1. Introduction
Although traditional cloud computing provides a platform for big data processing [
1], with the rapid development of the big data area, cloud computing is not as efficient as it used to be in processing large amounts of data [
2]. We need a technology that brings computing, resources and storage closer to edge devices. Edge computing is a new computing model [
3]. This model deploys computing and storage resources at the edge of the network, closer to mobile devices or sensors. Edge computing transfers data, storage, etc., to the edge, and meets real-time task requirements with lower power consumption [
4]. Therefore, the large-scale computing tasks are also transferred to the edge, including convolutional neural networks [
5,
6]. CNN is one of the most important deep neural networks, and plays an important role in tasks related to computer vision. It has a wide range of applications in image classification [
7,
8], image semantic segmentation [
9,
10], speech recognition [
11], target detection [
12,
13] and target tracking [
14,
15]. Deep learning algorithms based on convolutional neural networks involve many floating point operations. CNN models mostly run in the environment of CPU [
16] and GPU [
17,
18]. Although GPU can achieve real-time processing, its expensive cost and high power consumption make it difficult to satisfy the application requirements of edge computing scenarios. ARM architecture series microcontrollers are widely used in the industrial field due to their high performance, low cost and abundant software development support. The performance improvement of CNN is mainly driven by deeper and wider networks with increased parameters and operations (e.g., multiply-and-accumulate, MAC), which usually slow down their execution, especially on mobile devices. This is even more important for these mobile devices. Because single core ARM chips do not have the ability to perform parallel computing, their computing speed is far inferior to that of CPUs and GPUs. This motivates the design of compact models with reduced overhead while maintaining accuracy as much as possible. Therefore, it is of great significance to develop a low-cost, low-power, easy-to-develop and parallel computing embedded hardware platform for edge computing. In a prior survey [
19], the author summarized and reviewed the current development of machine learning in embedded microprocessors, compared the performance of various neural network algorithms on embedded platforms, and proposed a concept of model compression. However, no specific suggestions for platform construction were provided for specific microprocessors. In addition to improving the computing power of a single microprocessor, improving the system structure and improving the communication and data transmission efficiency of the system can also significantly enhance the computing power of embedded platforms. At the same time, this can simplify and compress the CNN algorithm to make it suitable for distributed operations and small-scale operations of ARM processors. In previous studies, there were still those that proposed decomposing the convolutional kernel of CNN, actively using smaller or asymmetric kernels to simplify the convolutional layer of CNN, reducing the computational complexity from O (
) to O (2n), saving a lot of computational overhead [
20]. In [
21], the authors discuss several techniques for reducing the computational complexity of CNNs; one approach is network pruning and another technique is quantization, which can make these models more feasible for deployment on devices with limited resources, such as mobile phones or embedded systems. There have also been studies on optimizing CNN and leNet-5 models for embedded platforms, such as FPGA, implementing a mixed stream transmission architecture for LeNeT-5, and accelerating single engine computing for LeNeT-5 [
22]. These studies provide ideas for simplifying CNN algorithms and making them more suitable for small-scale embedded computing platforms. The above studies provide ideas for innovative simplification and improvement of CNN algorithms to make them more suitable for small-scale embedded computing platforms.
In this work, we try to build an ARM-based CNN parallel computing hardware platform to provide the possibility of embedded edge computing for neural networks. We propose solutions to several key issues in the implementation process. We try to propose a CNN distributed computing method and build an ARM-based CNN parallel computing hardware platform to provide the possibility of embedded edge computing for neural networks. We propose solutions to several key issues in the implementation process. Specifically, the main contributions of this work include the following.
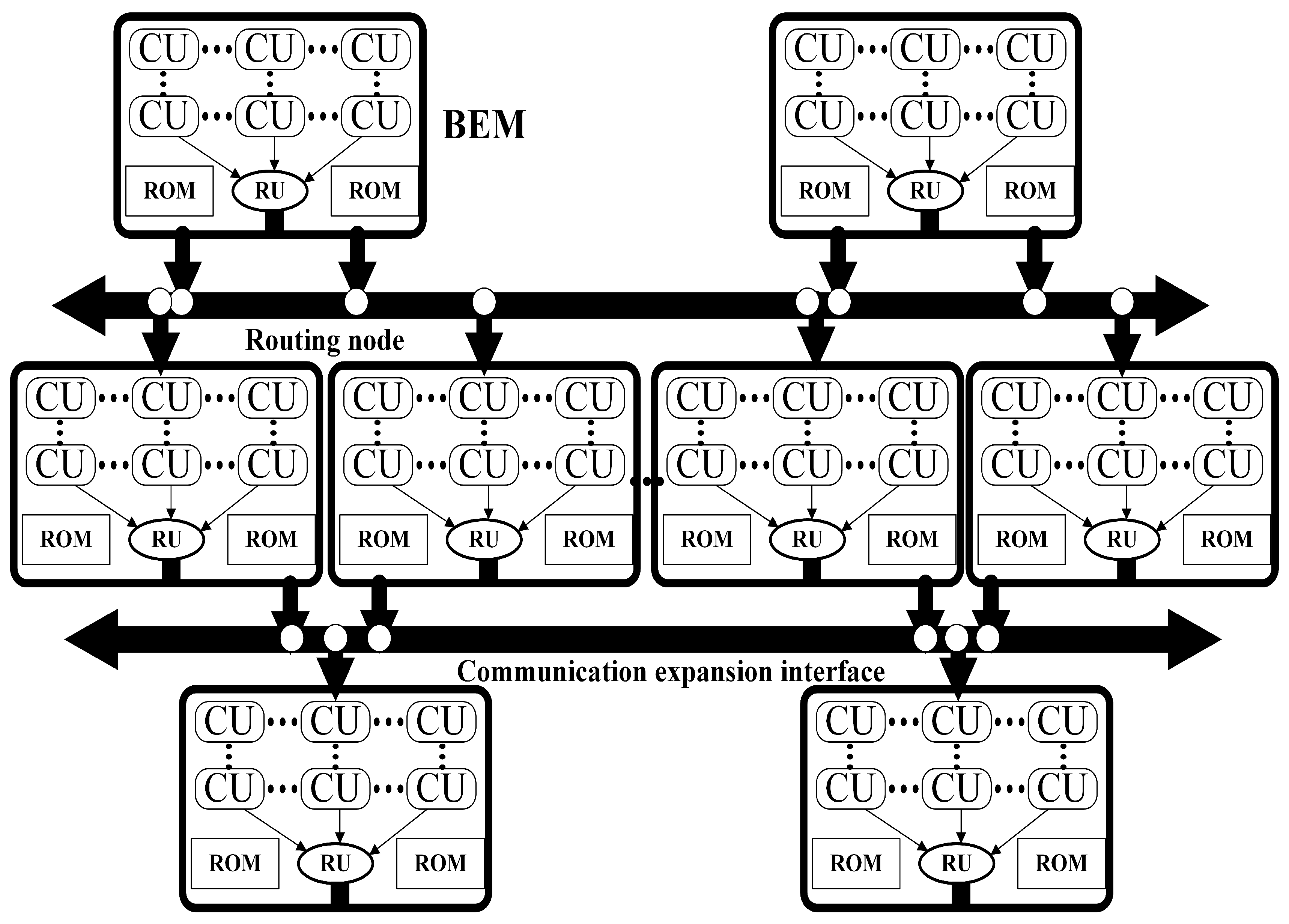
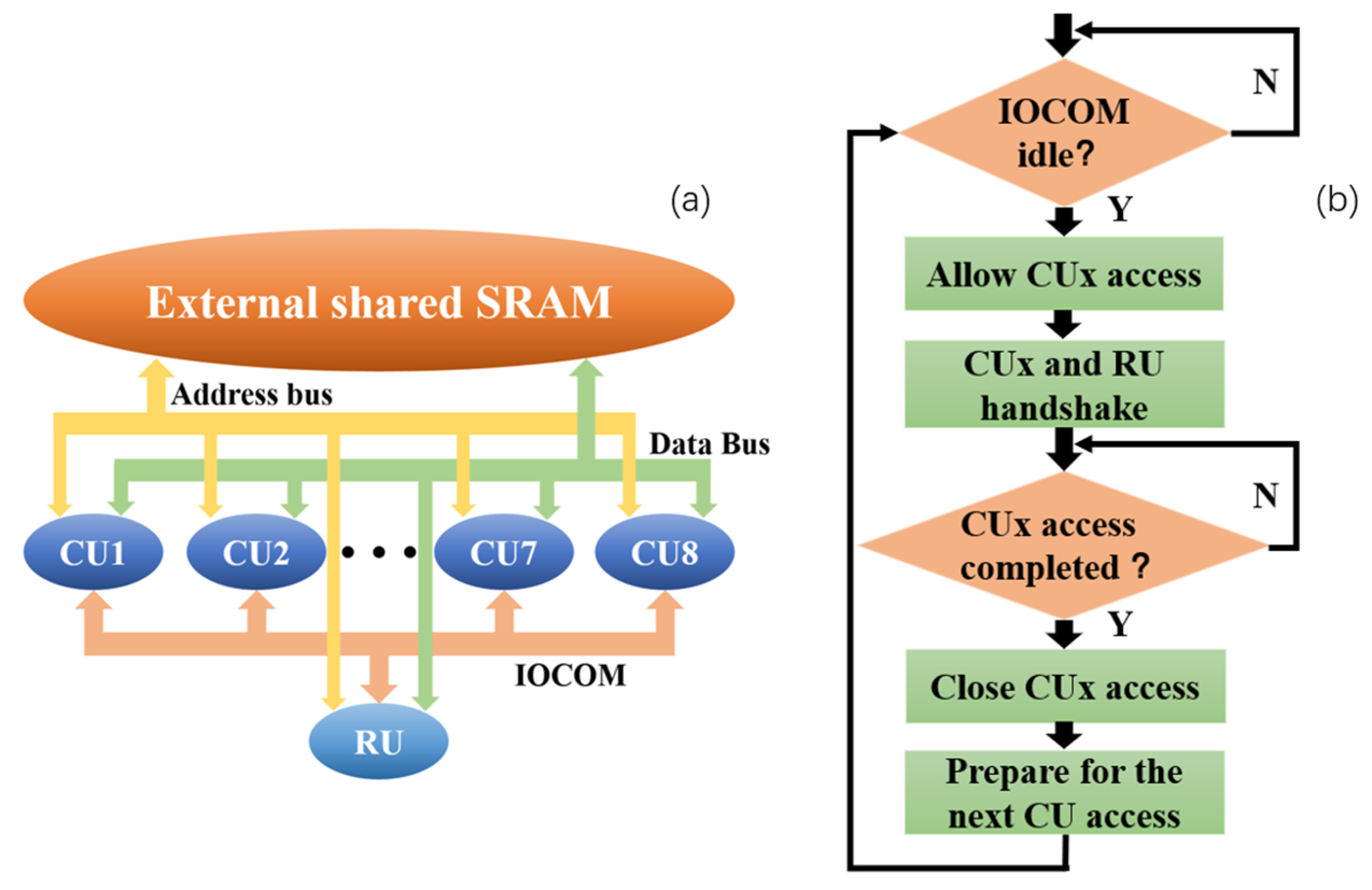
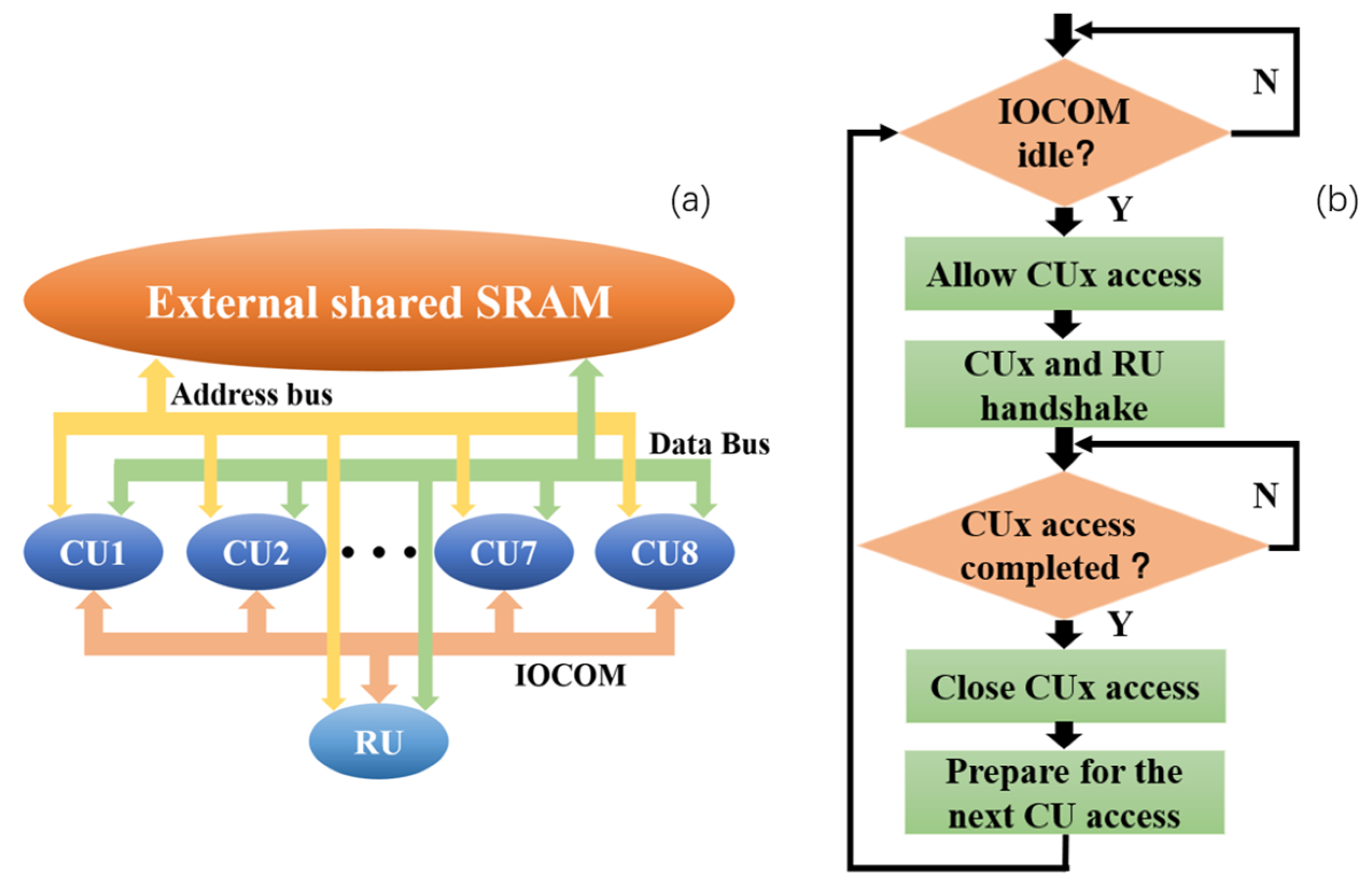
The front-end image acquisition and processing board is designed based on the hardware architecture of the CNN computing board for accomplishing image classification, target tracking and other front-end image acquisition tasks, as well as the distributed parallel processing of images. The front-end image acquisition and processing board and the bottom computing board designed in the laboratory constitute the CNN parallel computing hardware platform. We adopt the idea of time division multiplexing to realize multi-chip shared external static random access memory (SRAM) access. The routing unit controls and schedules the computing unit to access external storage in an orderly loop. Resource sharing and data integration are realized, and conflicts are avoided in the access process. At the same time, the routing unit is used to realize the board communication. In order to solve the problem of limited resources on the chip, a method of dimensionality reduction initialization is designed. In order to ensure the real-time calculation of the model under the selected chip operating frequency, according to the hierarchical structure of the CNN and the characteristics of the sliding window operation in the convolution process, the distribution mapping mechanism of the neural network is designed. In this way, the neural network tasks are distributed to multiple computing units to achieve parallel computing. The most time-consuming exponential function calculation in the nonlinear calculation process is optimized. At the cost of reducing a small part of the calculation accuracy, the exponential function calculation speed is greatly improved. We verify the effectiveness of the above method in large-scale real-time implementation of CNNs through experiments. Due to the convenience of ARM core software development, the hardware platform design is versatile and easy to implement with other network models.
