1. Introduction
Rotating machinery is an inevitable part of industrial infrastructure and bearings are a key component in rotating machinery. Industrial machines are typically functional all around the year and an unwanted interruption in their operation due to faults in the bearings can be costly. Over time, certain extreme operating temperature or load conditions can lead to bearing failures. It is important to identify such failures in order to schedule timely maintenance [
1] with minimal or almost no loss in operation pipeline. So far, the most common solution to this problem is to replace the bearings based on life cycle estimations. This leads to two possible unoptimized results. One is the replacement of still good bearings which would be operational for some time. The other is a sudden shut down in the operation line because of an unexpected fault occurring before the next maintenance cycle.
A considerable amount of research was done in the area of predictive maintenance (Pdm) to identify the defects, classify their type, or predict remaining useful life (RUL) of a bearing in a system with rotating machinery. Pdm is tackled using both traditional ML and end-to-end Deep Neural Network (DNN). While traditional ML involves an expensive feature engineering phase and a specific classifier, DNN approaches to identify the relevant features during training themselves. Most of the time, both methods are explored on public benchmark data to evaluate the performance of a solution and show promising results. However, the actual integration of a solution into the industrial process remains open. The main reasons are that these models are typically run on specialized hardware or servers in the cloud, while industrial partners prefer local on premise processing to ensure timely decisions and security. To cover this, the models should be executed closer to the actual machine and thus be realized as Edge-AI.
Shifting the execution of ML models to the edge for predictive maintenance is still an open problem and is typically not addressed by any SOTA works in the field of industrial machine diagnosis. In this paper, the term edge is strictly constrained to low power micro controller units (MCUs) rather than Jetson Nano, Raspberry Pi or other similar micro computers with significantly higher computational resources. We chose this definition because MCU-based components are easy to integrate into the machinery. This allows running a ML-model close to the actual industrial process. However, MCUs typically are constrained in computational resources as well as available memory. Therefore, executing SOTA ML-models becomes a challenge since their requirements typically do not match. In this paper, we will first highlight this mismatch and then introduce an approach to reduce the model size and thus mitigate the constraint. Our solution thus enables the integration of ML-solutions into the industrial process. In addition, we will discuss the impact of our approach on model accuracy and highlight further challenges towards the implementation into the machinery.
To prove the insufficiency of the SOTA solutions, we chose a benchmark study [
2] as the baseline of our work. Out of the discussed datasets in the study, we selected a public bearing dataset [
3] as a base for our work. Regarding the considered models, we follow the benchmark and considered the Autoencoder (AE), its variations Sparse Autoencoder (SAE) and Denoising Autoencoder (DAE) as well as CNN based models (AlexNet, ResNet, LeNet). Though these DNN models are accurate in classifying the type of bearing defect, it was impossible to inference them on MCUs as is.
Therefore, we focus on the deployment of pretrained models, i.e., models are trained on powerful hardware and then transferred together with the trained weights to the target hardware to perform inference. Transferring DNN models to MCUs poses memory problems because DNN models typically have a high number of parameters. In addition, DNN models require lots of computational cycles to get the desired inference result which also makes them power hungry. To solve these problems, we propose a solution to trim the benchmarked Pdm models using state of the art pruning algorithms [
4] in order to fit them into MCUs.
In this paper, we present the following contributions:
Evaluation of challenges in deploying state of the art DNN models to MCUs
Review options to reduce the model size
Show the impact of pruning the weights as reduction method on model size and inference time on the MCU
The remainder of the paper is organized as follows. In
Section 2, we first give an overview of the models targeting the bearing defect classification problem and then review works targeting model size reduction. Afterwards, we describe our method in
Section 3. We introduce the dataset and models used for our study as well as the required fundamentals of the pruning approach. In addition, we give details regarding model training and deployment.
Section 4 presents the results of our experiments which are then discussed in
Section 5. Finally, the paper is concluded in
Section 6 where we also indicate our plans for further studies.
2. Literature Review
In this section, we review a number of state of the art papers, that present approaches to handle bearing health prediction. With the advancement of high end ML libraries like TensorFlow [
5], keras and sklearn, it is possible to implement better data analysis algorithms and develop complex models to achieve benchmark results in fault diagnosis. Data driven models have gained popularity with help from such sophisticated APIs. As a result, many solutions to Pdm of bearings or other rotating machinery have been suggested and several different algorithms and flavors exist.
