
End-to-End Underwater Acoustic Communication Based on Autoencoder with Dense Convolution


Abstract
1. Introduction
2. FBMC System Model
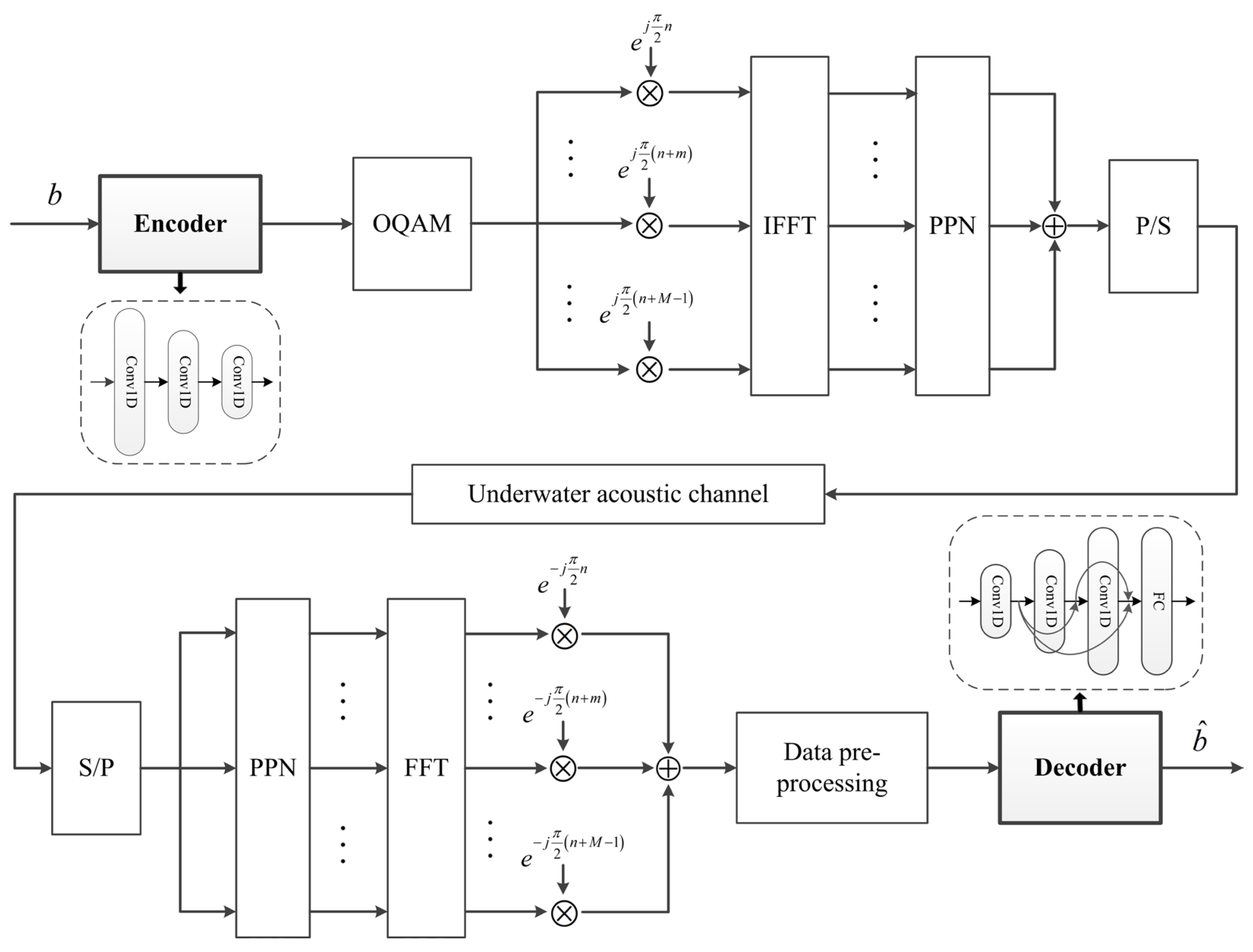
3. Dense-Convolutional-Autoencoder-Based UWA FBMC Communications System
3.1. Network Structure
3.2. System Model
4. Simulation Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Li, B.S.; Zhou, S.L.; Milica, S.; Lee, F.; Willett, P. Multicarrier Communication Over Underwater Acoustic Channels with Nonuniform Doppler Shifts. IEEE J. Ocean. Eng. 2008, 33, 198–209. [Google Scholar]
- Song, H. An Overview of Underwater Time-Reversal Communication. IEEE J. Ocean. Eng. 2015, 41, 644–655. [Google Scholar] [CrossRef]
- Ma, Y.L.; Zhang, Q.F.; Wang, H.L. 6G: Ubiquitously Extending to the Vast Underwater World of the Oceans. Engineering 2022, 8, 12–17. [Google Scholar] [CrossRef]
- Amini, P.; Chen, R.R.; Farhang-Boroujeny, B. Filterbank multicarrier communications for underwater acoustic channels. IEEE J. Ocean. Eng. 2015, 40, 115–130. [Google Scholar] [CrossRef]
- Jamal, H.; Matolak, D.W. Dual-Polarization FBMC for Improved Performance in Wireless Communication Systems. IEEE Trans. Veh. Technol. 2019, 68, 349–358. [Google Scholar] [CrossRef]
- Shen, B.; Huang, C.; Xu, W.; Yang, T.; Cui, S. Blind Channel Codes Recognition via Deep Learning. IEEE J. Sel. Areas Commun. 2021, 39, 2421–2433. [Google Scholar] [CrossRef]
- Dehdashtian, S.; Hashemi, M.; Salehkaleybar, S. Deep-Learning-Based Blind Recognition of Channel Code Parameters Over Can-didate Sets Under AWGN and Multi-Path Fading Conditions. IEEE Wirel. Commun. Lett. 2021, 10, 1041–1045. [Google Scholar] [CrossRef]
- Xiao, W.S.; Luo, Z.Q.; Hu, Q. A Review of Research on Signal Modulation Recognition Based on Deep Learning. Electronics 2022, 11, 2764. [Google Scholar] [CrossRef]
- Wang, Y.; Zhang, H.; Sang, Z.L.; Xu, L.W.; Cao, C.H.; Gulliver, T.A. Modulation Classification of Underwater Communication with Deep Learning Network. Comput. Intell. Neurosci. 2019, 2019, 8039632. [Google Scholar] [CrossRef]
- Soltani, M.; Pourahmadi, V.; Mirzaei, A.; Sheikhzadeh, H. Deep Learning-Based Channel Estimation. IEEE Commun. Lett. 2017, 23, 652–655. [Google Scholar] [CrossRef]
- Bai, Q.B.; Wang, J.T.; Zhang, Y.; Song, J. Deep Learning-Based Channel Estimation Algorithm Over Time Selective Fading Channels. IEEE Trans. Cogn. Commun. Netw. 2020, 6, 125–134. [Google Scholar] [CrossRef]
