
A Truthful and Reliable Incentive Mechanism for Federated Learning Based on Reputation Mechanism and Reverse Auction

 ,
, 
Abstract
1. Introduction
- We construct a reputation mechanism to detect malicious behaviors and negative behaviors of participating clients in the FL training process, and measure the truthfulness and reliability of clients through multiple reputation evaluations. Based on the reputation mechanism, we design a truthful and reliable client-selection scheme.
- We design a reverse auction that satisfies individual rationality, incentive compatibility, and weak budget balance, and use the deep reinforcement learning (DRL) algorithm D3QN to select the best set of clients from truthful and reliable clients to maximize the social surplus in the FL service trading market.
- Experimental simulations show that the FL incentive mechanism based on the reputation mechanism and reverse auction can motivate more clients with high-quality data and high reputation to participate in FL with fewer rewards, and can significantly improve the accuracy of FL tasks.
2. Related Work
3. Preliminary Knowledge and System Model
3.1. Preliminary Knowledge of Federated Learning
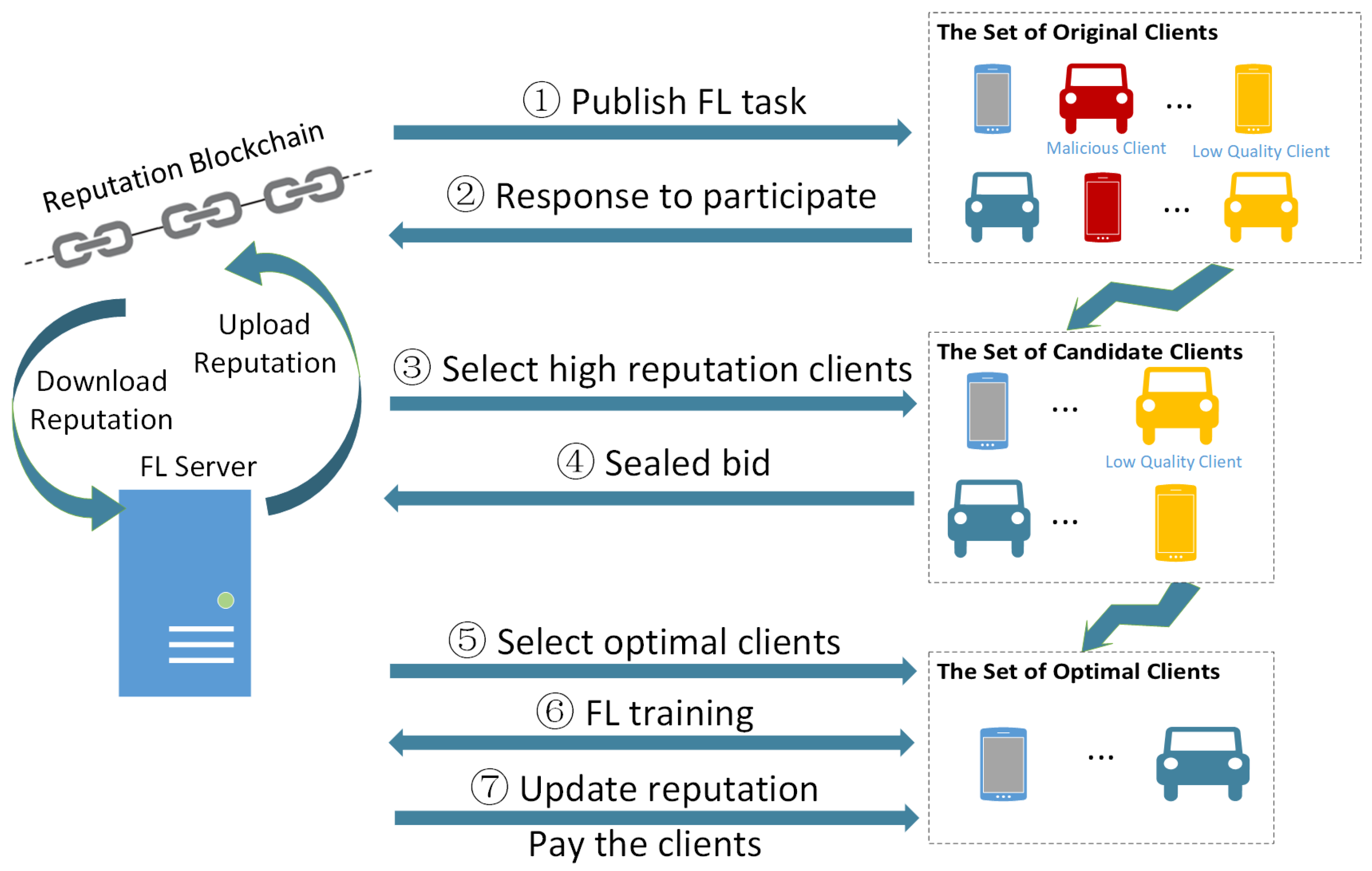
3.2. Truthful and Reliable Incentive Mechanism for FL
- Publish FL task. FL server broadcasts FL task information in the FL service trading market, including required data types, minimum requirements for computing resources, bidding rules, etc.
- Response to participate. After receiving the task information, the interested clients express their willingness to participate in FL by combining their own data and computing resources.
