
Few-Shot Object Detection Method Based on Knowledge Reasoning

Abstract
:1. Introduction
2. Related Work and Contribution
2.1. Few-Shot Learning
2.2. Knowledge Graphs
2.3. Object Detection
- (1)
- A few-shot object detection method based on knowledge reasoning was proposed. It applied knowledge graphs together with the visual information to the novel object detection.
- (2)
- We designed a general expression pattern of knowledge graphs, which can be flexibly applied to express the relationship between visible objects, and has good scalability.
- (3)
- By using GNN, a novel object can be recognized by the method of knowledge reasoning. The proposed methodology achieves state-of-the-art performance on object detection.
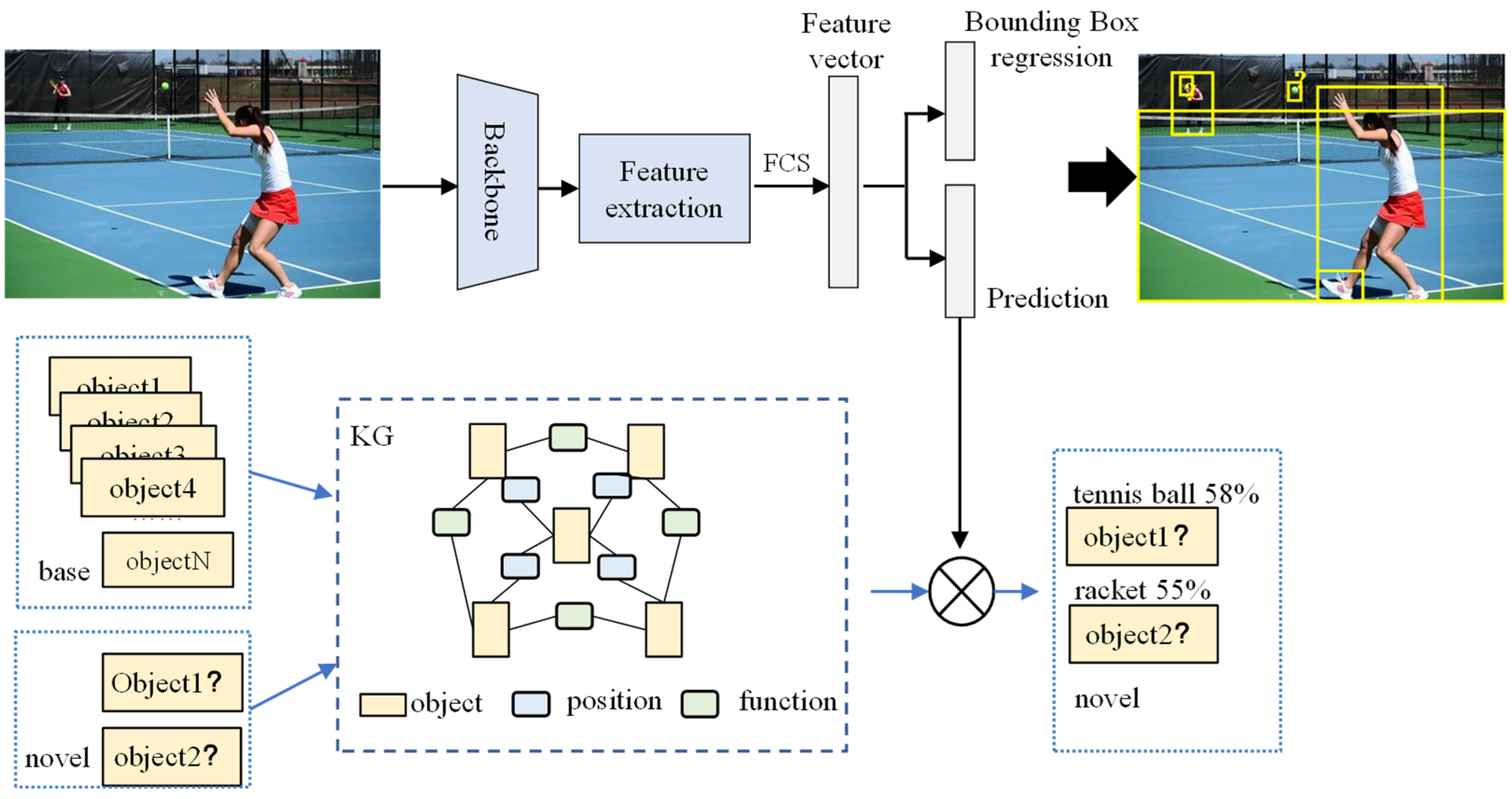
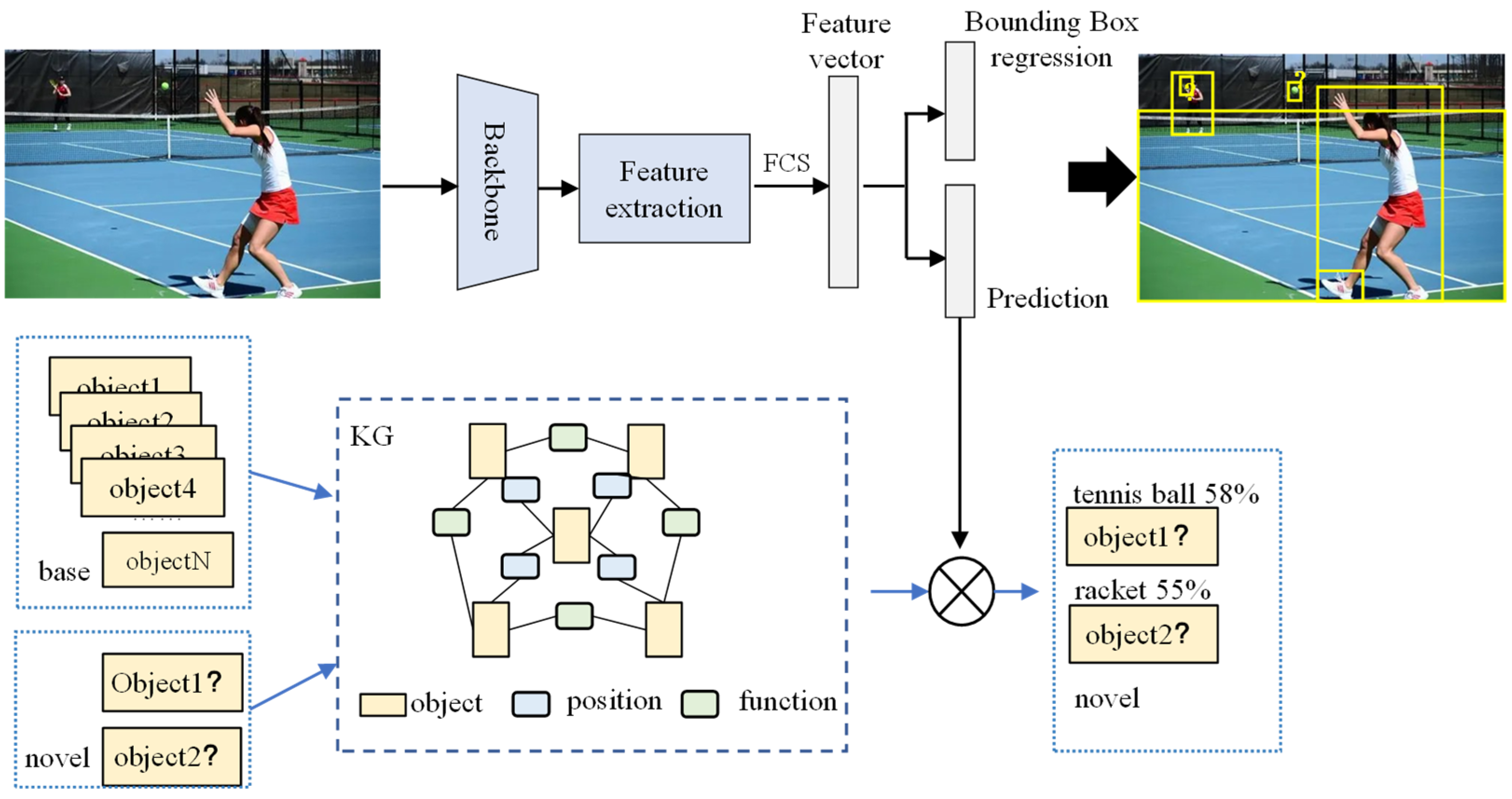
3. Methodology
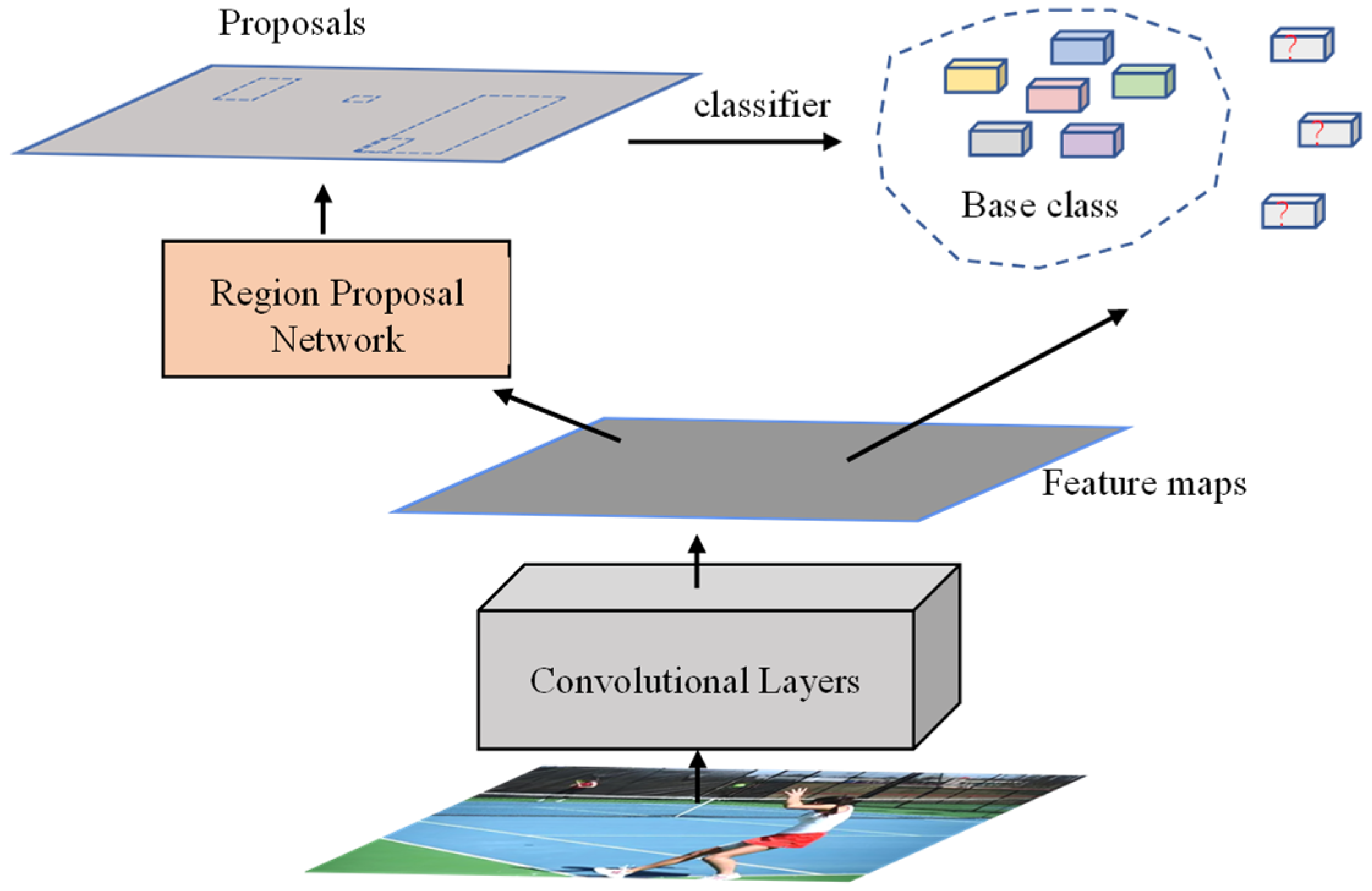
3.1. Few-Shot Object Detection
3.2. Few-Shot Detector
3.3. Knowledge Graph for a Scene
3.3.1. Knowledge Graph
3.3.2. Scene Graph
3.3.3. Object Detection
3.4. Reasoning Based on Knowledge Graph
3.5. Space Projection
4. Experiments
4.1. Datasets
4.2. Implementation Details
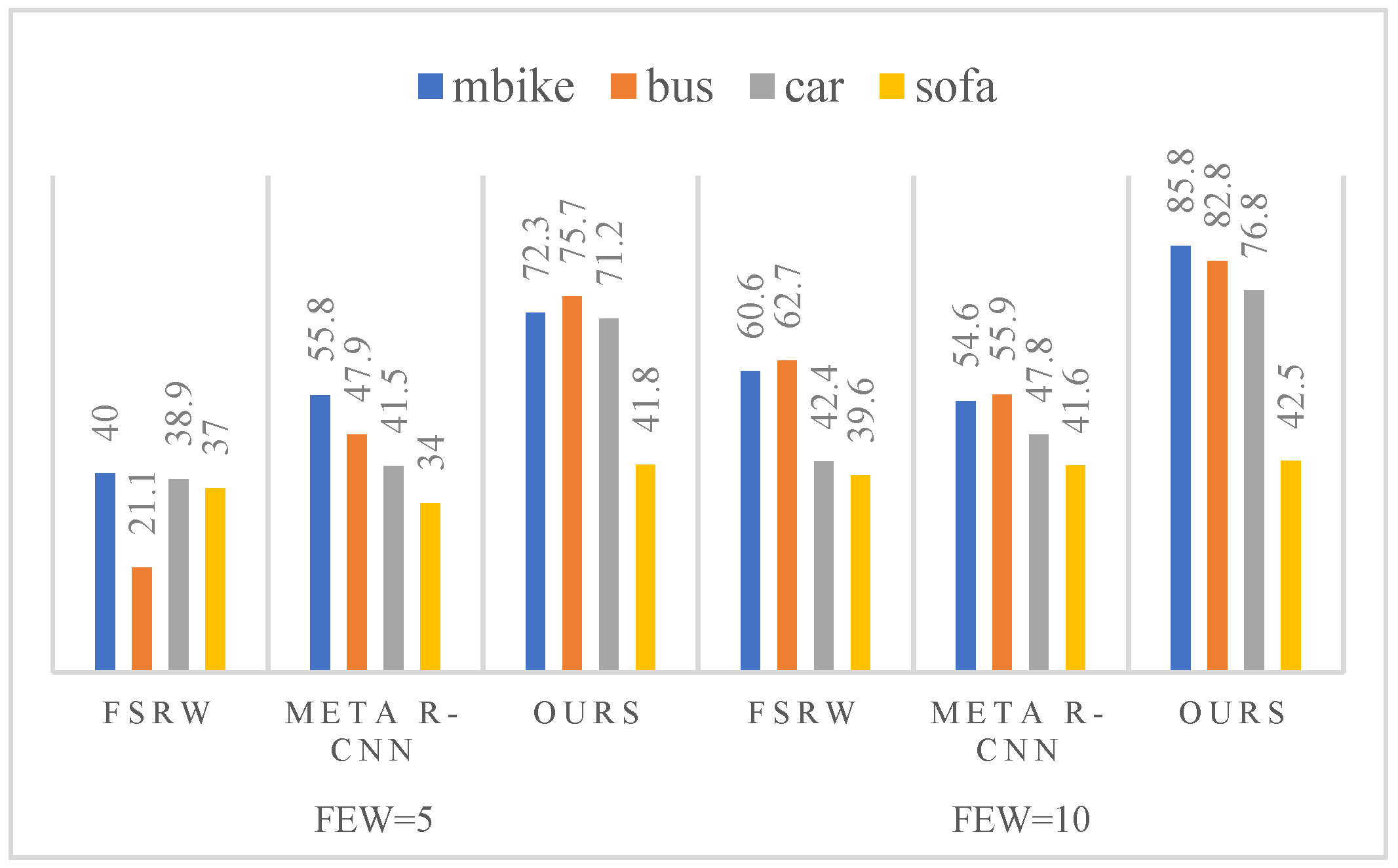
4.3. Results on VOC and COCO Datasets
4.4. Experiments on Relation Reasoning
5. Experimental Analysis
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| KR-FSD | Knowledge Reason Few-Shot Detection |
| KG | Knowledge Graphs |
| SGD | Stochastic Gradient Descent |
| CNN | Convolutional Neural Network |
| GNN | Graph Neural Network |
| RPN | Region Proposal Network |
