1. Introduction
The development of instruction set architecture (ISA) has never stopped, typically with x86 monopolizing the desktop and server markets, and ARM dominating the mobile computing market, respectively. The design of these ISAs usually differ, and respective applications are often incompatible with each other, thereby presenting a large obstacle to the development of ISA. To solve this problem, there have been many research papers related to virtualization [
1,
2,
3] and the binary translation of the ISAs.
In recent years, RISC-V has developed rapidly with widespread attention from ecosystem developers for its open ecosystem and scalable, customizable ISA features. In the years after its creation in 2010, RISC-V has been mainly used in specialized chips, such as power management and the RF protocol. With the gradual improvement in the basic RV32I and RV32E standard instruction sets, more and more SoC chips of the IoT and MCU are reportedly using RISC-V. In 2022, the shipment of RISC-V processors exceeded 10 billion, and the main work of the RISC-V International Foundation is moving from technology improvement to other key related areas, such as cloud computing, edge computing, and automotive. The RISC-V software ecosystem has also evolved rapidly from the bare metal programs for specialized chips to RTOS for MCUs. Especially in recent years, strong UI interactions and high-performance computing OS on AP chips, such as Android, Ubuntu, Fedora, Anolis, and Kirin already support RISC-V [
4,
5]. However, in the Android and Linux systems, their applications are still dominated by x86 and ARM, which greatly restricts the further development of the RISC-V ecosystem.
To further accelerate the integration of RISC-V and high-performance application ecosystems, a binary translator based on RISC-V is deemed as a viable path for rapid adaptation to the existing ecosystems. Binary translation techniques have been widely implemented in computer architecture research and commercial applications. Early implementations include FX!32 [
6], combined with dynamic translation and static translation, IA-32 EL [
7], realized by Intel for IA32 applications running on an IA64 system, and UQBT [
8], developed by the University of Queensland supporting multi-source and multi-target ISAs. The company Transmeta directly implemented the x86-like condition bit registers on its own VLIW processor Crusoe so that the binary translator CodeMorphing [
9] can directly map the condition bits instructions from x86 to Crusoe, and can reduce the computational complexity caused by the setting and referencing of the condition bits. Currently, there are many open-source binary translation implementations, the most typical of which are QEMU [
10], Box64 [
11], FEX-EMU [
12], and Instrew [
13], etc. In recent years, there are several binary translators, such as Apple’s Rosetta and Intel’s Houdini, used commercially due to their excellent translation efficiency.
