

Face Detection Based on DF-Net

Abstract
:1. Introduction
2. Related Work
2.1. Face Detection Method
2.2. Multi-scale Feature Fusion Module
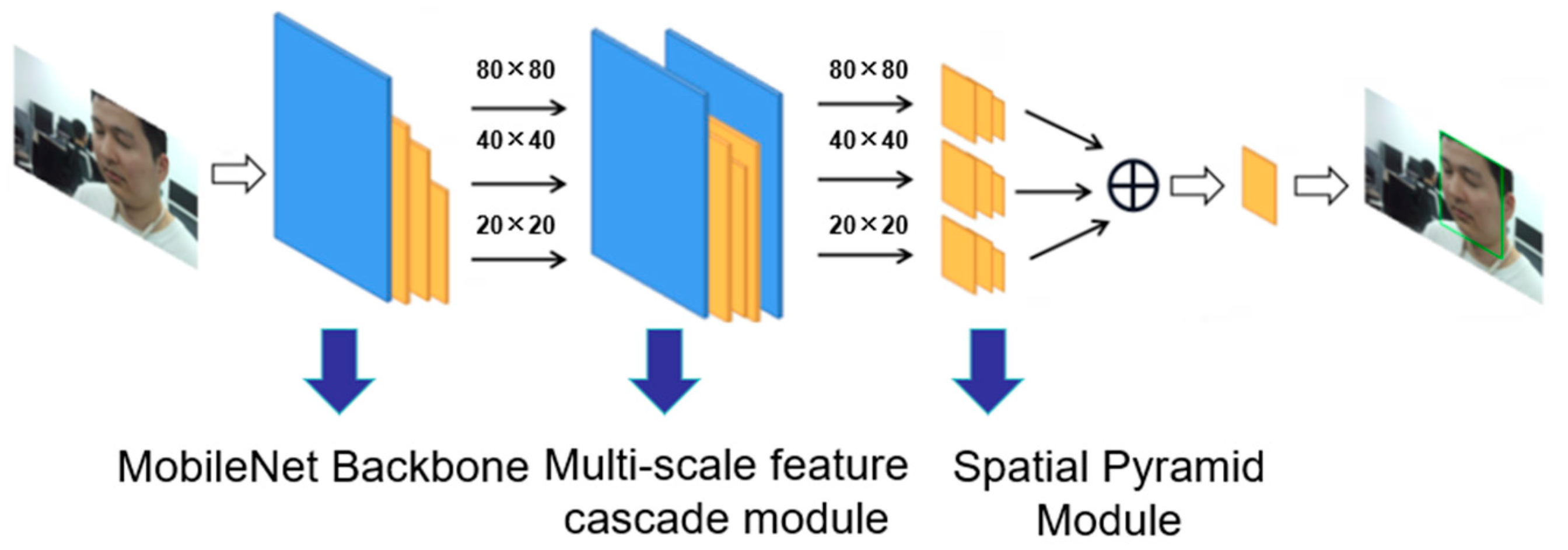
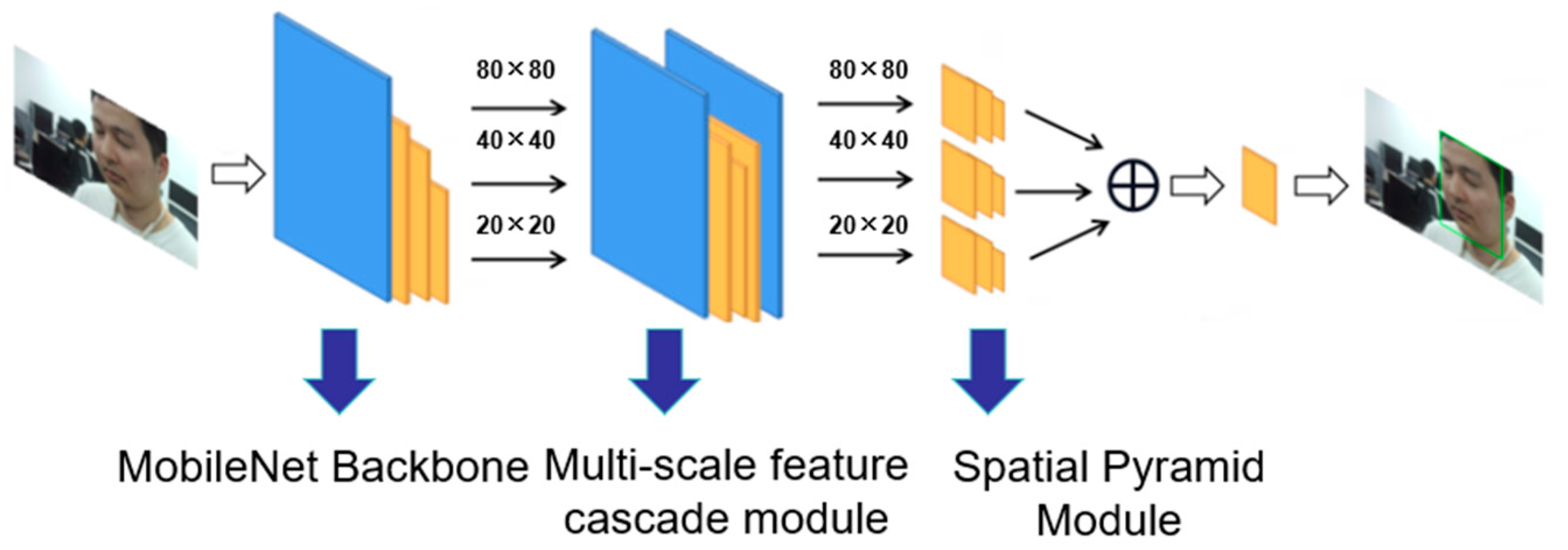
3. DF-Net Network Design
3.1. Backbone Network
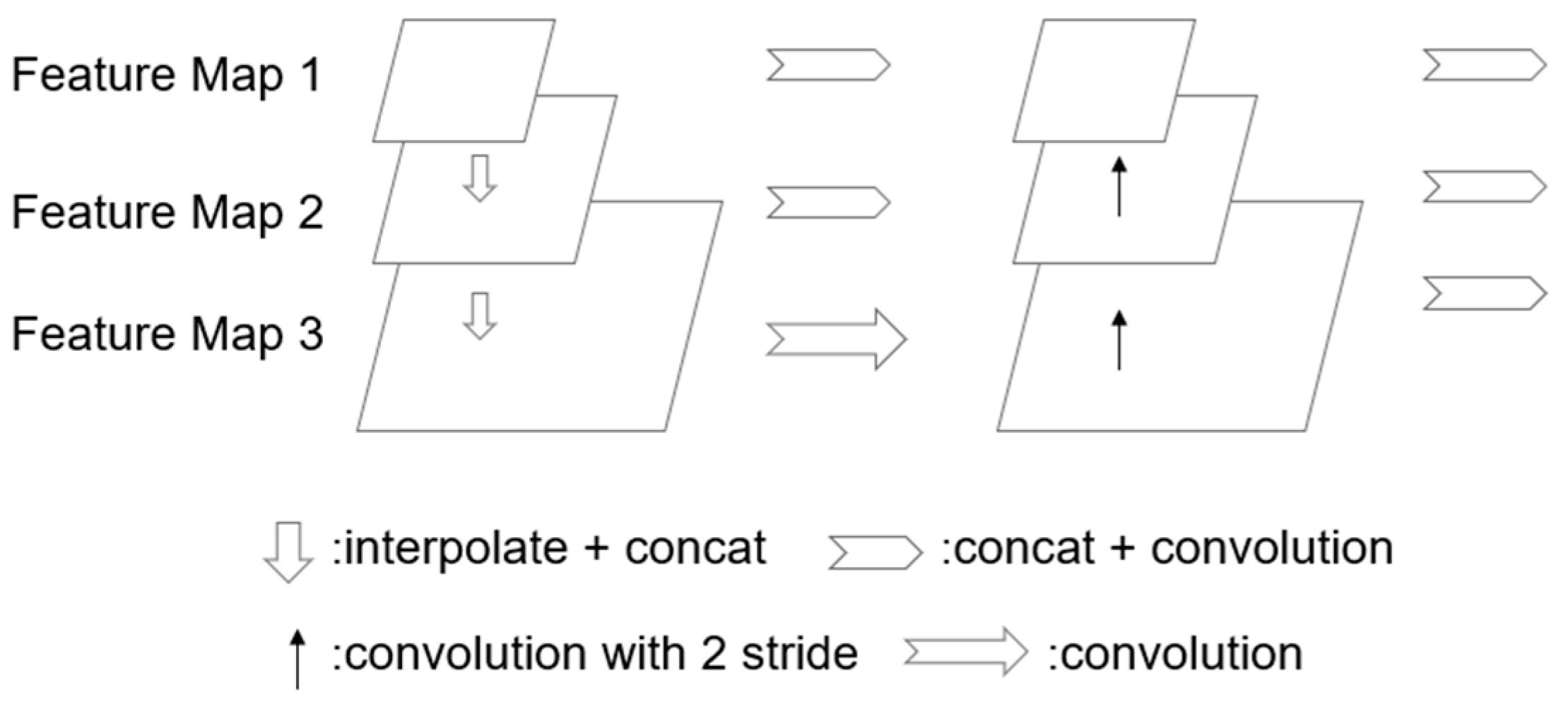
3.2. The Multi-Scale Feature Cascade Module
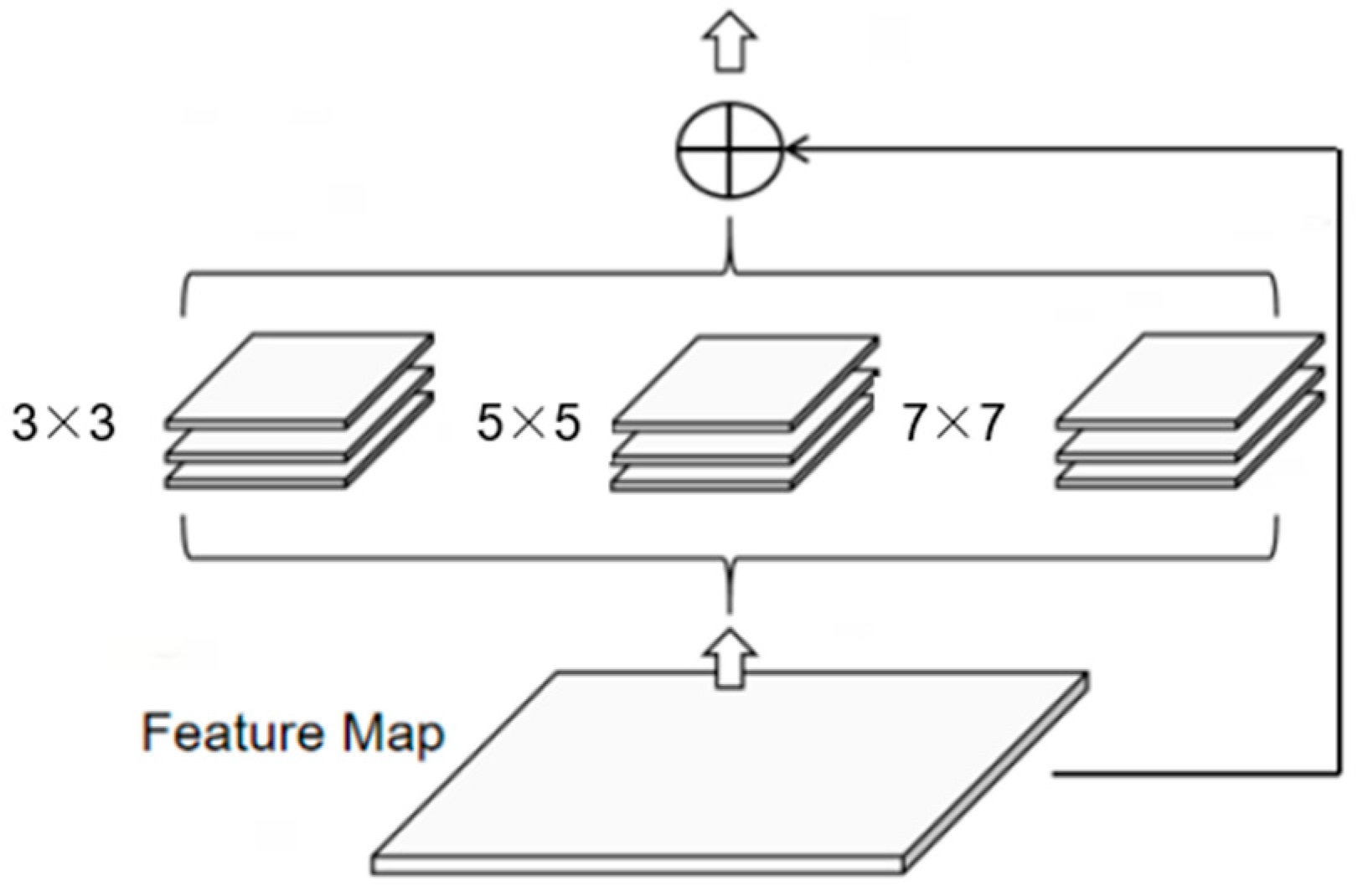
3.3. The Feature Pyramid Module
3.4. Definition of Loss Function
4. Experimental Result and Analysis
4.1. Experimental Environment
4.2. WiderFace Dataset
4.3. Network Training
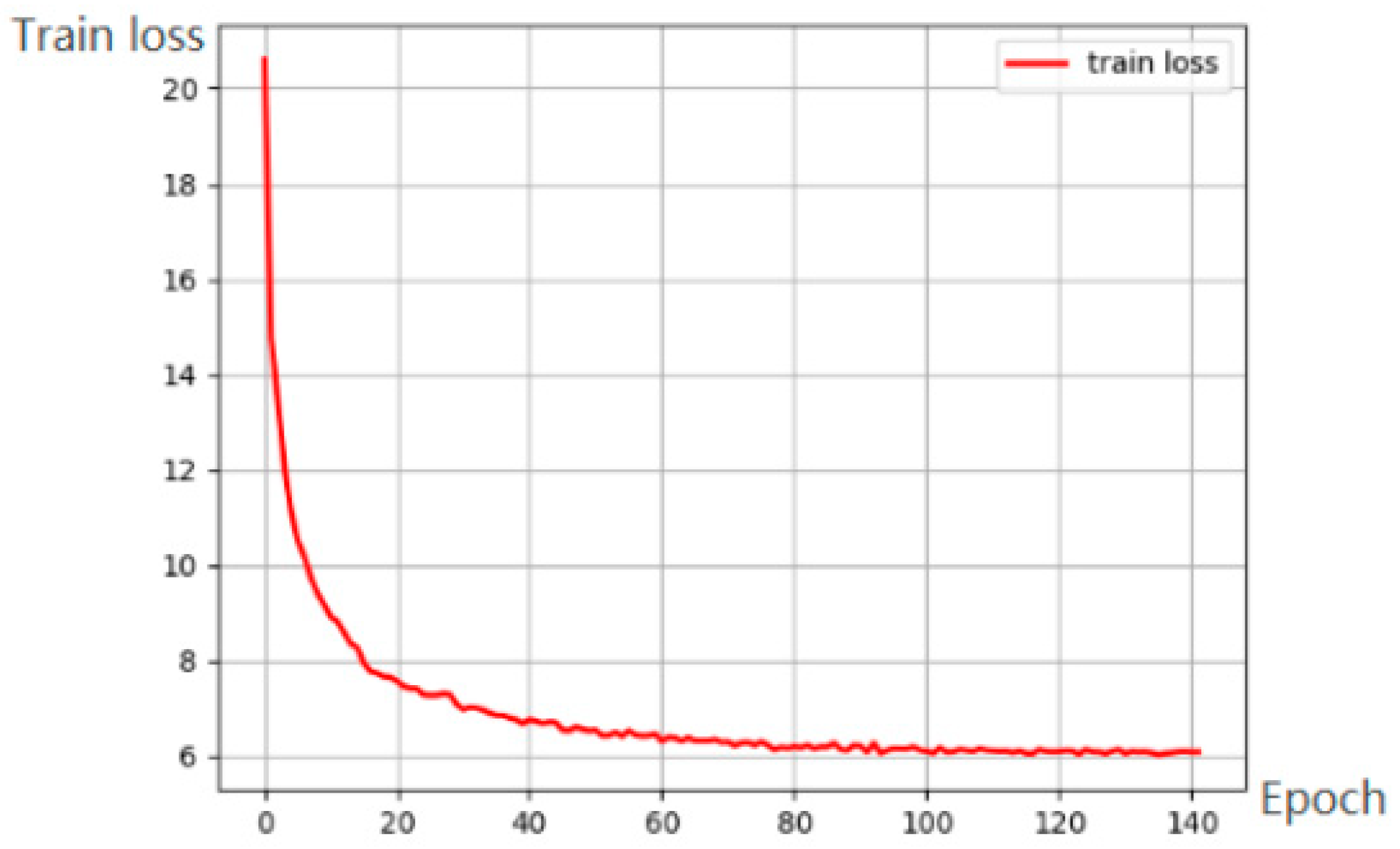
4.4. Results and Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Sun, Y.; Dong, J.; Jian, M. Fast 3D face reconstruction based on uncalibrated photometric stereo. Multimed. Tools Appl. 2015, 74, 3635–3650. [Google Scholar] [CrossRef]
- Roth, J.; Tong, Y.; Liu, X. Adaptive 3D Face Reconstruction from Unconstrained Photo Collections. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2127–2141. [Google Scholar]
- Yang, Y.; Kan, L.; Yu, J. 3D face reconstruction method based on laser scanning. Infrared Laser Eng. 2014, 43, 3946–3950. [Google Scholar]
- Fan, X.; Zhou, C.; Wang, S. 3D human face reconstruction based on band-limited binary patterns. Chin. Opt. Lett. 2016, 14, 81101. [Google Scholar] [CrossRef]
