
A Contrastive Evaluation Method for Discretion in Administrative Penalty

Abstract
:1. Introduction
- Discretion in deciding whether or not to punish: For example, the Blood Donation Law of the People’s Republic of China stipulates that “any of the following acts …confiscates illegal gains and may impose a fine of less than 100,000 yuan.” The wording on whether to impose a fine is “may”, and therefore, whether to fine or not is decided by on-site officers.
- Discretion in deciding what form of punishment to impose: The Law of the People’s Republic of China on Medical Practitioners states that “a warning or an order to suspend practice activities for more than six months or less than one year shall be given.” To perform just a warning or a more rigorous suspension of practice activities punishment is decided by law enforcement officers.
- Discretion when it comes to the severity of punishment: Law enforcement officers have relatively strong discretionary power regarding the extent of punishment, including fine amounts. The upper and lower bounds for fines are only set by law, while law enforcement officers decide the exact value of fines according to the extent of the law violation activities.
- We propose the CADRE framework to automatically process and identify reasonable and unreasonable penalty records in an unsupervised manner. Meanwhile, we collected China’s three-year health administrative penalty data to explore their practical application further.
- We propose a multi-task learning framework to predict the penalty amount for administrative punishment records and judge the corresponding reasonableness of a given penalty amount. Inspired by Contrastive Learning [8,9], our model treats positive (reasonable) punishment records and negative (unreasonable) ones from a different perspective, and we train it collaboratively from unlabeled data, which makes it easier for practical application.
