
Feature-Selection-Based Attentional-Deconvolution Detector for German Traffic Sign Detection Benchmark




Abstract
:1. Introduction
- 1.
- The inner structure of the backbone involves feature selection to group similar feature maps from the convolution layer using L1-norm. Since the backbone is based on the CSPDarknet [45], the feature maps are divided into two parts. One part of the feature maps is passed on to the next convolution layer for feature extraction, while the other part is concatenated with the transition layer. The L1-norm-based feature selection is applied to the latter concatenated feature maps, and the feature maps with low L1-norm values are removed.
- 2.
- The sizes of the receptive fields of the algorithm are adjusted for traffic signs instead of versatility. The receptive field sizes of most detection algorithms are designed for versatile situations, but, these are not appropriate for traffic signs, owing to their small sizes compared to other objects. Most detection algorithms have three different receptive fields for large-, medium-, and small-sized objects in general. However, the sizes of the receptive fields for small- and medium-sized objects are not designed adequately for traffic signs because the traffic signs are obviously smaller than the other objects.
- 3.
- ADM-Net is adopted as the inference model in the proposed algorithm. ADM-Net is designed to extract the feature information of German traffic signs by considering various external noises. Since the GTSDB dataset is used to detect German traffic signs in the images, the ADM-Net that was specially designed to classify German traffic signs shows superior performance in the experiments.
2. Network Architecture
2.1. Structure of YOLOv5
2.2. L1-Norm Feature Selection
2.3. Feature-Selection-Based Attentional-Deconvolution Detector
3. Traffic Sign Recognition and Comparison Results
3.1. Preprocess
3.2. Evaluation and Comparison Results
3.2.1. Detection Performance of the FSADD
3.2.2. Traffic Sign Recognition Performance Comparisons
4. Discussion

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset Size | Types of Detected Traffic Signs | # of Detected Traffic Signs | Accuracy (%) | GFLOPs | |
|---|---|---|---|---|---|
| Faster R-CNN -FPN [32,62] | 35 | 168 | 91.6 | 180 | |
| Faster R-CNN -FPN [32,62] | - | - | - | 180 | |
| YOLOv5 | 15 | 123 | 51.2 | 16.2 | |
| YOLOv6 | 22 | 123 | 67.4 | 44 | |
| YOLOv7 | 13 | 72 | 36.1 | 104.5 | |
| FSADD (Proposed) | 29 | 219 | 73.9 | 16.63 |
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Luo, H.; Yang, Y.; Tong, B.; Wu, F.; Fan, B. Traffic sign recognition using a multi-task convolutional neural network. IEEE Trans. Intell. Transp. Syst. 2018, 19, 1100–1111. [Google Scholar] [CrossRef]
- Liu, C.; Chang, F.; Chen, Z.; Liu, D. Fast traffic sign recognition via high-contrast region extraction and extended sparse representation. IEEE Trans. Intell. Transp. Syst. 2016, 17, 79–92. [Google Scholar] [CrossRef]
- Tabernik, D.; Skocaj, D. Deep learning for large-scale traffic-sign detection and recognition. IEEE Trans. Intell. Transp. Syst. 2020, 21, 1427–1440. [Google Scholar] [CrossRef]
- Ma, L.; Cheng, S.; Shi, Y. Enhancing learning efficiency of brain storm optimization via orthogonal learning design. IEEE Trans. Syst. Man Cybern. Syst. 2021, 51, 6723–6742. [Google Scholar] [CrossRef]
