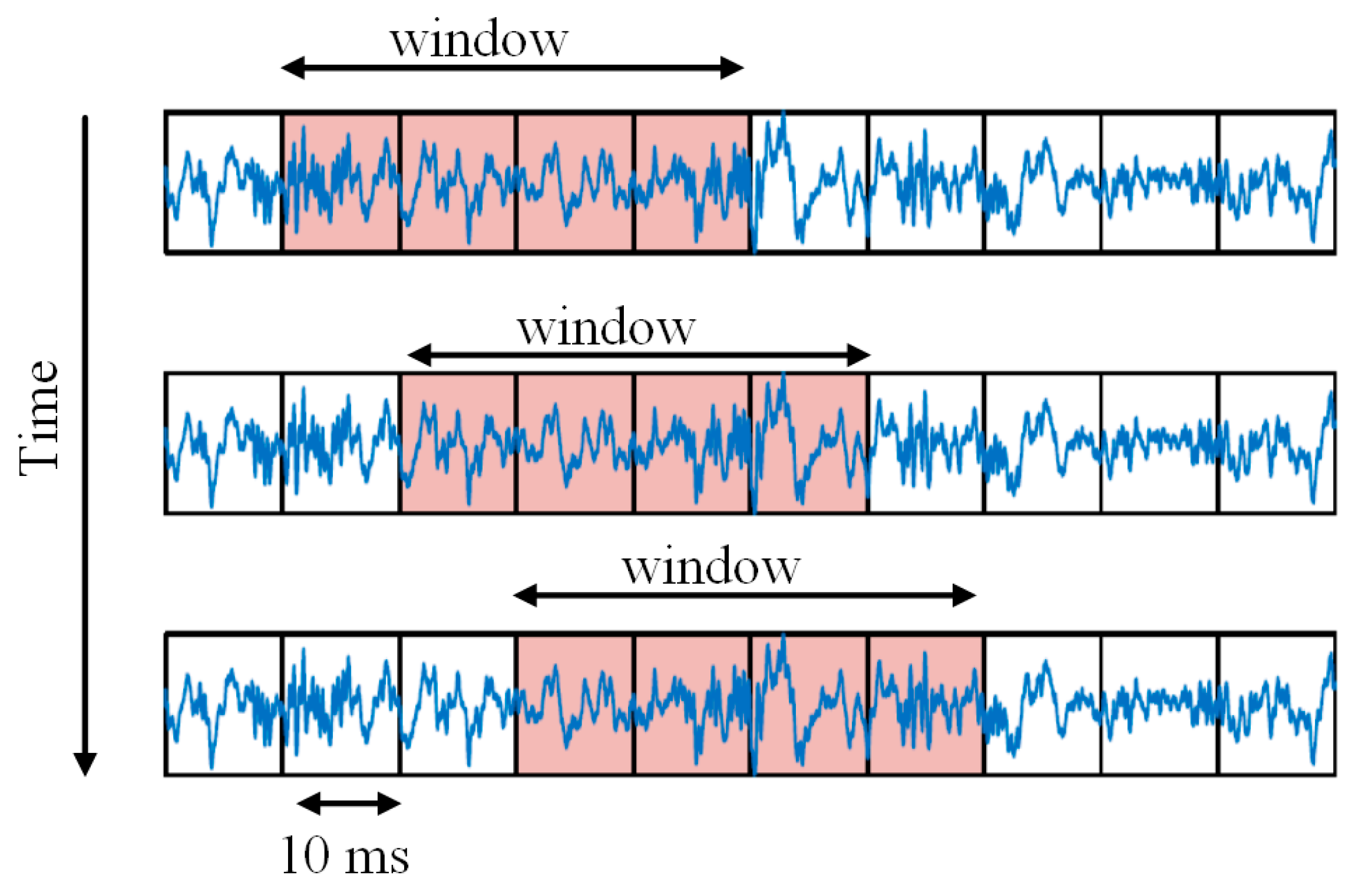
3.2. Proposed VAD Algorithm
3.3. Setting of the Proposed Circuit Parameters
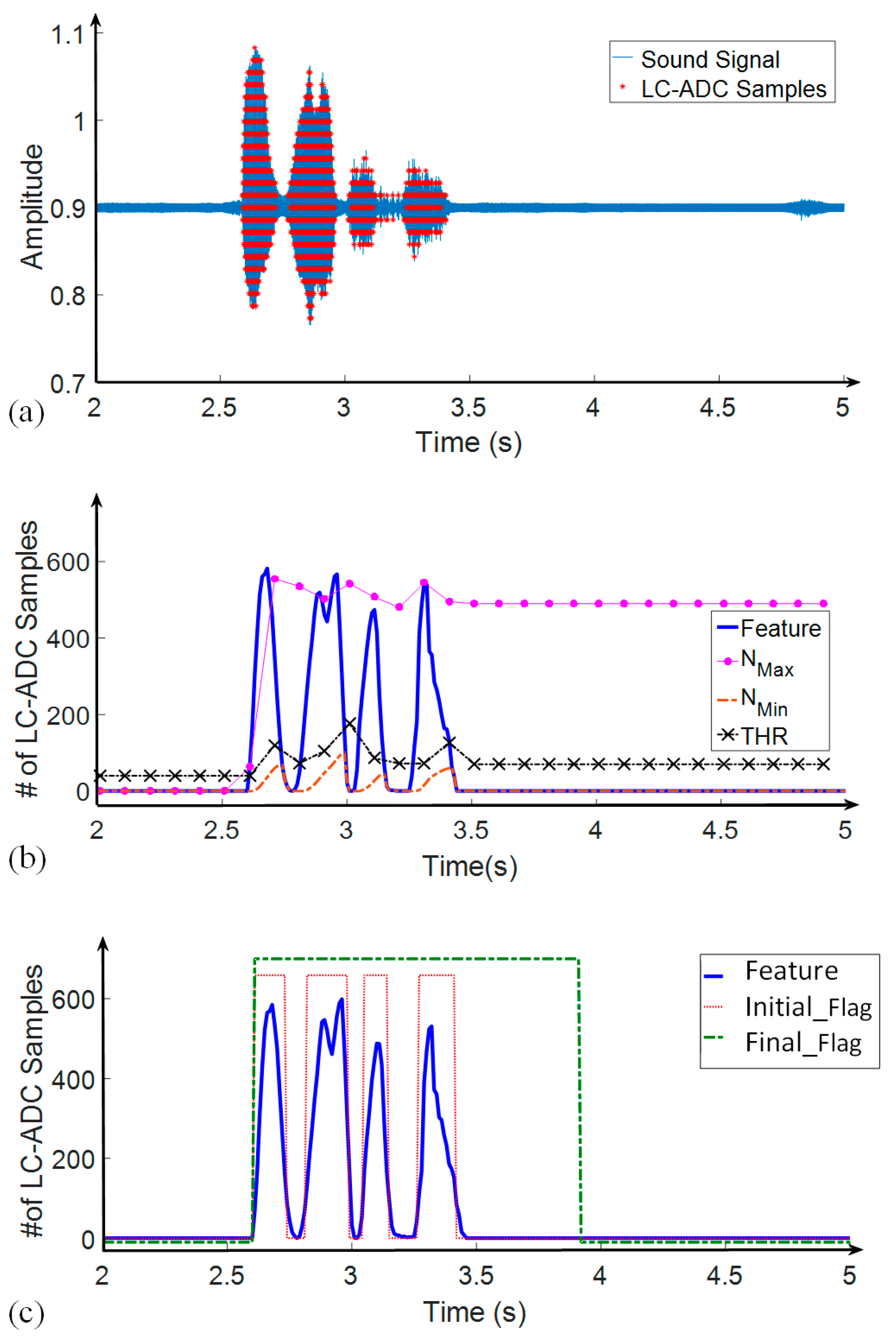
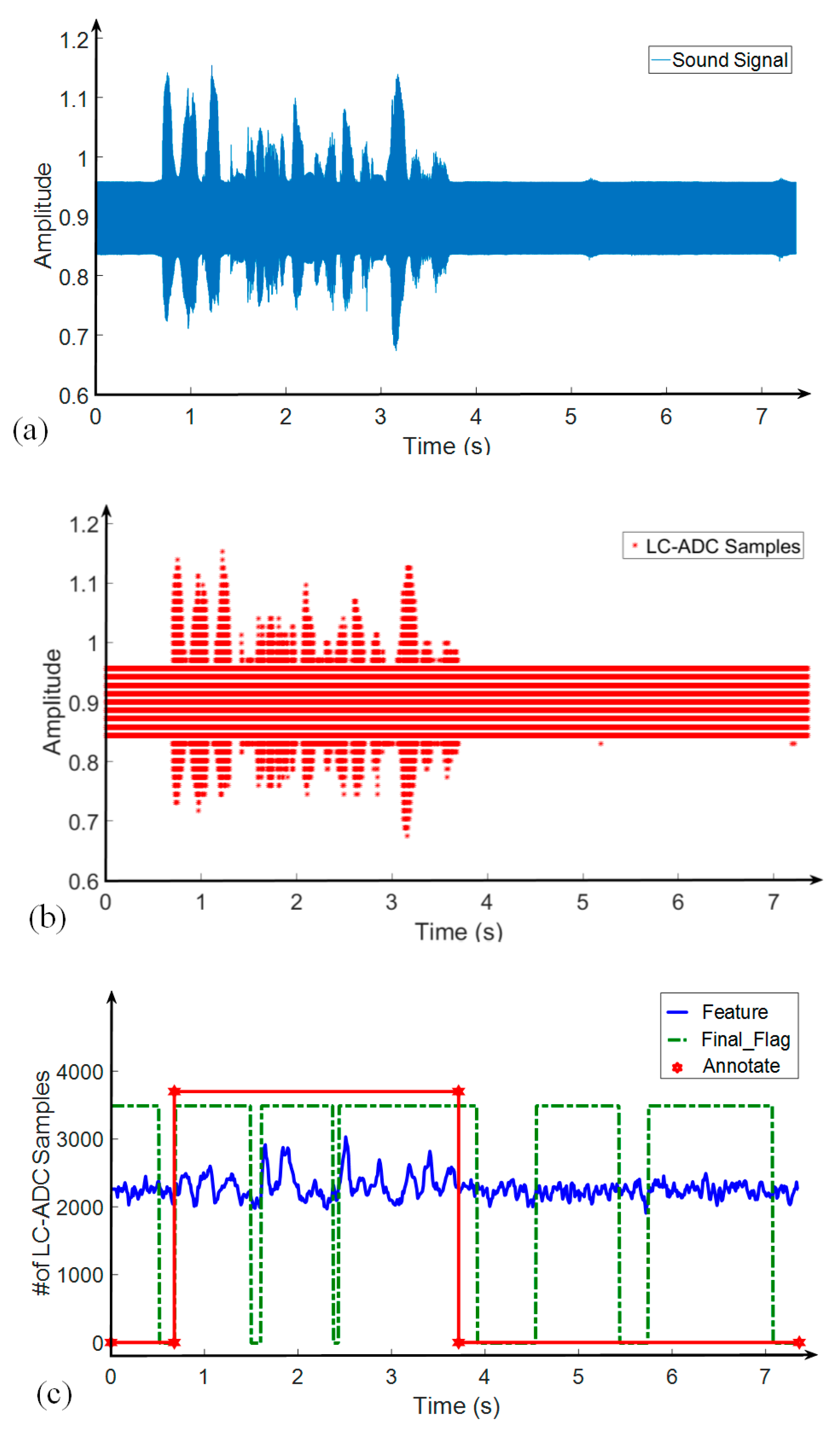
4. Behavioral Simulation Results of the Proposed Algorithm
5. Circuit Implementation and Performance Comparison
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Raychowdhury, A.; Tokunaga, C.; Beltman, W.; Deisher, M.; Tschanz, J.W.; De, V. A 2.3 nJ/frame Voice Activity Detector-Based Audio Front-End for Context-Aware System-On-Chip Applications in 32-nm CMOS. IEEE J. Solid-State Circuits 2013, 48, 1963–1969. [Google Scholar] [CrossRef]
- Price, M.; Glass, J.; Chandrakasan, A.P. A Low-Power Speech Recognizer and Voice Activity Detector Using Deep Neural Networks. IEEE J. Solid-State Circuits 2018, 53, 66–75. [Google Scholar] [CrossRef]
- Badami, K.M.H.; Lauwereins, S.; Meert, W.; Verhelst, M. A 90 nm CMOS, 6 mW Power-Proportional Acoustic Sensing Frontend for Voice Activity Detection. IEEE J. Solid-State Circuits 2016, 51, 291–302. [Google Scholar] [CrossRef]
- Oh, S.; Cho, M.; Shi, Z.; Lim, J.; Kim, Y.; Jeong, S.; Chen, Y.; Rothe, R.; Blaauw, D.; Kim, H.S.; et al. An Acoustic Signal Processing Chip with 142-nW Voice Activity Detection Using Mixer-Based Sequential Frequency Scanning and Neural Network Classification. IEEE J. Solid-State Circuits 2019, 54, 3005–3016. [Google Scholar] [CrossRef]