| ROI | Region of Interest |
| VOC | Visual Object Classes |
| COCO | Common Objects in Context |
| AP | Average Precision |
References
- Xu, X.f.; Hao, J.; Zheng, Y. Multi-objective Artificial Bee Colony Algorithm for Multi-stage Resource Leveling Problem in Sharing Logistics Network. Comput. Ind. Eng. 2020, 142, 106338. [Google Scholar] [CrossRef]
- Zou, Z.; Shi, Z.; Guo, Y.; Ye, J. Object detection in 20 years: A survey. arXiv 2019, arXiv:1905.05055. [Google Scholar]
- Chen, H.; Wang, Y.; Wang, G.; Qiao, Y. Lstd: A low-shot transfer detector for object detection. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Karlinsky, L.; Shtok, J.; Harary, S.; Schwartz, E.; Aides, A.; Feris, R.; Giryes, R.; Bronstein, A.M. Repmet: Representative-based metric learning for classification and few-shot object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5197–5206. [Google Scholar]
- Dong, X.; Zheng, L.; Fan Ma, Y.Y.; Meng, D. Few-example object detection with model communication. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 1641–1654. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kang, B.; Liu, Z.; Wang, X.; Yu, F.; Feng, J.; Darrell, T. Few-shot object detection via feature reweighting. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 8420–8429. [Google Scholar]
- Yan, X.; Chen, Z.; Xu, A.; Wang, X.; Liang, X.; Lin, L. Meta r-cnn: Towards general solver for instance-level low-shot learning. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 9577–9586. [Google Scholar]
