
Explainable Feature Extraction and Prediction Framework for 3D Image Recognition Applied to Pneumonia Detection


Abstract
:1. Introduction
- We propose an interpretable rotation-invariant feature extraction framework, formally defining and introducing a set of explainable features for 3D images.
- This contributes to explainable ML by providing an interpretation for ML decisions in critical real-world applications, such as pneumonia detection, through the incorporation of efficient and explainable latent image representations in order to build interpretable, trustful, and accurate prediction models.
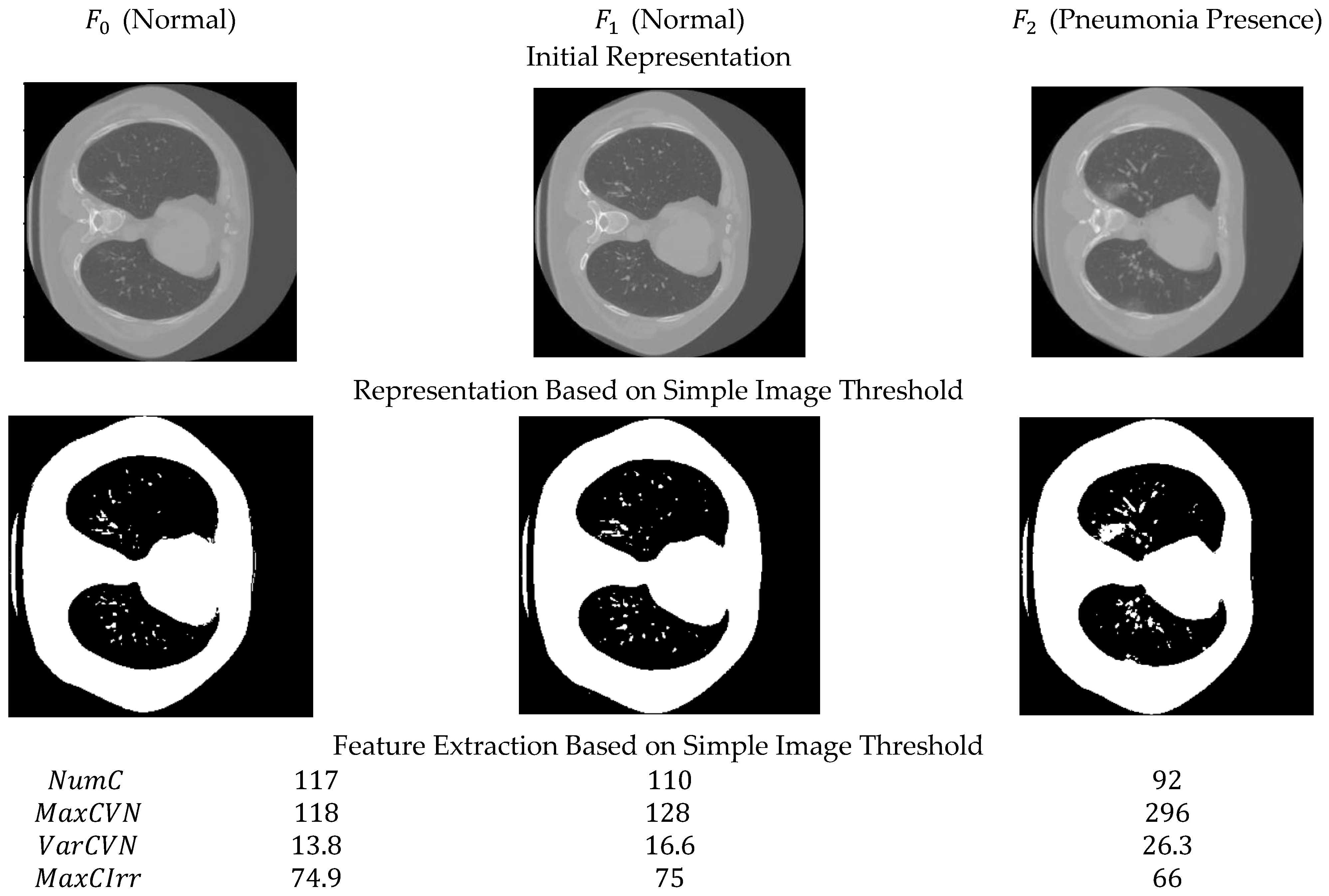
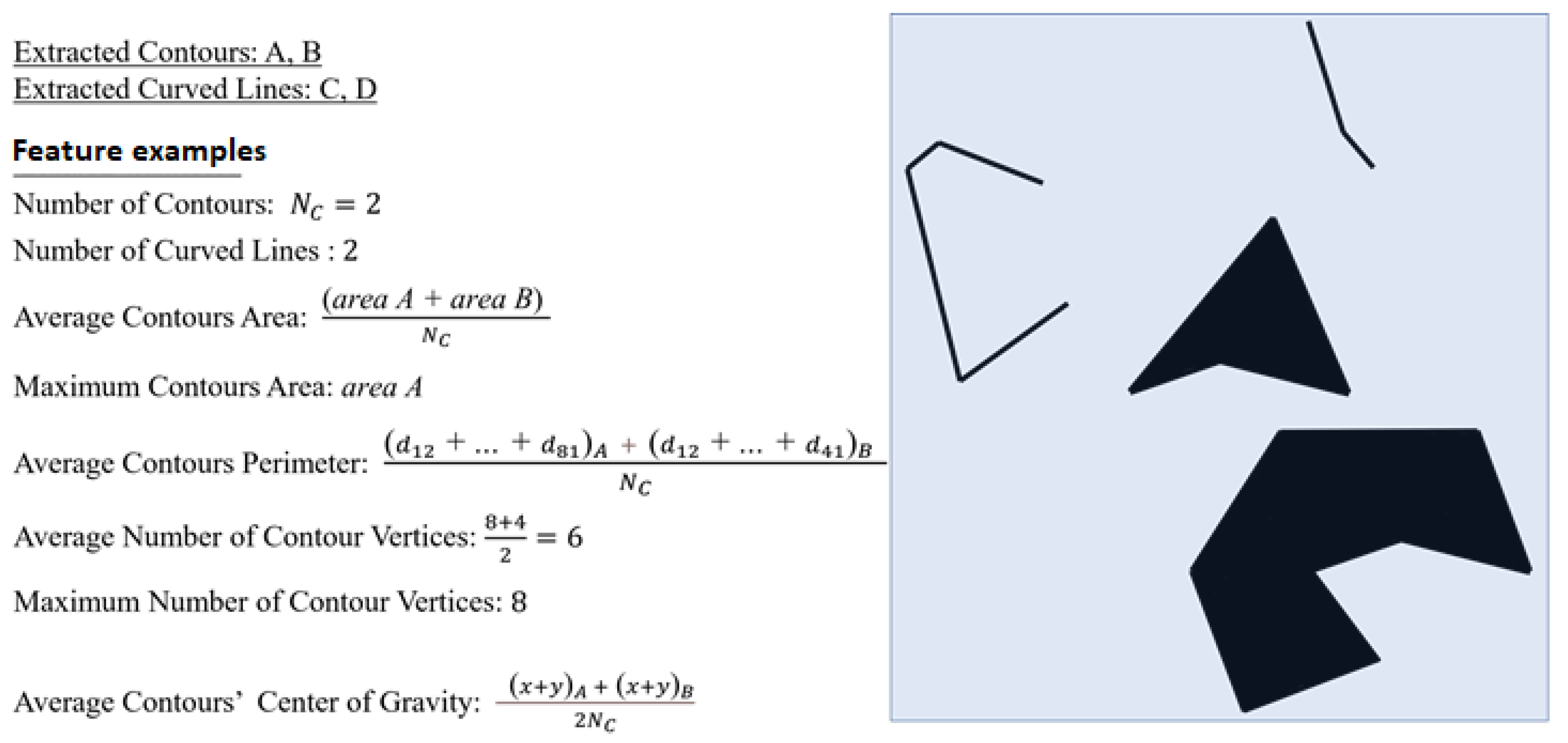
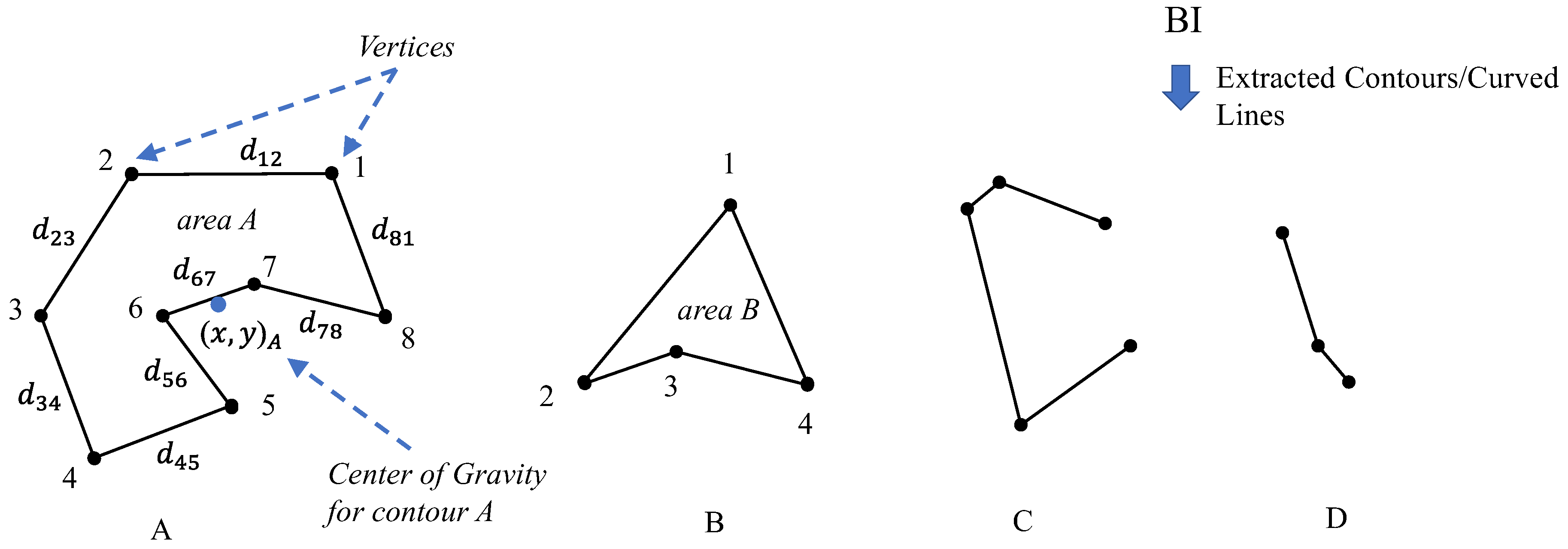
