
Long Short-Term Fusion Spatial-Temporal Graph Convolutional Networks for Traffic Flow Forecasting

Abstract
1. Introduction
- In earlier studies such as DCRNN [1], STGCN [2] and ASTGCN [3], two independent components were used to capture the temporal and spatial dependencies seperately. In these approaches, only spatial dependencies and temporal correlations are captured directly, without considering both temporal and spatial interaction dependencies, and these complex local spatial-temporal correlations can be captured simultaneously and would be highly effective for spatial-temporal data prediction as adopted by STSGCN [4], as this modeling approach reveals the fundamental way in which spatial-temporal network data can be generated.
- Existing studies of spatial-temporal data prediction fail to capture dependencies between local and global correlations simultaneously. RNN/LSTM-based models such as DCRNN and STGCN are time-consuming because the models are relatively complex and do not parallelize the processing task well, and may fade away or explode when capturing remote sequences [5]. The CNN-based approach requires layers to achieve global correlation of long sequences, and STGCN and GraphWaveNet [6] can lose local information if the rate of expansion is increased. STSGCN proposes a new localized spatio-temporal subgraph that synchronously captures local correlations and is only designed locally, ignoring the global information. The situation of learning only local noise is more severe in the presence of missing data.
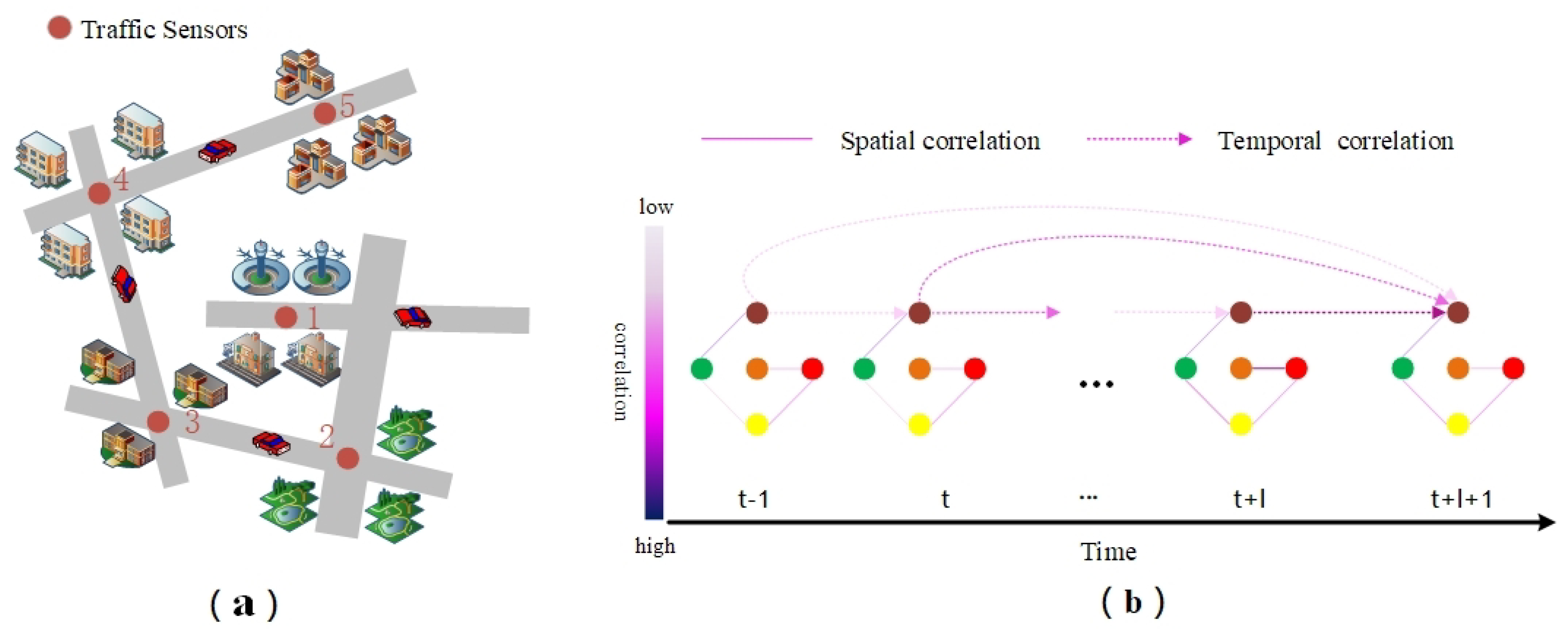
- The traffic flow of a spatial node is not only correlated with the previous time step of the current node, but with the entire history of traffic flow, and this correlation does not become weaker with longer time intervals; in the long run each node’s traffic flow has its own similar temporal “pattern”. As demonstrated in Figure 1a, in an urban transport network, node 1 denotes the station, where the traffic flow during a grand festival such as the Chinese New Year is very variable compared to the previous days, node 3 denotes the school, where the traffic flow on the opening day is quite dissimilar from the summer and winter holidays, and the other nodes often vary greatly in this time “pattern” because of their different locations. Traffic flows in public transport networks are constantly changing dynamically. For many areas of the public transport network, traffic flow at one point in time is closely linked to its historical traffic flow data, which makes long-term traffic flow prediction difficult. As demonstrated in Figure 1b, the color shades of the solid lines between nodes represent the spatial correlation between different roads, while the color shades of the dashed lines represent the temporal influence of historical traffic flow data on the current time point. By learning the short-term and long-term periodicity of historical time series of spatial nodes, the algorithm can better improve the accuracy of traffic flow prediction.
- We propose a novel ordinary differential equation graph convolution, which uses the global acceptance domain of a wider graph convolution to learn historical spatial-temporal characteristics by entering historical traffic data of current time step and current time step.
- We propose a novel spatial-temporal graph convolution attention module that can serially generate attentional feature map information in both the channel and spatial dimensions while simultaneously capturing local spatial-temporal correlations, which may be multiplied with previous feature maps for adaptive correction of the features.