- We conduct experiments on the collected data, and the results reveal that the adversarial training model can improve the performance on both tasks.
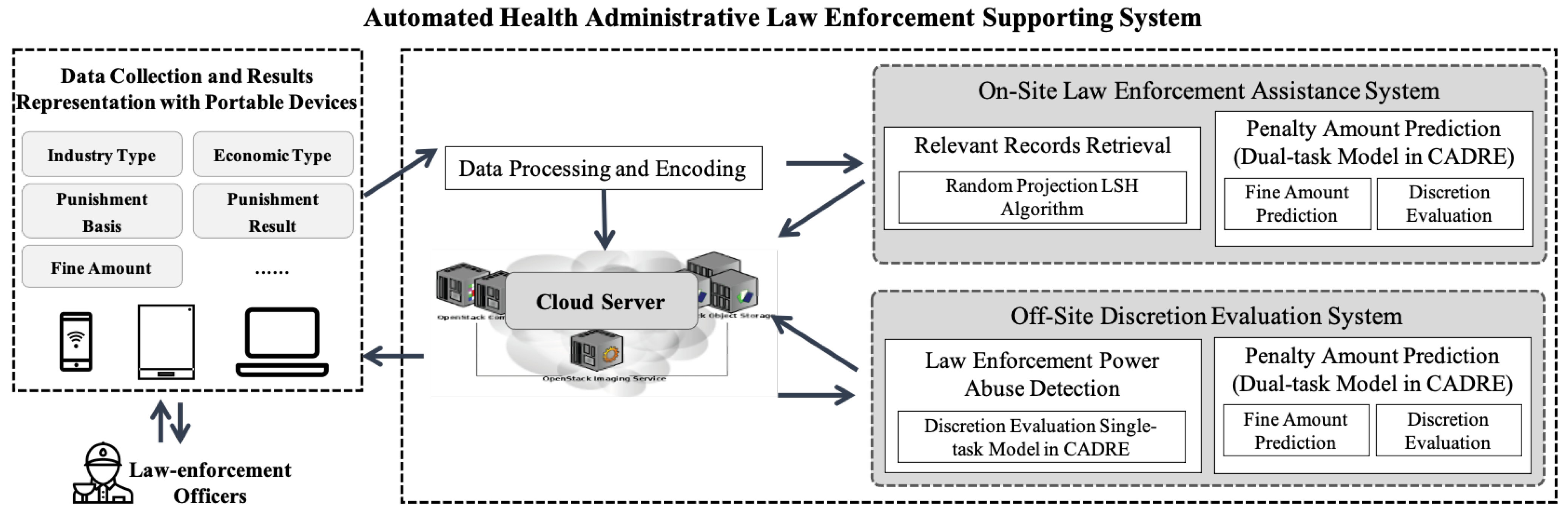
- We develop a complete system, including automated administrative punishment collection, amount prediction, and abuse detection. The system collects data from IoT devices, and then we follow the proposed approach to provide the service during individual enforcement. The officer could make proper decisions through the system recommendations and retrieval results from historical records, and the management could review and evaluate each administrative penalty.
2. Related Work
2.1. Multi-Task Learning
2.2. Label Classification Algorithm
2.3. Other Related Basic Methods
2.4. Penalty Amount Prediction Methods
3. Methods
3.1. Unsupervised Automated Sample Identification and Dataset Construction Method
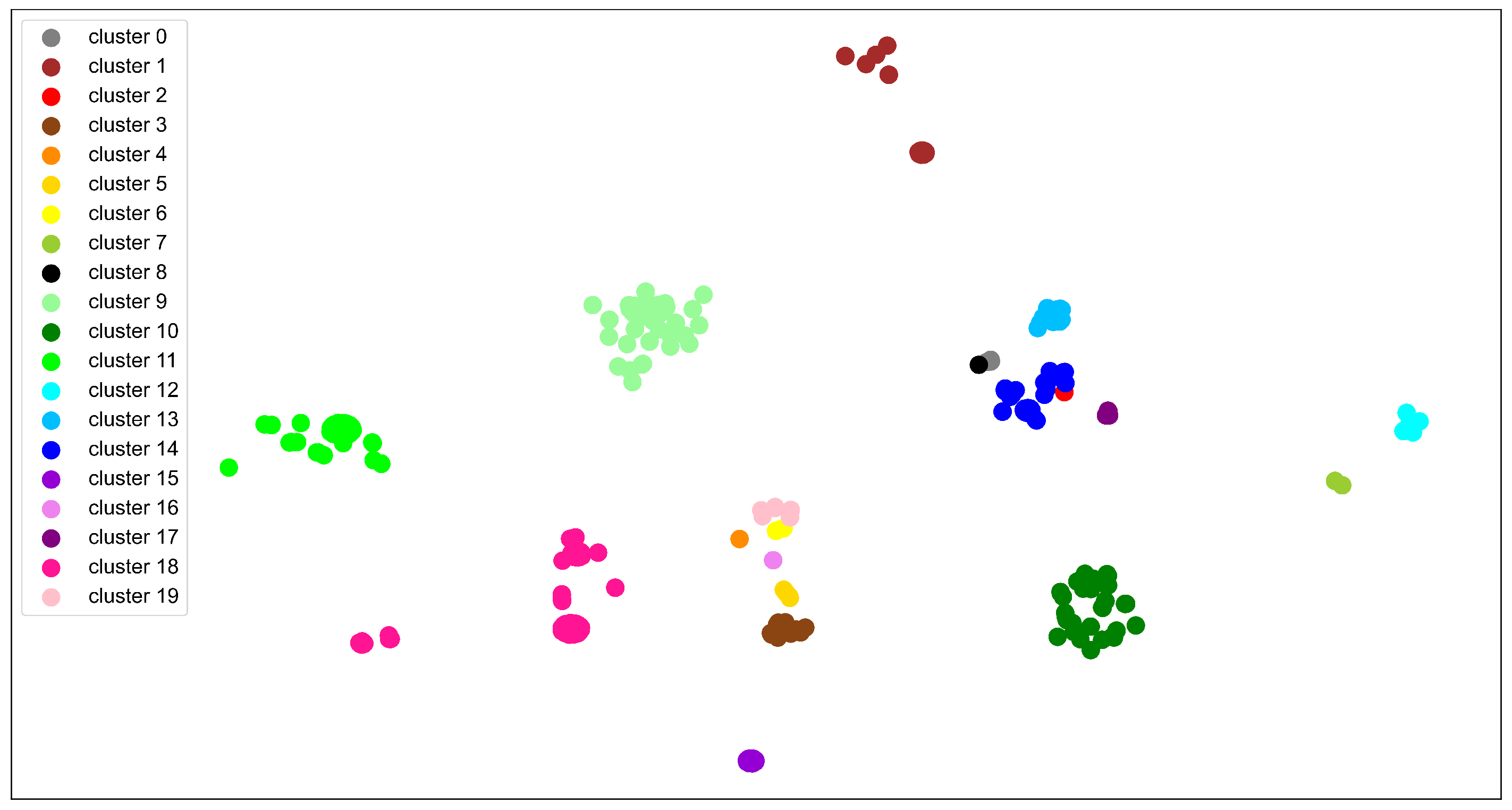
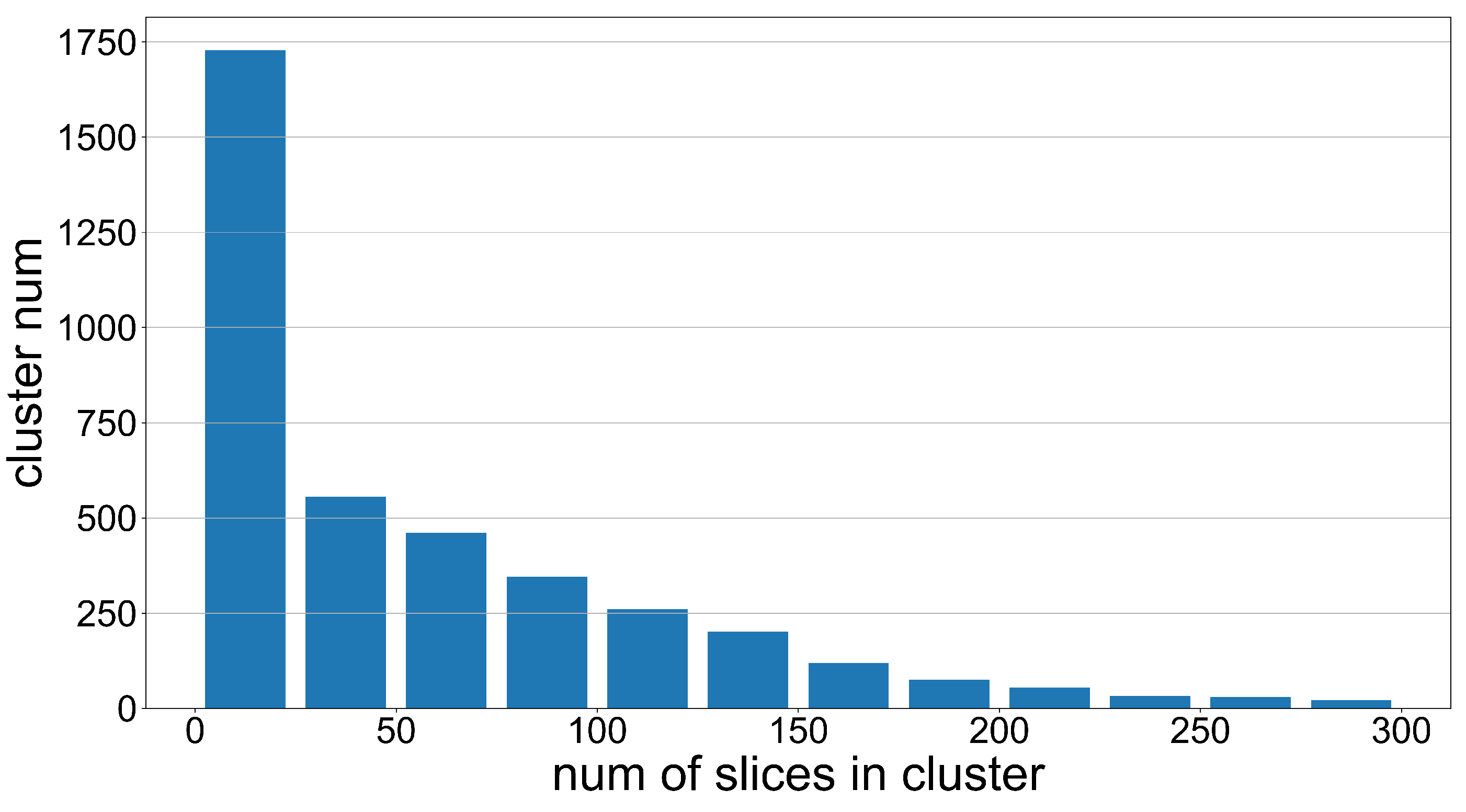
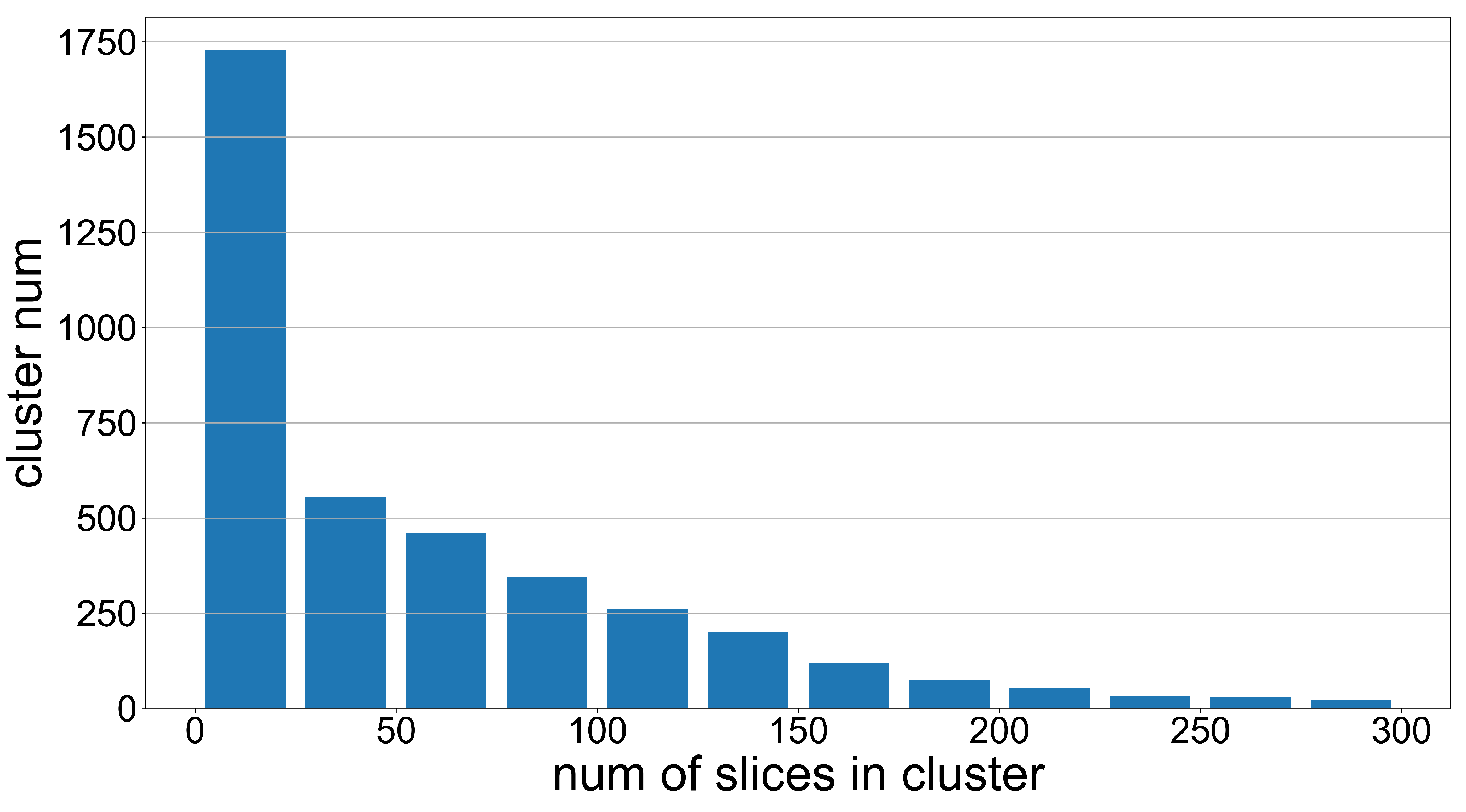
3.1.1. Data Clustering
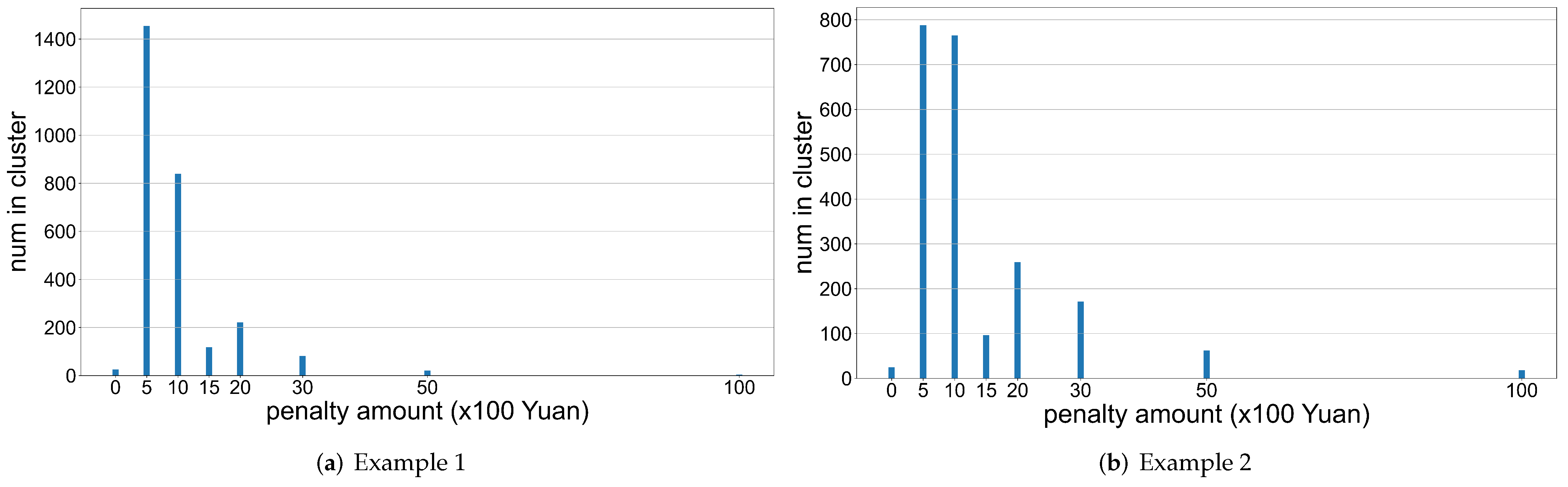
3.1.2. Identifying and Constructing Positive and Negative Samples
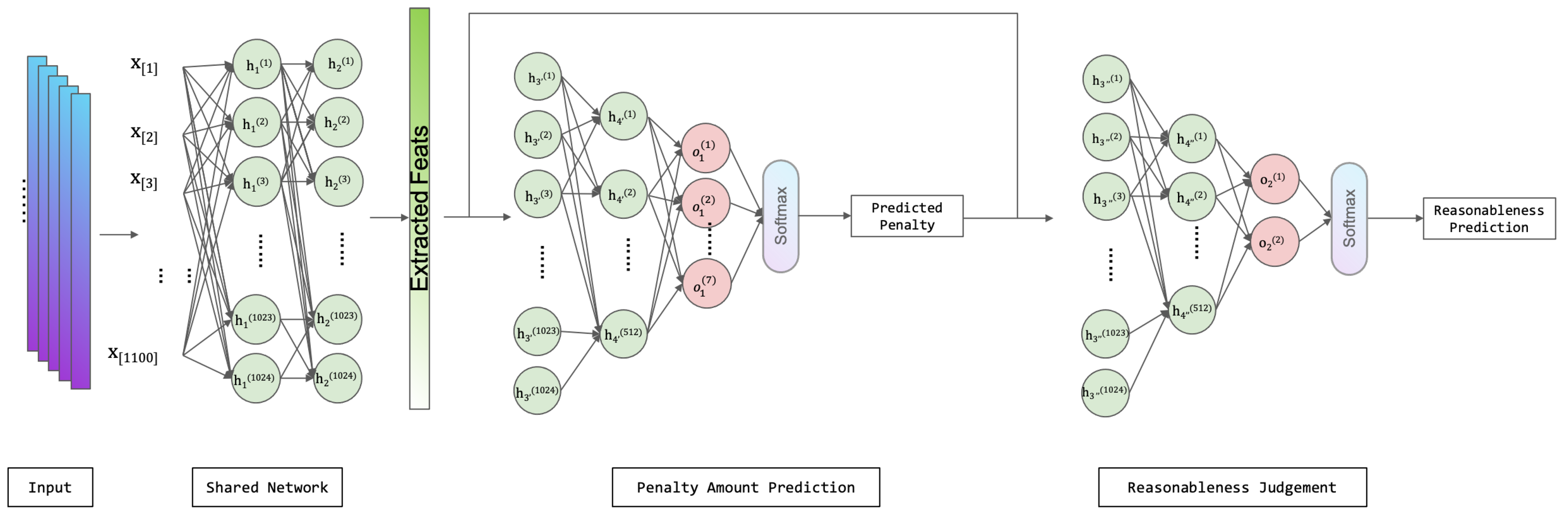
3.2. Network Architecture
3.3. Training Scheme
| Algorithm 1: The two-stage training method of the multi-task penalty amount prediction and reasonableness judgment model |
 |
4. Experiments
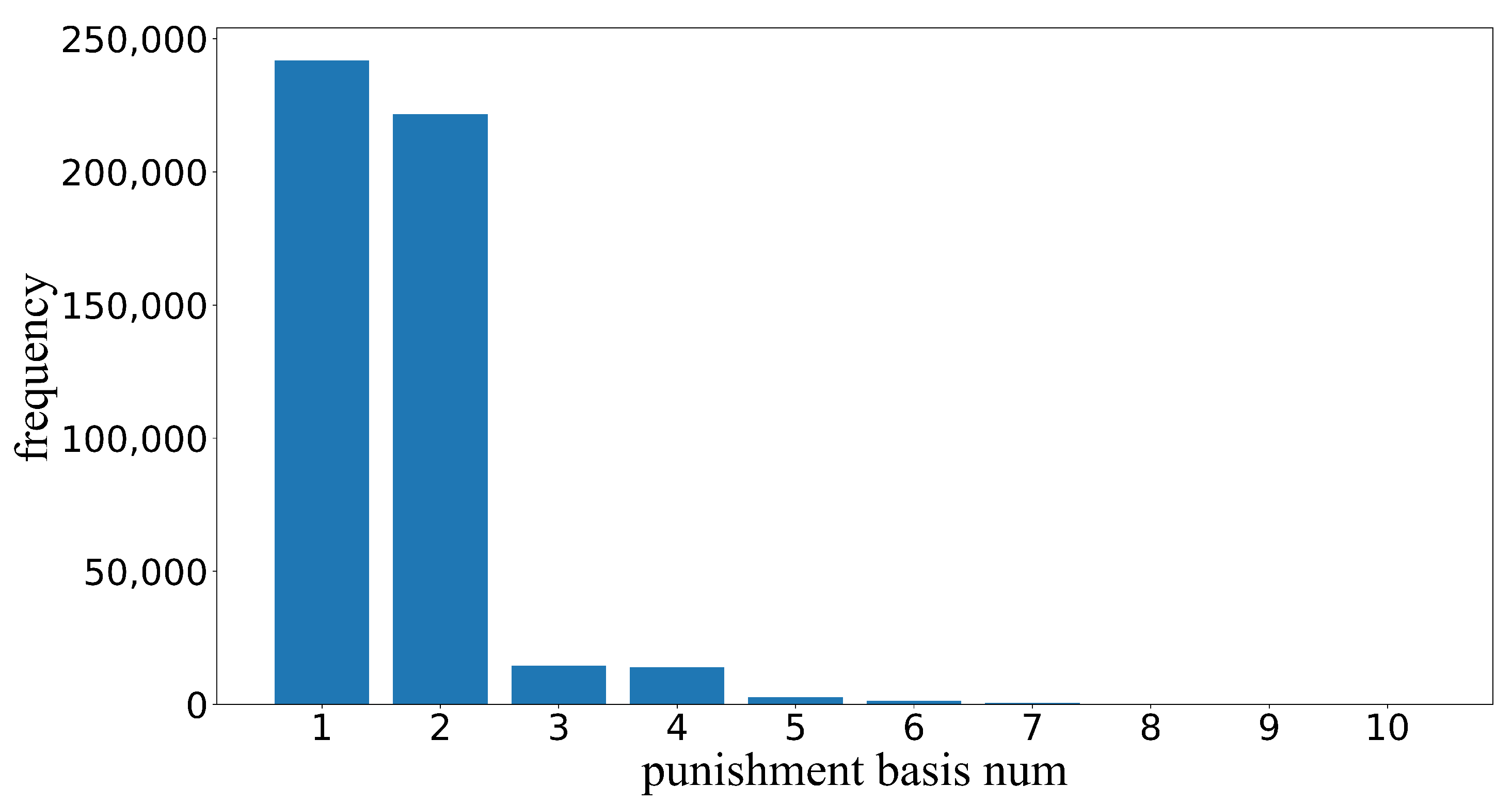
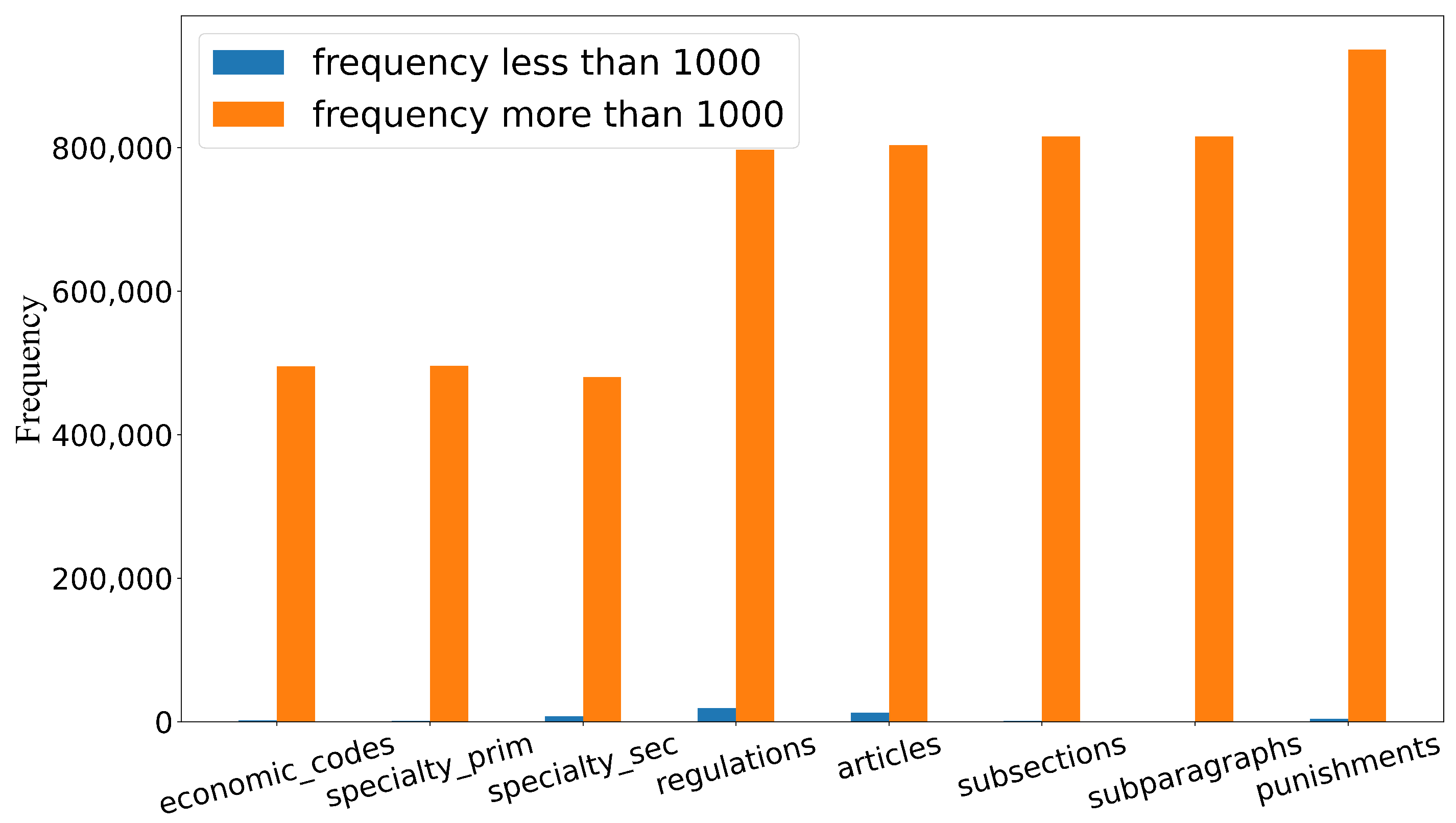
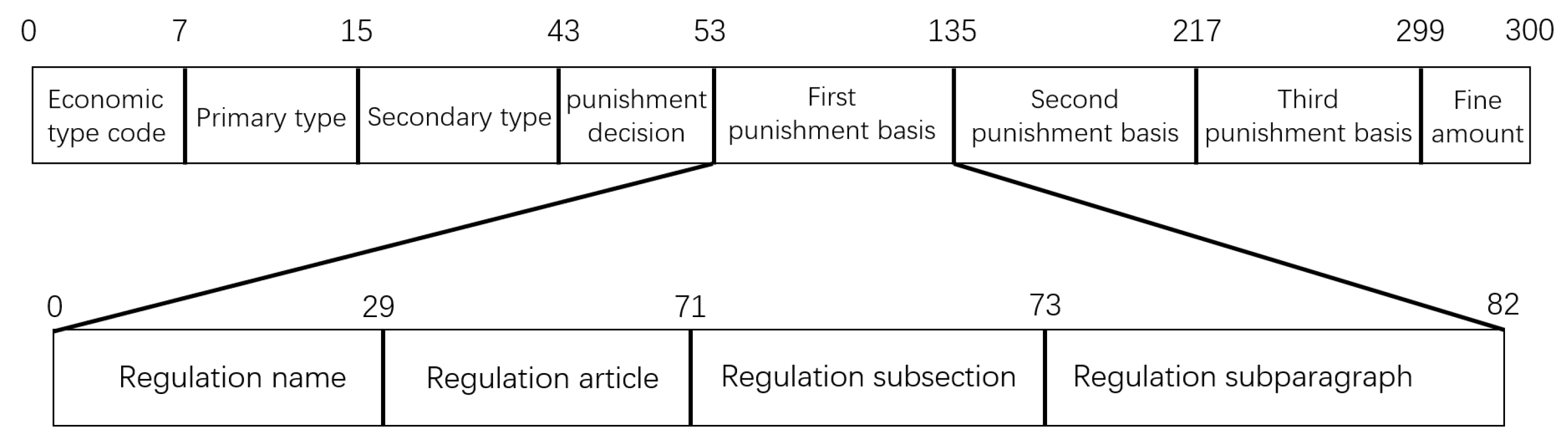
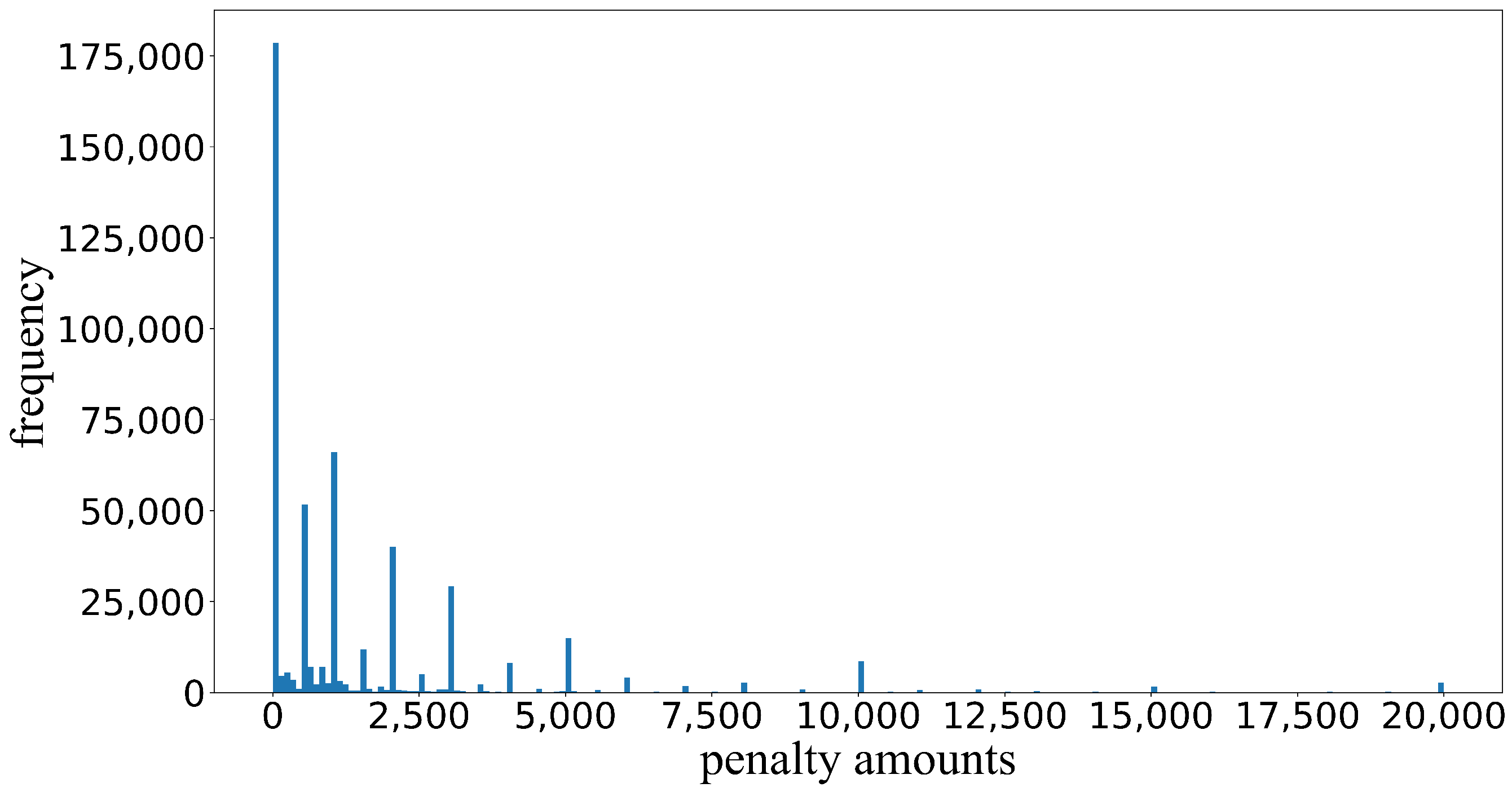
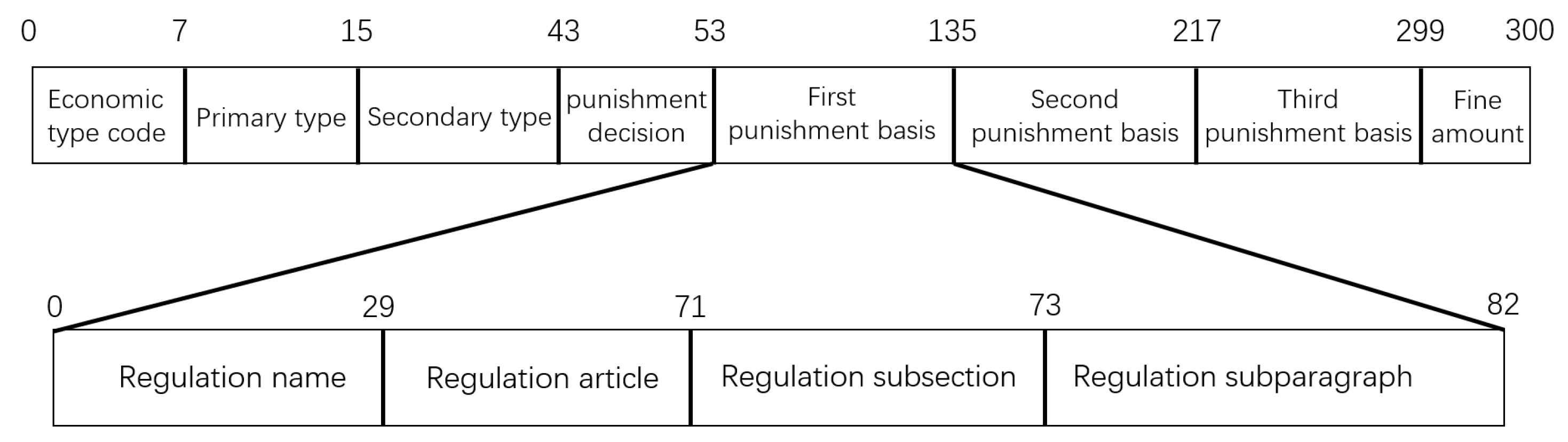
4.1. Data Introduction and Pre-Processing
4.2. Experiment Setup
4.3. Penalty Amount Prediction for New Penalty Records