- We propose the idea of extracting contours in order to create and employ features, which are based on mathematical and geometric concepts, such as the number of contours, average contour area, average perimeter, the contour center of gravity, vertices, and edges. Such features are universally easy to understand and accepted as explainable.
- We propose an explainable 3D image classification framework that exhibits high performance when applied to pneumonia detection, managing to achieve a performance similar to or marginally better than state-of-the-art 3D-CNN black-box models. Considering the fact that the proposed approach is explainable, such a performance is particularly significant and noteworthy.
2. Related Work
3. Proposed Methodology
3.1. Proposed Framework Mathematical Description
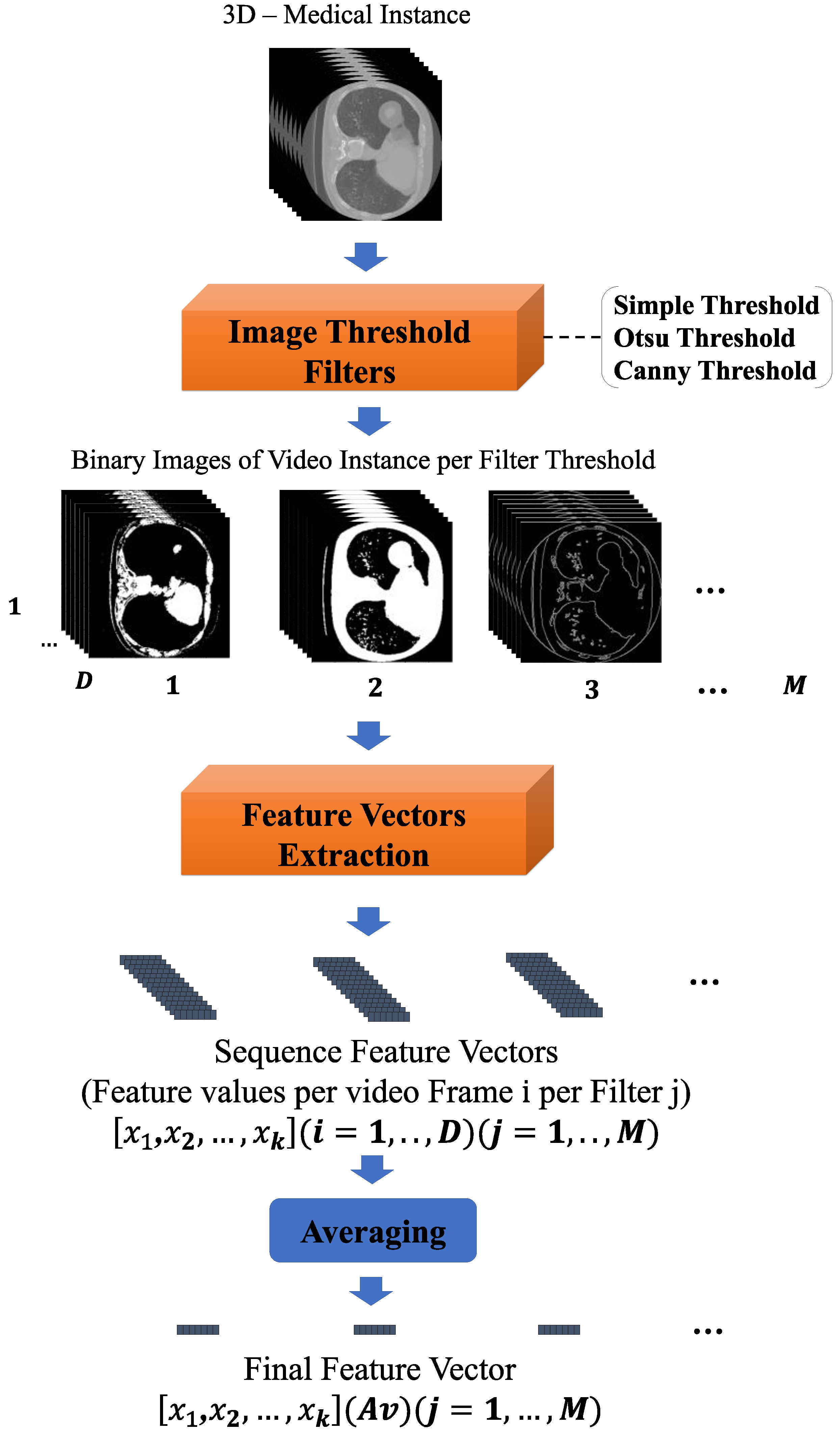
3.2. Feature Vectors Extraction Component
4. Experimental Setup and Results
4.1. Pneumonia Detection Problem
4.2. Presentation of Results
- Overall, the proposed framework exhibits better performance compared to other WB approaches when applied to the pneumonia detection problem.
- It also managed to outperform most of the other BB approaches. In particular, it slightly outperformed the best-identified BB approach (the I3D-SVM model managed to deliver the best results among the other BB approaches). However, it also managed to achieve the best geometric mean score of , surprisingly surpassing the I3D-SVM model. Considering the fact that the proposed approach is interpretable, such a performance is particularly significant.
- The Inception model produced the best results compared to ResNet for both their 2D and 3D versions.
- Among the ML models, the SVM classifier achieved, on average, the best results for all feature representation approaches.
- The best results, in general, were achieved for high compression sizes for the pneumonia dataset, while for lower compression sizes, rapid performance degradation was observed.
5. Discussion and Conclusions
- The whole feature extraction and classification procedure of the entire ML framework is totally transparent and interpretable.
- The final extracted features are explainable and meaningful in human terms.
