
Attention Mechanisms in Convolutional Neural Networks for Nitrogen Treatment Detection in Tomato Leaves Using Hyperspectral Images
 , , , ,
, , , ,  and
and 
Abstract
:1. Introduction
2. Materials and Methods
2.1. Data Collection
2.2. Hyperspectral Imaging and Spectral Information Extraction
2.3. CNN for Nitrogen Content Estimation
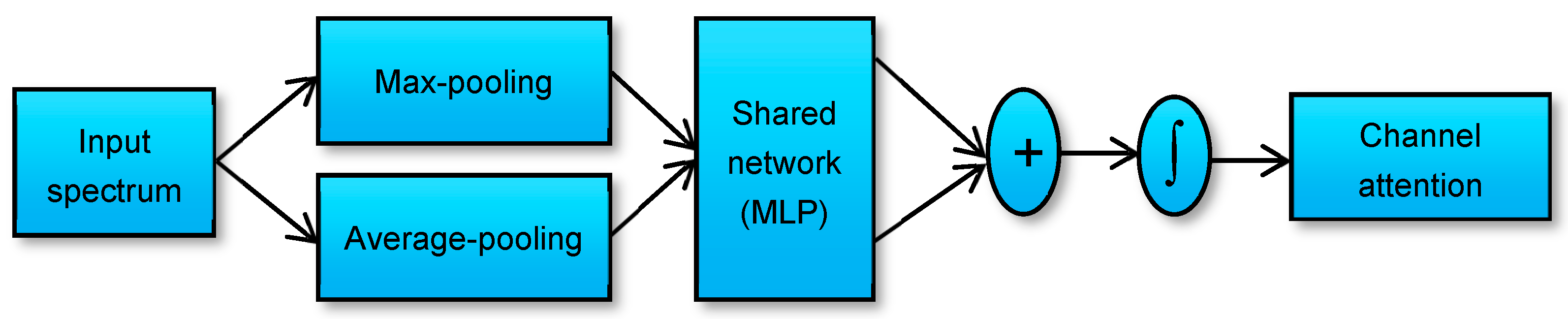
2.4. Attention-Based CNN for Nitrogen Estimation
3. Results
3.1. Determining the Optimal Learning Rate and Batch Size for the CNN
3.2. Nitrogen Estimation Using CNN without Attention
3.3. Nitrogen Estimation Using CNN with Attention Mechanism
3.4. Comparison of the CNN with/without Attention with Respect to the Training Set Size
3.5. Comparison of the Proposed Model with AlexNet and VGGNet
4. Discussion
- In the present study, two classification methods were compared using CNNs with and without attention mechanisms. The same CNN architecture and the same CNN model parameter configuration were used in both classifiers. Both CNN classifiers were trained three times using three different random seeds, with a training set size of 70%, a batch size of 8, and a learning rate of 0.0001 used to train the models in each experiment. To evaluate the effectiveness of the proposed attention mechanism-based CNN method, the proposed CNN model was trained with four different batch sizes (1, 4, 8, and 16) and three learning rates (0.001, 0.0001, and 0.00001). To investigate the effect of the training data size on the efficiency of the proposed method, the CNN model was trained with three different training set sizes (30%, 50%, and 70%).
- The experimental results showed that the proposed CNN with attention mechanism performed better when using a training set size of 70% and when using a batch size of 8 with a learning rate of 0.0001, achieving an overall CCR of 97.33% over 100 training epochs. These results indicate that the use of large training data with a small batch size and a low training rate can improve the proposed attention mechanism’s ability to provide more accurate and reliable results. Larger batch sizes negatively affect accuracy, while smaller learning rates make the training process convergence much slower. The alternative CNN classifier performed worse than the CNN with an attention mechanism, achieving an overall CCR of 94.94%, which is 2.39% lower than that obtained by the CNN with an attention mechanism.
- The obtained results suggest that the proposed attention mechanism-based CNN is a feasible method for detecting the amount of nitrogen overdose even after 24 h. This enables the farmers to take immediate corrective measures to prevent the risk of crop failure. Additionally, the nitrogen content estimation was very accurate for the first day (class T2), with only a 0.71% error for the CNN classifier with an attention mechanism. Since the fertilizer is mixed with irrigation water, the plants absorb it quickly, enabling early detection on the leaves. The precision of classes T2 and T4 is better than that of classes T1 and T3, indicating that most samples in those classes are correctly classified. These results are very promising for the practical feasibility of the proposed method. The error is consistently higher for class T1 in all the models, indicating some possible problem in the sampling and capture process. To increase precision and make the technique more robust to individual mistakes, a real use of the system should involve testing different leaves for each plant.
