1. Introduction
Sentiment analysis (SA) is a natural language processing (NLP) task that has gained great importance in recent years in the data analysis and information extraction field [
1]. The primary objective of SA is to detect sentiments articulated in text and classify the polarities of these sentiments as either binary or ternary polarity. Social media has become the main data source for analyzers to study internet users’ expressed opinions on a specific topic, thus allowing them to predict and adjust their strategies.
Opinions expressed in the Arabic language are estimated to populate 5% of the Internet language population [
2]. It is also seen as one of the most active up-and-coming languages on the internet in recent years [
3]. In the Arabic language, users can convey their views or ideas using either modern Arabic or dialectal Arabic, which can vary from one country to another. Alternatively, both standard and dialectal Arabic are combined on social media. As a result of the morphology, orthography, and complex nature of the language, the detection of sentiment words in Arabic dialects has been found to be particularly challenging. In addition, all Arabic-speaking states have their own dialect, which increases the ambiguity level of the language [
4]. That is, many textual contents have become available online, and they are written in the modern standard Arabic (MSA) and informal contexts, with a different meaning for the same word and expression. In addition, the root and the character of Arabic words can have many forms based on the context, such as (يتكلم ,كلام ,كلمات). Many words in Arabic also have different meanings with the same spelling depending on their diacritics. Hence, analyzing the sentence’s sentiment requires efforts beyond the approaches that only focus on syntactical and semantic features [
5].
Moreover, the Arabic dialect is considered a low-resource and non-structured language, making information extraction a difficult task [
6]. Furthermore, most tools and resources for MSA do not consider the Arabic dialects’ features and are not adapted to them [
7]. Besides that, lexical resources such as lexicons are not considered the best method to analyze Arabic sentiment due to the huge number of words from different dialects and the reality of covering all words in the lexicon [
2]. Moreover, developing resources and tools for Arabic dialects is considered arduous and time daunting [
8].
The existing approaches on Arabic sentiment analysis (ASA) have mainly focused on classifying tweets and reviews in either binary or ternary polarity. Most of these approaches [
9,
10,
11,
12,
13,
14] are based on handcrafted features, lexicon, and tweet-specific features that are utilized as inputs for machine learning (ML) algorithms, such as support vector machines (SVM), Naive Bayes (NB), multinomial Naive Bayes (MNB), logistic regression (LR), random forest (RF), and clustering. Other approaches utilized a rule-based approach such as the role of lexicalization by developing and prioritizing a set of heuristics rules that could be used in a chaining fashion to classify tweets as negative or positive [
15] while Arabic sentiment ontology (ASO) [
16] is introduced, which contains sentiment words with varying intensities. The ASO was used to discover user attitudes and classify tweets.
In contrast, deep learning (DL) approaches for SA, such as recurrent neural network (RNN) [
17], convolutional neural network (CNN) [
18,
19,
20,
21], and recursive auto encoder (RAE) [
22], have been identified as having the ability to provide superior adaptability and robustness in the past few years by extracting features automatically. However, deep neural network (DNN) approaches in Arabic dialect SA achievement are still limited in number compared with its applications in other areas, including chatbot [
23], recommendation systems [
24,
25], remote sensing [
26], and load monitoring [
27]. However, most of the approaches applied to ASA focus on binary and ternary classifications.
Therefore, we focus on the problem of the five-polarity ASA in this work. We evaluate our proposed model on four datasets, namely, book reviews from the Large-Scale Arabic Book Reviews Dataset (LABR) [
28], Book Reviews in Arabic Dataset (BRAD) [
29], Hotel Arabic-Reviews Dataset [
30], and Twitter Arabic dialect dataset (SemEval-2017) [
31], which are categorized based on five-point scales ranging from highly positive to highly negative. The SemEval-2017 dataset consists of three tasks. Tasks (B) and (A) focus on the binary (positive and negative) and ternary (positive, neutral, and negative) scales. Task (C) concentrates on classifying tweets based on five scales (highly positive to highly negative). Most of the approaches that are applied on these tasks are focused on binary and ternary classifications [
12,
13,
14,
32], while for a five-point classification, only two approaches have addressed this problem, which is based on supervised and unsupervised conventional machine learning [
33] and DNN [
34] (details will be provided in
Section 2).
A five-point polarity scale has low attention in ASA, and only a limited number of studies have tackled this problem. For example, the LABR comprises reviews ranked by users on a scale of 1 to 5. Most of the approaches that use this dataset address binary or ternary classifications, and only limited approaches tackle this problem using traditional ML algorithms, such as MNB and hierarchical classifier [
35,
36]. Similarly, for BRAD and HARD datasets, the existing approaches on both datasets are based on traditional ML algorithms [
29,
30]. The deep learning approaches applied on five-polarity classification tasks are distinctly insufficient.
This study mainly aims to manipulate the relation between ASA tasks (ternary and five polarities) and learning them simultaneously. We illustrate the benefit on two domains, namely, tweets and reviews. Multitasking learning (MTL) [
37] has demonstrated great potential in various fields, such as human action recognition [
38], lane image detection [
39], scene classification [
40], emotion detection [
41], text-video retrieval [
42], and image super-resolution [
43]. MTL improves the learning capabilities, encoder quality, and performance of sentiment classification of a conventional single-task classifier by learning the relative tasks in parallel using the shared representation of text sequences [
44]. In addition, the key advantage of multitasking learning is that it offers a sophisticated way to use various resources for similar tasks.
For instance, while data can be labeled with distant supervision using emoticons for ternary classification, the fine-grained classification does not offer a straightforward way to achieve it. Learning related tasks such as binary or ternary with five polarities jointly improve encoder quality in producing effective sentence representation and the performance on the five-point task [
45,
46]. ASA has shown a lack of DL approaches. Moreover, the current works are based on traditional ML algorithms that do not produce a robust latent feature representation [
46] and are based on single-task learning. In addition, the reported performance of existing works has a lot of room for improvement.
Our objective in this study is two-fold. First, we propose a multitasking model based on a hierarchical attention network with a shared private layer scheme to transfer and share the common knowledge between two ASA tasks (three and five polarities) during the training. The intent of the proposed model is to learn the significant sentence representation, increase the learning capabilities, and improve the final performance for five-point classification. Second, we evaluate and investigate the performance of two multitasking training techniques by alternate and joint training.
