1. Introduction
Image captioning is a crucial research task in the multimodal area where computer vision and natural language processing intersect. It aims to turn images into natural language descriptions that provide the basis for computers to achieve an understanding of images and generate human-readable text. Traditional image captioning methods depend heavily on supervised learning and require large amounts of paired image and text data for training [
1]. However, acquiring large-scale paired data is laborious and costly, imposing limitations on the applicability and scalability of such methods.
To overcome this limitation, the attention of researchers has gradually shifted towards unsupervised image captioning techniques. These techniques aim to learn the correspondence between images and text from unlabeled image data, enabling automated image description generation. For instance, Iro Laina et al. [
2] proposed an unsupervised image captioning method based on shared multimodal embeddings. They achieved cross-modal feature representation by combining image and text encoders. Similarly, Yang Feng et al. [
3] presented an unsupervised image description method utilizing generative adversarial networks (GAN) to generate diverse image captions. Using adversarial training of generators and discriminators, they generated more successful and diverse caption results. However, the approaches mentioned above no longer require manual labeling of image–text pairs but instead rely on matching image blocks to labels, which can be challenging to control. Furthermore, since the pseudo-descriptions are trained on a fixed label set, they may not be applicable to scenarios beyond the predefined label set. To address this issue, Yoad Tewel et al. [
4] put forward a zero-sample image-to-text generation method that utilizes visual-semantic arithmetic to generate images’ descriptive texts. Yixuan Su et al. [
5] introduced a text generation method with visual control, incorporating a visual control mechanism to generate image-related text descriptions by specifying visual conditions. This approach enhances the accuracy and semantic consistency of the generated descriptions. Challenges related to the modality gap in multimodal contrastive representation learning have been recognized in the literature [
6]; David Nukrai et al. [
7] proposed a noise-injection-based text training method for image description generation. By employing a contrast learning strategy for noise injection, they improved the diversity and quality of the generated descriptions.
Although previous works have explored various approaches and strategies to address the problem of modality gap and image–text mismatch, they still have several drawbacks. First, most existing models directly use the image feature vectors and text feature vectors in a shared space where multimodal representations are learned, yet the differences between different modalities in this shared space still exist, which inevitably leads to bias in the inference process. Even though this problem is recognized, they often address it by adding Gaussian noise without conducting further analysis [
7]. Secondly, most existing methods in the text generation stage rely on the widely used maximum probability decoding strategy commonly employed in natural language processing. However, this approach often leads to degradation in the generated results. Specifically, the generated text tends to be generic and exhibits unreasonable repetitions at various levels, including words, phrases, and sentences. This problem stems from the decoding strategy and the correspondence between the entire image and the generated words. Consequently, a significant number of repetitive words appear among the candidate words, resulting in varying degrees of semantic repetition in the generated sentences.
To address the aforementioned challenges, this study proposes a novel semantic-enhanced cross-modal fusion model. The model leverages a text semantic enhancement network to extract text-enhanced semantic representations, effectively capturing the semantic associations between texts, strengthening the semantic features, and attenuating the modal features. This process provides robust support for subsequent feature fusion. Furthermore, contrast learning is utilized to optimize similarity measures and feature representation consistency between texts. Meanwhile, an image enhancement decoding strategy is introduced to generate accurate and diverse description results. In contrast to the traditional maximum probability decoding strategy, this approach structures the decoding process and leverages the rich information present in the image. It employs a top-k sampling technique to generate a set of diverse candidate sentences, guaranteeing the diversity of the generated captions. Subsequently, a defined metric, such as cosine similarity or a learned distance function, is employed to calculate the similarity between the candidate sentences and the image. The sentence with the highest similarity to the image is selected as the final output, ensuring the accuracy and visual relevance of the description.
The central aim of this research is to propose and validate a novel semantic-enhanced cross-modal fusion model that addresses specific challenges in existing models. These challenges include bias in the inference process due to differences between modalities and degradation in the quality of generated results. Our approach leverages text semantic enhancement and a unique image enhancement decoding strategy to improve the accuracy, diversity, and quality of the generated image descriptions.
