1. Introduction
The integration of artificial intelligence (AI) methods into the healthcare domain has brought transformative advancements that hold substantial potential for improving medical practices and diagnostic capabilities [
1,
2]. Within this paradigm, the convergence of AI with medical image analysis is a notable achievement, offering profound insights into human anatomy and physiology through the intricate interpretation of visual data [
3]. This confluence of computational intelligence and medical imaging has propelled the development of sophisticated techniques with high significance for disease detection, prognosis, and treatment planning.
Medical imaging has evolved to be a foundation of modern clinical practice, enabling clinicians to gather valuable insights into the inner workings of the human body. However, the complexity of imaging modalities such as positron emission tomography (PET), magnetic resonance imaging (MRI), computed tomography (CT) and ultrasound imaging (UI) [
4,
5,
6,
7] has presented a challenge in efficient and accurate analysis. Manual interpretation of these images is highly influenced by subjectivity and time consumption, necessitating innovative solutions to harness the full potential of these visual data.
AI methods, particularly machine learning (ML) and deep learning (DL), have emerged as transformative solutions to address the challenges posed by the complex nature of modern imaging modalities. These advanced computational techniques have revolutionized how medical professionals extract meaningful information from complex visual data. By leveraging vast amounts of annotated medical images, ML algorithms have been trained to discern intricate patterns, anomalies, and correlations that might not be easily identifiable by the human eye. DL, a subset of ML, has refined this process by employing neural networks with numerous layers, enabling the extraction of hierarchical features from raw data.
Within the domain of medical imaging, AI-powered methods have demonstrated a remarkable ability for automating tasks that were previously vulnerable to subjectivity and variability. These encompass different tasks such as image classification [
8,
9], object localization and detection, segmentation [
10], synthetic image generation, and registration [
11,
12,
13]. These AI-powered methods enhance the precision and accuracy of diagnostic outcomes while simultaneously expediting the analysis process.
This work aims to provide a comprehensive overview of the rapidly evolving field of AI techniques in medical image analysis. The motivation behind this paper stems from the increasing significance of AI methodologies in revolutionizing healthcare and diagnostics. As medical imaging modalities advance in complexity and volume, the need for efficient and accurate analysis becomes more pronounced. This review paper addresses this need by exploring and evaluating various ML and DL methods and commonly used datasets in medical image analysis. By synthesizing existing research, methodologies, challenges, and breakthroughs, the paper aspires to serve as a valuable resource for researchers and practitioners in the medical and computer science fields. The contributions of this paper can be summarized as follows:
The paper synthesizes a diverse range of ML methods that have been developed and applied to medical image analysis. Through a critical analysis of various AI techniques, the paper offers insights into the strengths, limitations, and potential applications of each method.
The paper provides a comprehensive overview of existing publicly available datasets of various anatomical structures that are suitable for use in AI-powered medical image analysis.
The review identifies emerging trends and challenges within the field of AI-driven medical image analysis. By highlighting gaps in current research and pointing out areas that require further exploration, the paper fosters the growth of knowledge and innovation in this rapidly evolving field.
The paper discusses the translation of AI techniques from research to clinical practice, emphasizing their potential impact on healthcare delivery.
Through comprehensive exploration and evaluation of current state-of-the-art methodologies, we aim to contribute to the advancement of both academic research and practical applications in the pursuit of improving healthcare outcomes by addressing following research questions:
What are the prominent AI methods used in medical image analysis?
In what medical imaging tasks have AI methods shown the most promising results?
What are commonly observed anatomical structures and available datasets for the development of AI algorithms?
How can AI-driven medical image analysis be effectively translated into clinical practice?
The study is organized as follows.
Section 2 briefly describes the most essential learning methods in the ML field.
Section 3 provides a brief theoretical background on DL architectures commonly applied for medical image processing and analysis.
Section 4 overviews commonly solved medical imaging tasks, including medical image classification, object localization, detection, segmentation, synthetic image generation, and registration.
Section 5 overviews commonly observed anatomical structures in medical imaging, including abdominal, brain, breast, cardiac, musculoskeletal, pulmonary, and retinal imaging. This section also includes a list of datasets for each anatomical structure.
Section 6 discusses the possibility of translation of AI techniques into clinical practice. Finally,
Section 7 gives a concluding remarks.
2. Learning Methods in Medical Image Analysis
In medical image analysis, ML methods have emerged as essential tool for analyzing intricate patterns and insights encoded within medical images. These methods primarily address two distinctive problem categories, which are shown in
Figure 1.
The first category encompasses supervised learning, wherein algorithms learn from annotated data to predict output variables based on input features, facilitating accurate diagnoses and classifications. Unsupervised learning, in contrast, involves the exploration of unlabeled data to uncover latent structures and relationships within medical images, enabling the discovery of inherent patterns and clusters. Reinforcement learning introduces an agent–environment interaction dynamic based on cumulative reward maximization through iterative decision making. The second group of learning problems in medical image analysis encompasses hybrid methodologies. Semi-supervised learning leverages labeled and unlabeled data to enhance model performance in cases where comprehensive annotations are scarce. Self-supervised learning exploits intrinsic data relationships by predicting missing portions of the data themselves, thereby effectively harnessing unlabeled data for learning. Multi-instance learning suits scenarios where data instances are interconnected, allowing the algorithm to grasp relationships between instances within the broader context.
2.1. Supervised Learning
Supervised learning [
14] is a computational approach where a model learns to map input data to corresponding output labels through exposure to a labeled training dataset. The term
supervised stems from providing explicit guidance in the form of labeled examples during the model’s training phase. This guidance enables the model to generalize from the training data and subsequently predict labels for unseen instances. Supervised learning is a powerful approach in tasks with abundant labeled datasets when the goal is to make predictions or classifications based on historical patterns [
15]. Generally, supervised learning is often used for tasks like classification and regression in different fields such as categorizing emails as spam or non-spam [
16,
17] or estimating the price of a house based on features such as square footage and location [
18,
19].
In medical image analysis, supervised learning is frequently utilized for image segmentation [
20], and disease classification [
21]. For instance, supervised learning enables the accurate delineation of anatomical structures and pathological regions within medical images in segmentation tasks, facilitating precise treatment planning and monitoring [
22].
Supervised learning excels in detecting intricate patterns in medical images to accurately identify complex conditions often missed by human perception [
23]. Its quantitative nature enhances analysis reliability, minimizing variability between observers and enabling disease progression prediction. The trained models process images rapidly, expediting clinical workflows, and can generalize knowledge to diverse patient cases. However, high-quality labeled data are essential but resource-intensive to acquire [
24]. Moreover, overfitting often significantly affects generalization, biases in training data may lead to skewed predictions, and complex models can compromise interpretability, which is vital for informed medical decisions. To harness supervised learning’s potential in medical practice, addressing data dependencies, overfitting, bias, and interpretability is essential [
25,
26].
2.2. Unsupervised Learning
Unsupervised learning [
27] is a computational approach where algorithms seek to uncover latent patterns and structures within unlabeled data without the guidance of explicit output labels. Unlike supervised learning, the absence of labeled examples necessitates the model’s capacity to discern inherent relationships and groupings within the data, thereby facilitating its categorization and subsequent interpretation [
28]. Choosing unsupervised learning is beneficial when the goal is to explore and understand the inherent structure of the data, making it ideal for tasks where explicit output labels are either challenging to obtain or unnecessary, and in situations where labeled data are scarce or unavailable [
29]. Unsupervised learning is used for tasks like clustering [
30,
31,
32,
33], dimensionality reduction [
34,
35], and anomaly detection [
36].
In medical image analysis, unsupervised learning excels in different classification tasks like benign and malignant tumor detection [
37,
38,
39], domain adaptation in cardiac arrhythmia classification [
40,
41], brain disorder classification [
42,
43,
44], and mass detection in beast cancer [
45].
