
Human Motion Prediction Based on a Multi-Scale Hypergraph for Intangible Cultural Heritage Dance Videos


Abstract
:1. Introduction
- (1)
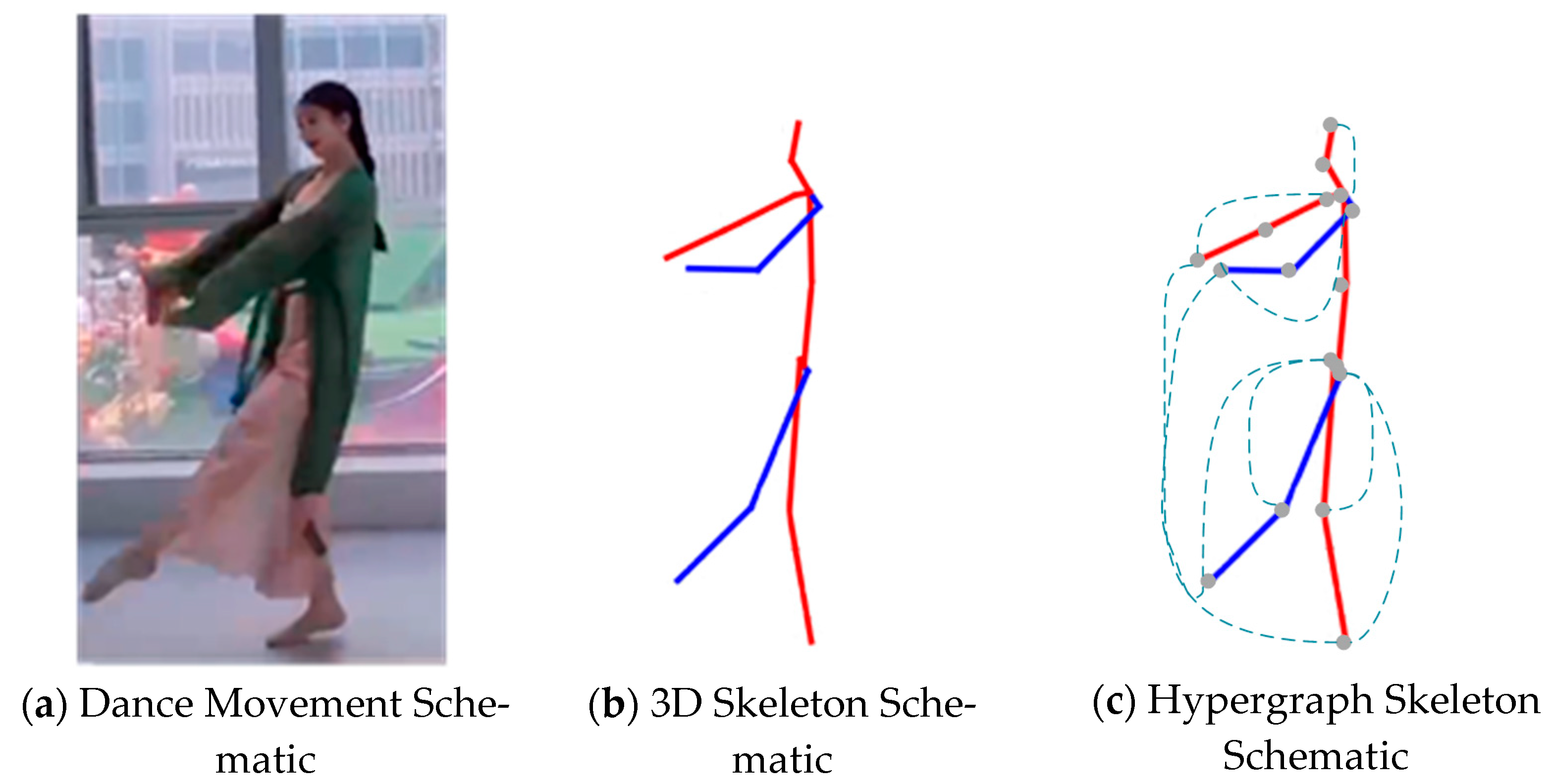
- We design joint point hypergraphs for representing 3D human gesture sequence spatial information for intangible cultural heritage dance videos’ joint point interaction information.
- (2)
- A multi-scale hypergraph convolutional network is constructed for the joint hypergraph, which extracts the spatial features of the 3D human posture sequence represented by the multi-scale hypergraph.
- (3)
- A Temporal Graph Transformer is introduced for the multi-scale hypergraph convolutional network, to extract the temporal features among 3D human posture sequences.
