1. Introduction
Graph neural networks have recently emerged as a powerful tool for modeling graph data. Classic models such as GCN [
1], GAT [
2], SGC [
3], and GraphSAGE [
4] have a wide range of applications in graph-related tasks such as medical data [
5,
6], city traffic data [
7,
8], and wireless networks [
9,
10]; moreover, these models have achieved the effect of SOTA. Additionally, these models iteratively aggregate the features of neighboring nodes to update the representation of their own nodes. Researchers in [
11] interpret it as a method for solving an optimization problem with neighborhood smoothing.
However, researchers have recently observed that nodes do not always tend to connect with nodes in the same class. This phenomenon is called heterophily, and there are also many cases in real scenes, such as heterosexual dating networks, protein interaction networks, and anomaly detection in systems that can be modeled as a graph [
12,
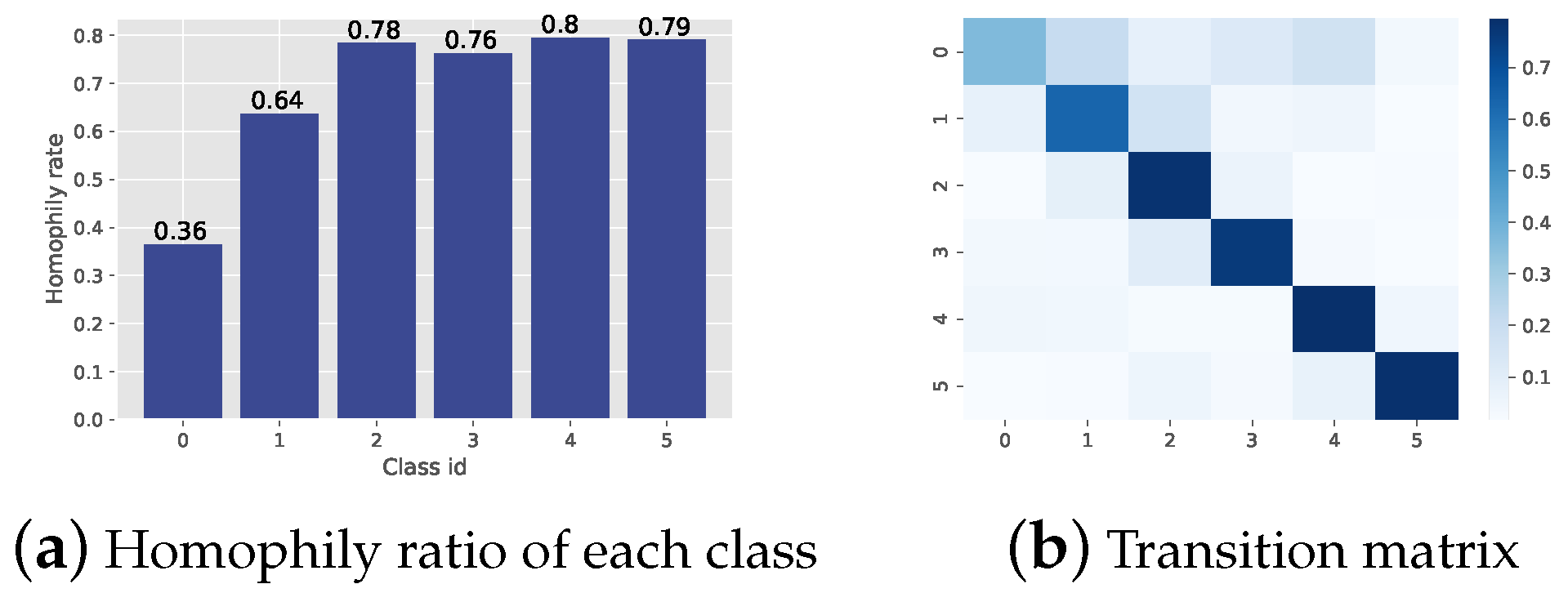
13]. Thus, the original neighbor smoothing strategy is no longer effective in theory. Therefore, in response to dealing with heterophilic graphs, researchers first defined the homophily ratio (HR) by the ratio of edges connecting nodes with the same class (intraclass edges) to total edges. Then, they proposed different strategies to process graphs guided by the homophily ratio. The definition of HR may have two fundamental problems that cause problems in processing graphs and even mislead research. First, the definition of the homophily ratio is based on the graph level, which ignores the multiple connection modes among classes, where some classes tend to connect with the same class while others may not. For instance, the homophily ratio of the commonly used dataset CiteSeer is 0.74, while as shown in
Figure 1a, the HR of Class 1 is only 0.36. In this case, the design of GNNs guided by HRs may uniformly treat them as the same, which is not fair for Class 1. Therefore, it is difficult to define homophily in a scalar [
14].