- Wang, Y.-X.; Ramanan, D.; Hebert, M. Meta-learning to detect rare objects. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 9925–9934. [Google Scholar]
- Fan, Q.; Zhuo, W.; Tang, C.-K.; Tai, Y.-W. Few-shot object detection with attention-rpn and multi-relation detector. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 4013–4022. [Google Scholar]
- Zhu, C.; Chen, F.; Ahmed, U.; Shen, Z.; Savvides, M. Semantic relation reasoning for shot-stable few-shot object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 8782–8791. [Google Scholar]
- Yang, J.; Liu, Y.L. The latest advances in face recognition with single training sample. J. Xihua Univ. (Nat. Sci. Ed.) 2014, 33, 1–5. [Google Scholar]
- Zhang, C.; Cai, Y.; Lin, G.; Shen, C. DeepEMD: Differentiable Earth Mover’s Distance for Few-Shot Learning. arXiv 2020, arXiv:2003.06777. [Google Scholar]
- Simon, C.; Koniusz, P.; Nock, R.; Harandi, M. Adaptive subspaces for few-shot learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 4136–4145. [Google Scholar]
- Snell, J.; Swersky, K.; Zemel, R. Prototypical networks for few-shot learning. arXiv 2017, arXiv:1703.05175. [Google Scholar]
- Vinyals, O.; Blundell, C.; Lillicrap, T.; Wierstra, D. Matching networks for one shot learning. Adv. Neural Inf. Process. Syst. 2016, 29, 3630–3638. [Google Scholar]
- Koch, G.; Zemel, R.; Salakhutdinov, R. Siamese neural networks for one-shot image recognition. In Proceedings of the ICML Deep Learning Workshop, Lille, France, 6–11 July 2015. [Google Scholar]
