
New Hybrid Graph Convolution Neural Network with Applications in Game Strategy




Abstract
:1. Introduction
- We propose a novel hybrid deep neural network learning framework that integrates the DCNN and the GCN to extract planar, spatial, and relational features from games;
- Our use of the graph data structure to represent the game state emphasizes the importance of the relationship between collectives and spatial position in game strategy;
- We develop an integrated method for the fusion of graph data features and image data features and solve the problem of the incompatibility of feature data in DCNNs and GCNs;
- We apply a hybrid model to the classic strategy game “Game of Go” and achieve better performance than traditional methods.
2. Related Works
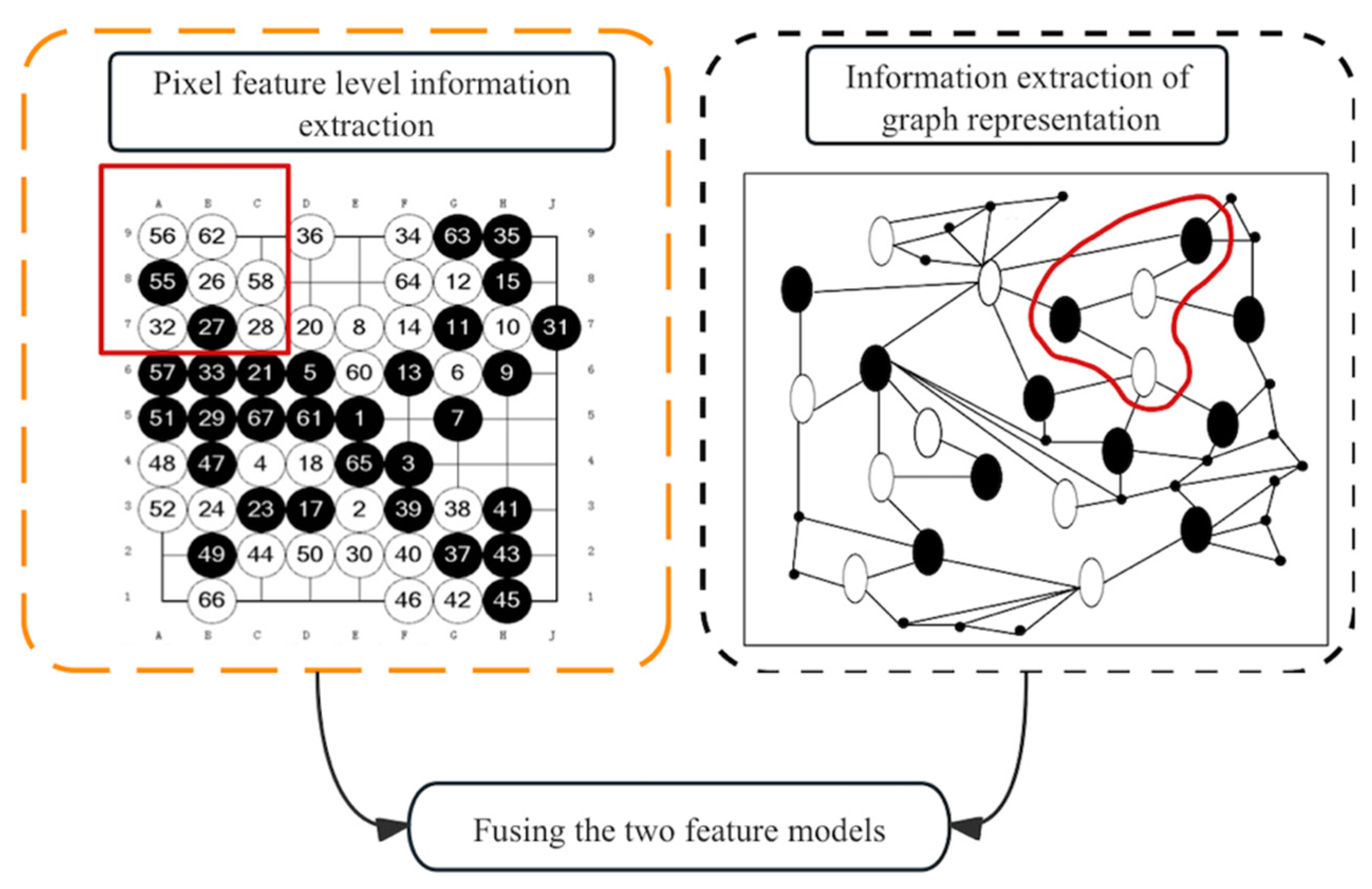
3. Proposed Methodology
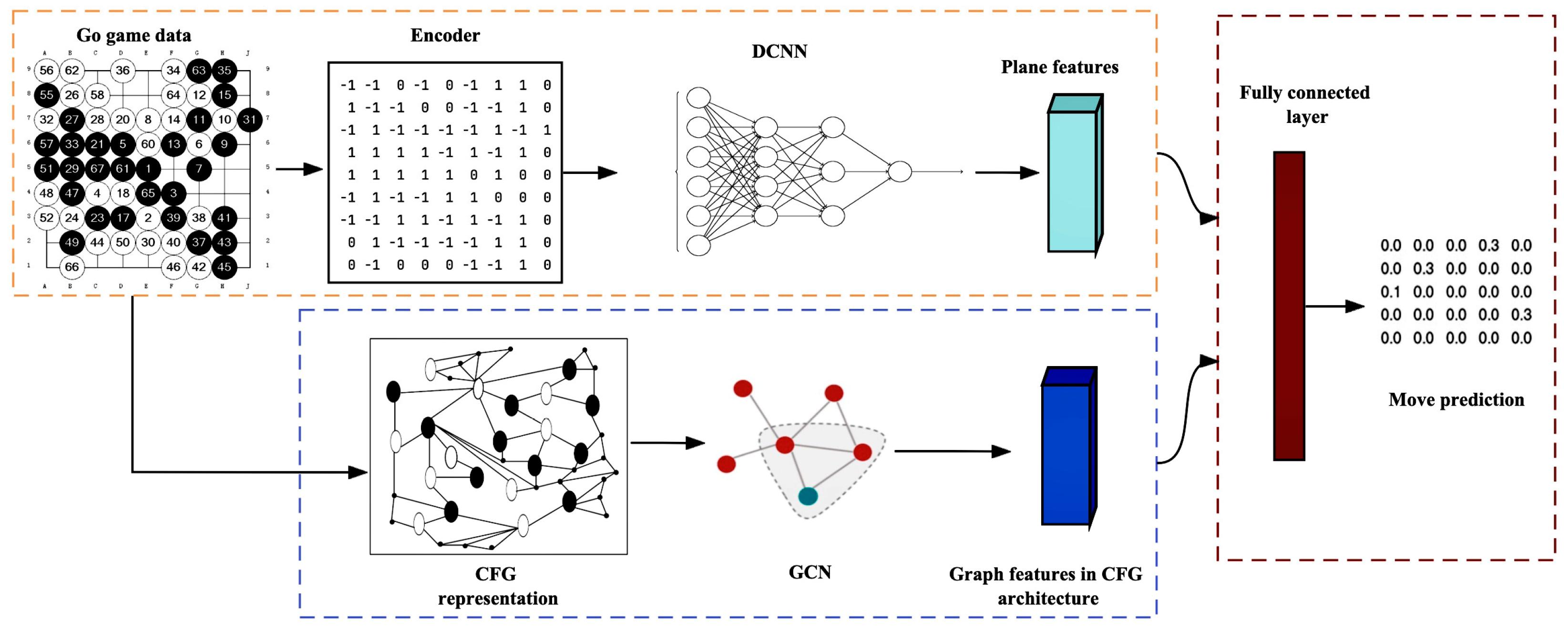
3.1. DCNN in Feature Extraction
| Algorithm 1 Encode Go data to vector |
| Input: game state of current play which includes the position tuple of move in the Go board [tuple(), ], and board size. Output: board tensor with 11 plane features . 1: Initialize board tensor with the size of zero vector . 2: if tuple() is black stone do 3: Add feature: 4: else 5: for r = 1 to range (1 to the length of the board) 6: for c = 1 to range (1 to the width of the board) 7: |