4.4. Reasonableness Judgment for Existing Penalty Records
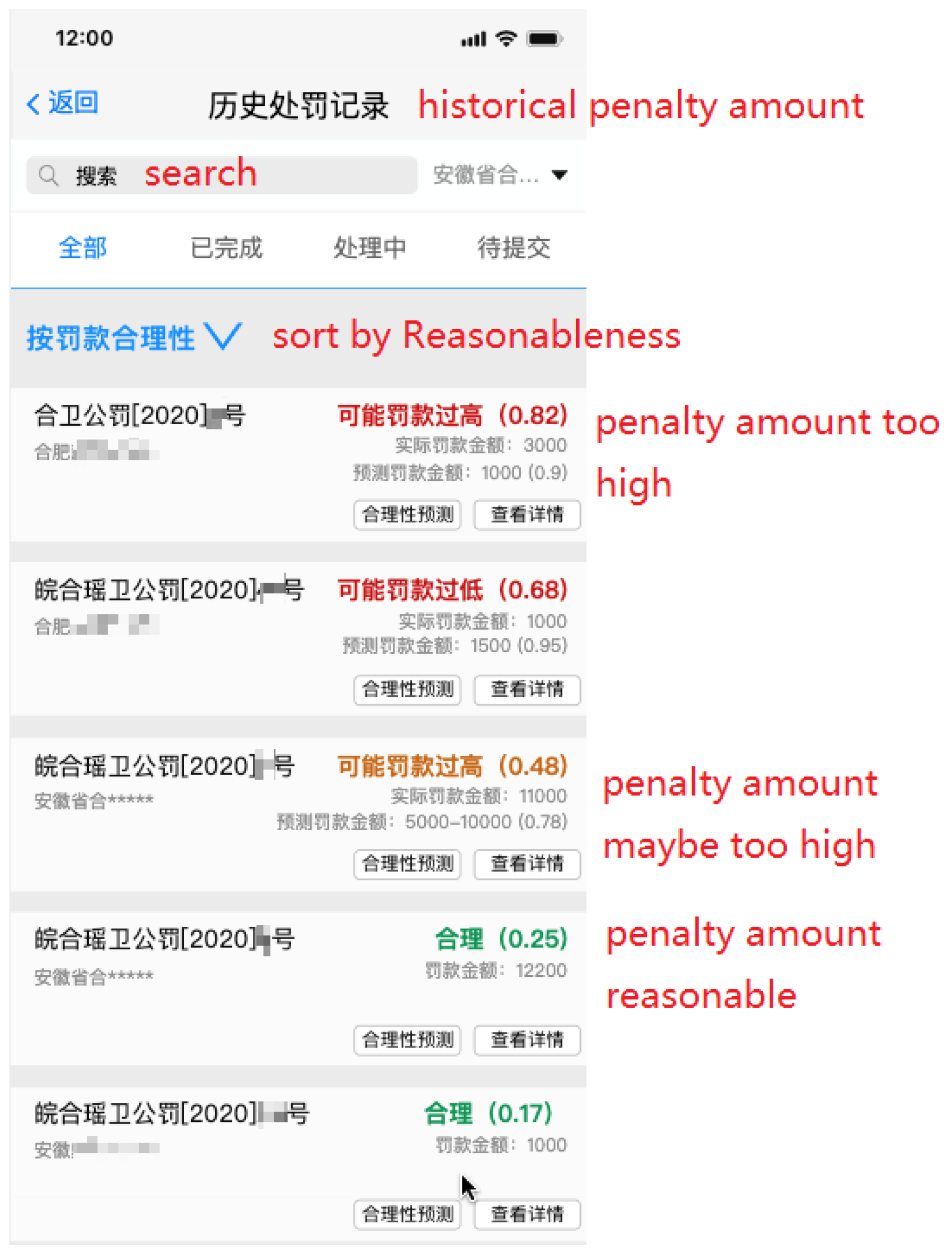
5. Applications
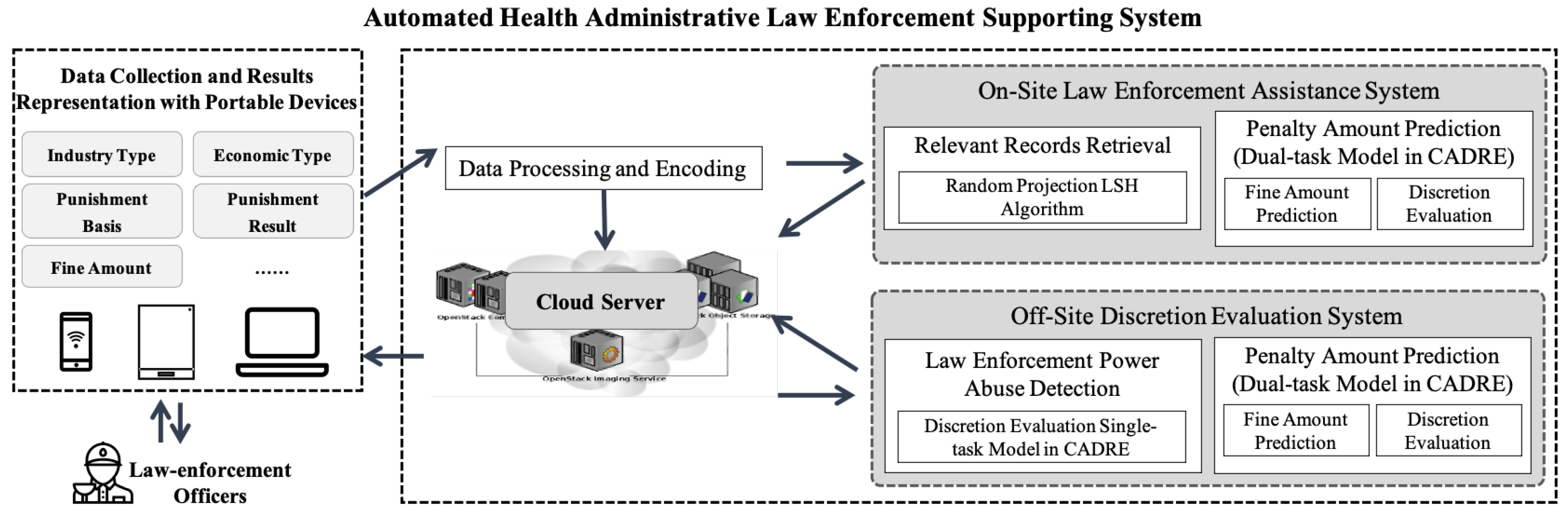
5.1. System Structure and Cloud Deployment
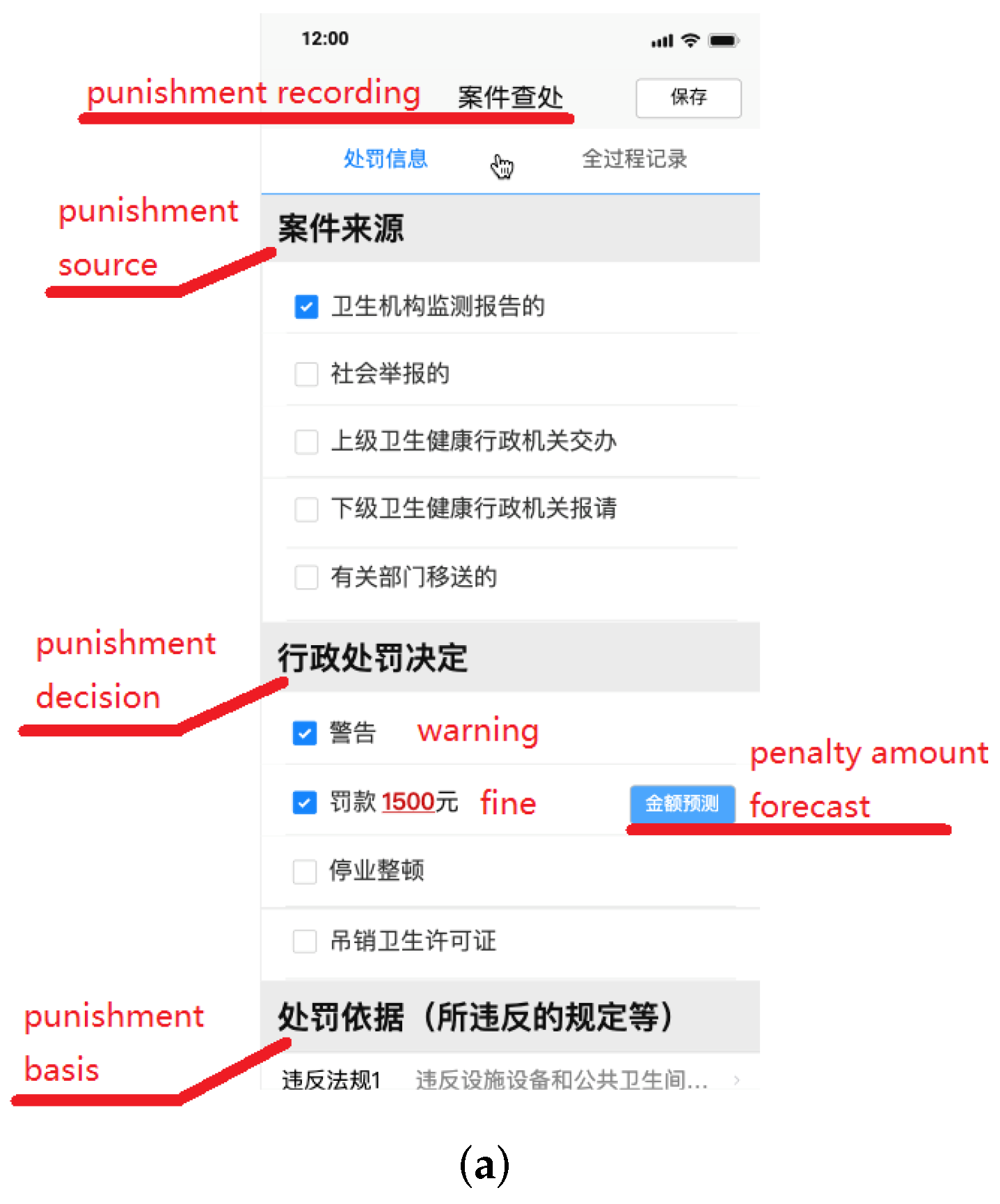
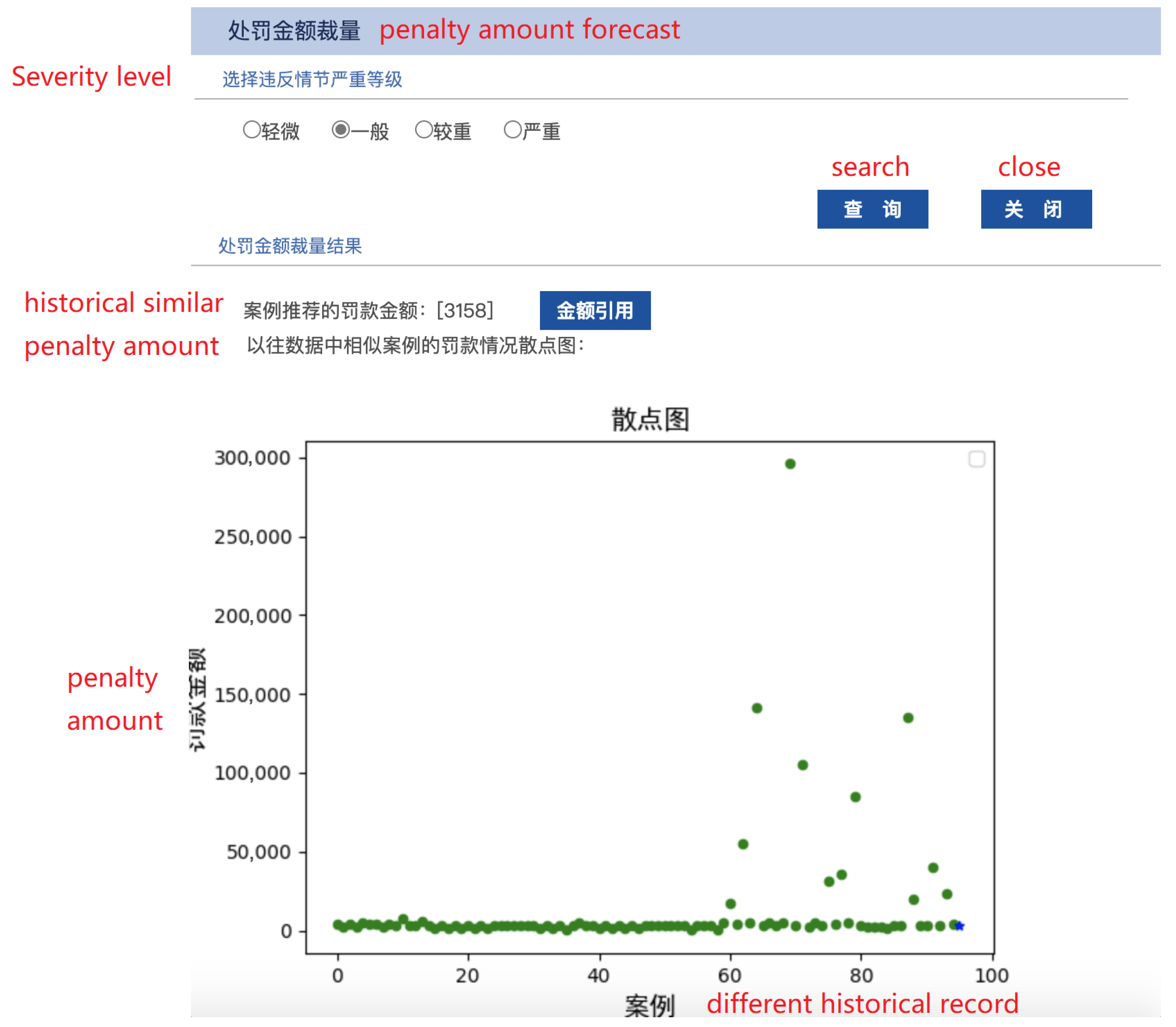
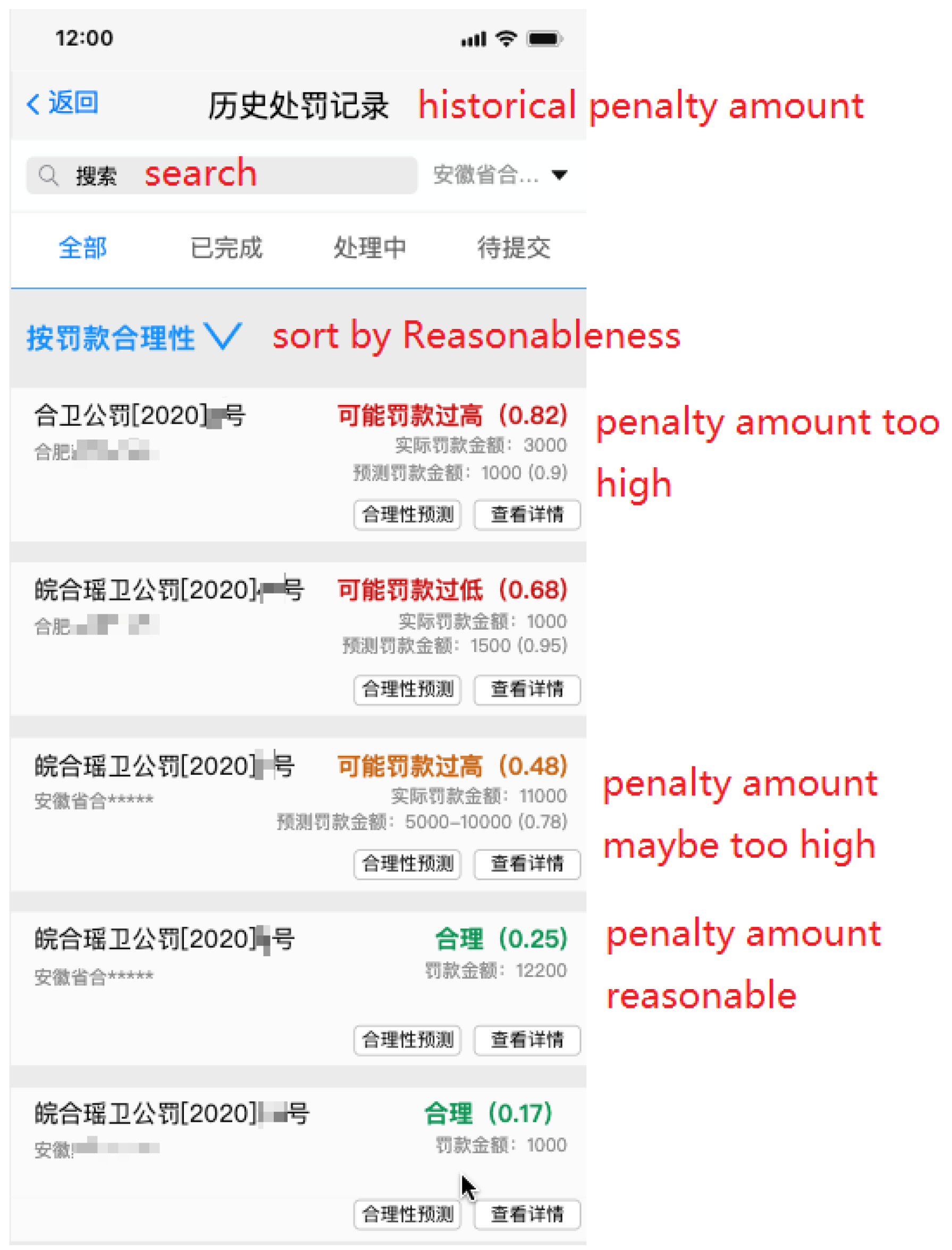
5.2. On-Site Law Enforcement Assistance System
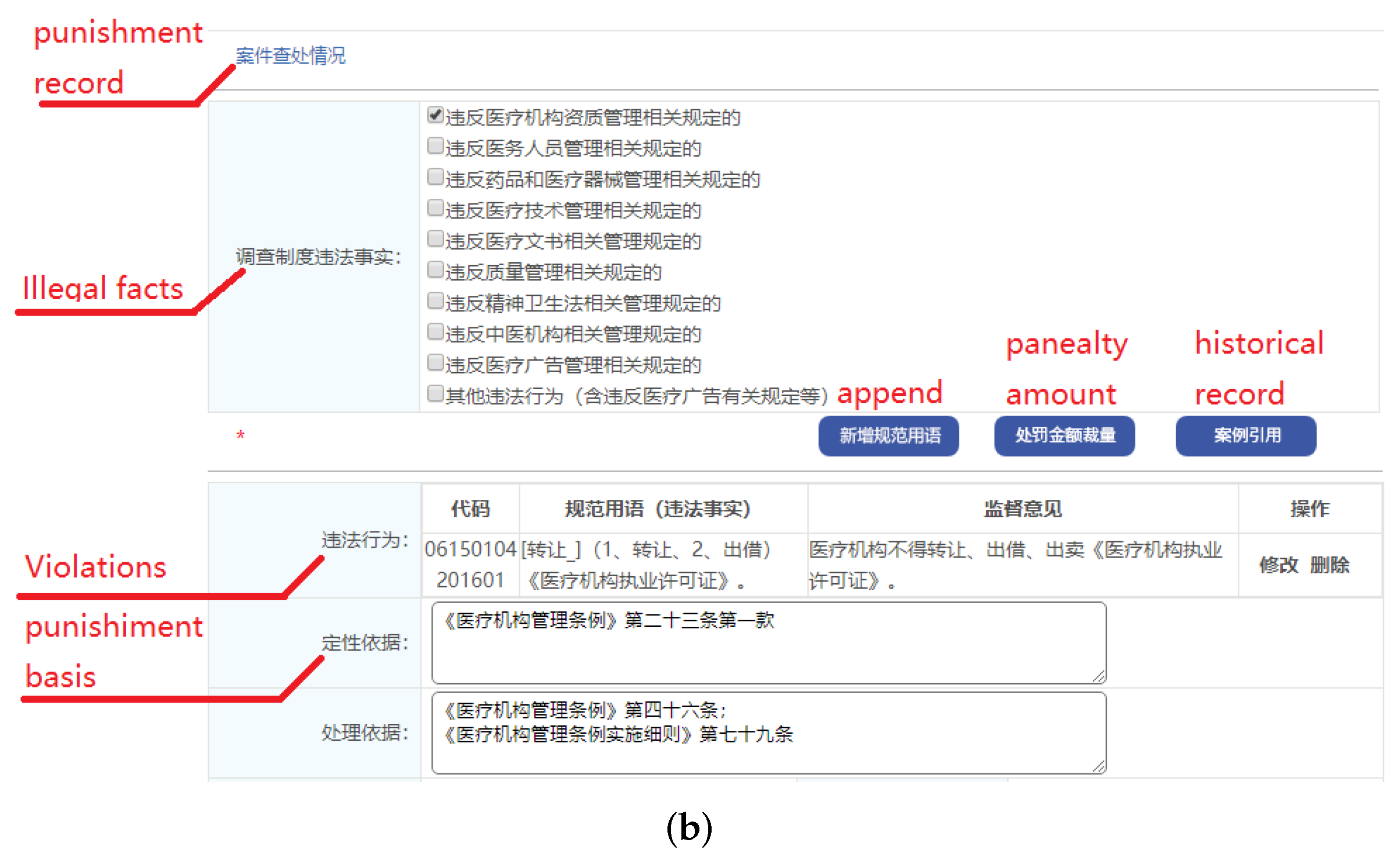
5.3. Off-Site Discretion Evaluation and Law Enforcement Power Abuse Detection System
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Cao, W.; Wan, L.; Tang, L.; Zhao, Y.; Chen, G. Compilation and Dynamic Adjustment of Health Administrative Law Enforcement Powers and Responsibilities list. Chin. J. Health Insp. 2021, 28, 320–326. [Google Scholar]
- Zhang, W. A Cognitive Study on the Implementation of Discretionary Power of Administrative Punishment of Medical and Health Supervisors in a Province. Master’s Thesis, Jilin University, Changchun, China, 2019. [Google Scholar]
- Li, B.; Li, J.; Huai, J.; Wo, T.; Li, Q.; Zhong, L. EnaCloud: An energy-saving application live placement approach for cloud computing environments. In Proceedings of the 2009 IEEE International Conference on Cloud Computing, Bangalore, India, 21–25 September 2009; pp. 17–24. [Google Scholar] [CrossRef]
- Li, J.; Li, B.; Wo, T.; Hu, C.; Huai, J.; Liu, L.; Lam, K. CyberGuarder: A virtualization security assurance architecture for green cloud computing. Future Gener. Comput. Syst. 2012, 28, 379–390. [Google Scholar] [CrossRef] [Green Version]
- Shi, L.L.; Liu, L.; Wu, Y.; Jiang, L.; Panneerselvam, J.; Crole, R. A Social Sensing Model for Event Detection and User Influence Discovering in Social Media Data Streams. IEEE Trans. Comput. Soc. Syst. 2020, 7, 141–150. [Google Scholar] [CrossRef]