- Abdallah, A.; Celik, A.; Mansour, M.M.; Eltawil, A.M. A Deep Learning-Based Frequency-Selective Channel Estimation for Hybrid mmWave MIMO Systems. IEEE Trans. Wirel. Commun. 2022, 21, 3804–3821. [Google Scholar] [CrossRef]
- Baek, M.S.; Kwak, S.; Jung, J.Y.; Kim, H.M.; Choi, D.J. Implementation Methodologies of Deep Learning-Based Signal Detection for Conventional MIMO Transmitters. IEEE Trans. Broadcast 2019, 65, 636–642. [Google Scholar] [CrossRef]
- Zhu, Y.N.; Wang, B.; Li, J.H.; Zhang, Y.W.; Xie, F.T. Y-Shaped Net-Based Signal Detection for OFDM-IM Systems. IEEE Commun. Lett. 2022, 26, 2661–2664. [Google Scholar] [CrossRef]
- Zhu, Y.N.; Wang, B.; Xie, F.T.; Wu, C.X.; Chao, P. Data-Driven Signal Detection for Underwater Acoustic Filter Bank Multicarrier Communications. Wirel. Commun. Mob. Comput. 2022, 2022, 4943442. [Google Scholar] [CrossRef]
- Ye, H.; Li, G.Y.; Juang, B.H. Power of Deep Learning for Channel Estimation and Signal Detection in OFDM Systems. IEEE Wirel. Commun. Lett. 2017, 7, 114–117. [Google Scholar] [CrossRef]
- Zhang, J.; Cao, Y.; Han, G.Y.; Fu, X.M. Deep Neural Network-based Underwater OFDM Receiver. IET Commun. 2019, 13, 1998–2002. [Google Scholar] [CrossRef]
- Zhu, Y.N.; Wang, B.; Zhang, Y.W.; Li, J.H.; Wu, C.Y. Convolutional neural network based filter bank multicarrier system for underwater acoustic communications. Appl. Acoust. 2021, 177, 107920. [Google Scholar] [CrossRef]
- Dorner, S.; Cammerer, S.; Hoydis, J.; ten Brink, S. Deep Learning Based Communication Over the Air. IEEE J. Sel. Top. Signal Process. 2017, 12, 132–143. [Google Scholar] [CrossRef]
- O’Shea, T.; Hoydis, J. An Introduction to Deep Learning for the Physical Layer. IEEE Trans. Cogn. Commun. Netw. 2017, 3, 563–575. [Google Scholar] [CrossRef]
- Aoudia, F.A.; Hoydis, J. End-to-End Learning for OFDM: From Neural Receivers to Pilotless Communication. IEEE Trans. Wirel. Commun. 2022, 21, 1049–1063. [Google Scholar] [CrossRef]
- Kofidis, E.; Katselis, D.; Rontogiannis, A.; Theodoridis, S. Preamble-based channel estimation in OFDM/OQAM systems: A review. Signal Process 2013, 93, 2038–2054. [Google Scholar] [CrossRef]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Pandey, A.; Wang, D.L. Dense CNN with Self-Attention for Time-Domain Speech Enhancement. IEEE-ACM Trans. Audio Speech Lang. Process. 2021, 29, 1270–1279. [Google Scholar] [CrossRef] [PubMed]