- Select high reputation clients. After receiving the participation response from clients, the FL server first downloads the clients’ reputation value from the reputation blockchain. Then FL server calculates the reputation of each client according to the reputation mechanism, so as to select the clients with high reputations to form a set of reliable clients.
- Sealed bid. The reliable clients make sealed bids to the FL server and report their own data quality and cost information.
- Select optimal clients. The FL server solves the reverse auction by using the DRL algorithm D3QN to select the set of optimal clients to participate in FL.
- FL training. The FL server aggregates and updates the global model, and the clients train and update the local models, repeating until the global loss function converges.
- Update reputation and pay the clients. The FL server evaluates the reputation of each client based on the information interacted with the clients in this task and uploads it to the reputation blockchain. If the client’s reputation declines, the server will not pay the client; otherwise, the client will be paid.
4. Reliable Client Selection Scheme Based on Reputation Mechanism
4.1. The Design of Reputation Mechanism
- Direct Reputation: The reputation value is obtained by the FL server in the current FL task through direct reputation assessment based on the interaction history with the clients.
- Indirect Reputation: The reputation value is derived from the reputation assessment of clients by other FL servers not in the current FL task based on their interaction history, which is an indirect reputation assessment compared to the FL server in the current task. Indirect reputation is also called recommended reputation, and the FL server that gives indirect reputation is also called recommended server.
- Comprehensive Reputation: When the direct reputation cannot evaluate the clients, the comprehensive reputation will be calculated by considering the direct reputation and the indirect reputation.
4.1.1. Client Behavior and Detection
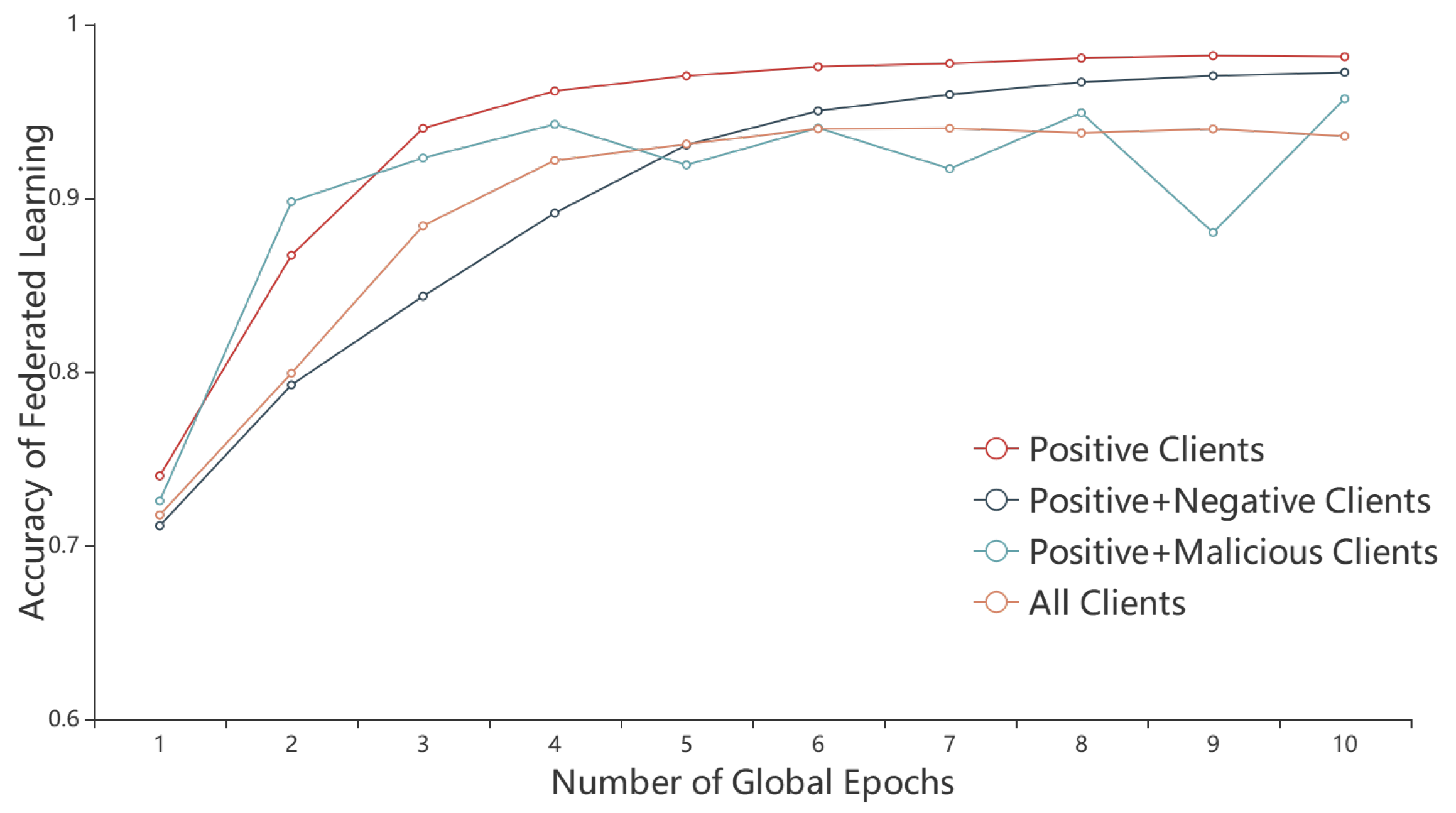
- Malicious Behavior: The client has poisoning attacks, including data poisoning and model poisoning. Data poisoning refers to the attacker contaminating the samples in the training set by adding wrong labels or flipping sample labels to reduce the accuracy of the data and increase the probability of misclassification, thus affecting the performance of the global model. Model poisoning differs from data poisoning in that the attacker does not directly manipulate the training data, but sends wrong parameters or corrupted models to corrupt the global model, thus affecting the change direction of the global model parameters, slowing down the convergence of the model, and even destroying the correctness of the global model, which seriously affects the performance of the model [15].
