
Mean Field Multi-Agent Reinforcement Learning Method for Area Traffic Signal Control



Abstract
:1. Introduction
2. The Regional Traffic Signal Control Model Based on MFMARL
2.1. Random Games
2.2. Nash Q-Learning
2.3. Mean Field Estimation
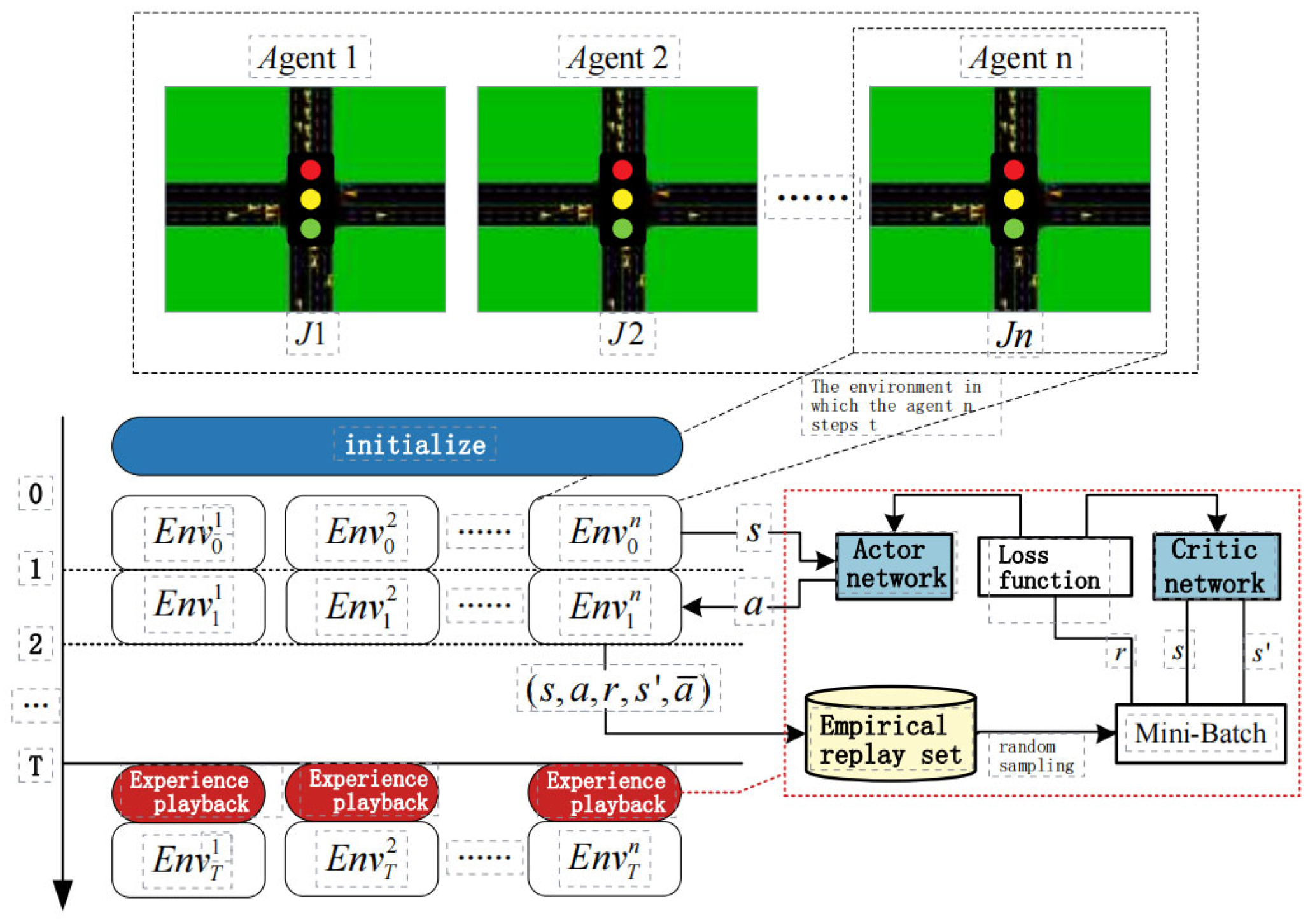
3. Introduction to the MFMARL-ATSC Model Algorithm
| Algorithm 1: MFQ-ATSC |
| 1: Initialize the values of and for all . |
| 2: while training is not finished yet do |
| 3: for do |
| 4: For each intersection agent , sample actions based on the existing average actions and exploration probabilities, using Equation (13); |
| 5: For each intersection agent , sample actions based on Equation (13); |
| 6: end |
| 7: Execute the joint action , receive rewards , and observe the next traffic state s′; |
| 8: Store in the replay buffer , where ; |
| 9: for do |
| 10: Select a small batch of K experiences from the replay buffer ; |
| 11: Let , choose actions based on ; |
| 12: Set according to Equation (11); 13: Minimize the loss function through ; 14: end 15: For each intersection agent , the target network parameters are updated based on the learning rate : ; 16: end |
| Algorithm 2: MFAC-ATSC |
| 1: Initialize the values of and for all . |
| 2: while training is not finished yet do |
| 3: For each intersection agent, select action and calculate the new average action . |
| 4: Execute the joint action , receive rewards , and observe the next time step’s traffic state s′ |
