1. Introduction
Many spatial applications, such as location-based services (LBS), carry out various searches based on the locations of the objects. For instance, the nearest neighbor (NN) search finds the object
(∈P) nearest to a given query object
q in a set
P of target objects (e.g., gas stations, restaurants, banks, and hospitals) [
1,
2]. Recently, since the number of mobile devices has dramatically increased and their applications have become diverse and frequent, more complicated spatial search algorithms have emerged than before. The aggregate nearest neighbor (ANN) search [
3,
4,
5,
6] is an extension of the NN search by introducing a set
Q of
M (≥1) query objects rather than a single query object
q. The ANN search finds the object
that minimizes the aggregate (e.g., max, sum) of the distances between
and all query objects
. The ANN search with
is equivalent to the NN search. Examples of the ANN search applications are as follows [
7]:
When holding a meeting, we choose a location so that the distance from the farthest (max) participant is minimized to quickly convene all participants.
When constructing a building such as a hospital or a mart, to maximize the profit from the customers, we choose a location of the new building to minimize the total (sum) distances from all potential customers living in various locations.
The flexible aggregate nearest neighbor (FANN) search [
7,
8,
9,
10,
11,
12] is an extension of the ANN search by introducing
flexibility factor . The FANN search with
is equivalent to the ANN search. In the above examples of the ANN search applications, if it is possible to host the meeting only with
participants, or if it is more effective to target only
customers instead of all the potential customers, it is more useful to find a solution for
, a subset of
Q with
. The FANN search finds the best subset
out of all possible query subsets.
This paper proposes an efficient
-approximate
k-FANN search algorithm for an arbitrary approximation ratio
(≥1) in road networks
, where
k is the number of FANN objects, i.e., the
k-FANN algorithm returns
k optimal FANN objects. Usually, FANN implies 1-FANN with
; however, in this paper,
k-FANN is simply denoted as FANN when there is no confusion. In general,
-approximate algorithms are expected to improve search performance at the cost of allowing an error ratio of up to the given
[
6,
8,
10,
11]. Since the optimal value of
varies greatly depending on applications and cases, the approximate algorithm for an arbitrary
is essential. In this paper, we prove that the error ratios of the approximate FANN objects returned by our algorithm do not exceed the given
. To the best of our knowledge, our algorithm is the first
-approximate
k-FANN search algorithm for road networks for an arbitrary
. Through a series of experiments using various real-world road network datasets, we demonstrated that the performance of our algorithm improved by up to 30.3% over FANN-PHL [
12], which is the state-of-the-art exact
k-FANN algorithm, for
, and the maximum error ratio of the approximate FANN objects was 1.147, which is very close to the optimal value of
. That is, our algorithm was able to quickly find very-near-optimal results even with a high value of
.
This paper is organized as follows. In
Section 2, the existing ANN and FANN algorithms are briefly introduced. In
Section 3, our
-approximate
k-FANN search algorithm is explained in detail. In
Section 4, the performance and accuracy of our algorithm are evaluated through various experiments. Finally, we conclude this paper in
Section 5.
2. Related Work
In this section, we briefly introduce the existing ANN and FANN search algorithms and discuss their pros and cons. The ANN search finds the object
that minimizes
from a set
Q of
M (≥1) query objects, where
is an aggregate function such as max and sum, and
is a distance function between two objects [
5,
6]. The FANN search is formally defined as the problem of finding
and
as follows [
7,
11,
12]:
The existing algorithms were studied separately in the Euclidean space and in road networks. In the Euclidean space, the distance between two objects can be calculated very quickly, and the nearest object can also be found quickly using an index structure such as the R-tree [
13]. In contrast, road networks are represented as graphs, and the distance between two objects in a road network is defined as their shortest-path distance [
2,
4,
11]. Calculating the shortest-path distance between two objects has a very high complexity of
, where
E and
V are the number of edges and vertices in the entire graph, respectively. In general, the distance between two objects in a road network is very different from their Euclidean distance. Therefore, the nearest neighbor search in road networks has higher complexity than in the Euclidean space, and the ANN and FANN searches in road networks also have higher complexity than in the Euclidean space.
Papadias et al. [
3,
14] proposed three algorithms using the R-tree and triangle inequality for the ANN search in the Euclidean space: the multiple query method (MQM), single-point method (SPM), and minimum bounding method (MBM). The MBM forms the minimum bounding rectangle (MBR) containing all query objects in
Q and then finds the ANN object using the distance equation defined between the MBR and an object. Li et al. [
6] improved MBM for a better performance of the ANN search with
max by replacing the MBR with the convex hull, minimum enclosing ball (MEB), and Voronoi cell for
Q. They also proposed a
-approximate algorithm for high-dimensional spaces.
Yiu et al. [
4] proposed three algorithms for the ANN search in road networks: the incremental Euclidean restriction (IER), threshold algorithm (TA), and concurrent expansion (CE). These algorithms use the indices based on the Euclidean coordinates instead of the actual shortest-path distances between objects. Ioup et al. [
5] proposed an ANN search algorithm in road networks using the M-tree [
15]. The M-tree index is constructed based on the actual distances between objects, and thus the ANN search using the M-tree is more efficient than using the R-tree. However, their algorithm only returns approximate search results, and the error range of the search results is not known.
Li et al. [
8,
10] handled the FANN search problem in the Euclidean space and proposed search algorithms using the R-tree and list data structure. In the algorithm using the R-tree, an R-tree node is pruned based on its FANN distance estimated using the
query objects closest to the MBR of the node. The subtree rooted by the pruned node is not further accessed, i.e., discarded from the search candidates. In the list-based algorithm, the final FANN object
is obtained by constructing gradually a nearest-object list for each query object
and finding the first object commonly contained in all the lists. In addition, Li et al. [
8,
10] proposed a 3-approximate algorithm and a
-approximate algorithm for
max. Li et al. [
10] added a 2-approximate algorithm in two-dimensional spaces and a
-approximate algorithm in low-dimensional spaces for an arbitrary
for both
sum and max. Houle et al. [
9] proposed an approximate FANN algorithm in the Euclidean space for
sum and max and showed through experiments that the accuracy and performance improved over the approximate algorithms by Li et al. [
8].
The FANN search problem in road networks was first dealt with by Yao et al. [
11]. They proposed three algorithms, namely, the Dijkstra-based algorithm, the R-List algorithm, and the IER-
kNN algorithm. Through experiments, it was shown that IER-
kNN always outperformed the others. In addition, they presented a 3-approximate algorithm that does not use an index for
sum. However, this algorithm showed lower search performance than IER-
kNN using an index. Chen et al. [
16] defined a new FANN distance that considers not only the aggregate of the distances from query objects in
but also keyword similarity in road networks. They proposed search algorithms based on the distance by extending the Dijkstra-based algorithm, the R-List algorithm, and the IER-
kNN algorithm proposed by Yao et al. [
11].
Chung and Loh [
7] proposed the
IER-LMDS algorithm, which is an efficient
-probabilistic FANN algorithm that uses landmark multidimensional scaling (LMDS) [
17,
18]. LMDS maps the objects in a road network to those in a Euclidean space while maintaining their relative distances as much as possible. Thus, we can perform the FANN search on the mapped objects efficiently by using, for instance, the R-tree. However, IER-LMDS only returns the search results within the given search probability
, and there may exist false drops. The FANN object is missed in case its distance change from query objects after LMDS mapping is in the probability range of
, i.e., the distance change is larger or smaller than the others. Chung et al. [
12] proposed the
FANN-PHL algorithm, which is an exact
k-FANN algorithm using the M-tree. The previous IER-
kNN incurs many unnecessary accesses to R-tree nodes and thus many unnecessary calculations of actual shortest-path distances of the objects in the nodes. It is because IER-
kNN uses the R-tree index constructed based on the Euclidean distances between objects. On the contrary, FANN-PHL improved the search performance significantly by greatly reducing accesses to unnecessary index nodes using the M-tree index constructed based on the actual distances between objects in a road network. The
-approximate FANN search algorithm for an arbitrary
proposed in this study is an extension of FANN-PHL. In
Section 4, we show that our algorithm always outperforms FANN-PHL while allowing only small error ratios.
3. Efficient -Approximate k-FANN Search Algorithm for Arbitrary
In this section, we explain our
-approximate
k-FANN search algorithm for an arbitrary approximation ratio
(≥1) in road networks
. The
-approximate object
should satisfy the following equation for the exact FANN object
:
We use the pruned highway labeling (PHL) algorithm [
19,
20] to find the shortest-path distance
D between two objects since it is known to be the fastest for finding
D until recently [
2,
11]. Although our algorithm uses the PHL algorithm, ANN and FANN search problems are difficult to solve by simply employing the PHL algorithm. A simple method for ANN search using only the PHL algorithm is to find an object
with the minimal aggregate of the distances to all query objects
(∈Q) among all data objects
p (∈P). The complexity of this method is
, where
C is the cost of the PHL algorithm. That is high complexity since
as well as
C are usually very high. A simple method for FANN search using an ANN algorithm is to perform ANN search for every possible
. However, for the default values
and
of our experiments in
Section 4, we should perform the ANN search as much as
times. The performance of the FANN search algorithms in road networks is highly dependent on the cost of the shortest-path distance calculation between two objects [
11,
12]. That is also demonstrated through experiments in
Section 4. Therefore, to improve the performance of the FANN algorithms in road networks, the algorithms should be designed to minimize the number of shortest-path distance calculations. Our algorithm may use any other shortest-path distance algorithm with better performance than the PHL algorithm.
Our
-approximate FANN search algorithm is an extension of FANN-PHL, an exact FANN search algorithm by Chung et al. [
12]. Thus, we denote our algorithm as
AFANN-PHL hereafter.
Table 1 summarizes the notations in this paper. Our algorithm uses the M-tree [
15,
21] as the index structure as FANN-PHL. The M-tree is a multi-level balanced tree index structure similar to the R-tree [
13]. While the R-tree index is built using the absolute Euclidean coordinates of the objects, the M-tree index is constructed using the metric distances between the objects. The M-tree uses triangular inequality for efficient range and
k-NN search as well as indexing [
15,
22]. Like other tree-based data structures, the M-tree consists of leaf and non-leaf nodes. Each leaf node has multiple data objects with unique identifiers, and each non-leaf node has multiple entries containing a pointer to a subtree. The region for each non-leaf node is represented as a sphere. When the sub-node is a leaf node, it is the minimum spherical region containing all objects in the sub-node; when the sub-node is a non-leaf node, it is the minimum spherical region containing all the minimum spherical regions for all entries in the sub-node. The object at the center of the minimum spherical region is called a
parent object.
