1. Introduction
The ocean plays a pivotal role in modern development, where the exploration and exploitation of marine resources are intrinsically linked to technological advancements [
1]. In this context, underwater imaging is a critical component, especially in navigation tasks that require precise and reliable visual information. However, the unique properties of seawater present significant challenges in capturing high-quality images. Common issues include blurred details, low contrast, color distortions, poor clarity, and uneven illumination, all of which hinder effective marine exploration and navigation [
2].
Underwater navigation tasks, such as Autonomous Underwater Vehicle (AUV) operation, seabed mapping, and environmental monitoring, depend heavily on the quality of captured images [
3]. Clear and accurate visual information is essential for obstacle avoidance, path planning, and data collection. In these scenarios, the specific imaging elements such as spatial resolution, color fidelity, and contrast levels become crucial. Enhanced imaging not only improves the visual quality but also aids in better interpreting the underwater environment, which is vital for safe and efficient navigation.
Traditional underwater image enhancement techniques have largely been dependent on physical models or adaptations of existing image enhancement algorithms. Techniques like histogram stretching and filtering, though effective in some scenarios, often fall short in addressing the complex optical properties of water. These methods, while enhancing certain aspects of an image, may inadvertently compromise others, such as darkening image details, thus failing to holistically improve underwater image quality.
The field has seen significant advancements with the introduction of sophisticated model-based methods by researchers like Peng et al. [
4], Ancuti et al. [
5], and Jobson et al. [
6]. These approaches, while innovative, often require intricate parameter estimations, making them less feasible in dynamic underwater environments.
The advent of deep learning-based underwater image enhancement methods marked a significant paradigm shift. Techniques like Li et al.’s Water Cycle-GAN [
7] and Guo et al.’s Dense GAN [
8] have introduced new dimensions in image processing, catering to the specific challenges of underwater imaging. These methods integrate advanced image processing techniques with deep learning architectures, aiming to overcome the limitations of traditional methods and enhance crucial imaging elements for navigation tasks.
Despite these advancements, a common limitation persists: many models apply generic deep network architectures without adequately addressing the distinct characteristics of underwater scenes. This oversight often results in a lack of robustness and limited generalization capabilities, hindering their practical application in real-world navigation scenarios.Addressing this, our research introduces a new method based on color feature fusion that is specifically designed for underwater image enhancement. This approach considers the distinct optical properties of water and the specific requirements of underwater navigation tasks, such as clarity in object identification and accuracy in spatial representation.
We have rigorously tested our method using the EUVP [
9] and UIEB [
10] underwater image datasets, demonstrating its superiority over existing techniques in enhancing crucial imaging elements for navigation tasks. Furthermore, our algorithm’s robustness has been validated through object detection tasks on enhanced and unenhanced images from an underwater object detection dataset. The results clearly indicate that images enhanced with our proposed method significantly improve performance in underwater navigation tasks, underscoring its potential in advancing the field of marine exploration and technology.
We will further explain the underwater image enhancement based on color feature fusion proposed in this paper.
Section 2, titled ‘Related Work’, offers a comprehensive review of current methodologies in this domain, classifying them into traditional image processing, physical model-based approaches, and deep learning techniques.
Section 3, ‘Overall Network Structure’, introduces our novel network architecture, detailing its three integral components and emphasizing its unique strategy for enhancing underwater images.
Section 4 provides a discussion of the ‘Multi-Channel Feature Extraction Module’, elucidating our method of assigning distinct receptive fields to different color channels for more effective feature extraction. In
Section 5, ‘Residual Enhancement Module Incorporating Attention Mechanism’, we discuss how the integration of the Convolutional Block Attention Module (CBAM) refines features by merging channel-specific information with attention-driven residual connections.
Section 6 focuses on the ‘Dynamic Feature Enhancement Module’, highlighting its use of deformable convolutions to adaptively augment feature extraction, thus addressing the constraints of traditional fixed-size kernels in underwater image processing.
Section 7 delineates the ‘Loss Function’ employed in model training, which combines Mean Square Error and VGG Perceptual Loss functions to ensure edge sharpness and the preservation of high-frequency details in the enhanced images.
Section 8, ‘Experimental Results and Analysis’, evaluates our proposed method, showcasing its superior performance through quantitative metrics and visual comparisons with existing algorithms across various datasets. Lastly,
Section 9, ‘Conclusions’, synthesizes the key findings and contributions of this research.