The rest of this paper is organized as follows. We introduce, in
Section 2, the structure design of the hardware platform, including the terminal acquisition and processing board. The external resource sharing mechanism, inter-chip communication and board communication mechanism for this platform are proposed.
Section 3 presents the dimensionality reduction initialization and the distribution mapping mechanism of the convolutional neural network model suitable for this platform. The nonlinear calculation process in the network is optimized. After that, we present experimental validation and result analysis in
Section 4. Experiments are designed to prove the effectiveness of the above method. The resource consumption and power consumption of the platform are analyzed. Finally, the paper is concluded in
Section 5.
3. CNN Dimensionality Reduction Initialization and Distribution Mapping Mechanism
Convolutional neural network is a special artificial neural network, which has significant advantages in image processing and feature extraction. A typical CNN includes convolutional layers, pooling layers, and fully connected layers. The convolution process can extract the features of the image. The pooling layer is followed by the convolution layer. The amount of calculation is reduced by reducing the image size. Finally, the classification result is output through the fully connected layer. CNN needs to use backpropagation algorithms to train model parameters [
23]. We mainly focus on the realization of forward calculation [
24] of the CNN model completed by offline training. Under the hardware architecture of the many-core embedded parallel computing platform MEPP, CNN needs to perform split calculations and integrate the calculation results. There are two main factors considered in the model splitting process. One is to ensure computational efficiency. The forward calculation process of CNN requires many multiplication and addition calculations. The calculation amount of CNN tends to increase exponentially when the input image pixels are high. It takes a lot of time to choose serial calculation in a single chip. The second is limited resource storage space. Each layer of CNN needs to consume a lot of storage resources to save the weight parameters. Aiming at these two problems, the dimensionality reduction initialization and CNN distribution mapping mechanism are designed to solve the two problems of storage and calculation that limit the application of the model.
3.1. Overview of CNN Neural Networks
A convolution neural network is a kind of feedforward neural network including convolution operation, which is one of the most representative neural networks for deep learning. Convolutional operations have gained widespread attention in academia and industry due to their powerful ability to extract image features. Convolutional neural networks have made remarkable achievements in fields such as image classification, face recognition, object detection, and object tracking. In 1998, LeCun et al. proposed the classic LeNet-5 network, which has achieved success in handwritten digit recognition. Afterwards, convolutional neural networks received widespread attention in the field of computer vision. Structurally, the CNN mainly includes an input layer, hidden layer, and output layer. The hidden layer includes the convolution layer, pooling layer, full connection layer and activation function. In some complex CNNs, residual modules composed of the above hidden layers [
23] and inception modules are also included. The convolutional layer is the core network layer of the entire CNN, used to extract the features of input image data. Each convolution core is connected to the region called the local receptive field in the upper layer, so as to learn the characteristics of this region. With the sliding window operation, the convolution kernel can learn the features of all receptive fields. In this process, the size, step size and filling of the convolution kernel can be manually set to obtain target feature maps of different sizes.
The pooling layer is another important component in CNN, usually following the convolutional layer to implement downsampling on the output feature map. The pooling layer can reduce model computation and memory usage while ensuring feature invariance. Common pooling operations include maximum pooling and average pooling. The fully connected layer usually appears at the end of the entire CNN. The feature map obtained after convolution is tiled and connected to each neuron in the fully connected layer. The calculation process of the fully connected layer is shown in the formulas below:
where
is the
i-th input neuron,
is the corresponding weight,
b is the offset, and
is the activation function.
The calculation process of neural network is usually linear, and the activation function can introduce nonlinear characteristics into CNN, thus strengthening the learning ability of the network. Common nonlinear activation functions include Sigmoid, ReLU, hyperbolic tangent function (tanh function) and Softmax. Among these, the Softmax activation function is usually used on the network output layer to normalize the output values to obtain the probability of each output value. The formulas of these activation function are as follows:
3.2. Dimensionality Reduction Initialization
There are many problems in implementing distributed parallel computing of the CNN model on a multi-core embedded hardware platform. To implement the CNN model through a hardware platform, the first factor that needs to be considered is that of hardware storage resources. The memory size of STM32F4 series chips is 192 KB, including 128 KB RAM and 64 KB CCM RAM. In the calculation of each network layer, memory must be allocated for the input and output data of the layer, i.e., the network layer is initialized.
