
DSA: Deformable Segmentation Attention for Multi-Scale Fisheye Image Segmentation


Abstract
:1. Introduction
- In semantic segmentation of fisheye images, we apply the concept of deformable attention to strike a balance between accuracy and speed. A deformable mechanism that improves local feature extraction and an attention mechanism that improves global nature can improve the capacity to capture nonlinear transformations while retaining performance.
- Thinking about semantic segmentation of fisheye images from the perspective of multiscale segmentation, we propose a DSA module to capture features from multiple scales using a combination of deformable attention and spatial pyramids to improve the model’s ability to segment minor and overlapping categories.
2. Materials and Methods
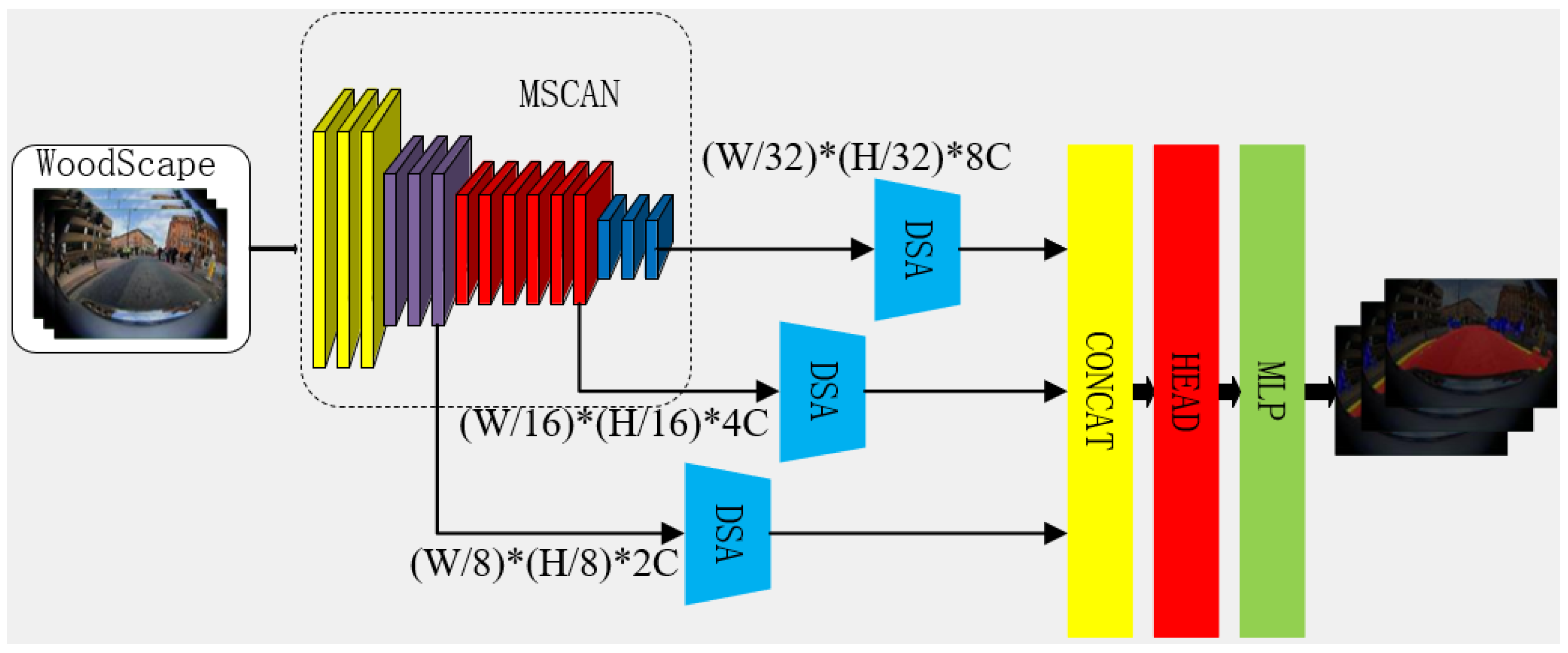
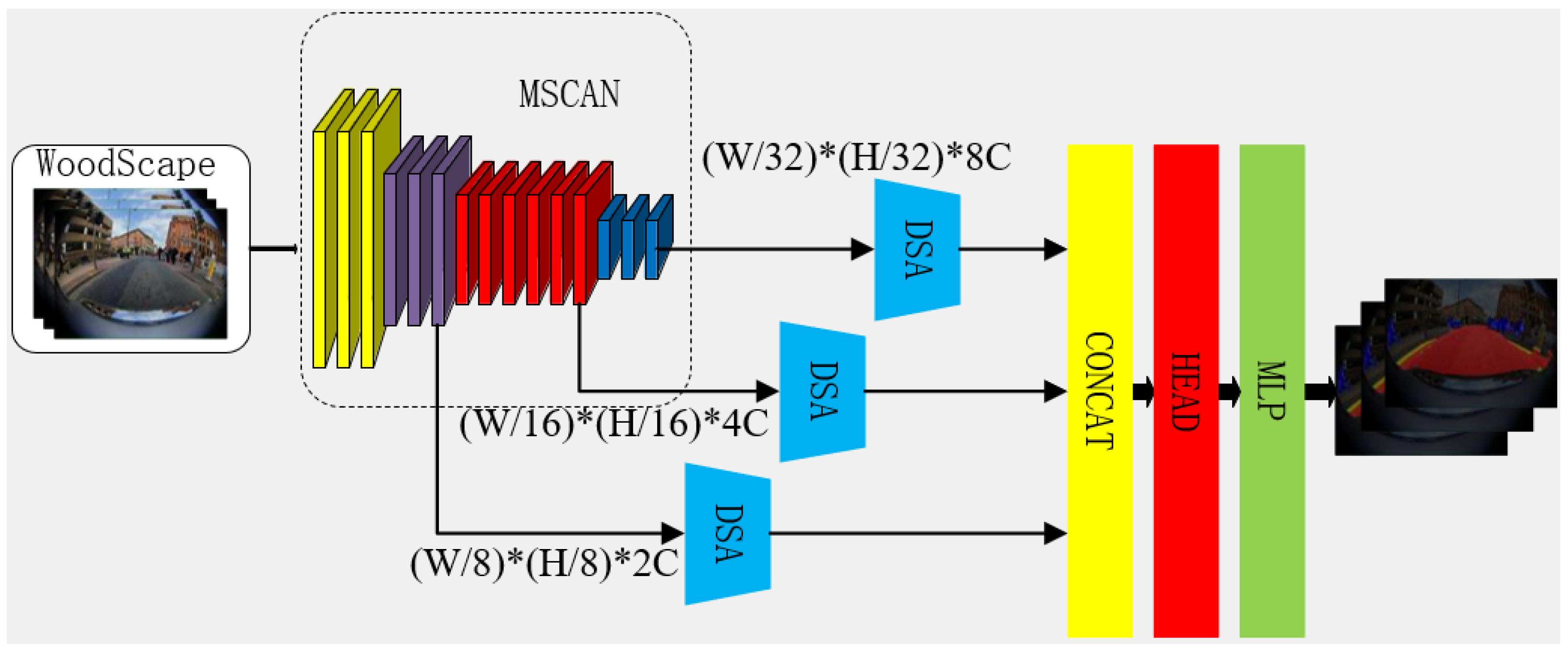
