1. Introduction
Today, robots are used in many areas, from automation systems to the defense industry. Artificial intelligence and learning algorithms are subject to continuous development and improvement so that robots can efficiently perform the daily tasks of humans. Thus, robotics has become an essential element and has found a place in many different actions in daily life.
Robotic systems can be classified into two main areas: manipulator robots with a fixed workspace and mobile robots with a portable workspace. Although the wheeled robots can travel quite quickly, they can only go across flat ground. While slower than wheeled robots, tracked robots can go across more difficult terrain. In challenging terrain, legged robots outperform wheeled and tracked robots, as they show greater mobility and flexibility, are highly adaptable to terrain differences, and cause less environmental damage. Considering this superiority and the fact that approximately 80% of the earth is inaccessible by conventional wheeled vehicles, legged robots are more prominent in the field of mobile robots [
1].
Humanoid robots are two-legged robots made with a human-like design and have different functions, such as being able to move and speak. They have an important place among mobile robots because of their similarity to humans, ability to move in environments suitable for humans, and ability to use tools designed for humans.
A humanoid robot’s design focuses primarily on balance control. A simple way to control the balance of a bipedal walking robot is to mimic the locomotion of humans, which is typically human. An average human gait consists of all the movements that occur with the forward orientation of the Center of Gravity (CoG) through the limbs and body. During walking, displacements and load are carried out by the legs, while, by adjusting to the CoG changes brought on by the movement of the legs, the remainder of the body moves on.
In biomechanical research, understanding the bipedal locomotion stability and gait mechanism is essential for better understanding how humans move from one place to another [
2]. Although it may seem simple, human locomotion is a highly complex state involving multiple Degrees of Freedom (DoF) combined with the complex nonlinear dynamics produced due to the various extensor and flexor muscle groups in the lower body. While humanoid robots are known for their ease and flexibility to move around a wide range of terrain, the main concern is stability as they have a high-dimensional and nonlinear system. Over the years, many control scientists have developed an interest in finding a solution to the stability issue with the bipedal gait system [
3].
There are approaches to the development of stable walking when recently proposed gait frameworks are reviewed. The dynamic model of a robot, for which the gait planner and controller are created, forms the basis of the fundamental framework. Some restrictions are taken into account in this framework to lessen the difficulty of creating a whole-body dynamics model Another framework’s primary component is a network of signal generators that together produce intrinsically rhythmic signals [
4,
5]. The Central Pattern Generator (CPG) is the basis for this kind of framework. It draws inspiration from research on the neurophysiology of vertebrate and invertebrate species [
6,
7]. These studies have demonstrated that CPGs in the spinal cord that are coupled in a specific way are responsible for rhythmic locomotion, including walking, running, and swimming. Oscillators are often assigned to each link in this kind of framework to produce set points (torque, position, etc.). Many humanoid robots have more than 20 DoF. As a result, adjusting the oscillators’ parameters is both challenging and labor-intensive in terms of experimentation. Robots’ knowledge is typically static in these two types of frameworks mentioned above. It does not improve from past experience. For this reason, they must at least reconfigure the parameters to adapt to new environments. According to another framework, based on Reinforcement Learning (RL), walking trajectories are generated [
8]. According to this framework, walking trajectories are generated following training that needs a lot of samples and takes a long time. The framework attempts to learn how to generate walking trajectories depending on a function during training. The methodologies outlined above are combined to create the final framework [
9,
10,
11,
12,
13]. This kind of framework is also referred to as a hybrid walking framework. It seeks to maximize performance by utilizing the various strengths of each strategy.
Traditional control theory methods rely on complex deterministic and mathematical engineering models. One of the most widely used models, the inverted pendulum, is the source of several algorithms, including those in [
14,
15,
16,
17]. The Zero Moment Point (ZMP) is the traditional method accepted as an indicator of dynamic stability in bipedal robots [
18]. The robot’s dynamic balance is preserved when it reaches the ZMP because the its foot’s response to the ground balances out the dynamics brought on by its locomotion [
18]. The robot’s Center of Mass (CoM) is calculated to acquire the ZMP. Therefore, it is necessary to use simulation computations or force sensors that are mounted to the robot’s feet. However, for a small-size humanoid robot with constrained system resources and processing rates, calculating the ZMP for each step takes some time. Moreover, traditional approaches mainly rely on dynamics and mathematical models for both the robot and terrain. Therefore, it requires a vast amount of time and effort for designers. The model needs to be redesigned when either the terrain or the kind of robot changes. In addition, the past knowledge and expertise of the designers, who cannot fully explore the robot’s potential, also impact the performance of the human-designed model. Traditional control systems’ fundamental drawback is their heavy dependence on the correctness of a mathematical model, which may be affected by joint friction, ground contact force, or other uncertainties.
The RL-based control approach is an alternate method of addressing the issues mentioned above with humanoid robot walking. Due to its adaptable learning capabilities, the RL is increasingly applied in the field of bipedal robotic gait control. The RL is a branch of machine learning that may be used to train complicated control systems without using models. An agent (robot) may learn how to control itself in various circumstances by interacting with the environment, thanks to the RL. According to the environmental states and the agent’s behaviors, the environment is modeled in real life to either reward or penalize the agent. The agent works on developing the ability to utilize the past to forecast which behaviors will result in the greatest reward in the future. The development of numerous action policy learning algorithms, many of which are based on the Markov Decision Process (MDP), has been crucial to the model-free learning of bipedal walking in particular [
19,
20]. The RL aids in getting over the difficulties of dynamic design and computation. For walking problems, the RL is a type of intelligent learning technique. The ZMP location can be controlled using RL approaches to ensure walking stability. While motion control problems can be handled with RL with great performance, legged robot gait control is still difficult because of its complexity.
For the walking pattern, trajectories are generated that allow the robot to walk as desired. Numerous walking parameters are involved in trajectory generation. The procedure of manually adjusting the walking parameters is quite difficult and complex, especially for a sophisticated robot with more than 10 DoF. Only little distortions are permitted by the controls used to construct typical trajectories. Walking might break down due to even the smallest shift. It is possible that these controllers cannot be adjusted to diverse terrains such as slopes and stairs. As a result, it becomes necessary to alter various walking parameters, which significantly raises the cost and workload.
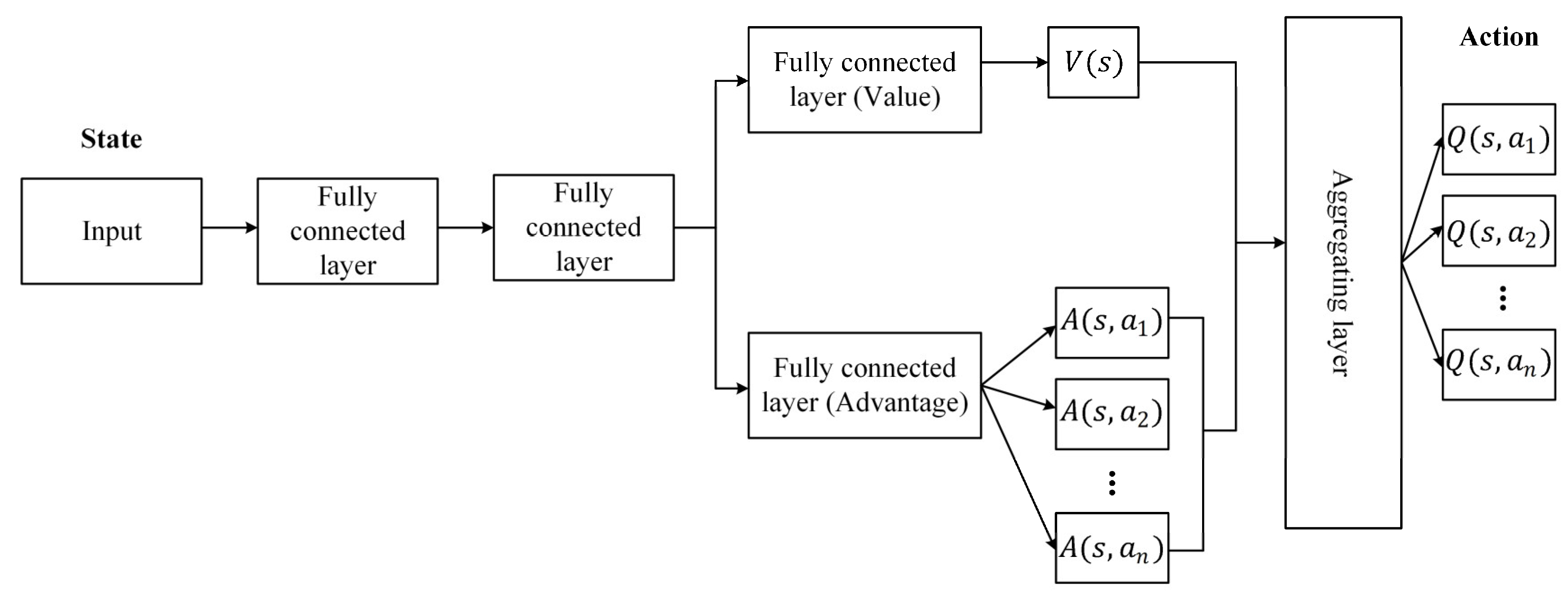
The feature engineering for traditional RL algorithms comes from observations. It might be difficult to extract features for complicated issues, or there may not be enough data from which to develop a strong model. The bipedal gait is substantially more difficult since it calls for a high-dimensional state and action space and demands careful control of each joint while maintaining stability. Extracting high-level features from data with a wide state space and missing observations is now possible thanks to a more recent technique called Deep Neural Networks (DNNs). Deep Reinforcement Learning (DRL) enables an agent to interact with the environment more complicatedly, thanks to recent developments in DNNs. Some end-to-end DRL techniques teach the robot model using the default reward of a simulator. Such DRL controllers, however, have the potential to produce movements that are unsuitable for robots. Utilizing a robot simulator and prior knowledge is one way to mitigate this scenario. Additionally, for RL without previous knowledge, hyperparameters are frequently sensitive. Applications are constrained by low convergence and ineffective training. In this study, an efficient new framework built on the humanoid robot model Robotis-OP2 combined with the controller that generates the traditional trajectory and DRL is proposed to get over these constraints. Most of the standard machine learning methods are suitable for supervised learning or unsupervised learning methods. The main reason for choosing DRL from the machine learning methods in this paper is its interaction with the environment and the high cost of creating datasets on robot systems. It is ensured that the robot can learn the optimum with the reward/punishment mechanism according to the status information received from the environment with the sensors during walking. In this study, the Artificial Neural Network (ANN) is trained directly with data from the robot, without any ready dataset. Thanks to the proposed framework, the optimum walking parameters of the trajectories generated with the walking pattern generator are obtained with the Dueling Double Deep Q Network (D3QN) [
21]. The training of the D3QN is carried out using the robot’s multi-sensors in the Webots [
22] simulator. After determining optimum gait parameters, a robot posture stabilization system in the sagittal plane is proposed. Experimental studies are performed in the Webots simulation environment and real environment with the proposed framework and Robotis-OP2’s walking algorithm by transferring the controllers to the real robot. Experimental results have shown that the Robotis-OP2 humanoid robot can walk more stably on flat ground both in the simulator and in the real environment with the proposed framework than Robotis-OP2’s walking algorithm. In addition, it is the first study in the literature to optimize walking parameters for the stable walking of humanoid robots using DRL.
There are many studies in the literature on bipedal walking using RL. In OpenAI Gym [
23], many algorithms are employed to resolve bipedal challenges by applying RL to directly control the joints [
24]. However, convergence and performance are degraded when these algorithms are utilized to control the gait of a robot whose dynamics are significantly more complicated. Additionally, a nonhuman gait may also be present in the trained model, which is often unsatisfactory. For RL-based gait controllers, previous knowledge-based training procedures have become a critical operational principle.