To the best of our knowledge, no study has used MTL for learning five-point ASA classification. The existing approaches that have tackled this classification problem are based on single-task learning. Moreover, a noticeable gap has been observed in the DL approaches applied to this task. In summary, our contributions are as follows:
The model proposed in this study is the first model that adopts MTL for ASA. The multitask learning model based on a hierarchical attention network (MTLHAN) is developed to exploit the relation between three and five polarities in ASA using a shared private layer. We show how learning two tasks (binary and ternary classification) simultaneously in MTL improves the text representation capability for each task and increases the usability of features. ASA has been demonstrated to lack DL approaches, particularly on the five-polarity classification. The existing DL works are based on single-task learning. In contrast, traditional ML algorithms based on extracted features are considered laborious and time consuming.
We propose a shared private layer consisting of a word encoder and word attention networks between ASA classification tasks, which add greater flexibility to share complementary features between tasks.
Through the results obtained from the experiment, the proposed MTLHAN model has been identified to achieve a lower macro average mean absolute error (MAEM) and greater accuracy (ACC) compared with benchmark approaches.
The rest of the paper is organized as follows. The related works are briefly presented in
Section 2. Then, we propose and discuss the MTL-HAN model in detail in
Section 3.
Section 4 presents the current study’s results and interpretations. Finally, we discuss the conclusion of our research in
Section 5.
2. Related Works
Most of the approaches applied to the Arabic dialect sentiment classification observed are based on traditional ML. Only three classifiers have regularly demonstrated exceptional results: SVM, k-nearest neighbor (KNN), and NB. The combination of bigrams feature and stemmer with term frequency–inverse document frequency (TF–IDF) functioned as a weighting schema to classify the tweets in Jordanian dialect using SVM and NB. They identified that an SVM with these combi-nations outperforms NB [
47]. Additionally, the SVM was used to classify 3015 Arabic tweets from the TAGREED corpus [
48]. Meanwhile, Meanwhile, three classifiers, namely, SVM, NB, and KNN, with various features and preprocessing steps have been used [
49] to study the impact of preprocessing techniques and n-gram features on the performance of ASA classification. They found that preprocessing, bigram, and character gram improves performance. Moreover, [
50] applied SVM on tweets written in Arabic dialect without the preprocessing step; their method achieved an accuracy of 96.1%. Conversely, the same classifier removed Latin letters as preprocessing for the text and achieved a lower accuracy of 95%.
Another work [
51] developed an ASA tool for Arabic dialects. Reviews from social media were gathered, which included Saudi, Iraqi, Lebanese, Egyptian, Syrian, and Jordanian dialects. Similarly, AraSenTi-Tweet dataset consisting of 17,573 tweets written in MSA and the Saudi dia-lect were presented [
52], where the tweets were manually annotated as negative, neu-tral, positive, or mixed. Several ML classifiers, namely, NB, DT, and SVM were evaluated with TF–IDF and stemming as preprocessing on Arabic tweets written in MSA to identify the simple and workable approach for ASA [
53]. The experimental results showed that DT achieved the best performance.
Emphasizing the scarcity of available lexicons for Algerian dialect, efforts on lexicon construction with three semi-automatically created lexicons (a nega-tion words lexicon, keywords lexicon, and intensification words lexicon) using MSA dictionary and Egyptian lexicons [
54]. Furthermore, they added the polarity for all the lexicons and used a list of common phrases with their polarities and emoticons. Another work [
55] presented the first Tunisian Sentiment Analysis Corpus (TSAC) collected from Facebook user comments. TSAC consists of 17,000 comments manually annotated to negative and positive. The previous approaches for ASA mostly focused on feature selection and creating sentiment resources.
DL models have been successfully used for ASA. Long short-term memory (LSTM) and CNN are the most recognized models. Several DL models on ASA, including a deep auto-encoder (DAE), deep belief networks (DBN), a recursive auto-encoder (RAE), and DNN were explored [
56]. They used the ArSenl lexicon and bag-of-words [
57] as feature vectors for DNN, DAE, and RAE. The results demonstrated that RAE outperformed all other models. The same authors also proposed an improved RAE model to come up with morphological complexity in Arabic text [
22]. Opinions from a Twitter dataset on health services were analyzed [
58] to investigate the performances of two DL models (DNN and CNN) and compared them with other ML algorithms (NB, LR, and SVM). The DL models demonstrated encouraging results with word embedding, where CNN and DNN had an accuracy of 90% and 85%, respectively. Arabic dialect of tweets and CNN were used with embedding features to address the highly imbalanced dataset [
17]. The same team [
59] evaluated several models of CNN, CNN-LSTM, and stacked LSTM. They used word embedding (CBOW and skip-gram (SG)) as features with two settings: dynamic and static. The results demonstrated that CNN-LSTM trained by CBOW achieves higher accuracy. However, in its performance, it exhibited sensitivity toward various datasets A character level with the CNN model compared with other ML classifiers, namely, SVM, LR, KNN, NB, decision tree (DT), and RF. CNN outperformed other ML algo-rithms with the highest accuracy of 94.33% [
60]. Another work [
61] studied two-word embedding (CBOW and SG) models using a corpus of 3.4 billion Arabic words. Then, CNN was used to classify sentiments. A corpus of 100,000 comments written in Algerian dialect on Facebook were collected manually by annotating the collected comments to negative, neutral, or positive [
62].They evaluated two neural network models, CNN and MLP. The authors reported the best performance of 89.5% accuracy was achieved by CNN.
One of the tasks in the SemEval-2017 challenge that utilized the Arabic Twitter dialect dataset ASA was created by [
31]. The state-of-the-art performance for Task A (three-polarity) [
12] used NB with several features, including lexicon scores, word embedding, unigrams, lexical features (positive word, negative word, emoticon, question, question mark, negative and positive word numbers, and a flag to show that the tweet ends or begins with the hashtag), and bigrams. Furthermore, numerous features were extracted [
13], including word embedding, bag of negated words, lexicons, POS, and POS with bigrams to enrich the sentiment. Then, SVM was used to classify the sentiment. The approaches here were mainly centered on the analysis of features to choose the discriminative features. One study investigated the efficacy of the unsupervised and supervised approaches and their hybrid. Two models that included NB with n-gram features as a supervised model and lexicon features were used [
14] to identify the tweet polarity. The researchers applied several weighting schemas (e.g., double and sum polarity) to assign the sentiment weights. Ultimately, the supervised model achieved higher performance.
