
A Survey on Sparsity Exploration in Transformer-Based Accelerators


Abstract
1. Introduction
2. Background
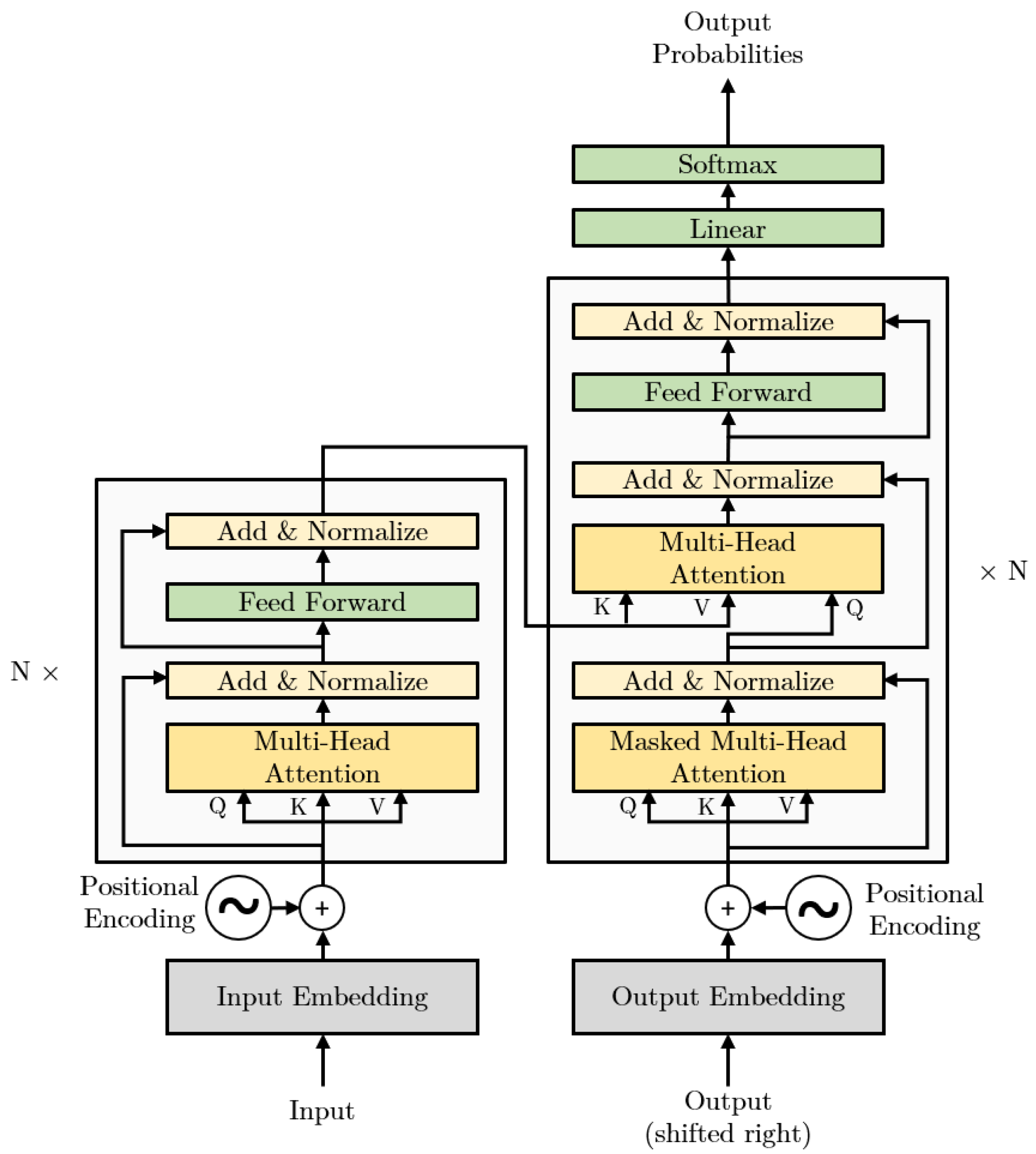
2.1. Transformer Architecture
2.1.1. Encoder
2.1.2. Decoder
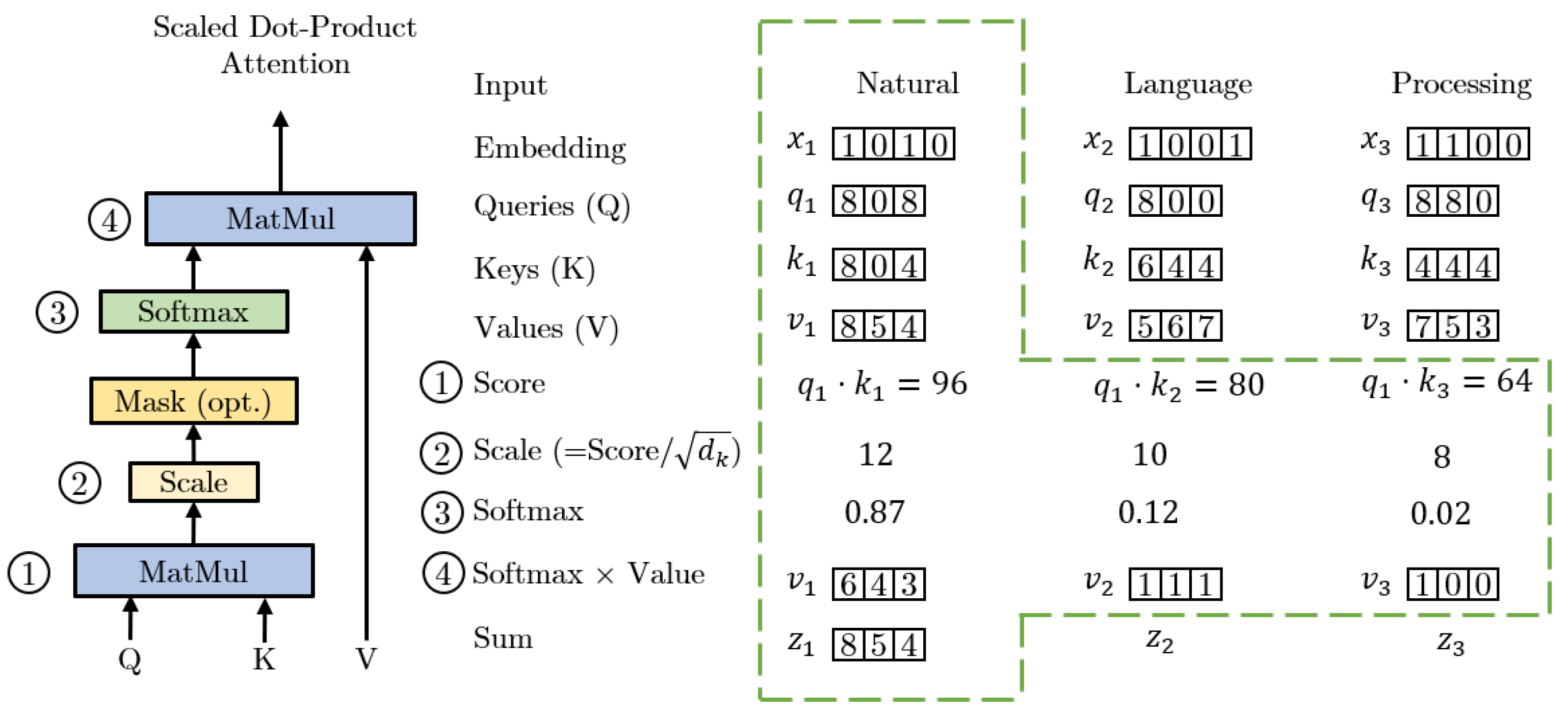
2.1.3. Transformer Attention Mechanism
2.1.4. Position-Wise Feed-Forward Network
2.1.5. Embedding and Positional Encoding
2.2. Sparsity in Deep Learning Models