The crucial benefit of unsupervised learning in medical image processing and analysis is in its ability to uncover hidden patterns and relationships, which reveals subtle variations in images. This aids in understanding complex anatomical and pathological phenomena. It facilitates novel insights and hypothesis generation by categorizing unlabeled data into clusters. Techniques like dimensionality reduction enhance interpretability by simplifying high-dimensional image analysis. Nevertheless, unsupervised models can capture noise, generating clinically irrelevant categories. Thus, applying unsupervised learning demands awareness of its challenges, reliance on clinical expertise, and rigorous validation.
2.3. Reinforcement Learning
Reinforcement learning [
46] has the capacity to adaptively learn from interactions, and aligns well with dynamic medical contexts, where optimal decisions depend on evolving patient conditions and complex imaging processes. Reinforcement learning is suitable for tasks where the optimal strategy unfolds over time through trial and error. Choosing this approach is recommended when the problem involves decision making under uncertainty, and the model needs to learn from its actions and experiences. Generally, reinforcement learning is used for tasks like game playing [
47,
48], robotic control [
49,
50], and autonomous driving systems [
51].
In medical image processing and analysis, reinforcement learning is used for tasks such as optimizing imaging parameters during acquisition [
52], designing patient-specific treatment regimens [
53,
54], and automating the exploration of diverse imaging sequences [
55]. Moreover, reinforcement learning is leveraged for image enhancement by tailoring post-processing algorithms to individual patients’ characteristics, which enhances diagnostic accuracy [
56]. It is also significant in anatomical and biological landmark and coordinate detection [
57,
58] when the task is to find landmarks that can be precisely reallocated on images produced by different imaging modalities, or reducing the needed time to reach the landmark by using a continuous action space [
59], or for localization of modality-invariant landmarks [
60]. In object detection and extraction tasks, reinforcement learning benefits in tasks like breast lesion detection [
61,
62], where learning agents gradually learn the policy to choose among actions to transit, scale the bounding box, and finally localize the breast lesion. It is also used to address the lack of labeled data in brain tumor detection tasks [
63,
64]. Therefore, reinforcement learning models could work as robust lesion detectors with limited training data [
65], reducing time consumption and providing some interpretability [
66]. Moreover, in segmentation and classification tasks, learning agents are used for finding optimal local thresholds and post-processing parameters [
67], finding the coarse location of region of interest, which is further used for final segmentation [
68], or for hyperparameter optimization of existing approaches [
69,
70,
71].
Reinforcement learning offers key benefits. Its adaptability supports personalized treatment strategies, aligning with precision medicine’s principles. Adaptive image acquisition optimizes protocols in real time, enhancing safety and efficiency while balancing exploration and exploitation as well as fostering innovation, and long-term planning optimizes patient outcomes [
72]. A common challenge occurs in sample complexity since it requires numerous interactions, which can be limited in medical contexts. Crafting accurate reward functions demands expertise. Ethical concerns arise due to real-world consequences of learning-phase decisions [
73]. Addressing these challenges ensures responsible reinforcement learning integration in clinical decision making.
2.4. Semi-Supervised Learning
Semi-supervised learning [
74] has elements of both supervised and unsupervised learning. This methodology uses a limited set of labeled data alongside a more extensive pool of unlabeled data to train models that harness labeled information for guidance while extrapolating latent patterns from the unlabeled data. Choosing semi-supervised learning is appropriate when there is a need to harness the benefits of labeled data while maximizing the utility of available unlabeled examples. Generally, semi-supervised learning is specially used in automated speech recognition [
75] and natural language processing [
76].
In medical image processing and analysis, semi-supervised learning is leveraged to mitigate the challenges posed by limited annotated medical datasets, fostering enhanced diagnostic accuracy and improved insights. It is commonly utilized in segmentation [
77], classification [
78], and artificial image generation tasks [
79].
Semi-supervised learning effectively uses limited labeled data by incorporating abundant unlabeled data, enhancing generalization and model robustness and overcomes supervised learning limitations by capturing latent patterns in unlabeled data. Nevertheless, designing models to balance labeled and unlabeled data requires careful consideration. Incorporating unlabeled data risks noise amplification, demanding quality control, and maintaining control over learning. To effectively employ semi-supervised learning in medical image analysis, balancing its benefits while addressing challenges is essential.
2.5. Self-Supervised Learning
Self-supervised learning [
80] is an approach where the model’s training procedure leverages intrinsic information within the data to generate surrogate labels for supervision. This is advantageous when generating labeled data is impractical or costly. It has emerged as a promising strategy to overcome the challenges of limited labeled datasets and is commonly used for tasks like contrastive predictive coding [
81], speech representation [
82], motion and depth estimation [
83], and cross-modal retrieval [
84,
85].
In medical image analysis, self-supervised learning is used for tasks such as finding similarities of adjacent frames in histopathological tissue images [
86], or MRI scans [
87], object tracking [
88], and correcting frame orders in 3D medical images [
89,
90].
Self-supervised learning enhances feature learning and model robustness, streamlining development and alleviating annotation burdens. Designing effective pretext tasks requires domain expertise and ensuring the seamless transfer of learned features to diverse medical tasks demands validation and adaptations. Moreover, intensive computational demands for tasks like contrastive learning may extend training times. Addressing these challenges is crucial for responsible integration and harnessing self-supervised learning’s potential in medical image analysis.
2.6. Multi-Instance Learning
Multi-instance learning [
91] refers to scenarios where data instances are organized into bags, with each bag containing multiple instances [
92]. Unlike traditional single-instance learning, where each instance is independently labeled, in multi-instance learning, bags are labeled based on the collective behavior of their instances [
93]. This introduces a level of ambiguity, as the specific instances responsible for the bag’s label are often unknown [
94]. Choosing multi-instance learning is suitable when there is a common underlying structure or shared information among tasks that leads to improved generalization and efficiency across a range of related problems. Generally, it is often used for tasks like object detection [
95], visual tracking in robotics [
96], and human activity recognition [
97], as well as in remote sensing for detecting objects in satellite imagery [
98].
When using multi-instance learning in medical image analysis, images are treated as bags of sub-regions or lesions, which allows for more detailed insights and holistic analysis. For example, it is commonly utilized for identifying regions of interest in different pathologies like mass retrieval in mammograms [
99]. Moreover, it is also used to incorporate patient-level data into the learning and prediction processes [
100,
101] and to fuse all relevant information within the examination record by including multiple potentially overlapping images or videos from different perspectives and with contextual details, which ultimately enhances performance [
102].
Multi-instance learning in medical image analysis offers several advantages [
103]. It enables a holistic approach by considering relationships among sub-regions within an image, enhancing understanding of intricate conditions. It reduces annotation effort by labeling entire images, streamlining the process. Enhanced interpretability highlights critical sub-regions, making diagnostic decisions more transparent. Its adaptability to image variability makes it promising for complex conditions, enhancing accuracy and depth of medical image analysis. However, integrating multi-instance learning into medical image processing brings challenges as well [
104]. For example, instance ambiguity and determining contributing sub-regions complicate the identification of critical areas and diagnostic precision. Moreover, treating images as bags may result in a loss of fine-grained data, impacting accuracy if important features are missed. Modeling interactions between instances within a bag is complex, requiring careful design and validation. Addressing these issues—instance ambiguity, information loss, model complexity, and overgeneralization—is vital for the effective use of multi-instance learning in medical image analysis [
105].
