

Predicting Loneliness through Digital Footprints on Google and YouTube
 , ,
, ,
Abstract
:1. Introduction
- RQ1: Can machine learning models use trace data from online platforms to predict loneliness?
- RQ2: Are there systematic differences in terms of the predictive ability of online platforms (Google search, YouTube) for loneliness?
2. Related Research
2.1. Theoretical Background: Motivations behind Online Media Usage
2.2. Loneliness and Online Behavior
3. Materials and Methods
3.1. Data Collection
3.2. Ethical Considerations and Permissions
3.3. Variables of Interest
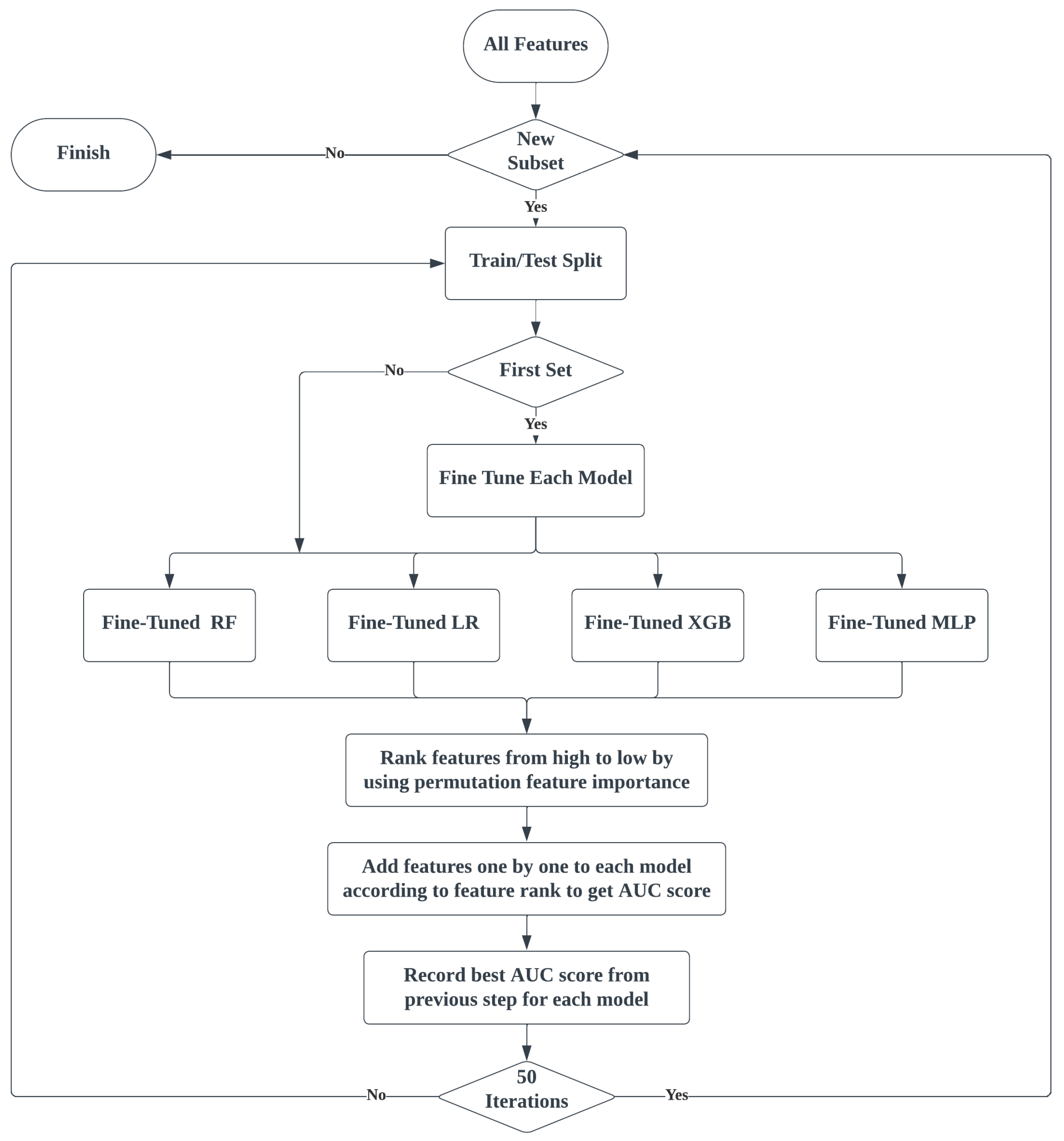
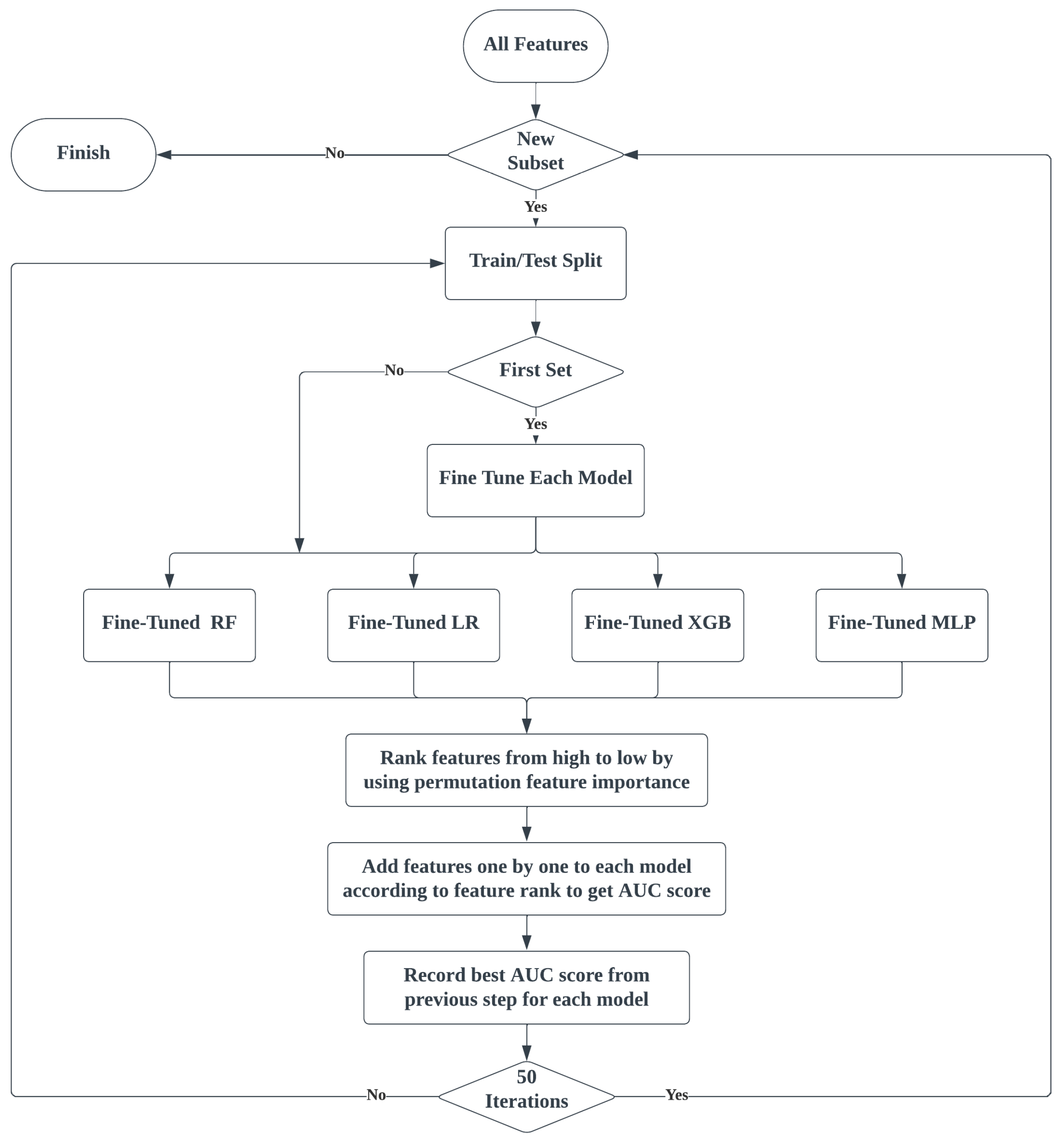
3.4. Data Preprocessing and Modeling
4. Results
4.1. Sample Population