Recently, there have been several attempts to incorporate RL into bipedal robotic gait control without computing the mathematical model based on model-free RL frameworks. The pose sequence that enables an NAO robot to travel the most distance in the least amount of time while walking on a level surface without falling was discovered by Gil et al. [
25] using Q-learning [
26]. Liu et al. [
27] used the Policy Gradient (PG) [
28], which is one of the RL algorithms, to correct the gait model parameters of the NAO humanoid robot to make the gait resistant to unknown disturbances. Lin et al. [
29] proposed a method for dynamic bipedal gait and balance control using Q-learning without prior knowledge of the dynamic model. The bipedal robot was able to maintain static stability thanks to the balancing learning approach, which shifts the ZMP on the robot’s soles using the movement of the arm and leg. The seesaw and bipedal walking on a level surface were subjected to balancing algorithms. According to the simulation results, the robot might learn to enhance its walking speed behavior using the proposed strategy.
Silva et al. [
30] proposed a Q-learning-based method for learning the action policy that enables a robot to walk upright on a slightly inclined surface. The system’s proposed design combines a standard gait generator with an RL component on two layers. This situation allows an accelerometer to be used when the slope of the ground the robot is walking on changes to provide a gait adjustment. Experimental studies on a real robot have shown that the stability problem can be successfully solved. Silva et al. [
31] aimed to optimize the parameter values of the gait model generator to provide a fast and dynamically stable gait for the DARwIn-OP humanoid robot. They achieved this by using the Temporal Difference (TD) [
32] algorithm from the RL methods.
In a two-dimensional simulator, robot walking was accomplished using the Deep Deterministic Policy Gradient (DDPG) [
33] technique by Kumar et al. [
34]. In around 25,000 episodes, their agents received the target score. The Recurrent Deep Deterministic Policy Gradient (RDDPG) [
35] algorithm was used by Song et al. [
36] to address the partial observability problem of bipedal walking, and the results were superior to those of the original DDPG approach. A modular framework was presented by Kasaei et al. [
37] to provide stable bipedal mobility by tightly linking the analytical walking method with the DRL. To identify the optimal parameters and learn how to increase the robot’s stability by modifying the height of the CoM, a learning framework based on evolutionary algorithms and Proximal Policy Optimization (PPO) [
38] was designed.
In [
39], a controller combined with conventional control and RL was trained to walk the Robotis-OP3 humanoid robot in the PyBullet simulation environment. The study is divided into two parts: pose optimization and DRL. In the first part, they used the RL algorithm, Q-learning, to obtain a combination of the walking parameters of the traditional controller and optimized it according to the robot’s state. The PPO algorithm was used to train the multi-layer neural network in the second part, where the action space was created with the first phase. Thus, they obtained which pose order would enable the bipedal robot to perform the required task.
Zhang et al. [
40] proposed the LORM (Learn and Outperform the Reference Motion) method, a DRL-based framework for the bipedal robot gait, utilizing prior knowledge of reference motion. In comparison to the reference motion and other motion-based approaches, the agent trained using the proposed method performed better. The proposed method has been validated on the DARwIn-OP humanoid robot in the Webots simulator. Christiano et al. [
41] compared the possible trajectories of humans and humanoid robots. They developed a reward function using the data, then improved it with RL and updated the technique to DRL.
A two-level hierarchical control system was used by DeepLoco [
42]. Low-level controllers first learned to work on a predetermined time scale and achieve stable walking. Second, by requesting the required step objectives from the low-level controller, the high-level controllers learned the time-scale policy of the steps. The actor-critic DRL method was applied to both levels of the hierarchy similarly. The NAO humanoid robot’s stability was maintained while walking on static and moving platforms in the simulated environment utilizing a new hybrid RL framework that was introduced in the study [
43]. An iterative actor-critic RL system was used by Wawrzynski [
44] to change a humanoid robot’s initial slow walk into a quick and capable one.
Two different forms of impedance controllers, to which RL algorithms were applied, were used by Feirstein et al. [
45] to the enable limit-loop walking of a straightforward bipedal gait model. Leng et al. [
46] proposed a Mean-Asynchronous Advantage Actor-Critic (M-A3C) RL algorithm to directly obtain the robot’s final gait without introducing the reference gait. It has been shown that the proposed method can provide continuous and stable gait planning for the bipedal robot. To solve the emerging problems of traditional gait control methods, the DRL algorithm was used in [
47,
48]. A biped controller based on the DDPG algorithm was created by Liu et al. [
49] that can keep stability against static and dynamic disturbances.
A novel reward-adaptive RL technique for bipedal movement was proposed by Huang et al. [
50]. They ensured that the control policy was optimized by more than one criterion simultaneously using a dynamic mechanism. The proposed approach used a multi-layered critic to identify a unique value function for each reward component, resulting in hybrid policy gradients. To construct a feedback system that can handle the walking pattern problem, a feedback system that combines an Adaptive Neural Fuzzy Inference System (ANFIS) [
51] and a Double Deep Q-network (DDQN) [
52] was proposed in [
53]. To update the walking parameters, the output of the ANFIS was utilized for training a predictive model called DDQN.
Wong et al. [
54] designed an oscillator-based gait model with sinusoidal functions for generating trajectory planning and obtaining bipedal motion for a humanoid robot. To ensure that the robot walks straight, the direction of rotation is considered a parameter of the walking pattern. They used Q-learning to create a simple walking pattern. According to the findings of experiments, the proposed framework enables the humanoid robot to walk steadily and straighter.
The rest of the paper is organized as follows.
Section 2 includes the walking pattern generator created for gait planning and inverse kinematics analysis to determine the angles that the robot’s leg joints should take with this pattern. To find the optimal walking parameters, calculations of the orientation angles and ZMPs that form the state space of the DRL structure using multi-sensors are given in
Section 3. In
Section 4, the proposed stable walking framework is detailed. In this section, the optimization system of the walking parameters with the D3QN architecture and the stabilization system of the robot pose in the sagittal plane are analyzed, respectively. Experimental results are given in
Section 5. The paper is concluded with the conclusions and future work in
Section 6.
2. Walking Pattern Generator
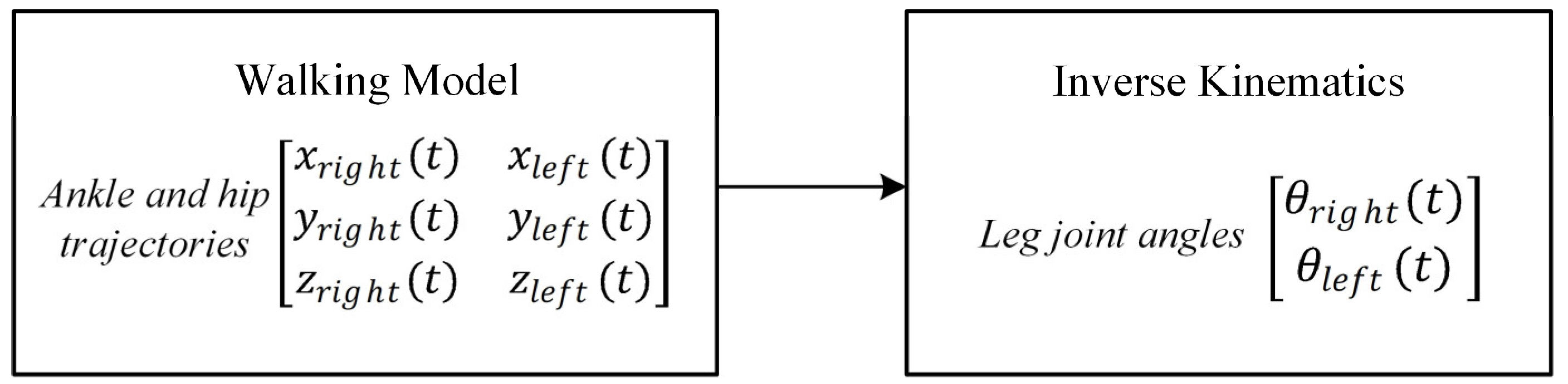
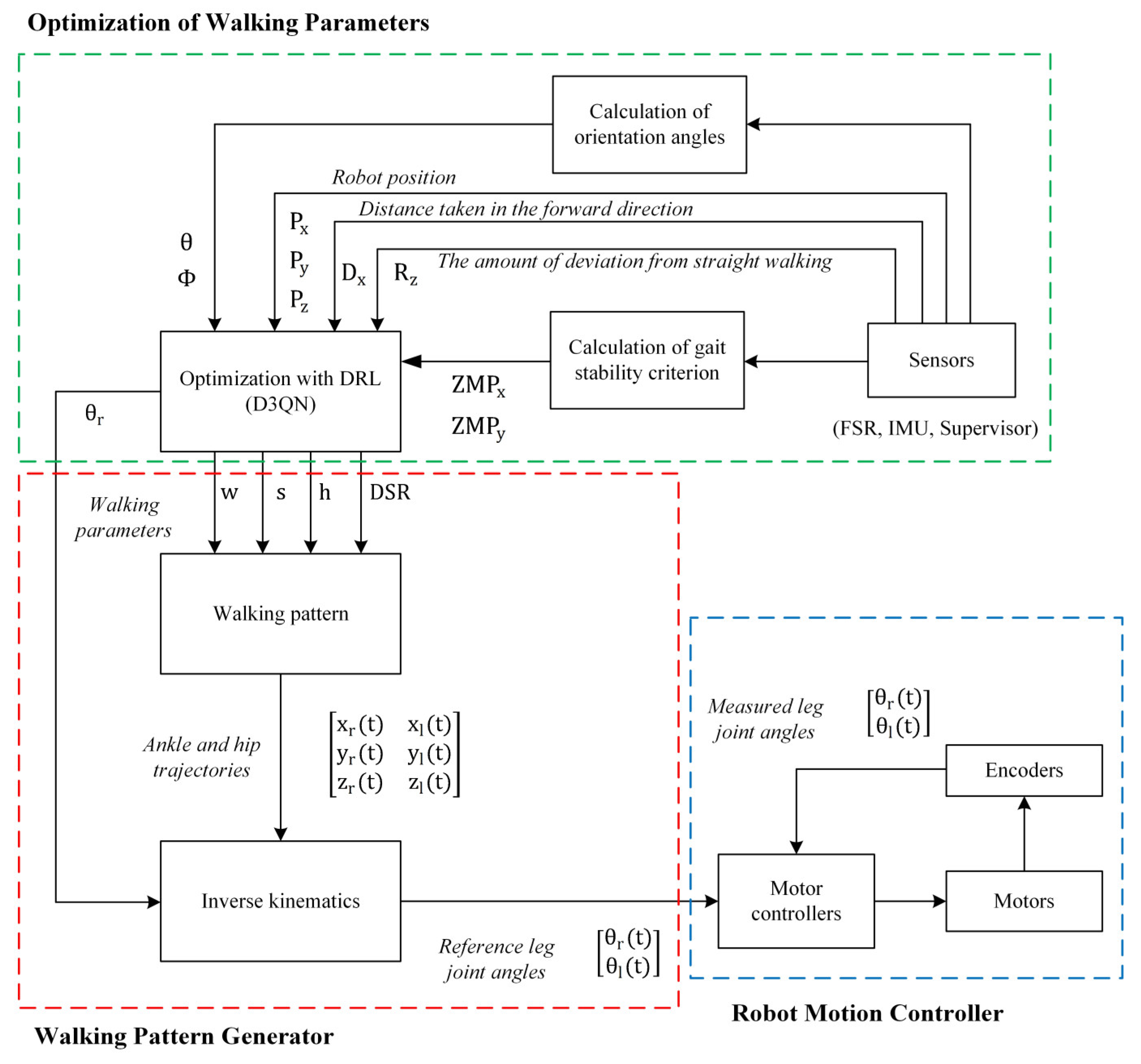
In this study, a walking pattern generator is created as given in the flowchart in
Figure 1. After determining the ankle and hip trajectories, the angle trajectories of the leg joints of Robotis-OP2 are obtained using inverse kinematic analysis.