2. Related Work
2.1. Motion Prediction
2.2. Hypergraph
2.3. Multi-Scale Convolutional Networks
2.4. Transformer Network
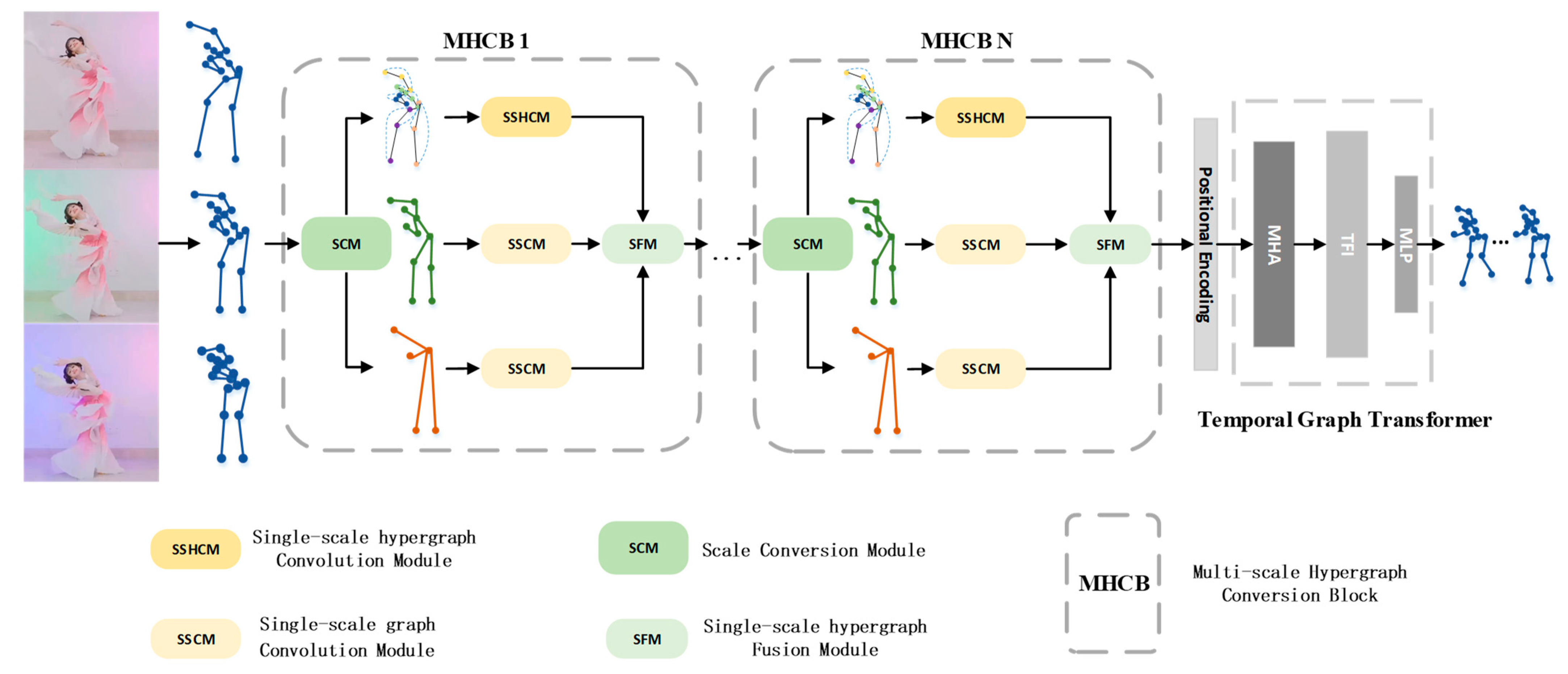
3. The Proposed Method
3.1. Joint Hypergraphs Generation
3.2. Multi-Scale Hypergraph Convolution Module Construction
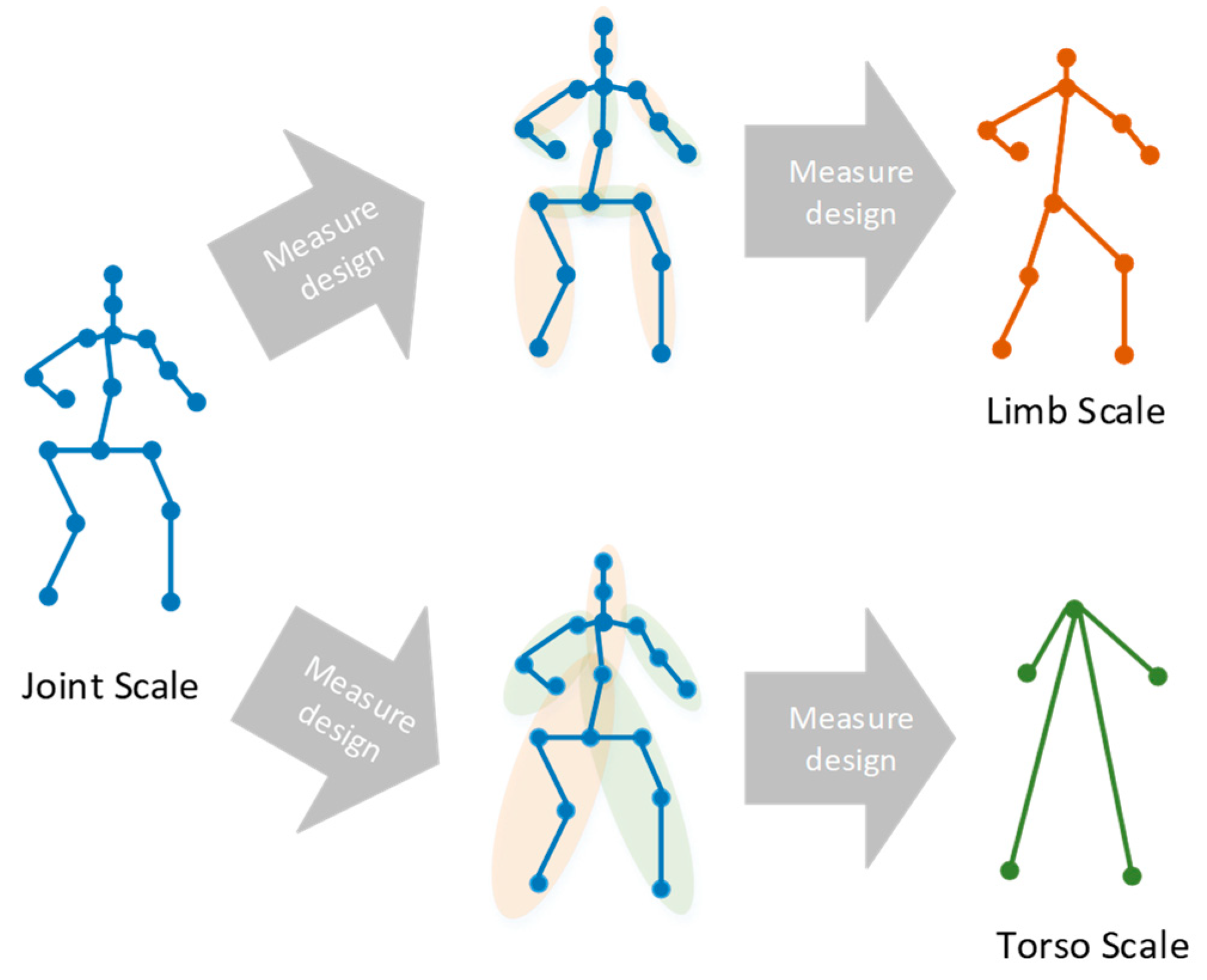
3.2.1. Constructing Multi-Scale Segmentation Operator Construction
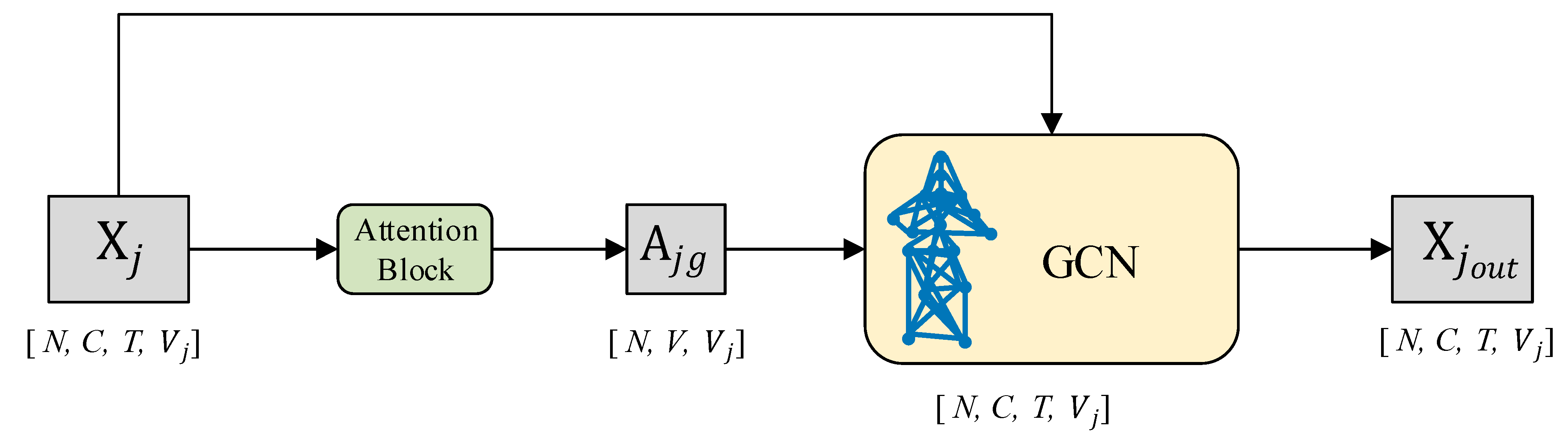
3.2.2. Single-Scale Graph Convolution and the Hypergraph Convolution Module Construction
3.2.3. Single-Scale Hypergraph Fusion Operator Construction
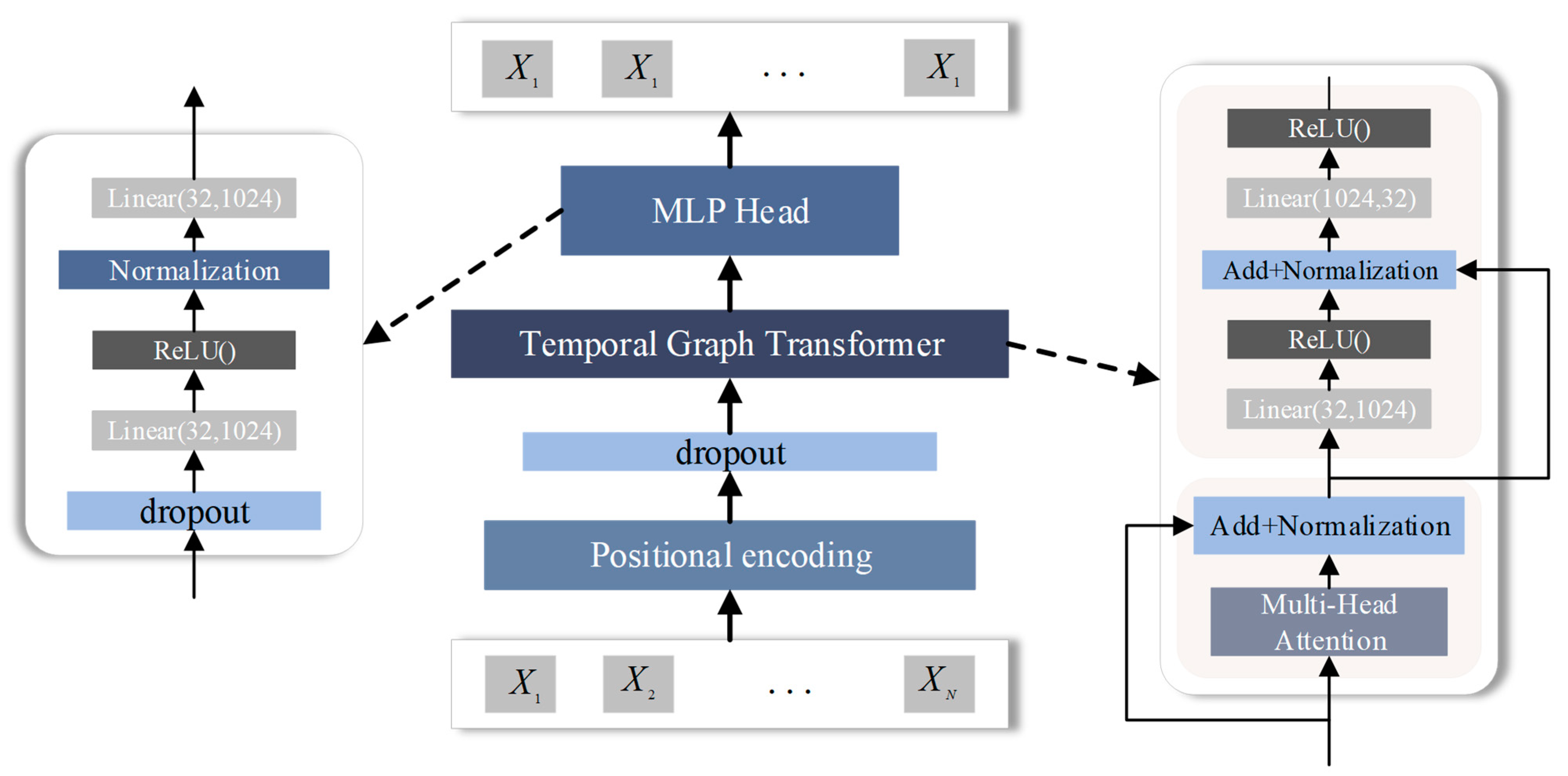
3.3. Temporal Graph Transformer to Extract Spatio-Temporal Features Introduction
4. Experimental Verification and Analysis
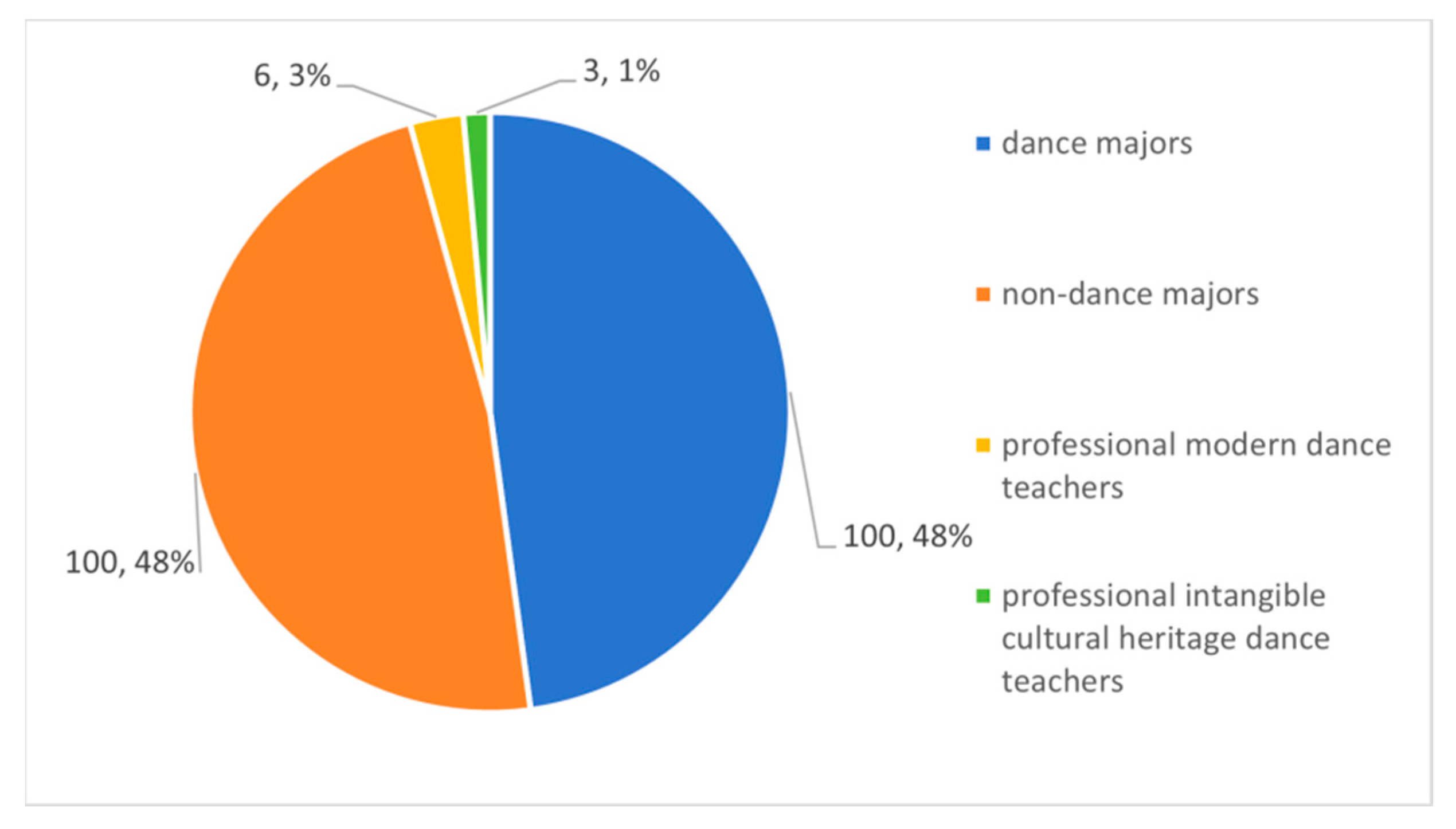
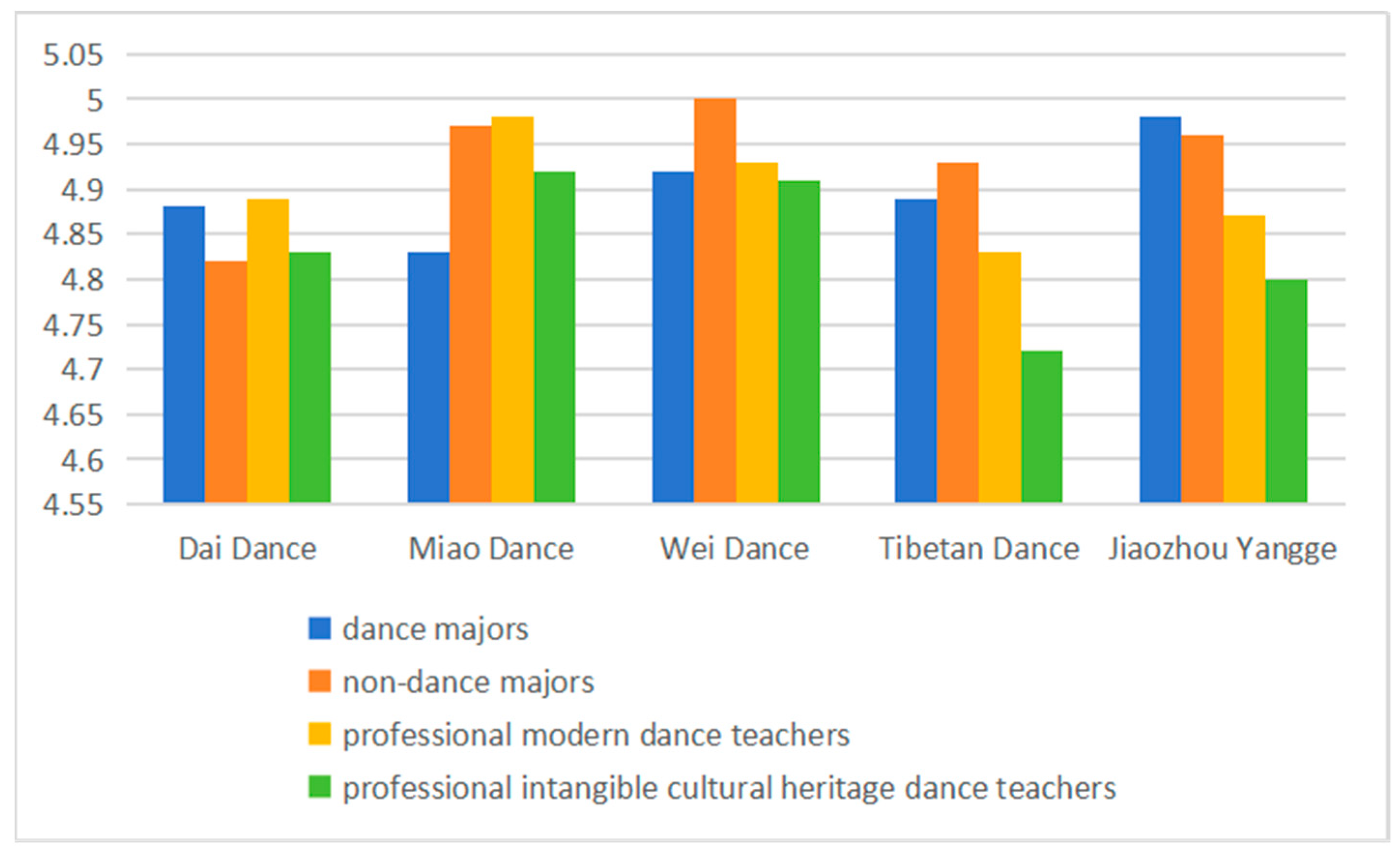
4.1. Datasets and Evaluation Indicators
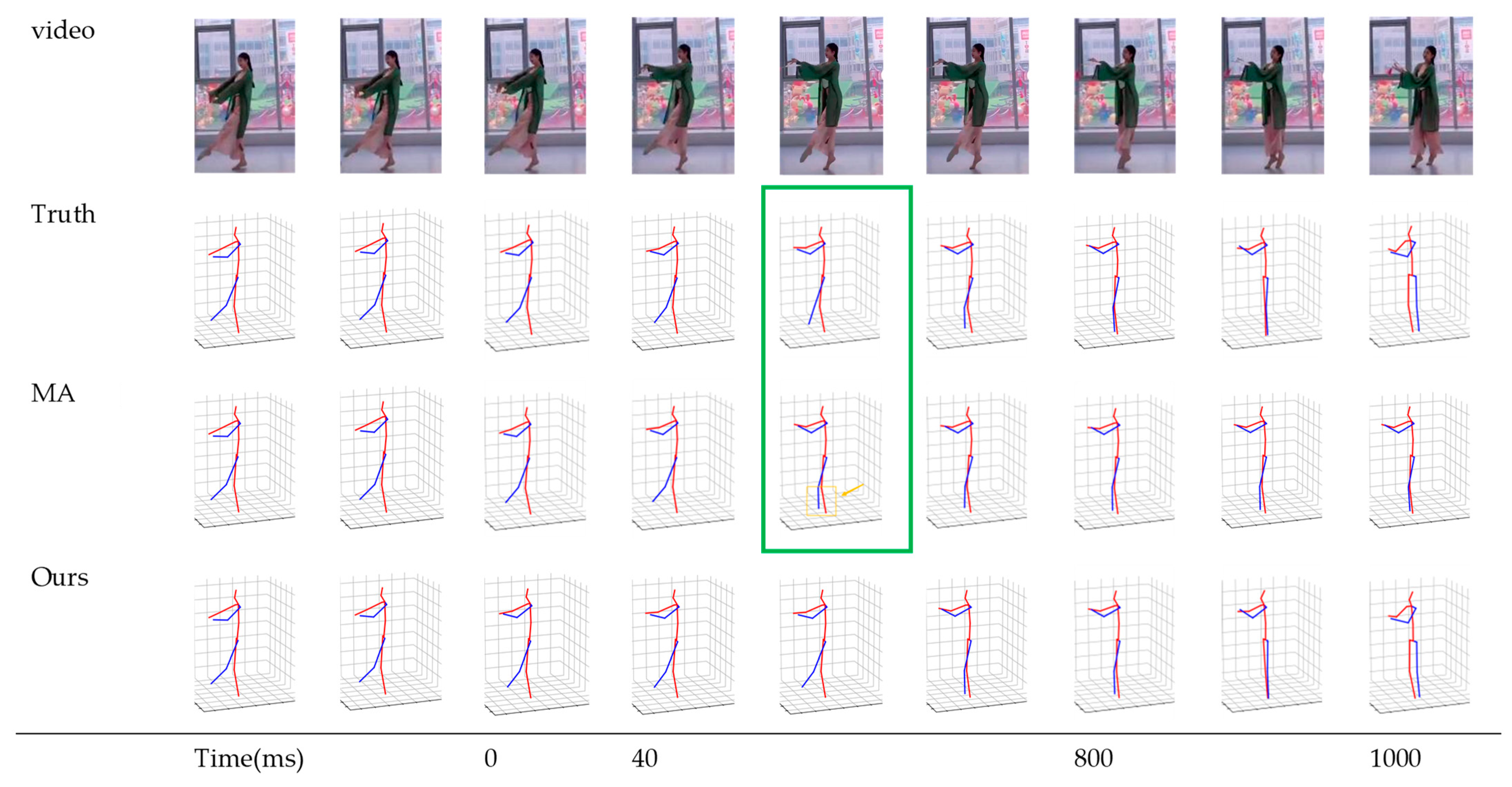
4.2. Comparative Experiments on 3D Motion Prediction
4.3. Ablation Experiments
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Yang, X.N. The physical anthropological value of “intangible cultural heritage” dances. House Dra. 2018, 32, 110. [Google Scholar]
- Li, K.N. Protection and inheritance of ethnic folk dances from the perspective of intangible cultural heritage. Dancefahion 2022, 12, 98–100. [Google Scholar]
- Chen, S.; Liu, B.; Feng, C.; Vallespi-Gonzalez, C.; Wellington, C. 3D point cloud processing and learning for autonomous driving. IEEE Signal Process 2020, 38, 68–86. [Google Scholar] [CrossRef]
- Troje, N.F. Decomposing biological motion: A framework for analysis and synthesis of human gait patterns. J. Vis. 2002, 2, 371–387. [Google Scholar] [CrossRef] [PubMed]
- Ankur, G.; Julieta, M.; James, L.; Robert, W. 3D pose from motion for cross-view action recognition via non-linear circulant temporal encoding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 2061–2068. [Google Scholar]