3. Deep Learning Architectures in Medical Image Analysis
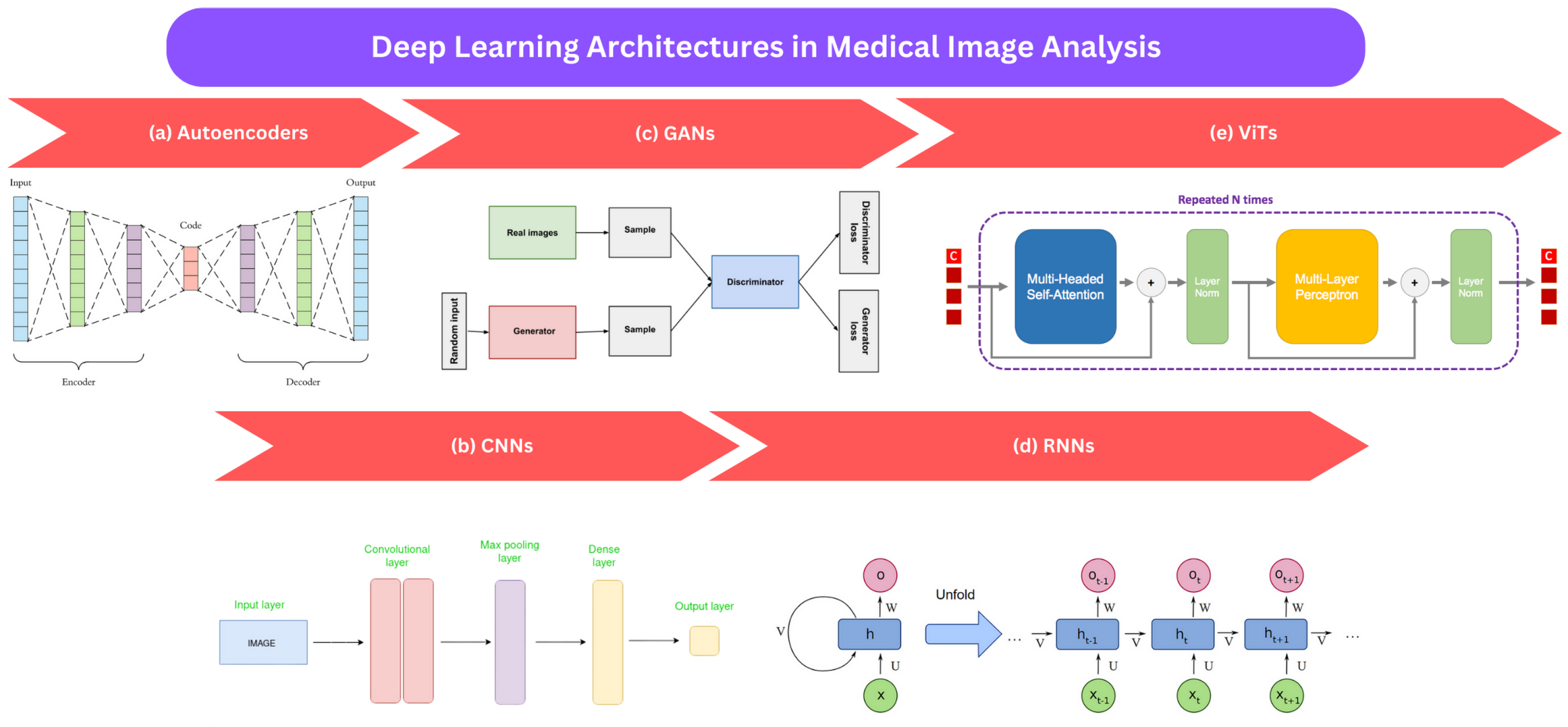
This section provides an overview of commonly employed deep learning approaches in medical image analysis. These techniques include autoencoders (AEs), convolutional neural networks (CNNs), recurrent neural networks (RNNs), generative adversarial networks (GANs), and vision transformers (ViTs), as shown in
Figure 2. We explain each method’s fundamental principles and outline their advantages and limitations.
3.1. Autoencoders (AEs)
AEs are designed to capture the essential features and underlying patterns within high-dimensional data while simultaneously reducing their dimensionality [
111]. This is achieved through a unique two-stage process: the model comprises an encoder and a decoder, with a bottleneck section in between, embodying the compact internal representation of the input. During training, AEs receive the input both as input and target output, compelling the model to reproduce the input by first encoding it into a compressed form and then decoding it back to the original state. After training, the decoder is typically removed, and the encoder is employed to produce compact input representations. In medical image processing and analysis, commonly employed AEs are denoising autoencoders [
112], variational autoencoders [
113], and stacked autoencoders [
114].
3.2. Convolutional Neural Networks (CNNs)
CNNs consist of numerous layers of filters that acquire local features from the input image and progressively merge them to construct more abstract representations. Typically, the initial layers of a CNN learn basic features like edges and corners, while the later layers focus on higher-level features such as object shapes and textures. In contrast, fully convolutional neural networks (FCNNs), a subset of CNNs, lack fully connected layers. They employ an encoder–decoder architecture, which enables processing input of different sizes while producing outputs of the same dimensions. The encoder converts the input image into a high-level feature representation, while the decoder interprets the feature maps and restores spatial details through a series of upsampling and convolution operations, enabling pixel-wise predictions. A prominent FCNN architecture is U-Net [
115], known for its capacity to locate objects within input images precisely.
3.3. Generative Adversarial Networks (GANs)
GANs represent an unsupervised learning technique for creating new data that closely mimic the provided data [
79]. They consist of two key components: a generator network responsible for producing new samples and a discriminator network that distinguishes between authentic and generated samples. In essence, the generator learns to create samples resembling real data, while the discriminator learns to tell the genuine from the generated. Deep convolutional generative adversarial networks (DCGANs) [
116] follow a similar GAN framework but employ deep convolutional networks for both the generator and discriminator. For example, the significant variant is the conditional GAN (cGAN), which can generate samples based on additional information like disease labels or image modalities [
117].
3.4. Recurrent Neural Networks (RNNs)
RNNs [
118] are especially suitable for dealing with data that unfold over time, like sequences or time-series data, where what happened before affects what happens next. Among the most popular RNN architectures is the long short-term memory (LSTM) network [
119]. LSTMs are successful at capturing long-term dependencies in sequences. Unlike traditional neural networks that quickly forget previous information, LSTMs introduce memory cells capable of retaining essential information for extended periods. There are several variations of LSTMs, such as bidirectional LSTM (BLSTM) and multidimensional LSTM (MDLSTM) [
120]. In medical image analysis, especially tasks involving sequential data, RNNs offer advantages over CNNs.
3.5. Vision Transformers (ViTs)
Vision Transformers (ViTs) [
121] rely on a self-attention mechanism [
122], enabling the network to attend to different regions of an image selectively, making them particularly well-suited for processing large, high-resolution medical images. They can efficiently capture contextual information across image patches, even in the presence of substantial anatomical variations [
123]. ViTs find applications in tasks like image classification, segmentation, and feature extraction [
123].
3.6. Advantages and Disadvantages of DL Architectures
As seen from previous sections, DL architectures have revolutionized various domains by offering powerful tools for automatic feature learning and complex pattern recognition. Here, we dive into the distinct advantages and challenges associated with them, since their understanding is crucial for optimizing the application of DL models, especially in the demanding field of medical image analysis.
