
An Improved CSMA/CA Protocol Anti-Jamming Method Based on Reinforcement Learning


Abstract
1. Introduction
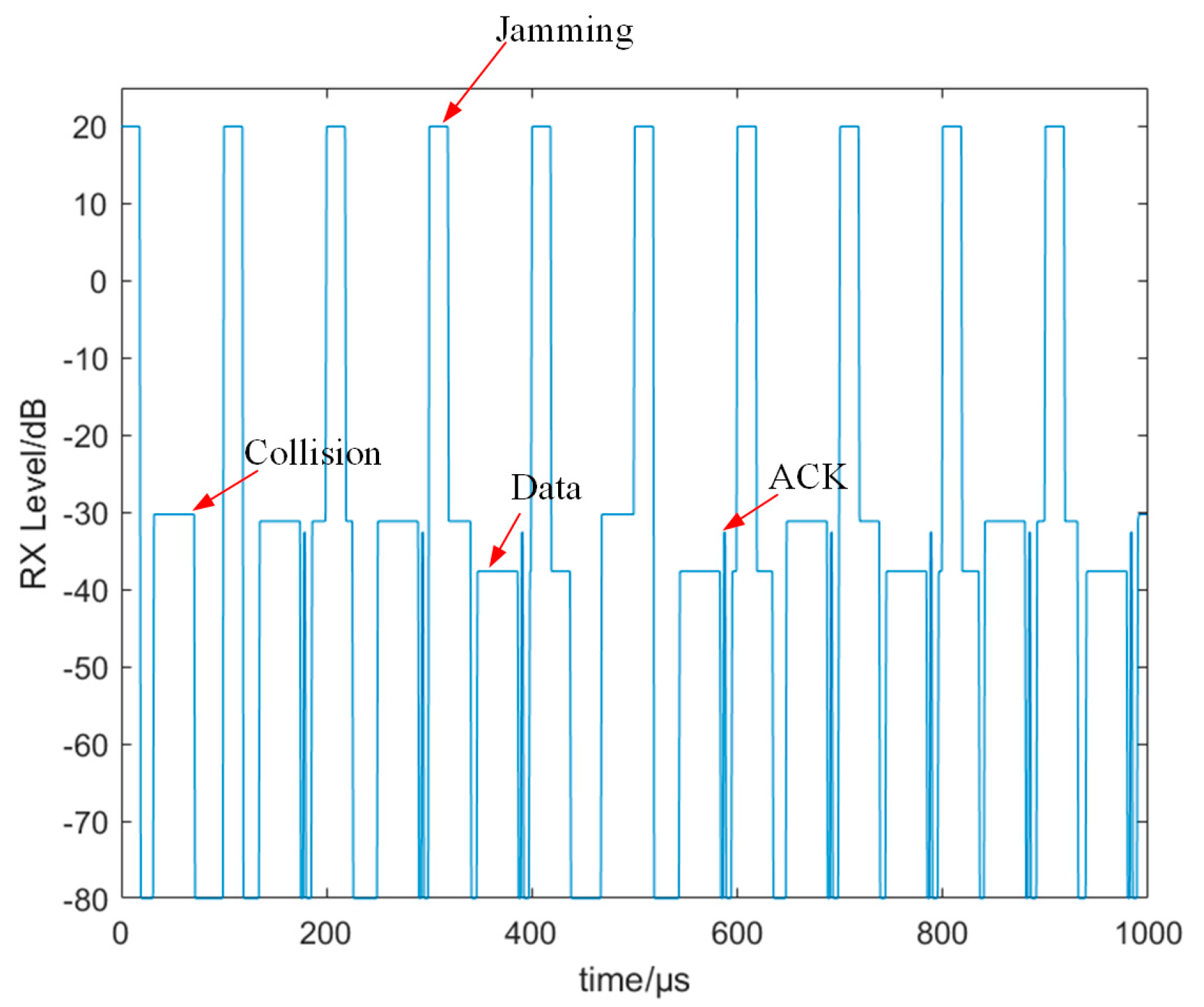
- We analyze the impact of malicious jamming on the CSMA/CA algorithm through simulations. In the jamming environment, the CSMA/CA protocol is difficult to distinguish between link collision and malicious jamming, which leads to a significant decrease in the performance of the CSMA/CA algorithm;
- We propose a Markov decision process (MDP) model for CSMA/CA. We consider the contention window (CW) as an environmental state, throughput as the reward value, and backoff action as the control variable;
- We propose an improved CSMA/CA protocol anti-jamming method based on distributed reinforcement learning. Each node adopts distributed learning decision-making, which needs to query and update information from a central SCE. By learning different environments, the optimal backoff action is learned, and adaptive changes are made for different environments to improve its anti-jamming performance;
- The proposed algorithm is compared with CSMA/CA and smart exponential threshold linear algorithm (SETL) in a non-jamming environment, intermittent jamming environment, and random jamming environment. The simulation results show that our proposed algorithm is significantly better than CSMA/CA and SETL algorithms in different environments; it significantly reduces the collision rate and effectively improves the network throughput performance.
2. Related Work
3. System Model
4. Principle of Algorithm
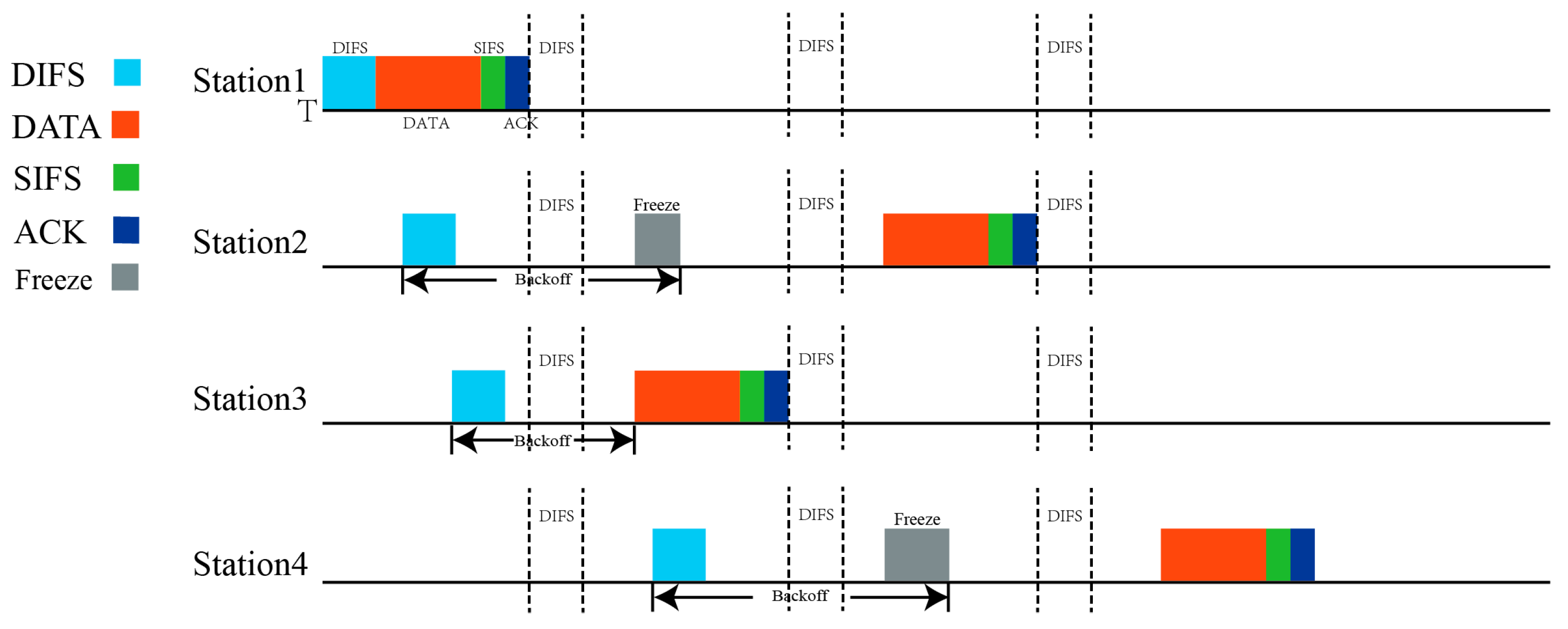
4.1. CSMA/CA Protocol Algorithm
4.2. SETL Algorithm
4.3. Reinforcement Learning
- (1)
- Define the state set . , denotes the user state at the moment in time. In our algorithm, we consider the as the environment state, and learn it through reinforcement learning to improve its network performance;
- (2)
- Define the action set . , where represents the adjustment action of at moment , and the node backoff decision is optimized through different actions;
- (3)
- Define the action transfer probability . , which denotes the probability of picking an action to transfer to in state ;
- (4)
- Define the reward value . denotes the reward value obtained by picking action in state . In the process of communication, the throughput performance of an environment can be tested by SCE, so it will be normalized, with throughput as a reward value.