- Kong, Y.; Fu, Y. Human action recognition and prediction: A survey. Int. J. Comput. Vis. 2022, 130, 1366–1401. [Google Scholar] [CrossRef]
- Martinez, J.; Black, M.J.; Romer, J. On human motion prediction using recurrent neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2891–2900. [Google Scholar]
- Sofianos, T.; Sampieri, A.; Franco, L.; Galasso, F. Spacetime-separable graph convolutional network for pose forecasting. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 11209–11218. [Google Scholar]
- Bouazizi, A.; Holzbock, A.; Kressel, U.; Dietmayer, K.; Belagiannis, V. Motionmixer: Mlp-based 3d human body pose forecasting. arXiv 2022, arXiv:2207.00499. [Google Scholar]
- Dang, L.; Nie, Y.; Long, C.; Zhang, Q.; Li, G. Msr-gcn: Multi-scale residual graph convolution networks for human motion prediction. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 11467–11476. [Google Scholar]
- Ionescu, C.; Papava, D.; Olaru, V.; Sminchisescu, C. Human3.6m: Large scale datasets and predictive methods for 3d human sensing in natural environments. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 36, 1325–1339. [Google Scholar] [CrossRef] [PubMed]
- Von Marcard, T.; Henschel, R.; Black, M.J.; Rosenhahn, B.; Pons-Moll, G. Recovering accurate 3d human pose in the wild using imus and a moving camera. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 601–617. [Google Scholar]
- Mao, W.; Liu, M.; Salzmann, M. History repeats itself: Human motion prediction via motion attention. In Proceedings of the 2020 16th Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; pp. 474–489. [Google Scholar]
- Fragkiadaki, K.; Levine, S.; Felsen, P.; Malik, J. Recurrent network models for human dynamics. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 4346–4354. [Google Scholar]
