

Stabilized Temporal 3D Face Alignment Using Landmark Displacement Learning



Abstract
:1. Introduction
2. Related Works
2.1. 3D Morphable Model
2.2. 3D Face Alignment
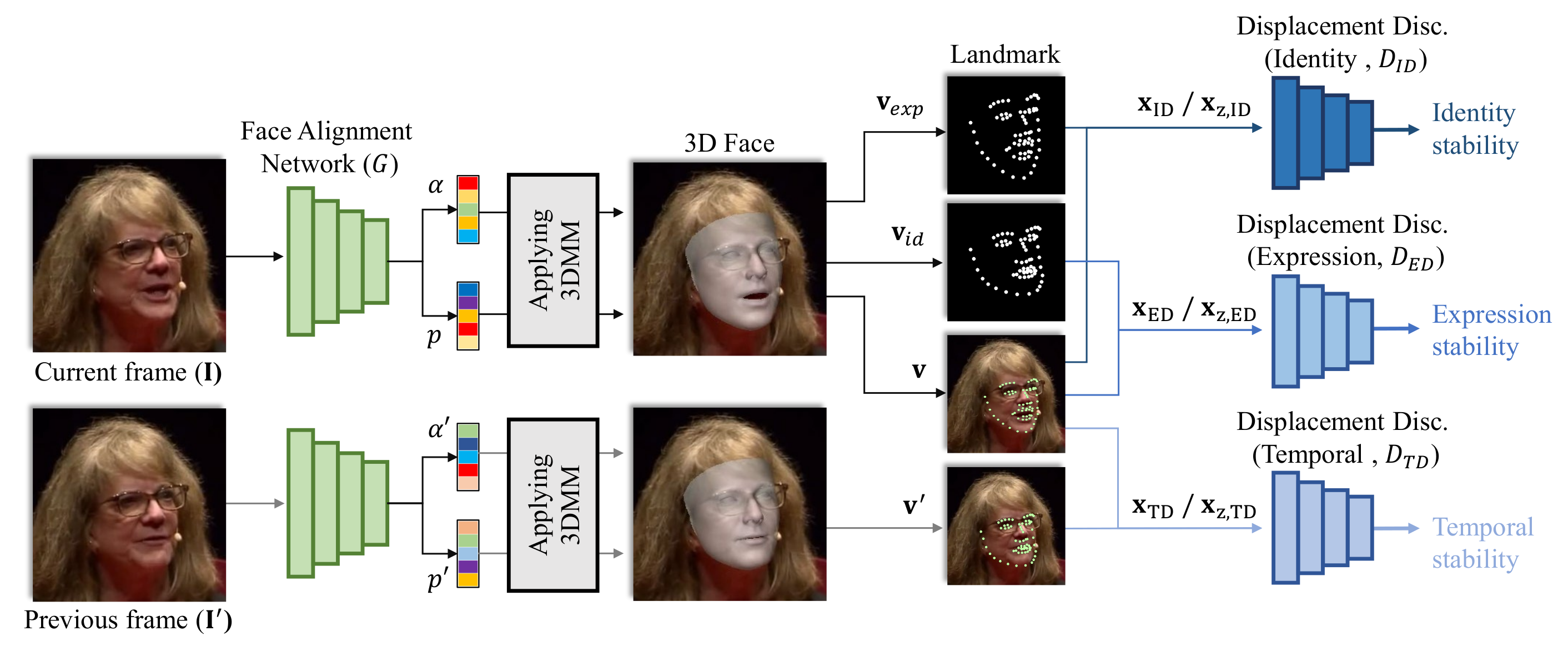
3. Method
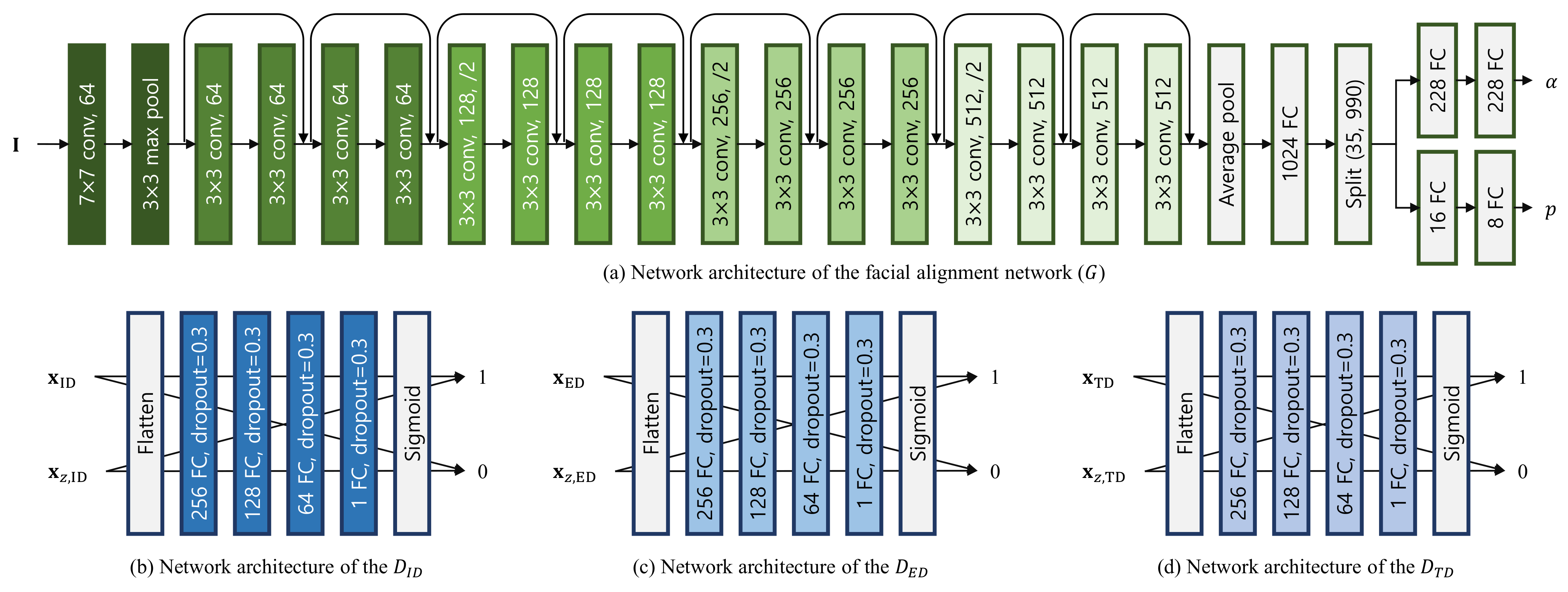
3.1. Facial Alignment Network
3.2. Displacement Discriminators
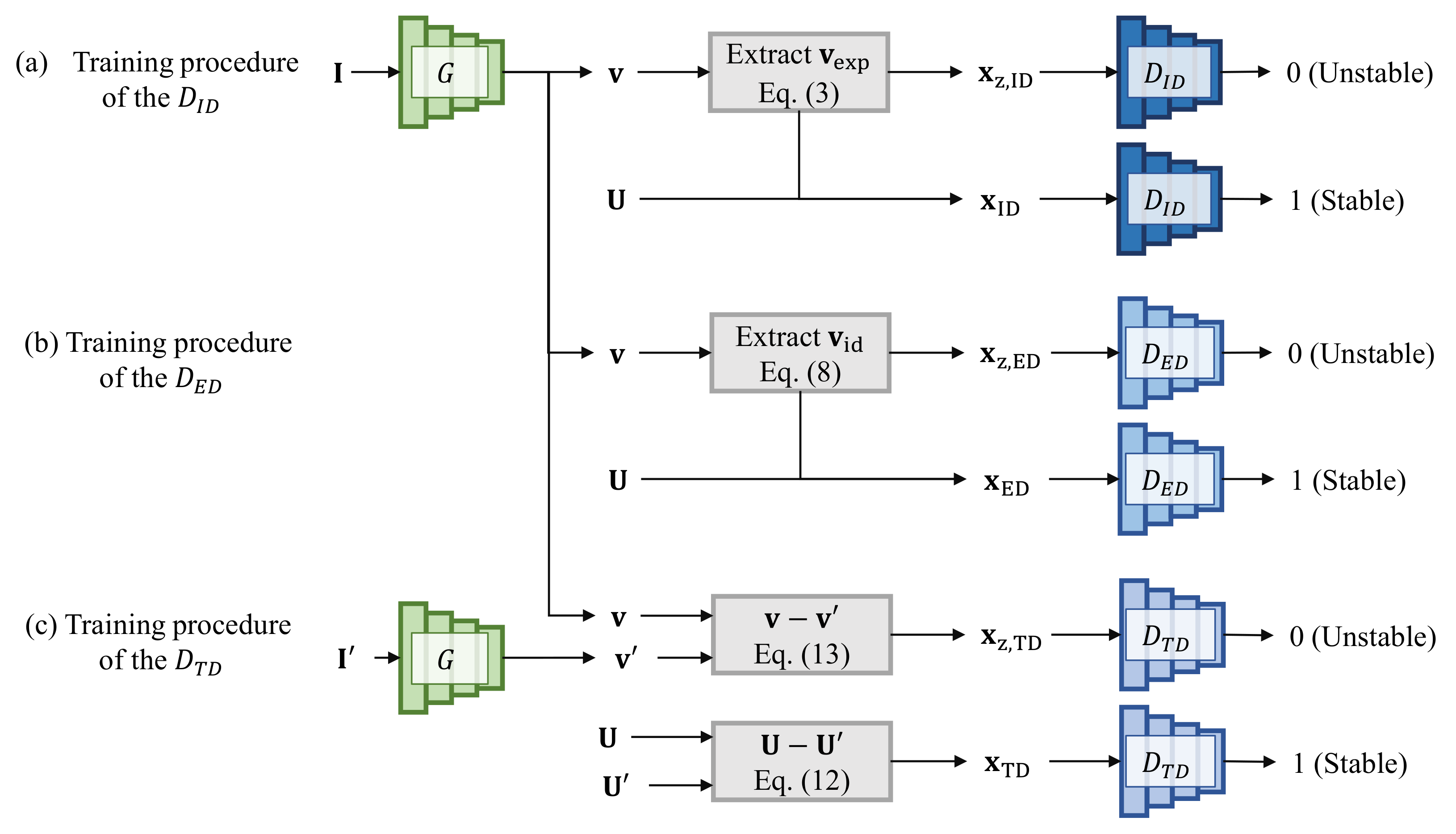
3.2.1. Identity Displacement Discriminator
3.2.2. Expression Displacement Discriminator
3.2.3. Temporal Displacement Discriminator
3.2.4. Adversarial Loss Function
4. Experimental Results
4.1. Implementation Details
4.2. Performance Evaluation
4.3. Ablation Study
5. Discussion and Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| IDD | Identity displacement discriminator |
| EDD | Expression displacement discriminator |
| TDD | Temporal displacement discriminator |
| 3D | Three-dimensional |
| 2S | Two-dimensional |
| GAN | Generative adversarial network |
| PCA | Principal component analysis |
| SVD | Singular value decomposition |
| TPS | Thin-plate splines |
| 3DMM | 3D morphable model |
References
- Blanz, V.; Vetter, T. A morphable model for the synthesis of 3D faces. In Proceedings of the 26th Annual Conference on Computer Graphics and Interactive Techniques, Los Angeles, CA, USA, 8–13 August 1999; pp. 187–194. [Google Scholar]
- Li, T.; Bolkart, T.; Black, M.J.; Li, H.; Romero, J. Learning a model of facial shape and expression from 4D scans. ACM Trans. Graph. (Proc. SIGGRAPH Asia) 2017, 36, 194:1–194:17. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Kim, J.; Oh, H.; Kim, S.; Tong, H.; Lee, S. A brand new dance partner: Music-conditioned pluralistic dancing controlled by multiple dance genres. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 3490–3500. [Google Scholar]
