
A Long Short-Term Memory-Based Prototype Model for Drought Prediction



Abstract
:1. Introduction
2. Materials and Methods
2.1. Review of Previous Works
2.2. Environmental Analysis
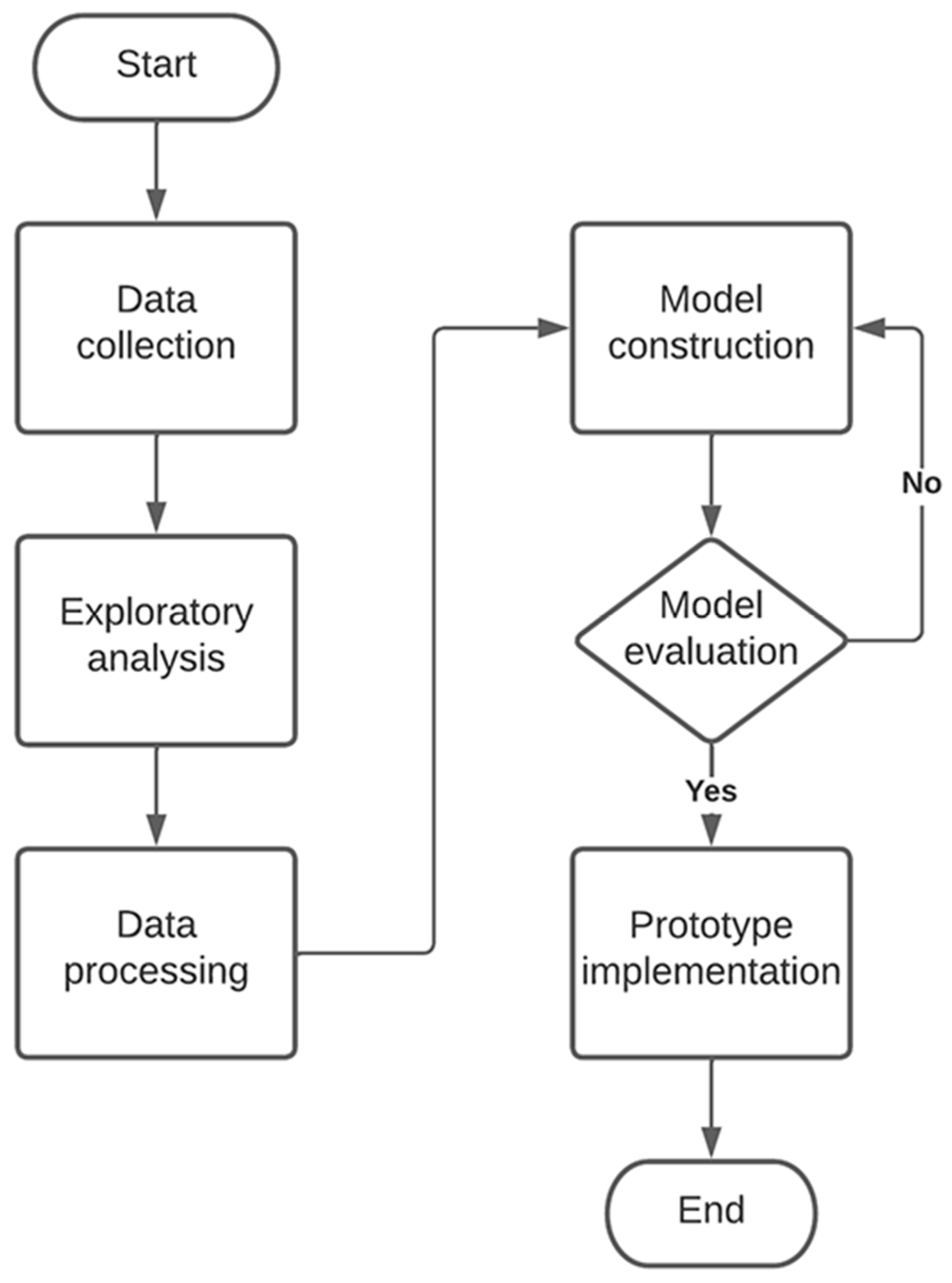
2.3. Method
2.3.1. Data Collection