- Li, C.; Zhang, Z.; Lee, W.S.; Lee, G.H. Convolutional sequence to sequence model for human dynamics. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 5226–5234. [Google Scholar]
- Zhou, D.; Huang, J.; Schölkopf, B. Learning with hypergraphs: Clustering, classification, and embedding. Adv. Neural Inf. Process. Syst. 2006, 19. [Google Scholar]
- Agarwal, S.; Lim, J.; Zelnik, M.L.; Perona, P.; Kriegman, D.; Belongie, S. Beyond pairwise clustering. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; pp. 838–845. [Google Scholar]
- Tian, Z.; Hwang, T.H.; Kuang, R. A hypergraph-based learning algorithm for classifying gene expression and arrayCGH data with prior knowledge. Bioinformatics 2009, 25, 2831–2838. [Google Scholar] [CrossRef]
- Bu, Y.; Howe, B.; Balazinska, M.; Ernst, M.D. HaLoop: Efficient iterative data processing on large clusters. In Proceedings of the VLDB Endowment, Seattle, WA, USA, 29 August–3 September 2010; Volume 3, pp. 285–296. [Google Scholar]
- Li, W.; Liu, X.; Liu, Z.; Du, F.; Zou, Q. Skeleton-based action recognition using multi-scale and multi-stream improved graph convolutional network. IEEE Access 2020, 8, 144529–144542. [Google Scholar] [CrossRef]
- Fan, Y.; Wang, X.; Lv, T.; Wu, L. Multi-scale adaptive graph convolutional network for skeleton-based action recognition. In Proceedings of the 15th International Conference on Computer Science & Education (ICCSE), Delft, The Netherlands, 18 August 2020; pp. 517–522. [Google Scholar]
- Li, T.; Zhang, R.; Li, Q. Multi scale temporal graph networks for skeleton-based action recognition. arXiv 2020, arXiv:2012.02970. [Google Scholar]
- Yuan, Y.; Kitani, K. Ego-pose estimation and forecasting as real-time pd control. In Proceedings of the the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 10082–10092. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2017; p. 30. [Google Scholar]