3. Overview of the Transformer-Based Accelerators Exploring Sparsity
4. In-Depth Analysis of Key Approaches
4.1. Accelerators Exploring Static Sparsity
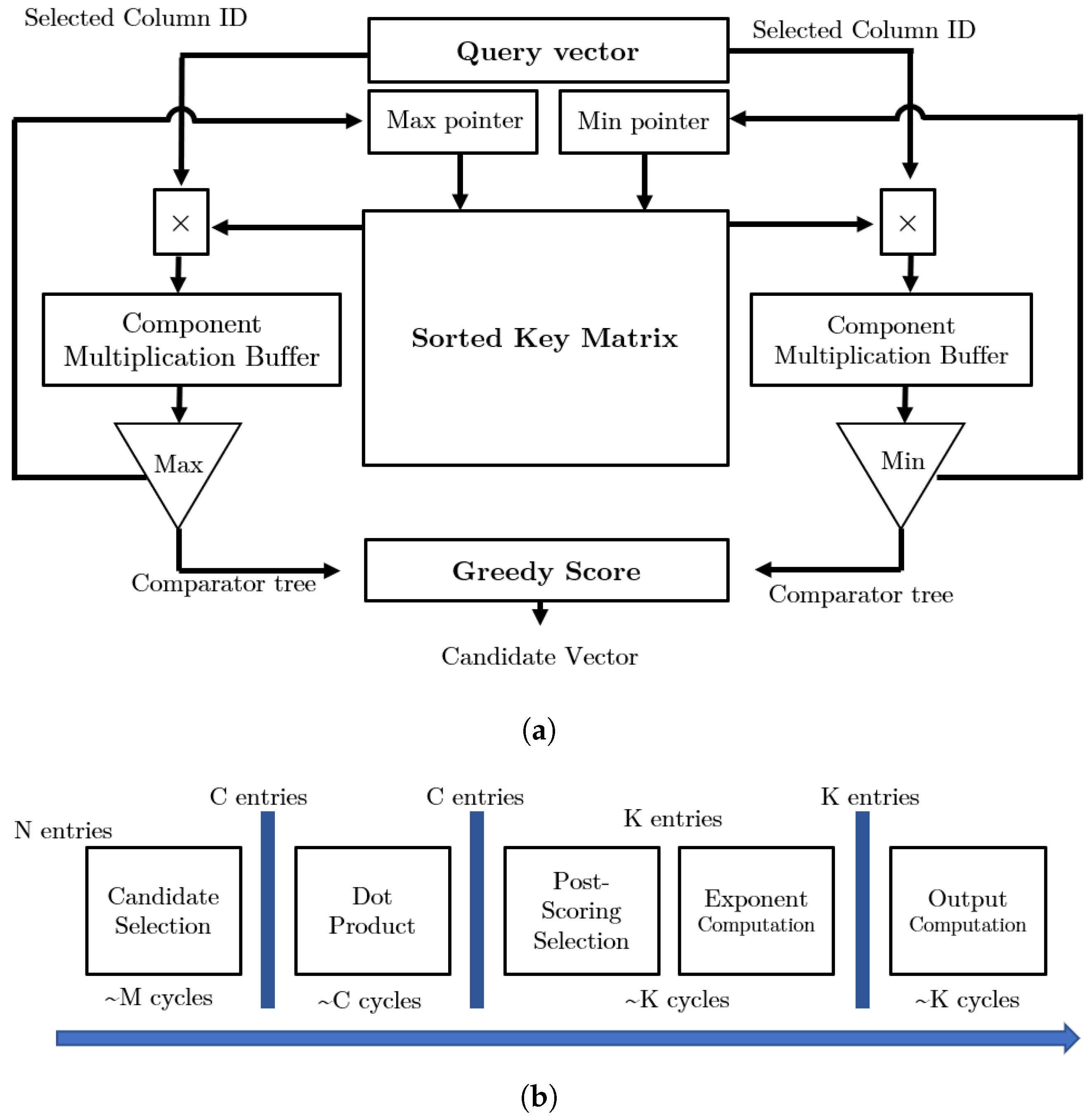
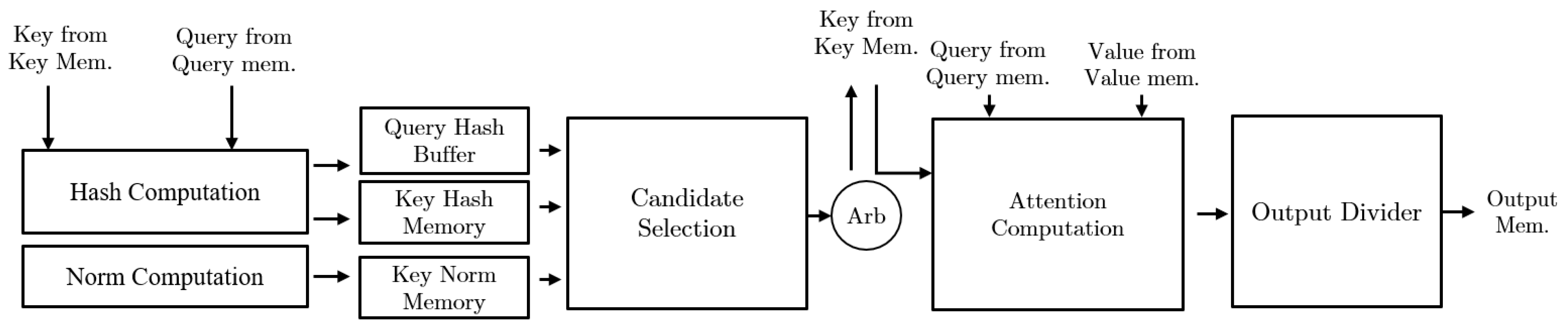
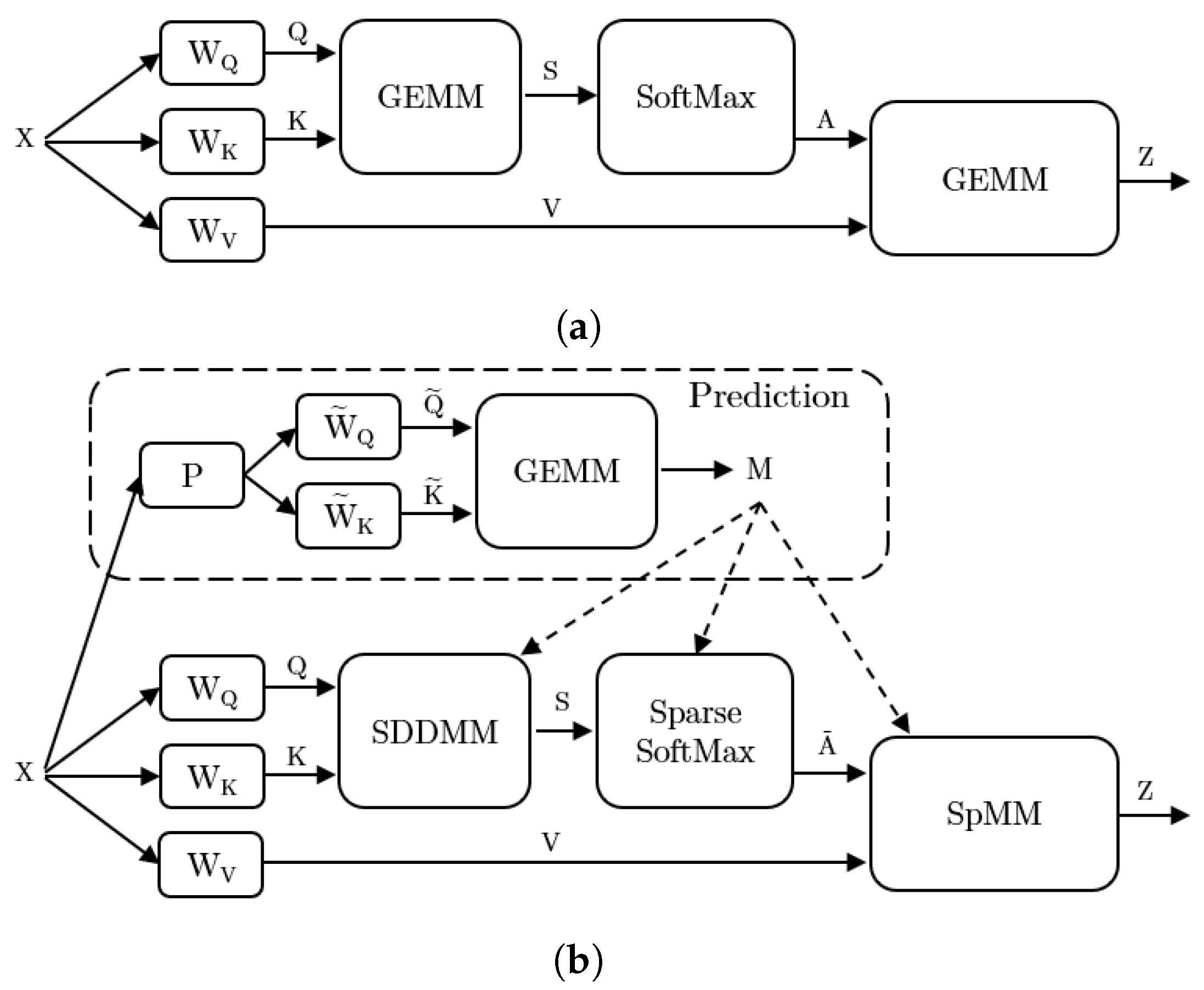
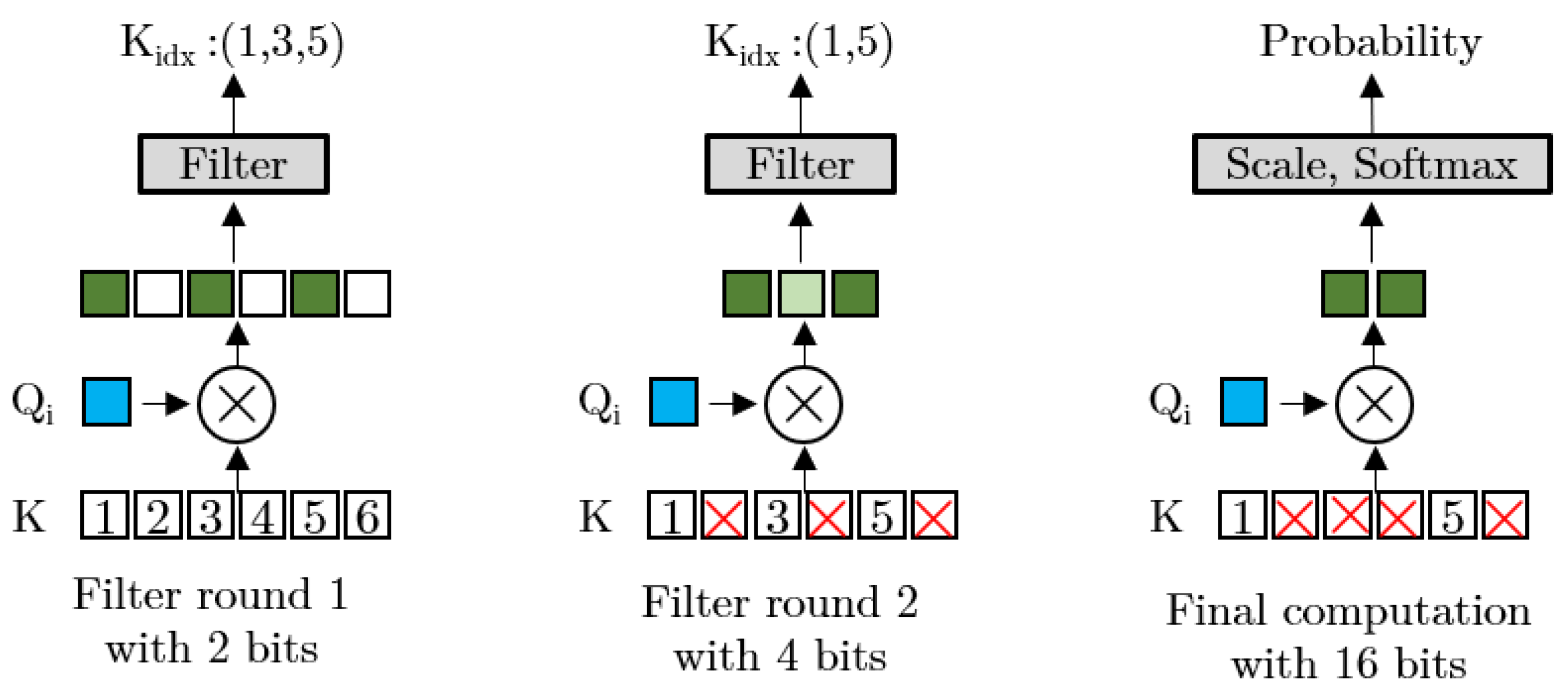
4.2. Accelerators Exploring Sparsity with Approximate Candidate Selection
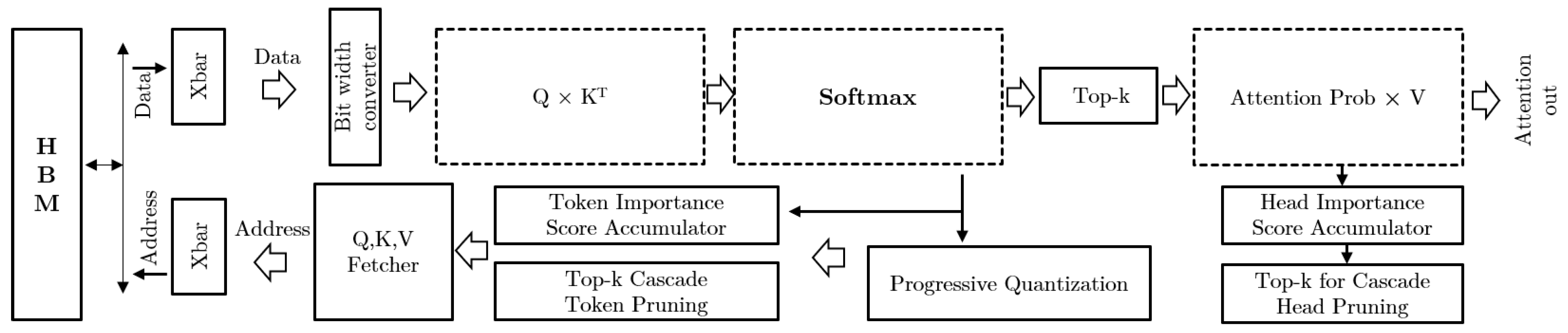
