
Vehicle Simulation Algorithm for Observations with Variable Dimensions Based on Deep Reinforcement Learning

Abstract
:1. Introduction
2. Related Work
2.1. Vehicle Simulation
2.2. Reinforcement Learning
2.3. Deep Q-Learning
3. Methods
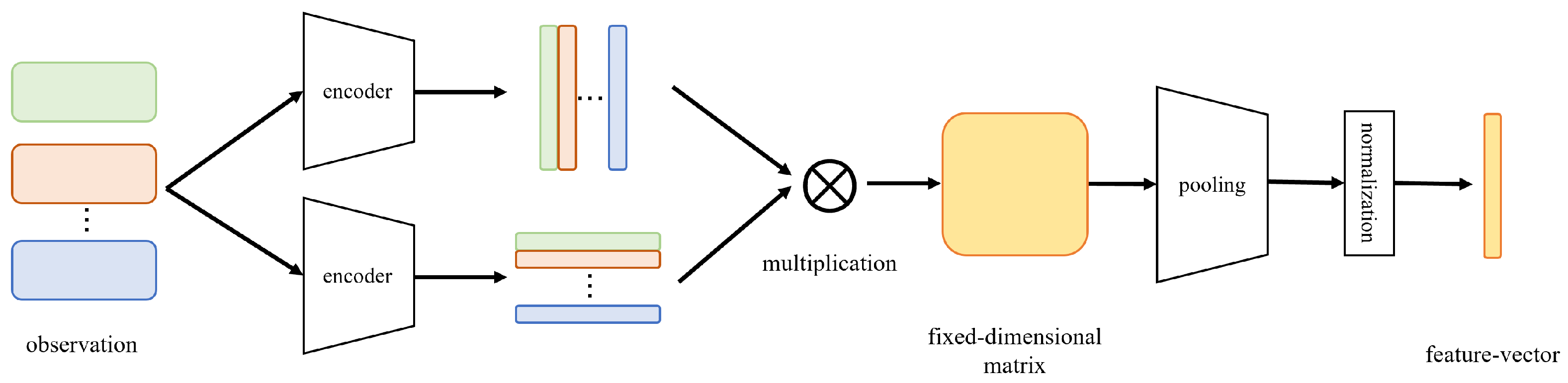
3.1. Variable-Dimensional Observation Processing Network
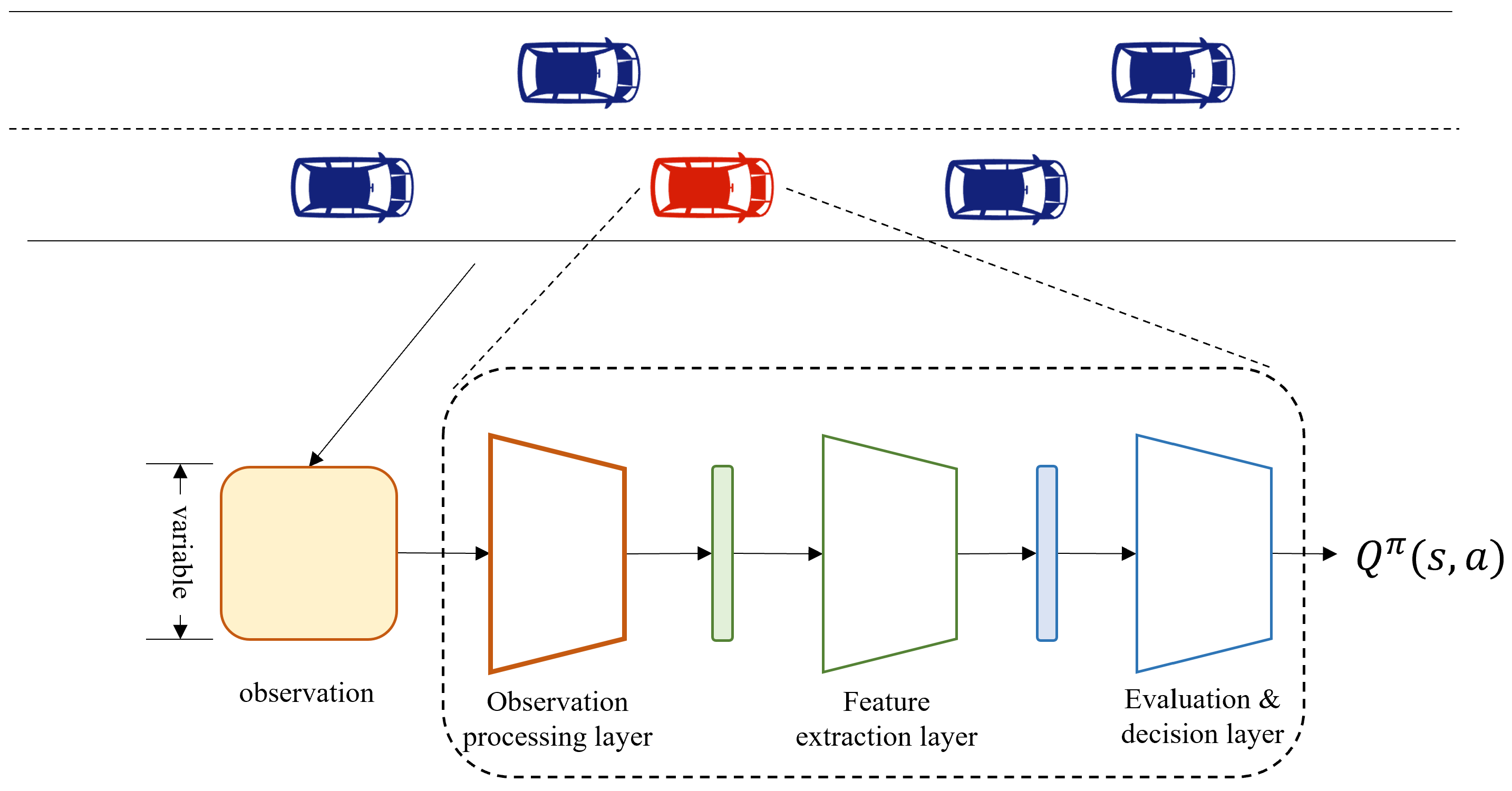
3.2. Decision Networks and Vehicle Simulation Algorithm
- (1)
- Purpose: Vehicles typically aim to reach a predefined destination, such as a specific exit at an intersection or a particular location on the road.
- (2)
- Velocity: Vehicles want to arrive at their destination as quickly as possible by increasing their driving speed.
- (3)
- Safety: Vehicles always strive to avoid collisions with other vehicles.
- (1)
- Purpose reward: If the target vehicle reaches its destination, it will receive the purpose reward.
- (2)
- Velocity reward: At each timestep, the target vehicle will receive a velocity reward related to its driving speed.
- (3)
- Collision reward (penalty): If the target vehicle collides with other vehicles, it will incur a collision reward (penalty).
- (1)
- Observation Processing Layer: The purpose of this layer is to map the input observations, which may vary in specific dimensions, to fixed-dimensional feature matrices. The fixed-dimensional matrices will be provided to downstream networks. In this paper, we employ the variable-dimensional observation processing network proposed in Section 3.1.
- (2)
- Feature Extraction Layer: The aim of the feature extraction layer is to extract the underlying information in the fixed-dimensional feature matrices to assist the downstream network in evaluating the expected rewards. A single-layer linear network is used to achieve this goal.
- (3)
- Evaluation & Decision Layer: The purpose of this layer is to estimate the reward the vehicle can gain after choosing each action in the current environmental state based on the input features. With the help of value estimation, the vehicle can always greedily select the action with the highest expected reward, in line with the goals encouraged by the rewards. A multi-layer perceptron is employed in this model for evaluating the actions.