2.1. Recap of MSCAN
2.2. Brief Description of SegNeXt’s Decoder
2.3. Brief Description of Deformable Attention
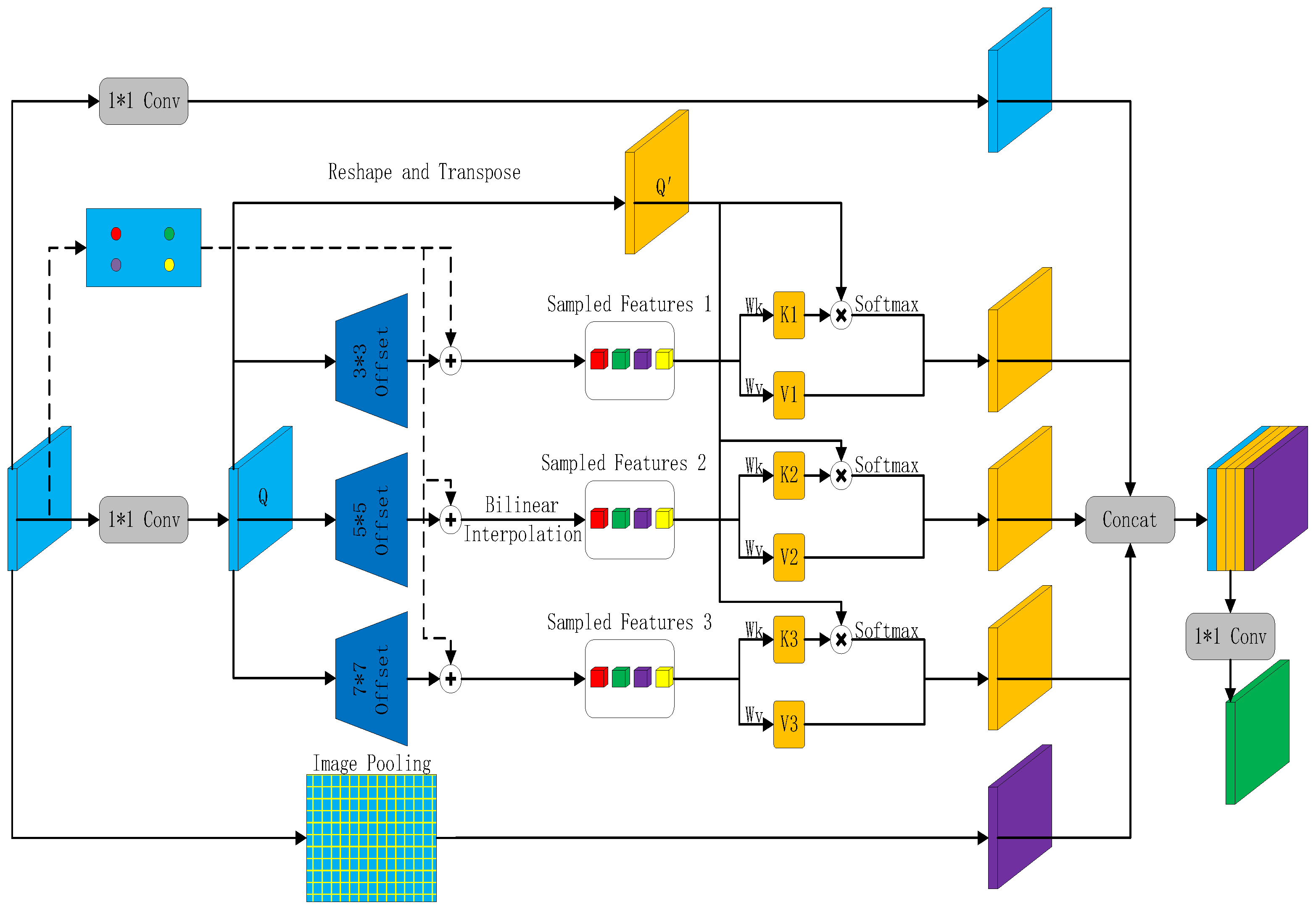
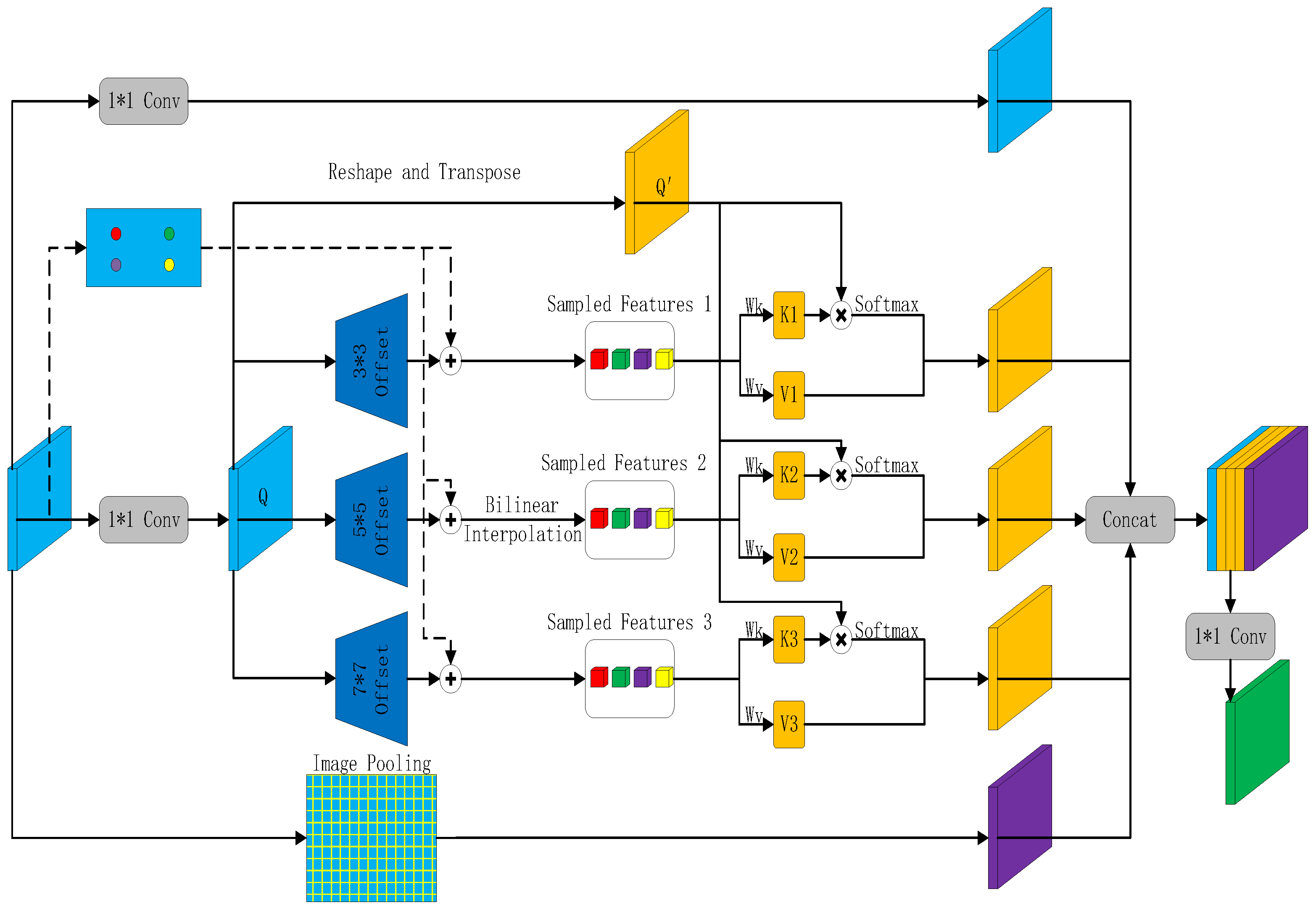
2.4. Deformable Segmentation Attention Module
- (1)
- A 1 × 1 convolutional layer and three deformable attention modules with different degrees of offset (offsets of 3, 5 and 7, respectively).
- (2)
- A global average pooling layer is used to capture the global context information, which is then fed into a 1 × 1 convolution layer to establish the association between pixels and the global distribution region and finally restored to its original size by bilinear interpolation.
- (3)
- The features obtained from the first and second steps are fused together in the channel dimension and then fed into a 1 × 1 convolution to adjust the channel to obtain new features.