- Negative Behavior: The client has no malicious behavior, but has deceptive behavior. In order to reduce resource consumption and obtain maximum individual benefits, the data size and EMD distance provided by the client during the actual training process don’t match the bidding time. Negative behavior refers to falsifying the data quality, i.e., the data quantity d and EMD distance are falsified, making the submitted local model accuracy rate much lower than expected.
- Positive Behavior: The client bids truthful data size and EMD distance, and is single-minded in completing the training task, with no malicious behaviors or negative behaviors during the training process.
- Malicious Behavior Detection: The FL server evaluates the quality of clients’ local model updates through the poisoning attack-detection scheme to determine whether the clients have malicious behaviors. RONI [4] and FoolsGold [16] are attack-detection schemes for IID and non-IID data scenarios respectively. The RONI scheme verifies local model updates by comparing the impact of local model updates on the FL server’s predefined database. If the performance degradation of local model updates on the database exceeds a specified threshold given by the system, the local model updates will be rejected during aggregated model updates. The FoolsGold scheme identifies malicious clients based on the diversity of local model gradients in the non-IID scenario, because malicious clients always repeatedly upload similar gradients as local model updates in each iteration. Through these two schemes, the FL server can identify the malicious behaviors and reject the local model parameters submitted by the malicious clients.
- Negative Behavior Detection: The negative behaviors of clients are deceptive behaviors of false reporting in the bidding stage, leading to much lower than the expected behavioral performance of clients in the subsequent training stage, such as significantly lower model accuracy. Therefore, detection for negative behaviors can be relatively detected among clients by using differences in the clients’ local model accuracy rates. Here, it is assumed that there is no client collusion and therefore no group cheating occurs. In order to obtain maximum benefits while reducing resource consumption, the clients have three specific behaviors for data quality fraud, whihch are as follows.
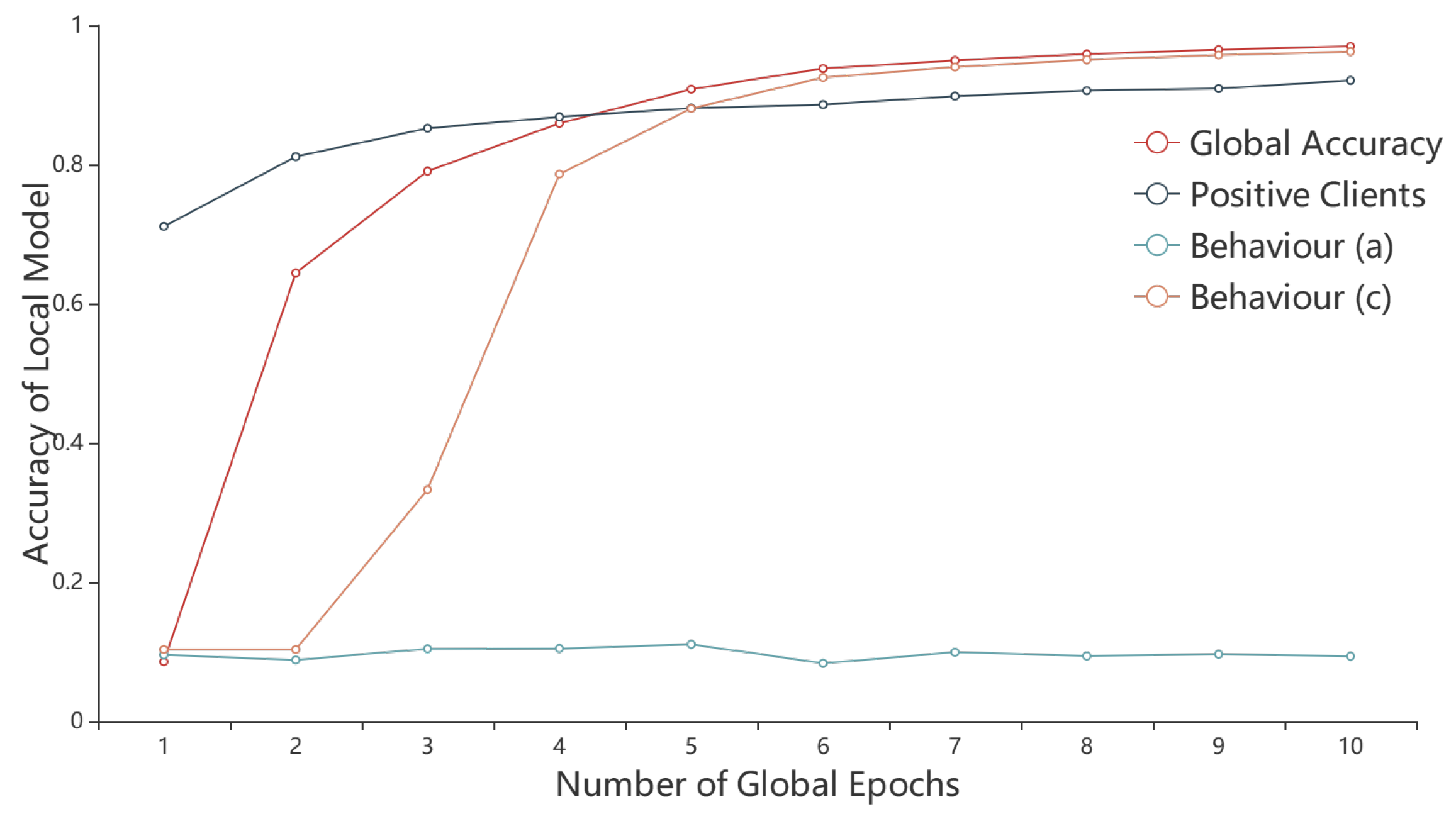
- (a)
- Randomly generate model parameters and upload them to the FL server. In this case, the clients don’t train locally, but directly generate model parameters through a random algorithm for upload. Due to the randomness of the parameters generated by the algorithm, the accuracy of the uploaded model is extremely low, much lower than that of other normal client uploaded models. Moreover, the parameters submitted by the client in each round are also random, which cannot reflect the direction of the local model updates at all.