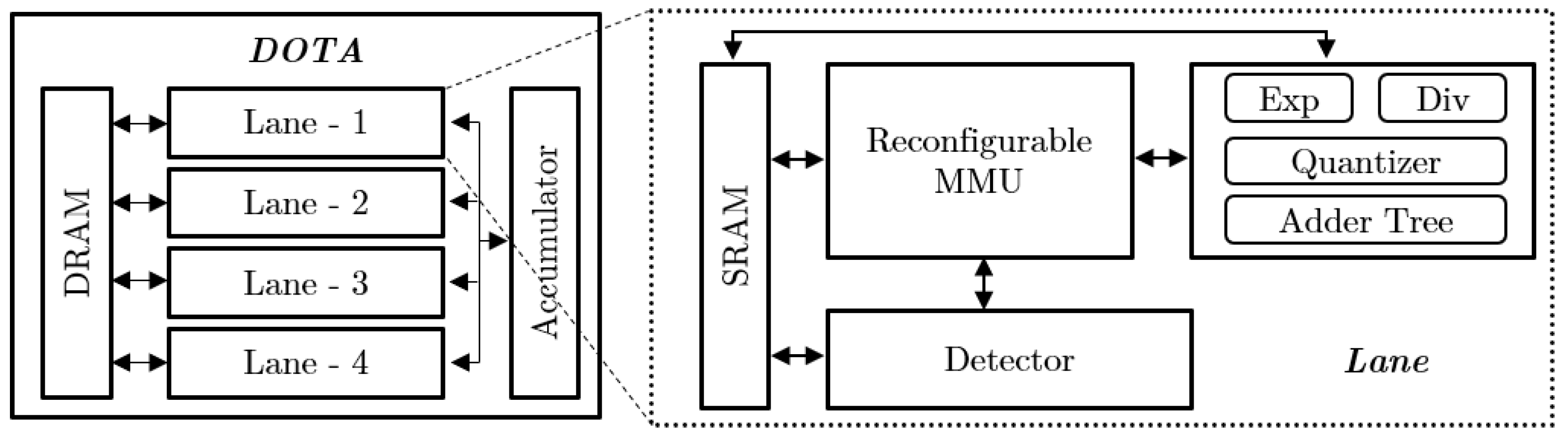
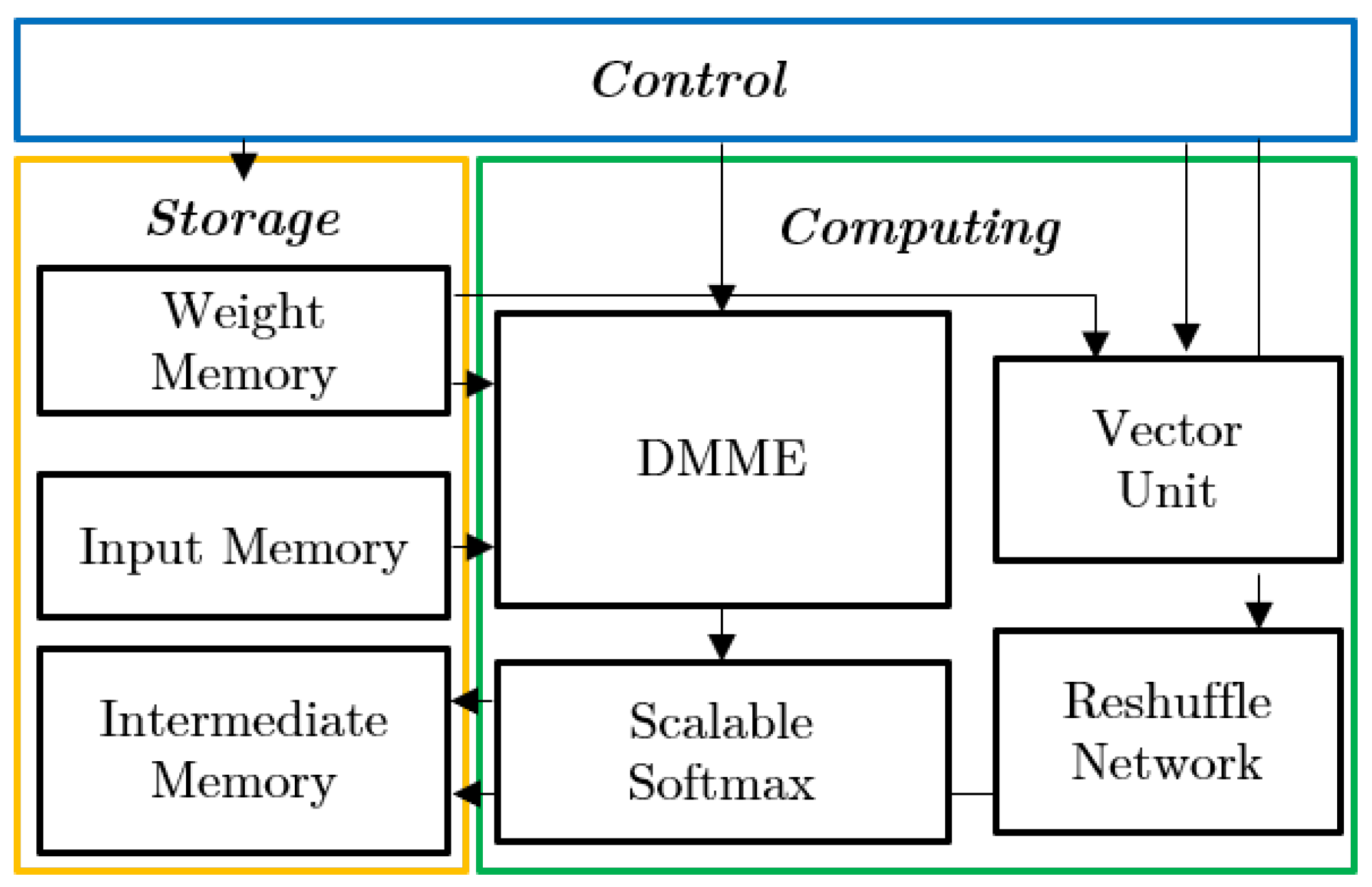
4.3. Accelerators Exploring Dynamic Sparsity with Mixed-Precision Selection
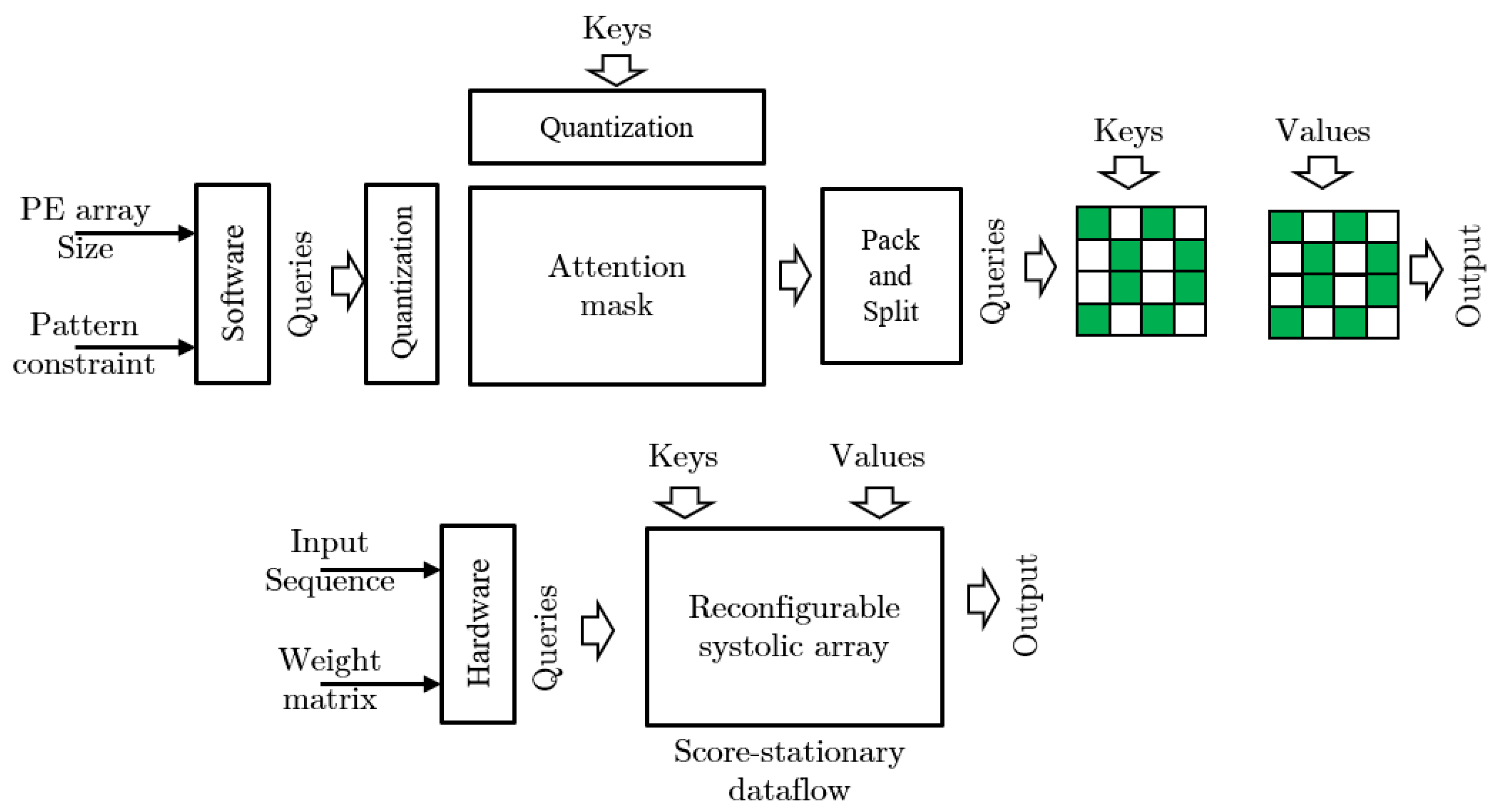
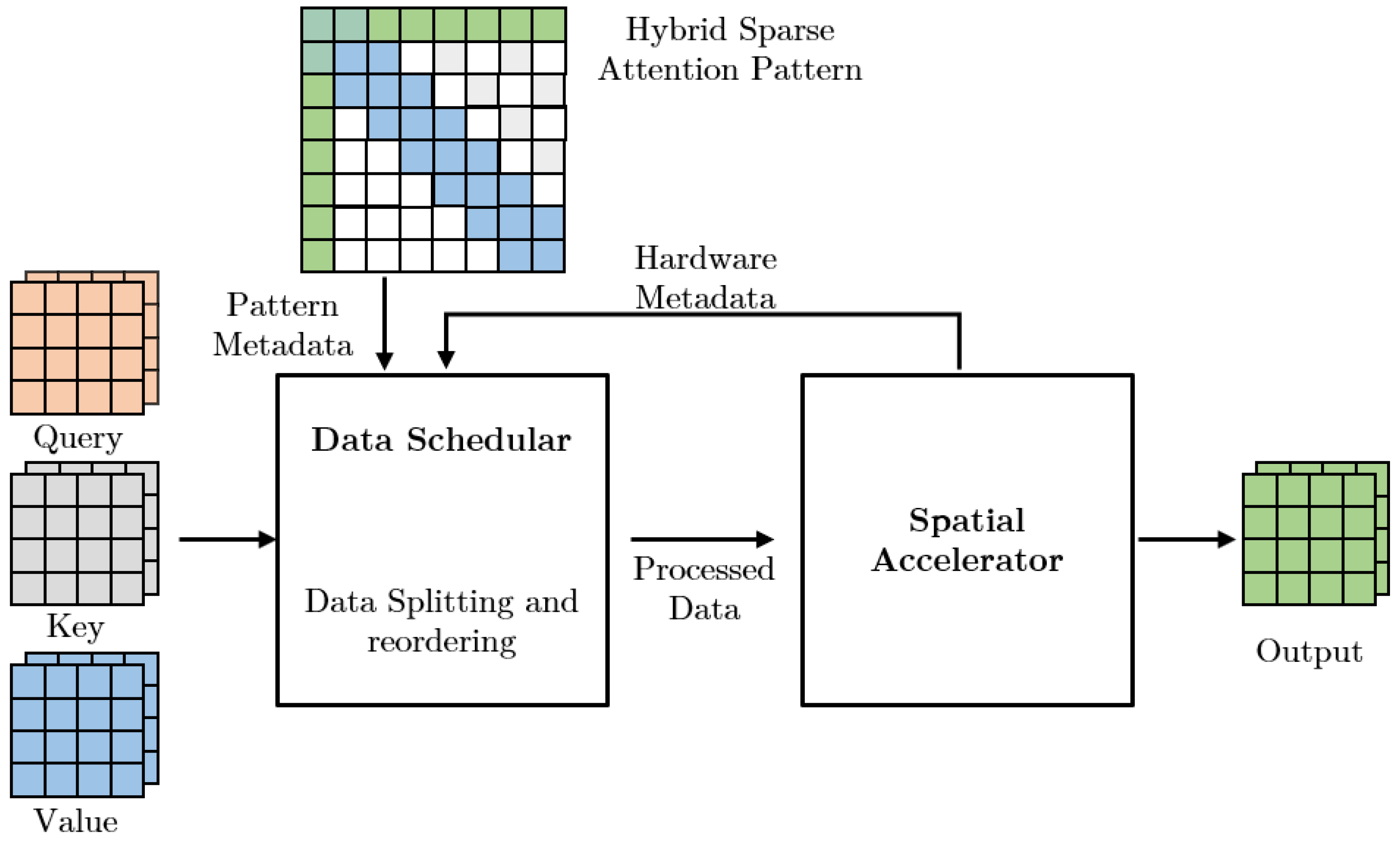
4.4. Accelerators Exploring Hybrid Sparse Pattern
5. Discussions and Future Directions
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems: Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