


AI to Train AI: Using ChatGPT to Improve the Accuracy of a Therapeutic Dialogue System
 , , , and
, , , and
Abstract
:1. Introduction
2. Material and Methods
2.1. Terabot—Therapeutic Spoken Dialogue System
2.2. Improving the Dialogue System Using ChatGPT
- Give a few examples with patients telling what recently made them anxious.
- Paraphrase briefly the sentence: “I usually avoid showing anger”.
- Paraphrase the sentence: “I feel relaxed” using the feminine gender”.
3. Experiments
4. Results
4.1. Intent Recognition Accuracy for the Model Enhanced with ChatGPT-Augmented Data
4.2. Intent Recognition Accuracy with Regard to ASR Errors
4.3. Satisfaction Survey
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sample Answer to Terabot’s Question in Polish (with English Translation) | Example Sentences Paraphrased by ChatGPT in Polish (with English Translation) |
|---|---|
| Zazwyczaj unikam okazywania złości. (I usually avoid showing anger.) | Z reguły ukrywam swoją frustrację. (I generally hide my frustration.) |
| Często maskuję swoje negatywne uczucia. (I often mask my negative feelings.) | |
| Zazwyczaj nie pokazuję swojej złości. (I don’t usually let my anger show.) | |
| Na ogół unikam demonstracji mojego gniewu. (In general, I avoid demonstrating my anger.) | |
| Zazwyczaj wybucham podczas okazywania złości. (I usually burst out while showing anger.) | Przeważnie tracę panowanie, gdy wybucham z powodu złości. (Most of the time, I lose my temper when I explode out of anger.) |
| W większości przypadków moje reakcje na frustrację są gwałtowne. (In most cases, my reactions to frustration are violent.) | |
| Często moje reakcje na gniew są wybuchowe. (A lot of times, my reactions to anger are explosive.) | |
| Przeważnie tracę cierpliwość, gdy okazuję swoje negatywne uczucia. (Mostly I lose patience when I show my negative feelings.) | |
| Moje ciało sztywnieje podczas odczuwania lęku, paraliżuje mnie. (When I feel fear, my body stiffens up and paralyzes me.) | W momencie odczuwania lęku, moje ciało staje się nieruchome, wywołując uczucie paraliżu. (My body becomes motionless and feels paralyzed when I have anxiety.) |
| Pod wpływem lęku, moja fizyczna reakcja to zazwyczaj uczucie sztywności i paraliżu. (Under anxiety, my physical reaction is usually a feeling of stiffness and paralysis.) | |
| Kiedy odczuwam lęk, moje ciało jest jakby unieruchomione, pozostawiając mnie w stanie paraliżu. (When I experience anxiety, my body is sort of immobilized, leaving me in a state of paralysis.) | |
| W obliczu lęku, moje ciało wydaje się być sparaliżowane, i to uniemożliwia mi jakiekolwiek działanie. (In the face of anxiety, my body seems paralyzed, preventing me from doing anything.) |
References
- Kozłowski, M.; Gabor-Siatkowska, K.; Stefaniak, I.; Sowański, M.; Janicki, A. Enhanced Emotion and Sentiment Recognition for Empathetic Dialogue System Using Big Data and Deep Learning Methods. In Proceedings of the International Conference on Computational Science (ICCS 2023), Prague, Czech Republic, 3–5 July 2023; pp. 465–480. [Google Scholar] [CrossRef]
- Gabor-Siatkowska, K.; Sowański, M.; Pudo, M.; Rzatkiewicz, R.; Stefaniak, I.; Kozłowski, M.; Janicki, A. Therapeutic Spoken Dialogue System in Clinical Settings: Initial Experiments. In Proceedings of the 30th International Conference on Systems, Signals and Image Processing, (IWSSIP 2023), Ohrid, North Macedonia, 27–29 June 2023; pp. 1–5. [Google Scholar] [CrossRef]