- Zhu, Y.; Zhang, C.; Zhou, D.; Wang, X.; Bai, X.; Liu, W. Traffic sign detection and recognition using fully convolutional network guided proposals. Neurocomputing 2016, 214, 758–766. [Google Scholar] [CrossRef]
- Yang, Y.; Luo, H.; Xu, H.; Wu, F. Towards real-time traffic sign detection and classification. IEEE Trans. Intell. Transp. Syst. 2016, 17, 2022–2031. [Google Scholar] [CrossRef]
- Lee, H.S.; Kim, K. Simultaneous traffic sign detection and boundary estimation using convolutional neural network. IEEE Trans. Intell. Transp. Syst. 2018, 19, 1652–1663. [Google Scholar] [CrossRef]
- Hu, Q.; Paisitkriangkrai, S.; Shen, C.; Hengel, A.V.D.; Porikli, F. Fast detection of multiple objects in traffic scenes with a common detection framework. IEEE Trans. Intell. Transp. Syst. 2016, 17, 1002–1014. [Google Scholar] [CrossRef]
- Mhalla, A.; Chateau, T.; Amara, N.E.B. Spatio-temporal object detection by deep learning: Video-interlacing to improve multi-object tracking. Image Vis. Comput. 2019, 88, 120–131. [Google Scholar] [CrossRef]
- Greenhalgh, J.; Mirmehdi, M. Real-time detection and recognition of road traffic signs. IEEE Trans. Intell. Transp. Syst. 2012, 13, 1498–1506. [Google Scholar] [CrossRef]
- Fang, C.Y.; Chen, S.W.; Fuh, C.S. Road-sign detection and tracking. IEEE Trans. Veh. Technol. 2003, 52, 1329–1341. [Google Scholar] [CrossRef]
- Bascon, S.M.; Arroyo, S.L.; Jimenez, P.G.; Moreno, H.G.; Ferreras, F.L. Road-sign detection and recognition based on support vector machines. IEEE Trans. Intell. Transp. Syst. 2007, 8, 264–278. [Google Scholar] [CrossRef]
- Zhang, J.; Xie, Z.; Sun, J.; Zou, X.; Wang, J. A cascaded R-CNN with multiscale attention and imbalanced samples for traffic sign detection. IEEE Access 2020, 8, 29742–29754. [Google Scholar] [CrossRef]
- Cao, J.; Zhang, J.; Jin, X. A traffic sign detection algorithm based on improved sparce R-CNN. IEEE Access 2021, 9, 122774–122788. [Google Scholar] [CrossRef]
- Kamal, U.; Tonmoy, T.I.; Das, S.; Hasan, M.K. Automatic traffic sign detection and recognition using SegU-Net and a modified tversky loss function with L1-constraint. IEEE Trans. Intell. Transp. Syst. 2020, 21, 1467–1479. [Google Scholar] [CrossRef]
- Krishnadas, P.; Chadaga, K.; Sampathila, N.; Rao, S.; Prabhu, S. Classification of malaria using object detection models. Informatics 2022, 9, 76. [Google Scholar] [CrossRef]
- Sampathila, N.; Chadaga, K.; Goswami, N.; Chadaga, R.P.; Pandya, M.; Prabhu, S.; Bairy, M.G.; Katta, S.S.; Bhat, D.; Upadya, S.P. Customized deep learning classifier for detection of acute lymphoblastic leukemia using blood smear images. Healthcare 2022, 10, 1812. [Google Scholar] [CrossRef]
- Acharya, V.; Dhiman, G.; Prakasha, K.; Bahadur, P.; Choraria, A.; Prabhu, S.; Chadaga, K.; Viriyasitavat, W.; Kautish, S. AI-assisted tuberculosis detection and classification from chest X-rays using a deep learning normalization-free network model. Comput. Intell. Neurosci. 2022, 2022, 1–19. [Google Scholar] [CrossRef]
- Bhatkalkar, B.; Hegde, G.; Prabhu, S.; Bhandary, S. Feature extraction for early detection of macular hole and glaucoma in fundus images. J. Med. Imaging Health Inform. 2016, 6, 1536–1540. [Google Scholar] [CrossRef]