Binary translation between these ISAs can be categorized into universal compilation technology. It includes the front-end, middle-end, and back-end, and implements a variety of optimization algorithms at each end. Its architecture covers an interpretive execution mode, a static translation mode, and a dynamic just-in-time translation mode, etc. In particular implementation, several modes are often combined to improve the execution performance of the translated target code. Due to the loss of information like indirect jumps information, variable life cycle, and register allocation [
14,
15,
16,
17,
18] in the source binary code, the optimization effect of pure software binary translation is quite limited. The mainstream optimization methodology includes register allocation and condition bit operation in translation, as well as the runtime native library call techniques. Among them, there has been much research performing regarding the conditional bit operation optimization technology of pure software, but few have been conducted on efficiency improvement. In particular, the target ISA, such as Alpha, MIPS, and RISC-V lacks condition bit registers, as well as the resources for the setting and referencing of the condition bits. Thus, additional computation instruction and memory access overhead are both required to achieve the mapping relationship between the source and target instructions when translating the condition bits instructions of source ISAs with multiple condition bits, such as x86 and ARM.
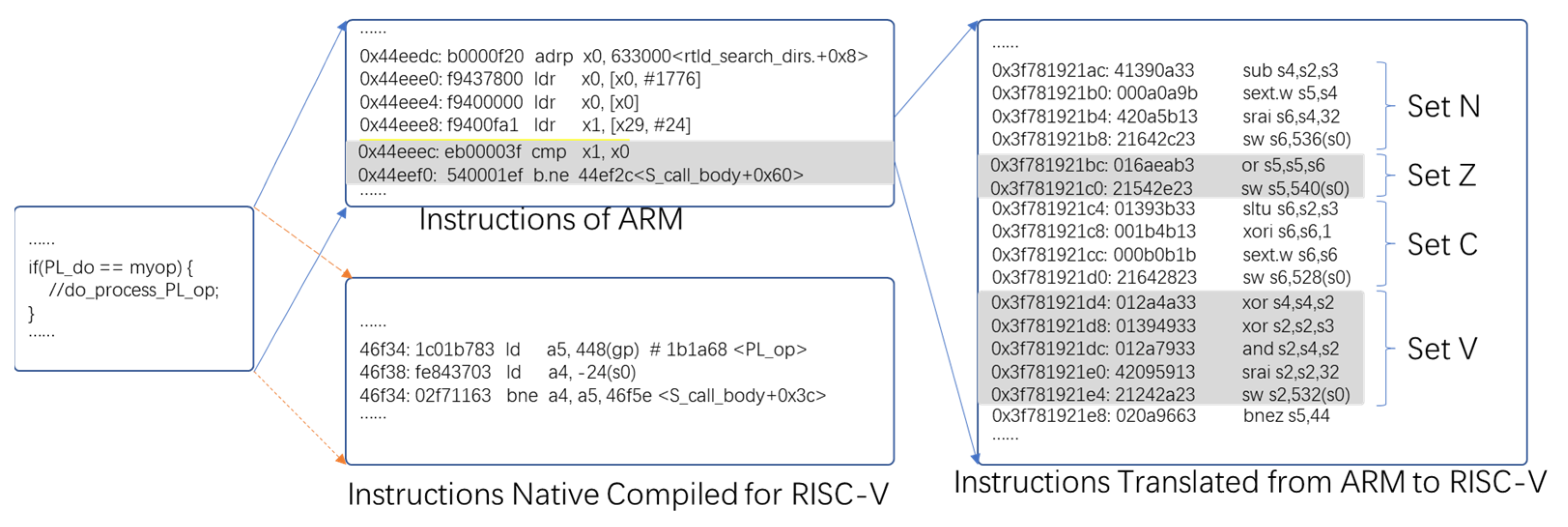
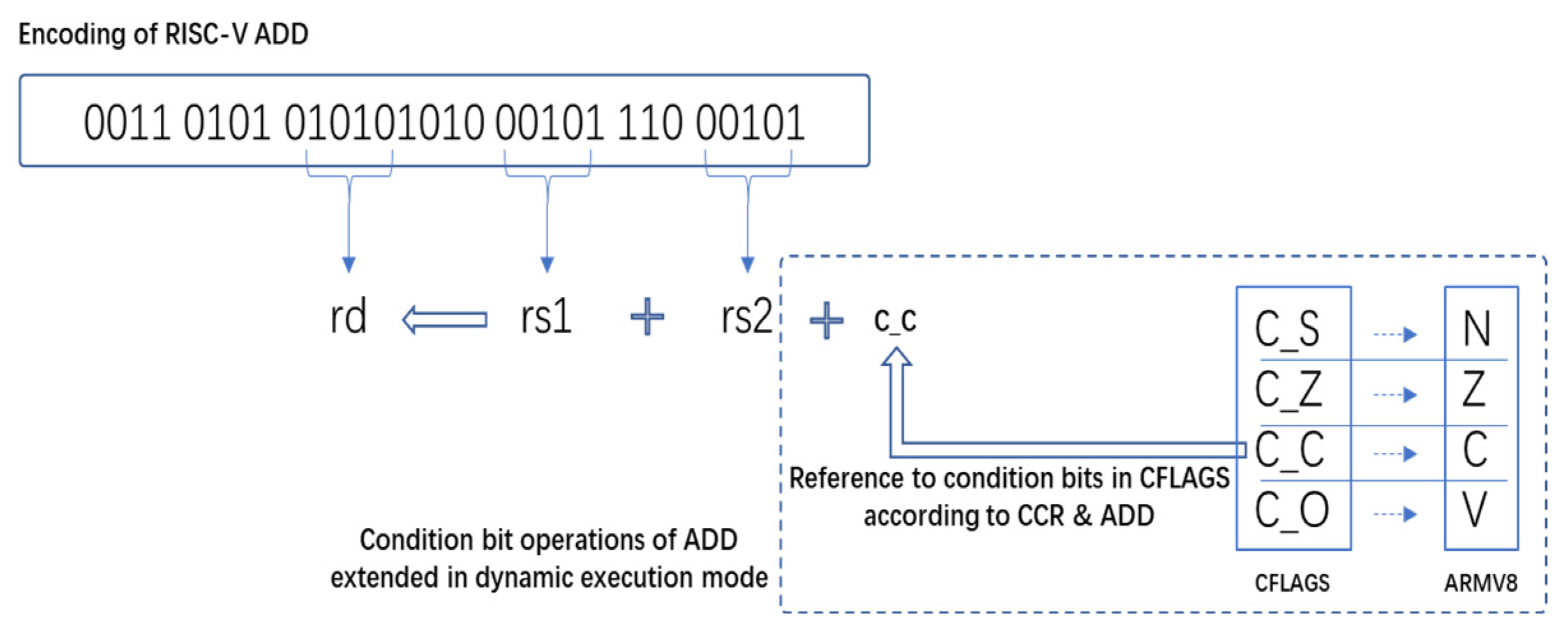
This paper takes the translation of ARM to RISC-V as an example. The ARM ISA contains N/Z/C/V condition bits, which will be set or referenced by various arithmetic instructions and comparison instructions, and even referenced by conditional codes in instruction encoding. Since RISC-V ISA design usually takes simplicity [
4,
5] into account, there is no design of the condition bit register, no setting, and no referencing of the condition bits, and usually comparisons and branch functions are completed directly in one instruction. As shown in
Figure 1, this difference makes the translation from an ARM’s setting and referencing instructions of the condition bits to RISC-V instructions requiring a lot of computation instructions and memory access operations.
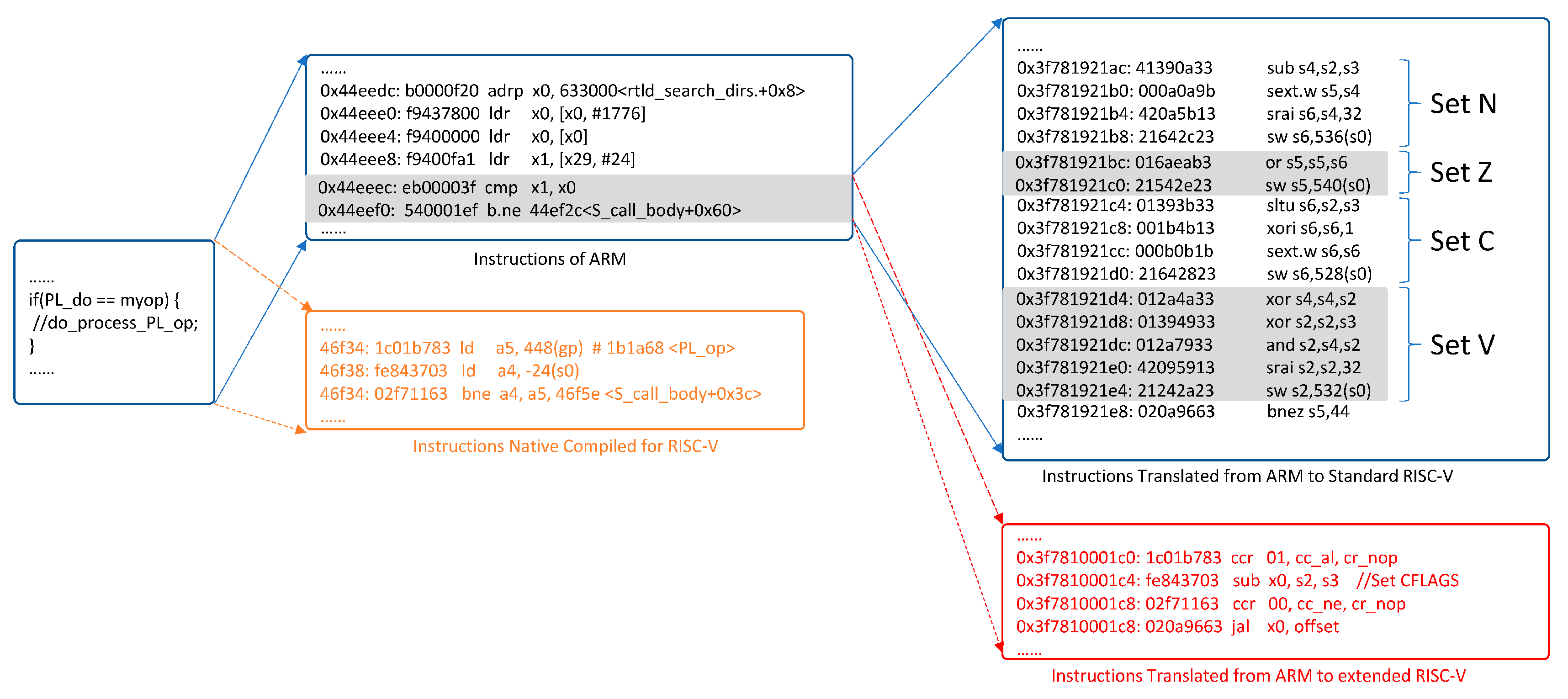
As shown in
Figure 1, the translated code fragment was obtained from the QEMU emulator. For the two-ARM condition bit instructions shown, it required 16 RISC-V instructions to simulate. This highlights the significant cost of translating condition bit instructions. Additionally, we can see that for the same source code, using a native RISC-V compiler requires only one RISC-V instruction, which is much more efficient than using binary translation. This indicates that binary translation techniques, like QEMU, are not competitive with native compilers, and we need to use a more efficient method for condition bit instruction translation.