- Cheng, Y.B.; Chen, X.; Zhang, D.; Lin, L. Motion-transformer: Self-supervised pre-training for skeleton-based action recognition. In Proceedings of the 2nd ACM International Conference on Multimedia in Asia, Beijing, China, 16–18 December 2021. [Google Scholar]
- Lin, H.; Cheng, X.; Wu, X.; Shen, D. Cat: Cross attention in vision transformer. In Proceedings of the 2022 IEEE International Conference on Multimedia and Expo (ICME), Taipei, Taiwan, 18–22 July 2022; pp. 1–6. [Google Scholar]
- Wu, N.; Green, B.; Ben, X.; O’Banion, S. Deep transformer models for time series forecasting: The influenza prevalence case. arXiv 2020, arXiv:2001.08317. [Google Scholar]
- Kanchana, R.; Muzammal, N.; Salman, K.; Fahad, S.K.; Michael, R. Self-supervised video transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2022. [Google Scholar]
- Lan, G.; Wu, Y.; Hu, F.; Hao, Q. Vision-based human pose estimation via deep learning: A survey. IEEE Trans. Hum. Mach. Syst. 2022, 53, 253–268. [Google Scholar] [CrossRef]
- Li, S.; Chan, A.B. 3D human pose estimation from monocular images with deep convolutional neural network. In Proceedings of the 2015 Computer Vision (ACCV), Singapore, 1–5 November 2015; Springer: Berlin/Heidelberg, Germany; pp. 332–347. [Google Scholar]
- Zheng, C.; Zhu, S.; Mendieta, M.; Yang, T.; Chen, C.; Ding, Z. 3D human pose estimation with spatial and temporal transformers. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 11656–11665. [Google Scholar]
- Sapp, B.; Taskar, B. Modec: Multimodal decomposable models for human pose estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 3674–3681. [Google Scholar]
- Li, W.; Liu, H.; Tang, H.; Wang, P.; Van Gool, L. Mhformer: Multi-hypothesis transformer for 3D human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2022; pp. 13147–13156. [Google Scholar]