Models like Autoencoders (AEs) have been a popular choice because of their semi-supervised learning approach. The authors in [
6] used a customized AE loss function and Artificial Fish Swarm Algorithm (AFSA) for parameter optimization. In [
7], the authors introduce stacked AE for bearings functioning at low operating speeds. The Sparse Autoencoder (SAE) was applied for data fusion and feature encoding in [
8] before classifying them with Deep Belief Network (DBN). Another variation of SAE called Deep Nonnegativity-Constraint SAE (DNSAE) was applied in [
9] to encode features and achieve high diagnosis accuracy even with few labeled dataset. AEs were also used with convolutional layers [
10] in some cases to denoise the input. These functional or structural modifications in AE produced better results compared to the general models.
Though AEs had an advantage of semi supervised learning and feature encoding capabilities, Convolutional Neural Networks (CNNs) outperform them in feature extraction with less trainable parameters. CNNs are used extensively in image classification as they can extract different types of features using stacked filters. One option to feed vibration signals into the CNN is to convert the signals to 2-D image and use this as input for the CNN. This allows the reuse of popular models from image classification. In [
11], the authors use Empirical Mode Decomposition (EMD) and CNN for signal analysis and feature extraction. EMD can decompose the signal into its components and CNN extracts the spatial features in the signal components. The extracted features are fused and used to classify faults. In [
12,
13], the authors used CNNs as replacement of hand crafted feature extraction.
Different structural formulations of CNNs have been experimented with bearing datasets for predictive maintenance applications. Different variations of AlexNet [
14,
15,
16,
17], ResNet [
18,
19,
20,
21,
22] and LeNet [
23,
24] are used in different research works for fault diagnosis of rolling bearing elements. In [
14,
15], the authors proposed an one dimensional model slightly deeper than the original AlexNet model to enhance the bearing fault classification and compared their model with AlexNet. Instead of this, [
17] shows that a AlexNet model can be used by just retraining the fully connected (FC) layers at the end to identify bearing defects. Thermal images were used as input to AlexNet in [
16] in order to detect bearing faults.
ResNet models have the potential to provide better diagnostic accuracy without increasing the model depth due to the residual blocks. This makes them interesting candidates for bearing diagnosis. In [
18], bearing faults were identified using continuous wavelet transform of raw signals by using pretrained ResNet-50 model with transfer learning. A wavelet transform based intelligent fault classifier for rolling bearing was built in [
19]. The classifier is based on ResNet with a new pooling layer. Principal Component Analysis was used in [
20] for noise reduction in bearing signals before using them to classify faults using ResNet. In [
21], ResNet is used to generalize the bearing fault diagnosis in a more generalized and unified way. A global average pooling layer is used in ResNet instead of multiple FC layer for classification in [
22] in order to reduce the parameters.
LeNet is comparatively the shallowest among the three CNN models mentioned here. It is therefore more interesting for inference on MCUs. Different variations of LeNet model have been used i.e., in [
23,
24] to improve the fault diagnosis results in comparison to the basic LeNet-5. In [
23], the authors added convolution and pooling layers and calculated the sensitivity of the pooling operation based on the error. The authors in [
24] focus on solving the convergence issue and generalization problem of LeNet-5 architecture. A batch normalization layer after every convolutional layer was added to improve the convergence speed and the one dimensional vibration signal was converted to 2D to improve the diagnosis results. Thus this paper aims at an improvement in model performance while not attempting to actually deploy the model to real hardware.
On one side, most of the research investigating the improvement in predictive maintenance proposed some novelty in model architecture, selection of hyper parameters or dataset preprocessing. On the other side, there has been extensive research in order to reduce the memory and computational requirement of DNN models. This broadly comprises two different strategies, quantization of the weights of the model and pruning the unnecessary weights. The authors in [
25,
26] proposed automatic model compression strategy in order to structurally prune weights based on Alternating Direction Method of Multipliers and Sparse Connectivity Learning, respectively. In [
27], network width search is automated by adding a depth-wise learnable binary convolutional layer. Quantization also reduces the number of flops in the network. A reduction in the number of bits directly accelerates the model inference time. In [
28], the authors used a hardware friendly quantization approach which tries to bring best of both uniform and non-uniform quantization. Value aware quantization can reduce the model size more aggressively as shown in [
29]. Here, the authors exploited the distribution of weight values to reduce the quantization results.