For example, AEs have demonstrated high capability in generating synthetic medical images, which can serve as valuable data augmentation techniques for training DL models or mitigating privacy concerns by generating synthetic data while preserving original data characteristics [
124]. When used in tasks like image denoising [
125] or image reconstruction, their primary challenge is striking the right balance between data compression and reconstruction accuracy. Overly aggressive compression can lead to a loss of clinically relevant information, thereby impacting diagnostic accuracy [
126]. Additionally, evaluating the quality of reconstructed or generated medical images can be intricate, as there may not always exist generally applicable and interpretable metrics for assessing accuracy [
127]. Despite these challenges, ongoing research efforts aim to explore variations and refinements of AEs to optimize their use and mitigate their limitations in the demanding field of medical image analysis. Moreover, CNNs excel in image-related tasks by learning hierarchical features through convolutional layers. They automatically extract local features, enabling the recognition of complex patterns in images [
128]. Despite their effectiveness, CNNs require large amounts of labeled data for training, which can be challenging to obtain in certain domains. Challenges like overfitting, interpretability, and computational intensity, which are shared among all DL architectures, are specifically expressed while training deep CNNs. Furthermore, GANs offer a unique approach to generative modeling by simultaneously training a generator and discriminator, leading to the creation of realistic synthetic data [
79]. They find applications in data augmentation and addressing privacy concerns in medical image analysis. Nevertheless, training GANs can be challenging, because they also require careful tuning and monitoring to achieve stable convergence. RNNs excel in handling sequential data with long-term dependencies. Their memory cells enable the retention of essential information over extended periods, making them suitable for tasks such as time-series analysis in medical data [
8]. Training RNNs can be computationally intensive, and may suffer from vanishing or exploding gradient problems, affecting the learning of long-term dependencies. While LSTMs address some of these issues, finding the right architecture and hyperparameter settings can be challenging. Interpreting the decisions made by RNNs, especially in complex medical tasks, remains a significant challenge. Furthermore, self-attention mechanisms in ViTs allow them to selectively attend to different regions of an image, making them well-suited for processing large, high-resolution medical images [
122]. Their ability to capture contextual information across image patches, even in the presence of substantial anatomical variations, is a distinctive strength. Nevertheless, they may require substantial computational resources for training due to the self-attention mechanism’s computational complexity. The lack of spatial hierarchies might pose challenges in tasks where local features are crucial.
All mentioned DL architectures share the ability to automatically learn representations from data, adaptability to diverse data types, and proficiency in handling large-scale datasets. Common challenges include the need for substantial computational resources, interpretability concerns, and the potential for biases in training data to affect model predictions. Ethical considerations related to fairness and accountability are shared challenges, especially as these models are increasingly integrated into critical decision-making processes. Balancing performance and interpretability remains a central challenge across these diverse DL architectures.
4. Common Tasks Solved by DL in Medical Image Analysis
DL has been applied to various medical imaging tasks, such as image classification, object localization, detection, segmentation, image generation, and registration. This section will discuss some key DL applications in medical image analysis.
4.1. Image Classification
Image classification is based on assigning images to predefined classes or categories to accurately determine the class to which a given image belongs, relying on its visual characteristics. In medical image analysis, classification serves two primary purposes: object classification and exam classification. Object classification aims to classify pre-identified objects into one of several distinct classes. Conversely, exam classification focuses on categorizing a diagnostic image as either representing a normal or abnormal condition or indicating the presence or absence of a particular disease.
CNNs are widely used for image classification, with various CNN frameworks, including AlexNet [
129], VGG [
130], inception [
131], and ResNet [
132] being among the most commonly utilized DL architectures. Since they can automatically learn discriminative features from medical images and classify them into different disease categories, they have been commonly utilized for classifying lung nodules in chest CT scans [
133,
134], breast tumors in mammograms [
135], diagnosing diabetic retinopathy in retinal fundus images [
136], brain tumor classification [
137,
138], and cardiovascular disease classification [
139]. Besides CNNs, ViTs are recently been used for medical brain and breast image classification tasks [
140,
141].
4.2. Object Localization and Detection
Object localization and detection are fundamental tasks within computer vision, involving identifying objects in images or videos. Object localization focuses explicitly on delineating the exact spatial boundaries of an object within an image. In contrast, object detection encompasses both localization and recognizing the object itself.
Object localization and detection are vital components of computer-aided diagnosis in medical image analysis. CNNs have demonstrated their effectiveness in identifying the presence and location of specific objects within medical images, such as lung nodules, breast tumors, and brain tumors. Different CNN architectures, including Faster R-CNN [
142], You Only Look Once (YOLO) [
143], and Single Shot MultiBox Detector (SSD) [
144], have been employed to achieve remarkable performance in object detection and localization tasks for medical images.
For example, the Faster R-CNN framework employs a region proposal network to identify potential object locations and a subsequent network to classify these proposals as either an object of interest or background. On the other hand, the YOLO framework utilizes a single network to analyze the entire image and directly predict bounding boxes and class probabilities for objects. Meanwhile, the SSD framework incorporates multiple layers to predict bounding boxes of varying sizes and aspect ratios, enabling precise object detection and localization within medical images.
These object detection and localization techniques have found successful applications across various medical imaging tasks, encompassing tasks like lung nodule detection in chest scans [
145], breast lesion identification in mammograms [
146], and brain tumor segmentation [
147]. Their capacity to accurately identify and locate objects of interest within medical images holds the potential to enhance diagnostic precision and support more effective clinical decision-making.
4.3. Image Segmentation
Image segmentation involves the intricate task of partitioning an image into multiple segments, each corresponding to a specific object or region of interest present within the image. These regions typically represent anatomical structures or any abnormalities that might be present. CNNs have exhibited exceptional performance in medical image segmentation, primarily due to their ability to autonomously learn features from extensive sets of annotated data.
Several architectures based on FCNNs, including U-Net [
115], DeepLab [
148], and Mask R-CNN [
149], have been leveraged to attain state-of-the-art results in medical image segmentation tasks. For example, the U-Net framework comprises an encoder network for extracting features from input images and a decoder network for generating segmentation maps. The DeepLab architecture utilizes techniques like atrous and dilated convolutions to capture multiscale contextual information, significantly enhancing segmentation accuracy. The Mask R-CNN architecture introduces an additional segmentation branch responsible for producing pixel-level segmentation masks. Furthermore, ViTs are being applied to segmentation tasks when small training datasets are available [
150], while GANs are often used as data augmentation techniques that precede segmentation tasks [
151].
These advanced medical image segmentation techniques have demonstrated successful applications across various imaging modalities and tasks. Examples include the segmentation of brain tumors in MRI [
152], lung nodules in chest CT scans [
153], polyps [
154], and vessel delineation [
155]. Additionally, they find widespread use in cardiovascular image segmentation tasks, encompassing the isolation of specific structures like the aorta [
156,
157], heart chambers [
158,
159,
160], epicardial tissue [
161], left atrial appendage [
162,
163], and coronary arteries [
164]. Precise segmentation is invaluable as it facilitates quantification, classification, and visualization of medical image data, ultimately supporting more informed clinical decision-making processes.
4.4. Image Generation
Image generation refers to creating novel images that closely resemble real patient data. This capability is valuable in diverse applications, including data augmentation or for creating synthetic patient data often used for training DL models. In the realm of medical imaging, GANs have emerged as a widely employed technique for image generation tasks.
For instance, GANs find common use in medical imaging tasks like generating MRI images from CT scans or producing realistic skin lesion images for dermatological purposes [
165]. Moreover, GANs and AEs are essential in creating synthetic medical images for training DL models [
166]. They have proven beneficial in tasks such as image denoising [
167] and image super-resolution [
168]. Specifically, cGANs have been harnessed in diverse medical image synthesis tasks. This includes tasks like synthesizing MRIs based on CT images and generating realistic CT images defining cardiovascular structures, particularly in cardiology applications [
117].
4.5. Image Registration
Image registration is another critical task within the domain of medical image analysis. This task refers to the alignment of two or more images. These images may originate from the same patient but differ in acquisition times or stem from different patients or imaging modalities. Image registration is immensely useful in various medical imaging applications, encompassing multi-modal and deformable image registration [
169]. The latter is indispensable for monitoring disease progression, formulating treatment plans, and guiding image-based medical interventions.
In deformable image registration, CNNs have found significant application [
170]. The primary objective here is to estimate a dense deformation field that maps the voxels of one image to their corresponding counterparts in another image. Typically, CNN-based registration methods entail training a network to predict this deformation field based on input images. This training process employs a similarity loss function, such as cross-correlation or mutual information.