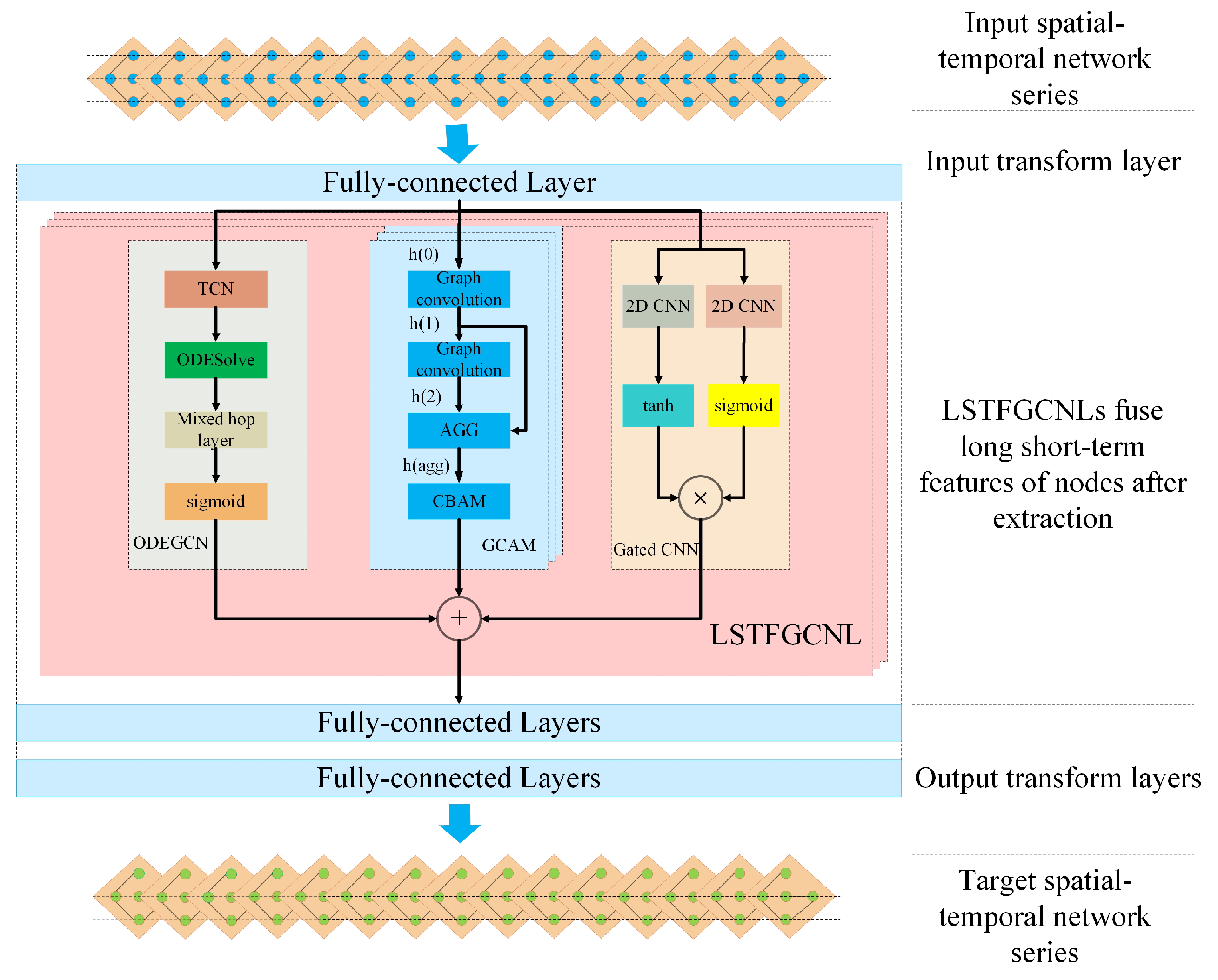
- We propose an efficient framework for capturing both local and global spatial-temporal correlations, and further extract long-range spatial-temporal dependencies by combining a gated extended convolution module with GCAM and ODEGCN in parallel to fuse the long short-term spatial-temporal features of nodes.
- We evaluated our proposed model on four datasets and processed extensive comparison experiments and compared the prediction results with recent model results, demonstrating that the model in this paper achieved better results.
2. Related Work
2.1. Spatial-Temporal Forecasting
2.2. Graph Convolutional Network
2.3. Attention Mechanism
2.4. Neural Ordinary Differential Equations
3. Preliminaries
4. Model
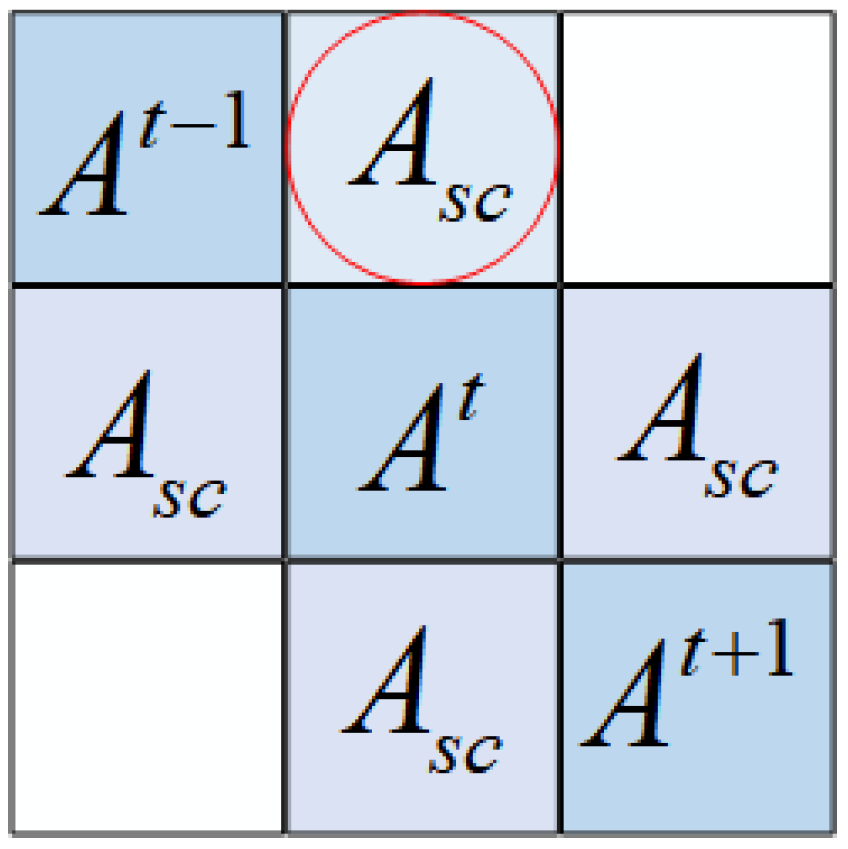
4.1. Localized Spatial-Temporal Graph Construction
4.2. Spatial-Temporal Graph Convolution Attention Module
- Aggregating operation: We chose maximum pooling as the aggregation operation. This algorithm applies a maximum element-wise operation to the output of all graph convolutions in GCAM. The maximal aggregation operation may be expressed as:where denotes the output of the l layer graph convolution, and denotes the output of the aggregating operation.