Another study [
33] proposed four models: supervised topic, unsupervised topic, supervised domain, and direct sentiment models. Moreover, the overall accuracy had been decreased by these mixtures of low and high variance features [
33]. Most of the above approaches are based on handcrafted features and lexicon features. Using lexicon for Arabic colloquial terms involves high concentricity, as the words can have many scores (sentiment strength). In addition, the process of feature selection and extraction for Arabic dialects is considered time-daunting and extremely arduous to define, which might cause an incomplete specificity or features of the tasks [
63]. For Task C (five polarities), limited works have been addressed compared with Task A in the SemEval-2017 challenge as shown in
Table 1. Three RNNs with a convolutional network were used [
34], where the word ‘embedding’ is used as a feature. Each CNN network is followed by an RNN; three inputs were used in their model: in and out domain embeddings and the lexicon score of the words. Furthermore, a combination of supervised and unsupervised models were used in [
33] to classify the tweet into a five-point scale.
ASA studies on five-point scales have gained the least popularity compared with other classification tasks of ternary and binary polarity. In addition, most of the approaches applied to this dataset are based on conventional ML algorithms, for example, the LABR dataset where the reviews were labeled from 1–5 (high negative to high positive). The lexicon-based approach and the corpus-based approach were experimented with n-gram features and evaluated several ML algorithms, including SVM, NB, stochastic gradient descent (SGD), passive aggressive (PA), LR, KNN, and perceptron [
64]. The impact of balancing and stemming on the LABR dataset using ML classifiers with bag-of-words was studied [
65].
Hierarchical classifier (HC) structures have been proposed in [
35] to handle a five-polarity classification problem. The HC model is based on the divide-and-conquer approach in which the five classes are divided into subproblems, where each node exemplifies a different classification subproblem. They found that hierarchical classifiers can outperform the flat classifier (FC). The same team [
36] suggested an enhanced version of the previous model by studying six different HC structures. They compared these structures with four ML classifiers (DT, KNN, NB, and SVM). The results revealed that the proposed HC enhanced the performance. However, not all HC structures outperform FC, whereas most HCs decrease the accuracy. The above-mentioned approaches have shown a noticeable lack of DL approaches applied on the LABR fine-grained dataset. All the approaches proposed are based on ML algorithms.
Table 2 summarizes the approaches applied to the LABR dataset. The HC [
36] is the best existing work on the imbalanced dataset, and MNB [
65] is the best existing work on the balanced dataset to date.
Several researchers created their own datasets in the style of the LABR dataset. The Book Reviews in Arabic Dataset (BRAD 1.0) [
29] consists of 510,600 reviews, where the reviews were labeled from 1–5 (high negative to high positive).Several classifiers have been examined, including SVM, LR, PA, and perceptron with n-gram features. They found LR and SVM achieved higher performance than perceptron [
29]. Similarly, the Hotel Arabic-Reviews Dataset (HARD) [
30] consists of 409,562 reviews labeled from 1–5 (high negative to high positive).They examined six sentiment classifiers, including AdaBoost, random forest (RF), PA, LR, SVM, and perceptron. They found SVM and LR produced the best performance with unigram and bigram features.
Table 3 summarizes the approaches that applied on BRAD and HARD. The LR [
30] is the best existing work on the HARD dataset, and LR [
29] is the best existing work on the BRAD dataset.
Other works have utilized the MTL approach to study the problem of five-point sentiment classification. For example, an MTL model based on a recurrent neural network by learning the ternary and five-point classification tasks jointly [
45] consists of BiLSTM followed by one hidden layer.They also used additional features such as counts of elongated words, punctuation symbols, emoticons, and word membership features in sentiment lexicons to enrich the sentence representation. They found that learning the related sentiment classification tasks jointly improved the performance on the five-point task.
Another effort in the same direction [
46] exploited the relation between binary and five-point sentiment classification tasks by learning them simultaneously. Their model consisted of LSTM as encoder with variational auto-encoder (VAE) as decoder, where the decoder parameters were shared among both tasks. The results revealed that their proposed model enhanced the performance on the five-point task. Furthermore, adversarial multitasking learning (AMTL) specifically on the encoder’s framework, consisting of three LSTM as a sentence encoder, two encoders represented the task-specific layers, and one encoder represented the shared layers [
44]. In their work, they added a multi-scale CNN as encoder beside the LSTM, and the output of both encoders was fused and concatenated with the output of the shared encoder to produce the final sentence representation. They found that the MTL model improves the encoder quality and the final performance of sentiment classification. The above-mentioned MTL approaches were applied to the English language. However, there is a lack of MTL and DL approaches usage for five-point ASA, and the existing works applied on this task are based on single task learning using ML algorithms. Thus, the performance of the current ASA on five polarities could be improved, as the performance is still relatively low.
3. Proposed Approach
This research proposes a multitasking model, in which the goal is to exploit the relation between ASA classification tasks (ternary and five polarities) to improve the final performance for the five-point Arabic sentiment classification problem. Recently, the Arabic literature review [
66] emphasized the need to use modernized deep learning techniques in ASA, such as hierarchical attention network (HAN) models [
67]. Therefore, we used the hierarchical attention model, as it accommodates and simultaneously learns various classification tasks. Consequently, the proposed MTLHAN is realized on the HAN model, as it accommodates and simultaneously learns various types of classification tasks.
Multitask learning has been demonstrated to deliver a more effective model than single classification tasks. MTL can simultaneously capture the intrinsic relativity of the tasks learned. MTL uses the relatedness and the shared representation with multiple loss functions by learning sentiment classification tasks in parallel, such as five and three polarities, to enhance the representation of features produced on a neural network. The information learned for each task can assist other tasks to learn effectively. An important benefit of MTL is that it offers an excellent way to access resources developed for similar tasks, enhancing the learning performance of the current task and increasing the amount of usable data. During learning, the correlated task-sharing layers can enhance the generalization performance, the pace of learning, and the intelligibility of learned models. A learner can learn several related tasks and, while doing so, use these tasks as an inductive bias for one another, which, in return, enhances the learning of the domain’s regularities. This feature allows better learning of the sentiment classification tasks with a minimum amount of training data.
To the best of our knowledge, no research has used MTL for learning a five-point ASA classification. The existing models that have tackled ordinal classification are based on traditional ML algorithms and a few DNNs. These approaches lack the ability to learn the relativity between different tasks. Based on this issue, we propose an MTLHAN to learn text representation for tweets and reviews, with ternary classification and five-point classification in parallel. The proposed MTL model relies on a general hierarchical attention network architecture [
67]. However, it accommodates different classification tasks and learns them simultaneously, i.e., ternary and five-polarity classification tasks. The shared private layer scheme in MTL allows for the transfer of the knowledge from a ternary task to a five-point task during the training, thus improving the capabilities of learning on the current task.
