
S2Former: Parallel Spectral–Spatial Transformer for Hyperspectral Image Classification


Abstract
:
1. Introduction
- 1.
- A parallel spectral–spatial transformer architecture is proposed for HSI classification, which is an efficient extraction of the spectral and spatial features in dual parallel branches.
- 2.
- MCSA and MSSA, which are tailored for spectral and spatial feature extraction, improve the mining of local–global spatial and spectral sequence features.
- 3.
- A local activation feed-forward network is proposed to enhance the extraction of local context signals by encoding information from spatially neighbouring pixel positions.
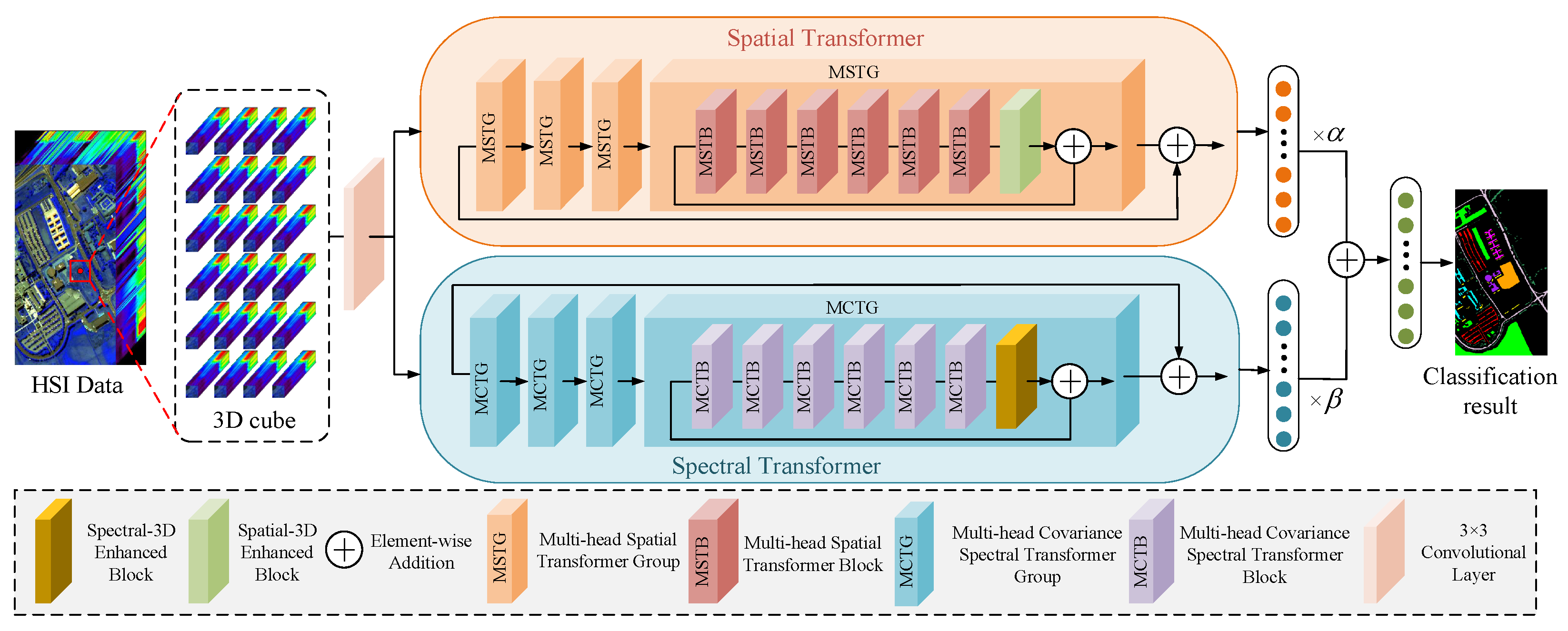
2. Methodology
2.1. Spatial Transformer
2.1.1. Multi-Head Spatial Self-Attention
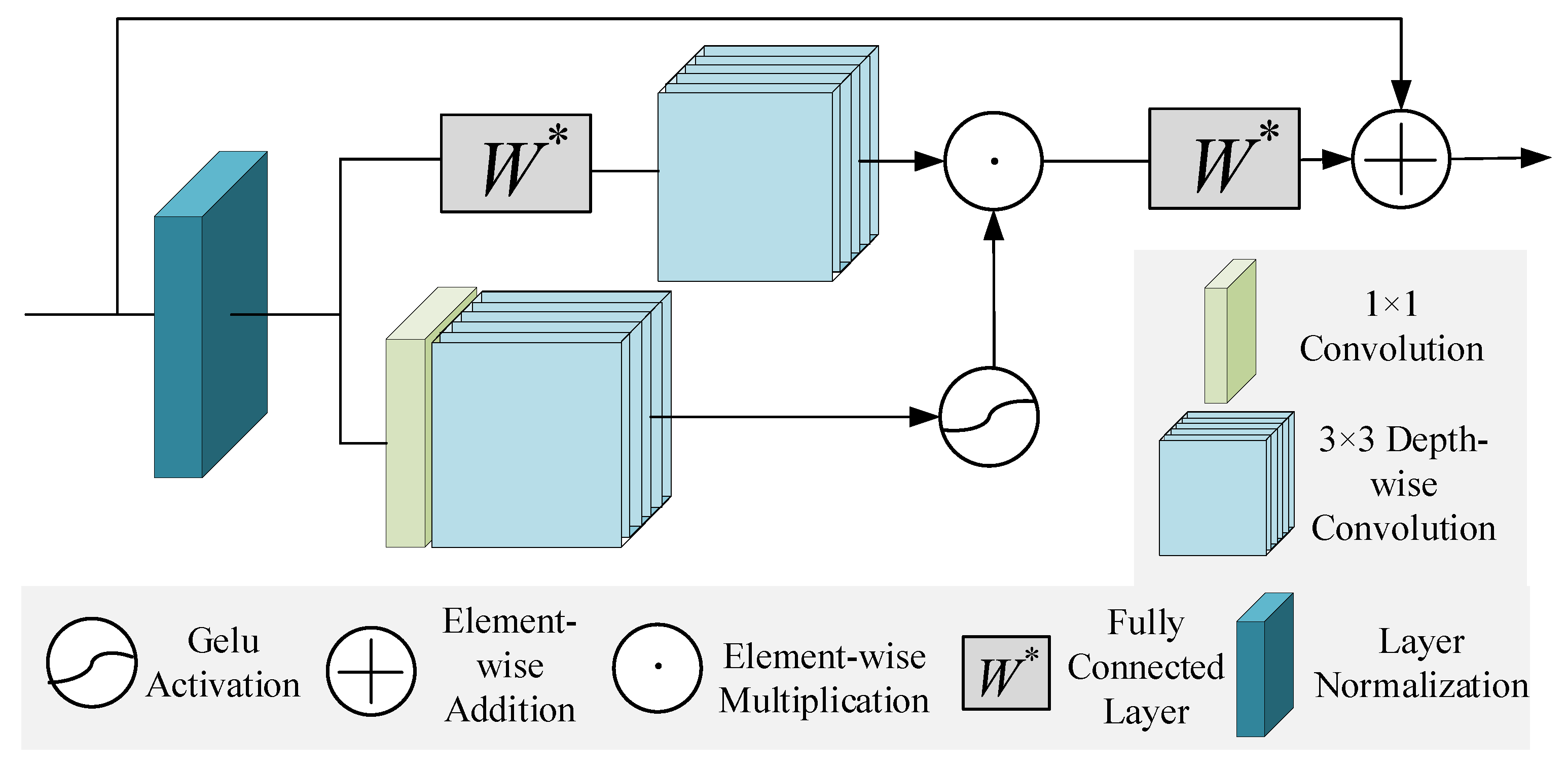
2.1.2. Local Activation Feed-Forward Network
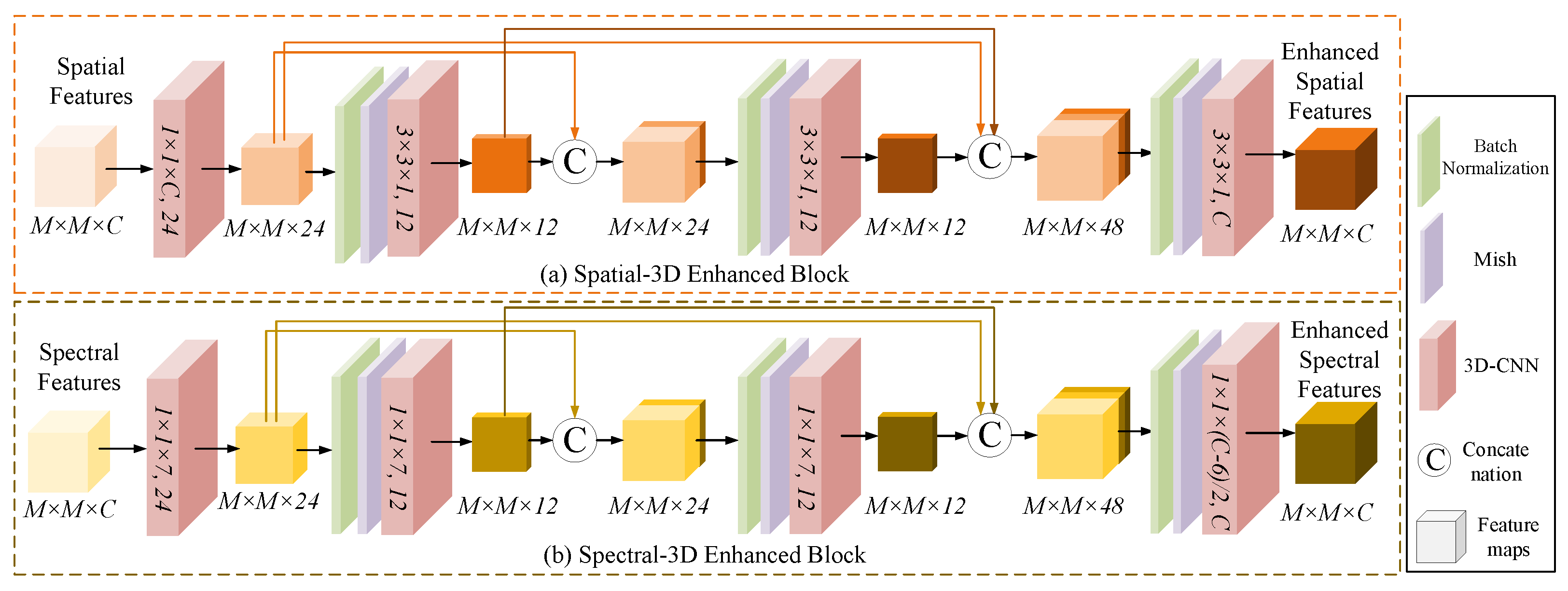
2.1.3. Spatial-3D Enhanced Block
2.2. Spectral Transformer
2.2.1. Multi-Head Covariance Spectral Attention
2.2.2. Spectral-3D Enhanced Block
3. Experimental Results
3.1. Experimental Settings
3.2. Ablation Studies
3.2.1. Discussion on Input Patch Size Comparison
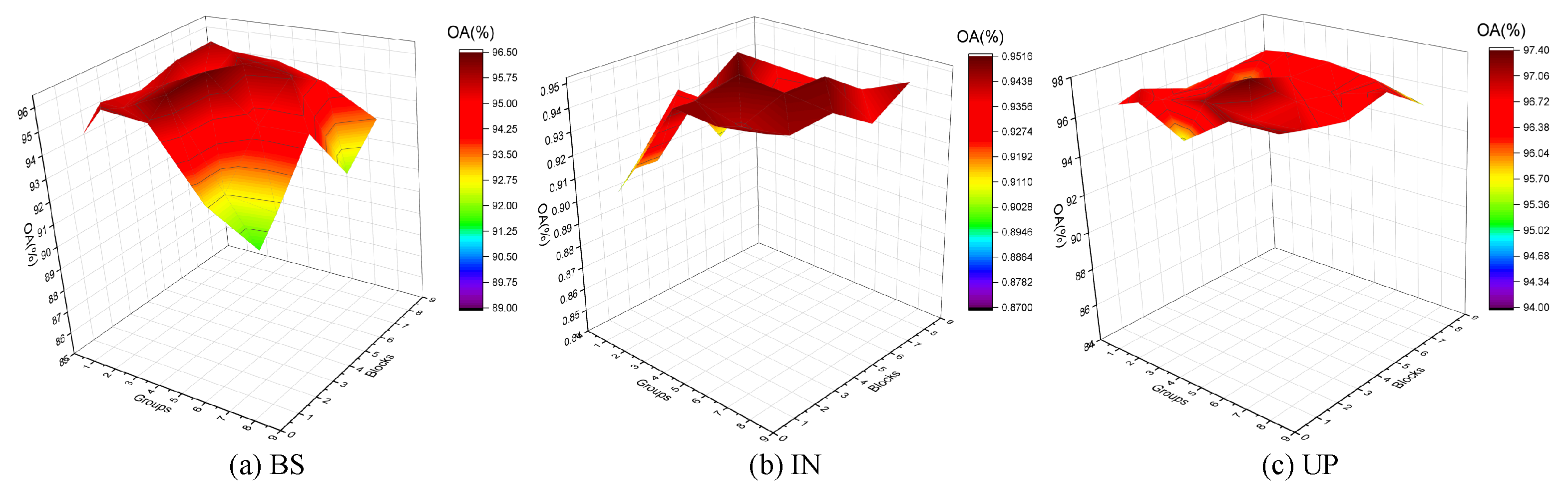
3.2.2. Discussion on Model Depth
3.2.3. Discussion on Parallel Spectral–Spatial Transformer Architecture
3.2.4. Discussion on Self-Attention and Feed-Forward Network
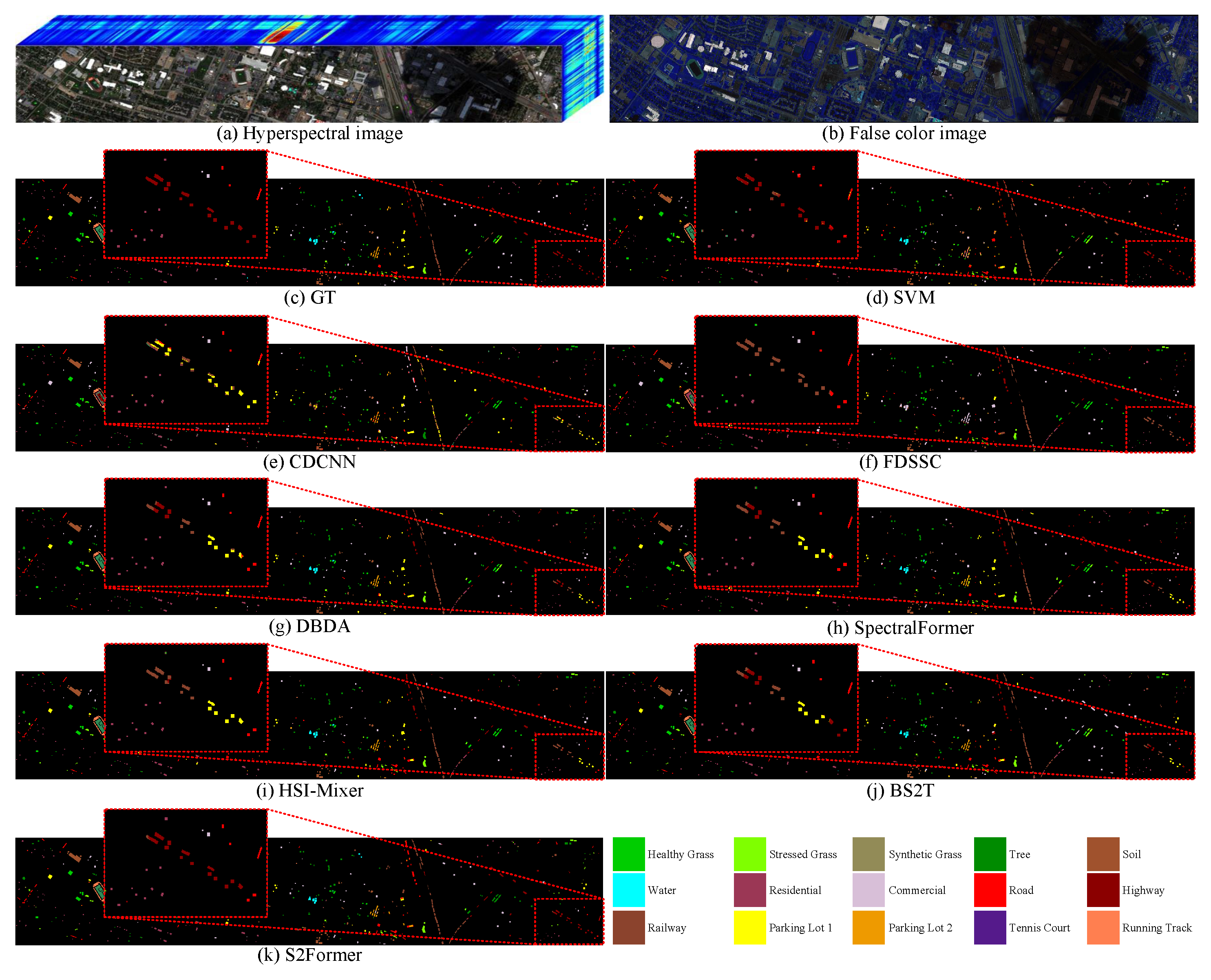
3.3. Comparison with Other Methods
3.4. Comparison of the Complexity
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Chen, F.; Jiang, H.; Van de Voorde, T.; Lu, S.; Xu, W.; Zhou, Y. Land cover mapping in urban environments using hyperspectral APEX data: A study case in Baden, Switzerland. Int. J. Appl. Earth Obs. Geoinf. 2018, 71, 70–82. [Google Scholar] [CrossRef]
- Sethy, P.K.; Pandey, C.; Sahu, Y.K.; Behera, S.K. Hyperspectral imagery applications for precision agriculture-a systemic survey. Multimed. Tools Appl. 2021, 81, 3005–3038. [Google Scholar] [CrossRef]
- Zhao, X.; Niu, J.; Liu, C.; Ding, Y.; Hong, D. Hyperspectral Image Classification Based on Graph Transformer Network and Graph Attention Mechanism. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Pour, A.B.; Zoheir, B.; Pradhan, B.; Hashim, M. Editorial for the special issue: Multispectral and hyperspectral remote sensing data for mineral exploration and environmental monitoring of mined areas. Remote Sens. 2021, 13, 519. [Google Scholar] [CrossRef]