- (b)
- Directly upload the global model parameters in the next round. In this case, the clients choose to directly upload the global model parameters downloaded from the FL server in the next round. In this way, the client can not only avoid resource-consuming local training, but also submit a local model with a higher accuracy rate and the same update direction as the global model, which is not considered in most incentive designs.
- (c)
- Use local low-quality data for training. Knowing that the local data quality is very poor (the amount of data d is small, and the EMD distance is large), the client submits false data-quality information when bidding in order to successfully pass the screening of the incentive mechanism, declaring that the amount of local data is large and the EMD distance is small. This type of client does not submit false model parameters during training, but trains with local low-quality data. Through the experiment in Section 6.2, it is found that the accuracy of the model submitted by this type of clients is very low in the first three rounds, which is much lower than the model submitted by the other normal clients, but after three rounds of global aggregation, the accuracy of the models submitted by this type of client does not differ much from the global model. Because the small amount of local data no longer affects the update of the global model.
4.1.2. Direct Reputation Assessment
- Activeness: The more times client i interacts with FL server , the more truthful and reliable the server’s reputation assessment of the client is. The activeness is the ratio of the number of interactions between server and client i in a time window and the average number of interactions between server and all clients, as shown in (5),where denotes the total number of interactions between server and client i in a time window, and denotes the set of clients that interacted with the FL server in the same time window.
- Freshness: During interactions between FL servers and clients, clients are not always truthful and reliable. The trustworthiness of a client varies over time, and more recent interactions with greater freshness are given more weight than past interactions. To accurately reflect the timeliness of reputation evaluation, a freshness decay function is introduced to account for the freshness of interactions, as shown in (6),where is a given decay parameter about the freshness of the interaction and is the time slot that determines the decay degree of the interaction freshness. Therefore, the direct reputation of FL server to client i within a time window is expressed as (7),
4.1.3. Indirect Reputation Assessment
- Similarity: The more similar the business between FL servers, the higher the overlap in the set of recruited clients, and the higher reliability of the indirect reputation of clients that interact more frequently between two FL servers. We represent each FL server’s reputation assessment of the interacted clients as a separate vector, and measure the similarity of the business between FL servers by solving the similarity of the vectors with Pearson’s correlation coefficient. The greater the similarity, the higher the reliability of the reputation given by the recommended servers. According to the definition of Pearson’s correlation coefficient [17], the similarity between server i and server j is shown in (8),where denotes the set of clients that have interacted with both FL server i and FL server j, that is, the set of clients for which both have reputation assessment; denotes the reputation assessment value of FL server i for client c, denotes the reputation assessment value of FL server j for client c; denotes the mean value of FL server i’s reputation assessment for clients in , denotes the mean value of FL server j’s reputation assessment for clients in .
- Dispersion: Considering that the reputation recommendation server may collude with some clients to cheat and maliciously increase the reputation value of some low-reputation clients, not all indirect reputation values are reliable. In this paper, we introduce information entropy to reflect the dispersion degree among indirect reputation values, that is, the degree of deviation of each indirect reputation value from the overall set of indirect reputation values. Information entropy can identify the excessively high and low reputation values in the overall indirect reputation, thus making the indirect reputation assessment more objective and accurate [18]. The dispersion of indirect reputation values of client c by recommended server j is calculated by using information entropy as shown in (9),where denotes the entropy of the indirect reputation value and n denotes the total number of recommended servers. The weight of the indirect reputation value from each recommended server j is set by considering the similarity between request server i and recommended server j and the dispersion between recommended servers. Finally, the global indirect reputation evaluation of client c is calculated as shown in (10),
4.1.4. Comprehensive Reputation Assessment
4.2. The Reliable Client Selection Scheme
| Algorithm 1 Reliable client-selection scheme. |
 |
5. Optimal Client-Selection Scheme Based on Reverse Auction
5.1. The Design of Reverse Auction
- Individual Rationality (IR): Only when all participating clients have nonnegative utility, the overall mechanism is IR. IR shows that clients are hesitant to join FL when the payment is lower than the cost.
