1. Introduction
Entity linking, the task of associating entity mentions present in textual data to their analogous entities within the knowledge base, holds a substantial role in the field of natural language processing (NLP). This procedure finds extensive application across various sectors, including, but not limited to, information retrieval, question answering, and machine translation, along with a myriad of other applications. These applications and their effectiveness fundamentally hinge on theories such as information retrieval theory and graph theory. The former addresses the problem of finding material that satisfies an information need within large collections, while the latter represents entities as nodes and their relationships as edges, thus providing a structural foundation for knowledge representation and processing.
However, notwithstanding the significant advancements achieved in the arena of entity linking in lengthy documents, the challenge escalates substantially when it comes to its application within Chinese short texts. This complexity remains a substantial hurdle in the field that continues to necessitate rigorous research and innovative methodologies.
First, long documents usually have rich context information, which can be used to extract more features to assist in entity recognition and disambiguation. In contrast, short texts usually only contain limited context information, thereby limiting feature acquisition and entity disambiguation. Secondly, the linguistic characteristics of Chinese, such as the polysemy of vocabulary and the complex naming of entities, further increase the difficulty of entity linking in Chinese short texts.
To navigate these complexities, this study proposes an innovative approach for entity linking specifically tailored for Chinese short texts. This approach leverages multiple embedding representations as a strategy to enhance the performance of entity linking. Our methodology not only encompasses the embedding representations of entities and their corresponding relations as derived from the current knowledge base triples but also integrates external semantic augmentations. Specifically, the embedding representations of entities and relations are utilized, which are obtained from the descriptive text present in the external Baidu Encyclopedia knowledge base. The amalgamation of these various aspects enables the model to encapsulate more semantic information, thereby significantly enhancing the precision of entity linking.
Additionally, The MER-BERT-BiGRU neural network model was developed for embedding learning. The MER-BERT-BiGRU model inherits the powerful contextual representation ability of the Bidirectional Encoder Representations from Transformers (BERT) model and also combines the sequence modeling capability of Bidirectional Gated Recurrent Unit (BiGRU), enabling the more effective learning of the context features of entities from short texts.
In essence, this study serves two primary goals: Primarily, our objective is to devise a pragmatic approach that adequately addresses the intricate challenges inherent to entity linking in Chinese short texts. Simultaneously, our endeavor contributes to the augmentation of the existing academic discourse in the domain of NLP and semantic understanding. Through this work, the intention is to propel forward the current understanding and development of solutions in these areas. The subsequent sections of this paper will provide a detailed exposition of our research methodology, the design of our experimental setup, the gathered findings, and the potential implications of this research. The following are the primary contributions of this study:
Addressing a unique challenge: A pragmatic approach was collectively developed to efficiently address the complex task of entity linking within Chinese short texts. This effort addresses a significant gap in existing NLP techniques.
Enriching academic discourse: The present research enhances the extant academic discourse in the domain of NLP and semantic understanding through the introduction of a novel integration of multiple embedding representations and external semantic supplements within an advanced MER-BERT-BiGRU model.
Impressive performance metrics: The efficiency of the proposed approach is underscored by its outstanding performance metrics. With a precision of 89.73%, a recall of 92.18%, and an F1 score of 90.94%, the model stands as a compelling solution for entity linking in Chinese short texts.
2. Related Work
The relevant work on entity linking primarily concentrates on two dimensions: feature-based approaches and embedding-based methods [
1]. A thorough review and analysis of these works was conducted to provide the theoretical foundations and inspirations for the proposed methodology.
2.1. Feature-Based Approaches for Entity Linking
Feature-based methods for entity linking primarily operate by designing and extracting various features [
2]. These often include local context features (such as surrounding words of the entity), global context features (such as the theme of the entire document), entity features (such as the entity’s type, aliases, etc.), and features concerning relationships between entities. The primary strength of this methodology lies in its capacity to exploit considerable domain knowledge. However, feature engineering often requires extensive resources and may require different features to be designed for different tasks and domains. The development of deep learning (DL) in recent years has noticeably alleviated this issue. Below are some representative works:
In 2015, Dawn Lawrie et al. [
3] proposed a cross-lingual entity-linking method that uses multiple features, including context matching, entity type matching, and string matching. This method can handle various cross-lingual types of entity-linking problems but requires extensive training data annotation.
In 2018, Jonathan Raiman and Olivier Raiman [
4] put forward the DeepType model, which successfully incorporated symbolic knowledge into neural networks and demonstrated significant advantages, particularly in entity-linking tasks, outperforming other contemporary methods. The model performed well in multilingual tasks, showing its broad adaptability. Moreover, DeepType reduced the complexity of entity linking from
O(N2) to
O(N) and allowed adding new entities without retraining. However, the primary challenge for the model lies in reducing the gap between the type classifier and oracle accuracy to improve disambiguation results.