- Soares, A.D.S.P.; Parreira, W.D.; Souza, E.G.; do Nascimento, C.D.D.; de Almeida, S.J.M. Voice Activity Detection Using Generalized Exponential Kernels for Time and Frequency Domains. IEEE Trans. Circuits Syst. I Regul. Pap. 2019, 66, 2116–2123. [Google Scholar] [CrossRef]
- Alías, F.; Socoró, J.C.; Sevillano, X. A Review of Physical and Perceptual Feature Extraction Techniques for Speech, Music and Environmental Sounds. Appl. Sci. 2016, 6, 143. [Google Scholar] [CrossRef]
- Liu, B.; Wang, Z.; Guo, S.; Yu, H.; Gong, Y.; Yang, J.; Shi, L. An Energy-Efficient Voice Activity Detector Using Deep Neural Networks and Approximate Computing. Microelectron. J. 2019, 87, 12–21. [Google Scholar] [CrossRef]
- Bachu, R.G.; Kopparthi, S.; Adapa, B.; Barkana, B.D. Voiced/Unvoiced decision for speech signals based on zero-crossing rate and energy. In Advanced Techniques in Computing Sciences and Software Engineering; Elleithy, K., Ed.; Springer: Dordrecht, The Netherlands, 2010; pp. 279–282. [Google Scholar] [CrossRef]
- Sakhnov, K.; Verteletskaya, E.; Simak, B. Approach for Energy-Based Voice Detector with Adaptive Scaling Factor. IAENG Int. J. Comput. Sci. 2009, 36. Available online: https://www.iaeng.org/IJCS/issues_v36/issue_4/IJCS_36_4_16.pdf (accessed on 27 November 2022).
- Yang, M.; Yeh, C.H.; Zhou, Y.; Cerqueira, J.P.; Lazar, A.A.; Seok, M. A 1μW Voice Activity Detector Using Analog Feature Extraction and Digital Deep Neural Network. In Proceedings of the 2018 IEEE International Solid-State Circuits Conference-(ISSCC), San Francisco, CA, USA, 11–15 February 2018; Volume 61, pp. 346–348. [Google Scholar] [CrossRef]