- Sun, N.; Zhou, C.; Zhao, L. A Survey of Face Detection. J. Circuits Syst. 2006, 6, 101–108. [Google Scholar]
- Li, Y.; Xi, Z. Based on the improved RetinaFace face detection method. Appl. Sci. Technol. 2023, 9, 1–7. [Google Scholar]
- Paul, V.; Michael, J. Robust real-time face detection. Int. J. Comput. Vis. 2004, 57, 137–154. [Google Scholar]
- Hinton, G.; Deng, L.; Yu, D. Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups. IEEE Signal Process. Mag. 2012, 29, 82–97. [Google Scholar] [CrossRef]
- Jones, M.; Viola, P. Fast multi-view face detection. Mitsubishi Electr. Res. Lab. 2003, 96, 3–14. [Google Scholar]
- Mathias, M.; Benenson, R.; Pedersoli, M.; Van Gool, L. Face detection without bells and whistles. In Proceedings of the ECCV Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 720–735. [Google Scholar]
- Yan, J.; Lei, Z.; Wen, L. The fastest deformable part model for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition(CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 2497–2504. [Google Scholar]
- Zhu, X.; Ramanan, D. Face detection, pose estimation, and land mark localization in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 2879–2886. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Geoffrey, E.H. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 6, 84–90. [Google Scholar] [CrossRef]