In summary, the focus of the state of the art work is either on fine tuning the pretrained models or compress the models in order to make them inference friendly. To the best of our knowledge, only few approaches consider the model deployment challenge. Authors in [
30] have discussed the cost of two spectral feature extraction methods and their trade offs while inferencing them on MCUs. But it does not involve DNNs and the the problem was addressed only from a theoretical perspective. Another example is described in [
31]. The proposed Deployment Oriented to Memory (DORY) tool for DNNs is focused on better memory hierarchy management and deployment on MCUs with less than 1 MB of on-chip SRAM. However, this approach is particularly tuned to Parallel Ultra Low Power Paradigm (PULP) architecture and thus not suitable for general purpose MCUs. In [
25], the researchers deploy a pruned model on a smartphone. This shows that pruning is suitable to reduce the model size to fit them into embedded devices. But modern smartphones feature rather powerful hardware and large memory.
Therefore, only powerful embedded hardware has been considered as deployment candidate. Our perspective on Edge AI is inspired by the industrial applications where general purpose MCUs are key to get the models close to the process in an energy-efficient way.
Table 1 provides a comparison among the SOTA results and the current work.
Hence, we suggest to investigate whether optimized deep learning models can be practically deployed to general purpose MCUs and thus check if they are feasible in industrial scenarios. Such an analysis is crucial to highlight open gaps towards actual deployment and application of Pdm within industrial machinery.