2. Related Work
The absorption and scattering of light by water bodies typically result in underwater images having low contrast, color distortion, and blurriness. To address these challenges, current approaches to underwater image enhancement can be primarily divided into three categories: methods based on traditional image processing, methods based on physical models, and methods based on deep learning.
2.1. Methods Based on Traditional Image Processing
These algorithms generally apply common techniques from digital image processing, including histogram equalization, color correction, and filtering. They directly adjust the pixel values of the image to enhance its quality. Histogram Equalization [
11], a typical image enhancement method, was introduced by Hu et al. in 1977. It adjusts the tonal distribution of an image to produce an output with more uniformly distributed pixels. Building on this, Pizer et al. [
12] proposed an Adaptive Histogram Equalization method. It emphasizes algorithmic improvements, such as contrast limiting and pixel weighting, to optimize image quality while mitigating noise amplification, particularly in medical imaging applications. Kim et al. [
13] introduced Local Histogram Equalization, focusing on technical enhancements like speed optimization and noise reduction.
In 1971, Land et al., based on human visual perception of color, proposed the Retinex method [
14], which achieves color constancy through the estimation of scene illumination. Rahman et al. developed a MultiScale Retinex algorithm [
15], which is a weighted average of single-scale Retinex methods at different scales. Jobson et al. introduced the MultiScale Retinex with Color Restoration [
6], balancing the relationship between color distortion and image detail to enhance the quality of underwater images. Images processed with the Retinex algorithm exhibit higher local contrast and brightness levels similar to the actual scene, making them appear more realistic to human perception.
Ancuti et al. [
5] were the pioneers in proposing an underwater image enhancement algorithm based on multiscale fusion. They employed white balancing and contrast enhancement algorithms to process underwater videos, effectively addressing the issue of color distortion in underwater images. Ghani et al. proposed a dual-image adaptive contrast stretching technique that focuses on both the global and local contrast of an image [
16], thereby enhancing the detail in underwater images. Li et al. [
17] introduced a hybrid correction method for underwater images, combining color correction with deblurring tasks. Liu et al. [
18] developed an automatic white balance algorithm that achieved impressive results in image enhancement.
Zhang et al. [
19] introduces an underwater image enhancement method based on an extended Multi-Scale Retinex algorithm, adapting it to address the unique challenges of underwater imaging, such as color distortion and low contrast. This approach utilizes the CIELAB color space and combines bilateral and trilateral filtering techniques to improve the clarity and visual quality of underwater images. Zhang et al. [
20] presents a novel algorithm for enhancing underwater images by employing a color correction method based on fractions and an adaptive contrast enhancement technique utilizing genetic optimization. It further improves image details using a traditional unsharp masking technique, significantly enhancing image quality without relying on deep learning or physical models.
2.2. Methods Based on Physical Models
Methods based on physical models mathematically model the degradation process of underwater images. They estimate parameters based on the model and then use formula inversion to reconstruct the clear image prior to degradation. Drews et al. built upon the Dark Channel Prior (DCP) [
21] concept introduced by He et al., proposing the Underwater Dark Channel Prior (UDCP) [
22]. This approach, which considers only the blue and green channels and ignores the red channel, significantly improves the visibility of underwater images. Song et al. [
23] introduced an Underwater Light Attenuation Prior algorithm, which more accurately estimates the transmission map and background light. Hou et al. [
24] combined the UDCP with a quadtree segmentation method to estimate background light and transmittance, markedly enhancing the clarity of underwater scenes. Yang et al. [
25] developed a novel underwater image restoration model, initially combining DCP with Retinex theory to estimate the transmission map, and then restoring image color based on certain optical properties. This model is capable of producing high-quality underwater images.