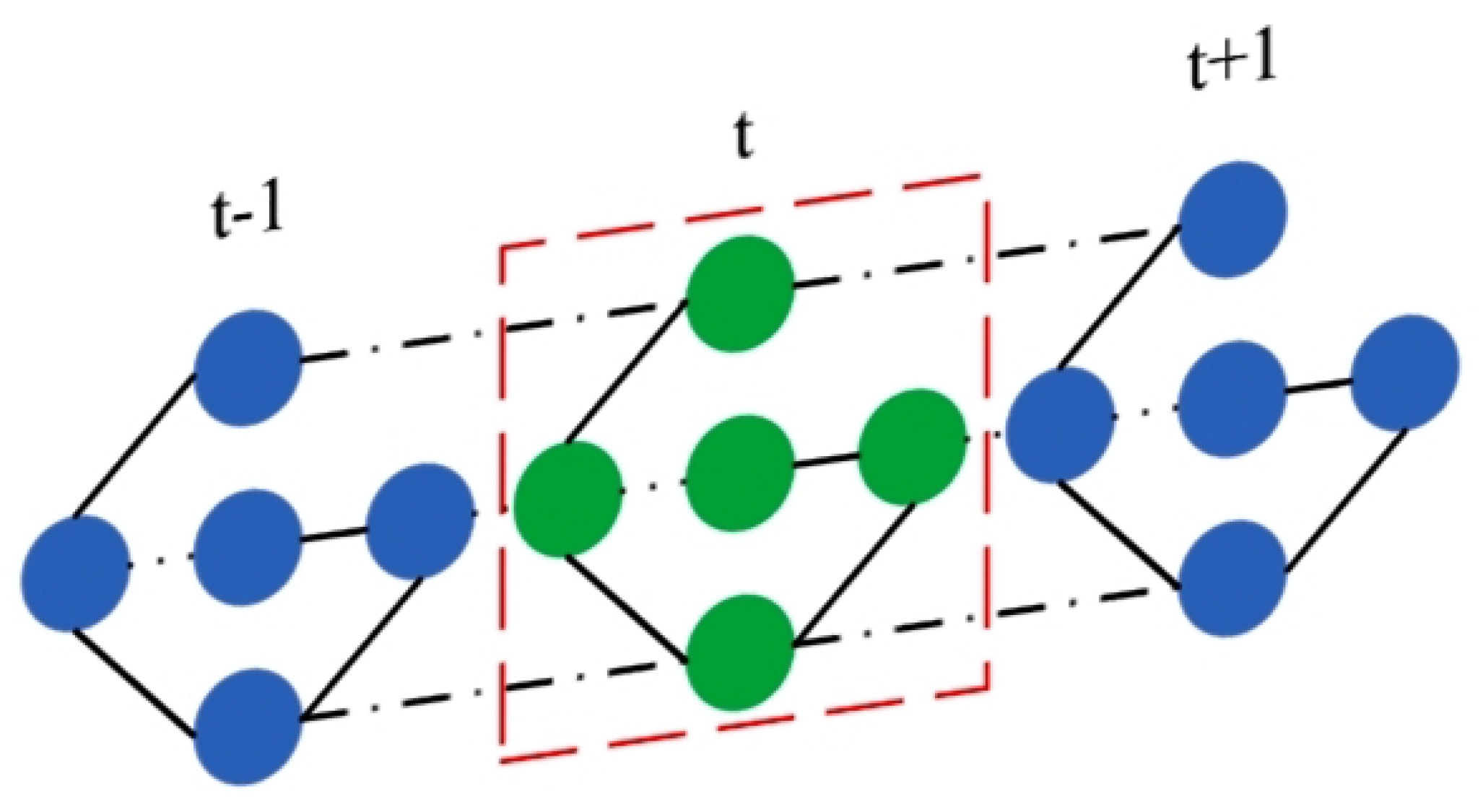
- Cropping operation: The cropping operation consists of removing redundant features from the previous and next time slices from the aggregate results and retaining only features from nodes in the intermediate moments. The reason for this is that the graph convolution operation has already aggregated the information from the previous and next time steps, and cropping two time steps will not result in the loss of important information and each node contains a local spatial-temporal correlation. By stacking multiple GCAMs and retaining the characteristics of all adjacent time-steps, a large amount of redundant information will reside in the model, thereby affecting the prediction effect. The cropping operation is demonstrated in Figure 4, showing cropping of the features of the previous time step and the next time step and keeping the features of the intermediate time step t.
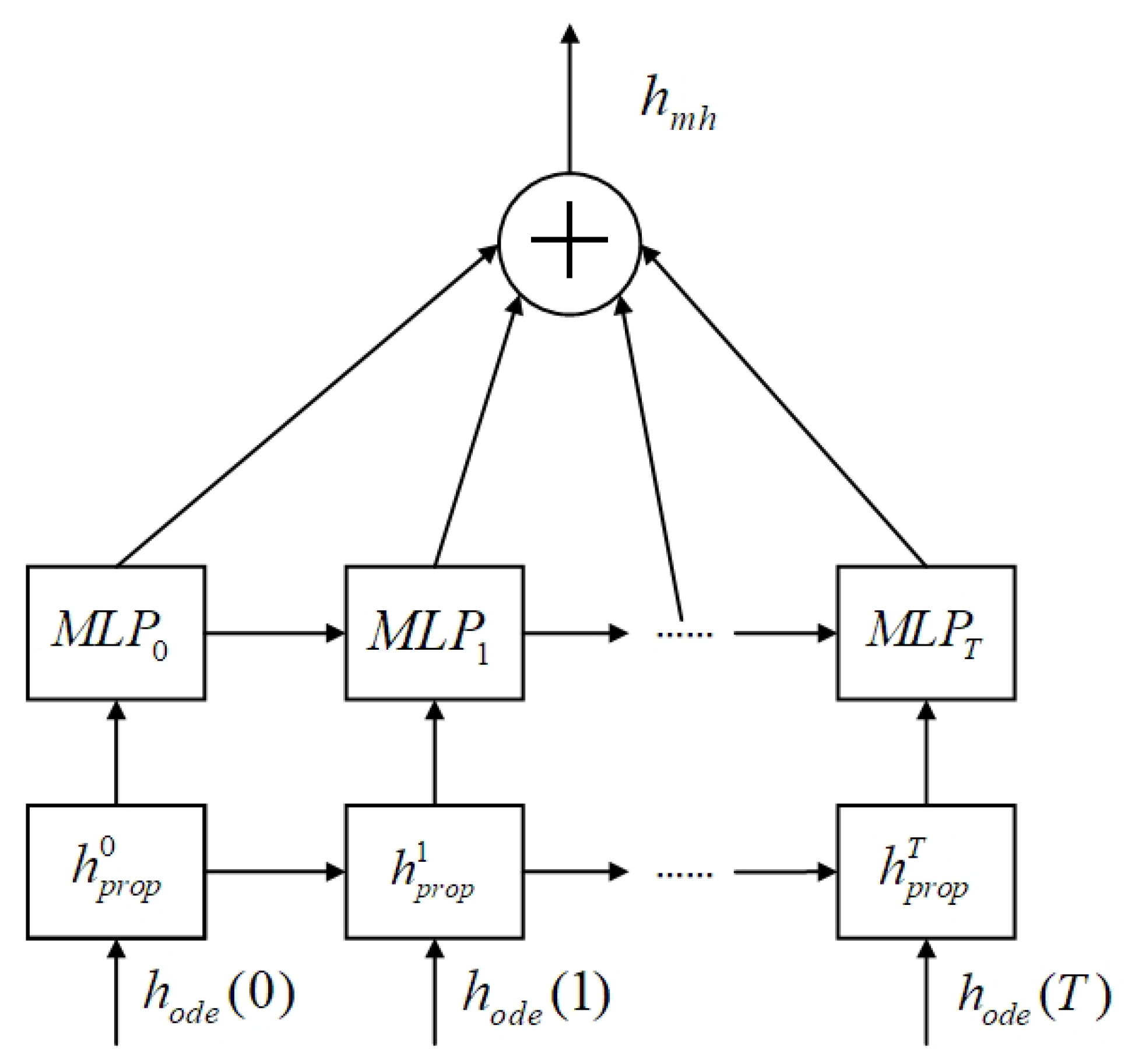
4.3. ODE Spatial-Temporal Graph Convolution Module
4.4. Gated Convolution Model
4.5. Loss Function
5. Experiments
5.1. Experiment Settings
5.2. Evaluation Functions
- Mean Absolute Error (MAE):where denotes the real value at the i-th time step, and denotes the predicted value of the model at the i-th time step.
