1. Introduction
The importance of enterprise systems to various business establishments cannot be overemphasized. These systems generate event logs that record all transactions and when they occur. An event is executing a specific action, such as validating a requisition as part of a particular case at an exact time. Consequently, an aggregate of these events, known as an event log, has the recorded actions of the process. Using these event logs, business process mining [
1] can uncover new details about an organization’s organizational structure, control, and process discovery. Process mining is handy when extracting these data and understanding the underlying processes. According to Van der Aalst et al. [
2], process mining helps practitioners get insight into extracted data from event logs. It focuses on knowledge extraction from data produced and kept in enterprise information systems for process modeling. Process mining has been employed in many industries, including the health industry, to increase the process intelligence of health systems [
3].
Business process systems are integral to many organizations’ day-to-day operations because they allow firms to distribute mission-critical information across groups through automated state transitions. Event logs generated during these transitions may help companies find critical data for streamlining their company’s business processes. Process modeling requires using temporal data, such as the timestamps of two events and how often an event has occurred in the past. In a nutshell, process mining aims to gather details about processes from event logs. Each event might have several different attributes, such as an action, a creator, an instance, a timestamp, and many more. A log containing 18 events, 8 activities, 7 creators, and 18 unique timestamps is shown in
Table 1. Event logs are the first step in the process mining process. There are several perspectives on process mining, including the control-flow-focused, the case, and organizational perspectives [
1]. The study focuses on the process perspective. An event log consists of several traces, each representing a sequence of events performed for a particular case, such as an individual order or request. Most foundational process mining techniques treat these traces as sequences of abstract symbols—e.g., a, b, c, d, e, f. In this manner, they make the events abstract, and therefore, uses techniques such as Markov chains, abstraction, evolutionary algorithms, state-based discovery algorithms and language-based region to estimate the control-flow processes of these activities but do not consider the semantics of the data attributes.
Based on empirical evidence, these logs often capture information on the tasks carried out: when they are performed, by whom, and within which circumstance (i.e., process instance). By using the case context in an obvious way, process-discovery algorithms can generate process models that show the process precisely as it happens in the real-life event log. The process perspective, which is our focus, focuses on the control flow, i.e., the ordering of activities. The goal of mining this perspective is to find a good characterization of all possible paths expressed in a Petri net. Process mining researchers, particularly those focusing on the process perspective, have generally concentrated on scanning each event trace in the event log and recording the fundamental ordering relations between activities. These relations provide information on the number of direct task successions. This might result in an object–relation impedance mismatch. However, among these activities, their text is crucial, since it provides a great deal of contextual information and requires a substantial amount of human intelligence.
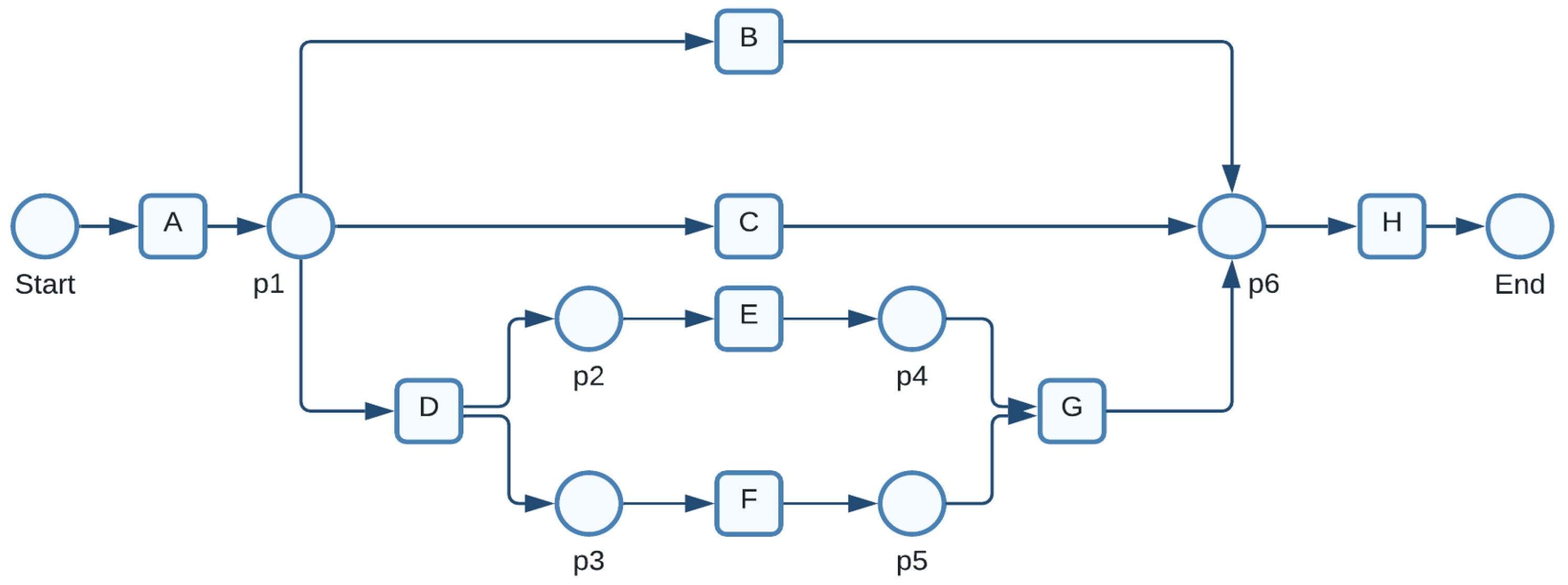
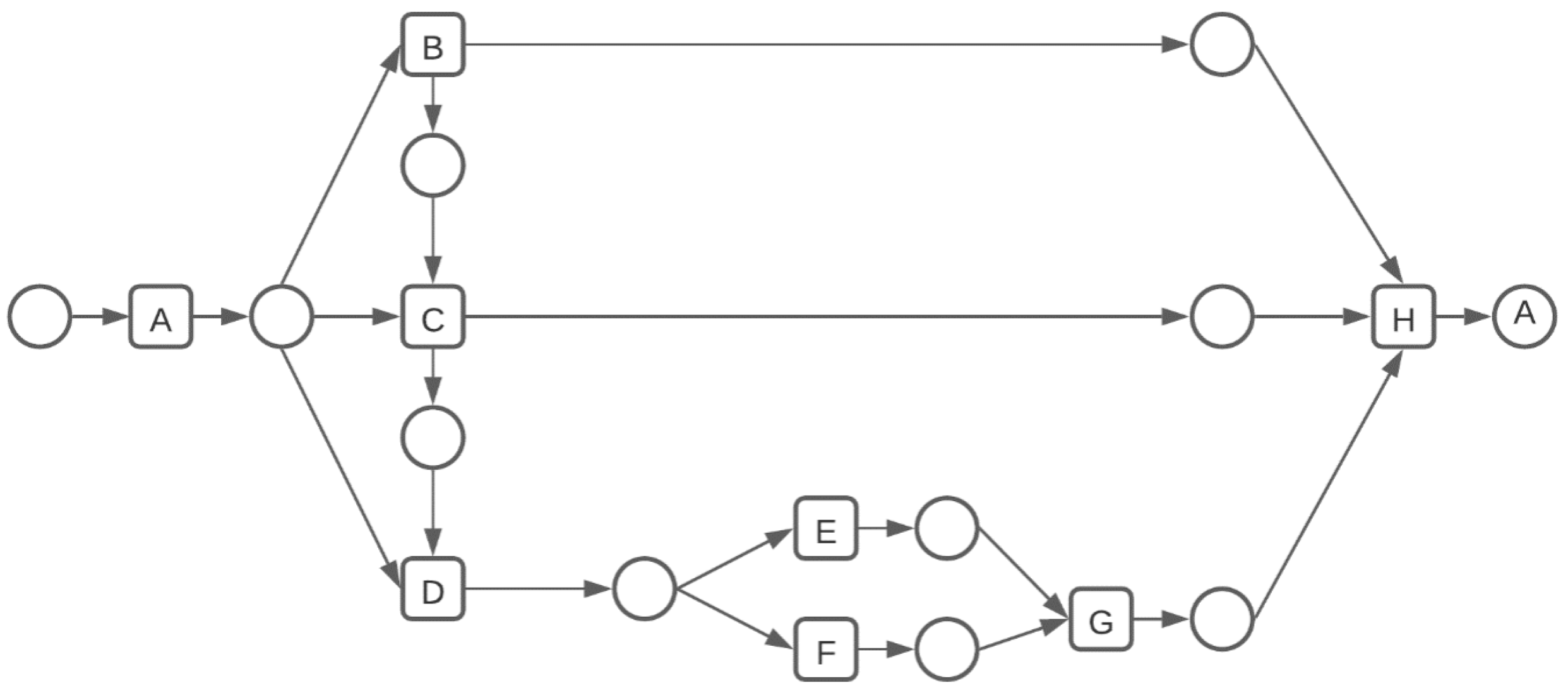
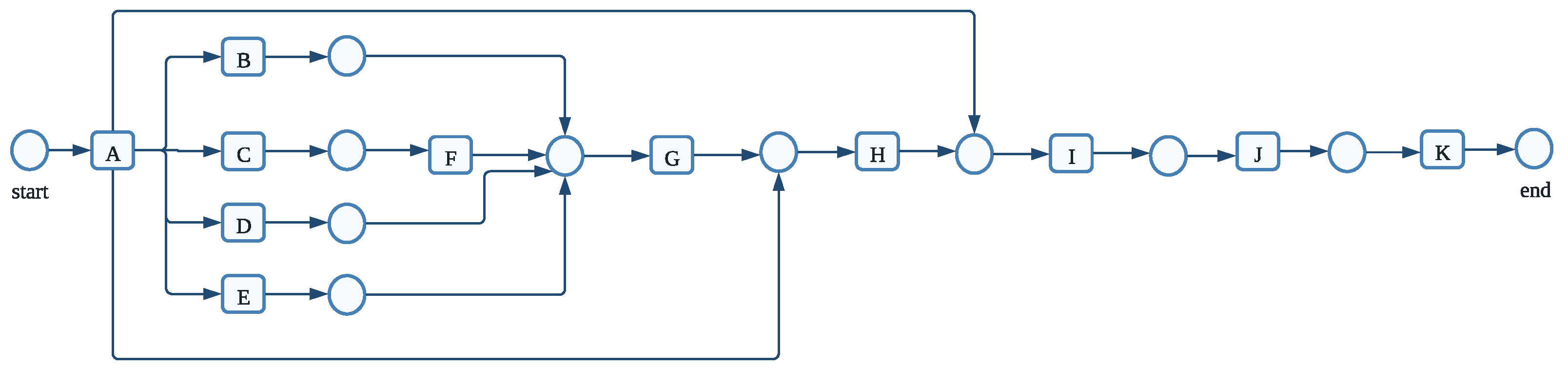
The following cases are observed in
Table 1:
;
;
;
—cases 1 to 4, respectively. We might discover the following details about the process by examining these four cases. The underlying process comprises eight activities
. Activity H is always the last activity that must be performed; activity A is always the first to be completed. Activities
can be performed after A is finished in any order. H is instantly executed when activities B or C are done, as indicated in cases 1 and 2. Activities E and F can be performed in no particular order after activity D. In this case, both E and F are concurrent. Activities E and F are connected directly by G. Activity H is performed after completing B, C, or G.