- Mumin, D.; Shi, L.L.; Liu, L.; Panneerselvam, J. Data-driven diffusion recommendation in online social networks for the internet of people. IEEE Trans. Syst. Man Cybern. Syst. 2020, 52, 166–178. [Google Scholar] [CrossRef]
- Keown, R. Mathematical models for legal prediction. Computer/lj 1980, 2, 829. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G.E. A simple framework for contrastive learning of visual representations. In Proceedings of the 37th International Conference on Machine Learning, ICML 2020, Virtual Event, 13–18 July 2020; Volume 119, pp. 1597–1607. [Google Scholar]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R.B. Momentum contrast for unsupervised visual representation learning. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2020, Seattle, WA, USA, 13–19 June 2020; pp. 9726–9735. [Google Scholar] [CrossRef]
- Ruder, S. An overview of multi-task learning in deep neural networks. arXiv 2017, arXiv:1706.05098. [Google Scholar]
- Jalali, A.; Sanghavi, S.; Ruan, C.; Ravikumar, P. A dirty model for multi-task learning. In Advances in Neural Information Processing Systems; Lafferty, J., Williams, C., Shawe-Taylor, J., Zemel, R., Culotta, A., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2010; Volume 23. [Google Scholar]
- Crammer, K.; Mansour, Y. Learning multiple tasks using shared hypotheses. In Advances in Neural Information Processing Systems; Pereira, F., Burges, C.J.C., Bottou, L., Weinberger, K.Q., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2012; Volume 25. [Google Scholar]
- Yang, X.; Zeng, Z.; Yeo, S.Y.; Tan, C.; Tey, H.L.; Su, Y. A novel multi-task deep learning model for skin lesion segmentation and classification. arXiv 2017, arXiv:1703.01025. [Google Scholar]
- Yang, Y.; Hospedales, T.M. Trace norm regularised deep multi-task learning. arXiv 2016, arXiv:1606.04038. [Google Scholar]