- Root Mean Squared Error (RMSE):
- Mean Absolute Percentage Error (MAPE):
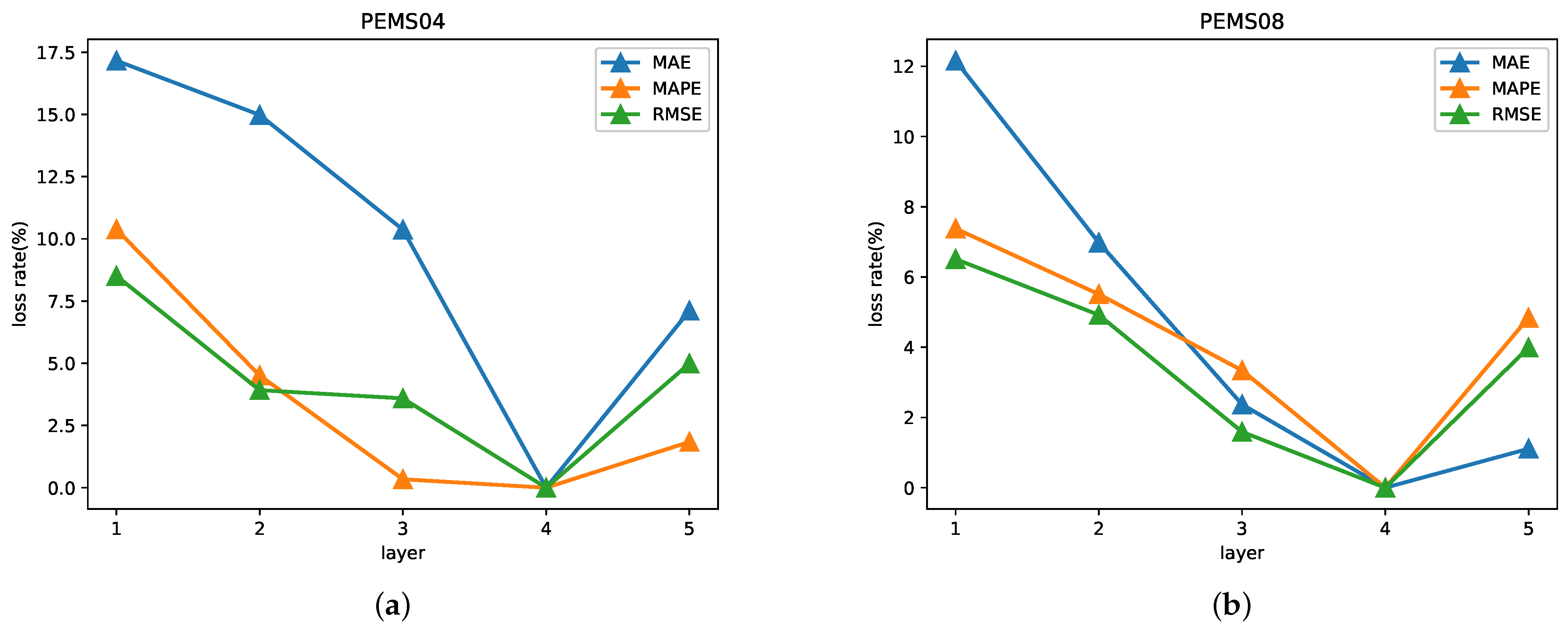
5.3. Study of the Layers of LSTFGCNL
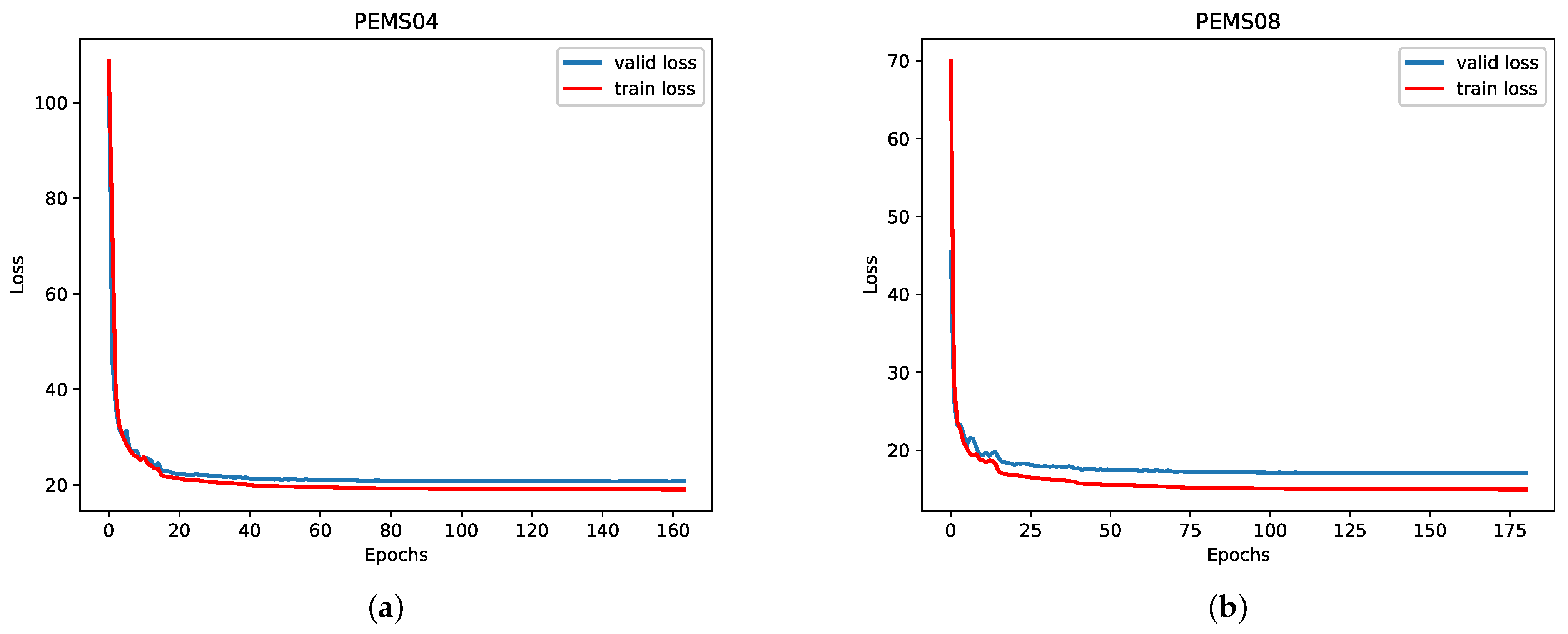
5.4. Convergence Analysis
5.5. Performance Comparison
- FC-LSTM [32]: Long short term memory network (LSTM) is a type of circular neural network that is completely connected to an LSTM hidden unit.