To address the challenge of limited memory resources, we propose a method that combines dynamic memory allocation and dimensionality reduction initialization. Dynamic memory allocation is a technique used to allocate and manage computer memory resources. When a memory application is executed, the required memory is allocated from the memory pool. After the data is processed, the memory resources are released and reclaimed. However, since the addresses of the two random-access memory (RAM) modules are not continuous, the actual RAM size that can support dynamic memory allocation is limited to 128 KB. Therefore, the amount of data declared through dynamic memory allocation at any given time must not exceed this limit.
As a single network layer typically involves a large amount of data, dynamic memory allocation alone is insufficient for initialization. To address this, we propose a method of dimensionality reduction and initialization. Typically, the feature map in a convolutional neural network (CNN) is represented as a three-dimensional matrix. Through dimensionality reduction initialization, we allocate memory only to the two-dimensional matrix when initializing a single network layer, i.e., a single feature map. Once the calculation of a single feature map is complete, we erase the data of the current feature map and write the data of the next feature map. In cases where the data volume of a single feature map is still too large, we can further reduce the dimensionality of the matrix allocation memory to allocate memory for a one-dimensional array. This approach allows us to optimize memory utilization while minimizing the impact on the performance of the CNN.
3.3. CNN Distribution Mapping Mechanism
Another key factor in implementing the CNN model on a multi-core embedded hardware platform is how to effectively map the CNN to multiple computing units. We propose a CNN distribution mapping mechanism based on the distributed characteristics of the hardware platform MEPP. It includes longitudinal layering, single-layer convolutional distribution mapping, single-channel image or feature map distribution after a single convolution, and fully-connected layer distribution mapping. In this way, the entire network can be gradually dispersed.
As a serial network model, CNN itself has a hierarchical structure. According to the hierarchical structure of the CNN model, multiple inter-layer pipeline mapping methods can be used. The network can be split layer by layer, allowing each BEM to perform operations on a single network layer, or it can be mapped based solely on convolution, pooling, or full connectivity, allowing each BEM to perform forward inference on multiple network layers. Due to the fixed computing tasks of each CU, it is necessary to consider issues such as inter module data dependency and load balancing when performing CNN hierarchical mapping. FAM and BEM1 complete the first frame calculation to generate the classification convolution kernel and regression convolution kernel required for the cross correlation process, and transmit them to BEM2. At the same time, the location, length, width, and other information of the target in the first frame are stored in BEM3, and they need to be updated during the subsequent tracking process. FAM collects front-end images and performs corresponding calculations, and then waits for permission from the lower layer to transmit the calculation results. The cycle through this process starts from the collection of images. BEM1-3 also completes the corresponding loop calculation according to the requirements in the flowchart and transmits the calculation results to the lower layer. BEM3 makes the final judgment based on the calculation results.
The convolution process occupies more than 90% of the operations in CNN [
8,
25]. As the network layer with the largest amount of calculation, the convolutional layers need to be distributed to multiple computing units to ensure real-time requirement. There are two ways to map the convolutional layer. The first is to perform distribution mapping according to the number of input feature map channels, and the second is to perform distribution mapping according to the number of convolution kernels, i.e., the number of output feature map channels. Only by understanding how the feature map is convolved can the difference between the two distribution mapping methods be known. Take
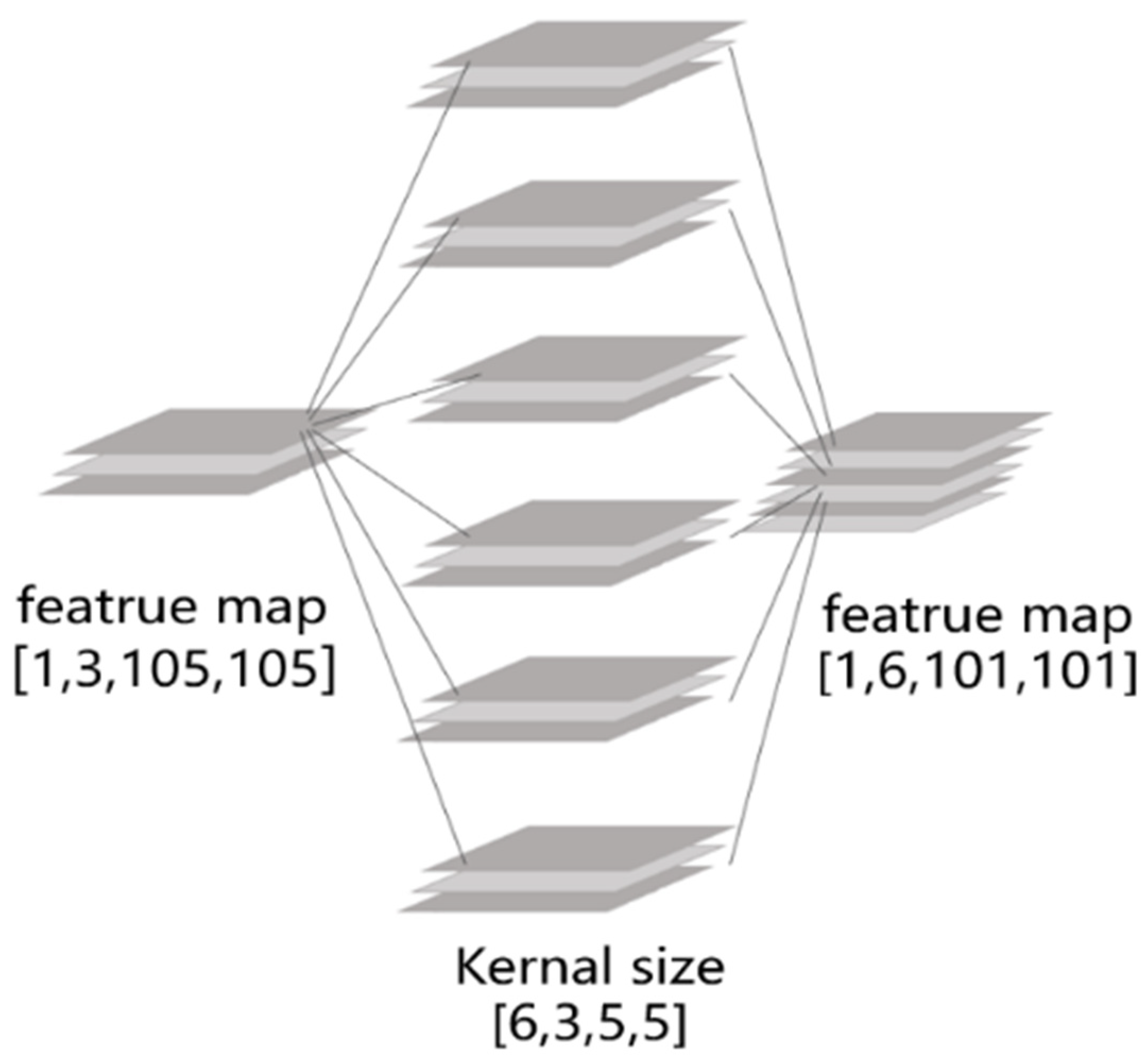
Figure 4 as an example. The input is a three-channel feature map. After convolution, a six-channel feature map is obtained. Therefore, it has to go through the convolution of six convolution kernels, and each convolution kernel is three-dimensional, corresponding to the input feature map of three channels. The three-channel feature map is convolved by a three-dimensional convolution kernel to obtain the output feature map of a single channel. After convolution of six three-dimensional convolution kernels, six-channel output feature maps are obtained. From this perspective, it can be said that each channel of the input feature map undergoes the convolution process of six convolution kernels, and it can also be said that each feature map of the output channel is convolved by three convolution kernels. In this way, the entire convolution process can be distributed to three calculation units and six calculation units. If the number of input feature map channels is the same as the number of convolution kernels, the time complexity of the distribution mapping method according to the number of input feature maps is smaller. In the process of network convolution layer by layer, in order to obtain more deep-level features, the number of feature map channels will gradually increase. Therefore, in this case, the distribution mapping according to the number of convolution kernels can make the network more decentralized.
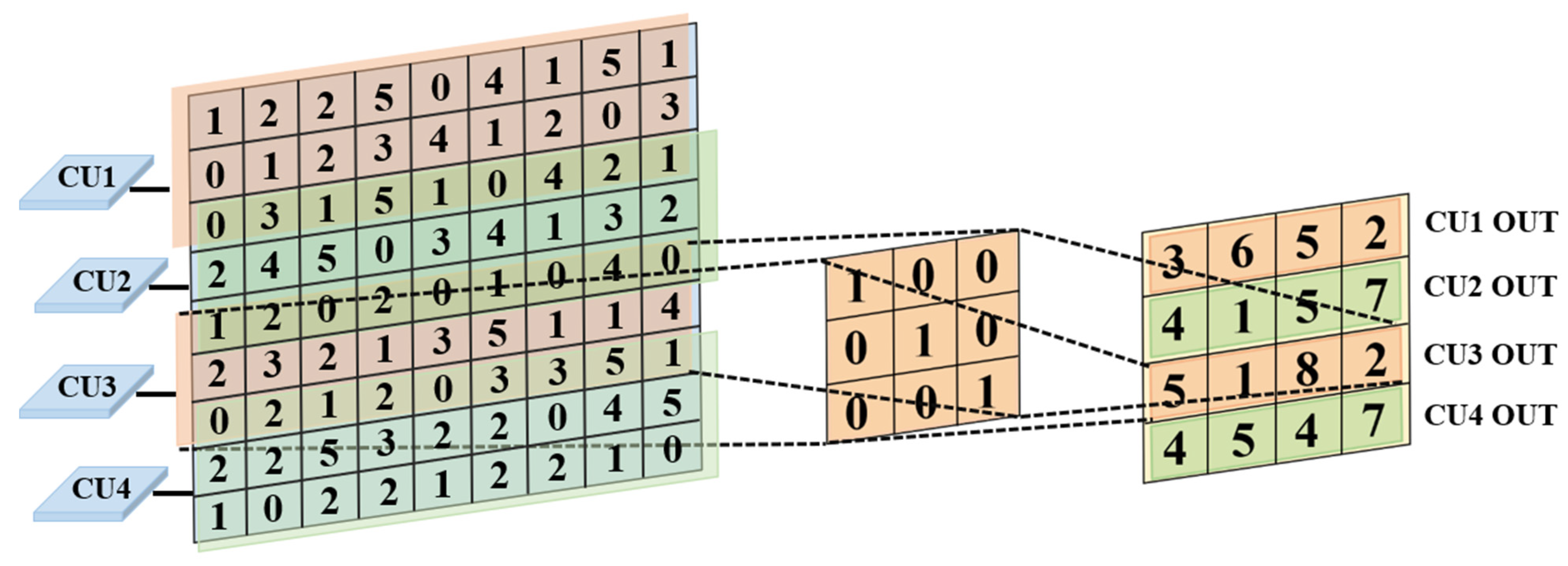
The convolution of the single-channel feature map through a single convolution kernel is the usual two-dimensional convolution process. In the convolution process, a sliding window operation is required, as can be seen from the example in
Figure 5. In
Figure 5, different colored boxes divide the feature map into four equal parts and are assigned to four computational kernels. The dashed box represents the calculation tasks assigned to CU3, and displays the calculation process of CU3 using dashed lines.
