





Beyond Benchmarks: Spotting Key Topical Sentences While Improving Automated Essay Scoring Performance with Topic-Aware BERT


Abstract
1. Introduction
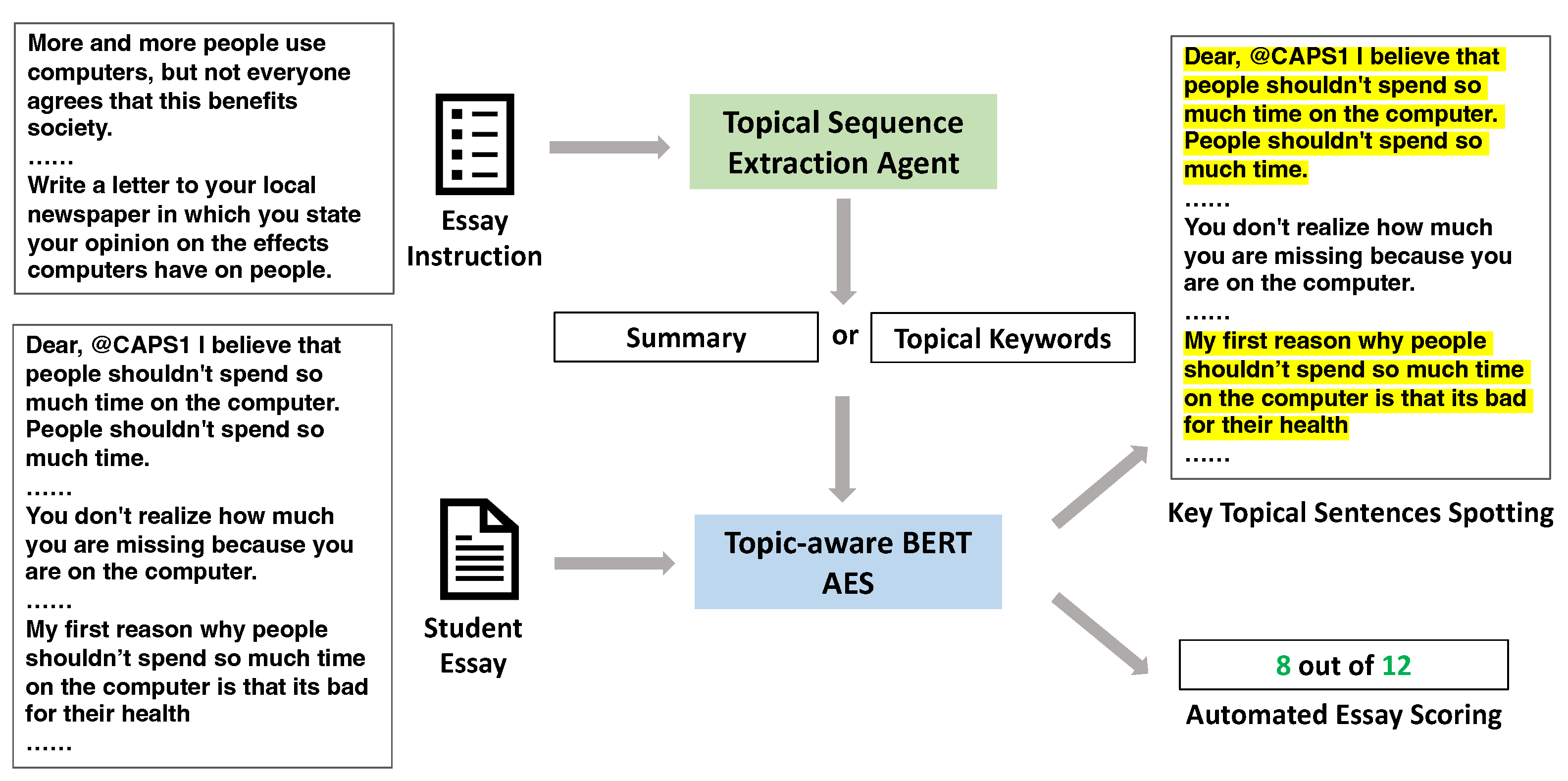
- We successfully link neural AES and AWE by designing a fully automatic multiagent AES + AWE system.
- We propose Topic-aware BERT and improve AES performance significantly by introducing prompt-specific knowledge.
- This is the first study to build an AWE system by interpreting self-attention layers in BERT. The experiments show that Topic-aware BERT achieves robust performance in spotting key topical sentences from argumentative essays as AWE feedback, by probing attention weight maps.