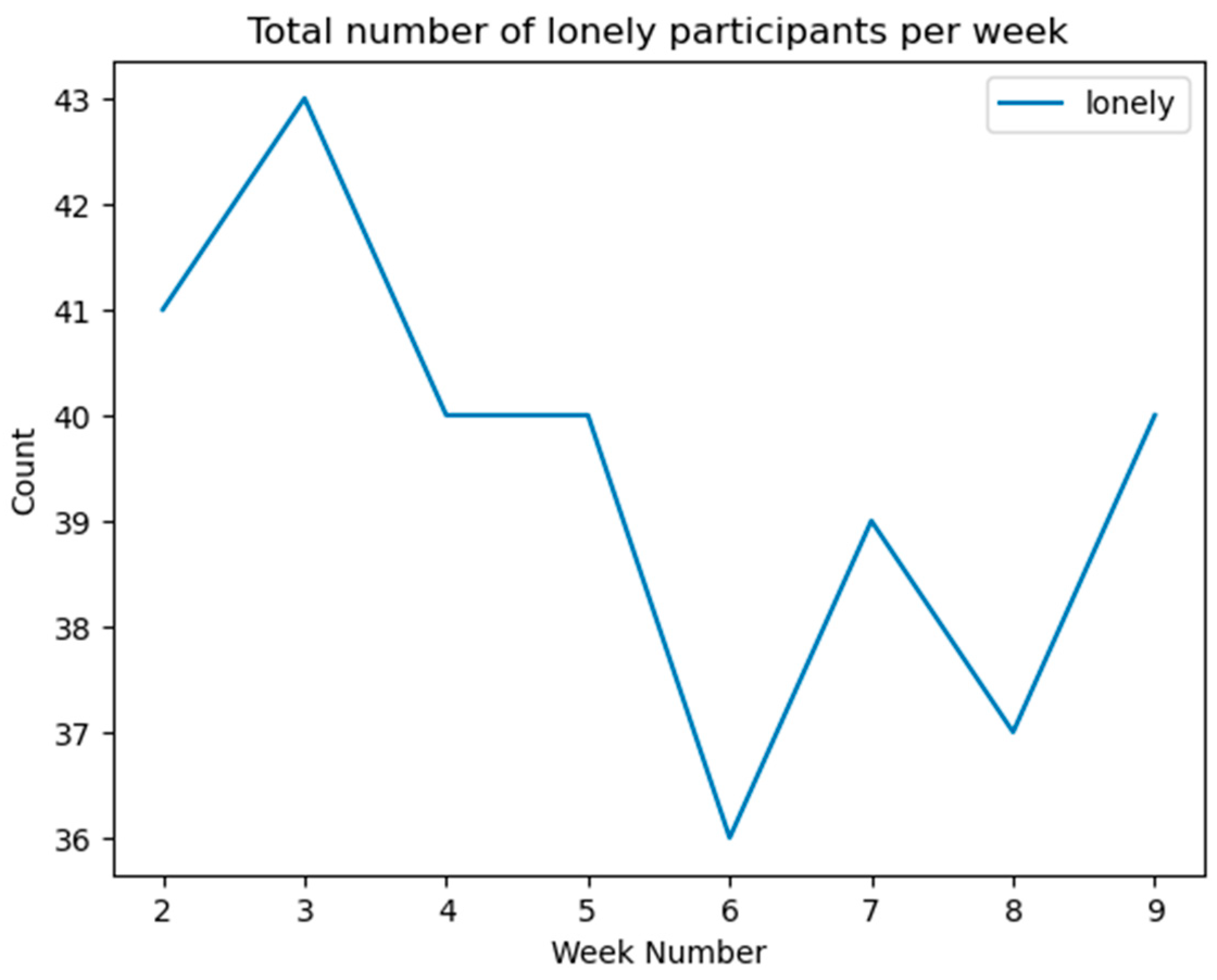
4.2. Loneliness in Participants
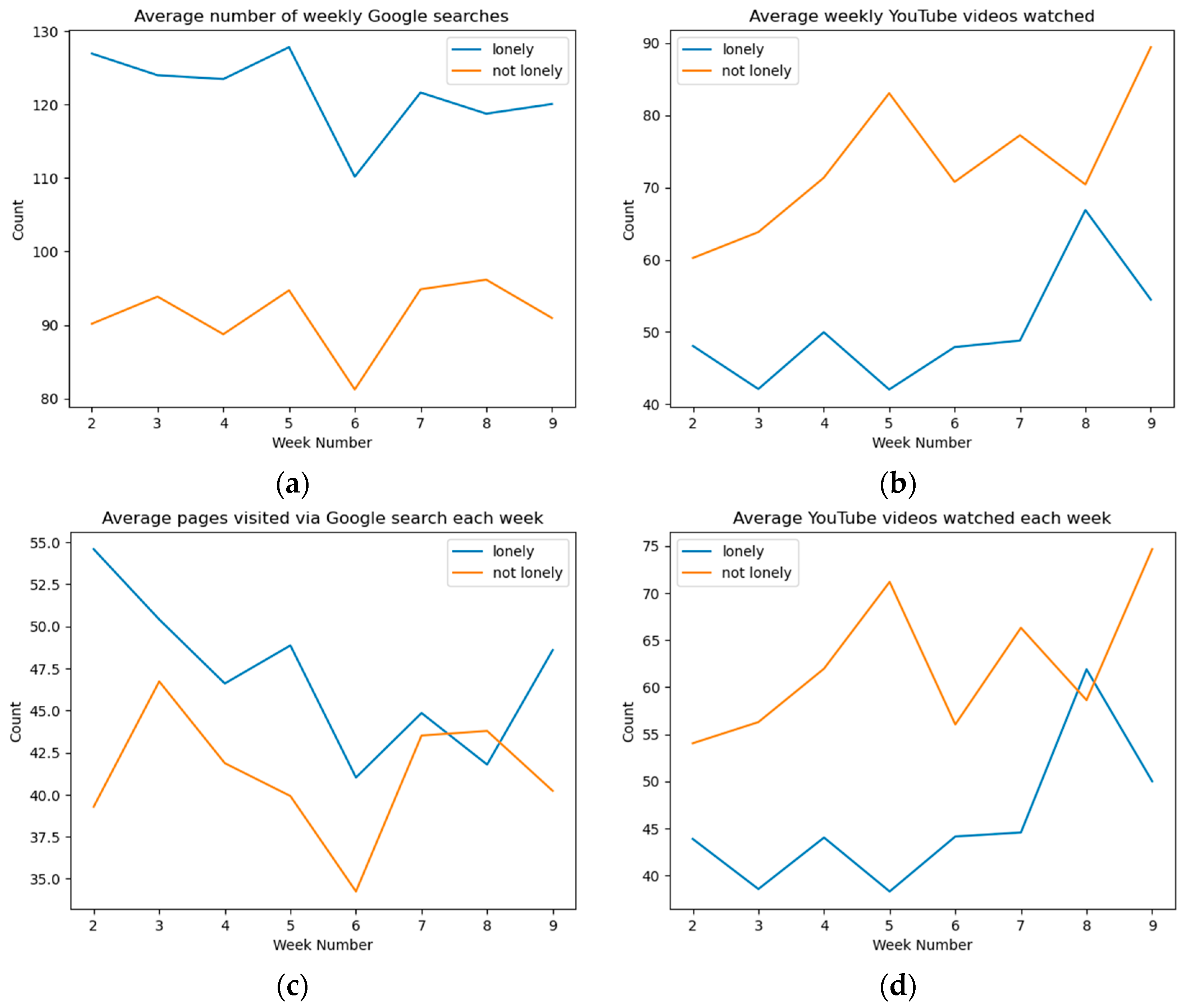
4.3. Online Behavior and Loneliness
4.4. Biggest Differences Observed
4.5. Prediction Results
5. Discussion
5.1. Initial Remarks
5.2. Deployment Scenarios
5.3. Limitations
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Russell, D.; Peplau, L.A.; Cutrona, C.E. The Revised UCLA Loneliness Scale: Concurrent and Discriminant Validity Evidence. J. Personal. Soc. Psychol. 1980, 39, 472–480. [Google Scholar] [CrossRef]
- Leland, J. How Loneliness Is Damaging Our Health. The New York Times. 20 April 2022. Available online: https://www.nytimes.com/2022/04/20/nyregion/loneliness-epidemic.html (accessed on 26 September 2023).