Second, a low homophily ratio is not the true factor that causes the GNN’s performance to decline. This phenomenon has been shown in many prior works, such as [
14,
15]. The level of the homophily ratio is not strictly linear with the performance of GNNs, and even in some cases of a low homophily ratio, the classic GNN still performs well. Therefore, a new quantitative index is needed to determine which data are bad or good and to indicate the reason affecting the GNNs. In this work, we proposed a transition matrix to describe the probability that a class of nodes may connect to another class of nodes through an edge, as shown in
Figure 1b. Guided by this transition matrix and a simple assumption via stochastic equivalence, we first construct an interpretable model WTGNN that explicitly takes the multiconnection mode into consideration. In addition, each layer of the WTGNN can be explained through a neighbor prediction. Then, we quantify the information that edges can provide via entropy and find that it strongly affects the performance of GNNs through a series of experiments on synthetic and real graphs. Finally, we raise a label-edge mismatch argument that may cause low edge information and propose a corresponding method to test whether the labels match the edges on the graphs. Experimental results show that the most commonly used benchmark datasets treated as heterophilic graphs with poor performance have label-edge mismatch problems.
The main contributions are summarized as follows:
1. The label relationship between connected nodes is described via a transition matrix, and a highly interpretable model called the Walk and Transit Graph Neural Network (WTGNN) is derived. This model transforms the node classification problem into the aggregation of neighbor predictions and can solve constraint satisfaction problems. The calculation process of the model also conforms to the traditional graph neural network paradigm and is equivalent to prior work under certain conditions.
2. The information that edges provide via information entropy is measured, and it is found that it is closely related to the performance of GNNs rather than the homophily ratio. The lower the edge information entropy is, the better the performance of GNNs. Meanwhile, almost all real-world heterophilic graphs have high edge information entropy, which indicates that even though intractable graphs show low HR and high information entropy, we should address the problems caused by low edge information rather than low HR because it is the factor that truly affects the performance of GNNs.
3. The problem of mismatch between labels and edges is considered, and a method to test it is proposed. We first generate a large number of graphs with labels and edge relationships removed as null models and then calculate the probability that the edge information entropy of the generated graph is less than that of the original graph. If the probability is high, the graph has a label-edge mismatch problem. The edge of the randomly generated graph can provide more information with high probability. The experimental results show that almost all heterophilic datasets have label-edge mismatch problems.
The organization of this paper is as follows. In
Section 2, related works are introduced. In
Section 3, the definition of the problem, the assumptions required to derive the model, the definition of the transition matrix, and the related proposition are provided. In
Section 4, the WTGNN based on neighbor prediction is introduced, the information entropy of the edge is calculated as an evaluation metric of the graph, and a method to test the label-edge mismatch problem is proposed. In
Section 5, the features of the specifics of works are discussed. In
Section 6, the performance of the WTGNN is tested, the correlation between edge information entropy and GNN performance is proven, and whether a label-edge mismatch problem exists in the benchmark datasets is determined through a series of experiments. In
Section 7, concluding remarks are provided.
2. Related Work
GNNs. Graph neural networks show excellent data mining ability in semi-supervised node classification tasks because of their strong expression ability. An early version of GNN was proposed by extending the convolutional neural network of conventional meshes (such as images) to irregular meshes (such as graphics). Kipf and Welling [
1] simplified the previous work and proposed a popular graph convolution network GCN. Velickovic et al. [
2] and Hekumparampil et al. [
16] introduced the attention mechanism into graph neural networks, which is also a classical graph neural network defined in the vertex domain. GraphSAGE [
4], GIN [
17], etc., have enhanced the aggregation function to capture information in graphs. The former can be applied to inductive learning on large-scale graphs. Furthermore, JumpingKnowledge Net [
18] made use of the representation from the middle layer to make the GNN deeper. Similarly, APPNP [
19] incorporated personalized PageRank into the aggregation function. Recently, GNN has been integrated with classical theories, such as fuzzy theory [
13] and dynamic planning [
20], resulting in corresponding work, such as FGNN [
21] and DAGFM [
21]. Our work is consistent with JumpingKnowledge and APPNP under certain conditions and this feature will be described in
Section 5.2.