The dashed lines indicate the start and the end of the calculation for CU3. In order to obtain a 4 × 4 feature map, four horizontal sliding windows are performed in the case of a step size of two. Under the premise of ensuring real-time performance, the single-channel feature map is split and mapped to multiple CUs. A single feature map can be divided into halves and quarters according to the number of horizontal sliding windows, i.e., the number of output channels. In this way, the distribution mapping of a single feature map for a single convolution is completed effectively.
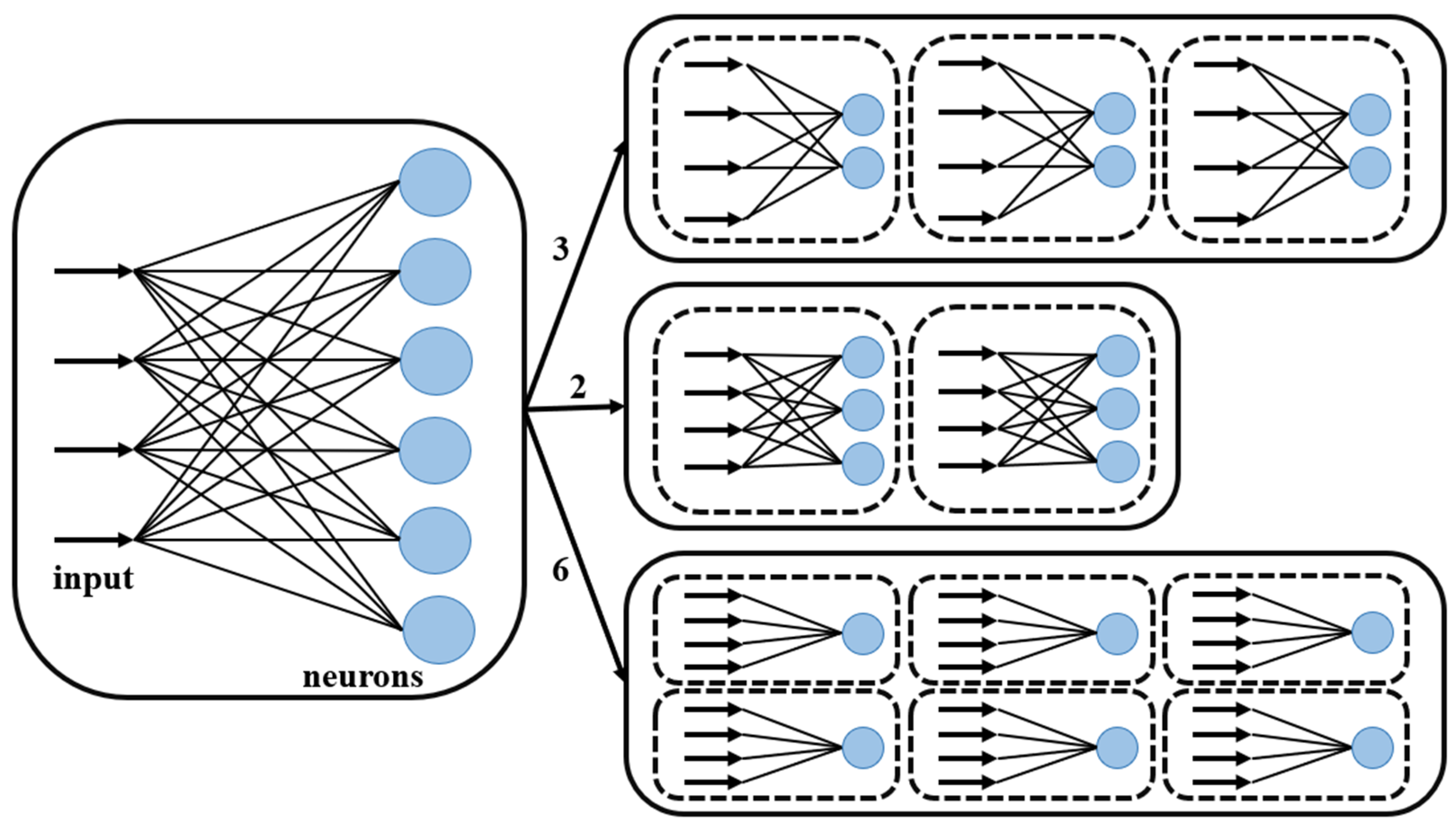
The fully connected layer is divided into smaller neuron groups according to the number of neurons. Under the premise that each computing unit performs the same number of tasks, the fully connected layer is divided into equal parts according to the number of neurons. As shown in
Figure 6, this is a fully connected layer with six neurons. The distribution can be mapped to two, three, and six computing units.
The CNN mapping mechanism can decentralize the CNN network effectively. After decentralization, the integration and horizontal collaboration of the computing output are realized through the shared resource access and storage mechanism in the layer. The vertical cascade is completed between the layers through external communication between the groups.
3.4. Calculation Optimization
In the process of neural network calculation, exponential functions may be involved in the nonlinear calculation process, such as sigmoid function and softmax function. The index calculation process consumes a lot of time. The chip we chose has a floating-point unit (FPU). It has excellent floating-point multiplication capability. Therefore, we replace the exponential operation in the standard library function with repeated multiplication according to the following formula.
The accuracy of this approximation method is gradually improved with the increase of n in the formula, and the calculation efficiency will decrease at the same time. In order to reduce the number of calculations as much as possible, we choose n to be converted to an exponential multiple of two. The reason is that, after such processing, when the model is converted into a difference equation to solve, the specific calculation steps are as follows:
This calculation method can obtain a larger value of n through a small number of times of accumulation, so as to achieve both calculation efficiency and accuracy. This optimization mechanism improves the exponential calculation process. It greatly reduces the time overhead in the model calculation process.
In order to analyze the lightweight degree of deep separable convolution, the computational and parameter quantities of conventional convolution and deep separable convolution are calculated separately. The computational and parameter quantities of both are as follows:
From the above two equations, it can be seen that deep separable convolution significantly reduces the computational and parameter complexity of the model.
4. Experimental Verification and Result Analysis
We implement the LeNet-5 [
26] model, which has different input sizes on this hardware platform. The LeNet-5 model of different input sizes is shown in
Figure 7. In the implementation process, we design different experiments to verify the effectiveness of the dimensionality reduction initialization and CNN distribution mapping mechanism. Finally, we analyze the running time, resource consumption and power consumption.
We verify the effectiveness of this method by comparing the memory occupied by the model before and after the dimensionality reduction initialization.
Figure 7 mainly describes the processing method of LeNet-5 for feature maps. The input feature map is convolutionally processed through convolution layer C1, pooling layer P1, convolution layer C2, and pooling layer P2, and then linearized through two fully connected layers to obtain the output result.