Beyond CNNs, other DL techniques, including GANs and Siamese networks [
171], have been deployed for image registration tasks within medical imaging. GANs, for example, have been instrumental in multi-modal image registration tasks, aligning images acquired through distinct imaging modalities like CT and MRI [
172]. Siamese networks, on the other hand, have proven effective in registration tasks centered on matching image patches. This is particularly useful in tasks such as landmark detection within brain MRI scans [
173]. Despite the successes achieved by DL methods in image registration tasks, several challenges remain. These include the need for robust and efficient registration techniques and the potential for overfitting of models.
5. Commonly Observed Anatomical Structures and Publicly Available Datasets
Commonly observed anatomical structures in medical imaging, such as the brain, bones, heart, lungs, liver, and breast, have been the focus of extensive research and analysis within the field of ML. Researchers and practitioners have curated publicly available datasets encompassing various modalities and applications for these structures. These publicly available datasets play a crucial role in advancing the development and evaluation of ML algorithms for medical image analysis, fostering collaboration, and driving innovation in the field.
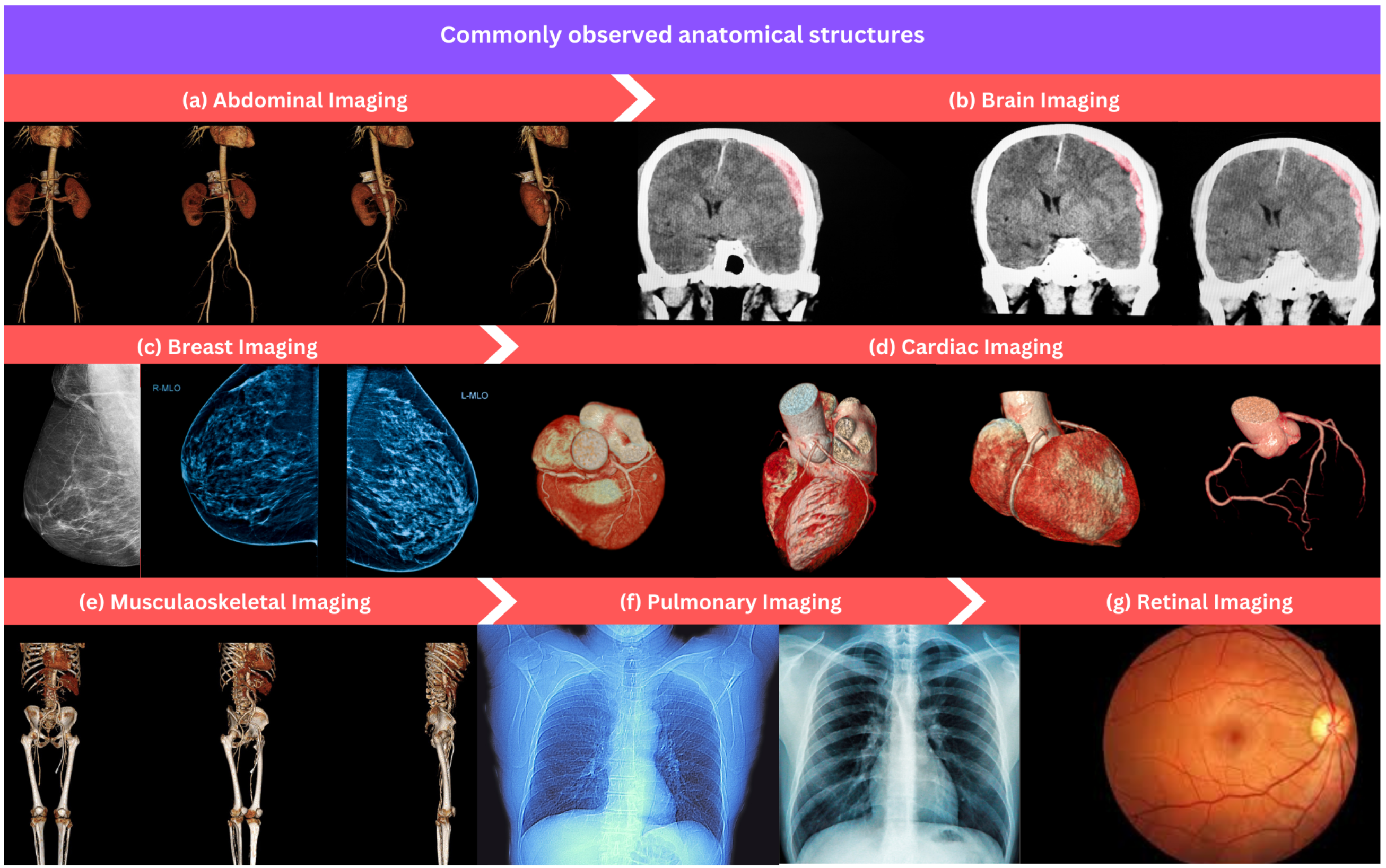
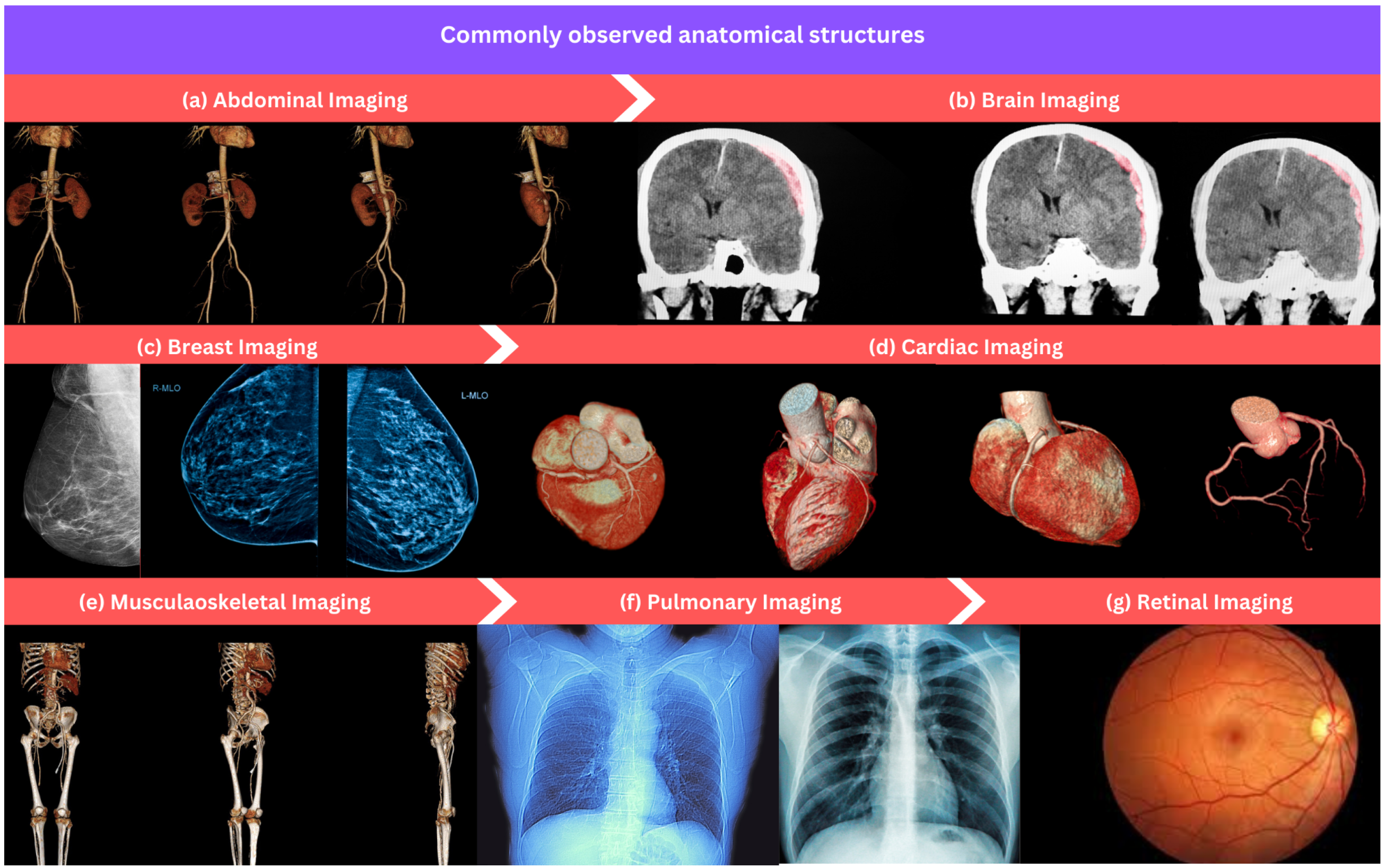
This section overviews commonly used anatomical structures for developing ML algorithms in medical image processing and analysis as shown in
Figure 3. We provide a list of datasets for each anatomical structure that can serve as a valuable resource for researchers and practitioners developing ML algorithms in different medical areas.
