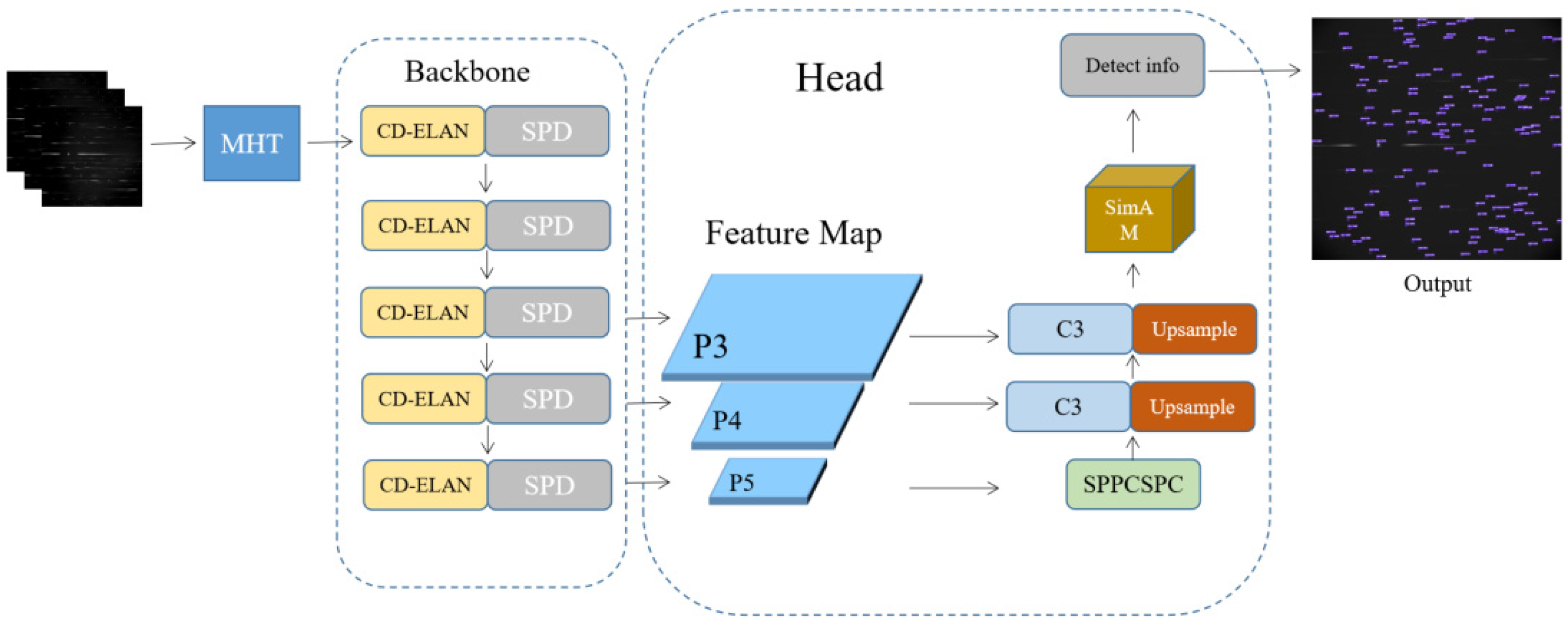
As shown in
Figure 1, our SOD-YOLO mainly includes three parts: a pre-processing module for 16-bit data, a backbone composed of CD-ELAN and SPD modules, and a high- and low-level feature fusion head with a SimAM attention module. Concentrated-Comprehensive Convolution (C3) is stacked by CBS (Conv + Batch Normalization + Silu) with identity mapping [
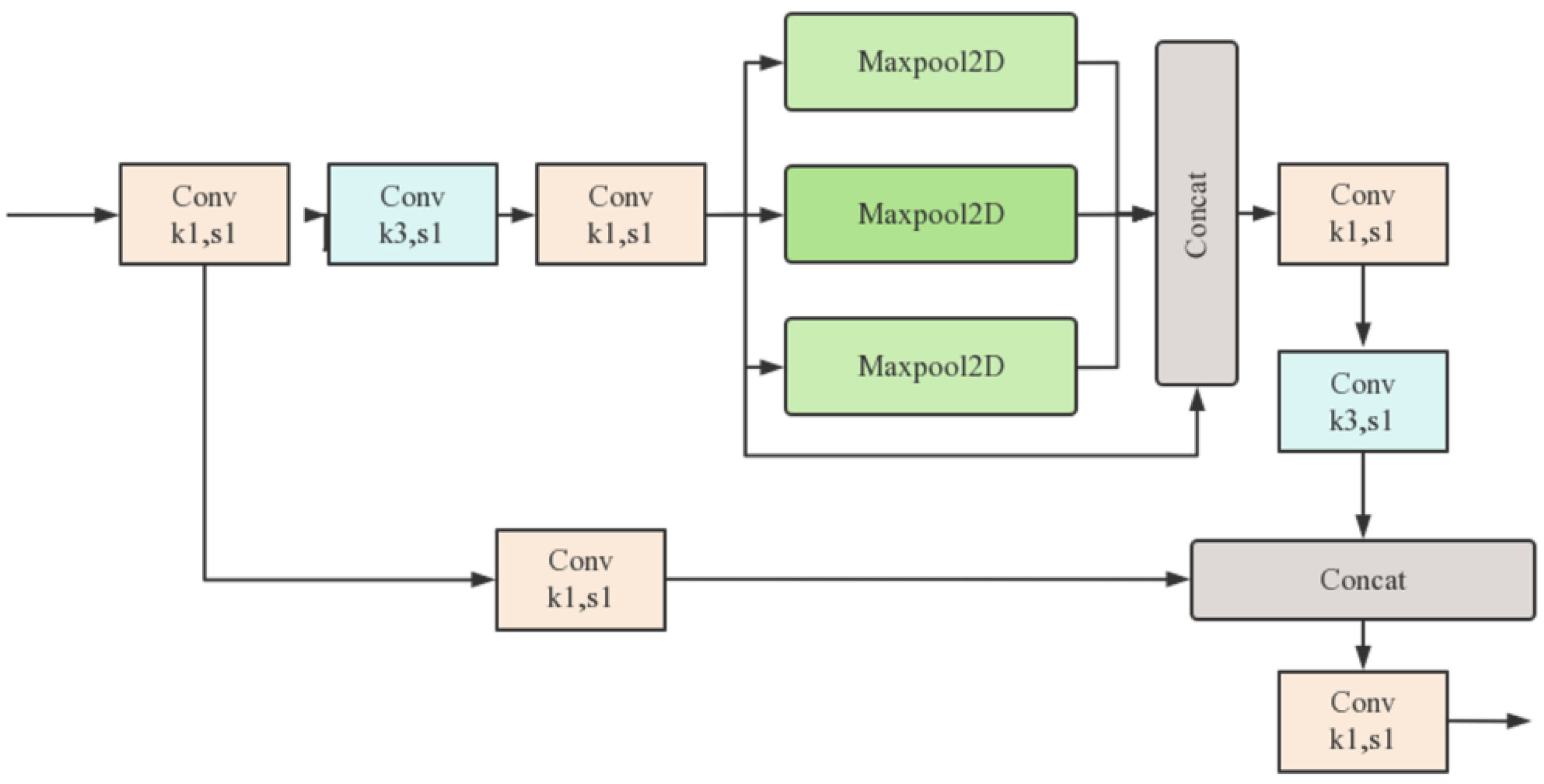
31] added. SPPCSPC is an improved spatial pyramid pool module with stronger abilities of feature fusion and extraction. The overall process of Spatial Pyramid Pooling and Channel-wise Spatial Pyramid Convolution (SPPCSPC) is depicted in
Figure 2.
The C3 module and SPPCSPC module are both the same as the previous YOLO series, and the other improved modules compared to YOLOv7 will be detailed in the following sections.
3.1. Multi-Channel Histogram Truncation Module (MHT)
As an effective image processing technique, histogram truncation is commonly used for enhancing image contrast by restricting or eliminating pixel values beyond a specific range. By defining a threshold, the high and low pixel values in the histogram are clipped or truncated, leading to a narrower intensity range. This process accentuates crucial details while mitigating the impact of outliers or extreme values, thereby improving the overall quality and visual appearance of the image.
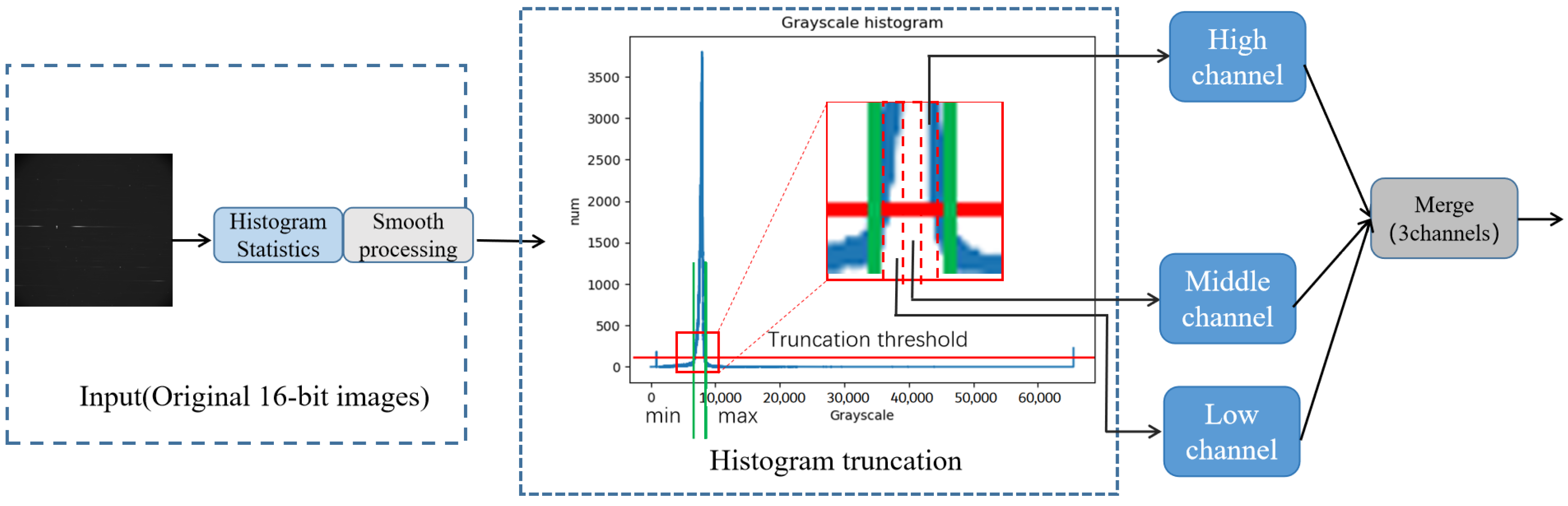
The original astronomical grayscale data is typically represented in 16 bits, with pixel values ranging from 0 to 65,536. However, as shown in
Figure 3, the brightness of the objects is often concentrated within a narrow range. If it is normalized directly, the dim objects may become drowned out. Histogram truncation is highly suitable for addressing this issue. Building upon histogram truncation, we leverage the autonomous learning capabilities of neural networks to design a preprocessing module named Multi-channel Histogram Truncation (MHT). This facilitates the narrowing of intensity ranges, thereby further enhancing the processing effectiveness. The processing flow of MHT is shown in