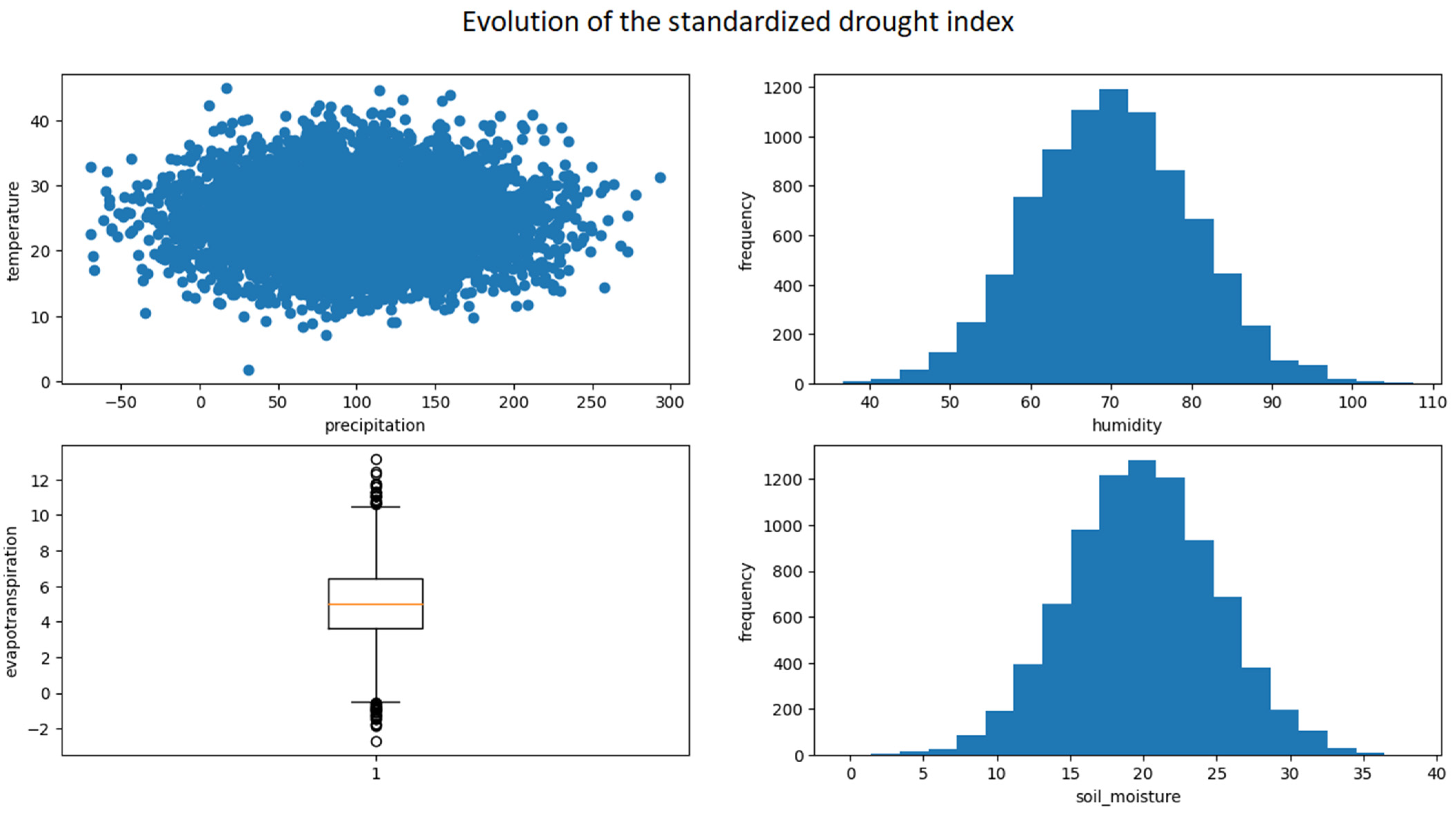
2.3.2. Exploratory Analysis
- r: is the Pearson correlation coefficient;
- n: is the number of observations;
- x: are the values of the variable X;
- y: are the values of the variable Y;
- Σ: is the sum of the values.