| 5: Store in the replay buffer ; |
| 6: for do |
| 7: Select a small batch of K experiences from the replay buffer ; |
| 8: Set based on Equation (11); |
| 9: Minimize the loss function through ; |
| 10: Update the actor network with policy gradients as calculated below: |
| 11: end |
| 12: Update the target network parameters for each intersection agent based on the learning rate : 13: end |
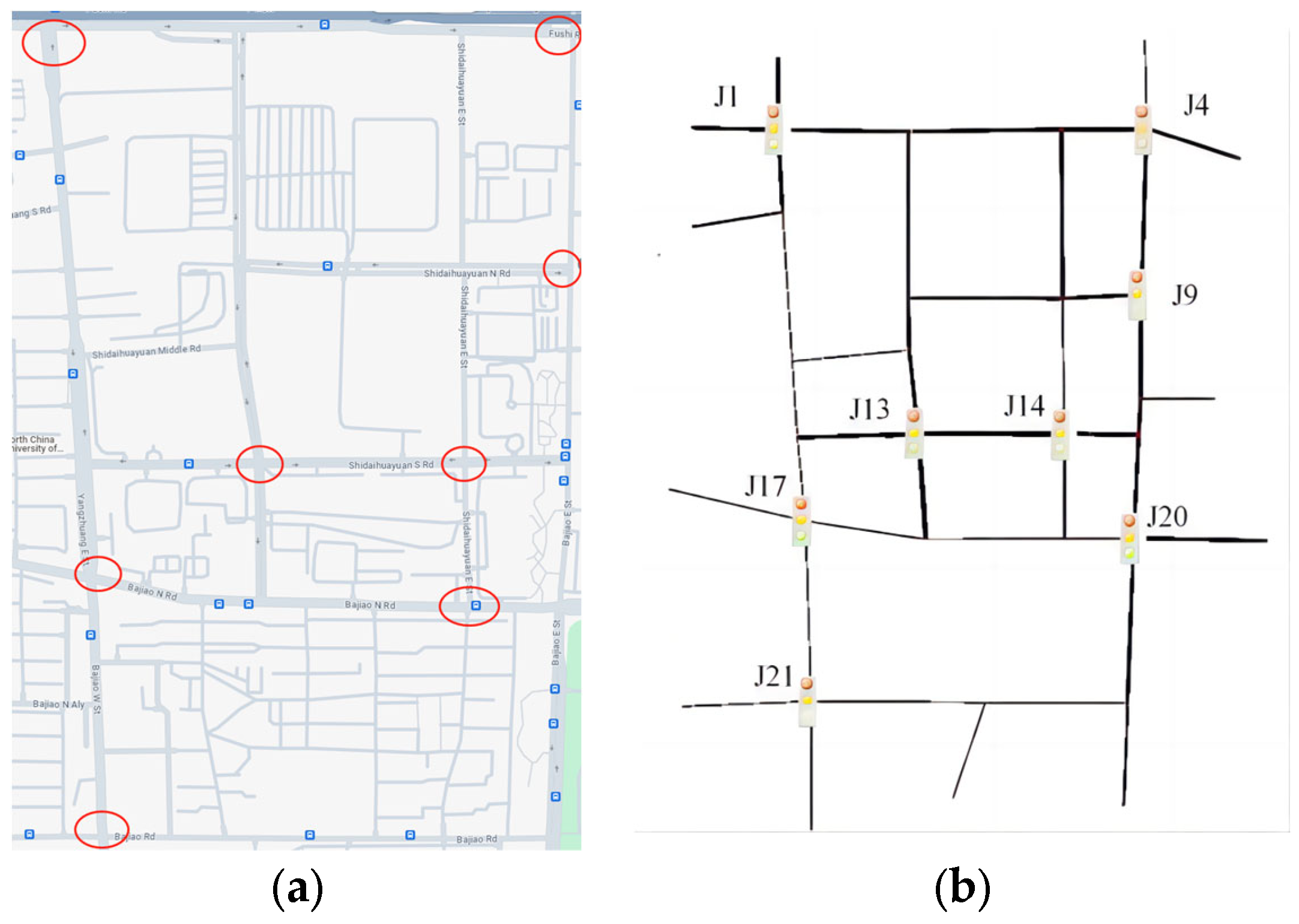
4. Simulation Experiment Settings and Results Analysis
4.1. Simulation Experiment Settings and Results Analysis
4.2. Experimental Setup
4.2.1. State Definition
4.2.2. Action Definition
- Discrete Action Space
- 2.
- Continuous Action Space
4.2.3. Reward Function
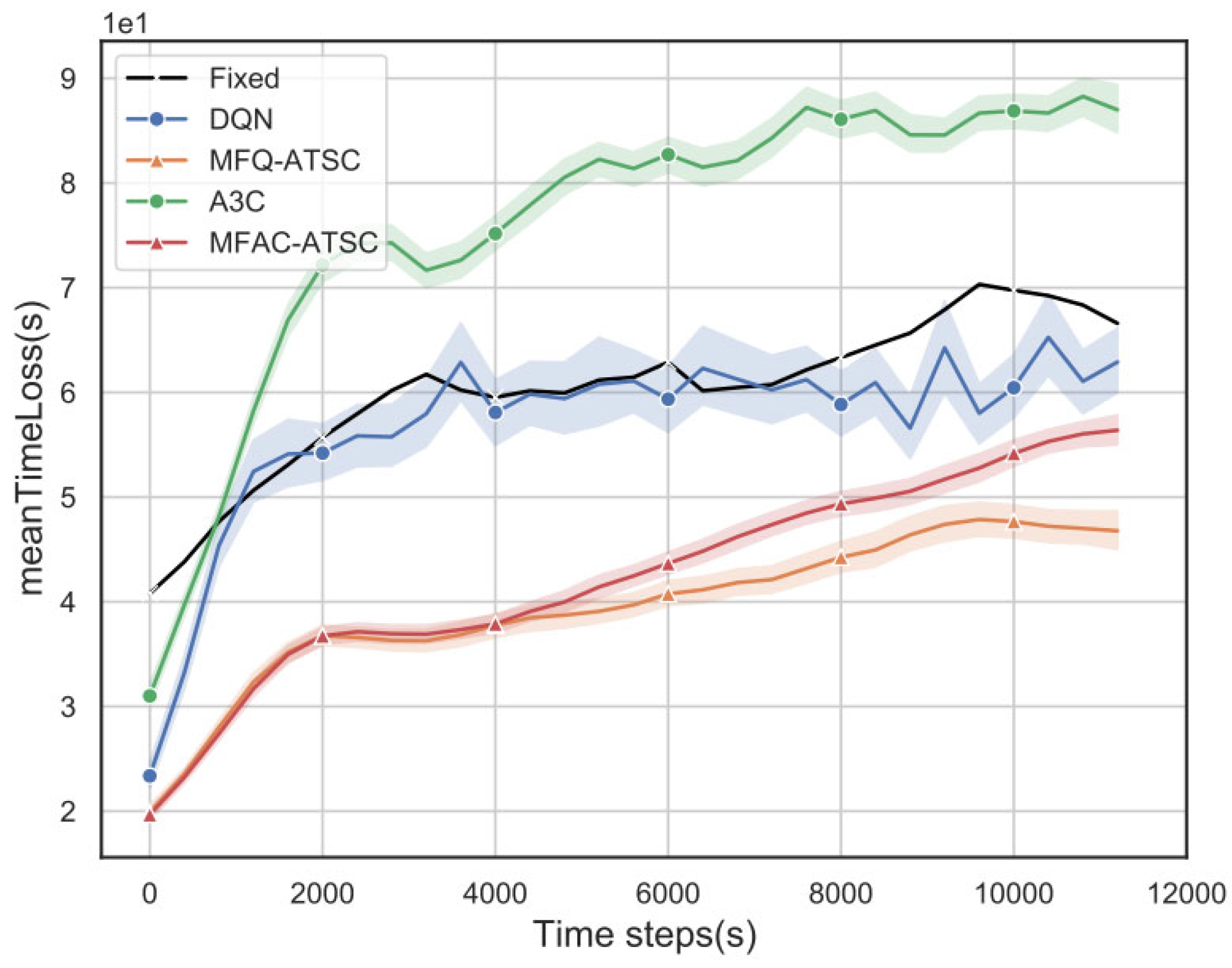
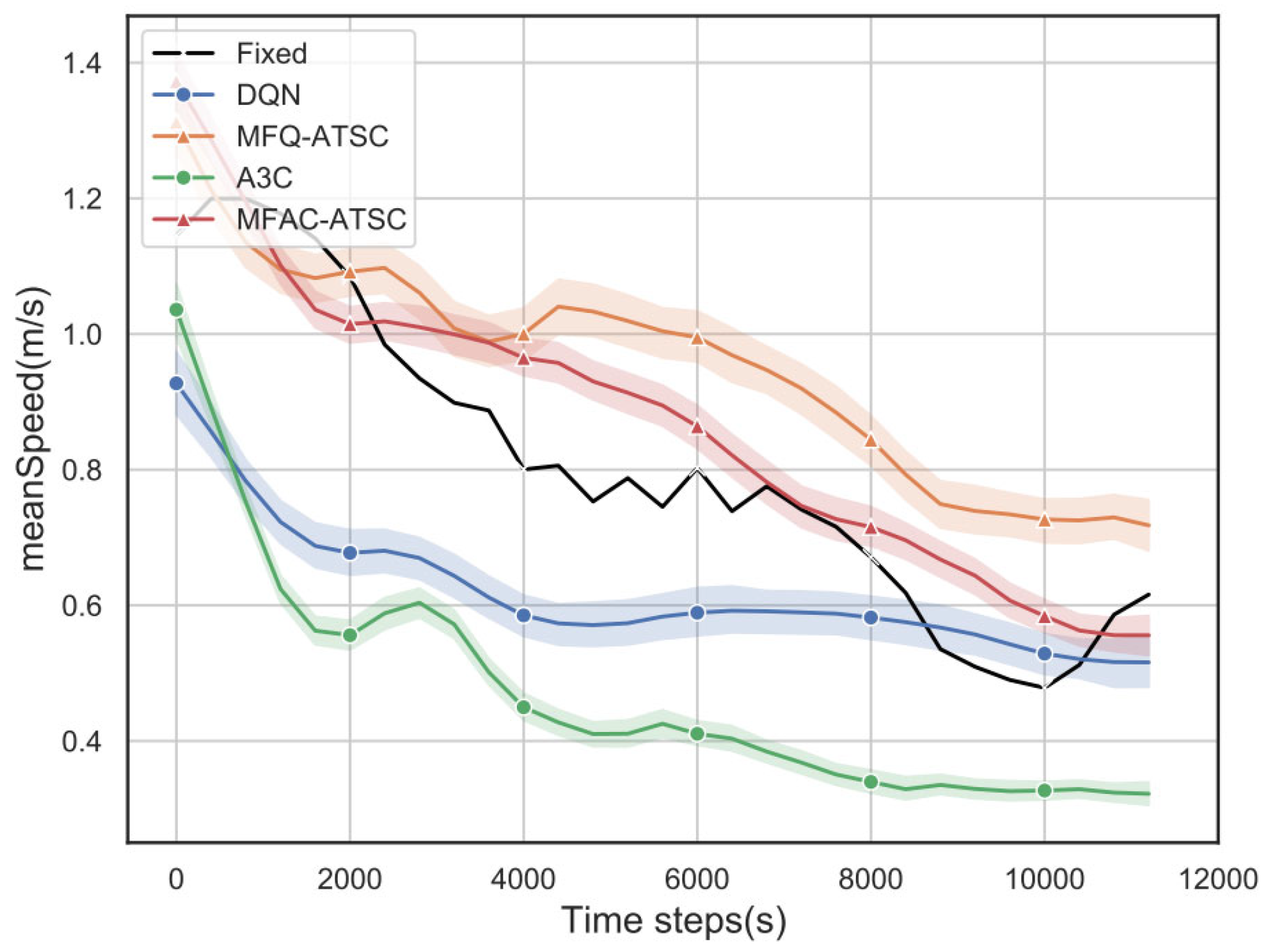
4.3. Simulation Experiment Results Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Hua, W.; Zheng, G.J. Recent Advances in Reinforcement Learning for Traffic Signal Control. ACM SIGKDD Explor. Newsl. 2020, 22, 12–18. [Google Scholar]
- Mikami, S.; Kakazu, Y. Genetic reinforcement learning for cooperative traffic signal control. In Proceedings of the First IEEE Conference on Evolutionary Computation, IEEE World Congress on Computational Intelligence, Orlando, FL, USA, 27–29 June 1994; Volume 1, pp. 223–228. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- Shang, C.L.; Liu, X.M.; Tian, Y.L.; Tian, Y.L.; Dong, L.X. Priority of Dedicated Bus Arterial Control Based on Deep Reinforcement Learning. J. Transp. Syst. Eng. Inf. Technol. 2021, 21, 64–70. [Google Scholar]