- Rosenbaum, A.; Soltan, S.; Hamza, W.; Versley, Y.; Boese, M. LINGUIST: Language Model Instruction Tuning to Generate Annotated Utterances for Intent Classification and Slot Tagging. In Proceedings of the 29th International Conference on Computational Linguistics, Gyeongju, Republic of Korea, 12–17 October 2022; International Committee on Computational Linguistics: Gyeongju, Republic of Korea, 2022; pp. 218–241. [Google Scholar]
- Chen, M.; Papangelis, A.; Tao, C.; Kim, S.; Rosenbaum, A.; Liu, Y.; Yu, Z.; Hakkani-Tur, D. PLACES: Prompting Language Models for Social Conversation Synthesis. In Proceedings of the Findings of the Association for Computational Linguistics: EACL 2023, Dubrovnik, Croatia, 2–6 May 2023; pp. 814–838. [Google Scholar]
- Zheng, C.; Sabour, S.; Wen, J.; Huang, M. Augesc: Large-scale data augmentation for emotional support conversation with pre-trained language models. arXiv 2022, arXiv:2202.13047. [Google Scholar]
- Dino, F.; Zandie, R.; Abdollahi, H.; Schoeder, S.; Mahoor, M.H. Delivering Cognitive Behavioral Therapy Using A Conversational Social Robot. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS 2019), Macau, China, 3–8 November 2019; pp. 2089–2095. [Google Scholar] [CrossRef]
- Craig, T.K.; Rus-Calafell, M.; Ward, T.; Leff, J.P.; Huckvale, M.; Howarth, E.; Emsley, R.; Garety, P.A. AVATAR therapy for auditory verbal hallucinations in people with psychosis: A single-blind, randomised controlled trial. Lancet Psychiatry 2018, 5, 31–40. [Google Scholar] [CrossRef] [PubMed]
- Stefaniak, I.; Sorokosz, K.; Janicki, A.; Wciórka, J. Therapy based on avatar-therapist synergy for patients with chronic auditory hallucinations: A pilot study. Schizophr. Res. 2019, 211, 115–117. [Google Scholar] [CrossRef]
- Fernández-Caballero, A.; Navarro, E.; Fernández-Sotos, P.; González, P.; Ricarte, J.; Latorre, J.; Rodriguez-Jimenez, R. Human-Avatar Symbiosis for the Treatment of Auditory Verbal Hallucinations in Schizophrenia through Virtual/Augmented Reality and Brain-Computer Interfaces. Front. Neuroinform. 2017, 11, 64. [Google Scholar] [CrossRef] [PubMed]
- Weizenbaum, J. ELIZA—A computer program for the study of natural language communication between man and machine. Commun. ACM 1966, 9, 36–45. [Google Scholar] [CrossRef]
- Chen, Q.; Zhuo, Z.; Wang, W. BERT for joint intent classification and slot filling. arXiv 2019, arXiv:1902.10909. [Google Scholar]
- Zhong, V.; Xiong, C.; Socher, R. Global-Locally Self-Attentive Encoder for Dialogue State Tracking. In Proceedings of the 56th Annual Meeting of the ACL (Volume 1: Long Papers), Melbourne, Australia, 15–20 July 2018; pp. 1458–1467. [Google Scholar] [CrossRef]
- Su, P.H.; Gasic, M.; Mrkšić, N.; Barahona, L.M.R.; Ultes, S.; Vandyke, D.; Wen, T.H.; Young, S. On-line Active Reward Learning for Policy Optimisation in Spoken Dialogue Systems. In Proceedings of the 54th Annual Meeting of the ACL (Volume 1: Long Papers), Berlin, Germany, 7–12 August 2016; pp. 2431–2441. [Google Scholar]
- Sharma, S.; He, J.; Suleman, K.; Schulz, H.; Bachman, P. Natural Language Generation in Dialogue using Lexicalized and Delexicalized Data. In Proceedings of the International Conference on Learning Representations: Workshop Track, Toulon, France, 24–26 April 2017; pp. 1–6. [Google Scholar]
- Fitzpatrick, K.K.; Darcy, A.; Vierhile, M. Delivering Cognitive Behavior Therapy to Young Adults with Symptoms of Depression and Anxiety Using a Fully Automated Conversational Agent (Woebot): A Randomized Controlled Trial. JMIR Ment Health 2017, 4, e19. [Google Scholar] [CrossRef]
- Spillane, B.; Saam, C.; Gilmartin, E.; Cowan, B.R.; Wade, V.P. ADELE: Evaluating and Benchmarking an Artificial Conversational Care Agent. In Proceedings of the Conversational Agents for Health and Wellbeing Workshop (CHI 2020), Honolulu, HI, USA, 25–30 April 2020. [Google Scholar]