- DCRNN [1]: The cyclic diffusion convolution neural network, which embeds graph convolution into cyclic encoder–decoder units.
- STGCN [2]: Spatial-temporal graph convolution network, integrating graph convolution into one-dimensional convolution units.
- ASTGCN(r) [3]: Attention-based spatial-temporal graph convolution network, which introduces spatial and temporal attentional mechanisms into the model. In order to maintain a fair comparison, only the most recent component of the modeling periodicity is used.
- GraphWaveNet [6]: GraphWaveNet is a framework that combines adaptive adjacency matrices with one-dimensional extended convolution.
- STSGCN [4]: Spatial-temporal synchronous graph convolutional network, which utilizes a local spatial-temporal subgraph module to synchronously capture local spatial-temporal correlativity of node.
- STFGNN [5]: Spatial-temporal fusion graph neural network, which uses the DTW algorithm to construct data-driven graphs to effectively capture hidden spatial dependencies.
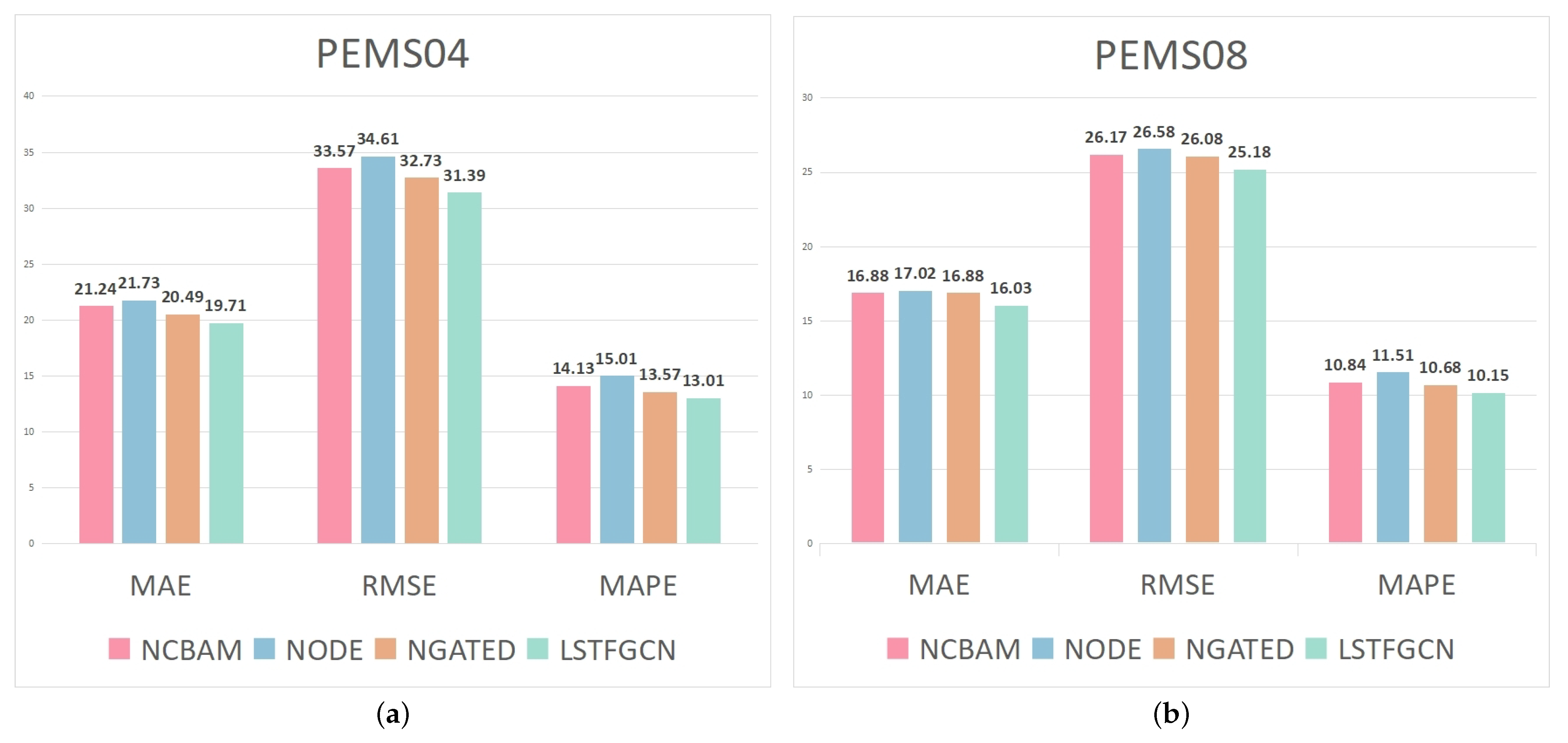
5.6. Ablation Experiments
- CBAM can carry out adaptive correction to the local spatial-temporal feature map, assign a higher weight to important node information through effective learning, and extract more complex hidden local spatial-temporal dependences.
- The ODEGCN module significantly improves the extraction of long-term spatial-temporal dependence of the model, and obtains more hidden information from longer time series, thus making the model achieve the optimal average prediction results in the end.
- The gated convolution module effectively enhances the ability of ODEGCN to learn the long-term spatial-temporal dependence of nodes, thereby improving the overall performance of the model.