- Li, L.; Lv, Y.S.; Wang, F.Y. Traffic signal timing via deep reinforcement learning. IEEE/CAA J. Autom. Sin. 2016, 3, 247–254. [Google Scholar]
- Chu, T.; Wang, J.; Codecà, L.; Li, Z. Multi-Agent Deep Reinforcement Learning for Large-Scale Traffic Signal Control. IEEE Trans. Intell. Transp. Syst. 2020, 21, 1086–1095. [Google Scholar] [CrossRef]
- Liang, X.; Du, X.; Wang, G.; Han, Z. A Deep Reinforcement Learning Network for Traffic Light Cycle Control. IEEE Trans. Veh. Technol. 2019, 68, 1243–1253. [Google Scholar] [CrossRef]
- Prashanth, L.A.; Bhatnagar, S. Reinforcement learning with average cost for adaptive control of traffic lights at intersections. In Proceedings of the 2011 14th International IEEE Conference on Intelligent Transportation Systems(ITSC), Washington, DC, USA, 5–7 October 2011; pp. 1640–1645. [Google Scholar]
- Rasheed, F.; Yau, K.; Low, Y.C. Deep reinforcement learning for traffic signal control under disturbances: A case study on Sunway city, Malaysia. Future Gener. Comput. Syst. 2020, 109, 431–445. [Google Scholar] [CrossRef]
- Tan, T.; Bao, F.; Deng, Y.; Jin, A.; Dai, Q.; Wang, J. Cooperative Deep Reinforcement Learning for Large-Scale Traffic Grid Signal Control. IEEE Trans. Cybern. 2020, 50, 2687–2700. [Google Scholar] [CrossRef] [PubMed]
