
A Spatio-Temporal Spotting Network with Sliding Windows for Micro-Expression Detection


 and
and 
Abstract
:1. Introduction
- A spatio-temporal network with sliding windows is proposed for effective micro-expression spotting.
- A key-frame-extraction method is fused into the spatio-temporal network so that spatial features of the video clip are denoted as a more concise key-frame-based representation.
- Experiments show that the proposed model achieves F1-scores of on the CAS(ME) and on the SAMM Long Videos for micro-expression spotting and performs better with a large margin compared with the state-of-the-art methods.
2. The Spatio-Temporal Spotting Network with Sliding Windows
2.1. Spatial Information Extraction
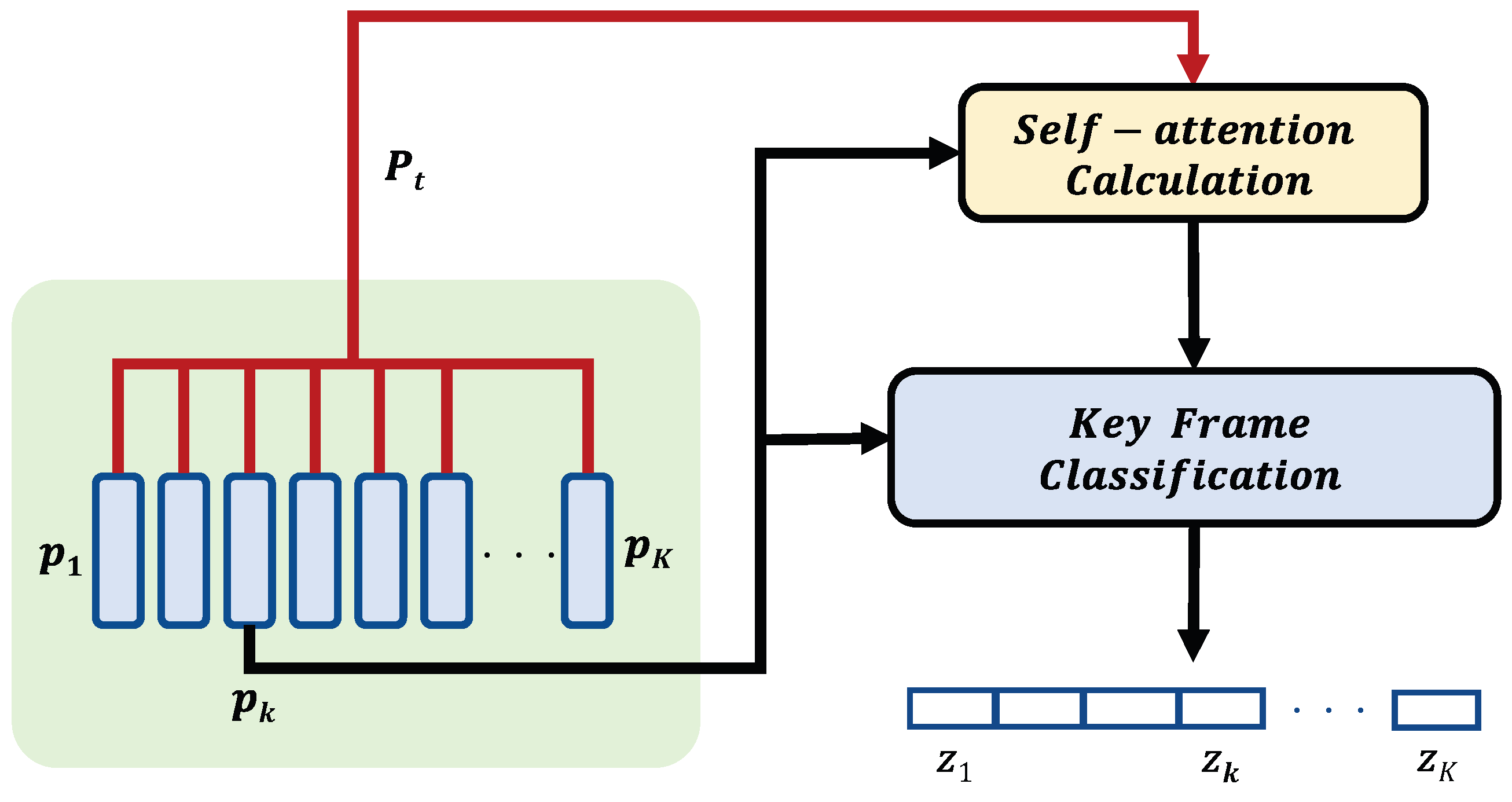
2.2. Key Frames Extraction
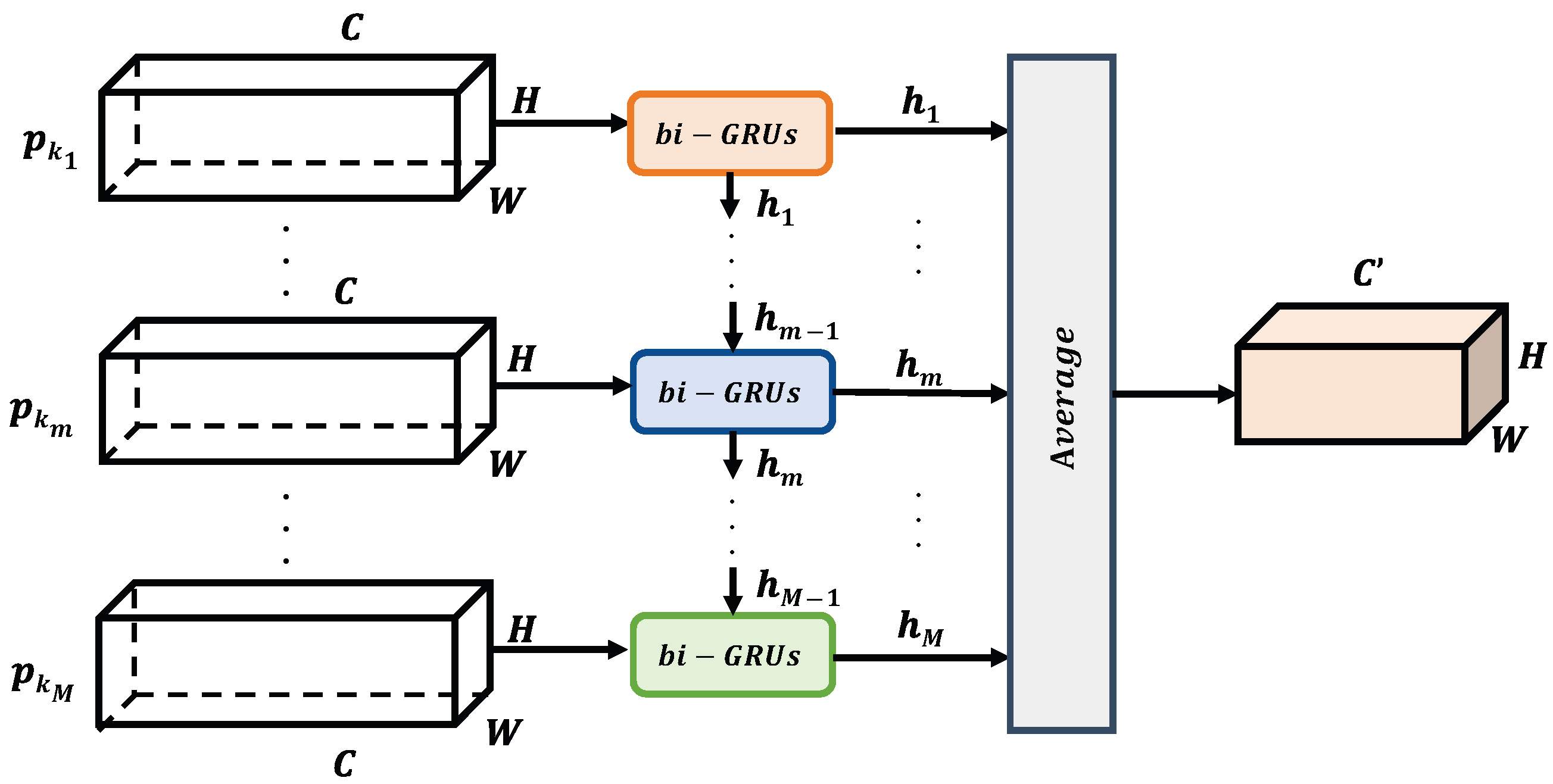
2.3. Temporal Information Extraction
2.4. Segment Merging
3. Experiments
3.1. Datasets and Evaluation Metrics
3.2. Experiments and Results
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ekman, P. Darwin, deception, and facial expression. Ann. N. Y. Acad. Sci. 2003, 1000, 205–221. [Google Scholar] [CrossRef] [PubMed]
- Gottschalk, L.A.; Auerbach, A.H.; Haggard, E.A.; Isaacs, K.S. Micromomentary facial expressions as indicators of ego mechanisms in psychotherapy. In Methods of Research in Psychotherapy; Springer: Boston, MA, USA, 1966; pp. 154–165. [Google Scholar] [CrossRef]
- Ekman, P.; Friesen, W.V. Nonverbal leakage and clues to deception. Psychiatry 1969, 32, 88–106. [Google Scholar] [CrossRef] [PubMed]
- Yan, W.J.; Wu, Q.; Liang, J.; Chen, Y.H.; Fu, X. How fast are the leaked facial expressions: The duration of micro-expressions. J. Nonverbal Behav. 2013, 37, 217–230. [Google Scholar] [CrossRef]
- Porter, S.; Ten Brinke, L. Reading between the lies: Identifying concealed and falsified emotions in universal facial expressions. Psychol. Sci. 2008, 19, 508–514. [Google Scholar] [CrossRef] [PubMed]
- Stewart, P.A.; Waller, B.M.; Schubert, J.N. Presidential speechmaking style: Emotional response to micro-expressions of facial affect. Motiv. Emot. 2009, 33, 125–135. [Google Scholar] [CrossRef]
- O’sullivan, M.; Frank, M.G.; Hurley, C.M.; Tiwana, J. Police lie detection accuracy: The effect of lie scenario. Law Hum. Behav. 2009, 33, 530–538. [Google Scholar] [CrossRef]