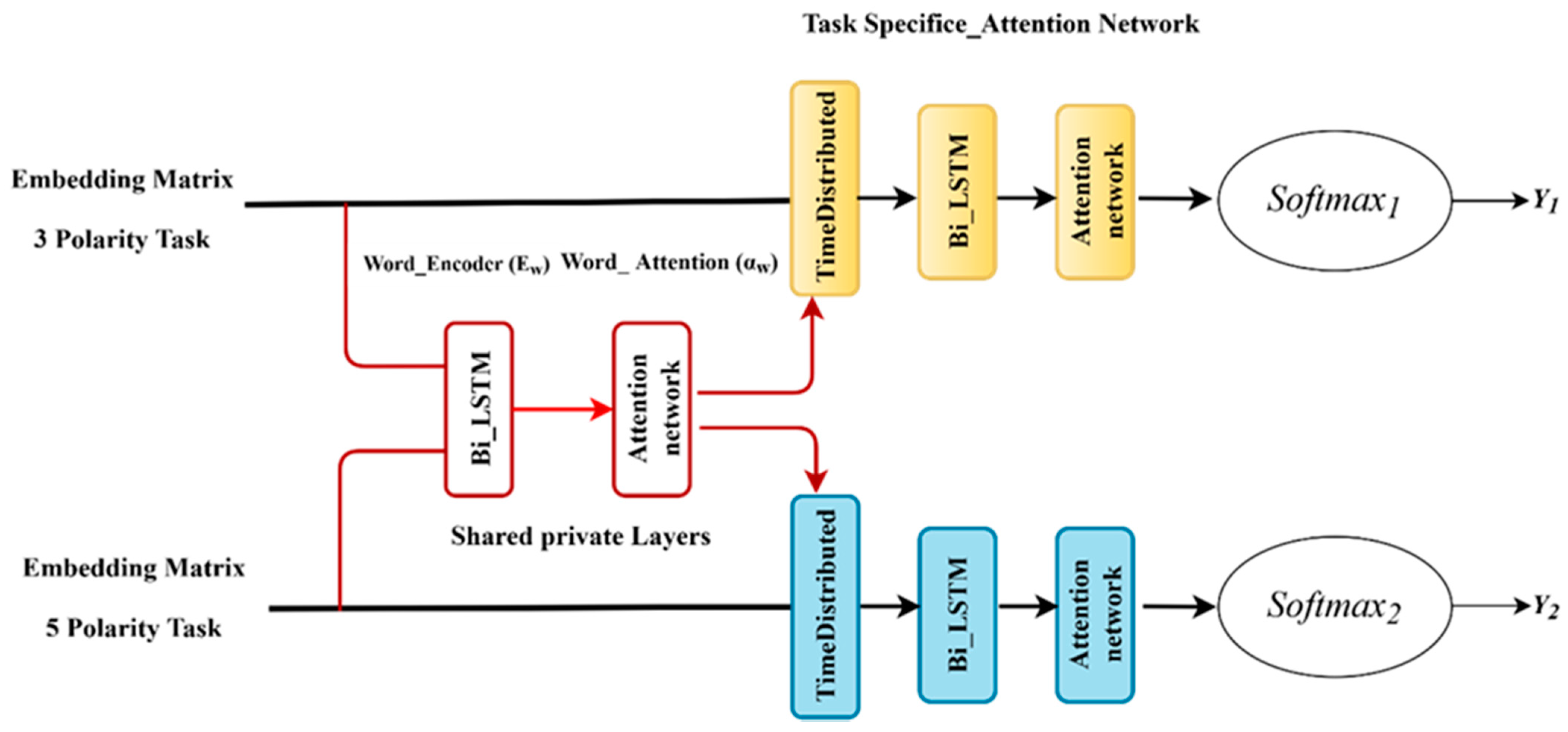
Moreover, informative text features are shared between tasks. Knowing that a text sequence is positive in a ternary task narrows the classification decision in a five-point task between high positive and positive. The overall structure of our proposed model, MTLHAN, consists of two parts, as shown in
Figure 1, where the first part is the shared private layers and the second is the task-specific layers.
Our objective is to construct an MTL model based on BiLSTM and attention mechanism for learning ternary and five-point classifications in parallel. The function of the proposed model is to learn the mapping , where X and are the text input and text sequence prediction, respectively. represents three polarity scales, e.g., positive, neutral, and negative, and represents five-polarity scales, e.g., high negative, negative, neutral, positive, and high positive. Our model consists of three attention models as follows:
Attention model for shared private layer;
Attention model for ternary polarities (task-specific layer);
Attention model for five polarities (task-specific layer).
Each attention model consists of BiLSTM and attention networks. Our model intends to learn the significant representation of text sequences for tweets and reviews and improve the final performance for five-point classification. We focused on five-point classification, as it has gained less attention, with limited existing works that have tackled this task in ASA. To enable multitask learning, we propose a distinct way of sharing parameters between tasks. We used BiLSTM as a word encoder (E
w) to obtain the annotation of words followed by word attention
to distinguish salient features in a given text sequence. Both networks represented the shared private layers. The representations of informative words from
were aggregated and then fed to task-specific layers, where the yellow and blue boxes in
Figure 1 represent ternary classification and fine-grained classification tasks, respectively. Each task structure consisted of BiLSTM on the sentence level (E
s) and attention model
on the sentence level. This model has the capability to attain better and competitive performance. In addition, our model can produce a robust latent representation and extract the most important words in a text sequence. The elaboration on each component in the model is provided below.
3.1. Arabic Dialect Encoding with Bi-LSTM
The RNN [
68] is a deep network used to process sequential data. It can preserve the previous information on account. However, vanilla RNN cannot handle the long dependencies in input sequences due to the exploding and vanishing gradients problem. Through LSTM, this issue has fortunately been addressed. LSTM can withstand the previous information for long dependencies, thus helping to preserve more information. Therefore, it is the best option in training text classification. LSTM networks consist of four layers that interact in a unique way. These layers include the input gate, forget gate, output gate, and memory cell, which are defined as
,
,
, and
.
is a vector to generate candidate values. We used Bi-LSTM in the shared private layer and the task-specific layer. Below is the computation at each step:
where
is the input at the current time
,
is the logistic sigmoid function and
denotes the element-wise multiplication. Each vector,
it,
,
is equal to the dimension of hidden layer
. In our model, we used bidirectional LSTM. Forward LSTM computes the representation of the sentence at every word from the left context
and backward LSTM computes the representation of the sentence at every word from the right context
, which will add useful information. The final representation is obtained by concatenating its left and right context representations
.