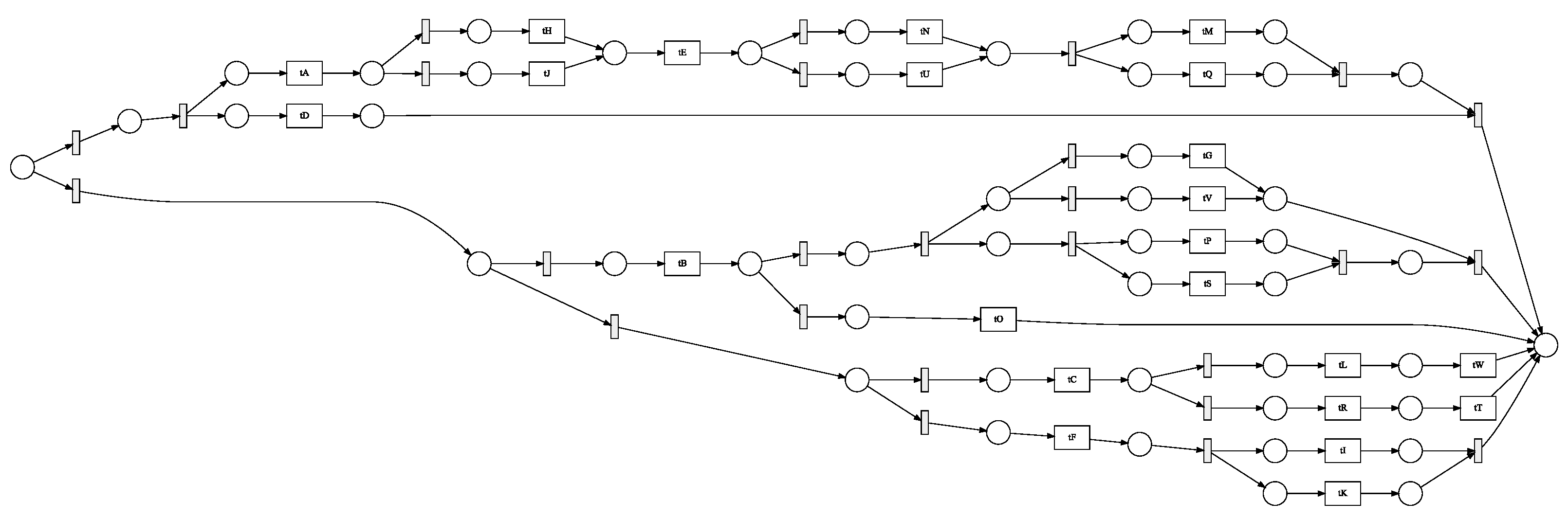
to
are set of places of a Petri net represented by circles As shown in
Figure 1, a Petri net (see definition in
Section 3.1) may mimic the four event-log scenarios listed in
Table 1. A significant field of study that creates an effective tool for text comprehension is the measurement of the semantic relatedness between phrases.
Understanding textual materials more effectively is facilitated by assessing the semantic similarity of terms. This has led to semantic similarity’s use in various tasks, including word-sense disambiguation [
5,
6], document classification, and clustering [
7,
8,
9]. The taxonomic closeness between words is referred to as semantic similarity or relatedness. Similarity measures calculate a score for semantic evidence obtained in one or more knowledge sources to quantify this closeness. Since the homogenization of web ontology language, numerous developers have built and maintained their systems by augmenting their data vocabularies to precisely describe more constructs from their application domains [
10]. For example, there is a relationship among login, logout, confirm payment, checkout, etc. For instance, login has an antonymic relation with log out. Additionally, “checking a receipt” is similar to “confirmation of checking a receipt”, which can be found in an enterprise ticketing system. Since activity names are words used in describing the various components of enterprise systems, this study employs this information-content-based technique to evaluate activity similarity as a function of the information content (IC) that two activities share in a particular log trace. The quantity of information an activity provides when it appears in a trace to another is indicated by its information content (IC). When detected in a discourse, general and abstract entities display less IC than more specific and specialized ones. This paper implements a unique way to parse event activities in an event log by utilizing the information content of the least common submsume of event log attributes. Finally, it provides an algorithm for process mining based on the parsing process using an enhanced gray wolf optimizer with backpropagation.
We recognize that real-world problems are seldom easy to solve. Hence, we employ fuzzy logic to express the similarity values between activities to characterize an event log by considering the information content of the least common subsume between these activities. A fuzzy system is a technique for processing variables that allows for processing several possible truth values using a single variable. It attempts to address problems by using an open, erroneous spectrum of facts and heuristics, resulting in a wide range of reliable findings [
11,
12,
13,
14,
15]. This generalizes from conventional logic, which holds that all statements have a truth value of one or zero, making it essential for our research. Our method also allows us to define a threshold below which some events may cause the execution of other actions. It is intuitively possible to choose which input and output activities can be executed based on the exact relative weights of activities.
The rest of the paper is presented in the following sections:
Section 2 discusses the related work and research gap;
Section 3 states the preliminaries;
Section 4 and
Section 5 present our proposed methodology and a process mining algorithm based on our approach, respectively;
Section 6 presents the experimental results. Finally,
Section 7 completes the study and provides recommendations for future works.
2. Literature Review
In the past, several process-discovery techniques have been suggested. We go over a few of them in terms of model discovery. Li and Li [
16] developed a multi-step process-mining technique for process mining between activities, analyzing a workflow log to accomplish workflow reconstruction using the Markov transition matrix. However, their strategy did not account for sub-processes. Algorithms for discovering genetic process models described in [
17,
18] use a causal matrix to represent the relationship between activities in an event log. This matrix is represented by 0 s and 1 s, which means activities in a distant relation cannot be represented as activities with a relation. A streamlined process construct tree is a parsing approach to locate block structures in process models, through which soundness can be verified, or an unconstrained model may be transformed into a block-structured one [
19]. Joo and Choi [
20] defined a stochastic process tree and proposed a tabu search-genetic process mining algorithm for a stochastic process tree. This was done to address the issue of time complexity in genetic algorithms. This is quite similar to our design process in the stochastic process. However, whereas they used a stochastic process tree, we used a levy flight distribution. Interestingly, their approach does not enable the construction of a reliable or accurate model; it simply analyzes or alters an existing model.
The language mining method of Bergenthun et al. [
21] pre-structures the input log into new chunks using regular expression; this block-structuring of the log is then employed during discovery to create a fitted, although potentially flawed, process model. The heuristics miner [
4] and other frequency-based approaches do not ensure soundness or fitness. Tang et al. [
22] proposed a hybrid mining algorithm based on trace clustering population to augment the inefficiencies of genetic process miners. The idea was to simplify the search space, since genetic algorithms inherently do not perform so well on large event logs. Clustering is prone to biases, primarily if the entire population is formed under a biased opinion.
De Leoni, M. et al. [
23] proposed a process analysis use case which requires the selection of dependent and independent characteristics and an event filter to describe which events to retain for analysis. They achieved this by incorporating characteristics that are not (yet) available in the event log. These characteristics are added by deriving their values through computations over the event log or from external information sources. Then, the event log is manipulated and enriched with additional characteristics. Finally, based on the correlation analysis results, the traces in an event log are clustered. Song et al. [
24] also applied trace clustering for pre-processing event logs. Notably, however, these approaches mainly rely on syntactic information (either control-flow-based or data-flow-based) in the event logs for the pre-processing, leaving a distinct research gap for approaches utilizing semantic information in the pre-processing phase. Additionally, their works concentrate more on event log pre-processing, which is slightly different from ours. Our work seeks to use natural language to generate a process model by using the semantics of the words or phrases used in describing the activity-name event attribute in an event log. Additionally, Sadeghianasl et al. [
25] proposed an automatic approach for detecting two types of data quality issues related to activities: synonymous labels (same semantics with different syntax) and polluted labels (same semantics and same label structures) by using activity context, i.e., control-flow, resource, time, and data attributes to detect semantically identical activity labels for detecting frequent imperfect activity labels, just as [
26] focuses on event log pre-processing but not the actual process mining itself. Their work tends to correct incorrect labeling of event attributes to enhance the outcome of a process model. Using it to correct incorrect or duplicate labels will further enhance the correctness of our model, since our approach relies on the semantics of the words used in describing processes.
Though clustering-based approaches can increase the simplicity and generalizability of process models, they also lead to a loss of information during the clustering process and introduce biases toward some clusters. Integrating semantic information extracted from the event logs with the mined process models can alleviate this information loss issue. Ideally, a formalized knowledge structure, such as process ontologies, that systematically reflects concepts and their relations could be used as a basis for event-log clustering. However, existing process ontologies are usually generic and lack domain-specificity. Accordingly, lower-level process ontologies require finer granularity and capture domain-specific details through event classes and hierarchical relationships between these classes.
Event log pre-processing before the actual process mining activities is more effective at simplifying the outcomes of process models [
26]. Bose et al. [
27] have proposed an abstraction-based pre-processing method to deal with loops in mined process models. Abstraction-based approaches usually leverage the premise that all processes are at the same level in an event log, which is not always the case. Additionally, Rebmann, A., and van der Aa, H. [
28] identified up to eight semantic components per event. Revealing information on the actions, business objects, and resources recorded in an event log and further categorizing the identified actions and actors allows for a more in-depth analysis of crucial process perspectives. Furthermore, Deokar, A. V., and Tao, J. [
29] proposed a computational framework for event log pre-processing, emphasizing event log aggregation. They used phrase-based semantic similarity between normalized event names to aggregate event logs in a hierarchical form.