- Sung, F.; Yang, Y.; Zhang, L.; Xiang, T.; Torr, P.H.; Hospedales, T.M. Learning to compare: Relation network for few-shot learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1199–1208. [Google Scholar]
- Song, J.; Shen, C.; Yang, Y.; Liu, Y.; Song, M. Transductive unbiased embedding for zero-shot learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1024–1033. [Google Scholar]
- Vyas, M.R.; Venkateswara, H.; Panchanathan, S. Leveraging seen and unseen semantic relationships for generative zero-shot learning. In Proceedings of the European Conference on Computer Vision, virtual, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 70–86. [Google Scholar]
- Xian, Y.; Lampert, C.H.; Schiele, B.; Akata, Z. Zero-shot learning—A comprehensive evaluation of the good, the bad and the ugly. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 2251–2265. [Google Scholar] [CrossRef] [Green Version]
- Chen, X.; Jia, S.; Xiang, Y. A review: Knowledge reasoning over knowledge graph. Expert Syst. Appl. 2020, 141, 112948. [Google Scholar] [CrossRef]
- Google Inside Search. Available online: https://www.google.com/intl/es419/insidesearch/features/search/knowledge.html (accessed on 23 April 2017).
- Wang, H.; Zhao, M.; Xie, X.; Li, W.; Guo, M. Knowledge graph convolutional networks for recommender systems. In Proceedings of the World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 3307–3313. [Google Scholar]
- Ehrlinger, L.; Wöß, W. Towards a Definition of Knowledge Graphs. SEMANTiCS 2016, 48, 2. [Google Scholar]
- Yang, Z.; Wang, Y.; Chen, X.; Liu, J.; Qiao, Y. Context-transformer: Tackling object confusion for few-shot detection. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12653–12660. [Google Scholar]