3. Experiment
3.1. Dataset and Implementations
3.2. Comparison with State-of-the-Art Methods
3.3. Ablation Studies
Contributions of the Proposed Method
3.4. Choice of K-Values in Deformable Attention Mechanism
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Choi, S.; Kim, J.T.; Choo, J. Cars Can’t Fly Up in the Sky: Improving Urban-Scene Segmentation via Height-Driven Attention Networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 9370–9380. [Google Scholar] [CrossRef]
- Komatsu, R.; Fujii, H.; Tamura, Y.; Yamashita, A.; Asama, H. 360° Depth Estimation from Multiple Fisheye Images with Origami Crown Representation of Icosahedron. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 25–29 October 2020; pp. 10092–10099. [Google Scholar] [CrossRef]
- Li, D.; Ma, N.; Gao, Y. Future vehicles: Learnable wheeled robots. Sci. China Ser. F Inf. Sci. 2020, 63, 193201. [Google Scholar] [CrossRef]
- Yang, Q.; You, L.; Zhao, L. Study of fisheye image correction algorithm based on improved spherical projection model. Chin. J. Electron. Devices 2019, 42, 449–452. [Google Scholar] [CrossRef]
- Ma, H.; Zhu, L.; Zeng, J. Fisheye image distortion correction algorithm based on mapping adaptive convolution and isometric projection. Mod. Comput. 2021, 51–56. [Google Scholar] [CrossRef]
- Deng, L.; Yang, M.; Li, H.; Li, T.; Hu, B.; Wang, C. Restricted Deformable Convolution-Based Road Scene Semantic Segmentation Using Surround View Cameras. IEEE Trans. Intell. Transp. Syst. 2020, 21, 4350–4362. [Google Scholar] [CrossRef]
- Playout, C.; Ahmad, O.; Lecue, F.; Cheriet, F. Adaptable Deformable Convolutions for Semantic Segmentation of Fisheye Images in Autonomous Driving Systems. arXiv 2021, arXiv:2102.10191. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Ramachandran, S.; Sistu, G.; McDonald, J.; Yogamani, S. Woodscape Fisheye Semantic Segmentation for Autonomous Driving—CVPR 2021 OmniCV Workshop Challenge. arXiv 2021, arXiv:2107.08246. [Google Scholar] [CrossRef]
- Cao, H.; Wang, Y.; Chen, J.; Jiang, D.; Zhang, X.; Tian, Q.; Wang, M. Swin-Unet: Unet-Like Pure Transformer for Medical Image Segmentation. In Proceedings of the Computer Vision—ECCV 2022 Workshops, Tel Aviv, Israel, 23–27 October 2022; Karlinsky, L., Michaeli, T., Nishino, K., Eds.; pp. 205–218. [Google Scholar] [CrossRef]
- Yogamani, S.; Hughes, C.; Horgan, J.; Sistu, G.; Chennupati, S.; Uricar, M.; Milz, S.; Simon, M.; Amende, K.; Witt, C.; et al. WoodScape: A Multi-Task, Multi-Camera Fisheye Dataset for Autonomous Driving. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9307–9317. [Google Scholar] [CrossRef]
- Yang, K.; Zhang, J.; Reis, S.; Hu, X.; Stiefelhagen, R. Capturing Omni-Range Context for Omnidirectional Segmentation. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Los Alamitos, CA, USA, 19–25 June 2021; pp. 1376–1386. [Google Scholar] [CrossRef]
- Dai, J.; Qi, H.; Xiong, Y.; Li, Y.; Zhang, G.; Hu, H.; Wei, Y. Deformable Convolutional Networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 764–773. [Google Scholar] [CrossRef]
- Guo, M.H.; Lu, C.Z.; Hou, Q.; Liu, Z.; Cheng, M.M.; Hu, S.M. SegNeXt: Rethinking Convolutional Attention Design for Semantic Segmentation. arXiv 2022, arXiv:2209.08575. [Google Scholar] [CrossRef]
- Wang, J.; Sun, K.; Cheng, T.; Jiang, B.; Deng, C.; Zhao, Y.; Liu, D.; Mu, Y.; Tan, M.; Wang, X.; et al. Deep High-Resolution Representation Learning for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 3349–3364. [Google Scholar] [CrossRef] [PubMed]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.u.; Polosukhin, I. Attention is All you Need. In Proceedings of the Advances in Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Volume 30, pp. 6000–6010. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar] [CrossRef]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers. In Proceedings of the Advances in Neural Information Processing Systems, Online, 6–14 December 2021; Ranzato, M., Beygelzimer, A., Dauphin, Y., Liang, P., Vaughan, J.W., Eds.; Volume 34, pp. 12077–12090. [Google Scholar]
- Geng, Z.; Guo, M.H.; Chen, H.; Li, X.; Wei, K.; Lin, Z. Is Attention Better Than Matrix Decomposition? arXiv 2021, arXiv:2109.04553. [Google Scholar] [CrossRef]
- Chen, Z.; Zhu, Y.; Zhao, C.; Hu, G.; Zeng, W.; Wang, J.; Tang, M. DPT: Deformable Patch-Based Transformer for Visual Recognition. In Proceedings of the 29th ACM International Conference on Multimedia MM ’21, New York, NY, USA, 20–24 October 2021; pp. 2899–2907. [Google Scholar] [CrossRef]
- Xia, Z.; Pan, X.; Song, S.; Li, L.E.; Huang, G. Vision Transformer With Deformable Attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 4794–4803. [Google Scholar]
- Dai, X.; Chen, Y.; Yang, J.; Zhang, P.; Yuan, L.; Zhang, L. Dynamic DETR: End-to-End Object Detection With Dynamic Attention. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 2988–2997. [Google Scholar]
- Ma, N.; Li, D.; He, W.; Deng, Y.; Li, J.; Gao, Y.; Bao, H.; Zhang, H.; Xu, X.; Liu, Y.; et al. Future vehicles: Interactive wheeled robots. Sci. China Inf. Sci. 2021, 64, 208–210. [Google Scholar] [CrossRef]
- Hendrycks, D.; Gimpel, K. Bridging NONLINEARITIES and Stochastic Regularizers with Gaussian Error Linear Units. 2017. Available online: https://openreview.net/forum?id=Bk0MRI5lg (accessed on 24 September 2023).