GNNs for heterophily. Recently, many studies on heterophily in graphs have emerged. First, H2GCN [
22], Mix-hop [
23], etc., alleviated the problem of heterophily by directly increasing the range of the receipt field and enhancing the weight of their own nodes during updates. H2GCN verifies that high-order neighbors contain more nodes with the same class when the labels of one-hop neighbors are conditionally independent of the label of the ego node. Following a similar idea, UGCN [
24] introduces a multitype convolution to extract information from 1-hop and 2-hop and designs a discriminative aggregation to sufficiently fuse them to provide learning objectives. In addition, TDGNN [
25] leverages tree decomposition to separate neighbors at different k-hops into multiple subgraphs and then propagates information on these subgraphs in parallel. GPR-GNN, APPNP, and other methods that expand the receipt field by stacking layers are also effective for mismatched maps. In the spectral domain, in contrast to Laplacian smoothing [
26] and low-pass filtering [
3] that approximate graph Fourier transformations on homophilic graphs, spectral GNNs on heterophilic graphs involve both low-pass and high-pass filters to adaptively extract low-frequency and high-frequency graph signals [
27]. Typically, FAGCN [
28] adopts a self-gating attention mechanism to learn the proportion of low-frequency and high-frequency signals. The other type of work is to guide neighbor aggregation by identifying the category of connected nodes. The representative works are GBK-GNN [
29], GAM [
30], GGCN [
31], etc. They modeled homophily at the node level. Different messages are transmitted through the similarity between different nodes or the consistency of labels to strengthen the influence of the same class and weaken the influence of different classes. However, these studies were not focused on the description and modeling of the relationship between classes, and heterophily was regarded as the reason for the decline in GNN performance. However, both our experiment and the experiment in [
15] provided negative examples.
4. Proposed Method and Metrics
In this section, the proposed method is shown starting with an overview of the model design in the model construction part, following the training workflow with model details. Finally, the metrics for edge information and the label-mismatch problem are introduced.
4.1. Model Construction
The construction of the model is introduced from top to bottom. First, the goal of node classification task can be transformed into the aggregation of ), and then is decomposed into the aggregation of , and finally, the transition matrix is learned via a self-supervised fashion. C. A detailed introduction is as follows:
Given that