Figure 1 shows the node entry structures of the M-tree, and the description for each attribute is summarized in
Table 2 and
Table 3. The minimum bounding region containing all the objects in an M-tree leaf node
L is represented as a sphere. In
Table 2, the parent object
is the central object that represents all the objects
in the leaf node
L. The entry structure of the M-tree leaf node used in our algorithm is the same as before. The minimum bounding region containing all the objects in an M-tree non-leaf node
N is also represented as a sphere. In
Table 3,
n is the subnode of
N corresponding to an entry
e in
N, and
is the parent object of
N. The region of node
n is represented as a sphere centered by the routing object
(i.e., the parent object of node
n) with a radius of
. The attribute
count is newly added in our algorithm. If the node
n pointed to by the pointer
in an entry
e is a leaf node, the value of
is the number of all objects in the node
n. If the node
n pointed to by
is a non-leaf node, the value of
is set as
for all entries
in node
n. Thus, the
count value for an entry
e is the number of all objects contained in the subtree
rooted by the node
n.
Algorithm 1 shows the AFANN-PHL algorithm. This algorithm has almost the same structure as the exact FANN-PHL [
12]; the approximation task is added in line 14. In line 1 of Algorithm 1,
is the current candidate FANN object, and
H is the priority queue that includes the M-tree non-leaf entries
e and is sorted in the ascending order of
values. In line 5,
is the subnode corresponding to
e, i.e., the root node of the subtree pointed to by the pointer
. In line 7, the FANN distance
of an entry
is defined as follows [
12]:
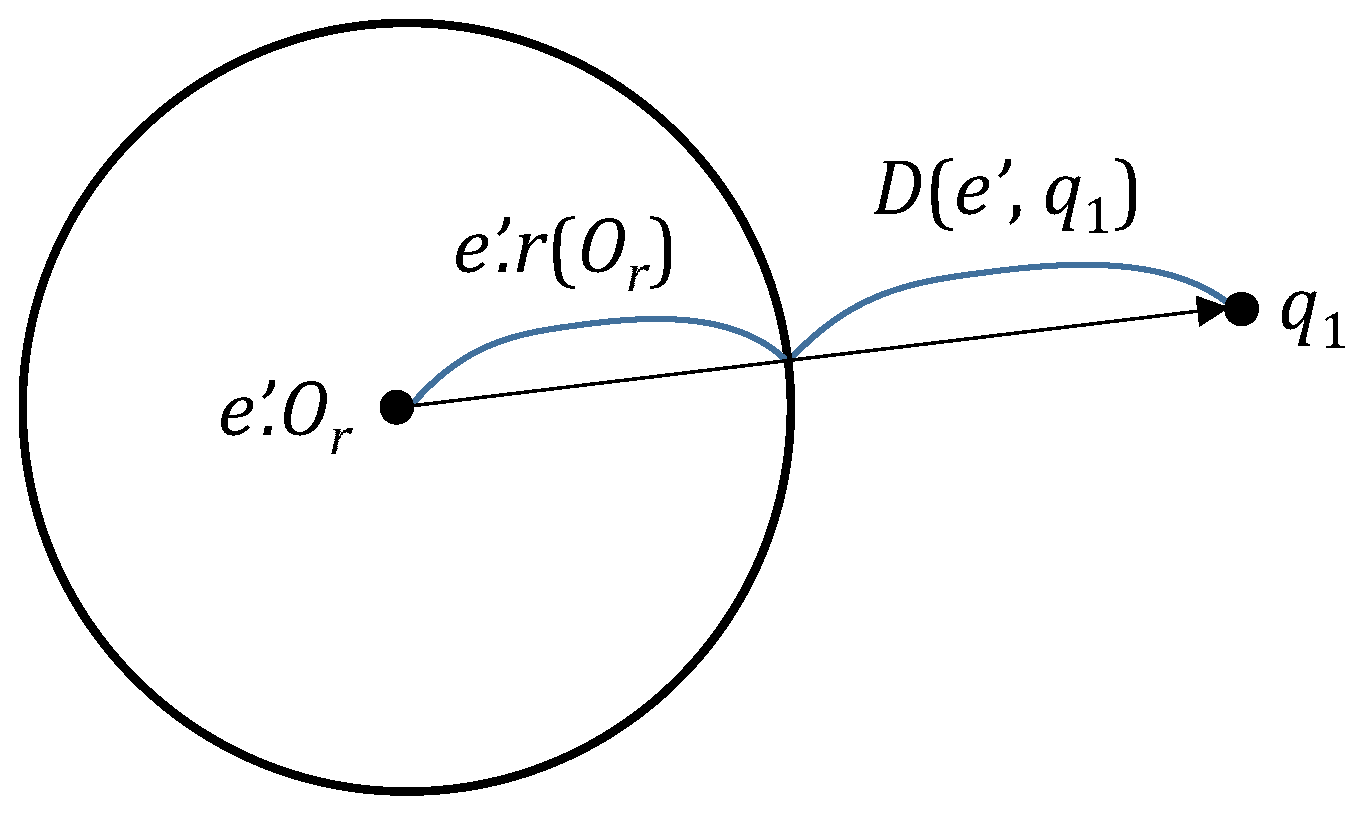
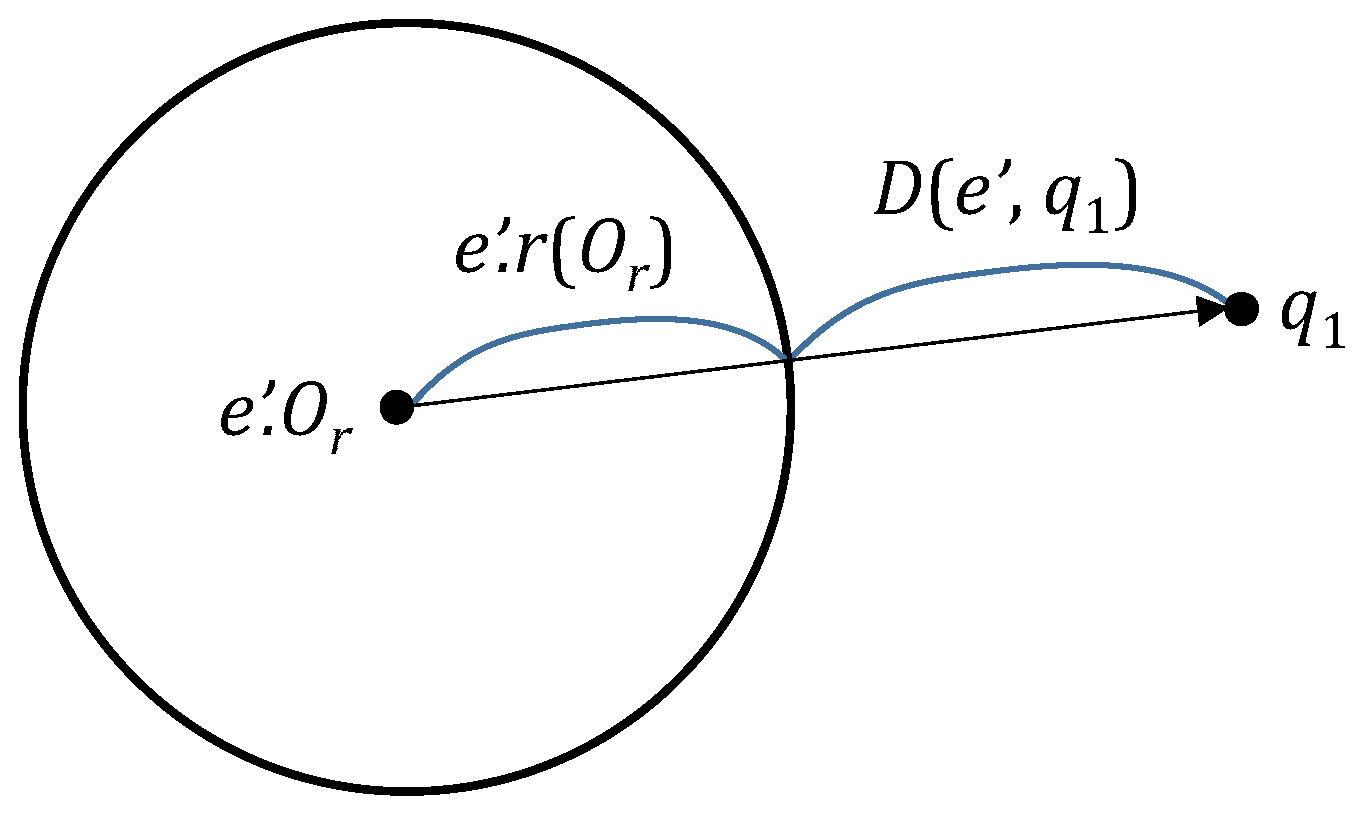
where
is the distance between the spherical region for a node
and a query object
; it is defined as
(refer to
Figure 2) [
12].
| Algorithm 1 AFANN-PHL Algorithm. |
Require:
Ensure: - 1:
- 2:
for all entries e in - 3:
while do - 4:
- 5:
if is a non-leaf node then - 6:
for each entry in do - 7:
if then end if - 8:
end for - 9:
else - 10:
for each object p in such that do - 11:
if then end if - 12:
end for - 13:
end if - 14:
Invoke Algorithm 2 /* Perform approximation */ - 15:
end while - 16:
Return
|
We first describe the case that the number of FANN objects
k is 1, and the natural generalization for
is described later in this section. The approximate FANN object
returned by the AFANN-PHL algorithm for a given
(≥ 1) should satisfy the following condition for the exact FANN object
:
For
, the AFANN-PHL returns the same result as the exact FANN-PHL. For
, when the AFANN-PHL finds the object
that satisfies Equation (
5) in line 14 of Algorithm 1, it returns the object and terminates right away. Therefore, since the algorithm terminates early even before the exact FANN object
is found, it has the advantage of improving search performance. There is a tradeoff between the search performance and the accuracy of the approximate FANN object
; it can be adjusted as needed by changing
appropriately. In
Section 4, as the experimental result using real road network datasets, we show that the approximate FANN object
is very close to the exact FANN object
even with a high value of
.