- Brodeur, A.; Clark, A.E.; Fleche, S.; Powdthavee, N. Assessing the Impact of the Coronavirus Lockdown on Unhappiness, Loneliness, and Boredom Using Google Trends. arXiv 2020, arXiv:2004.12129. [Google Scholar] [CrossRef]
- Murthy, V.; Work and the Loneliness Epidemic. Harvard Business Review. Available online: https://hbr.org/2017/09/work-and-the-loneliness-epidemic (accessed on 26 September 2023).
- Holt-Lunstad, J.; Smith, T.B.; Baker, M.; Harris, T.; Stephenson, D. Loneliness and Social Isolation as Risk Factors for Mortality: A Meta-Analytic Review. Perspect. Psychol. Sci. 2015, 10, 227–237. [Google Scholar] [CrossRef]
- Deckx, L.; van den Akker, M.; Buntinx, F. Risk Factors for Loneliness in Patients with Cancer: A Systematic Literature Review and Meta-Analysis. Eur. J. Oncol. Nurs. 2014, 18, 466–477. [Google Scholar] [CrossRef]
- Alun, J.; Murphy, B. Loneliness, Social Isolation and Cardiovascular Risk. Br. J. Card. Nurs. 2019, 14, 1–8. [Google Scholar] [CrossRef]
- Beutel, M.E.; Klein, E.M.; Brähler, E.; Reiner, I.; Jünger, C.; Michal, M.; Wiltink, J.; Wild, P.S.; Münzel, T.; Lackner, K.J.; et al. Loneliness in the General Population: Prevalence, Determinants and Relations to Mental Health. BMC Psychiatry 2017, 17, 97. [Google Scholar] [CrossRef]
- Elhai, J.D.; Tiamiyu, M.F.; Weeks, J.W.; Levine, J.C.; Picard, K.J.; Hall, B.J. Depression and Emotion Regulation Predict Objective Smartphone Use Measured over One Week. Personal. Individ. Differ. 2018, 133, 21–28. [Google Scholar] [CrossRef]
- Guntuku, S.C.; Schneider, R.; Pelullo, A.; Young, J.; Wong, V.; Ungar, L.; Polsky, D.; Volpp, K.G.; Merchant, R. Studying Expressions of Loneliness in Individuals Using Twitter: An Observational Study. BMJ Open 2019, 9, e030355. [Google Scholar] [CrossRef]
- Zhang, B.; Zaman, A.; Silenzio, V.; Kautz, H.; Hoque, E. The Relationships of Deteriorating Depression and Anxiety with Longitudinal Behavioral Changes in Google and YouTube Use during COVID-19: Observational Study. JMIR Ment. Health 2020, 7, e24012. [Google Scholar] [CrossRef]
- Petrosyan, A. Topic: Internet Usage in the United States. Statista. Available online: https://www.statista.com/topics/2237/internet-usage-in-the-united-states/#topicOverview (accessed on 26 September 2023).