- Endres, J.; Laidlaw, A. Micro-expression recognition training in medical students: A pilot study. BMC Med. Educ. 2009, 9, 47. [Google Scholar] [CrossRef] [PubMed]
- Lin, W.; Zhu, M.; Zhou, X.; Zhang, R.; Zhao, X.; Shen, S.; Sun, L. A Deep Neural Collaborative Filtering based Service Recommendation Method with Multi-Source Data for Smart Cloud-Edge Collaboration Applications. Tsinghua Sci. Technol. 2023. [Google Scholar]
- Zhang, P.; Chen, N.; Shen, S.; Yu, S.; Kumar, N.; Hsu, C.H. AI-Enabled Space-Air-Ground Integrated Networks: Management and Optimization. IEEE Netw. 2023, 23, 6792. [Google Scholar] [CrossRef]
- Feng, S.; Zhao, L.; Shi, H.; Wang, M.; Shen, S.; Wang, W. One-dimensional VGGNet for high-dimensional data. Appl. Soft Comput. 2023, 135, 110035. [Google Scholar] [CrossRef]
- Jingting, L.; Wang, S.J.; Yap, M.H.; See, J.; Hong, X.; Li, X. MEGC2020-the third facial micro-expression grand challenge. In Proceedings of the 2020 15th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2020), Buenos Aires, Argentina, 16–20 November 2020; pp. 777–780. [Google Scholar] [CrossRef]
- Li, X.; Hong, X.; Moilanen, A.; Huang, X.; Pfister, T.; Zhao, G.; Pietikäinen, M. Towards reading hidden emotions: A comparative study of spontaneous micro-expression spotting and recognition methods. IEEE Trans. Affect. Comput. 2017, 9, 563–577. [Google Scholar] [CrossRef]
- Davison, A.; Merghani, W.; Lansley, C.; Ng, C.C.; Yap, M.H. Objective micro-facial movement detection using facs-based regions and baseline evaluation. In Proceedings of the 2018 13th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2018), Xi’an, China, 15–19 May 2018; pp. 642–649. [Google Scholar] [CrossRef]
- Lu, H.; Kpalma, K.; Ronsin, J. Micro-expression detection using integral projections. J. WSCG 2017, 25, 87–96. [Google Scholar]
- Duque, C.A.; Alata, O.; Emonet, R.; Legrand, A.C.; Konik, H. Micro-expression spotting using the riesz pyramid. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 66–74. [Google Scholar] [CrossRef]
- Liong, S.T.; See, J.; Phan, R.C.W.; Oh, Y.H.; Le Ngo, A.C.; Wong, K.; Tan, S.W. Spontaneous subtle expression detection and recognition based on facial strain. Signal Process. Image Commun. 2016, 47, 170–182. [Google Scholar] [CrossRef]