- Gómez-Guzmán, M.A.; Jiménez-Beristaín, L.; García-Guerrero, E.E.; López-Bonilla, O.R.; Tamayo-Perez, U.J.; Esqueda-Elizondo, J.J.; Palomino-Vizcaino, K.; Inzunza-González, E. Classifying Brain Tumors on Magnetic Resonance Imaging by Using Convolutional Neural Networks. Electronics 2023, 12, 955. [Google Scholar] [CrossRef]
- Li, Z.; Tang, X.; Han, J. PyramidBox++ : High performance detector for finding tiny face. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Lei, H.L.; Zhang, B.H. Crowd count algorithm based on multi-model deep convolution network integration. Laser Technol. 2019, 43, 476–481. [Google Scholar]
- Chen, Q.X.; Wu, W.C.; Askar, H. Detection algorithm based on multi-scale spotted target modeling. Laser Technol. 2020, 44, 520–524. [Google Scholar]
- Li, H.; Lin, Z.; Shen, X.; Brandt, J.; Hua, G. A convolutional neural network cascade for face detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 5325–5334. [Google Scholar]
- Li, Y.; Lv, X.; Gu, Y. Face detection algorithm based on improved S3FD network. Laser Technol. 2021, 45, 722–728. [Google Scholar]
- Zhan, K.; Zhang, Z.; Li, Z.; Qiao, Y. Joint Face Detection and Alignment Using Multitask Cascaded Convolutional Networks. IEEE Signal Process. Lett. 2016, 23, 1499–1503. [Google Scholar] [CrossRef]