- Y is the dependent variable;
- X is the independent variable (in this case, time);
- a is the intersection of the regression line with the Y axis;
- b is the slope of the regression line.
- F is the ANOVA test statistic;
- SSB is the sum of squares between groups;
- k is the number of groups;
- SSE is the sum of squares within the groups;
- n is the total number of observations in all groups.
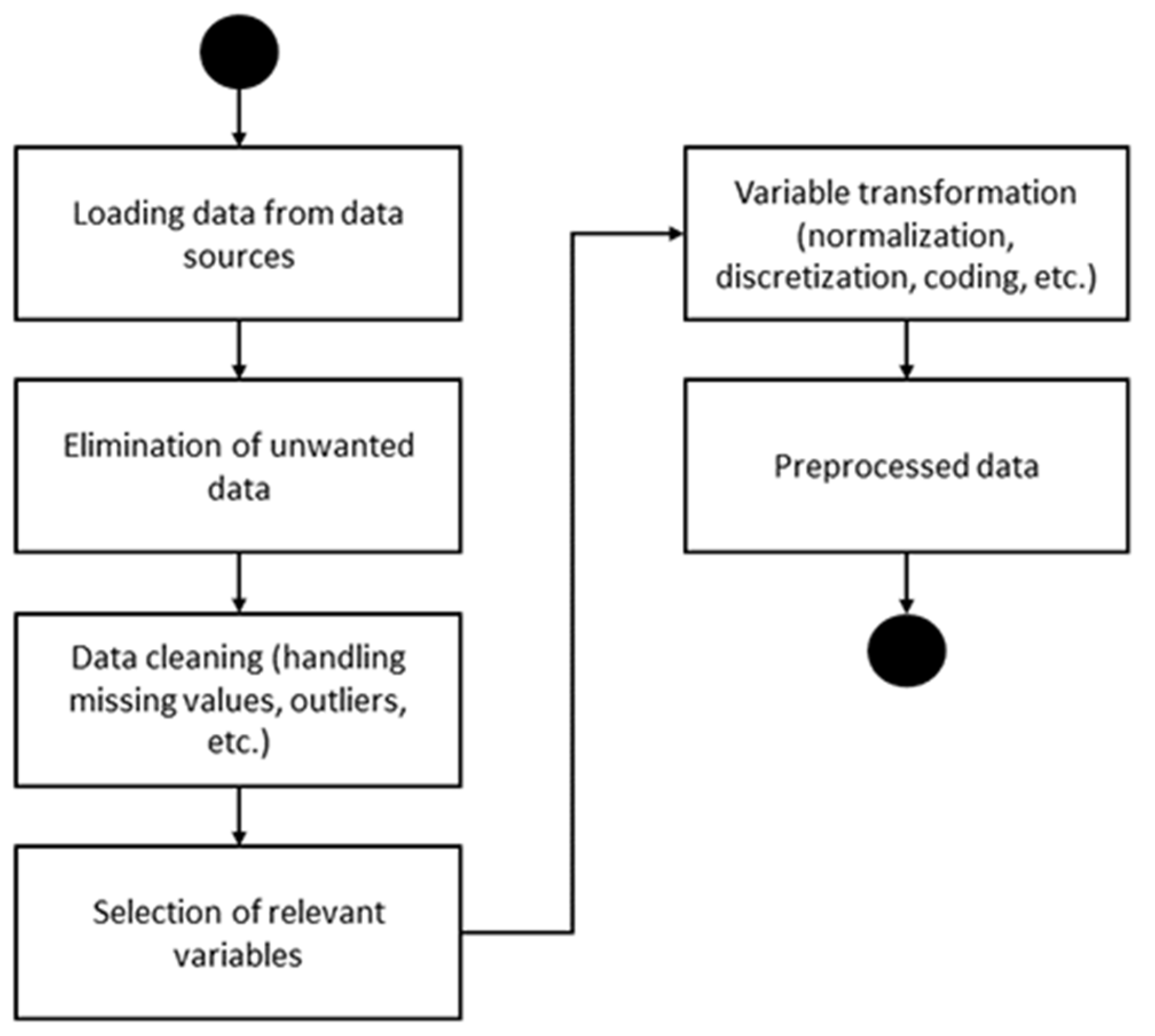
2.3.3. Data Preprocessing
2.3.4. Construction of the Method
- Precipitation;
- Temperature;
- Humidity;
- Evapotranspiration.