- Peyghambari, S.; Zhang, Y. Hyperspectral remote sensing in lithological mapping, mineral exploration, and environmental geology: An updated review. J. Appl. Remote Sens. 2021, 15, 031501. [Google Scholar] [CrossRef]
- Cao, X.; Fu, X.; Xu, C.; Meng, D. Deep spatial-spectral global reasoning network for hyperspectral image denoising. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–14. [Google Scholar] [CrossRef]
- Zhang, H.; Cai, J.; He, W.; Shen, H.; Zhang, L. Double low-rank matrix decomposition for hyperspectral image denoising and destriping. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–19. [Google Scholar] [CrossRef]
- Rasti, B.; Koirala, B. SUnCNN: Sparse unmixing using unsupervised convolutional neural network. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Zhang, X.; Sun, Y.; Zhang, J.; Wu, P.; Jiao, L. Hyperspectral unmixing via deep convolutional neural networks. IEEE Geosci. Remote Sens. Lett. 2018, 15, 1755–1759. [Google Scholar] [CrossRef]
- He, J.; Yuan, Q.; Li, J.; Xiao, Y.; Liu, X.; Zou, Y. DsTer: A dense spectral transformer for remote sensing spectral super-resolution. Int. J. Appl. Earth Obs. Geoinf. 2022, 109, 102773. [Google Scholar] [CrossRef]
- Li, Q.; Wang, Q.; Li, X. Exploring the Relationship Between 2D/3D Convolution for Hyperspectral Image Super-Resolution. IEEE Trans. Geosci. Remote Sens. 2021, 59, 8693–8703. [Google Scholar] [CrossRef]
- Zou, C.; Zhang, C. Hyperspectral image super-resolution using cluster-based deep convolutional networks. Signal Process. Image Commun. 2023, 110, 116884. [Google Scholar] [CrossRef]
- Zou, C.; Huang, X. Hyperspectral image super-resolution combining with deep learning and spectral unmixing. Signal Process. Image Commun. 2020, 84, 115833. [Google Scholar] [CrossRef]
- Xie, W.; Zhang, X.; Li, Y.; Wang, K.; Du, Q. Background learning based on target suppression constraint for hyperspectral target detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 5887–5897. [Google Scholar] [CrossRef]
- Zhao, X.; Hou, Z.; Wu, X.; Li, W.; Ma, P.; Tao, R. Hyperspectral target detection based on transform domain adaptive constrained energy minimization. Int. J. Appl. Earth Obs. Geoinf. 2021, 103, 102461. [Google Scholar] [CrossRef]