- Wang, X.; Huang, T.E.; Darrell, T.; Gonzalez, J.E.; Yu, F. Frustratingly simple few-shot object detection. arXiv 2020, arXiv:2003.06957. [Google Scholar]
- Wu, J.; Liu, S.; Huang, D.; Wang, Y. Multi-scale positive sample refinement for few-shot object detection. In Proceedings of the European Conference on Computer Vision, virtual, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 456–472. [Google Scholar]
- Xiao, Y.; Marlet, R. Few-shot object detection and viewpoint estimation for objects in the wild. In Proceedings of the European Conference on Computer Vision, virtual, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 192–210. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Everingham, M.; van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Cham, Switzerland, 2014. [Google Scholar] [CrossRef] [Green Version]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Object Instance | Attributes |
|---|---|
| people1 | Gender—“female” |
| people2 | Gender—“unknown” |
| places | Style—“tennis court” |
| shoes | Style—“sports shoes”, Color—“white” |
| object1? | Color—“green”, Shape—“round”, Size—“small” |
| object2? | Color—?, Shape—?, Size—? |
| Relationships | Map |
|---|---|
| —“on” | (people2, places) |
| —“over” | (object1, places) |
| —“hold” | (people2, object2) |
| —“wear” | (people1, shoes) |
| Datasets | WordNet IDs [10] |
|---|---|
| aeroplane | n02690373, n02692877, n04552348 |