Figure 3.
Specifically, the steps involved in how MHT enhances the representation of features of space objects in 16-bit astronomical images are as follows:
Firstly, the MHT module performs a histogram analysis on the input image, allowing it to identify the specific range within which the most significant features are concentrated by examining the distribution of grayscale values. It is worth noting that in 16-bit astronomical images, this range is often quite narrow. This range typically encapsulates the crucial information within the image, while extraneous noise and irrelevant details are typically situated outside of this range.
Next, MHT applies a smoothing process to the resulting histogram curve. This process helps reduce any irregularities or noise present in the curve, making it more reliable for subsequent calculations.
Based on the smoothed curve, MHT determines the maximum and minimum values for normalization. A threshold is set on the number of pixels in order to identify the range within which the relevant features are concentrated. This ensures that the normalization process focuses on the most significant information and disregards potentially irrelevant details.
Within the determined truncation range, the grayscale values are further divided into high, medium, and low channels. These channels are normalized separately, allowing for more precise adjustment of their contrast and brightness levels. This division into multiple channels helps to preserve and enhance different aspects of the image, such as fine details, textures, and overall contrast.
Finally, the normalized channels are concatenated along the channel dimension and fed into the subsequent network or analysis. By combining the enhanced information from the different channels, MHT ensures a comprehensive and refined representation of the spatial object features in the image.
Overall, the MHT module enhances the representation of spatial object features in 16-bit astronomical images by identifying the relevant range of grayscale values, smoothing the histogram curve, normalizing the values within the truncation range, and combining the enhanced channels. This process effectively improves the contrast, clarity, and overall visibility of important features in the image, making it easier to distinguish between noise and signal.
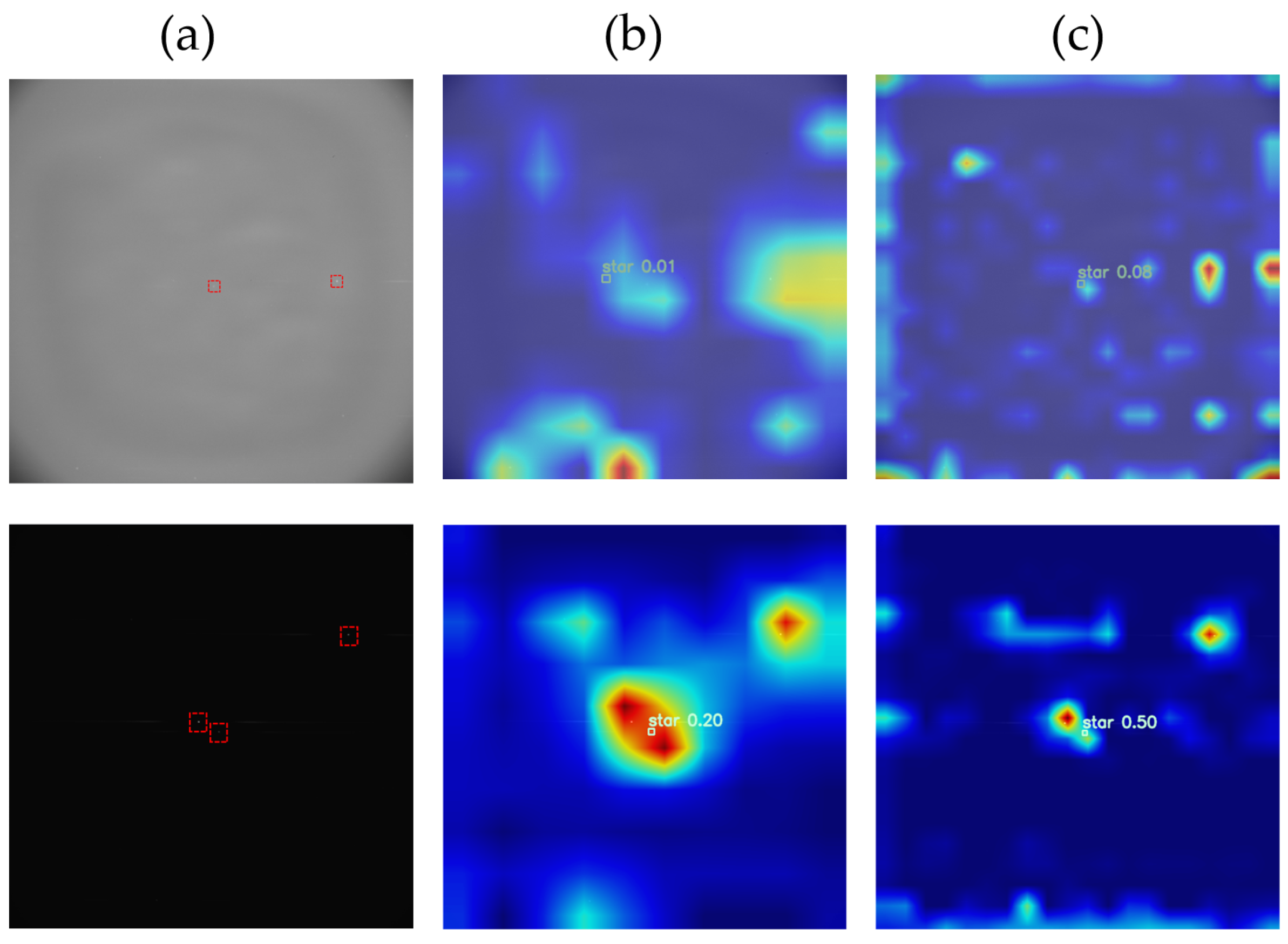
Through a number of experiments and statistics, we suggest that the threshold value of the number of pixels should be set to 0.5–1% of the number of pixels of the original 16-bit image, which can enhance the space objects and at the same time ensure they will not be removed. In this way, the characteristics of dim objects become more obvious and easier to be detected by the network. As for the MHT processing effect shown in
Figure 4, it can be observed that some objects that were originally drowned out in the background, making them nearly indistinguishable to the naked eye, become significantly apparent after undergoing MHT processing. The network can enhance the likelihood of detecting dim space objects by autonomously selecting information from different channels through learning.
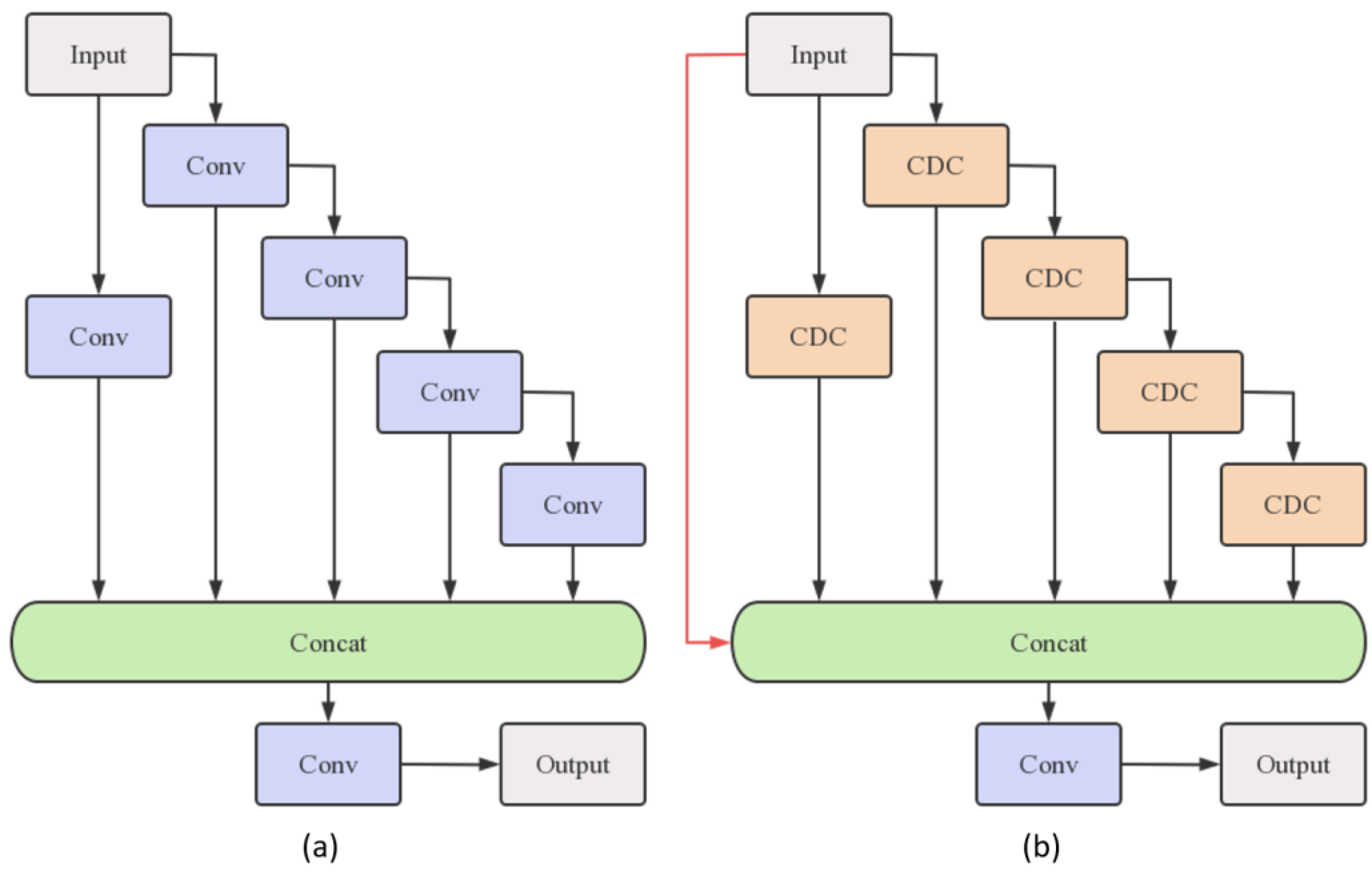
3.2. Central Differential-ELAN (CD-ELAN)
Convolution can effectively extract color, shape, texture, and other information, while standard convolution may be limited by the lack of information in space object detection tasks. Inspired by the human visual system’s sensitivity to intensity difference and contrast, we reconstruct the ELAN module in YOLOv7 based on central differential convolution to make the local contrast information more prominent, and name the new module CD-ELAN. The structures of ELAN and CD-ELAN are shown in