- Lugrin, B.; Pelachaud, C.; Traum, D. (Eds.) The Handbook on Socially Interactive Agents: 20 Years of Research on Embodied Conversational Agents, Intelligent Virtual Agents, and Social Robotics Volume 2: Interactivity, Platforms, Application, 1st ed.; ACM: New York, NY, USA, 2022; Volume 48. [Google Scholar]
- Zygadło, A.; Kozłowski, M.; Janicki, A. Text-Based emotion recognition in English and Polish for therapeutic chatbot. Appl. Sci. 2021, 11, 10146. [Google Scholar] [CrossRef]
- Liu, X.; Zhou, G.; Kong, M.; Yin, Z.; Li, X.; Yin, L.; Zheng, W. Developing Multi-Labelled Corpus of Twitter Short Texts: A Semi-Automatic Method. Systems 2023, 11, 390. [Google Scholar] [CrossRef]
- Liu, X.; Shi, T.; Zhou, G.; Liu, M.; Yin, Z.; Yin, L.; Zheng, W. Emotion classification for short texts: An improved multi-label method. Humanit. Soc. Sci. Commun. 2023, 10, 306. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Fan, A.; Lewis, M.; Dauphin, Y. Hierarchical Neural Story Generation. In Proceedings of the Proceedings of the 56th Annual Meeting of the ACL (Volume 1: Long Papers), Melbourne, Australia, 15–20 July 2018; pp. 889–898.
- Holtzman, A.; Buys, J.; Du, L.; Forbes, M.; Choi, Y. The Curious Case of Neural Text Degeneration. In Proceedings of the International Conference on Learning Representations (ICLR 2019), New Orleans, LA, USA, 6–9 May 2019; pp. 1–6. [Google Scholar]
- Bender, E.M.; Gebru, T.; McMillan-Major, A.; Shmitchell, S. On the Dangers of Stochastic Parrots: Can Language Models Be Too Big? In Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency, Virtual Event, Canada, 3–10 March 2021; pp. 610–623. [Google Scholar]
- Merrill, W.; Goldberg, Y.; Schwartz, R.; Smith, N.A. Provable Limitations of Acquiring Meaning from Ungrounded Form: What Will Future Language Models Understand? Trans. Assoc. Comput. Linguist. 2021, 9, 1047–1060. [Google Scholar] [CrossRef]
- Kasneci, E.; Sessler, K.; Küchemann, S.; Bannert, M.; Dementieva, D.; Fischer, F.; Gasser, U.; Groh, G.; Günnemann, S.; Hüllermeier, E.; et al. ChatGPT for good? On opportunities and challenges of large language models for education. Learn. Individ. Differ. 2023, 103, 102274. [Google Scholar] [CrossRef]
- OpenAI. GPT-4 Technical Report. arXiv 2023, arXiv:2303.08774. [Google Scholar]
- Balas, M.; Ing, E.B. Conversational AI Models for ophthalmic diagnosis: Comparison of ChatGPT and the Isabel Pro Differential Diagnosis Generator. JFO Open Ophthalmol. 2023, 1, 100005. [Google Scholar] [CrossRef]
- Liu, S.; Wright, A.P.; Patterson, B.L.; Wanderer, J.P.; Turer, R.W.; Nelson, S.D.; McCoy, A.B.; Sittig, D.F.; Wright, A. Assessing the Value of ChatGPT for Clinical Decision Support Optimization. medRxiv 2023. [Google Scholar] [CrossRef]
- Bang, Y.; Cahyawijaya, S.; Lee, N.; Dai, W.; Su, D.; Wilie, B.; Lovenia, H.; Ji, Z.; Yu, T.; Chung, W.; et al. A multitask, multilingual, multimodal evaluation of chatgpt on reasoning, hallucination, and interactivity. arXiv 2023, arXiv:2302.04023. [Google Scholar]
- Ji, Z.; Lee, N.; Frieske, R.; Yu, T.; Su, D.; Xu, Y.; Ishii, E.; Bang, Y.J.; Madotto, A.; Fung, P. Survey of Hallucination in Natural Language Generation. ACM Comput. Surv. 2023, 55, 248. [Google Scholar] [CrossRef]
- Weidinger, L.; Mellor, J.; Rauh, M.; Griffin, C.; Uesato, J.; Huang, P.S.; Cheng, M.; Glaese, M.; Balle, B.; Kasirzadeh, A.; et al. Ethical and social risks of harm from Language Models. arXiv 2021, arXiv:2112.04359. [Google Scholar]
- Bunk, T.; Varshneya, D.; Vlasov, V.; Nichol, A. DIET: Lightweight Language Understanding for Dialogue Systems. arXiv arXiv:2004.09936, 2020.