2.3. Methods Based on Deep Learning
The rapid advancement in marine exploration and underwater robotics has resulted in an abundance of underwater video and image data. Concurrently, the tremendous success of deep learning in the field of computer vision in recent years has led an increasing number of scholars to apply deep learning techniques to underwater image enhancement tasks. Yeh et al. [
26] proposed an underwater image processing framework trained with multiple Convolutional Neural Networks (CNNs), performing enhancement tasks in stages. The first network converts underwater images into grayscale, the second enhances the grayscale images, and the third corrects the color, with the output of these three networks being merged for the final output. Isola et al. [
27] introduced the pix2pix method for model training, which is a machine learning approach that translates one type of image into another using a conditional Generative Adversarial Network (cGAN). Li et al. [
10] proposed the Water-Net method based on gated fusion, initially processing the input image with white balance, gamma correction, and histogram equalization, followed by generating three confidence maps through a gated fusion network to determine the significance of each feature in the output, and finally merging the three processed images using a U-Net network for the enhanced result. Li et al. [
7] developed a weakly supervised network, training it with a fusion loss function that includes adversarial loss, cycle consistency loss, and structural similarity loss, effectively correcting the colors in underwater images. Guo et al. [
8] designed a new multiscale dense Generative Adversarial Network (Dense GAN) for enhancing underwater images, separating tasks for rendering details and improving overall performance. Islam et al. [
28] introduced the Deep SESR network, designing a multimodal objective function that combines the clarity, color, and global contrast of underwater images. He also proposed a Funie-GAN [
9] method based on Generative Adversarial Networks, combining U-Net networks with the depth of underwater scenes. Naik et al. [
29] proposed Shallow-UWnet, successfully accomplishing underwater image enhancement with a smaller model. Xing et al. [
30] improved upon this, proposing Shallow-UWnet-I, achieving superior performance with an equal amount of parameters. Sharma et al. [
31], considering the underwater environment, designed the Deep WaveNet network, which is applicable for both underwater image enhancement and super-resolution tasks.
3. Overall Network Structure
Most contemporary underwater image enhancement methods grounded in deep learning tend to rely directly on deep Convolutional Neural Networks (CNNs) for feature extraction and model training. However, these often fall short in capturing the intricacies of underwater scenarios, leading to subpar feature extraction. Additionally, some approaches leverage Generative Adversarial Networks (GANs), but these can exhibit training instabilities, especially when grappling with lower-quality underwater scenes.
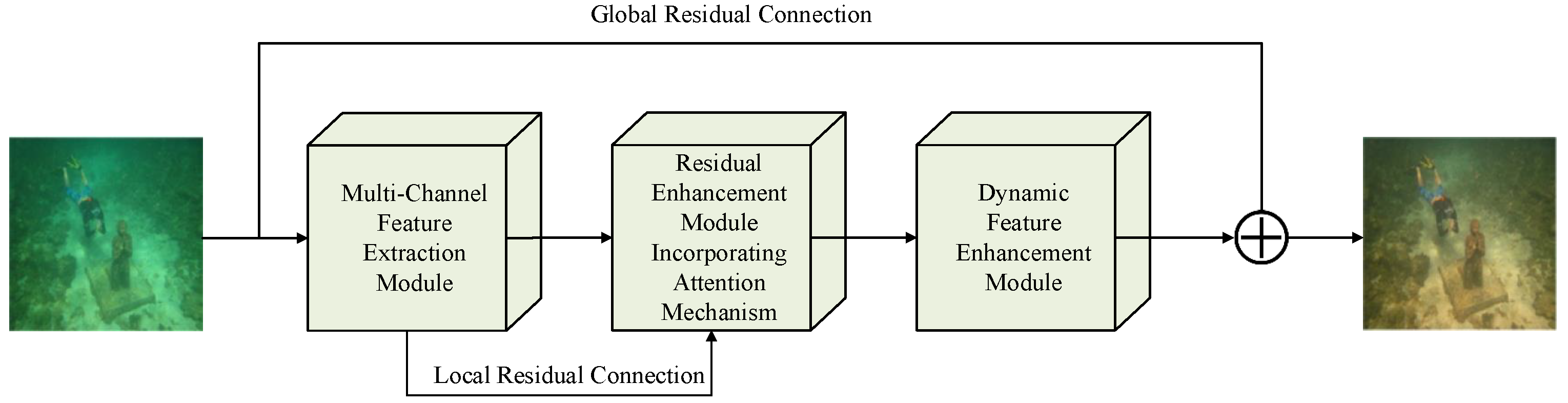
As depicted in
Figure 1, our proposed solution intricately weaves an underwater image enhancement framework rooted in color feature fusion. This architecture unfolds across three interconnected stages:
Global and Local Feature Learning. Acknowledging the nuances of underwater light propagation, varying receptive field sizes are allocated across color channels. This fine-tuning allows the network to adeptly discern both macro and micro-image features. Meanwhile, an enhanced emphasis on dropout layers, replacing many within the Batch Normalization (BN) convolution blocks, optimizes model generalization in challenging visual terrains.
Feature Fusion. This stage hones in on melding features, utilizing skip connections from the prior phase to generate channel-specific residuals. The integration of the Convolutional Block Attention Module (CBAM) refines each channel’s details, meticulously fine tuning the channel-specific residuals.