In line 14 of Algorithm 1, the AFANN-PHL algorithm carries out the approximation task as described in Algorithm 2. In lines 1 and 2 of Algorithm 2,
is the priority queue created separately from
H; a tuple
for the current candidate FANN object
and a tuple
for each entry
e in
H are inserted in
. All the tuples in
are sorted in the ascending order of the second attribute values. In line 4, the tuple
that satisfies the following Equation (
6) is extracted:
where
is the third attribute of a tuple
. If a tuple that satisfies Equation (
6) does not exist,
is set as
. If the condition in line 5 is satisfied for the tuple
, the algorithm returns the current candidate FANN object
and terminates. Here,
is the second attribute of the tuple
.
| Algorithm 2 Approximation by AFANN-PHL. |
- 1:
for current candidate FANN object - 2:
for each entry e in H - 3:
Sort in the ascending order of second attribute values - 4:
Find the tuple satisfying Equation ( 6) - 5:
if then return end if
|
The generalization of the AFANN-PHL algorithm for
is straightforward as follows. First, an array
is allocated to store the
k approximate FANN objects, and Equation (
5) is modified as the following:
where
is the exact
k-th FANN object. The array
is always sorted in the ascending order of the values of
. In line 1 of Algorithm 2, a tuple
for each approximate candidate FANN object
is inserted, and in line 4, the tuple
that satisfies the following Equation (
8) is extracted:
The condition in the if statement in line 5 is modified to
. The following Lemma 1 shows the correctness of the AFANN-PHL algorithm for the general case of
, i.e., the returned approximate FANN objects satisfy Equation (
7).
Lemma 1. The approximate FANN object returned by the AFANN-PHL algorithm satisfies Equation (7). Proof. For each tuple
in
, any object
p contained in the spherical region of the entry
e satisfies
[
12]. For each tuple
in
, we associate a spherical region centered by the approximate FANN object
with a radius of 0. Since there are
k or more objects in the spherical regions for the tuples
that satisfy Equation (
8), it holds that
, where
is the second attribute value of the tuple
, and
, is the exact
k-th FANN object. If not, i.e., if it holds that
, all the objects
p in the region for the tuple
satisfy
. Moreover, since the tuples in
are sorted in the ascending order of the second attribute values, all the remaining tuples
satisfy
, and thus all the objects
p in the region for
satisfy
. That is, in the regions for the tuples
in
, we cannot find any FANN object. However, since there exist less than
k objects in the regions for the tuples
, there cannot exist
k FANN objects, which is a contradiction. Therefore, it holds that
. If the condition
is satisfied in line 5 of Algorithm 2, since it holds that
, the AFANN-PHL algorithm satisfies
(Equation (
7)). □
Our algorithm has the worst-case complexity for since it cannot terminate early, and the complexity is the same as that of the exact FANN algorithm. The exact FANN algorithm has the worst-case complexity when the number and distribution of query objects are set so that the algorithm should access all leaf nodes in the M-tree. In this case, the shortest-path distances from all data objects to all query objects should be calculated. Thus, the worst-case complexity of our algorithm is , where C is the cost of the shortest-path distance calculation. However, the practical search cost is usually much lower than the worst-case complexity.
4. Experimental Evaluation
In this section, we carry out a series of experiments to compare the search performance of the existing exact FANN-PHL algorithm [
12] and our AFANN-PHL algorithm and to verify the search accuracy of our algorithm for various approximation ratios
. In our experiments, the performance of our algorithm is compared only with the FANN-PHL algorithm [
12] since it is the state-of-the-art exact FANN search algorithm. The platform for the experiments is a workstation equipped with an AMD 3970X CPU, 128GB memory, and a 1.2TB SSD. Both FANN-PHL and AFANN-PHL algorithms were implemented in C/C++. In our experiments, to quickly calculate the shortest-path distance
D between two objects (vertices), we used the C/C++ source code written by the original author of the PHL algorithm (
http://github.com/kawatea/pruned-highway-labeling (accessed on 1 July 2023)).
The datasets in our experiments are the real-world road network datasets of five regions in the USA, which have also been used in the 9th DIMACS Implementation Challenge—Shortest Paths (
http://www.diag.uniroma1.it/challenge9/download.shtml (accessed on 1 July 2023)) and in various previous studies [
2,
11,
12].
Table 4 summarizes the experimental datasets. A road network dataset is represented as a graph composed of a set of vertices and a set of undirected edges. Each vertex represents a single object in a road network, and each edge represents a single road segment directly connecting two neighboring vertices. Since the datasets contain noises such as self-loop edges for a vertex and unconnected graph segments [
2,
11,
12], we carried out preprocessing to remove the noises.
Table 5 summarizes the parameters considered in our experiments; the values in parentheses indicate default values.
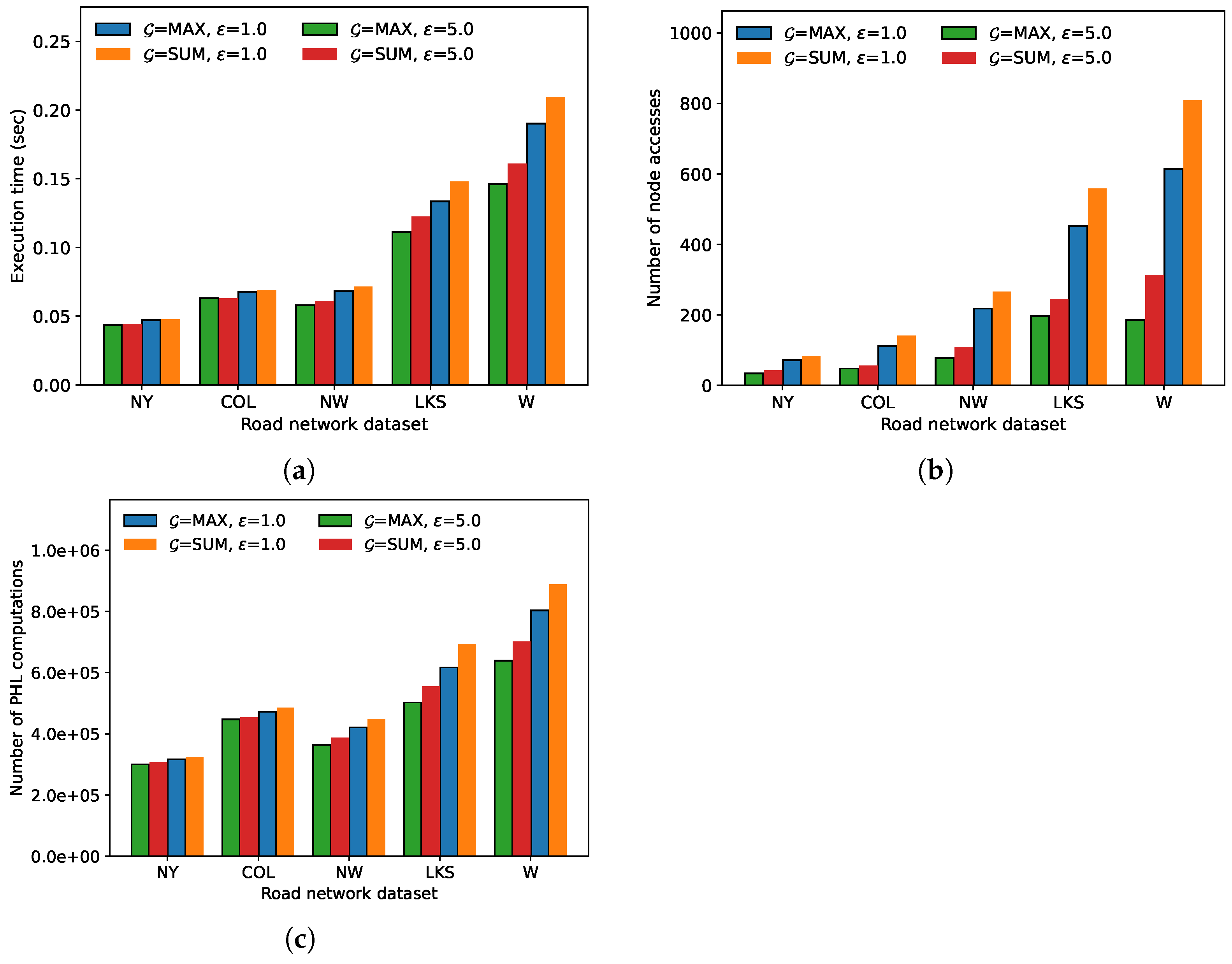
In the first experiment, we compared the execution time, the number of node accesses, and the number of distance
D calculations needed for the FANN search for each road network dataset in
Table 4. Here, all the other parameter values were set to their default values indicated in
Table 5. For each parameter combination, we averaged the results obtained using an arbitrary 1000 query sets
Q.