In 2019, Xiyuan Yang et al. [
5] proposed a dynamic context augmentation (DCA) model. Serving as an enhancement plugin for existing entity-linking models, it introduces topic consistency without changing the original model’s design or structure. Compared with global entity-linking models, DCA only needs to traverse all mentions once, improving training and inference efficiency. Although numerous experiments have shown DCA’s effectiveness in different learning environments, base models, decision orders, attention mechanisms, and further research and verification are needed to ascertain its applicability to all data types and environments.
In 2022, Nicola De Cao et al. [
6] developed mGENRE, a system for multilingual entity linking that predicts entity names in an autoregressive manner across multiple languages. It retains entity names in various languages, maximizing linguistic connections. Notably, it improves performance by 50% for languages not seen during training, though its wider application requires further examination.
In 2022, Chao Zhang et al. [
7] introduced a novel entity-linking model based on multi-topic global consistency feature extraction, involving the construction of an entity mention association graph and a candidate entity association graph. To effectively manipulate these graphical constructs, they employed the advanced techniques offered in graph neural networks. The model can better handle documents with multiple topics but might face challenges in handling a vast number of topics, selecting appropriate similarity thresholds and hyperparameters, and improving training speed.
2.2. Embedding-Based Approaches for Entity Linking
Embedding-based methods conduct entity linking primarily by learning low-dimensional, dense vector representations (i.e., embeddings) of entities and their contexts. These methods usually employ DL models, such as neural networks or transformers, to learn embedding representations. Embedding representations hold the capacity to encapsulate the intricate semantic information intrinsic to entities and their respective contexts, thereby improving the accuracy of entity linking. Furthermore, these methods do not require substantial feature engineering, hence providing better generality and scalability. Nonetheless, such methodologies necessitate substantial volumes of annotated data for the effective training of the model, and they may demand high computational resources. The following are some representative works:
In 2019, Ledell Wu et al. [
8] introduced a two-stage entity-linking model based on BERT. This model’s key advantages are its simplicity, scalability, and efficiency. Using short text descriptions to define each entity, the model achieves high-precision entity linking without the need for concrete entity embeddings or handcrafted mention tables specifically curated for the task. However, the entity representation in this model is overly simplified, lacking entity type and entity graph information. Furthermore, a joint model design for mention detection and entity linking has yet to be pursued.
In 2020, Zheng Fang et al. [
9] proposed an entity-linking model combining BERT and sequential GAT. This model features an innovative candidate generation mechanism, enhancing link accuracy. Its strength lies in its capacity to disambiguate entities from both local and global perspectives, using topic consistency to reduce noise interference. Additionally, the authors provide a user-friendly API for application to other datasets. Nevertheless, the model still needs to handle the dynamic graph entity linking issue, implying it does not automatically detect changes in the intensity of associations between entities, which is a direction for future improvement.
In 2021, Hongyin Tang et al. [
10] proposed an innovative bidirectional multi-paragraph reading model explicitly tailored for zero-shot entity-linking tasks. One of the model’s key assets is its capability to identify long-range text dependencies existing between mention and entity documents. Nevertheless, a potential limitation of this model may reside in the extended inference time required for comprehending across paragraphs, which could potentially restrict its applicability to large-scale datasets. Regardless of these potential challenges, empirical evidence affirms that the model delivers unrivaled performance across diverse domains.
In 2022, Hairong Wang et al. [
11] presented a BERT binary-based entity linking approach to enhance entity recognition accuracy in Chinese texts. While the method demonstrated a significant increase in the F1 score by leveraging multiple data sources for generating entity sets, the model’s classifiers present an opportunity for improvement. Future work may focus on optimizing the decision variables of neural networks to enhance the overall performance.
In 2023, Zhenran Xu et al. [
12] launched Hansel, a unique Chinese entity linking benchmark. While it addresses the challenge of linking uncommon or emerging entities, top systems struggle with this task. Despite this, they developed a promising method for gathering zero-shot entity datasets, although its application needs further testing across different languages.
2.3. Gap Identification in Current Approaches
To summarize, traditional feature-based methodologies rely heavily on manually curated features and sophisticated machine learning models [
13], whereas embedding-based strategies endeavor to convert entities and relations into continuous vector representations, which are then utilized for entity linking. In recent years, due to their enhanced performance and broad applicability [
14], embedding-based methodologies have been increasingly under the spotlight. Nevertheless, most approaches grapple with constraints such as a lack of context information and a sparse presence of entities in the knowledge graph, specifically when tackling Chinese short texts. In response to these particular challenges, this paper introduces a novel model for entity linking in Chinese short texts, which is designed to amalgamate multiple embedding representations to provide a targeted solution.