- (1)
- Before making a decision, each node obtains the CW value of all nodes from the SCE device as the status information. Then, query the Q value table to obtain the optimal decision based on ε-greedy. This value is fed back to the SCE;
- (2)
- Wait for a fixed period to calculate the throughput of the time period itself. Its own throughput value is sent to SCE, and the instantaneous throughput and CW value of other nodes are queried from SCE;
- (3)
- The throughput of the whole network is calculated as the reward value. Then, the Q value table is updated based on the decision and the state changes.
| Algorithm 1: An improved CSMA/CA protocol anti-jamming method based on reinforcement learning | ||
| Initialize each node table | ||
| Initialize discount factor | ||
| Initialize learning factor | ||
| Initialize epsilon greedy | ||
| Initialize epsilon greedy decrement | ||
| Initialize normalized throughput | ||
| Initialize starte state | ||
| For each, do: | ||
| The each node gets the state from SCE, select action based on ε-greedy, and is fed back to SCE; | ||
| Execute action , update each node , get the next state from SCE; | ||
| Wait for a fixed period, observe its normalized throughput, and is fed back to SCE; | ||
| The SCE calculates the current total normalized throughput ; | ||
| ; | ||
| Update each node Q table:; | ||
| Update to ; | ||
| Decrease ; | ||
| End | ||
5. Simulation Results and Analysis
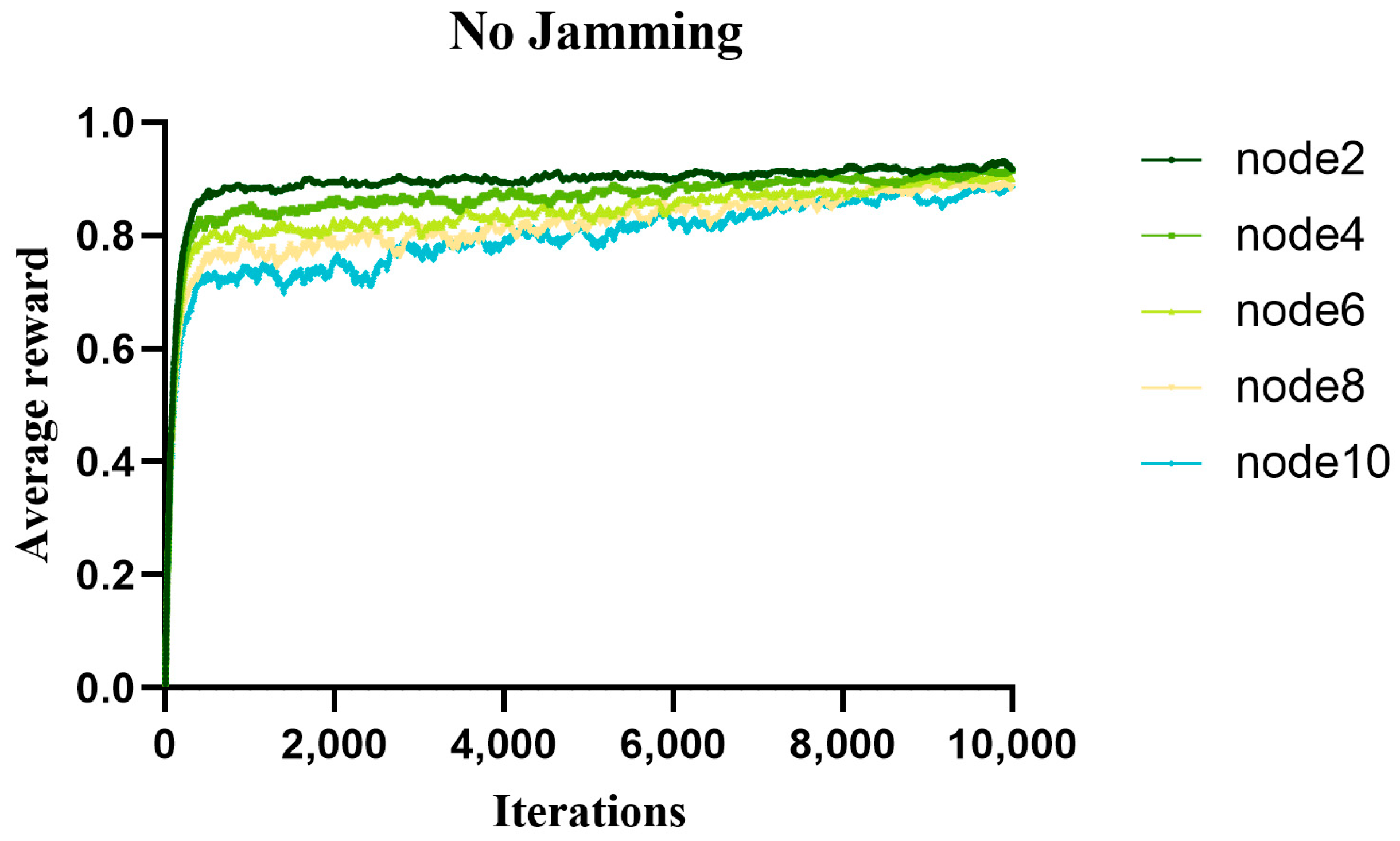
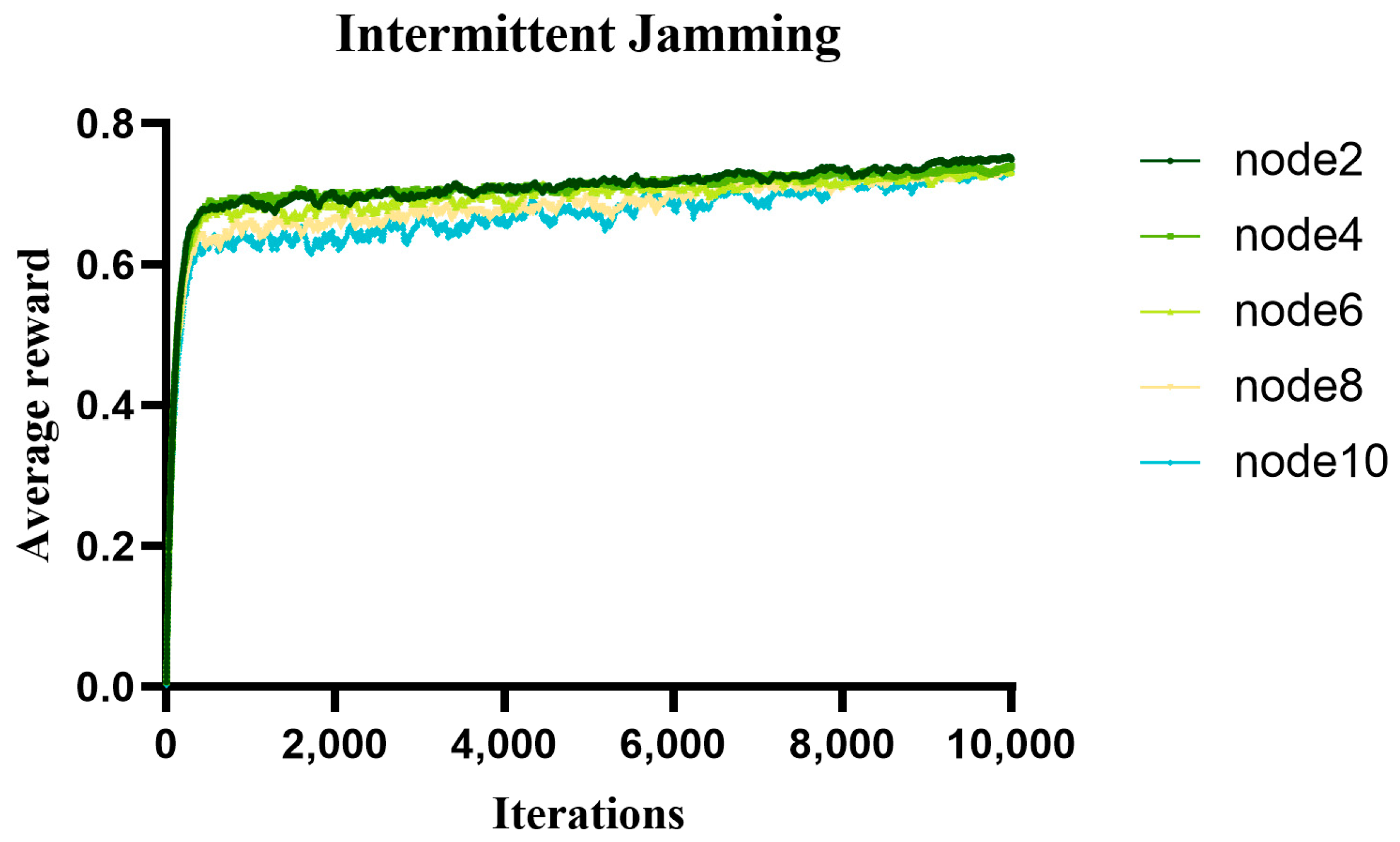
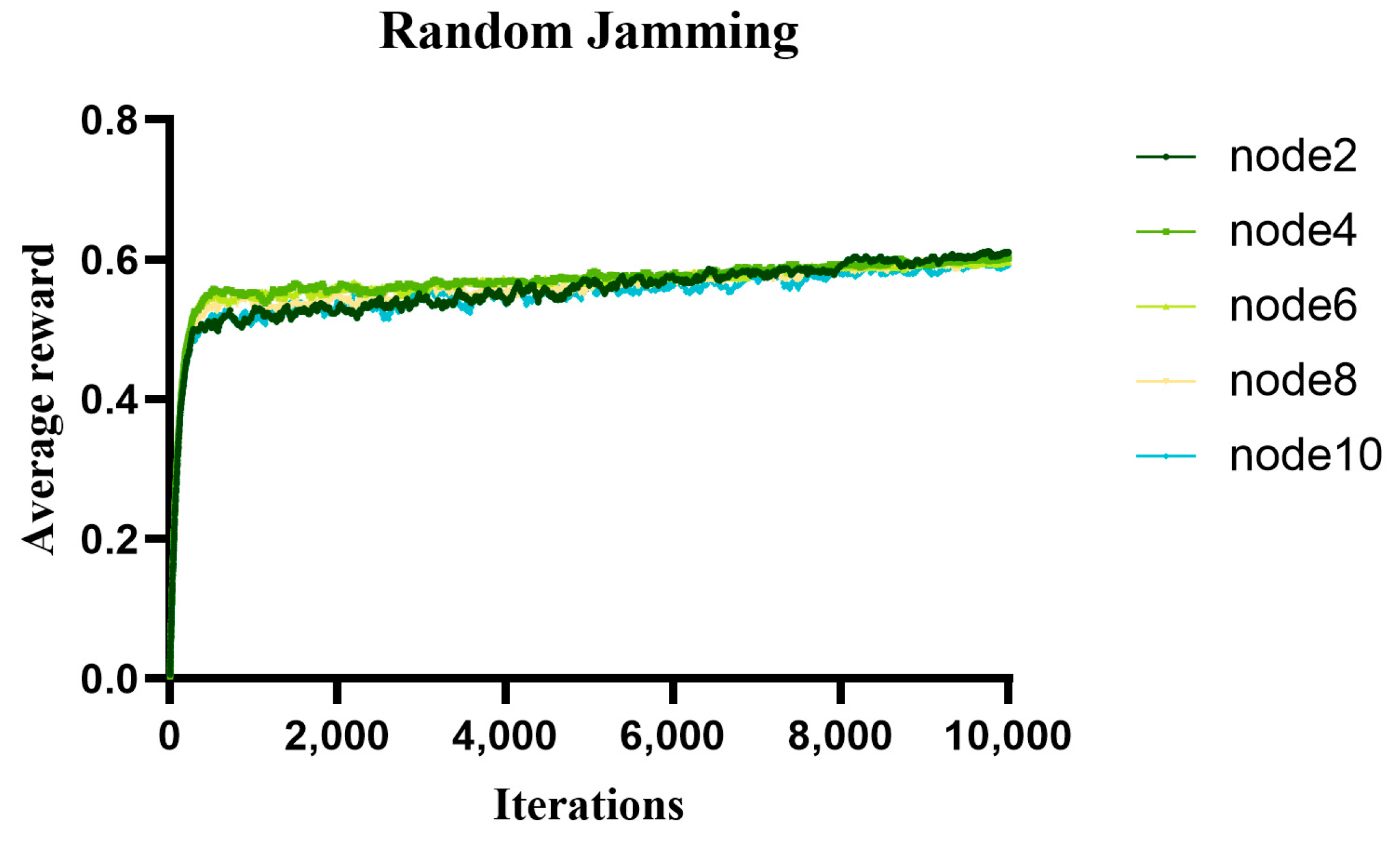
5.1. Analysis of the Average Reward
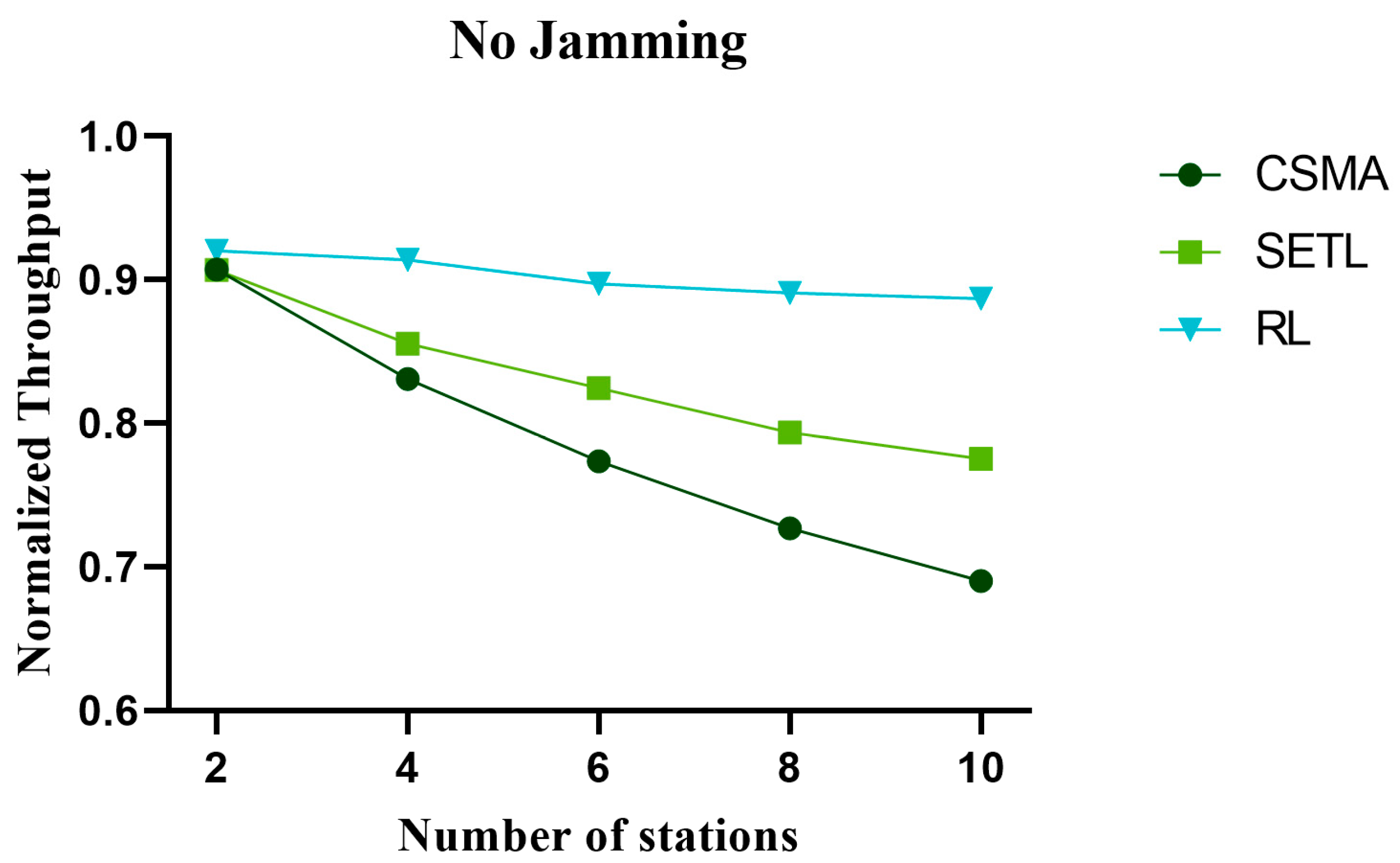
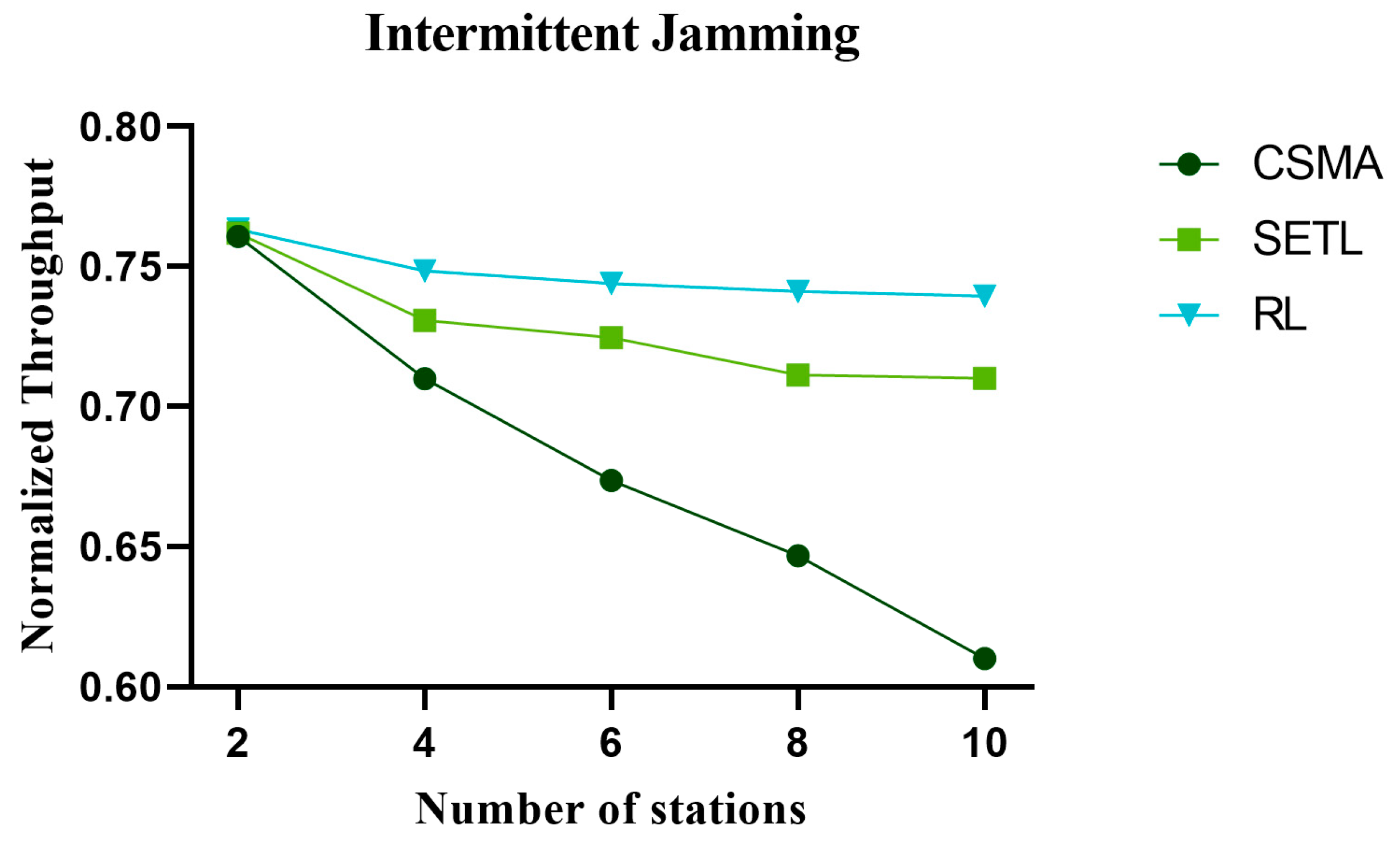
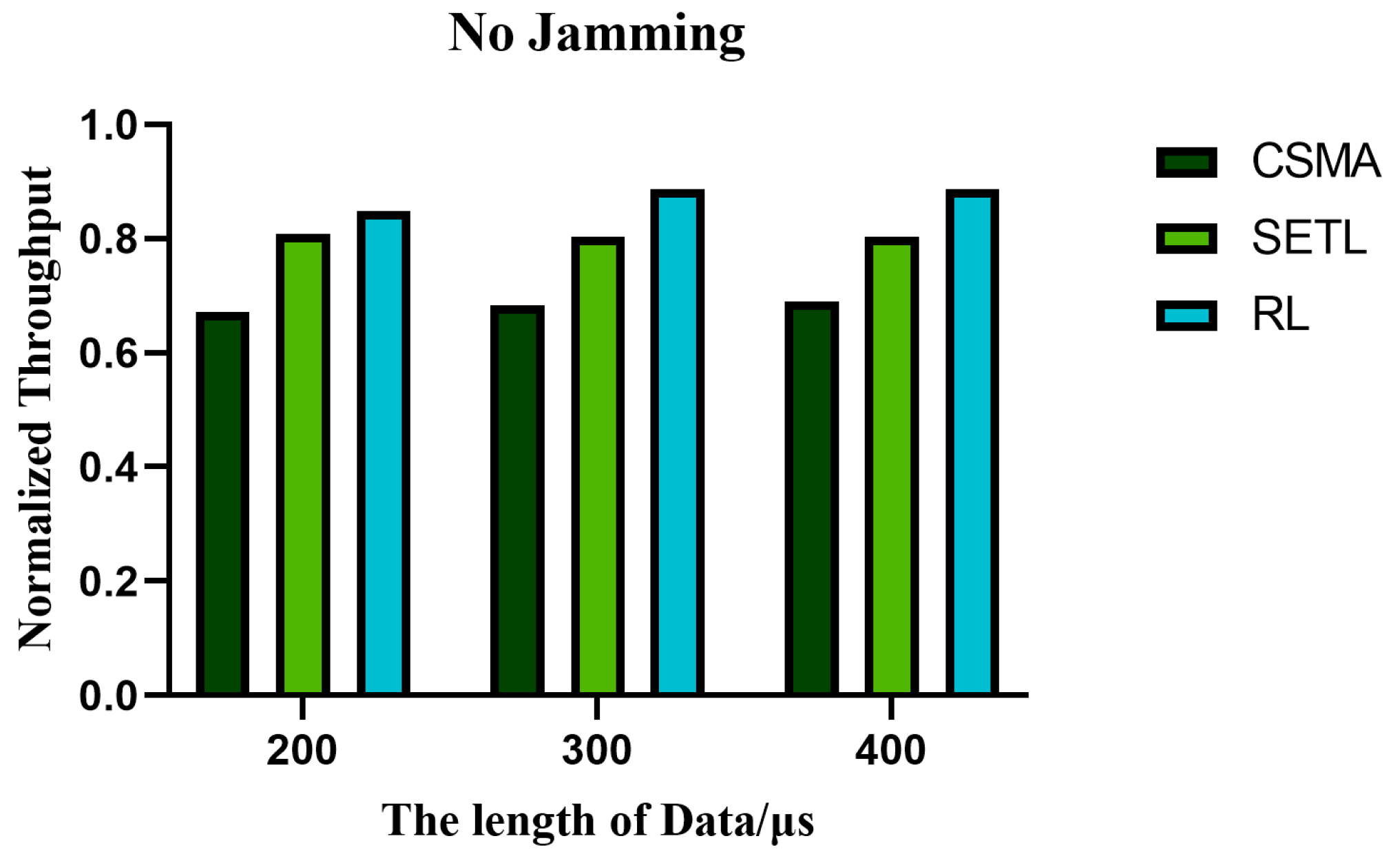
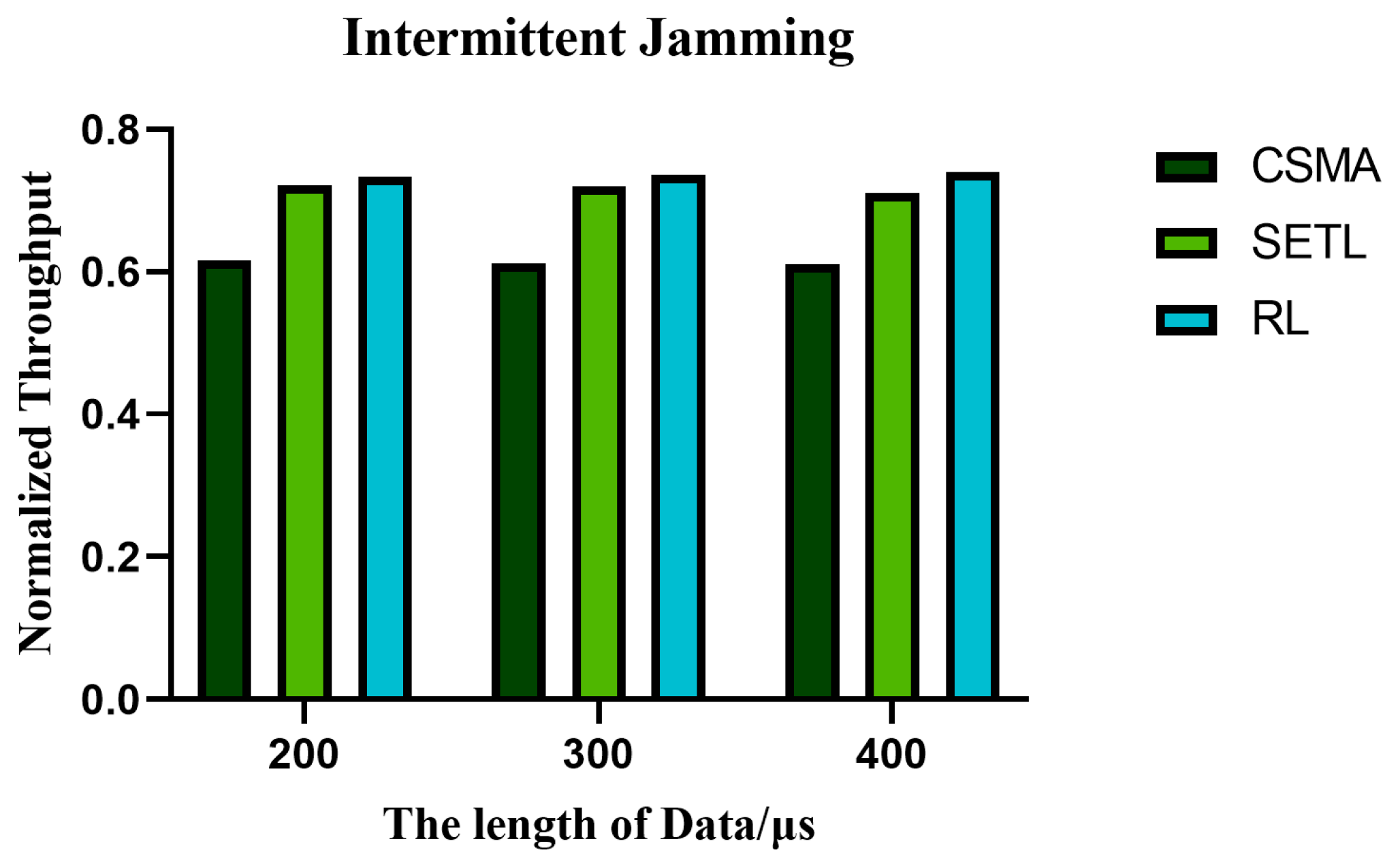
5.2. Analysis of Throughput
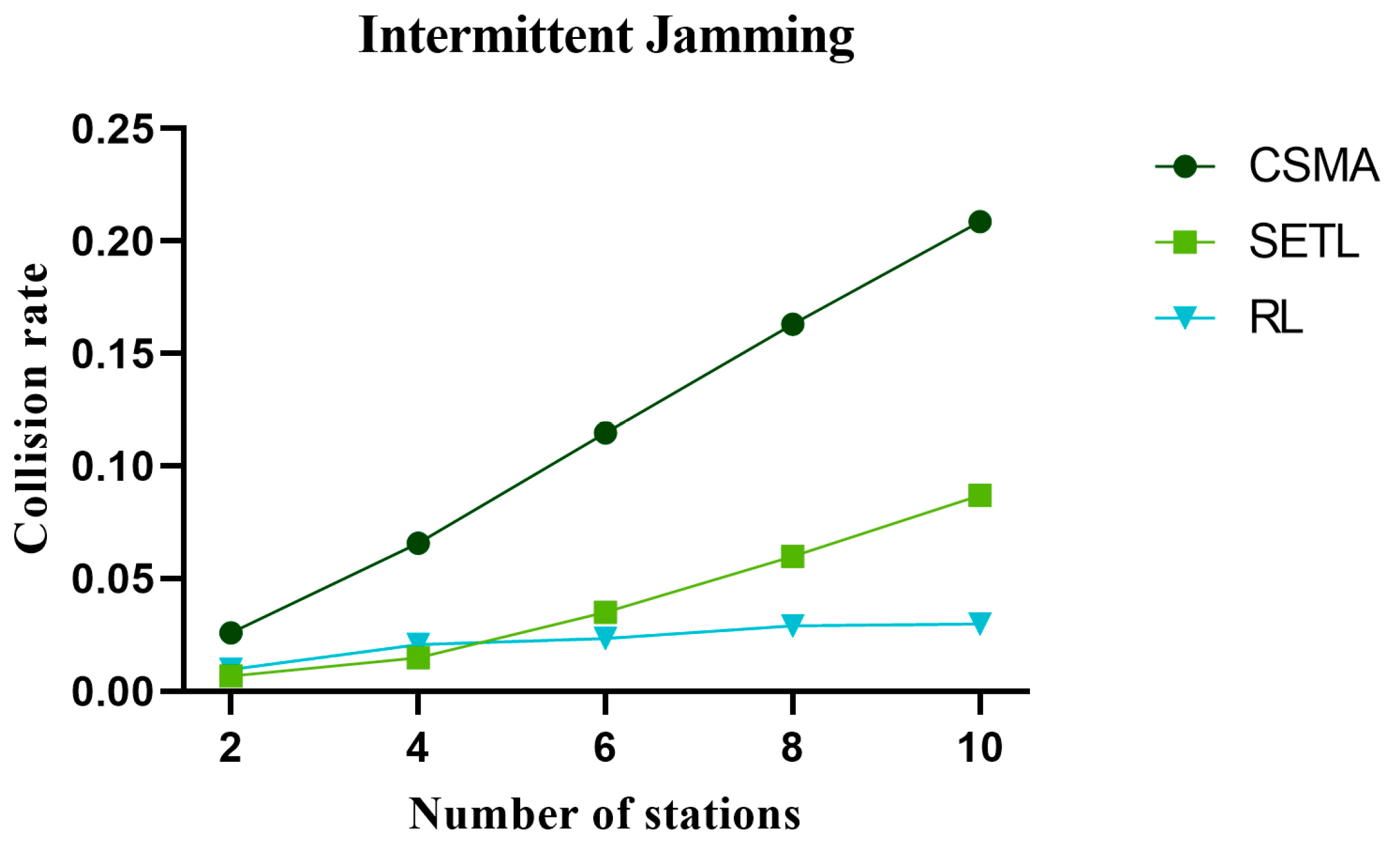
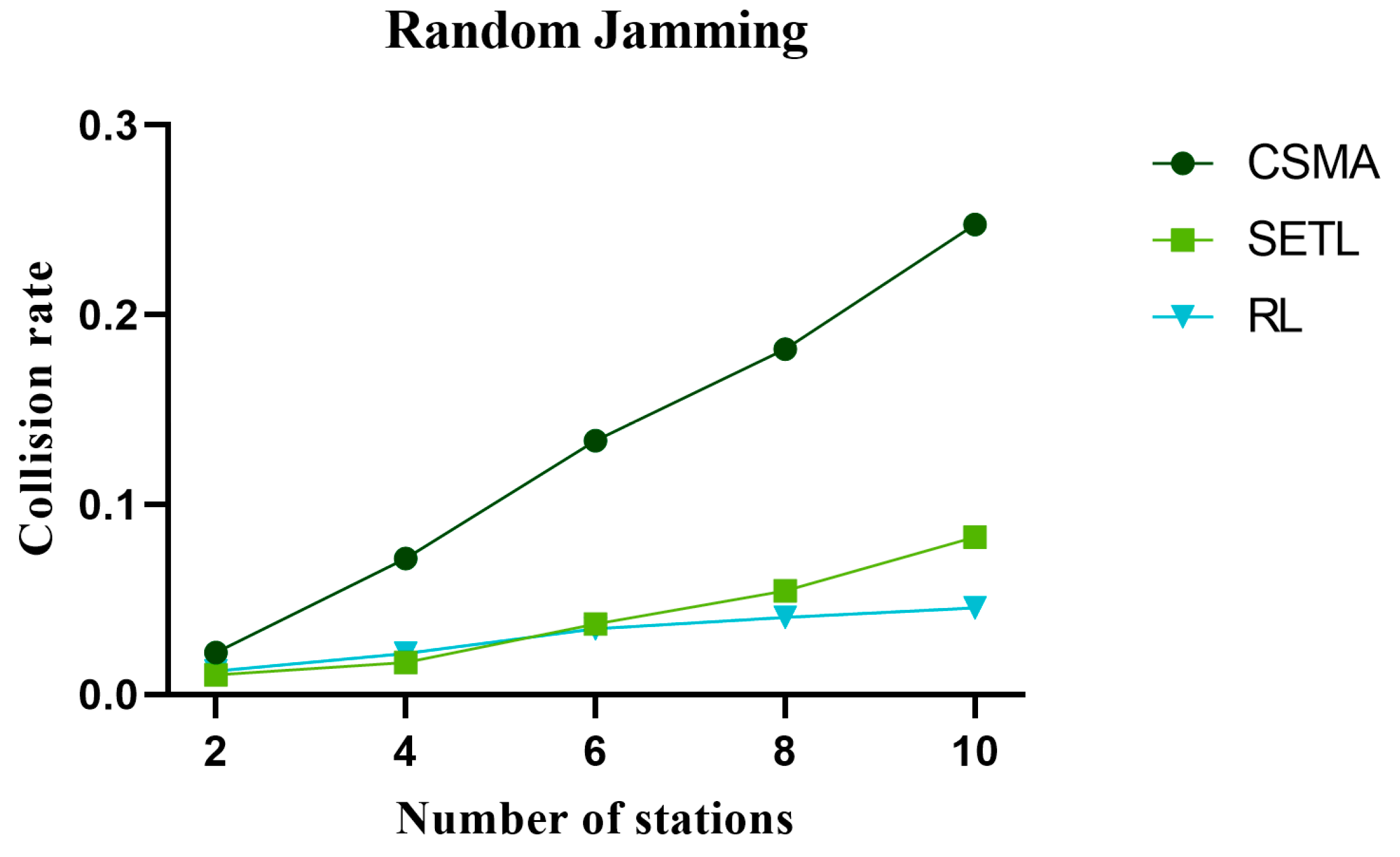
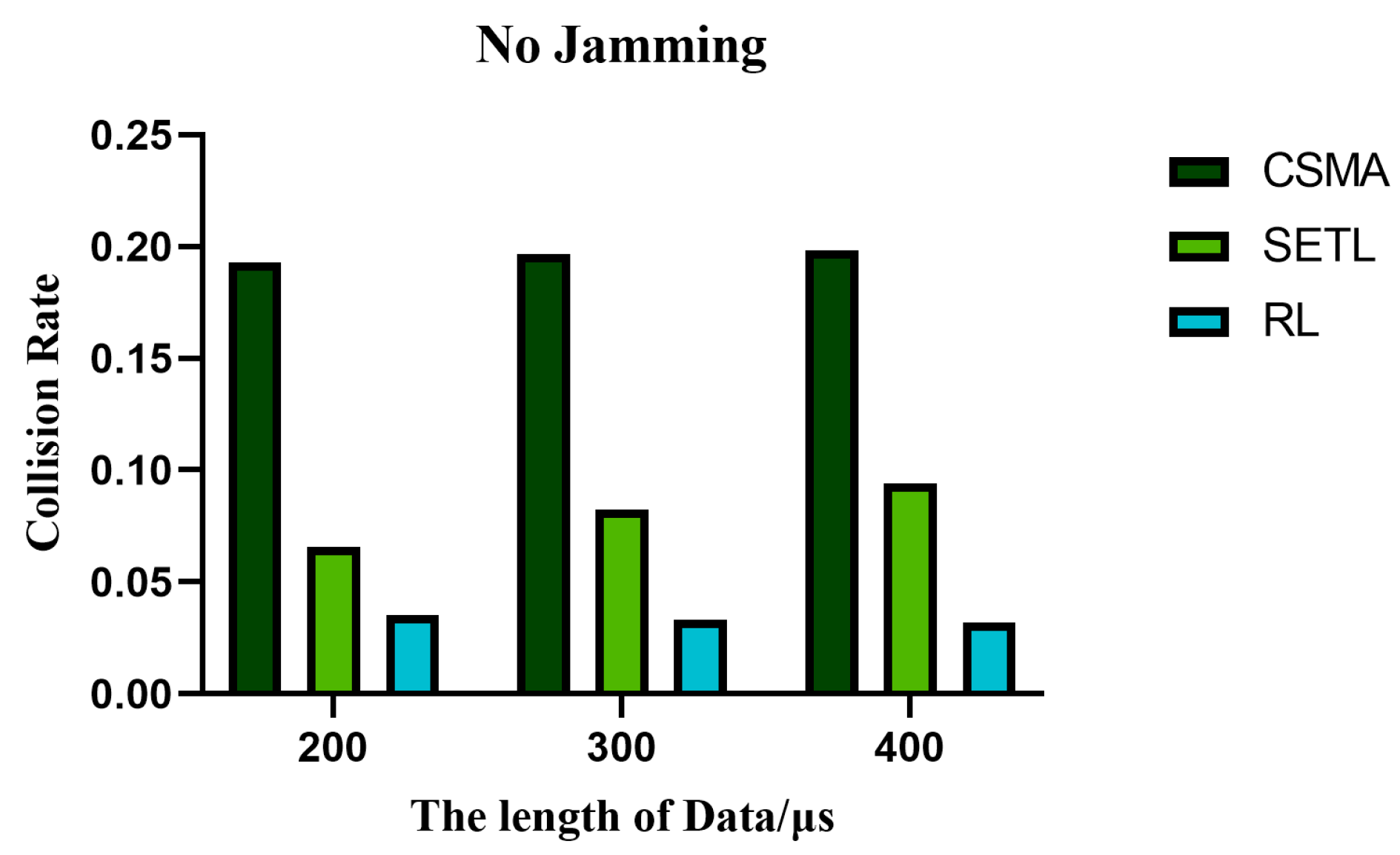
5.3. Analysis of the Collision Probability
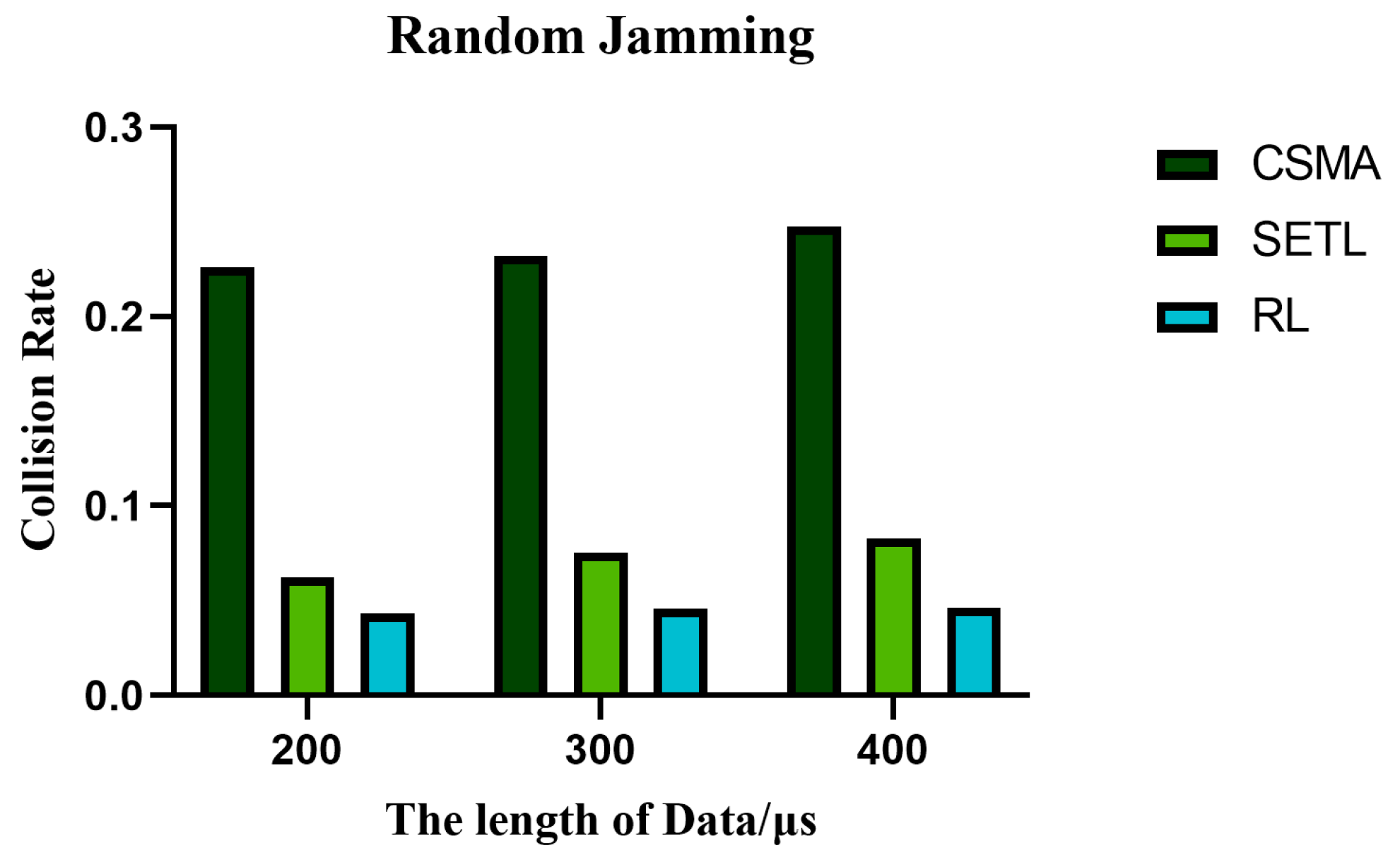
5.4. The Influence of Different Data Lengths on the Performance of the Algorithm
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Rong, B. 6G: The Next Horizon: From Connected People and Things to Connected Intelligence; Cambridge Univ. Press: Cambridge, UK, 2021. [Google Scholar]
- Meneghello, F.; Calore, M.; Zucchetto, D.; Polese, M.; Zanella, A. IoT: Internet of Threats? A survey of practical security vulnerabilities in real IoT devices. IEEE Internet Things J. 2019, 6, 8182–8201. [Google Scholar] [CrossRef]
- Mpitziopoulos, A.; Gavalas, D.; Konstantopoulos, C.; Pantziou, G. A survey on jamming attacks and countermeasures in WSNs. IEEE Commun. Surv. Tutorials 2009, 11, 42–56. [Google Scholar] [CrossRef]