- Qu, J.; Xu, Y.; Dong, W.; Li, Y.; Du, Q. Dual-Branch Difference Amplification Graph Convolutional Network for Hyperspectral Image Change Detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–12. [Google Scholar] [CrossRef]
- Sun, G.; Zhang, X.; Jia, X.; Ren, J.; Zhang, A.; Yao, Y.; Zhao, H. Deep fusion of localized spectral features and multi-scale spatial features for effective classification of hyperspectral images. Int. J. Appl. Earth Obs. Geoinf. 2020, 91, 102157. [Google Scholar] [CrossRef]
- Yu, D.; Li, Q.; Wang, X.; Xu, C.; Zhou, Y. A Cross-Level Spectral—Spatial Joint Encode Learning Framework for Imbalanced Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–17. [Google Scholar] [CrossRef]
- Kumar, V.; Singh, R.S.; Dua, Y. Morphologically dilated convolutional neural network for hyperspectral image classification. Signal Process. Image Commun. 2022, 101, 116549. [Google Scholar] [CrossRef]
- Mookambiga, A.; Gomathi, V. Kernel eigenmaps based multiscale sparse model for hyperspectral image classification. Signal Process. Image Commun. 2021, 99, 116416. [Google Scholar] [CrossRef]
- Ghasrodashti, E.K.; Sharma, N. Hyperspectral image classification using an extended Auto-Encoder method. Signal Process. Image Commun. 2021, 92, 116111. [Google Scholar] [CrossRef]
- Lee, H.; Kwon, H. Contextual deep CNN based hyperspectral classification. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 3322–3325. [Google Scholar]
- Chen, Y.; Jiang, H.; Li, C.; Jia, X.; Ghamisi, P. Deep feature extraction and classification of hyperspectral images based on convolutional neural networks. IEEE Trans. Geosci. Remote Sens. 2016, 54, 6232–6251. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Zhong, Z.; Li, J.; Luo, Z.; Chapman, M. Spectral–spatial residual network for hyperspectral image classification: A 3-D deep learning framework. IEEE Trans. Geosci. Remote Sens. 2017, 56, 847–858. [Google Scholar] [CrossRef]
- Wang, W.; Dou, S.; Jiang, Z.; Sun, L. A fast dense spectral–spatial convolution network framework for hyperspectral images classification. Remote Sens. 2018, 10, 1068. [Google Scholar] [CrossRef]
- Fang, B.; Li, Y.; Zhang, H.; Chan, J.C.W. Hyperspectral images classification based on dense convolutional networks with spectral-wise attention mechanism. Remote Sens. 2019, 11, 159. [Google Scholar] [CrossRef]
- Ma, W.; Yang, Q.; Wu, Y.; Zhao, W.; Zhang, X. Double-branch multi-attention mechanism network for hyperspectral image classification. Remote Sens. 2019, 11, 1307. [Google Scholar] [CrossRef]