| 8: Find tuple() whether has a stone group 9: if tuple() do not in a stone group do 10: if tuple( is not in ko situation (illegal move) do 11: 12: else liberty_plane = 13: if color of Go group white do 14: liberty_plane += 4 15: |
3.2. Construct the Graph Data Structure
3.3. Branch Model Based on Graph Learning
| Algorithm 2 The proposed method for move prediction |
| Input: Plane vector of Go game data batch size number of epoch in model training ; learning rate ; number of graph neural networks’ layers . Output: The accuracy of move prediction. 1: Train DCNN model by training data of 11 plane features vector . 2: Fine-tune DCNN model by validation dataset. 3: Generate - plane feature map through global average pool. 4: Construct the CFG, G= by manually adding node features and edge features based on the Go game architecture. 5: for e = 1 to E do 6: Training on R-GCN model in layers. 7: Calculate loss based on cross-entropy loss function and update weight through SGD. |
| 8: end for 9: Calculate the final output through fusion work and conduct move prediction |
3.4. Hybrid Model with Feature Fusion
4. Experiments
4.1. Experiment Dataset
4.2. Details of Implementation
4.3. Experiment Results
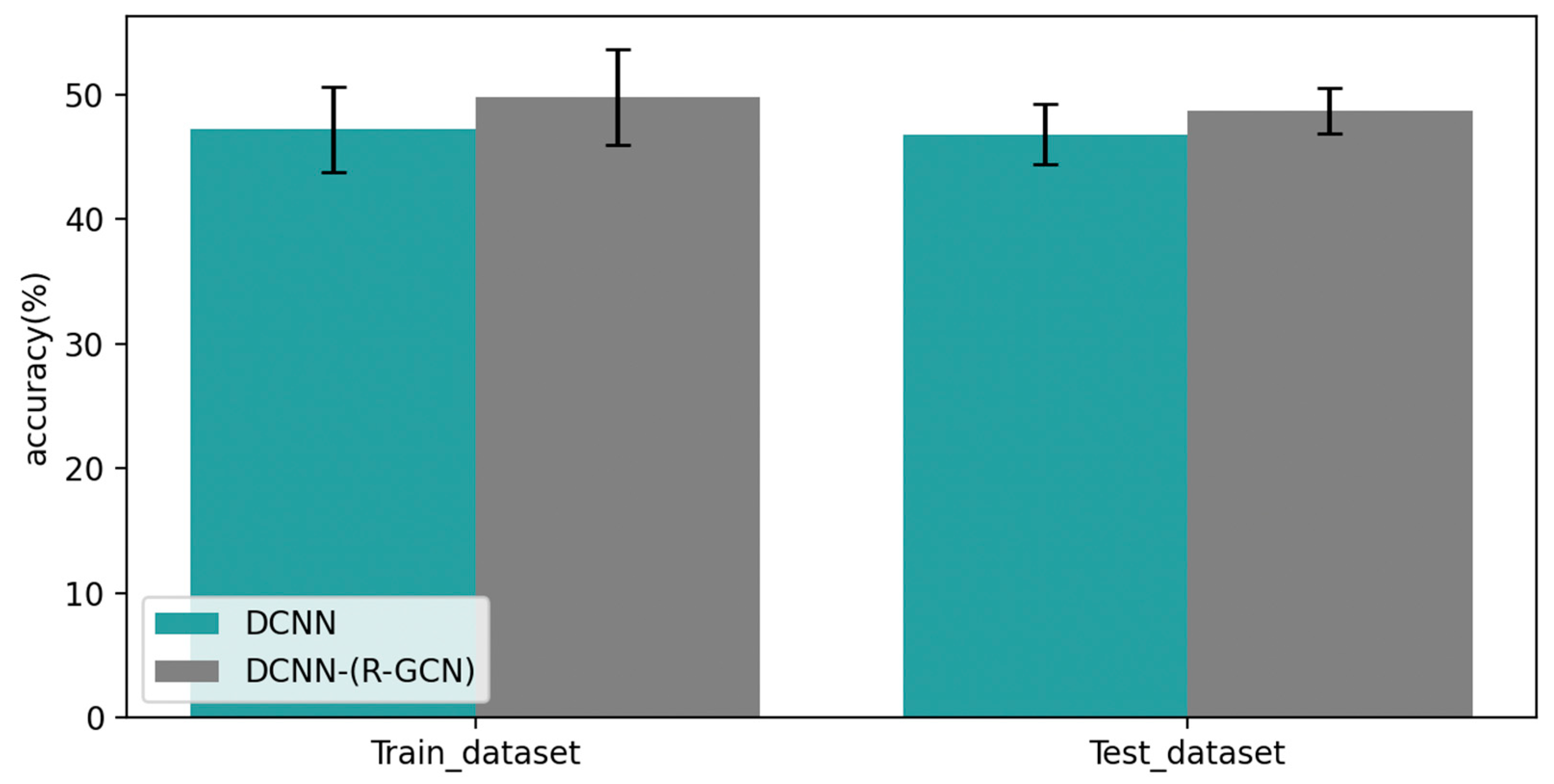
4.3.1. Comparison of Different Models
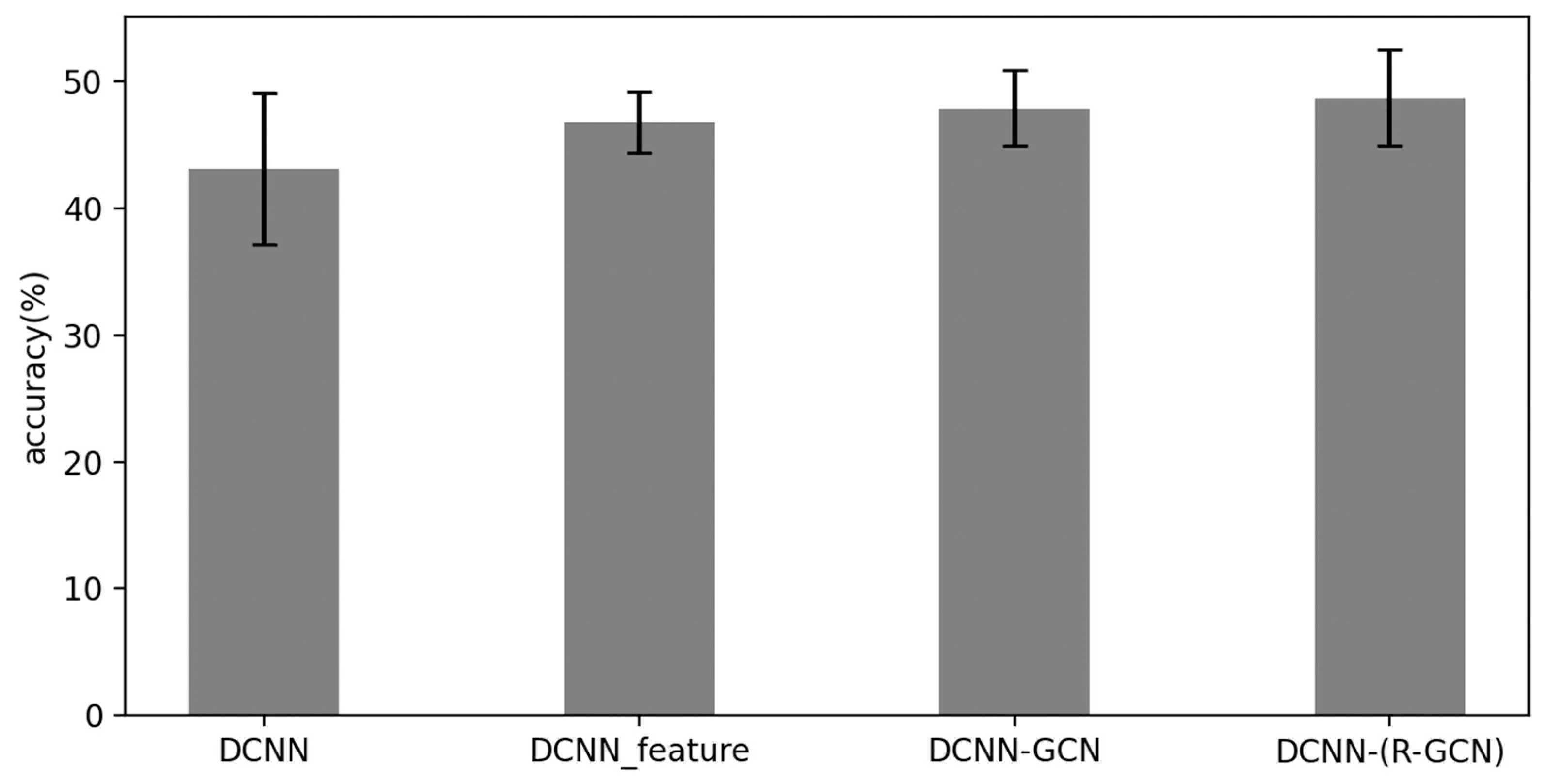
4.3.2. Performance of Feature Extraction
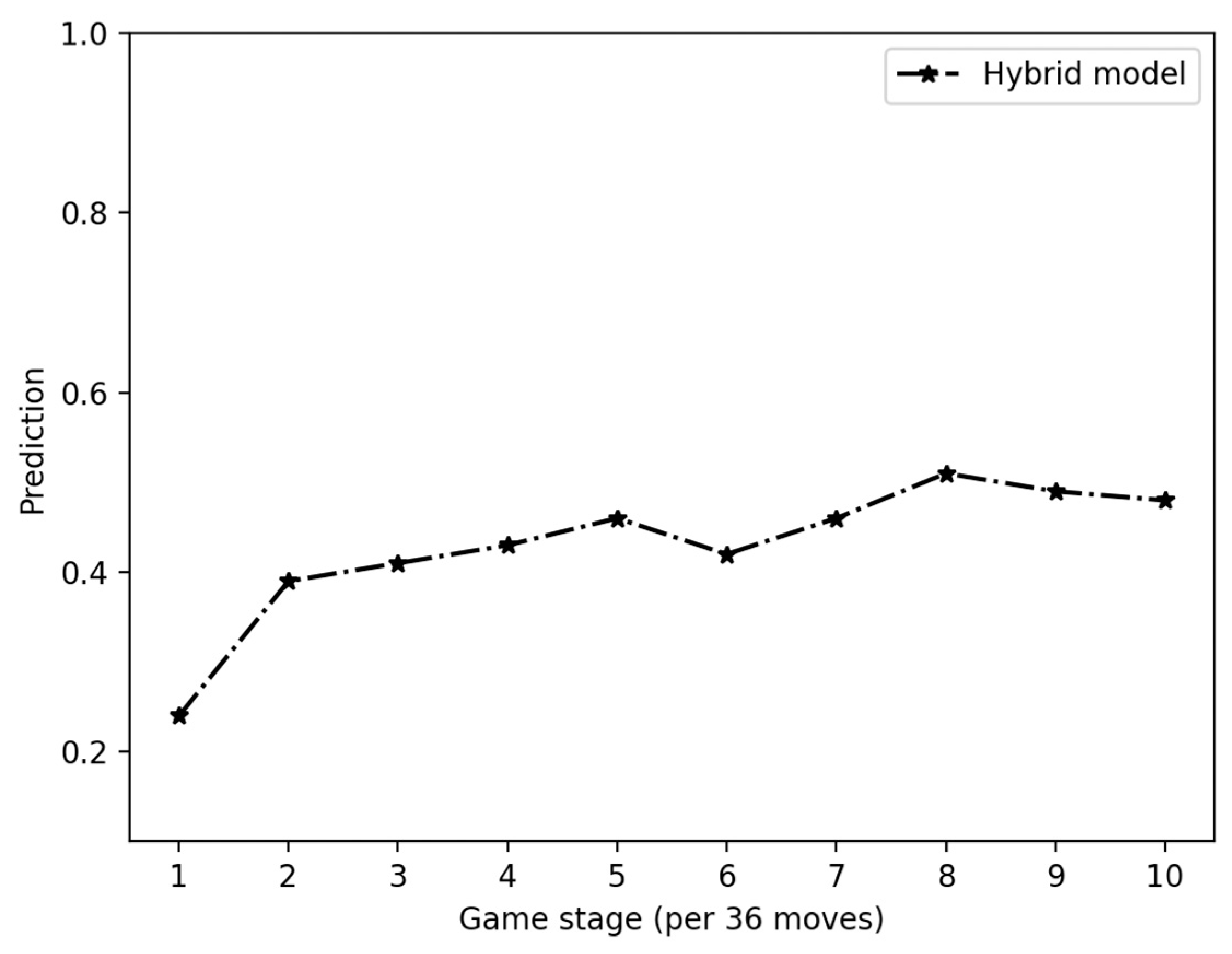