- Katz, E.; Blumler, J.G.; Gurevitch, M. Uses and gratifications research. Public Opin. Q. 1973, 37, 509–523. [Google Scholar] [CrossRef]
- Elhai, J.D.; Levine, J.C.; Hall, B.J. The Relationship between Anxiety Symptom Severity and Problematic Smartphone Use: A Review of the Literature and Conceptual Frameworks. J. Anxiety Disord. 2019, 62, 45–52. [Google Scholar] [CrossRef]
- Pittman, M.; Reich, B. Social Media and Loneliness: Why an Instagram Picture May Be Worth More than a Thousand Twitter Words. Comput. Hum. Behav. 2016, 62, 155–167. [Google Scholar] [CrossRef]
- Boursier, V.; Gioia, F.; Musetti, A.; Schimmenti, A. Facing Loneliness and Anxiety during the COVID-19 Isolation: The Role of Excessive Social Media Use in a Sample of Italian Adults. Front. Psychiatry 2020, 11, 586222. [Google Scholar] [CrossRef]
- Yoder, V.C.; Virden, T.B.; Amin, K. Internet Pornography and Loneliness: An Association? Sex. Addict. Compulsivity 2005, 12, 19–44. [Google Scholar] [CrossRef]
- Du, J.; Zhang, Y.; Luo, J.; Jia, Y.; Wei, Q.; Tao, C.; Xu, H. Extracting Psychiatric Stressors for Suicide from Social Media Using Deep Learning. BMC Med. Inform. Decis. Mak. 2018, 18, 43. [Google Scholar] [CrossRef]
- Reece, A.G.; Danforth, C.M. Instagram Photos Reveal Predictive Markers of Depression. EPJ Data Sci. 2017, 6, 15. [Google Scholar] [CrossRef]
- Cheng, Q.; Li, T.M.; Kwok, C.-L.; Zhu, T.; Yip, P.S. Assessing Suicide Risk and Emotional Distress in Chinese Social Media: A Text Mining and Machine Learning Study. J. Med. Internet Res. 2017, 19, e243. [Google Scholar] [CrossRef]
- Kim, J.; Lee, D.; Park, E. Machine Learning for Mental Health in Social Media: Bibliometric Study. J. Med. Internet Res. 2021, 23, e24870. [Google Scholar] [CrossRef]
- Lee, J.M. An Exploratory Study on Effects of Loneliness and YouTube Addiction on College Life Adjustment in the Distance Education During COVID-19. J. Korea Contents Assoc. 2020, 20, 342–351. [Google Scholar]
- Silaban, P.H.; Chen, W.-K.; Nababan, T.S.; Eunike, I.J.; Silalahi, A.D.K. How Travel Vlogs on YouTube Influence Consumer Behavior: A Use and Gratification Perspective and Customer Engagement. Hum. Behav. Emerg. Technol. 2022, 2022, 4432977. [Google Scholar] [CrossRef]
- Möller, A.M.; Kühne, R.; Baumgartner, S.E.; Peter, J. Exploring User Responses to Entertainment and Political Videos: An Automated Content Analysis of YouTube. Soc. Sci. Comput. Rev. 2019, 37, 510–528. [Google Scholar] [CrossRef]
- Haridakis, P.; Hanson, G. Social Interaction and Co-Viewing With YouTube: Blending Mass Communication Reception and Social Connection. J. Broadcast. Electron. Media 2009, 53, 317–335. [Google Scholar] [CrossRef]
- Coppersmith, G.; Leary, R.; Crutchley, P.; Fine, A. Natural Language Processing of Social Media as Screening for Suicide Risk. Biomed. Inform. Insights 2018, 10, 1178222618792860. [Google Scholar] [CrossRef]
- Mazuz, K.; Yom-Tov, E. Analyzing Trends of Loneliness through Large-Scale Analysis of Social Media Postings: Observational Study. JMIR Ment. Health 2020, 7, e17188. [Google Scholar] [CrossRef]
- O’Day, E.B.; Heimberg, R.G. Social Media Use, Social Anxiety, and Loneliness: A Systematic Review. Comput. Hum. Behav. Rep. 2021, 3, 100070. [Google Scholar] [CrossRef]
- Willard, B.; Fair, G. Introducing Data Transfer Project: An Open Source Platform Promoting Universal Data Portability. Google Open Source Blog. Available online: https://opensource.googleblog.com/2018/07/introducing-data-transfer-project.html (accessed on 16 November 2023).
- Donovan, N.J.; Blazer, D. Social Isolation and Loneliness in Older Adults: Review and Commentary of a National Academies Report. Am. J. Geriatr. Psychiatry 2020, 28, 1233–1244. [Google Scholar] [CrossRef]
- Hudiyana, J.; Lincoln, T.M.; Hartanto, S.; Shadiqi, M.A.; Milla, M.N.; Muluk, H.; Jaya, E.S. How Universal Is a Construct of Loneliness? Measurement Invariance of the UCLA Loneliness Scale in Indonesia, Germany, and the United States. Assessment 2022, 29, 1795–1805. [Google Scholar] [CrossRef]
- Lim, M.H.; Eres, R.; Vasan, S. Understanding Loneliness in the Twenty-First Century: An Update on Correlates, Risk Factors, and Potential Solutions. Soc. Psychiatry Psychiatr. Epidemiol. 2020, 55, 793–810. [Google Scholar] [CrossRef]
- WHOIS API|565M+ Active Domains & 7596 TLDs Tracked|WhoisXML API. Available online: https://whois.whoisxmlapi.com (accessed on 16 November 2023).