- Zheng, G.; Zang, X.; Xu, N.; Wei, H.; Yu, Z.; Gayah, V.; Xu, K.; Li, Z. Diagnosing Reinforcement Learning for Traffic Signal Control. arXiv 2019, arXiv:abs/1905.04716. [Google Scholar]
- Xu, M.; Wu, J.; Huang, L.; Zhou, R.; Wang, T.; Hu, D. Network-wide traffic signal control based on the discovery of critical nodes and deep reinforcement learning. J. Intell. Transp. Syst. 2020, 24, 1–10. [Google Scholar] [CrossRef]
- Yang, Y.; Luo, R.; Li, M.; Zhou, M.; Zhang, W.; Wang, J. Mean Field Multi-Agent Reinforcement Learning. In Proceedings of the 35th International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; Volume 80, pp. 5571–5580. [Google Scholar]
- Hu, S.; Leung, C.; Leung, H. Modelling the Dynamics of Multiagent Q-Learning in Repeated Symmetric Games: A Mean Field Theoretic Approach. In Proceedings of the Advances in Neural Information Processing Systems 32 (NeurIPS 2019), Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Mangasaria, O.L. Equilibrium Points of Bimatrix Games. J. Soc. Ind. Appl. Math. 1964, 12, 778–780. [Google Scholar] [CrossRef]
- Wu, T.; Zhou, P.; Liu, K.; Yuan, Y.; Wang, X.; Huang, H.; Wu, D.O. Multi-Agent Deep Reinforcement Learning for Urban Traffic Light Control in Vehicular Networks. IEEE Trans. Veh. Technol. 2020, 69, 8243–8256. [Google Scholar] [CrossRef]