To validate the effectiveness of our proposed model and strategy, extensive experiments are conducted on four widely recognized datasets: MS COCO and Flickr30k for standard image captioning and cross-domain image captioning experiments, and FlickrStyle10K and SentiCap for stylized image captioning experiments. The experimental results demonstrate that our model and strategy significantly enhance the performance of the image description task. Specifically, our approach improves the description accuracy, diversity, and quality of the generated results compared to traditional methods. The main contributions of this paper can be summarized as follows:
(1) In this paper, we introduce a text semantic enhancement network designed to extract enhanced semantic representations of text. This network is capable of effectively capturing the semantic associations between texts, thereby providing robust support for subsequent feature fusion. To optimize the similarity measure and ensure consistency in feature representation between different texts, we employ contrastive learning. This technique emphasizes the semantic properties of texts by maximizing text differences, reducing the correlation between texts, and attenuating the modal properties of texts. As a result, the proposed network significantly enhances the model’s ability to comprehend and articulate the semantics of textual content.
(2) This paper introduces an enhanced decoding strategy to generate precise and diverse caption results by structuring the decoding process and incorporating attention mechanisms and language models. By adopting this strategy, the flexibility and diversity of the generated captions are significantly enhanced, resulting in improved quality and appeal of the generated results.
(3) Comprehensive experiments were conducted on two widely recognized image captioning datasets to evaluate the proposed approach. Comparative analysis against traditional methods demonstrates significant enhancements achieved by our approach in the image captioning task, notably in terms of description accuracy, diversity, and the overall quality of the generated results.
2. Related Work
2.1. Image Captioning
Image captioning is a crucial task in multimodal learning, with the goal of generating accurate and grammatically correct natural language descriptions for images. The general approach for image captioning is the encoder–decoder architecture, where a convolutional neural network (CNN) serves as the encoder to extract image features, and a recurrent neural network (RNN) functions as the decoder to generate image descriptions [
8,
9]. To enhance the effectiveness of image captioning, various models and methods have been proposed. For instance, Zhou et al. [
10] introduced the deep modular co-attention network, which utilizes a cascade of modular co-attention layers to model the relationship between language and vision. Huang et al. [
11] proposed the attention over attention (AoA) network, which filters out irrelevant or misleading attention results in the decoder, retaining only useful attention results. Pan et al. [
12] addressed existing models’ limitations by introducing the X-LAN attention module, enabling the capture of higher-order or infinite-order interactions between modalities through bilinear pooling. These methods have shown promising performance on supervised training with large-scale annotated image–text pairs and have achieved good results on various evaluation benchmarks. However, collecting such annotated datasets is challenging. Therefore, some researchers have explored weakly supervised approaches for model training. For example, Feng et al. [
3] proposed a method that solely relies on individual image data and a sentence corpus, eliminating the need for manual annotation of image–text pairs of datasets. Laina et al. [
2] connected image information and text information through shared multimodal encoding, leveraging image–label datasets instead of paired image–text datasets. Pseudo-descriptions are generated using object labels and visual content retrieval modules and used as new labels for training. While these approaches partially overcome dataset limitations, they still face issues such as a lack of one-to-one correspondence between generated pseudo-descriptions and images, resulting in descriptions that may contain objects not present in the images.
To address these challenges, recent works have emerged that completely forego the use of existing datasets containing both images and texts for model training. For instance, Tewel et al. [
4] proposed ZeroCap, a zero-shot learning method for image captioning that employs CLIP [
13] for image feature extraction and GPT2 [
14] for caption generation. However, due to the absence of domain-specific training, this method performs poorly on evaluation benchmarks. Nukrai et al. [
7] introduced a training approach where textual data are utilized to adapt the language model to a target style, and image substitution is employed during the inference phase to obtain the desired output. While this approach enables style adaptation and improves performance, it under-utilizes image information, leading to descriptions that may not accurately describe the images.
Despite the advancements in image captioning, current methods still struggle with challenges such as the one-to-one correspondence between generated descriptions and images, lack of domain-specific training, and under-utilization of image information, leading to mismatched descriptions and images.