G is a connected graph and K ≥ the diameter of G, the sum of the k-hop neighborhood of any node contains all nodes and edges in the graph G. Thus, the node classification task can be transformed into using k-hop neighborhoods to predict the node and can be written as:
where
is the prior probability that measures the impact of each
k-hop neighborhood on classification.
The next step is to calculate
. Each k-hop neighborhood consists of the nodes that can walk to Node
in the exact k step, and their predictions to
are
. The random walk probability is used to average all predictions from
; thus, the probability estimation of
v can be obtained as:
In this case, Equation (
7) rewritten in matrix level is:
This Equation (
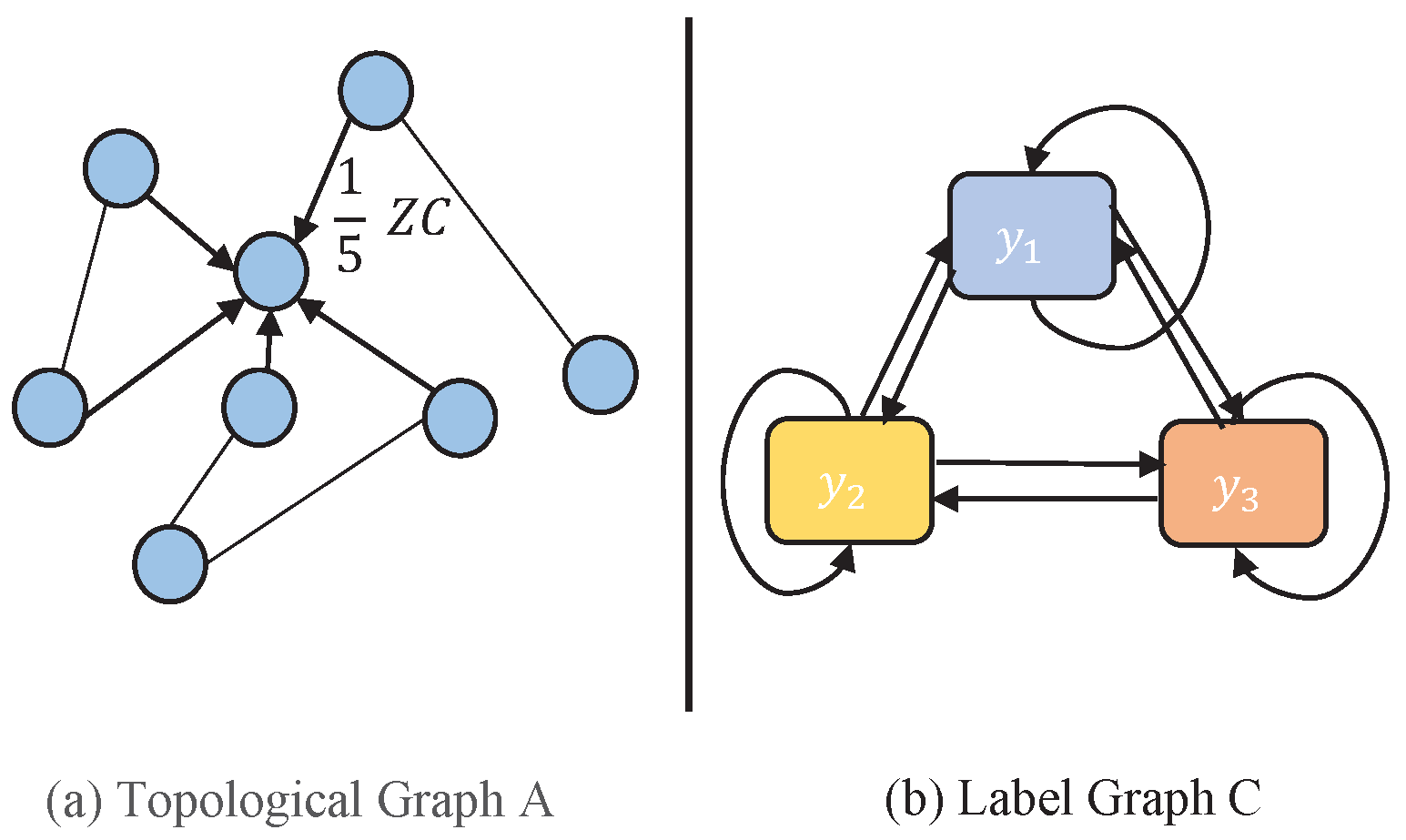
8) indicates that each node receives the probability prediction from its k-hop neighborhood. Compared with GCN, SGC, APPNP, etc., nodes directly propagate and aggregate the information of neighboring nodes, and the proposed method aggregates the label information transited k steps via transition matrix C from its k-hop neighbor and weighted with the probability of random walk. Therefore, as shown in
Figure 2, it can be explained as node random walks on two graphs: Node
walks k steps in the topological graph
to propagate its transited label (which is reflected in the equation
), and its label transits k steps on the label graph C (which is reflected in the equation
). Therefore, the proposed method is called the Walk and Transit GNN (WTGNN). In particular, if
, then the probability that
walks to
is the same as the weight that
accepts the transited label of
. Thus, the label propagation and aggregation
C on the graph become a dual problem.
Meanwhile, the calculation of the transition matrix
C should be performed. The inherent requirement of
C is to predict neighboring nodes via edges and labels. Therefore, we use a self-supervised auxiliary task to solve it:
The task can be seemed as solving least square problem, where each node should predict its neighbor, and is the weight for each problem.
So the whole model of WTGNN can be explained as solving the following problem:
4.2. Training Process
Through the overall description of the model, the end-to-end model training process can be divided into three parts. The first part obtains the probability distribution of initial node labels, the second part trains the transition matrix, and the third part is the aggregation. The details are shown in
Figure 3, and the parts are described as follows:
Part 1: Initialize the label distribution of nodes. As shown in
Figure 3, the label distribution of nodes can be initialized through multilayer perception:
Or it can even be calculated by an existing GNNslayer such as GCN [
1]:
Since the topology of a graph is not always trustworthy [
33], it is a more generalized choice to use only feature information to obtain an initial evaluation. However, if the edges provide useful information, then using GNN is an option to obtain higher performance.