- Li, R.; Zheng, S.; Duan, C.; Yang, Y.; Wang, X. Classification of hyperspectral image based on double-branch dual-attention mechanism network. Remote Sens. 2020, 12, 582. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Xue, Z.; Tan, X.; Yu, X.; Liu, B.; Yu, A.; Zhang, P. Deep Hierarchical Vision Transformer for Hyperspectral and LiDAR Data Classification. IEEE Trans. Image Process. 2022, 31, 3095–3110. [Google Scholar] [CrossRef]
- Zhao, Z.; Hu, D.; Wang, H.; Yu, X. Convolutional Transformer Network for Hyperspectral Image Classification. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Hong, D.; Han, Z.; Yao, J.; Gao, L.; Zhang, B.; Plaza, A.; Chanussot, J. SpectralFormer: Rethinking hyperspectral image classification with transformers. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–15. [Google Scholar] [CrossRef]
- Song, R.; Feng, Y.; Cheng, W.; Mu, Z.; Wang, X. BS2T: Bottleneck Spatial–Spectral Transformer for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–17. [Google Scholar] [CrossRef]
- Liang, H.; Bao, W.; Shen, X.; Zhang, X. HSI-mixer: Hyperspectral image classification using the spectral–spatial mixer representation from convolutions. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.U.; Polosukhin, I. Attention is All you Need. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Nice, France, 2017; Volume 30. [Google Scholar]
- Melgani, F.; Bruzzone, L. Classification of hyperspectral remote sensing images with support vector machines. IEEE Trans. Geosci. Remote Sens. 2004, 42, 1778–1790. [Google Scholar] [CrossRef]
- Gao, H.; Chen, Z.; Xu, F. Adaptive spectral-spatial feature fusion network for hyperspectral image classification using limited training samples. Int. J. Appl. Earth Obs. Geoinf. 2022, 107, 102687. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Category | Total Samples | Training | Test |
|---|---|---|---|---|
| 1 | Asphalt | 6631 | 33 | 6598 |
| 2 | Meadows | 18,649 | 93 | 18,556 |
| 3 | Gravel | 2078 | 10 | 2068 |
| 4 | Trees | 3033 | 15 | 3018 |
| 5 | Metal Sheets | 1331 | 6 | 1325 |
| 6 | Bare Soil | 4978 | 25 | 4953 |
| 7 | Bitumen | 1316 | 6 | 1310 |
| 8 | Bricks | 3645 | 18 | 3627 |
| 9 | Shadows | 937 | 4 | 933 |
| Total | 42,344 | 210 | 42,134 |
| Class | Category | Total Samples | Training | Test |