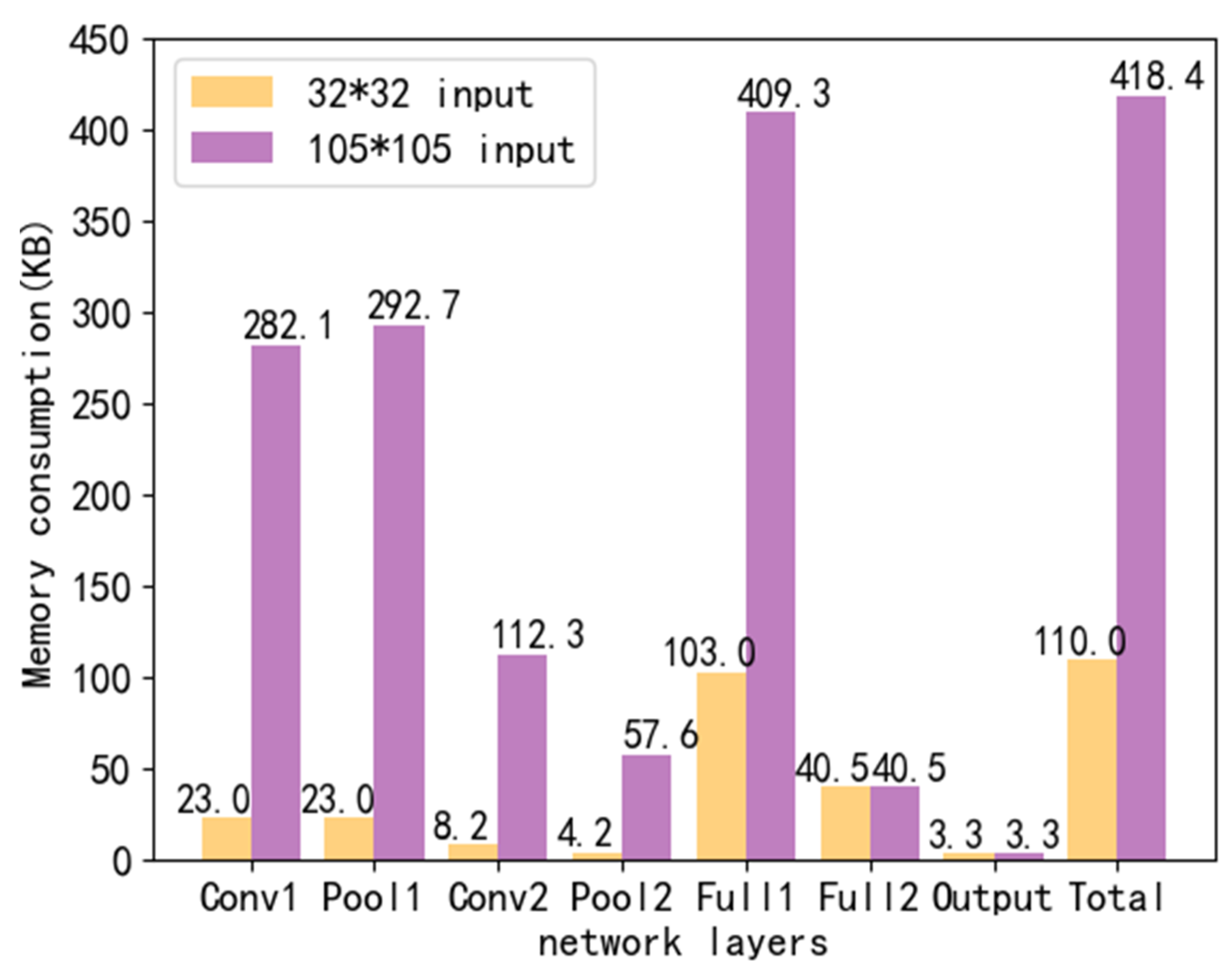
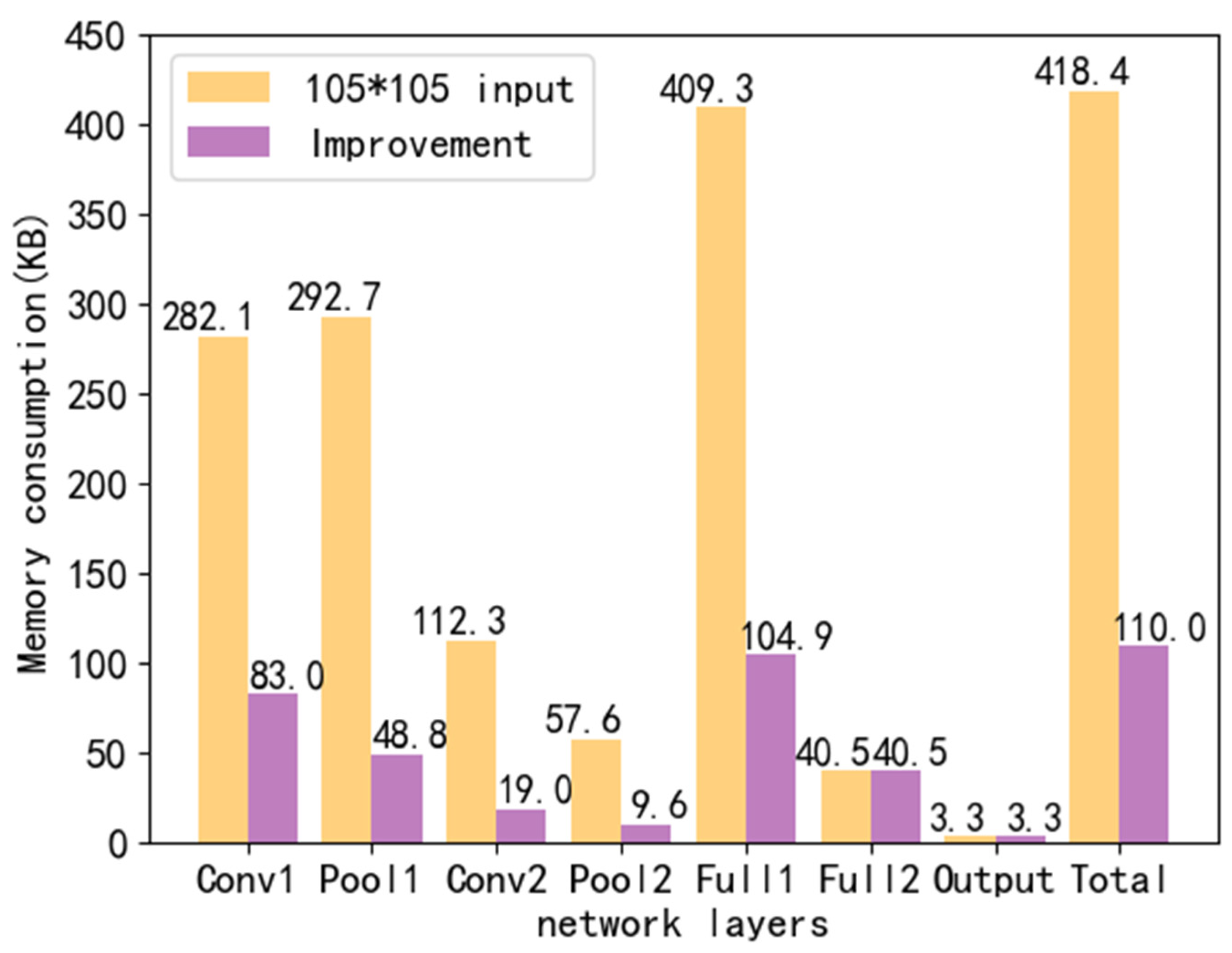
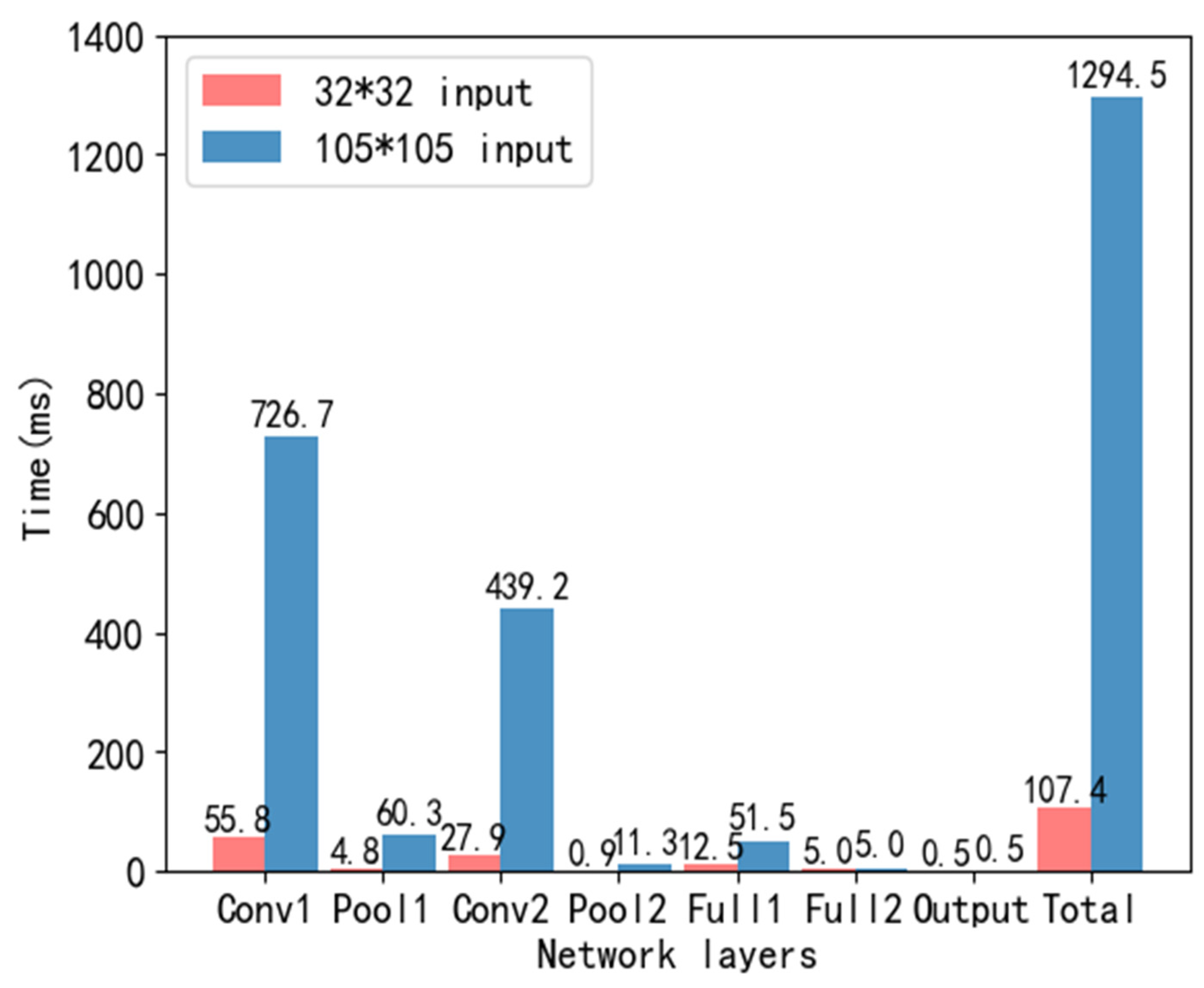
Figure 8 points out that, when the input image size is 32 × 32 or 105 × 105, each network layer needs to occupy memory during the calculation process. When the input image size is 32 × 32, a single chip can only provide memory for the data of a single network layer. When the input image size is 105 × 105, the amount of memory required for a single network layer data exceeds the maximum memory amount of the chip. Because of this, our experiment is mainly based on the image of 105 × 105.