- Jiao, A. An Intelligent Chatbot System Based on Entity Extraction Using RASA NLU and Neural Network. J. Phys. Conf. Ser. 2020, 1487, 012014. [Google Scholar] [CrossRef]
- Vlasov, V.; Mosig, J.E.M.; Nichol, A. Dialogue Transformers. arXiv 2019, arXiv:1910.00486. [Google Scholar]
- Oliver, A.; Odena, A.; Raffel, C.A.; Cubuk, E.D.; Goodfellow, I. Realistic evaluation of deep semi-supervised learning algorithms. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018; Volume 31. [Google Scholar]
- Pudo, M.; Szczepanek, N.; Lukasiak, B.; Janicki, A. Semi-Supervised Learning with Limited Data for Automatic Speech Recognition. In Proceedings of the IEEE 7th Forum on Research and Technologies for Society and Industry Innovation (RTSI 2022), Paris, France, 24–26 August 2022; pp. 136–141. [Google Scholar] [CrossRef]
- Roziewski, S.; Kozłowski, M. LanguageCrawl: A generic tool for building language models upon common Crawl. Lang. Resour. Eval. 2021, 55, 1047–1075. [Google Scholar] [CrossRef]
- Reimers, N.; Gurevych, I. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. In Proceedings of the Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP 2019), Hong Kong, China, 3–7 November 2019; pp. 3973–3983. [Google Scholar] [CrossRef]
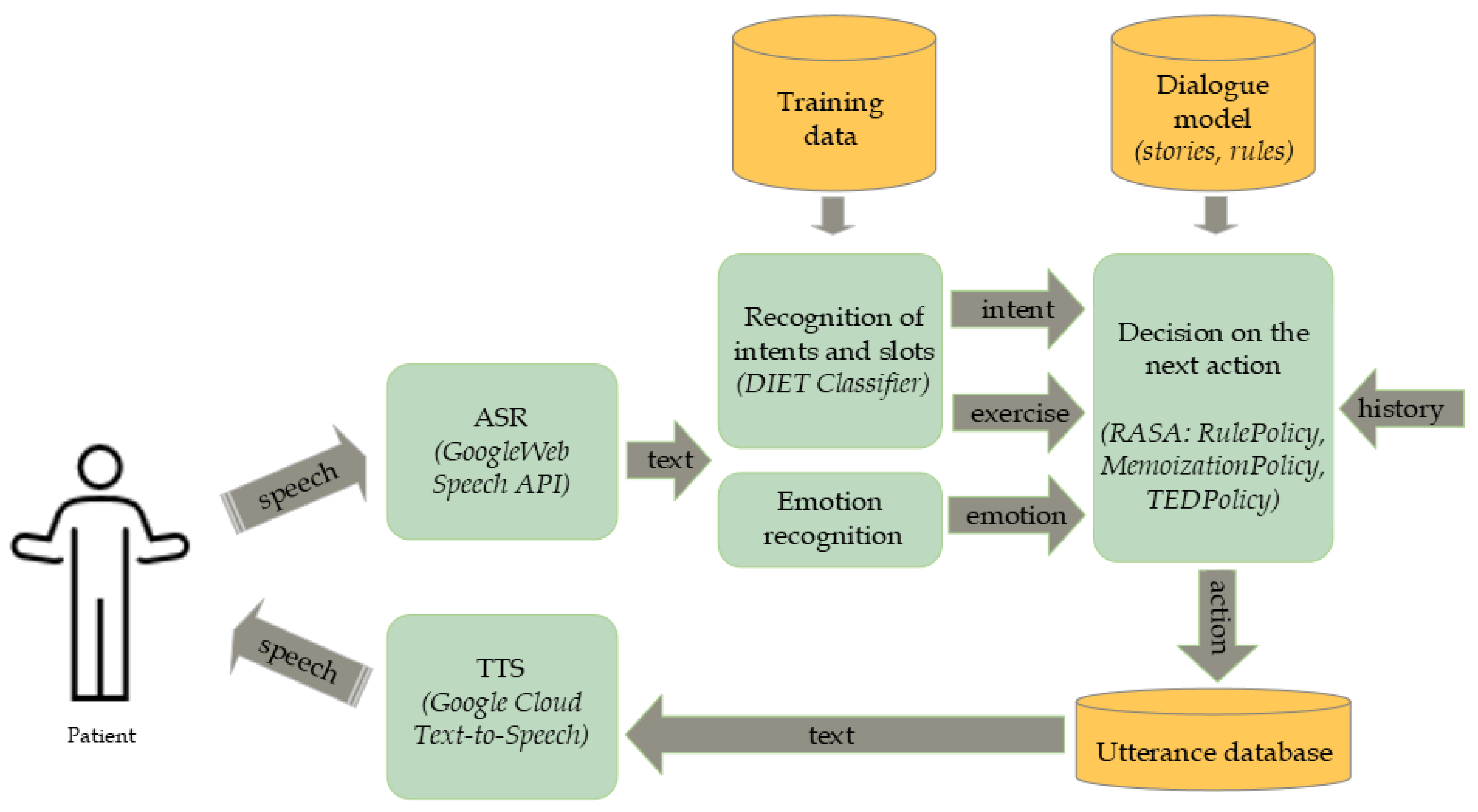
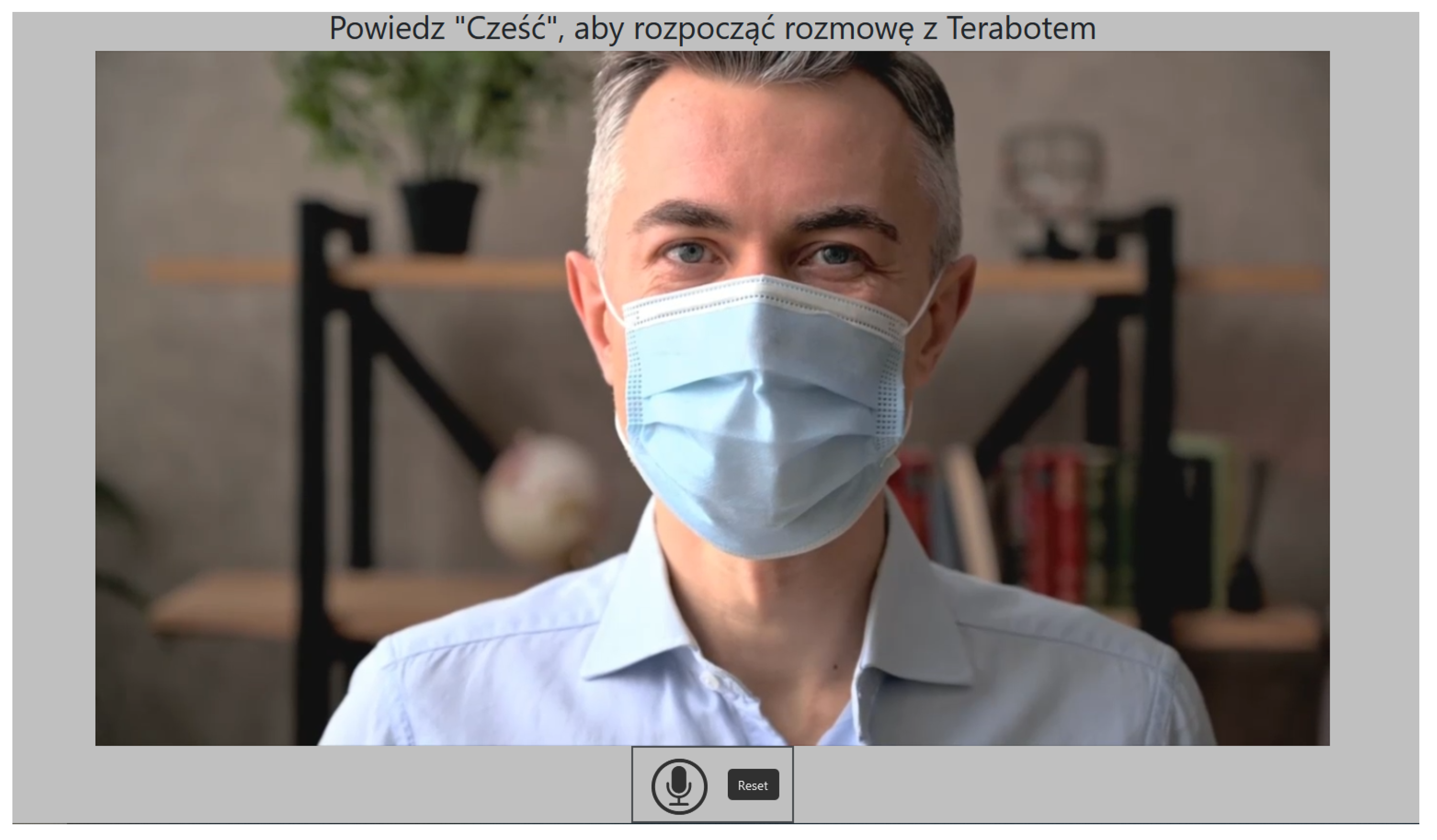
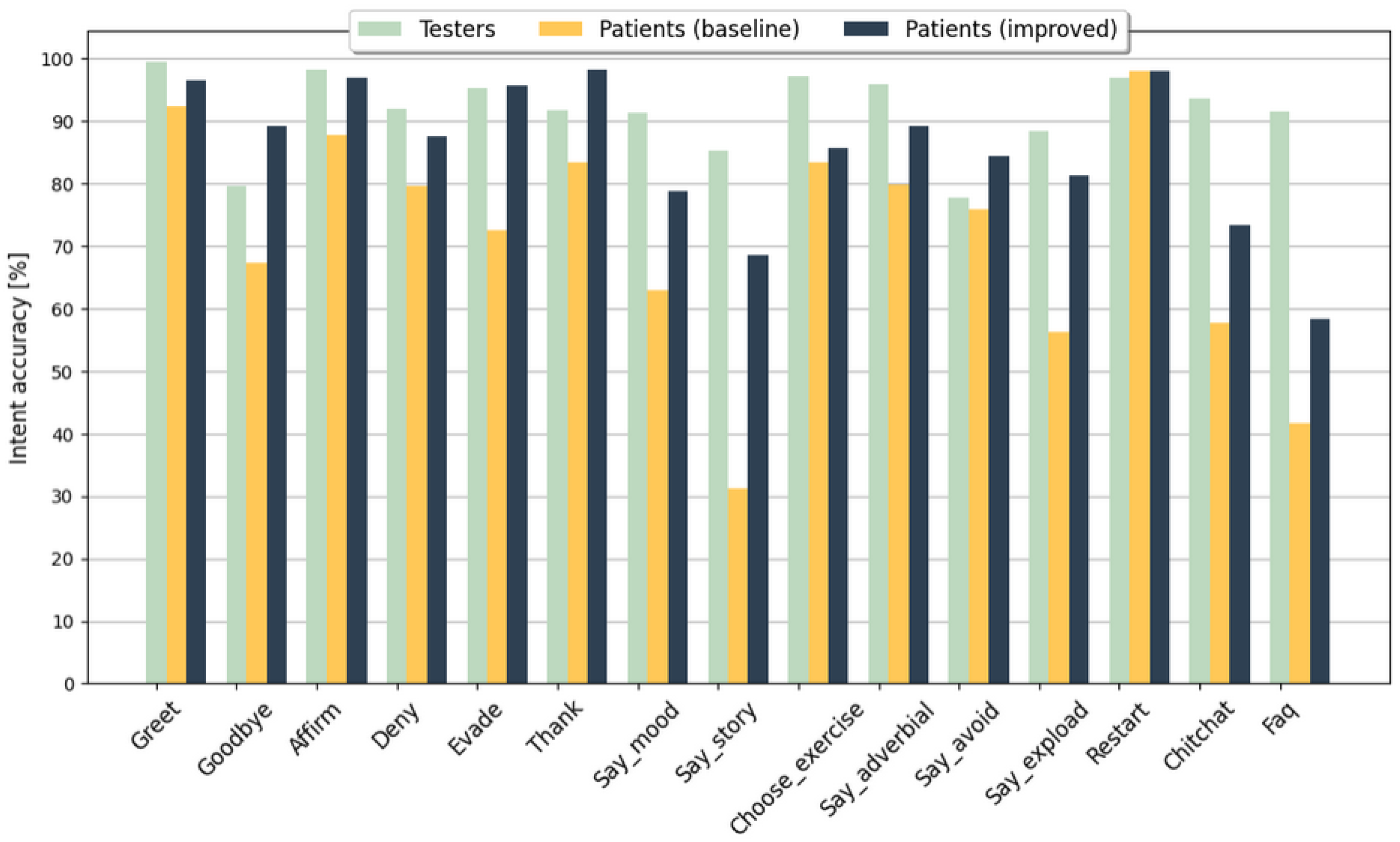
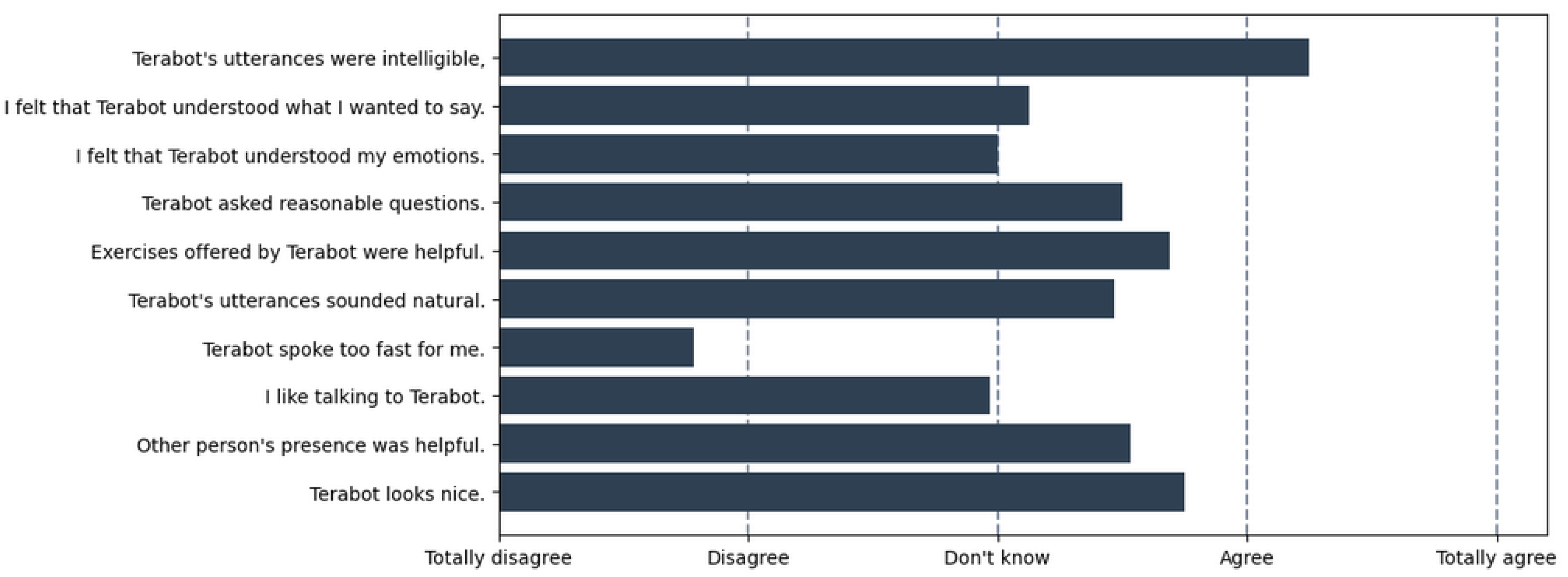
| Intent | Training Data | ChatGPT-Added [%] | ||
|---|---|---|---|---|
| Initial | ChatGPT | Total | ||
| Greet | 85 | 21 | 106 | 24.7 |
| Goodbye | 84 | 21 | 105 | 25.0 |
| Affirm | 245 | 38 | 283 | 15.5 |
| Deny | 39 | 11 | 50 | 28.2 |
| Evade | 80 | 49 | 129 | 61.3 |
| Thank | 14 | 30 | 44 | 214.3 |
| Say_mood | 202 | 412 | 614 | 204.0 |
| Say_story | 120 | 621 | 741 | 517.5 |
| Choose_exercise | 160 | 29 | 189 | 18.1 |
| Say_adverbial | 44 | 59 | 103 | 134.1 |
| Say_avoid | 14 | 46 | 60 | 328.6 |
| Say_expload | 19 | 44 | 63 | 231.6 |