- Patel, D.; Zhao, G.; Pietikäinen, M. Spatiotemporal integration of optical flow vectors for micro-expression detection. In Proceedings of the International Conference on Advanced Concepts for Intelligent Vision Systems, Catania, Italy, 26–29 October 2015; Springer: Cham, Swizerland, 2015; pp. 369–380. [Google Scholar] [CrossRef]
- Li, X.; Yu, J.; Zhan, S. Spontaneous facial micro-expression detection based on deep learning. In Proceedings of the 2016 IEEE 13th International Conference on Signal Processing (ICSP), Chengdu, China, 6–10 November 2016; pp. 1130–1134. [Google Scholar] [CrossRef]
- Wang, S.J.; Wu, S.; Fu, X. A main directional maximal difference analysis for spotting micro-expressions. In Proceedings of the Asian Conference on Computer Vision, Taipei, Taiwan, 20–24 November 2016; Springer: Cham, Swizerland, 2016; pp. 449–461. [Google Scholar] [CrossRef]
- Han, Y.; Li, B.; Lai, Y.K.; Liu, Y.J. CFD: A collaborative feature difference method for spontaneous micro-expression spotting. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 1942–1946. [Google Scholar] [CrossRef]
- Li, Y.; Huang, X.; Zhao, G. Can micro-expression be recognized based on single apex frame? In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 3094–3098. [Google Scholar] [CrossRef]
- Shreve, M.; Godavarthy, S.; Manohar, V.; Goldgof, D.; Sarkar, S. Towards macro-and micro-expression spotting in video using strain patterns. In Proceedings of the 2009 Workshop on Applications of Computer Vision (WACV), Snowbird, UT, USA, 7–8 December 2009; pp. 1–6. [Google Scholar] [CrossRef]
- Shreve, M.; Godavarthy, S.; Goldgof, D.; Sarkar, S. Macro-and micro-expression spotting in long videos using spatio-temporal strain. In Proceedings of the 2011 IEEE International Conference on Automatic Face & Gesture Recognition (FG), Santa Barbara, CA, USA, 21–23 March 2011; pp. 51–56. [Google Scholar] [CrossRef]
- Moilanen, A.; Zhao, G.; Pietikäinen, M. Spotting rapid facial movements from videos using appearance-based feature difference analysis. In Proceedings of the 2014 22nd International Conference on Pattern Recognition, Stockholm, Sweden, 24–28 August 2014; pp. 1722–1727. [Google Scholar] [CrossRef]
- Beh, K.X.; Goh, K.M. Micro-expression spotting using facial landmarks. In Proceedings of the 2019 IEEE 15th International Colloquium on Signal Processing & Its Applications (CSPA), Penang, Malaysia, 8–9 March 2019; pp. 192–197. [Google Scholar] [CrossRef]