- Regarding the evaluation of the time required for the execution of the training process, the total time required for the execution of the training process of the attention mechanism-based CNN model was about 33 min and 45 s, while the total time required for the execution of the training process of the CNN model without attention was about 40 min and 51 s. It can be deduced that the proposed attention method is not only able to improve the accuracy of the system, but it also reduces the training time by improving the convergence of the network.
- The comparison of the proposed method with two classic neural networks, AlexNet and VGGNet, has clearly proven the positive effect of introducing the attention mechanism as the first step of the network. The improvement of the attention layers in both models varies from 5% for AlexNet to 3% for VGGNet, compared to 2.4% for the proposed CNN. Obviously, as the CCR of the model without attention is higher, the ability of the attention mechanism to improve this accuracy is smaller. VGGNet with attention achieves an excellent CCR of 97.54%, slightly higher than the proposed CNN with attention. However, the VGGNet method is more computationally expensive, with 30 times more training parameters. This translated into a slower training process, which required more than one hour for each execution. It can be concluded that the proposed CNN model is the most cost-effective from the point of view of the accuracy obtained.
- Several studies have been conducted to estimate the nitrogen content in the leaves of plants using hyperspectral images, most of them dealing with regression issues. For example, Du et al. [38] applied support vector machine (SVM) regression on rice leaves, obtaining a coefficient of determination (R2) of 0.75. Liang et al. [39] applied random forest regression (RFR) and least squares support vector regression (LS-SVR) models on wheat leaves with an R2 of 0.75. In another study, Fan et al. [40] used partial least squares (PLS) regression on corn leaves, achieving an R2 of 0.77. In some recent studies, Yang et al. [41] proposed three machine learning techniques, gradient boosting decision tree (GBDT), partial least squares regression (PLS), and support vector regression (SVR), on wheat leaves; the best model was GBDT with calibration and validation R2 of 0.975 and 0.861, respectively. Pourdarbani et al. [42] developed a 1D-CNN regression model to classify different nitrogen fertilizer treatments (30%, 60%, and 90% excess) in cucumber leaves. The spectral information of the cucumber leaves of four classes (control, 30%, 60%, and 90%) was studied. The results indicated that the classes 30%, 60%, and 90% had coefficients of determination of 0.962, 0.968, and 0.967, respectively. Hyperspectral imaging techniques were used in each of these studies to estimate the amount of nitrogen in plant leaves. In general, it can be seen that the most advanced techniques based on deep learning and convolutional neural networks are able to obtain the best results. However, the aim of this study is not related to the direct estimation of the amount of nitrogen in plants but to detect the misapplication of nitrogen fertilizers in plants. We are therefore dealing with a problem of classification of nitrogen treatments rather than a case of regression. Although these studies were selected among the most comparable to our case in the field of the estimation of the nitrogen content in plant leaves, this comparison must be viewed in context since they used different types of plants, capture tools, datasets, and classification models.