Dynamic Feature Enhancement. Introducing the agile deformable convolution module in this phase ensures a rich tapestry of feature information. The dynamism of its kernels curtails issues like texture erosion or the emergence of smoothing artifacts often associated with static convolution kernels, thereby amplifying the network’s efficacy.
4. Multi-Channel Feature Extraction Module
In neural networks, the term “receptive field” describes the portion of an image that each neuron can access and interpret. A vast receptive field allows neurons to capture a wider span of image areas, which is essential for understanding global and high-level semantic attributes. Conversely, a more confined receptive field focuses on the nuanced, detailed features of an image. This receptive field size is pivotal, shaping the neural network’s learning efficacy and its feature extraction capabilities.
Underwater images frequently exhibit noticeable color distortions, which is primarily due to the selective absorption properties of light in water. Specifically, red light, with its longer wavelength, is absorbed more intensively by seawater than its blue and green counterparts. This results in underwater images predominantly casting a blue or green tint. With this in mind, we introduce a specialized multi-channel feature extraction module for these underwater nuances.
Referencing
Figure 2’s left portion, we divide the input into red, green, and blue channels, symbolized as
,
, and
. Given the blue-dominant nature of underwater images, it is inferred that the blue channel houses expansive global data. Hence, it is allocated a larger receptive field to optimize the extraction of overarching image characteristics with the green channel following suit. The red light, given its significant attenuation underwater, likely holds a wealth of localized information, thereby receiving the most restricted receptive field. This tailored multi-channel strategy ensures a nuanced extraction of each channel’s salient features.
Additionally, in advanced vision models, as the network’s depth amplifies, Batch Normalization (BN) is commonly employed in feature extraction modules, aiding rapid model convergence and staving off overfitting. However, for tasks dealing with lower-quality visuals, there is a stronger inclination to discern and emphasize the image’s unique characteristics to enhance detail rendition. Over-reliance on BN can inadvertently infuse non-essential information, sidelining specific details and undermining performance. While “Dropout” was initially conceptualized to combat overfitting in high-end visual tasks, it is rarely harnessed in low-level visual challenges. A recent study by Kong et al. [
32] has shed light on the value of dropout within these networks. Their findings corroborated that integrating Dropout enhances the expressive capacity of intermediary features and amplifies model adaptability, paving the way for innovative approaches in tasks like image enhancement within low-quality visual domains.
Building upon the aforementioned insights, we devised a feature extraction module specifically tailored for each color channel’s information. As depicted in
Figure 3, convolutional layers with kernel sizes of 3 × 3, 5 × 5, and 7 × 7 are employed to process the red, green, and blue channels, respectively. Notably, we eschew the conventional Batch Normalization (BN) layer in favor of a dropout layer, which is strategically positioned between the convolutional and activation layers. This configuration selectively discards a subset of the features, emphasizing the prominence of essential attributes.
In terms of dropout strategy, the blue channel, enriched with spatial and local nuances due to its 7 × 7 convolution, has its dropout parameter set at its apex to accentuate overarching features. In contrast, the red channel, primarily capturing localized structures via a 3 × 3 convolution, is allocated the most conservative dropout parameter. Furthermore, Kong et al. [
32] established that a dropout parameter surpassing 0.5 could potentially hinder the network’s holistic efficacy. Informed by our empirical tests, we have assigned dropout parameters of 0.4, 0.3, and 0.2 to the blue, green, and red channels, respectively.
To round off the module, the PReLU activation function is adopted. Superior to the traditional ReLU, PReLU introduces a trainable parameter that facilitates a diminutive negative output for sub-zero inputs, effectively mitigating the “dying neuron” phenomenon. Additionally, PReLU’s resilience to data noise and outliers fortifies model training stability [
33].
The above process can be specifically expressed as follows:
In the context provided,
,
, and
denote the features extracted from the red, green, and blue channels, respectively, after passing through the first stage of the network.
,
, and
symbolize convolutional layers with kernel sizes of 3 × 3, 5 × 5, and 7 × 7, respectively. The notations
,
, and
correspond to dropout layers with discard parameters set at 0.2, 0.3, and 0.4, respectively. Meanwhile, PLU represents the PReLU activation function. After fusing these three features along the channel dimension, we obtain the output of the first stage,
. This relationship can be mathematically expressed as:
where ⊗ denotes the fusion of features in the channel dimension.