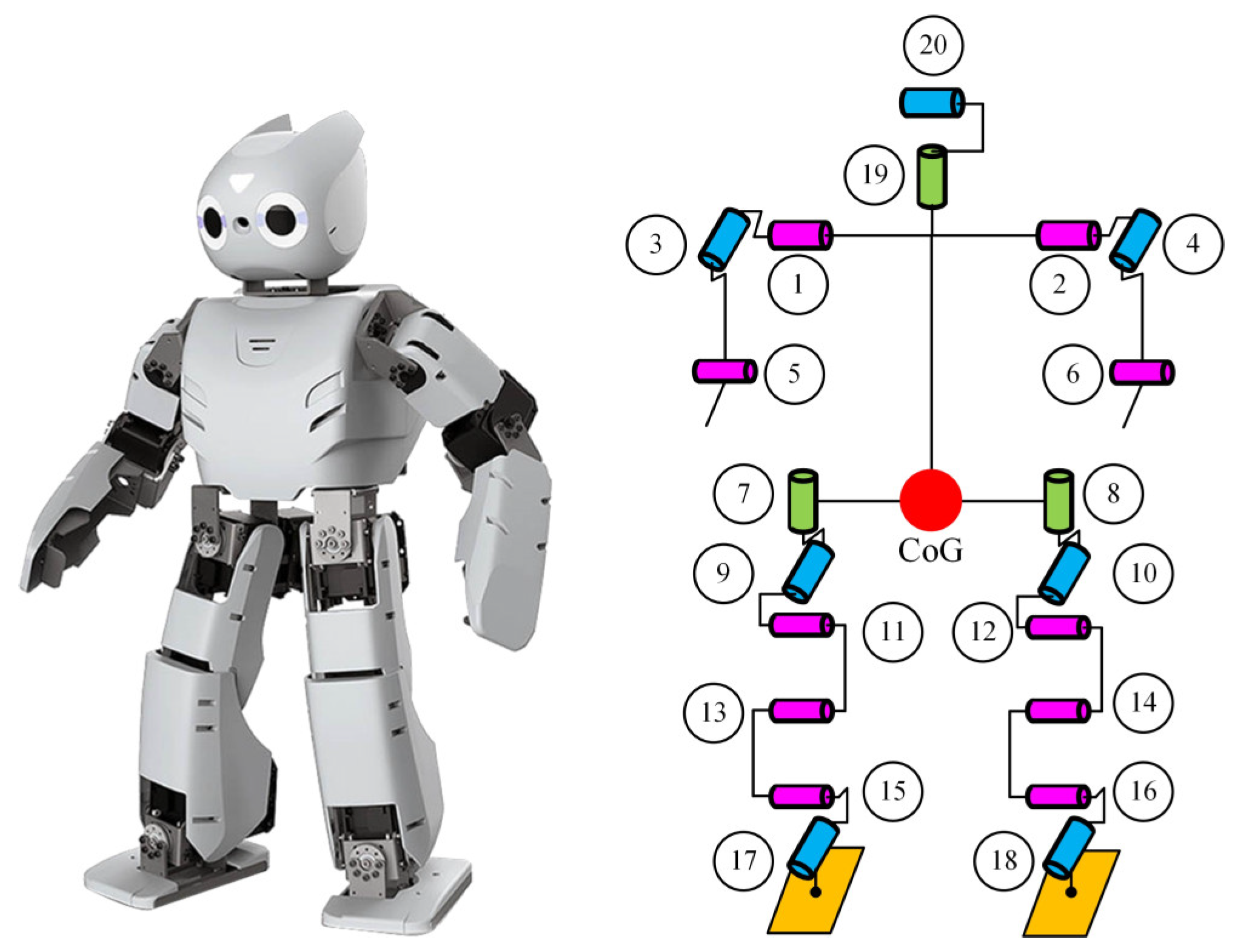
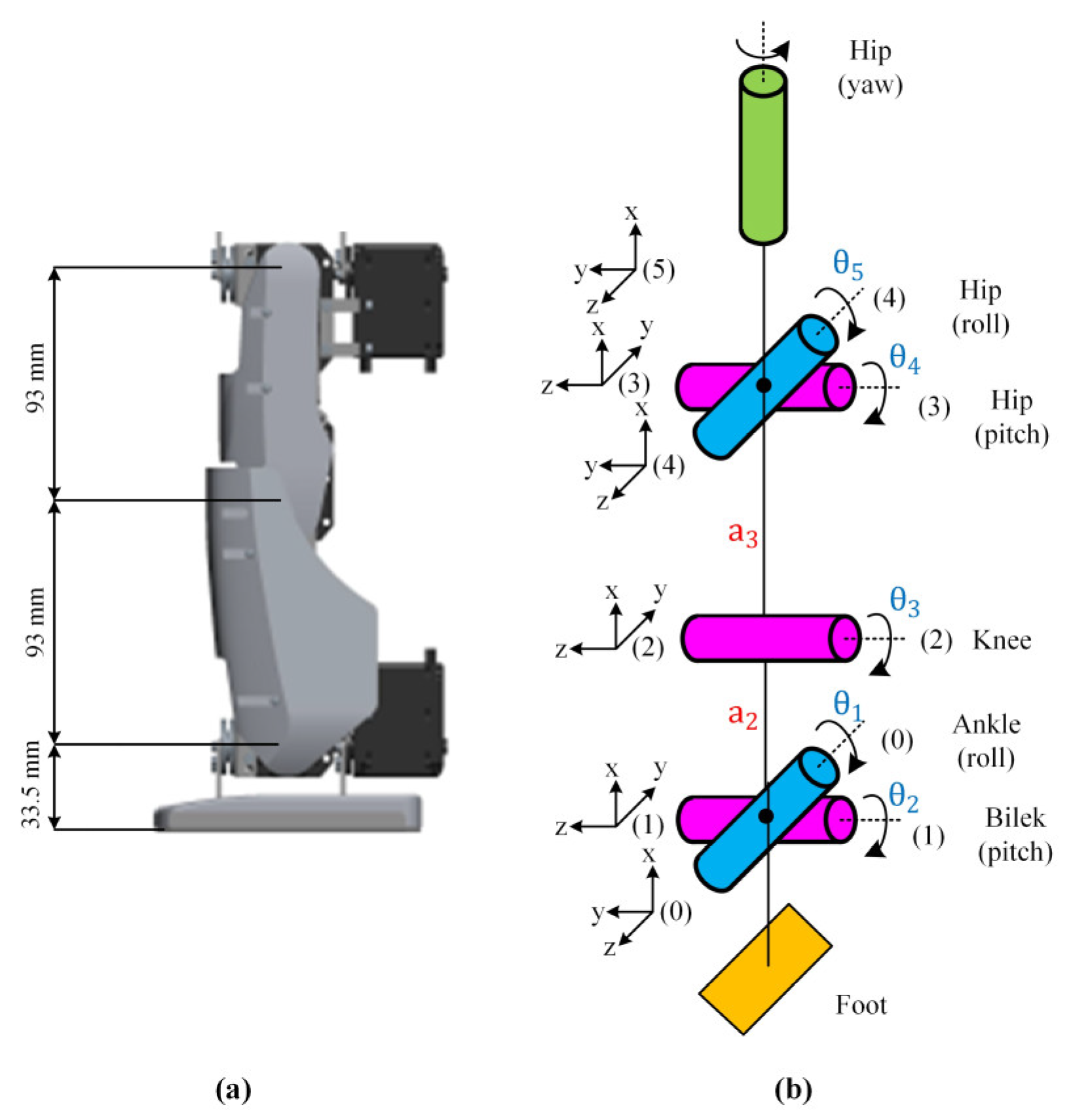
The Robotis-OP2 humanoid robot with 20 DoF weighing 3 kg and its joint placement are shown in
Figure 2. The robot’s joints are all actuated by the high-torque Dynamixel MX-28T smart servo motor.
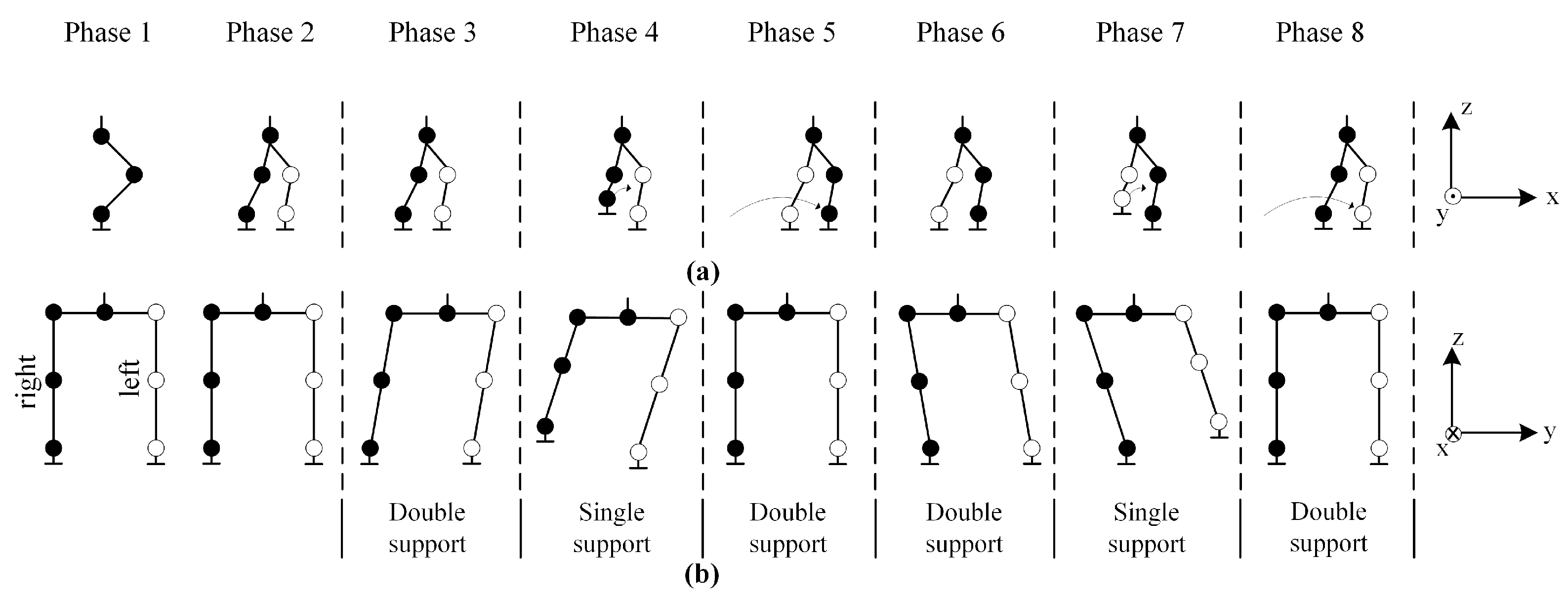
An eight-phase walking cycle is planned to perform the basic walking process, as shown in
Figure 3. The first two phases are the beginning phases of walking and include the necessary preparations for trajectory planning.
Phase 1: It is the initial phase used to define the robot’s trajectory coordinates.
Phase 2: It is the preparation phase of the robot before it starts walking. In this phase, the robot is ready to walk by moving the left foot forward a certain quantity and the right foot a certain quantity back.
Phase 3: This is the phase where the robot starts walking. The robot moves its CoG to the left foot. At this time, the feet are fixed on the ground and only the hip joints are shifted to the left.
Phase 4: When the CoG is moved to the left foot, the right foot begins to step.
Phase 5: The right foot finishes stepping and returns to the support area, and the CoG is ready to move to the right foot.
Phase 6: The robot moves its CoG to the right foot. In the meantime, the feet are fixed on the ground and only the hip joints are shifted to the right.
Phase 7: When the CoG is moved to the right foot, the left foot begins to step.
Phase 8: The left foot finishes stepping and returns to the support area.
Considering these eight phases, the six phases between Phase 3 and Phase 8 are repeated continuously to obtain a continuous walking process. A walking trajectory is planned for this process.