| Restart | 22 | 0 | 22 | 0.0 |
| Chitchat | 198 | 329 | 527 | 166.2 |
| Faq | 199 | 0 | 199 | 0.0 |
| Total | 1525 | 1710 | 3235 | 112.1 |
| Terabot | Patient |
|---|---|
| Do you recall a situation when you felt anxious? | |
| Yes, uhm, I do very well. | |
| (intent: Affirm) | |
| What caused your anxiety then? | |
| I realized that I’d lost a fortune when, um, gambling. | |
| (intent: Say_story) | |
| This is serious, indeed. Notice how quickly anxiety grows within you… |
| Input Data | DIET Intent Recognition Module | |
|---|---|---|
| Baseline | ChatGPT-Augmented | |
| Actual (with ASR errors) | ||
| Theoretical (for ideal ASR) | ||
| Intent | Testers | Patients | ||||
|---|---|---|---|---|---|---|
| #Test | WRR | SRR | #Test | WRR | SRR | |
| Greet | 654 | 96.67 | 97.39 | 258 | 95.25 | 90.63 |
| Goodbye | 98 | 96.56 | 90.82 | 46 | 98.47 | 97.83 |
| Affirm | 556 | 97.40 | 94.63 | 671 | 94.14 | 90.69 |
| Deny | 74 | 100.00 | 100.00 | 88 | 87.62 | 90.91 |