- Liao, J.; Xu, J.; Shen, Y.; Lin, S. THANet: Transferring Human Pose Estimation to Animal Pose Estimation. Electronics 2023, 12, 4210. [Google Scholar] [CrossRef]
- Li, M.; Chen, S.; Chen, X.; Zhang, Y.; Wang, Y.; Tian, Q. Symbiotic graph neural networks for 3d skeleton-based human action recognition and motion prediction. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 3316–3333. [Google Scholar] [CrossRef] [PubMed]
- Li, M.; Chen, S.; Zhang, Z.; Xie, L.; Tian, Q.; Zhang, Y. Skeleton-parted graph scattering networks for 3d human motion prediction. In European Conference on Computer Vision; Springer Nature: Cham, Switzerland, 2022; pp. 18–36. [Google Scholar]
- Li, M.; Chen, S.; Zhao, Y.; Zhang, Y.; Wang, Y.; Tian, Q. Multiscale spatio-temporal graph neural networks for 3d skeleton-based motion prediction. IEEE Trans. Image Process. 2021, 30, 7760–7775. [Google Scholar] [CrossRef] [PubMed]
- Gui, Z.; Peng, D.; Wu, H.; Long, X. MSGC: Multi-scale grid clustering by fusing analytical granularity and visual cognition for detecting hierarchical spatial patterns. Future Gener. Comput. Syst. 2020, 112, 1038–1056. [Google Scholar] [CrossRef]
- Zhai, D.H.; Yan, Z.; Xia, Y. Lightweight Multiscale Spatiotemporal Locally Connected Graph Convolutional Networks for Single Human Motion Forecasting. IEEE Trans. Autom. Sci. Eng. 2023. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Motion | Res.Sup [7] | convSeq2Seq [15] | LTD-10-25 [13] | MotionMixer [9] | STSGCN [8] | SPGSN [36] | Ours |
|---|---|---|---|---|---|---|---|
| Walking | 66.1 | 63.6 | 44.4 | 42.4 | 45.9 | 41.5 | 38.4 |
| Eating | 61.7 | 48.4 | 38.6 | 36.1 | 45.0 | 38.0 | 35.8 |
| Smoking | 65.4 | 48.9 | 39.5 | 36.8 | 44.7 | 34.6 | 36.0 |
| Discussion | 91.3 | 77.6 | 68.1 | 64.1 | 68.5 | 67.1 | 63.9 |
| Direction | 84.1 | 69.7 | 58.0 | 53.4 | 53.2 | 50.3 | 53.5 |
| Greeting | 108.8 | 96.0 | 82.6 | 82.2 | 87.6 | 86.4 | 76.3 |
| Phoning | 76.4 | 59.9 | 50.8 | 51.1 | 52.0 | 48.5 | 48.2 |