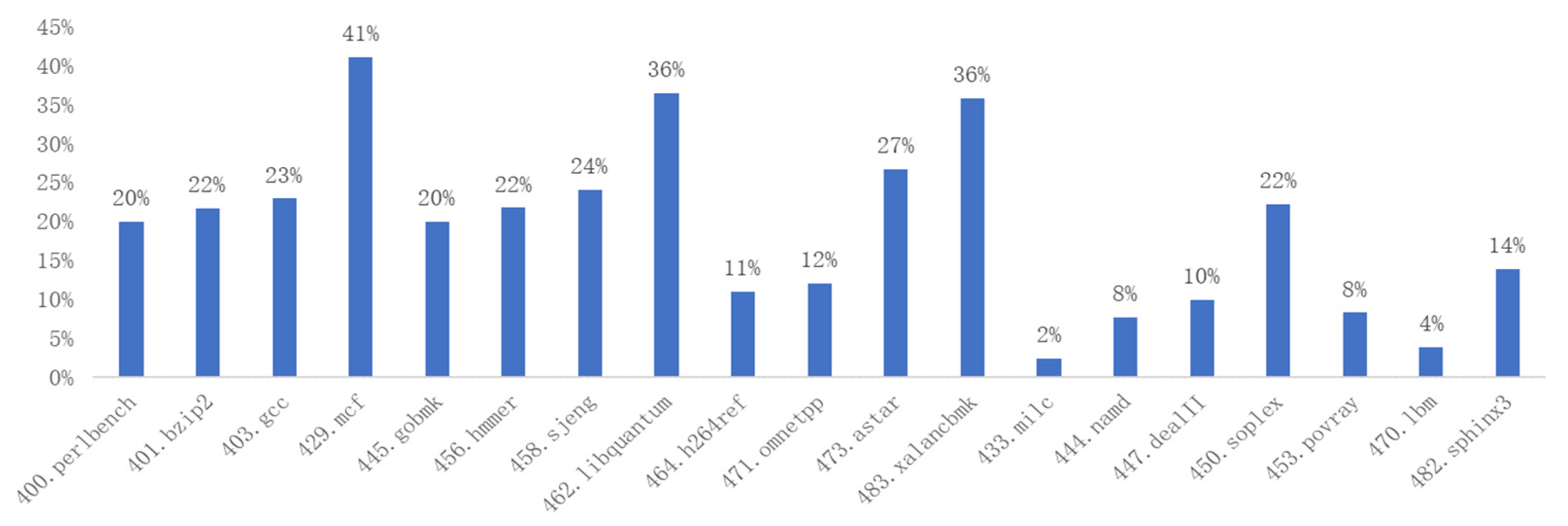
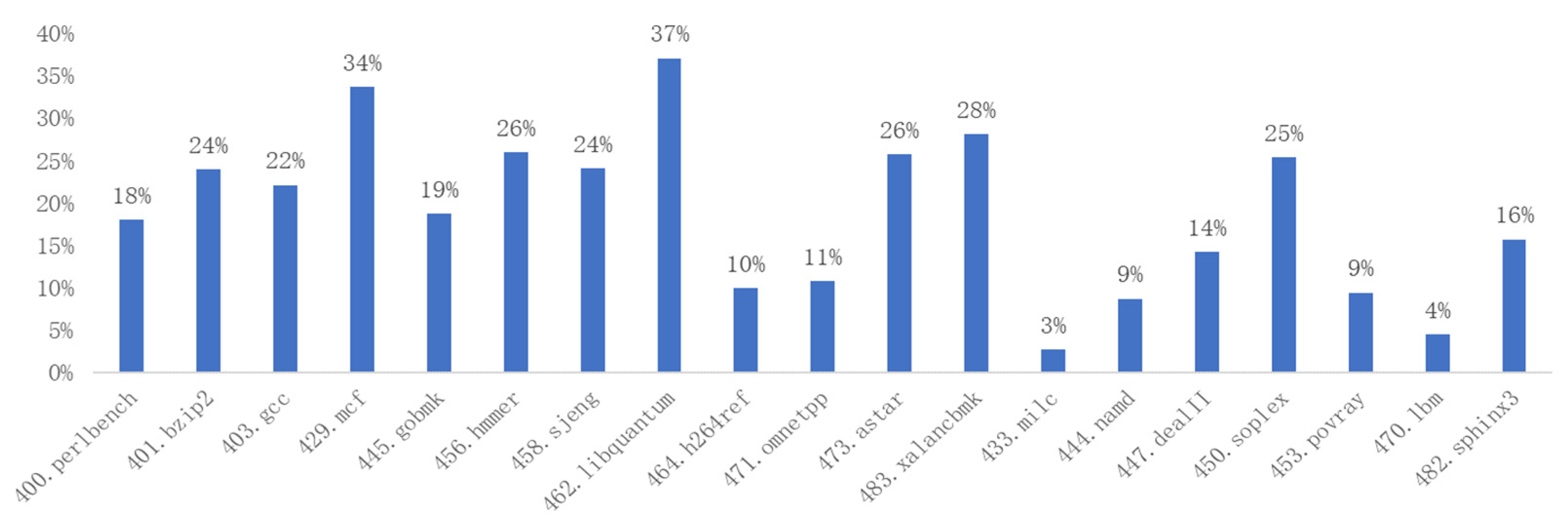
In order to analyze the impact of translation optimization for condition bit instructions on binary translation efficiency, we have recorded the number and proportions of condition bit instructions during the dynamic execution of the SPEC 2006 benchmark on ARM A64, as shown in
Table 1.
According to
Table 1, the proportion of condition bit instructions in ARM SPEC 2006 programs peaks at 34.8%, with an average proportion of 13%. As shown in
Figure 1, due to the differences between the ARM and the RISC-V ISAs, a series of RISC-V arithmetic and memory access instructions are therefore required to translate a single ARM condition bit instruction, which severely affects their translation performance. All of these indicate the significant importance of optimizing the translation of the condition bit instructions for the ARM to RISC-V binary translation.
The difference of condition bits resources between the source and the target ISAs leads to a large number of computational instructions and memory access operations in the translation of the setting and the referencing of the condition bits. To solve the problem, this paper proposed a hardware non-invasive mapping method for condition bits (HNIMCB) in binary translation. By adding a new execution mode to the target ISA, this method expands the condition bit register which is mapped one-to-one with the condition bit of the source ISA and realizes the setting and referencing of the condition bits on the original target ISA without destroying the standard instruction set and programming model. Thus, this method achieves the efficient translation of the condition bit instructions from the source ISA to the target ISA, effectively reduces the translation complexity, and at the same time, reduces the count of computation instructions and memory access operations after mapping.