In order to affirm the efficacy of our proposed approach, a dataset, Chinese Short-Text Knowledge Graph (CNSKG), was constructed, which is expressly tailored for the purpose of entity linking within Chinese short texts. This dataset is a fusion of the China Conference on Knowledge Graph and Semantic Computing (CCKS) evaluation task dataset, the Open Knowledge Graph (OpenKG) open-source knowledge graph, and data crawled from Baidu Encyclopedia and other websites by our team. Comparative experiments were performed on this dataset using both conventional baseline methodologies and the strategy proposed in this study, ultimately substantiating the superior performance of our proposed method.
3. Materials and Methods
Given that entity linking can be divided into two subtasks, entity recognition and entity disambiguation [
15], our model follows this approach, realizing entity linking for Chinese short texts through multi-embedding representation (MER), a multi-layer BERT-BiGRU, and convolutional neural networks and fully connected networks.
In this section, the primary presentation is of the MER-BERT-BiGRU model, which is proposed for the problem of entity linking in Chinese short texts.
Section 3.1 delves into the principles of the BERT-BiGRU model,
Section 3.2 emphasizes the multi-embedding representation (MER) method proposed in this study, and
Section 3.3 outlines the architecture and specific approach used in our model.
3.1. BERT-BiGRU
BERT is a pre-trained model widely used in NLP [
16]. BERT, being one of the most powerful transformer-based networks, is unique for its bidirectional nature [
17]. This characteristic enables BERT to consider the context of a word from both preceding and succeeding words in a sentence, thereby ensuring a comprehensive understanding of the text. However, not only is it strong suit, but the model’s robust performance is also attributed to its ability to model complex patterns in data using deep learning architectures and large-scale pre-training on diverse language data.
The foundational architecture of BERT is derived from the encoder segment of the transformer model, which utilizes a self-attention mechanism to capture context dependencies within a text. This can be mathematically expressed as follows:
For a given input sequence
X, its three transformations (Query
Q, Key
K, and Value
V) are initially computed, which is achieved through linear transformations:
In the above equation,
WQ,
WK, and
WV represent the weight matrices to be learned. Subsequently, the attention scores are calculated and normalized:
In this equation, dK signifies the dimensionality of keys, and the division by sqrt(dK) is designed to prevent the dot product from becoming excessively large.
BERT primarily undergoes pre-training through two distinct tasks: masked language model (MLM) and next sentence prediction (NSP) [
18]. During the MLM task, BERT substitutes certain words in the input randomly with a unique [MASK] token, followed by predicting these masked words. On the other hand, the NSP task equips BERT to comprehend the relationship existing between two sentences by predicting whether the second sentence in a pair was sequentially succeeding the first one in the original document [
19].
The BiGRU model, a variant of the recurrent neural network (RNN), was conceived to address the issues related to disappearing or escalating gradients in extended sequences. BiGRU amalgamates the characteristics of the gated recurrent unit (GRU) and bidirectional RNN [
20], providing a powerful tool for sequence-based tasks.
The GRU model, an advanced version of the RNN, incorporates two types of gate mechanisms: the update
gate (
z) and the reset
gate (
r). These gates govern the flow of information inside the GRU unit. A GRU unit can be mathematically formulated as follows:
Herein,
xt denotes the input at time step
t, whereas
h(t−1) represents the hidden state from the preceding step. The elements
W,
U, and
b are trainable parameters within this framework. The symbol
σ is used to signify the sigmoid function, and
⊙ is utilized to represent element-wise multiplication [
21].
The term “Bi-directional” implies that the model processes information in both forward and backward directions. Specifically, BiGRU consists of two independent GRU layers: one processing the sequence in chronological order (forward GRU), and the other in reverse chronological order (backward GRU) [
22]. The output at each time step is a concatenation of the outputs from the forward and backward GRUs, thereby incorporating both past and future contexts at each time step [
23].
The BERT-BiGRU model combines the benefits of BERT and BiGRU to address a range of challenges in NLP. BERT, as a pre-trained model, captures complex contextual relationships in text, and BiGRU is adept at retaining and utilizing information from both past and future contexts.
In the combined BERT-BiGRU model, the input data are first processed through a pre-trained BERT model. This stage enables the model to learn rich representations of words in their contextual environment. Subsequently, the output from the BERT model, that is, the word embeddings, is introduced into a BiGRU network. BiGRU, standing for bidirectional gated recurrent unit, comprises two distinct GRU layers. One of these processes the sequence in the forward direction, and the other does so in reverse [
24]. This ensures that the output at each time step integrates information from both the past, as provided in the forward sequence, and the future, as given in the reverse sequence. This model’s strength lies in its ability to contextually enrich language understanding while being dynamic and adaptive to sequence variations [
25].