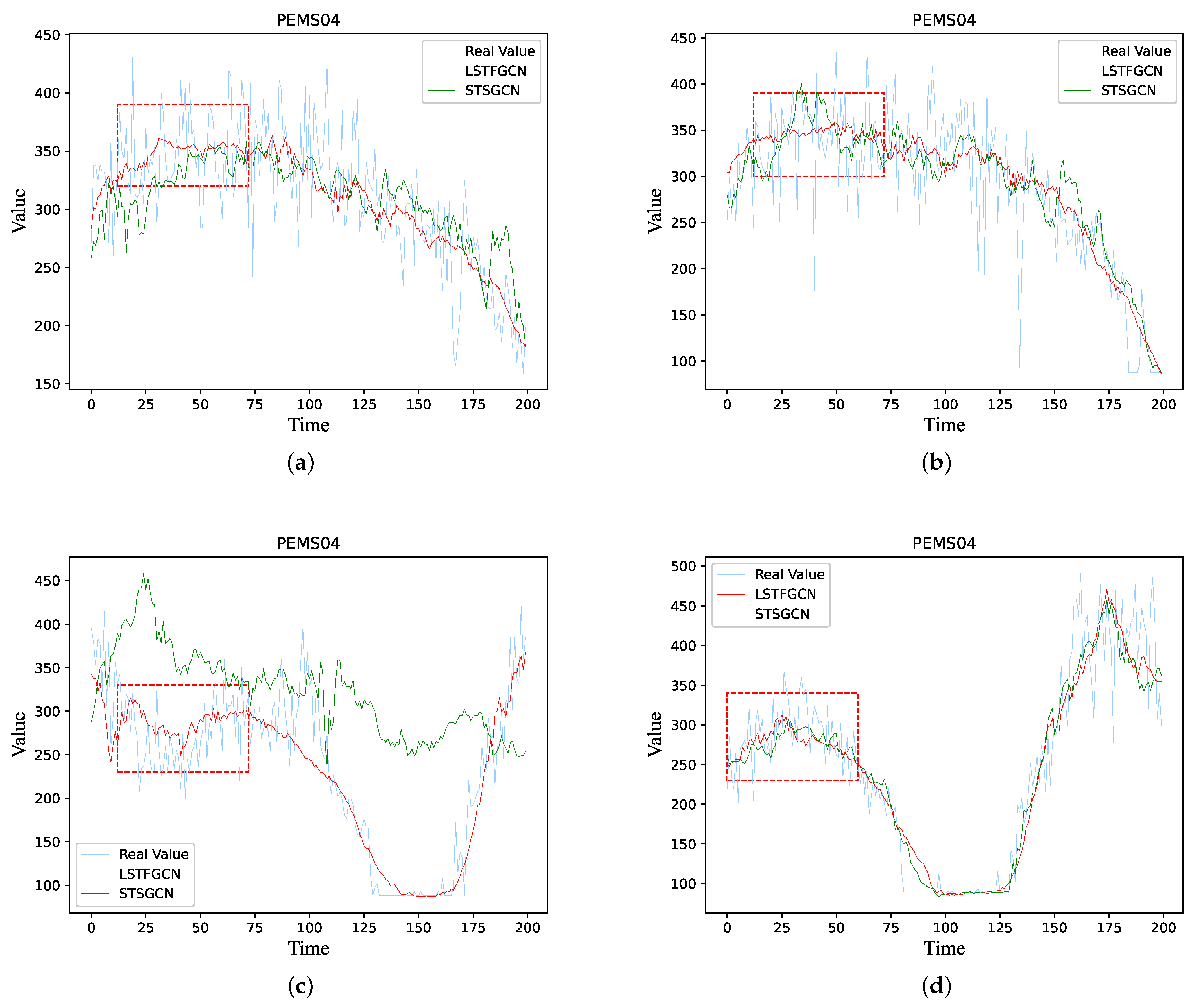
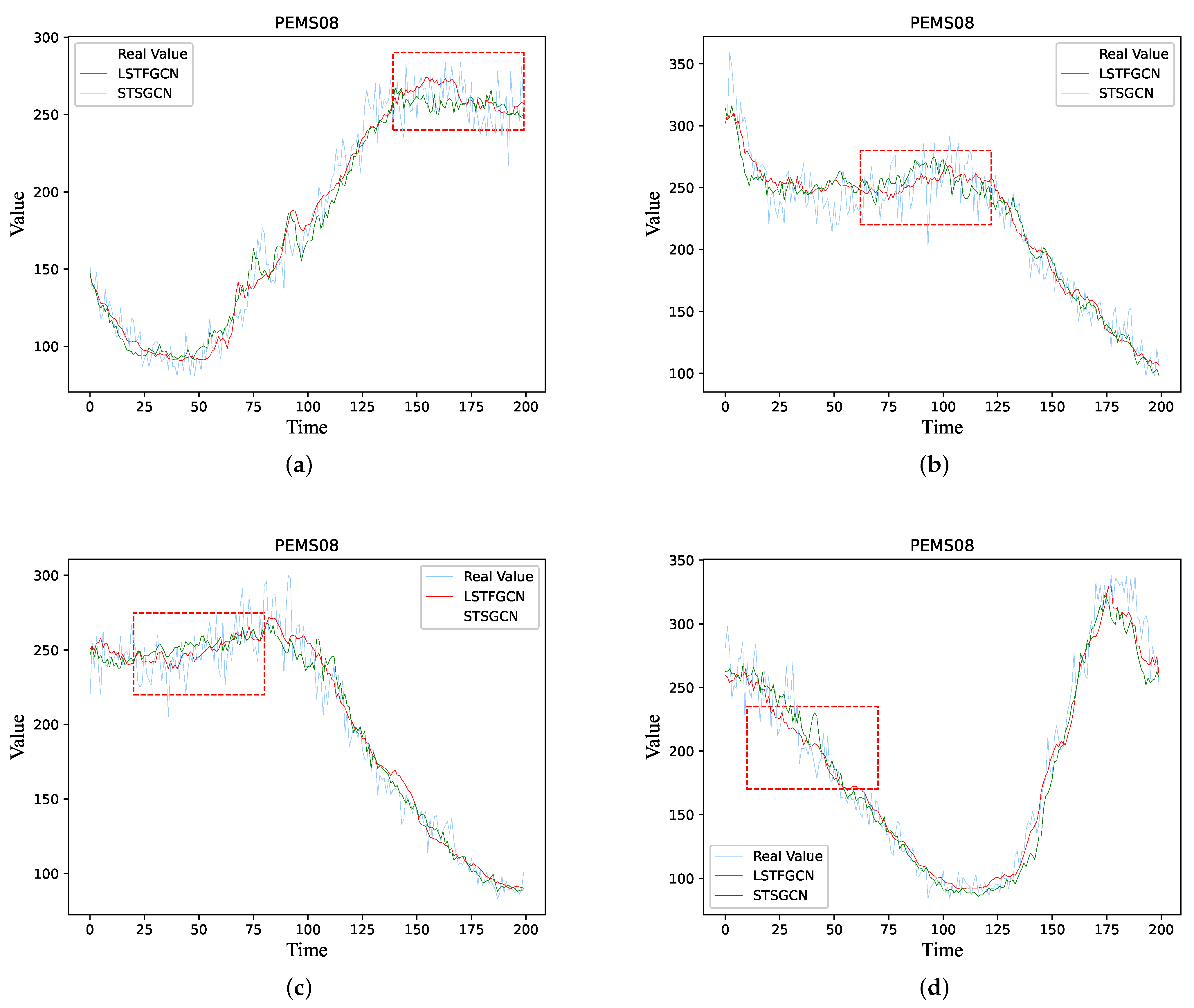
6. Case Study
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Li, Y.; Yu, R.; Shahabi, C.; Liu, Y. Diffusion Convolutional Recurrent Neural Network: Data-Driven Traffic Forecasting. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Yan, S.; Xiong, Y.; Lin, D. Spatial Temporal Graph Convolutional Networks for Skeleton-Based Action Recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–3 February 2018; Volume 32. [Google Scholar]
- Guo, S.; Lin, Y.; Feng, N.; Song, C.; Wan, H. Attention based spatial-temporal graph convolutional networks for traffic flow forecasting. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January 2019; Volume 33, pp. 922–929. [Google Scholar]
- Song, C.; Lin, Y.; Guo, S.; Wan, H. Spatial-temporal synchronous graph convolutional networks: A new framework for spatial-temporal network data forecasting. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 914–921. [Google Scholar]
- Li, M.; Zhu, Z. Spatial-temporal fusion graph neural networks for traffic flow forecasting. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtually, 2–9 February 2021; Volume 35, pp. 4189–4196. [Google Scholar]
- Wu, Z.; Pan, S.; Long, G.; Jiang, J.; Zhang, C. Graph WaveNet for deep spatial-temporal graph modeling. In Proceedings of the International Joint Conference on Artificial Intelligence, Macao, China, 10–16 August 2019; pp. 1907–1913. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European conference on computer vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Wang, X.; Ma, Y.; Wang, Y.; Jin, W.; Wang, X.; Tang, J.; Jia, C.; Yu, J. Traffic flow prediction via spatial temporal graph neural network. In Proceedings of the Web Conference 2020, Taipei, Taiwan, 20–24 April 2020; pp. 1082–1092. [Google Scholar]
- Park, C.; Lee, C.; Bahng, H.; Tae, Y.; Jin, S.; Kim, K.; Ko, S.; Choo, J. ST-GRAT: A novel spatio-temporal graph attention networks for accurately forecasting dynamically changing road speed. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management, Virtual, 19–23 October 2020; pp. 1215–1224. [Google Scholar]
- Chiang, W.L.; Liu, X.; Si, S.; Li, Y.; Bengio, S.; Hsieh, C.J. Cluster-gcn: An efficient algorithm for training deep and large graph convolutional networks. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 257–266. [Google Scholar]
- Bruna, J.; Zaremba, W.; Szlam, A.; Lecun, Y. Spectral Networks and Locally Connected Networks on Graphs. In Proceedings of the 2nd International Conference on Learning Representations, ICLR 2014, Banff, AB, Canada, 14–16 April 2014. Conference Track Proceedings. [Google Scholar]
- Defferrard, M.; Bresson, X.; Vandergheynst, P. Convolutional neural networks on graphs with fast localized spectral filtering. Adv. Neural Inf. Process. Syst. 2016, 29, 3837–3845. [Google Scholar]
- Welling, M.; Kipf, T.N. Semi-supervised classification with graph convolutional networks. In Proceedings of the International Conference on Learning Representations (ICLR 2017), Toulon, France, 24–26 April 2017. [Google Scholar]
- Velickovic, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lio, P.; Bengio, Y. Graph Attention Networks. Stat 2018, 1050, 4. [Google Scholar]
- Hamilton, W.; Ying, Z.; Leskovec, J. Inductive representation learning on large graphs. Adv. Neural Inf. Process. Syst. 2017, 30, 1024–1034. [Google Scholar]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhudinov, R.; Zemel, R.; Bengio, Y. Show, attend and tell: Neural image caption generation with visual attention. In Proceedings of the International Conference on Machine Learning. PMLR, Lille, France, 6–11 July 2015; pp. 2048–2057. [Google Scholar]