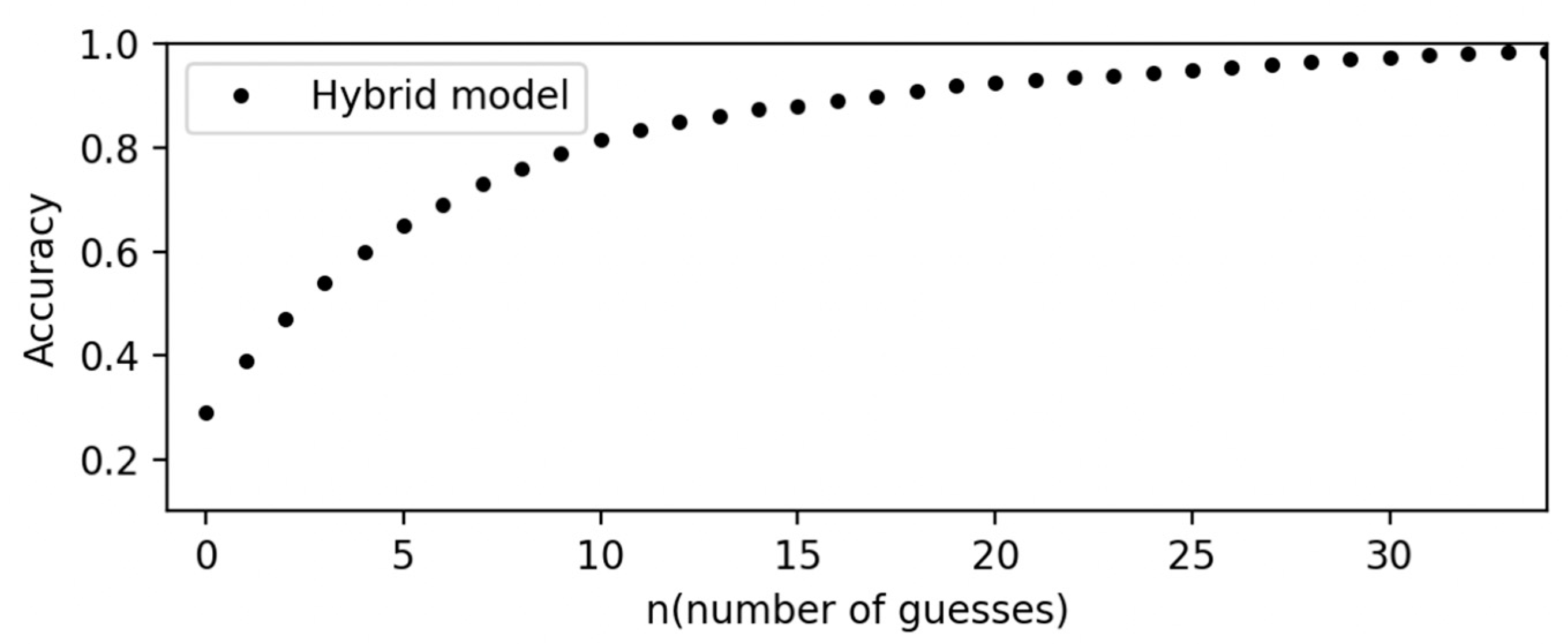
4.3.3. Performance of Hybrid Graph Convolution Neural Networks
4.4. Theoretical Applications in Other Strategy Games
5. Conclusions and Future Work
- Enhance the identification of strategic situations: The model can identify common formations that indicate strong and weak positions, enhancing the impact of a team’s overall strength on the game as a whole rather than that of a single individual.
- Assess the game on multiple levels: The model can consider regional characteristics based on the graph structure, explicitly capturing the connections between game nodes (relationships, rewards, resources), their territorial impact, and potential correlations.
