


A Two-Path Multibehavior Model of User Interaction


Abstract
1. Introduction
- In order to distinguish the ability of different users’ behavior perception preferences, we propose a two-path multibehavior model framework of user interaction (TP_MB). The strategy of the multibehavior interaction sequence path according to the timeline of the interaction and the multibehavior interaction graph path based on attention is proposed.
- To make full use of the auxiliary behavior information, we propose two-path modeling. This focuses on the dependencies between multiple behaviors obtained through attention mechanisms within each of the two paths. It emphasizes the necessity of modeling the dependency relationship between different behaviors of users.
- In order to capture the commonality of multiple behaviors of users, we design three contrastive learning methods. This not only enhances the representation results of two paths, but also enables the model to obtain more auxiliary supervision signals in the self-supervised learning within paths and between paths. It effectively alleviates the problem of sparse supervisory signals.
- We conduct extensive experiments on two real-world user behavior datasets. Experiments show that the recommendation performance of TP_MB outperforms many current popular baseline models.
2. Related Work
2.1. Self-Supervised Representation Learning
2.2. General Recommendation
2.3. Multibehavior Recommendation System
3. Problem Formulation
3.1. Methods
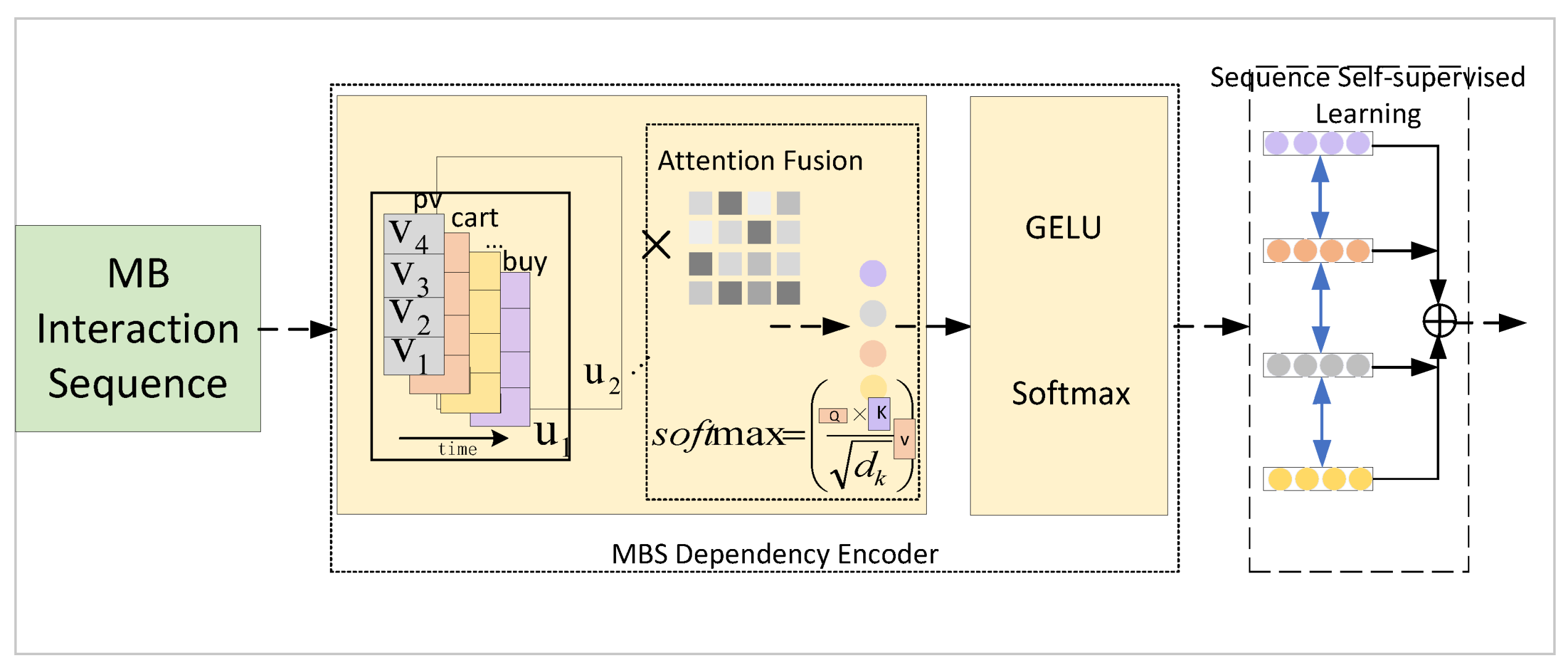
3.2. Multibehavior Interaction Sequence Path
3.2.1. Multibehavior Interaction Sequence Embedding
3.2.2. Multibehavior Interaction Sequence-Dependent Encoder
3.2.3. Multibehavior Interaction Sequence Modeling
3.2.4. Multibehavior Interaction Sequence Self-Supervised Learning
3.3. Multibehavior Interaction Graph Path
3.3.1. Multibehavior Interaction Graph Embedding
3.3.2. Multibehavior Interaction Graph Dependency Encoder
3.3.3. Multibehavior Interaction Graph Self-Supervised Learning