- Zou, Y.; Zhu, J.; Wang, X.; Hanzo, L. A Survey on Wireless Security: Technical Challenges, Recent Advances, and Future Trends. Proc. IEEE 2016, 104, 1727–1765. [Google Scholar] [CrossRef]
- Tianyang, P.; Yonggui, L.; Yingtao, N.; Chen, H.; Zhi, X. Classification and Development of Communication Electronic Interference. Commun. Technol. 2018, 51, 2271–2278. [Google Scholar]
- Parras, J.; Zazo, S. Wireless Networks under a Backoff Attack: A Game Theoretical Perspective. Sensors 2018, 18, 404. [Google Scholar] [CrossRef] [PubMed]
- Medal, H.R. The wireless network jamming problem subject to protocol interference. Networks 2016, 67, 111–125. [Google Scholar] [CrossRef]
- Liu, X.; Xu, Y.; Jia, L.; Wu, Q.; Anpalagan, A. Anti-Jamming Communications Using Spectrum Waterfall: A Deep Reinforcement Learning Approac. IEEE Commun. Lett. 2018, 22, 998–1001. [Google Scholar] [CrossRef]
- Salameh, H.B.; Al-Quraan, M. Securing Delay-Sensitive CR-IoT Networking under Jamming Attacks: Parallel Transmission and Batching Perspective. IEEE Internet Things J. 2020, 7, 7529–7538. [Google Scholar] [CrossRef]
- Halloush, R.D. Transmission Early-Stopping Scheme for Anti-Jamming over Delay-Sensitive IoT Applications. IEEE Internet Things J. 2019, 6, 7891–7906. [Google Scholar] [CrossRef]
- Ng, J.; Cai, Z.; Yu, M. A New Model-Based Method to Detect Radio Jamming Attack to Wireless Networks. In Proceedings of the 2015 IEEE Globecom Workshops (GC Wkshps), San Diego, CA, USA, 6–10 December 2015; pp. 1–6. [Google Scholar] [CrossRef]