- Last but not least, the final extracted features are invariant to image rotations.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Frameworks | Brief Description | Abstract Architecture | |
|---|---|---|---|
| HC Features (Explainable/WB) | HC1 (Proposed), HC2 [19], HC3 [2] | In the first phase, an HC approach extracts features for every 2D image frame of the 3D image input. In the second phase, the extracted feature vectors are averaged and finally fed into an ML model, which performs the classification task. | 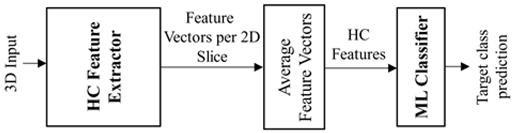 |
| 2D CNN Features (Non-Explainable/BB) | 2D-CNN–ML [28] | In the first phase, a 2D-CNN model extracts features for every 2D image frame/slice of the 3D image input. In the second phase, the extracted features are aggregated and fed into an ML model, which performs the classification task. | 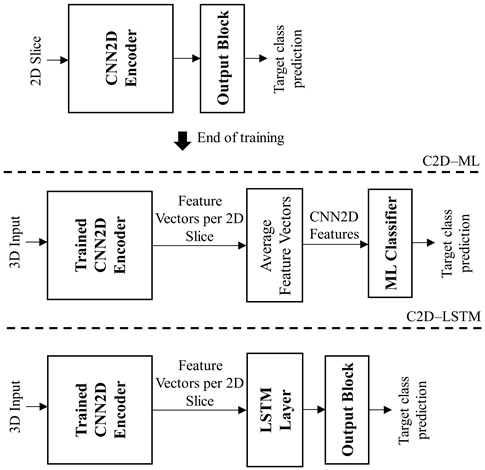 |
| 2D-CNN-LSTM [30] | Similar to the above approach, in the first phase, a trained 2D-CNN model extracts features for every 2D image frame/slice of the 3D image input. However, in the second phase, an LSTM layer is fed with the 2D-CNN features ordered in the time/spatial domain, followed by the final output layer, which performs the classification task. | ||
| 3D CNN Features (Non-Explainable/BB) | 3D-CNN E-E [31] | End–end (E-E) CNN approach. A 3D-CNN model, such as I3D and R3D, followed by an output block is trained with respect to a 3D classification task. | 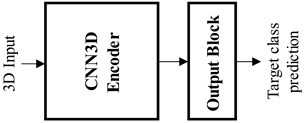 |
| 3D-CNN-ML [29,31] | The output block is discarded, while the 3D-CNN features are used for training a ML classification model, such as SVM. | 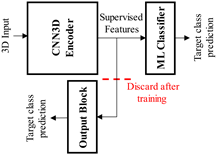 | |
 | |||
| ML | Machine Learning |
| CNN | Convolutional Neural Network |
| HC | Hand Crafted |
| WB | White Box |
| BB | Black Box |
| LR | Logistic Regression |
| DT | Decision Tree |
| I3D | 3D Inception |
| R3D | 3D ResNet |
| GAP | Global Averaging Pooling |
| FC | Fully Connected |
| BI | Binary Image |
References
- Pintelas, E.; Liaskos, M.; Livieris, I.E.; Kotsiantis, S.; Pintelas, P. Explainable Machine Learning Framework for Image Classification Problems: Case Study on Glioma Cancer Prediction. J. Imaging 2020, 6, 37. [Google Scholar] [CrossRef]
- Pintelas, E.; Liaskos, M.; Livieris, I.E.; Kotsiantis, S.; Pintelas, P. A novel explainable image classification framework: Case study on skin cancer and plant disease prediction. Neural Comput. Appl. 2021, 33, 15171–15189. [Google Scholar] [CrossRef]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Atkinson, K.; Bench-Capon, T.; Bollegala, D. Explanation in AI and law: Past, present and future. Artif. Intell. 2020, 289, 103387. [Google Scholar] [CrossRef]
- Xing, X.; Rafique, M.U.; Liang, G.; Blanton, H.; Zhang, Y.; Wang, C.; Jacobs, N.; Lin, A.-L. Efficient Training on Alzheimer’s Disease Diagnosis with Learnable Weighted Pooling for 3D PET Brain Image Classification. Electronics 2023, 12, 467. [Google Scholar] [CrossRef]
- Thandapani, S.; Mahaboob, M.I.; Iwendi, C.; Selvaraj, D.; Dumka, A.; Rashid, M.; Mohan, S. IoMT with Deep CNN: AI-Based Intelligent Support System for Pandemic Diseases. Electronics 2023, 12, 424. [Google Scholar] [CrossRef]