- Kumar, N.; Rahman, S.S.; Dhakad, N. Fuzzy Inference Enabled Deep Reinforcement Learning-Based Traffic Light Control for Intelligent Transportation System. IEEE Trans. Intell. Transp. Syst. 2020, 22, 4919–4928. [Google Scholar] [CrossRef]
- Mnih, V.; Badia, A.P.; Mirza, M.; Graves, A.; Lilicrap, T.; Herlay, T.; Silver, D.; Kavukcuoglu, K. Asynchronous methods for deep reinforcement learning. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 1928–1937. [Google Scholar]
- Wei, W.; Wu, Q.; Wu, J.Q.; Du, B.; Shen, J.; Li, T. Multi-agent deep reinforcement learning for traffic signal control with Nash Equilibrium. In Proceedings of the 2021 IEEE 23rd International Conference on High Performance Computing & Communications; 7th International Conference on Data Science & Systems; 19th International Conference on Smart City; 7th International Conference on Dependability in Sensor, Cloud & Big Data Systems & Application, Haikou, China, 20–22 December 2021; pp. 1435–1442. [Google Scholar]
- Zhang, X.; Xiong, G.; Ai, Y.; Liu, K.; Chen, L. Vehicle Dynamic Dispatching using Curriculum-Driven Reinforcement Learning. Mech. Syst. Signal Process. 2023, 204, 110698. [Google Scholar] [CrossRef]
- Wang, X.; Yang, Z.; Chen, G.; Liu, Y. A Reinforcement Learning Method of Solving Markov Decision Processes: An Adaptive Exploration Model Based on Temporal Difference Error. Electronics 2023, 12, 4176. [Google Scholar] [CrossRef]