5.1. Abdominal Imaging
Abdominal imaging plays a vital role in the medical field, offering a comprehensive and non-invasive visualization of the internal structures and abnormalities within the abdominal region. Its primary application lies in the diagnosis and monitoring of various medical conditions, including abdominal tumors [
174], gastrointestinal disorders [
175], liver diseases [
176], and kidney ailments. Through the detailed imaging of abdominal organs, healthcare professionals can accurately identify abnormalities, assess disease progression, and plan suitable treatment strategies [
177].
Beyond its clinical applications, abdominal imaging is fundamental in medical research. It empowers scientists to explore abdominal organs’ functions, interactions, and connectivity. It contributes to a deeper understanding of physiological processes, metabolic functions, and the mechanisms underlying various abdominal-related conditions. Functional imaging techniques, such as dynamic contrast-enhanced MRI and nuclear medicine scans, can reveal how different abdominal organs respond to specific stimuli or diseases [
178]. Moreover, abdominal imaging is indispensable in developing and evaluating novel medical interventions and therapies. Researchers utilize it to assess the effects of experimental treatments, study the response of abdominal organs to medications, and refine therapeutic approaches.
Table 1 summarizes commonly used abdominal organ benchmark datasets for developing and testing ML algorithms.
5.2. Brain Imaging
Brain imaging offers a comprehensive and non-invasive method of visualizing the brain’s internal structure, function, and abnormalities [
187]. Its primary application is diagnosing and monitoring neurological disorders, including brain tumors, stroke, Alzheimer’s disease, and multiple sclerosis [
188]. Healthcare professionals can identify abnormalities, assess disease progression, and plan appropriate treatment strategies by capturing detailed brain images. Brain imaging also provides precise anatomical information, aiding neurosurgeons in navigating delicate procedures during surgical planning [
189]. Moreover, brain imaging helps develop and evaluate novel therapies and interventions. Researchers use it to assess the effects of experimental treatments, study the brain’s response to medications, and refine therapeutic approaches. Brain imaging has also become increasingly important in the emerging field of neuroinformatics [
190], where machine learning and data-driven techniques are employed to analyze large-scale datasets and advance our understanding of brain disorders.
Beyond clinical diagnosis and treatment, brain imaging serves as a foundation of neuroscience research. It allows scientists to investigate brain functions, connectivity, and neural pathways, leading to a deeper understanding of cognitive processes, behavior, and the underlying mechanisms of various brain-related conditions. Functional brain imaging techniques such as fMRI and PET scans can reveal how different brain regions become active during specific tasks or emotional states [
191].
Table 2 summarizes commonly used brain benchmark datasets for developing and testing ML algorithms.
5.3. Breast Imaging
Breast imaging is a critical medical technique that provides a non-invasive means of visualizing the internal structures of the breast. Its primary application is in detecting, diagnosing, and monitoring breast-related health concerns. Through precise imaging, healthcare professionals can identify abnormalities, assess disease stages, and formulate appropriate treatment plans [
202]. Breast imaging, which includes mammography, ultrasound, and MRI, is instrumental in early breast cancer detection, significantly improving survival rates [
203]. Breast imaging also contributes to the development and evaluation of novel therapies and interventions. Researchers use it to assess the effectiveness of experimental treatments, study the response of breast tissue to medications, and refine therapeutic strategies. Additionally, breast imaging is at the forefront of emerging fields like radiogenomics, where ML and data-driven approaches are applied to analyze complex imaging data and genetic information. This interdisciplinary approach holds the potential to uncover personalized treatment options and tailor healthcare strategies for individuals at risk of breast-related conditions.
Besides its clinical significance, breast imaging plays a essential role in advancing medical research. It empowers scientists to investigate breast tissue composition, hormonal influences, and genetic factors, leading to a deeper understanding of breast physiology, disease mechanisms, and risk factors. Functional imaging techniques, such as contrast-enhanced breast MRI [
204], offer insights into vascularization patterns and breast tissue behavior during different phases of the menstrual cycle.
Table 3 summarizes commonly used breast benchmark datasets for developing and testing ML algorithms.
5.4. Cardiac Imaging
Cardiac imaging is a crucial medical field that provides a non-invasive means of visualizing the heart’s structure, function, and any potential abnormalities [
209]. Its primary application lies in diagnosing and monitoring various cardiovascular disorders, including coronary artery disease, heart valve problems, congenital heart defects, and heart failure. By obtaining detailed images of the heart, healthcare professionals can identify issues, assess disease progression, and formulate precise treatment plans. Cardiac imaging techniques, such as echocardiography, cardiac magnetic resonance imaging (CMRI), and cardiac computed tomography (CCT), are essential tools in cardiology [
139,
210]. Cardiac imaging also contributes to the development and evaluation of novel cardiovascular therapies. Researchers utilize these imaging techniques to examine the effects of experimental treatments, study the heart’s response to medications, and refine therapeutic strategies. Additionally, in the era of precision medicine, cardiac imaging plays a crucial role in tailoring treatments for individuals based on their unique cardiac anatomy and function.
Beyond clinical diagnosis and treatment, cardiac imaging plays a pivotal role in advancing cardiovascular research. It enables scientists to explore cardiac functions, blood flow dynamics [
211], and the interaction between different heart chambers [
158,
159,
160]. This deeper understanding of cardiac physiology and pathology helps researchers uncover the mechanisms behind heart-related conditions and develop innovative treatment approaches. Functional imaging methods like cardiac stress tests can assess how the heart responds to physical or pharmacological stress, providing valuable insights into its performance under different conditions [
212].
Table 4 summarizes commonly used cardiovascular benchmark datasets for developing and testing ML algorithms.
5.5. Musculaoskeletal Imaging
Musculoskeletal imaging is a pivotal field in medical diagnostics that offers a non-invasive way to visualize the bones, joints, muscles, and related structures of the body [
219]. Its primary application is to diagnose and manage various musculoskeletal disorders and conditions, including fractures, arthritis, ligament injuries, and tumors [
220,
221]. By generating detailed images of the musculoskeletal system, healthcare professionals can accurately identify issues, assess the extent of injuries, and plan appropriate treatment strategies. This imaging domain encompasses various techniques, including X-rays, MRI, CT, and ultrasound.
In addition to clinical diagnosis and treatment planning, musculoskeletal imaging plays a vital role in advancing musculoskeletal research and orthopedic medicine [
222]. It allows researchers to delve into the intricacies of bone and joint anatomy, biomechanics, and pathology. By studying musculoskeletal images, scientists can gain insights into how injuries occur, how bones and joints heal, and how the body’s mechanical systems function. This knowledge is essential in developing innovative surgical techniques, orthopedic implants, and rehabilitation strategies. Musculoskeletal imaging is also indispensable in guiding surgical interventions. Orthopedic surgeons and other specialists use pre-operative imaging to plan procedures such as joint replacements [
223], fracture fixation [
224], and ligament repairs. During surgery, real-time imaging, such as fluoroscopy, helps ensure the accuracy of procedures and minimizes damage to surrounding tissues. Furthermore, musculoskeletal imaging contributes to sports medicine, enabling sports physicians and trainers to assess and manage athletic injuries [
225]. It aids in evaluating the severity of injuries, tracking healing progress, and determining an athlete’s readiness to return to sports activities.