- Adapt to different stages of the game: Strategy games have different stages, such as the opening, mid-game, and end game. The versatility of the hybrid approach in capturing different aspects of the game allows it to adapt to the strategic needs of these different phases. For example, the GCN can learn the long-term dependencies of games, while the CNN is good at learning tactical patterns.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Silver, D.; Schrittwieser, J.; Simonyan, K.; Antonoglou, I.; Huang, A.; Guez, A.; Hubert, T.; Baker, L.; Lai, M.; Bolton, A.; et al. Mastering the game of Go without human knowledge. Nature 2017, 550, 354–359. [Google Scholar] [CrossRef]
- Silver, D.; Hubert, T.; Schrittwieser, J.; Antonoglou, I.; Lai, M.; Guez, A.; Lanctot, M.; Sifre, L.; Kumaran, D.; Graepel, T.; et al. Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm. arXiv 2017, arXiv:1712.01815. [Google Scholar]
- Silver, D.; Hubert, T.; Schrittwieser, J.; Antonoglou, I.; Lai, M.; Guez, A.; Lanctot, M.; Sifre, L.; Kumaran, D.; Graepel, T.; et al. A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play. Science 2018, 362, 1140–1144. [Google Scholar] [CrossRef] [PubMed]
- Neven, F.; Schwentick, T.; Vianu, V. Finite state machines for strings over infinite alphabets. ACM Trans. Comput. Log. 2004, 5, 403–435. [Google Scholar] [CrossRef]
- Browne, C.; Powley, E.J.; Whitehouse, D.; Lucas, S.M.; Cowling, P.I.; Rohlfshagen, P.; Tavener, S.; Liebana, D.P.; Samothrakis, S.; Colton, S. A Survey of Monte Carlo Tree Search Methods. IEEE Trans. Comput. Intell. AI Games 2012, 4, 1–43. [Google Scholar] [CrossRef]
- Furukawa, M.; Abe, M.; Watanabe, T. A Study on Utility Based Game AI Considering Long-Term Goal Achievement. J. Soc. Art Sci. 2021, 20, 139–148. [Google Scholar] [CrossRef]
- Silver, D.; Huang, A.; Maddison, C.J.; Guez, A.; Sifre, L.; Driessche, G.V.; Schrittwieser, J.; Antonoglou, I.; Panneershelvam, V.; Lanctot, M.; et al. Mastering the game of Go with deep neural networks and tree search. Nature 2016, 529, 484–489. [Google Scholar] [CrossRef] [PubMed]
- Hazra, T.; Anjaria, K. Applications of game theory in deep learning: A survey. Multimed. Tools Appl. 2022, 81, 8963–8994. [Google Scholar] [CrossRef]
- Mahajan, C. Reinforcement Learning Game Training: A Brief Intuitive. MatSciRN Other Electron. 2020. [Google Scholar] [CrossRef]
- Yasruddin, M.L.; Hakim Ismail, M.A.; Husin, Z.; Tan, W.K. Feasibility Study of Fish Disease Detection using Computer Vision and Deep Convolutional Neural Network (DCNN) Algorithm. In Proceedings of the 2022 IEEE 18th International Colloquium on Signal Processing & Applications (CSPA), Selangor, Malaysia, 12–12 May 2022; pp. 272–276. [Google Scholar]
- Hou, J.; Gao, T. Explainable DCNN based chest X-ray image analysis and classification for COVID-19 pneumonia detection. Sci. Rep. 2021, 11, 16071. [Google Scholar] [CrossRef]
- Yang, J.H.; Choi, W.Y.; Lee, S.; Chung, C.C. Autonomous Lane Keeping Control System Based on Road Lane Model Using Deep Convolutional Neural Networks. In Proceedings of the 2019 IEEE Intelligent Transportation Systems Conference (ITSC), Auckland, New Zealand, 27–30 October 2019; pp. 3393–3398. [Google Scholar]
- Wang, B.; Ma, R.; Kuang, J.; Zhang, Y. How Decisions Are Made in Brains: Unpack “Black Box” of CNN With Ms. Pac-Man Video Game. IEEE Access 2020, 8, 142446–142458. [Google Scholar] [CrossRef]
- Sutskever, I.; Nair, V. Mimicking Go Experts with Convolutional Neural Networks. In Proceedings of the International Conference on Artificial Neural Networks, Prague, Czech Republic, 3–6 September 2008. [Google Scholar]
- Clark, C.; Storkey, A.J. Training Deep Convolutional Neural Networks to Play Go. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015. [Google Scholar]
- Li, Z.; Zhu, C.; Gao, Y.; Wang, Z.; Wang, J. AlphaGo Policy Network: A DCNN Accelerator on FPGA. IEEE Access 2020, 8, 203039–203047. [Google Scholar] [CrossRef]
- Ichsan, M.N.; Armita, N.; Minarno, A.E.; Sumadi, F.D.; Hariyady. Increased Accuracy on Image Classification of Game Rock Paper Scissors using CNN. J. RESTI (Rekayasa Sist. Dan Teknol. Inf.) 2022, 6, 606–611. [Google Scholar] [CrossRef]