- Chadaga, K.; Prabhu, S.; Sampathila, N.; Chadaga, R.; Swathi, K.S.; Sengupta, S. Predicting cervical cancer biopsy results using demographic and epidemiological parameters: A custom stacked ensemble machine learning approach. Cogent Eng. 2022, 9, 2143040. [Google Scholar] [CrossRef]
- Houben, S.; Stallkamp, J.; Salmen, J.; Schlipsing, M.; Igel, C. Detection of traffic signs in real-world images: The german traffic sign detection benchmark. In Proceedings of the 2013 International Joint Conference on Neural Networks (IJCNN), Dallas, TX, USA, 4–9 August 2013; pp. 1–8. [Google Scholar]
- Zhang, H.; Qin, L.; Li, J.; Guo, Y.; Zhou, Y.; Zhang, J.; Xu, Z. Real-time detection method for small traffic signs based on Yolov3. IEEE Access 2020, 8, 64145–64156. [Google Scholar] [CrossRef]
- Arcos-Garcia, A.; Alvarez-Garcia, J.A.; Soria-Morill, L.M. Evaluation of deep neural networks for traffic sign detection systems. Neurocomputing 2018, 316, 332–344. [Google Scholar] [CrossRef]
- Liu, C.; Chang, F.; Chen, Z. Rapid multiclass traffic sign detection in high-resolution images. IEEE Trans. Intell. Transp. Syst. 2014, 15, 2394–2403. [Google Scholar] [CrossRef]
- Liu, Z.; Shen, C.; Qi, M.; Fan, X. SADANet: Intergrating scale-aware and domain adaptive for traffic sign detection. IEEE Access 2020, 8, 77920–77933. [Google Scholar] [CrossRef]
- Li, C.; Chen, Z.; Wu, Q.M.J.; Liu, C. Deep saliency with channel-wise hierarchical feature responses for traffic sign detection. IEEE Trans. Intell. Transp. Syst. 2019, 20, 2497–2509. [Google Scholar] [CrossRef]
- Zhu, Z.; Liang, D.; Zhang, S.; Huang, X.; Li, B.; Hu, S. Traffic-sign detection and classification in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2110–2118. [Google Scholar]
- Larsson, F.; Felsberg, M. Using fourier descriptors and spatial models for traffic sign recognition. In Scandinavian Conference on Image Analysis. Lecture Notes in Computer Science; Heyden, A., Kahl, F., Eds.; Springer: Berlin/Heidelberg, Germany, 2011; pp. 238–249. [Google Scholar]
- Mogelmose, A.; Trivede, M.M.; Moeslund, T.B. Vision based traffic sign detection and analysis for intelligment driver assistance systems. IEEE Trans. Intell. Transp. Syst. 2012, 13, 1484–1497. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Using fourier descriptors and spatial models for traffic sign recognition. In Proceedings of the 28th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Ahmed, I.; Din, S.; Jeon, G.; Piccialli, F. Exploring deep learning models for overhead view multiple object detection. IEEE Internet Thing J. 2020, 7, 5737–5744. [Google Scholar] [CrossRef]
- Baoyuan, C.; Yitong, L.; Kun, S. Research on object detection method based on FF-YOLO for complex scenes. IEEE Access 2021, 9, 127950–127960. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C.P. SSD: Single shot multibox detector. In European Conference on Computer Vision. Lecture Notes in Computer Science; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer International Publishing AG: Amsterdam, The Netherlands, 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 22–25 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. Yolov7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar]
- Jocher, G. YOLOv5 by Ultralytics. Available online: https://github.com/ultralytics/yolov5 (accessed on 1 August 2022).