- Incentive Compatibility (IC): All participating clients can get the best compensation only when they honestly report the type of resources and costs, and the overall mechanism is IC. In other words, each participating client cannot increase its revenue by submitting false information.
- Weak Budget Balance (WBB): The utility of the FL server is nonnegative, when the FL services transaction is completed.
5.2. The Optimal Client-Selection Scheme
- States: The state of the execution to step m is , indicating that client i is selected into the candidate set V; otherwise, it is not selected.
- Actions: The action in step m is the client number i, which is not in the candidate set V, indicating that the client i is selected by the FL server in the current step.
- State transition: The state transition from to is determined by the action at step m, i.e., , and will be put into the candidate set V.
- Reward: The reward at step m is the social surplus increased by the action , i.e., . The cumulative reward is the goal of optimization, which ultimately maximizes the social surplus of the FL task.
- Policy: D3QN uses the evaluation network to obtain the action corresponding to the optimal action value in the state , and then uses the target network to calculate the action value of the action to obtain the target value. The interactions between the two networks effectively avoid the algorithm overestimation problem. The FL server interacts with the environment by using the -greedy policy, which can be expressed by Equation (25),
- (1)
- Client misrepresentation of bid costs.
- (2)
- Client misrepresentation of data quality.
6. Performance Evaluation
6.1. The Settings of Simulation
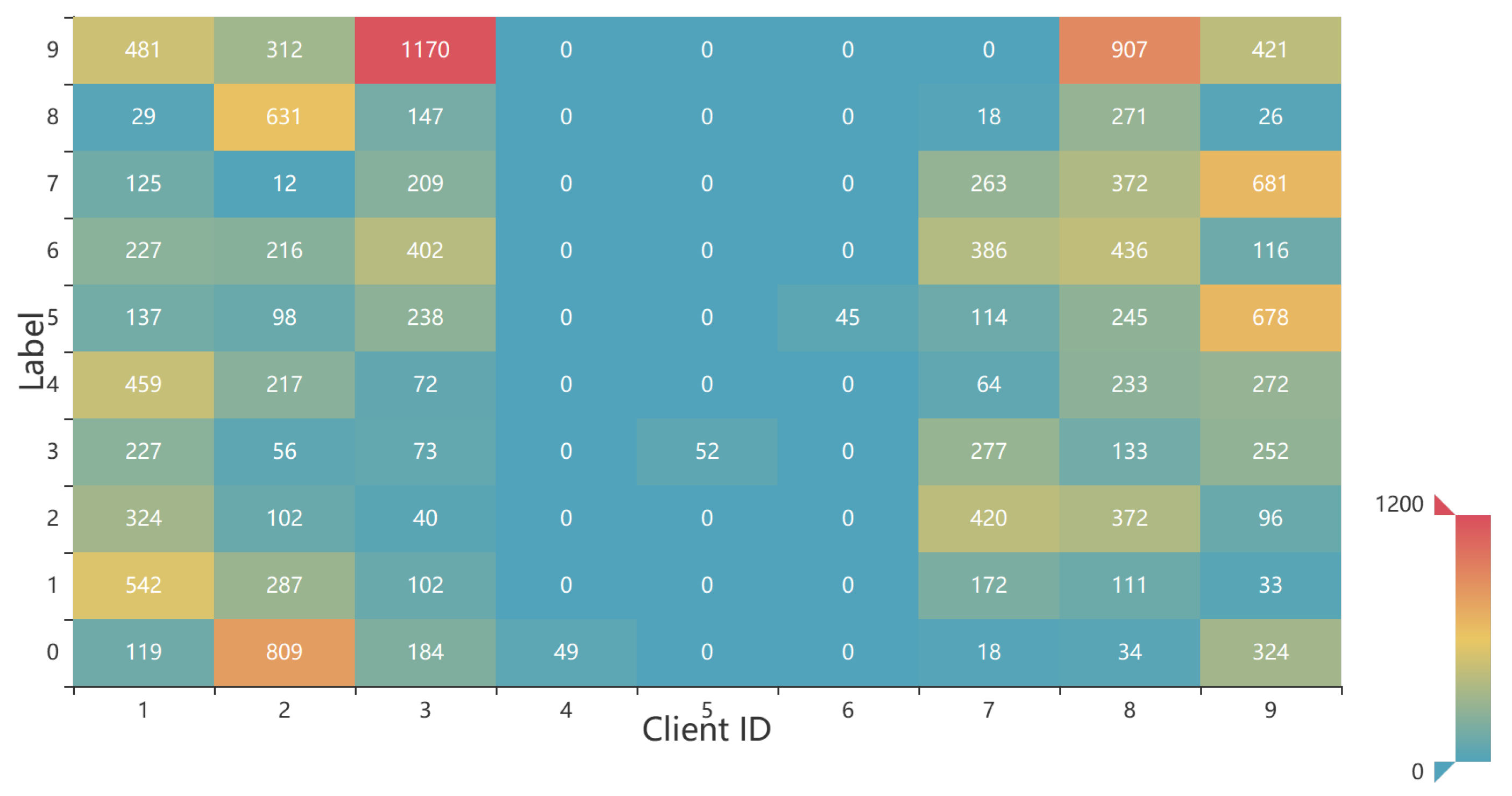
6.2. Performances of the Reputation Mechanism
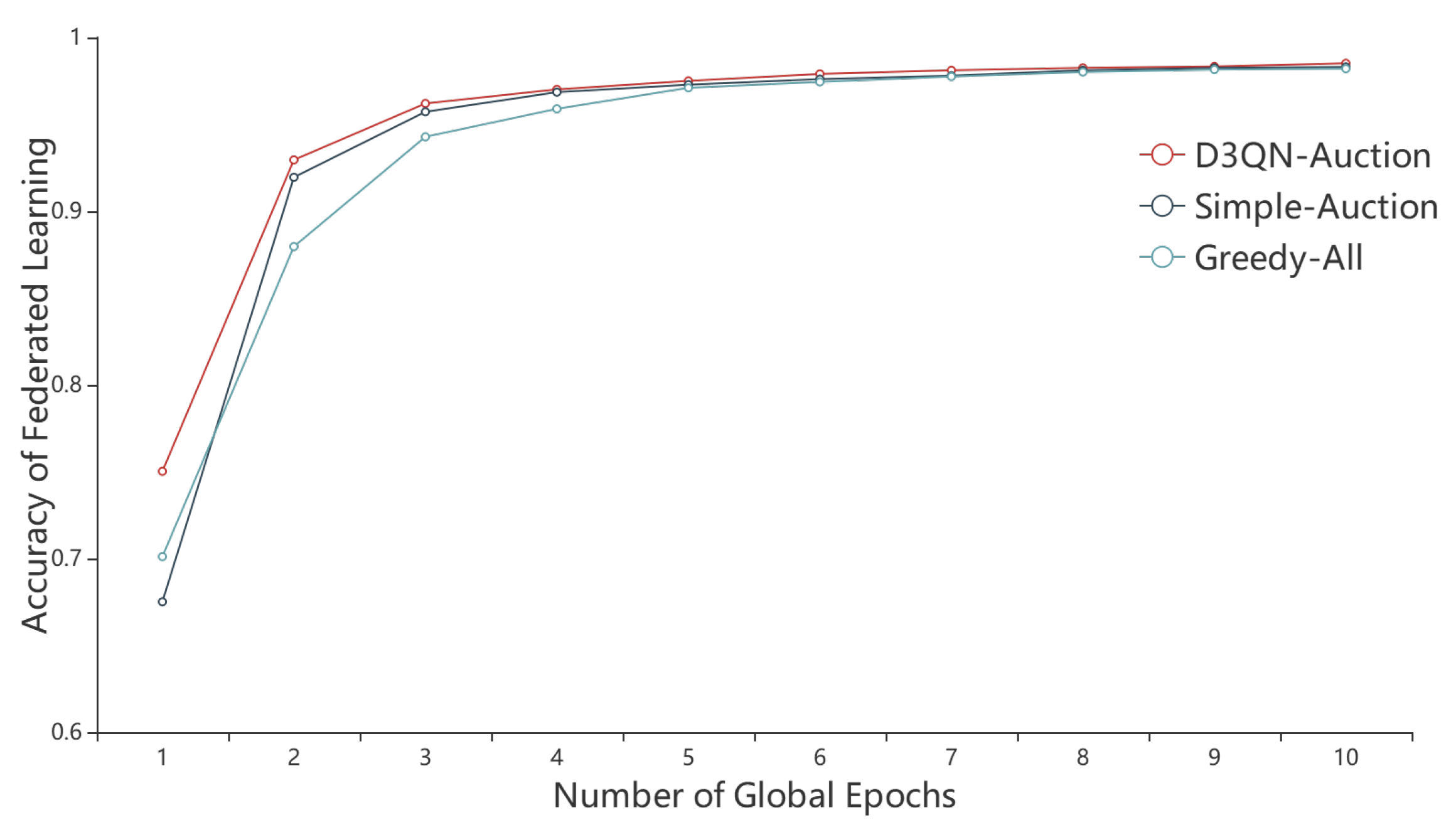
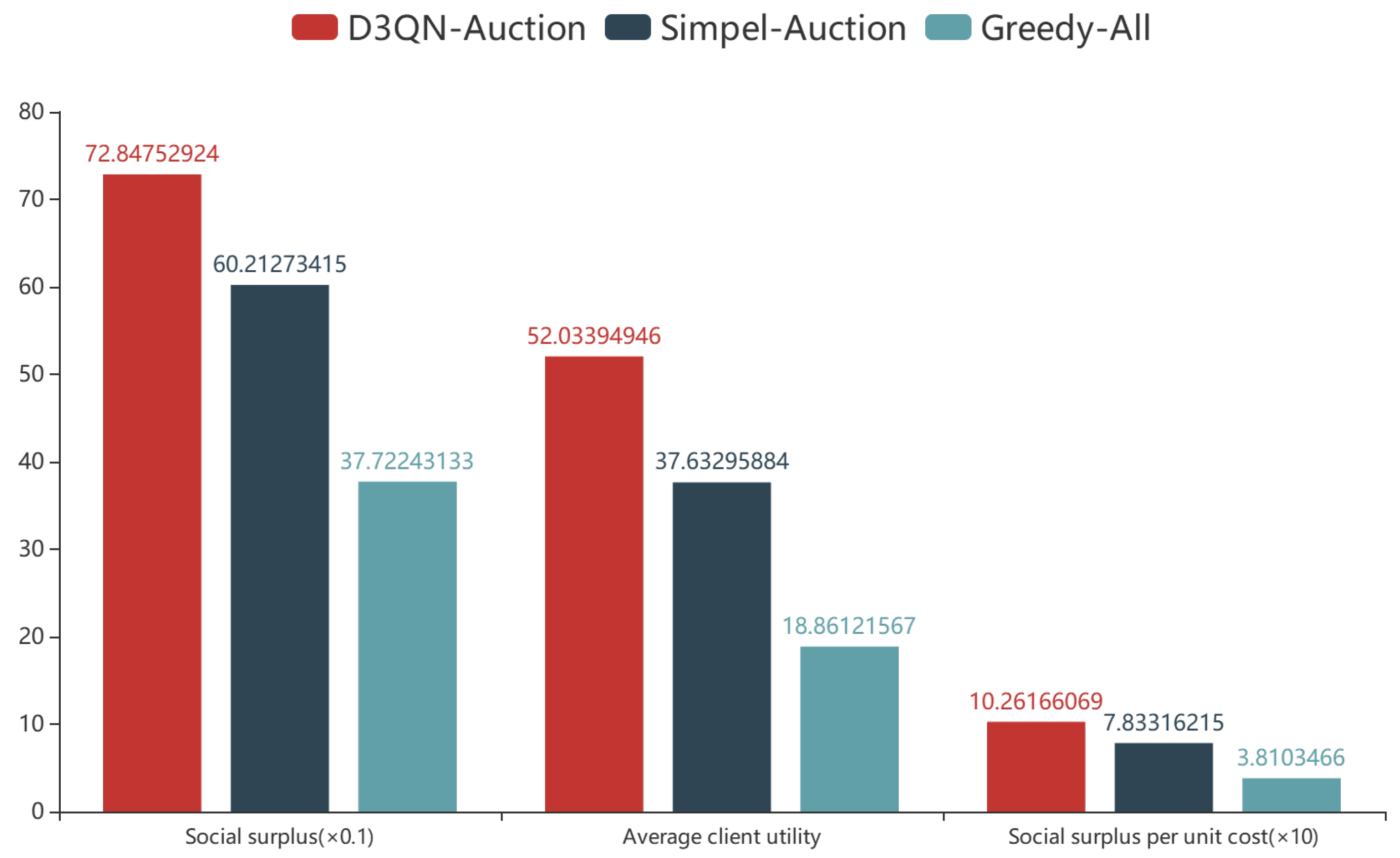
6.3. Performances of the Reverse Auction
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhan, Y.; Li, P.; Guo, S.; Qu, Z. Incentive mechanism design for federated learning: Challenges and opportunities. IEEE Netw. 2021, 35, 310–317. [Google Scholar] [CrossRef]
- Federated Learning: Collaborative Machine Learning without Centralized Training Data. Available online: https://ai.googleblog./com/2017/04/federated-learning-collaborative.html (accessed on 6 April 2017).