- Zhang, Z.; Chen, T.; Meng, H.; Liu, G.; Fu, X. SMEConvNet: A convolutional neural network for spotting spontaneous facial micro-expression from long videos. IEEE Access 2018, 6, 71143–71151. [Google Scholar] [CrossRef]
- Nag, S.; Bhunia, A.K.; Konwer, A.; Roy, P.P. Facial micro-expression spotting and recognition using time contrasted feature with visual memory. In Proceedings of the ICASSP 2019–2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 2022–2026. [Google Scholar] [CrossRef]
- Pan, H.; Xie, L.; Wang, Z. Spatio-temporal Convolutional Attention Network for Spotting Macro-and Micro-expression Intervals. In Proceedings of the 1st Workshop on Facial Micro-Expression: Advanced Techniques for Facial Expressions Generation and Spotting, Virtual Event China, 24 October 2021; pp. 25–30. [Google Scholar] [CrossRef]
- Yang, B.; Wu, J.; Zhou, Z.; Komiya, M.; Kishimoto, K.; Xu, J.; Nonaka, K.; Horiuchi, T.; Komorita, S.; Hattori, G.; et al. Facial Action Unit-based Deep Learning Framework for Spotting Macro-and Micro-expressions in Long Video Sequences. In Proceedings of the 29th ACM International Conference on Multimedia, Virtual Event China, 20–24 October 2021; pp. 4794–4798. [Google Scholar] [CrossRef]
- Pan, H.; Xie, L.; Wang, Z. Local bilinear convolutional neural network for spotting macro-and micro-expression intervals in long video sequences. In Proceedings of the 2020 15th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2020), Buenos Aires, Argentina, 16–20 November 2020; pp. 749–753. [Google Scholar] [CrossRef]
- Xue, L.; Zhu, T.; Hao, J. A Two-stage Deep Neural Network for Macro-and Micro-Expression Spotting from Long-term Videos. In Proceedings of the 2021 14th International Symposium on Computational Intelligence and Design (ISCID), Hangzhou, China, 11–12 December 2021; pp. 282–286. [Google Scholar] [CrossRef]
- Yap, C.H.; Yap, M.H.; Davison, A.K.; Cunningham, R. Efficient lightweight 3d-cnn using frame skipping and contrast enhancement for facial macro-and micro-expression spotting. arXiv 2021, arXiv:2105.06340. [Google Scholar] [CrossRef]