- Correlation between precipitation and drought: 0.15;
- Correlation between temperature and drought: −0.12;
- Correlation between humidity and drought: 0.08;
- Correlation between evapotranspiration and drought: −0.19.
- Z score or standardization: a variable’s mean is subtracted and divided by the standard deviation.
- Minimum–maximum scaling: the variable is transformed so that it has a range between 0 and 1.
- Scaling per unit p: the variable is transformed so that it has a range between −1 and 1.
- Number of LSTM units in each layer: values between 30 and 100 were explored.
- Dropout rate: values between 0.1 and 0.3 were considered.
- Number of training epochs: models trained with ages 10, 20, and 30 were evaluated.
- Lot size (batch size): lot size was tested with 16, 32, and 64 values.
2.3.5. Model Training
- CPU: Intel Core i7-9700K;
- GPU: NVIDIA GeForce RTX 2080 Ti;
- RAM: 32 GB DDR4.
2.3.6. Model Evaluation
2.4. Model Fit
2.5. Prediction of New Data
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Nichol, J.E.; Abbas, S. Integration of Remote Sensing Datasets for Local Scale Assessment and Prediction of Drought. Sci. Total Environ. 2015, 505, 503–507. [Google Scholar] [CrossRef]
- Khan, N.; Sachindra, D.A.; Shahid, S.; Ahmed, K.; Shiru, M.S.; Nawaz, N. Prediction of Droughts over Pakistan Using Machine Learning Algorithms. Adv. Water Resour. 2020, 139, 103562. [Google Scholar] [CrossRef]
- Park, H.; Kim, K.; Lee, D.K. Prediction of Severe Drought Area Based on Random Forest: Using Satellite Image and Topography Data. Water 2019, 11, 705. [Google Scholar] [CrossRef]
- Hao, Z.; Singh, V.P.; Xia, Y. Seasonal Drought Prediction: Advances, Challenges, and Future Prospects. Rev. Geophys. 2018, 56, 108–141. [Google Scholar] [CrossRef]
- Cavus, N.; Mohammed, Y.B.; Gital, A.Y.; Bulama, M.; Tukur, A.M.; Mohammed, D.; Isah, M.L.; Hassan, A. Emotional Artificial Neural Networks and Gaussian Process-Regression-Based Hybrid Machine-Learning Model for Prediction of Security and Privacy Effects on M-Banking Attractiveness. Sustainability 2022, 14, 5826. [Google Scholar] [CrossRef]
- Sokkhey, P.; Okazaki, T. Hybrid Machine Learning Algorithms for Predicting Academic Performance. Int. J. Adv. Comput. Sci. Appl. 2020, 11, 32–41. [Google Scholar] [CrossRef]
- Márquez-Vera, C.; Romero Morales, C.; Ventura Soto, S. Predicting School Failure and Dropout by Using Data Mining Techniques. Rev. Iberoam. Tecnol. Del Aprendiz. 2013, 8, 7–14. [Google Scholar] [CrossRef]
- Kogan, F.N. Droughts of the Late 1980s in the United States as Derived from NOAA Polar-Orbiting Satellite Data. Bull. Am. Meteorol. Soc. 1995, 76, 655–668. [Google Scholar] [CrossRef]
- Saboia, J.L.M. Autoregressive Integrated Moving Average (ARIMA) Models for Birth Forecasting. J. Am. Stat. Assoc. 1977, 72, 264–270. [Google Scholar] [CrossRef]