| bird | n01514668, n01514859, n01518878, n01530575, n01531178, n01532829, n01534433, n01537544, n01558993, n01560419, n01580077, n01582220, n01592084, n01601694, n01608432, n01614925, n01616318, n01622779, n01795545, n01796340, n01797886, n01798484, n01806143, n01806567, n01807496, n01817953, n01818515, n01819313, n01820546, n01824575, n01828970, n01829413, n01833805, n01843065, n01843383, n01847000, n01855032, n01855672, n01860187, n02002556, n02002724, n02006656, n02007558, n02009229, n02009912, n02011460, n02012849, n02013706, n02017213, n02018207, n02018795, n02025239, n02027492, n02028035, n02033041, n02037110, n02051845, n02056570, n02058221 |
| boat | n02687172, n02951358, n03095699, n03344393, n03447447, n03662601, n03673027, n03873416, n03947888, n04147183, n04273569, n04347754, n04606251, n04612504 |
| bottle | n02823428, n03062245, n03937543, n03983396, n04522168, n04557648, n04560804, n04579145, n04591713 |
| bus | n03769881, n04065272, n04146614, n04487081 |
| cat | n02123045, n02123159, n02123394, n02123597, n02124075, n02125311, n02127052 |
| cow | n02403003, n02408429, n02410509 |
| horse | n02389026, n02391049 |
| motorbike | n03785016, n03791053 |
| sheep | n02412080, n02415577, n02417914, n02422106, n02422699, n02423022 |
| sofa | n04344873 |
| Shot | Method | Novel Sets | |||||
|---|---|---|---|---|---|---|---|
| Bird | Bus | Cow | Mbike | Sofa | Mean | ||
| 1 | FSRW | 13.5 | 10.6 | 31.5 | 13.8 | 4.3 | 14.8 |
| Meta R-CNN | 6.1 | 32.8 | 15 | 35.4 | 0.2 | 19.9 | |
| ours | 35.2 | 49.8 | 56.3 | 61.4 | 22.6 | 45.8 | |
| 5 | FSRW | 31.5 | 21.1 | 39.8 | 40.0 | 37.0 | 33.9 |