| Algorithm 1: Deep Neural Network Model | |
| Data: Current observation of vehicle | |
| Result: Estimated value of each action | |
| 1 | Initialize the following network: , , ; |
| 2 | Map observations to the specified feature space: ; |
| 3 | Multiply matrices: . Pool and normalize the fixed-dimensional matrices into input feature vectors: ; |
| 4 | Extract features of input vectors: ; |
| 5 | Calculate reward expectations for each action through evaluation layer: |
| Algorithm 2: Training Algorithm for Deep Neural Network | |
| Data: Simulation environment | |
| Result: A deep neural network model based on environment | |
| 1 | #training phase; |
| 2 | Initialize the experience replay buffer and parameter of model; |
| 3 | while training do |
 | |
| 15 | end |
| Algorithm 3: Simulation Algorithm | |
| Data: Simulation environment | |
| Result: Simulated trajectory of vehicle | |
| 1 | Initialize the simulation environment; |
| 2 | while This round of simulation has not terminated do |
 | |
| 5 | end |
4. Experiments
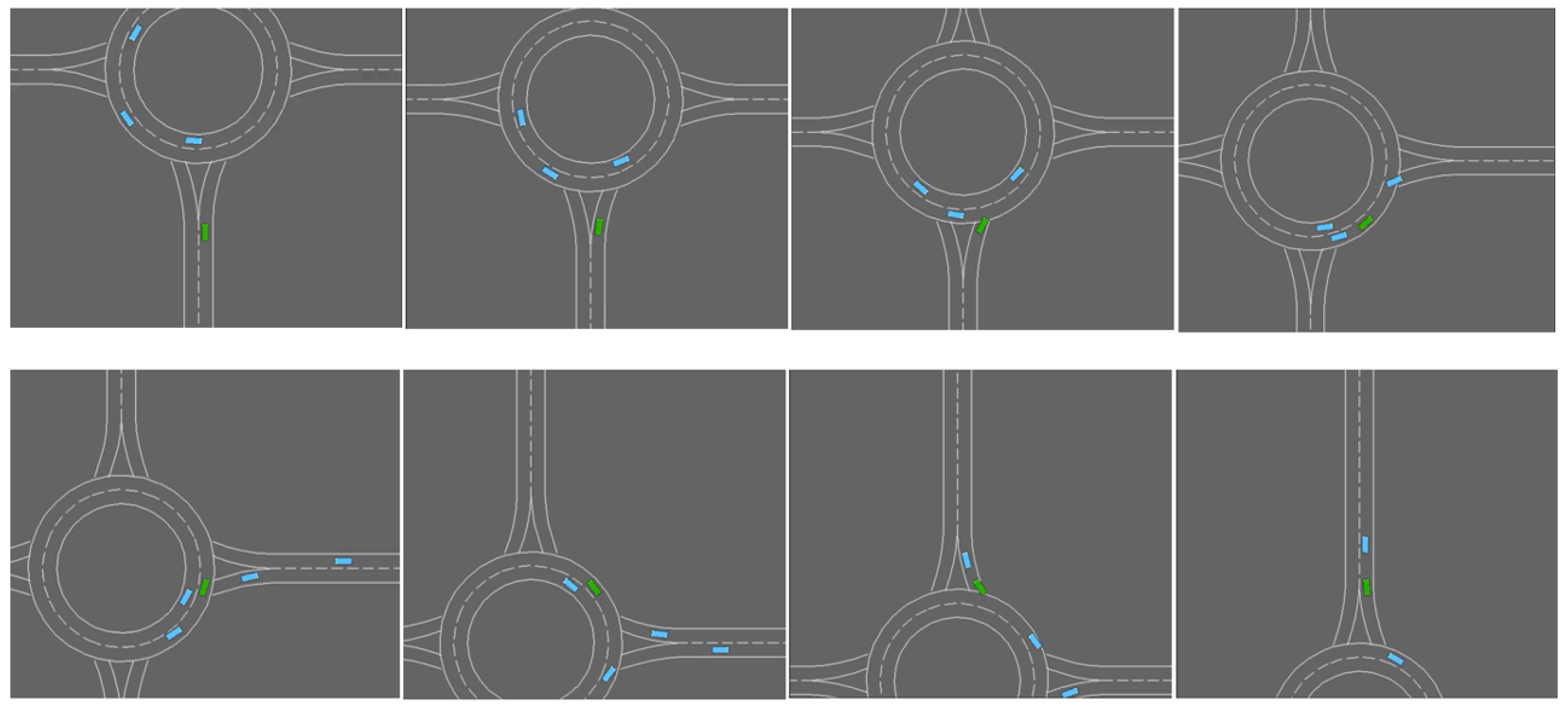
4.1. Experimental Environment and Setting
- (1)
- Learning rate: . The learning rate determines the update extent to the parameters of the neural network at each step based on the loss function during the training process. A higher learning rate leads to larger parameter updates per iteration, making it less likely to get stuck in local optima; however, stability becomes a challenge, and vice versa. To strike a balance, we opted for the value of which is commonly used in most reinforcement learning models.