| Waiting | 87.7 | 69.7 | 44.4 | 56.4 | 59.2 | 54.1 | 53.5 |
| WalkingDog | 110.6 | 103.3 | 38.6 | 87.8 | 93.3 | 84.9 | 87.0 |
| WalkingToge | 67.3 | 61.2 | 39.5 | 43.5 | 43.9 | 40.9 | 38.5 |
| Posing | 114.3 | 92.9 | 79.9 | 79.5 | 73.1 | 76.5 | 68.8 |
| Purchases | 100.7 | 89.9 | 78.1 | 76.1 | 79.6 | 74.4 | 73.7 |
| Sitting | 91.2 | 63.1 | 58.3 | 54.5 | 57.8 | 53.4 | 54.8 |
| Sitting down | 112.0 | 82.7 | 76.4 | 74.5 | 76.8 | 70.7 | 73.7 |
| Taking photo | 87.6 | 63.6 | 54.3 | 51.6 | 56.3 | 52.7 | 50.1 |
| Average | 88.3 | 72.7 | 68.1 | 59.3 | 62.9 | 58.3 | 56.8 |
| Motion | Res.Sup [7] | convSeq2Seq [15] | LTD-10-25 [13] | MotionMixer [9] | STSGCN [8] | SPGSN [36] | Ours |
|---|---|---|---|---|---|---|---|
| Walking | 79.1 | 82.3 | 60.9 | 59.9 | 66.7 | 53.6 | 55.2 |
| Eating | 98.0 | 87.1 | 75.8 | 76.6 | 75.1 | 73.4 | 73.1 |
| Smoking | 102.1 | 81.7 | 72.1 | 68.5 | 74.1 | 68.6 | 70.2 |
| Discussion | 131.8 | 129.3 | 118.5 | 117.4 | 107.7 | 118.6 | 117.1 |
| Direction | 129.1 | 115.8 | 105.5 | 105.4 | 109.9 | 100.5 | 105.2 |
| Greeting | 153.9 | 147.3 | 136.8 | 136.5 | 103.8 | 143.2 | 136.7 |
| Phoning | 126.4 | 114.0 | 105.1 | 104.4 | 109.9 | 102.5 | 103.2 |
| Waiting | 135.4 | 117.7 | 108.3 | 107.7 | 118.3 | 103.6 | 103.8 |
| WalkingDog | 164.5 | 162.4 | 146.4 | 142.2 | 118.3 | 138.0 | 145.5 |
| WalkingToge | 98.2 | 87.4 | 65.7 | 65.4 | 95.8 | 60.9 | 61.8 |
| Posing | 183.2 | 187.4 | 174.8 | 174.9 | 107.6 | 165.4 | 168.4 |
| Purchases | 154.0 | 151.5 | 134.9 | 135.1 | 119.3 | 133.9 | 132.6 |
| Sitting | 152.6 | 120.7 | 118.7 | 115.7 | 119.8 | 116.2 | 114.7 |
| SittingDown | 187.4 | 150.3 | 143.8 | 141.1 | 129.7 | 149.9 | 141.5 |
| TakingPhoto | 153.9 | 128.1 | 115.9 | 114.6 | 119.8 | 118.2 | 111.9 |
| Average | 136.6 | 124.2 | 112.4 | 111.0 | 113.3 | 109.6 | 109.4 |
| Millisecond | 400 | 1000 |
|---|---|---|
