
Random Convolutional Kernels for Space-Detector Based Gravitational Wave Signals

Abstract
:1. Introduction
2. Materials and Methods
2.1. Convolutional Neural Networks (CNN)
2.2. Time Series Classification (TSC) Models
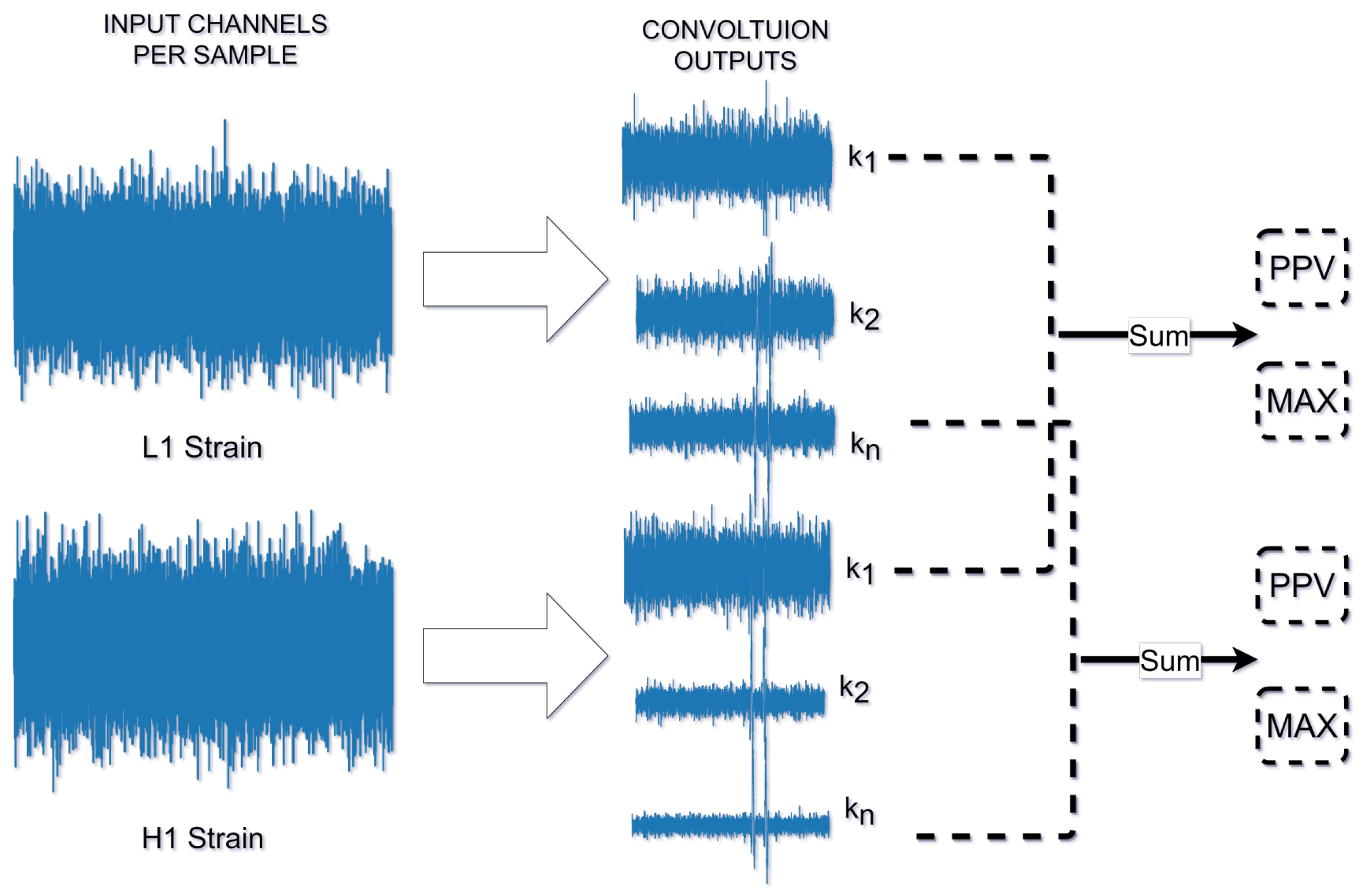
3. Model
3.1. Rocket and MiniRocket
- Length—While ROCKET initially employs kernels generated from a set of lengths, it is interesting to note that it observes comparable accuracy when using fixed lengths of 7, 9, and 11, as well as random length selections from . Importantly, these differences in accuracy do not reach statistical significance. Based on our experimental findings, we have determined that a fixed kernel size of 9 is an effective choice for our experiment.