2. Related Works
2.1. Automated Essay Scoring
2.2. Automated Writing Evaluation
3. Data and Methods
3.1. Datasets
3.1.1. Automated Student Assessment Prize (ASAP) Dataset
3.1.2. Human Annotated KTS Dataset
3.2. Method
3.2.1. Topical Sequence Extraction
- Manual topical keyword extraction (denoted by Manual). We recruited three experts with knowledge backgrounds in NLP and TEL to pick the topical keywords from essay prompts 1, 2, and 7. Each expert was asked to construct a list of words as the topical keyword candidates from the essay instructions. Afterwards, we used the NLTK (NLTK Library: https://www.nltk.org/, accessed on 10 January 2022) toolkit to get the lemmatized versions of the topical keyword candidates. Then, we took the intersection of the lemmatized topical keyword candidates from each expert for each prompt as the final topical keywords.
- Automatic key-phrase extraction (denoted by YAKE). We used YAKE! [33], the current SOTA unsupervised approach to extract key phrases based on the local statistical features from the single documents, to automate the process of topical keyword extraction. Specifically, we utilized the YAKE! python library (YAKE source code: https://github.com/LIAAD/yake, accessed on 10 January 2022) to process essay instructions from prompts 1, 2, and 7 and took the outputs as the topical sequences for each essay prompt.
- Automatic single-sentence summarization (denoted by Xsum). The current SOTA summarization model PEGASUS [34] was deployed as the base model to produce summaries from essay instructions automatically. We used PEGASUS fine-tuned with the XSum [35] dataset for single-sentence summarization. The XSum dataset was constructed with BBC articles covering various subjects together with expert-written single-sentence summaries.
- Automatic multiple-sentence summarization (denoted by CNN). Like single-sentence summarization, PEGASUS also served as the base model for multiple-sentence summarization. Especially, the PEGASUS model, fine-tuned with the CNN/DailyMail [36] dataset, was deployed to generate multiple-sentence summaries from essay instructions. The CNN/DailyMail dataset consists of articles from CNN and Daily Mail newspapers, along with bullet-point summaries.
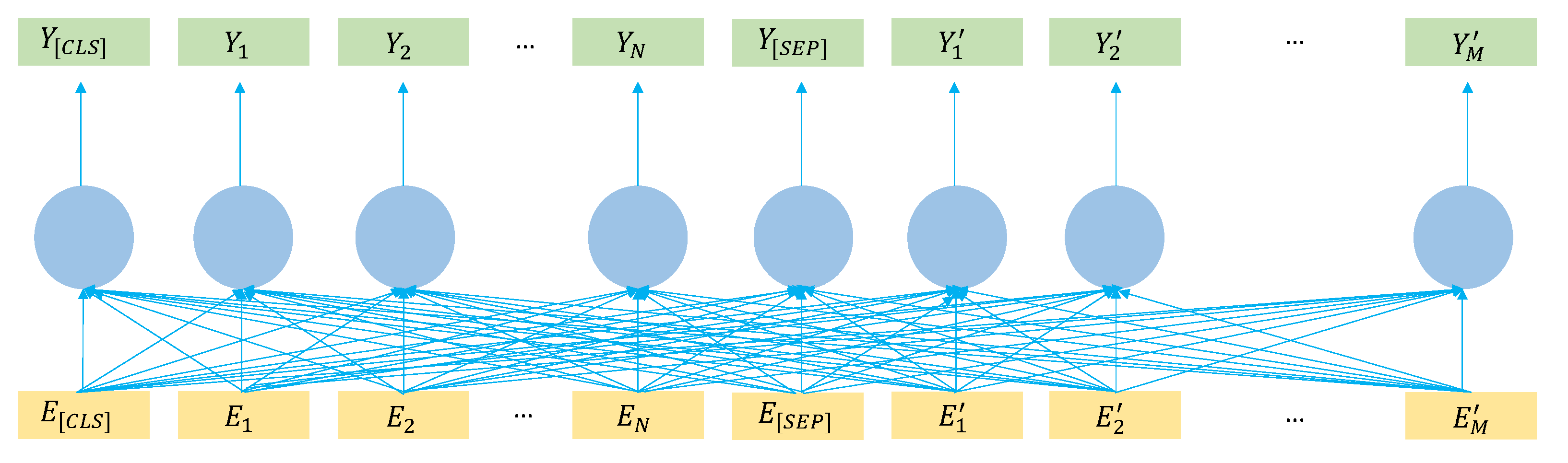
3.2.2. Topic-Aware BERT Architecture
3.2.3. Using Self-Attention for Retrieval of Key Topical Sentences
| Algorithm 1: Algorithm for Key Topical Sentence Retrieval from Layer l |
 |
4. Experiments
4.1. Setup
4.2. Evaluation Metrics
4.2.1. Evaluation Metrics for Automated Essay Scoring
4.2.2. Evaluation Metrics for Key Topical Sentence Retrieval
4.3. Baselines and Comparison Models for Automated Essay Scoring and Key Topical Sentence Retrieval
- CNN-LSTM. CNN-LSTM was proposed by Taghipour and Ng [11], which assembled CNN and LSTM to learn student essay representations.