- Sun, G.; Wong, Y.; Cheng, Z.; Kankanhalli, M.S.; Geng, W.; Li, X. DeepDance: Music-to-dance motion choreography with adversarial learning. IEEE Trans. Multimed. 2020, 23, 497–509. [Google Scholar] [CrossRef]
- Shen, J.; Zafeiriou, S.; Chrysos, G.G.; Kossaifi, J.; Tzimiropoulos, G.; Pantic, M. The first facial landmark tracking in-the-wild challenge: Benchmark and results. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Santiago, Chile, 7–13 December 2015; pp. 50–58. [Google Scholar]
- Cao, C.; Weng, Y.; Zhou, S.; Tong, Y.; Zhou, K. Facewarehouse: A 3d facial expression database for visual computing. IEEE Trans. Vis. Comput. Graph. 2013, 20, 413–425. [Google Scholar]
- Paysan, P.; Knothe, R.; Amberg, B.; Romdhani, S.; Vetter, T. A 3D face model for pose and illumination invariant face recognition. In Proceedings of the 2009 Sixth IEEE International Conference on Advanced Video and Signal Based Surveillance, Genova, Italy, 2–4 September 2009; pp. 296–301. [Google Scholar]
- Vlasic, D.; Brand, M.; Pfister, H.; Popovic, J. Face transfer with multilinear models. In Proceedings of the SIGGRAPH06: Special Interest Group on Computer Graphics and Interactive Techniques Conference, Boston, MA, USA, 30 July–3 August 2006; p. 24. [Google Scholar]
- Bookstein, F.L.; Green, W. A thin-plate spline and the decomposition of deformations. Math. Methods Med. Imaging 1993, 2, 3. [Google Scholar]
- Amberg, B.; Romdhani, S.; Vetter, T. Optimal step nonrigid ICP algorithms for surface registration. In Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007; pp. 1–8. [Google Scholar]
- Blanz, V.; Vetter, T. Face recognition based on fitting a 3D morphable model. IEEE Trans. Pattern Anal. Mach. Intell. 2003, 25, 1063–1074. [Google Scholar] [CrossRef]
- Jourabloo, A.; Liu, X. Pose-invariant face alignment via CNN-based dense 3D model fitting. Int. J. Comput. Vis. 2017, 124, 187–203. [Google Scholar] [CrossRef]