Figure 5.
In addition to adding identity mapping, the standard convolutions are replaced by CDC in our module. CDC can introduce additional contrast information by computing the difference between the center point and other points within the convolution window and can be described as Equation (1) [
19].
In our module,
CDC is combined with standard convolution to retain some of the common feature extraction capabilities, and the whole process can be expressed as Equation (2),
where the hyperparameter
is used to determine the contribution between CDC and vanilla convolution. The window size
used to calculate the difference is equal to the convolution kernel size.
The backbone network composed of CD-ELAN can extract local contrast information from input images better, exhibiting enhanced sensitivity to pixel grayscale value differences within astronomical images, thereby assisting the network in identifying dim space objects.
3.3. SimAM Attention Module
The attention mechanism is a crucial concept in neural networks which simulates the selective mechanism of human visual attention. Its core purpose is to filter out noise from cluttered information and selectively focus on the more relevant and critical information for the current task [
32]. Initially proposed by the Google team in 2017 [
33], it has since evolved into various variants and has been widely applied in the natural language processing and computer vision domains. By allocating different weights to different parts of feature maps, attention modeling indeed emphasizes the valuable regions while suppressing those dispensable ones. Naturally, one can deploy this superior scheme to highlight the small objects that are inclined to be dominated by the background and noisy patterns in an image.
Previous studies, such as the Bottleneck Attention Module (BAM) [