3.2. Multi-Embedding Representation (MER)
In response to the limited contextual information in Chinese short texts and the insufficient semantic information of target entities in the knowledge base, this paper proposes a model incorporating a multi-embedding representation.
Before building the model, an entity name dictionary was first constructed using entity names from the knowledge base and alias information from Baidu Encyclopedia. Through character matching in a trie structure, the mentioned entities can be identified.
Initially, all the triples in the knowledge base pertaining to the mentioned entity are linked to obtain its descriptive text, denoted as Edes. Secondly, to address the issue of limited entities in the constructed knowledge base, the encyclopedia descriptive text of the mentioned entity, Ebk, is obtained based on the alias entity description information from Baidu Encyclopedia. Since BERT can take a maximum of 512 tokens per input, there are cases where the text may be too long. Therefore, the entity description text E is truncated proportionally if it exceeds 512 tokens. This rule ensures the handling of lengthy entity descriptions within BERT’s maximum input limit.
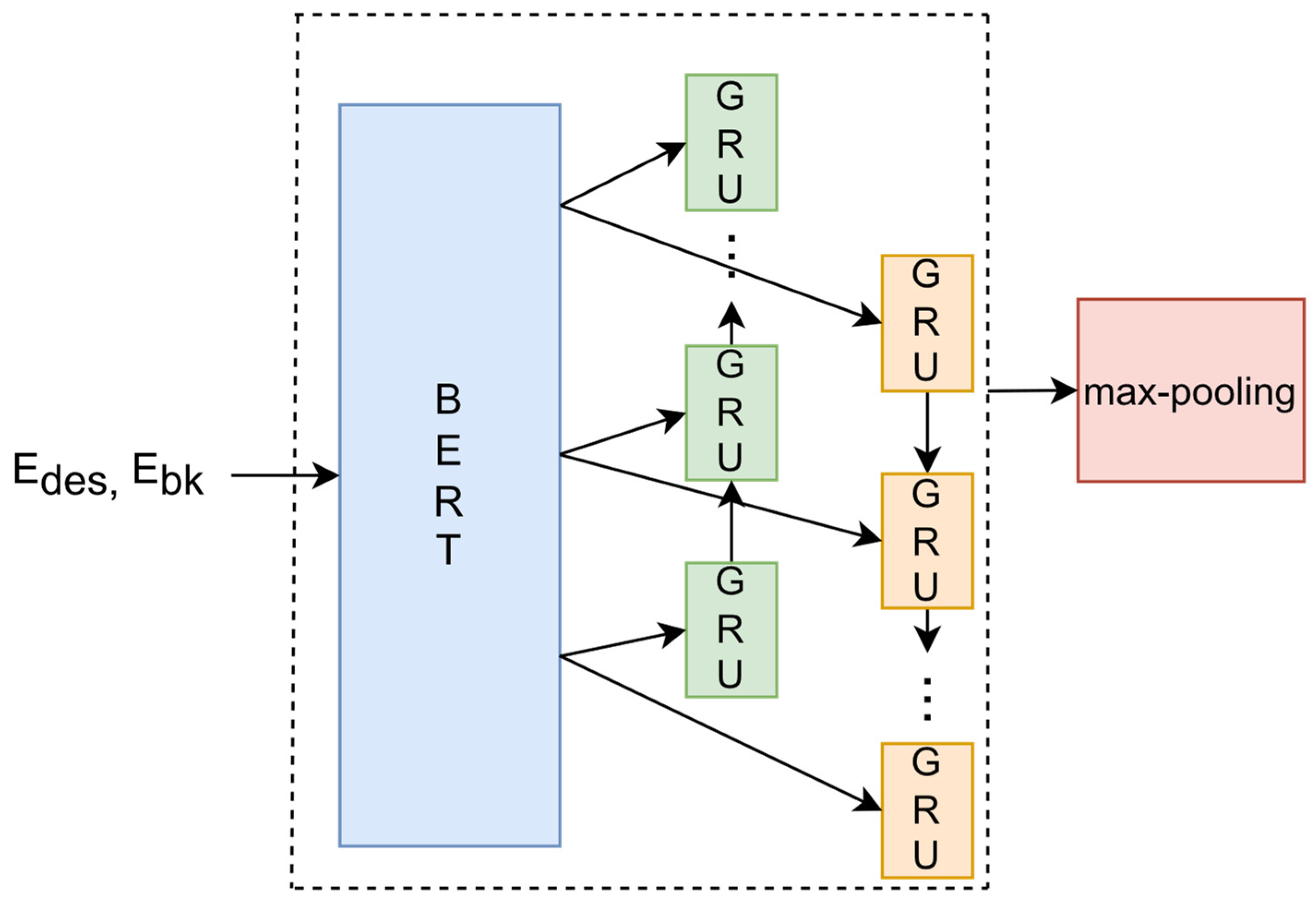
As illustrated in
Figure 1, the entity description text, E
des and E
bk, is input into BERT, and the output from BERT is obtained. This output is then fed into both the forward and backward GRU networks. To learn information from the entire text, a max-pooling operation is applied to the outputs of both the forward GRU and backward GRU [
26]. This generates a vector,
Y{max}, that represents the semantics of the entity description text.