Part 2: Calculate the transition matrix. Since there is no way to obtain the estimated value of C directly from the label, C can only be solved through neighbor prediction tasks. We take the mean square error as the loss function:
Part 3: Aggregation. The aggregation Equation (
9) can be rewritten as a layer-by-layer convolution type:
In each layer, the aggregating operation is equal to each node aggregates predictions from its k-hop neighbors weighted by the probability of random walk. The results of each layer
are integrated according to the influence coefficient
of different k hops. This step can also be regarded as a dense connection layer [
34]. We take the cross-entropy function as the loss function:
where
is the parameter of MLP or GNN in the first part,
are the labeled nodes. So the whole loss function is:
4.3. Proposed Measurement
Heterophily, which is a research direction of graph neural networks, is often considered a kind of graph that does not conform to the design of classical graph neural networks. Some recent studies [
14,
15,
35] found through experiments that heterophily does not necessarily lead to a decline in the GNN performance, and there are still good or bad differences in heterophily. However, little work has been performed to propose a quantitative indicator that affects the performance of graph neural networks. In our work, we divide the graph into two types of data, node features, and edges, and consider that the performance of the GNN is affected by the information they provide.
Through the assumption of stochastic equivalence, we can calculate the entropy of edges
which describes how many bits of information are still needed on average for a node to predict a connected node via an edge:
A high indicates that the edges provide little information for the node classification task, and vice versa.
4.4. Proposed Argument
However, what leads to this intractable graph data (bad heterophily with high edge information entropy) is a question that must be answered for further research. In this work, we consider an argument that edges cannot always reflect the relationship between the labels of connected nodes, which is called the label-edge mismatch problem. For example, in a lawyer network, each edge between two lawyers was built when they were assigned to handle the same case in a law firm. If the node/lawyer is labeled with a graduate school, obviously, the relationship between the edges and labels is weak. According to the content of the previous section, we propose a test method using the idea of the method of contradiction. It first assumes that the current edges and labels have the best matching relationship, that is,
is assumed to be maximum, then a random perturbation graph
is taken as a null model and its
is calculated. Finally, the probability of
is calculated namely as follows:
It is worth noting that a low
value does not mean that the edges have provided the best description of the labels, but a high
value can prove that it does have a label-edge mismatch problem. We consider an example on multilabel graph data, the Lazega Lawyers [
36] datasets, to show the different
values among different labels in the same structure, the results are shown in
Table 1.
In the Lazega lawyer network, there are three subgraphs constructed according to different relationships. Each lawyer has multiple types of labels, such as gender, graduation school, office location, and practice. If 0.1 is taken as the significance level, it is easy to find in
Table 1 that the relationship between the graduation school, practice, and the network constructed according to friendship, advice, and cowork is weak.
6. Experiments
In this section, we evaluate the proposed WTGNN with a node classification task on benchmark datasets, explore the effects of HR and the edge information entropy on the GNN performance, and test whether the heterophilic datasets in the benchmark suffer from the label-edge mismatch problem.
6.1. Data Description
Experiments are performed on nine datasets from PyTorch-Geometric [
42], which are commonly used in graph neural network literature. We use a public data split provided by [
43], the nodes of each class are 48%, 32%, and 20% for the training, validation, and testing sets, respectively. An introduction to the datasets is presented in
Table 4. All benchmark datasets presented here are similar to graph-structured data in the electronic realm, such as wireless networks, and the implemented model can be easily generalized to the electronic realm.
Cora, CiteSeer and PubMed [44] are citation network-based datasets. In these datasets, nodes represent papers, and edges represent citations of one paper by another. The node features are the bag-of-words representation of papers, and the node labels denote the academic topic of a paper. Since these citation datasets have a high homophily ratio, they are considered homophily datasets.
Wisconsin, Cornell, and Texas are subdatasets of WebKB collected by Carnegie Mellon University. In these datasets, the nodes represent web pages, and the edges represent hyperlinks between them. The node features are the bag-of-words representation of web pages. The task is to classify the nodes into one of the following five categories: Student, project, course, staff, and faculty.
Actor [43] is the actor-only induced subgraph of the film– director–actor–writer network. Each node corresponds to an actor, and the edge between two nodes denotes co-occurrence on the same Wikipedia page. Node features correspond to some keywords on Wikipedia pages. The task is to classify the nodes into five categories in terms of words of actor’s Wikipedia.
Chameleon and Squirrel [45] are two page–page networks on specific topics in Wikipedia. The nodes represent web pages, and the edges are mutual links between the pages. The node features correspond to several informative nouns on Wikipedia pages. The labels of the nodes are five categories in terms of the number of the average monthly traffic of the web page.