Table 5 summarizes commonly used musculoskeletal benchmark datasets for developing and testing ML algorithms.
5.6. Pulmonary Imaging
The pulmonary imaging field employs non-invasive techniques to visualize the respiratory system, including the lungs and associated structures [
230]. This imaging is instrumental in diagnosing and managing a wide range of pulmonary conditions and diseases, such as pneumonia, chronic obstructive pulmonary disease (COPD), lung cancer, and pulmonary embolism. By producing detailed images of the respiratory system, healthcare professionals can accurately detect abnormalities, assess disease severity, and develop tailored treatment plans.
The primary modalities used in pulmonary imaging include chest X-rays, CT scans, MRI, and PET scans. Each of these techniques provides specific insights into lung anatomy, functionality, and pathology [
231].
Beyond clinical diagnosis and treatment, pulmonary imaging plays a significant role in advancing respiratory medicine and pulmonary research. It allows scientists and clinicians to explore lung function, mechanics, and responses to various stimuli. Research involving pulmonary imaging has led to breakthroughs in understanding lung diseases’ underlying mechanisms and developing innovative therapies. For example, functional imaging techniques like pulmonary function testing (PFT) can assess lung capacity and airflow, aiding in the diagnosis and management of conditions like asthma and COPD [
232].
Table 6 summarizes commonly used pulmonary benchmark datasets for developing and testing ML algorithms.
5.7. Retinal Imaging
Retinal imaging is a specialized field of medical diagnostics that employs non-invasive imaging techniques to visualize the retina, the light-sensitive tissue at the back of the eye [
239]. It plays a critical role in diagnosing and monitoring various ocular conditions, including diabetic retinopathy [
240,
241], macular degeneration [
242], glaucoma [
243], and retinal vascular diseases [
244]. By providing detailed retina images, retinal imaging enables eye care professionals to detect abnormalities, assess disease progression, and tailor treatment plans for optimal outcomes.
Various modalities are used in retinal imaging, with fundus photography [
245,
246] and optical coherence tomography (OCT) [
247] being among the most common. Fundus photography captures high-resolution color images of the retina, allowing for the identification of structural changes, such as bleeding or swelling. On the other hand, OCT provides cross-sectional images of retinal layers and helps visualize subtle changes in retinal thickness and integrity [
248].
Table 7 summarizes commonly used retina benchmark datasets for developing and testing ML algorithms.
6. The Translation of AI Techniques from Research to Clinical Practice
The successful translation of AI-driven medical image analysis from research to clinical practice entails a multifaceted approach that encompasses technical, ethical, regulatory, and clinical considerations [
256]. This section gives details about steps involved in overcoming the gap between AI innovation and its meaningful integration into the clinical domain. Addressing the question of how AI-driven medical image analysis can be effectively translated into clinical practice necessitates a thorough examination of essential factors and strategies. Here are some guiding points which must be addressed:
Integration frameworks and workflow adaptation. A fundamental aspect of facilitating the transition of AI techniques to clinical application is in the development of integration frameworks tailored to the specific needs of healthcare environments. Collaborative efforts between computer scientists, medical professionals, and regulatory bodies are imperative to design workflows that seamlessly incorporate AI outputs into existing diagnostic and decision-making processes.
Validation and regulatory compliance. The validation of AI algorithms to ensure their safety, accuracy, and reliability is a major step in the translation process. Rigorous validation studies that adhere to established standards, such as those outlined by the U.S. Food and Drug Administration (FDA) and the European Medicines Agency (EMA), contribute to establishing the credibility of AI methods. Comprehensively documenting algorithm behavior, training data, and validation protocols not only ensures confidence in clinical users but also facilitates regulatory compliance.
Ethical considerations and human–AI collaboration. Ethical deliberations underpinning the integration of AI into clinical practice are of paramount significance. Transparency in AI decision-making processes, interpretability of results, and mitigation of bias are pivotal to engendering trust between clinicians and AI systems. Human–AI collaboration models, where AI outputs are presented as supportive tools rather than autonomous decision makers, foster a cooperative environment where clinical expertise harmoniously interacts with AI-generated insights.
Education and training. The integration of AI techniques necessitates the provision of comprehensive education and training for medical professionals. Knowledge dissemination on AI’s capabilities, limitations, and clinical relevance enables clinicians to harness AI insights optimally. Robust training programs tailored to diverse healthcare settings aid in fostering the requisite proficiency to interpret, validate, and incorporate AI outputs effectively.
Longitudinal evaluation and continuous improvement. Sustaining the translation of AI techniques into clinical practice mandates a commitment to longitudinal evaluation and continuous improvement. Regular assessment of AI-generated outcomes in real-world scenarios facilitates the identification of shortcomings, iterative refinement, and the incorporation of feedback from clinical practitioners. This iterative approach fosters the evolution of AI algorithms that align with dynamic clinical demands.
Therefore, effectively translating AI-driven medical image analysis into clinical practice involves a concerted effort encompassing integration frameworks, rigorous validation, ethical considerations, education, and continuous refinement. The confluence of technical robustness, regulatory compliance, and ethical mindfulness is essential in realizing the full potential of AI to augment and elevate clinical decision making within the medical imaging domain.
7. Discussion and Conclusions
In this work, we gave a comprehensive overview of fundamental concepts and state-of-the-art medical image processing and analysis approaches. We gave a brief overview of learning problems commonly employed in medical image processing and commonly used deep learning methods. We highlighted commonly observed anatomical areas and publicly available datasets for ML algorithm development.