- Kang, J.; Lee, S. A greedy pursuit approach for fitting 3d facial expression models. IEEE Access 2020, 8, 192682–192692. [Google Scholar] [CrossRef]
- Kang, J.; Lee, S.; Lee, S. Competitive learning of facial fitting and synthesis using uv energy. IEEE Trans. Syst. Man Cybern. Syst. 2021, 52, 2858–2873. [Google Scholar] [CrossRef]
- Kang, J.; Song, H.; Lee, K.; Lee, S. A Selective Expression Manipulation with Parametric 3D Facial Model. IEEE Access 2023, 11, 17066–17084. [Google Scholar] [CrossRef]
- Kang, J.; Lee, S.; Lee, S. UV Completion with Self-referenced Discrimination. In Proceedings of the EUROGRAPHICS 2020, Norrköping, Sweden, 25–29 May 2020; pp. 61–64. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Zhang, K.; Zhang, Z.; Li, Z.; Qiao, Y. Joint face detection and alignment using multitask cascaded convolutional networks. IEEE Signal Process. Lett. 2016, 23, 1499–1503. [Google Scholar] [CrossRef]
- Guo, J.; Zhu, X.; Yang, Y.; Yang, F.; Lei, Z.; Li, S.Z. Towards fast, accurate and stable 3d dense face alignment. In Computer Vision—ECCV 2020, Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 152–168. [Google Scholar]
- Sanyal, S.; Bolkart, T.; Feng, H.; Black, M.J. Learning to regress 3D face shape and expression from an image without 3D supervision. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7763–7772. [Google Scholar]
- Li, H.; Wang, B.; Cheng, Y.; Kankanhalli, M.; Tan, R.T. DSFNet: Dual Space Fusion Network for Occlusion-Robust 3D Dense Face Alignment. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 4531–4540. [Google Scholar]
- Ruan, Z.; Zou, C.; Wu, L.; Wu, G.; Wang, L. Sadrnet: Self-aligned dual face regression networks for robust 3d dense face alignment and reconstruction. IEEE Trans. Image Process. 2021, 30, 5793–5806. [Google Scholar] [CrossRef] [PubMed]