- da Cruz, H.F.; Pfahringer, B.; Martensen, T.; Schneider, F.; Meyer, A.; Böttinger, E.; Schapranow, M.-P. Using interpretability approaches to update “black-box” clinical prediction models: An external validation study in nephrology. Artif. Intell. Med. 2020, 111, 101982. [Google Scholar] [CrossRef]
- Molnar, C. Interpretable Machine Learning: A Guide for Making Black Box Models Explainable; Leanpub: Victoria, BC, Canada, 2018. [Google Scholar]
- Setzu, M.; Guidotti, R.; Monreale, A.; Turini, F.; Pedreschi, D.; Giannotti, F. GLocalX—From Local to Global Explanations of Black Box AI Models. Artif. Intell. 2021, 294, 103457. [Google Scholar] [CrossRef]
- Pintelas, E.; Livieris, I.E.; Pintelas, P. A Grey-Box Ensemble Model Exploiting Black-Box Accuracy and White-Box Intrinsic Interpretability. Algorithms 2020, 13, 17. [Google Scholar] [CrossRef] [Green Version]
- Gao, Q.; Lim, S. Classification of hyperspectral images with convolutional neural networks and probabilistic relaxation. Comput. Vis. Image Underst. 2019, 188, 102801. [Google Scholar] [CrossRef]
- Mishra, R.K.; Urolagin, S.; Jothi, J.A.A.; Gaur, P. Deep hybrid learning for facial expression binary classifications and predictions. Image Vis. Comput. 2022, 128, 104573. [Google Scholar] [CrossRef]
- Chen, S.; Liu, D.; Pu, Y.; Zhong, Y. Advances in deep learning-based image recognition of product packaging. Image Vis. Comput. 2022, 128, 104571. [Google Scholar] [CrossRef]
- Ye, X.; Bilodeau, G.-A. Video prediction by efficient transformers. Image Vis. Comput. 2023, 130, 104612. [Google Scholar] [CrossRef]
- Lu, L.; Wang, X.; Carneiro, G.; Yang, L. (Eds.) Deep Learning and Convolutional Neural Networks for Medical Imaging and Clinical Informatics; Springer International Publishing: Berlin/Heidelberg, Germany, 2019. [Google Scholar]
- Hemanth, D.J.; Estrela, V.V. (Eds.) Deep Learning for Image Processing Applications; IOS Press: Amsterdam, The Netherlands, 2017; Volume 31. [Google Scholar]
- Kenny, E.M.; Ford, C.; Quinn, M.; Keane, M.T. Explaining black-box classifiers using post-hoc explanations-by-example: The effect of explanations and error-rates in XAI user studies. Artif. Intell. 2021, 294, 103459. [Google Scholar] [CrossRef]
- Pintelas, E.; Pintelas, P. A 3D-CAE-CNN model for Deep Representation Learning of 3D images. Eng. Appl. Artif. Intell. 2022, 113, 104978. [Google Scholar] [CrossRef]
- Durall, R.; Keuper, M.; Pfreundt, F.J.; Keuper, J. Unmasking deepfakes with simple features. arXiv 2019, arXiv:1911.00686. [Google Scholar]
- Hejazi, S.M.; Abhayaratne, C. Handcrafted localized phase features for human action recognition. Image Vis. Comput. 2022, 123, 104465. [Google Scholar] [CrossRef]
- Esteves, C.; Allen-Blanchette, C.; Zhou, X.; Danilidis, K. Polar transformer networks. In Proceedings of the ICLR, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Harmon, S.A.; Sanford, T.H.; Xu, S.; Turkbey, E.B.; Roth, H.; Xu, Z.; Yang, D.; Myronenko, A.; Anderson, V.; Amalou, A.; et al. Artificial intelligence for the detection of COVID-19 pneumonia on chest CT using multinational datasets. Nat. Commun. 2020, 11, 4080. [Google Scholar] [CrossRef]