- Although the results obtained are very promising, two main limitations of the methodology proposed in this research can be highlighted. The first limitation is that the imaging is performed under laboratory conditions. This means that the study was conducted in a controlled environment, which may not fully represent outdoor conditions. It is important to validate the findings of the study by conducting similar experiments in more realistic settings, such as actual agricultural fields or greenhouses, to assess the effectiveness of the proposed approach in practical scenarios. The second limitation is the pixel-by-pixel processing done on the images. This implies that the analysis and processing of the images are performed on individual pixels rather than considering the entire image as a whole. While this approach may have its advantages, such as fine-grained analysis at the pixel level, it may not capture the broader context and spatial relationships between different regions of the image. Future research could explore methodologies that take into account the global features and relationships within the images to improve the accuracy and efficiency of the analysis.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Brentrup, F.; Pallière, C. Nitrogen Use Efficiency as an Agro-Environmental Indicator. In Proceedings of the OECD Workshop on Agrienvironmental Indicators, Leysin, Switzerland, 23–26 March 2010; pp. 23–26. [Google Scholar]
- Warner, J.; Zhang, T.Q.; Hao, X. Effects of nitrogen fertilization on fruit yield and quality of processing tomatoes. Can. J. Plant Sci. 2004, 84, 865–871. [Google Scholar] [CrossRef]
- Adhikary, S.; Biswas, B.; Naskar, M.K.; Mukherjee, B.; Singh, A.P.; Atta, K. Remote Sensing for Agricultural Applications. In Arid Environment; Elsevier: Amsterdam, The Netherlands, 2022. [Google Scholar]
- Moghadam, P.; Ward, D.; Goan, E.; Jayawardena, S.; Sikka, P.; Hernandez, E. Plant Disease Detection Using Hyperspectral Imaging. In Proceedings of the 2017 International Conference on Digital Image Computing: Techniques and Applications (DICTA), Sydney, NSW, Australia, 29 November–1 December 2017; pp. 1–8. [Google Scholar]
- Tao, H.; Feng, H.; Xu, L.; Miao, M.; Long, H.; Yue, J.; Li, Z.; Yang, G.; Yang, X.; Fan, L. Estimation of Crop Growth Parameters Using UAV-Based Hyperspectral Remote Sensing Data. Sensors 2020, 20, 1296. [Google Scholar] [CrossRef] [Green Version]
- Park, E.; Kim, Y.-S.; Faqeerzada, M.A.; Kim, M.S.; Baek, I.; Cho, B.-K. Hyperspectral reflectance imaging for nondestructive evaluation of root rot in Korean ginseng (Panax ginseng Meyer). Front. Plant Sci. 2023, 14, 1109060. [Google Scholar] [CrossRef]
- Nguyen, N.M.T.; Liou, N.-S. Ripeness Evaluation of Achacha Fruit Using Hyperspectral Image Data. Agriculture 2022, 12, 2145. [Google Scholar] [CrossRef]
- Pourdarbani, R.; Sabzi, S.; Arribas, J.I. Nondestructive estimation of three apple fruit properties at various ripening levels with optimal Vis-NIR spectral wavelength regression data. Heliyon 2021, 7, e07942. [Google Scholar] [CrossRef]
- Xuan, G.; Gao, C.; Shao, Y.; Wang, X.; Wang, Y.; Wang, K. Maturity determination at harvest and spatial assessment of moisture content in okra using Vis-NIR hyperspectral imaging. Postharvest Biol. Technol. 2021, 180, 111597. [Google Scholar] [CrossRef]