In contrast to the aforementioned methods, our work incorporates image information twice during inference. Initially, we input the image information into the language model, allowing the model to generate multiple candidate sentences through random decoding. Subsequently, we calculate the similarity between the candidate sentences and the image, selecting the sentence that exhibits the highest similarity to the image as the final description. This approach maximizes the utilization of image information and resolves the issue of mismatched descriptions and images encountered in previous methods.
2.2. Contrastive Models
In recent years, several visual-language contrastive models have emerged, including CLIP [
13], ALIGN [
15], UniCL [
16], and OpenCLIP [
17]. These models have shown promising performance in zero-shot image classification and feature extraction for downstream tasks. For example, Clip2Video [
18] utilizes contrastive learning for video–text retrieval tasks, while the object detection model introduced by Gu et al. [
19] employs contrastive learning to detect objects with an open vocabulary. Khandelwal et al. [
20] applied CLIP and contrastive learning to acquire visual and language knowledge for robot navigation tasks. Clip4Clip [
21] utilizes contrastive learning for video clip retrieval and description, and Portillo-Quintero et al. [
22] presented a video retrieval method based on CLIP. Shen et al. [
23] have also explored the performance improvements achieved by CLIP contrastive learning in various visual-language tasks. However, it remains challenging to apply these models to complex tasks such as image captioning.
To address this challenge, we propose a method that combines unsupervised contrastive learning with a semantic-enhanced cross-modal fusion model to significantly improve the zero-shot performance of contrastive models in image captioning. CLIP consists of separate encoders for visual and textual information and leverages unsupervised contrastive loss trained on a large-scale image–text dataset. This training enables CLIP to establish a shared semantic space for visual and textual information. In our work, we utilize CLIP for image captioning, style image captioning, and story generation tasks, demonstrating the effectiveness and scalability of the semantically enhanced cross-modal fusion model.
2.3. Text Generation
Text generation is a significant task in natural language processing, attracting substantial research attention in recent years. Traditional methods for text generation often rely on language-model-based decoding approaches, which can be categorized into deterministic and stochastic methods. Deterministic methods, such as greedy search and beam search, select the most probable text based on the model’s output probability. However, these methods often suffer from issues such as monotonicity [
24] and degradation [
25,
26], which limit the diversity and creativity of the generated text. To address these limitations, stochastic methods have been introduced, including sampling-based techniques such as top-k sampling. These methods select multiple candidate texts with higher probabilities and perform random sampling within the set, thereby enhancing the diversity of the generated text.
In image captioning, the key challenge in text generation is effectively leveraging the abundant information from images to generate accurate and diverse descriptions. Traditional approaches employ multimodal representation learning methods that aim to map image and text features into a shared semantic space, facilitating fusion and association between the modalities. However, these methods often encounter issues related to modality discrepancy and information inconsistency, leading to generated text that is not fully aligned with the images. To overcome these challenges, this paper proposes a novel semantic-enhanced cross-modal fusion model for image captioning.
In summary, despite substantial progress in image captioning, contrastive models, and text generation, existing methods face several challenges such as modality discrepancy, information inconsistency, a lack of one-to-one correspondence between descriptions and images, and difficulties in handling complex tasks such as zero-shot image captioning. These issues often lead to mismatched descriptions and images, lack of diversity in generated text, and poor performance on evaluation benchmarks. In contrast to these methods, our work aims to address the following tasks: (1) Maximize the utilization of image information to ensure that generated descriptions accurately correspond to the images. (2) Enhance the zero-shot performance of contrastive models in image captioning by combining unsupervised contrastive learning with a semantic-enhanced cross-modal fusion model. (3) Implement a novel semantic-enhanced cross-modal fusion model to overcome the challenges of modality discrepancy and information inconsistency, ensuring that generated text is fully aligned with the images.
Our proposed method is designed to resolve the aforementioned limitations by introducing novel techniques such as leveraging image information twice during inference and utilizing CLIP for various tasks. In achieving this, our work offers a significant advancement in the field of image captioning.