- Croce, M.; Friend, B.; Nesta, F.; Crespi, L.; Malcovati, P.; Baschirotto, A. A 760-nW, 180-nm CMOS Fully Analog Voice Activity Detection System for Domestic Environment. IEEE J. Solid-State Circuits 2021, 56, 778–787. [Google Scholar] [CrossRef]
- Shi, E.; Tang, X.; Pun, K.P. A 270 nW Switched-Capacitor Acoustic Feature Extractor for Always-On Voice Activity Detection. IEEE Trans. Circuits Syst. I Regul. Pap. 2021, 68, 1045–1054. [Google Scholar] [CrossRef]
- Yang, M.; Yeh, C.H.; Zhou, Y.; Cerqueira, J.P.; Lazar, A.A.; Seok, M. Design of an Always-On Deep Neural Network-Based 1-μW Voice Activity Detector Aided with a Customized Software Model for Analog Feature Extraction. IEEE J. Solid-State Circuits 2019, 54, 1764–1777. [Google Scholar] [CrossRef]
- Ravanshad, N.; Rezaee-Dehsorkh, H. Level-Crossing Sampling: Principles, Circuits, and Processing for Healthcare Applications. In Compressive Sensing in Healthcare; Khosravy, M., Dey, N., Duque, C.A., Eds.; Elsevier Academic Press Inc.: Amsterdam, The Netherlands, 2020; pp. 223–246. ISBN 9780128212479. [Google Scholar] [CrossRef]
- Ravanshad, N.; Rezaee-Dehsorkh, H.; Lotfi, R.; Lian, Y. A Level-Crossing Based QRS-Detection Algorithm for Wearable ECG Sensors. IEEE J. Biomed. Health Inform. 2014, 18, 183–192. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.; Member, S.; Lian, Y. A 300-mV 220-nW Event-Driven ADC with Real-Time QRS Detection for Wearable ECG Sensors. IEEE Trans. Biomed. Circuits Syst. 2014, 8, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Ravanshad, N.; Rezaee-dehsorkh, H. An Event-Based ECG-Monitoring and QRS-Detection System Based on Level-Crossing Sampling. In Proceedings of the 2017 25th Iranian Conference on Electrical Engineering, ICEE, Tehran, Iran, 2–4 May 2017; pp. 302–307. [Google Scholar] [CrossRef]
- Jimenez, J.; Dai, S.; Rosenstein, J.K. A Microwatt Front End and Asynchronous ADC for Sparse Biopotential Acquisition. In Proceedings of the 2017 IEEE 60th International Midwest Symposium on Circuits and Systems (MWSCAS), Boston, MA, USA, 6–9 August 2017; Volume 2017, pp. 503–506. [Google Scholar]
- Kurchuk, M.; Tsividis, Y. Signal-Dependent Variable-Resolution Clockless A/D Conversion with Application to Continuous-Time Digital Signal Processing. IEEE Trans. Circuits Syst. I Regul. Pap. 2010, 57, 982–991. [Google Scholar] [CrossRef]
- Garofolo, J.; Lamel, L.; Fisher, W.; Fiscus, J.; Pallett, D.; Dahlgren, N. The DARPA TIMIT Acoustic-PhoneticContinuous Speech Corpus CD-ROM; Technical Report NISTIR 4930; National Institute of Standards and Technology: Gaithersburg, MD, USA, 1993. [Google Scholar]
- Ma, Y. Efficient Voice Activity Detection and Speech Enhancement Algorithms Based on Spectral Features. Ph.D. Thesis, Tokyo Institute of Technology, Tokyo, Japan, 2014. [Google Scholar]
- Sohn, J. A Statistical Model-Based Voice Activity Detection. IEEE Signal Process. Lett. 1999, 6, 1–3. [Google Scholar] [CrossRef]