- Li, H.; Kadav, A.; Durdanovic, I.; Samet, H.; Graf, H.P. Pruning filters for efficient convnets. arXiv 2016, arXiv:1608.08710. [Google Scholar]
- Kumar, A.; Shaikh, A.; Li, Y.; Bilal, H.; Yin, B. Pruning filters with L1-norm and capped L1-norm for CNN compression. Appl. Intell. 2021, 51, 1152–1160. [Google Scholar] [CrossRef]
- Lin, M.; Ji, R.; Wnag, Y.; Zhang, Y.; Zhang, B.; Tian, Y.; Shao, L. Hrank: Filter pruning using high-rank feature map. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 14–19 June 2020; pp. 1529–1538. [Google Scholar]
- Chung, J.H.; Kim, D.W.; Kang, T.K.; Lim, M.T. ADM-Net: Attentional-deconvolution module-based net for noise-coupled traffic sign recognition. Multimed. Tools Appl. 2022, 81, 23373–23397. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Luo, S.; Yu, J.; Xi, Y.; Liao, X. Aircraft target detection in remote sensing images based on improved YOLOv5. IEEE Access 2022, 10, 5184–5192. [Google Scholar] [CrossRef]
- Wang, C.Y.; Lio, H.Y.M.; Wu, Y.H.; Chen, P.Y.; Hsieh, J.W.; Yeh, I.H. CSPNet: A new backbone that can enhance learning capability of CNN. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 14–19 June 2020; pp. 390–391. [Google Scholar]
- Lin, T.Y.; Dollar, P.; Girshick, R. Feature pramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 22–25 July 2017; pp. 2117–2125. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 8759–8768. [Google Scholar]
- Akbas, C.E.; Bozkurt, A.; Arslan, M.T.; Aslanoglu, H.; Cetin, A.E. L1 norm based multiplication-free cosine similarity measures for big data analysis. In Proceedings of the 2014 International Workshop on Computational Intelligence for Multimedia Understanding (IWCIM), Paris, France, 1–2 November 2014; pp. 1–5. [Google Scholar]
- Zou, L.; Song, L.T.; Weise, T.; Wang, X.F.; Huang, Q.J.; Deng, R.; Wu, Z.Z. A survey on regional level set image segmentation models based on the energy functional similarity measure. Neurocomputing 2021, 452, 606–622. [Google Scholar] [CrossRef]
- Zhao, X.; Li, X.; Bi, D.; Wang, H.; Xie, Y.; Alhudhaif, A.; Alenezi, F. L1-norm constraint kernel adaptive filtering framework for precise and robust indoor localization under the internet of things. Inf. Sci. 2022, 587, 206–225. [Google Scholar] [CrossRef]