- Sekkat, A.R.; Dupuis, Y.; Kumar, V.R.; Rashed, H.; Yogamani, S.; Vasseur, P.; Honeine, P. SynWoodScape: Synthetic Surround-View Fisheye Camera Dataset for Autonomous Driving. IEEE Robot. Autom. Lett. 2022, 7, 8502–8509. [Google Scholar] [CrossRef]
- Bjorck, J.; Weinberger, K.; Gomes, C. Understanding Decoupled and Early Weight Decay. arXiv 2020, arXiv:2012.13841. [Google Scholar] [CrossRef]
- Sekkat, A.R.; Dupuis, Y.; Honeine, P.; Vasseur, P. A comparative study of semantic segmentation of omnidirectional images from a motorcycle perspective. Sci. Rep. 2022, 12, 4968. [Google Scholar] [CrossRef] [PubMed]
- Romera, E.; Álvarez, J.M.; Bergasa, L.M.; Arroyo, R. ERFNet: Efficient Residual Factorized ConvNet for Real-Time Semantic Segmentation. IEEE Trans. Intell. Transp. Syst. 2018, 19, 263–272. [Google Scholar] [CrossRef]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6230–6239. [Google Scholar] [CrossRef]
- Pohlen, T.; Hermans, A.; Mathias, M.; Leibe, B. Full-Resolution Residual Networks for Semantic Segmentation in Street Scenes. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3309–3318. [Google Scholar] [CrossRef]
- Jegou, S.; Drozdzal, M.; Vazquez, D.; Romero, A.; Bengio, Y. The One Hundred Layers Tiramisu: Fully Convolutional DenseNets for Semantic Segmentation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Los Alamitos, CA, USA, 21–26 July 2017; pp. 1175–1183. [Google Scholar] [CrossRef]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the Computer Vision—ECCV 2018: 15th European Conference, Munich, Germany, 8–14 September 2018; pp. 833–851. [Google Scholar] [CrossRef]
- Zhang, E.; Xie, R.; Bian, Y.; Wang, J.; Tao, P.; Zhang, H.; Jiang, S. Cervical cell nuclei segmentation based on GC-UNet. Heliyon 2023, 9, e17647. [Google Scholar] [CrossRef] [PubMed]
- Jiang, S.; Cui, R.; Wei, R.; Fu, Z.; Hong, Z.; Feng, G. Tracking by segmentation with future motion estimation applied to person-following robots. Front. Neurorobot. 2023, 17, 1255085. [Google Scholar] [CrossRef] [PubMed]
- Jiang, S.; Hong, Z. Unexpected Dynamic Obstacle Monocular Detection in the Driver View. IEEE Intell. Transp. Syst. Mag. 2023, 15, 68–81. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
| Method | FPS | Quantity | |
|---|---|---|---|
| MAP (%) | MIoU (%) | ||
| ERFNet | 33.33 | - | 43.3 |
| PSPnet | - | 67.00 | 50.00 |
| Swin-Unet(L) | 0.82 | - | 44.03 |
| ECANet | - | - | 60.2 |
| FRRN | 2.86 | 73.11 | 22.18 |
| FC-DenseNet103 | 1.26 | 67.5 | 31.67 |
| DeepLabv3+ | 9.71 | 73.22 | 60.69 |
| DeepLabv3+&DSA(ours) | 9.17 | 74.52 | 61.44 |
| SegNeXt | 9.18 | 73.6 | 64.11 |