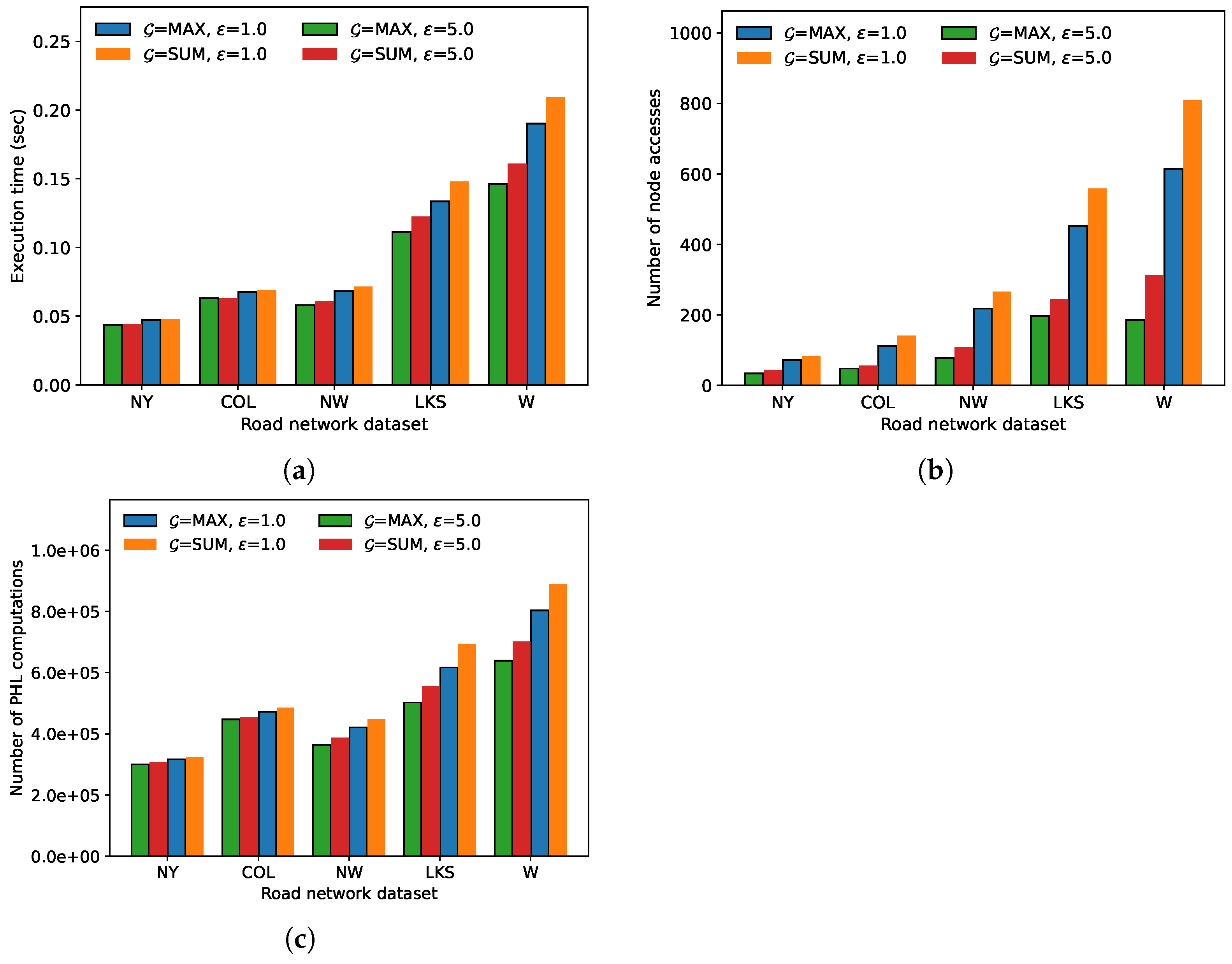
Figure 3 demonstrates the results of the first experiment. The execution time, the number of node accesses, and the number of distance calculations show similar trends for both algorithms. As the number of objects in a road network increases, the number of index nodes within a query region of the same size increases. Thus, the number of distance calculations to the objects in the index nodes also increases, thereby making the execution time of the algorithms increase. In the first experiment, the AFANN-PHL algorithm always showed a higher performance than the exact algorithm; for the W dataset, the performance improved by up to 30.3% for
max.
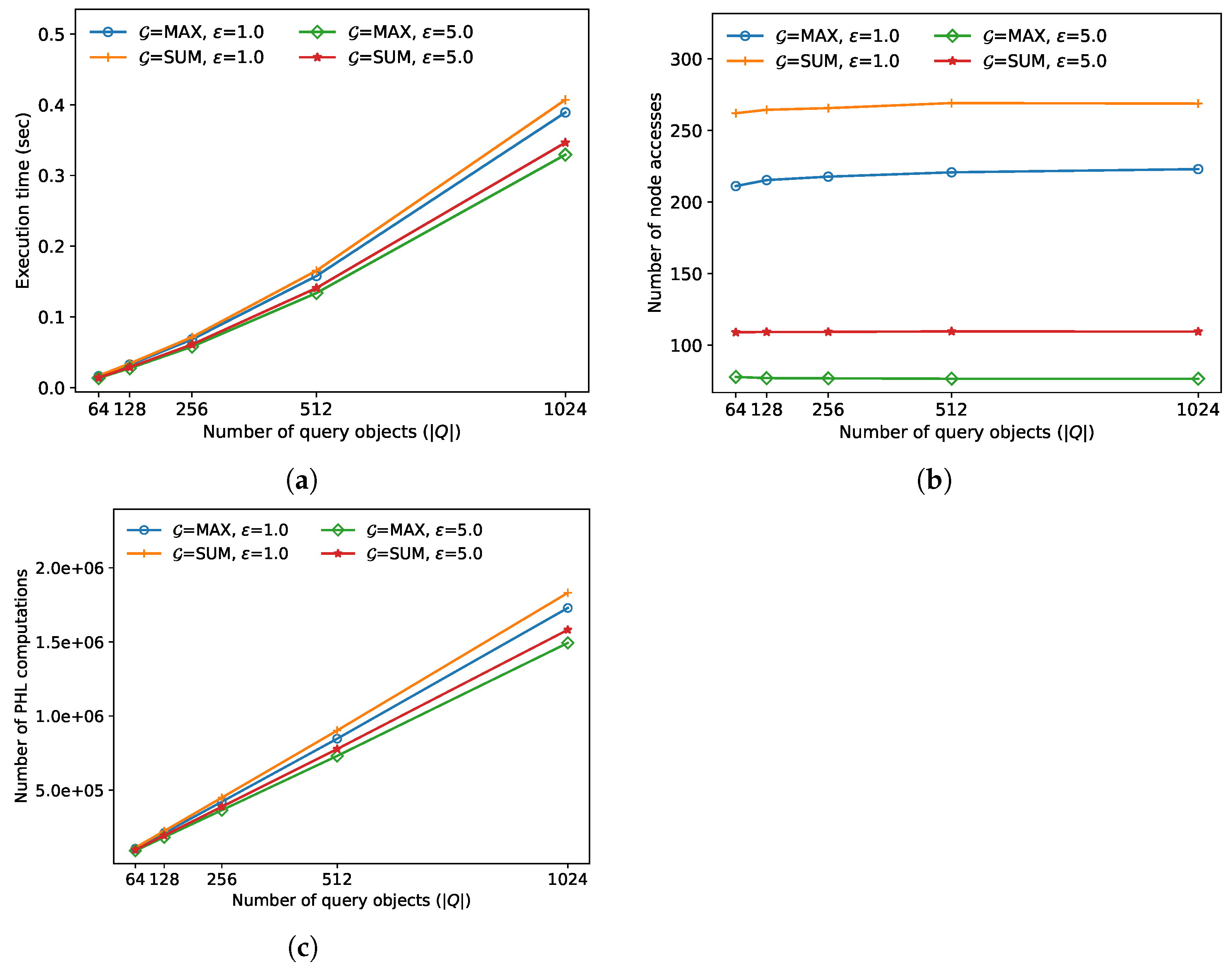
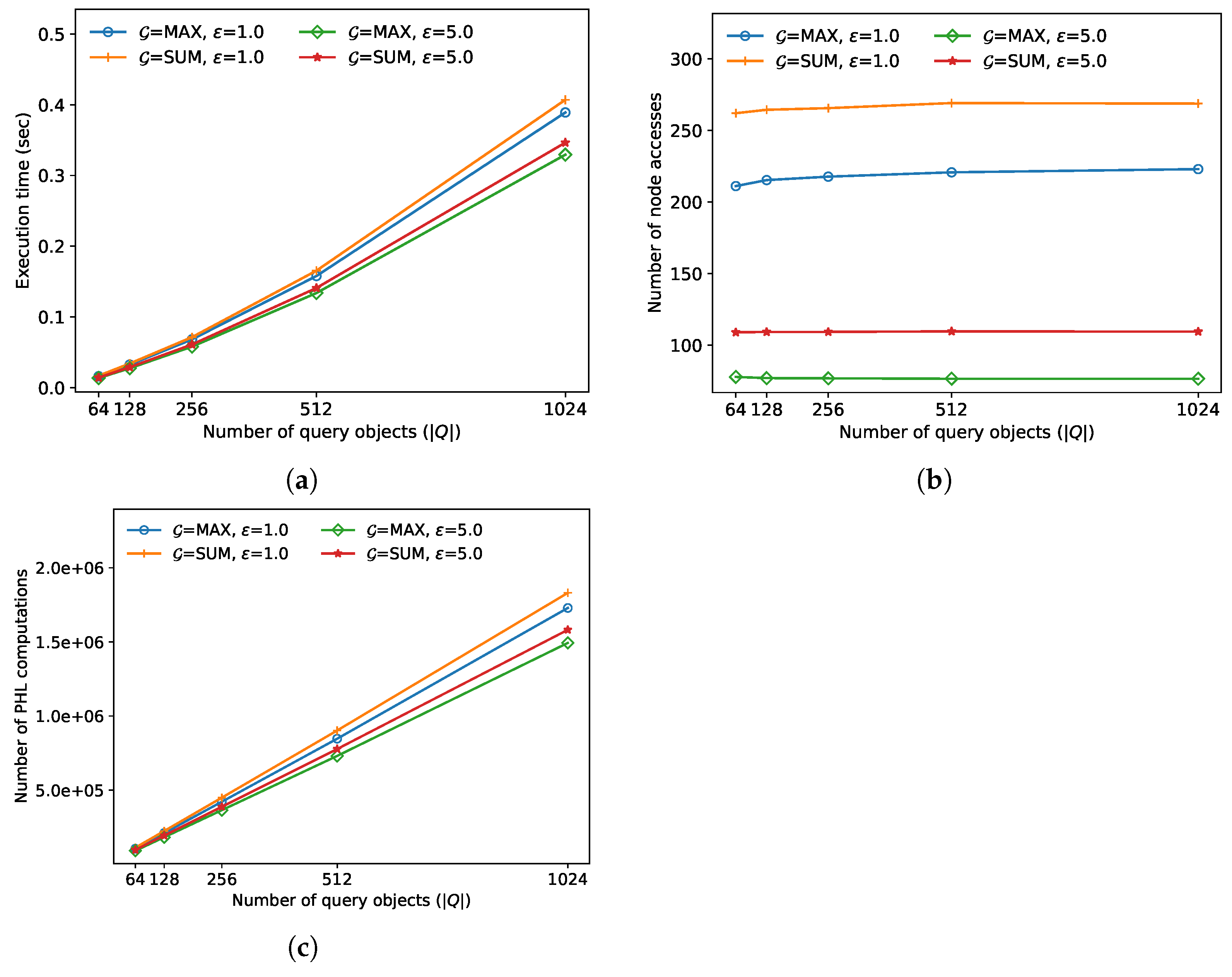
In the second experiment, we compared the FANN search performance for various query sizes
M. As demonstrated in
Figure 4, the execution time and the number of distance calculations increases almost linearly as
M increases for both algorithms. This is because both algorithms need to calculate the exact distances
D to
M query objects
to find both
and
[
12]. Meanwhile, the number of node accesses has not changed much as
M increases for both algorithms. This is because, if the regions containing the query objects are similar, both
and
remain similar even though
M increases [
12]. In this experiment, the approximate algorithm always outperformed the exact algorithm; the performance improved by up to 18.7% when
and
sum.