Lu, L.; Jin, Y.; Bi, H.; Luo, Z.; Li, P.; Wang, T.; Liang, Y. Sanger: A Co-Design Framework for Enabling Sparse Attention Using Reconfigurable Architecture. In Proceedings of the MICRO ’21, MICRO-54: 54th Annual IEEE/ACM International Symposium on Microarchitecture, Virtual, 18–22 October 2021; Association for Computing Machinery: New York, NY, USA, 2021; pp. 977–991. [Google Scholar] [CrossRef]
- Ham, T.J.; Lee, Y.; Seo, S.H.; Kim, S.; Choi, H.; Jung, S.J.; Lee, J.W. ELSA: Hardware-Software Co-design for Efficient, Lightweight Self-Attention Mechanism in Neural Networks. In Proceedings of the 2021 ACM/IEEE 48th Annual International Symposium on Computer Architecture (ISCA), Valencia, Spain, 14–18 June 2021; pp. 692–705. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- Shoeybi, M.; Patwary, M.; Puri, R.; LeGresley, P.; Casper, J.; Catanzaro, B. Megatron-lm: Training multi-billion parameter language models using model parallelism. arXiv 2019, arXiv:1909.08053. [Google Scholar]
- Rosset, C. Turing-NLG: A 17-Billion-Parameter Language Model by Microsoft. 2020. Available online: https://www.microsoft.com/en-us/research/blog/turing-nlg-a-17-billion-parameter-language-model-by-microsoft/ (accessed on 19 December 2022).