- VideoCategories: List|YouTube Data API. Google for Developers. Available online: https://developers.google.com/youtube/v3/docs/videoCategories/list (accessed on 16 November 2023).
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016. [Google Scholar] [CrossRef]
- Dreiseitl, S.; Ohno-Machado, L. Logistic Regression and Artificial Neural Network Classification Models: A Methodology Review. J. Biomed. Inform. 2002, 35, 352–359. [Google Scholar] [CrossRef]
- Murtagh, F. Multilayer Perceptrons for Classification and Regression. Neurocomputing 1991, 2, 183–197. [Google Scholar] [CrossRef]
- Müller, A.C.; Guido, S. Introduction to Machine Learning with Python: A Guide for Data Scientists, 1st ed.; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2017. [Google Scholar]
- Altmann, A.; Toloşi, L.; Sander, O.; Lengauer, T. Permutation Importance: A Corrected Feature Importance Measure. Bioinformatics 2010, 26, 1340–1347. [Google Scholar] [CrossRef]
- Tufekci, Z. Algorithmic Harms beyond Facebook and Google: Emergent Challenges of Computational Agency. Colo. Technol. Law J. 2015, 13, 203. [Google Scholar]
- Ernst, M.; Niederer, D.; Werner, A.M.; Czaja, S.J.; Mikton, C.; Ong, A.D.; Rosen, T.; Brähler, E.; Beutel, M.E. Loneliness before and during the COVID-19 Pandemic: A Systematic Review with Meta-Analysis. Am. Psychol. 2022, 77, 660–677. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
| Platform 1 | Feature | Explanation |
|---|---|---|
| num_google_searches | Weekly number of Google searches | |
| num_websites_visited | Weekly number of websites visited through Google search | |
| weekly_use_count_google | Weekly number of engagements with Google products (e.g., Search and GMail) | |
| COVID_terms_google_search | Weekly Google searches with COVID-19 related glossary terms | |
| url_category_x | Weekly number of websites visited using Google search per category using the WhoisXML API [33]. Here, we focus on 21 categories that were used by at least half the users during the study period. (21 different features.) | |
| unique-url_cat_visited_weekly | Weekly number of unique Google search categories visited over the week | |
| total_url_weekly_top_cats | Weekly sum of pages visited via Google search (for the selected 21 categories) | |
| YouTube | num_videos_watched | Weekly number of videos watched on YouTube |
| average_num_sessions_per_week | Weekly number of YouTube sessions. Here, two videos belong in a session if they were watched within 60 min of each other | |
| weekly_use_count_youtube | Weekly number of times YouTube is used (e.g., videos watched and comments) | |
| yt_category_x | Weekly number of videos watched on YouTube per category as defined by the YouTube API [34]. We retain 11 such categories based on active use by the participants (11 different features). | |
| num_comments | Weekly number of YouTube comments | |
| unique_yt_cat_visited_weekly | Weekly number of unique YouTube categories visited | |
| total_yt_weekly_top_cats | Weekly sum of YouTube videos watched for the 11 selected categories |
| Sociodemographic Feature | Category | Frequency | Percentage |
|---|---|---|---|
| Gender | Female | 64 | 69.57% |
| Male | 28 | 30.43% | |
| Race/Ethnicity | White | 36 | 39.13% |
| Asian | 32 | 34.78% | |
| Other | 24 | 26.09% | |