- (2)
- Replay buffer capacity: 15,000. The capacity of the replay buffer determines the number of tuples it can store. When the number of stored tuples reaches the limit, the earliest data in the buffer are replaced by the most recently obtained data. A larger capacity means data can be stored in the buffer for a longer interval. This provides a greater quantity of diverse data but also leads to lower policy consistency, and vice versa. Since the value-based methods employed in this paper require a considerable amount of data for training and necessitate diverse data for a comprehensive environmental assessment, we chose a larger capacity for the replay buffer.
- (3)
- Discount factor: 0.8. The discount factor determines the model’s emphasis on future rewards. A higher discount factor means that future rewards have a larger value at the current timestep, indicating a greater emphasis on future rewards, and vice versa. The traffic simulation problem can be considered a Markov decision process with evenly distributed rewards. Vehicles should focus more on the reward of the current timestep. To achieve this goal, a relatively lower discount factor should be selected.
- (4)
- Target network update interval: 50. The target network update interval determines the frequency at which the target network synchronizes with the source network. A larger interval leads to a lower synchronization frequency, resulting in more stable training but also in poorer consistency between the target and source networks, and vice versa. With the aim of balancing stability and consistency during the training process, the update interval is set to a moderately averaged value.
4.2. Feasibility Verification
4.3. Comparative Analysis
5. Conclusions and Discussion
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Dawood, N.N.; Castro, S.S. Automating road construction planning with a specific-domain simulation system. J. Inf. Technol. Constr. 2009, 1, 556–573. [Google Scholar]
- Gambardella, L.M.; Rizzoli, A.E.; Funk, P. Agent-based planning and simulation of combined rail/road transport. Simulation 2002, 78, 293–303. [Google Scholar] [CrossRef]
- Wang, J.; Yan, Y.; Zhang, K.; Chen, Y.; Cao, M.; Yin, G. Path planning on large curvature roads using driver-vehicle-road system based on the kinematic vehicle model. IEEE Trans. Veh. Technol. 2021, 71, 311–325. [Google Scholar] [CrossRef]
- Aycin, M.; Benekohal, R. Comparison of car-following models for simulation. Transp. Res. Rec. 1999, 1678, 116–127. [Google Scholar] [CrossRef]
- Li, Y.; Sun, D. Microscopic car-following model for the traffic flow: The state of the art. J. Control Theory Appl. 2012, 10, 133–143. [Google Scholar] [CrossRef]
- Wang, J.; Lv, W.; Jiang, Y.; Qin, S.; Li, J. A multi-agent based cellular automata model for intersection traffic control simulation. Phys. A Stat. Mech. Its Appl. 2021, 584, 126356. [Google Scholar] [CrossRef]
- Krajzewicz, D.; Brockfeld, E.; Mikat, J.; Ringel, J.; Rössel, C.; Tuchscheerer, W.; Wagner, P.; Wösler, R. Simulation of modern traffic lights control systems using the open source traffic simulation SUMO. In Proceedings of the 3rd Industrial Simulation Conference 2005, EUROSIS-ETI, Berlin, Germany, 9–11 June 2005; pp. 299–302. [Google Scholar]
- Gipps, P.G. A behavioural car-following model for computer simulation. Transp. Res. Part B Methodol. 1981, 15, 105–111. [Google Scholar] [CrossRef]
- Koukounaris, A.I.; Stephanedes, Y.J. Connected Intelligent Transportation System Model to Minimize Societal Cost of Travel in Urban Networks. Sustainability 2023, 15, 15383. [Google Scholar] [CrossRef]