- LSTM-CNN-Att. Dong et al. [12] developed hierarchical CNN-LSTM networks with an attention mechanism to conduct the AES task.
- Vanilla BERT. BERT was fine-tuned with student essays as the sole inputs for essay grading, without the awareness of any topical information from essay instructions.
- Our approach. Topic-aware BERT was fine-tuned with inputs from both student essays as well as topical sequences extraction by the strategies (Manual, YAKE, Xsum, CNN) mentioned in Section 3.2.1, denoted by Manual-T BERT, YAKE-T BERT, Xsum-T BERT, and CNN-T BERT, respectively.
- Random. The sentences from student essays were randomly selected as key topical sentences.
- TF-IDF. The sentences from student essays with higher TF-IDF scores were regarded as key topical sentences.
- Our approach. The sentences from student essays were ranked by scores from trained checkpoints of Manual-T BERT, YAKE-T BERT, Xsum-T BERT, and CNN-T BERT. Sentences with higher scores served as key topical sentences.
5. Result and Analysis
5.1. Automated Essay Scoring Result and Analysis
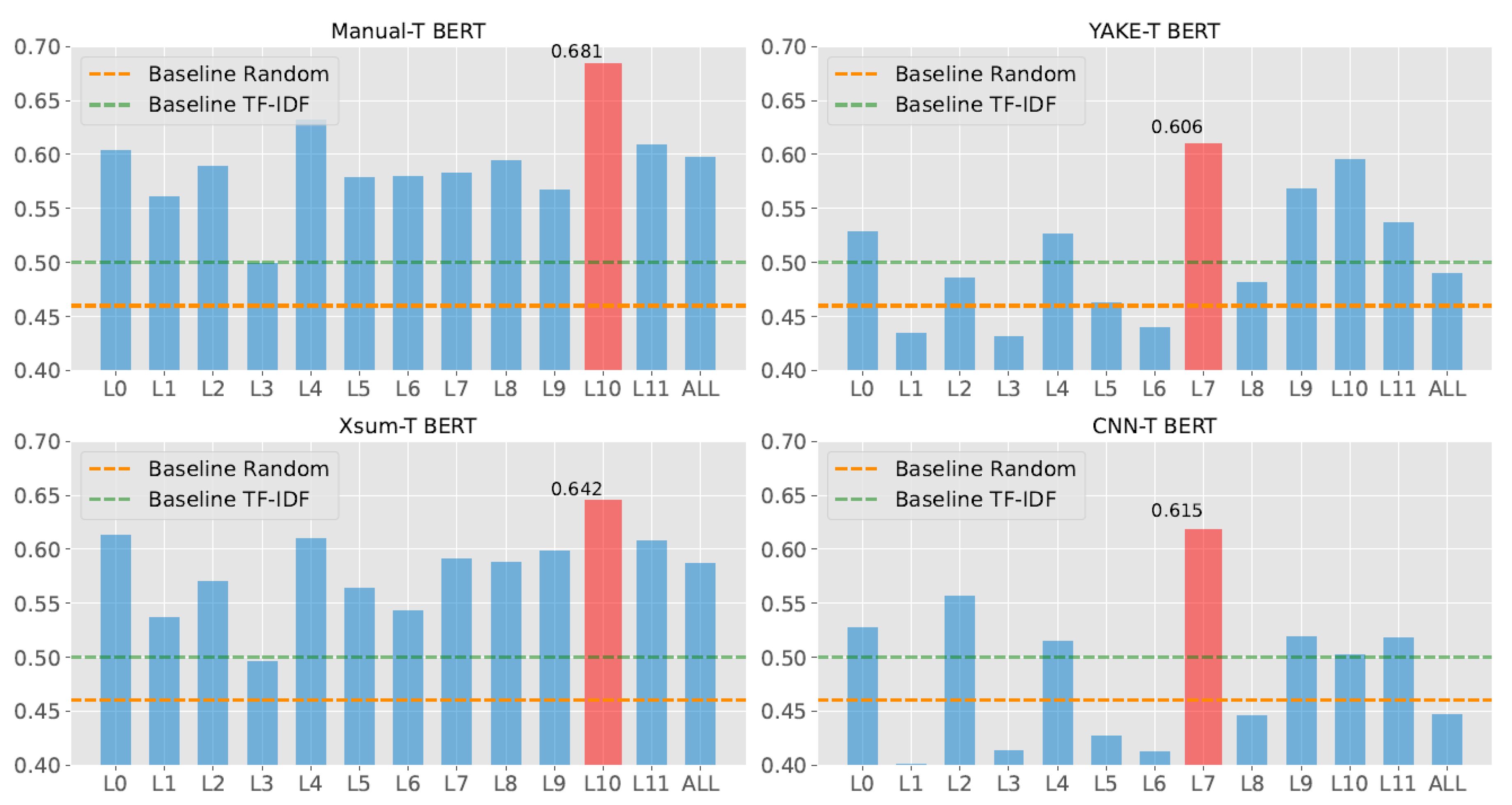
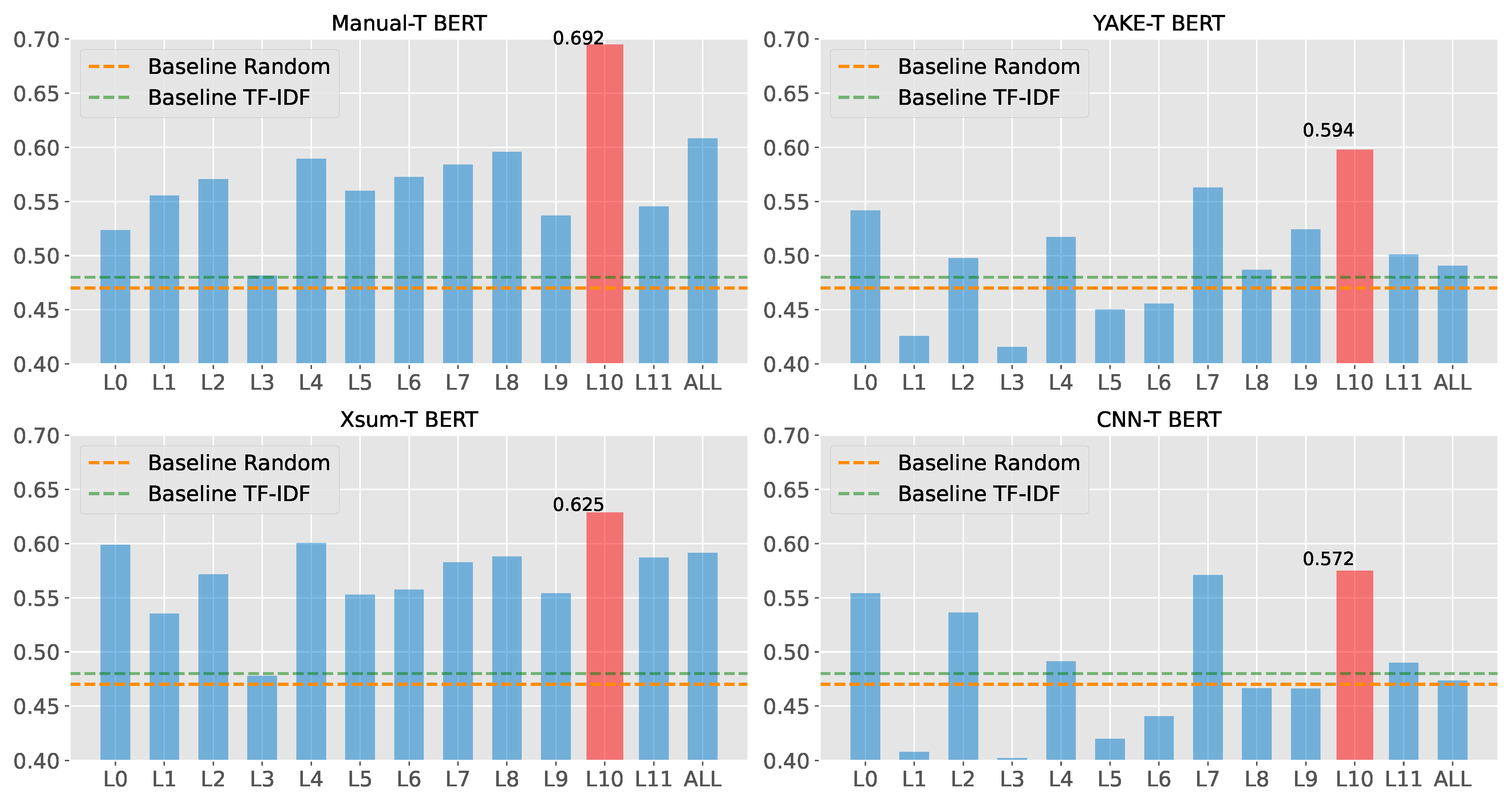
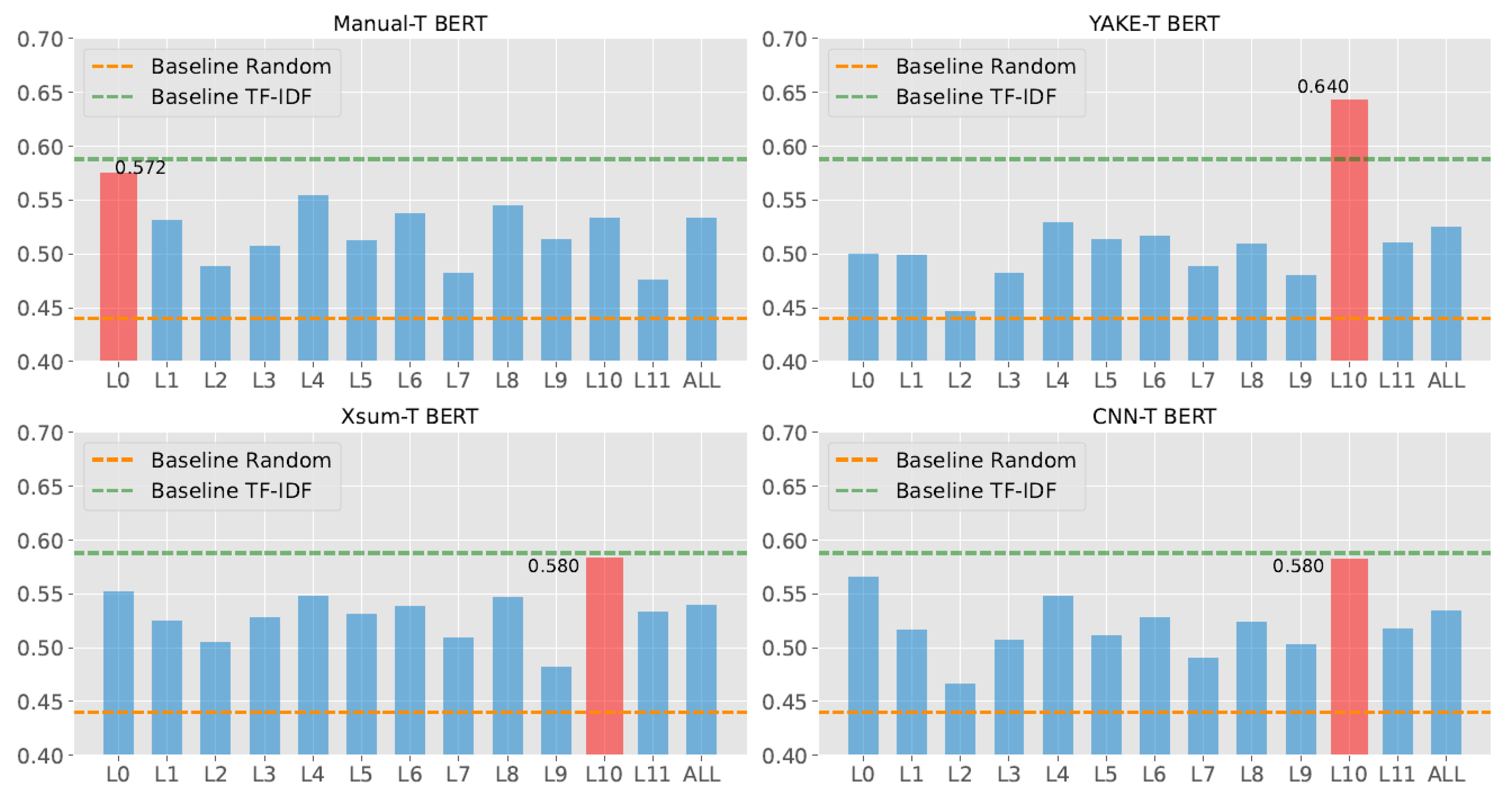
5.2. Key Topical Sentence Retrieval Result and Analysis
5.3. Summary of AES and KTS Retrieval Results and Analysis
- With the awareness of the essay topics, all variants of topic-aware BERT outperformed current best AES baselines on average QWK.
- Automatic Topic-aware BERT further improved the AES performance and indicated a potential for being deployed in practice at scale.
- All variants of topic-aware BERT showed reliable KTS retrieval performance in argumentative essays.
- Topical sequence extraction strategies, such as Xsum, which produced a proper length of topical sequences, could stimulate AES and KTS retrieval performance.