6.2. Baselines Description
We compare our model with five baselines including two classic GNNs, an attribute-only based MLP, and two GNN-based SOTA methods aiming to analyze heterophilic graphs.
6.3. Parameter Settings
For the baselines, we use their default parameter settings as they often lead to the best results. For our proposed method, we use the Adam [
46] optimizer and set the number of hidden labels to {16, 32}, set the regularization term to {
}, and the learning rate is chosen from {0.01, 0.05}. Set the balance parameter of loss
to 0.5, dropout ratio to 0.5, and learning rate to { 0.01, 0.05}. The initialization part is a 1-layer MLP with softmax activation for all datasets. In the aggregation part, the number of layers
k is searched between 5 to 10 for all datasets, and we use the
as a random walk matrix. Model training is performed on Nvidia Tesla V100 GPU with 16 GB memory.
6.4. Experimental Result
This section aims to evaluate the proposed WTGNN with node classification task on benchmark datasets and design experiments to explore how HR and edge information entropy affects GNN performance, and test whether the heterophilic datasets in the benchmark exist in label-edge mismatch problems.
6.5. Experiment on Node Classification
The results are shown in
Table 5, where the best results are in bold fonts. The proposed method achieved the best performance on seven of the nine datasets and the second-best performance on the remaining dataset. Considering the seven datasets, our WTGNN is on average 2.86%, 1.34%, 23.61%, 0.65%, 2.6%, 2.3%, and 0.23% more accurate than GCN, H2GCN, GPRGNN on Texas, Wisconsin, Squirrel, Cornell, Citeseer, Cora and PubMed, respectively. Specifically, on the Chameleon, Actor, and WebKB datasets, H2GCN and GPRGNN both show an improvement compared with the ordinary GCN, which shows the effectiveness of the heterophily design. However, on the Squirrel dataset, the GCN model exceeds the H2GCN and GPRGNN designed for heterophily, indicating that this HR-based design cannot cover all cases. However, our method shows a good generalization performance on almost all datasets, which verifies the express ability of the proposed transition matrix.
6.6. Experiment on Information Entropy of Edge
To test the impact of
, we should show its relationship with the accuracy of GNNs minus two-layer MLPs, which can remove the influence of the features provided by information nodes. WTGNNs and GCNs are evaluated on synthetic datasets generated by cSBM [
47] and real-world benchmark datasets, and both have different levels of the homophily ratio. Synthetic datasets can facilitate analyses based on ideal conditions and can eliminate the impact of node features on the performance to the maximum extent, letting us focus only on the influence of the connection mode. The result is demonstrated in
Figure 4, and the following conclusions can be determined through their impact on the performances GNNs:
First, by comparing (a) and (b), the improved performance of graph neural networks has a significant negative correlation with edge information entropies but has no linear relationship with the homophily ratio on synthetic datasets. In real datasets, as shown in (c) and (d), the improved performance also does not show a significant linear relationship with HR. However, there is basically a negative relationship with edge information entropy, except for chameleon and squirrel. This may be because the labels of the two datasets are not discrete but are continuous web traffic divided into different categories, and the transition matrix is more appropriate for describing the mapping relationship between labels.
Second, in the case of an extremely low homophily situation, the classic GCN can still perform well, as (a) shows. The reason is that in this case, the weight matrices of GCNs can capture the relationship between the labels of connected nodes because there is a significant mapping relation between them, even if an opposite effect occurs. The proposed WTGNN captures this relationship through an auxiliary task and uses it to classify nodes. If edges provide more information, the classification performance would be good, and vice versa. Therefore, when the label distribution of connected nodes tends to be uniform, the amount of information it provides is the least, and the performance of all GNNs is also the worst; in this case, the edge information entropy is .
Finally, the WTGNN can maintain the performance of MLP compared with GCN, and enhance the utilization of structural information because its curve is always above 0 in all datasets.