- Martín-Guerrero, J.D.; Lamata, L. Reinforcement Learning and Physics. Appl. Sci. 2021, 11, 8589. [Google Scholar] [CrossRef]
- Alhassan, I.B.; Mitchell, P.D. Packet Flow Based Reinforcement Learning MAC Protocol for Underwater Acoustic Sensor Networks. Sensors 2021, 21, 2284. [Google Scholar] [CrossRef]
- Lee, T.; Jo, O.; Shin, K. CoRL: Collaborative Reinforcement Learning-Based MAC Protocol for IoT Networks. Electronics 2020, 9, 143. [Google Scholar] [CrossRef]
- Elgendy, I.A.; Zhang, W.-Z.; He, H.; Gupta, B.B.; El-Latif, A.A.A. Joint computation offloading and task caching for multi-user and multi-task MEC systems: Reinforcement learning-based algorithms. Wirel. Netw. 2021, 27, 2023–2038. [Google Scholar] [CrossRef]
- Murad, M.; Eltawil, A.M. Performance Analysis and Enhancements for In-Band Full-Duplex Wireless Local Area Networks. IEEE Access 2020, 8, 111636–111652. [Google Scholar] [CrossRef]
- Lin, C.-L.; Chang, W.-T.; Lu, M.-H. MAC Throughput Improvement Using Adaptive Contention Window. J. Comput. Chem. 2015, 3, 1–14. [Google Scholar] [CrossRef][Green Version]
- Lin, C.-H.; Tsai, M.-F.; Hwang, W.-S.; Cheng, M.-H. A Collision Rate-Based Backoff Algorithm for Wireless Home Area Networks. In Proceedings of the 2020 2nd International Conference on Computer Communication and the Internet (ICCCI), Nagoya, Japan, 26–29 June 2020; pp. 51–56. [Google Scholar] [CrossRef]