- Wang, H.; Li, Z.; Ji, X.; Wang, Y. Face R-CNN. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Li, C.; Li, L.; Jiang, H. YOLOv6: A single-stage object detection framework for industrial applications. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition(CVPR), New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Wang, C.; Bochkovskiy, A.; Mark Liao, H. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Deng, J.; Guo, J.; Ververas, E.; Kotsia, I.; Zafeiriou, S. RetinaFace: Single-Shot Multi-Level Face Localisation in the Wild. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 5202–5211. [Google Scholar]
- Li, J. DSFD: Dual Shot Face Detector. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 5055–5064. [Google Scholar]
- Qi, D.; Tan, W.; Yao, Q. YOLO5Face: Why reinventing a face detector. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Tel Aviv, Israel, 13–27 October 2022; pp. 228–244. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed]
- Wang, Q.; Bhowmik, N.; Breckon, T.P. Multi-Class 3D Object Detection within Volumetric 3D Computed Tomography Baggage Security Screening Imagery. In Proceedings of the IEEE International Conference on Machine Learning and Applications (ICMLA), Miami, FL, USA, 14–17 December 2020; pp. 13–18. [Google Scholar]
- Han, L.; Zou, Y.; Cheng, L. A Convolutional Neural Network with Multi-scale Kernel and Feature Fusion for sEMG-based Gesture Recognition. In Proceedings of the IEEE International Conference on Robotics and Biomimetics (ROBIO), Sanya, China, 27–31 December 2021; pp. 774–779. [Google Scholar]