- Sun, H.; Zheng, X.; Lu, X.; Wu, S. Spectral–Spatial Attention Network for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2019, 58, 3232–3245. [Google Scholar] [CrossRef]
- Mei, X.; Pan, E.; Ma, Y.; Dai, X.; Huang, J.; Fan, F.; Du, Q.; Zheng, H.; Ma, J. Spectral-Spatial Attention Networks for Hyperspectral Image Classification. Remote Sens. 2019, 11, 963. [Google Scholar] [CrossRef] [Green Version]
- Nagasubramanian, K.; Jones, S.; Singh, A.K.; Sarkar, S.; Singh, A.; Ganapathysubramanian, B. Plant disease identification using explainable 3D deep learning on hyperspectral images. Plant Methods 2019, 15, 98. [Google Scholar] [CrossRef] [Green Version]
- Zhu, Y.; Abdalla, A.; Tang, Z.; Cen, H. Improving rice nitrogen stress diagnosis by denoising strips in hyperspectral images via deep learning. Biosyst. Eng. 2022, 219, 165–176. [Google Scholar] [CrossRef]
- Benmouna, B.; García-Mateos, G.; Sabzi, S.; Fernandez-Beltran, R.; Parras-Burgos, D.; Molina-Martínez, J.M. Convolutional Neural Networks for Estimating the Ripening State of Fuji Apples Using Visible and Near-Infrared Spectroscopy. Food Bioprocess Technol. 2023, 15, 2226–2236. [Google Scholar] [CrossRef]
- Xiang, Y.; Chen, Q.; Su, Z.; Zhang, L.; Chen, Z.; Zhou, G.; Yao, Z.; Xuan, Q.; Cheng, Y. Deep Learning and Hyperspectral Images Based Tomato Soluble Solids Content and Firmness Estimation. Front. Plant Sci. 2022, 13, 860656. [Google Scholar] [CrossRef]
- Jian, M.; Zhang, L.; Jin, H.; Li, X. 3DAGNet: 3D Deep Attention and Global Search Network for Pulmonary Nodule Detection. Electronics 2023, 12, 2333. [Google Scholar] [CrossRef]
- Chuma, E.L.; Iano, Y. Human Movement Recognition System Using CW Doppler Radar Sensor with FFT and Convolutional Neural Network. In Proceedings of the 2020 IEEE MTT-S Latin America Microwave Conference (LAMC 2020), Cali, Colombia, 26–28 May 2021; pp. 1–4. [Google Scholar]
- Baradaran, F.; Farzan, A.; Danishvar, S.; Sheykhivand, S. Customized 2D CNN Model for the Automatic Emotion Recognition Based on EEG Signals. Electronics 2023, 12, 2232. [Google Scholar] [CrossRef]
- Liu, G.; Guo, J. Bidirectional LSTM with attention mechanism and convolutional layer for text classification. Neurocomputing 2019, 337, 325–338. [Google Scholar] [CrossRef]
- Yang, J.; Sun, Y.; Liang, J.; Ren, B.; Lai, S.-H. Image captioning by incorporating affective concepts learned from both visual and textual components. Neurocomputing 2019, 328, 56–68. [Google Scholar] [CrossRef]
- Jia, Y. Attention Mechanism in Machine Translation. J. Phys. Conf. Ser. 2019, 1314, 012186. [Google Scholar] [CrossRef]
- Song, K.; Yao, T.; Ling, Q.; Mei, T. Boosting image sentiment analysis with visual attention. Neurocomputing 2018, 312, 218–228. [Google Scholar] [CrossRef]
- Tian, H.; Wang, P.; Tansey, K.; Han, D.; Zhang, J.; Zhang, S.; Li, H. A deep learning framework under attention mechanism for wheat yield estimation using remotely sensed indices in the Guanzhong Plain, PR China. Int. J. Appl. Earth Obs. Geoinf. 2021, 102, 102375. [Google Scholar] [CrossRef]
- Qian, X.; Zhang, C.; Chen, L.; Li, K. Deep Learning-Based Identification of Maize Leaf Diseases Is Improved by an Attention Mechanism: Self-Attention. Front. Plant Sci. 2022, 13, 864486. [Google Scholar] [CrossRef]
- Wang, Y.; Tao, J.; Gao, H. Corn Disease Recognition Based on Attention Mechanism Network. Axioms 2022, 11, 480. [Google Scholar] [CrossRef]