- Gamal, M.; Sadek, N.; Rizk, M.R.; Ahmed, M.A.E. Optimization and modeling of modified unslotted CSMA/CA for wireless sensor networks. Alex. Eng. J. 2020, 59, 681–691. [Google Scholar] [CrossRef]
- Qiao, J.; Shen, X.S.; Mark, J.W.; Cao, B.; Shi, Z.; Zhang, K. CSMA/CA-based medium access control for indoor millimeter wave networks. Wirel. Commun. Mob. Comput. 2014, 16, 3–17. [Google Scholar] [CrossRef]
- Park, J.; Yoon, C. Distributed Medium Access Control Method through Inductive Reasoning. Int. J. Fuzzy Log. Intell. Syst. 2021, 21, 145–151. [Google Scholar] [CrossRef]
- Chao, I.-F.; Lai, C.-W.; Chung, Y.-H. A reservation-based distributed MAC scheme for infrastructure wireless networks. In Proceedings of the 2018 3rd International Conference on Intelligent Green Building and Smart Grid (IGBSG), Yilan, Taiwan, 22–25 April 2018; pp. 1–4. [Google Scholar] [CrossRef]
- Zerguine, N.; Aliouat, Z.; Mostefai, M.; Harous, S. M-BEB: Enhanced and Fair Binary Exponential Backoff. In Proceedings of the 2020 14th International Conference on Innovations in Information Technology (IIT), Al Ain, United Arab Emirates, 17–18 November 2020; pp. 142–147. [Google Scholar] [CrossRef]