- Hayes, M.J.; Svoboda, M.D.; Wiihite, D.A.; Vanyarkho, O. V Monitoring the 1996 Drought Using the Standardized Precipitation Index. Bull. Am. Meteorol. Soc. 1999, 80, 429–438. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, Z.; Luo, Y.; Cao, J.; Xie, R.; Li, S. Integrating Satellite-Derived Climatic and Vegetation Indices to Predict Smallholder Maize Yield Using Deep Learning. Agric. Meteorol. 2021, 311, 108666. [Google Scholar] [CrossRef]
- Hamed, M.M.; Khalafallah, M.G.; Hassanien, E.A. Prediction of Wastewater Treatment Plant Performance Using Artificial Neural Networks. Environ. Model. Softw. 2004, 19, 919–928. [Google Scholar] [CrossRef]
- Aggarwal, S.K.; Saini, L.M. Solar Energy Prediction Using Linear and Non-Linear Regularization Models: A Study on AMS (American Meteorological Society) 2013–14 Solar Energy Prediction Contest. Energy 2014, 78, 247–256. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Wu, N.; Green, B.; Ben, X.; O’Banion, S. Deep Transformer Models for Time Series Forecasting: The Influenza Prevalence Case. arXiv 2020, arXiv:2001.08317. [Google Scholar]
- Mehrvand, M.; Baghanam, A.H.; Zahra, R.; Nourani, V. AI-Based (ANN and SVM) Statistical Downscaling Methods for Precipitation Estimation under Climate Change Scenarios. Environ. Sci. 2017, 19, 210615566. [Google Scholar]
- Polanco-Martínez, J.M.; Fernández-Macho, J.; Medina-Elizalde, M. Dynamic Wavelet Correlation Analysis for Multivariate Climate Time Series. Sci. Rep. 2020, 10, 21277. [Google Scholar] [CrossRef]
- Jafarian-Namin, S.; Shishebori, D.; Goli, A. Analyzing and Predicting the Monthly Temperature of Tehran Using ARIMA Model, Artificial Neural Network, and Its Improved Variant. J. Appl. Res. Ind. Eng. 2023; in press. [Google Scholar] [CrossRef]
- Weckwerth, T.M.; Parsons, D.B.; Koch, S.E.; Moore, J.A.; LeMone, M.A.; Demoz, B.B.; Flamant, C.; Geerts, B.; Wang, J.; Feltz, W.F. An Overview of the International H2O Project (IHOP_2002) and Some Preliminary Highlights. Bull. Am. Meteorol. Soc. 2004, 85, 253–278. [Google Scholar] [CrossRef]
- Beguería, S.; Vicente-Serrano, S.M.; Reig, F.; Latorre, B. Standardized Precipitation Evapotranspiration Index (SPEI) Revisited: Parameter Fitting, Evapotranspiration Models, Tools, Datasets and Drought Monitoring. Int. J. Climatol. 2014, 34, 3001–3023. [Google Scholar] [CrossRef]
- Villegas-Ch, W.; Palacios-Pacheco, X.; Ortiz-Garcés, I.; Luján-Mora, S. Management of Educative Data in University Students with the Use of Big Data Techniques. Rev. Ibérica Sist. E Tecnol. Informação 2019, E19, 227–238. [Google Scholar]
- Villegas-Ch, W.; Jaramillo-Alcázar, A.; Mera-Navarrete, A. Assistance System for the Teaching of Natural Numbers to Preschool Children with the Use of Artificial Intelligence Algorithms. Future Internet 2022, 14, 266. [Google Scholar] [CrossRef]
- Benesty, J.; Chen, J.; Huang, Y. On the Importance of the Pearson Correlation Coefficient in Noise Reduction. IEEE Trans. Audio Speech Lang. Process. 2008, 16, 757–765. [Google Scholar] [CrossRef]
- Tadesse, T.; Brown, J.F.; Hayes, M.J. A New Approach for Predicting Drought-Related Vegetation Stress: Integrating Satellite, Climate, and Biophysical Data over the US Central Plains. ISPRS J. Photogramm. Remote Sens. 2005, 59, 244–253. [Google Scholar] [CrossRef]