- Padding—In the majority of neural networks employing convolutional architectures, a consistent fixed padding is applied across all channels. This practice helps prevent the loss of crucial features at the edges of signals or images during the feature extraction process. Drawing from both standard conventions and insights gleaned from the work of ROCKET, which extensively compared various padding settings, we have arrived at a conclusion: ’zero’ padding proves to be entirely adequate for our purposes.
- Dilation—In the context of ROCKET, various methods of utilizing dilation were analyzed. The findings indicate that employing dilation significantly enhances accuracy, particularly when dilations are sampled from a uniformly distributed exponential scale. This approach effectively enables the capture of both short and long-term patterns in a signal, effectively addressing the issue of the local receptive field.where
- Weights and Bias—Using weights from a fixed set produces similar results to weights initialized randomly, as such and to reduce the computations as proposed in (mini) ROCKET we choose to sample the weights from a set of two values {−1, 2}.
- Biases—Biases are calculated from the outputs of the convolutions. We compute the convolution output for a randomly selected training sample for each kernel/dilation combination and use the quantiles of this output as bias values.
3.2. Feature Map Analysis
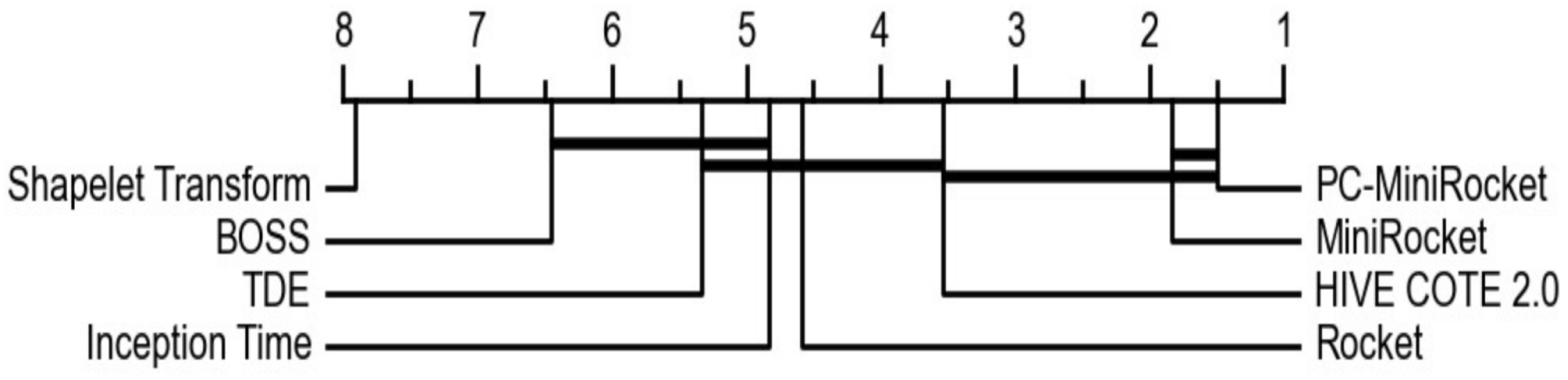
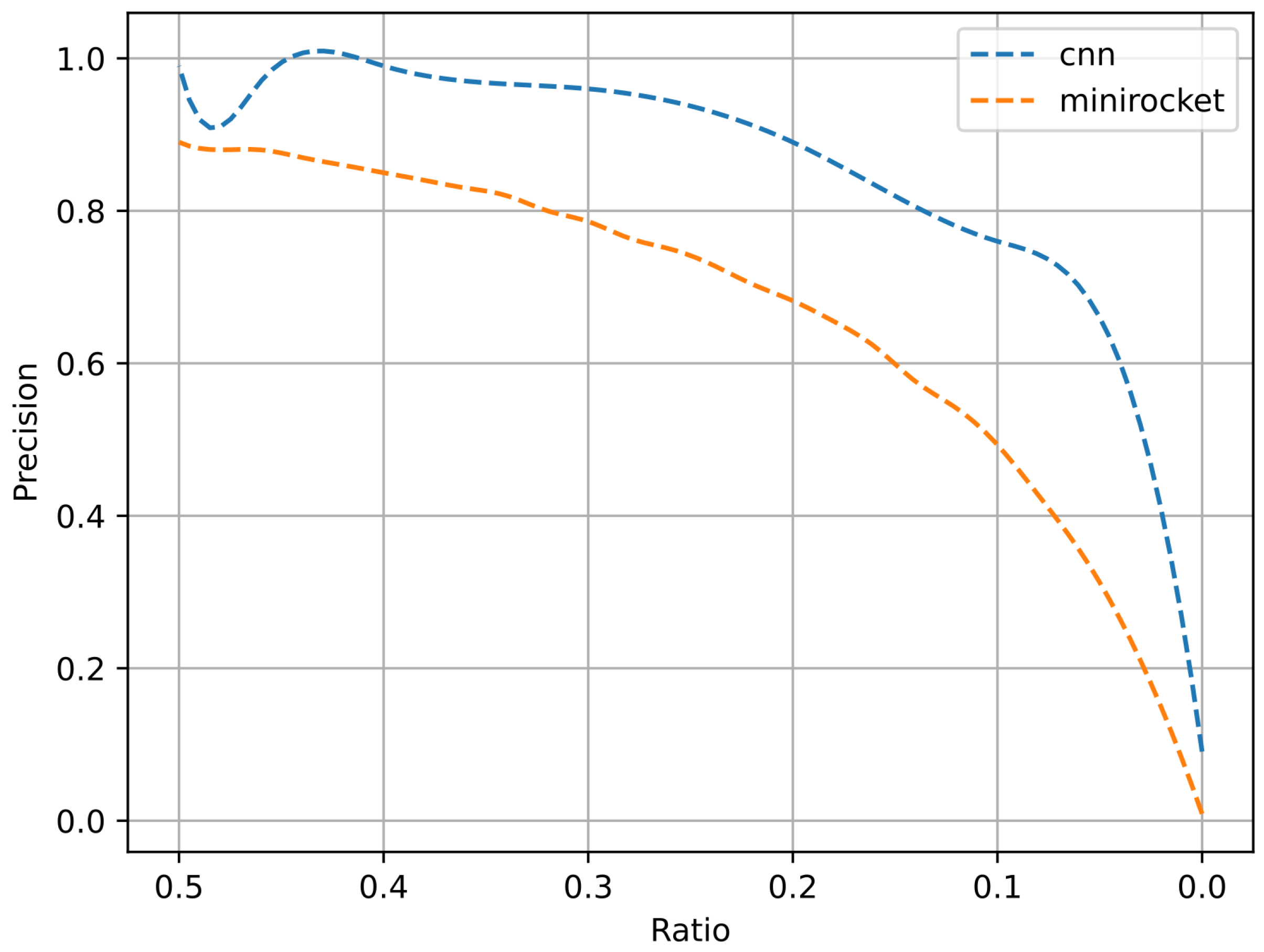