| convSeq2Seq [15] | 58.8 | 87.8 |
| LTD-10-25 [13] | 46.6 | 75.5 |
| Motion-Attention [9] | 44.4 | 71.8 |
| AuxFormer [36] | 58.5 | 107.5 |
| Ours | 40.2 | 68.3 |
| Graph Structures | MPJPE | |
|---|---|---|
| 400 | 1000 | |
| Traditional Graphs [10] | 58.9 | 113.5 |
| Multi-Scale Graphs [35] | 58.6 | 110.1 |
| Spatial Hypergraphs [17] | 57.2 | 109.8 |
| Multi-Scale Hypergraphs | 56.8 | 109.4 |
| Segmentation Method/Scale | MPJPE | ||||
|---|---|---|---|---|---|
| Joint Scale | Skeleton Scale | Component Scale | 400 | 1000 | |
| MSGC [38] | √ | √ | √ | 69.2 | 119.4 |
| Ours-1L | √ | 69.6 | 119.8 | ||
| Ours-2L | √ | √ | 69.1 | 119.3 | |
| Ours | √ | √ | √ | 68.4 | 118.9 |
| Number of (MCM) | MPJPE | ||||
|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 0 | |
| 400 ms | 57.4 | 56.9 | 56.8 | 57.2 | 57.6 |
| 1000 ms | 109.9 | 109.8 | 109.4 | 110.7 | 110.9 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cai, X.; Cheng, P.; Liu, S.; Zhang, H.; Sun, H. Human Motion Prediction Based on a Multi-Scale Hypergraph for Intangible Cultural Heritage Dance Videos. Electronics 2023, 12, 4830. https://doi.org/10.3390/electronics12234830
Cai X, Cheng P, Liu S, Zhang H, Sun H. Human Motion Prediction Based on a Multi-Scale Hypergraph for Intangible Cultural Heritage Dance Videos. Electronics. 2023; 12(23):4830. https://doi.org/10.3390/electronics12234830
Chicago/Turabian StyleCai, Xingquan, Pengyan Cheng, Shike Liu, Haoyu Zhang, and Haiyan Sun. 2023. "Human Motion Prediction Based on a Multi-Scale Hypergraph for Intangible Cultural Heritage Dance Videos" Electronics 12, no. 23: 4830. https://doi.org/10.3390/electronics12234830
APA StyleCai, X., Cheng, P., Liu, S., Zhang, H., & Sun, H. (2023). Human Motion Prediction Based on a Multi-Scale Hypergraph for Intangible Cultural Heritage Dance Videos. Electronics, 12(23), 4830. https://doi.org/10.3390/electronics12234830