When the input image size is 32 × 32, the chip memory can meet the requirements. We initialize the LeNet-5 network with an input image size of 105 × 105 for dimensionality reduction. This is mainly to initialize the dimensionality reduction of the convolutional layer and the pooling layer in the network. It can be seen from
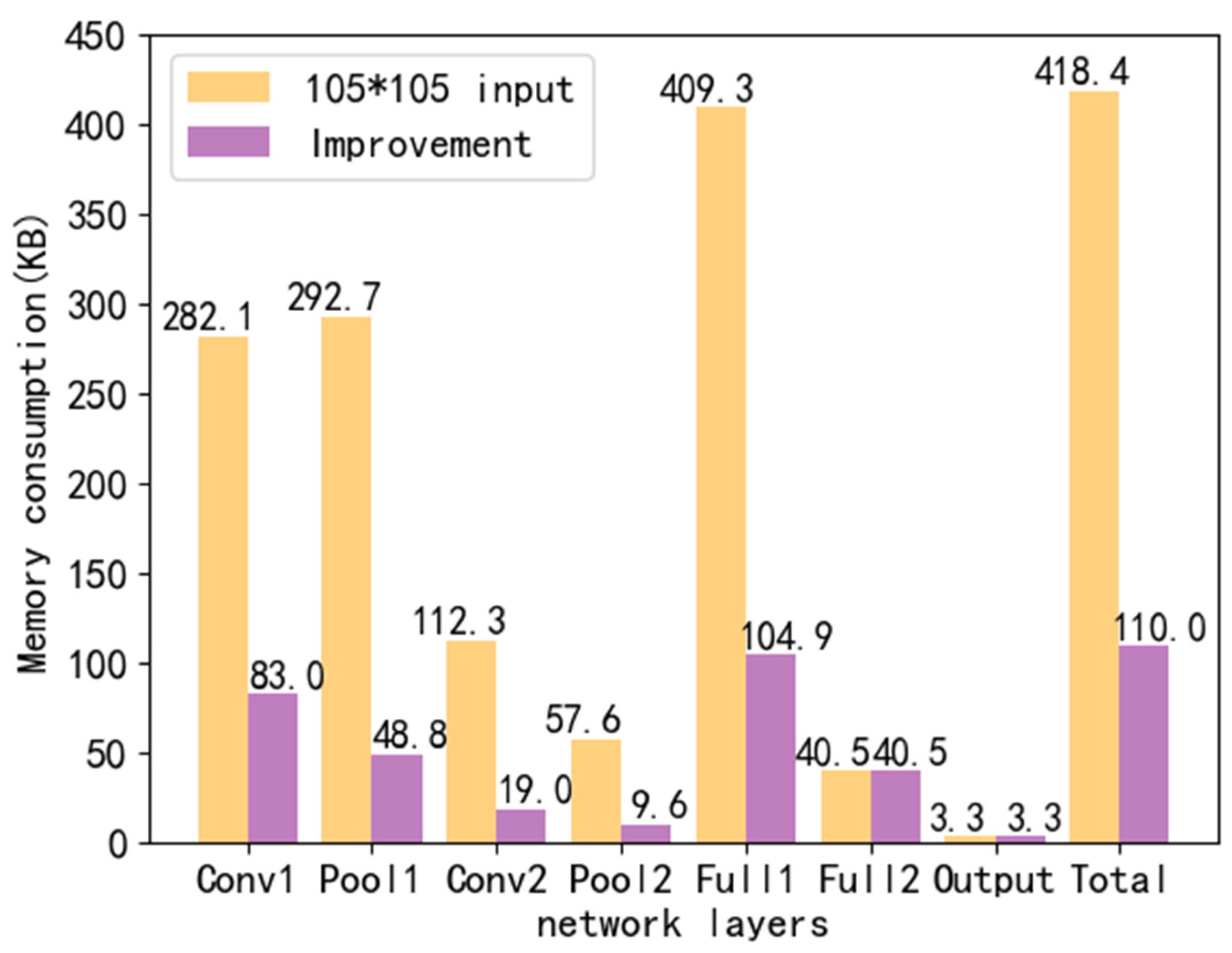
Figure 9 that in the 105 × 105 LeNet-5 model after dimensionality reduction, the memory occupied by the initialization of a single network layer is effectively limited to the chip memory size. The analysis results prove the effectiveness of the dynamic memory allocation and dimensionality reduction initialization method. This method can completely solve the problem of insufficient memory.
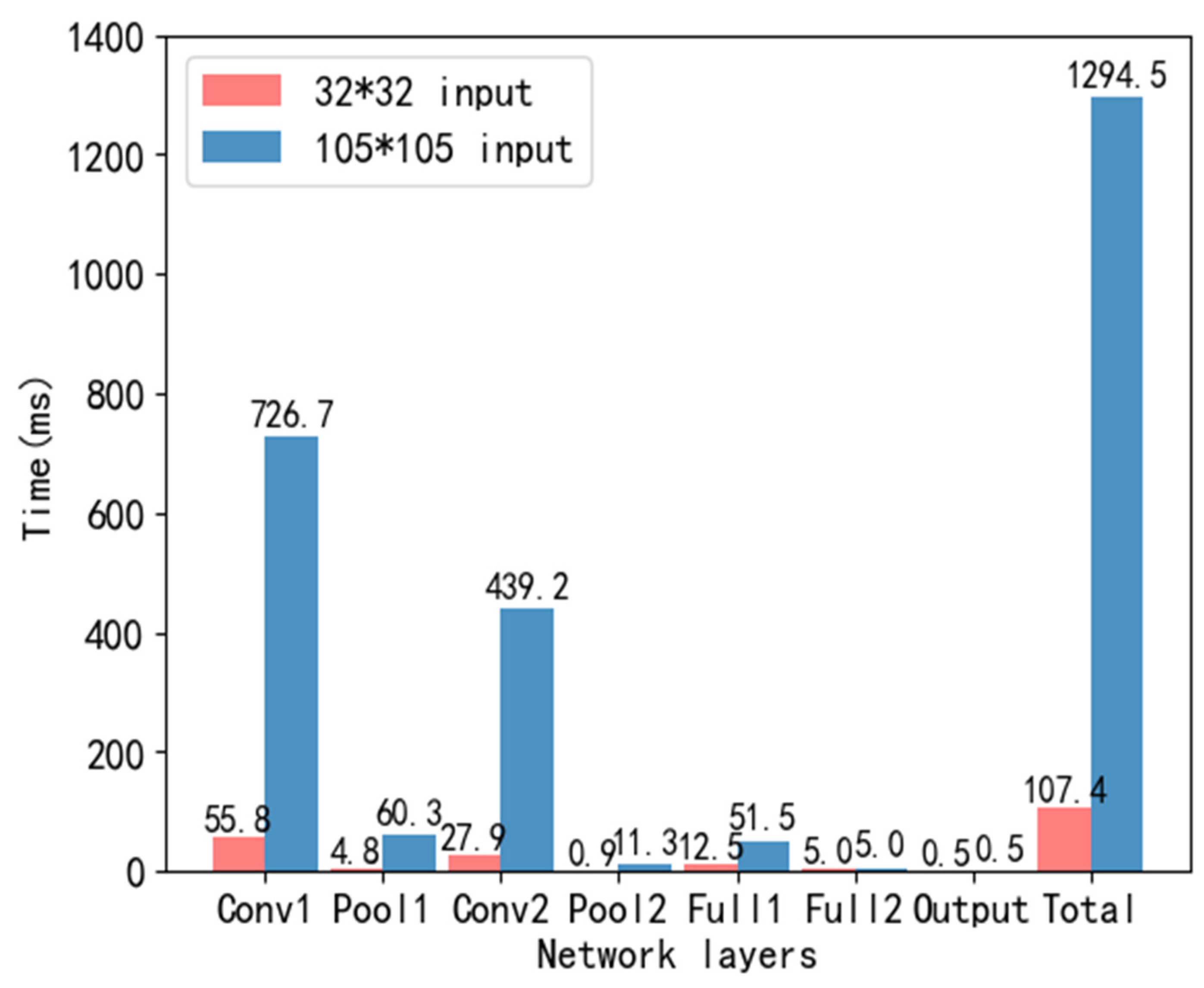
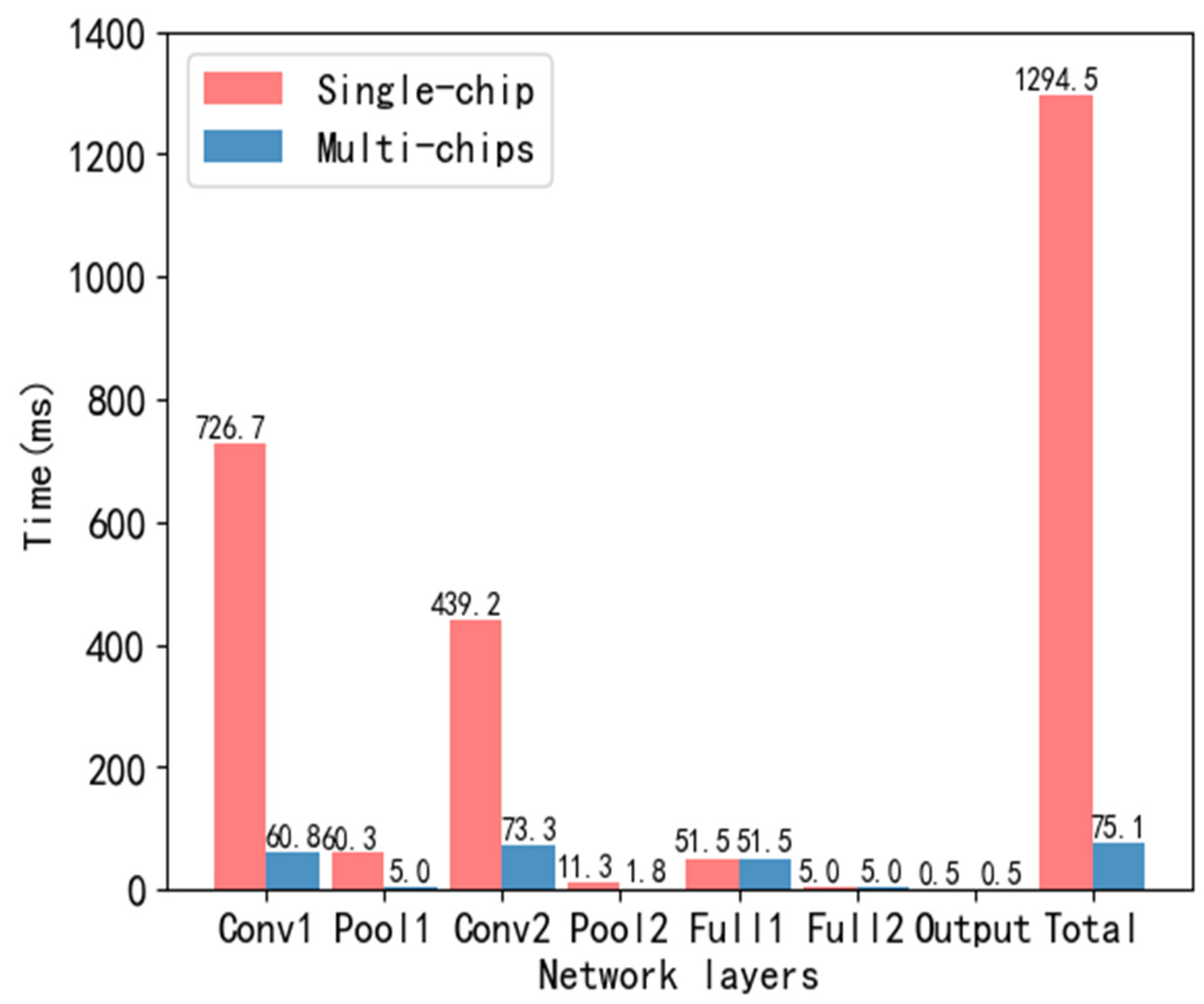
Without considering real-time performance, we use a single core to implement LeNet-5 models of different sizes.