4. Results
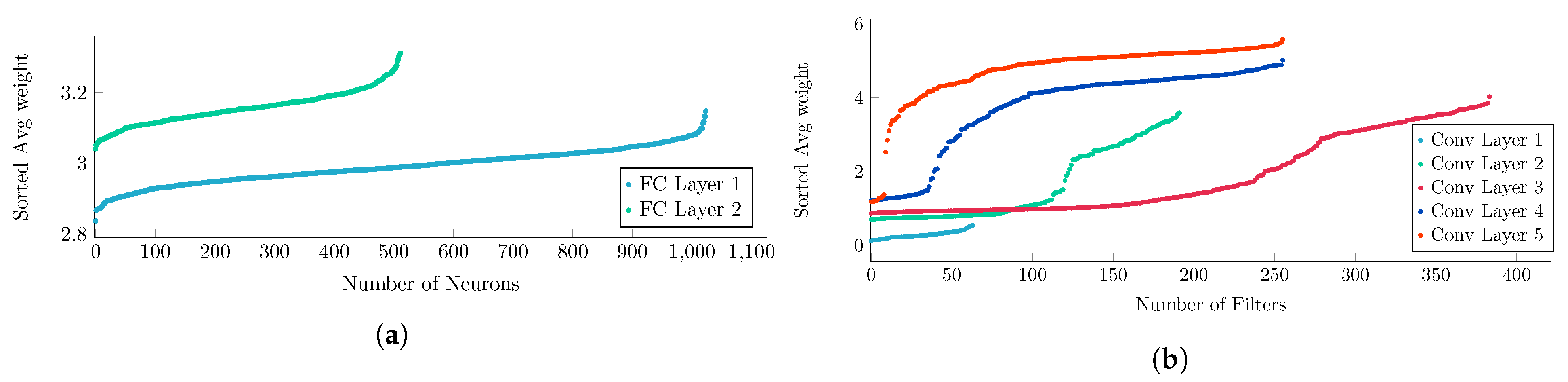
Using the presented pruning method, we were able to reduce the memory requirement of the models. A comparison of the pruned and original learnable model parameters is shown in
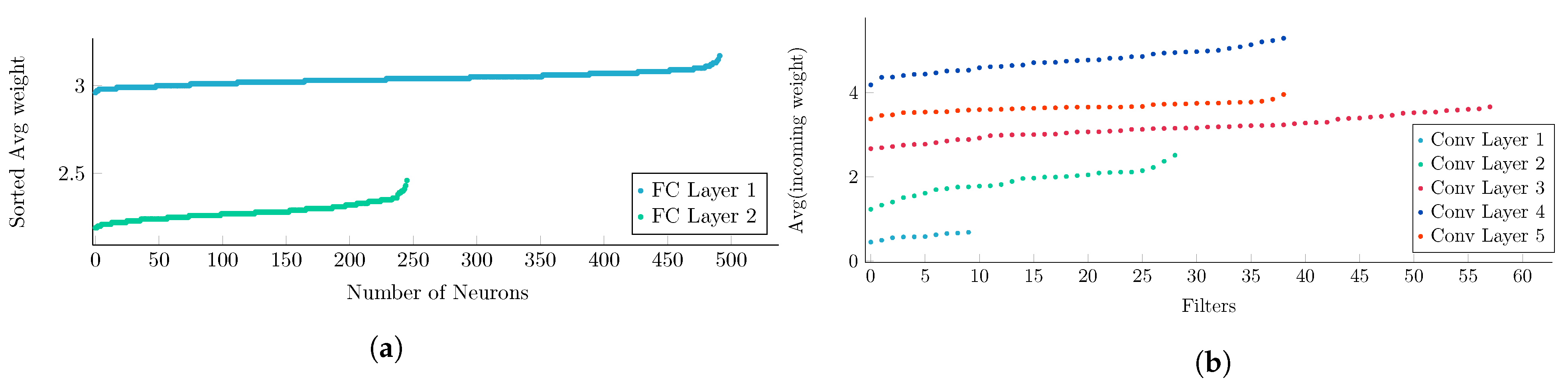
Table 5. A smaller number of parameters implies less computational overhead and smaller memory footprint. This is very important during the inference phase. The impact of reducing the redundant parameters can be realized from the sorted average weights of the layers in
Figure 9a,b.
After pruning the layers, the average weights are illustrated in
Figure 9a and
Figure 9b for two FC layers of the Autoencoder and five convolutional layers of AlexNet respectively. The layers used in
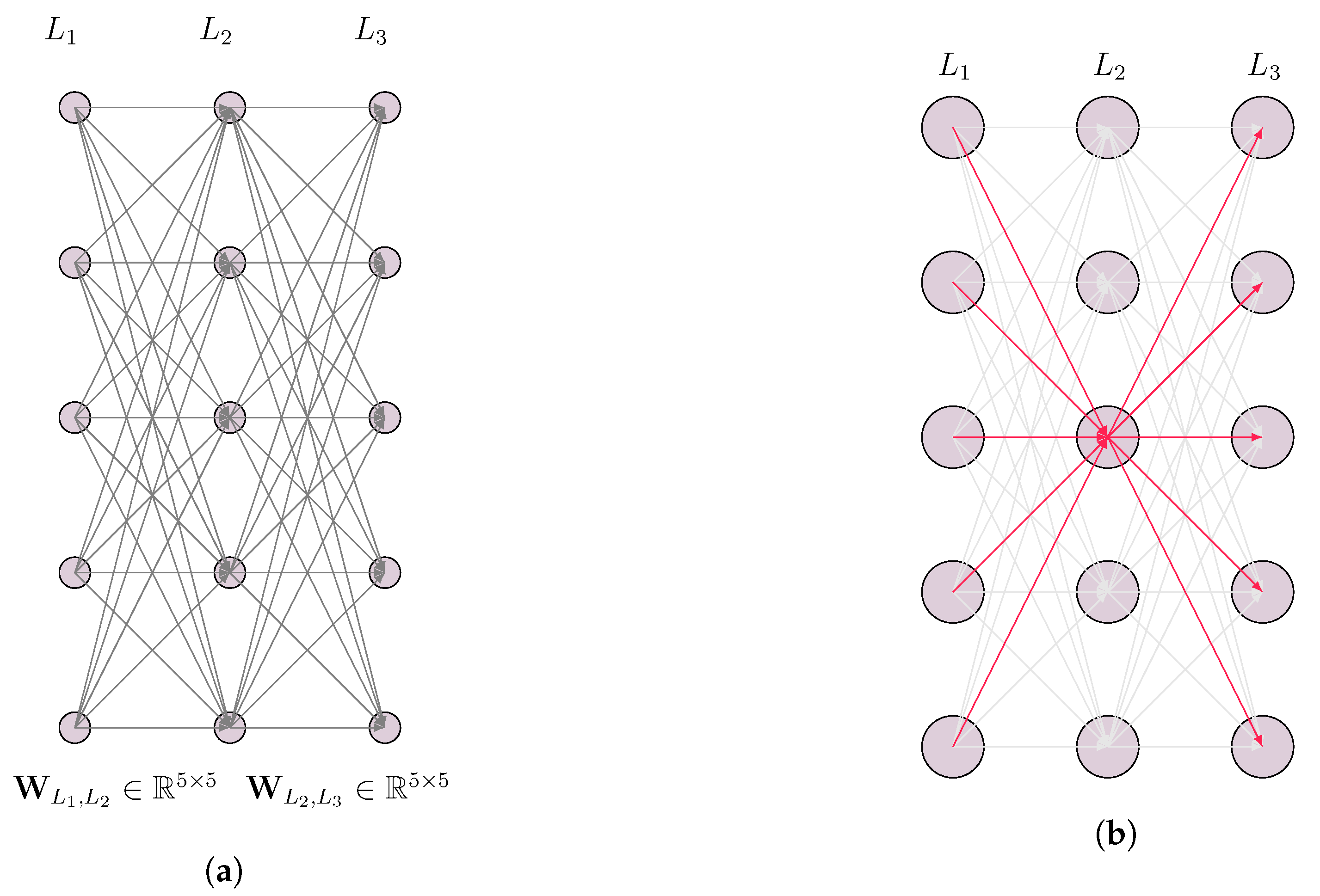
Figure 5 and
Figure 9 are the same except for the fact that the former are from the original model and later from the pruned model. Changes in the number of neurons and average weights result from the changed layer structure after pruning.
The sorted average weights have a flatter distribution after pruning compared to the weights in the original model. This justifies that after pruning the models, the remaining neurons contribute equally to the decision making for the current layer, while reducing the memory requirement.
Whether a model is suitable for the given inference task, does however depend on its accuracy. Therefore, there is a trade off between size reduction and achievable accuracy. The maximum accuracy difference between the pruned models and the original models is . An aggressive structured pruning is used in this work which is inference friendly for its dense matrix operations. But this poses a disadvantage of steep degradation in accuracy if no threshold is used. We chose a 3% threshold in this work. This explains the maximum accuracy loss, since the method ensures a minimal model size while staying within the threshold. Whether 3% are too much loss, is application specific and the threshold needs to be tuned for each scenario.
The confusion matrix from the original and pruned model predictions are shown in
Figure 10 for LeNet. We chose to highlight the confusion matrix only for one model with CWT features, the results are however similar for all other combinations. There are three different types of bearing usage and each type has five bearing defects. In the figures showing confusion matrix, the three columns represent the three different bearing usage types. The first row of sub figures in
Figure 10 are the results from the original models while the second row of confusion matrices are from pruned models for the same features.
In some cases individual classes might show an accuracy difference higher than
compared to the original model. The average accuracy difference of the pruned models are not higher than
when compared to average accuracy of the original model. This can be verified from
Table 6, which also shows the accuracy of all combinations under test. It should be noted that the accuracy difference threshold (
in this work) is a sensitive parameter and depending on the application it can be bigger or smaller. A bigger threshold margin increases the chance to reduce the memory footprint of the model. We selected this threshold arbitrarily to demonstrate the pruning bottleneck in the work. For real applications, this threshold can be different for various applications and datasets.