In the third experiment, we compared the FANN search performance for various numbers of nearest neighbors
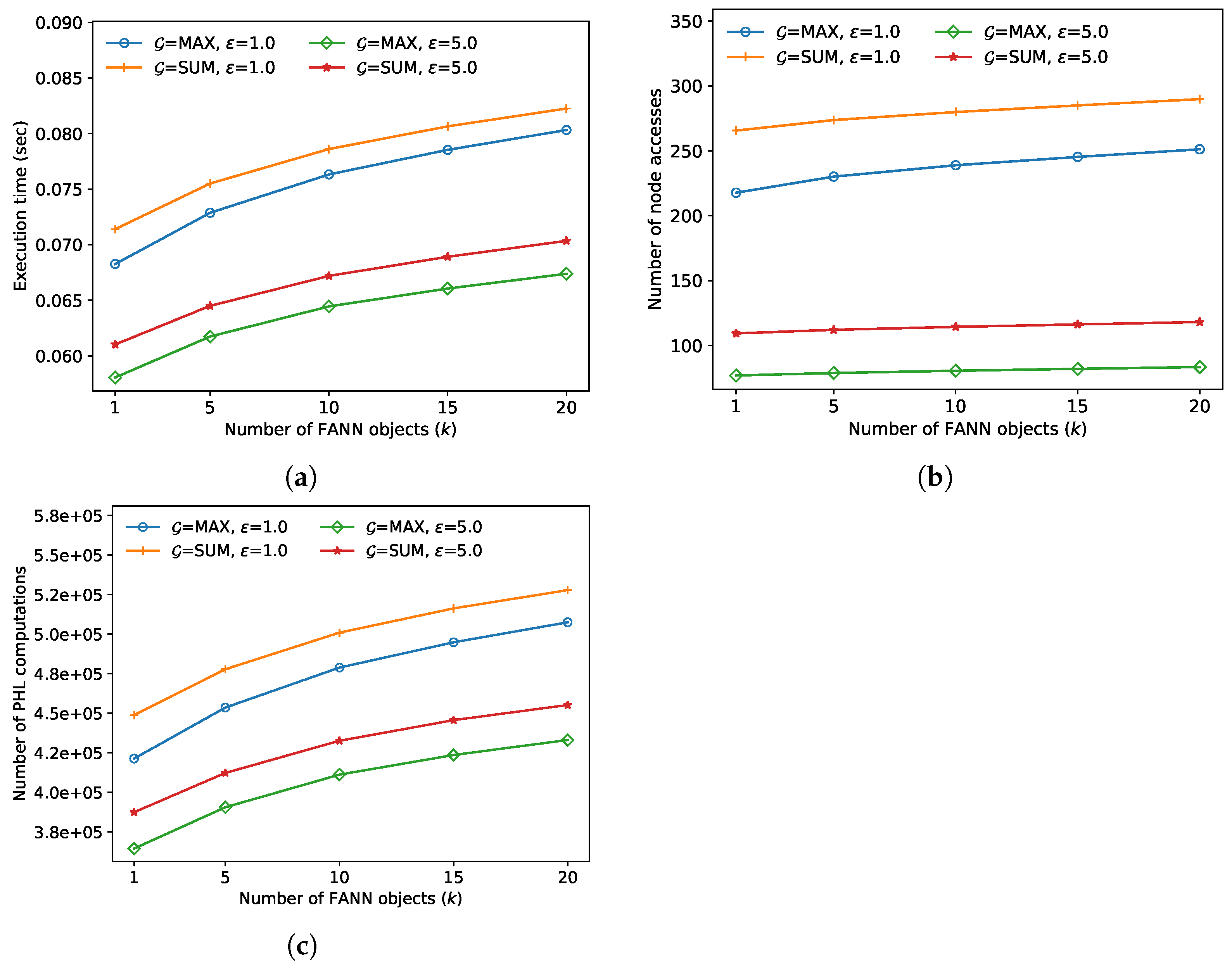
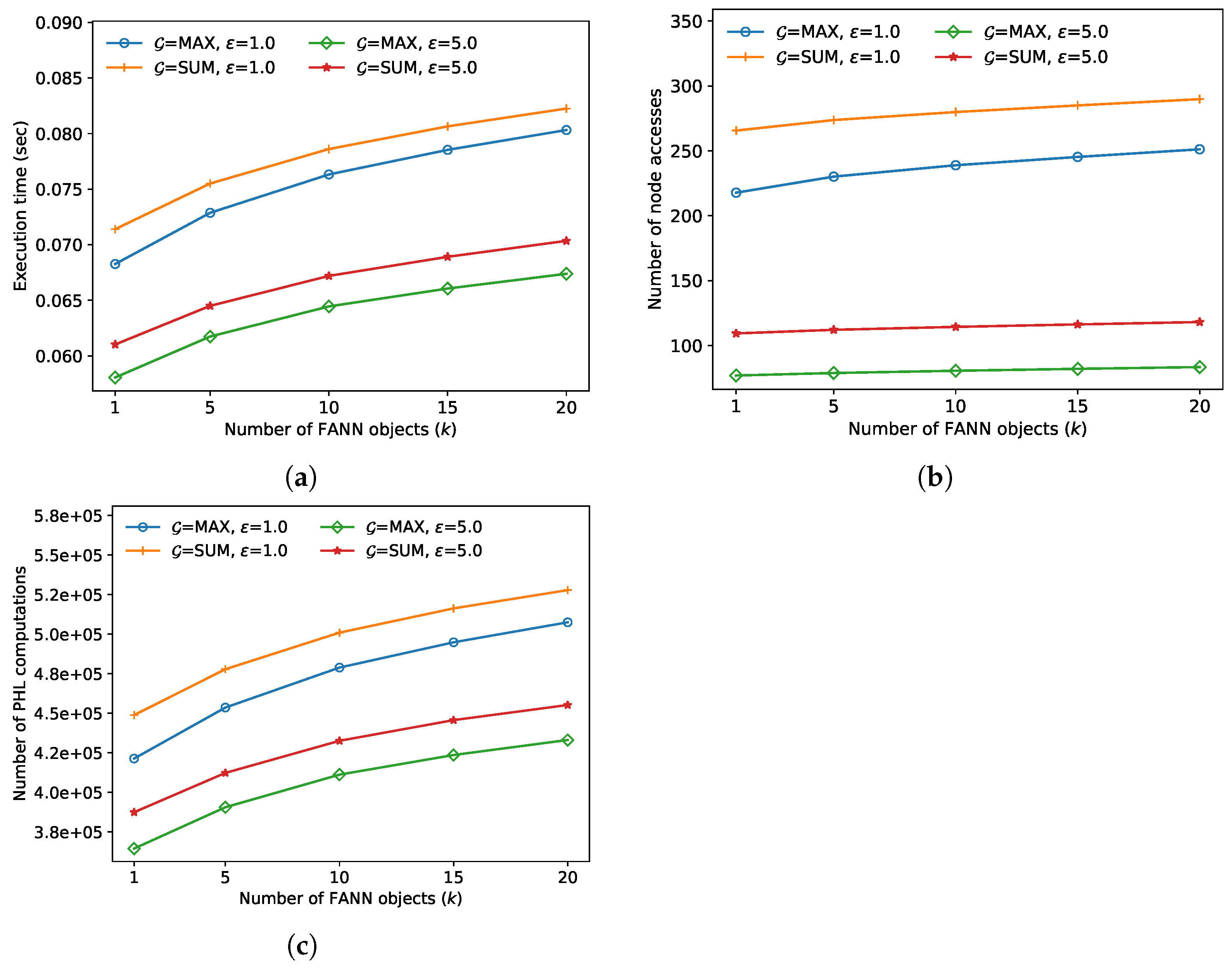
k, and the results are demonstrated in
Figure 5. For both algorithms, in lines 7 and 11 of Algorithm 1, the pruning bounds become larger as
k increases. Thus, more index nodes are accessed, and more distance calculations to the objects in the index nodes are performed, thereby increasing the execution time of both algorithms. In this experiment, the approximate algorithm always outperformed the exact algorithm; the performance improved by up to 19.2% when
and
max.