Overall, existing clustering-based methods used in process mining have changed focus and do not leverage semantics during the pre-processing phase.
Richetti et al. [
30] proposed the discovery of declarative process models by mining event logs. It aims to represent flexible or unstructured processes, making them visible to the business and improving their manageability. Although promising, the declarative perspective may still produce models that are hard to understand, due to both their size and the high number of restrictions on the process activities. This work presents an approach to reduce declarative model complexity by aggregating activities according to inclusion and hierarchy semantic relations. The approach was evaluated through a case study with an artificial event log, and its results show complexity reduction in the resulting hierarchical model.
Although numerous researchers have committed efforts to designing efficient algorithms for process mining, an essential difference exists in the parsing of activities. As per available literature, most of the works concentrated on preprocessing event logs for process mining using event-log clustering; others used semantics to correct incorrect attributes labels and to remove duplicates, and finally, semantics of attributes of an event log were used to add invisible attributes that might not have been captured by event log to add more meaning to process mining. Knowing the structural relationship between activities in an event log is not enough. The meaning of the relationship needs to be streamlined, as this will enable process miners to discover how various processes in an enterprise system relate to one another. This will enable terms to be related by natural language processing engines when used for designing process mining algorithms. Thus, we aimed to create a technique that can accurately parse activities in an event log using the semantic relatedness between activities in the event log.
3. Preliminaries
The basic notation used in fuzzy calculus and Petri nets is presented in this section. Petri nets are bipartite-directed graphs for describing concurrent processes [
31]. They have places and transitions as their two main types of nodes. The places signify the steps in the process, and transitions indicate actions. The transitions in Petri nets match the events in the event logs. The placement of tokens (black dots) at certain places represents a Petri net’s current state. The firing rule determines the Petri net’s dynamics. If all of a transition’s input places include at least as many tokens as the number of directed arcs that connects them to the transition, following the execution, the transition creates tokens for the output places and deletes tokens from the originating place; thus, a token is eliminated for each input arc from the place to the transition, and on the other hand, a token is created for every output arc.
In the initial stage of the procedure for the Petri net shown in
Figure 1, there is just one token, Start. This means that in the starting state, only transition A is viable. A removes one token from the initial point and adds one to p1 when it fires. The event log, comprising the four instances (see
Table 1), is elegantly represented by the Petri net in
Figure 1. Be aware that the Petri net shown in
Figure 1 can reproduce each of the four instances, including every observable activity. In this case, the log consists of each possible firing pattern for the Petri net seen in
Figure 1. Generally speaking, this is not the case because it is improbable that the log would ever contain all conceivable activity.
3.1. Petri Nets
A Petri net is a four-tuple , where P is a set of m places represented by circles; T is a set of n transitions represented by bars; and are the pre and post-incidence functions, respectively, that specify the arcs in the net and are represented as matrices in , where . For transitions , the set of input places , and the set of its output places . Similarly, for places , the set of input transitions and the set of its output transitions .
A marking is a vector that assigns to each place a Petri net, a non-negative integer number of tokens, represented by black dots, and it can also be represented as an m-component vector. denotes the marking of place p. A marked Petri net is a net N with an initial marking . This is denoted as —the set of all markings reachable from the initial one. A transition t is enabled at M if and may fire, reaching a new marking , where .
We denote as the sequence of transitions enabled at M and to denote that the firing of yields A marked Petri net is said to be bounded if and holds. A Petri net is structurally bounded if, for any , the marked net is bounded.
3.2. Fuzzy Systems
Fuzzy logic entails a type of logic in which variables’ truth values might be any real integer between 0 and 1. It deals with the idea of partial truth, in which the truth value might vary from totally true to completely false. In contrast, the truth values of variables in Boolean logic can only be the integer values 0 or 1 [
32]. Fuzzy logicis mathematically presented as follows [
33].
A fuzzy number is a fuzzy set such that:
u is upper semi-continuous.
outside some interval .
There are real numbers b and c; .
is monotonically increasing on .
is monotonically decreasing on .
.
5. Designing a Process Mining Algorithm Using Our Approach
The technique outlined in
Section 4 was applied to construct a novel process mining algorithm from a gradient-based and a meta-heuristic algorithm. The powers of the gray wolf optimizer’s global search ability and the backpropagation algorithm’s strong local search ability are combined to profit from the advantages of both approaches while building our mining algorithm. This strategy was chosen to avoid local optimum entrapment, improving the efficiency of discovering optimal process models while also improving the convergence rate. The Levy flight first improves the gray wolf optimizer’s (GWO) global search capability before combining it with back propagation (BP). These techniques are discussed in
Section 5.1,
Section 5.2 and
Section 5.3.
5.1. Gray Wolf Optimization Algorithm
The GWO is a meta-heuristic algorithm based on swarm intelligence that arithmetically replicates gray wolves’ natural leadership mechanism and foraging behavior [
36]. They typically live together and go on hunts. Gray wolves’ predatory behavior is modeled using GWO, an adaptive intelligence method based on particle swarm optimization. When it comes to complex function optimization and engineering problems, it works well. The fundamental premise is that gray wolves have a hunting area where they may look for prey. Four divisions of the gray wolf pack may be distinguished based on their hierarchical relationships: alpha, beta, delta, and omega. The alphas are the leaders and are in charge of making hunting decisions. The betas come next, helping the alphas with decision making and other group activities. Omega wolves are at the bottom of the hierarchy and are subservient to alpha, beta, and delta wolves.
The three most essential wolves are
and
, who frequently direct the omegas (
) toward areas with higher hunting potential. We will refer to each alpha, beta, delta, and omega in the search space as a unique process model, and the prey is the model we are trying to reproduce. A population is the limited number of wolves found in any pack at any moment. Each wolf has an internal representation, and the quality of each wolf is assessed using a fitness value calculated using Equation (34) presented in
Section 5.4. Observing, encircling, and attacking prey is mathematically characterized by Equations (5) and (6) and results in new places in the search space as the hunt for prey proceeds. We try to mine a process model that reflects the structure and behavior of an event log. Thus, the wolves carry out the hunting process, and the prey, in our case, is the true model we are trying to mine.
where
t shows the current iteration,
,
,
is the position vector for the process model we want to model, and
shows the position vector of a gray wolf (an individual, i.e, the process models generated by our approach).
is a parameter that is linearly decreased from 2 to 0 for
and
(random vectors in the range
). Equation (5) indicates the step size of the omega wolf (that is a generated process model with the least fitness measure) towards the specified leader (
,
and
); thus, process models with higher fitness values and Equation (6) represent the final position of a process model with the lowest fitness value (the omega
). From Equations (5) and (6), a gray wolf (an individual), i.e.,
, can update its position to
. Henceforth, individuals shall be used interchangeably with process models to describe the process model generated by our approach.
To model the mining process mathematically, we assume that
,
, and
individuals have more knowledge about the potential structure and behavior of the true process model we wish to mine. Therefore, they are considered the best candidates, and the omega wolves are forced to update their structural and behavioral constructs according to the best individuals (
,
and
). The following equations are used to achieve that.
where
,
, and
are the best behavior and structure for
,
, and
, respectively.
,
, and
are random vectors; and
represents the behavior of the potential process model solution.
,
, and
are randomly distributed vectors.
t represents the number of iterations, and Equations (7)–(21) indicate the final nature of the omega wolves.
is the log trace, m is our model, and o is the original model. The principle of the GWO algorithm is that the omegas update their next behavior for search according to the positions of alpha, beta, and delta wolves. This makes sure that the individuals with the least fitness measures diverge from each other and converge toward the process model we are trying to mine. When , the omegas converge towards the desired model, but there is a risk of getting stuck in the local optimum; to prevent it from getting stuck in the local optimum entrapment and emphasizing exploration, values are considered greater than 1 or small than −1 to force the search agent to diverge from the intended process model.
Again,
is an additional parameter that emphasizes exploration. If
, it is highlighted; otherwise, it deemphasizes the effect of the process model in defining the distance in Equation (5). It should be noted that
is lowered linearly to encourage exploitation during the iterations.
, on the other hand, offers random values to emphasize both exploration and exploitation during optimization. Mirjalili et al. [
36] states that it is an effective method for dealing with local optimum stagnation.
5.2. Why Levy Flight?
When the GWO algorithm cannot find the optimal individual after a predetermined number of iterations, levy flight, which follows the levy probability distribution function-based search, is used to enhance the global and local search abilities of the algorithm to prevent it from getting stuck in local optima. This is done by using a random process to come up with random directions and steps that match the levy distribution [
37,
38]. The levy flight distribution is given as
where
is an index. A concise mathematical representation of the levy distribution is presented as follows [
39].
where
and
are the shift and scale parameters, respectively, and
s is the sample distribution. Firstly, a random population is generated, and then the fitness of each individual in that population is determined. Alpha, beta, delta, and omega are initialized in the next stage. After that, the hunting process begins. This process is repeated until there are no further improvements in the outcome. Then, the levy flight is used to continue the search, causing the individuals in the search space to be redistributed. Equations (18)–(20) [
40] are then modified to the following.
where ⊕ is an entry-wise multiplication product and
is a random number in Equation (23). As can be seen in Equations (24)–(26), the behavior and structure of the individuals are added to
S.
S is calculated by the method defined by [
40] as follows:
where
v and
u are random numbers generated by a normal distribution:
with
where
is the standard gamma function. For each individual as the best candidate, a random number
is generated between 0 and 2. The smaller the value of
, the higher the jumps, and the larger the values of
, the lower the jumps. It means higher values of
will cause jumps to unexplored search space, and as a consequence, prevent it from getting stuck in local optima. On the other hand, smaller values of
trigger new search spaces to be considered near the obtained solutions.
The gray wolf algorithm has a tremendous global search ability but a low convergence rate. To deal with this flaw, the BP algorithm, which has strong local and poor global search capabilities, is paired with the gray wolf to profit from the advantages of both approaches while constructing our mining algorithm. Consequently, the BP algorithm refines the GWO results to generate more accurate results, enhancing the efficiency of our proposed technique in discovering optimum models and accelerating the rate of convergence.