- Rossel, R.A.V. ParLeS: Software for chemometric analysis of spectroscopic data. Chemom. Intell. Lab. Syst. 2008, 90, 72–83. [Google Scholar] [CrossRef]
- Benmouna, B.; Pourdarbani, R.; Sabzi, S.; Fernandez-Beltran, R.; García-Mateos, G.; Molina-Martínez, J.M. Comparison of Classic Classifiers, Metaheuristic Algorithms and Convolutional Neural Networks in Hyperspectral Classification of Nitrogen Treatment in Tomato Leaves. Remote Sens. 2022, 14, 6366. [Google Scholar] [CrossRef]
- Niu, Z.; Zhong, G.; Yu, H. A review on the attention mechanism of deep learning. Neurocomputing 2021, 452, 48–62. [Google Scholar] [CrossRef]
- Ghaffarian, S.; Valente, J.; van der Voort, M.; Tekinerdogan, B. Effect of Attention Mechanism in Deep Learning-Based Remote Sensing Image Processing: A Systematic Literature Review. Remote Sens. 2021, 13, 2965. [Google Scholar] [CrossRef]
- Weng, W.; Zhu, X.; Jing, L.; Dong, M. Attention Mechanism Trained with Small Datasets for Biomedical Image Segmentation. Electronics 2023, 12, 682. [Google Scholar] [CrossRef]
- Chen, J.; Lu, Y.; Yu, Q.; Luo, X.; Adeli, E.; Wang, Y.; Lu, L.; Yuille, A.L.; Zhou, Y. Transunet: Transformers Make Strong Encoders for Medical Image Segmentation. arXiv 2021, arXiv:2102.04306. [Google Scholar]
- Wang, F.; Jiang, M.; Qian, C.; Yang, S.; Li, C.; Zhang, H.; Wang, X.; Tang, X. Residual Attention Network for Image Classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3156–3164. [Google Scholar]
- Ji, Z.; Xiong, K.; Pang, Y.; Li, X. Video Summarization with Attention-Based Encoder–Decoder Networks. IEEE Trans. Circuits Syst. Video Technol. 2019, 30, 1709–1717. [Google Scholar] [CrossRef] [Green Version]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11534–11542. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional Block Attention Module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef] [Green Version]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Du, L.; Gong, W.; Shi, S.; Yang, J.; Sun, J.; Zhu, B.; Song, S. Estimation of Rice Leaf Nitrogen Contents Based on Hyperspectral LIDAR. Int. J. Appl. Earth Obs. Geoinf. 2016, 44, 136–143. [Google Scholar] [CrossRef]
- Liang, L.; Di, L.; Huang, T.; Wang, J.; Lin, L.; Wang, L.; Yang, M. Estimation of Leaf Nitrogen Content in Wheat Using New Hyperspectral Indices and a Random Forest Regression Algorithm. Remote Sens. 2018, 10, 1940. [Google Scholar] [CrossRef] [Green Version]
- Fan, L.; Zhao, J.; Xu, X.; Liang, D.; Yang, G.; Feng, H.; Wang, Y.; Chen, G.; Wei, P. Hyperspectral-Based Estimation of Leaf Nitrogen Content in Corn Using Optimal Selection of Multiple Spectral Variables. Sensors 2019, 19, 2898. [Google Scholar] [CrossRef] [Green Version]
- Yang, B.; Ma, J.; Yao, X.; Cao, W.; Zhu, Y. Estimation of Leaf Nitrogen Content in Wheat Based on Fusion of Spectral Features and Deep Features from Near Infrared Hyperspectral Imagery. Sensors 2021, 21, 613. [Google Scholar] [CrossRef]
- Pourdarbani, R.; Sabzi, S.; Rohban, M.H.; Hernández-Hernández, J.L.; Gallardo-Bernal, I.; Herrera-Miranda, I.; García-Mateos, G. One-Dimensional Convolutional Neural Networks for Hyperspectral Analysis of Nitrogen in Plant Leaves. Appl. Sci. 2021, 11, 11853. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer (Type) | Filter Size | Number of Filters | Output Shape | Parameters |
|---|---|---|---|---|
| Conv1D_1 | 13 × 1 | 64 | (316, 64) | 832 |