|---|---|---|---|---|
| 1 | Alfalfa | 46 | 3 | 43 |
| 2 | Corn-notill | 1428 | 42 | 1386 |
| 3 | Corn-mintill | 830 | 24 | 806 |
| 4 | Corn | 237 | 7 | 230 |
| 5 | Grass-pasture | 483 | 14 | 469 |
| 6 | Grass-trees | 730 | 21 | 709 |
| 7 | Grass-pasture-mowed | 28 | 3 | 25 |
| 8 | Hay-windrowed | 478 | 14 | 464 |
| 9 | Oats | 20 | 3 | 17 |
| 10 | Soybean-notill | 972 | 29 | 943 |
| 11 | Soybean-mintill | 2455 | 73 | 2382 |
| 12 | Soybean-clean | 593 | 17 | 576 |
| 13 | Wheat | 205 | 6 | 199 |
| 14 | Woods | 1265 | 37 | 1228 |
| 15 | Buildings-Grass-Trees-Drivers | 386 | 11 | 375 |
| 16 | Stone-Steel-Towers | 93 | 3 | 90 |
| Total | 10,249 | 307 | 9942 |
| Class | Category | Total Samples | Training | Test |
|---|---|---|---|---|
| 1 | Water | 270 | 3 | 267 |
| 2 | Hippo grass | 101 | 2 | 99 |
| 3 | Floodplain grasses1 | 251 | 3 | 248 |
| 4 | Floodplain grasses2 | 215 | 3 | 212 |
| 5 | Reeds1 | 269 | 3 | 266 |
| 6 | Riparian | 269 | 3 | 266 |
| 7 | Fierscar2 | 259 | 3 | 256 |
| 8 | Island interior | 203 | 3 | 200 |
| 9 | Acacia woodlands | 314 | 3 | 311 |
| 10 | Acacia shrublands | 248 | 2 | 246 |
| 11 | Acacia grasslands | 305 | 3 | 302 |
| 12 | Short mopane | 181 | 2 | 179 |
| 13 | Mixed mopane | 268 | 3 | 265 |
| 14 | Exposed soils | 95 | 2 | 93 |
| Total | 3248 | 42 | 3206 |
| Class | Category | Total Samples | Training | Test |
|---|---|---|---|---|
| 1 | Healthy Grass | 1251 | 13 | 1238 |
| 2 | Stressed Grass | 1254 | 13 | 1241 |
| 3 | Synthetic Grass | 697 | 7 | 690 |
| 4 | Tree | 1244 | 12 | 1232 |
| 5 | Soil | 1252 | 13 | 1239 |
| 6 | Water | 325 | 3 | 322 |
| 7 | Residential | 1268 | 13 | 1255 |
| 8 | Commercial | 1244 | 12 | 1232 |
| 9 | Road | 1252 | 13 | 1239 |
| 10 | Highway | 1227 | 12 | 1215 |
| 11 | Railway | 1235 | 12 | 1223 |
| 12 | Parking Lot 1 | 1234 | 12 | 1222 |
| 13 | Parking Lot 2 | 469 | 5 | 464 |
| 14 | Tennis Court | 428 | 4 | 424 |
| 15 | Running Track | 660 | 7 | 653 |
| Total | 15,011 | 151 | 14,860 |
| Spatial Transformer | Spectral Transformer | OA | AA | Kappa | |||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| (a) | MSSA+MLP | - | 81.76 | 94.42 | 93.24 | 84.68 | 93.79 | 92.89 | 80.28 | 92.54 | 92.67 |
| (b) | MSSA+LAFN | - | 84.6 | 96.94 | 95.51 | 86.10 | 97.00 | 95.41 | 83.34 | 95.92 | 95.13 |
| (c) | MSSA+MLP +Spatial-3D | - | 83.53 | 96.40 | 95.10 | 86.41 | 96.47 | 95.12 | 82.18 | 95.21 | 94.69 |