- Kamatekar, S.L.; Hiremath, S.M. Domination, Easymove Game Represented in Graph. Int. J. Math. Arch. 2018, 9, 179–185. [Google Scholar]
- Yun, W.J.; Yi, S.; Kim, J. Multi-Agent Deep Reinforcement Learning using Attentive Graph Neural Architectures for Real-Time Strategy Games. In Proceedings of the 2021 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Melbourne, Australia, 17–20 October 2021; pp. 2967–2972. [Google Scholar]
- Graf, T.; Platzner, M. Common fate graph patterns in Monte Carlo Tree Search for computer go. In Proceedings of the 2014 IEEE Conference on Computational Intelligence and Games, Dortmund, Germany, 26–29 August 2014; pp. 1–8. [Google Scholar]
- Xia, F.; Sun, K.; Yu, S.; Aziz, A.; Wan, L.; Pan, S.; Liu, H. Graph Learning: A Survey. IEEE Trans. Artif. Intell. 2021, 2, 109–127. [Google Scholar] [CrossRef]
- Zhai, Z.; Staring, M.; Zhou, X.; Xie, Q.; Xiao, X.; Bakker, M.E.; Kroft, L.J.; Lelieveldt, B.P.; Boon, G.J.; Klok, F.A.; et al. Linking Convolutional Neural Networks with Graph Convolutional Networks: Application in Pulmonary Artery-Vein Separation. In Proceedings of the Graph Learning in Medical Imaging: First International Workshop, GLMI 2019, Held in Conjunction with MICCAI 2019, Shenzhen, China, 17 October 2019. [Google Scholar]
- Zhong, T.; Zhang, S.; Zhou, F.; Zhang, K.; Trajcevski, G.; Wu, J. Hybrid graph convolutional networks with multi-head attention for location recommendation. World Wide Web 2020, 23, 3125–3151. [Google Scholar] [CrossRef]
- Wilkens, R.S.; Ognibene, D. MB-Courage@EXIST: GCN Classification for Sexism Identification in Social Networks. In Proceedings of the IberLEF 2021, Málaga, Spain, 21–24 September 2021. [Google Scholar]
- Liang, J.; Deng, Y.; Zeng, D. A Deep Neural Network Combined CNN and GCN for Remote Sensing Scene Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 4325–4338. [Google Scholar] [CrossRef]
- Graepel, T.; Goutrie, M.; Kruger, M.; Herbrich, R. Learning on Graphs in the Game of Go. In Proceedings of the International Conference on Artificial Neural Networks, Vienna, Austria, 21–25 August 2001. [Google Scholar]
- Defferrard, M.; Bresson, X.; Vandergheynst, P. Convolutional Neural Networks on Graphs with Fast Localized Spectral Filtering. In Proceedings of the Conference on Neural Information Processing Systems (NIPS), Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- Kipf, T.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Li, Y.; Yu, R.; Shahabi, C.; Liu, Y. Diffusion Convolutional Recurrent Neural Network: Data-Driven Traffic Forecasting. arXiv 2017, arXiv:1707.01926. [Google Scholar]
- Gao, H.; Wang, Z.; Ji, S. Large-Scale Learnable Graph Convolutional Networks. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018. [Google Scholar]
- Mosella-Montoro, A.; Ruiz-Hidalgo, J. SkinningNet: Two-Stream Graph Convolutional Neural Network for Skinning Prediction of Synthetic Characters. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 18572–18581. [Google Scholar]
- Li, W.; He, H.; Hsueh, C.; Ikeda, K. Graph Convolutional Networks for Turn-Based Strategy Games. In Proceedings of the International Conference on Agents and Artificial Intelligence, Online Streaming, 3–5 February 2022. [Google Scholar]
- Liu, Y.; Wang, W.; Hu, Y.; Hao, J.; Chen, X.; Gao, Y. Multi-Agent Game Abstraction via Graph Attention Neural Network. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019. [Google Scholar]
- Lee, E.S.; Zhou, L.; Ribeiro, A.; Kumar, V. Learning Decentralized Strategies for a Perimeter Defense Game with Graph Neural Networks. arXiv 2022, arXiv:2211.01757. [Google Scholar]
- Bisberg, A.; Ferrara, E. GCN-WP—Semi-Supervised Graph Convolutional Networks for Win Prediction in Esports. In Proceedings of the 2022 IEEE Conference on Games (CoG), Beijing, China, 21–24 August 2022; pp. 449–456. [Google Scholar]
- Liu, Q.; Xiao, L.; Yang, J.; Wei, Z. CNN-Enhanced Graph Convolutional Network with Pixel- and Superpixel-Level Feature Fusion for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2020, 59, 8657–8671. [Google Scholar] [CrossRef]
- Wang, L.; Wang, X. Dual-Coupled CNN-GCN-Based Classification for Hyperspectral and LiDAR Data. Sensors 2022, 22, 5735. [Google Scholar] [CrossRef] [PubMed]