34] and Convolutional Block Attention Module (CBAM) [
35], have separately combined spatial attention and channel attention in parallel or sequential manners. However, the two types of attention in the human brain often work collaboratively. SimAM simulates the spatial inhibition characteristics of brain neurons by constructing an energy function and obtaining the minimum energy value of neurons through analytical solutions. This function can be expressed as Equation (3), where
represents the values of individual pixels in the image,
denotes the pixel mean value of the image,
represents the channel variance, and
is a manually set hyperparameter [
21].
By calculating the above energy function, the SimAM attention module obtains the three-dimensional weight of the current feature map and assigns a unique weight to each neuron. And the flowchart of SimAM is shown below (
Figure 6).
The original head layer in YOLOv7 was composed of stacked ELAN, resulting in a substantial computational burden and limited improvement in the detection capability of small objects. Furthermore, it was not conducive to the integration of attention modules. Therefore, we adopted the same head layer as YOLOv5. The SimAM attention module was inserted after the C3 module. Multiple hierarchical feature maps extracted by the backbone were fused within the C3 module. The SimAM attention module enriches feature representation and refines the extracted feature maps by computing adaptive weights assigned to each pixel on the feature map, thereby complementing the C3 module. This refined information is then used by the subsequent layers for object detection and localization within the YOLOv5-based head layer. The novel head, incorporating the SimAM attention mechanism, exhibits reduced computational complexity and enables better detection of dim and small objects by leveraging global information.