| (d) | MSSA+LAFN +Spatial-3D | - | 84.93 | 97.21 | 95.89 | 86.57 | 97.07 | 95.77 | 83.36 | 96.30 | 95.54 |
| (e) | - | MCSA+MLP | 82.45 | 94.24 | 94.02 | 83.76 | 93.54 | 94.31 | 81.03 | 92.66 | 93.52 |
| (f) | - | MCSA+LAFN | 84.54 | 96.93 | 96.33 | 85.00 | 97.11 | 95.75 | 83.30 | 95.91 | 96.03 |
| (g) | - | MCSA+MLP +Spectral-3D | 84.25 | 96.39 | 95.19 | 84.26 | 96.54 | 94.99 | 82.99 | 95.19 | 94.79 |
| (h) | - | MCSA+LAFN + Spectral -3D | 84.81 | 97.08 | 96.19 | 86.10 | 97.41 | 96.13 | 83.34 | 96.27 | 96.01 |
| S2Former | MSSA+LAFN Spatial-3D | MCSA+LAFN Spectral -3D | 85.12 | 97.40 | 96.49 | 86.96 | 97.71 | 96.42 | 83.92 | 96.54 | 96.20 |
| Class | SVM | CDCNN | FDSSC | DBDA | Spectral Former | HSI-Mixer | BS2T | S2Former |
|---|---|---|---|---|---|---|---|---|
| 1 | 83.87 | 80.60 | 87.22 | 94.15 | 85.97 | 92.77 | 93.93 | 94.77 |
| 2 | 86.33 | 93.10 | 99.50 | 99.01 | 96.26 | 97.10 | 98.64 | 98.16 |
| 3 | 67.75 | 62.45 | 72.42 | 95.06 | 92.43 | 93.70 | 97.90 | 98.02 |
| 4 | 96.89 | 98.76 | 97.11 | 97.76 | 97.71 | 98.66 | 98.36 | 99.06 |
| 5 | 94.28 | 99.45 | 99.01 | 99.34 | 99.23 | 98.35 | 98.61 | 100.00 |
| 6 | 84.55 | 86.04 | 97.83 | 98.11 | 94.48 | 97.32 | 98.55 | 98.99 |
| 7 | 66.46 | 73.84 | 69.78 | 99.68 | 89.36 | 96.56 | 99.20 | 98.80 |
| 8 | 70.70 | 72.71 | 82.76 | 86.61 | 77.95 | 87.03 | 84.39 | 91.55 |
| 9 | 99.89 | 98.32 | 99.55 | 98.47 | 97.90 | 98.95 | 98.83 | 100.00 |
| OA(%) | 83.99 | 87.48 | 94.30 | 96.56 | 92.43 | 96.48 | 96.97 | 97.40 |
| AA(%) | 83.41 | 85.03 | 89.46 | 96.47 | 92.37 | 95.60 | 96.69 | 97.71 |
| Kappa(%) | 78.24 | 83.20 | 92.41 | 95.43 | 89.84 | 95.31 | 95.92 | 96.54 |
| Class | SVM | CDCNN | FDSSC | DBDA | Spectral Former | HSI-Mixer | BS2T | S2Former |
|---|---|---|---|---|---|---|---|---|
| 1 | 24.20 | 90.39 | 89.55 | 99.76 | 69.23 | 99.67 | 100.00 | 100.00 |
| 2 | 55.98 | 74.08 | 95.02 | 95.10 | 83.63 | 89.43 | 93.50 | 95.48 |
| 3 | 64.45 | 60.55 | 93.05 | 94.53 | 84.21 | 80.86 | 93.94 | 89.28 |
| 4 | 43.19 | 86.67 | 96.75 | 95.23 | 96.33 | 93.76 | 95.78 | 98.70 |
| 5 | 84.59 | 88.08 | 97.63 | 95.23 | 96.62 | 95.43 | 98.62 | 98.34 |
| 6 | 82.11 | 86.31 | 97.34 | 97.84 | 88.36 | 92.94 | 97.93 | 99.70 |
| 7 | 58.75 | 87.08 | 80.78 | 73.47 | 63.98 | 86.82 | 76.89 | 100.00 |
| 8 | 87.87 | 86.51 | 98.41 | 100.00 | 88.12 | 89.51 | 99.98 | 100.00 |
| 9 | 46.58 | 71.92 | 58.33 | 96.54 | 74.37 | 91.58 | 94.43 | 100.00 |