3.4. Contrast Loss for Two-Path Enhancement
4. Experiments
- RQ1: Can TP_MB achieve better performance compared to the state-of-the-art model?
- RQ2: In our designed TP_MB, what is the influence of each component on each other?
- RQ3: How do different hyperparameters affect model performance?
4.1. Experimental Results and Analysis
4.2. Datasets
4.3. Implementation Details and Environment
4.4. Baseline
- LightGCN [32]: A simplified method of traditional GCN. This model removed the feature transformation and nonlinear activation operations of the aggregation layer and propagation layer in the standard GCN, and only consisted of neighborhood aggregation, making it more concise and more suitable for recommendation systems.
- BERT4Rec [30]: This modeled user behavior through self-attention mechanism, and fused project neighbor information for recommendation.
- Caser [33]: For the most recent projects, graph convolution was embedded in time and space to model the dynamic change of user interest over time.
- GHCF [3]: The model encoded the behavior of users interacting with items, and the behavior pattern was embedded into the overall heterogeneous graph as a node when composing the graph. At the same time, LightGCN was used to realize aggregation and propagation between nodes.
- DHSL-GM [34]: Similar users and similar items constituted hypergraphs, respectively. The gated neural network was used to predict less popular items in a more balanced manner. This was the latest use of self-supervised learning to model the representation of users and products on the dual hypergraph. This model is a relatively advanced method at present, and is also the main comparison object of this paper.
4.5. Performance Comparison
4.6. Ablation Study
- Removing path attention w/o-Att: Different modal relationships between multiple behaviors are not captured using attention in the two paths.
- Removing two-path self-supervision w/o-DCL: No two-path contrastive learning strategy is used to supplement sparse data.