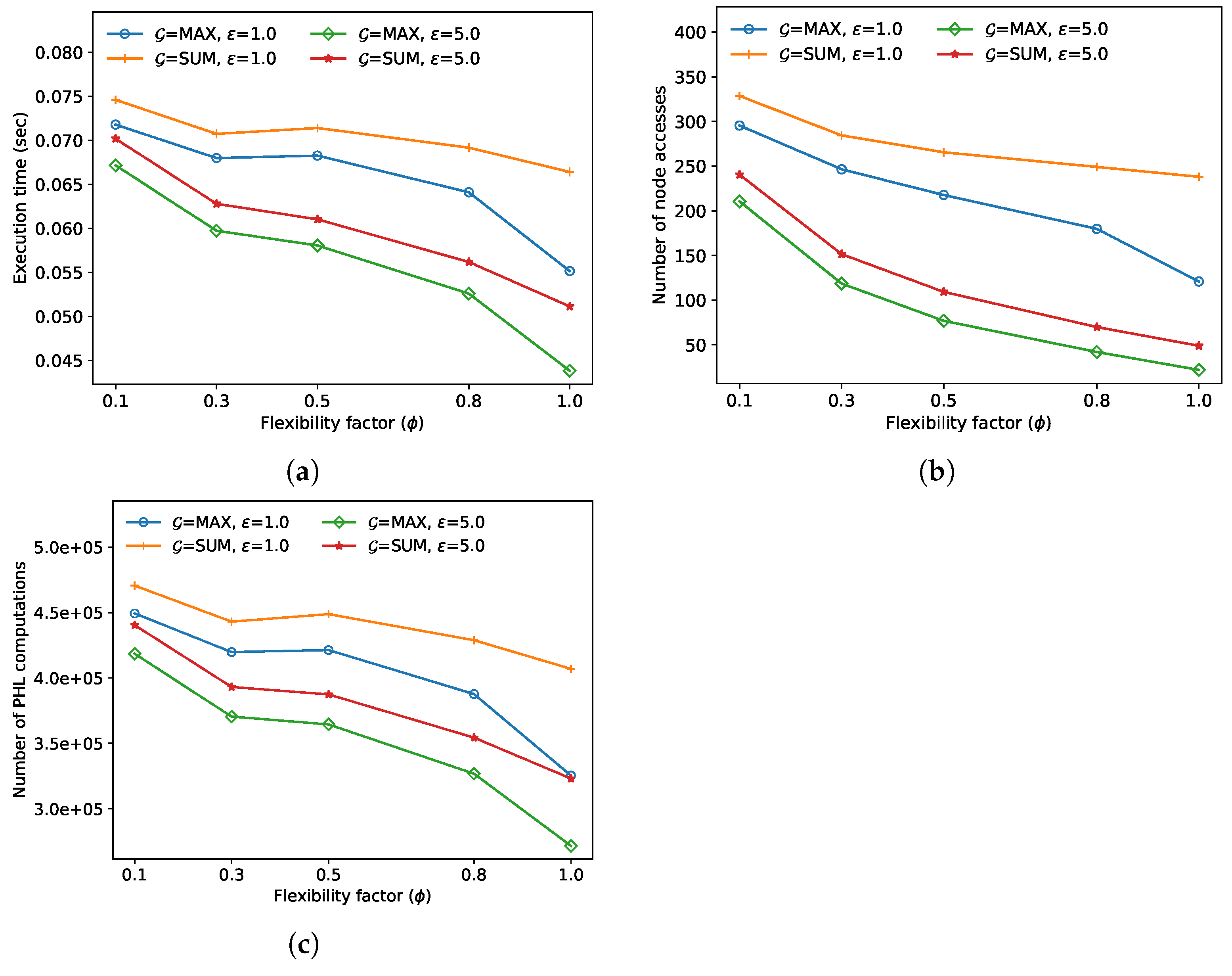
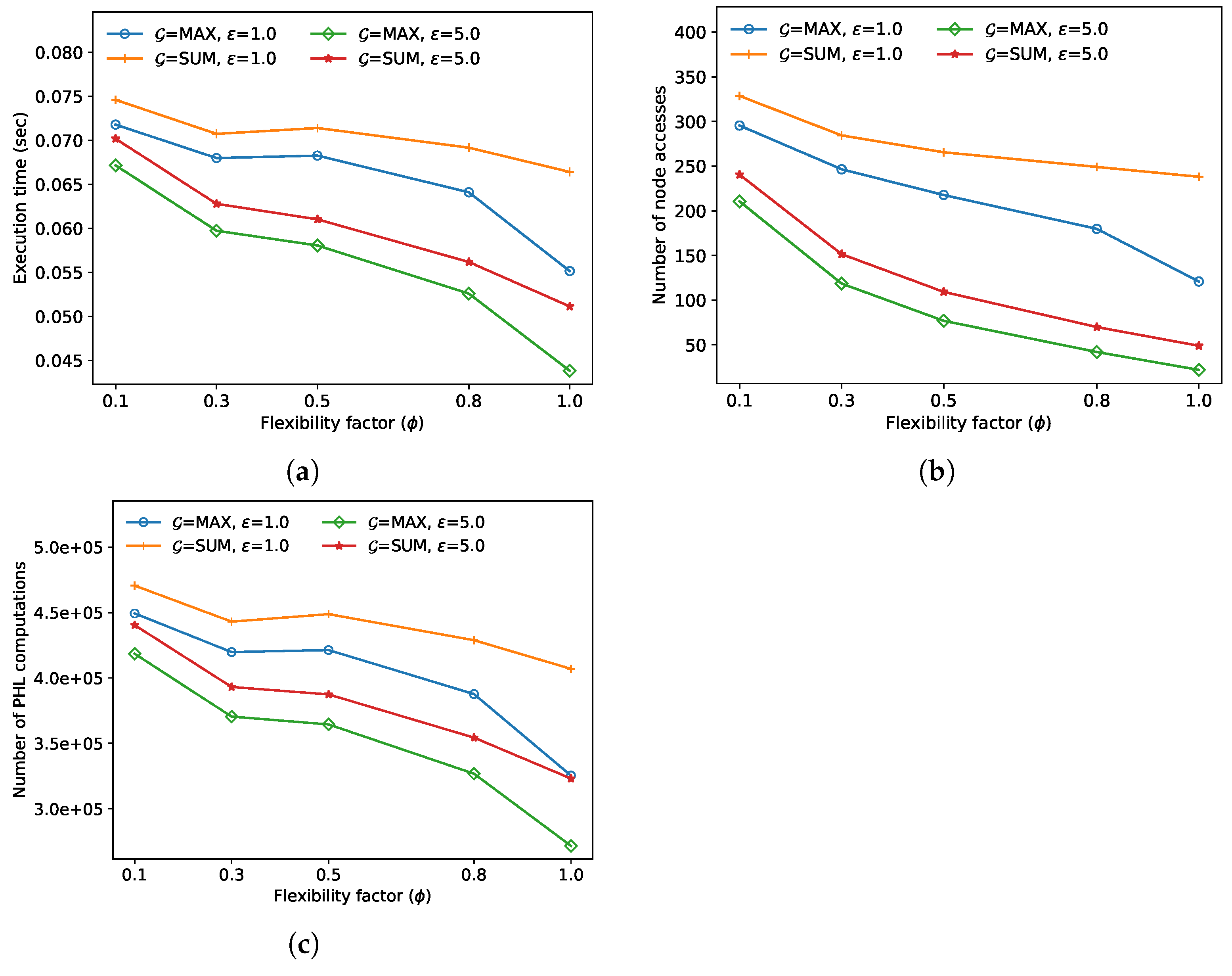
In the fourth experiment, we compared the FANN search performance for various flexibility factors
. In
Figure 6, as
increases, the execution time, the number of node accesses, and the number of distance calculations tend to decrease for both algorithms. This is because, as
increases in line 7 of Algorithm 1,
increases more rapidly than
, and thus the number of entries
added in the priority queue
H decreases. In this experiment, the approximate algorithm always outperformed the exact algorithm; the performance improved by up to 29.9% when
and
sum.
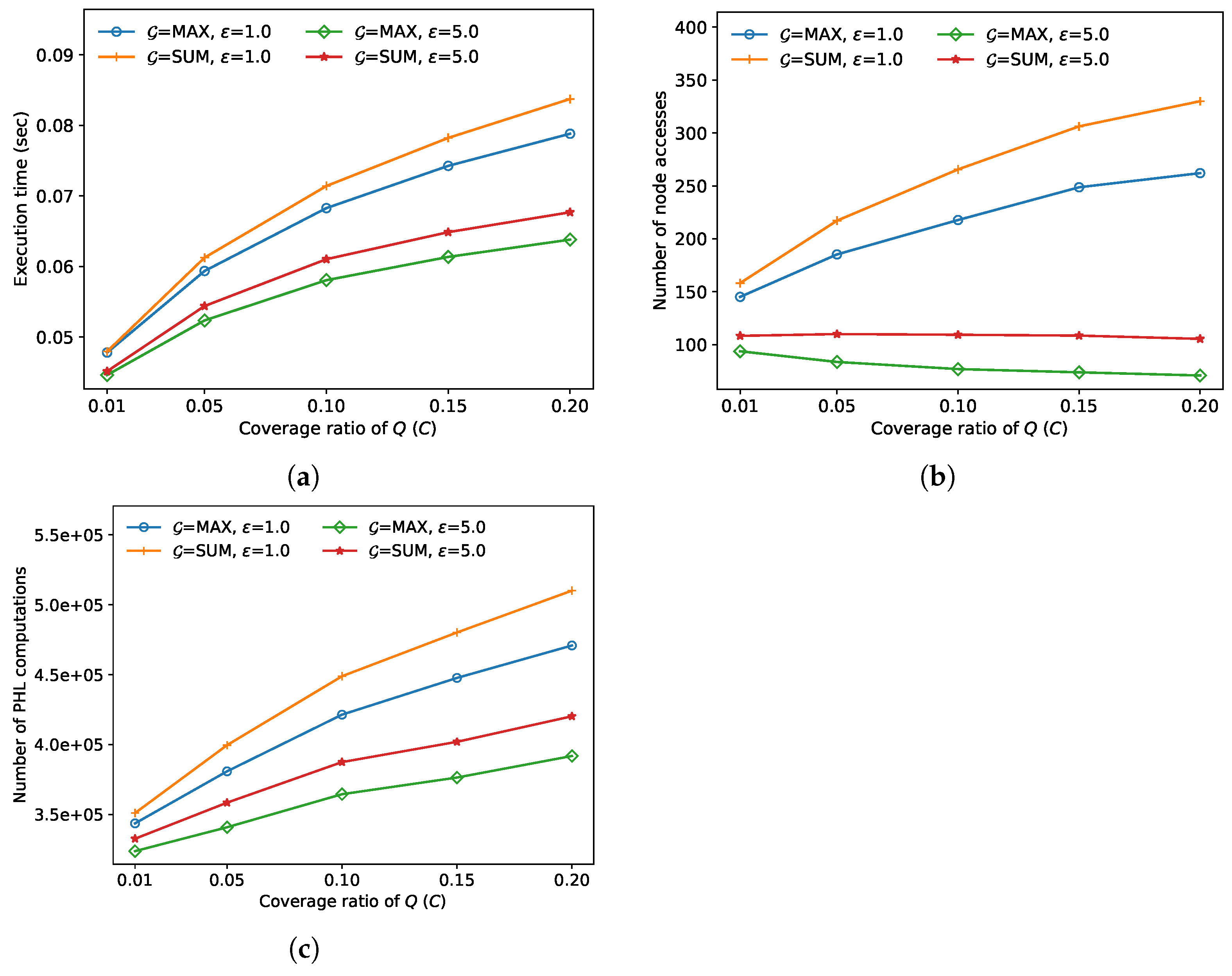
In the fifth experiment, we compared the FANN search performance for various coverage ratios
of query sets
Q, where
C is defined as (the minimum region covered by all the query objects in
Q) divided by (the region covered by the whole road network). The results of this experiment are demonstrated in
Figure 7. As
C increases, the execution time, the number of node accesses, and the number of distance calculations increase generally. The number of node accesses of the approximate algorithm decreases as
C increases. That is because the approximate algorithm terminates early very often as
increases in line 5 of Algorithm 2. In this experiment, the approximate algorithm always outperformed the exact algorithm; the performance improved by up to 23.7% when
and
sum.