3.3. Overall Model Architecture
As depicted in
Figure 2, a model for Chinese short-text entity linking is proposed, composed of two modules: named-entity recognition (NER) and named-entity disambiguation (NED).
In the NER module, first, a multi-embedding representation is employed to obtain an embedded vector representation of an entity, denoted as
Y{
max}. This representation includes not only entity description information from the existing knowledge base but also alias entity description information from Baidu Encyclopedia. The aim is to compensate for the lack of entity information in the knowledge base in the context of short texts. When the predicted candidate entity corresponds to an alias entity in Baidu Encyclopedia, this entity and its description information are supplemented into the knowledge base. Subsequently, the short text is fed into the BERT layer, and the output is then input into a BiGRU network. Applying max-pooling operations to the outputs from both the forward and backward GRU networks generates a vector, represented as
X{max}, which can capture the semantics of the entire Chinese short text. Furthermore, the vectors
X{end} and
X{begin} are extracted, which correspond to the ending position of the forward GRU and the beginning position of the backward GRU for the matched entity mention [
27]. Concatenating these two vectors yields
X{con}, which serves as the semantic representation of the entity mention in the short text. Finally,
X{max},
X{con}, and the multi-embedding representation
Y{max} of the corresponding entity name of the mentioned entity are concatenated, passed through a convolutional layer, a fully connected layer, and a sigmoid activation function, resulting in the prediction probability.
In the NED module, entity disambiguation is achieved based on a classification approach. Initially, during the training process, positive examples are selected from the entities that have been linked within the training set. These are entities that have already been verified and annotated, serving as supervised data. Conversely, negative examples are chosen from the candidate entities, which were initially identified in the NER stage. These candidate entities represent potential entities predicted with the model that may not necessarily be accurate. This strategy enables the model to learn from both known (supervised) and predicted (unsupervised) data, allowing it to adjust its parameters based on the confidence of its predictions [
28]. The Chinese short text, along with the description text of the candidate entities (entities awaiting disambiguation), is input into the BERT model. The output vector at the CLS position is then extracted, as well as the feature vectors corresponding to the beginning and ending positions of the candidate entities. After concatenating these three vectors, they are fed into a fully connected neural network layer. Finally, through a sigmoid activation function, the probability scores of the candidate entities are obtained. After ranking all the candidate entities based on these probability scores, the entity with the highest score is identified as the correct entity to be linked to the knowledge base.
4. Experiments
This section provides a demonstration of the effectiveness of the proposed method through a series of experiments conducted on a custom-built dataset of a Chinese short-text knowledge graph. The detailed steps of our experimental validation are divided into several subsections as follows.
4.1. Dataset
In response to the absence of publicly available datasets designed for Chinese short-text entity linking tasks, a domain-oriented dataset was constructed, termed CNSKG. This dataset amalgamates data extracted from diverse sources, including the CCKS Evaluation Knowledge Graph, the OpenKG open-source knowledge graph, as well as data collected via web scraping from sites such as Baidu Encyclopedia by our team. Annotation procedures were performed on our bespoke dataset, which is composed of three distinct files. The first, denoted as KB_Data, serves as the target knowledge base for the entity-linking task, comprising in excess of 1.53 million records. The second is the set of training data, which was not initially divided into training and validation subsets due to our adoption of a K-fold cross-validation approach for training. The third and final file is a test dataset for Chinese short texts.
Table 1 lists the respective quantities of samples present within the dataset.
4.2. Experimental Settings
To ensure a rigorous and unbiased assessment of our proposed method, the following subsections provide a detailed overview of our experimental settings. These settings not only establish the framework for our experiments but also shape the interpretation of the results.
4.2.1. Evaluation Metrics
The evaluation metrics used for the entity-linking model for Chinese short texts included precision (
P), recall (
R), and
F1 score [
29]. Given a test text set A, for each individual Chinese short text a in A, assuming
a contains
Q entity mentions, the evaluation metrics of our model were defined as follows:
where
Ea = {
e1,
e2,
e3,...} denotes the set of correctly annotated results, and
E′a = {
e′1, e′2, e′3,...} represents the results predicted with our entity-linking model.
4.2.2. Experimental Environment
As illustrated in
Table 2, our experimental environment was as follows.