- Sun, Y.; Zhang, X.; Zhao, X.; Xin, Q. Extracting building boundaries from high resolution optical images and LiDAR data by integrating the convolutional neural network and the active contour model. Remote Sens. 2018, 10, 1459. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollar, P.; Zitnick, C.L. Microsoft COCO: Common objects in context. In European Conference on Computer Vision. Lecture Notes in Computer Science; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Springer International Publishing: Zurich, Switzerland, 2014; pp. 740–755. [Google Scholar]
- Bi, Q.; Qin, K.; Zhang, H.; Li, Z.; Xu, K. RADC-Net: A residual attention based convolution network for aerial scene classification. Neurocomputing 2020, 377, 345–359. [Google Scholar] [CrossRef]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A single-stage object detection framework for industrial applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Mai, X.; Zhang, H.; Jia, W.; Meng, M.Q.H. Faster R-CNN with classifier fusion for automatic detection of small fruits. IEEE Trans. Autom. Sci. Eng. 2021, 17, 1555–1569. [Google Scholar] [CrossRef]
- Li, J.; Liang, X.; Shen, S.; Xu, T.; Feng, J.; Yan, S. Scale-aware fast R-CNN for pedestrian detection. IEEE Trans. Multimed. 2018, 20, 985–996. [Google Scholar] [CrossRef]
- Zhai, S.; Dong, S.; Shang, D.; Wang, S. An improved faster R-CNN pedestrian detection algorithm based on feature fusion and context analysis. IEEE Access 2020, 9, 138117–138128. [Google Scholar] [CrossRef]
- Li, H.; Huang, Y.; Zhang, Z. An improved faster R-CNN for same object retrieval. IEEE Access 2017, 5, 13665–13676. [Google Scholar] [CrossRef]
- Guo, Y.; Du, L.; Lyu, G. SAR target detection based on domain adaptive faster R-CNN with small training data size. Remote Sens. 2021, 13, 4202. [Google Scholar] [CrossRef]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In European Conference on Computer Vision. Lecture Notes in Computer Science; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.M., Eds.; Springer Nature Switzerland AG: Glasgow, UK, 2020; pp. 213–229. [Google Scholar]
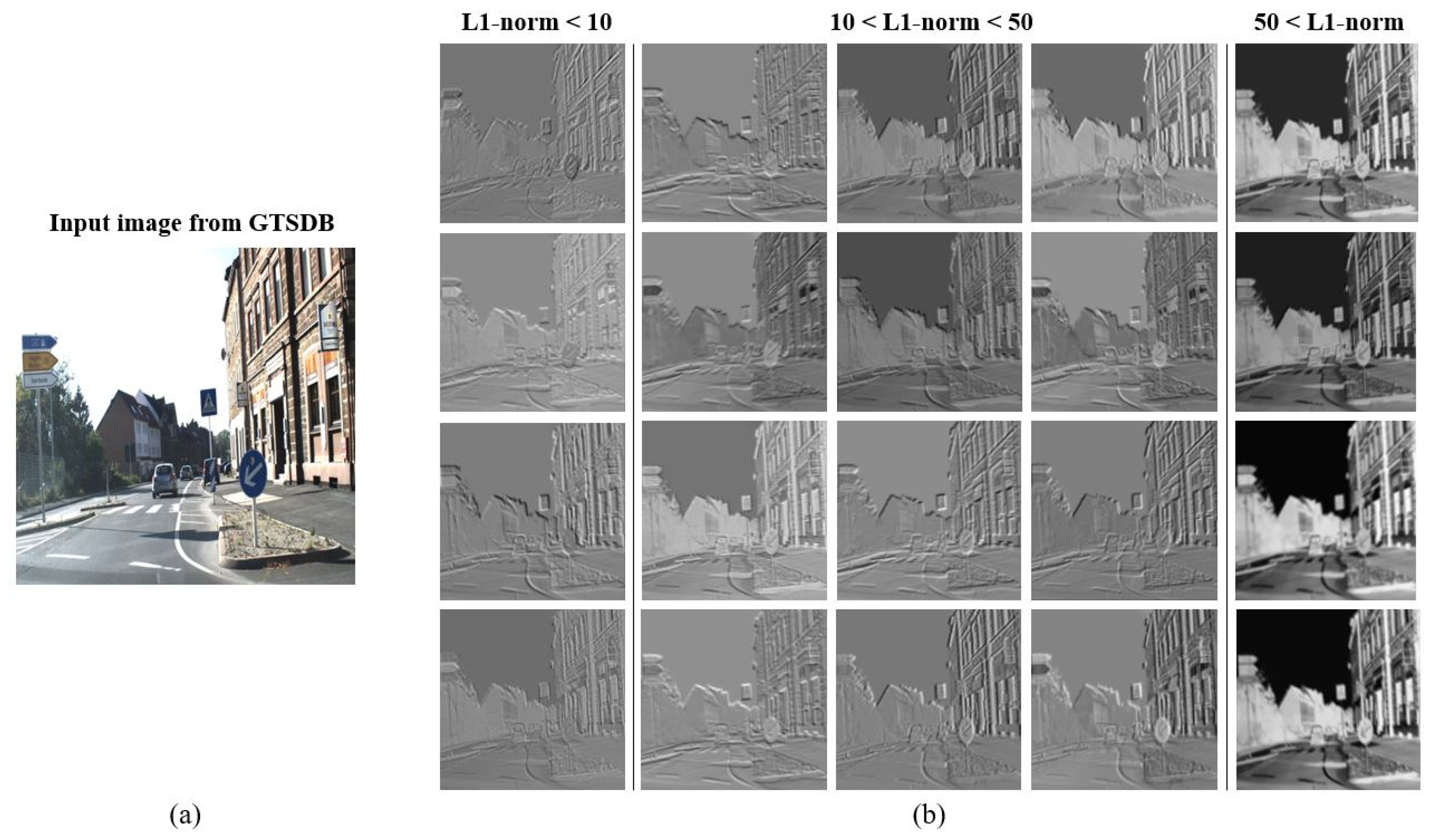










| # of Detected Traffic Sign Types | # of Detected Traffic Signs | # of Correctly Detected Signs | Accuracy (%) | |
|---|---|---|---|---|
| L1-norm = 5 | 20 | 158 | 85 | 53.7 |
| L1-norm = 10 | 22 | 162 | 92 | 56.7 |
| L1-norm = 20 | 18 | 164 | 90 | 54.8 |
| L1-norm = 30 | 18 | 140 | 72 | 51.4 |
| YOLOv5 (No L1-norm) | 15 | 123 | 53 | 51.2 |