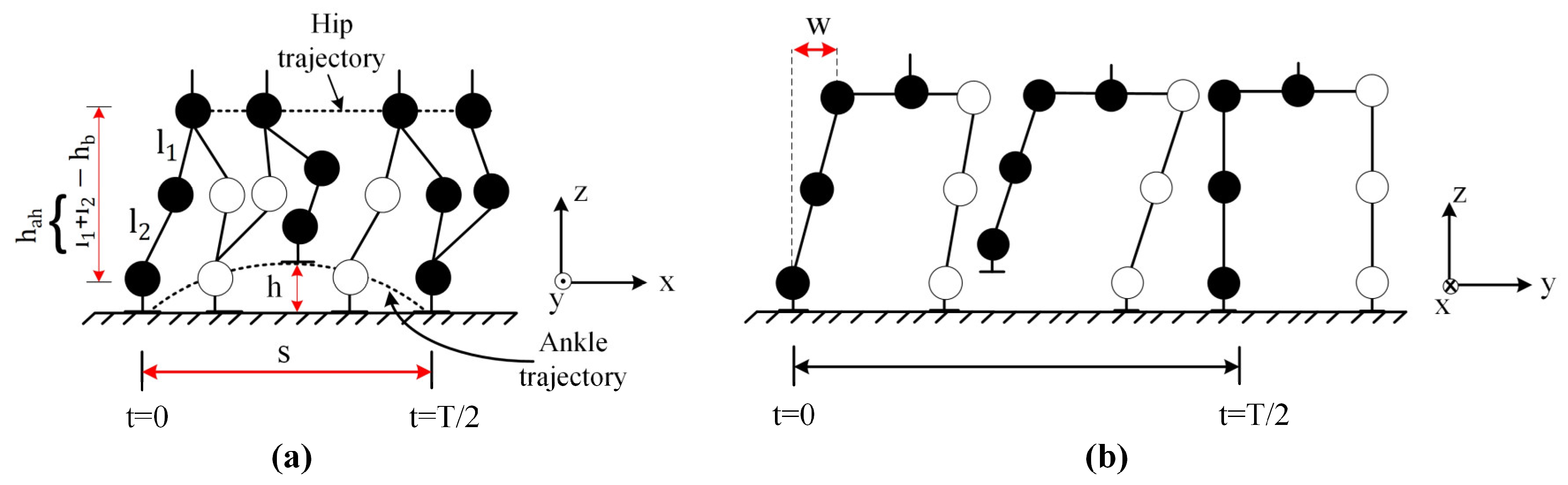
2.1. Walking Trajectory
In the gait model, cycloid curve functions are used to generate the ankle and hip trajectories. The walking pattern is generated separately in the x–z planes for the ankle and x–y planes for the hip. The ankle joints are the starting point of trajectory planning, and the hip joints are the ending point of trajectory planning.
2.1.1. Ankle Trajectory
The swing trajectory of the right ankle joint in the x–z plane is given in Equations (1)–(3) for Phase 3, Phase 4, and Phase 5, respectively. The swing trajectory, including these three phases for the left ankle joint, is given in Equation (4).
where
is the current time (s),
is the time of shift of the CoG in double support in Phase 5 to Phase 6 and Phase 8 to Phase 3 (s),
is one step length (mm),
is the maximum foot lift height (mm), and
is the walking cycle (Phase 3–8) time (s). In addition,
,
,
and
,
,
(mm) represent the trajectories of the right and left ankle joints in the x, y, and, z axes, respectively.
is calculated by Equation (5).
where
is the double support ratio.
The swing trajectory for the right ankle joint, which includes Phase 6, Phase 7, and Phase 8, is given in Equation (6). The swing trajectory of the left ankle joint is given in Equations (7)–(9) for Phase 6, Phase 7, and Phase 8, respectively.
2.1.2. Hip Trajectory
The swing trajectories of the right and left hip joints in the x–y plane are given in Equations (10) and (11) for Phase 3, Phase 4, and Phase 5, respectively.
The swing trajectories of the right and left hip joints are given in Equations (12) and (13) for Phase 6, Phase 7, and Phase 8, respectively.
where
is the height between the ankle joint and hip joint (mm),
is the bending height used to adjust the ground clearance of the hip joint (mm), and
is the maximum right-to-left translation when the hip is swinging (mm). In addition,
,
,
and
,
,
represent the trajectories of the right and left hip joints in the x, y, and z axes, respectively.
Walking parameters for the half gait cycle (Phase 3, Phase 4, and Phase 5) are shown in
Figure 4. As can be seen from the equations generated for the walking trajectory and
Figure 4, the gait model can be adjusted by changing three length parameters (
,
,
), a time parameter (T), and a rate parameter (
).
2.2. Kinematic Analysis
2.2.1. Forward Kinematics
For the forward kinematics, firstly, the rotation axes of the robot leg are determined, and axes are placed on the joints. The yaw joint in the hip of the robot is not included in the kinematic analysis as it does not affect the walking trajectory for a straight walking task. The lengths of the leg links and placement of the axes are shown in
Figure 5.
In
Figure 6, the representation of the leg joint angles is given.
The D-H table for the leg of the Robotis-OP2 robot is created as given in
Table 1.
Homogeneous transformation matrices (Equation (A1)) of the leg, which determine the orientation and position of a joint relative to the previous joint, are obtained by using the parameters in the D-H table given in
Table 1.
The transformation matrix according to the ankle joint, where the main coordinate system of the Robotis-OP2 hip joint is located, is obtained as in Equation (A2).
In the matrix given in Equation (A2), represents the orientation of the hip joint, which indicates the angle of rotation of one coordinate system with relation to another coordinate system, and represents the x, y, and z position coordinates of the hip joint relative to the ankle joint, respectively.
Equation (A3) is obtained using the homogeneous transformation matrices previously obtained.
,
, and
are obtained as in Equations (14)–(16), respectively, and forward kinematic analysis is completed.
2.2.2. Inverse Kinematics
When the leg structure of Robotis-OP2 is examined, the first three axes cause the displacement of the hip joint, which is the endpoint, while the last two axes change the rotation of the hip joint. Since the equations to be obtained by inverse kinematics may have more than one solution set, the angle limits are chosen considering the joint angle limits of the Robotis-OP2 legs [
55] in
Table 2.
For inverse kinematic analysis, firstly, both sides of the equation in Equation (A2) are multiplied first by , and then by , and , , and are obtained, respectively.
is calculated by Equation (17).
is calculated as in Equation (20) using Equations (18) and (19).
is calculated as in Equation (23) using Equations (21) and (22).
The equation in Equation (A2) is multiplied by
. The rotation matrix representing pitch used in obtaining
and
angles is given in Equation (24).
is calculated as in Equation (25).
is calculated as in Equation (26).
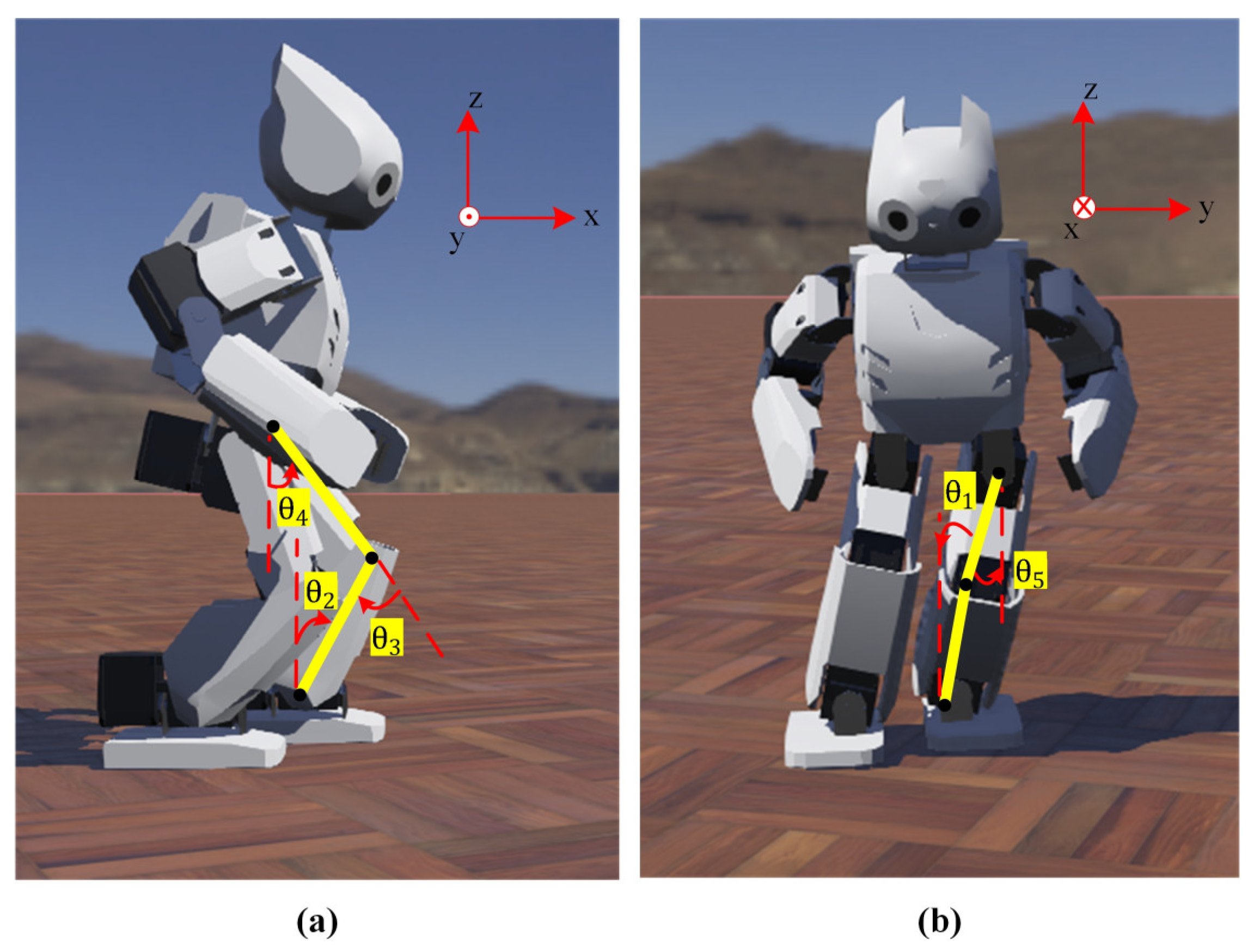
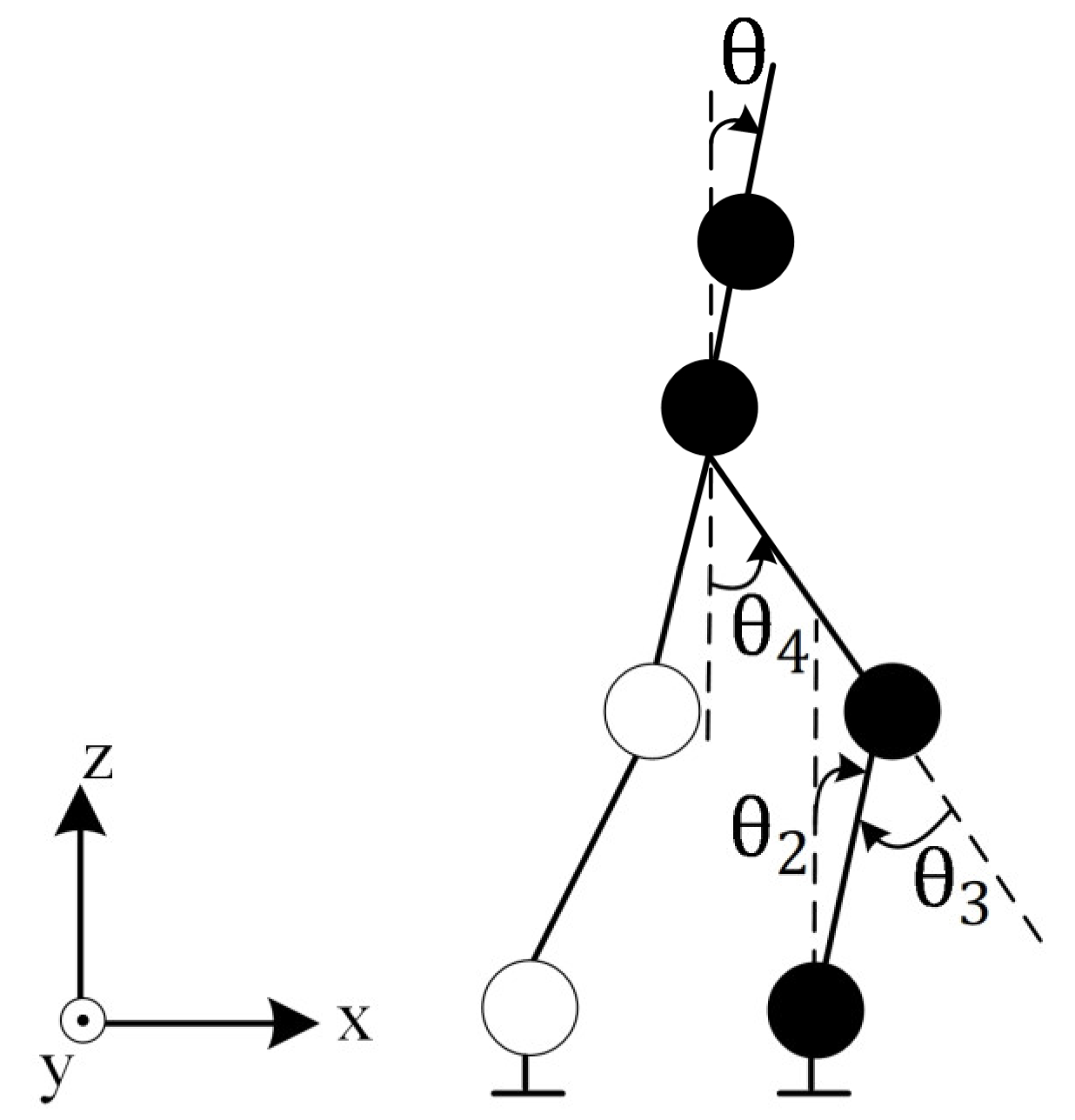
With the rotation matrix in Equation (24), the
value, which is the robot’s body tilt angle in the sagittal plane, is adjusted. The
shown in
Figure 7 is equal to the sum of the pitch angles of the leg (
+
+
) and can be selected at desired values so as not to cause the robot to fall while walking.