In
Section 1, we analyze the problem of the translation efficiency of the setting and referencing of these condition bits and put forward the corresponding solutions. In
Section 2, we analyze the current mainstream binary translator, especially in the translation and optimization of the setting and referencing of the condition bits.
Section 3 introduces the general framework and the implementation details of applying the HNIMCB in binary translation. The experimental data on a functional simulation level were presented and analyzed in
Section 4.
Section 5 evaluates the impact of the microarchitecture and the cost of extending the technique to X86 translation. In
Section 6, the overall effects and significance of the proposed method are summarized.
2. Related Work
QEMU [
10] is a typical, open-source binary translator that supports dynamic JIT translation technology. It supports the user mode and the system mode, and improves performance through basic block translation, translation cache, and TB call chains. QEMU achieves simple optimization in terms of the setting and referencing of condition bits and does some combination optimization of the setting and storage of the condition bits within a basic block. However, it still cannot avoid the situation in that the source ISA has abundant condition bits, while the target ISA does not contain the condition bit resources, leading to a low translation efficiency. For example, when the ARM binary code is translated into RISC-V, a large number of computation instructions and memory access operations are generated as a result due to the setting and referencing of the condition bits.
Box86 [
11] enables the running of x86 Linux applications on non-x86 Linux systems, including ARM. Its performance is enhanced by two key features. Firstly, the native library twist allows the program to utilize native versions of the “system” libraries, like libc, libm, SDL, and OpenGL, on the target platform. Secondly, the JIT engine (Dynatec) provides a speed boost of five-to-ten times faster than only using an interpreter. In terms of the setting and referencing of the condition bits, Dynatec checks these operations for each instruction in one basic block, and then each instruction knows if and which condition bits must be set after its execution. This condition bit propagation technique of Dynatec effectively avoids unnecessary calculations of the condition bits.
FEX-EMU [
12] is a specialized emulator designed for AArch64 that enables the execution of the x86 and x86-64 games. It has several features which contribute to achieving performance levels that are only 25% to 50% slower than the native code, including the native libraries call technology, offline compilation, and tooling for performance analysis, etc. The emulator also implements several IR optimizations passes, one of which is the dead condition bit elimination. This pass eliminates the redundant calculations of the condition bits that are overwritten without being used. It breaks out the condition bits to independent memory locations to reuse the store elimination optimization in three steps: computing which condition bits are read and written per block, determining which condition bits are stored but will be overwritten by the next block(s), and finally removing the dead stores.
Instrew [
13] is an LLVM-based dynamic binary translator that utilizes LLVM’s mature and efficient optimizations [
19]. It converts the source binary code to LLVM IR through a process called lifting, which results in IR functions rather than basic blocks or superblocks. This makes non-local optimizations possible and reduces the number of jumps between the code blocks. During the lifting stage, it divides the condition bit register into seven stored flags (sign, zero, carry, overflow, parity, adjust, and direction) as these flags are typically written and evaluated independently of each other, and are rarely used in the format outlined by the x86 architecture. In addition, the flag evaluation is optimized so that subsequent condition queries, like those in jumps, can easily be folded into a single LLVM ‘icmp’ instruction during optimization. In the translation stage, within an LLVM function, the dead code elimination pass will be used to remove the compilation of the condition bits that are not used by the succeeding code. Another optimization in the translation stage for the condition bits is that all the condition bits are discarded when a call or ret instruction is encountered, since no compiler or calling conversion necessitates condition bit preservation over the function boundaries.
Rosetta is an early version of Apple’s commercial binary translator that allows applications to migrate from the PPC to the x86 architecture. In 2020, Apple released the ARM-based M1 chip, and at the same time, delivered Rosetta2 to run x86 applications on the ARM ISA. According to the data provided by Apple on Geekbench’s official website [
20], the single core scores of the M1 chips running x86 binary programs with Rosetta2 are 1313, compared with the single core scores of 1687 directly running on the M1 chip, respectively. Rosetta2, running x86 code, achieves a 78% straight-up performance. It is worth learning that the excellent performance of Rosetta2 is not only due to native library mapping optimization, RAS indirect jump elimination, and other methods, but also due to the combination of the software and hardware translation architecture and the AOT + JIT architecture. Apple designs the hardware acceleration of instructions for binary translation in the M1 chip to achieve a direct one-to-one mapping of the instructions. In addition, although ARM is a RISC ISA, it has similar condition bits and operations to x86. Therefore, Rosetta2 does not need to do much work on the translation of the condition bit operations and can directly carry out register mapping on x86 condition bits, reducing the complexity of calculation and memory access caused by the setting and referencing of the condition bits.
Ma Xiangning et al. [
21] proposed a method with combining real-time computation and delayed computation, and with combining data flow analysis and delayed computation to optimize the computation and memory access cost of the target code from the dynamic translation of the setting and referencing of the condition bits. This method effectively reduces the target code caused by redundant condition bit changes. However, the translation cost caused by data flow analysis during the dynamic translation should not be ignored. Meanwhile, complex computation instructions and memory access operations are still needed for necessary condition bit setting and referencing on the target ISA in this method. Tang Feng et al. [
22] proposed a linear analysis method of the condition bits for successor basic blocks to obtain the relationship between the basic blocks for the setting and the referencing of the condition bits. This method further reduced the redundant calculation of the condition bits. However, the analysis of successor base blocks incurs additional translation overhead, and this method does not effectively reduce the overhead caused by the computation and memory access for the setting and referencing of the condition bits in the dynamic run time. Wang Wenwen et al. [
23] proposed a method of condition bit pattern search and translation. This method optimized the setting and referencing instruction sequences of the necessary condition bits on the target ISA to a certain extent, but further increased the overhead in the dynamic translation and failed to deal with the complex condition bit patterns and their distributions. Wang Ronghua et al. [
24] proposed an efficient mapping method termed the compare and condition branch fast mapping algorithm. This algorithm focuses on the “compare and condition branch” instruction pairs which occupy a large proportion of the program, and it realizes the efficient mapping of the “compare and condition branch” instruction pairs using the inherent conditional dependencies of the target ISA. This algorithm improves the efficiency of the dynamic translation and execution by avoiding the complex and uniform traditional processes for these special instruction pairs. However, in the data flow analysis of the dynamic translation, this method needs to store multiple information of each condition bit setting instruction, which brings extra memory access overhead.