- Chen, Q.; Meng, X.; Li, W.; Fu, X.; Deng, X.; Wang, J. A multi-scale fusion convolutional neural network for face detection. In Proceedings of the IEEE International Conference on Systems, Man, and Cybernetics (SMC), Banff, AB, Canada, 5–8 October 2017; pp. 1013–1018. [Google Scholar]
- Lin, T.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- Wu, W.; Qian, C.; Yang, S. Look at Boundary: A Boundary-Aware face alignment algorithm. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 2129–2138. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 28, 1137–1149. [Google Scholar] [CrossRef] [PubMed]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Input | Operator | c | n | s |
|---|---|---|---|---|
| 640 × 640 × 3 | Conv3 × 3 | 16 | 1 | 2 |
| 320 × 320 × 16 | Depthwise Conv3 × 3 | 32 | 2 | 2 |
| 160 × 160 × 32 | Depthwise Conv3 × 3 | 64 | 3 | 2 |
| (S3)80 × 80 × 64 | Depthwise Conv3 × 3 | 128 | 3 | 2 |
| 40 × 40 × 128 | Depthwise Conv3 × 3 | 128 | 3 | 1 |
| (S2)40 × 40 × 128 | Depthwise Conv3 × 3 | 256 | 1 | 2 |
| (S1)20 × 20 × 256 | Depthwise Conv3 × 3 | 256 | 1 | 1 |
| Item | Parameter |
|---|---|
| Operating system | Windows11 |
| CPU | Intel Core i5 11260H |
| CPU frequency | 3.90 GHz |
| GPU | NVIDIA RTX 3050 |
| Memory | 32 GB |
| Deep learning framework | Pytorch |