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ke, Z.; Ng, V. Automated essay scoring: A survey of the state of the art. In Proceedings of the International Joint Conference on Artificial Intelligence, Macao, China, 10 August 2019; pp. 6300–6308. [Google Scholar]
- Hussein, M.A.; Hassan, H.A.; Nassef, M. Automated language essay scoring systems: A literature review. PeerJ Comput. Sci. 2019, 8, e208. [Google Scholar] [CrossRef] [PubMed]
- Balfour, S.P. Assessing Writing in MOOCs: Automated Essay Scoring and Calibrated Peer Review™. Res. Pract. Assess. 2013, 8, 40–48. [Google Scholar]
- Reilly, E.D.; Stafford, R.E.; Williams, K.M.; Corliss, S.B. Evaluating the validity and applicability of automated essay scoring in two massive open online courses. Int. Rev. Res. Open Distrib. Learn. 2014, 15, 83–98. [Google Scholar] [CrossRef]
- Smolentzov, A. Automated Essay Scoring: Scoring Essays in Swedish; Stockholm University: Stockholm, Sweden, 2013. [Google Scholar]
- Yang, R.; Cao, J.; Wen, Z.; Wu, Y.; He, X. Enhancing Automated Essay Scoring Performance via Fine-tuning Pre-trained Language Models with Combination of Regression and Ranking. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2020, Online, 7 November 2020; pp. 1560–1569. [Google Scholar]
- Kumar, V.S.; Boulanger, D. Automated Essay Scoring and the Deep Learning Black Box: How Are Rubric Scores Determined? Int. J. Artif. Intell. Educ. 2021, 9, 538–1584. [Google Scholar] [CrossRef]
- Attali, Y.; Burstein, J. Automated Essay Scoring With e-rater® V.2. ETS Res. Rep. Ser. 2004, 12, i-21. [Google Scholar] [CrossRef]
- Rahimi, Z.; Litman, D.J.; Correnti, R.; Matsumura, L.C.; Wang, E.; Kisa, Z. Automatic Scoring of an Analytical Response-to-Text Assessment. In Intelligent Tutoring Systems. ITS 2014; Springer: Cham, Switzerland, 2014; pp. 601–610. [Google Scholar]
- Wang, Y.; Wang, C.; Li, R.; Lin, H. On the Use of Bert for Automated Essay Scoring: Joint Learning of Multi-Scale Essay Representation. In Proceedings of the Annual Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Seattle, WA, USA, 7 July 2022; pp. 3416–3425. [Google Scholar]
- Taghipour, K.; Ng, H.T. A Neural Approach to Automated Essay Scoring. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1 November 2016; pp. 1882–1891. [Google Scholar]
- Dong, F.; Zhang, Y.; Yang, J. Attention-based Recurrent Convolutional Neural Network for Automatic Essay Scoring. In Proceedings of the 21st Conference on Computational Natural Language Learning (CoNLL 2017), Vancouver, BC, Canada, 3 August 2017; pp. 153–162. [Google Scholar]
- Coron, C.; Porcher, S. Algorithms and Ethics: Evidence from Two HR Algorithms Developed by a Major French Digital Company. In Academy of Management Proceedings; Academy of Management: Briarcliff Manor, NY, USA, 2022; p. 17537. [Google Scholar]
- Higgins, D.; Burstein, J.; Marcu, D.; Gentile, C. Evaluating Multiple Aspects of Coherence in Student Essays. In Proceedings of the Human Language Technology Conference of the North American Chapter of the Association for Computational Linguistics: HLT-NAACL, Boston, MA, USA, 2 May 2004; pp. 185–192. [Google Scholar]
- Woods, B.; Adamson, D.; Miel, S.; Mayfield, E. Formative Essay Feedback Using Predictive Scoring Models. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD’17), Halifax, NS, Canada, 13 August 2017; pp. 2071–2080. [Google Scholar]
- Shibani, A.; Knight, S.; Shum, S. Contextualizable Learning Analytics Design: A Generic Model and Writing Analytics Evaluations. In Proceedings of the 9th International Conference on Learning Analytics & Knowledge (LAK19), Tempe, AZ, USA, 4 March 2019; pp. 210–219. [Google Scholar]
- Zhang, H.; Magooda, A.; Litman, D.; Correnti, R.; Wang, E.; Matsmura, L.; Howe, E.; Quintana, R. eRevise: Using Natural Language Processing to Provide Formative Feedback on Text Evidence Usage in Student Writing. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January 2019; pp. 9619–9625. [Google Scholar]
- Newell, G.; Beach, R.; Smith, J.; VanDerHeide, J. Teaching and Learning Argumentative Reading and Writing: A Review of Research. Read. Res. Q. 2011, 46, 273–304. [Google Scholar] [CrossRef]
- Hillocks, G. Teaching argument for critical thinking and writing: An introduction. Engl. J. 2010, 99, 24–32. [Google Scholar]
- Lam, Y.W.; Hew, K.F.; Chiu, K.F. Improving argumentative writing: Effects of a blended learning approach and gamification. Lang. Learn. Technol. 2018, 22, 97–118. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the Annual Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 3 June 2019; pp. 4171–4186. [Google Scholar]