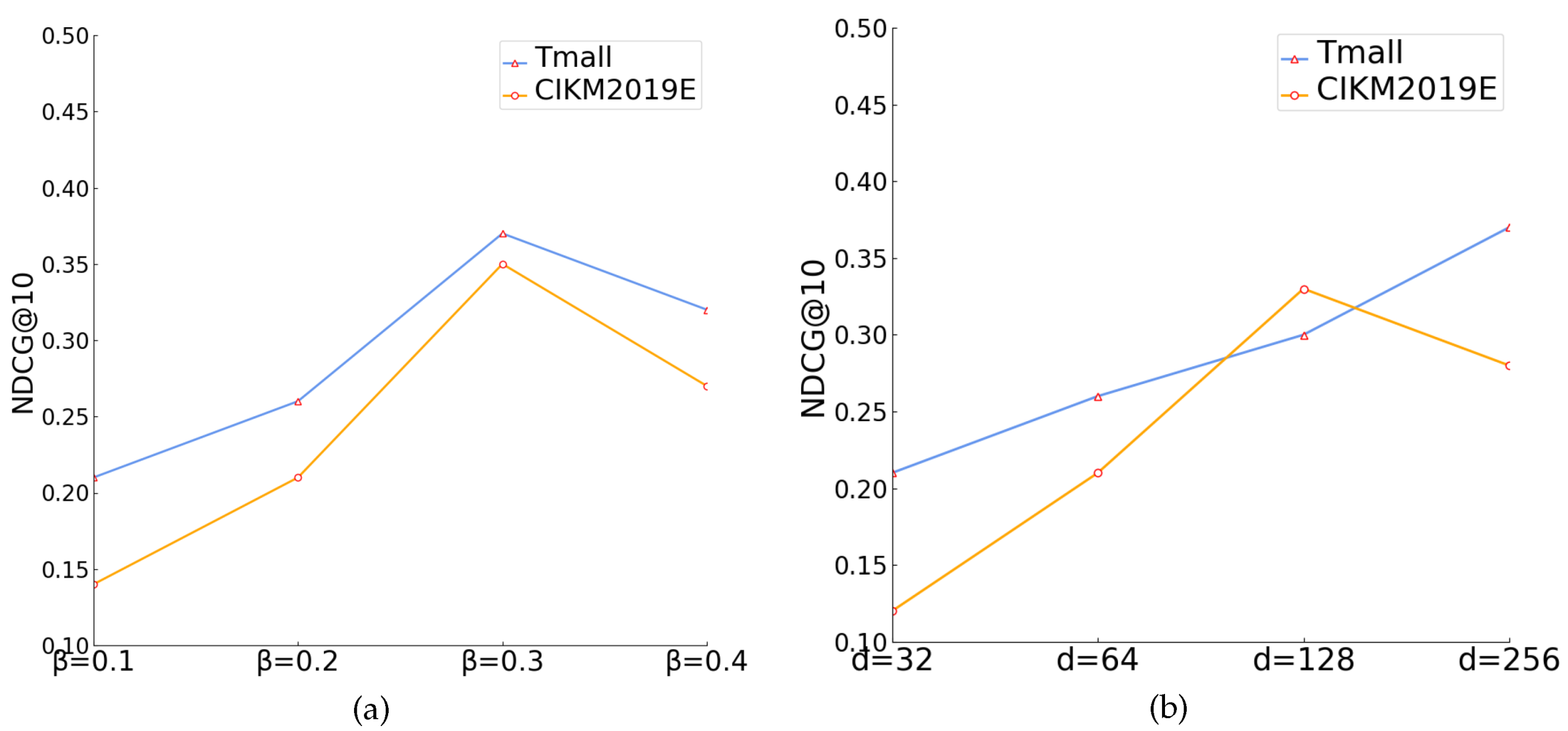
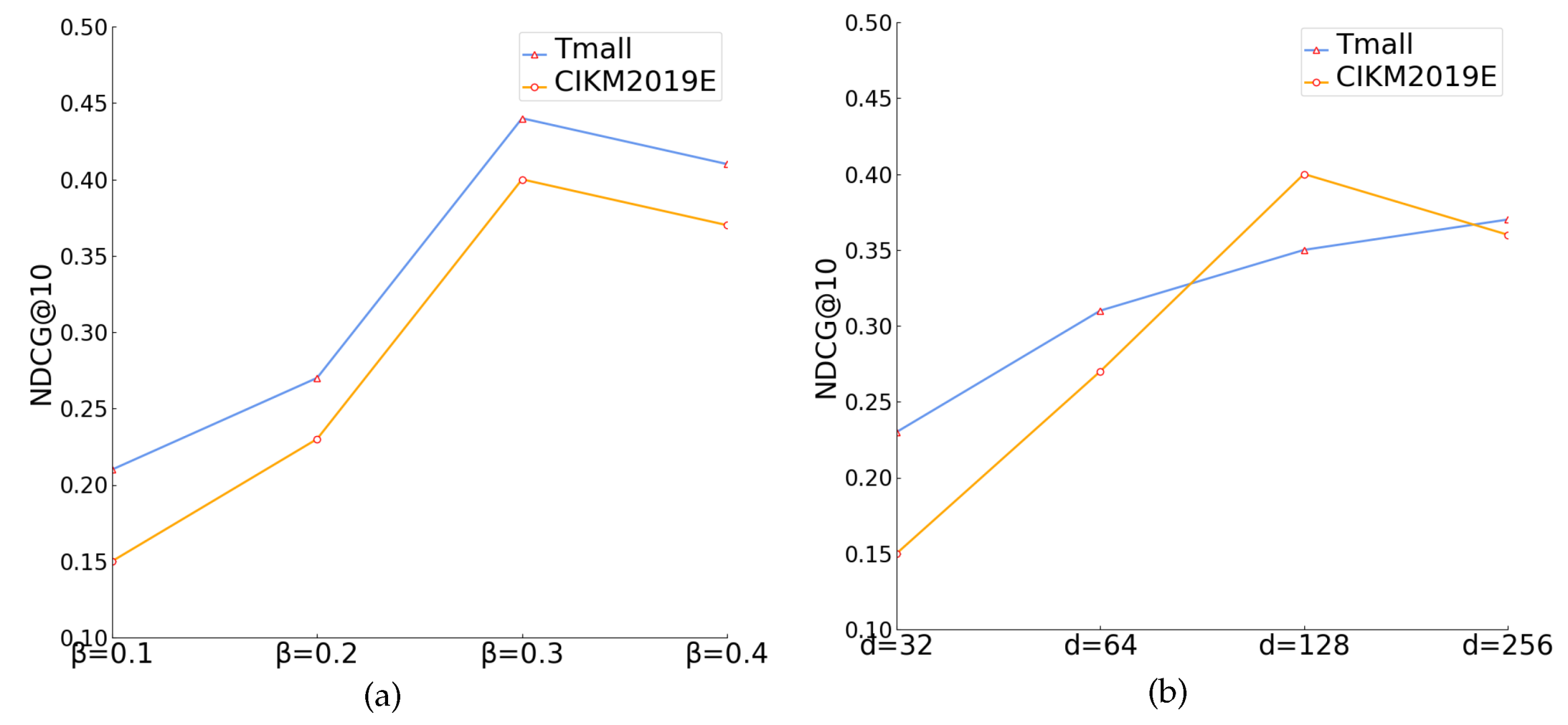
4.7. Loss Weight Analysis
4.8. Hyperparameter Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Sample Availability
Abbreviations
| TP_MB | Two-Path Multibehavior Model of User Interaction |
References
- Wang, J.; Huang, P.; Zhao, H.; Zhang, Z.; Zhao, B.; Lee, D.L. Billion-scale Commodity Embedding for E-commerce Recommendation in Alibaba. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, New York, NY, USA, 19–23 August 2018. [Google Scholar]
- Chen, C.; Zhang, M.; Zhang, Y.; Ma, W.; Liu, Y.; Ma, S. Efficient Heterogeneous Collaborative Filtering without Negative Sampling for Recommendation. In Proceedings of the AAAI Conference on Artificial Intelligence 2020, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 19–26. [Google Scholar]
- Chen, C.; Ma, W.; Zhang, M.; Wang, Z.; He, X.; Wang, C.; Liu, Y.; Ma, S. Graph heterogeneous multi-relational recommendation. In Proceedings of the AAAI Conference on Artificial Intelligence 2021, Online, 2–9 February 2021; Volume 35, pp. 3958–3966. [Google Scholar]
- Koren, Y.; Rendle, S.; Bell, R. Advances in collaborative filtering. In Recommender Systems Handbook; Springer: New York, NY, USA, 2021; pp. 91–142. [Google Scholar]
- Koren, Y.; Bell, R.; Volinsky, C. Matrix Factorization Techniques for Recommender Systems. Computer 2009, 42, 30–37. [Google Scholar] [CrossRef]
- Salakhutdinov, R.R.; Mnih, A. Probabilistic Matrix Factorization. In Proceedings of the 20th International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 3–6 December 2007. [Google Scholar]
- Li, C.; Liu, Z.; Wu, M.; Xu, Y.; Zhao, H.; Huang, P.; Kang, G.; Chen, Q.; Li, W.; Lee, D.L. Multi-Interest Network with Dynamic Routing for Recommendation at Tmall. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management, Beijing, China, 3–7 November 2019. [Google Scholar] [CrossRef]
- Zhou, G.; Zhu, X.; Song, C.; Fan, Y.; Zhu, H.; Ma, X.; Yan, Y.; Jin, J.; Li, H.; Gai, K. Deep Interest Network for Click-Through Rate Prediction. arXiv 2017, arXiv:1706.06978. [Google Scholar]