3.2. Word Embedding and Sentence Representation
Word representations, namely, one-hot vectors, are able to attain great performance in text classification [
69]. Nevertheless, as the problem is sparse, this method of word encoding encounters the dimensionality problem when used to classify short sentences. Recent research has shown that the continuous representations of words, e.g., word embedding, provide the addition of powerful DL models for SA classification. Typically, these representations encode the syntactic and semantic features of the words. GloVe [
70], Word2Vecv [
71], and FastText [
72] are the three most commonly used pre-trained word embedding methods. One study [
20], which evaluated various word embeddings on Arabic dialect SA, discovered that the model CBOW performs better than other models, namely, GloVe and SG. In this study, we used FastText pre-trained word embedding, where the word embeddings are produced by the CBOW model (enhanced by sub-word information and position weights), which generates high-quality word vectors and captures positional information.
The input to MTLHAN were reviews or tweets, where their contents were each treated as a sequence of words. Given a sentence with length m, for each word , we could obtain a low-dimensional distributional vector by look-up operation from , where is the embedding dimension and is the vocabulary size.
3.3. Shared Private Layers
The core of designing a multitasking network is the scheme for parameter sharing. The shared knowledge scheme enables the sharing and transferring of knowledge between task 1
and task 2
by sharing and exploiting the common features between these tasks. The shared parameters help the model learn a universal representation for the text sequence inputs, improve the learning performance on the current tasks, and increase the amount of usable data. The MTLHAN uses Bi-LSTM as a word encoder