- Clark, K.; Khandelwal, U.; Levy, O.; Manning, C. What Does BERT Look at? An Analysis of BERT’s Attention. In Proceedings of the 2019 ACL Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP, Florence, Italy, 1 August 2019; pp. 276–286. [Google Scholar]
- Page, E.B. The imminence of grading essays by computer. Phi Delta Kappan 1966, 47, 238–243. [Google Scholar]
- Chen, H.; He, B. Automated Essay Scoring by Maximizing Human-Machine Agreement. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, Seattle, WA, USA, 19 October 2013; pp. 1741–1752. [Google Scholar]
- Zesch, T.; Wojatzki, M.; Scholten-Akoun, D. Task-Independent Features for Automated Essay Grading. In Proceedings of the Tenth Workshop on Innovative Use of NLP for Building Educational Applications, Denver, CO, USA, 4 June 2015; pp. 224–232. [Google Scholar]
- Elliot, S. IntelliMetric: From here to validity. In Automated Essay Scoring: A Cross-Disciplinary Perspective; Shermi, M., Burstein, J., Eds.; Lawrence Erlbaum Associates: Mahwah, NJ, USA, 2008; pp. 71–86. [Google Scholar]
- Chodorow, M.; Burstein, J. Beyond essay length: Evaluating e-rater®’s performance on toefl® essays. TETS Res. Rep. Ser. 2004, 8, i-38. [Google Scholar] [CrossRef]
- Madnani, N.; Burstein, J.; Elliot, N.; Klebanov, B.; Napolitano, D.; Andreyev, S.; Schwartz, M. Writing Mentor: Self-Regulated Writing Feedback for Struggling Writers. In Proceedings of the 27th International Conference on Computational Linguistics: System Demonstrations, Santa Fe, NM, USA, 20 August 2018; pp. 113–117. [Google Scholar]
- Zhang, H.; Litman, D. Automated Topical Component Extraction Using Neural Network Attention Scores from Source-based Essay Scoring. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 6 July 2020; pp. 8569–8584. [Google Scholar]
- Helen, Y.; Briscoe, T.; Medlock, B. A new dataset and method for automatically grading ESOL texts. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Portland, OR, USA, 19 June 2011; pp. 180–189. [Google Scholar]
- Blanchard, D.; Tetreault, J.; Higgins, D.; Cahill, A.; Chodorow, M. TOEFL11: A corpus of non-native English. ETS Res. Rep. Ser. 2013, 2, i-15. [Google Scholar] [CrossRef]
- Manning, C.D. Introduction to Information Retrieval, 1st ed.; Cambridge University Press: Cambridge, UK, 2007; pp. 151–175. [Google Scholar]
- Campos, R.; Mangaravite, V.; Pasquali, A.; Jatowt, A.; Jorge, A.; Nunes, C.; Jatowt, A. YAKE! Keyword Extraction from Single Documents using Multiple Local Features. Inf. Sci. 2020, 509, 257–289. [Google Scholar] [CrossRef]
- Zhang, J.; Zhao, Y.; Saleh, M.; Liu, P. PEGASUS: Pre-training with extracted gap-sentences for abstractive summarization. In Proceedings of the 37th International Conference on Machine Learning (ICML’20), Virtual, 13 July 2020; pp. 11328–11339. [Google Scholar]
- Narayan, S.; Cohen, S.B.; Lapata, M. Don’t Give Me the Details, Just the Summary! Topic-Aware Convolutional Neural Networks for Extreme Summarization. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October 2018; pp. 1797–1807. [Google Scholar]
- Hermann, K.M.; Kocisky, T.; Grefenstette, E.; Espeholt, L.; Kay, W.; Suleyman, M.; Blunsom, P. Teaching machines to read and comprehend. In Proceedings of the 28th International Conference on Neural Information Processing Systems—Volume 1 (NIPS’15), Cambridge, MA, USA, 7 December 2015; pp. 1693–1701. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł. Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS’17), Long Beach, CA, USA, 4 December 2017; pp. 6000–6010. [Google Scholar]
- Wu, H.C.; Luk, R.W.; Wong, K.F.; Kwok, K.L. Interpreting TF-IDF term weights as making relevance decisions. ACM Trans. Inf. Syst. 2008, 26, 1–37. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Prompt | Essay Size | Genre | Avg. Len. |
|---|---|---|---|
| 1 | 1783 | ARG | 350 |
| 2 | 1800 | ARG | 350 |
| 3 | 1726 | RTA | 150 |
| 4 | 1772 | RTA | 150 |
| 5 | 1805 | RTA | 150 |
| 6 | 1800 | RTA | 150 |
| 7 | 1569 | NAR | 250 |
| 8 | 723 | NAR | 650 |
| Topical Sequence Extraction Methods | Agent Type | Topical Sequence Type | Topical Sequence Length | Essay Truncation? |
|---|---|---|---|---|
| Manual | Manual | Topical keywords | 4 | No |
| YAKE | Automatic | Key phrases, keywords | 32 | Yes |
| Xsum | Automatic | Single-sentence summary | 12 | No |
| CNN | Automatic | Multiple-sentence summary | 42 | Yes |
| Essay instruction prompt 1: More and more people use computers, but not everyone agrees that this benefits society. Those who support advances in technology believe that computers have a positive effect on people. Some experts are concerned that people are spending too much time on their computers. Write a letter to your local newspaper in which you state your opinion on the effects computers have on people. |