- Du, C.; Li, C.; Zheng, Y.; Zhu, J.; Zhang, B. Collaborative Filtering with User-Item Co-Autoregressive Models. arXiv 2016, arXiv:1612.07146. [Google Scholar] [CrossRef]
- Zheng, Y.; Tang, B.; Ding, W.; Zhou, H. A Neural Autoregressive Approach to Collaborative Filtering. arXiv 2016, arXiv:1605.09477. [Google Scholar]
- Guo, L.; Hua, L.; Jia, R.; Zhao, B.; Wang, X.; Cui, B. Buying or Browsing?: Predicting Real-time Purchasing Intent using Attention-based Deep Network with Multiple Behavior. In Proceedings of the KDD ’19: The 25th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Anchorage, AK, USA, 4–8 August 2019. [Google Scholar] [CrossRef]
- Jin, B.; Gao, C.; He, X.; Jin, D.; Li, Y. Multi-behavior Recommendation with Graph Convolutional Networks. In Proceedings of the SIGIR ’20: The 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Xi’an, China, 25–30 July 2020. [Google Scholar]
- Xia, L.; Huang, C.; Xu, Y.; Dai, P.; Zhang, X.; Yang, H.; Bo, L. Knowledge-Enhanced Hierarchical Graph Transformer Network for Multi-Behavior Recommendation. arXiv 2021, arXiv:2110.04000. [Google Scholar] [CrossRef]
- Huang, Z.; Hou, L.; Shang, L.; Jiang, X.; Chen, X.; Liu, Q. GhostBERT: Generate More Features with Cheap Operations for BERT. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), Online, 5–6 August 2021; Association for Computational Linguistics: Stroudsburg, PA, USA, 2021. [Google Scholar] [CrossRef]
- Huang, C.; Chen, J.; Xia, L.; Xu, Y.; Dai, P.; Chen, Y.; Huang, J.X. Graph-Enhanced Multi-Task Learning of Multi-Level Transition Dynamics for Session-based Recommendation. arXiv 2021, arXiv:2110.03996. [Google Scholar] [CrossRef]
- Hjelm, R.D.; Fedorov, A.; Lavoie-Marchildon, S.; Grewal, K.; Bachman, P.; Trischler, A.; Bengio, Y. Learning deep representations by mutual information estimation and maximization. arXiv 2018, arXiv:1808.06670. [Google Scholar]