- Zhu, X.; Liu, X.; Lei, Z.; Li, S.Z. Face alignment in full pose range: A 3d total solution. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 41, 78–92. [Google Scholar] [CrossRef] [PubMed]
- Jourabloo, A.; Liu, X. Large-pose face alignment via CNN-based dense 3D model fitting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4188–4196. [Google Scholar]
- Dong, J.; Zhang, Y.; Fan, L. A Multi-View Face Expression Recognition Method Based on DenseNet and GAN. Electronics 2023, 12, 2527. [Google Scholar] [CrossRef]
- Białek, C.; Matiolański, A.; Grega, M. An Efficient Approach to Face Emotion Recognition with Convolutional Neural Networks. Electronics 2023, 12, 2707. [Google Scholar] [CrossRef]
- Lee, S.; Lee, J.; Kim, M.; Lee, S. Region Adaptive Self-Attention for an Accurate Facial Emotion Recognition. In Proceedings of the 2022 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Chiang Mai, Thailand, 7–10 November 2022; pp. 791–796. [Google Scholar]
- Bi, S.; Lombardi, S.; Saito, S.; Simon, T.; Wei, S.E.; Mcphail, K.; Ramamoorthi, R.; Sheikh, Y.; Saragih, J. Deep relightable appearance models for animatable faces. ACM Trans. Graph. (TOG) 2021, 40, 1–15. [Google Scholar] [CrossRef]
- Sevastopolsky, A.; Ignatiev, S.; Ferrer, G.; Burnaev, E.; Lempitsky, V. Relightable 3d head portraits from a smartphone video. arXiv 2020, arXiv:2012.09963. [Google Scholar]
- Zhang, Y.; Yang, J.; Liu, Z.; Wang, R.; Chen, G.; Tong, X.; Guo, B. Virtualcube: An immersive 3d video communication system. IEEE Trans. Vis. Comput. Graph. 2022, 28, 2146–2156. [Google Scholar] [CrossRef] [PubMed]
- Ahn, S.J.; Levy, L.; Eden, A.; Won, A.S.; MacIntyre, B.; Johnsen, K. IEEEVR2020: Exploring the first steps toward standalone virtual conferences. Front. Virtual Real. 2021, 2, 648575. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Configuration | Size |