5.3. Backpropagation
We assume our generated process model to be a neural network, and the input activities are the inputs to the network. The activity directly above an element with a higher value of
than it is an input to that activity. Finally, activities with lower values of
Ŝ are the hidden nodes of the network. There are as many events in an event log as there are nodes in the input layer, and vice versa for the output layer. However, depending on the number of activities and their relationships in an event log’s trace, the number of hidden activities might vary. We take
i as the number of activities in the input layer,
h as the number of activities in the hidden layer, and
o as the number of activities in the output layer. It can therefore be calculated as:
where
is the output of the
node in the output layer of the individual;
is the input of the
node in the input layer;
is the semantic value between two activities;
and
represent bias terms of the sigmoid function
f of nodes
m in layer
h of activities and nodes
n in the output layer. We calculate the transfer function f using the sigmoid function as follows:
The semantic value between activities and the bias term of each trace constitutes the causal relationship between activities. We can calculate the error of obtaining the required process model by calculating the loss function. This is used to measure the discrepancy between the target and generated models. Equation (33) is used to calculate the loss function as follows:
where
k shows the number of tasks in the log; the lower the value difference, the closer the mined process model will be to the actual model.
5.4. Fitness Calculation
Process mining aims to discover a process model from an event log. The mined process model should provide helpful insight into the log’s behavioral characteristics. In other words, from a behavioral and structural standpoint, the mined process model should be accurate and comprehensive. A model is complete when it can analyze or replicate every event trace in the log and is precise when it cannot parse more than the traces in the log [
3]. Models that can parse all event traces may provide an additional activity that does not belong in the log, making it crucial that the mined model also be exact. As a result, each individual’s fitness is determined, and the results are
as the model with the lowest cost,
as the model with the second-lowest cost, and
as the model with the third-lowest cost.
The fitness of the generated process models assesses how effectively an individual represents the behavior in an event log, new solutions are created, and their fitness is calculated to generate new process models. We determine the fitness of each trace and aggregate them. Our fitness measure, the “completeness” metric, is based on how individuals parse event traces. The ideal individual or model should have a fitness score of one for a noise-free log. The following equation is used to calculate the fitness at the trace level of an event log.
where
m is the number of missing tokens,
c the number of tokens consumed,
r is the tokens left after it reaches an output place, and p is the number of tokens produced. From
Section 3, we learned that an event log contains several traces; hence, we aggregate all cost functions of all the traces. The following is the combined fitness function of a log.
where
is the number of times the trace occurred in the log.
5.5. Analysis Metrics
Medeiros et al. [
17] defined evaluating metrics to evaluate mined models on completeness and precision. To check for completeness, a partial function measure is defined as.
where
where
is the total number of successful parsed activities in the event log,
Indicates all missing tokens in a trace, where n = number of traces in the log, e = all missing tokens, f = number of traces missing tokens, g = all extra tokens left behind, and h = number of extra tokens that are left behind. g(L,FCM) denotes unconsumed tokens after the parsing of activities has completed, in addition to tokens at the end place minus 1, and n(L) represents the number of traces in L. (L,FCM) and h(L,FCM), respectively, represent the numbers of traces with missing tokens and the remaining tokens after the parsing process has completed.
This metric provides more specific information on how well a certain process model fits a particular log. It accurately determines how much other behavior an individual permits. Medeiros et al. [
17] checked the number of activated visible tasks. Others who allow extra behavior typically have more enabled tasks than those who do not. The primary purpose is to benefit individuals with fewer enabled tasks while parsing the log. Precision is defined using the following equation.
where
denotes all enabled activities during the parsing process of log L,
applies enabled activities to each activity in the matrix, and (allEA(L,FCM[]) returns the maximum value of the number of enabled activities in the given population (FCM[]) while parsing the log (L). Therefore, the complete fitness function for our evaluation combines both
and
, such that, for a none empty log (L), the fuzzy causal matrix, a bag of causal matrices FCM[], and a real number k, F(L,FCM,FCM[]) =
, where
k punishes an individual for extra behavior.
We established two measures, behavioral precision and behavioral recall, because we needed to compare the behavior of the original model with that of the mined model. Both are based on the original model and the mined model’s parsing of an event log. These metrics function by comparing the number of tasks enabled in the original model and the mined model for the continuous semantics parsing of every task in every process instance of the event log. The models’ behaviors are increasingly similar with the more enabled tasks they share. The behavioral precision determines how much deviation from the mined model the original model permits, in contrast to the behavioral recall. Both metrics also include the frequency with which a trace appears in the log. As deviations belonging to uncommon pathways are less significant than deviations related to normal behavior, this is particularly essential when working with logs in which specific paths are more prevalent than others. The more similar
and
behaviors are to one, the closer their behaviors are.
is defined as [
17].
where
) returns the enabled tasks at the fuzzy causal matrix before the parsing of the activity at position
i in the trace
and behavioral recall as:
Additionally, we used the following equations to assess the structural similarity of the original and the mined models. This metric checks the number of causal relations shared by the original and the mined model. The higher the number of causal relationships that exist between them, the more similar their structures are. There are two metrics, structural precision and structural recall. The former assesses the difference in causal relations between the mined and the original model, and the latter evaluates otherwise. Structural precision is defined mathematically as.
, , , , , and are the metrics used to analyze the mined models in this paper.
5.6. Pseudocode of the Algorithm
After generating the fuzzy causal matrix, we use it to construct our mining algorithm. The pseudocode of the mining algorithm is presented in Algorithm 4.
| Algorithm 4: Pseudocode of the mining algorithm. |
 |
6. Experimental Results
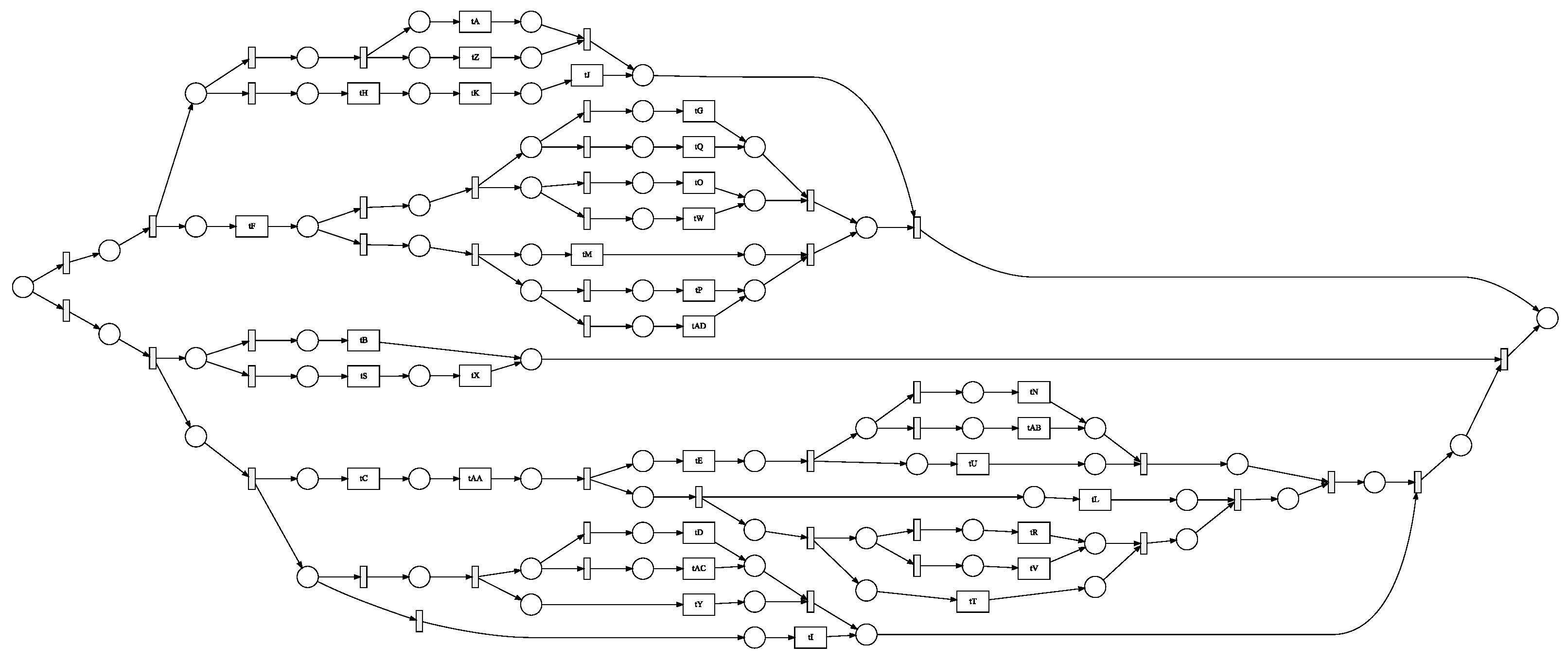
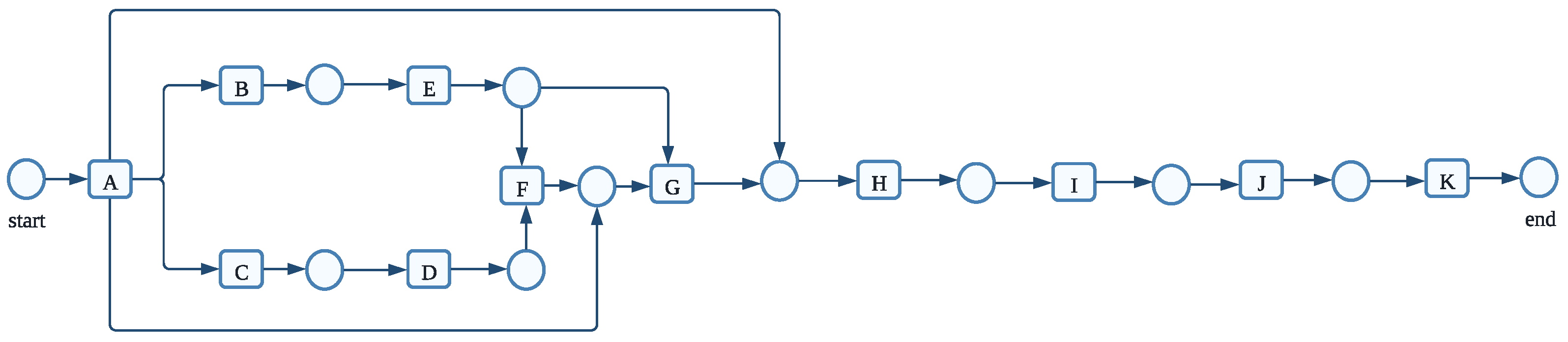
We employed four distinct process models with 7, 14, 24, and 30 activities to test our enhanced gray wolf optimizer (GWO) with backpropagation for process mining. We tested the effects of the basic gray wolf optimizer (GWO), an enhanced gray wolf optimizer (EGWO), and the enhanced gray wolf optimizer with backpropagation (EGWO + BP) on the proposed parsing of event logs. These models were created artificially using the ProM6.10 for process mining plugin (to generate a block-structured stochastic Petri net). They include concurrency, loops, and sequences.