The current binary translation for condition bit operations mostly adopts the method of delayed computation to reduce the condition bit computation, the pattern matching to reduce the number of instructions for the setting and referencing of the condition bit, and data flow analysis to implement optimization methods, such as deleting the redundant calculations of the condition bit. However, these methods bring new problems while optimizing the translation efficiency. The delayed computation method needs to save the instruction code, operands, and other information, which increases the memory access consumption during dynamic execution. Pattern matching and data flow analysis algorithms increase the complexity of translation. Moreover, in the necessary condition bit operation of the source instructions, a large number of computation instructions and memory access are still needed to achieve the setting and referencing of the condition bits. In general, the current binary translation has mainly been based on the existing hardware implementation, and mostly uses pure software translation frameworks and optimization techniques. This makes it difficult to achieve the commercial indicators for the translation efficiency when there are significant differences between the source and the target ISAs. In recent years, in order to solve the limitations of pure software translation optimization, there have gradually been some research performed on improving the efficiency of binary translation through software-hardware collaboration technology, such as Apple’s Rosetta, which makes it possible to commercialize translation between the x86 and ARM. For a RISC-V open ISA, this kind of software-hardware collaboration optimization technology is precisely in the innovative direction of binary translation.
3. Design
3.1. Implementation Framework
In this paper, we proposed a hardware non-invasive mapping method for condition bits in binary translation. The purpose of using this method was to provide hardware resources to achieve an efficient mapping between the source and the target ISA for binary translation without modifying the target ISA and the programming model. In view of the problems summarized in
Section 2, we need to effectively reduce the complexity of translation and reduce the condition bit calculation instructions and memory access operations through the one-to-one mapping of the condition bit registers, setting, and referencing between the source and the target architecture. In order to achieve the above purpose, this paper added a dynamic execution mode to the target ISA, and cleverly realizes the switching mechanism between the translation mode and the dynamic execution mode on the existing ISA.
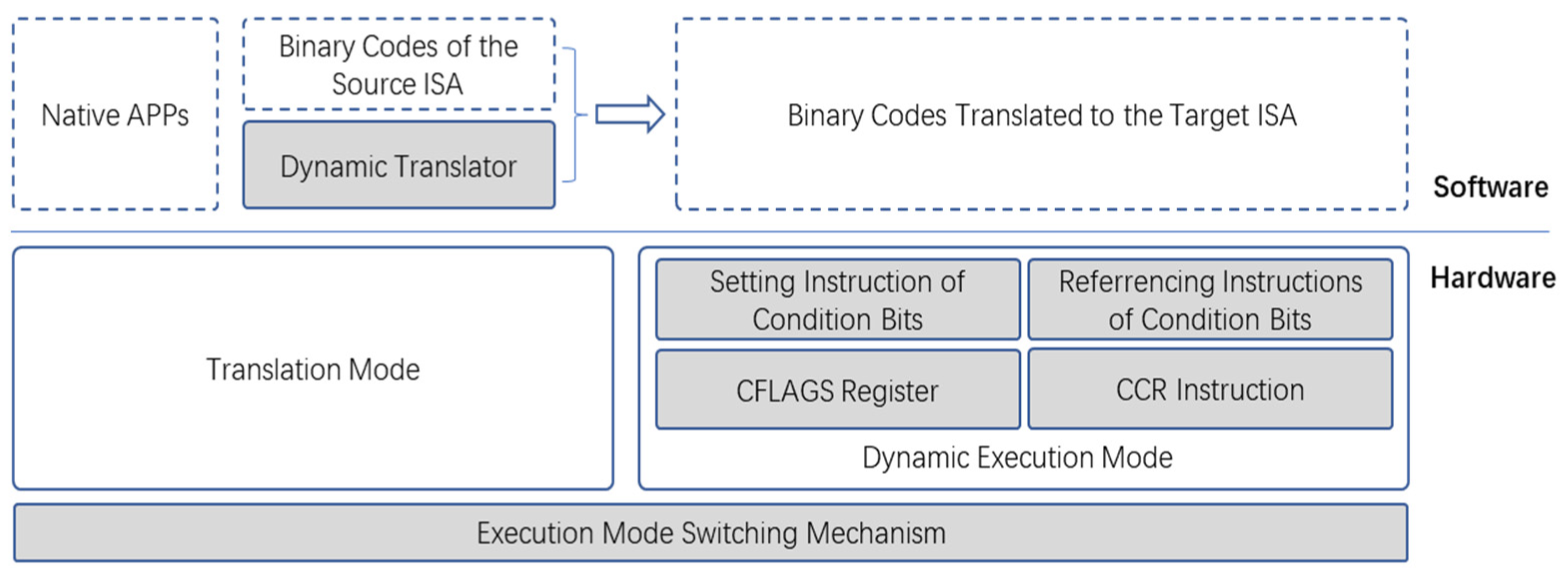
Figure 2 illustrates the design framework of the hardware non-invasive mapping method for condition bits in binary translation.
The mode switching mechanism is responsible for switching between the translation mode and the dynamic execution mode. In the translation mode, the running resources of the target processor are fully compatible with the original target ISA, and the ordinary native applications and the dynamic translator are run in this mode. In the dynamic execution mode, the target processor is extended with the condition bit register CFLAGS, and innovatively introduces the identifier instruction for the condition bit (CCR instruction). Thus, the successor arithmetic instructions following the CCR instruction can carry out the function expansion based on the semantics of the original instruction, which is the corresponding condition bit in the CFLAGS register that will be set or referenced.
Taking the translation from ARM to RISC-V as an example, the dynamic execution mode on RISC-V provides the hardware running environment for the translated target binary program. First of all, the condition bit register CFLAGS maps the condition bits of ARM one by one, so that the target binary program does not need extra storage to simulate the condition bits when running, thereby reducing the memory access operation. Secondly, the CCR instruction is used to indicate whether the successor instruction following it sets or references the condition bit register CFLAGS. Thirdly, aiming at the arithmetic instruction for ARM through setting or referencing the condition bits, we extended the corresponding RISC-V arithmetic instruction function with the setting or referencing of the condition bit so that the translated setting and referencing instructions for the condition bit do not need additional calculation operations, thereby improving the efficiency of the dynamic execution. Finally, the IR was designed according to the source ISA in the dynamic translator to match and keep the information of the source program instruction sequence for the condition bit operation as far as possible. Thus, the translation does not need complex data flow graph analysis and pattern matching algorithms within and between the basic blocks, and direct instruction mapping is adopted, which greatly reduces the translation complexity. For conditional codes implicitly referencing the condition bits in the ARMV8 A32 instruction code, we can also identify them by CCR instructions during translation, thus archiving rapid translation to the RISC-V instruction, and greatly simplifying the translation complexity and translated instruction sequence.
As shown in
Figure 2, the hardware non-invasive mapping method for condition bits for binary translation proposed in this paper includes an execution mode switching mechanism, a condition bit register CFLAGS, the identifier instruction for the condition bit, extension instructions for the setting of the condition bit, and an extension of the instructions for the referencing of the condition bit and the dynamic translator.