- Ke, C.-H.; Wei, C.-C.; Lin, K.W.; Ding, J.-W. A smart exponential threshold-linear backoff mechanism for IEEE 802. 11 WLANs. Int. J. Commun. Syst. 2011, 24, 1033–1048. [Google Scholar] [CrossRef]
- Bharghavan, V.; Demers, A.; Shenker, S.; Zhang, L. MACAW: A Media Access Protocol for Wireless LAN’s. In Proceedings of the ACK SIGCOMM’94, London, UK, 31 August–2 September 1994. [Google Scholar]
- Song, N.-O.; Kwak, B.-J.; Song, J.; Miller, L. Enhancement of IEEE 802.11 distributed coordination function with exponential increase exponential decrease backoff algorithm. In Proceedings of the 57th IEEE Semiannual Vehicular Technology Conference, Jeju, Republic of Korea, 22–25 April 2003; IEEE: Manhattan, NY, USA, 2003; Volume 4, pp. 2775–2778. [Google Scholar] [CrossRef]
- Bayraktaroglu, E.; King, C.; Liu, X.; Noubir, G.; Rajaraman, R.; Thapa, B. Performance of IEEE 802.11 under Jamming. Mob. Netw. Appl. 2013, 18, 678–696. [Google Scholar] [CrossRef]
- Wei, X.; Wang, T.; Tang, C. Throughput Analysis of Smart Buildings-oriented Wireless Networks under Jamming Attacks. Mob. Netw. Appl. 2021, 26, 1440–1448. [Google Scholar] [CrossRef]
- López-Vilos, N.; Valencia-Cordero, C.; Azurdia-Meza, C.; Montejo-Sánchez, S.; Mafra, S.B. Performance Analysis of the IEEE 802.15.4 Protocol for Smart Environments under Jamming Attacks. Sensors 2021, 21, 4079. [Google Scholar] [CrossRef] [PubMed]