4.2.3. Parameter Configuration
Our proposed model for entity linking in Chinese short texts, which incorporates multi-representational embeddings, entails a two-step training process. The experimental results from the second step constitute the final results.
For the first step, the entity recognition phase, The training dataset was partitioned into ten subsets, and a ten-fold cross-validation approach was implemented. The BERT model used was the BERT Base variant, which includes 12 transformer encoder layers. A single-layer BiGRU was utilized, along with 256 CNN filters. The optimizer chosen was Adam with a learning rate of 1 × 10−5. The batch size was set at 12, with a dropout rate of 0.2.
For the second step, the entity disambiguation phase, the training dataset was partitioned into five subsets with a five-fold cross-validation approach in place. The BERT model employed was the BERT Large variant, incorporating 24 transformer encoder layers. Following this, the fully connected layer included 128 hidden neurons. The batch size was set at 8, with a dropout rate of 0.15. Finally, the model architecture concluded with a single-layer fully connected neural network. Adam was again chosen as the optimizer, with a learning rate of 1 × 10−6 for the initial 3 epochs, and 1 × 10−7 for the subsequent epochs.
4.3. Experimental Results and Analysis
In the following sections, the outcomes of the experiments and an analysis of these results will be presented. This discussion is designed to showcase the effectiveness of our proposed method and its superiority in certain contexts when compared with other approaches. This section is further divided into specific areas of interest as outlined below.
4.3.1. Comparative Experiments
The recurrent-random-walk-based EL (RRWEL) model [
30] and the dynamic graph convolutional networks (DGCN) model [
31] were selected as baseline models for comparison. The RRWEL model is an end-to-end neural network with a random walk layer, which introduces an external knowledge base to enhance the semantic dependency among EL decisions. The DGCN model is a type of entity-linking model that can adaptively adjust the architecture of the graph network, thereby enhancing the model’s ability to capture structural information between entities.
As depicted in
Figure 3, in addressing the problem of entity linking in Chinese short texts, the F1 score of the model proposed in this study is the highest, which demonstrates the advanced nature of our proposed model.
4.3.2. Comparison of Different Numbers of BiGRU Layers
In NLP tasks, the common choice for the number of layers of BiGRU typically ranges from one to three. Increasing the number of layers can capture more complex contextual information, but it will also increase the computational requirements of the model and possibly increase the risk of overfitting. In order to determine the optimal number of layers, a comparative experiment was conducted, as shown in
Table 3. As the number of layers increases, the F1 score of the model gradually decreases. Given the limited size of the dataset constructed in this study, this could potentially lead to overfitting issues. Therefore, a single-layer BiGRU was ultimately chosen for incorporation into the model.
4.3.3. Comparison of Different Numbers of “Folds”
K-fold cross-validation is a common method for assessing model performance and robustness, where k represents the division of data into k parts (or “folds”). For model parameter fine-tuning, varying numbers of folds (five, seven, and ten) were set in the two training phases of the model, resulting in nine different combinations. The experimental results are shown in
Figure 4. It can be seen that the best F1 score is achieved when using 10-fold cross-validation in the entity recognition phase and 5-fold cross-validation in the entity disambiguation phase.
4.3.4. Ablation Experiment
Ablation experiments were also carried out, where the BiGRU module and the multi-layer embedding module were individually removed for comparative tests. As demonstrated in
Figure 5, it is observed that after the removal of the BiGRU module, the F1 score dropped by 2.72 percent. Similarly, after removing the multi-layer embedding representation module, the F1 score declined by 4.78 percent. These experimental results suggest that our proposed model, which combines multi-layer embedding representation for entity linking, is effective for the task of entity linking (EL) in Chinese short texts.
5. Conclusions
This paper critically evaluated the complexities and challenges associated with Chinese short-text entity linking and put forth an efficient solution. The uniqueness of short texts lies in their limited contextual information and the intricacies of Chinese language structures, such as polysemic words and the multifaceted naming conventions of entities. These aspects significantly heighten the challenges of entity linking.
To counter these obstacles, a novel approach for Chinese short-text entity linking was proposed that capitalizes on multi-embedding representations. The merging of various embedding representations facilitates the capture of an expansive spectrum of semantic information, thereby enhancing the accuracy of entity linking. Furthermore, the integration of external semantic supplements was also incorporated to enhance the feature-learning capacities of the model.
Regarding the model design, our strategy utilizes an MER-BERT-BiGRU neural network model for the learning of embeddings. This model synergizes the contextual representation abilities of BERT with the sequence-modeling prowess of BiGRU, allowing the effective contextual feature learning of entities from short texts. Thus, our paper contributes a unique and efficient methodology for Chinese short-text entity linking.