- Wu, Y.; Wu, X.; Qiu, S.; Xiang, W. A Method for High-Value Driving Demonstration Data Generation Based on One-Dimensional Deep Convolutional Generative Adversarial Networks. Electronics 2022, 11, 3553. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Evaluation Metrics | Fixed-Timing Control | DQN | MFQ- ATSC | A3C | MFAC- ATSC |
|---|---|---|---|---|---|
| Average Reward Value | - | 6 × 10−4 | 1.45 × 10−3 | 0.7 × 10−4 | 1.08 × 10−3 |
| Number of Waiting Vehicles | 1717 | 1790 | 1694 | 1797 | 1701 |
| Travel Time (s) | 998 | 993 | 977 | 995 | 986 |
| Loss Time (s) | 60.21 | 56.79 | 39.44 | 65.92 | 42.39 |
| Speed (m/s) | 0.81 | 0.62 | 0.95 | 0.57 | 0.87 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Z.; Zhang, W.; Liu, Y.; Xiong, G. Mean Field Multi-Agent Reinforcement Learning Method for Area Traffic Signal Control. Electronics 2023, 12, 4686. https://doi.org/10.3390/electronics12224686
Zhang Z, Zhang W, Liu Y, Xiong G. Mean Field Multi-Agent Reinforcement Learning Method for Area Traffic Signal Control. Electronics. 2023; 12(22):4686. https://doi.org/10.3390/electronics12224686
Chicago/Turabian StyleZhang, Zundong, Wei Zhang, Yuke Liu, and Gang Xiong. 2023. "Mean Field Multi-Agent Reinforcement Learning Method for Area Traffic Signal Control" Electronics 12, no. 22: 4686. https://doi.org/10.3390/electronics12224686
APA StyleZhang, Z., Zhang, W., Liu, Y., & Xiong, G. (2023). Mean Field Multi-Agent Reinforcement Learning Method for Area Traffic Signal Control. Electronics, 12(22), 4686. https://doi.org/10.3390/electronics12224686