3. Method
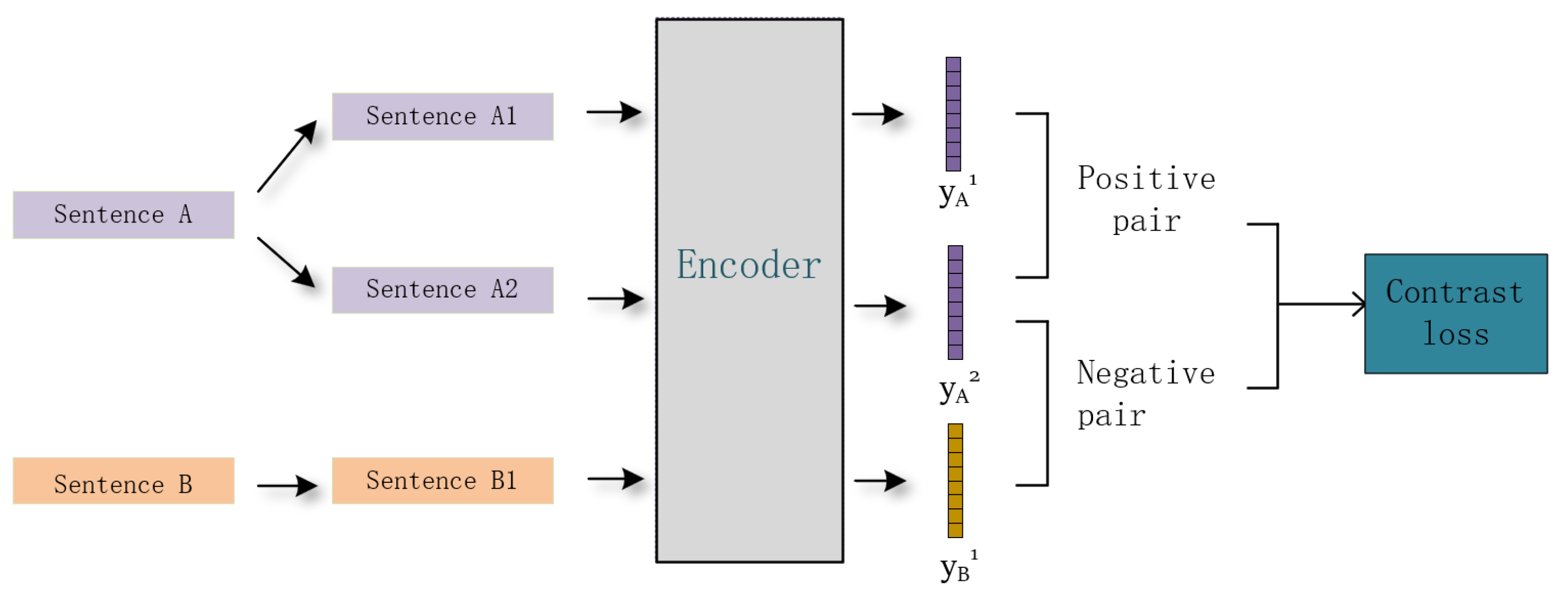
In the pursuit of mitigating the challenges of the modality gap and the image–text mismatch problem, this paper puts forward a groundbreaking semantic-enhanced cross-modal fusion model (SCFM). This model is meticulously designed to address the inherent complexities in bridging the visual and textual modalities, offering a unique approach that distinguishes it from existing methods. The SCFM is built upon three carefully interwoven components that work in harmony to enhance the entire process of image captioning. As illustrated in
Figure 1, these components are (1) a text semantic enhancement network: this part of the SCFM focuses on extracting and enhancing the semantic features within the text. It employs a combination of encoding techniques, enhancement strategies, and advanced network architectures to capture and emphasize the intricate semantic relationships within the text content. The enhancement of these features is pivotal in forming an initial semantic representation that resonates with the visual content. (2) Contrast learning: this component plays a central role in optimizing the consistency between texts by focusing on similarity measures. By employing a contrastive learning approach, it works in conjunction with the text semantic enhancement network to fine-tune the semantic representations. This joint operation enables a more precise alignment between visual and textual modalities, making this part essential for bridging the modality gap. (3) Image enhancement decoding strategy: tailoring the final stage of the model, this strategy emphasizes the generation of accurate and diverse captions. It not only adopts cutting-edge sampling techniques but also employs well-defined metrics to calculate the compatibility between textual descriptions and visual content. The intelligent integration with the preceding components ensures that the generated captions are not only relevant but also rich in diversity and accuracy.