6.7. Experiment on Label-Edge Mismatch Problem
We examine the
value on commonly used benchmark datasets, and the results are shown in
Table 6. To better clarify the relationship between the heterophily and the
-value, we set HR = 0.5 as the discriminant for the homophily and heterophily and take M-value = 0.1 as the significance level for the label-edge mismatch problem. As shown in
Figure 5, the
value of five of the six heterophilic datasets is higher than 0.1, which indicates that they have a label-edge mismatch problem. This demonstrates that these datasets may be labeled inappropriately, such as in the Lazega Layers network being only labeled with the graduate school, which cannot reflect their relationship with co-workers. Alternatively, the edges do not describe the relationship between labels. For example, the lower
-value of Actor indicates that using the co-occurrence to build edges is of little help to actor classification. GNNs usually have a low accuracy on these low
-value datasets (except WebKB datasets, in which the node features provide much information for classification). Therefore, when evaluating graph-structured data, we should not only evaluate the relationship between labels and node features but also consider the relationship between edges and labels in nodes. Compared with the homophily ratio, the entropy of the edge can describe the information that edges provide, while the
-value can test the problem behind the dataset.
6.8. Ablation Study
6.8.1. Number of Layers
The performance of the WTGNN under different layers is tested and shown in
Figure 6. In our method, the kth layer represents the aggregation of the probability estimates from the k-hop neighborhood.
Figure 6 shows that the WTGNN basically achieves the optimal results when k = 5 and k = 6. This coincides with the six-degree separation theory [
48]. When k = 6, the WTGNN aggregates information from almost the whole map. After layer 6, in contrast to that of the traditional GCN, its performance does not decline sharply but can remain at a good level. GCNs will be excessively smooth after 2–3 layers in homophilic datasets. This is because the layer coefficient alpha can balance the credibility of the probability estimates of each k-hop neighborhood, thus alleviating the problem of oversmoothing in the GNN.
6.8.2. Auxiliary Task and Layer Influence Coefficient
The extent to which self-supervised auxiliary tasks and the layer influence coefficient
can influence the proposed method is explored in this section. Ablation experiments are performed in which only one feature is removed at a time and compared with the original WTGNN. Removing alpha means using the average of each layer to output the result, and removing ancillary tasks means that the transition matrix
C is completely optimized by the loss function of the classification task. The results are shown in
Figure 7. Both have a greater impact on the performance of the WTGNN, and the two designs have a greater improvement on the heterophilic data than homophilic data. The layer influence coefficients have a greater impact. The first reason is that WTGNN also uses neighbor prediction to handle node classification tasks, which is similar to the auxiliary tasks of neighbor predictions. The second reason is that layer influence coefficients can learn the hard-to-predict effects of different hop neighborhoods.
6.8.3. Initialize Method
The impact of two different initialization labels/hidden labels on the nine datasets with 10-fold different splits is tested in this section. The MLP denotes the use of a 1-layer MLP with softmax as the activation function to output soft labels, as shown in Equation (
12). The GCN means using 1 layer of the graph convolution layer, as shown in Equation (
13), which also uses softmax to output soft labels. The result is shown in
Table 7 and the better results are in bold fonts. On heterophilic datasets that also have a high edge information entropy, initialization with GCNs can result in dramatic performance degradation. For example, on Chameleon datasets, performance decreases by 15.3%, while on Cornell, performance decreases by 38.06%. Not only do the edges not provide valid information, but they also mislead the accuracy level of soft labels, which can affect the training of the transition matrix C. Therefore, using GCN as an initialization tag function on such datasets is not an ideal choice. On datasets where labels and edges match, such as Cora, it has the smallest edge information entropy and the highest HR and taking GCN as an initialization function can outperform the MLP. In general, using the MLP as an initialization function is adequate for most situations and is not susceptible to the edges.
7. Conclusions
In this work, we use the stochastic equivalence assumption to describe the relationship between the labels of connected nodes in graph data, which can more accurately describe the connection modes on discrete graphs than the homophily ratio. With this assumption, we transform the node classification problem into a k-hop neighbor prediction problem and construct an interpretable model, WTGNN. The experimental results on nine benchmark datasets demonstrate the superiority of the proposed model, which is suitable for both homophily and heterophily. In addition, we provide a measurement of the information that edges can provide to the node classification task called edge information entropy and find that high edge information entropy is the main factor contributing to the performance degradation of GNNs, instead of a low homophily ratio. Furthermore, we raise an argument that the label-edge mismatch problem leads to intractable data and develop a test method for the problem. The experimental results show that this problem exists in five of the six heterophilic datasets. That means although researchers have theoretically completed the design for heterophily, it is not heterophily that truly makes the dataset difficult to process; thus, more and deeper problems remain to be explored and solved. In the future, WTGNN and related test methods can be further extended to networks in the electronic field, such as evaluating the reliability of wireless networks and electronic communication networks.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}