|---|---|---|
| Input | Flatten landmark | B × 136 |
| FC1 | Node = 256, Activation = RELU, dropout = 0.3 | B × 256 |
| FC2 | Node = 128, Activation = RELU, dropout = 0.3 | B × 128 |
| FC3 | Node = 64, Activation = RELU, dropout = 0.3 | B × 64 |
| FC4 | Node = 1, Activation = Sigmoid, dropout = 0.3 | B × 1 |
| Method | 300VW-A | 300VW-B | 300VW-C |
|---|---|---|---|
| 3DDFA [20] | 2.913 | 3.035 | 3.387 |
| RingNet [21] | 2.845 | 2.983 | 3.343 |
| DSFNet [22] | 2.799 | 2.878 | 3.214 |
| SADRNet [23] | 2.745 | 2.770 | 2.858 |
| Ours | 2.495 | 2.549 | 2.734 |
| Method | 300VW-A | 300VW-B | 300VW-C |
|---|---|---|---|
| Without all | 3.731 | 4.060 | 4.677 |
| With DID | 3.315 | 3.575 | 3.912 |
| With DED | 3.133 | 3.284 | 3.665 |
| With DTD | 3.078 | 3.192 | 3.504 |
| With DID, DED | 3.099 | 3.227 | 3.601 |
| With DID, DTD | 2.912 | 3.085 | 3.311 |
| With DED, DTD | 2.721 | 2.801 | 3.057 |
| With DID, DED, DTD | 2.495 | 2.549 | 2.734 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, S.; Yoon, H.; Park, S.; Lee, S.; Kang, J. Stabilized Temporal 3D Face Alignment Using Landmark Displacement Learning. Electronics 2023, 12, 3735. https://doi.org/10.3390/electronics12173735
Lee S, Yoon H, Park S, Lee S, Kang J. Stabilized Temporal 3D Face Alignment Using Landmark Displacement Learning. Electronics. 2023; 12(17):3735. https://doi.org/10.3390/electronics12173735
Chicago/Turabian StyleLee, Seongmin, Hyunse Yoon, Sohyun Park, Sanghoon Lee, and Jiwoo Kang. 2023. "Stabilized Temporal 3D Face Alignment Using Landmark Displacement Learning" Electronics 12, no. 17: 3735. https://doi.org/10.3390/electronics12173735
APA StyleLee, S., Yoon, H., Park, S., Lee, S., & Kang, J. (2023). Stabilized Temporal 3D Face Alignment Using Landmark Displacement Learning. Electronics, 12(17), 3735. https://doi.org/10.3390/electronics12173735