- Zhao, X.M.; Gao, Z.Y. A new car-following model: Full velocity and acceleration difference model. Eur. Phys. J. B-Condens. Matter Complex Syst. 2005, 47, 145–150. [Google Scholar] [CrossRef]
- Saifuzzaman, M.; Zheng, Z. Incorporating human-factors in car-following models: A review of recent developments and research needs. Transp. Res. Part C Emerg. Technol. 2014, 48, 379–403. [Google Scholar] [CrossRef]
- Ranjitkar, P.; Nakatsuji, T.; Kawamua, A. Car-following models: An experiment based benchmarking. J. East. Asia Soc. Transp. Stud. 2005, 6, 1582–1596. [Google Scholar]
- Shokri, D.; Larouche, C.; Homayouni, S. A Comparative Analysis of Multi-Label Deep Learning Classifiers for Real-Time Vehicle Detection to Support Intelligent Transportation Systems. Smart Cities 2023, 6, 2982–3004. [Google Scholar] [CrossRef]
- Wang, X.; Yang, Z.; Feng, H.; Zhao, J.; Shi, S.; Cheng, L. A Multi-Stream Attention-Aware Convolutional Neural Network: Monitoring of Sand and Dust Storms from Ordinary Urban Surveillance Cameras. Remote Sens. 2023, 15, 5227. [Google Scholar] [CrossRef]
- Alsrehin, N.O.; Gupta, M.; Alsmadi, I.; Alrababah, S.A. U2-Net: A Very-Deep Convolutional Neural Network for Detecting Distracted Drivers. Appl. Sci. 2023, 13, 11898. [Google Scholar] [CrossRef]
- Wang, N.; Zhang, B.; Gu, J.; Kong, H.; Hu, S.; Lu, S. Urban Road Traffic Spatiotemporal State Estimation Based on Multivariate Phase Space–LSTM Prediction. Appl. Sci. 2023, 13, 12079. [Google Scholar] [CrossRef]
- Jin, Z.; Noh, B. From prediction to prevention: Leveraging deep learning in traffic accident prediction systems. Electronics 2023, 12, 4335. [Google Scholar] [CrossRef]
- Bowman, L.A.; Narayanan, R.M.; Kane, T.J.; Bradley, E.S.; Baran, M.S. Vehicle Detection and Attribution from a Multi-Sensor Dataset Using a Rule-Based Approach Combined with Data Fusion. Sensors 2023, 23, 8811. [Google Scholar] [CrossRef]
- Manderna, A.; Kumar, S.; Dohare, U.; Aljaidi, M.; Kaiwartya, O.; Lloret, J. Vehicular Network Intrusion Detection Using a Cascaded Deep Learning Approach with Multi-Variant Metaheuristic. Sensors 2023, 23, 8772. [Google Scholar] [CrossRef]
- Liu, G.; He, S.; Han, X.; Luo, Q.; Du, R.; Fu, X.; Zhao, L. Self-Supervised Spatiotemporal Masking Strategy-Based Models for Traffic Flow Forecasting. Symmetry 2023, 15, 2002. [Google Scholar] [CrossRef]
- Zhu, M.; Wang, X.; Wang, Y. Human-like autonomous car-following model with deep reinforcement learning. Transp. Res. Part C Emerg. Technol. 2018, 97, 348–368. [Google Scholar] [CrossRef]
- Wei, H.; Zheng, G.; Yao, H.; Li, Z. Intellilight: A reinforcement learning approach for intelligent traffic light control. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 2496–2505. [Google Scholar]
- Chinchali, S.; Hu, P.; Chu, T.; Sharma, M.; Bansal, M.; Misra, R.; Pavone, M.; Katti, S. Cellular network traffic scheduling with deep reinforcement learning. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- François-Lavet, V.; Henderson, P.; Islam, R.; Bellemare, M.G.; Pineau, J. An introduction to deep reinforcement learning. Found. Trends® Mach. Learn. 2018, 11, 219–354. [Google Scholar] [CrossRef]
- Henderson, P.; Islam, R.; Bachman, P.; Pineau, J.; Precup, D.; Meger, D. Deep reinforcement learning that matters. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Dai, X.; Li, C.K.; Rad, A.B. An approach to tune fuzzy controllers based on reinforcement learning for autonomous vehicle control. IEEE Trans. Intell. Transp. Syst. 2005, 6, 285–293. [Google Scholar] [CrossRef]
- Yurtsever, E.; Lambert, J.; Carballo, A.; Takeda, K. A survey of autonomous driving: Common practices and emerging technologies. IEEE Access 2020, 8, 58443–58469. [Google Scholar] [CrossRef]