3.2. Execution Mode Switching Mechanism
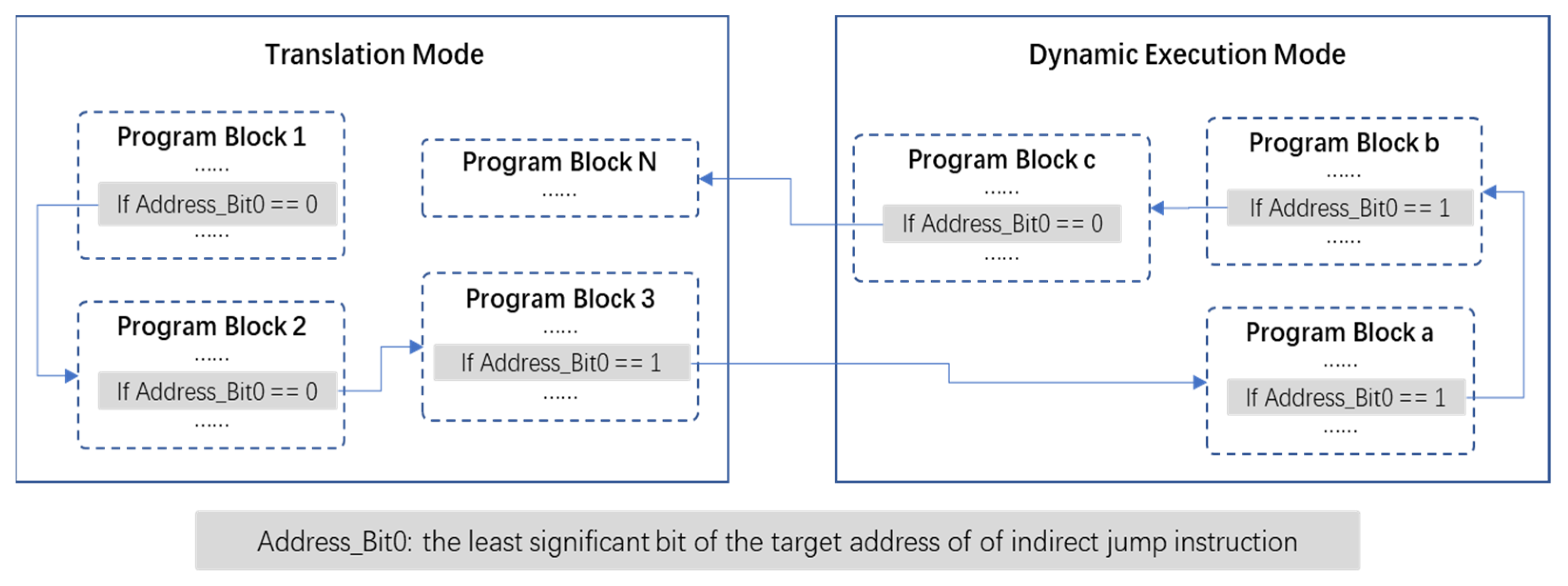
The execution mode switching mechanism is responsible for switching back and forth between the translation mode and the dynamic execution mode. As shown in
Figure 3, in order to be compatible with the original programming model and not modify the original instruction code, we used the target address least significant bit of the indirect jump instruction in the target ISA to identify mode switching. When the least significant bit of the target address of the indirect jump instruction is ‘1’, the target processor enters or stays in the dynamic execution mode, and can access the condition bit register, extension instructions, etc. Meanwhile, when the least significant bit of the target address of the indirect jump instruction is ‘0’, the target processor enters or remains in the translation mode.
After the dynamic translator completes a section of code translation, the system needs to jump from the translator to the translated target binary program block. At this time, the target address least significant bit of the indirect jump instruction is set to ‘1’, so as to achieve the switch from the translation mode to the dynamic execution mode. When the target processor is found at the untranslated code during executing the target binary program block, it needs to be switched to the translator for the translation task. At this time, the target address least significant bit of the indirect jump instruction is cleared to ‘0’, so as to achieve the switch from the dynamic execution mode to the translation mode. When the target processor is started, it runs in the translation mode at first.
3.3. Condition Bit Register (CFLAGS Register)
This paper took ARMV8 and RISC-V as an example to design condition bit mapping between the source and the target ISA. In the ARM ISA, there are NZCV condition bits in the PSTATE register, and arithmetic, comparison, or MSR instructions can potentially set or reference these condition bits. However, there are no condition bits in RISC-V, and the setting and referencing of the condition bits are directly implemented within a single branch instruction. This difference makes the translation from the ARM’s setting and referencing instructions of the condition bits to RISC-V instructions requiring a lot of computation instructions and memory access operations.
As shown in
Table 2, this paper designs and implements the condition bit register (CFLAGS) in the dynamic execution mode for RISC-V. The condition bits in the register directly map to the condition bits of ARM. C_S is the negative status flag bit corresponding to the ARM N bit, C_Z is the 0-status flag bit corresponding to the ARM Z bit, C_C is the carry status flag bit corresponding to the ARM C bit, and C_O is the overflow flag bit corresponding to the ARM V bit.
3.4. Identifier Instruction for the Condition Bits (CCR Instruction)
As there are no condition bits in RISC-V, the setting and referencing of the condition bits are directly implemented within a single branch instruction [
4,
5], and arithmetic instructions do not set or reference the condition bits. As shown in
Table 3, in order to be compatible with the original programming model of RISC-V, this paper proposes the extension of the identifier instruction for condition bit (CCR Instruction), which can be combined with the succeeding instruction to set or reference the condition bits based on the identification specified by the CCR instruction.
When the extended RISC-V executes the CCR instruction in the dynamic execution mode, the hardware firstly decodes the CO [0:2], COND [3:6], and CC [7:10] operand information encoded in the CCR instruction. During the succeeding instruction execution, the target processor hardware determines the appropriate setting and referencing of the condition bit based on the CCR operand information and the value of the condition bit in the CFLAGS register.
3.5. Translation of the Setting of the Condition Bits
In the ARM ISA, arithmetic instructions, comparison, or MSR instructions can potentially set or reference the condition bits. While in the RISC-V ISA, there are no condition bits, and the setting and referencing of the condition bits are directly implemented within a single instruction [
4,
5]. This can lead to a low efficiency of translation from the source ISA to the target ISA or require more redundant computation. A more detailed instructions list and the condition bits setting method have been depicted in
Table 4.
As shown in
Table 4, in the dynamic execution mode, this paper extended the functionality of the RISC-V arithmetic instructions. A pair of RISC-V arithmetic instruction and CCR instructions complete the translation of the ARM instruction which sets the condition bits.