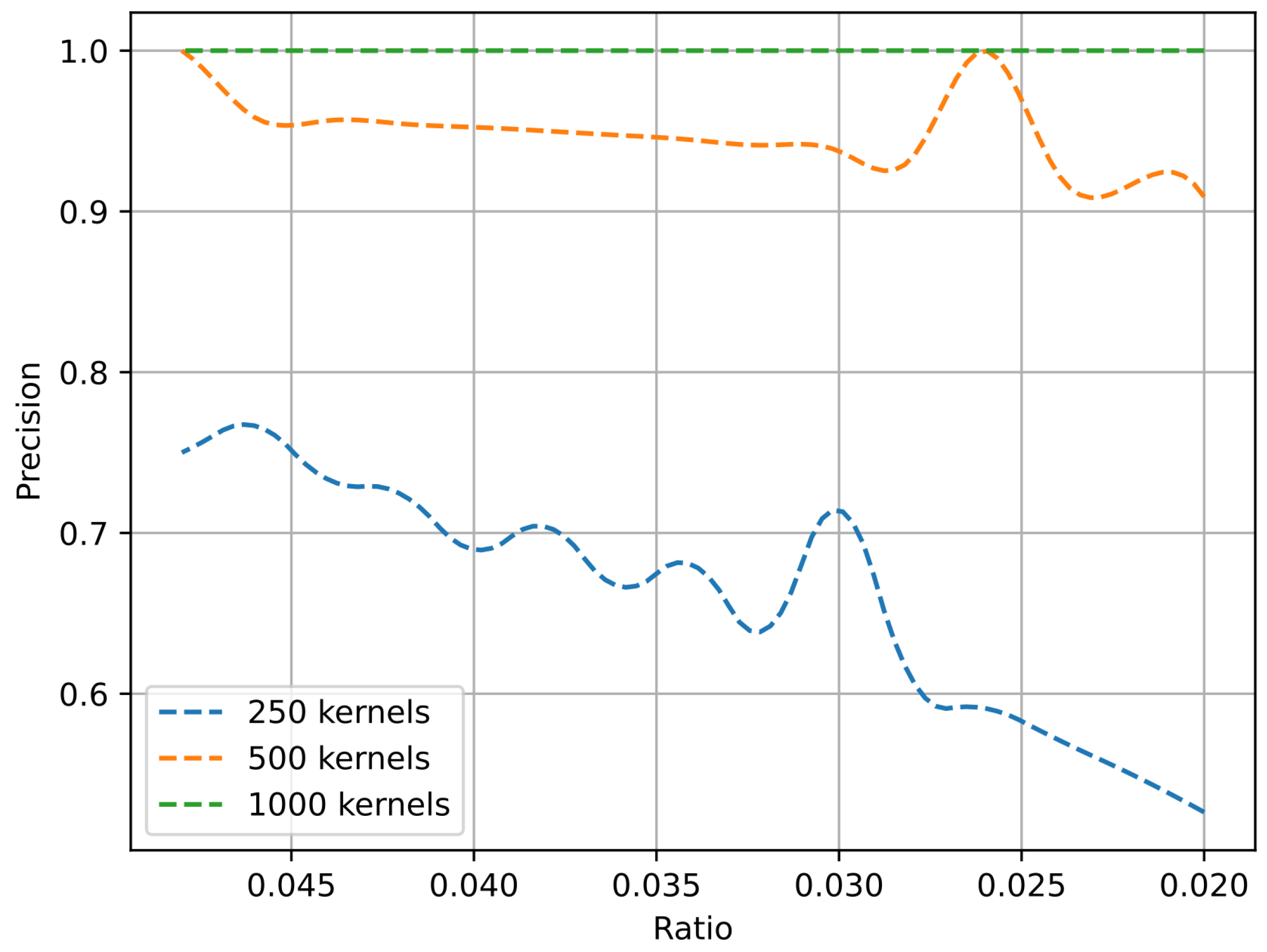
4. Results
4.1. Dataset
- Gravitational wave signals are generated using one of the models provided by the “PyCBC” package, specifically the effective-one-body model designed for spinning, nonprecessing binary black hole mergers, known as SEOBNRV4 [41]. The key input parameters for this model include the masses and spins of the two black holes, which are drawn from Uniform(10, 80) and Uniform(0, 0.998) distributions, respectively. It is worth noting that the SEOBNR family of models has a limitation in that it supports mass ratios only up to 100. Consequently, in cases where one of the celestial bodies possesses significantly more mass than the other, it is advisable to explore alternative numerical models.