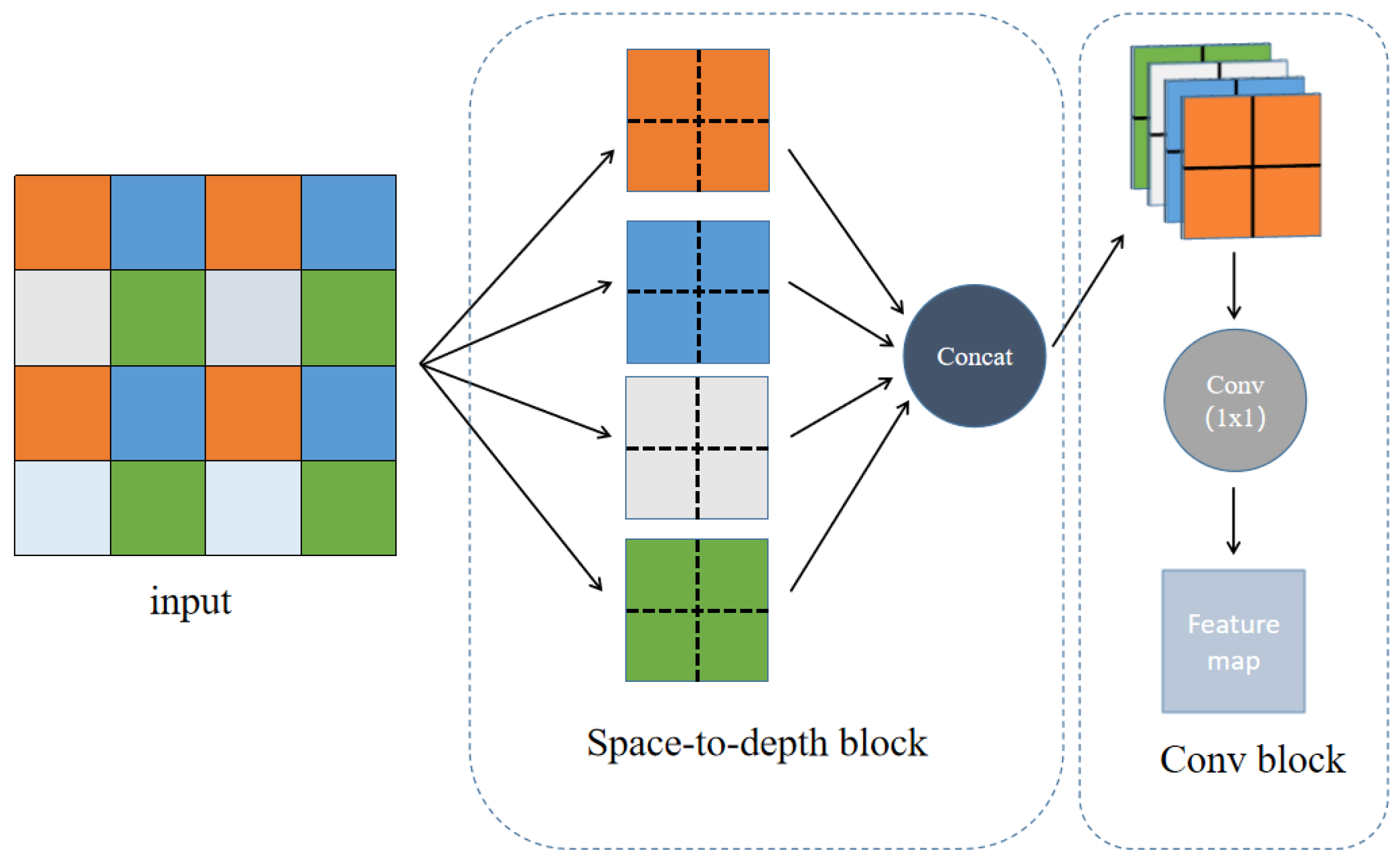
3.4. Space-to-Depth Module (SPD)
Convolutional Neural Networks (CNNs) have achieved significant success in various computer vision tasks such as image classification and object detection. However, their performance rapidly deteriorates in more challenging tasks with low image resolutions or small objects. Sunkara R et al. [
22] claim that the root cause lies in the flawed yet common design of existing CNN architectures, which employ hierarchical convolutions and pooling layers, leading to the loss of fine-grained information and inefficient learning of feature representations. To solve this problem, they devised an alternative to the average pooling layer named the space-to-depth module (SPD).
The SPD module consists of a Space-to-depth (SPD) layer and a non-strided convolution (Conv) layer, as shown in
Figure 7. This module can be applied to most CNN architectures. The SPD layer is responsible for downsampling the image. For any feature map
, it is divided into a grid based on the scale size, as shown in
Figure 5 with an example of
, resulting in four sub-maps
,
,
and
. Each sub-map is one-quarter the size of the original feature map. After concatenating the four sub-maps in the depth dimension, they are compressed to match the depth of the original map through the Conv layer, completing the downsampling process.