- Wang, H.; Zhang, Z.; Han, S. SpAtten: Efficient Sparse Attention Architecture with Cascade Token and Head Pruning. arXiv, 2012. [Google Scholar]
- Ham, T.; Jung, S.; Kim, S.; Oh, Y.H.; Park, Y.; Song, Y.; Park, J.; Lee, S.; Park, K.; Lee, J.W.; et al. A3: Accelerating Attention Mechanisms in Neural Networks with Approximation. In Proceedings of the 2020 IEEE International Symposium on High Performance Computer Architecture (HPCA), San Diego, CA, USA, 22–26 February 2020; IEEE Computer Society: Los Alamitos, CA, USA, 2020; pp. 328–341. [Google Scholar] [CrossRef]
- Strubell, E.; Ganesh, A.; McCallum, A. Energy and policy considerations for deep learning in NLP. arXiv 2019, arXiv:1906.02243. [Google Scholar]
- So, D.; Le, Q.; Liang, C. The evolved transformer. In Proceedings of the International Conference on Machine Learning. PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 5877–5886. [Google Scholar]
- Sze, V.; Chen, Y.H.; Yang, T.J.; Emer, J.S. Efficient processing of deep neural networks: A tutorial and survey. Proc. IEEE 2017, 105, 2295–2329. [Google Scholar] [CrossRef]
- Zhou, Z.; Liu, J.; Gu, Z.; Sun, G. Energon: Towards Efficient Acceleration of Transformers Using Dynamic Sparse Attention. arXiv, 2010. [Google Scholar]
- Tambe, T.; Hooper, C.; Pentecost, L.; Jia, T.; Yang, E.Y.; Donato, M.; Sanh, V.; Whatmough, P.; Rush, A.M.; Brooks, D.; et al. EdgeBERT: Sentence-Level Energy Optimizations for Latency-Aware Multi-Task NLP Inference. In Proceedings of the MICRO ’21, MICRO-54: 54th Annual IEEE/ACM International Symposium on Microarchitecture, Virtual, 18–22 October 2021; Association for Computing Machinery: New York, NY, USA, 2021; pp. 830–844. [Google Scholar] [CrossRef]
- Graves, A. Generating sequences with recurrent neural networks. arXiv 2013, arXiv:1308.0850. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Ba, J.L.; Kiros, J.R.; Hinton, G.E. Layer normalization. arXiv 2016, arXiv:1607.06450. [Google Scholar]
- Dave, S.; Baghdadi, R.; Nowatzki, T.; Avancha, S.; Shrivastava, A.; Li, B. Hardware acceleration of sparse and irregular tensor computations of ml models: A survey and insights. Proc. IEEE 2021, 109, 1706–1752. [Google Scholar] [CrossRef]
- Park, J.; Yoon, H.; Ahn, D.; Choi, J.; Kim, J.J. OPTIMUS: OPTImized matrix MUltiplication Structure for Transformer neural network accelerator. Proc. Mach. Learn. Syst. 2020, 2, 363–378. [Google Scholar]
- Li, B.; Pandey, S.; Fang, H.; Lyv, Y.; Li, J.; Chen, J.; Xie, M.; Wan, L.; Liu, H.; Ding, C. Ftrans: Energy-efficient acceleration of transformers using fpga. In Proceedings of the ACM/IEEE International Symposium on Low Power Electronics and Design, Boston, MA, USA, 10–12 August 2020; pp. 175–180. [Google Scholar]
- Liu, L.; Qu, Z.; Chen, Z.; Tu, F.; Ding, Y.; Xie, Y. Dynamic Sparse Attention for Scalable Transformer Acceleration. IEEE Trans. Comput. 2022, 71, 3165–3178. [Google Scholar] [CrossRef]
- Qu, Z.; Liu, L.; Tu, F.; Chen, Z.; Ding, Y.; Xie, Y. DOTA: Detect and Omit Weak Attentions for Scalable Transformer Acceleration. In Proceedings of the ASPLOS ’22, 27th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Lausanne, Switzerland, 28 February–4 March 2022; Association for Computing Machinery: New York, NY, USA, 2022; pp. 14–26. [Google Scholar] [CrossRef]
- Shen, G.; Zhao, J.; Chen, Q.; Leng, J.; Li, C.; Guo, M. SALO: An Efficient Spatial Accelerator Enabling Hybrid Sparse Attention Mechanisms for Long Sequences. In Proceedings of the DAC ’22, 59th ACM/IEEE Design Automation Conference, San Francisco, CA, USA, 10–14 July 2022; Association for Computing Machinery: New York, NY, USA, 2022; pp. 571–576. [Google Scholar] [CrossRef]
- Fang, C.; Zhou, A.; Wang, Z. An Algorithm–Hardware Co-Optimized Framework for Accelerating N:M Sparse Transformers. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2022, 30, 1573–1586. [Google Scholar] [CrossRef]
- Fang, C.; Guo, S.; Wu, W.; Lin, J.; Wang, Z.; Hsu, M.K.; Liu, L. An Efficient Hardware Accelerator for Sparse Transformer Neural Networks. In Proceedings of the 2022 IEEE International Symposium on Circuits and Systems (ISCAS), Austin, TX, USA, 27 May–1 June 2022; pp. 2670–2674. [Google Scholar] [CrossRef]
- Sanh, V.; Wolf, T.; Rush, A. Movement Pruning: Adaptive Sparsity by Fine-Tuning. In Proceedings of the Advances in Neural Information Processing Systems, Online, 6–12 December 2020; Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., Lin, H., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2020; Volume 33, pp. 20378–20389. [Google Scholar]
- Han, S.; Mao, H.; Dally, W.J. Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding. arXiv 2015, arXiv:1510.00149. [Google Scholar]
- NVIDIA. NVIDIA AMPERE GA102 GPU Architecture; Technical Report; NVIDIA: Santa Clara, CA, USA, 2021. [Google Scholar]
- Lu, S.; Wang, M.; Liang, S.; Lin, J.; Wang, Z. Hardware accelerator for multi-head attention and position-wise feed-forward in the transformer. In Proceedings of the 2020 IEEE 33rd International System-on-Chip Conference (SOCC), Virtual, 8–11 September 2020; pp. 84–89. [Google Scholar]
- Tu, F.; Wu, Z.; Wang, Y.; Liang, L.; Liu, L.; Ding, Y.; Liu, L.; Wei, S.; Xie, Y.; Yin, S. TranCIM: Full-Digital Bitline-Transpose CIM-based Sparse Transformer Accelerator With Pipeline/Parallel Reconfigurable Modes. IEEE J. Solid-State Circuits 2022, 1–12. [Google Scholar] [CrossRef]
- Tuli, S.; Jha, N.K. EdgeTran: Co-designing Transformers for Efficient Inference on Mobile Edge Platforms. arXiv 2023, arXiv:2303.13745. [Google Scholar]
- Tuli, S.; Jha, N.K. AccelTran: A sparsity-aware accelerator for dynamic inference with transformers. arXiv 2023, arXiv:2302.14705. [Google Scholar] [CrossRef]
- Zhou, A.; Ma, Y.; Zhu, J.; Liu, J.; Zhang, Z.; Yuan, K.; Sun, W.; Li, H. Learning N: M fine-grained structured sparse neural networks from scratch. arXiv 2021, arXiv:2102.04010. [Google Scholar]