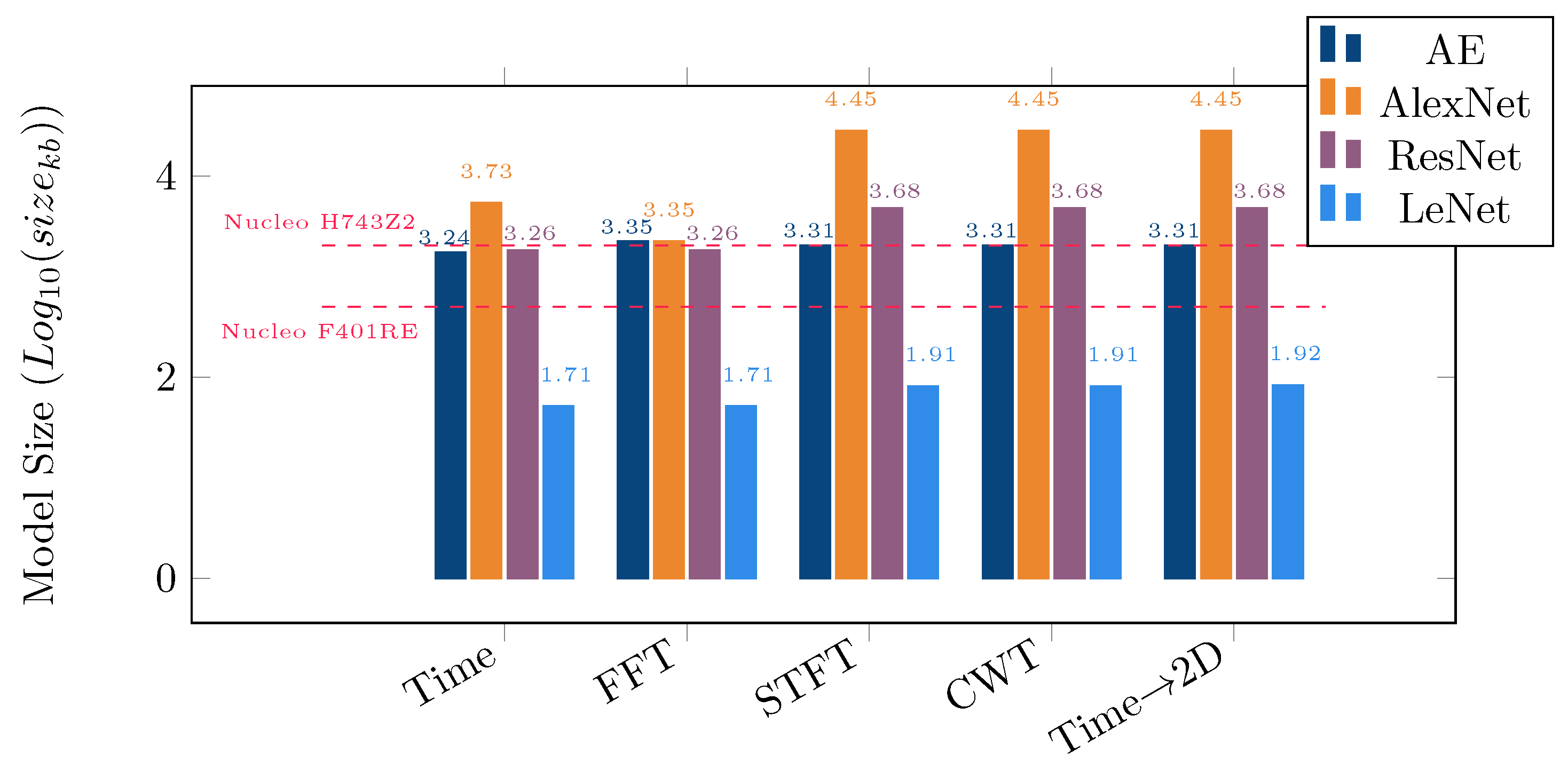
Table 7 shows the inference time for AE and AlexNet model. Three different features STFT, CWT and 2D Time Signal were selected for this comparison as all of them have same dimensions. The model size corresponding to these features provides a bigger spectrum of analysis. While the STFT feature corresponds to one of the smallest models, CWT and 2D Time Signal correspond to models with more parameters. As already discussed in
Section 3.4, the models were deployed on two different MCUs. Here, only the inference time on Nucleo H743Z2 is shown as the available flash memory suits the memory requirement of all the selected models. From the inference results, it is evident that XCubeAI is faster in comparison to TF Lite. As the MCU does not have a neural network accelerator hence the better performance in fast calculation can only be justified by a better software framework implementation from STM for XCubeAI. The inference time comparisons are consistent with the model size or the number of parameters for the TF Lite framework. On the other hand XCubeAI has ≈
inference time for models with ≈3k, ≈75k and with ≈95k parameters.