| Size of Receptive Fields | # of Detected Traffic Sign Types | # of Detected Traffic Signs | # of Correctly Detected Signs | Accuracy (%) | |
|---|---|---|---|---|---|
| L1-norm = 10 | 80, 60, 40 | 28 | 219 | 146 | 66.6 |
| L1-norm = 10 | 80, 60, 10 | 24 | 257 | 144 | 56.0 |
| L1-norm = 10 | 80, 40, 10 | 25 | 198 | 95 | 47.9 |
| YOLOv5 (No L1 norm) | 80, 40, 20 | 15 | 123 | 63 | 51.2 |
| Weight Decay | Epoch | Learning Rate | Momentum | Optimizer | |
|---|---|---|---|---|---|
| YOLOv5 | 0.0005 | 300 | 0.01 | 0.937 | SGD |
| YOLOv6 | 0.0005 | 300 | 0.01 | 0.937 | SGD |
| YOLOv7 | 0.0005 | 300 | 0.01 | 0.937 | SGD |
| FSADD | 0.0005 | 300 | 0.01 | 0.937 | SGD |
| Label | # of Detected Traffic Signs | # of Incorrectly Detected Signs | # of Correctly Detected Signs | Accuracy (%) | |
|---|---|---|---|---|---|
| Types of traffic sign | 1 | 11 | 3 | 8 | 72.7 |
| 2 | 6 | 0 | 6 | 100.0 | |
| 3 | 5 | 1 | 4 | 80.0 | |
| 4 | 12 | 1 | 11 | 91.6 | |
| 5 | 7 | 2 | 5 | 71.4 | |
| 7 | 6 | 0 | 6 | 100.0 | |
| 8 | 6 | 1 | 5 | 83.3 | |
| 9 | 8 | 0 | 8 | 100.0 | |
| 10 | 20 | 1 | 19 | 95.0 | |
| 11 | 15 | 0 | 15 | 93.3 | |
| 12 | 16 | 3 | 13 | 81.2 | |
| 13 | 11 | 1 | 10 | 54.5 | |
| 14 | 4 | 0 | 4 | 100.0 | |
| 15 | 12 | 12 | 0 | 0.0 | |
| 16 | 2 | 1 | 1 | 50.0 | |
| 17 | 10 | 0 | 10 | 100.0 | |
| 18 | 10 | 4 | 6 | 60.0 | |
| 19 | 3 | 3 | 0 | 0.0 | |
| 20 | 12 | 11 | 1 | 8.3 | |
| 22 | 2 | 0 | 2 | 100.0 | |
| 23 | 3 | 1 | 2 | 66.6 | |
| 25 | 4 | 0 | 4 | 100.0 | |
| 26 | 2 | 2 | 0 | 0.0 | |
| 29 | 1 | 1 | 0 | 0.0 | |
| 32 | 2 | 1 | 1 | 50.0 | |
| 33 | 1 | 1 | 0 | 0.0 | |
| 35 | 9 | 6 | 3 | 33.3 | |
| 37 | 1 | 1 | 0 | 0.0 | |
| 38 | 18 | 0 | 18 | 100.0 | |
| Summary | 29 | 219 | 162 | 73.9 |
| Label | # of Detected Traffic Signs | # of Incorrectly Detected Signs | # of Correctly Detected Signs | Accuracy | |
|---|---|---|---|---|---|
| Types of traffic sign | 1 | 13 | 9 | 4 | 30.7 |
| 2 | 19 | 12 | 7 | 36.8 | |
| 5 | 13 | 9 | 4 | 30.7 | |
| 6 | 5 | 5 | 0 | 0.0 | |
| 7 | 7 | 4 | 3 | 42.8 | |
| 8 | 8 | 3 | 5 | 62.5 | |
| 9 | 2 | 1 | 1 | 50.0 | |
| 10 | 11 | 2 | 9 | 81.8 | |
| 12 | 12 | 5 | 7 | 58.3 | |
| 13 | 5 | 1 | 4 | 80.0 | |
| 14 | 4 | 2 | 2 | 50.0 | |
| 17 | 6 | 1 | 5 | 83.3 | |
| 25 | 1 | 1 | 0 | 0.0 | |
| 30 | 3 | 3 | 0 | 0.0 | |
| 38 | 14 | 0 | 12 | 85.7 | |
| Summary | 15 types | 123 | 63 | 51.2 |