5. Residual Enhancement Module Incorporating Attention Mechanism
The Convolutional Block Attention Module (CBAM) was proposed by Woo et al. in their work [
34]. It represents an innovative yet straightforward attention mechanism specifically tailored for feed-forward convolutional neural networks. When presented with a feature map, CBAM adaptively discerns channel-wise attention coefficients, emphasizing pivotal features and diminishing irrelevant ones. Such adaptability and precision enable the CBAM to excel with diverse input data, enhancing the model’s performance substantially.
In the context of the multi-channel feature extraction module, the features derived from the red, green, and blue channels are seamlessly fused via channel concatenation, producing the somewhat preliminary feature . To truly capitalize on the advantages of the multi-channel extraction approach, there is a necessity for further refinement. Hence, we introduce an attention-enhanced residual block. By integrating the CBAM attention module and aligning it with residual connections, we endeavor to further refine and optimize the amalgamated feature data.
As depicted in the right portion of
Figure 2, to further refine the intricacies of each channel’s information derived from the initial
feature, we continue to segregate this feature into three distinct pathways using convolutional layers with varying receptive field sizes. Since
encompasses all channel information, the dropout strategy applied here diverges from the one used in the multi-channel feature extraction module. For all three pathways, we set a dropout rate of 0.1. Kong et al. [
32] have already validated this as the optimal rate when incorporating multiple dropout layers within the network. Subsequent to the dropout layer, PReLU is consistently chosen as the activation function. This process can be articulated as shown below:
, , and denote the features of the red, green, and blue channels, respectively, after activation through PReLU. The term represents a dropout layer with a rate of 0.1.
Diverging from many conventional networks, this section does not directly apply the CBAM module to process the features of the three branches. Instead, it opts to combine the individual channel information,
,
, and
, from the first phase using skip connections to generate feature residuals for each branch. Residual connections alleviate the vanishing gradient problem, facilitating easier model training and optimization. Moreover, incorporating single-channel information from the first phase enhances the clarity of the feature information in each branch, bolstering their representational power. The CBAM module is then used to refine the feature residuals of each branch, further distinguishing primary and secondary features, thereby enhancing the model’s learning capacity. The overall process for this part can be depicted as shown below:
where ⊗ denotes the residual connection. After refinement by CBAM, the information from the three branches is fused again along the channel dimension, yielding the outcome for the second phase,
:
6. Dynamic Feature Enhancement Module
Traditional CNN models predominantly utilize convolutional modules with fixed-sized kernels for feature extraction. This conventional approach has an inherent limitation in its restricted receptive field, which inhibits the optimal utilization of structural information within the features. The research highlighted in Xu et al. [
35] suggests that the persistent use of such fixed-size convolutional kernels can lead to texture distortion or the emergence of unwanted artifacts in the image output. To counter this challenge, certain techniques have been developed that use dilated convolutional layers to broaden the receptive field. However, these too can sometimes introduce challenges, such as grid-like artifacts. Moreover, the receptive field’s shape is instrumental in effective image feature extraction, emphasizing the need for dynamic and adaptable convolutional kernels to capture more nuanced information. With this in mind, we propose a Dynamic Feature Enhancement Module that harnesses deformable convolutions. This method allows for a more robust extraction of features in underwater settings, thereby significantly enhancing image quality.
Deformable convolution stands out as a technique wherein the convolutional kernel’s size and position can adapt dynamically based on the input image’s content. In stark contrast to traditional convolutional operations, where the kernel’s attributes are static, deformable convolution introduces an offset to alter the kernel’s sampling pattern. This offset is derived from the input features, which are coupled with another standard convolutional unit operating in parallel. Consequently, the deformable convolutional kernel can adapt in real time, aligning with shifts in image content, facilitating superior feature sampling. Research by Wu et al. showcased the prowess of deformable convolution in atmospheric dehazing, noting a marked improvement in the network’s feature extraction capabilities [
36]. Given that underwater imagery often exhibits inferior quality compared to atmospheric counterparts, the direct application of deformable convolution might not meet expectations due to various image degradation factors. Nonetheless, after proceeding through the second phase’s residual enhancement module, which emphasizes deeper semantic features, deformable convolution is optimally positioned to unleash its full potential in dynamic feature extraction.