Nevertheless, our method still has room for refinement. Potential future research trajectories could focus on (1) improving the quality and diversity of embedding representations; (2) optimizing the learning efficiency and performance of the model design; and (3) enhancing the application of external semantic supplements. Ultimately, the research presented in this paper lays the groundwork for novel perspectives and innovative approaches in the field of entity linking, thereby serving as a foundation for further explorations into optimizing Chinese short-text entity linking.
Author Contributions
Conceptualization, Y.S. and R.Y.; methodology, Y.S.; software, Y.S. and C.Y.; validation, Y.S., C.Y. and Y.L.; formal analysis, Y.Y. and Y.T.; investigation, R.Y. and Y.T.; resources, Y.L. and Y.T.; data curation, C.Y.; writing—original draft preparation, Y.S.; writing—review and editing, Y.S.; funding acquisition, Y.Y. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Natural Science Foundation of China, grant number 62206302.
Data Availability Statement
The data are unavailable due to privacy or ethical restrictions.
Acknowledgments
We wish to extend our heartfelt thanks to the reviewers for their invaluable and constructive criticisms.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Shen, W.; Li, Y.; Liu, Y.; Han, J.; Wang, J.; Yuan, X. Entity Linking Meets Deep Learning: Techniques and Solutions. IEEE Trans. Knowl. Data Eng. 2023, 35, 2556–2578. [Google Scholar] [CrossRef]
- Zhang, B.; Feng, Y.; Fu, L.; Gu, J.; Xu, F. Candidate Set Expansion for Entity and Relation Linking Based on Mutual Entity–Relation Interaction. Big Data Cogn. Comput. 2023, 7, 56. [Google Scholar] [CrossRef]
- Lawrie, D.; Mayfield, J.; McNamee, P.; Oard, D.W. Cross-Language Person-Entity Linking from 20 Languages. J. Assoc. Inf. Sci. Technol. 2015, 66, 1106–1123. [Google Scholar] [CrossRef]
- Raiman, J.; Raiman, O. DeepType: Multilingual Entity Linking by Neural Type System Evolution. arXiv 2018, arXiv:1802.01021. [Google Scholar] [CrossRef]
- Yang, X.; Gu, X.; Lin, S.; Tang, S.; Zhuang, Y.; Wu, F.; Chen, Z.; Hu, G.; Ren, X. Learning Dynamic Context Augmentation for Global Entity Linking. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, Hong Kong, China, 3–7 November 2019; pp. 271–281. [Google Scholar]
- De Cao, N.; Wu, L.; Popat, K.; Artetxe, M.; Goyal, N.; Plekhanov, M.; Zettlemoyer, L.; Cancedda, N.; Riedel, S.; Petroni, F. Multilingual Autoregressive Entity Linking. Trans. Assoc. Comput. Linguist. 2022, 10, 274–290. [Google Scholar] [CrossRef]
- Zhang, C.; Li, Z.; Wu, S.; Chen, T.; Zhao, X. Multitopic Coherence Extraction for Global Entity Linking. Electronics 2022, 11, 3638. [Google Scholar] [CrossRef]
- Wu, L.; Petroni, F.; Josifoski, M.; Riedel, S.; Zettlemoyer, L. Scalable Zero-Shot Entity Linking with Dense Entity Retrieval. arXiv 2019, arXiv:1911.03814. [Google Scholar]
- Fang, Z.; Cao, Y.; Li, R.; Zhang, Z.; Liu, Y.; Wang, S. High Quality Candidate Generation and Sequential Graph Attention Network for Entity Linking. In Proceedings of the Web Conference 2020, Taipei, Taiwan, 20–24 April 2020; pp. 640–650. [Google Scholar]
- Tang, H.; Sun, X.; Jin, B.; Zhang, F. A Bidirectional Multi-paragraph Reading Model for Zero-shot Entity Linking. Proc. AAAI Conf. Artif. Intell. 2021, 35, 13889–13897. [Google Scholar] [CrossRef]
- Wang, H.; Zhou, B.; Li, B.; Xu, X. Research of Vertical Domain Entity Linking Method Fusing Bert-Binary. Sensors 2022, 2022, 4262270. [Google Scholar] [CrossRef]