with parameters
and attention mechanism (
) with parameters
as shared private layers between ternary and five-polarity classification tasks. The shared knowledge can be considered as the hidden states of the word encoder and the attention network, which are denoted as
for a given sentence with words
. The structure of the shared private layers is depicted in
Figure 2.
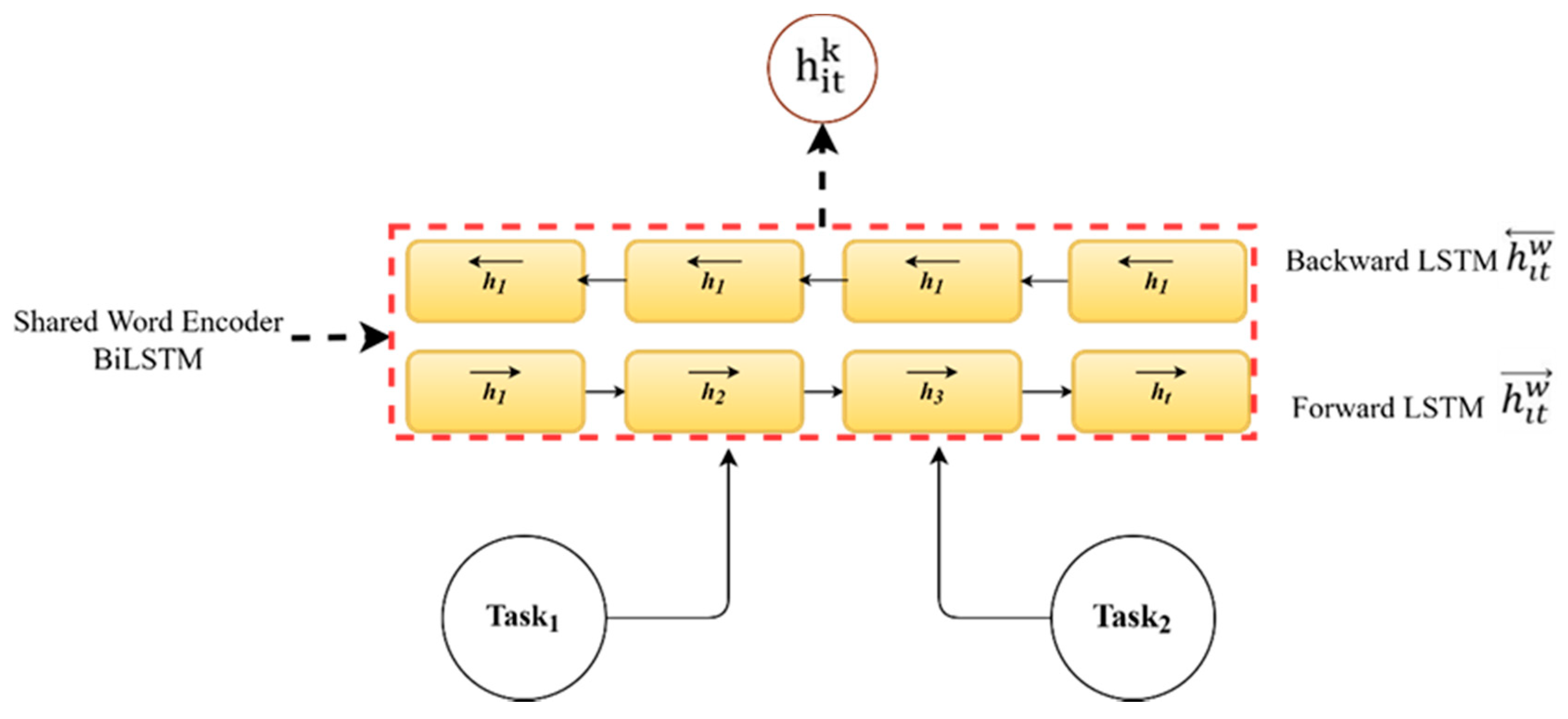
3.3.1. The Shared Word Encoder
A word encoder is used to obtain word annotations by summarizing information for words from both directions (forward and backward) and therefore incorporating the contextual information in the annotation. The bidirectional LSTM contains the forward
, which computes the representation of the sentence
from
to
, and backward
, which computes the representation from
to
For a given word
Wit, we obtain its annotation by concatenating the forward hidden state
and backward hidden state
, i.e.,
, which summarizes the information of the whole sentence centered around
. The shared knowledge can be considered the word encoder’s hidden states between ADSA classification tasks, as depicted in
Figure 3. Formally, for any sentence in task
, the shared hidden representation for each task has been computed as follows:
3.3.2. The Shared Attention Networks
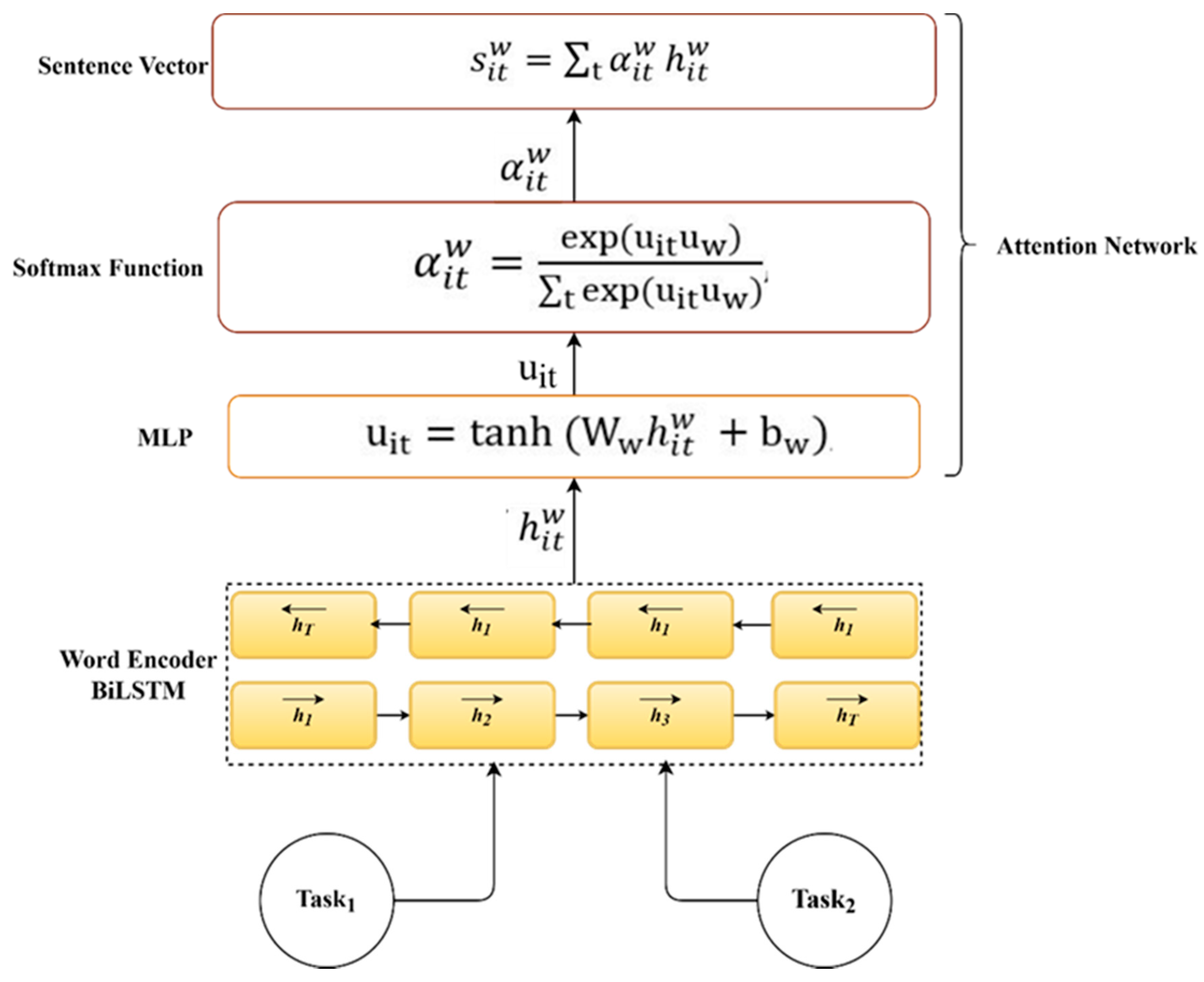
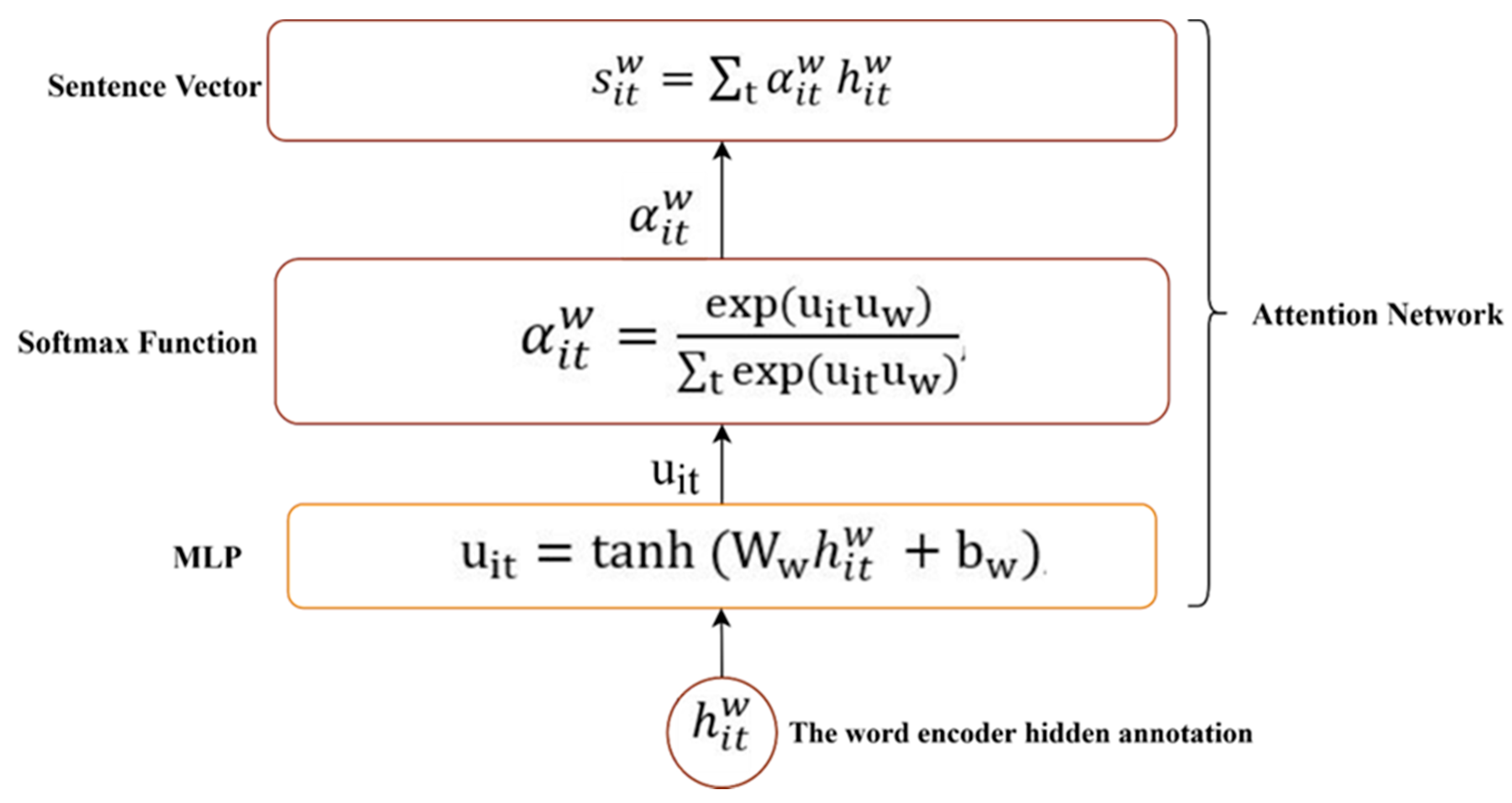
The MTLHAN utilizes the attention network on two levels. The word level enables the model to pay less or more attention to words that contribute to the sentence meaning when constructing the representation of sentences. The attention on a sentence level is used to allow the task to learn task-dependent features by rewarding the words that are indicators to classify the sentence accurately.