- Hard, A.; Rao, K.; Mathews, R.; Ramaswamy, S.; Beaufays, F.; Augenstein, S.; Eichner, H.; Kiddon, C.; Ramage, D. Federated learning for mobile keyboard prediction. arXiv 2018, arXiv:1811.03604. [Google Scholar]
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; Arcas, B.A. Communication-efficient learning of deep networks from decentralized data. In Proceedings of the 20th International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 20–22 April 2017; PMLR: New York, NY, USA, 2017; pp. 1273–1282. [Google Scholar]
- Zhan, Y.; Zhang, J.; Hong, Z.; Wu, L.; Li, P.; Guo, S. A survey of incentive mechanism design for federated learning. IEEE Trans. Emerg. Top. Comput. 2021, 10, 1035–1044. [Google Scholar] [CrossRef]
- Tu, X.; Zhu, K.; Luong, N.C.; Niyato, D.; Zhang, Y.; Li, J. Incentive mechanisms for federated learning: From economic and game theoretic perspective. IEEE Trans. Cogn. Commun. Netw. 2022, 8, 1566–1593. [Google Scholar] [CrossRef]
- Zeng, R.; Zhang, S.; Wang, J.; Chu, X. Fmore: An incentive scheme of multi-dimensional auction for federated learning in mec. In Proceedings of the 2020 IEEE 40th International Conference on Distributed Computing Systems (ICDCS), Singapore, 29 November–1 December 2020; pp. 278–288. [Google Scholar]
- Zeng, R.; Zeng, C.; Wang, X.; Li, B.; Chu, X. A comprehensive survey of incentive mechanism for federated learning. arXiv 2021, arXiv:2106.15406. [Google Scholar]
- Feng, S.; Niyato, D.; Wang, P.; Kim, D.I.; Liang, Y.C. Joint service pricing and cooperative relay communication for federated learning. In Proceedings of the 2019 International Conference on Internet of Things (iThings) and IEEE Green Computing and Communications (GreenCom) and IEEE Cyber, Physical and Social Computing (CPSCom) and IEEE Smart Data (SmartData), Atlanta, GA, USA, 14–17 July 2019; pp. 815–820. [Google Scholar]
- Jiao, Y.; Wang, P.; Niyato, D.; Lin, B.; Kim, D.I. Toward an automated auction framework for wireless federated learning services market. IEEE Trans. Mob. Comput. 2020, 20, 3034–3048. [Google Scholar] [CrossRef]
- Kang, J.; Xiong, Z.; Niyato, D.; Lin, B.; Kim, D.I. Incentive mechanism for reliable federated learning: A joint optimization approach to combining reputation and contract theory. IEEE Internet Things J. 2019, 6, 10700–10714. [Google Scholar] [CrossRef]