- Liang, Y.; Ke, S.; Zhang, J.; Yi, X.; Zheng, Y. Geoman: Multi-level attention networks for geo-sensory time series prediction. Proc. IJCAI 2018, 2018, 3428–3434. [Google Scholar]
- Fang, Z.; Long, Q.; Song, G.; Xie, K. Spatial-temporal graph ode networks for traffic flow forecasting. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, Singapore, 14–18 August 2021; pp. 364–373. [Google Scholar]
- Lu, Y.; Zhong, A.; Li, Q.; Dong, B. Beyond finite layer neural networks: Bridging deep architectures and numerical differential equations. In Proceedings of the International Conference on Machine Learning, PMLR, Stockholm, Sweden, 10–15 July 2018; pp. 3276–3285. [Google Scholar]
- Weinan, E. A proposal on machine learning via dynamical systems. Commun. Math. Stat. 2017, 1, 1–11. [Google Scholar]
- Chen, R.T.; Rubanova, Y.; Bettencourt, J.; Duvenaud, D.K. Neural ordinary differential equations. Adv. Neural Inf. Process. Syst. 2018, 31, 6572–6583. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Davis, J.Q.; Choromanski, K.; Sindhwani, V.; Varley, J.; Lee, H.; Slotine, J.J.; Likhosterov, V.; Weller, A.; Makadia, A. Time Dependence in Non-Autonomous Neural ODEs. In Proceedings of the ICLR 2020 Workshop on Integration of Deep Neural Models and Differential Equations, online, 26 April–1 May 2020. [Google Scholar]
- Dupont, E.; Doucet, A.; Teh, Y.W. Augmented neural odes. Adv. Neural Inf. Process. Syst. 2019, 32, 3134–3144. [Google Scholar]
- Ghosh, A.; Behl, H.; Dupont, E.; Torr, P.; Namboodiri, V. Steer: Simple temporal regularization for neural ode. Adv. Neural Inf. Process. Syst. 2020, 33, 14831–14843. [Google Scholar]
- Massaroli, S.; Poli, M.; Bin, M.; Park, J.; Yamashita, A.; Asama, H. Stable neural flows. arXiv 2020, arXiv:2003.08063. [Google Scholar]
- Hanshu, Y.; Jiawei, D.; Vincent, T.; Jiashi, F. On Robustness of Neural Ordinary Differential Equations. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep sparse rectifier neural networks. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics. JMLR Workshop and Conference Proceedings, Fort Lauderdale, FL, USA, 11–13 April 2011; pp. 315–323. [Google Scholar]
- Dauphin, Y.N.; Fan, A.; Auli, M.; Grangier, D. Language modeling with gated convolutional networks. In Proceedings of the International Conference on Machine Learning, PMLR, Sydney, Australia, 6–11 August 2017; pp. 933–941. [Google Scholar]
- Wu, Z.; Pan, S.; Long, G.; Jiang, J.; Chang, X.; Zhang, C. Connecting the dots: Multivariate time series forecasting with graph neural networks. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Virtual Event, CA, USA, 6–10 July 2020; pp. 753–763. [Google Scholar]
- Chen, C.; Petty, K.; Skabardonis, A.; Varaiya, P.; Jia, Z. Freeway performance measurement system: Mining loop detector data. Transp. Res. Rec. 2001, 1748, 96–102. [Google Scholar] [CrossRef]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to sequence learning with neural networks. Adv. Neural Inf. Process. Syst. 2014, 27, 3104–3112. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Nodes | Edges | Time Steps | Time Range |
|---|---|---|---|---|
| PEMS03 | 358 | 547 | 26,208 | 9/1/2018–11/30/2018 |
| PEMS04 | 307 | 340 | 16,992 | 1/1/201–2/28/2018 |
| PEMS07 | 883 | 866 | 28,224 | 5/1/2017–8/31/2017 |