| 10 | 65.10 | 83.29 | 91.48 | 89.57 | 83.27 | 89.01 | 88.00 | 94.82 |
| 11 | 63.11 | 72.24 | 93.08 | 94.23 | 80.52 | 95.21 | 96.10 | 97.21 |
| 12 | 49.67 | 69.71 | 90.21 | 91.85 | 84.57 | 82.56 | 90.94 | 99.42 |
| 13 | 88.59 | 96.55 | 99.58 | 98.92 | 92.47 | 98.76 | 98.39 | 100.00 |
| 14 | 89.89 | 90.37 | 97.85 | 97.89 | 91.97 | 94.14 | 96.10 | 97.90 |
| 15 | 61.63 | 75.65 | 93.40 | 95.57 | 89.87 | 89.43 | 94.84 | 91.22 |
| 16 | 99.23 | 91.30 | 98.80 | 96.95 | 89.87 | 95.69 | 96.69 | 78.76 |
| OA(%) | 69.06 | 78.24 | 92.35 | 94.89 | 85.46 | 92.50 | 94.94 | 95.16 |
| AA(%) | 66.56 | 81.92 | 91.95 | 94.80 | 84.79 | 91.55 | 94.51 | 96.30 |
| Kappa(%) | 64.28 | 74.94 | 91.25 | 94.17 | 83.29 | 91.44 | 94.73 | 94.47 |
| Class | SVM | CDCNN | FDSSC | DBDA | Spectral Former | HSI-Mixer | BS2T | S2Former |
|---|---|---|---|---|---|---|---|---|
| 1 | 90.38 | 89.29 | 97.21 | 98.56 | 89.76 | 96.02 | 93.92 | 98.74 |
| 2 | 34.58 | 74.72 | 87.97 | 93.38 | 56.31 | 83.03 | 82.76 | 86.48 |
| 3 | 86.71 | 68.45 | 99.54 | 99.27 | 83.01 | 100.00 | 100.00 | 100.00 |
| 4 | 56.73 | 57.03 | 84.71 | 89.87 | 83.99 | 87.93 | 94.60 | 97.99 |
| 5 | 87.27 | 81.65 | 94.07 | 94.28 | 90.21 | 90.82 | 92.38 | 81.72 |
| 6 | 56.63 | 59.85 | 82.08 | 92.01 | 70.31 | 90.41 | 94.90 | 97.80 |
| 7 | 89.09 | 89.39 | 98.54 | 97.84 | 99.53 | 99.39 | 100.00 | 100.00 |
| 8 | 76.91 | 69.52 | 96.99 | 99.20 | 96.77 | 99.45 | 97.04 | 98.00 |
| 9 | 75.78 | 74.52 | 88.85 | 96.09 | 96.49 | 90.55 | 96.94 | 98.02 |
| 10 | 87.69 | 75.26 | 91.42 | 91.35 | 93.33 | 93.07 | 74.08 | 94.42 |
| 11 | 82.25 | 95.84 | 97.57 | 98.61 | 83.06 | 97.67 | 100.00 | 100.00 |
| 12 | 60.38 | 89.73 | 99.72 | 99.89 | 86.26 | 97.78 | 99.44 | 96.72 |
| 13 | 91.06 | 71.00 | 93.01 | 96.86 | 89.88 | 99.39 | 100.00 | 100.00 |
| 14 | 79.91 | 91.09 | 98.18 | 97.67 | 99.55 | 99.29 | 100.00 | 100.00 |
| OA(%) | 73.15 | 74.89 | 91.94 | 95.47 | 83.42 | 94.11 | 94.34 | 96.49 |
| AA(%) | 75.38 | 77.67 | 93.56 | 96.06 | 87.03 | 94.63 | 94.71 | 96.42 |
| Kappa(%) | 71.03 | 72.85 | 91.27 | 95.09 | 82.08 | 93.62 | 93.87 | 96.20 |
| Class | SVM | CDCNN | FDSSC | DBDA | Spectral Former | HSI-Mixer | BS2T | S2Former |
|---|---|---|---|---|---|---|---|---|
| 1 | 69.46 | 92.73 | 79.90 | 83.77 | 77.60 | 83.97 | 94.19 | 85.92 |
| 2 | 93.52 | 93.20 | 95.09 | 93.75 | 88.60 | 93.22 | 94.13 | 95.38 |