Figure 8,
Figure 9,
Figure 10 and
Figure 11 each describe one of these nets. We employed six distinct forms of noise to examine how our proposed method deals with noise-free and noisy event logs. The types of noise examined include exchanged activities, mixed noise, missing head, missing activity, missing tail, and a missing body. These noise types behave as follows, assuming an event trace
.
Missing head, tail, and body noise involves randomly removing sub-traces of activities in the head, tail, and body of . The head goes from to . The body goes from to , and the tail goes from . Missing activity randomly removes an activity from the trace. Two activities are exchanged in the exchanged activity noise type. The mixed noise type comprises a mixture of the five above mentioned noise types. Real-world logs frequently include a variety of noise. However, the distinction between the noise types enables us to more accurately evaluate how the various noise types impact the algorithms used in generating a process model from event logs. We produced logs with 5%, 10%, and 15% noise for each category of noise. Therefore, we had 18 noisy logs in each process model in our experiments.
We tested our methodology with noise-free logs from process models which should provide similar results. We initialized the number of activities per generated process model; the dimensions were set to , depending on the number of activities in the corresponding process model. We set the lower and upper bounds to −10 and 10, respectively. The population had 300 individuals and was iterated a maximum number (max_iter) of 150 times. After several iterations, the best models with suitable fitness measures were obtained. Each event log consists of 500 traces. For each log, the three algorithms ran five tests with randomized seeds. As we know, for the model used to generate the event logs, we expect the various GWO techniques to yield the same model during experimentation. In a more realistic setting, though, the underlying model is unknown, and we will have to search for it. The only realistic answer seems to be the definition of a suitable algorithm that will provide us with the best fitness metric. The gray wolf optimizer (GWO) was tested alone without levy flight and with Levy flight (EGWO), and the enhanced GWO with backpropagation (EGWO + BP) was tested. It is possible to calculate a fitness index from each of these algorithms. One way we have found to quantify the efficacy of our algorithm in this experimental situation is by tallying the frequency with which the GWO search yields the process model employed while generating the noise-free event logs. This metric will be used even if there is extra noise in the event log.
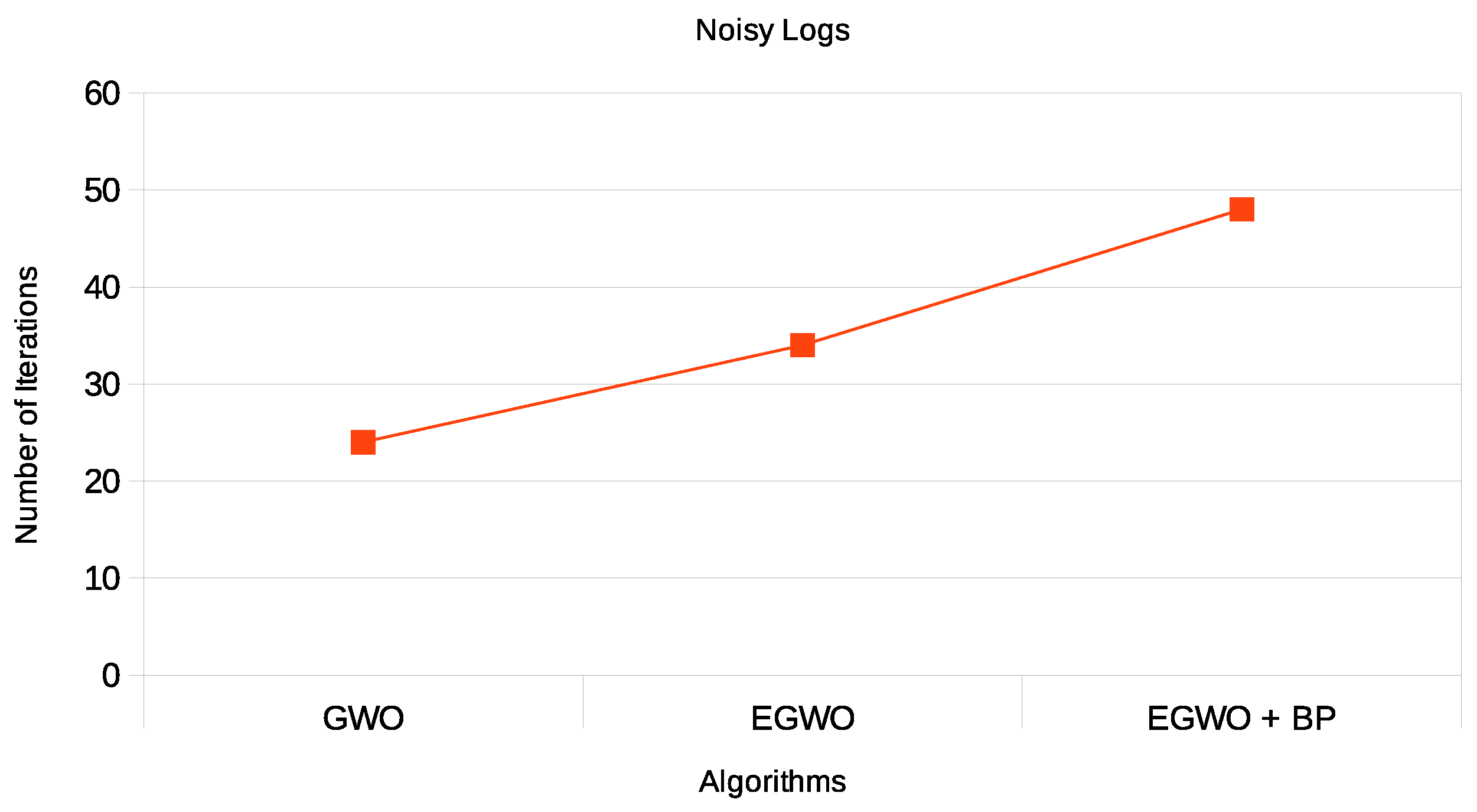
Let us first have a look at the results for the noise-free logs. As shown in
Figure 12, the algorithm works for noise-free logs. For the three scenarios w.r.t. to fitness, the smaller the net, the more frequently the gray wolf algorithm without enhancement finds the desired process model. Additionally, the enhanced version performs slightly better than the GWO. This could be attributed to the dynamic position updating of the best solutions by incorporating the levy flight distribution, which is stochastic, since GWO disregards the positional interaction information about the best three solutions. For process models that contain more activities, the enhanced gray wolf with backpropagation produced better process models than both the GWO alone and its enhanced version (EGWO). This could be attributed to the stagnation of the GWO in local optima when the search space is relatively large.
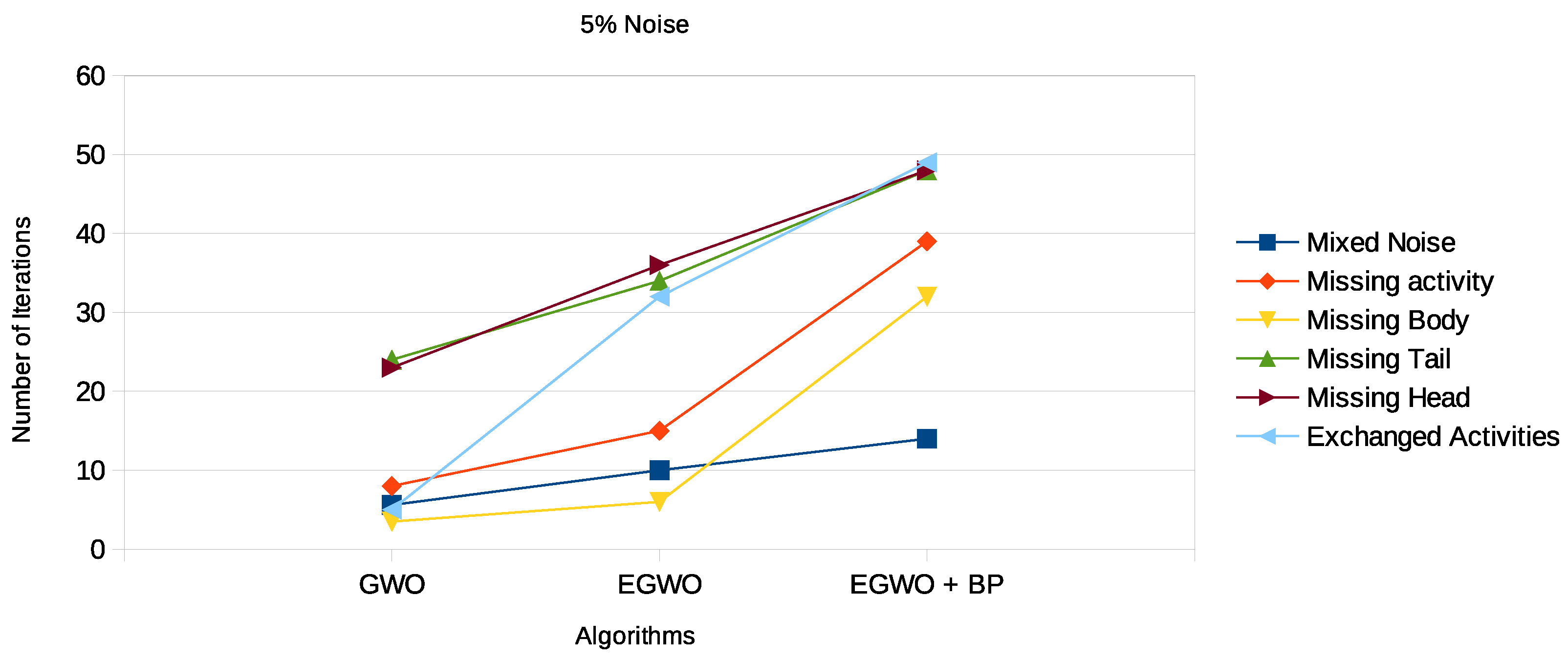
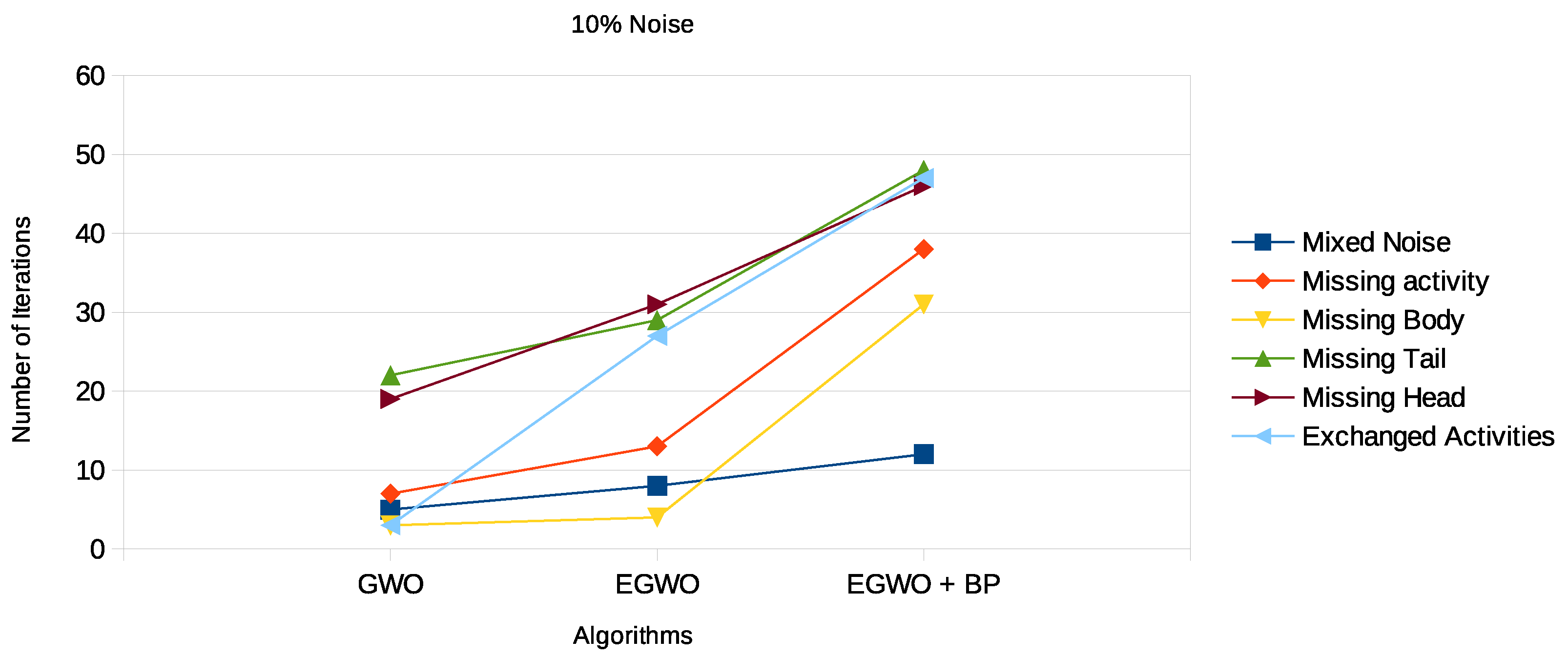
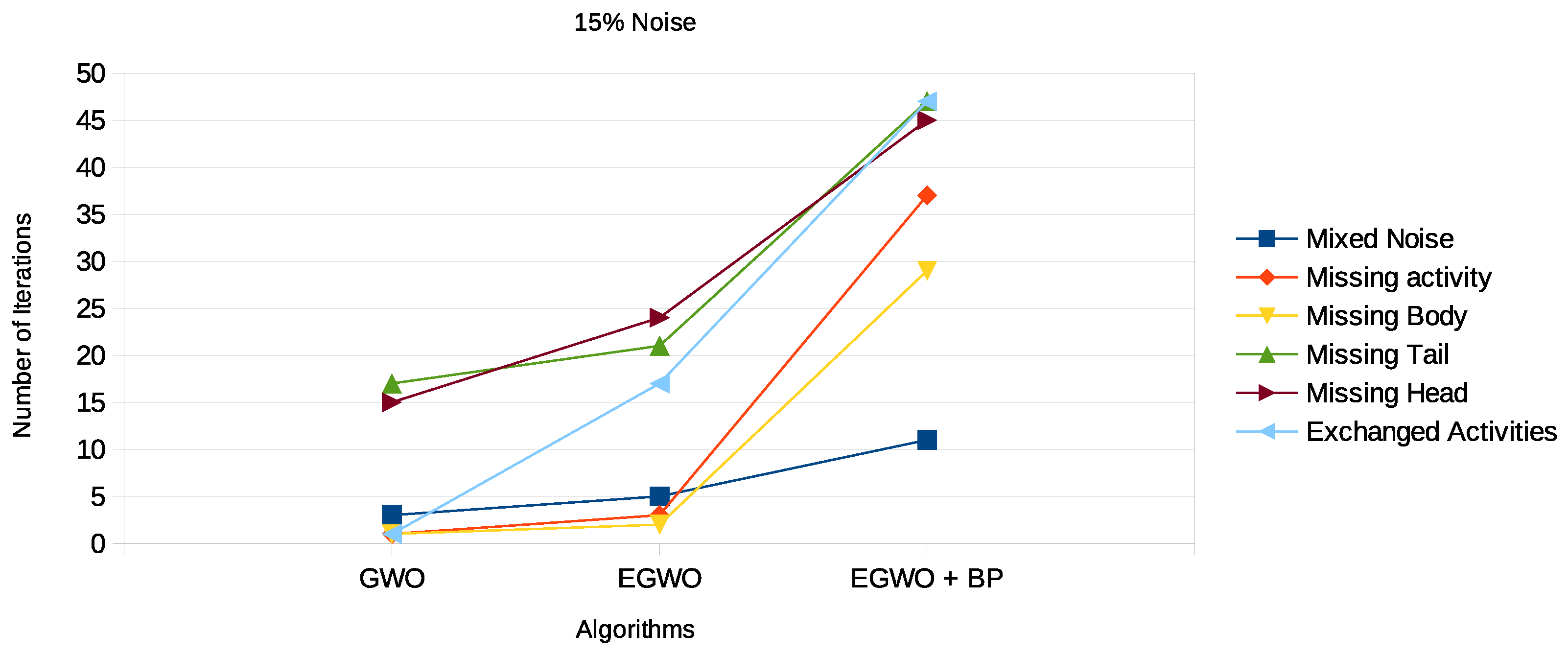
“Noise” in the log is defined as infrequent and improper behavior. Some activities in an event trace in a log may be missing a tail, head, or body; be exchanged with other activities; or be missing entirely. There may also be a mixture of all the noise types. In any case, noise might be a problem that prevents a process model from being discovered accurately. As it is similar to other low-frequency appropriate behavior in the log, noisy behavior is tough to spot. However, our approach to parsing activities makes noise easily detectable by the various algorithms. With the introduction of noise into the logs, the results for the mixed noise type in
Table 6,
Table 7 and
Table 8 and
Figure 13,
Figure 14 and
Figure 15, respectively, show that the proposed algorithm indeed works for noisy logs as well.