- Meng, Y.; Wei, M.; Gao, D.; Zhao, Y.; Yang, X.; Huang, X.; Zheng, Y. CNN-GCN Aggregation Enabled Boundary Regression for Biomedical Image Segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Lima, Peru, 4–8 October 2020. [Google Scholar]
- Duan, S.; Huang, P.; Chen, M.; Wang, T.; Sun, X.; Chen, M.; Dong, X.; Jiang, Z.; Li, D. Semi-supervised classification of fundus images combined with CNN and GCN. J. Appl. Clin. Med. Phys. 2022, 23, e13746. [Google Scholar] [CrossRef]
- Wang, H.; Xu, L.; Bezerianos, A.; Chen, C.; Zhang, Z. Linking Attention-Based Multiscale CNN With Dynamical GCN for Driving Fatigue Detection. IEEE Trans. Instrum. Meas. 2021, 70, 2504811. [Google Scholar] [CrossRef]
- McDonnell, K.; Abram, F.; Howley, E. Application of a Novel Hybrid CNN-GNN for Peptide Ion Encoding. J. Proteome Res. 2022, 22, 323–333. [Google Scholar] [CrossRef]
- Liang, Y.; Jiang, S.; Gao, M.; Jia, F.; Wu, Z.; Lyu, Z. GLSTM-DTA: Application of Prediction Improvement Model Based on GNN and LSTM. J. Phys. Conf. Ser. 2022, 2219, 012008. [Google Scholar] [CrossRef]
- Li, B.; Zhu, Z. GNN-Based Hierarchical Deep Reinforcement Learning for NFV-Oriented Online Resource Orchestration in Elastic Optical DCIs. J. Light. Technol. 2022, 40, 935–946. [Google Scholar] [CrossRef]
- Ralaivola, L.; Wu, L.; Baldi, P. SVM and pattern-enriched common fate graphs for the game of go. In Proceedings of the The European Symposium on Artificial Neural Networks, Bruges, Belgium, 27–29 April 2005. [Google Scholar]
- Schlichtkrull, M.; Kipf, T.; Bloem, P.; Berg, R.V.; Titov, I.; Welling, M. Modeling Relational Data with Graph Convolutional Networks. In Proceedings of the Extended Semantic Web Conference, Portorož, Slovenia, 28 May 28–1 June 2017. [Google Scholar]
- Maddison, C.J.; Huang, A.; Sutskever, I.; Silver, D. Move Evaluation in Go Using Deep Convolutional Neural Networks. arXiv 2014, arXiv:1412.6564. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Features | Num of Vectors | Details |
|---|---|---|---|
| Node | Black, white, empty | 3 | The color of the stones-occupied intersections |
| Node | Per liberty in stone group | 4 | The liberty in the stone group divided by the total number of stones |
| Node | Legal move | 1 | Whether the move of stone is legal or not |
| Node | Turns of move | 5 | The number of moves in the group |
| Node | Rewarding move | 1 | Whether a move results in the capture of an opponent’s stone |
| Node | Number of captures | 8 | How many of the opponent’s stones have been captured |
| Edge | Relationship of groups | 3 | Whether the connected stone group is an opponent or empty point, and if it is an opponent, whether it is greater than it |
| Model | Layer | Num of Filters | Size of Filter |
|---|---|---|---|
| DCNN | 3 layers | 256 | 7 × 7 |
| 5 layers | 128 | 5 × 5 | |
| 2 layers | 192 | 5 × 5 | |
| R-GCN | 1 layer | 256 |
| Model | Test Dataset | Train Dataset | ||||
|---|---|---|---|---|---|---|
| Accuracy | Rank | Stderr | Accuracy | Rank | Stderr | |
| DCNN | 46.8% | 6.87 | 1.2% | 47.2% | 6.35 | 1.7% |
| DCNN-(R-GCN) | 48.7% | 6.87 | 0.9% | 49.8% | 6.35 | 1.9% |
| Model | Features | Accuracy | Stderr |
|---|---|---|---|
| DCNN | None | 43.1% | 3.0% |
| DCNN | 11 | 46.8% | 1.2% |
| DCNN–GCN | 11 plane features No Edge feature | 47.9% | 1.5% |
| DCNN–(R-GCN) | 11 plane features Have Edge feature | 48.7% | 1.9% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, H.; Seng, K.P.; Ang, L.-M. New Hybrid Graph Convolution Neural Network with Applications in Game Strategy. Electronics 2023, 12, 4020. https://doi.org/10.3390/electronics12194020
Xu H, Seng KP, Ang L-M. New Hybrid Graph Convolution Neural Network with Applications in Game Strategy. Electronics. 2023; 12(19):4020. https://doi.org/10.3390/electronics12194020
Chicago/Turabian StyleXu, Hanyue, Kah Phooi Seng, and Li-Minn Ang. 2023. "New Hybrid Graph Convolution Neural Network with Applications in Game Strategy" Electronics 12, no. 19: 4020. https://doi.org/10.3390/electronics12194020
APA StyleXu, H., Seng, K. P., & Ang, L.-M. (2023). New Hybrid Graph Convolution Neural Network with Applications in Game Strategy. Electronics, 12(19), 4020. https://doi.org/10.3390/electronics12194020