- Sun, T.; Shao, Y.; Li, X.; Liu, P.; Yan, H.; Qiu, X.; Huang, X. Learning sparse sharing architectures for multiple tasks. In Proceedings of the Thirty-Fourth AAAI Conference on Artificial Intelligence, AAAI 2020: The Thirty-Second Innovative Applications of Artificial Intelligence Conference, IAAI 2020: The Tenth AAAI Symposium on Educational Advances in Artificial Intelligence, EAAI 2020, New York, NY, USA, 7–12 February 2020; pp. 8936–8943. [Google Scholar]
- Schreiber, J.; Sick, B. Emerging relation network and task embedding for multi-task regression problems. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 2663–2670. [Google Scholar]
- Nguyen, T.A.; Jeong, H.; Yang, E.; Hwang, S.J. Clinical risk prediction with temporal probabilistic asymmetric multi-task learning. arXiv 2020, arXiv:2006.12777. [Google Scholar]
- Chen, Z.; Jiaze, E.; Zhang, X.; Sheng, H.; Cheng, X. Multi-task time series forecasting with shared attention. In Proceedings of the 2020 International Conference on Data Mining Workshops (ICDMW), Sorrento, Italy, 17–20 November 2020; pp. 917–925. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- MacQueen, J. Some methods for classification and analysis of multivariate observations. In Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability, Oakland, CA, USA, 21 June–18 July 1965; Volume 1, pp. 281–297. [Google Scholar]
- Cover, T.; Hart, P. Nearest neighbor pattern classification. IEEE Trans. Inf. Theory 1967, 13, 21–27. [Google Scholar] [CrossRef]
- Kong, S.; Li, Y.; Wang, J.; Rezaei, A.; Zhou, H. KNN-enhanced Deep Learning Against Noisy Labels. arXiv 2020, arXiv:2012.04224. [Google Scholar]
- Schmarje, L.; Brünger, J.; Santarossa, M.; Schröder, S.M.; Kiko, R.; Koch, R. Beyond Cats and Dogs: Semi-supervised Classification of fuzzy labels with overclustering. arXiv 2020, arXiv:2012.01768. [Google Scholar]