Again, we see that the smaller the net, the more frequently the GWO algorithm finds the correct process model. The higher the noise percentage, the lower the probability the GWO algorithm will end up with the original process model. However, the EGWO is more robust to noise than just the GWO as the percentage of noise increases. The best of them all is the combination of the enhanced GWO with backpropagation (EGWO + BP); it has the highest noise tolerance level. The use of backpropagation helps the algorithm achieve better process models by comparing the desired output model to the achieved model outputs. The models are tuned by adjusting weights to narrow the difference between the two as much as possible. It also updates the weights backward, from output to input. It does not have any parameters to tune except for the number of inputs, as seen in
Figure 13,
Figure 14 and
Figure 15. We can make the following observations by looking at the results for the different noise types. The enhanced gray wolf with backpropagation (EGWO + BP) algorithm for process mining can handle the exchanged activities noise type well. It has less impact on the algorithm’s performance than the missing body and missing activity noise types due to the random generation of the initial population. Additionally, it can handle the missing tail noise type better than the other two.
The missing head noise is the most significant, since process models cannot be completed successfully without the head. When tested on this particular noise, the GWO and its improved variant again underperformed. However, when EGWO was combined with backpropagation, the performance increased significantly. The algorithm’s capacity to both globally and locally search accounts for this behavior. We also evaluated our proposed method on real-life event logs; see the following section.
6.1. Evaluation
To conduct our evaluation, we selected Road Traffic Fine Management (RTFM) [
41] real-life event logs publicly available in the 4TU.ResearchData repository. It has 11 activities and describes all the control-flow processes exhibited by any complete event log. A workflow log usually records the actual implementation process of the workflow model, and the log is usually made up of the workflow instance names “Case_id”, “Activity_name”, “Resource”, and “Timestamp”, etc. Among these, “Case_id” is used to identify the execution times of one workflow, such as case l or case 2; “Activity_name” is used to identify a specific activity of the workflow process, such as a1 or a2; “Resource” and “Timestamp” are used to represent the specific actors and execution time of the activity. We focus on the activity names. Due to the input errors that might occur, there may be missing records, duplicate records, and other reasons which may cause the workflow logs to be incomplete. For incomplete logs, we filtered them by removing an instance if its end event does not belong to the set of traces and if a task only has the end event without a corresponding start event or the start event without a corresponding end event for our analysis.
The activity names used in describing the various processes are as follows: (A) create fine; (B) receive result from prefecture; (C) insert date appeal to prefecture (D) send appeal to prefecture; (E) notify result appeal to offender; (F) appeal to judge; (G) send fine; (H) insert fine notification; (I) add penalty; (J) payment; (K) send for credit collection. In the above description, the uppercase letters A–K represent each activity name. According to the description, the flow control of activities in the event log [
41] is depicted in the Petri net shown in
Figure 16 using the traditional direct flows approach.
Our work used the semantics of the textual attributes to construct a process model reflecting direct follows, loops, and concurrency in a Petri net. All events have an event label (concept: name) specified using attributes from the XES standard [
42]. We used the following steps to compute the semantic relatedness between these attribute names. Step 1. An event log L consists of several traces T; in each trace, several activities are arranged in an orderly manner via its timestamp attribute. We identify the activity names of each trace. Given an activity name in a trace, we tokenize each activity name which splits the textual attribute value into lowercase tokens based on white space and omit any numeric ones or stop words. For example, using Buijs and Joos’ [
43] real-life event log, given s1 = “Confirmation of receipt”, s2 = “T02 Check confirmation of receipt”, s3 = “T04 Determine confirmation of receipt”, s4 = “T05 Print and send confirmation of receipt”, s5 = “T06 Determine necessity of stop advice”, and s6 = “T10 Determine necessity to stop indication”, we obtain: tokenize (s1) = [Confirmation, of, receipt], tokenize (s2) = [Check, Confirmation, of, receipt ] and tokenize (s3) = [Determine, Confirmation, of, receipt], s4 = [Print, and, send, Confirmation, of, receipt], s5 = [Determine, necessity, of, stop, advice], and s6 = [Determine, necessity, to, stop, indication].