The Dynamic Feature Enhancement Module is depicted in
Figure 4. Wu et al. [
36] validated that successive utilization of deformable convolutions can capture a more enriched understanding of the scene. Therefore, for the output result of the second phase,
, this section first applies two layers of deformable convolutions for its processing. Simultaneously, a residual connection is designed to combine features from the standard convolution and the dynamic convolution, thereby obtaining a more diverse set of feature information, resulting in the fused feature,
:
wherein
symbolizes the deformable convolution layer. Upon obtaining the fused features, a global residual connection is introduced, integrating the three-channel information of the input image,
,
, and
. This approach not only elevates the model’s training efficiency but also helps mitigate significant deviations during the training phase by reintroducing the original information. Moreover, to optimize the efficacy of the global residual connection, the divided feature processing method from the residual enhancement module is once again employed. This yields the third phase’s divided features,
,
, and
, as represented by:
Ultimately, the features from the three paths are amalgamated. After this fusion, a
convolution is utilized to adjust dimensions before the output:
7. Loss Function
This section discusses the loss functions used in model training. For tasks in low-quality visual domains, such as image enhancement, it is pivotal not just to maintain edge sharpness and bolster the structural and textural similarity of the image but also to consider how best to preserve the high-frequency details in the image. Overlooking these high-frequency details could lead to the omission of crucial information in the final outcome.
The model in this study employs multiple loss functions for joint training, ensuring that the network’s output closely approximates the reference image. The total loss is computed based on the following two components:
Mean Square Error (MSE) or
Loss. The
loss is computed by calculating the squared sum of differences between the generated and reference images. It can be represented as shown below:
where
represents the enhanced image generated by the network, and
is the corresponding reference image.
VGG Perceptual Loss. Given the high dependency of the
norm-based loss on the reference image, there might be disruptions in training due to poor-quality reference images, especially in underwater image datasets. To address this, a perceptual loss is introduced to help the image retain high-frequency details. This loss is based on the pretrained 19-layer VGG network activated by ReLU. The enhanced image and its corresponding reference image are fed into the last layer of the pretrained VGG network, and the
norm of their differences is computed as the loss function:
where
represents the pretrained VGG19 network model. The model’s overall loss function can be expressed as the weighted sum of these components:
8. Experimental Results and Analysis
8.1. Dataset Selection and Experimental Setup
Datasets are crucial for tasks related to deep learning, and underwater image datasets mainly originate from two methods. One method involves artificial synthesis, using techniques like CycelGAN [
37] to achieve image style transformation. This simulates clear images corresponding to underwater scenes. Such methods are cost effective and suitable for generating large-scale image datasets. The other method involves directly collecting low-quality underwater images from the real world. These images undergo quality enhancement through various traditional image processing techniques, thereby obtaining corresponding reference images. Although this method is more costly, the resulting datasets more accurately reflect the complex information of underwater scenes.
This section employs the EUVP and UIEB datasets for experimentation. The paired dataset of EUVP comprises three subsets. Two of these subsets, amounting to 11,435 paired images, were selected as the training set, while the remaining subset with 515 paired images served as the test set. The UIEB dataset encompasses a total of 890 paired images of which the initial 800 pairs were chosen for training, and the subsequent 90 pairs were used for testing. Additionally, the UIEB dataset contains 60 underwater images that, in the authors’ assessment, present significant challenges. These images lack corresponding reference images but were nonetheless subjected to comparative image enhancement experiments within this study.
8.1.1. Dataset
EUVP Dataset [
9]: This dataset primarily utilizes images captured by Remotely Operated Vehicles (ROVs) and Autonomous Underwater Vehicles (AUVs) equipped with advanced underwater cameras and lighting systems. The images are collected from diverse underwater environments, including deep sea and coastal regions, under various lighting and clarity conditions. The EUVP dataset is characterized by its large number of diverse underwater scenes, which are annotated for tasks like object detection and image enhancement. These are particularly relevant for underwater navigation and exploration, offering a wide range of perspectives and scenarios.
UIEB Dataset [
10]: In contrast, the UIEB dataset employs high-resolution underwater cameras mounted on different underwater vehicles, which are often enhanced with specialized filters and lighting. The dataset focuses on a variety of underwater settings, such as coral reefs and shipwrecks, considering factors like turbidity and light variability. It includes a vast collection of images depicting diverse underwater conditions and is annotated for image quality assessment and enhancement. This makes the UIEB dataset a valuable resource for improving underwater image processing techniques.
8.1.2. Experimental Setup
In the image preprocessing phase of this study, two key steps were undertaken: resizing and format conversion. The images were resized to a uniform resolution of pixels. Subsequent to resizing, the images were subject to a format conversion process, which was achieved through the application of the ToTensor conversion function. This conversion entailed transforming the images into PyTorch tensors, utilizing the transforms.ToTensor() method. An aspect of this transformation is the automatic normalization of pixel values to a range of [0, 1].