| Label | # of Detected Traffic Signs | # of Incorrectly Detected Signs | # of Correctly Detected Signs | Accuracy (%) | |
|---|---|---|---|---|---|
| Types of traffic sign | 1 | 3 | 0 | 3 | 100.0 |
| 2 | 12 | 8 | 4 | 33.3 | |
| 4 | 6 | 3 | 3 | 50.0 | |
| 5 | 11 | 8 | 3 | 27.2 | |
| 6 | 2 | 2 | 0 | 0.0 | |
| 7 | 9 | 5 | 4 | 44.4 | |
| 8 | 6 | 2 | 4 | 66.6 | |
| 9 | 8 | 2 | 6 | 75.0 | |
| 10 | 11 | 2 | 9 | 81.8 | |
| 11 | 6 | 0 | 6 | 100.0 | |
| 12 | 9 | 0 | 9 | 100.0 | |
| 13 | 4 | 0 | 4 | 100.0 | |
| 14 | 2 | 0 | 2 | 100.0 | |
| 16 | 1 | 0 | 1 | 100.0 | |
| 17 | 6 | 0 | 6 | 100.0 | |
| 18 | 5 | 3 | 2 | 40.0 | |
| 20 | 1 | 1 | 0 | 0.0 | |
| 23 | 1 | 1 | 0 | 0.0 | |
| 25 | 2 | 0 | 2 | 100.0 | |
| 26 | 1 | 1 | 0 | 0.0 | |
| 36 | 2 | 1 | 1 | 50.0 | |
| 38 | 15 | 1 | 14 | 93.3 | |
| Summary | 22 types | 123 | 83 | 67.4 |
| Label | # of Detected Traffic Signs | # of Incorrectly Detected Signs | # of Correctly Detected Signs | Accuracy (%) | |
|---|---|---|---|---|---|
| Types of traffic sign | 1 | 18 | 16 | 2 | 11.1 |
| 2 | 16 | 13 | 3 | 18.7 | |
| 7 | 3 | 3 | 0 | 0.0 | |
| 8 | 3 | 2 | 1 | 33.3 | |
| 10 | 4 | 1 | 3 | 75.0 | |
| 11 | 2 | 1 | 1 | 50.0 | |
| 12 | 2 | 0 | 2 | 100.0 | |
| 13 | 2 | 1 | 1 | 50.0 | |
| 14 | 5 | 3 | 2 | 40.0 | |
| 25 | 1 | 0 | 1 | 100.0 | |
| 30 | 2 | 2 | 0 | 0.0 | |
| 33 | 1 | 1 | 0 | 0.0 | |
| 38 | 13 | 3 | 10 | 76.9 | |
| Summary | 13 types | 72 | 26 | 36.1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chung, J.; Park, S.; Pae, D.; Choi, H.; Lim, M. Feature-Selection-Based Attentional-Deconvolution Detector for German Traffic Sign Detection Benchmark. Electronics 2023, 12, 725. https://doi.org/10.3390/electronics12030725
Chung J, Park S, Pae D, Choi H, Lim M. Feature-Selection-Based Attentional-Deconvolution Detector for German Traffic Sign Detection Benchmark. Electronics. 2023; 12(3):725. https://doi.org/10.3390/electronics12030725
Chicago/Turabian StyleChung, Junho, Sangkyoo Park, Dongsung Pae, Hyunduck Choi, and Myotaeg Lim. 2023. "Feature-Selection-Based Attentional-Deconvolution Detector for German Traffic Sign Detection Benchmark" Electronics 12, no. 3: 725. https://doi.org/10.3390/electronics12030725
APA StyleChung, J., Park, S., Pae, D., Choi, H., & Lim, M. (2023). Feature-Selection-Based Attentional-Deconvolution Detector for German Traffic Sign Detection Benchmark. Electronics, 12(3), 725. https://doi.org/10.3390/electronics12030725