Finally, the start and end activities are extracted from the list of activity names. The start activity is used as the hypernym with the assumption that, for each trace, the ordering of the activities from its first activity to the last activity are in a hypernym and hyponymy relations. This enables us to calculate their similarity based on their word sense. For instance, case 1 in BPIC [
41] has the following activities: <CREATE FINE, RECEIVE RESULT APPEAL FROM PREFECTURE, SEND FINE, INSERT FINE NOTIFICATION, ADD PENALTY, PAYMENT, SEND FOR CREDIT COLLECTION∼
.
Using Algorithm 1 to extract the start and end activities, CREATE FINE (start activity) and SEND FOR CREDIT COLLECTION (end activity), the remaining activities are assumed to be in a hypernym and hyponymy relation with the start activity. This assumption is made based on the fact that every event log describes a particular event type in an enterprise system. For instance, de Leoni et al. [
41] described a real-life event log for an information system managing road traffic fines. Thus, we assume that process names used in such systems describe textual events related to road traffic and fines. Additionally, the event log WABO [
43] contains records of the execution of the receiving phase of the building permit application process in an anonymous municipality. All textual descriptions of the process are expected to be related to receiving some form of a receipt.
Step 2 After identifying the start and end activities, we construct the subsume tree described in
Section 4.1. The subsume tree is created based on ordering the activities from the root node. For example, take CREATE FINE. The activity following it is the next activity on the subsume tree. After constructing the tree, the information content of each activity name is calculated and based on the information content of their least common subsume value. A fuzzy causal matrix is generated. This is achieved by calculating the semantics of each phrase making up the name of an activity. For instance, we tokenize each activity name, remove all stop words, and create a set containing keywords of both activity names under comparison. These keywords are converted to vectors, and their similarity is calculated based on their semantics.
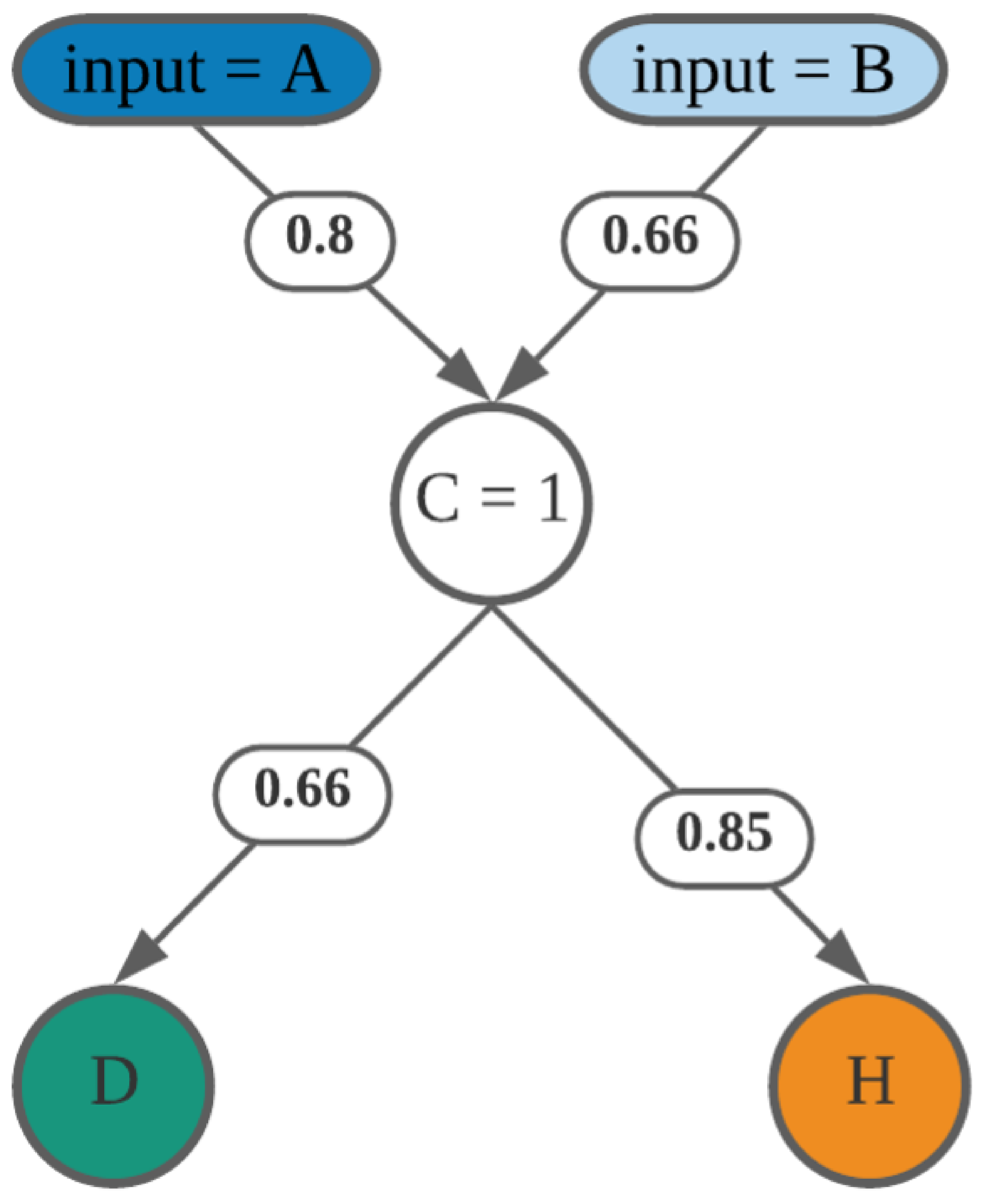
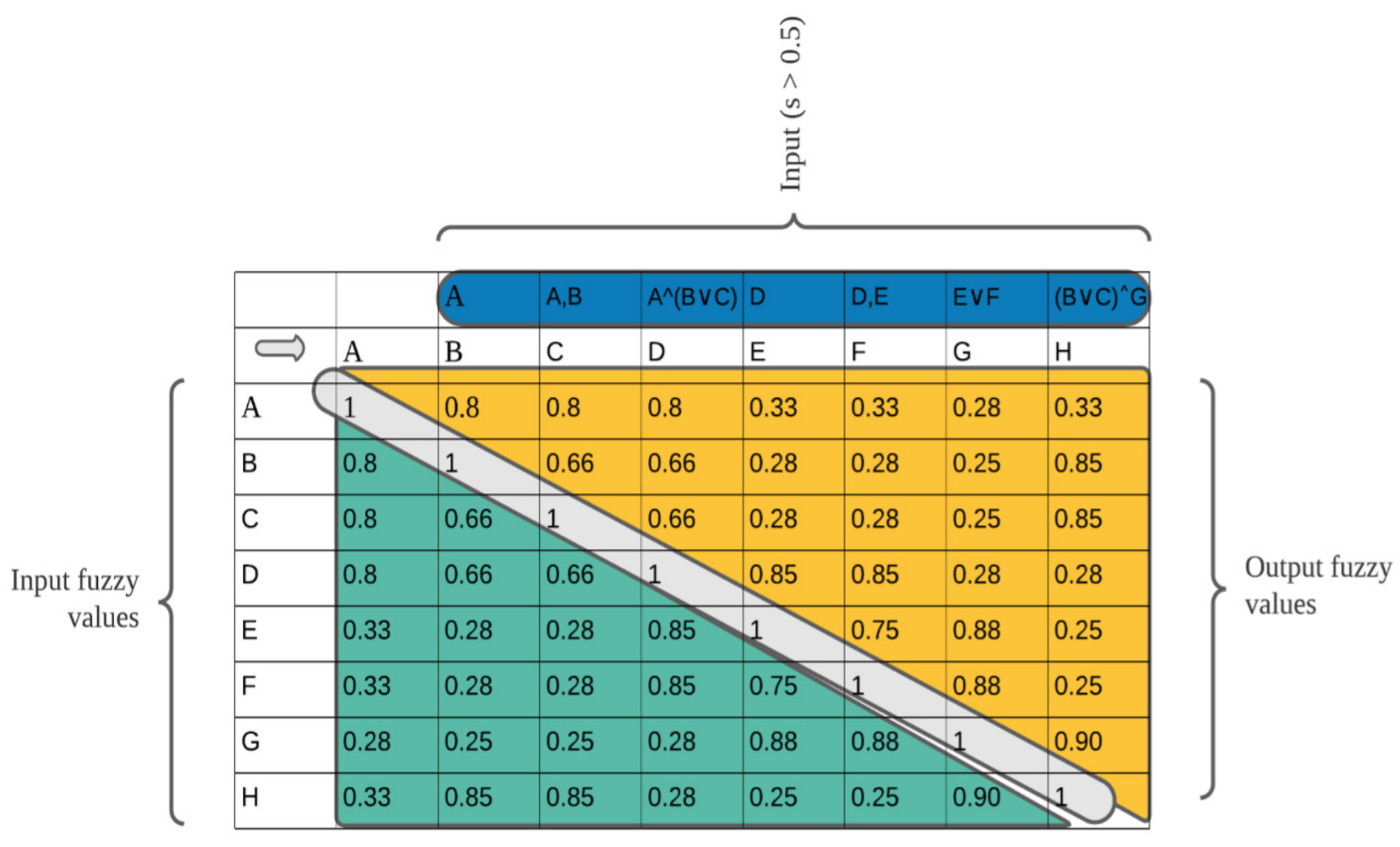
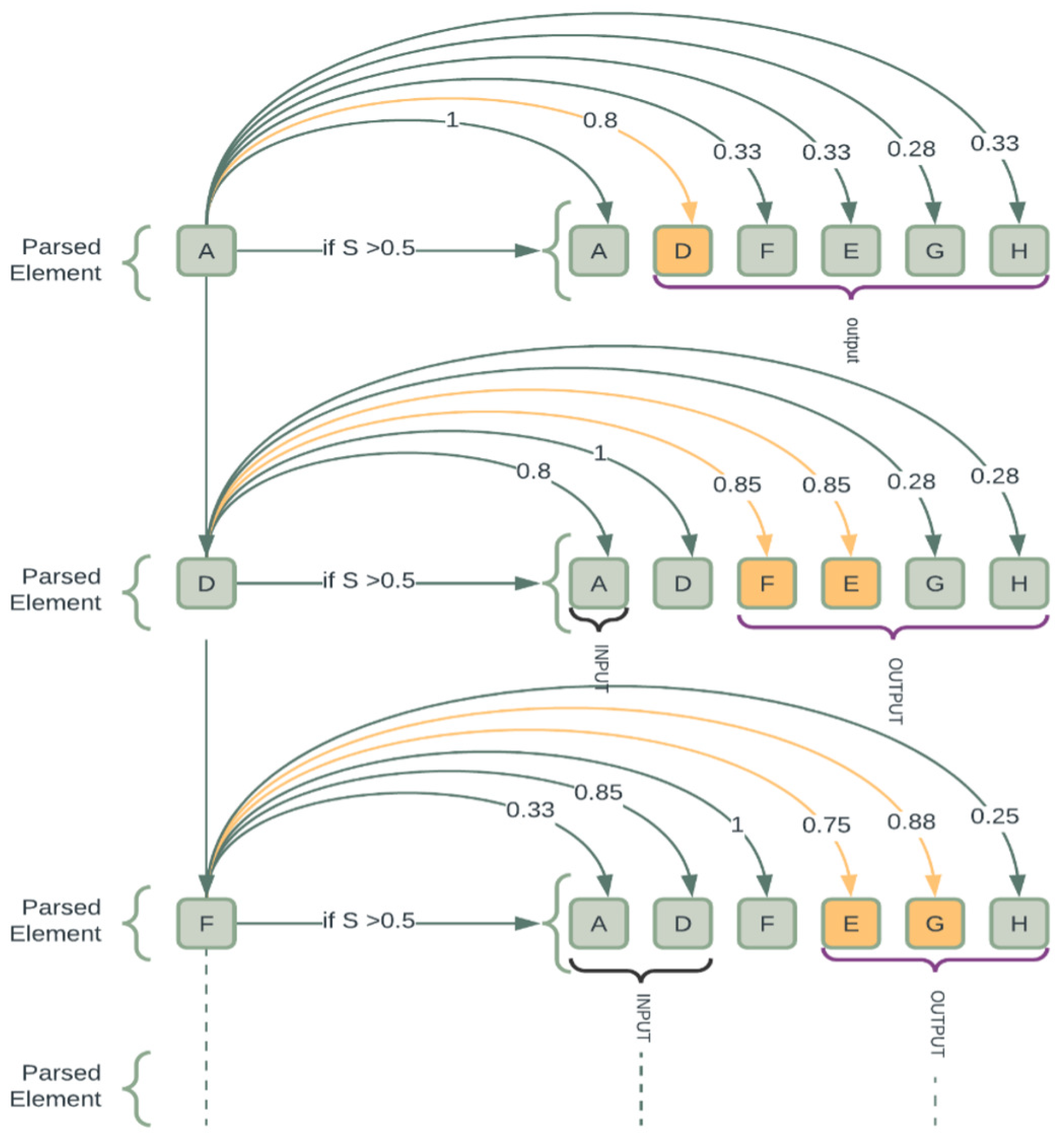
Each activity’s pair similarity values are calculated. Those activities with higher semantic value are considered to have a relation, as indicated in
Table 2. For activity A in
Table 2, activities
have higher values of relatedness than 0.5, and as such, share a relation with A. Activities with the same semantic value are in a choice relation with activities A, B, and C, and have the same similarity value with A. If two activities have different similarity values greater than 0.5 with another activity, those activities can be executed concurrently (see activities F and G in
Table 9). If there is only one activity with semantic value greater than 0.5, those activities are in a sequential relation (see activities I and J in
Table 9).
The log has 1424 instances. As for space, we selected 37 from it, as seen in
Table 10 and then reconstructed the workflow net in terms of Petri based on our methodology. The event log has 11 activities. Note that the activities’ names are being represented as
.
Table 10 illustrates the workflow log generated by our method by selecting a similarity threshold of 0.5 to get more information content but also to eliminate rare event occurrences. According to the semantic relationship matrix generated, the reconstructed process model of the event log is shown in
Figure 17.
After creating the process model using the methodology we suggested, we discovered that activities A and G were not carried out in a synchronous relationship in the predefined process model in
Figure 16. A was in a sequence relationship with H and I. Further research into the business process revealed that, in reality, there is a clear causal relationship between activities A and G. The two tasks being carried out in sync did alter the outcomes of the tasks done and could increase the effectiveness of the process execution. Therefore, in this regard, the method of event activity parsing we have suggested for use in process mining satisfies the requirements for a process discovery algorithm’s actual implementation. We have compared our proposed method with existing state-of-the-art algorithms in
Section 6.1.
6.2. Comparative Analysis
Process discovery aims to understand how the events reported in the event log have transpired. Process discovery becomes an intrinsically descriptive process. It is, therefore, reasonable to compare the learned process models on the same sequence from which the process models are learned to assess the correctness of the found process model. Several authors have used the training-log-based assessment technique [
17,
44] in the literature for comparison techniques. We employed such a metric to draw comparisons with other process discovery methods. As indicated in
Table 11, we employed 24 benchmark process models and introduced noise using the ProM6.1 framework’s AddNoiseFilter plugin.
Six forms of artificial noise have been published in the literature [
17,
45], as detailed in
Section 6 when comparing the performances of the algorithms employed in our suggested technique.
Our suggested solution was not implemented in the ProM framework; we developed it in Python using the Pm4Py package as a comparison. For the sake of brevity, we mixed all possible noise types in our tests. We implemented 10% and 5% noise levels. To make a fair comparison, we used Equations (34)–(42) to compute each log’s behavioral accuracy and recall and compared our results to those reported in the literature.
Results from the 24 related event logs that correlate with the found process models are summarized in
Table 11. Unlike the formal techniques of
and
and the genetic miner, known to overfit the noise in event logs, heuristics miners are immune to noise. Multiple trials revealed that the