The model was trained using the PyTorch deep learning framework, which was optimized with the Adam optimizer. The network parameters were set as follows: learning rate: 0.0002; BatchSize: 4; total training epochs: 200; Here, ‘BatchSize’ denotes the size of batch processing, and ‘epoch’ represents the number of training iterations.
8.2. Overall Performance Evaluation
This section juxtaposes the proposed method against several advanced underwater image enhancement algorithms that have emerged in recent years. The evaluation metrics employed are Peak Signal-to-Noise Ratio (PSNR), Structural Similarity Index (SSIM), and Underwater Image Quality Measure (UIQM). To ascertain the efficacy of the algorithm, tests were conducted on the EUVP and UIEB datasets. Comparative methods included GDCP [
4], Water Net [
10], Funie-GAN [
9], Water CycleGAN [
7], Deep SESR [
28], Dense GAN [
8], Shallow-UWnet [
29], Shallow-UWnet-I [
36], and Deep WaveNet [
31].
Table 1 and
Table 2 present the PSNR, SSIM, and UIQM values derived from the proposed method and the aforementioned comparative algorithms on both datasets. Based on the data in these tables, the proposed method outperforms the competing algorithms on both datasets. Notably, on the real-world underwater dataset UIEB, the performance of the proposed method was especially commendable, underscoring the efficacy of the integrated color feature strategy.
In
Table 3, we observe a comparative analysis of the processing times for different underwater image enhancement methods, including the method presented in our paper. Our method demonstrates a processing time of approximately 0.1 s per image. This performance positions our method favorably in terms of efficiency, outpacing the WaterNet [
10] method, which requires 0.50 s, and the Funie-GAN [
9] approach, taking 0.18 s. However, it is important to note that our method is not as swift as the Shallow-UWnet [
29] and Shallow-UWnet-I [
30] methods, both of which lead the group with an impressive processing speed of just 0.02 s per image. This indicates that while our method offers a significant improvement over some existing techniques, there is still room for optimization to reach the speed of the fastest methods in this domain.
To provide a more comprehensive assessment of the image quality obtained from the proposed method,
Figure 5 offers a subjective visual comparison between the color feature-integrated underwater image enhancement method and recent methods such as Shallow-UWnet [
29] and Deep WaveNet [
31] on the EUVP and UIEB datasets. From the figure, one can discern that the Shallow-UWnet [
29] can rectify certain color deviations in underwater images; however, due to its rudimentary network structure, the contrast in the enhanced images is suboptimal. In contrast, the Deep WaveNet [
31] provides enhancement results that align more closely with reference images. Owing to the specialized processing of individual color channel information in the proposed method, the enhanced images exhibit vibrant and authentic colors without noticeable deviation.
To further demonstrate the robustness of the proposed algorithm, this section utilized 60 images from the UIEB dataset that were deemed challenging. These images were enhanced using the method introduced in this paper and subsequently compared, in terms of subjective visual quality, with the results from both the Shallow-UWnet [
29] and Deep WaveNet [
31] approaches. As illustrated in
Figure 6, all three methods markedly improved the clarity of underwater images with high turbidity. Both Shallow-UWnet [
29] and Deep WaveNet [
31] produced enhancements with comparable outcomes. However, images enhanced using the method presented in this paper exhibited more vivid colors and superior clarity, thereby affirmatively attesting to the efficacy of the algorithm.
8.3. Ablation Experiment
8.3.1. Validation of Multi-Channel Feature Extraction Strategy
This section introduces a multi-channel feature extraction strategy that effectively leverages the unique propagation characteristics of light in water. By allocating distinct receptive fields to each channel, the strategy optimizes feature extraction. Additionally, the strategy integrates the benefits of dropout for enhancing model generalization in low-quality visual tasks. To validate the efficacy of this approach, we initially adopted a conventional feature extraction method, modifying all convolution kernel sizes in the module to 3 and replacing dropout with Batch Normalization (BN) in the network. Under conditions with identical training parameters and iteration counts, the model was retrained, which was denoted as Method A. Subsequently, feature extraction was performed using multiple convolution kernels of varying sizes, still employing the BN layer for training, which is denoted as Method B. Finally, training was executed using the method proposed in this paper, which was denoted as Method C. All three approaches were trained and tested on the EUVP dataset, and their performances were compared using PSNR, SSIM, and UIQM metrics.