Figure 10 indicates the time consumption. When the image input size is 105 × 105, the model running time exceeds 1s, which can no longer fulfil the real-time requirement. Among them, the convolutional layer occupies most of the calculation of the entire network.
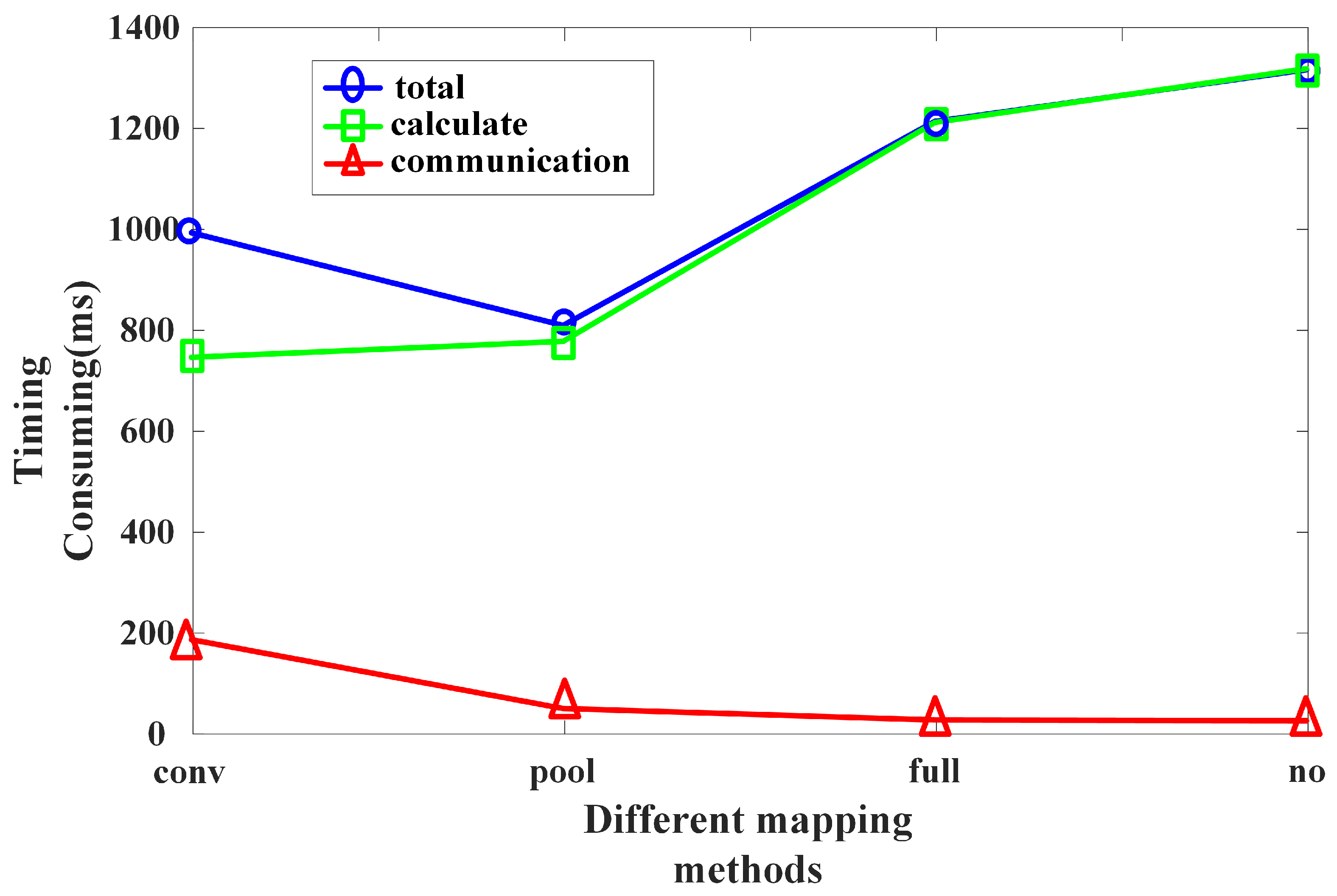
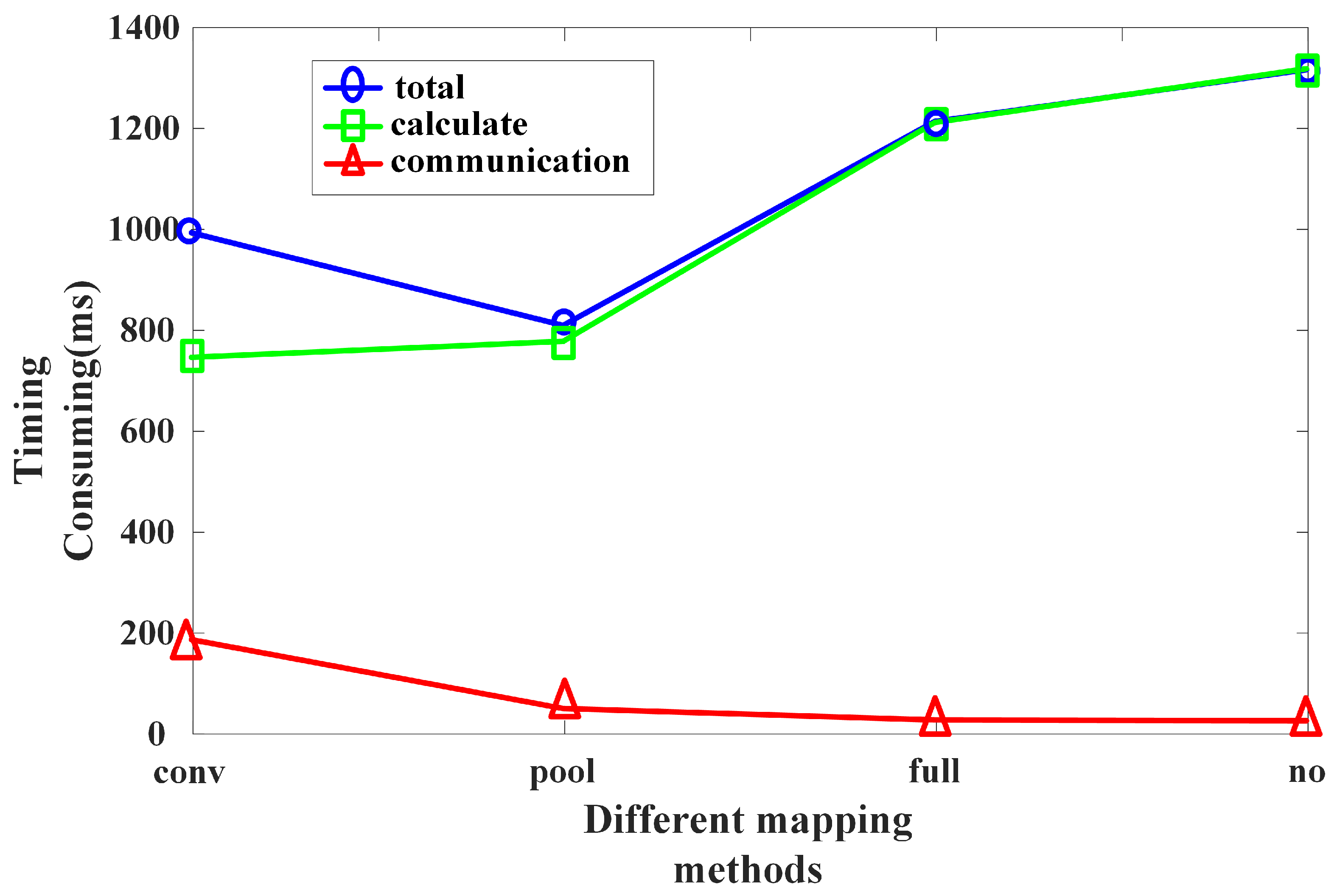
Next, we verify the effectiveness of the CNN distribution mapping mechanism. Respectively, the convolutional layer, pooling layer or fully connected layer are used as the scattered points for mapping. In addition, every layer of the entire network is decentralized. Compare the effects of various mapping methods.
Figure 11 points out the time consumption of different distribution mapping methods. The method of board data transmission uses SPI (Serial Peripheral interface, serial peripheral interface). It can be seen that the running time of the model is significantly shortened after the distributed mapping of the network. The distributed mapping method that takes the pooling layer as the dispersion point consumes the shortest time. The reason is that the amount of calculation in the pooling layer is not large. Secondly, the pooling layer reduces the resolution of the feature map to obtain features that are not spatially deformed. The amount of data transmitted during board communication is greatly reduced, so the board communication time is shorter. Therefore, when the convolutional layer is followed by the pooling layer, taking pooling as the dispersion point, each unit completes a layer of convolution and pooling. This can achieve the optimal mapping.
The effect of distribution mapping is analyzed according to the number of convolution kernels and distribution mapping according to the number of input feature maps. The 6 × 50 × 50 feature map convolution is implemented in two ways to obtain a 6 × 48 × 48 feature map. Finally, it takes 3.5 ms longer for the distribution mapping according to the number of convolution kernels than the distribution mapping according to the number of input feature map channels. When the number of input feature map channels and the number of convolution kernels are the same, the mapping is performed in two ways, and the calculation amount in a single calculation board is the same. The calculation time should be equal. The reason for the time-consuming difference between the two mapping methods is that the data needs to be read from the external RAM when the feature map is initialized. However, the distribution mapping according to the number of convolution kernels requires multiple initializations, i.e., multiple accesses to the external RAM. Therefore, when the number of input feature map channels is equal to the number of convolution kernels, the time complexity of distribution mapping according to the number of input feature maps is smaller.