- Gelman, A. Analysis of Variance—Why It Is More Important than Ever. Ann. Stat. 2005, 33, 1–53. [Google Scholar] [CrossRef]
- Prodhan, F.A.; Zhang, J.; Yao, F.; Shi, L.; Pangali Sharma, T.P.; Zhang, D.; Cao, D.; Zheng, M.; Ahmed, N.; Mohana, H.P. Deep Learning for Monitoring Agricultural Drought in South Asia Using Remote Sensing Data. Remote Sens. 2021, 13, 1715. [Google Scholar] [CrossRef]
- Xu, L.; Abbaszadeh, P.; Moradkhani, H.; Chen, N.; Zhang, X. Continental Drought Monitoring Using Satellite Soil Moisture, Data Assimilation and an Integrated Drought Index. Remote Sens. Environ. 2020, 250, 112028. [Google Scholar] [CrossRef]
- Lemenkova, P. Processing Oceanographic Data by Python Libraries NumPy, SciPy and Pandas. Aquat. Res. 2019, 2, 73–91. [Google Scholar] [CrossRef]
- Vidal-Silva, C.L.; Sánchez-Ortiz, A.; Serrano, J.; Rubio, J.M. Experiencia Académica En Desarrollo Rápido de Sistemas de Información Web Con Python y Django. Form. Univ. 2021, 14, 85–94. [Google Scholar] [CrossRef]
- Ismael, K.D.; Irina, S. Face Recognition Using Viola-Jones Depending on Python. Indones. J. Electr. Eng. Comput. Sci. 2020, 20, 1513–1521. [Google Scholar] [CrossRef]
- Marchand-Niño, W.-R.; Vega Ventocilla, E.J. Modelo Balanced Scorecard Para Los Controles Críticos de Seguridad Informática Según El Center for Internet Security (CIS). Interfases 2020, 13, 57–76. [Google Scholar] [CrossRef]
- Ziogas, A.N.; Ben-Nun, T.; Schneider, T.; Hoefler, T. NPBench: A Benchmarking Suite for High-Performance NumPy. In Proceedings of the ACM International Conference on Supercomputing, Virtual Event, 14–17 June 2021; pp. 63–74. [Google Scholar]
- Ha, S.; Liu, D.; Mu, L. Prediction of Yangtze River Streamflow Based on Deep Learning Neural Network with El Niño–Southern Oscillation. Sci. Rep. 2021, 11, 11738. [Google Scholar] [CrossRef]
- Panda, D.K.; Bhoi, R.K. Artificial Neural Network Prediction of Material Removal Rate in Electro Discharge Machining. Mater. Manuf. Process. 2005, 20, 645–672. [Google Scholar] [CrossRef]
- Goethals, P.L.M.; Dedecker, A.P.; Gabriels, W.; Lek, S.; De Pauw, N. Applications of Artificial Neural Networks Predicting Macroinvertebrates in Freshwaters. Aquat. Ecol. 2007, 41, 491–508. [Google Scholar] [CrossRef]
- Sánchez, S.E.T.; Rodríguez, M.O.; Jiménez, A.E.; Soberanes, H.J.P. Implementación de Algoritmos de Inteligencia Artificial Para El Entrenamiento de Redes Neuronales de Segunda Generación. Jóvenes En La Cienc. 2016, 2, 6–10. [Google Scholar]
- Ortiz-Aguilar, L.D.M.; Carpio, M.; Soria-Alcaraz, J.A.; Puga, H.; Díaz, C.; Lino, C.; Tapia, V. Training OFF-Line Hyperheuristics For Course Timetabling Using K-Folds Cross Validation. La Rev. Program. Matemática Y Softw. 2016, 8, 1–8. [Google Scholar]