| 3 | 61.67 | 96.62 | 99.15 | 96.66 | 96.00 | 100.00 | 100.00 | 100.00 |
| 4 | 91.26 | 98.57 | 94.90 | 93.85 | 92.59 | 97.33 | 85.64 | 98.82 |
| 5 | 80.70 | 93.72 | 93.81 | 94.75 | 90.75 | 94.33 | 88.44 | 96.08 |
| 6 | 94.08 | 100.00 | 90.00 | 92.26 | 97.27 | 97.75 | 100.00 | 100.00 |
| 7 | 65.85 | 73.68 | 72.55 | 83.14 | 78.23 | 79.01 | 80.58 | 84.16 |
| 8 | 57.54 | 66.31 | 72.30 | 92.44 | 85.19 | 93.08 | 88.99 | 85.32 |
| 9 | 75.37 | 65.18 | 73.16 | 75.81 | 69.60 | 71.34 | 70.05 | 76.64 |
| 10 | 66.04 | 69.31 | 74.23 | 72.73 | 64.94 | 64.88 | 68.89 | 74.44 |
| 11 | 61.10 | 61.46 | 69.28 | 80.09 | 69.27 | 71.29 | 63.11 | 80.60 |
| 12 | 67.74 | 63.82 | 76.41 | 71.64 | 63.52 | 72.64 | 65.79 | 71.20 |
| 13 | 97.02 | 26.30 | 49.08 | 89.70 | 73.16 | 90.51 | 65.98 | 74.82 |
| 14 | 83.87 | 93.19 | 98.23 | 90.51 | 95.32 | 95.10 | 97.22 | 92.92 |
| 15 | 65.75 | 98.86 | 96.80 | 89.48 | 92.78 | 95.58 | 95.74 | 86.82 |
| OA(%) | 71.92 | 78.75 | 80.62 | 83.95 | 79.07 | 82.70 | 81.78 | 85.12 |
| AA(%) | 75.40 | 79.53 | 82.33 | 86.69 | 82.32 | 86.67 | 83.92 | 86.96 |
| Kappa(%) | 69.58 | 76.99 | 79.00 | 82.63 | 77.35 | 81.28 | 80.30 | 83.92 |
| CDCNN | FDSSC | DBDA | Spectral Former | HSI-Mixer | BS2T | S2Former | |
|---|---|---|---|---|---|---|---|
| Training time (s) | 498.97 | 1459.14 | 1229.35 | 1307.76 | 1752.50 | 1549.89 | 1855.85 |
| Flops (G) | 2.60 | 22.71 | 13.82 | 13.25 | 12.57 | 13.84 | 12.76 |
| params (M) | 2.91 | 1.23 | 0.38 | 0.51 | 0.25 | 0.38 | 0.54 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yuan, D.; Yu, D.; Qian, Y.; Xu, Y.; Liu, Y. S2Former: Parallel Spectral–Spatial Transformer for Hyperspectral Image Classification. Electronics 2023, 12, 3937. https://doi.org/10.3390/electronics12183937
Yuan D, Yu D, Qian Y, Xu Y, Liu Y. S2Former: Parallel Spectral–Spatial Transformer for Hyperspectral Image Classification. Electronics. 2023; 12(18):3937. https://doi.org/10.3390/electronics12183937
Chicago/Turabian StyleYuan, Dong, Dabing Yu, Yixi Qian, Yongbing Xu, and Yan Liu. 2023. "S2Former: Parallel Spectral–Spatial Transformer for Hyperspectral Image Classification" Electronics 12, no. 18: 3937. https://doi.org/10.3390/electronics12183937
APA StyleYuan, D., Yu, D., Qian, Y., Xu, Y., & Liu, Y. (2023). S2Former: Parallel Spectral–Spatial Transformer for Hyperspectral Image Classification. Electronics, 12(18), 3937. https://doi.org/10.3390/electronics12183937