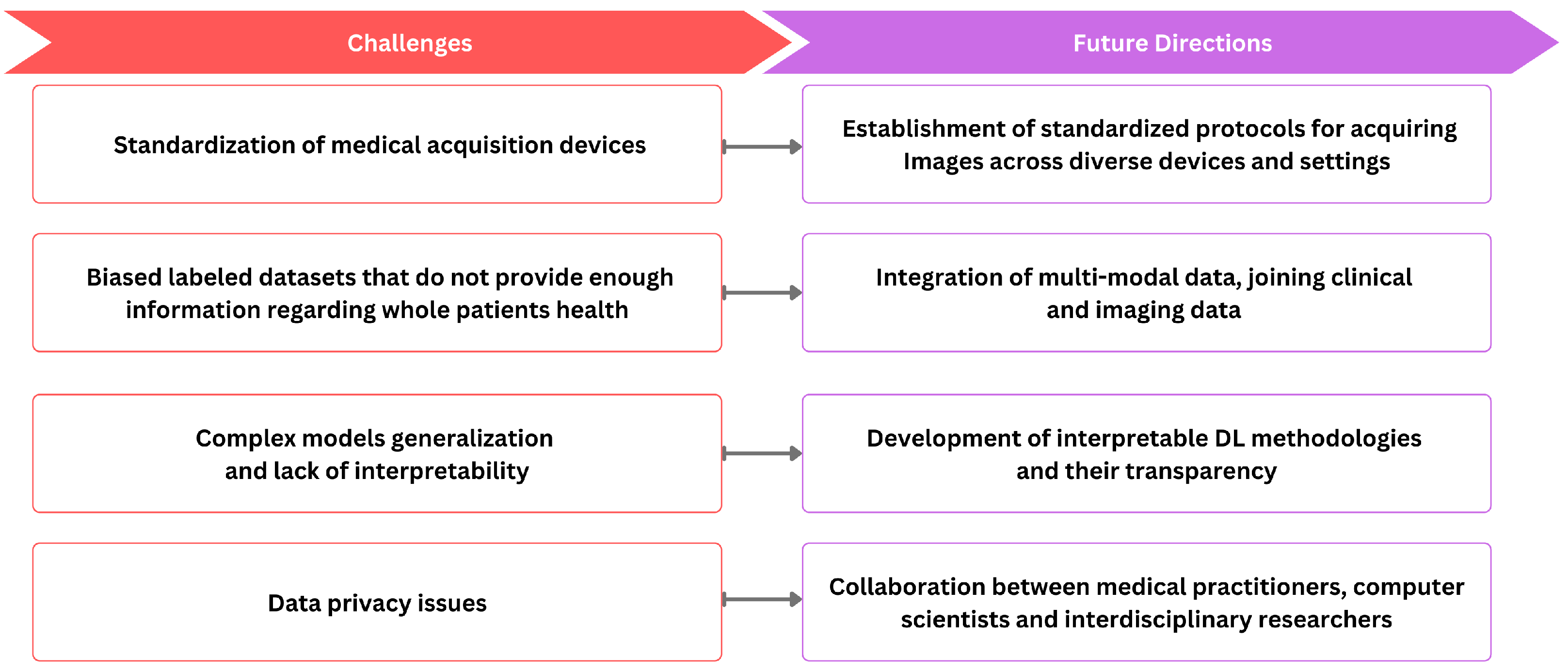
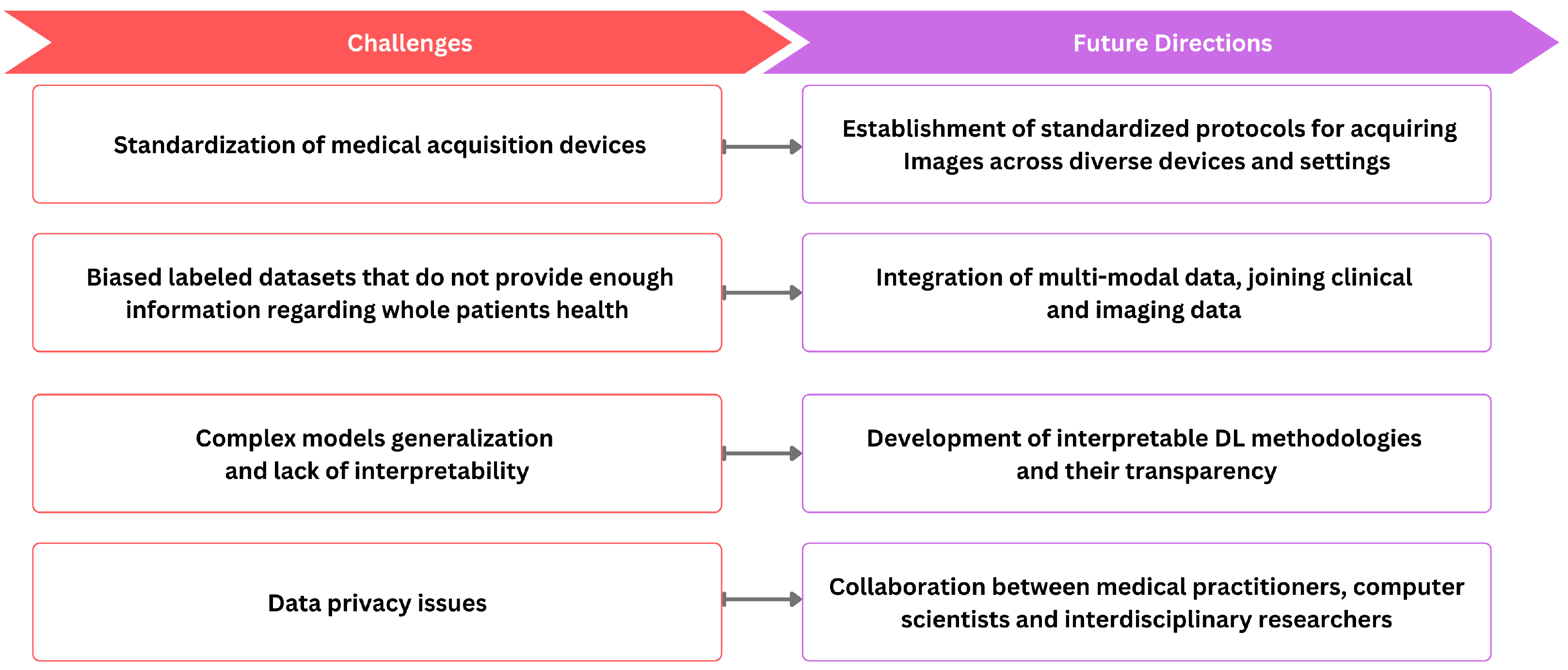
ML and DL techniques have emerged as effective tools for various medical imaging tasks, but their widespread integration faces notable challenges, as shown in
Figure 4. One notable obstacle is the inherent variability of medical image data, stemming from differences in resolution, contrast, and signal-to-noise ratios due to diverse clinical protocols. The standardization of medical image acquisition to ensure uniformity remains a significant challenge. Further, precise medical image annotations are required for DL models. However, the limited availability of annotated data and the intricacies involved in annotating medical images impose constraints on their applicability. Moreover, dataset bias arises when the data used to train a model differ from the data on which the model is applied, leading to potential shortcomings in the study. For example, datasets collected as part of population studies may differ from those of patients referred to hospitals, introducing biases in the data. Biases can also stem from imaging devices or procedures, introducing specific measurement biases. For example, in chest X-rays, images may include interventions like chest drains, impacting the accuracy of automated diagnosis [
257]. Labeling errors arising from systematic biases in human annotators or automatic methods extracting labels from patient reports further contribute to dataset bias. This discrepancy can result in algorithms that perform well in benchmarks but poorly in real-world scenarios. The importance of unbiased evaluation in assessing model performance emphasizes the need for independent sets of data for training and testing. It cautions against incorrect implementations that can lead to overoptimistic results. For instance, some studies on ADHD classification based on brain imaging have employed circular analysis, performing feature selection on the entire dataset before cross-validation [
258]. Another issue arises when repeated measures of an individual are split between the training and test sets, causing the algorithm to recognize individual patients instead of condition markers. Additionally, data privacy concerns reduce medical data sharing for deep learning training. The inherent diversity of medical images further complicates the task of model generalization across varied datasets. The black-box nature of DL models, lacking interpretability, presents an additional limitation.
Addressing the challenge of standardizing medical image acquisition involves the establishment of clear protocols that define standardized procedures for acquiring images across diverse devices and settings. This includes specifying crucial imaging parameters such as resolution, contrast, and orientation. Moreover, embracing widely accepted industry standards like DICOM is essential to ensure compatibility and interoperability among different imaging systems. Simultaneously, the implementation of quality assurance programs is crucial to monitor and maintain the performance of imaging equipment, ensuring ongoing consistency in image quality. Furthermore, the future direction of research in medical image analysis should encompass the development of interpretable DL methodologies, facilitating the comprehension of DL models and augmenting transparency. Moreover, significant progression could be obtained by integrating images with additional clinical context, incorporating information from patient records, and including various clinical descriptors such as blood tests, genomics, medications, vital signs, and non-imaging data like ECG. This integration facilitates a shift from the realm of images to comprehensive patient-level information. It would allow for population-level statistical analysis, offering insights into disease manifestations, treatment responses, adverse reactions, and medication interactions. Therefore, integrating multi-modal data, joining clinical and imaging data, holds immense potential to enhance the precision of medical image analysis while fostering a holistic understanding of underlying pathologies. However, implementing this step necessitates establishing intricate infrastructure and formulating new privacy and security regulations, spanning interactions between hospitals and academic research institutes, among hospitals, and across international consortia.








{kind=link}
{kind=link}
{kind=link}
{kind=link}