Using the generated walking trajectory, the position coordinates , , and of the hip joint relative to the ankle joint are calculated for both legs. The calculation operations consist of subtracting the ankle joint’s position from the position of the hip joint at each time step.
5. Experimental Results
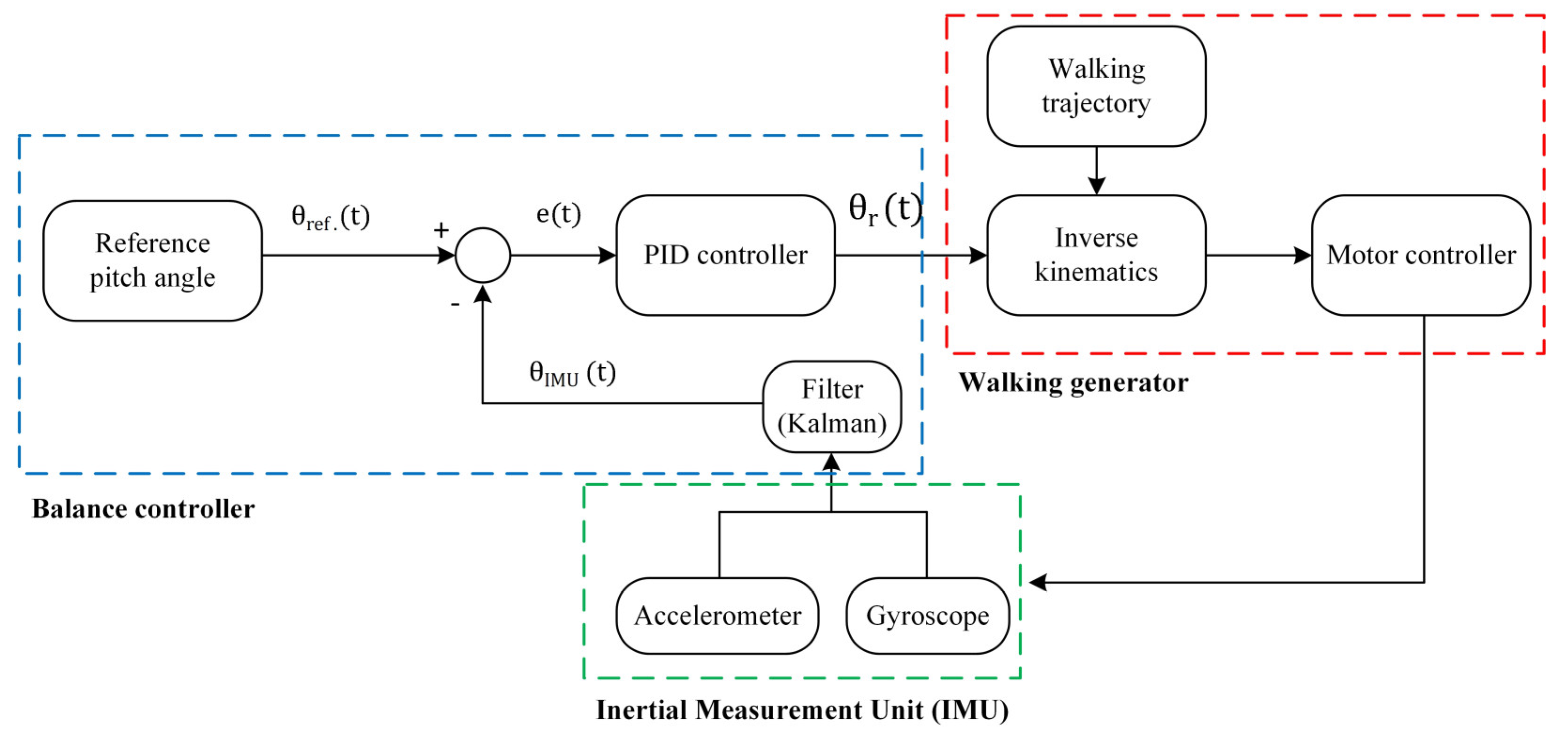
First, experimental studies were carried out to determine the parameters used to calculate the orientation angles and gait stability criterion. The accelerometer, bias, and measurement noise variances of the Kalman filter were determined as 0.001, 0.003, and 0.03, respectively, by taking a time step of 16 ms. Initial values of the process noise, measurement noise, and estimated error variances of the one-dimensional Kalman filter were determined as 0.001, 0.25, and 1, respectively. Moreover, by default, only the P controller with a gain coefficient of 10 is used for the position control of the servo motor in the Webots. In the experimental studies, proportional gain and integral gain coefficients were determined as 30 and 0.9, respectively, by trial and error.
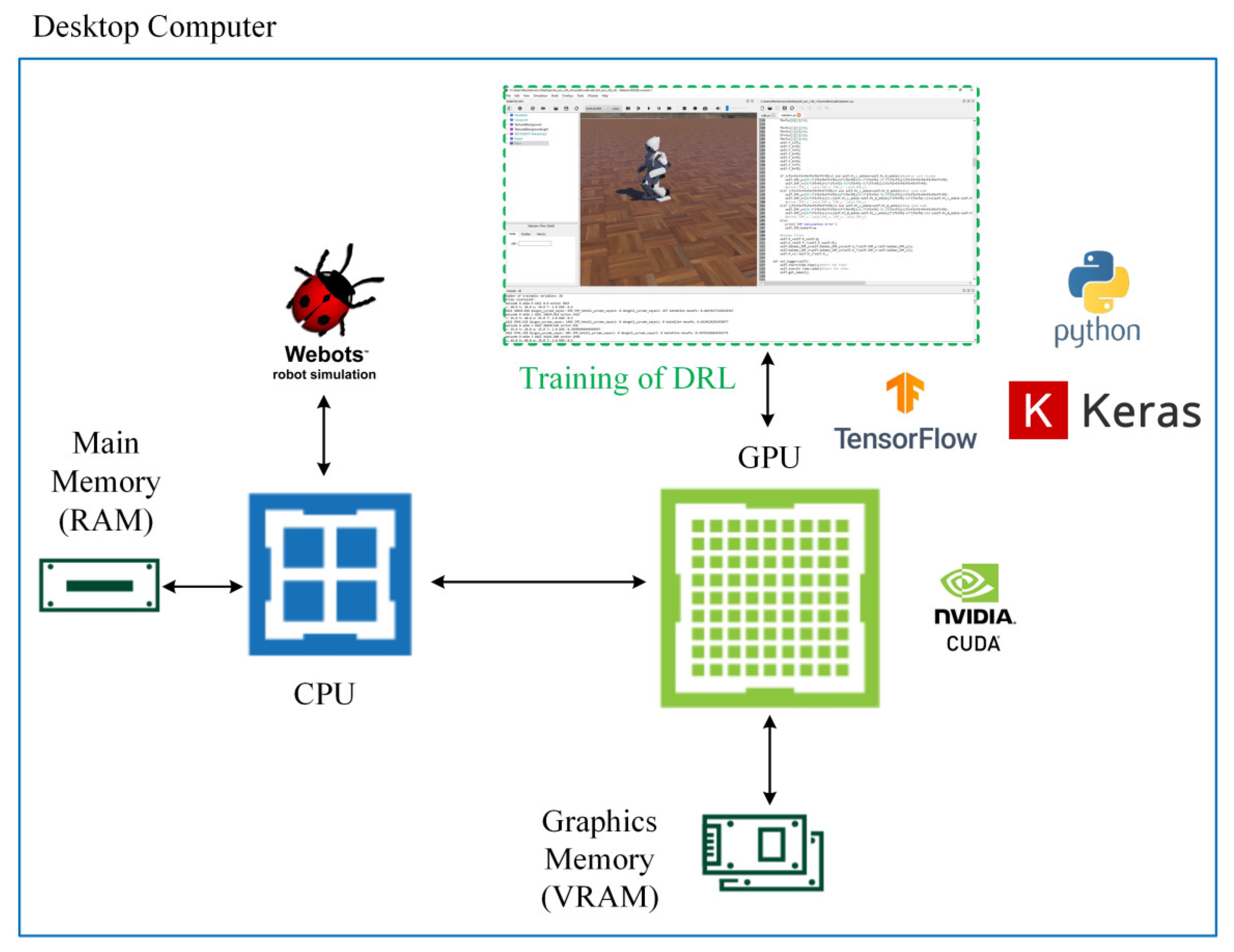
As shown in
Figure 16, experimental studies were carried out on a desktop computer with NVIDIA GTX Titan X Pascal GPU, Intel i5 4th generation 3.4 GHz processor, and 8 GB RAM. The training of the D3QN was carried out in the Webots simulator with the controller written using Tensorflow 2.2.0, Keras 2.3.1, and Python 3.8 versions by utilizing the power of parallel computing thanks to the CUDA support of the GPU.