| Manual: computer, positive effect, concern |
| YAKE: benefits society, people, computers, society, benefits, time, support advances, advances in technology, effects computers, give people, positive effect, teach hand-eye coordination, hand-eye coordination, support, advances, technology, positive, teach hand-eye, ability to learn, learn about faraway |
| Xsum: what do you think about the effects computers have on people |
| CNN: Those who support advances in technology believe that computers have a positive effect on people. Some experts are concerned that people are spending too much time on their computers and less time exercising. Write a letter to your local newspaper in which you state your opinion on the effects computers have on people |
| Essay instruction prompt 2: Write a persuasive essay to a newspaper reflecting your vies on censorship in libraries. Do you believe that certain materials, such as books, music, movies, magazines, etc., should be removed from the shelves if they are found offensive? |
| Manual: censorship, library |
| YAKE: children, shelf, Katherine Paterson, Libraries, hope, book, books, work I abhor, Censorship, censorship in libraries, Author, books left, Katherine, Paterson, abhor, remove, work, music, movies, magazines |
| Xsum: what do you think about censorship in libraries |
| CNN: Do you believe certain materials, such as books, music, movies, magazines, should be removed from the shelves if they are found offensive? Support your position with convincing arguments from your own experience, observations, and/or reading. |
| Essay instruction prompt 7: A patient person experience difficulties without complaining. Do only one of the following: write a story about a time when you were patient OR write a story about a time when someone you know was patient OR write a story in your own way about patience. |
| Manual: patience, story |
| YAKE: Write, write a story, patient, patience, story, time, understanding and tolerant, patient OR write, Write about patience, tolerant, patient person, difficulties without complaining, patient person experience, understanding, complaining, person experience, experience difficulties, person experience difficulties, person experience |
| Xsum: write a story about a time when you were patient or when someone you know was patient |
| CNN: Do only one of the following: write a story about a time when you were patient. Write a story about a time when someone you know was patient |
| Models | Essay Prompt ID | Average QWK | |||
|---|---|---|---|---|---|
| 1 | 2 | 7 | |||
| Baselines | CNN-LSTM | 0.789 (0.821) | 0.687 (0.688) | 0.805 (0.808) | 0.760 (0.772) |
| CNN-LSTM-Att | 0.825 (0.822) | 0.658 (0.682) | 0.788 (0.801) | 0.757 (0.768) | |
| Vanilla BERT | 0.814 (0.821) | 0.689 (0.678) | 0.820 (0.802) | 0.774 (0.767) | |
| Topic-aware BERT | Manual-T BERT | 0.822 | 0.702 | 0.818 | 0.781 |
| YAKE-T BERT | 0.813 | 0.717 | 0.837 | 0.789 | |
| Xsum-T BERT | 0.821 | 0.710 | 0.836 | 0.789 | |
| CNN-T BERT | 0.803 | 0.714 | 0.833 | 0.783 | |
| Topic-Aware BERT Variants | Manual-T BERT | YAKE-T BERT | Xsum-T BERT | CNN-T BERT | |
|---|---|---|---|---|---|
| Outperforms AES baseline on Average QWK? | Yes (3rd) | Yes (1st) | Yes (1st) | Yes (2nd) | |
| Outperforms KTS retrieval baseline? | Prompt 1 | Yes (1st) | Yes (4th) | Yes (2nd) | Yes (3rd) |
| Prompt 2 | Yes (1st) | Yes (3rd) | Yes (2nd) | Yes (4th) | |
| Prompt 7 | No (3rd) | Yes (1st) | No (2nd) | No (2nd) | |
| Best layer in KTS retrieval | Prompt 1 | 10 | 7 | 10 | 7 |
| Prompt 2 | 10 | 10 | 10 | 10 | |
| Prompt 7 | 1 | 10 | 10 | 10 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, Y.; Henriksson, A.; Nouri, J.; Duneld, M.; Li, X. Beyond Benchmarks: Spotting Key Topical Sentences While Improving Automated Essay Scoring Performance with Topic-Aware BERT. Electronics 2023, 12, 150. https://doi.org/10.3390/electronics12010150
Wu Y, Henriksson A, Nouri J, Duneld M, Li X. Beyond Benchmarks: Spotting Key Topical Sentences While Improving Automated Essay Scoring Performance with Topic-Aware BERT. Electronics. 2023; 12(1):150. https://doi.org/10.3390/electronics12010150
Chicago/Turabian StyleWu, Yongchao, Aron Henriksson, Jalal Nouri, Martin Duneld, and Xiu Li. 2023. "Beyond Benchmarks: Spotting Key Topical Sentences While Improving Automated Essay Scoring Performance with Topic-Aware BERT" Electronics 12, no. 1: 150. https://doi.org/10.3390/electronics12010150
APA StyleWu, Y., Henriksson, A., Nouri, J., Duneld, M., & Li, X. (2023). Beyond Benchmarks: Spotting Key Topical Sentences While Improving Automated Essay Scoring Performance with Topic-Aware BERT. Electronics, 12(1), 150. https://doi.org/10.3390/electronics12010150