- Ryant, N.; Liberman, M.; Yuan, J. Speech Activity Detection on Youtube Using Deep Neural Networks. In Proceedings of the 14th Annual Conference of the International Speech Communication Association (INTERSPEECH 2013), Lyon, France, 25–29 August 2013; pp. 728–731. [Google Scholar]
- Ying, D.; Yan, Y.; Dang, J.; Soong, F.K. Voice Activity Detection Based on an Unsupervised Learning Framework. IEEE Trans. Audio Speech Lang. Process. 2011, 19, 2624–2632. [Google Scholar] [CrossRef]
- Kim, J.T.; Jung, S.H.; Cho, K.H. Efficient Harmonic Peak Detection of Vowel Sounds for Enhanced Voice Activity Detection. IET Signal Process. 2018, 12, 975–982. [Google Scholar] [CrossRef]
- Ariav, I.; Cohen, I. An End-to-End Multimodal Voice Activity Detection Using WaveNet Encoder and Residual Networks. IEEE J. Sel. Top. Signal Process. 2019, 13, 265–274. [Google Scholar] [CrossRef]
- Qaisar, S.M.; Niyazi, S.; Subasi, A. Efficient Isolated Speech to Sign Conversion Based on the Adaptive Rate Processing. In Proceedings of the 16th International Learning & Technology Conference 2019, Jeddah, Saudi Arabia, 30–31 January 2019; Volume 163, pp. 35–40. [Google Scholar]
- Teimoori, H.; Ravanshad, N.; Rezaee-Dehsorkh, H. Ultra-Low-Power Fully-Synchronous Level-Crossing Analog-to-Digital Converter for Biomedical Signal Acquisition. In Proceedings of the 2017 29th International Conference on Microelectronics (ICM), Beirut, Lebanon, 10–13 December 2017; pp. 1–4. [Google Scholar]