- Shehada, D.; Gawanmeh, A.; Yeun, C.Y.; Zemerly, M.J. Fog-based distributed trust and reputation management system for internet of things. J. King Saud-Univ.-Comput. Inf. Sci. 2022, 34, 8637–8646. [Google Scholar] [CrossRef]
- Din, I.U.; Awan, K.A.; Almogren, A.; Kim, B.S. ShareTrust: Centralized trust management mechanism for trustworthy resource sharing in industrial Internet of Things. Comput. Electr. Eng. 2022, 100, 108013. [Google Scholar] [CrossRef]
- Zhao, Y.; Li, M.; Lai, L.; Suda, N.; Civin, D.; Chandra, V. Federated learning with non-iid data. arXiv 2018, arXiv:1806.00582. [Google Scholar] [CrossRef]
- Shayan, M.; Fung, C.; Yoon, C.J.M.; Beschastnikh, I. Biscotti: A ledger for private and secure peer-to-peer machine learning. arXiv 2018, arXiv:1811.09904. [Google Scholar]
- Fung, C.; Yoon, C.J.M.; Beschastnikh, I. Mitigating sybils in federated learning poisoning. arXiv 2018, arXiv:1808.04866. [Google Scholar]
- Sheugh, L.; Alizadeh, S.H. A note on pearson correlation coefficient as a metric of similarity in recommender system. In Proceedings of the 2015 AI & Robotics (IRANOPEN), Qazvin, Iran, 12 April 2015; pp. 1–6. [Google Scholar]
- Yang, M.; Hu, X.X.; Zhang, Q.H.; Wei, J.H.; Liu, W.F. Federated learning scheme for mobile network based on reputation evaluation mechanism and blockchain. Chin. J. Netw. Inf. Secur. 2021, 7, 99–112. [Google Scholar]
- Tran, N.H.; Bao, W.; Zomaya, A.; Nguyen, M.N.; Hong, C.S. Federated learning over wireless networks: Optimization model design and analysis. In Proceedings of the IEEE INFOCOM 2019—IEEE Conference on Computer Communications, Paris, France, 29 April–2 May 2019; pp. 1387–1395. [Google Scholar]
- Kang, J.; Xiong, Z.; Niyato, D.; Yu, H.; Liang, Y.C.; Kim, D.I. Incentive design for efficient federated learning in mobile networks: A contract theory approach. In Proceedings of the 2019 IEEE VTS Asia Pacific Wireless Communications Symposium (APWCS), Singapore, 28–30 August 2019; pp. 1–5. [Google Scholar]
- Van Hasselt, H.; Guez, A.; Silver, D. Deep reinforcement learning with double q-learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; Volume 30. [Google Scholar]