- Bachman, P.; Hjelm, R.D.; Buchwalter, W. Learning Representations by Maximizing Mutual Information Across Views. arXiv 2019, arXiv:1809.10341. [Google Scholar]
- Veličković, P.; Fedus, W.; Hamilton, W.L.; Liò, P.; Bengio, Y.; Hjelm, R.D. Deep Graph Infomax. arXiv 2018, arXiv:1809.10341. [Google Scholar]
- Wang, W.; Zhang, W.; Liu, S.; Liu, Q.; Zhang, B.; Lin, L.; Zha, H. Beyond Clicks: Modeling Multi-Relational Item Graph for Session-Based Target Behavior Prediction. In Proceedings of the Web Conference 2020, Taipei, Taiwan, 20–24 April 2020. [Google Scholar]
- Hu, Z.; Dong, Y.; Wang, K.; Chang, K.W.; Sun, Y. GPT-GNN: Generative Pre-Training of Graph Neural Networks. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Virtual Event, 6–10 July 2020. [Google Scholar] [CrossRef]
- Liu, Z.; Chen, Y.; Li, J.; Yu, P.S.; McAuley, J.; Xiong, C. Contrastive Self-supervised Sequential Recommendation with Robust Augmentation. arXiv 2021, arXiv:2108.06479. [Google Scholar]
- Zou, D.; Wei, W.; Mao, X.L.; Wang, Z.; Qiu, M.; Zhu, F.; Cao, X. Multi-level Cross-view Contrastive Learning for Knowledge-aware Recommender System. arXiv 2022, arXiv:2204.08807. [Google Scholar]
- Sharma, S.; Shakya, H.K.; Marriboyina, V. A location based novel recommender framework of user interest through data categorization—ScienceDirect. Mater. Today Proc. 2021, 47, 7155–7161. [Google Scholar] [CrossRef]
- Behera, R.K.; Gunasekaran, A.; Gupta, S.; Kamboj, S.; Bala, P.K. Personalised Digital Marketing Recommender Engine. J. Retail. Consum. Serv. 2019, 53, 101799. [Google Scholar] [CrossRef]
- Siino, M.; Cascia, M.L.; Tinnirello, I. WhoSNext: Recommending Twitter Users to Follow Using a Spreading Activation Network Based Approach. In Proceedings of the 2020 International Conference on Data Mining Workshops (ICDMW), Sorrento, Italy, 17–20 November 2020. [Google Scholar] [CrossRef]
- Guan, Y.; Wei, Q.; Chen, G. Deep learning based personalized recommendation with multi-view information integration. Decis. Support Syst. 2019, 118, 58–69. [Google Scholar] [CrossRef]