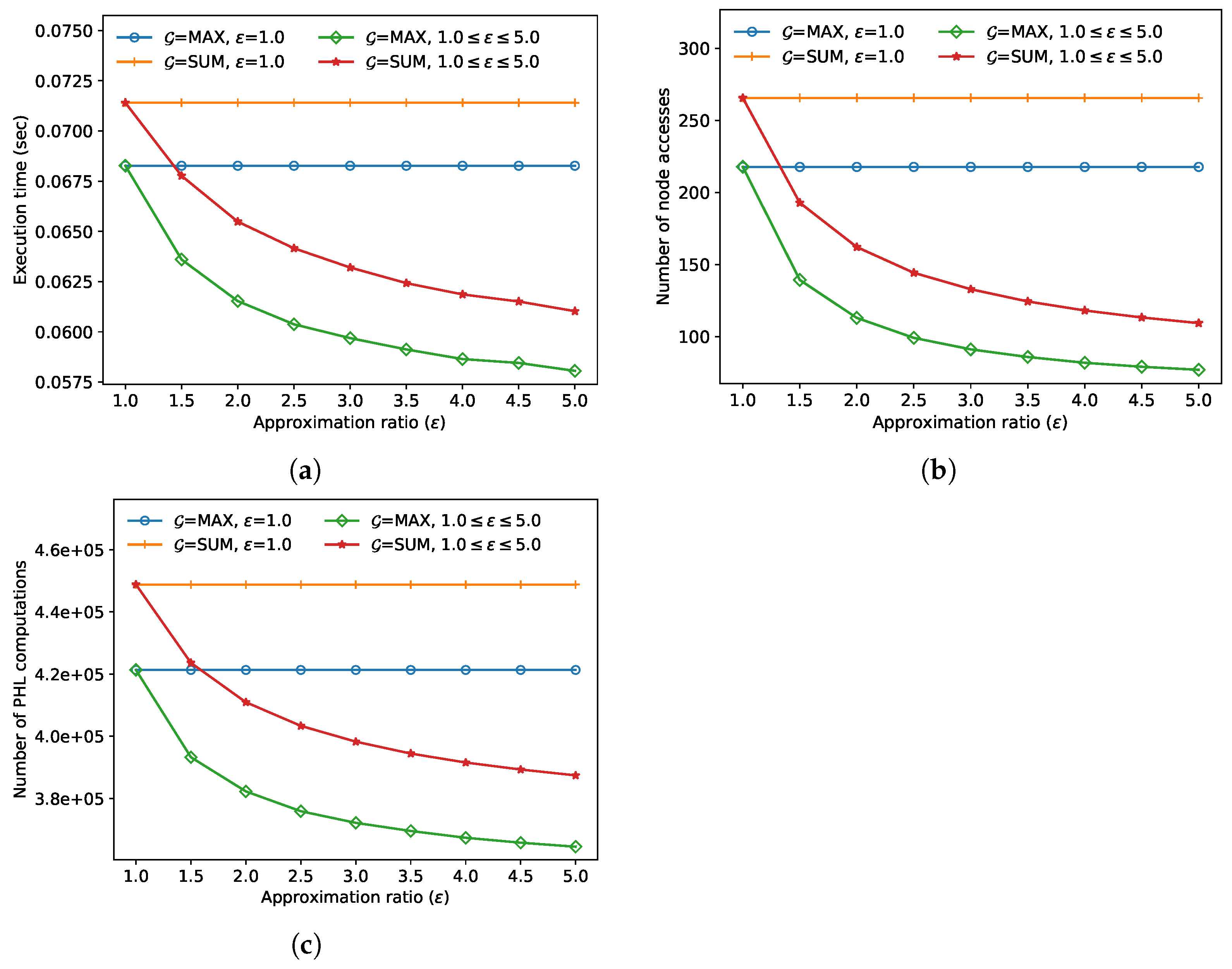
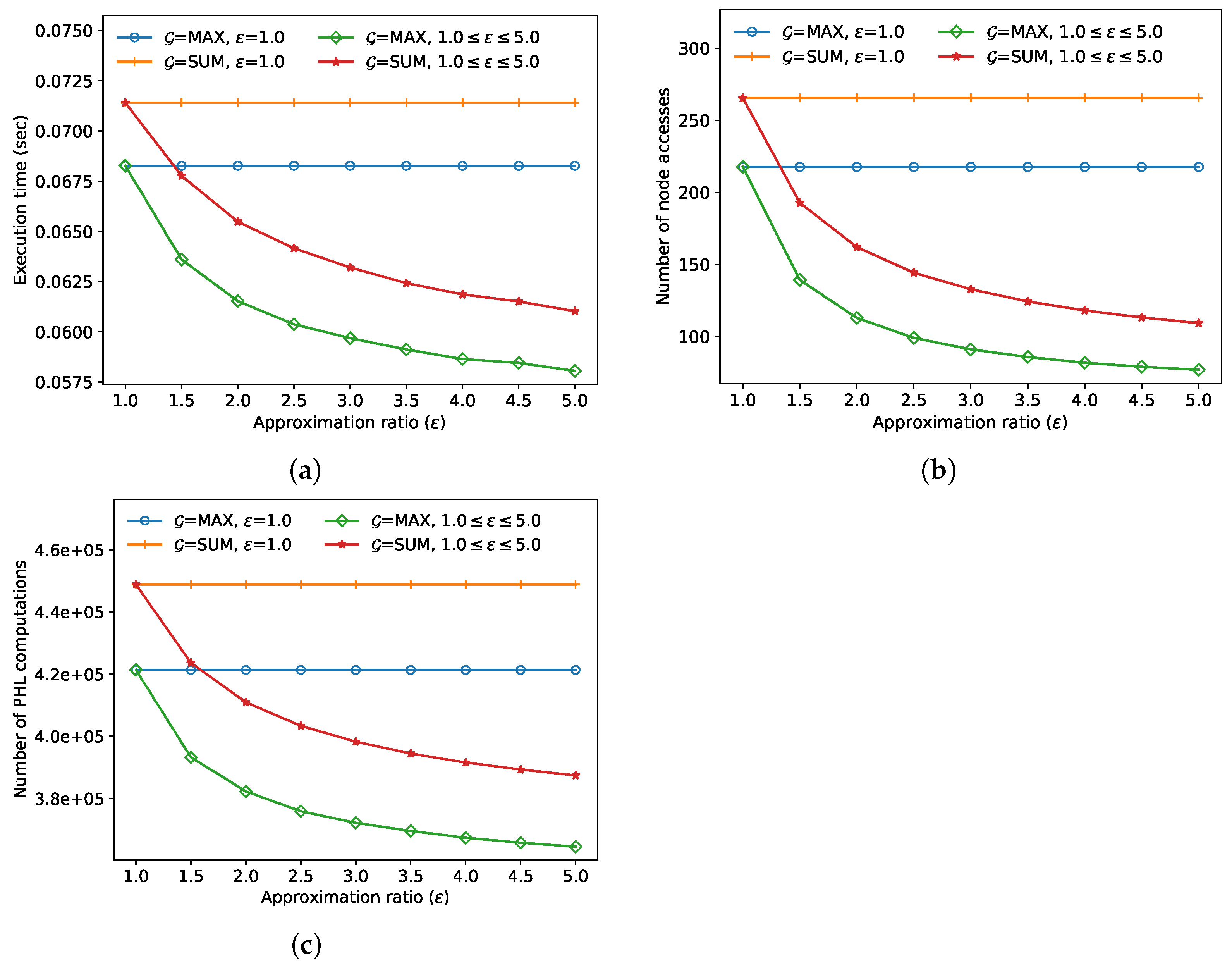
In the final experiment, we compared the FANN search performance and accuracy for various approximation ratios
. In
Figure 8, the execution time, the number of node accesses, and the number of distance calculations of the AFANN-PHL algorithm decrease as
increases, as expected. In this experiment, the approximate algorithm always outperformed the exact algorithm; the performance improved by up to 17.6% when
and
max.