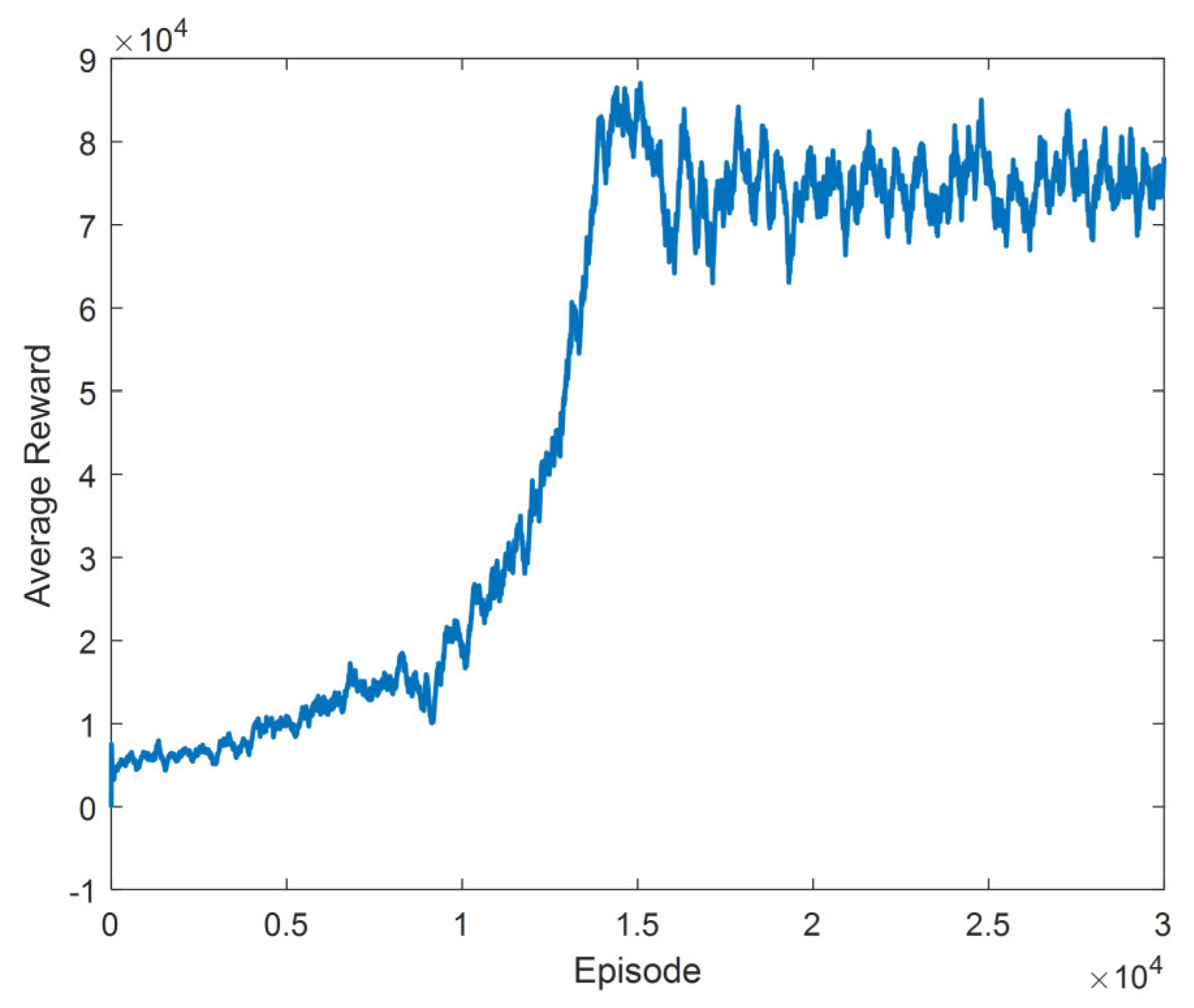
During the training process, the rewards received in each episode were recorded. Weights were stored in every 100 episodes. After the training was completed, the average reward obtained by taking the average of the last 40 episodes was drawn, and it was observed that a highly fluctuating graph appeared. This situation is because training includes too many episodes. The graph obtained by taking the average of the last 200 episodes instead of the last 40 episodes is obtained in
Figure 17.
When the training results in
Figure 17 are examined, it is seen that the average reward increases exponentially up to the roughly 16,000th episode. Afterwards, the average reward remained within a specific range. During the training, it has been observed that it converges to the parameters that can perform many successful walking processes. However, action sequences consisting of the actions in
Table 8 were obtained repeatedly in at least the last 9000 episodes.
With the values in
Table 8,
,
,
, and
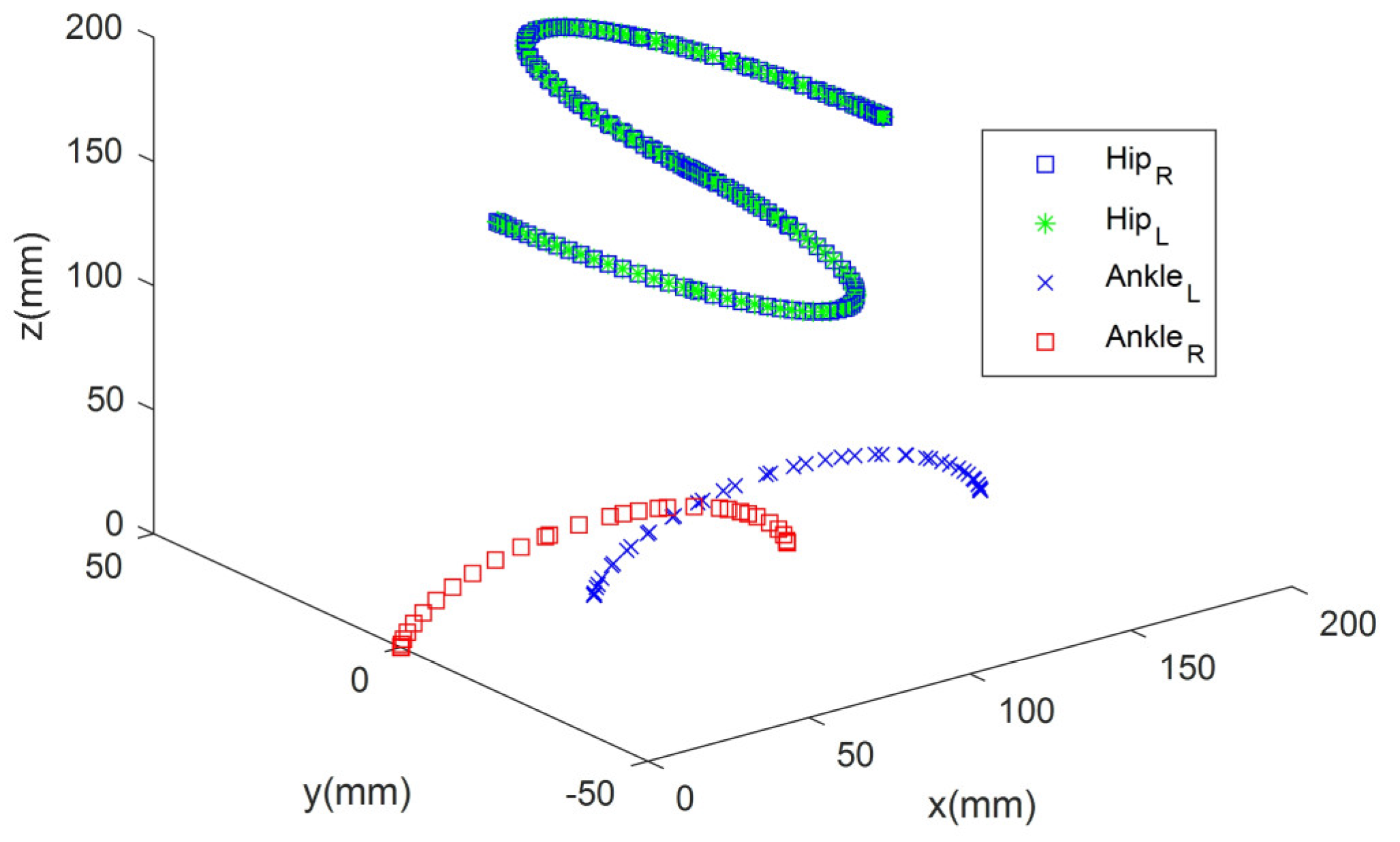
for six walking cycles (6T) were obtained as 709.2 mm, 711, 581, and 0, respectively, and the reward value calculated by Equation (34) was obtained as 12,711. The saved weights were loaded and tested in the Webots R2020b simulator. The walking trajectories obtained with the optimized gait parameters were visualized with graphs in MATLAB R2021b for the gait cycle. The three-dimensional representation of the walking model is given in
Figure 18.
When
Figure 18 is examined, the robot’s speed is 60 mm/s in the x-axis, and the robot’s hip performs a swinging movement of a maximum of 50 mm. In addition, while walking, the robot’s foot rises a maximum of 30 mm from the ground.
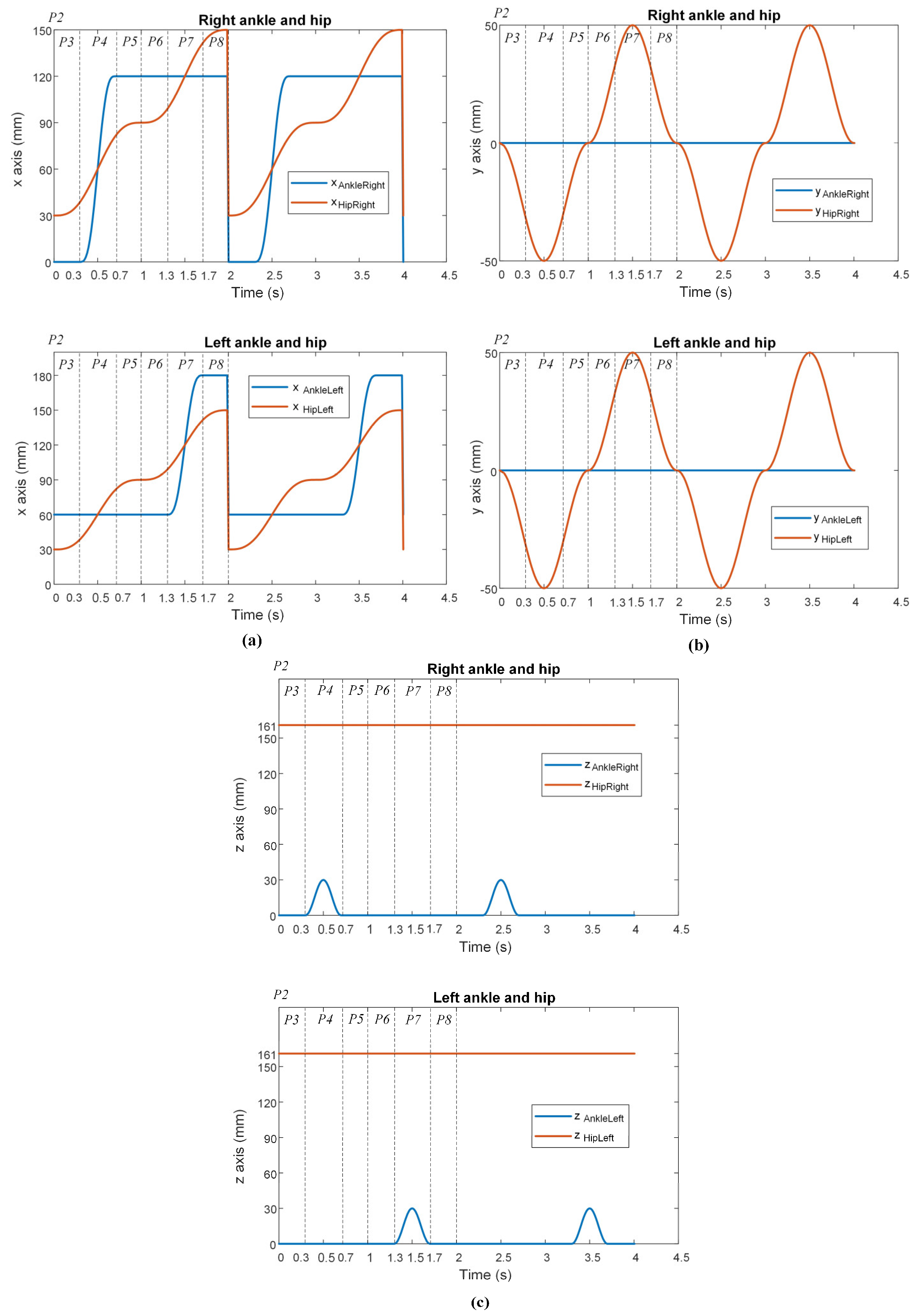
The ankle and hip joint trajectories for the right and left legs, along with their phases, are shown in
Figure 19. The position coordinates of the hip joint relative to the ankle joint
,
, and
were calculated for both legs by the walking trajectory. The calculation process consists of subtracting the ankle joint’s position from the hip joint’s position at each time step.