The collaboration and interrelation of these three components form the crux of the SCFM, providing a seamless, integrative solution to the complex challenges of cross-modal learning. By delving into the architecture and methodology of each component, the following subsections will provide a clearer and more in-depth understanding of our innovative approach.
3.1. Text Semantic Enhancement Network
The text semantic enhancement network aims to extract enhanced semantic representations of text by capturing semantic associations, enhancing semantic features, and attenuating modal features. It consists of two main components: a text encoder and a semantic enhancement module. The text encoder maps the input text sequence into a semantic space, generating an initial semantic representation. To enhance the sentences, text enhancement techniques such as rule enhancement and semantic enhancements are applied. The CLIP network model is utilized for encoding the enhanced text sequence into a fixed-length vector representation. The semantic enhancement module incorporates key components including a multilayer perceptron (MLP), a residual network, atrous convolution, and a pooling layer. The MLP consists of multiple fully connected layers, enabling the extraction of higher-order features and semantic information. The introduction of residual connectivity helps to alleviate the issues of gradient disappearance and enhances the expressiveness of feature representation, thereby improving the quality of semantic representation. Atrous convolution, also known as dilated convolution, is employed to expand the effective receptive field of the convolutional kernel by introducing holes (dilation) in the kernel. This allows the network to capture a broader range of contextual information, enhancing its ability to understand and represent the semantics of text. Furthermore, a pooling layer is employed to reduce the spatial dimensionality of the feature map, facilitating more efficient processing. Through the combination of the multilayer perceptron, residual network, atrous convolution, and pooling layer, the semantic enhancement module effectively extracts and merges features to generate a more comprehensive and semantically rich representation of the input text.
3.2. Contrast Learning to Optimize Feature Representations
To enhance the similarity measurement and promote feature consistency between texts, we adopt a contrastive learning approach in our model. Contrastive learning aims to optimize feature representations by maximizing the similarity between positive sample pairs and minimizing the similarity between negative sample pairs. For each text sample, As illustrated in
Figure 2, we randomly select a positive sample that belongs to the same category as the input text. Additionally, we choose multiple negative samples that differ from the input text in terms of category. The similarity between the input text and the positive samples, as well as the similarity between the input text and the negative samples, is computed using cosine similarity. By maximizing the similarity of positive sample pairs, we encourage the semantic features to be more consistent. Conversely, minimizing the similarity of negative sample pairs reduces their semantic correlation. The loss function employed in our approach is designed to reinforce these objectives during training. The specific formulation of the loss function depends on the chosen contrastive learning framework and network architecture. It typically incorporates margin-based or contrastive loss terms, aiming to increase the similarity of positive pairs and decrease the similarity of negative pairs. By optimizing the contrastive loss, our model effectively learns discriminative and consistent semantic representations. This enables the model to bridge the modality gap, mitigate the image–text mismatch, and improve its capability to comprehend and express the semantics of text.
where
,
.
is the temperature parameter.
s is the similarity function; it is defined as follows:
The total comparison loss is defined as follows:
where
is the contrast loss after rule enhancement for the
i-th sample,
is the contrast loss after semantic enhancement for the
i-th sample, and
N is the total number of samples.
Through the optimization process driven by contrastive learning, our model achieves a more consistent representation between texts. This enhanced representation enables the model to better understand and capture the relationships between texts, leading to improved accuracy and diversity in the generated caption results.
3.3. Enhanced Visual Selection Decoding
To generate accurate and diverse caption results, we propose an image enhancement decoding strategy. Departing from the traditional maximum probability decoding approach, we adopt a structured decoding process that leverages the rich information present in the images. Our strategy incorporates the use of the top-k sampling technique to generate a set of diverse candidate sentences. This step ensures the production of varied captions and avoids the generation of singular or repetitive results.