- Hou, Y.; Yousef, K.; Atef, M.; Wang, G.; Lian, Y. A 1-to-1-kHz, 4.2-to-544-nW, Multi-Level Comparator Based Level-Crossing ADC for IoT Applications. IEEE Trans. Circuits Syst. II Express Briefs 2018, 65, 1390–1394. [Google Scholar] [CrossRef]
- Ravanshad, N.; Rezaee-Dehsorkh, H.; Lotfi, R. A Fully-Synchronous Offset-Insensitive Level-Crossing Analog-To-Digital Converter. In Proceedings of the 2016 IEEE 59th International Midwest Symposium on Circuits and Systems (MWSCAS), Abu Dhabi, United Arab Emirates, 6–19 October 2016; pp. 1–4. [Google Scholar]
- Muralishankar, R.; Ghosh, D.; Gurugopinath, S. A Novel Modified Mel-DCT Filter Bank Structure with Application to Voice Activity Detection. IEEE Signal Process. Lett. 2020, 27, 1240–1244. [Google Scholar] [CrossRef]
- Moattar, M.H.; Homayounpour, M.M. A Simple but Efficient Real-Time Voice Activity Detection Algorithm. In Proceedings of the 2009 17th European Signal Processing Conference, Glasgow, UK, 24–28 August 2009; pp. 2549–2553. [Google Scholar]
- Varga, A.; Steeneken, H.J.M. Assessment for Automatic Speech Recognition: II. NOISEX-92: A Database and an Experiment to Study the Effect of Additive Noise on Speech Recognition Systems. Speech. Commun. 1993, 12, 247–251. [Google Scholar] [CrossRef]
- Kim, J.; Hahn, M. Voice Activity Detection Using an Adaptive Context Attention Model. IEEE Signal Process. Lett. 2018, 25, 1181–1185. [Google Scholar] [CrossRef]





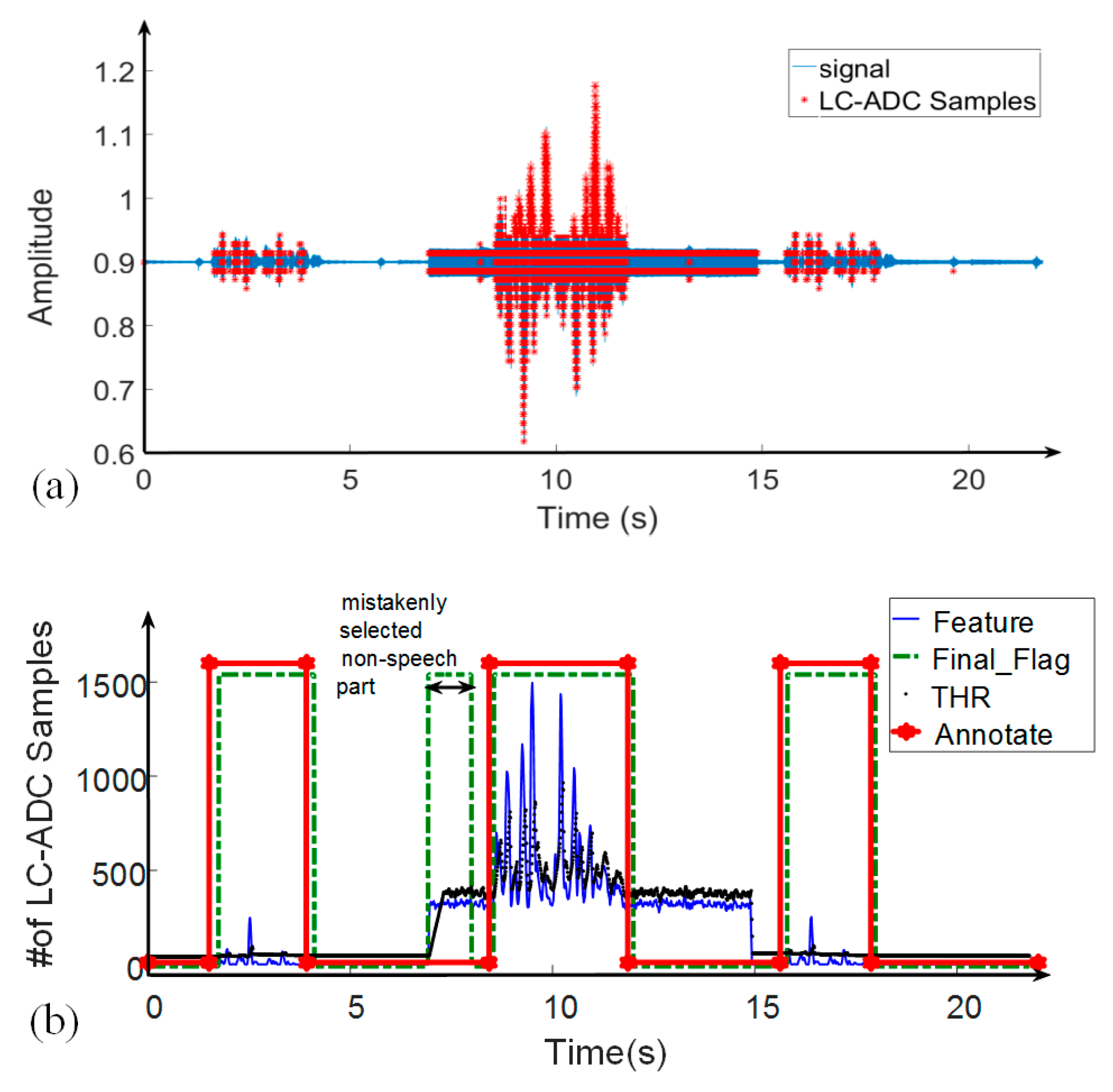
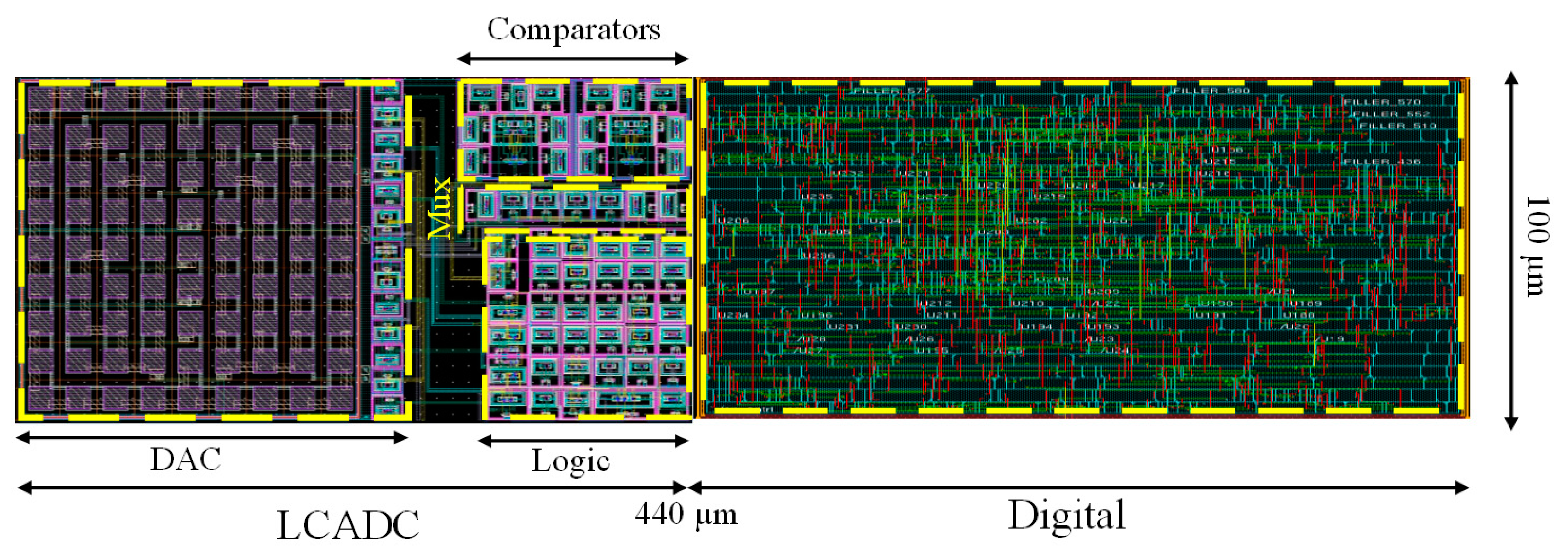