Although there was no disturbance on the ground, the results of straight walking were obtained using the same walking parameters (
Table 8) for the four walking cycles with the closed loop. The gain coefficients
,
, and
obtained by trial and error for the PID controller for body posture balancing were determined as 0.8, 7.1, and 0.01, respectively.
According to
Figure 19a, although the hip trajectory in the x-axis is the same for the right and left legs, it has mirrored oscillations for the ankle. According to
Figure 19b, the ankle and hip trajectories are the same for both legs. According to
Figure 19c, although the hip trajectory is the same for the right and left legs, the ankle trajectory differs.
The walking algorithm inside the Robotis-OP2 uses a method to construct a gait model based on CPG-based paired oscillators that perform sinusoidal trajectories [
60]. Many parameters are available in the algorithm to adjust the gait. However, it has been decided that only a subset of these parameters can be set to facilitate its use by the user [
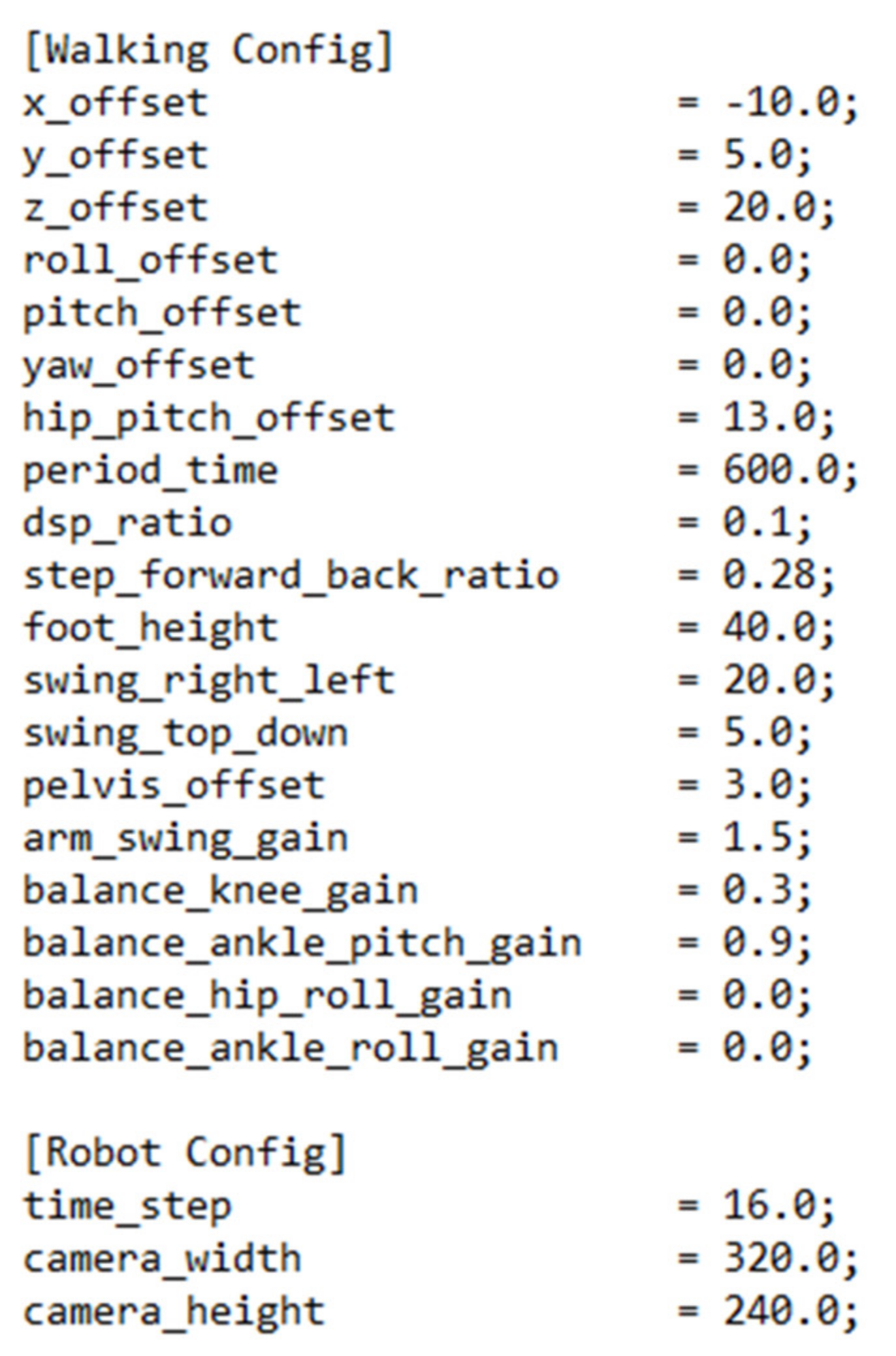
55]. Other parameters are set to default values that are known to work well. The robot’s gait can be adjusted if the user wishes by changing the default values stored in the “config.ini” configuration file shown in
Figure 20 [
55].
The results for walking obtained with the proposed framework and Robotis-OP2’s walking algorithm [
60] are compared as in
Figure 21 and
Figure 22.
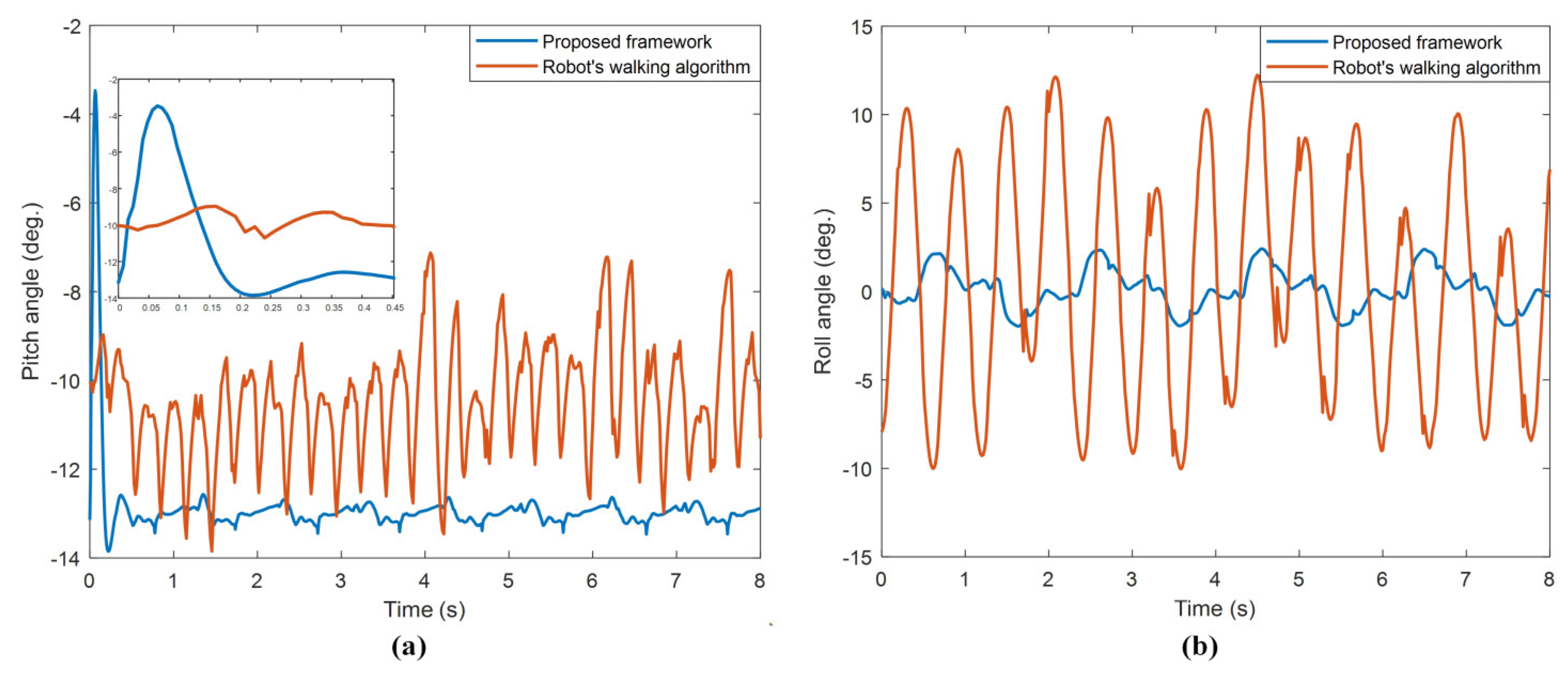
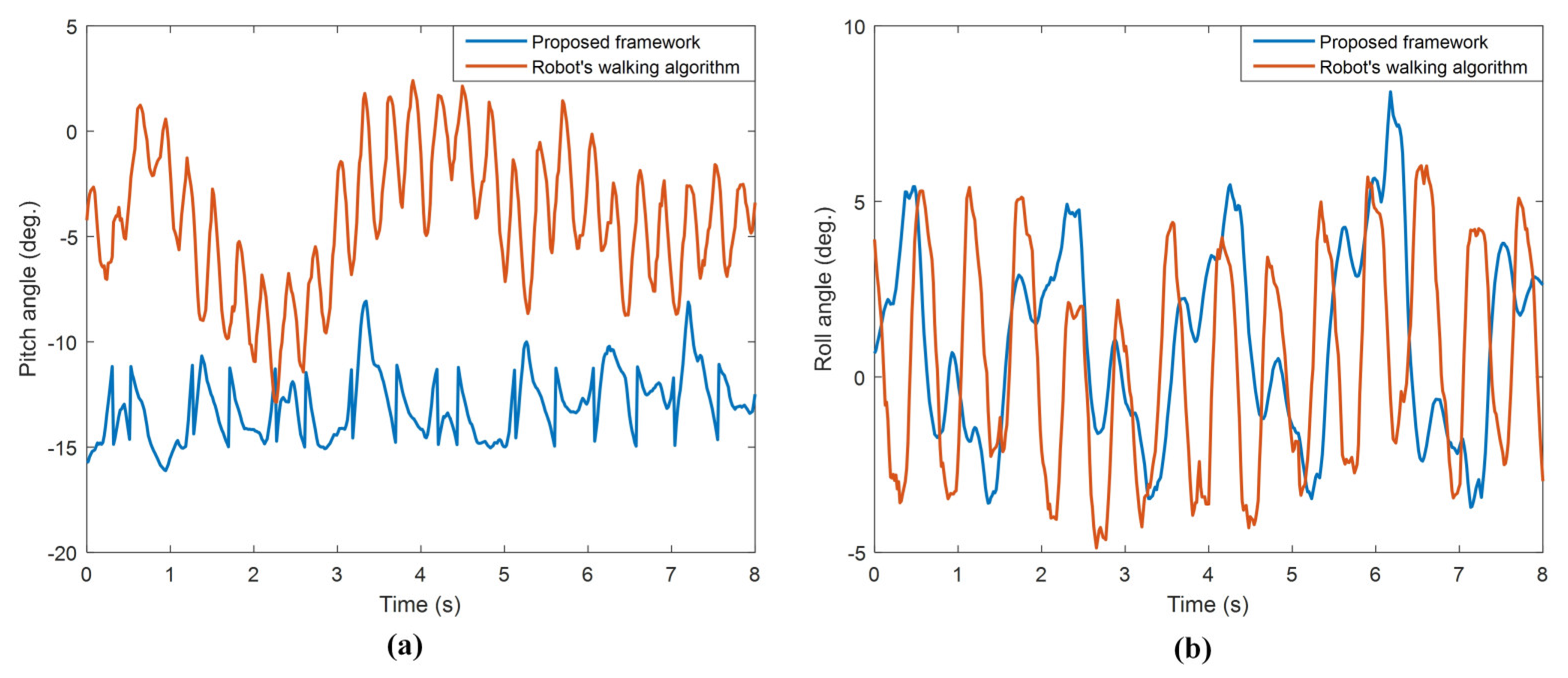
When
Figure 21a is observed, at the beginning of the walking, an instantaneous jumping movement occurred in the time it took for the system response with the PID controller to settle on the reference input. However, since this jumping is in the first approx. 0.18 s of walking, it is observed that it did not adversely affect the walking stability of the robot. When the oscillations of the orientation angles in
Figure 21 are examined, it is seen that the proposed framework has very little angle change compared to the other. In
Table 9, the ranges of the robot orientation angles given in
Figure 21 are compared.