- The generated signal is mapped to the detectors using the corresponding antenna patterns, i.e., and , which are determined by specific values of right ascension, declination, and polarization. These three parameters are randomly sampled from uniform distributions.
- We inject the projected GW signals into additive white Gaussian noise, adjusting their amplitude through rescaling to attain a specific , as outlined in the study by Cutler (1994) [42].where denotes the SNR for channel i, the final strain can be calculated as follows
- The output is then high-passed at 20 Hz to remove some of the simulation’s non-physical turn-on artifacts before being whitened with PYCBC using a local estimate of the power spectral density. The example is then cut to the appropriate length, in this case, 8 seconds, in a way that ensures the signal maximum always falls within the same (relative) region of the sample.
4.2. Experimental Section
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Abbott, B.P.; Abbott, R.; Abbott, T.D.; Abernathy, M.R.; Acernese, F.; Ackley, K.; Adams, C.; Adams, T.; Addesso, P.; Adhikari, R.X.; et al. Observation of Gravitational Waves from a Binary Black Hole Merger. Phys. Rev. Lett. 2016, 116, 061102. [Google Scholar] [CrossRef] [PubMed]
- Abbott, B.P.; Abbott, R.; Abbott, T.D.; Abernathy, M.R.; Acernese, F.; Ackley, K.; Adams, C.; Adams, T.; Addesso, P.; Adhikari, R.X.; et al. Tests of General Relativity with GW150914. Phys. Rev. Lett. 2016, 116, 221101. [Google Scholar] [CrossRef]
- Branchesi, M. Multi-messenger astronomy: Gravitational waves, neutrinos, photons, and cosmic rays. J. Phys. Conf. Ser. 2016, 718, 022004. [Google Scholar] [CrossRef]
- Abbott, B.P.; Abbott, R.; Abbott, T.D.; Abernathy, M.R.; Acernese, F.; Ackley, K.; Adams, C.; Adams, T.; Addesso, P.; Adhikari, R.X.; et al. GW151226: Observation of Gravitational Waves from a 22-Solar-Mass Binary Black Hole Coalescence. Phys. Rev. Lett. 2016, 116, 241103. [Google Scholar] [CrossRef]
- Abbott, B.P.; Abbott, R.; Abbott, T.D.; Abernathy, M.R.; Acernese, F.; Ackley, K.; Adams, C.; Adams, T.; Addesso, P.; Adhikari, R.X.; et al. GW170104: Observation of a 50-Solar-Mass Binary Black Hole Coalescence at Redshift 0.2. Phys. Rev. Lett. 2017, 118, 221101. [Google Scholar] [CrossRef]
- Abbott, B.P.; Abbott, R.; Abbott, T.D.; Abernathy, M.R.; Acernese, F.; Ackley, K.; Adams, C.; Adams, T.; Addesso, P.; Adhikari, R.X.; et al. GWTC-2: Compact Binary Coalescences Observed by LIGO and Virgo during the First Half of the Third Observing Run. Phys. Rev. X 2021, 11, 021053. [Google Scholar] [CrossRef]
- Abbott, B.P.; Abbott, R.; Abbott, T.D.; Abernathy, M.R.; Acernese, F.; Ackley, K.; Adams, C.; Adams, T.; Addesso, P.; Adhikari, R.X.; et al. Observation of Gravitational Waves from Two Neutron Star–Black Hole Coalescences. Astrophys. J. Lett. 2021, 915, L5. [Google Scholar] [CrossRef]