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| SNR | HR0 (%) | HR1 (%) | CORRECT (%) |
|---|---|---|---|
| 10 dB | 93.97 | 89.15 | 92.12 |
| 5 dB | 92.42 | 89.97 | 91.48 |
| 0 dB | 82.79 | 91.41 | 86.09 |
| −5 dB | 61.20 | 93.91 | 73.74 |
| Average | 82.64 | 91.02 | 85.85 |
| Blocks | Sub-Blocks | Cell Internal + Net Switching Power (nW) | Cell Leakage Power (nW) | Power (nW) | VAD Total Power (nW) |
|---|---|---|---|---|---|
| Digital Part | Feature Extraction | 2.66 | 39.3 | 100.9 | 394.6 |
| Threshold Calculation | 4.77 | 40.3 | |||
| Decision | 9.23 | 4.69 | |||
| LC-ADC | 1-Bit DAC | 1.76 | 293.7 | ||
| Mux | 0.158 | ||||
| Comparators | 291.8 | ||||
| Control Logic | 0.023 | ||||
| Ref. | Method | Database | Technology (nm) | Supply Voltage (V) | HR0% | HR1% | Power | |
|---|---|---|---|---|---|---|---|---|
| Feature Extractor | Processor | |||||||
| [1] | Programmable filters, noise floor estimator, and a decision engine | NA | 32 | 0.65 | 97.67% | 96.63% | NA | 50 µW |
| [2] | Energy/harmonicity/modulation frequency calculation | Aurora2 | 65 | 1.2 | 90% @ 7 dB | 90% @ 7 dB | 147.3 µW to 7.76 mW | 22.3 µW |
| [3] | Sensing paradigm algorithm, machine learning | 160 s of NOISEUS | 90 | NA | 85% @ 12 dB babble noise | 89% @ 12 dB babble noise | 6 µW, worst case | |
| [4] | mixer-based architecture, ultra-low-power | LibriSpeech+NOISEX-92 | 180 | NA | 90% @ 10 dB babble | 91.5% @ 10 dB babble | 142 nW | |