- Liu, L.; Lu, S.; Zhong, R.; Wu, B.; Yao, Y.; Zhang, Q.; Shi, W. Computing systems for autonomous driving: State of the art and challenges. IEEE Internet Things J. 2020, 8, 6469–6486. [Google Scholar] [CrossRef]
- Liu, H.; Kiumarsi, B.; Kartal, Y.; Taha Koru, A.; Modares, H.; Lewis, F.L. Reinforcement learning applications in unmanned vehicle control: A comprehensive overview. Unmanned Syst. 2023, 11, 17–26. [Google Scholar] [CrossRef]
- Ma, X.; Driggs-Campbell, K.; Kochenderfer, M.J. Improved robustness and safety for autonomous vehicle control with adversarial reinforcement learning. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 June 2018; pp. 1665–1671. [Google Scholar]
- Alghodhaifi, H.; Lakshmanan, S. Autonomous vehicle evaluation: A comprehensive survey on modeling and simulation approaches. IEEE Access 2021, 9, 151531–151566. [Google Scholar] [CrossRef]
- Yang, Q.I.; Koutsopoulos, H.N. A microscopic traffic simulator for evaluation of dynamic traffic management systems. Transp. Res. Part C Emerg. Technol. 1996, 4, 113–129. [Google Scholar] [CrossRef]
- Adams, S.; Yu, L. An Evaluation of Traffic Simulation Models for Supporting Its Development; Technical Report; Center for Transportation Training and Research, Texas Southern University: Houston, TX, USA, 2000. [Google Scholar]
- Ruskin, H.J.; Wang, R. Modeling traffic flow at an urban unsignalized intersection. In Proceedings of the Computational Science—ICCS 2002: International Conference, Amsterdam, The Netherlands, 21–24 April 2002; Springer: Berlin/Heidelberg, Germany, 2002; pp. 381–390. [Google Scholar]
- Reece, D.A.; Shafer, S.A. A computational model of driving for autonomous vehicles. Transp. Res. Part A Policy Pract. 1993, 27, 23–50. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 1998; Volume 22447. [Google Scholar]
- Russell, S.J.; Norvig, P. Artificial Intelligence a Modern Approach; Prentice Hall: London, UK, 2010. [Google Scholar]
- Puterman, M.L. Markov Decision Processes: Discrete Stochastic Dynamic Programming; John Wiley & Sons: Hoboken, NJ, USA, 2014. [Google Scholar]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal policy optimization algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing atari with deep reinforcement learning. arXiv 2013, arXiv:1312.5602. [Google Scholar]
- Bellman, R. On the theory of dynamic programming. Proc. Natl. Acad. Sci. USA 1952, 38, 716–719. [Google Scholar] [CrossRef] [PubMed]
- Whiteson, S. A Theoretical and Empirical Analysis of Expected Sarsa. In Proceedings of the 2009 IEEE Symposium on Adaptive Dynamic Programming and Reinforcement Learning, Nashville, TN, USA, 30 March–2 April 2009. [Google Scholar]
- Watkins, C.J.C.H. Learning from Delayed Rewards. Ph.D. Thesis, Cambridge University, Cambridge, UK, 1989. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- Hausknecht, M.; Stone, P. Deep recurrent q-learning for partially observable mdps. In Proceedings of the 2015 AAAI Fall Symposium Series, Arlington, VA, USA, 12–14 November 2015. [Google Scholar]
- Tesauro, G. Temporal difference learning and TD-Gammon. Commun. ACM 1995, 38, 58–68. [Google Scholar] [CrossRef]
- Hu, Q.; Yue, W. Markov Decision Processes with Their Applications; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2007; Volume 14. [Google Scholar]
- Schaul, T.; Quan, J.; Antonoglou, I.; Silver, D. Prioritized experience replay. arXiv 2015, arXiv:1511.05952. [Google Scholar]
- Leurent, E. An Environment for Autonomous Driving Decision-Making. 2018. Available online: https://github.com/eleurent/highway-env (accessed on 28 April 2018).