- Mishra, A.; Latorre, J.A.; Pool, J.; Stosic, D.; Stosic, D.; Venkatesh, G.; Yu, C.; Micikevicius, P. Accelerating sparse deep neural networks. arXiv 2021, arXiv:2104.08378. [Google Scholar]
- Hoefler, T.; Alistarh, D.; Ben-Nun, T.; Dryden, N.; Peste, A. Sparsity in deep learning: Pruning and growth for efficient inference and training in neural networks. J. Mach. Learn. Res. 2021, 22, 10882–11005. [Google Scholar]
- Wang, S.; Li, B.Z.; Khabsa, M.; Fang, H.; Ma, H. Linformer: Self-attention with linear complexity. arXiv 2020, arXiv:2006.04768. [Google Scholar]
- Qin, Z.; Sun, W.; Deng, H.; Li, D.; Wei, Y.; Lv, B.; Yan, J.; Kong, L.; Zhong, Y. cosFormer: Rethinking Softmax in Attention. arXiv 2022, arXiv:2202.08791. [Google Scholar]
- Choromanski, K.; Likhosherstov, V.; Dohan, D.; Song, X.; Gane, A.; Sarlos, T.; Hawkins, P.; Davis, J.; Mohiuddin, A.; Kaiser, L.; et al. Rethinking attention with performers. arXiv 2020, arXiv:2009.14794. [Google Scholar]
- Katharopoulos, A.; Vyas, A.; Pappas, N.; Fleuret, F. Transformers are rnns: Fast autoregressive transformers with linear attention. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 13–18 July 2020; pp. 5156–5165. [Google Scholar]
- Peng, H.; Pappas, N.; Yogatama, D.; Schwartz, R.; Smith, N.A.; Kong, L. Random feature attention. arXiv 2021, arXiv:2103.02143. [Google Scholar]
- Tay, Y.; Dehghani, M.; Bahri, D.; Metzler, D. Efficient transformers: A survey. ACM Comput. Surv. 2022, 55, 1–28. [Google Scholar] [CrossRef]
- Venkataramani, S.; Ranjan, A.; Banerjee, S.; Das, D.; Avancha, S.; Jagannathan, A.; Durg, A.; Nagaraj, D.; Kaul, B.; Dubey, P.; et al. ScaleDeep: A Scalable Compute Architecture for Learning and Evaluating Deep Networks. In Proceedings of the ISCA ’17, 44th Annual International Symposium on Computer Architecture, Toronto, ON, Canada, 24–28 June 2017; Association for Computing Machinery: New York, NY, USA, 2017; pp. 13–26. [Google Scholar] [CrossRef]
- Song, L.; Mao, J.; Zhuo, Y.; Qian, X.; Li, H.; Chen, Y. Hypar: Towards hybrid parallelism for deep learning accelerator array. In Proceedings of the 2019 IEEE International Symposium on High Performance Computer Architecture (HPCA), Washington, DC, USA, 16–20 February 2019; pp. 56–68. [Google Scholar]
- Zhang, X.; Wang, J.; Zhu, C.; Lin, Y.; Xiong, J.; Hwu, W.; Chen, D. DNNBuilder: An automated tool for building high-performance DNN hardware accelerators for FPGAs. In Proceedings of the 2018 IEEE/ACM International Conference on Computer-Aided Design, ICCAD 2018—Digest of Technical Papers, San Diego, CA, USA, 5–8 November 2018. [Google Scholar] [CrossRef]
- Sharma, H.; Park, J.; Mahajan, D.; Amaro, E.; Kim, J.K.; Shao, C.; Mishra, A.; Esmaeilzadeh, H. From high-level deep neural models to FPGAs. In Proceedings of the 2016 49th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), Taipei, Taiwan, 15–19 October 2016; pp. 1–12. [Google Scholar] [CrossRef]
- Kwon, H.; Samajdar, A.; Krishna, T. MAERI: Enabling Flexible Dataflow Mapping over DNN Accelerators via Reconfigurable Interconnects. SIGPLAN Not. 2018, 53, 461–475. [Google Scholar] [CrossRef]
- Mattson, P.; Cheng, C.; Diamos, G.; Coleman, C.; Micikevicius, P.; Patterson, D.; Tang, H.; Wei, G.Y.; Bailis, P.; Bittorf, V.; et al. Mlperf training benchmark. Proc. Mach. Learn. Syst. 2020, 2, 336–349. [Google Scholar]
- Ben-Nun, T.; Besta, M.; Huber, S.; Ziogas, A.N.; Peter, D.; Hoefler, T. A modular benchmarking infrastructure for high-performance and reproducible deep learning. In Proceedings of the 2019 IEEE International Parallel and Distributed Processing Symposium (IPDPS), Rio de Janeiro, Brazil, 20–24 May 2019; pp. 66–77. [Google Scholar]
- Blalock, D.; Gonzalez Ortiz, J.J.; Frankle, J.; Guttag, J. What is the state of neural network pruning? Proc. Mach. Learn. Syst. 2020, 2, 129–146. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Accelerators | Sparse Pattern | Pattern Regularity | Sparsity | Algorithm | Accuracy Loss | Design Process | Design Objective |
|---|---|---|---|---|---|---|---|
| EdgeBERT [15] | Static | Coarse-grained structured | Medium | Movement, Magnitude pruning | Negligible | SW-HW | Energy |
| OPTIMUS [20] | Static | Coarse-grained structured | Low | Compression and SA-RCSC | Negligible | HW | Latency, Throughput, Energy |
| FTRANS [21] | Static | Coarse-grained structured | Low | Block-circulant matrix (BCM) | 0% | HW | Speedup, Energy |
| [10] | Dynamic | Unstructured | Medium | Approximation | Negligible | SW-HW | Energy |
| SpAtten [9] | Dynamic | Coarse-grained structured | Low | Cascade Token and Head Pruning | 0% | SW-HW | Speedup, Energy |
| ELSA [3] | Dynamic | Unstructured | Medium | Approximation | <1% | SW-HW | Speedup |
| DOTA [22,23] | Dynamic | Fine-grained structured | High | Approximate | 0.12% | HW | Speedup |
| Sanger [2] | Dynamic | Fine-grained structured | High | Attention Pruning | 0% | SW-HW | Speedup |
| Energon [14] | Dynamic | Fine-grained | High | MP-MRF | 0.50% | SW-HW | Speedup, Energy |
| SALO [24] | Static | Hybrid Sparsity | Medium | Data Reordering and Splitting | 0% | HW | Speedup |
| STA [25,26] | Static | Fine-grained N:M | High | IDP and Model Compression | Improved 6.7% | SW-HW | Speedup, Memory |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fuad, K.A.A.; Chen, L. A Survey on Sparsity Exploration in Transformer-Based Accelerators. Electronics 2023, 12, 2299. https://doi.org/10.3390/electronics12102299
Fuad KAA, Chen L. A Survey on Sparsity Exploration in Transformer-Based Accelerators. Electronics. 2023; 12(10):2299. https://doi.org/10.3390/electronics12102299
Chicago/Turabian StyleFuad, Kazi Ahmed Asif, and Lizhong Chen. 2023. "A Survey on Sparsity Exploration in Transformer-Based Accelerators" Electronics 12, no. 10: 2299. https://doi.org/10.3390/electronics12102299
APA StyleFuad, K. A. A., & Chen, L. (2023). A Survey on Sparsity Exploration in Transformer-Based Accelerators. Electronics, 12(10), 2299. https://doi.org/10.3390/electronics12102299