- Turin, G. An introduction to matched filters. IRE Trans. Inf. Theory 1960, 6, 311–329. [Google Scholar] [CrossRef]
- Owen, B.J.; Sathyaprakash, B.S. Matched filtering of gravitational waves from inspiraling compact binaries: Computational cost and template placement. Phys. Rev. D 1999, 60, 022002. [Google Scholar] [CrossRef]
- Purwins, H.; Li, B.; Virtanen, T.; Schlüter, J.; Chang, S.Y.; Sainath, T. Deep Learning for Audio Signal Processing. IEEE J. Sel. Top. Signal Process. 2019, 13, 206–219. [Google Scholar] [CrossRef]
- Li, X.; Ban, Y.; Girin, L.; Alameda-Pineda, X.; Horaud, R. Online Localization and Tracking of Multiple Moving Speakers in Reverberant Environments. IEEE J. Sel. Top. Signal Process. 2019, 13, 88–103. [Google Scholar] [CrossRef]
- Famoriji, O.J.; Shongwe, T. Deep Learning Approach to Source Localization of Electromagnetic Waves in the Presence of Various Sources and Noise. Symmetry 2023, 15, 1534. [Google Scholar] [CrossRef]
- Famoriji, O.J.; Ogundepo, O.Y.; Qi, X. An Intelligent Deep Learning-Based Direction-of-Arrival Estimation Scheme Using Spherical Antenna Array with Unknown Mutual Coupling. IEEE Access 2020, 8, 179259–179271. [Google Scholar] [CrossRef]
- Famoriji, O.J.; Shongwe, T. Multi-Source DoA Estimation of EM Waves Impinging Spherical Antenna Array with Unknown Mutual Coupling Using Relative Signal Pressure Based Multiple Signal Classification Approach. IEEE Access 2022, 10, 103793–103805. [Google Scholar] [CrossRef]
- Li, X.; Girin, L.; Horaud, R.; Gannot, S. Multiple-Speaker Localization Based on Direct-Path Features and Likelihood Maximization With Spatial Sparsity Regularization. IEEE/ACM Trans. Audio Speech Lang. Process. 2017, 25, 1997–2012. [Google Scholar] [CrossRef]
- Gebhard, T.D.; Kilbertus, N.; Harry, I.; Schölkopf, B. Convolutional neural networks: A magic bullet for gravitational-wave detection? Phys. Rev. D 2019, 100, 063015. [Google Scholar] [CrossRef]
- George, D.; Huerta, E.A. Deep neural networks to enable real-time multimessenger astrophysics. Phys. Rev. D 2018, 97, 044039. [Google Scholar] [CrossRef]
- Bagnall, A.; Lines, J.; Bostrom, A.; Large, J.; Keogh, E. The Great Time Series Classification Bake Off: A Review and experimental evaluation of recent algorithmic advances. Data Min. Knowl. Discov. 2016, 31, 606–660. [Google Scholar] [CrossRef] [PubMed]
- Dempster, A.; Petitjean, F.; Webb, G.I. ROCKET: Exceptionally fast and accurate time series classification using random convolutional kernels. Data Min. Knowl. Discov. 2020, 34, 1454–1495. [Google Scholar] [CrossRef]
- Dempster, A.; Schmidt, D.F.; Webb, G.I. MiniRocket: A Very Fast (Almost) Deterministic Transform for Time Series Classification. In Proceedings of the KDD’21 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining; Association for Computing Machinery: New York, NY, USA, 2021; pp. 248–257. [Google Scholar] [CrossRef]