The word level attention network
is the second component in the shared private layers in MTLHAN. The shared word encoder can be regarded as a shared feature pool, and the attention mechanism is used to determine the importance of the shared features; besides, these informative features are shared between tasks. Attention mechanisms help to improve the global sentence representation by focusing on and attending to a smaller part of the data [
73,
74]. The attention mechanism
is used to extract the important words that contribute to the representation of sentence meaning and then form the sentence vector by aggregating the representation of those informative words.
Figure 4 illustrates the components of the shared word level attention network. Specifically, the hidden annotation of words
from the shared word encoder feed through a fully connected neural network (MLP) with parameters
.
The idea is to allow the model to learn through training with randomly assigned weights and biases. The new annotations of MLP are represented as
.
, which is computed by Equation (10).
The importance of a word is measured by multiplied
with trainable context vector
and then passed to the SoftMax function to obtain the normalized importance weights
. The context vector
is randomly initialized and learned during the training.
is computed by Equation (11).
Subsequently, the sentence vector
is produced, as the weighted sum of the word annotations
with importance weights
, which can be interpreted as a high-level representation of the informative word.
is computed by Equation (12).
3.4. Task-Specific Layers
Given the sentence vectors
, we used two Bi-LSTM as sentence encoders with different parameters; one for ternary classification and another for five-point classification. Similarly, we acquire the text sequence vectors by concatenating
and
to obtain the annotation of sentence
. Formally, for any sentence in task
, we can compute task-specific representation as follows:
The attention mechanism is also used here to allow the task to learn task-dependent features by rewarding the words that are indicators to classify the sentence accurately. The normalized importance weights of sentences are similarly computed as in Equations (10)–(12). Subsequently, the final sentence vector is produced as the weighted sum of the word annotations.
3.5. Training
To learn the parameters of the proposed MTLHAN model, the cycle of training can be summarized as Algorithm 1. The proposed model trains and learns the ternary and binary classification tasks jointly. For example, HARD dataset, the MTLHAN train, the five-polarity and ternary classification tasks jointly, where
and
. In the last layer of task
, the final vector representation
is fed into the corresponding SoftMax layers to fit the number of classes.
where
denotes the ternary-classification prediction probabilities,
represents the fine-grained prediction probabilities.
b and
W are the bias and weight to be learned, respectively.
Two techniques have been evaluated for the model training process through alternate [
75,
76] and joint learning. We can conduct MTL by alternately calling each task loss and optimizer, which means the training process runs for a specified number of iterations on the ternary classification task and then continues to five-polarity classification tasks. Both tasks are trained to reduce cross-entropy. Thus, we acquire:
where
and
are the predicted probabilities and ground-true label, respectively.
and
are the number of training samples in the ternary and five-point classification tasks, respectively. To implement the joint training of the ternary and five-point classifications to train the MTLHAN model, we obtain the following global loss function:
where
and
are the weights for ternary and five-point tasks, respectively. The parameters
and
are used for balancing both losses by the equal weighting scheme (
).
| Algorithm 1: Multitask Learning-based Hierarchical Attention |
 |
3.6. Datasets
The model was trained on four benchmark datasets. The first one was LABR [
64]. The reviews were gathered from Goodreads website and ranked by users on a scale of 1 to 5. They provided two datasets, namely, balanced and imbalanced.
Table 4 and
Table 5 summarize the class distribution for Arabic Book Reviews on imbalanced and balanced datasets, respectively.
The second dataset was the Arabic Twitter dataset provided by SemEval-2017 [
31]. The dataset was annotated according to three and five scales. The dataset had multiple dialects, including Levantine, Egyptian, and Gulf. In these dialects, the same word comes in different forms, such as suffixes and prefixes, and holds various definitions. In turn, this variation adds more complexity to the task of classification. In addition, the training data size is very small and highly imbalanced.
Table 6 summarizes the polarity distribution for each task.
The third dataset was BRAD [
29]. The reviews were gathered from the same source as the LABR dataset and annotated according to five scales. The fourth dataset was HARD [
30]. The reviews were collected from the booking website and annotated to five scales.
Table 7 and
Table 8 summarize the class distribution for the BRAD and HARD datasets.
3.6.1. Data Preprocessing
Diacritics, punctuation, non-Arabic words and letters, hashtags, and URL were removed.
Emoticons were replaced with their meaning.
Letters were normalized.
Elongated words and Kashida were normalized.