- Liong, G.B.; See, J.; Wong, L.K. Shallow optical flow three-stream CNN for macro-and micro-expression spotting from long videos. In Proceedings of the 2021 IEEE International Conference on Image Processing (ICIP), Anchorage, AK, USA, 19–22 September 2021; pp. 2643–2647. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Li, F. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar] [CrossRef]
- Mollahosseini, A.; Hasani, B.; Mahoor, M.H. Affectnet: A database for facial expression, valence, and arousal computing in the wild. IEEE Trans. Affect. Comput. 2017, 10, 18–31. [Google Scholar] [CrossRef]
- Liong, S.T.; See, J.; Wong, K.; Phan, R.C.W. Less is more: Micro-expression recognition from video using apex frame. Signal Process. Image Commun. 2018, 62, 82–92. [Google Scholar] [CrossRef]
- Peng, M.; Wang, C.; Bi, T.; Shi, Y.; Zhou, X.; Chen, T. A novel apex-time network for cross-dataset micro-expression recognition. In Proceedings of the 2019 8th International Conference on Affective Computing and Intelligent Interaction (ACII), Cambridge, UK, 3–6 September 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Zhou, L.; Mao, Q.; Xue, L. Cross-database micro-expression recognition: A style aggregated and attention transfer approach. In Proceedings of the 2019 IEEE International Conference on Multimedia & Expo Workshops (ICMEW), Shanghai, China, 8–12 July 2019; pp. 102–107. [Google Scholar] [CrossRef]
- Qu, F.; Wang, S.J.; Yan, W.J.; Li, H.; Wu, S.; Fu, X. CAS(ME)2: A database for spontaneous macro-expression and micro-expression spotting and recognition. IEEE Trans. Affect. Comput. 2017, 9, 424–436. [Google Scholar] [CrossRef]
- Davison, A.K.; Lansley, C.; Costen, N.; Tan, K.; Yap, M.H. Samm: A spontaneous micro-facial movement dataset. IEEE Trans. Affect. Comput. 2016, 9, 116–129. [Google Scholar] [CrossRef]
- Loshchilov, I.; Hutter, F. Sgdr: Stochastic gradient descent with warm restarts. arXiv 2016, arXiv:1608.03983. [Google Scholar]
- Williams, R.J. Simple statistical gradient-following algorithms for connectionist reinforcement learning. Mach. Learn. 1992, 8, 229–256. [Google Scholar] [CrossRef]
- Yu, W.W.; Jiang, J.; Li, Y.J. LSSNet: A two-stream convolutional neural network for spotting macro-and micro-expression in long videos. In Proceedings of the 29th ACM International Conference on Multimedia, Virtual Event China, 20–24 October 2021; pp. 4745–4749. [Google Scholar] [CrossRef]