- Martynov, D.; Hall, E.D.; Abbott, B.P.; Abbott, R.; Abbott, T.D.; Adams, C.; Adhikari, R.X.; Anderson, R.A.; Anderson, S.B.; Arai, K.; et al. Sensitivity of the Advanced LIGO detectors at the beginning of gravitational wave astronomy. Phys. Rev. D 2016, 93, 112004. [Google Scholar] [CrossRef]
- Amaro-Seoane, P.; Audley, H.; Babak, S.; Baker, J.; Barausse, E.; Bender, P.; Berti, E.; Binetruy, P.; Born, M.; Bortoluzzi, D.; et al. Laser Interferometer Space Antenna. arXiv 2017, arXiv:1702.00786. [Google Scholar]
- Hu, W.R.; Wu, Y.L. The Taiji Program in Space for gravitational wave physics and the nature of gravity. Natl. Sci. Rev. 2017, 4, 685–686. [Google Scholar] [CrossRef]
- Luo, J.; Chen, L.S.; Duan, H.Z.; Gong, Y.G.; Hu, S.; Ji, J.; Liu, Q.; Mei, J.; Milyukov, V.; Sazhin, M.; et al. TianQin: A space-borne gravitational wave detector. Class. Quantum Gravity 2016, 33, 035010. [Google Scholar] [CrossRef]
- Gair, J.; Hewitson, M.; Petiteau, A.; Mueller, G. Space-Based Gravitational Wave Observatories. In Handbook of Gravitational Wave Astronomy; Bambi, C., Katsanevas, S., Kokkotas, K.D., Eds.; Springer: Singapore, 2020; pp. 1–71. [Google Scholar] [CrossRef]
- Kupfer, T.; Korol, V.; Shah, S.; Nelemans, G.; Marsh, T.R.; Ramsay, G.; Groot, P.G.; Steeghs, D.T.H.; Rossi, E.M. LISA verification binaries with updated distances from Gaia Data Release 2. Mon. Not. R. Astron. Soc. 2018, 480, 302–309. [Google Scholar] [CrossRef]
- Zhao, T.; Lyu, R.; Wang, H.; Cao, Z.; Ren, Z. Space-based gravitational wave signal detection and extraction with deep neural network. Commun. Phys. 2023, 6. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. arXiv 2018, arXiv:1708.02002. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2015, arXiv:1409.1556. [Google Scholar]
- Kiranyaz, S.; Ince, T.; Abdeljaber, O.; Avci, O.; Gabbouj, M. 1-D Convolutional Neural Networks for Signal Processing Applications. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 8360–8364. [Google Scholar] [CrossRef]
- Fan, S.; Wang, Y.; Luo, Y.; Schmitt, A.; Yu, S. Improving Gravitational Wave Detection with 2D Convolutional Neural Networks. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 7103–7110. [Google Scholar] [CrossRef]
- Jiang, L.; Luo, Y. Convolutional Transformer for Fast and Accurate Gravitational Wave Detection. In Proceedings of the 2022 26th International Conference on Pattern Recognition (ICPR), Montreal, QC, Canada, 21–25 August 2022; pp. 46–53. [Google Scholar] [CrossRef]
- Aveiro, J.; Freitas, F.F.; Ferreira, M.; Onofre, A.; Providência, C.; Gonçalves, G.; Font, J.A. Identification of binary neutron star mergers in gravitational-wave data using object-detection machine learning models. Phys. Rev. D 2022, 106, 084059. [Google Scholar] [CrossRef]
- Chris, M.; Christopher, Z.; Elena, C.; Michael, J.W.; Walter, R. G2Net Gravitational Wave Detection. 2021. Available online: https://kaggle.com/competitions/g2net-gravitational-wave-detection (accessed on 17 October 2023).