| Meta R-CNN | 35.8 | 47.9 | 54.9 | 55.8 | 34.0 | 45.7 | |
| ours | 42.2 | 55.7 | 60.6 | 62.3 | 41.8 | 52.5 | |
| 10 | FSRW | 30.0 | 62.7 | 43.2 | 60.6 | 39.6 | 47.2 |
| Meta R-CNN | 52.5 | 55.9 | 52.7 | 54.6 | 41.6 | 51.5 | |
| ours | 44.5 | 65.8 | 62.7 | 65.8 | 42.5 | 56.3 | |
| Shot | Method | AP50 | AP75 | AP |
|---|---|---|---|---|
| 10 | FSRW | 12.3 | 4.6 | 5.6 |
| Meta R-CNN | 19.1 | 6.6 | 8.7 | |
| ours | 21.5 | 8.7 | 10.2 | |
| 20 | FSRW | 16.5 | 6.3 | 7.8 |
| Meta R-CNN | 22.8 | 9.1 | 10.9 | |
| ours | 26.1 | 11.5 | 13.2 | |
| 30 | FSRW | 19.0 | 7.6 | 9.1 |
| Meta R-CNN | 25.3 | 10.8 | 12.4 | |
| ours | 28.6 | 13.2 | 14.1 |
| KERRYPNX | KR | 1-Shot | 2-Shot | 3-Shot | 5-Shot | 10-Shot |
|---|---|---|---|---|---|---|
| Faster R-CN | 32.8 | 44.7 | 46.1 | 49.8 | 55.8 | |
| ours | √ | 45.8 | 46.2 | 47.3 | 52.5 | 56.3 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, J.; Chen, D. Few-Shot Object Detection Method Based on Knowledge Reasoning. Electronics 2022, 11, 1327. https://doi.org/10.3390/electronics11091327
Wang J, Chen D. Few-Shot Object Detection Method Based on Knowledge Reasoning. Electronics. 2022; 11(9):1327. https://doi.org/10.3390/electronics11091327
Chicago/Turabian StyleWang, Jianwei, and Deyun Chen. 2022. "Few-Shot Object Detection Method Based on Knowledge Reasoning" Electronics 11, no. 9: 1327. https://doi.org/10.3390/electronics11091327
APA StyleWang, J., & Chen, D. (2022). Few-Shot Object Detection Method Based on Knowledge Reasoning. Electronics, 11(9), 1327. https://doi.org/10.3390/electronics11091327