- Aguilar, L.D.M.O.; Valadez, J.M.C.; Alcaraz, J.A.S.; Soberanes, H.J.P.; Díaz, C.; Ramírez, C.L.; Aldape, J.E.; Alatorre, O.; Reyes, A.A.; Tapia, V. Entrenamiento de una Hiperheurística con aprendizaje fuera de línea para el problema de Calendarización de horarios usando Validación Cruzada. Program. Matemática Y Softw. 2016, 8, 1–8. [Google Scholar]
- Park, K.; Choi, Y.; Choi, W.J.; Ryu, H.-Y.; Kim, H. LSTM-Based Battery Remaining Useful Life Prediction with Multi-Channel Charging Profiles. IEEE Access 2020, 8, 20786–20798. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Study | Approach | Data Used | Modeling Technique | Performance Evaluation | Originality | Comparison with Previous Works | Contribution |
|---|---|---|---|---|---|---|---|
| [16] | SVM-based Model X | Historical weather data from local stations | Support Vector Machine | Accuracy and F1 score | Conventional SVM approach | Mentioned, but no details | Limited contribution to prediction |
| [17] | Model Y with LSTM networks | Data from time series of climate variables | Recurrent Neural Networks (LSTM) | RMSE and MAE | Novel LSTM approach | Limited comparison with previous approaches | Outstanding contribution to accuracy |
| [18] | Z model using ARIMA | Meteorological data and historical statistics | Time series model (ARIMA) | AIC and BIC | Traditional ARIMA approach | Comparison with similar works | Contribution to statistical analysis |
| This Proposal | Deep learning model with LSTM networks | Historical weather data from local stations | Recurrent Neural Networks (LSTM) | Accuracy, sensitivity, and RMSE | Innovative approach with deep learning | Detailed comparison with previous approaches | Contribution to precision and sensitivity |
| Precipitation | Temperature | Humidity | Evapotranspiration | Soil Moisture | |
|---|---|---|---|---|---|
| Count | 8132 | 8132 | 8132 | 8132 | 8132 |
| Mean | 103.653 | 24.933 | 70.166 | 5.043 | 19.958 |
| Std | 47.201 | 5.097 | 9.941 | 1.974 | 5.003 |
| Min | 0.062 | 1.791 | 36.709 | 0.007 | 2.172 |
| 25% | 69.848 | 21.504 | 63.276 | 3.655 | 16.590 |
| 50% | 101.329 | 24.861 | 70.173 | 5.014 | 19.941 |
| 75% | 135.436 | 28.339 | 76.829 | 6.414 | 23.309 |
| Max | 293.501 | 44.945 | 107.540 | 13.129 | 38.396 |
| Metric | Value |
|---|---|
| RMSE | 0.1654 |
| MAE | 5.0686 |
| R^2 | 0.8437 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Villegas-Ch, W.; García-Ortiz, J. A Long Short-Term Memory-Based Prototype Model for Drought Prediction. Electronics 2023, 12, 3956. https://doi.org/10.3390/electronics12183956
Villegas-Ch W, García-Ortiz J. A Long Short-Term Memory-Based Prototype Model for Drought Prediction. Electronics. 2023; 12(18):3956. https://doi.org/10.3390/electronics12183956
Chicago/Turabian StyleVillegas-Ch, William, and Joselin García-Ortiz. 2023. "A Long Short-Term Memory-Based Prototype Model for Drought Prediction" Electronics 12, no. 18: 3956. https://doi.org/10.3390/electronics12183956
APA StyleVillegas-Ch, W., & García-Ortiz, J. (2023). A Long Short-Term Memory-Based Prototype Model for Drought Prediction. Electronics, 12(18), 3956. https://doi.org/10.3390/electronics12183956