implementation always failed to yield results. As for these missing values, all the metrics were given a score of 0.00. In addition, the genetic mining method creates 11 instances of erroneous outputs due to the state space analysis needed to calculate the behavioral appropriateness metric.
As can be seen in
Table 12, the algorithm with the highest average score across all noise levels for the parsing measure (PM), fitness (f), advanced behavioral appropriateness (
), accuracy (Acc), behavioral recall (
), behavioral precision (
), and accuracy of behavioral recall and precision metrics (
) is bold faced. It is shown that our suggested technique produces accurate results that are resilient and not substantially different from the results produced by heuristics miners for all noise levels. Our suggested approach can detect more sophisticated process structures, such as duplicate and invisible activities, since it does not see events in the log as syntactic labels. Instead, it uses the semantics underlying those labels to develop a process model.
Our approach’s resistance to noise stems from the fact that we use semantics to disentangle event activities. If a train ticketing system keeps an event log, for instance, all of its procedures should include relevant information in the context of railway ticketing; otherwise, an activity with the information content of a supermarket might be regarded as noise. To compare our proposed model comprehensively in the future with the current approaches, we intend to develop it as a ProM plugin to compute the fitness of mined process models through compliance testing. Despite this, our suggested method has shown more potential in dealing with noise, which is inescapable in any event log.
7. Conclusions
Everyday transactions are made on several enterprise systems. These transactional changes leave traces, which are recorded as event logs from which insights into these systems’ operations and execution can be realized. Unfortunately, sometimes, these transactions deviate from the predefined organizational workflow structure due to noise. Therefore, management and process mining practitioners may want to reconstruct this workflow according to the actual situation to mitigate all shortcomings, and if there are any, to seek redress. To overcome the limitation of the existing process mining algorithms, this paper presented a new approach to parsing activities in an event log for process mining using the information content of the least common subsume of event log attributes. This approach was subsequently used in designing an enhanced gray wolf optimizer with backpropagation to mine process models.
After introducing process mining and its practical relevance, we described the parsing process of activities and presented the gray wolf and backpropagation algorithms. Using an enhanced gray wolf optimizer with backpropagation for an event log containing noise provides a promising perspective for process mining. After introducing a new framework for representing processes (the fuzzy causal matrix), we went into the specifics of three algorithms: the gray wolf optimizer, the Levy flight, and backpropagation. These algorithms’ fitness metrics depend on successfully parsing the activities in the event log. However, fitness parsing semantics are stopped when the gray wolf optimizer becomes trapped in the local optimum. Then, for improved results, Levy flight is included to redistribute the individuals stochastically in the search space. However, modifying the GWO with the Levy flight did not offer so much; hence, we introduced a backpropagation algorithm to guide the search to the local space due to its strong local search ability to give a good fitness measure. In the experimental section, we provided the enhanced grey wolf optimizer with backpropagation algorithm for process mining from event logs with and without noise. The performance variations among the gray wolf optimizer (GWO), the enhanced gray wolf optimizer with levy flight (EGWO), and the enhanced gray wolf optimizer with backpropagation (EGWO + BP) were the subjects of our study.
The key finding is that the performance of EGWO + BP, with the best fitness measure, appears to be superior for both noise-free and noisy event logs. We examined the performance behavior of the EGWO + BP for various noise types, including missing head, a missing body, missing tail, missing activity, exchanged activities, and mixed noise. We found that the missing-body and missing-activity noise types present unique mining challenges because they frequently introduce unnecessary connections into the process model. Though the EGWO + BP has shown high tolerance to missing body and missing activity noise types, it could still be enhanced to improve the noise tolerance level, especially for those two noisy types. Furthermore, the workflow instances may diverge from those in the preset models due to the company’s changing internal and external environments; therefore, modelers must reconstruct the model per the actual scenario. This article developed a new method of parsing event activities by using the information content of their least common subsume values to automatically deduce the actual structure of the relationship between activities and thus implement workflow reconstruction. An actual simulated case study demonstrated the method’s viability and applicability. To strengthen and extend the method’s mining capability, follow-up studies will concentrate on how to automatically derive sub-processes and mine other attributes, such as the relationship between resources in an event log. The proposed algorithm mines process models that are robust to noisy logs and can be used by process modelers to gain insight into their systems. The next step of this project is to turn the suggested approach into a ProM6 plugin. This will give process miners more choices when doing process analysis.


 ,
, 





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}