| SegNeXt-HSA | 8.93 | 72.62 | 63.0 |
| SegNeXt-DSA(ours) | 8 | 74.5 | 65.33 |
| Class | DeepLabv3 Plus | SegNeXt | SegNeXt-DSA |
|---|---|---|---|
| Background | 96.46 | 96.93 | 97.07 |
| Road | 92.22 | 93.04 | 92.94 |
| Lanemarks | 65.18 | 66.44 | 66.77 |
| Curb | 51.28 | 49.88 | 50.63 |
| Person | 53.12 | 63.41 | 61.38 |
| Rider | 44.55 | 51.51 | 52.91 |
| Vehicles | 77.45 | 81.54 | 82.28 |
| Bicycle | 45.87 | 47.13 | 51.78 |
| Motorcycle | 47.49 | 50.04 | 53.16 |
| Traffic_sign | 40.76 | 42.98 | 44.35 |
| Method | MAP (%) | MIoU (%) |
|---|---|---|
| SegNeXt | 73.6 | 64.11 |
| SegNeXt-DAT | 72.4 | 63.59 |
| SegNeXt-ASPP | 73.34 | 64.61 |
| SegNeXt-DSA | 74.5 | 65.33 |
| Category | [3, 5, 7] | [3, 7, 9] | [3, 5, 9] | [5, 7, 9] |
|---|---|---|---|---|
| Background | 97.07 | 96.84 | 96.94 | 96.90 |
| Road | 92.94 | 92.41 | 92.64 | 92.54 |
| Lanemarks | 66.77 | 66.22 | 66.46 | 66.51 |
| Curb | 50.63 | 49.84 | 49.86 | 49.98 |
| Person | 61.38 | 61.43 | 61.70 | 61.68 |
| Rider | 52.91 | 52.40 | 53.06 | 52.75 |
| Vehicles | 82.28 | 81.97 | 82.02 | 82.03 |
| Bicycle | 51.78 | 51.25 | 50.60 | 51.07 |
| Motorcycle | 53.16 | 53.82 | 54.09 | 53.99 |
| Traffic_sign | 44.35 | 42.49 | 43.18 | 43.48 |
| Category | [3, 5, 7] | [3, 7, 9] | [3, 5, 9] | [5, 7, 9] |
|---|---|---|---|---|
| Background | 98.86 | 98.8 | 98.87 | 98.79 |
| Road | 96.27 | 95.93 | 95.93 | 96.06 |
| Lanemarks | 74.28 | 73.25 | 74.17 | 74.01 |
| Curb | 63.11 | 62.55 | 61.71 | 62.05 |
| Person | 71.48 | 71.3 | 72.44 | 72.65 |
| Rider | 66.57 | 63.6 | 66.69 | 65.26 |
| Vehicles | 89.62 | 89.42 | 89.56 | 89.46 |
| Bicycle | 66.15 | 65.9 | 63.48 | 65.17 |
| Motorcycle | 65.9 | 65.53 | 67.83 | 66.68 |
| Traffic_sign | 52.83 | 49.59 | 50.37 | 51.36 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, J.; Xu, C.; Liu, H.; Fu, Y.; Jian, M. DSA: Deformable Segmentation Attention for Multi-Scale Fisheye Image Segmentation. Electronics 2023, 12, 4059. https://doi.org/10.3390/electronics12194059
Jiang J, Xu C, Liu H, Fu Y, Jian M. DSA: Deformable Segmentation Attention for Multi-Scale Fisheye Image Segmentation. Electronics. 2023; 12(19):4059. https://doi.org/10.3390/electronics12194059
Chicago/Turabian StyleJiang, Junzhe, Cheng Xu, Hongzhe Liu, Ying Fu, and Muwei Jian. 2023. "DSA: Deformable Segmentation Attention for Multi-Scale Fisheye Image Segmentation" Electronics 12, no. 19: 4059. https://doi.org/10.3390/electronics12194059
APA StyleJiang, J., Xu, C., Liu, H., Fu, Y., & Jian, M. (2023). DSA: Deformable Segmentation Attention for Multi-Scale Fisheye Image Segmentation. Electronics, 12(19), 4059. https://doi.org/10.3390/electronics12194059