| [12] | 10-band passive switched-capacitor, bandpass filter bank, | TIMIT 6 h @ various noises | 180 | 0.65 | 86% @ 10 dB SNR | 90% @ 10 dB SNR | 270 nW | NA |
| [13] | analog signal processing, event driven-ADC, and deep neural network. | Aurora4 | 180 | 0.6 | 85% @ 10 dB restaurant noise | 84% @ 10 dB restaurant noise | 0.38 µW | 1 µW |
| Thiswork | Number of samples extracted from LC-ADC output | 168 sentences of TIMIT over 12 noise type at 10 dB | 180 | 1.8 | 93.97% @ 10 dB SNR of all noise types | 89.15% @ 10 dB SNR of all noise types | 294 nW † | 101 nW † |
| 395 nW † | ||||||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Faghani, M.; Rezaee-Dehsorkh, H.; Ravanshad, N.; Aminzadeh, H. Ultra-Low-Power Voice Activity Detection System Using Level-Crossing Sampling. Electronics 2023, 12, 795. https://doi.org/10.3390/electronics12040795
Faghani M, Rezaee-Dehsorkh H, Ravanshad N, Aminzadeh H. Ultra-Low-Power Voice Activity Detection System Using Level-Crossing Sampling. Electronics. 2023; 12(4):795. https://doi.org/10.3390/electronics12040795
Chicago/Turabian StyleFaghani, Maral, Hamidreza Rezaee-Dehsorkh, Nassim Ravanshad, and Hamed Aminzadeh. 2023. "Ultra-Low-Power Voice Activity Detection System Using Level-Crossing Sampling" Electronics 12, no. 4: 795. https://doi.org/10.3390/electronics12040795
APA StyleFaghani, M., Rezaee-Dehsorkh, H., Ravanshad, N., & Aminzadeh, H. (2023). Ultra-Low-Power Voice Activity Detection System Using Level-Crossing Sampling. Electronics, 12(4), 795. https://doi.org/10.3390/electronics12040795