Next, we employ a defined metric to calculate the similarity between the candidate sentences and the image. By measuring the compatibility between textual descriptions and visual content, we select the sentence that exhibits the highest similarity to the image as the final output. This selection process guarantees the accuracy and visual relevance of the generated captions. For the input image I, the vector of image information in the shared semantic space is
, Then, the set of generated candidate sentences is
Q:
where
refers to the mapping vector of the input image
I in the shared space.
is the value of Gaussian noise,
is the decoding strategy, and the obtained
,
, …,
are the top n sentences from the top-k sampling.
The sentences in the candidate sentence set are mapped to the low-dimensional shared semantic space, and the sentence with the highest similarity to the image is searched. The definition of similarity is shown in (3). The final result,
, is defined as:
where
is the mapping vector of image
I, and
q is the candidate sentence.
Through the utilization of our image enhancement decoding strategy, we aim to enhance the quality and diversity of the generated captions. By considering the inherent information within the images and selecting the most appropriate textual descriptions, our approach ensures the production of accurate and diverse results that effectively convey the content of the images.
5. Result and Discussion
In the realm of weakly or unsupervised image captioning methods, the comparison of our semantic-enhanced cross-modal fusion model (SCFM) with other contemporary models offers crucial insights. The comparison is grounded in experiments conducted on the MS COCO and Flickr30k datasets, utilizing standard metrics such as BLEU-1, BLEU-4, METEOR, ROUGE-L, and CIDEr (
Table 1). ZeroCap’s utilization of zero-shot techniques renders a performance that is appreciably surpassed by SCFM, evidenced by B@1 and CIDEr scores of 49.8 and 34.5 against SCFM’s 69.0 and 94.3, respectively, on MS COCO. The marked enhancement accentuates the potency of our model’s semantic and decoding strategies. The performance of MAGIC, another weakly supervised model, is somewhat superior to ZeroCap but still falls behind SCFM. With B@1 and CIDEr scores of 56.8 and 49.3, it underscores SCFM’s advanced capabilities in both granular and overall performance measures. Comparatively, CapDec exhibits a competitive approach, with B@1 and CIDEr scores of 69.2 and 91.8 on MS COCO. Nonetheless, SCFM slightly surpasses CapDec in key domains, with B@4 and CIDEr scores of 27.3 and 94.3 versus 26.4 and 91.8, respectively, cementing the relative strength of our approach. An examination of SCFM through ablation studies further elucidates the individual impacts of its components (
Table 3). The introduction of the TSE-Net led to an elevation in B@1 and CIDEr to 68.6 and 92.3. The implementation of contrast learning yielded a nuanced performance shift, while the incorporation of EVSD boosted B@1 and CIDEr to 68.8 and 93.7. The full SCFM model combined these incremental enhancements, solidifying the B@1 at 69.0 and CIDEr at 94.3.
In the field of image captioning, our semantic-enhanced cross-modal fusion model carves out its distinctive niche when juxtaposed with prominent methods such as ZeroCap, MAGIC, and CapDec. While ZeroCap showcases innovation by combining CLIP with GPT-2 for zero-shot captioning and pivoting to a novel data source, our approach delves deeper, emphasizing a comprehensive strategy to address the modality gap and image–text mismatches. This commitment to excellence is further evidenced as we not only forge a closer image–text alignment but also overshadow ZeroCap’s key performance metrics, underscoring our capability for a refined captioning control. Diverging from MAGIC’s zero-shot approach, our model is grounded in a bespoke design that marries a cutting-edge semantic enhancement network with a heightened decoding strategy. This amalgamation not only propels innovation but also triumphs in crucial metrics such as BLEU-4, METEOR, ROUGE-L, and CIDEr. Meanwhile, in comparison to CapDec, known for its decoding of image embeddings supplemented by noise-injection as a bridge over the image–text domain chasm, our methodology leans heavily on semantic fortification and methodical decoding. This deliberate emphasis equips us with the tools to tackle age-old challenges, ranging from inference bias to output degradation. By prioritizing the symbiotic relationship between textual and visual information over mere noise injections, our approach marks a significant leap in performance, reinforcing its unique stature in image captioning research.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}