- Liong, G.B.; Liong, S.T.; See, J.; Chan, C.S. MTSN: A Multi-Temporal Stream Network for Spotting Facial Macro-and Micro-Expression with Hard and Soft Pseudo-labels. In Proceedings of the 2nd Workshop on Facial Micro-Expression: Advanced Techniques for Multi-Modal Facial Expression Analysis, Lisboa, Portugal, 14 October 2022; pp. 3–10. [Google Scholar] [CrossRef]
- Yap, C.H.; Yap, M.H.; Davison, A.; Kendrick, C.; Li, J.; Wang, S.J.; Cunningham, R. 3d-cnn for facial micro-and macro-expression spotting on long video sequences using temporal oriented reference frame. In Proceedings of the 30th ACM International Conference on Multimedia, Lisboa, Portugal, 10–14 October 2022; pp. 7016–7020. [Google Scholar] [CrossRef]
- Yap, C.H.; Kendrick, C.; Yap, M.H. Samm long videos: A spontaneous facial micro-and macro-expressions dataset. In Proceedings of the 2020 15th IEEE International Conference on Automatic Face and Gesture Recognition (FG 2020), Buenos Aires, Argentina, 16–20 November 2020; pp. 771–776. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | CAS(ME) | SAMM Long Videos | ||||
|---|---|---|---|---|---|---|
| Method | Macro-Expression | Micro-Expression | Overall | Macro-Expression | Micro-Expression | Overall |
| EL-FACE [33] | 0.0841 | 0.0184 | 0.0620 | 0.1973 | 0.0426 | 0.1261 |
| SOFTNet(w/o) [34] | 0.1615 | 0.1379 | 0.1551 | 0.1463 | 0.1063 | 0.1293 |
| 3D-CNN [47] | 0.2158 | 0.0253 | 0.1417 | 0.1921 | 0.0425 | 0.1066 |
| SOFTNet [34] | 0.2410 | 0.1173 | 0.2022 | 0.2169 | 0.1520 | 0.1881 |
| TSMSNet(w/o) [32] | 0.2440 | 0.2275 | 0.2407 | 0.2342 | 0.1899 | 0.2144 |
| TSMSNet [32] | 0.2515 | 0.2275 | 0.2466 | 0.2395 | 0.1969 | 0.2213 |
| Yang et al. [30] | 0.2599 | 0.0339 | 0.2118 | 0.3553 | 0.1155 | 0.2736 |
| Yap et al. [48] | - | - | - | 0.4081 | 0.0508 | 0.3299 |
| LSSNet-LSM [45] | 0.3800 | 0.0630 | 0.3270 | 0.3360 | 0.2180 | 0.2900 |
| MTSN [46] | 0.4101 | 0.0808 | 0.3620 | 0.3459 | 0.0878 | 0.2867 |
| STSNet_SW | 0.6694 | 0.6600 | 0.6678 | 0.5539 | 0.6091 | 0.5697 |
| Dataset | CAS(ME) | SAMM Long Videos | ||||
|---|---|---|---|---|---|---|
| Expression | Macro-Expression | Micro-Expression | Overall | Macro-Expression | Micro-Expression | Overall |
| Total | 300 | 57 | 357 | 343 | 159 | 502 |
| TP | 166 | 33 | 199 | 167 | 74 | 241 |
| FP | 30 | 10 | 40 | 93 | 10 | 103 |