- Wang, Z.; Schaul, T.; Hessel, M.; Lanctot, M.; Freitas, N. Dueling network architectures for deep reinforcement learning. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; PMLR: New York, NY, USA, 2016; pp. 1995–2003. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Hsu, T.M.H.; Qi, H.; Brown, M. Measuring the effects of non-identical data distribution for federated visual classification. arXiv 2019, arXiv:1909.06335. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | Main Technique | Features | Limitations |
|---|---|---|---|
| [9] | Stackelberg game |
|
|
| [10] | Reverse auction |
|
|
| [11] | Contract theory |
|
|
| Parameter | Setting |
|---|---|
| Learning rate | |
| Training batch size | batch_size = 64 |
| The number of local iteration epochs | |
| The number of global iteration epochs | |
| The number of CPU cycles to execute one data sample in local training | |
| The CPU operating frequency of client | |
| The effective capacitance parameter of the client’s computational chipset | |
| The energy consumption of uploading local model updates for all clients | |
| The energy consumption weight parameter for client | |
| The satisfaction weight parameter on the accuracy of the global model |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xiong, A.; Chen, Y.; Chen, H.; Chen, J.; Yang, S.; Huang, J.; Li, Z.; Guo, S. A Truthful and Reliable Incentive Mechanism for Federated Learning Based on Reputation Mechanism and Reverse Auction. Electronics 2023, 12, 517. https://doi.org/10.3390/electronics12030517
Xiong A, Chen Y, Chen H, Chen J, Yang S, Huang J, Li Z, Guo S. A Truthful and Reliable Incentive Mechanism for Federated Learning Based on Reputation Mechanism and Reverse Auction. Electronics. 2023; 12(3):517. https://doi.org/10.3390/electronics12030517
Chicago/Turabian StyleXiong, Ao, Yu Chen, Hao Chen, Jiewei Chen, Shaojie Yang, Jianping Huang, Zhongxu Li, and Shaoyong Guo. 2023. "A Truthful and Reliable Incentive Mechanism for Federated Learning Based on Reputation Mechanism and Reverse Auction" Electronics 12, no. 3: 517. https://doi.org/10.3390/electronics12030517
APA StyleXiong, A., Chen, Y., Chen, H., Chen, J., Yang, S., Huang, J., Li, Z., & Guo, S. (2023). A Truthful and Reliable Incentive Mechanism for Federated Learning Based on Reputation Mechanism and Reverse Auction. Electronics, 12(3), 517. https://doi.org/10.3390/electronics12030517