We have tested the recognition accuracy of multi-core LeNet-5 through a large number of experiments. Under the normal use of the sigmoid function, the recognition accuracy of LeNet-5 is 88.2%. After simplifying the sigmoid function calculation, the recognition accuracy of LeNet-5 for the same conditions and samples decreases to 83.3%. The accuracy has decreased by 4.9%, but according to the above equation the calculation amount has been reduced to of the pre simplification level. This 4.9% decrease in accuracy results in a savings of around 25% in computational complexity. This is very meaningful for STM32, which has far less computing power and memory than GPUs. Our embedded platform expects to achieve lightweight and portable CNN operations, while ensuring an accuracy rate of 80%, and striving for lightweight and efficient models and calculations as much as possible. Balancing the two, as the recognition accuracy is still above 80%, we believe that the simplified sigmoid function is more suitable for our platform.
We complete the entire improved LeNet-5 model mapping process through layer-by-layer mapping, convolution kernel mapping, single convolution or fully connected distributed mapping. The specific distribution details are shown in
Table 1. The task used 26 chips, 22 of which are used for the CNN network part. The C1 and P1 layers are scattered according to the size of the convolution kernel, and then a single feature map is scattered into two parts and mapped into 12 computing units. We adopted an equal division method during the experimental process. After the grouping calculation is completed, merge again to obtain the convolution calculation results. The C2 and P2 layers only need to be mapped to six computing units according to the size distribution of the convolution kernel to meet the requirements. The calculation amount of the fully connected part is relatively small, and initialization through dimensionality reduction can be completed by a single calculation unit.
The CU calculates the time loss of a synchronization operation and inter core communication in sequence. Based on the average polling time of 100,000 word iterations, we measured the average polling time of the calculation module to be 488 . The proportion of polling time to the total calculation time cycle is 39.8%. The experimental results indicate that a large number of neurons can further reduce the proportion of polling time and improve the computational efficiency of the platform.
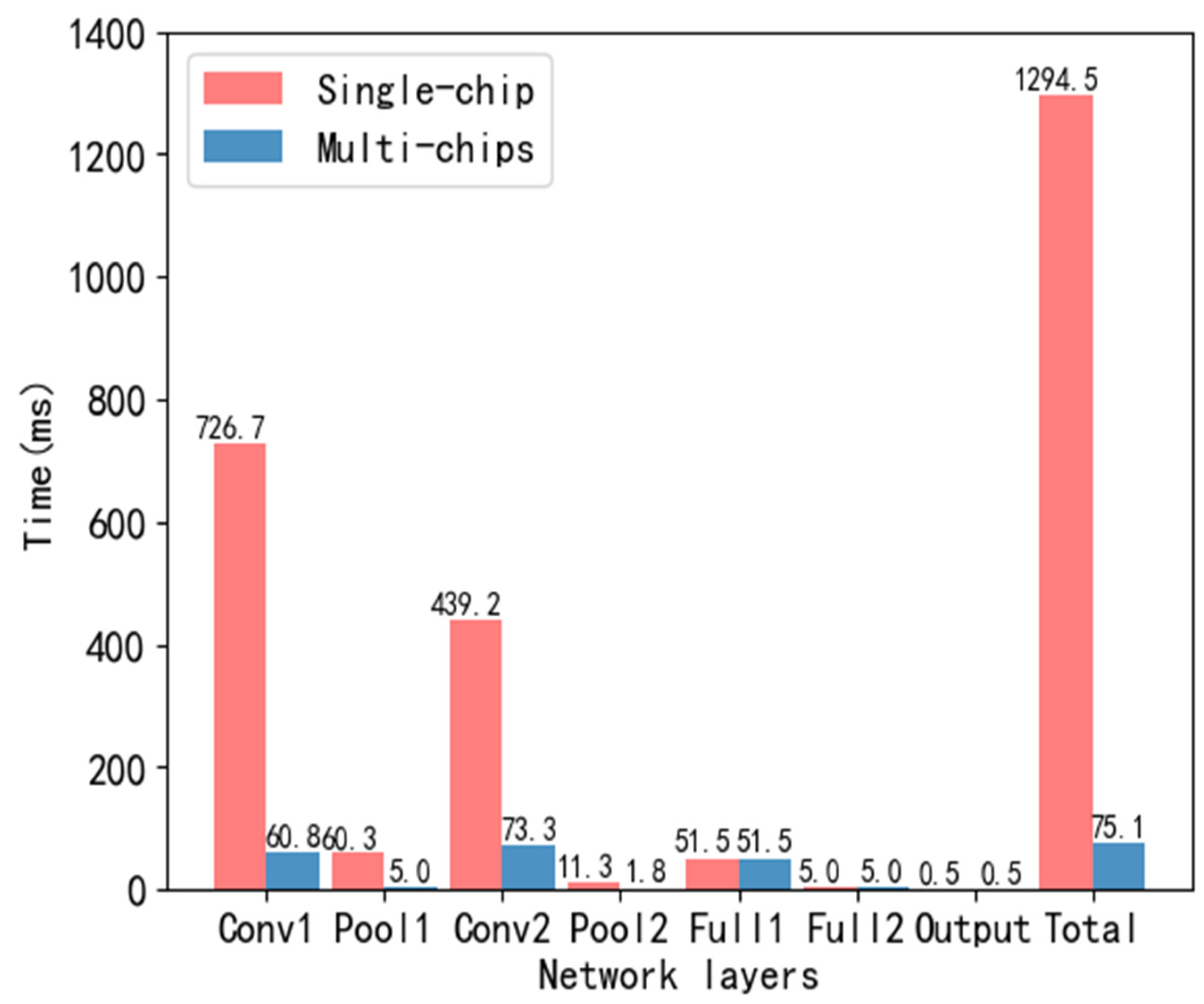
Figure 12 is a comparison of the time consumption of single-core and multi-core implementation of improved LeNet-5. The model is distributed to the neural network parallel computing hardware platform MEPP through the dimensionality reduction initialization and the CNN distribution mapping mechanism, which effectively shortens the model running time.
Table 2 lists the power consumption of the CU responsible for different functions in the platform MEPP. The power consumption of the system is at a relatively low level. This is one of the important advantages of the platform in specific application scenarios.
Table 3 shows the resource consumption of a single chip. The fully connected layer is still the network layer that consumes the most memory. These analysis results characterize the practical capabilities of this system in CNN applications. The good scalability brought by its modular organizational structure of MEPP also lays the foundation for the realization of more complex algorithms and larger-scale tasks.
We analyze the time complexity of convolution operations in a lightweight CNN using techniques such as the sliding window method to count the number of operations required for each convolutional layer. We analyze the memory requirements of lightweight CNNs and how they scale with the number of parameters and layers in the network.
5. Conclusions
Edge computing can decompose large-scale neural networks into multiple real-time computing tasks, greatly saving the energy and time consumption of computing, but the implementation of edge computing in traditional embedded single core microcontroller is not easy. We envisage improving the CNN algorithm to decompose the computational tasks of CNN, realizing part of the tasks of edge computing in a single core microprocessor, and realizing lightweight edge computing with less time cost and resource cost through parallel cooperation among multiple single core microcontrollers. In this paper, in response to the requirements of edge computing for power consumption and real-time performance, we build an ARM-based embedded parallel computing hardware platform MEPP. In order to complete the front-end image acquisition tasks such as image classification and target tracking, a front-end acquisition and computing board hardware architecture is designed. Drawing on the idea of time division multiplexing, we propose a multi-chip shared external static random access memory (SRAM) access mechanism. This method solves the communication problem between chips. Then, we propose a method of dimensionality reduction initialization to solve the problem of on-chip resources. According to the hierarchical structure of the convolutional neural network and the characteristics of the sliding window operation in the convolution process, a multi-level CNN distribution mapping mechanism is designed. The most time-consuming exponential function calculation in the nonlinear calculation process is optimized, and the exponential function calculation speed is greatly improved at the cost of reducing a small part of the calculation accuracy.
The experiments verify that the neural network parallel computing hardware platform can implement the CNN model. It has the advantages of low power consumption, scalability, and low cost. At the same time, the effectiveness of dimensionality reduction initialization and the CNN distribution mapping mechanism in real-time realization of convolutional neural network is verified. In the follow-up work, we will consider changing the communication method and control chip of the board. Faster data transmission communication methods and higher-end chips can better ensure real-time performance. On the basis of this architecture, we can replace the STMF407 series, which is currently used on the platform and has relatively low main frequency and computing power, with more powerful chips to achieve more efficient computing functions. Based on these experiments, we will iteratively upgrade STM32 in the embedded platform architecture, replacing STM32 with more advanced embedded chips such as Raspberry Pie. In future experiments, we will have the conditions to conduct experiments using these modern CNN networks.
The real-time of model computation is one of the core issues of convolutional neural network hardware acceleration. Real time performance is mainly constrained by computational power and inter core communication latency. In this experiment, we have demonstrated the effectiveness of achieving high-speed communication through shared RAM. However, the performance of hardware platforms has not been fully utilized, and it is still necessary to discuss methods to achieve higher computational power in future work, introducing a more powerful kernel and larger off-chip storage space under the current architecture, and expanding more diverse means of off chip communication. In future work, we will further expand the platform’s application scenarios by adding hardware resources, such as external cameras and infrared cameras, to achieve target recognition and tracking functions. At the same time, the platform can only achieve large-scale CNN operations and has a narrow application range. However, other physiological neural networks can also perform distributed computing based on the structure of our platform. In the future, we will investigate the performance of other physiological neural networks on the platform. On the basis of CNN experiments, we also conducted experiments on pulse neural network SNN on the platform. In addition to designing a multi-core system, we also designed a lightweight pulse neural network for the multi core system to optimize the model deployment process, making the network design more hardware friendly. In future research, we will continuously optimize our platform and the networks it adapts to from two aspects: reduce network size and compression weight parameters, in order to achieve richer parallel computing functions.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}