As space objects in astronomical images are often smaller than 20 pixels, using excessive average pooling for downsampling would result in the objects being overwhelmed by the background. Therefore, we use the SPD module to replace the stride convolution and pooling layers to map the feature information from spatial to depth. This approach aims to prevent the loss of space object feature information during the downsampling process.
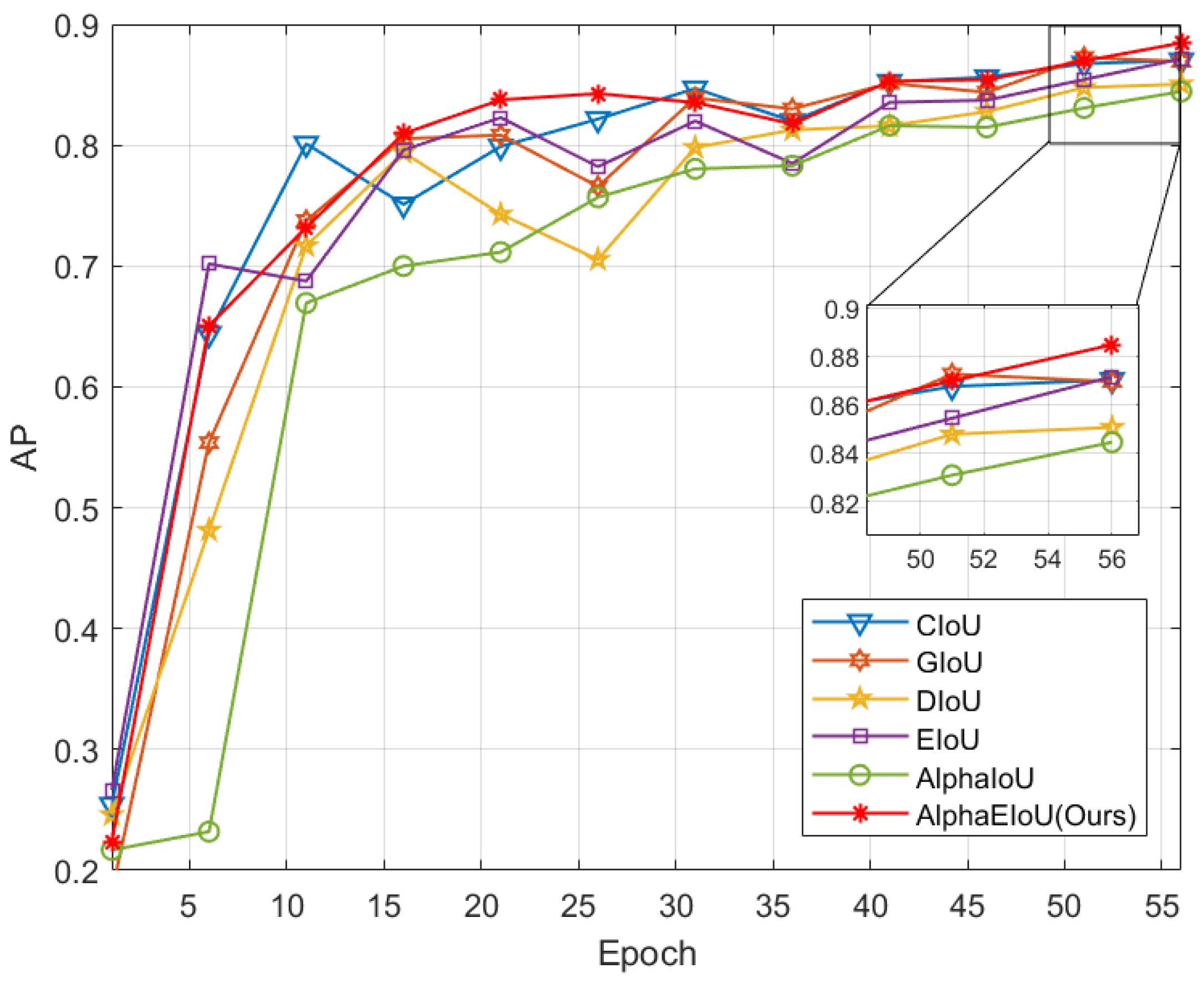
3.5. Alpha-EIoU Loss Function
The choice of loss function plays a critical role in the learning ability of neural networks during the training process. A suitable loss function can help improve the convergence speed and accuracy of the algorithm.