With the proposed framework according to
Table 9, the robot has very little swinging during walking compared to the robot’s walking algorithm for both pitch and roll orientation angles.
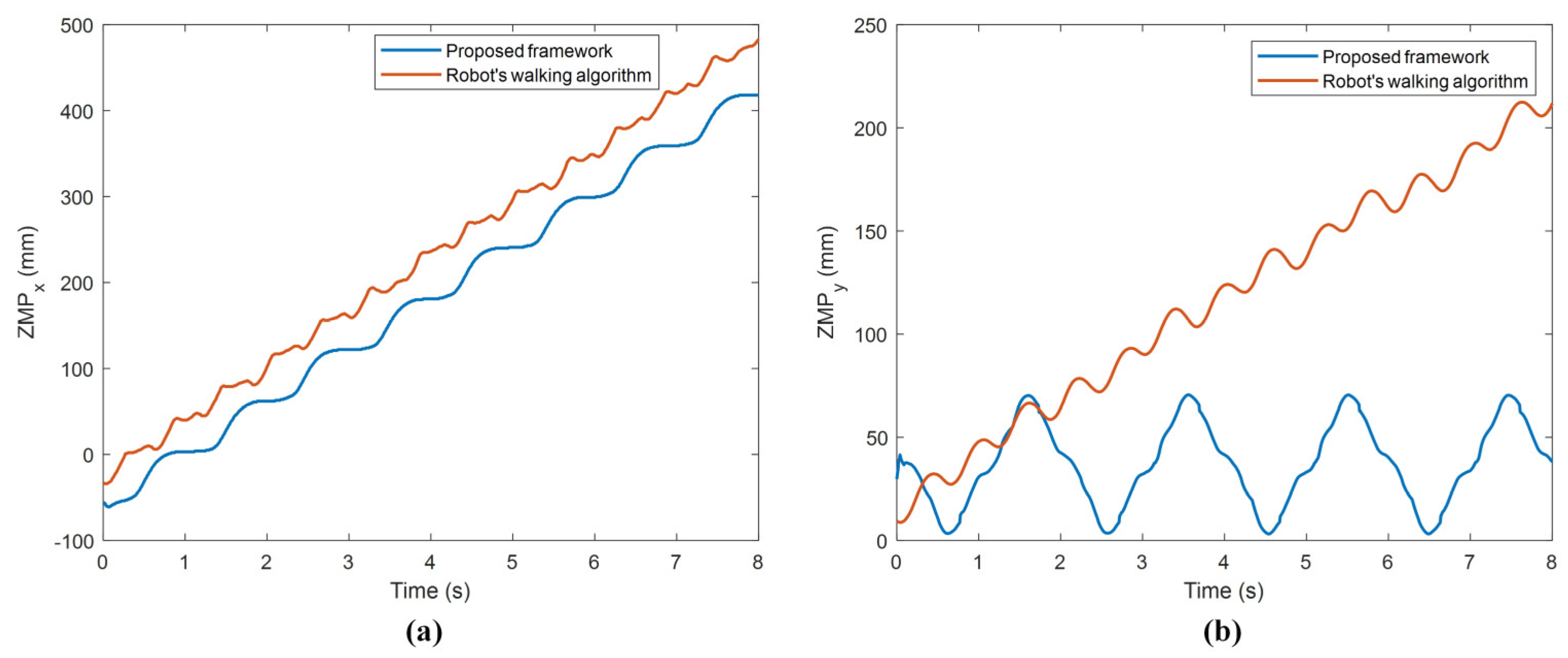
When
Figure 22a is examined, it is seen that the
increases by oscillating more smoothly with the proposed frame compared to the other. Considering the step length is 60 mm, the fact that the robot’s
moves on 474 mm in the forward direction during four gait cycles indicates quite stable walking. When
Figure 22b is examined, it is seen that, with the proposed framework,
oscillates regularly in a certain period, and there is only about 12 mm of vertical misalignment at the end of the walk. The other method deviates considerably from the vertical alignment compared to the proposed framework. These experimental results showed that very stable walking was obtained with the proposed framework. In addition, when all the experimental results were evaluated, it was seen that the proposed framework was quite successful in terms of both the balanced walking and stable walking of the robot. The proposed framework is also very useful for optimizing gait parameters for different state and action spaces of the DRL. The user can optimize the robot’s gait using the proposed framework for the robot’s desired speed and walking pattern generator.
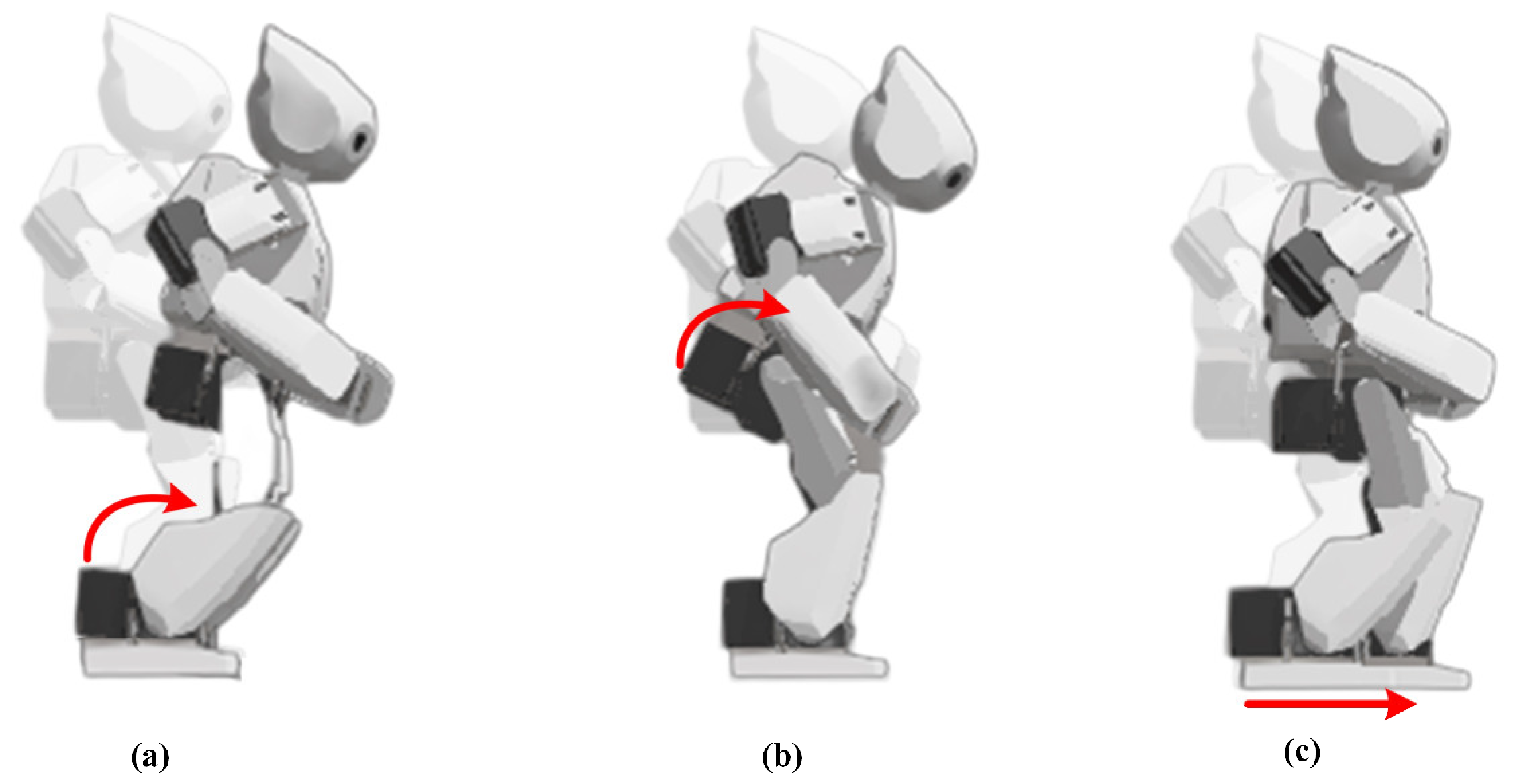
The controller, which was developed after the experimental studies at Webots, was transferred to the real Robotis-OP2 humanoid robot with the remote control tool located in the robot window of Webots.
Figure 23 shows the robot’s initial states of walking.
A comparison of the orientation angles of the walking performed with the proposed framework and Robotis-OP2’s walking algorithm is given in
Figure 24.
In
Figure 24a, it was observed that the oscillation amplitude of the pitch angle was lower. The results in
Figure 24b showed that the roll angles of the robot oscillate quite close to each other. Experimental results on the real robot also proved that the robot is more stable during walking.
6. Conclusions and Future Work
In this paper, a robust algorithm is developed with the proposed framework for the stable walking of a humanoid robot. The proposed framework consists of a traditional trajectory generator controller and DRL structure. This study is the first study in the literature on the walking of a humanoid robot using the DRL algorithm, D3QN.
Experimental studies were carried out on the Robotis-OP2 humanoid robot in both simulation and real environments. For experimental studies, the walking trajectory of the robot was created using cycloid curves. Leg kinematic analyses were performed to obtain the angles of the leg joints so that the robot could reach the desired trajectories. The data obtained from multi-sensors on the robot were made sense of. The training of the D3QN for the optimization of walking parameters was carried out in the Webots simulator. With the system based on the training of the D3QN, the optimum parameters of the walking trajectory were obtained for stable walking. It converged to the optimum parameters approximately in the 21,000th episode.
For the robot body to maintain its balance in the sagittal plane, a stabilization system was created using the hip strategy and PID controller. Experimental results were obtained by performing walking tests by combining the obtained values and the balancing system. When the robot body was asked to walk with a pitch angle of −13° in the sagittal plane, the robot successfully walked with a swing between −13.446° and −12.995°. The body roll angle was between −1.964° and 2.332°. It was observed that the ZMP values in the x and y axes, which are the stable walking criteria of the robot, also have a very smooth oscillation. For walking where the robot has a step of 60 mm per second, over four walking periods, the moved on 474 mm. Moreover, the shifted only 12 mm from the starting coordinate. These experimental results proved that the robot has a stable gait. Experimental results were also compared with the Robotis-OP2 robot’s walking algorithm, and it was seen that the proposed framework had a more stable gait.
Based on the study in this paper, many future studies are planned. Firstly, using the proposed framework in this paper, the robot will be able to walk stably on an unknown inclined ground. The robot’s posture will be adjusted in real-time to ensure that the body pitch angle is at the desired reference value as if it were walking on flat ground. Then, studies will be carried out to enable the robot to walk longer with lower energy consumption. Next, more detailed research will be conducted to understand better the natural bipedal gait mechanisms, including in humans. In addition, it is aimed to develop a gait model for applications to the lower limbs’ exoskeleton for both healthy and disabled people.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}