| PEMS08 | 170 | 295 | 17,856 | 7/1/2016–8/31/2016 |
| Datasets | Metric | FC-LSTM | DCRNN | STGCN | ASTGCN(r) | Graph WaveNet | STSGCN | STFGNN | LSTFGCN |
|---|---|---|---|---|---|---|---|---|---|
| PEMS03 | MAE | 21.33 ± 0.24 | 18.18 ± 0.15 | 17.49 ± 0.46 | 17.69 ± 1.43 | 19.85 ± 0.03 | 17.48 ± 0.15 | 16.77 ± 0.09 | 16.47 ± 0.05 |
| MAPE (%) | 23.33 ± 4.23 | 18.91 ± 0.82 | 17.15 ± 0.45 | 19.40 ± 2.24 | 19.31 ± 0.49 | 16.78 ± 0.20 | 16.30 ± 0.09 | 15.51 ± 0.10 | |
| RMSE | 35.11 ± 0.50 | 30.31 ± 0.25 | 30.12 ± 0.70 | 29.66 ± 1.68 | 32.94 ± 0.18 | 29.21 ± 0.56 | 28.34 ± 0.46 | 27.83 ± 0.34 | |
| PEMS04 | MAE | 27.14 ± 0.20 | 24.70 ± 0.22 | 22.70 ± 0.64 | 22.93 ± 1.29 | 25.45 ± 0.03 | 21.19 ± 0.10 | 19.83 ± 0.06 | 19.71 ± 0.07 |
| MAPE (%) | 18.20 ± 0.40 | 17.12 ± 0.37 | 14.59 ± 0.21 | 16.56 ± 1.36 | 17.29 ± 0.24 | 13.90 ± 0.05 | 13.02 ± 0.05 | 13.01 ± 0.03 | |
| RMSE | 41.59 ± 0.21 | 38.12 ± 0.26 | 35.55 ± 0.75 | 35.22 ± 1.90 | 39.70 ± 0.04 | 33.65 ± 0.20 | 31.88 ± 0.14 | 31.39 ± 0.20 | |
| PEMS07 | MAE | 29.98 ± 0.42 | 25.30 ± 0.52 | 25.38 ± 0.49 | 28.05 ± 2.34 | 26.85 ± 0.05 | 24.26 ± 0.14 | 22.07 ± 0.11 | 21.39 ± 0.18 |
| MAPE (%) | 13.20 ± 0.53 | 11.66 ± 0.33 | 11.08 ± 0.18 | 13.92 ± 1.65 | 12.12 ± 0.41 | 10.21 ± 1.65 | 9.21 ± 0.07 | 9.06 ± 0.09 | |
| RMSE | 45.94 ± 0.57 | 8.58 ± 0.70 | 38.78 ± 0.58 | 42.57 ± 3.31 | 42.78 ± 0.07 | 39.03 ± 0.27 | 35.80 ± 0.18 | 34.86 ± 0.15 | |
| PEMS08 | MAE | 22.20 ± 0.18 | 17.86 ± 0.03 | 18.02 ± 0.14 | 18.61 ± 0.40 | 19.13 ± 0.08 | 17.13 ± 0.09 | 16.64 ± 0.09 | 16.03 ± 0.02 |
| MAPE (%) | 14.20 ± 0.59 | 11.45 ± 0.03 | 11.40 ± 0.10 | 13.08 ± 1.00 | 12.68 ± 0.57 | 10.96 ± 0.07 | 10.60 ± 0.06 | 10.15 ± 0.01 | |
| RMSE | 34.06 ± 0.32 | 27.83 ± 0.05 | 27.83 ± 0.20 | 28.16 ± 0.48 | 1.05 ± 0.07 | 26.80 ± 0.18 | 26.22 ± 0.15 | 25.18 ± 0.05 |
| Method | PEMS04 | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Horizon 3 | Horizon 6 | Horizon 12 | |||||||
| MAE | MAPE (%) | RMSE | MAE | MAPE (%) | RMSE | MAE | MAPE (%) | RMSE | |
| STSGCN | 19.8 | 13.41 | 31.58 | 21.3 | 14.27 | 33.83 | 24.47 | 16.27 | 38.46 |
| LSTFGCN | 18.77 | 12.45 | 29.89 | 19.64 | 13.05 | 31.34 | 21.37 | 14.23 | 33.87 |
| Method | PEMS08 | ||||||||
| Horizon 3 | Horizon 6 | Horizon 12 | |||||||
| MAE | MAPE (%) | RMSE | MAE | MAPE (%) | RMSE | MAE | MAPE (%) | RMSE | |
| STSGCN | 16.59 | 10.98 | 25.37 | 17.74 | 11.56 | 27.27 | 20.11 | 13.04 | 30.64 |
| LSTFGCN | 15.13 | 9.65 | 23.58 | 15.97 | 10.15 | 25.14 | 17.54 | 11.69 | 27.61 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zeng, H.; Jiang, C.; Lan, Y.; Huang, X.; Wang, J.; Yuan, X. Long Short-Term Fusion Spatial-Temporal Graph Convolutional Networks for Traffic Flow Forecasting. Electronics 2023, 12, 238. https://doi.org/10.3390/electronics12010238
Zeng H, Jiang C, Lan Y, Huang X, Wang J, Yuan X. Long Short-Term Fusion Spatial-Temporal Graph Convolutional Networks for Traffic Flow Forecasting. Electronics. 2023; 12(1):238. https://doi.org/10.3390/electronics12010238
Chicago/Turabian StyleZeng, Hui, Chaojie Jiang, Yuanchun Lan, Xiaohui Huang, Junyang Wang, and Xinhua Yuan. 2023. "Long Short-Term Fusion Spatial-Temporal Graph Convolutional Networks for Traffic Flow Forecasting" Electronics 12, no. 1: 238. https://doi.org/10.3390/electronics12010238
APA StyleZeng, H., Jiang, C., Lan, Y., Huang, X., Wang, J., & Yuan, X. (2023). Long Short-Term Fusion Spatial-Temporal Graph Convolutional Networks for Traffic Flow Forecasting. Electronics, 12(1), 238. https://doi.org/10.3390/electronics12010238