- Xu, Z.; Shan, Z.; Li, Y.; Hu, B.; Qin, B. Hansel: A Chinese Few-Shot and Zero-Shot Entity Linking Benchmark. In Proceedings of the Sixteenth ACM International Conference on Web Search and Data Mining, Singapore, 27 February–3 March 2023; pp. 832–840. [Google Scholar]
- Liu, S.; Zhou, G.; Xia, Y.; Wu, H.; Li, Z. A Data-Centric Way to Improve Entity Linking in Knowledge-Based Question Answering. PeerJ Comput. Sci. 2023, 9, e1233. [Google Scholar] [CrossRef]
- Zhang, Z.-B.; Zhong, Z.-M.; Yuan, P.-P.; Jin, H. Improving Entity Linking in Chinese Domain by Sense Embedding Based on Graph Clustering. J. Comput. Sci. Technol. 2023, 38, 196–210. [Google Scholar] [CrossRef]
- Hou, F.; Wang, R.; Ng, S.-K.; Witbrock, M.; Zhu, F.; Jia, X. Exploiting Anonymous Entity Mentions for Named Entity Linking. Knowl. Inf. Syst. 2023, 65, 1221–1242. [Google Scholar] [CrossRef]
- Dost, S.; Serafini, L.; Rospocher, M.; Ballan, L.; Sperduti, A. Aligning and Linking Entity Mentions in Image, Text, and Knowledge Base. Data Knowl. Eng. 2022, 138, 101975. [Google Scholar] [CrossRef]
- Jia, B.; Wang, C.; Zhao, H.; Shi, L. An Entity Linking Algorithm Derived from Graph Convolutional Network and Contextualized Semantic Relevance. Symmetry 2022, 14, 2060. [Google Scholar] [CrossRef]
- Levin, D. On Bert Meyers. Poetry 2023, 221, 317–320. [Google Scholar]
- Keyse-Walker, J. Bert and Mamie Take a Cruise. Libr. J. 2023, 148, 55. [Google Scholar]
- Liu, J.; Lei, X.; Zhang, Y.; Pan, Y. The Prediction of Molecular Toxicity Based on BiGRU and GraphSAGE. Comput. Biol. Med. 2023, 153, 106524. [Google Scholar] [CrossRef]
- Lei, D.; Liu, H.; Le, H.; Huang, J.; Yuan, J.; Li, L.; Wang, Y. Ionospheric TEC Prediction Base on Attentional BiGRU. Atmosphere 2022, 13, 1039. [Google Scholar] [CrossRef]
- Lu, Y.; Yang, R.; Jiang, X.; Zhou, D.; Yin, C.; Li, Z. MRE: A Military Relation Extraction Model Based on BiGRU and Multi-Head Attention. Symmetry 2021, 13, 1742. [Google Scholar] [CrossRef]
- Chen, J.; Zhang, J.; Chen, H.; Zhao, Y.; Wang, H. A TDV-Attention based BiGRU Network for AIS-based Vessel Trajectory Prediction. iScience 2023, 26, 106383. [Google Scholar] [CrossRef]
- Gao, Z.; Li, Z.; Luo, J.; Li, X. Short Text Aspect-Based Sentiment Analysis Based on CNN + BiGRU. Appl. Sci. 2022, 12, 2707. [Google Scholar] [CrossRef]
- Zhang, H.; Chen, Q.; Zhang, W. Improving Entity Linking with Two Adaptive Features. Front. Inf. Technol. Electron. Eng. 2022, 23, 1620–1630. [Google Scholar] [CrossRef]
- Soares, L.D.; Queiroz, A.d.S.; López, G.P.; Carreño-Franco, E.M.; López-Lezama, J.M.; Muñoz-Galeano, N. BiGRU-CNN Neural Network Applied to Electric Energy Theft Detection. Electronics 2022, 11, 693. [Google Scholar] [CrossRef]
- Chi, D.; Yang, C. Wind Power Prediction Based on WT-BiGRU-attention-TCN Model. Front. Energy Res. 2023, 11, 1156007. [Google Scholar] [CrossRef]
- Ruas, P.; Couto, F.M. NILINKER: Attention-based Approach to NIL Entity Linking. J. Biomed. Inform. 2022, 132, 104137. [Google Scholar] [CrossRef] [PubMed]
- Zhang, F.; Liu, X.; Tang, J.; Dong, Y.; Yao, P.; Zhang, J.; Gu, X.; Wang, Y.; Kharlamov, E.; Shao, B.; et al. OAG: Linking Entities across Large-scale Heterogeneous Knowledge Graphs. IEEE Trans. Knowl. Data Eng. 2022, 1–14. [Google Scholar] [CrossRef]
- Xue, M.; Cai, W.; Su, J.; Song, L.; Ge, Y.; Liu, Y.; Wang, B. Neural Collective Entity Linking Based on Recurrent Random Walk Network Learning. arXiv 2019, arXiv:1906.09320. [Google Scholar]
- Wu, J.; Zhang, R.; Mao, Y.; Guo, H.; Soflaei, M.; Huai, J. Dynamic Graph Convolutional Networks for Entity Linking. In Proceedings of the Web Conference 2020, Taipei, Taiwan, 20–24 April 2020; pp. 1149–1159. [Google Scholar]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}