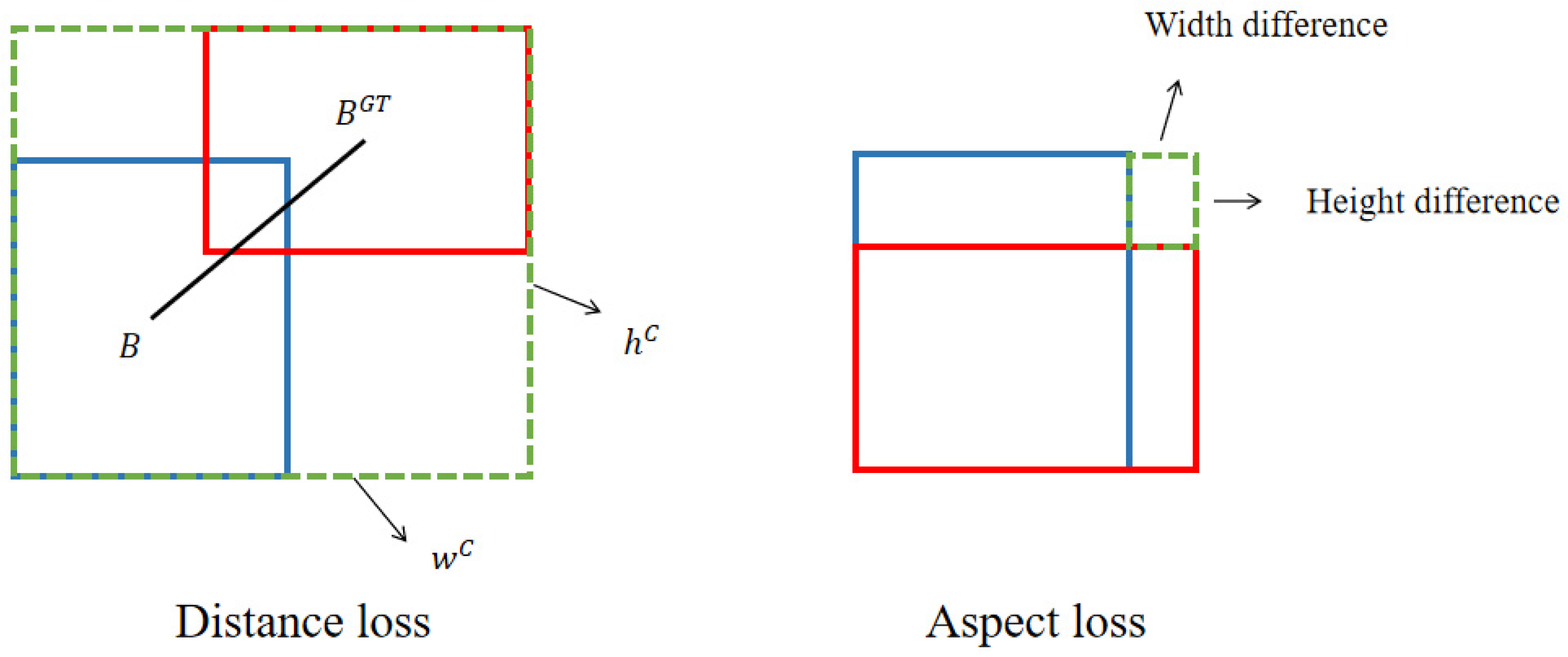
The Complete-IoU (CIoU) [
36] loss function used in YOLOv7 can be expressed as Equations (4)–(6), where
represents the Euclidean distance between two points,
is the center point of the box, and
and
represent the width and height of the bounding box, respectively.
In Equation (6),
only reflects the discrepancy of aspect ratio, rather than the real relations between
and
or
and
. Namely, all the boxes with property
have
, which is inconsistent with reality. In addition, in this equation, we have
. Here,
and
have opposite signs. Thus, at any time, if one of these two variables (
or
) is increased, the other one will decrease. This is unreasonable, especially when
and
or
and
. Due to the high sensitivity of small object detection to IoU variations, these deficiencies can lead to slow convergence speed and low efficiency while training the model on datasets in which objects are small [
24,
37]. Therefore, Zhang et al. improved the CIoU loss function and proposed Efficient-IoU (EIoU). Compared to CIoU, EIoU decomposes the orientation loss term into the differences between the predicted width and height and the width and height of the ground truth bounding box, providing a more accurate orientation representation, which can be expressed as Equation (4). In Equation (7),
and
represent the width and height of the minimum enclosing rectangle of the predicted bounding box and the ground truth bounding box.
Additionally, He et al. [
38] demonstrated through empirical studies that bounding box regression loss exhibits greater robustness towards datasets with low signal-to-noise ratios (SNR) when combined with an artificially-set power term
. They named this loss function Alpha-IoU, and the equation is as follows:
The in Equation (8) represents an arbitrary regularization term.
Due to the characteristics of astronomical images having severe noise interference and small targets, we believe that the aforementioned two improvements to the loss function are highly applicable in the field of space object detection. Therefore, we combine Alpha-IoU and EIoU and propose Alpha-EIoU, a novel loss function for detecting small objects in low-SNR images. The function is expressed as Equation (9).
Alpha-EIoU consists of three components: Intersection over Union (IoU) loss, distance loss, and aspect loss. A hyperparameter
is introduced as the exponent for each term. This novel loss function combines the advantages of EIoU and Alpha-IoU, enabling more precise localization of small objects and enhanced handling of noise interference. We firmly believe that Alpha-EIoU represents a superior choice for training models in the context of space object detection. The schematic diagram of Alpha-EIoU is shown in
Figure 8.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}