| FN | 134 | 24 | 158 | 176 | 85 | 261 |
| Precision | 0.8469 | 0.7674 | 0.8326 | 0.6423 | 0.8810 | 0.7006 |
| Recall | 0.5533 | 0.5789 | 0.5574 | 0.4869 | 0.4654 | 0.4801 |
| F1-score | 0.6694 | 0.6600 | 0.6678 | 0.5539 | 0.6091 | 0.5697 |
| Dataset | CAS(ME) | SAMM Long Videos | ||||
|---|---|---|---|---|---|---|
| Expression | Macro-Expression | Micro-Expression | Overall | Macro-Expression | Micro-Expression | Overall |
| Total | 300 | 57 | 357 | 343 | 159 | 502 |
| TP | 165 | 33 | 198 | 175 | 80 | 255 |
| FP | 30 | 10 | 40 | 87 | 11 | 98 |
| FN | 135 | 24 | 159 | 168 | 79 | 247 |
| Precision | 0.8462 | 0.7674 | 0.8319 | 0.6679 | 0.8791 | 0.7224 |
| Recall | 0.5500 | 0.5789 | 0.5546 | 0.5102 | 0.5031 | 0.5080 |
| F1-score | 0.6667 | 0.6600 | 0.6655 | 0.5785 | 0.6400 | 0.5965 |
| Dataset | CAS(ME) | SAMM Long Videos | ||||
|---|---|---|---|---|---|---|
| Expression | Macro-Expression | Micro-Expression | Overall | Macro-Expression | Micro-Expression | Overall |
| Total | 300 | 57 | 357 | 343 | 159 | 502 |
| TP | 167 | 22 | 189 | 179 | 49 | 228 |
| FP | 32 | 42 | 74 | 87 | 76 | 163 |
| FN | 133 | 35 | 168 | 164 | 110 | 274 |
| Precision | 0.8392 | 0.3438 | 0.7186 | 0.6729 | 0.3920 | 0.5831 |
| Recall | 0.5567 | 0.3860 | 0.5294 | 0.5219 | 0.3082 | 0.4542 |
| F1-score | 0.6693 | 0.3636 | 0.6097 | 0.5878 | 0.3451 | 0.5106 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fu, W.; An, Z.; Huang, W.; Sun, H.; Gong, W.; Gonzàlez, J. A Spatio-Temporal Spotting Network with Sliding Windows for Micro-Expression Detection. Electronics 2023, 12, 3947. https://doi.org/10.3390/electronics12183947
Fu W, An Z, Huang W, Sun H, Gong W, Gonzàlez J. A Spatio-Temporal Spotting Network with Sliding Windows for Micro-Expression Detection. Electronics. 2023; 12(18):3947. https://doi.org/10.3390/electronics12183947
Chicago/Turabian StyleFu, Wenwen, Zhihong An, Wendong Huang, Haoran Sun, Wenjuan Gong, and Jordi Gonzàlez. 2023. "A Spatio-Temporal Spotting Network with Sliding Windows for Micro-Expression Detection" Electronics 12, no. 18: 3947. https://doi.org/10.3390/electronics12183947
APA StyleFu, W., An, Z., Huang, W., Sun, H., Gong, W., & Gonzàlez, J. (2023). A Spatio-Temporal Spotting Network with Sliding Windows for Micro-Expression Detection. Electronics, 12(18), 3947. https://doi.org/10.3390/electronics12183947