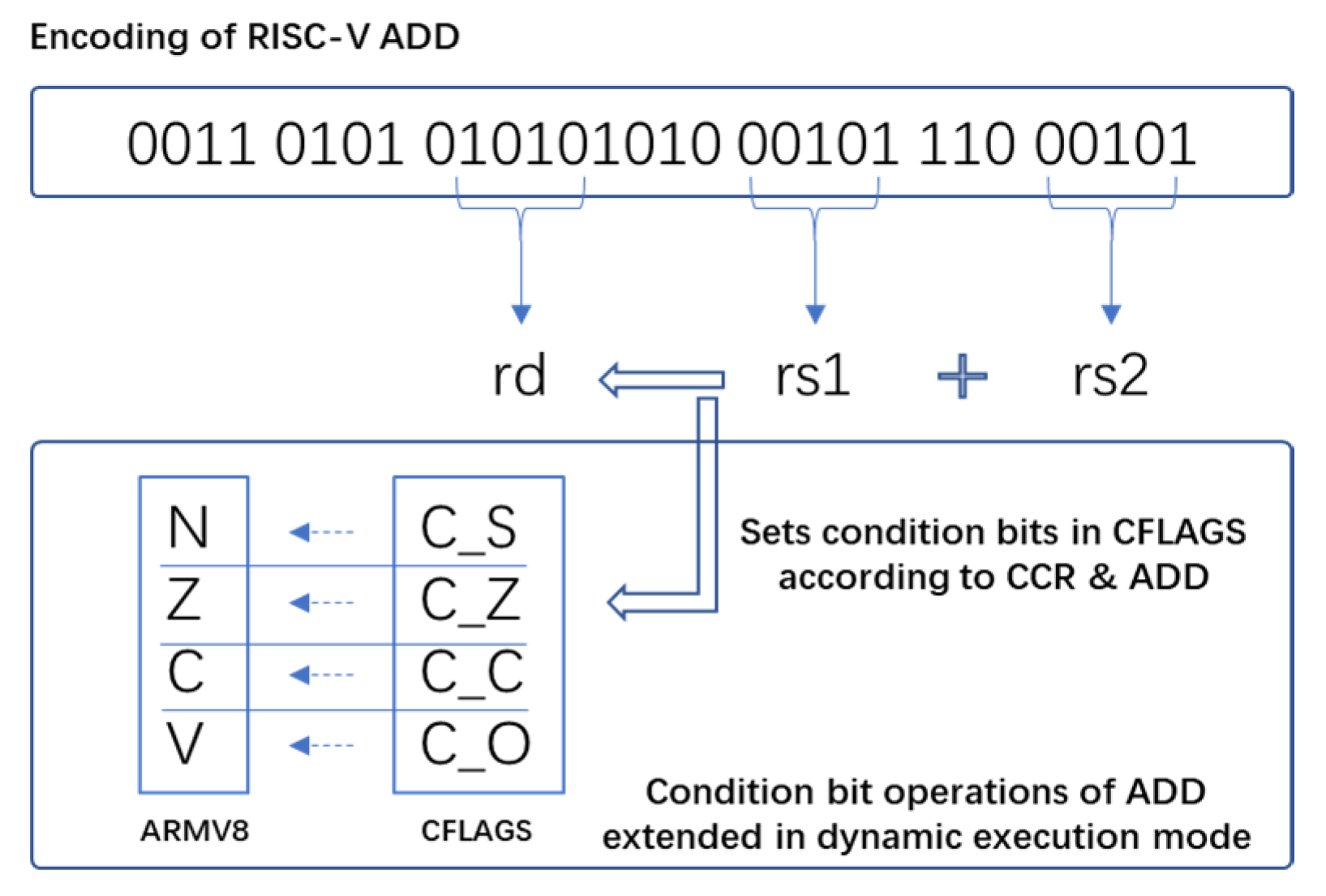
As shown in
Figure 4, taking ARM ADDS instruction as an example, in order to make the function of the RISC-V ADD instruction consistent with the ARM ADDS instruction, the setting of the condition bits in the CFLAGS register is added through the CCR instruction.
3.6. Translation of the Referencing of the Condition Bits
In the ARM ISA, some arithmetic instructions, branch instructions, or MRS may refer to the condition bits, such as carry-addition, borrow-subtraction, and other arithmetic instructions, as well as conditional jump instructions. However, the RISC-V does not have condition bits, and the setting and referencing of the condition bits are directly implemented in one instruction [
4,
5]. This can cause the generation of a low efficiency of translation from the ARM to the RISC-V or lead to the requiring of more redundant calculations. A more detailed instructions list and the condition bits referencing method have been depicted in
Table 5.
As shown in
Table 5, in the dynamic execution mode, this paper extended the corresponding arithmetic instructions in RISC-V for the referencing instructions of the condition bit in the ARM ISA. By combining the identifier instruction of the condition bit, a one-to-one mapping relationship is thereby achieved from the ARM to the RISC-V.
As shown in
Figure 5, taking the ARM ADC instruction as an example, the RISC-V ADD instruction corresponds to its functionality. In order to make the RISC-V ADD instruction function consistent with that of the ARM ADC instruction, on the basis of the original rd = rs1 + rs2 function of ADD, the referencing of the condition bits in the CFLAGS register is added through the CCR instruction, so that the function is directly mapped with the ARM ADC instruction.
Figure 6 shows an example of the translation from the ARM to RISC-V with an extension for the CCR instruction and arithmetic instruction extended for the condition bit setting or referencing. The subsequent target instruction sequence of the translation mapping is much simpler after the extension compared to before.
3.7. Dynamic Translator
Binary translation technology includes static translation and dynamic translation. Due to the limitations of information in source binary programs, static translation technology cannot solve all the problems, such as indirect jumps, code and data mixing, self-generated codes, and so on. The translator implemented in this paper adopted the dynamic translation mode.
This translator has its own intermediate representation (IR) and consists of a front end and a back end. The front end converts the binary code of the source ISA to IR, and the back end implements the mapping of the IR to the target ISA. The design of the IR is crucial in compilation technology, as it determines how much information is provided for the back-end translation and optimization. As shown in
Figure 7, taking the ARM ADDS instruction as an example, if the design of the IR refers to the target ISA rather than the source ISA, it is possible that ADDS can be transformed into multiple independent IR representations during front-end conversion. In this case, the back end of the translator needs to implement a complex pattern-matching algorithm to reintegrate these multiple IR representations into a single back-end instruction description, greatly increasing the complexity of translation.
To reduce the complexity of data flow analysis and pattern-matching algorithms, the dynamic translator employed in this paper defined many new IRs that are close to the source ISA. If the source instruction includes a condition code, such as the CCMP instruction, the condition code will also be encoded as an immediate parameter to the IR. This allows the front end of the translator to preserve the information of the original instructions as much as possible when translating them into IR. When converting the IR into the target ISA in the back end of a translator, the original information of the source instruction can be obtained as much as possible, thereby allowing for a one-to-one mapping with extended resources or instructions in dynamic execution mode. This simplifies the analysis of data flow and control flow, reduces the fusion of multiple IRs, and thus reduces the translation complexity.
In the conversion of the IRs to the back-end RISC-V instructions, usually a CCR instruction will be emitted first according to the IR semantics. As shown in
Figure 7, the ‘adds_i64’ IR mapping to the ARM ADDS instruction will emit a ‘ccr 0, cc_al, co_set’ instruction, which combines with the RISC-V ADD instruction to achieve the function of setting the CFLAGS register like the ADDS in the ARM ISA.