The results, as presented in
Table 4, reveal that Model A’s performance was markedly inferior to those of Models B and C. This underscores the significant impact of the multi-channel feature extraction strategy on underwater imagery. Furthermore, compared to Model B, Model C exhibited noticeable improvements in SSIM and UIQM metrics, validating the proposition of substituting the BN layer with dropout for underwater datasets, thereby attesting to the method’s effectiveness.
8.3.2. Experiments Related to Residual Enhancement Module
The residual enhancement module proposed in this study initially merges features from the network’s first phase to create channel-specific feature residuals. This is further refined using the CBAM module. To validate its efficacy, we first removed both the CBAM module and residual connections and then trained the model under the same conditions (denoted as Method 1). Subsequently, we employed CBAM for feature enhancement without the incorporation of residual connections (denoted as Method 2). Finally, a combined approach of CBAM with residual connections was adopted for training (denoted as Method 3). All models were trained and tested using the EUVP dataset with performance evaluation based on the PSNR, SSIM, and UIQM metrics.
The outcomes, as presented in
Table 5, reveal that the CBAM module indeed contributes to feature enhancement when contrasting the results of Models 1 and 2. However, in the absence of a dedicated strategy, the overall enhancement was somewhat subdued. Conversely, with the integration of residual connections, Model 3 showcased superior performance, illustrating that the combination of residual connections and the CBAM module can robustly amplify channel-specific features.
8.3.3. Dynamic Feature Enhancement Module
The dynamic feature enhancement module, incorporating deformable convolution designs, is adept at extracting irregular features unique to underwater images. This allows the network to capture a richer array of underwater scene information. The study employs two layers of deformable convolution. To ascertain the impact of the number of convolution layers on model performance, experiments were conducted with varying numbers of deformable convolution layers. For models without deformable convolution, a standard 3 × 3 convolution layer was utilized as a replacement.
As illustrated in
Table 6, it is evident that deformable convolution notably boosts model performance. However, an intriguing observation is that performance plateaus upon using three layers; the model exhibited optimal performance with two deformable convolution layers.
8.4. Underwater Target Detection Experiment
To assess the robustness and applicability of the underwater image enhancement algorithm proposed in this paper, we conducted experiments related to advanced underwater visual tasks. We selected the Detecting Underwater Objects (DUO) dataset, introduced by Liu et al. [
38], as the test set. This dataset comprises 7782 images and is stored in the COCO format. The majority of the images are sourced from the URPC series dataset provided by underwater robotic competitions. The dataset encompasses various underwater environments and scenarios such as deep-sea, shallow sea, coral reefs, and underwater mountain ranges, allowing for a comprehensive evaluation of the efficacy and robustness of underwater image processing algorithms.
Our experiments are based on the MMDetection framework, utilizing Resnet50 as the backbone network and employing FasterRCNN [
39] as the object detection network for testing. As an evaluation metric, we chose the Mean Average Precision (mAP). To mitigate the impact of the long-tail effect inherent in the data, we also provided mAP values across different Intersection over Union (IoU) thresholds and object sizes. Detailed detection results are presented in
Table 6.
From
Table 7, it is evident that the enhanced underwater images exhibit superior performance across various object detection metrics. Furthermore, as visualized in
Figure 7, the enhanced images can detect elements that were not identifiable in the original images, thereby bolstering the reliability of the detection results. These outcomes further affirm the robustness of the underwater enhancement algorithm proposed in this paper and underscore its practical significance in the domain of underwater object detection. When applied to underwater navigation tasks, our algorithm demonstrates a remarkable improvement in the reliability of object detection. This enhancement is critical for Autonomous Underwater Vehicles (AUVs) and Remote-Operated Vehicles (ROVs) engaged in complex navigation tasks, where the accurate identification and interpretation of underwater objects and terrains are paramount for safe and efficient operation.
9. Conclusions
The underwater image enhancement algorithm presented in this study uniquely integrates deep learning techniques with the distinct attributes of underwater environments. Unlike conventional approaches that directly apply CNNs and similar networks for image enhancement, our method employs a modified multi-channel convolution block to extract features from each color channel. Furthermore, it incorporates the CBAM module for residual enhancement and introduces a dynamic feature enhancement module that integrates deformable convolution to further refine deep features. Empirical tests have demonstrated that our proposed method excels in both subjective quality and objective evaluation metrics, outperforming traditional underwater image processing techniques and deep learning algorithms. Additionally, when applied to underwater object detection tasks, our method enhances the reliability of detection results, substantiating the advanced nature and efficacy of our algorithm. However, it is important to note that the performance in computational time is relatively average. This aspect suggests room for further optimization and efficiency improvements in future iterations of the algorithm.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}