- Chu, Z.; Stratos, K.; Gimpel, K. Unsupervised label refinement improves dataless text classification. arXiv 2020, arXiv:2012.04194. [Google Scholar]
- Sculley, D. Web-scale k-means clustering. In Proceedings of the 19th International Conference on World Wide Web, Raleigh, NC, USA, 26–30 April 2010; pp. 1177–1178. [Google Scholar]
- Leung, K.M. Naive bayesian classifier. Polytech. Univ. Dep. Comput. Sci. Risk Eng. 2007, 2007, 123–156. [Google Scholar]
- Friedman, N.; Geiger, D.; Goldszmidt, M. Bayesian network classifiers. Mach. Learn. 1997, 29, 131–163. [Google Scholar] [CrossRef] [Green Version]
- Heckerman, D. A tutorial on learning with Bayesian networks. In Innovations in Bayesian Networks; Springer: Berlin/Heidelberg, Germany, 2008; pp. 33–82. [Google Scholar]
- Zhang, N.; Pu, Y.f.; Yang, S.; Gao, J.; Wang, Z.; Zhou, J.l. A Chinese legal intelligent auxiliary discretionary adviser based on GA-BP NNs. Electron. Libr. 2018, 36, 1135–1153. [Google Scholar] [CrossRef]
- Yeguang, Z. Classification, Prediction Method and Device for Fine Range of Long Text Cases Based on Document Embedding. 2019. Available online: http://www.soopat.com/Patent/201811237399 (accessed on 2 March 2022).
- Yuting, W. Deep Learning-Based Procuratorial Case Handling Auxiliary Sentencing Rule Mining. Ph.D. Thesis, North China Electric Power University, Beijing, China, 2019. [Google Scholar]
- Zhang, S.; Yan, G.; Li, Y.; Liu, J. Evaluation of judicial imprisonment term prediction model based on text mutation. In Proceedings of the 2019 IEEE 19th International Conference on Software Quality, Reliability and Security Companion (QRS-C), Sofia, Bulgaria, 22–26 July 2019; pp. 62–65. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Halko, N.; Martinsson, P.; Tropp, J.A. Finding Structure with Randomness: Probabilistic Algorithms for Constructing Approximate Matrix Decompositions. SIAM Rev. 2011, 53, 217–288. [Google Scholar] [CrossRef]