3.8. Optimization of Translation Efficiency
The efficiency of binary translation is measured by the additional time consumption
Ttotal during the process of translation and execution of the program, including the time consumption of the translation process itself
Ttranslate, as well as the difference between the execution time of the translated program
Trun and the execution time of the same program natively
Trun_in_native, as shown in Formula (1):
Binary translators pay more attention to (
Trun −
Trun_in_native), ignoring
Ttranslate, resulting in increasingly complex translation algorithms. For example, pattern matching is used to reduce the number of setting and referencing instructions for the condition bits, and data flow analysis is used to achieve optimization methods, such as deleting redundant condition bit calculations. The complexity of these algorithms is directly related to the number of basic blocks. Assuming that each basic block has 2 branches and there are n layers of successor basic blocks, the calculation complexity is O(2
n) [
22]. By extending the hardware functions for the condition bit of the arithmetic instructions in the target ISA and the corresponding IR descriptions in the translator, this paper thereby achieved the efficient mapping from the source instructions to the target instructions, which eliminates the data flow analysis process, simplifies instruction pattern matching, and greatly reduces the complexity of dynamic translation. Additionally, there is no need for additional information storage when executing the translated code.
Currently, binary translators mostly use delayed calculation to reduce the calculation of the condition bits in translation optimization. However, delayed calculations increases the memory access consumption during dynamic execution, as it needs to save instruction codes, operands, and other information [
21]. This paper expands the condition bit register “CFLAGS”, and the function of the setting and referencing instruction for the condition bits in the target ISA so that it achieves a one-to-one mapping of the condition bit instructions between the source and the target ISA. As a result, there is no need for delayed calculations to obtain the value and save of the condition bits, eliminating the memory access operation caused by the delayed calculation of the condition bits. As shown in
Figure 6, the one-to-one mapping of the condition bit instructions between the source and target ISA greatly eliminates additional calculations for the condition bits and the memory access operation for simulating the condition bits.
In summary, the hardware non-invasive mapping method for the condition bits in this paper eliminates the process of pattern matching and data flow analysis, eliminates the storage of the instructions/operands for delayed calculations, and further eliminates the additional operations, such as the calculations of the condition bit and memory simulation for the condition bit, so as to significantly improve the efficiency of binary translation.
6. Conclusions
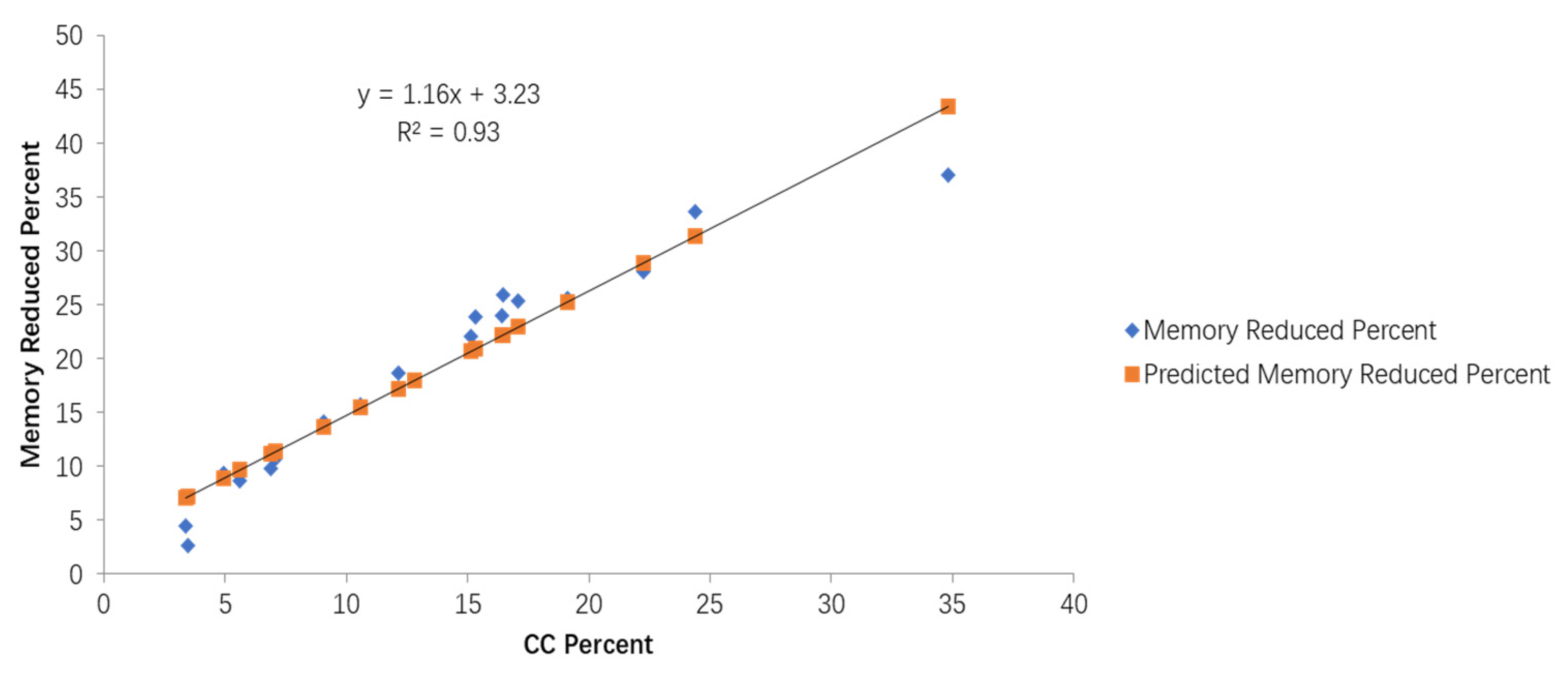
This paper presents a statistical analysis of the percentage of condition bit instructions in the SPEC 2006 Benchmark and analyzes the condition bit instruction translation techniques of the existing mainstream binary translation tools. Based on previous research, this paper proposes a hardware non-invasive mapping method for the translation of condition bit instructions in the RISC-V open-source architecture. This method extends the RISC-V dynamic execution mode to implement hardware functions and resources, such as the condition bit register, and the setting or referencing of the condition bits, enabling the efficient translation of the condition bit instructions from the source instruction set to RISC-V, while ensuring RISC-V compatibility with the existing software ecosystem. The experimental data show that the proposed method reduces the total number of instructions by up to 41%, and the number of memory access instructions by up to 37%, respectively, effectively reducing the translation complexity and improving the translation performance.
RISC-V has achieved a significant technological and commercial development due to its open-source and open ecosystem. However, its software and application ecosystem in high-performance areas like in mobile devices, desktops, and data centers falls short. The proposed hardware non-invasive mapping method for condition bits can effectively optimize the binary translation performance from ARM or x86 to RISC-V, and further promotes the commercialization process of RISC-V across high-performance fields.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}