| Programming language | Python |
| Network Backbone | Easy Accuracy (%) | Medium Accuracy (%) | Hard Accuracy (%) | Model Size (Million Bytes) |
|---|---|---|---|---|
| MobileNet v1 | 78.32 | 73.45 | 44.64 | 4.34 |
| MobileNet v2 with 1 | 82.43 | 77.21 | 47.65 | 4.34 |
| MobileNet v2 with 0.75 | 79.92 | 74.88 | 45.84 | 4.22 |
| MobileNet v2 with 0.5 | 79.19 | 73.25 | 43.06 | 4.14 |
| MobileNet v2 with 0.25 | 79.46 | 69.28 | 41.10 | 3.90 |
| Quality Factor | Easy Accuracy (%) | Medium Accuracy (%) | Hard Accuracy (%) |
|---|---|---|---|
| 1 | 74.97 | 68.82 | 41.21 |
| 0.75 | 75.92 | 69.61 | 39.06 |
| 0.5 | 76.21 | 69.18 | 41.22 |
| 0.25 | 76.73 | 70.83 | 42.67 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tang, Q.; Li, Y.; Cai, Y.; Peng, X.; Liu, X. Face Detection Based on DF-Net. Electronics 2023, 12, 4021. https://doi.org/10.3390/electronics12194021
Tang Q, Li Y, Cai Y, Peng X, Liu X. Face Detection Based on DF-Net. Electronics. 2023; 12(19):4021. https://doi.org/10.3390/electronics12194021
Chicago/Turabian StyleTang, Qijian, Yanfei Li, Yinhe Cai, Xiang Peng, and Xiaoli Liu. 2023. "Face Detection Based on DF-Net" Electronics 12, no. 19: 4021. https://doi.org/10.3390/electronics12194021
APA StyleTang, Q., Li, Y., Cai, Y., Peng, X., & Liu, X. (2023). Face Detection Based on DF-Net. Electronics, 12(19), 4021. https://doi.org/10.3390/electronics12194021