| Max_pooling1d_1 | (158, 64) | 0 | ||
| Conv1D_2 | 5 × 64 | 128 | (154, 128) | 41,088 |
| Conv1D_3 | 5 × 64 | 128 | (150, 128) | 82,048 |
| Max_pooling1D_2 | (75, 128) | 0 | ||
| Conv1D_4 | 5 × 128 | 256 | (71, 256) | 164,096 |
| Max_pooling1d_3 | (35, 256) | 0 | ||
| Conv1D_5 | 5 × 256 | 256 | (31, 256) | 327,936 |
| Max_pooling1d_4 | (15, 256) | 0 | ||
| Conv1D_5 | 3 × 256 | 512 | (13, 512) | 393,728 |
| Flatten | (6656) | 0 | ||
| Dense | (4) | 26,628 |
| Layer (Type) | Filter Size | Number of Filters | Output Shape | Parameters |
|---|---|---|---|---|
| Channel_attention | (327, 1) | 0 | ||
| Conv1D_1 | 13 × 1 | 64 | (316, 64) | 832 |
| Max_pooling1d_1 | (158, 64) | 0 | ||
| Conv1D_2 | 5 × 64 | 128 | (154, 128) | 41,088 |
| Conv1D_3 | 5 × 64 | 128 | (150, 128) | 82,048 |
| Max_pooling1D_2 | (75, 128) | 0 | ||
| Conv1D_4 | 5 × 128 | 256 | (71, 256) | 164,096 |
| Max_pooling1d_3 | (35, 256) | 0 | ||
| Conv1D_5 | 5 × 256 | 256 | (31, 256) | 327,936 |
| Max_pooling1d_4 | (15, 256) | 0 | ||
| Conv1D_5 | 3 × 256 | 512 | (13, 512) | 393,728 |
| Flatten | (6656) | 0 | ||
| Dense | (4) | 26,628 |
| Model | Training Set Size | Learning Rate | Epochs | Batch Size | Random Seed | CCR (%) | Overall CCR (%) |
|---|---|---|---|---|---|---|---|
| CNN with attention mechanism | 70% | 0.0001 | 100 | 1 | 0 | 96.10 | 94.32 |
| 1 | 92.21 | ||||||
| 2 | 94.67 | ||||||
| 4 | 0 | 96.51 | 96.64 | ||||
| 1 | 95.69 | ||||||
| 2 | 97.74 | ||||||
| 8 | 0 | 96.51 | 97.33 | ||||
| 1 | 97.33 | ||||||
| 2 | 98.15 | ||||||
| 16 | 0 | 95.08 | 96.31 | ||||
| 1 | 96.72 | ||||||
| 2 | 97.13 |
| Model | Training Set Size | Batch Size | Epochs | Learning Rate | Random State | CCR (%) | Overall CCR (%) |
|---|---|---|---|---|---|---|---|
| CNN with attention mechanism | 70% | 8 | 100 | 0.001 | 0 | 91.39 | 92.89 |
| 1 | 91.39 | ||||||
| 2 | 95.90 | ||||||
| 0.0001 | 0 | 96.51 | 97.33 | ||||
| 1 | 97.33 | ||||||
| 2 | 98.15 | ||||||
| 0.00001 | 0 | 95.90 | 96.10 | ||||
| 1 | 95.90 | ||||||
| 2 | 96.51 |
| Model | Training Set Size | Batch Size | Learning Rate | Epochs | Random Seed | Training Time (Min:Sec) | CCR (%) | Overall CCR (%) |
|---|---|---|---|---|---|---|---|---|
| CNN | 8 | 0.0001 | 0 | 13:19 | 94.46 | 94.94 | ||
| 70% | 100 | 1 | 11:57 | 94.87 | ||||
| 2 | 15:35 | 95.49 |
| Class | T1 | T2 | T3 | T4 | Overall Classification Error per Class (%) | Overall AUC | Overall CCR (%) |
|---|---|---|---|---|---|---|---|
| T1 | 295 | 2 | 34 | 3 | 3.89 | 0.93 | 94.94 |
| T2 | 4 | 357 | 4 | 0 | 0.73 | 0.98 | |
| T3 | 13 | 6 | 390 | 0 | 1.54 | 0.95 | |
| T4 | 3 | 0 | 0 | 353 | 0.28 | 0.99 |
| Class | Recall | Accuracy | Specificity | FP-Rate | Precision | F-Score |
|---|---|---|---|---|---|---|
| T1 | 88.32 | 95.96 | 98.23 | 1.76 | 93.65 | 90.90 |
| T2 | 97.80 | 98.90 | 99.27 | 0.72 | 97.80 | 97.80 |
| T3 | 95.35 | 96.10 | 96.39 | 3.60 | 91.12 | 93.18 |
| T4 | 99.15 | 99.59 | 99.72 | 0.27 | 99.15 | 99.15 |
| Model | Training Set Size | Batch Size | Learning Rate | Epochs | Random Seed | Training Time (Min:Sec) | CCR (%) | Overall CCR (%) |
|---|---|---|---|---|---|---|---|---|
| CNN with attention mechanism | 8 | 0.0001 | 0 | 10:57 | 96.51 | 97.33 | ||
| 70% | 100 | 1 | 11:39 | 97.33 | ||||
| 2 | 12:12 | 98.15 |
| Class | T1 | T2 | T3 | T4 | Overall Classification Error per Class (%) | Overall AUC | Overall CCR (%) |
|---|---|---|---|---|---|---|---|