- Rauber, P.E.; Falcão, A.X.; Telea, A.C. Visualizing time-dependent data using dynamic t-SNE. In Proceedings of the 18th Eurographics Conference on Visualization, EuroVis 2016–Short Papers, Groningen, The Netherlands, 6–10 June 2016; pp. 73–77. [Google Scholar] [CrossRef]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep sparse rectifier neural networks. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 11–13 April 2011; pp. 315–323. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Charikar, M.S. Similarity estimation techniques from rounding algorithms. In Proceedings of the Thiry-Fourth Annual ACM Symposium on Theory of Computing, Montreal, QC, Canada, 19–21 May 2002; pp. 380–388. [Google Scholar]
- Rajaraman, A.; Ullman, J.D. Mining of Massive Datasets; Cambridge University Press: Cambridge, UK, 2011. [Google Scholar]
- Broder, A.Z. On the resemblance and containment of documents. In Proceedings of the Compression and Complexity of SEQUENCES 1997 (Cat. No. 97TB100171), Salerno, Italy, 13 June 1997; pp. 21–29. [Google Scholar]
- Datar, M.; Immorlica, N.; Indyk, P.; Mirrokni, V.S. Locality-sensitive hashing scheme based on p-stable distributions. In Proceedings of the Twentieth Annual Symposium on Computational Geometry, Brooklyn, NY, USA, 8–11 June 2004; pp. 253–262. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Task | Input | Output | Label | Network Components Used | |
|---|---|---|---|---|---|
| reasonableness judgment | all punishment records & fine amount | credibility | fair/unfair | shared layers, reasonableness judgment network | |
| penalty prediction and judgment | fair punishment records | fine amount prediction | fine amount in the record | shared layers, amount prediction network | |