| Marital Status | Single | 75 | 81.52% |
| Married | 8 | 8.70% | |
| Other | 9 | 9.78% | |
| Age | 18–21 | 40 | 43.48% |
| 22–25 | 23 | 25.00% | |
| 26 and older | 29 | 31.52% |
| Digital Trace Feature | Overall Mean | Mean: “Not Lonely” | Mean: “Lonely” | Difference in Means | Percent Difference |
|---|---|---|---|---|---|
| YouTube: Sports category | 3.07 | 4.82 | 0.74 | 4.08 | 132.78% |
| YouTube: Music category | 12.03 | 14.92 | 8.18 | 6.75 | 56.09% |
| YouTube: Education category | 2.61 | 3.08 | 1.98 | 1.10 | 42.09% |
| URLs visited: Miscellaneous category | 15.72 | 13.36 | 18.85 | −5.49 | −34.91% |
| Google search: COVID related terms | 1.75 | 1.47 | 2.11 | −0.64 | −36.62% |
| URLs visited: Hobbies and Interest category | 1.17 | 0.92 | 1.50 | −0.58 | −49.93% |
| Features | RF | XGB | LR | MLP |
|---|---|---|---|---|
| Demo | 78.07% | 79.94% | 79.52% | 80.66% |
| Google Features | 68.02% | 65.52% | 65.11% | 73.89% |
| YouTube Features | 62.11% | 61.96% | 66.27% | 68.09% |
| Google Features + YouTube Features | 66.16% | 66.56% | 68.04% | 73.89% |
| Demo + Google Features | 78.13% | 79.95% | 78.65% | 84.69% |
| Demo + YouTube Features | 79.83% | 80.30% | 84.42% | 83.65% |
| Demo + Google Features + YouTube Features | 75.50% | 80.60% | 78.88% | 82.59% |
| Features | RF | XGB | LR | MLP |
|---|---|---|---|---|
| Demo | 75.74% | 74.61% | 74.78% | 77.65% |
| Google Features | 64.39% | 65.17% | 62.48% | 71.13% |
| YouTube Features | 62.48% | 62.43% | 59.83% | 64.39% |
| Google Features + YouTube Features | 65.83% | 65.13% | 61.17% | 69.35% |
| Demo + Google Features | 72.78% | 75.26% | 75.17% | 80.17% |
| Demo + YouTube Features | 77.04% | 72.87% | 78.57% | 77.26% |
| Demo + Google Features + YouTube Features | 73.43% | 75.04% | 77.65% | 77.91% |
| Features | RF | XGB | LR | MLP |
|---|---|---|---|---|
| Demo | 71.34% | 70.27% | 69.54% | 74.01% |
| Google Features | 54.70% | 57.37% | 52.81% | 66.21% |
| YouTube Features | 42.76% | 47.97% | 34.37% | 58.83% |
| Google Features + YouTube Features | 57.16% | 58.40% | 55.26% | 62.22% |
| Demo + Google Features | 67.64% | 70.75% | 70.79% | 74.49% |
| Demo + YouTube Features | 71.96% | 67.80% | 74.28% | 72.31% |
| Demo + Google Features + YouTube Features | 68.06% | 70.58% | 73.14% | 73.34% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ahmed, E.; Xue, L.; Sankalp, A.; Kong, H.; Matos, A.; Silenzio, V.; Singh, V.K. Predicting Loneliness through Digital Footprints on Google and YouTube. Electronics 2023, 12, 4821. https://doi.org/10.3390/electronics12234821
Ahmed E, Xue L, Sankalp A, Kong H, Matos A, Silenzio V, Singh VK. Predicting Loneliness through Digital Footprints on Google and YouTube. Electronics. 2023; 12(23):4821. https://doi.org/10.3390/electronics12234821
Chicago/Turabian StyleAhmed, Eiman, Liyang Xue, Aniket Sankalp, Haein Kong, Arcadio Matos, Vincent Silenzio, and Vivek K. Singh. 2023. "Predicting Loneliness through Digital Footprints on Google and YouTube" Electronics 12, no. 23: 4821. https://doi.org/10.3390/electronics12234821
APA StyleAhmed, E., Xue, L., Sankalp, A., Kong, H., Matos, A., Silenzio, V., & Singh, V. K. (2023). Predicting Loneliness through Digital Footprints on Google and YouTube. Electronics, 12(23), 4821. https://doi.org/10.3390/electronics12234821