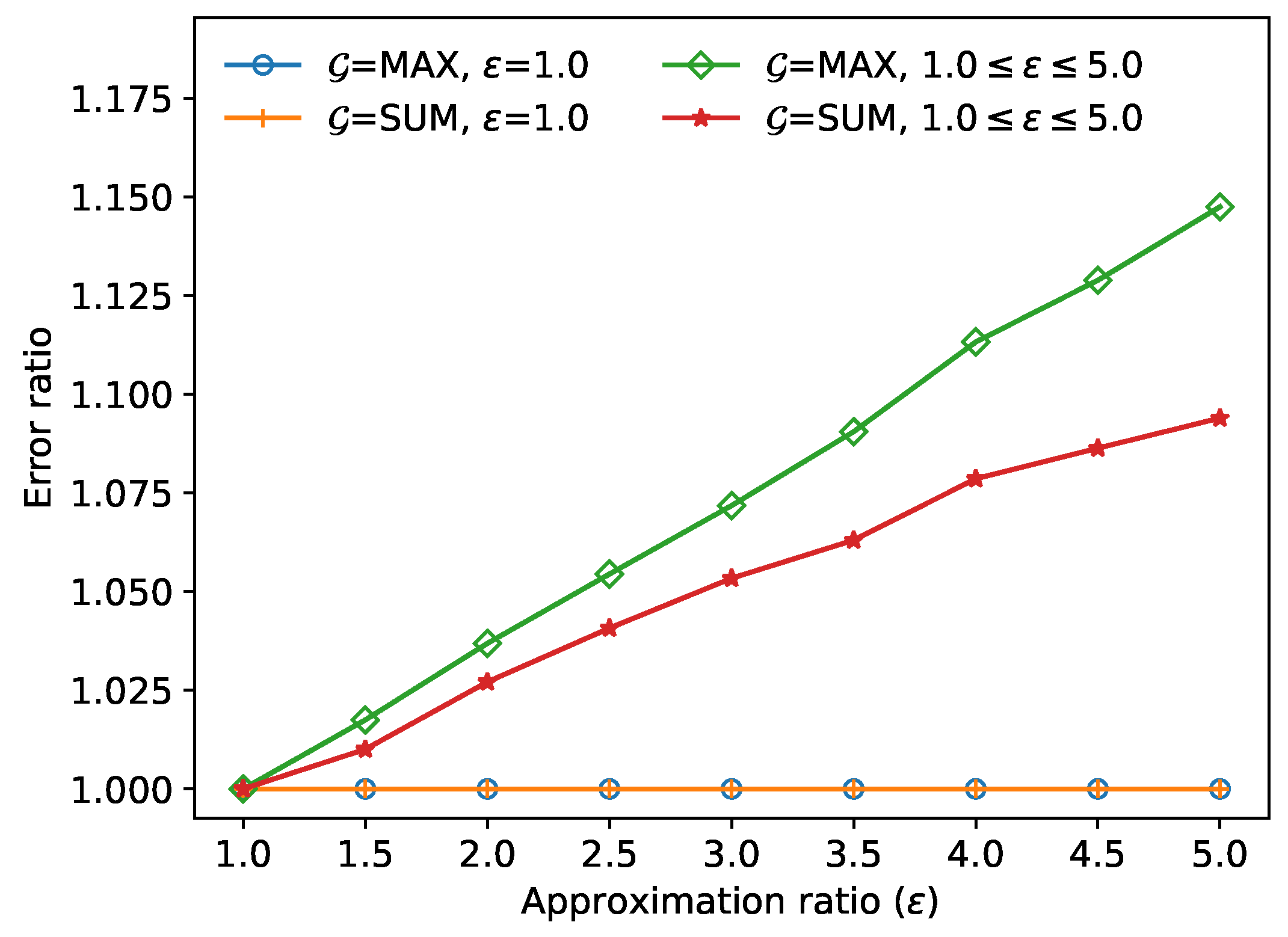
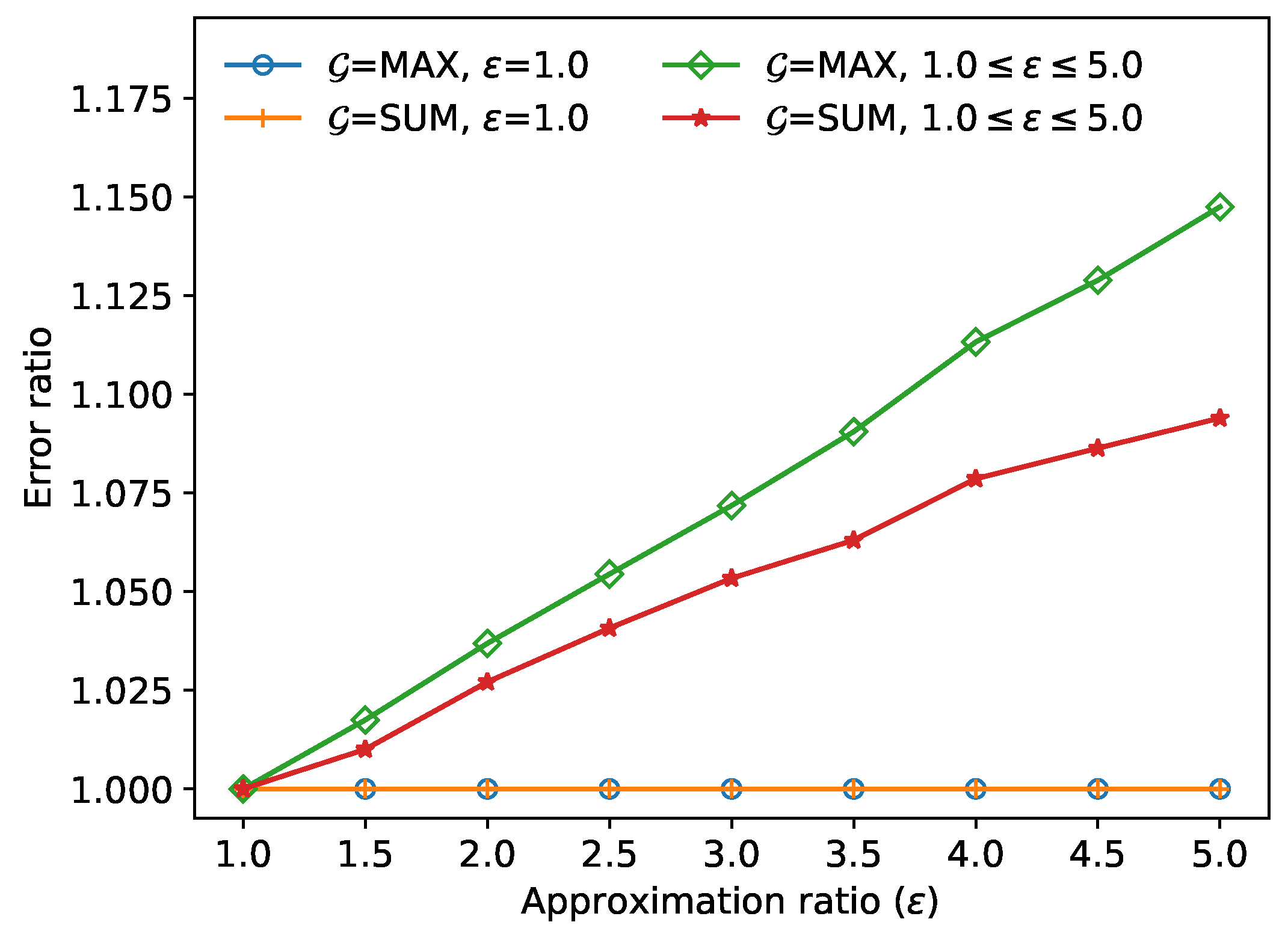
Figure 9 demonstrates the error ratio
(i.e., the left-hand side of Equation (
3)) for the FANN objects
and
obtained in the approximate and the exact FANN algorithms, respectively. The largest error ratio was
when
and
max. This value
is much smaller than the given approximation ratio
; i.e., the approximate FANN object
is very close to the exact FANN object
.



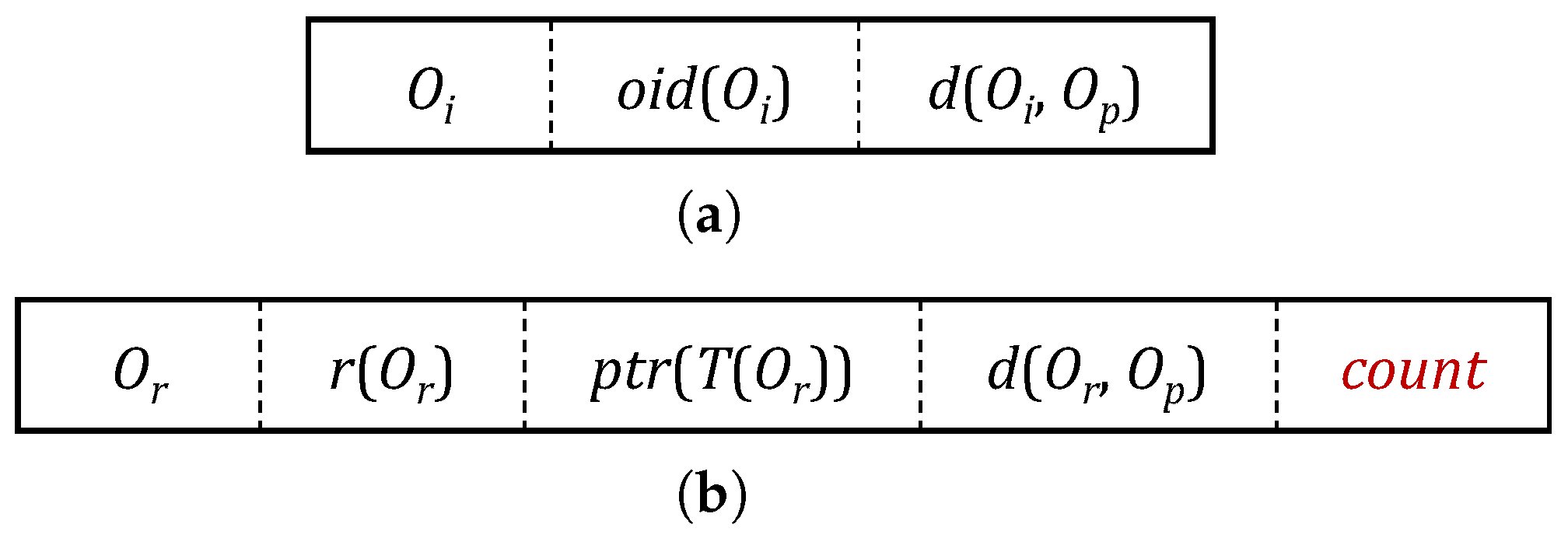


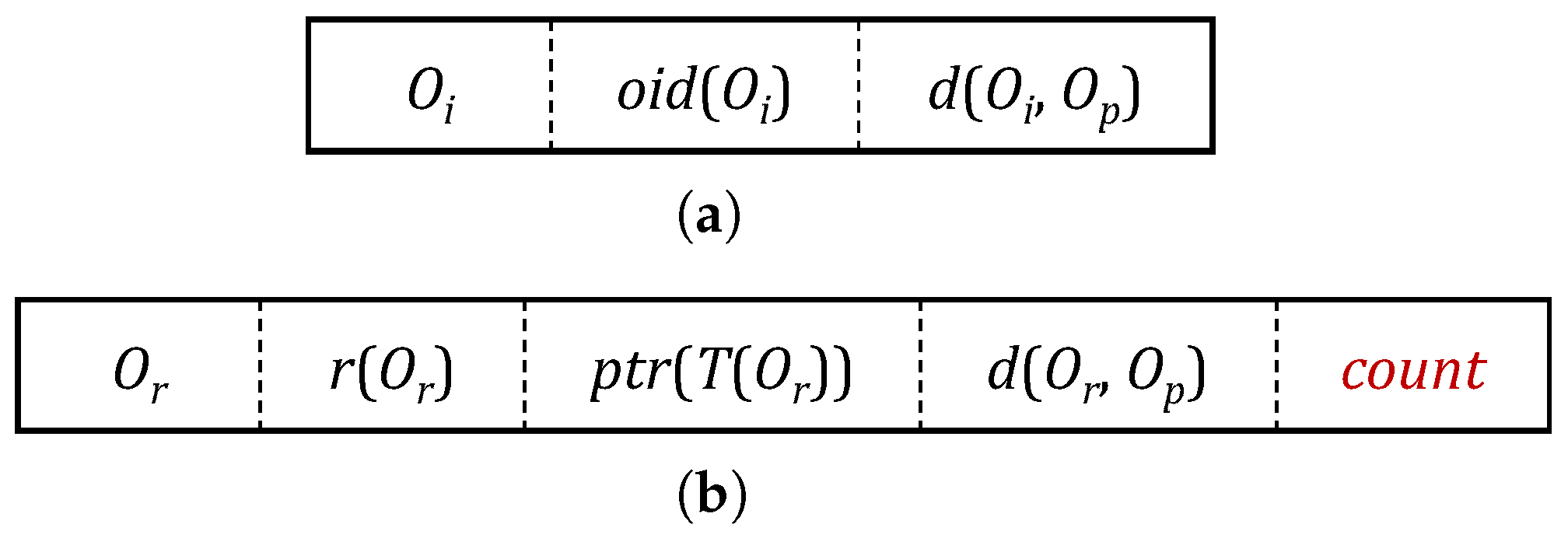{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}