5. Discussion
The evaluation results show that the proposed MTLHAN model with joint and alternate learning achieves superior performance. The performance of joint training is higher than that of alternate training, with a difference of 3.12% and 5.12% in the LABR balanced and imbalanced datasets, respectively, and 0.39% in the Arabic tweet dataset. The difference in the performance between both methods is that the alternate training is affected by the dataset size of each task. More information will be dominant in the shared private layers when the task has a larger dataset. In some cases, alternate training can easily become biased if one of the tasks has datasets much larger than the other. Therefore, joint training is more preferred in SA tasks. Conversely, alternate training is more suitable if we have two different datasets for each of the different tasks, for example, machine translation tasks translating from Arabic dialect to MSA and MSA to English [
75]. By designing a network in an alternate setting, the performance of each task can be improved without having to find more training data [
76].
When comparing the proposed MTLHAN model performance with the best performing model in the Arabic tweet dataset, results obtained by MTLHAN outperform AraBERT [
79], with a difference of 0.169%. In addition, our model outperforms other approaches on the same dataset, NCNN [
19], OMAM [
33], and RCNN [
34] with clear differences of 0.282%, 0.311%, and 0.632%, respectively. NCNN uses a convolutional network trained on top of word embedding. On the other hand, OMAM uses a combination of supervised and unsupervised models based on ML algorithms and lexicons. However, using this combination does not produce a robust sentence representation [
46]. The RCNN surprisingly has the worst performance. Combining the convolutional and Bi-LSTM enables the model to obtain comprehensive representation, namely, the historical, future, and local context of any position in a sentence. Despite the small dataset, given the high complexity and complicated nature of the model, the performances might be affected by over-fitting, which loses the semantic and sentiment representations [
34]. Therefore, multitask learning is more suited when the dataset size is small. Learning-related tasks simultaneously increase the amount of usable data, and the risk of over-fitting is reduced [
83].
The proposed model results show that the MTLHAN model achieves the best performance on the LABR imbalanced dataset, thus outperforming the HC model [
36] with a significant difference of 11.34% on the imbalanced dataset. The HC model is based on the divide-and-conquer approach, where the five classes are divided into subproblems. However, the authors only focus on selecting core classifiers without considering sentence representation. Meanwhile, the other approaches, namely AraBERT [
79], SVM [
65], and MNB [
64], achieved the worst performance on the same dataset. Our proposed model outperforms AraBERT [
79] and MNB [
64], with a huge difference of 19.77% and 33.97%, respectively, on the balanced dataset. Moreover, our proposed MTLHAN outperforms all competing approaches on the five-polarity classification for the LABR balanced and imbalanced datasets. Similarly, the proposed MTLHAN achieves the best performance on the BRAD imbalanced dataset, thus outperforming the AraBERT [
79] and LR [
29], with a difference of 23.74% and 36.89%, respectively.
All of the approaches applied on LABR and BRAD datasets are not DL models that have no capabilities of producing a richer sentence representation compared with DL models [
46] and are based on single-task learning. Conversely, the performance of AraBERT is very low. This is due to the fact that the model does not learn the decision boundaries between polarity classes well, which is justified by a large number of false-positives and high positives, as well as for negatives and high negatives. Similarly, on the HARD dataset, the MTLHAN outperforms AraBERT and LR [
30], with a difference of 6.83% and 11.58%, respectively.
Other relative tasks can improve the performance of the five-point classification. The comparison analysis with benchmark approaches directly elucidates that joint learning in five-polarity classification can learn additional rich feature representations among the text sequence than the single-learning task. This outcome also indicates that joint learning is better suited to solving complex classification tasks and can learn and produce a more robust latent representation in fine-grained tasks for Arabic colloquial SA.
6. Conclusions
The current study has successfully developed the first multitask learning model for five-point classification in Arabic dialect SA. The proposed multitask architecture with shared private parameters helps to improve the global text sequence representation. Moreover, the attention mechanism can extract the most informative words in text sequences. Limited works on colloquial Arabic that are applied to this task are based on single task learning and do not consider the relative tasks. Moreover, these studies are based on conventional ML algorithms, feature selection, and sentiment resources that are time-consuming, arduous, and unable to produce a richer feature representation. In addition, Arabic dialect SA, in particular, are still suffering from a lack of sentiment resources. In contrast, the limited number of deep-neural networks used for this task for the Arabic dialect are based on the single-learning task. These approaches are highly complicated and complex for a small amount of data.
We have conducted several experiments on five-point ASA datasets. We empirically determine the best training technique (alternate and joint) for multitask learning in ASA. The experiment results show that joint learning achieves higher performance than alternate training, as the latter is influenced by the dataset size of each task. The empirical results demonstrate that our model outperforms other state-of-the-art approaches on three datasets. We have found that we can significantly enhance the performance of five-point classification through jointly learning the tasks of fine-grained and ternary classifications with a multitasking model. By determining that a text is “negative” in the ternary setting, the classification decision between the high negative and negative categories in the five-point setting can be narrowed down.
Furthermore, the performance of fine-grained tasks with joint learning is greater than ternary tasks, thus showing that joint learning is better suited in solving complex classification tasks. In addition, it uses a shared private layer to reduce over-fitting and increase the amount of usable data. This ability demonstrates the effectiveness of our proposed model structure. Our model produces a robust latent feature representation for text sequence. The proposed model is trained end-to-end. Based on the total accuracy of 83.98%%, 87.68%, and 84.59% on the LABR, HARD, and BRAD datasets, respectively, the results of the experiments show that our model enhances the existing state-of-the-art approaches. On the Arabic tweet dataset, the proposed model achieved minimum MAEM with a performance of 0.632. It is noted that the performance of the proposed model is not comparable with the state-of-art approaches for LABR, HARD, and BRAD, such as LR, MNB, and HC. However, the authors insist that the performance of the five-polarity ASA classification has been largely improved. The time complexity of the proposed MTLHAN is also not the main concern since the SA application can always be performed offline.
Plans for future work include redeveloping a multitask architecture based on transformers and evaluating other multitasking frameworks based on transformers such as the Framework for Adapting Representation Models (FARM) (
https://farm.deepset.ai/. Accessed on 25 November 2021). Moreover, we plan to incorporate the character level to the proposed approaches and use convolutional neural networks as a sentence level encoder in the proposed approach. Moreover, incorporating the sarcasm detection task is another crucial area to work on to enhance ASA’s performance, and to evaluate the proposed model and transformer performance on other domains such as Arabic aspect level sentiment analysis, Arabic text categorization, and Arabic text entailment.


 ,
, 

{kind=link}
{kind=link}
{kind=link}
{kind=link}