- Bellanger, M. FBMC Physical Layer: A Primer. PHYDYAS EU FP7 Project. 2010. Available online: http://www.ict-phydyas.org (accessed on 17 November 2022).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer Name | Kernel Size | Stride | Input Features Dimension | |
|---|---|---|---|---|
| Encoder | Conv1D + BN | 3 | 1 | |
| Conv1D + BN | 3 | |||
| Conv1D + BN | 2 | 2 | ||
| Untrainable FBMC modulation | ||||
| Decoder | Conv1D + BN | 2 | 2 | |
| Conv1D + BN | 3 | |||
| Conv1D + BN | 3 | |||
| Flatten + FC | - | - | - | |
| Parameter | Setting |
|---|---|
| Sampling rate | 128 kHz |
| Number of subcarriers | 512 |
| Prototype filter | PHYDYAS |
| Bandwidth Carrier frequency | 6.4 kHz 12.8 kHz |
| Constellation mapping | 4 QAM |
| Parameter | Setting |
|---|---|
| Learning rate | |
| Initialization algorithm | He initialization |
| Mini-batch size | 512 |
| Zero padding | Same |
| Early stopping (patience = 5) |
| Conv1D AE | Dense Conv1D AE | ||||
|---|---|---|---|---|---|
| Training | Testing | Training | Testing | ||
| case1 | 1 s 15 ms | 7 ms | 1 s 22 ms | 8 ms | |
| 6 s 15 ms | 3 s 8 ms | 9 s 23 ms | 3 s 8 ms | ||
| case2 | 2 s 38 ms | 1 s 12 ms | 2 s 48 ms | 1 s 14 ms | |
| 21 s 54 ms | 5 s 13 ms | 24 s 3 ms | 6 s 16 ms | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xie, F.; Zhu, Y.; Wang, B.; Wang, W.; Jin, P. End-to-End Underwater Acoustic Communication Based on Autoencoder with Dense Convolution. Electronics 2023, 12, 253. https://doi.org/10.3390/electronics12020253
Xie F, Zhu Y, Wang B, Wang W, Jin P. End-to-End Underwater Acoustic Communication Based on Autoencoder with Dense Convolution. Electronics. 2023; 12(2):253. https://doi.org/10.3390/electronics12020253
Chicago/Turabian StyleXie, Fangtong, Yunan Zhu, Biao Wang, Wu Wang, and Pian Jin. 2023. "End-to-End Underwater Acoustic Communication Based on Autoencoder with Dense Convolution" Electronics 12, no. 2: 253. https://doi.org/10.3390/electronics12020253
APA StyleXie, F., Zhu, Y., Wang, B., Wang, W., & Jin, P. (2023). End-to-End Underwater Acoustic Communication Based on Autoencoder with Dense Convolution. Electronics, 12(2), 253. https://doi.org/10.3390/electronics12020253