| Evade | 207 | 99.62 | 98.53 | 69 | 92.44 | 92.75 |
| Thank | 12 | 100.00 | 100.00 | 54 | 94.23 | 87.50 |
| Say_mood | 159 | 98.38 | 94.12 | 244 | 89.10 | 79.84 |
| Say_story | 122 | 94.34 | 80.17 | 385 | 80.69 | 74.41 |
| Choose_exer. | 326 | 95.94 | 89.97 | 307 | 92.60 | 86.60 |
| Say_adverb. | 49 | 97.75 | 93.62 | 75 | 89.46 | 88.00 |
| Say_avoid | 9 | 100.00 | 100.00 | 58 | 87.35 | 86.21 |
| Say_expload | 26 | 90.81 | 70.37 | 16 | 95.78 | 81.25 |
| Restart | 65 | 95.63 | 93.18 | 253 | 95.69 | 94.05 |
| Restart_exer. | 22 | 98.68 | 95.46 | 3 | 100.00 | 100.00 |
| Chitchat | 269 | 96.98 | 85.04 | 262 | 92.72 | 83.94 |
| Faq | 131 | 89.41 | 68.75 | 13 | 97.69 | 92.31 |
| Total | 2779 | – | – | 2802 | – | – |
| Weight.avg. | – | 96.70 | 91.99 | – | 91.39 | 86.64 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gabor-Siatkowska, K.; Sowański, M.; Rzatkiewicz, R.; Stefaniak, I.; Kozłowski, M.; Janicki, A. AI to Train AI: Using ChatGPT to Improve the Accuracy of a Therapeutic Dialogue System. Electronics 2023, 12, 4694. https://doi.org/10.3390/electronics12224694
Gabor-Siatkowska K, Sowański M, Rzatkiewicz R, Stefaniak I, Kozłowski M, Janicki A. AI to Train AI: Using ChatGPT to Improve the Accuracy of a Therapeutic Dialogue System. Electronics. 2023; 12(22):4694. https://doi.org/10.3390/electronics12224694
Chicago/Turabian StyleGabor-Siatkowska, Karolina, Marcin Sowański, Rafał Rzatkiewicz, Izabela Stefaniak, Marek Kozłowski, and Artur Janicki. 2023. "AI to Train AI: Using ChatGPT to Improve the Accuracy of a Therapeutic Dialogue System" Electronics 12, no. 22: 4694. https://doi.org/10.3390/electronics12224694
APA StyleGabor-Siatkowska, K., Sowański, M., Rzatkiewicz, R., Stefaniak, I., Kozłowski, M., & Janicki, A. (2023). AI to Train AI: Using ChatGPT to Improve the Accuracy of a Therapeutic Dialogue System. Electronics, 12(22), 4694. https://doi.org/10.3390/electronics12224694