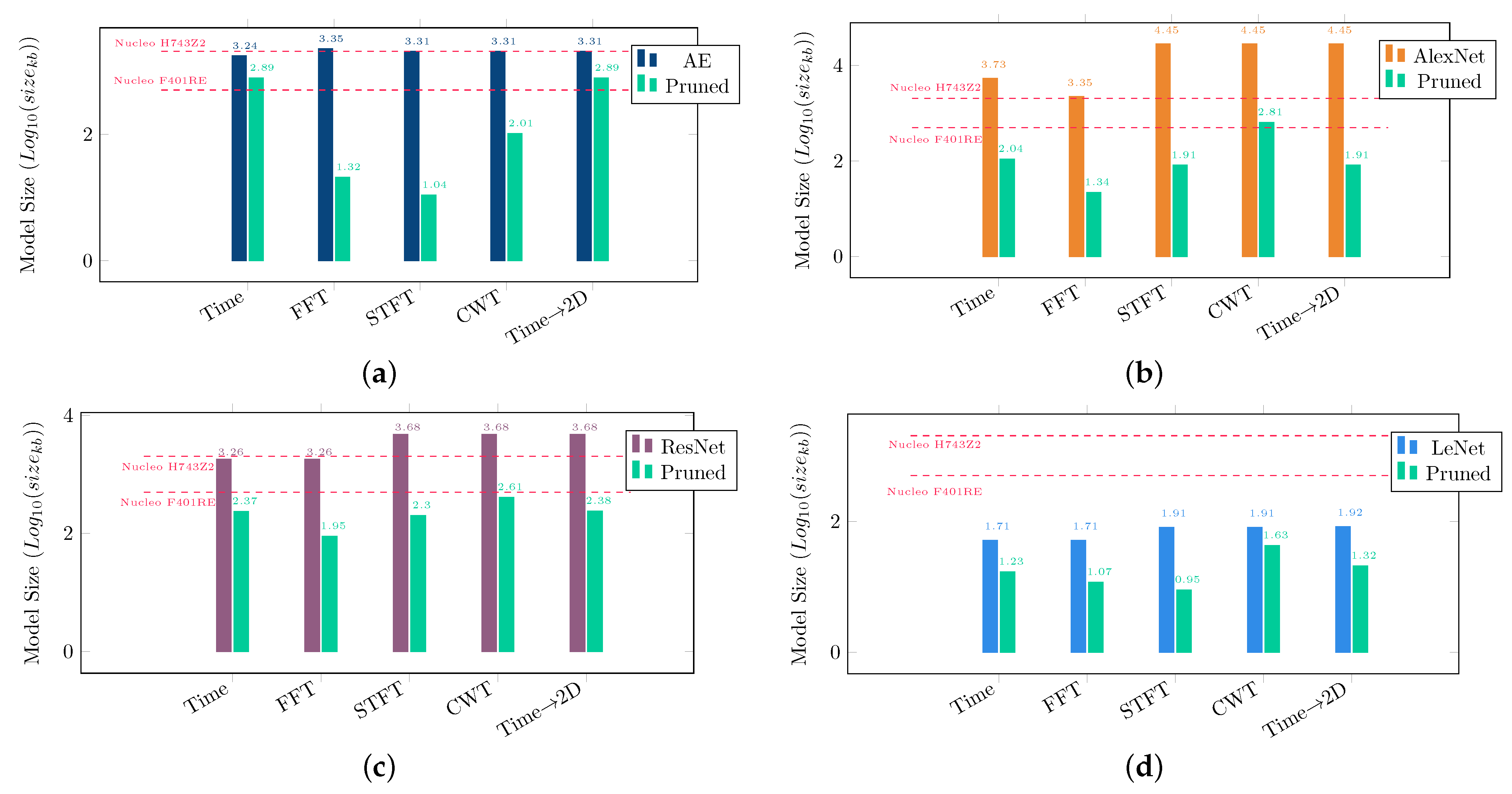
Figure 11a–d show the size comparison between the original model and the pruned model for different feature sets. This shows that most of the pruned models fit in both STM32 MCUs discussed in this work irrespective of the features used. However, there are differences in the resulting size depending on the choice of combination of feature and model. Clearly, spectral features (STFT and FFT) are the best choice for bearing classification. All the different types of model require less parameters to train on the spectral features. It is though interesting to observe that all the CNN models (AlexNet, ResNet, LeNet) use more parameters to train on CWT. On the other hand, 2D Time Signals needs less parameters to train on the same models. Although there have been many instances of application of Wavelet transforms (DWT) [
36] for bearing fault detection but authors in this work have avoided to change the features compared to the benchmark study. It would interesting to investigate this in our future work though. The DWT implementation on arm MCUs are more energy efficient in comparison to the CWT implementation.