- Brockman, G.; Cheung, V.; Pettersson, L.; Schneider, J.; Schulman, J.; Tang, J.; Zaremba, W. OpenAI Gym. arXiv 2016, arXiv:1606.01540. [Google Scholar]
- Raffin, A.; Hill, A.; Gleave, A.; Kanervisto, A.; Ernestus, M.; Dormann, N. Stable-Baselines3: Reliable Reinforcement Learning Implementations. J. Mach. Learn. Res. 2021, 22, 12348–12355. [Google Scholar]
- Sunehag, P.; Lever, G.; Gruslys, A.; Czarnecki, W.M.; Zambaldi, V.; Jaderberg, M.; Lanctot, M.; Sonnerat, N.; Leibo, J.Z.; Tuyls, K.; et al. Value-decomposition networks for cooperative multi-agent learning. arXiv 2017, arXiv:1706.05296. [Google Scholar]
- Rashid, T.; Samvelyan, M.; De Witt, C.S.; Farquhar, G.; Foerster, J.; Whiteson, S. Monotonic value function factorisation for deep multi-agent reinforcement learning. J. Mach. Learn. Res. 2020, 21, 7234–7284. [Google Scholar]
- Pan, X.; You, Y.; Wang, Z.; Lu, C. Virtual to real reinforcement learning for autonomous driving. arXiv 2017, arXiv:1704.03952. [Google Scholar]
- Kiran, B.R.; Sobh, I.; Talpaert, V.; Mannion, P.; Al Sallab, A.A.; Yogamani, S.; Pérez, P. Deep reinforcement learning for autonomous driving: A survey. IEEE Trans. Intell. Transp. Syst. 2021, 23, 4909–4926. [Google Scholar] [CrossRef]
- Taylor, M.E.; Stone, P. Transfer learning for reinforcement learning domains: A survey. J. Mach. Learn. Res. 2009, 10, 1633–1685. [Google Scholar]
- Da Silva, F.L.; Costa, A.H.R. A survey on transfer learning for multiagent reinforcement learning systems. J. Artif. Intell. Res. 2019, 64, 645–703. [Google Scholar] [CrossRef]
- Kaushik, M.; Singhania, N.; Krishna, K.M. Parameter sharing reinforcement learning architecture for multi agent driving. In Proceedings of the Advances in Robotics, Chennai, India, 2–6 July 2019; pp. 1–7. [Google Scholar]
- Comanici, G.; Precup, D.; Barreto, A.; Toyama, D.K.; Aygün, E.; Hamel, P.; Vezhnevets, S.; Hou, S.; Mourad, S. Knowledge Representation for Reinforcement Learning Using General Value Functions. 2018; openreview. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Name | Dimension | Activation Function |
|---|---|---|---|
| Observation Processing Layer | ReLU | ||
| ReLU | |||
| Feature Extraction Layer | ReLU | ||
| Evaluation & Decision Layer | - |
| Layer | Name | Dimension | Activation Function |
|---|---|---|---|
| Feature Extraction Layer | ReLU | ||
| ReLU | |||
| Evaluation & Decision Layer | - |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Y.; Zhang, R.; Zhou, S. Vehicle Simulation Algorithm for Observations with Variable Dimensions Based on Deep Reinforcement Learning. Electronics 2023, 12, 5029. https://doi.org/10.3390/electronics12245029
Liu Y, Zhang R, Zhou S. Vehicle Simulation Algorithm for Observations with Variable Dimensions Based on Deep Reinforcement Learning. Electronics. 2023; 12(24):5029. https://doi.org/10.3390/electronics12245029
Chicago/Turabian StyleLiu, Yunzhuo, Ruoning Zhang, and Shijie Zhou. 2023. "Vehicle Simulation Algorithm for Observations with Variable Dimensions Based on Deep Reinforcement Learning" Electronics 12, no. 24: 5029. https://doi.org/10.3390/electronics12245029
APA StyleLiu, Y., Zhang, R., & Zhou, S. (2023). Vehicle Simulation Algorithm for Observations with Variable Dimensions Based on Deep Reinforcement Learning. Electronics, 12(24), 5029. https://doi.org/10.3390/electronics12245029