| T1 | 313 | 1 | 14 | 1 | 1.62 | 0.97 | 97.33 |
| T2 | 2 | 364 | 6 | 0 | 0.71 | 0.98 | |
| T3 | 8 | 6 | 402 | 0 | 1.12 | 0.97 | |
| T4 | 1 | 0 | 0 | 346 | 0.096 | 1.00 |
| Class | Recall | Accuracy | Specificity | FP-Rate | Precision | F-Score |
|---|---|---|---|---|---|---|
| T1 | 95.13 | 98.15 | 99.03 | 0.96 | 96.60 | 95.86 |
| T2 | 97.84 | 98.97 | 99.35 | 0.64 | 98.11 | 97.98 |
| T3 | 96.63 | 97.67 | 98.09 | 1.90 | 95.26 | 95.94 |
| T4 | 99.71 | 99.86 | 99.91 | 0.089 | 99.71 | 99.71 |
| Model | Learning Rate | Batch Size | Epochs | Training Set Size | Random State | CCR (%) | Overall CCR (%) |
|---|---|---|---|---|---|---|---|
| CNN with attention mechanism | 0.0001 | 8 | 100 | 30% | 0 | 91.18 | 92.61 |
| 1 | 91.18 | ||||||
| 2 | 95.49 | ||||||
| 50% | 0 | 92.62 | 95.14 | ||||
| 1 | 95.49 | ||||||
| 2 | 97.33 | ||||||
| 70% | 0 | 96.51 | 97.33 | ||||
| 1 | 97.33 | ||||||
| 2 | 98.15 |
| Model | Learning Rate | Batch Size | Epochs | Training Set Size | Random State | CCR (%) | Overall CCR (%) |
|---|---|---|---|---|---|---|---|
| CNN without attention | 0.0001 | 8 | 100 | 30% | 0 | 92.00 | 93.16 |
| 1 | 92.82 | ||||||
| 2 | 94.67 | ||||||
| 50% | 0 | 91.93 | 93.48 | ||||
| 1 | 93.23 | ||||||
| 2 | 95.28 | ||||||
| 70% | 0 | 94.46 | 94.94 | ||||
| 1 | 94.94 | ||||||
| 2 | 94.87 |
| Model | Training Set Size | Batch Size | Learning Rate | Epochs | Random Seed | Training Time (Hr:Min:Sec) | CCR (%) | Overall CCR (%) |
|---|---|---|---|---|---|---|---|---|
| AlexNet | 8 | 0.0001 | 0 | 1:34:36 | 81.56 | 81.00 | ||
| 70% | 100 | 1 | 1:34:46 | 78.68 | ||||
| 2 | 1:37:26 | 82.78 | ||||||
| AlexNet with attention | 70% | 8 | 0.0001 | 100 | 0 | 1:23:20 | 85.05 | |
| 1 | 1:23:04 | 86.06 | 86.20 | |||||
| 2 | 1:28:20 | 87.50 | ||||||
| VGGNet | 70% | 8 | 0.0001 | 100 | 0 | 1:22:06 | 92.82 | |
| 1 | 1:26:28 | 97.13 | 94.53 | |||||
| 2 | 1:28:02 | 93.64 | ||||||
| VGGNet with attention | 70% | 8 | 0.0001 | 100 | 0 | 1:15:01 | 97.33 | |
| 1 | 1:15:25 | 96.92 | 97.54 | |||||
| 2 | 1:15:47 | 98.36 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Benmouna, B.; Pourdarbani, R.; Sabzi, S.; Fernandez-Beltran, R.; García-Mateos, G.; Molina-Martínez, J.M. Attention Mechanisms in Convolutional Neural Networks for Nitrogen Treatment Detection in Tomato Leaves Using Hyperspectral Images. Electronics 2023, 12, 2706. https://doi.org/10.3390/electronics12122706
Benmouna B, Pourdarbani R, Sabzi S, Fernandez-Beltran R, García-Mateos G, Molina-Martínez JM. Attention Mechanisms in Convolutional Neural Networks for Nitrogen Treatment Detection in Tomato Leaves Using Hyperspectral Images. Electronics. 2023; 12(12):2706. https://doi.org/10.3390/electronics12122706
Chicago/Turabian StyleBenmouna, Brahim, Raziyeh Pourdarbani, Sajad Sabzi, Ruben Fernandez-Beltran, Ginés García-Mateos, and José Miguel Molina-Martínez. 2023. "Attention Mechanisms in Convolutional Neural Networks for Nitrogen Treatment Detection in Tomato Leaves Using Hyperspectral Images" Electronics 12, no. 12: 2706. https://doi.org/10.3390/electronics12122706
APA StyleBenmouna, B., Pourdarbani, R., Sabzi, S., Fernandez-Beltran, R., García-Mateos, G., & Molina-Martínez, J. M. (2023). Attention Mechanisms in Convolutional Neural Networks for Nitrogen Treatment Detection in Tomato Leaves Using Hyperspectral Images. Electronics, 12(12), 2706. https://doi.org/10.3390/electronics12122706