- Ko, H.; Chung, H.; Kang, W.S.; Kim, K.W.; Shin, Y.; Kang, S.J.; Lee, J.H.; Kim, Y.J.; Kim, N.Y.; Jung, H.; et al. COVID-19 pneumonia diagnosis using a simple 2d deep learning framework with a single chest ct image: Model development and validation. J. Med. Internet Res. 2020, 22, e19569. [Google Scholar] [CrossRef]
- Comito, C.; Pizzuti, C. Artificial intelligence for forecasting and diagnosing COVID-19 pandemic: A focused review. Artif. Intell. Med. 2022, 128, 102286. [Google Scholar] [CrossRef]
- Ciocca, G.; Napoletano, P.; Schettini, R. CNN-based features for retrieval and classification of food images. Comput. Vis. Image Underst. 2018, 176–177, 70–77. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Rabinovich, A. GoogLeNet/Inception Going deeper with convolutions. In Proceedings of the CVPR, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Karpathy, A.; Toderici, G.; Shetty, S.; Leung, T.; Sukthankar, R.; Li, F.-F. Large-scale video classification with convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2014; pp. 1725–1732. [Google Scholar]
- Niu, X.-X.; Suen, C.Y. A novel hybrid CNN–SVM classifier for recognizing handwritten digits. Pattern Recognit. 2012, 45, 1318–1325. [Google Scholar] [CrossRef]
- Güera, D.; Delp, E.J. Deepfake video detection using recurrent neural networks. In Proceedings of the 2018 15th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Auckland, New Zealand, 27–30 November 2018; pp. 1–6. [Google Scholar]
- Carreira, J.; Zisserman, A. Quo vadis, action recognition? a new model and the kinetics dataset. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6299–6308. [Google Scholar]
- Vernikos, I.; Mathe, E.; Spyrou, E.; Mitsou, A.; Giannakopoulos, T.; Mylonas, P. Fusing Handcrafted and Contextual Features for Human Activity Recognition. In Proceedings of the 2019 14th International Workshop on Semantic and Social Media Adaptation and Personalization (SMAP), Larnaca, Cyprus, 9–10 June 2019; pp. 1–6. [Google Scholar]
- Senthilkumaran, N.; Vaithegi, S. Image Segmentation by Using Thresholding Techniques For Medical Images. Comput. Sci. Eng. Int. J. 2016, 6, 1–13. [Google Scholar]
- Savant, S. A review on edge detection techniques for image segmentation. Int. J. Comput. Sci. Inf. Technol. 2014, 5, 5898–5900. [Google Scholar]
- Morozov, S.P.; Andreychenko, A.E.; Blokhin, I.A.; Gelezhe, P.B.; Gonchar, A.P.; Nikolaev, A.E.; Pavlov, N.A.; Chernina, V.Y.; Gombolevskiy, V.A. MosMedData: Chest CT Scans with COVID-19 Related Findings Dataset. Preprint 2020. [Google Scholar] [CrossRef]
- Livieris, I.E.; Pintelas, P. A novel multi-step forecasting strategy for enhancing deep learning models’ performance. Neural Comput. Appl. 2022, 34, 19453–19470. [Google Scholar] [CrossRef]
- Livieris, I.E.; Kiriakidou, N.; Stavroyiannis, S.; Pintelas, P. An Advanced CNN-LSTM Model for Cryptocurrency Forecasting. Electronics 2021, 10, 287. [Google Scholar] [CrossRef]
- Livieris, I.E.; Kiriakidou, N.; Kanavos, A.; Vonitsanos, G.; Tampakas, V. Employing constrained neural networks for forecasting new product’s sales increase. In Artificial Intelligence Applications and Innovations; Springer International Publishing: Berlin/Heidelberg, Germany, 2019; pp. 161–172. [Google Scholar]
- Zhang, Z. Improved ADAM optimizer for deep neural networks. In Proceedings of the 2018 IEEE/ACM 26th International Symposium on Quality of Service (IWQoS), Banff, AB, Canada, 4–6 June 2018; pp. 1–2. [Google Scholar]