- Peng, H.; Zhang, R.; Dou, Y.; Yang, R.; Zhang, J.; Yu, P.S. Reinforced Neighborhood Selection Guided Multi-Relational Graph Neural Networks. arXiv 2021, arXiv:2104.07886. [Google Scholar] [CrossRef]
- Singh, A.P.; Gordon, G.J. Relational learning via collective matrix factorization. In Proceedings of the ACM Sigkdd International Conference on Knowledge Discovery & Data Mining, Las Vegas, NV, USA, 24–27 August 2008. [Google Scholar]
- Zhao, Z.; Cheng, Z.; Hong, L.; Chi, E.H. Improving User Topic Interest Profiles by Behavior Factorization. In Proceedings of the 24th International Conference, International World Wide Web Conferences Steering Committee, Florence, Italy, 18–22 May 2015. [Google Scholar]
- Sun, F.; Liu, J.; Wu, J.; Pei, C.; Lin, X.; Ou, W.; Jiang, P. BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management, Beijing, China, 3–7 November 2019. [Google Scholar]
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lio, P.; Bengio, Y. Graph Attention Networks. arXiv 2017, arXiv:1710.10903. [Google Scholar]
- He, X.; Deng, K.; Wang, X.; Li, Y.; Zhang, Y.; Wang, M. LightGCN: Simplifying and Powering Graph Convolution Network for Recommendation. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual Event, 25–30 July 2020. [Google Scholar]
- Tang, J.; Wang, K. Personalized Top-N Sequential Recommendation via Convolutional Sequence Embedding. In Proceedings of the Eleventh ACM International Conference on Web Search and Data Mining, Marina Del Rey, CA, USA, 5–9 February 2018. [Google Scholar]
- Gao, R.; Liu, J.; Yu, Y.; Liu, D.; Shao, X.; Ye, Z. Gated Dual Hypergraph Convolutional Networks for Recommendation with Self-supervised Learning. In Proceedings of the 2022 International Joint Conference on Neural Networks (IJCNN), Padua, Italy, 18–23 July 2022. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | User | Item | Interaction | Interaction Behavior Types |
|---|---|---|---|---|
| Tmall | 27,155 | 22,014 | 613,978 | {click,add_to_cart,buy} |
| CIKM2019EComm AI | 23,023 | 25,054 | 41,526 | {click,add_to_cart,buy} |