- Jiaqi, C.; Jianfeng, Y.; Jun, X.; Chengcheng, G. Performance analysis of CSMA/CA in CSMA/TDMA mixed network. Comput. Eng. Appl. 2017, 53, 83–88+127. [Google Scholar]





























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Value |
|---|---|
| Channel bit rate | 1 Mbits/s |
| Slots | 20 μs |
| SIFS | 10 μs |
| DIFS | 50 μs |
| Data | 400 μs |
| ACK | 20 μs |
| Decision time interval ∆t | 200 slots |
| 8 | |
| 256 |
| Parameters | Value |
|---|---|
| 0.9 | |
| 0.5 | |
| (8, 16, 32, 48, 64, 96, 128, 192, 256) | |
| 1.0 | |
| Epsilon greedy decrement | 0.0001 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ming, Z.; Liu, X.; Yang, X.; Wang, M. An Improved CSMA/CA Protocol Anti-Jamming Method Based on Reinforcement Learning. Electronics 2023, 12, 3547. https://doi.org/10.3390/electronics12173547
Ming Z, Liu X, Yang X, Wang M. An Improved CSMA/CA Protocol Anti-Jamming Method Based on Reinforcement Learning. Electronics. 2023; 12(17):3547. https://doi.org/10.3390/electronics12173547
Chicago/Turabian StyleMing, Zidong, Xin Liu, Xiaofei Yang, and Mei Wang. 2023. "An Improved CSMA/CA Protocol Anti-Jamming Method Based on Reinforcement Learning" Electronics 12, no. 17: 3547. https://doi.org/10.3390/electronics12173547
APA StyleMing, Z., Liu, X., Yang, X., & Wang, M. (2023). An Improved CSMA/CA Protocol Anti-Jamming Method Based on Reinforcement Learning. Electronics, 12(17), 3547. https://doi.org/10.3390/electronics12173547