| 3D Image Dimension Sizes | Val. Metrics | HC Features (Explainable) | 2D-CNN Features (Non-Explainable) | 3D-CNN Features (Non-Explainable) | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| HC1 (Proposed) | HC2 | HC3 | R2D | I2D | R3D | I3D | |||||||||
| LR | DT | LR | DT | LR | DT | LSTM | SVM | LSTM | SVM | E-E | SVM | E-E | SVM | ||
| GM | 0.816 | 0.728 | 0.586 | 0.519 | 0.706 | 0.673 | 0.707 | 0.737 | 0.807 | 0.790 | 0.755 | 0.767 | 0.835 | 0.840 | |
| Sen | 0.824 | 0.765 | 0.471 | 0.412 | 0.647 | 0.588 | 0.765 | 0.706 | 0.706 | 0.706 | 0.706 | 0.765 | 0.824 | 0.706 | |
| Spe | 0.808 | 0.692 | 0.731 | 0.654 | 0.769 | 0.769 | 0.654 | 0.769 | 0.923 | 0.885 | 0.808 | 0.654 | 0.846 | 1.0 | |
| GM | 0.883 | 0.737 | 0.669 | 0.638 | 0.605 | 0.689 | 0.638 | 0.688 | 0.804 | 0.822 | 0.673 | 0.707 | 0.840 | 0.824 | |
| Sen | 0.882 | 0.706 | 0.647 | 0.588 | 0.529 | 0.824 | 0.588 | 0.647 | 0.647 | 0.765 | 0.588 | 0.765 | 0.706 | 0.706 | |
| Spe | 0.885 | 0.769 | 0.692 | 0.692 | 0.692 | 0.577 | 0.692 | 0.731 | 1.000 | 0.885 | 0.769 | 0.654 | 1.000 | 0.962 | |
| GM | 0.723 | 0.622 | 0.620 | 0.638 | 0.638 | 0.656 | 0.688 | 0.673 | 0.761 | 0.737 | 0.723 | 0.773 | 0.737 | 0.761 | |
| Sen | 0.647 | 0.529 | 0.588 | 0.529 | 0.588 | 0.588 | 0.647 | 0.588 | 0.941 | 0.882 | 0.647 | 0.706 | 0.882 | 0.941 | |
| Spe | 0.808 | 0.731 | 0.654 | 0.769 | 0.692 | 0.731 | 0.731 | 0.769 | 0.615 | 0.615 | 0.808 | 0.846 | 0.615 | 0.615 | |
| GM | 0.804 | 0.688 | 0.642 | 0.638 | 0.654 | 0.659 | 0.755 | 0.740 | 0.760 | 0.807 | 0.737 | 0.790 | 0.790 | 0.822 | |
| Sen | 0.765 | 0.647 | 0.765 | 0.706 | 0.529 | 0.471 | 0.706 | 0.647 | 0.882 | 0.706 | 0.706 | 0.706 | 0.706 | 0.765 | |
| Spe | 0.846 | 0.731 | 0.538 | 0.577 | 0.808 | 0.923 | 0.808 | 0.846 | 0.654 | 0.923 | 0.769 | 0.885 | 0.885 | 0.885 | |
| GM | 0.822 | 0.712 | 0.642 | 0.659 | 0.631 | 0.602 | 0.673 | 0.706 | 0.706 | 0.688 | 0.718 | 0.718 | 0.740 | 0.721 | |
| Sen | 0.765 | 0.824 | 0.824 | 0.706 | 0.471 | 0.588 | 0.588 | 0.647 | 0.647 | 0.647 | 0.706 | 0.824 | 0.647 | 0.588 | |
| Spe | 0.885 | 0.615 | 0.500 | 0.615 | 0.846 | 0.615 | 0.769 | 0.769 | 0.769 | 0.731 | 0.731 | 0.615 | 0.846 | 0.846 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pintelas, E.; Livieris, I.E.; Pintelas, P. Explainable Feature Extraction and Prediction Framework for 3D Image Recognition Applied to Pneumonia Detection. Electronics 2023, 12, 2663. https://doi.org/10.3390/electronics12122663
Pintelas E, Livieris IE, Pintelas P. Explainable Feature Extraction and Prediction Framework for 3D Image Recognition Applied to Pneumonia Detection. Electronics. 2023; 12(12):2663. https://doi.org/10.3390/electronics12122663
Chicago/Turabian StylePintelas, Emmanuel, Ioannis E. Livieris, and Panagiotis Pintelas. 2023. "Explainable Feature Extraction and Prediction Framework for 3D Image Recognition Applied to Pneumonia Detection" Electronics 12, no. 12: 2663. https://doi.org/10.3390/electronics12122663
APA StylePintelas, E., Livieris, I. E., & Pintelas, P. (2023). Explainable Feature Extraction and Prediction Framework for 3D Image Recognition Applied to Pneumonia Detection. Electronics, 12(12), 2663. https://doi.org/10.3390/electronics12122663