- Fawaz, H.I.; Lucas, B.; Forestier, G.; Pelletier, C.; Schmidt, D.F.; Weber, J.; Webb, G.I.; Idoumghar, L.; Muller, P.-A.; Petitjean, F. InceptionTime: Finding AlexNet for time series classification. Data Min. Knowl. Discov. 2020, 34, 1936–1962. [Google Scholar] [CrossRef]
- Dau, H.A.; Bagnall, A.; Kamgar, K.; Yeh, C.C.M.; Zhu, Y.; Gharghabi, S.; Ratanamahatana, C.A.; Keogh, E. The UCR Time Series Archive. arXiv 2019, arXiv:1810.07758. [Google Scholar] [CrossRef]
- Tan, C.W.; Dempster, A.; Bergmeir, C.; Webb, G.I. MultiRocket: Multiple pooling operators and transformations for fast and effective time series classification. arXiv 2022, arXiv:2102.00457. [Google Scholar] [CrossRef]
- Salehinejad, H.; Wang, Y.; Yu, Y.; Jin, T.; Valaee, S. S-Rocket: Selective Random Convolution Kernels for Time Series Classification. arXiv 2022, arXiv:2203.03445. [Google Scholar]
- Thorne, K.S.; Blandford, R.D. Modern Classical Physics; Princeton University Press: Princeton, NJ, USA, 2017. [Google Scholar]
- Bohé, A.; Shao, L.; Taracchini, A.; Buonanno, A.; Babak, S.; Harry, I.W.; Hinder, I.; Ossokine, S.; Pürrer, M.; Raymond, V.; et al. Improved effective-one-body model of spinning, nonprecessing binary black holes for the era of gravitational-wave astrophysics with advanced detectors. Phys. Rev. D 2017, 95, 044028. [Google Scholar] [CrossRef]
- Cutler, C.; Flanagan, E.E. Gravitational waves from merging compact binaries: How accurately can one extract the binary’s parameters from the inspiral waveform? Phys. Rev. D 1994, 49, 2658–2697. [Google Scholar] [CrossRef] [PubMed]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| S/T | Precision | Recall | AUC | F1 |
|---|---|---|---|---|
| 3:1 | 0.961 | 1 | 0.961 | 0.980 |
| 1:1 | 0.896 | 1 | 0.963 | 0.945 |
| 1:3 | 0.737 | 1 | 0.961 | 0.848 |
| S/T | Precision | Recall | AUC | F1 |
|---|---|---|---|---|
| 3:1 | 0.990 | 0.984 | 0.998 | 0.987 |
| 1:1 | 0.958 | 0.993 | 0.998 | 0.975 |
| 1:3 | 0.941 | 0.980 | 0.990 | 0.960 |
| FPR | 6% | 8.5% | 10% |
|---|---|---|---|
| 1DCNN | 0.993 | 0.996 | 0.997 |
| PC-MiniRocket | 0.659 | 0.881 | 1 |
| Model | Training | Inference | ||
|---|---|---|---|---|
| CPU | GPU | CPU | GPU | |
| 1D CNN | N/A | 81.25 m | N/A | 1.24 ms |
| PC-MiniRocket | 14.4 m | 13.5 m | 3.64 ms | 0.658 ms |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Poghosyan, R.; Luo, Y. Random Convolutional Kernels for Space-Detector Based Gravitational Wave Signals. Electronics 2023, 12, 4360. https://doi.org/10.3390/electronics12204360
Poghosyan R, Luo Y. Random Convolutional Kernels for Space-Detector Based Gravitational Wave Signals. Electronics. 2023; 12(20):4360. https://doi.org/10.3390/electronics12204360
Chicago/Turabian StylePoghosyan, Ruben, and Yuan Luo. 2023. "Random Convolutional Kernels for Space-Detector Based Gravitational Wave Signals" Electronics 12, no. 20: 4360. https://doi.org/10.3390/electronics12204360
APA StylePoghosyan, R., & Luo, Y. (2023). Random Convolutional Kernels for Space-Detector Based Gravitational Wave Signals. Electronics, 12(20), 4360. https://doi.org/10.3390/electronics12204360