Regardless of features convolutional neural networks like AlexNet, ResNet and LeNet all perform quite well in bearing defect classification. Due to the smaller design and less number of layers in the LeNet model it is considered to be the most energy efficient and inference friendly. But the same design finds learning the CWT features problematic where the model achieves only ≈78% accuracy. Authors can only justify by understanding that the CWT feature needs deeper models like ResNet with ≈90% accuracy. ResNet model being the deepest of all, with highest number of parameters achieves best accuracy but requires larger memory and more flops while inferencing.
It should be noted, that the models which do not fit on the MCU is not because of a direct shortcoming of the pruning framework. This is rather the size we achieved when applying the accuracy vs memory footprint trade off with an accuracy difference threshold. In case of more sensitive applications where accuracy loss is unaffordable, other pruning approaches should be used.
In this work, we have not focused on a comparison of the available pruning approaches but rather on enabling inferencing the model on the edge for Pdm applications. Hence, we have not explored other ideas in order to reduce the memory footprint while keeping the model accuracy as it is. The results show, that there is further potential in testing different options to reduce the memory footprint.
In addition to the model memory footprint, other code will have to be executed. When inferencing our deployed models, we used a test dataset suitable to the model but the features were not extracted on the edge. The models which do fit into the memory but with a very slight margin cannot be considered a success because the data acquisition and feature extraction has to be done on edge as well and thus will add further code overhead.
5. Discussion
The goal of this work was to bring DNN based decision making models for predictive maintenance on low power MCUs which is demonstrated successfully in the results. This is helpful in optimized replacement strategies of bearings and avoiding sudden shut down in industrial appliances. Enabling the execution on the MCU comes at the cost of some compromise in accuracy. There is a trade off between model size and accuracy. The threshold of loss in accuracy between the original and the pruned model was decided before training and pruning the models. If the loss in accuracy is not feasible, decreasing the pruning percentage would also decrease the accuracy loss but will lead to bigger models as in our study. Hence there is a constrained bottleneck but our analysis on the weight distribution of fully connected and convolutional layers gives us new insights on further pruning strategies.
A pruning requirement for more sensitive industrial application cannot be neglected where margin of compromise of accuracy will be minimum or almost zero. In such cases, the pruning of the model becomes a strict constrained optimization problem. The discussion in
Section 3.3 portrays optimization of only nodes or filters in detail which is one DNN hyperparameter as the pruning framework in [
4] works only on trimming the network based on weights. But there can be several more approaches in optimizing the hyperparameters of the network which are unexplored for pruning the predictive maintenance models. This can be help in achieving the goal even with less loss in accuracy between the original and the pruned model.
The actual deployment of the model on MCU moves the theoretical perspective to a more pragmatic point of view. The deployment and inferencing of DNN models on MCU is a key novelty of this work. Clearly, as discussed in
Section 4 XCubeAI inferences the DNN models faster as compared to TF Lite. But this has a vendor constraint. In order to deploy model with XCubeAI, only MCUs from STM must be used as of now as it does not support MCU from other vendors. But it should be understood that inference time is a very application dependent parameter. In a scenario of object tracking or detection on MCU, inference time is of utmost importance. On the other hand, in industrial scenarios where measurements are sometimes collected once or twice in a day an inference time of 40 s or even 1 min will not be a problematic parameter. In addition to this, we understand that more parameters imply a higher number of flops which inherently implies more clock cycles and larger inference time. Therefore, an important concern can be raised about energy consumption for all models implemented with XCubeAI with network parameters up to ≈95k. As the scope of the work does not include energy benchmarking based on the inference time, we will address this in our future work.
Our work focused on the deployment of DNN models on arm based MCUs with two STM MCUs as example. Further hardware such as MCUs from different vendors will be tested in the future. We did not consider specialized signal processing hardware such as Digital Signal Processors (DSPs) or Field Programmable Gate Arrays (FPGAs). DSPs and FPGAs can accelerate the execution of models thanks to specialized blocks. However, this kind of hardware can be programmed and tuned quite flexibly. Thus, this requires specific development to utilize the specific capabilities. Our method is however applicable to other hardware as well, because the pruning is the first step to fit the model into the memory which is then followed by a hardware dependent implementation. Therefore, the results will differ depending on the used toolchain, as e.g., XCubeAI gives specific optimized results for STM MCUs only.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}