| Tmall | ||||
|---|---|---|---|---|
| NDCG@10 | Hit@10 | MRR@10 | AUC@10 | |
| Bert4Rec | 0.1985 | 0.3274 | 0.1447 | 0.6583 |
| LightGCN | 0.2051 | 0.3447 | 0.1503 | 0.6539 |
| Caser | 0.1933 | 0.3231 | 0.1522 | 0.6876 |
| GHCF | 0.3754 | 0.4635 | 0.3164 | 0.6873 |
| DHSL_GM | 0.3983 | 0.5126 | 0.3437 | 0.6981 |
| TP_MB | 0.4393 | 0.6053 | 0.4066 | 0.7505 |
| TP_MB_t | 0.4471 | 0.6241 | 0.4137 | 0.7601 |
| Impro[TP_MB] | 10.3% | 18.1% | 8.2% | 7.5% |
| Impro[TP_MB_t] | 12.3% | 21.8% | 20.3% | 8.9% |
| CIKM2019E | ||||
|---|---|---|---|---|
| NDCG@10 | Hit@10 | MRR@10 | AUC@10 | |
| Bert4Rec | 0.2264 | 0.2896 | 0.1878 | 0.6686 |
| LightGCN | 0.2352 | 0.2534 | 0.1811 | 0.6671 |
| Caser | 0.2139 | 0.2962 | 0.1790 | 0.6731 |
| GHCF | 0.3244 | 0.4337 | 0.2926 | 0.6866 |
| DHSL_GM | 0.3662 | 0.4537 | 0.3108 | 0.6874 |
| TP_MB | 0.3970 | 0.5277 | 0.3344 | 0.7273 |
| TP_MB_t | 0.4037 | 0.5394 | 0.3421 | 0.7314 |
| Impro [TP_MB] | 8.4% | 16.3% | 7.6% | 5.8% |
| Impro [TP_MB_t] | 10.2% | 18.8% | 9.8% | 6.4% |
| Data | Tmall | CIKM2019E | ||
|---|---|---|---|---|
| Metric | Hit@10 | NDCG@10 | Hit@10 | NDCG@10 |
| w/o-Att | 0.3431 | 0.1863 | 0.2581 | 0.1264 |
| w/o-DCL | 0.3108 | 0.1773 | 0.3630 | 0.1973 |
| TP_MB | 0.6053 | 0.4393 | 0.5277 | 0.3970 |
| TP_MB_t | 0.6241 | 0.4471 | 0.5394 | 0.4037 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qu, M.; Wang, N.; Li, J. A Two-Path Multibehavior Model of User Interaction. Electronics 2023, 12, 3048. https://doi.org/10.3390/electronics12143048
Qu M, Wang N, Li J. A Two-Path Multibehavior Model of User Interaction. Electronics. 2023; 12(14):3048. https://doi.org/10.3390/electronics12143048
Chicago/Turabian StyleQu, Mingyue, Nan Wang, and Jinbao Li. 2023. "A Two-Path Multibehavior Model of User Interaction" Electronics 12, no. 14: 3048. https://doi.org/10.3390/electronics12143048
APA StyleQu, M., Wang, N., & Li, J. (2023). A Two-Path Multibehavior Model of User Interaction. Electronics, 12(14), 3048. https://doi.org/10.3390/electronics12143048