| fine amount prediction | credibility | whether predicted amount matches with labels | shared layers, reasonableness judgment network | ||
| Feature Name | Number of Possible Values |
|---|---|
| Economic type code | 7 |
| Primary Type | 8 |
| Secondary Type | 28 |
| Regulation name | 30 |
| Chapter Number of the Regulation | 43 |
| Section Number of the Regulation | 3 |
| Article Number of the Regulation | 10 |
| Punishment Decision | 10 |
| Ground Truth | |||
|---|---|---|---|
| Positive | Negative | ||
| Prediction | Positive | True Positive (TP) | False Positive (FP) |
| Negative | False Negative (FN) | True Negative (TN) | |
| Model | Accuracy |
|---|---|
| SVM | 63.5% |
| Random Forest | 88.6% |
| single-task model | 98.5% |
| Multi-task model (ours) | 99.6% |
| Model | Accuracy |
|---|---|
| SVM | 96.2% |
| Random Forest | 87.2% |
| single-task model | 96.5% |
| Multi-task model (ours) | 99.4% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, H.; Xu, H.; Zhou, Y.; Li, X. A Contrastive Evaluation Method for Discretion in Administrative Penalty. Electronics 2022, 11, 1388. https://doi.org/10.3390/electronics11091388
Wang H, Xu H, Zhou Y, Li X. A Contrastive Evaluation Method for Discretion in Administrative Penalty. Electronics. 2022; 11(9):1388. https://doi.org/10.3390/electronics11091388
Chicago/Turabian StyleWang, Hui, Haoyu Xu, Yiyang Zhou, and Xueqing Li. 2022. "A Contrastive Evaluation Method for Discretion in Administrative Penalty" Electronics 11, no. 9: 1388. https://doi.org/10.3390/electronics11091388
APA StyleWang, H., Xu, H., Zhou, Y., & Li, X. (2022). A Contrastive Evaluation Method for Discretion in Administrative Penalty. Electronics, 11(9), 1388. https://doi.org/10.3390/electronics11091388